本文是 VLN综述:基于视觉语言的导航 的配套论文精读,收录 VLN 经典论文与依赖基础工作。
VLN 模型性能排行榜
⚠️ 不同基准不可直接混比:本文论文覆盖三类任务设定——指令跟随·连续环境(分为单语言 R2R-CE 与多语言 RxR-CE,机器人第一视角逐步控制)、指令跟随·离散全景(R2R / REVERIE,DUET / HAMT 体系全景 RGB-D)、目标导航(ObjectNav / 实例图像导航,HM3D / MP3D / Gibson 等)。它们任务定义或基准不同,SR 数值不可跨表比较,故分表列出。NE / OSR 仅在 R2R 系列基准中定义。
① 指令跟随 · 连续环境 - 英文
| 模型 | 年份 | 基准 | SR ↑ | SPL ↑ | NE ↓ | OSR ↑ | 开源 | 备注 |
|---|---|---|---|---|---|---|---|---|
| Qwen-RobotNav-8B (全景) | 2026 | R2R-CE | 72.1 | 66.6 | 3.53 | 78.5 | 否 | 全景相机 |
| OmniNav | 2026 | R2R-CE | 69.5 | 66.1 | 3.74 | 74.6 | 是 | 前后左右4机位输入 |
| AstraNav-World | 2025 | R2R-CE | 67.9 | 65.4 | – | – | 是 | – |
| SEDualVLN | 2026 | R2R-CE | 67.3 | 62.5 | 3.75 | 73.7 | 是 | – |
| AgentVLN-3B | 2026 | R2R-CE | 67.2 | 64.7 | – | – | 是 | – |
| Qwen-RobotNav-8B (单目) | 2026 | R2R-CE | 66.9 | 60.5 | – | – | 否 | 单前向相机 |
| ABot-N0 | 2026 | R2R-CE | 66.4 | – | – | – | 否 | – |
| Dual-Anchoring | 2026 | R2R-CE | 65.6 | 62.1 | – | – | 否 | – |
| AwareVLN | 2026 | R2R-CE | 65.4 | 55.1 | 4.02 | 73.5 | 是 | – |
| NavFoM | 2025 | R2R-CE | 64.9 | 56.2 | – | – | 否 | – |
| DGNav | 2026 | R2R-CE | 64.82 | 50.08 | – | – | 是 | – |
| DualVLN | 2025 | R2R-CE | 64.3 | 58.5 | 4.05 | 70.7 | 是 | – |
| VLN-Cache | 2026 | R2R-CE | 63.1 | 57.6 | – | – | 否 | – |
| GA-VLN | 2026 | R2R-CE | 61.0 | 55.2 | 4.80 | 67.6 | 是 | |
| JanusVLN | 2026 | R2R-CE | 60.5 | 56.8 | 4.78 | 65.2 | 是 | – |
| BudVLN | 2026 | R2R-CE | 57.6 | 51.1 | – | – | 是 | – |
| StreamVLN | 2025 | R2R-CE | 56.9 | 51.9 | 4.98 | 64.2 | 是 | – |
| Goal2Pixel | 2025 | R2R-CE | 54.1 | 52.5 | 4.85 | 59.9 | 否 | – |
| MapNav | 2025 | R2R-CE | 53.0 | 39.7 | – | – | 是 | – |
| HSGM | 2026 | R2R-CE | 47.9 | 32.8 | 5.42 | 58.7 | 是 | – |
| TopoGraph-VLN | 2025 | R2R-CE | 41.0 | 25.4 | 6.12 | 55.0 | 否 | – |
| VLN-R1 (Qwen2-VL-7B) | 2025 | R2R-CE | 30.2 | 21.8 | 7.0 | 41.2 | 是 | – |
| VLN-R1 (Qwen2-VL-2B) | 2025 | R2R-CE | 25.6 | 20.5 | 10.2 | 37.5 | 是 | – |
| OneVLA | 2026 | R2R-CE | – | – | – | 68.6 | 是 | 仅评估 OSR |
注:NavFoM 为单视角 VLN-CE R2R 结果;DualVLN 与 StreamVLN 为同口径单视角对比;VLN-Cache 为对 DualVLN 的加速方案,几乎无损(基线 64.3 / 58.5)。
② 指令跟随 · 连续环境 - 多语言
| 模型 | 年份 | 基准 | SR ↑ | SPL ↑ | NE ↓ | OSR ↑ | 开源 | 备注 |
|---|---|---|---|---|---|---|---|---|
| Qwen-RobotNav-8B (全景) | 2026 | RxR-CE | 76.5 | 65.7 | 3.58 | – | 否 | 全景相机 |
| OmniNav | 2026 | RxR-CE | 73.6 | 62.0 | 3.77 | – | 是 | 三目全景相机 |
| Qwen-RobotNav-8B (单目) | 2026 | RxR-CE | 73.4 | 63.5 | – | – | 否 | 单前向相机 |
| AstraNav-World | 2025 | RxR-CE | 72.9 | – | – | – | 是 | – |
| ABot-N0 | 2026 | RxR-CE | 69.3 | 60.0 | – | – | 否 | – |
| AwareVLN | 2026 | RxR-CE | 67.6 | 56.1 | 3.95 | – | 是 | – |
| SEDualVLN | 2026 | RxR-CE | 63.9 | 52.4 | 4.12 | – | 是 | nDTW=72.8 |
| Dual-Anchoring | 2026 | RxR-CE | 61.7 | 53.3 | – | – | 否 | – |
| DualVLN | 2025 | RxR-CE | 61.4 | 51.8 | 4.58 | – | 是 | – |
| JanusVLN | 2026 | RxR-CE | 56.2 | 47.5 | 6.06 | – | 是 | – |
| RynnBrain-Nav-8B | 2026 | RxR-CE | 56.1 | – | 4.92 | – | 是 | – |
| GA-VLN | 2026 | RxR-CE | 55.4 | 45.2 | 5.88 | 67.0 | 是 | 代码与模型权重已开源 |
| StreamVLN | 2025 | RxR-CE | 52.9 | – | – | – | 是 | – |
| Goal2Pixel | 2025 | RxR-CE | 43.8 | 40.4 | 7.50 | – | 否 | – |
| HSGM | 2026 | RxR-CE | 41.8 | 25.1 | 7.43 | – | 是 | – |
| TopoGraph-VLN | 2025 | RxR-CE | 35.7 | 21.7 | 7.56 | – | 否 | – |
| VLN-R1 (Qwen2-VL-7B) | 2025 | RxR-CE | 22.7 | 17.6 | 9.1 | 30.4 | 是 | – |
| VLN-R1 (Qwen2-VL-2B) | 2025 | RxR-CE | 20.7 | 16.9 | 10.2 | 30.1 | 是 | – |
| OneVLA | 2026 | RxR-CE | – | – | – | 58.2 | 是 | 仅评估 OSR |
注:RynnBrain-Nav-8B 指标来自 RxR-CE(R2R 结果未详述);Dual-Anchoring 与 StreamVLN 基线(52.9%)对比来自 Dual-Anchoring 原文。
③ 指令跟随 · 离散全景
| 模型 | 年份 | 基准 | SR ↑ | SPL ↑ | NE ↓ | OSR ↑ | 开源 | 备注 |
|---|---|---|---|---|---|---|---|---|
| VLN-Imagine (DUET) | 2025 | R2R | ≈80.9 | ≈74.3 | – | – | 是 | – |
| Uncertainty-Aware Gaussian Map | 2026 | R2R | 78.3 | 66 | – | – | 是 | – |
| R³ | 2026 | R2R | 77 | 66 | 2.76 | – | 是 | – |
| CA-VLN | 2026 | R2R | 73.3 | 62.0 | 3.03 | – | 是 | – |
| NavGPT-2 | 2024 | R2R | 71 | 60 | 3.18 | 80 | 是 | – |
| Slow4fast-VLN | 2026 | GSA-R2R (ID) | 70.8 | 65.0 | 2.9 | – | 否 | – |
| GR-DUET | 2024 | GSA-R2R (ID) | 69.3 | 64.3 | 3.1 | – | 是 | – |
| Slow4fast-VLN | 2026 | GSA-R2R (OOD) | 58.4 | 52.9 | 4.2 | – | 否 | – |
| GR-DUET | 2024 | GSA-R2R (OOD) | 56.6 | 51.5 | 4.4 | – | 是 | – |
| CA-VLN | 2026 | REVERIE | 51.0 | 35.5 | – | 56.3 | 是 | – |
| NavGPT (零样本 GPT-4) | 2024 | R2R | 34 | 29 | – | 42 | 是 | GPT-4 零样本 |
注:VLN-Imagine 在 DUET(基线 79.9 / 73.75)基础上于 val-unseen 约 +1.0 SR / +0.5 SPL,绝对值为估算。GSA-R2R 区分住宅(ID,Test-R-Basic)与非住宅(OOD,Test-N-Basic)场景,Slow4fast-VLN 相对 GR-DUET 性能有所提升。REVERIE 基准另用 RGS / RGSPL 指标:R³ 为 53.76 / 42.14 / 37.94 / 29.86(SR/SPL/RGS/RGSPL),Uncertainty-Aware Gaussian Map 的 RGS / RGSPL 为 37.65 / 27.01。
④ 目标导航 / 实例图像导航
| 模型 | 年份 | 基准 | SR ↑ | SPL ↑ | 开源 |
|---|---|---|---|---|---|
| Hydra-Nav | 2026 | HM3D | 84.8 | 28.8 | 否 |
| VLFM | 2023 | Gibson | 84.0 | 52.2 | 是 |
| VLingNav | 2026 | HM3D-v2 | 83.0 | 40.5 | 是 |
| SysNav | 2026 | HM3D-v2 | 80.8 | 37.2 | 否 |
| WAM-Nav | 2026 | Clutter/Intern (Point-Goal) | 80.4 | 78.0 | 否 |
| 3DGSNav | 2026 | HM3D-v1 | 80.0 | 51.8 | 否 |
| VLingNav | 2026 | HM3D-v1 | 79.1 | 42.9 | 是 |
| NavDP | 2025 | Clutter/Intern (Point-Goal) | 77.8 | 74.8 | 是 |
| Qwen-RobotNav-4B | 2026 | HM3Dv2 | 75.6 | 30.6 | 否 |
| 3DGSNav | 2026 | HM3D-v2 | 75.0 | 44.2 | 否 |
| GaussNav | 2025 | HM3D(实例图像) | 72.5 | 57.8 | 是 |
| Qwen-RobotNav-8B | 2026 | HM3Dv2 | 71.2 | 33.0 | 否 |
| LagMemo | 2025 | GOAT-Core | 70.8 | – | 否 |
| GSMem | 2025 | GOAT-Bench | 67.2 | 46.9 | 是 |
| EvoMemNav | 2026 | HM3D-v2 | 63.8 | 39.4 | 否 |
| VLingNav | 2026 | HM3D (实例图像) | 60.8 | 37.4 | 是 |
| EvoMemNav | 2026 | GOAT-Bench | 59.6 | 38.9 | 否 |
| EvoMemNav | 2026 | HM3D-v1 | 59.2 | 33.6 | 否 |
| OmniNav | 2026 | HM3D-OVON (Object-Goal), Val-Unseen | 59.2 | 33.2 | 是 |
| VLingNav | 2026 | MP3D | 58.9 | 26.5 | 是 |
| ABot-N0 | 2026 | HM3D-OVON | 54.0 | – | 否 |
| Qwen-RobotNav-4B | 2026 | HM3D-OVON (Unseen) | 53.1 | 20.9 | 否 |
| VLFM | 2023 | HM3D | 52.5 | 30.4 | 是 |
| Qwen-RobotNav-8B | 2026 | HM3D-OVON (Unseen) | 51.2 | 24.0 | 否 |
| WAM-Nav | 2026 | Clutter/Intern (Image-Goal) | 50.2 | 48.2 | 否 |
| VLingNav | 2026 | HM3D-OVON | 50.1 | 24.6 | 是 |
| AstraNav-World | 2025 | HM3D-OVON | 45.7 | – | 否 |
| NavFoM | 2025 | HM3D-OVON | 45.2 | – | 否 |
| JanusVLN | 2026 | HM3D-OVON | 44.9 | 31.7 | 是 |
| 3DGSNav | 2026 | MP3D | 43.6 | 21.3 | 否 |
| PanoNav | 2025 | HM3D | 43.5 | 23.7 | 否 |
| NavDP | 2025 | Clutter/Intern (Image-Goal) | 43.4 | 41.4 | 是 |
注:各行基准数据集 / 任务及物理模型不同(HM3D-v1与v2、Gibson、OVON、GOAT、实例图像导航IIN、以及IsaacSim下的Clutter/Intern等口径各异),SR不可直接横比;ObjectNav系列不定义NE/OSR。GSMem的GOAT-Bench为多模态长程导航;WAM-Nav与NavDP的Clutter/Intern包含Image-Goal与Point-Goal两类任务,采用端到端扩散/世界模型高频输出轨迹控制动作。SysNav同时报告HM3D-v1(63.7/30.5)、MP3D(50.7/18.1)、HM3D-OVON(54.9/26.1);VLFM另有MP3D(36.4/17.5)。
说明:以下论文因评测于真实世界 / 自建或非标准基准(如 Open-Nav、SparseVideoNav、CausalNav、VL-Nav 等),或属运动控制 / 操作 / 生成等非导航指标任务(Skill-Nav、RoboClaw、ABot-Claw 等),或为依赖性基础工作,未列入上述指标表。详见各自章节。
具身导航经典论文
1. DualVLN/InternVLN (2025)
——Ground Slow, Move Fast
📄 Paper: arXiv:2512.08186
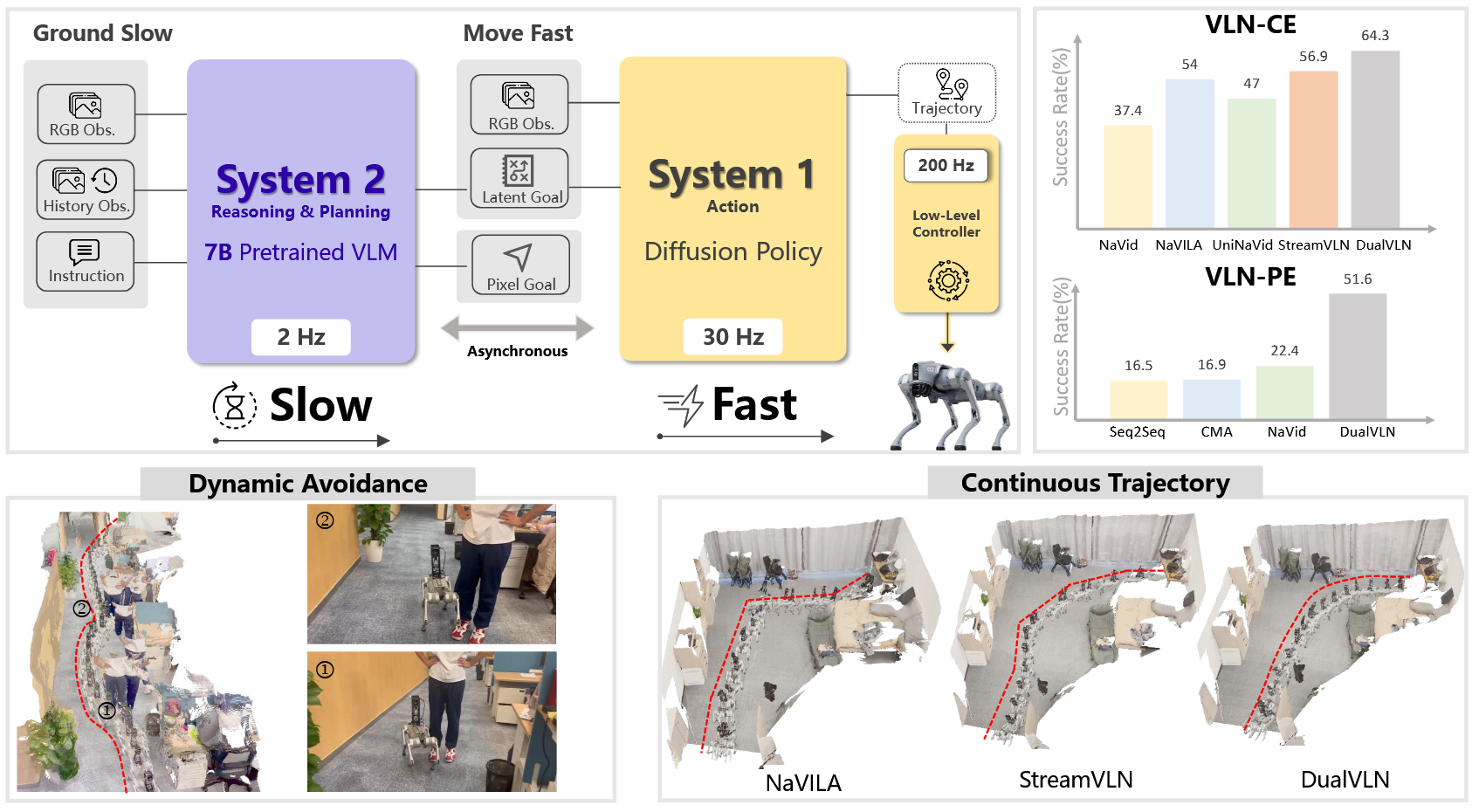
研究背景/问题
VLN领域存在基本矛盾:强大的推理能力需要”慢思考”,而流畅的导航行动需要”快反应”。传统端到端模型存在三大瓶颈:
- 动作碎片化:每一步都需调用大模型,产生离散的短视野动作(如”前进0.25m”)
- 响应延迟高:无法实现高频控制(30Hz+),导致运动不自然
- 缺乏层次协调:语义理解、全局规划和局部避障耦合在一起,难以应对动态障碍物
主要方法/创新点
DualVLN提出首个双系统VLN基础模型,将高级语义理解与低级轨迹执行解耦,形成互补的快慢系统:
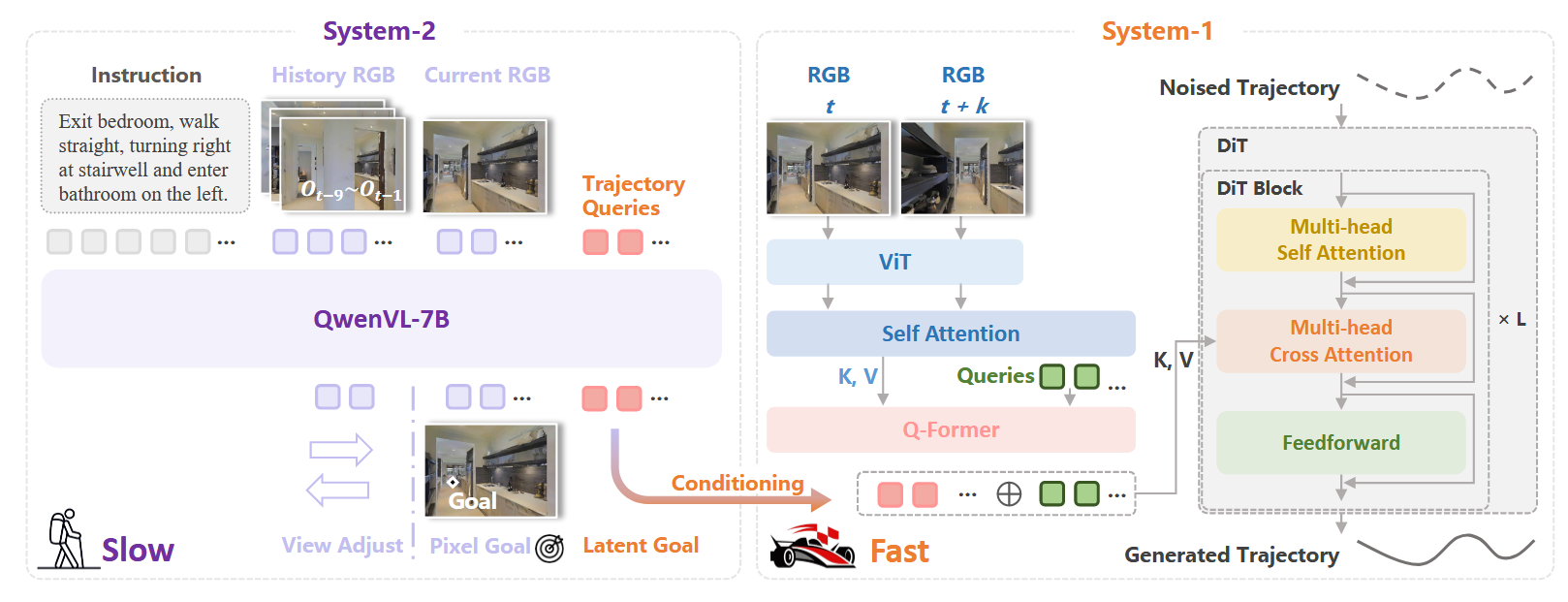
系统2(慢思考的”大脑”)
核心功能:
- 全局规划器:基于Qwen-VL-2.5(7B参数),以约2 Hz频率运行
- 像素级目标预测:将3D导航任务转化为2D像素级目标定位问题
- 自动生成训练数据:
- 通过3D→2D投影,将未来轨迹点投影到当前视角
- 利用深度图过滤遮挡点(距离>深度值的点被视为不可见)
- 选择最远可见点作为”像素目标”(farthest pixel goal)
- 智能视角调整:
- 当未来轨迹无法投影到当前视角时(如连续转弯动作的起点)
- 自主预测视角调整动作(Turn Left/Right 15°, Look Up/Down 15°)
- 最多支持4次连续视角调整,模仿人类”环顾四周、低头看路”的行为
设计动机:为什么是”最远可见路点” + “最多 4 次连续转向”
这两个看似不起眼的取舍,恰恰决定了双系统能否高效协同:
- 为什么选”最远”的路点:在仍然可见(未被遮挡)的前提下取最远的投影点,等于给系统1尽可能长的前瞻目标——horizon 越长,系统2的高层调用越稀疏(2Hz 即够用),系统1也能跟踪更长、更稳定的轨迹段,减少频繁急停急转。
- 为什么强制”可见”:用深度图过滤掉”距离 > 深度值”的被遮挡点,保证像素目标始终落在当前可观测的自由空间内,不会把目标放到墙后/障碍后的点上(否则反投影到世界坐标会产生严重的深度歧义)。
- 两端的权衡:目标取得太远 → 易被遮挡、且把地板点人为抬高会引入深度歧义;取得太近 → 系统2调用过频、退化为”一步一问”。”最远可见”正是 horizon 与可达性之间的平衡点。
- 为什么转向要”分块且封顶 4 次”:当下一路点落在视野(FOV)之外时(急转弯/连续转向起点),系统2先输出转向动作再 ground 像素目标。这里沿用了 StreamVLN 的动作分块(action chunk)设计——一次
model.generate()产出一个 chunk 的动作,”4 个一组”在推理成本(StreamVLN 实测 4 动作仅 ~0.27s/次)与规划粒度之间取得平衡;4×15°=60° 已足以把多数下一路点重新转入视野。 - 为什么要封顶:限制单 chunk 最多转 60°,是为了避免开环过度旋转 / 原地打转——转够 60° 后必须重新观测、用新视觉证据再决策,而不是盲目地一口气转 180°,这与”看一眼→微调朝向→再确认”的人类行为一致。
训练策略(Stage 1:监督微调 Qwen-VL-2.5):
系统2被训练为根据”历史观测 + 当前帧 + 语言指令”自回归地输出三类动作,三者在同一段对话序列里统一建模:
| 输出类型 | 触发条件 | 监督信号 |
|---|---|---|
| 视角调整(View Adjustment) | 未来轨迹无法投影到当前视角(如连续转弯的起点) | 离散转向动作序列(Turn Left/Right 15°、Look Up/Down 15°),每个 chunk 最多预测 4 个连续转向 |
| 像素目标(Pixel-Goal Grounding) | 当前视角中至少有一个未来路点可见 | 监督模型输出最远可见路点的像素坐标文本(如 234 447) |
| STOP | 任务完成 | 对话序列的最后一步监督输出 STOP |
对话模板(监督格式,见原文附录 A.1)——三类输出被统一在同一段多轮对话里监督,模型自行决定每一步该”转头看”还是”给目标”还是”停”:
User: You are an autonomous navigation assistant. Your task is <instruction>.
... These are your historical observations: <history>.
Your current observation is <image>.
Assistant: → → → → # ① 视角调整:4 个箭头 = Turn right 60°(未来路点不可见时先转头)
Assistant: 234 447 # ② 像素目标:最远可见路点的像素坐标文本
Assistant: STOP # ③ 终止:判定任务完成
- 离散真值动作集:
0: STOP、1: Move forward 25cm、2: Turn left 15°、3: Turn right 15°;像素目标样本由 3D→2D 投影 + 深度可见性过滤后,从原始 VLN-CE 轨迹切分得到 - 全量微调:视觉编码器与 LLM 骨干全部解冻,训练 1 个 epoch
- 优化器:AdamW,初始学习率 2e-5,批量大小 128(对话样本),共 14,000 步
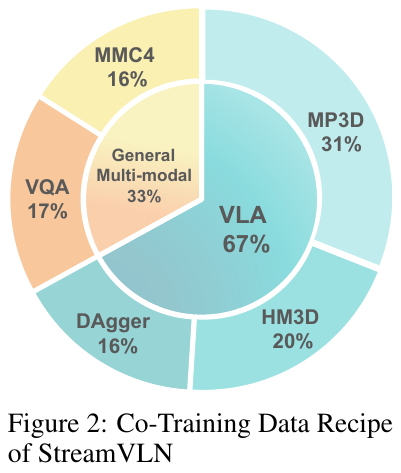
数据配方(沿用 StreamVLN 的协同训练配方 Co-Training Recipe):系统2并非只喂导航数据,而是按 VLA 导航数据 67% : 通用多模态数据 33% 的比例协同训练,后者用于保住预训练 Video-LLM 的通用推理能力、防止灾难性遗忘。总量约 147 万样本,构成如下:
| 大类 | 子集 | 占比 | 规模 | 来源 / 作用 |
|---|---|---|---|---|
| VLA 导航(67%) | MP3D | 31% | 450K | R2R / R2R-EnvDrop / RxR,60 个 Matterport3D 场景 |
| HM3D | 20% | 300K | ScaleVLN 子集,700 个 HM3D 场景(提升场景多样性) | |
| DAgger | 16% | 240K | 用 Habitat 最短路径专家在模型 rollout 上采集的纠错示范(增强误差恢复与泛化) | |
| 通用多模态(33%) | VQA | 17% | 248K | LLaVA-Video-178K + ScanQA(视频问答 + 3D 场景理解,强化时空/几何推理) |
| MMC4 | 16% | 230K | 图文交错样本(强化多轮视觉-语言交互) |
注:上述比例与规模是 StreamVLN 的原始配方;DualVLN 直接沿用,区别在于把其中的 VLN-CE 轨迹重新切分为”最远像素目标 grounding + 视角调整 + STOP”的对话样本用于系统2监督。
系统1(快行动的”小脑”)
核心功能:
- 高频轨迹生成:轻量级扩散Transformer策略,以30 Hz频率运行
- 多模态条件扩散:
- 显式像素目标:提供可解释的空间引导
- 隐式潜在目标:从系统2的隐藏状态中提取丰富的任务相关语义
- 语义特征提取:
- 在像素目标文本后追加4个可学习的特殊token
<TRAJ> - 通过prompt tuning优化这些潜在查询向量
- 从冻结的VLM最后一层隐藏状态中提取紧凑特征
- 在像素目标文本后追加4个可学习的特殊token
- 双时间步RGB融合:
- 编码系统2最后一帧(时间t)和当前帧(时间t+k)
- 通过自注意力融合两个时间步的ViT特征
- 用Q-Former压缩为32个token,作为高频视觉条件
- Flow Matching训练:
- 噪声轨迹:$X_u = \alpha_u X_0 + \sigma_u \epsilon$
- 速度预测:$\hat{\dot{X}}u = f\theta(X_u, u, Z’ \oplus F)$
- 损失函数:$\mathcal{L}{flow} = \mathbb{E}{u,X_0,\epsilon}[|\hat{\dot{X}}_u - \dot{X}_u|_2^2]$
架构细节:
- RGB编码器:DepthAnythingV2-Small的ViT骨干
- DiT设计:隐藏维度384,12层Transformer,6个注意力头
- 潜在嵌入:从3584维线性投影到768维后进行交叉注意力
- 输出:32个密集路径点的平滑轨迹
训练策略(Stage 2:参数高效地训练扩散策略):
冻结整个系统2(Qwen-VL),端到端地只训练”潜在查询 + DiT 扩散策略”两个轻量模块,以 Flow Matching 目标监督轨迹生成:
| 可训练模块 | 作用 |
|---|---|
潜在查询(4 个 <TRAJ> token 对应的可学习嵌入) |
从冻结 VLM 的最后一层隐藏状态中提取紧凑的潜在目标表征 |
| DiT 扩散策略 | 以潜在目标 + 高频 RGB 为条件,生成平滑、避障的世界坐标轨迹 |
潜在目标的提取机制(见原文附录 A.2):在像素目标文本末尾追加 4 个 <TRAJ> 特殊 token,把它们的词嵌入替换为可学习的 latent queries,再过一遍冻结的 QwenVL;取最后一层、末尾 4 个 token 位置的隐藏状态作为 pixel_goal_latents,条件化 DiT:
inputs_embeds = QwenVL.embed_tokens(input_ids)
traj_idx = (input_ids == TRAJ_TOKEN) # 定位 4 个 <TRAJ>
inputs_embeds[traj_idx] = latent_queries # 替换为可学习查询(prompt tuning)
hidden = QwenVL.forward(inputs_embeds)
pixel_goal_latents = hidden[-1][:, -4:, :] # 最后一层、末尾 4 个位置
noise_pred = DiT(traj_encoder(gt_rel_poses), timestep, pixel_goal_latents)
这样系统1的梯度只回传到 latent queries 与 DiT,VLM 本体保持冻结,是一种参数高效的端到端训练。
- 轨迹标签预处理:将离散动作路点通过插值重采样为 32 个等间隔的平滑路点,作为扩散策略的监督目标
- 关键设计:仅使用像素目标 grounding 样本进行轨迹监督(不含视角调整样本),使扩散策略学到的是”朝目标平滑前进”而非离散转向
- 优化器:AdamW,初始学习率 1e-4,批量大小 128(轨迹样本),共 15,000 步

协同机制
异步推理流水线:
- 系统2(2Hz):每0.5秒生成新的像素目标和潜在特征
- 系统1(30Hz):每0.03秒基于最新RGB和缓存的潜在特征更新轨迹
- 低级控制器(200Hz):MPC控制器跟踪系统1生成的轨迹
- 关键优势:利用KV-cache复用,将系统2推理时间从1.1s降至0.7s;系统1用TensorRT并行生成32个轨迹点仅需0.03s
训练范式:两阶段渐进式解耦训练
DualVLN 的核心训练理念是解耦的、渐进式两阶段训练(progressive two-stage decoupled training),而非把两个系统端到端联合优化。整体流程为:
- Stage 1 — 训练系统2:以”最远像素目标 grounding”任务全量微调 Qwen-VL-2.5(同时学会视角调整与 STOP),得到一个泛化能力强的高层规划器;
- Stage 2 — 冻结系统2、训练系统1:固定系统2权重,引入可学习潜在查询并通过 prompt tuning 优化,再以 Flow Matching 训练 DiT 扩散策略,把像素/潜在目标翻译为连续轨迹。
为什么要解耦顺序训练?
- 各司其职、按需扩展:系统2是”数据饥饿”的 VLM,可随大规模、多源推理数据持续扩展;系统1只需少量低级目标到达数据即可快速饱和(消融显示仅用系统2约 10% 的轨迹数据,系统1性能就已接近上限)
- 保住 VLM 泛化:若改为联合端到端训练,VLM 的泛化能力会严重退化、扩散策略也收敛缓慢(消融中 w/o Sys.2 Train 掉 9.1% SR);解耦训练用显式像素目标作为中间监督,既保住 VLM 先验,又让低级策略训练高效
- 解耦控制频率:系统1独立享有高频 RGB 输入与异步推理,从而在动态场景下实现 30Hz 控制
为什么显式像素目标 + 隐式潜在目标缺一不可?
- 仅用显式 2D 像素目标,会把双系统退化为浅层耦合的”模块化管线”,无法利用 VLM 丰富的隐藏特征
- 显式像素目标先提升系统2的可解释性与泛化;在此之上,隐式潜在特征再为系统1提供更丰富、可自适应的引导,使其主动从 VLM 的异构隐藏状态中抽取任务相关表征
核心结果/发现
1. 仿真基准测试(VLN-CE)
R2R Val-Unseen(仅单视角RGB输入)
| 方法 | SR ↑ | SPL ↑ | NE ↓ | OS ↑ |
|---|---|---|---|---|
| StreamVLN(前SOTA) | 56.9% | 51.9% | 4.98m | 64.2% |
| DualVLN | 64.3% | 58.5% | 4.05m | 70.7% |
| 提升幅度 | +7.4% | +6.6% | -0.93m | +6.5% |
RxR Val-Unseen(多语言指令)
| 方法 | SR ↑ | SPL ↑ | NE ↓ | nDTW ↑ |
|---|---|---|---|---|
| NaVILA(前SOTA) | 49.3% | 44.0% | 6.77m | 58.8% |
| DualVLN | 61.4% | 51.8% | 4.58m | 70.0% |
| 提升幅度 | +12.1% | +7.8% | -2.19m | +11.2% |
关键观察:
- 在RxR基准上,DualVLN的优势更明显(+12.1% SR),说明双系统设计对复杂多语言指令有更好的泛化能力
- 与使用全景RGB+深度+里程计的多传感器方法(如ETPNav)相比,DualVLN仅用单视角RGB即达到更高的64.3% SR(ETPNav仅57.0%)
2. 物理仿真基准(VLN-PE)
R2R Val-Unseen(Humanoid H1机器人)
| 方法 | SR ↑ | SPL ↑ | NE ↓ | FR ↓ | StR ↓ |
|---|---|---|---|---|---|
| NaVid(零样本迁移) | 22.42% | 18.58% | 5.94m | 8.61% | 0.45% |
| RDP(在VLN-PE上训练) | 25.24% | 17.73% | 6.72m | 24.57% | 3.11% |
| DualVLN(零样本迁移) | 51.60% | 42.49% | 4.66m | 12.32% | 2.23% |
关键发现:
- 尽管DualVLN未在VLN-PE上微调,但仍大幅超越所有基线(包括在VLN-PE上训练的方法)
- 成功率提升超过2倍(51.60% vs 22.42%),证明双系统设计对物理真实环境有更强的泛化能力
- 跌倒率(FR)虽高于NaVid,但成功率显著提升,表明DualVLN在探索效率和安全性之间取得了更好的平衡
3. Social-VLN基准(动态障碍物)
新基准设计:
- 在R2R-CE基础上,沿ground-truth轨迹放置动态人形机器人(Habitat 3.0)
- 引入Human Collision Rate(HCR)指标,量化与行人的不安全交互
- 收集763K社交导航样本(60个MP3D场景),用改进的A*算法生成避障轨迹
性能对比(R2R Val-Unseen):
| 方法 | 静态VLN SR | Social-VLN SR | SR下降 | HCR |
|---|---|---|---|---|
| StreamVLN | 56.9% | 31.4% | -25.5% | 36.4% |
| DualVLN | 64.3% | 37.2% | -27.1% | 35.4% |
关键观察:
- 两种方法的成功率都大幅下降(~26%),说明Social-VLN极具挑战性
- DualVLN在动态场景中仍保持6%的绝对优势,HCR略低于StreamVLN
- 改进空间:尽管DualVLN表现最佳,但仍有很大提升空间(37.2% SR远低于静态场景的64.3%)
4. 真实世界跨具身实验
实验设置:
- 机器人平台:轮式(Turtlebot4)、四足(Unitree Go2)、人形(Unitree G1)
- 传感器配置:Intel RealSense D455(不同安装高度,下倾15°)
- 推理硬件:远程服务器(RTX 4090 GPU,占用20GB显存)
- 控制流程:机器人流式传输RGB-D图像 → 服务器异步推理(输出连续轨迹或离散视角调整动作)→ 经里程计转换为世界坐标 → MPC控制器跟踪
- 评测协议:3 种难度场景,每个场景每个模型 20 次试验,以 SR 与 NE 度量;基线为输出离散动作的 CMA 及 VLM 方法 NaVid / NaVILA / StreamVLN
定量评估(3种场景难度):
- 走廊(简单):DualVLN SR 100% vs 基线25%-80%
- 单卧室(中等):DualVLN SR 100% vs 基线0%-70%
- R2R办公室(困难,跨房间):DualVLN SR 85% vs 基线0%-60%
导航误差对比:
| 场景 | CMA | NaVid | NaVILA | StreamVLN | DualVLN |
|---|---|---|---|---|---|
| 走廊 | 3.2m | 0.9m | 0.3m | 0.2m | 0.2m |
| 卧室 | 5.3m | 2.5m | 0.6m | 0.3m | 0.3m |
| 办公室 | 15.4m | 10.1m | 2.2m | 0.5m | 0.4m |
各基线的典型失败模式(Figure 6 实拍分析):
- NaVid:难以应对复杂、长指令任务,易中途碰撞或迷失方向
- NaVILA:能跟随长程指令,但在办公室跨房间场景中常错失最终目标(miss goal)
- StreamVLN:低动作延迟使其部分情况下能避障,但以牺牲任务完成为代价(偏离轨迹或提前停止)
- DualVLN:在静态与动态场景下都同时保持高 SR、低 NE,是唯一稳定完成跨房间困难任务的方法
定性分析(见补充视频):
- 场景多样性:办公室、食堂、街道、便利店,零样本设置(无场景特定微调)
- 像素目标精准:准确选择安全、可达的像素目标
- 轨迹流畅性:生成平滑、避障的连续轨迹,避免频繁停止或转向
- 地形适应性:成功处理楼梯、斜坡、门槛等复杂地形
- 动态避障:实时躲避行走的行人,保持任务轨迹
- 跨平台鲁棒性:在不同相机高度、振动、跟踪精度下表现稳定
5. 消融实验
5.1 目标表征的作用
实验设计(R2R Val-Unseen):
- w/o Sys.2 Train:系统1和系统2联合端到端训练,不使用显式像素目标
- w/o Pixel Goal:训练系统1时,移除像素目标文本(潜在查询无法关注显式目标)
- w/o Latent Goal:仅使用冻结VLM的像素目标文本的最后一层隐藏状态
结果对比:
| 配置 | SR | SPL | OS | NE |
|---|---|---|---|---|
| DualVLN(完整) | 64.3% | 58.5% | 70.7% | 4.05m |
| w/o Sys.2 Train | 55.2% | 51.5% | 60.9% | 4.98m |
| w/o Pixel Goal | 62.2% | 55.8% | 68.0% | 4.22m |
| w/o Latent Goal | 60.9% | 55.1% | 67.7% | 4.26m |
关键发现:
- 解耦训练至关重要(w/o Sys.2 Train -9.1% SR):
- 联合训练导致扩散策略收敛缓慢
- 系统2的泛化能力严重退化
- 证明了显式像素目标作为中间监督的必要性
- 显式像素目标增强可解释性(w/o Pixel Goal -2.1% SR):
- 为扩散策略提供明确的空间引导
- 提升系统2的可解释性和泛化能力
- 仅依赖隐式特征会损失部分性能
- 隐式潜在目标提供丰富语义(w/o Latent Goal -3.4% SR):
- 被动使用固定VLM特征限制了信息流
- 可学习的潜在查询能主动提取任务相关表征
- 两种目标表征互补,缺一不可
5.2 与SOTA点目标导航策略对比
实验设计(VLN-PE R2R,flash controller):
- 移除隐式潜在目标,并借助额外的 oracle 深度把显式像素目标投影成点目标
- 用SOTA点目标导航策略替换系统1:
- iPlanner:命令式路径规划(Yang et al., 2023)
- NavDP:导航扩散策略(Cai et al., 2025)
结果对比(即便给点目标方法喂 oracle 深度,模块化管线仍全面落后):
| 局部规划器 | Seen SR | Seen SPL | Unseen SR | Unseen SPL | Unseen NE |
|---|---|---|---|---|---|
| iPlanner | 58.66% | 49.43% | 47.07% | 41.09% | 4.91m |
| NavDP | 66.11% | 56.26% | 58.72% | 50.98% | 4.22m |
| System 1(完整) | 73.25% | 64.00% | 63.62% | 56.49% | 3.90m |
性能差距分析:
- 轨迹分布不匹配:
- 点目标规划器生成的轨迹与系统2训练数据分布不同
- 导致系统2的像素目标预测质量下降
- 像素目标误差的鲁棒性差异:
- 系统1:对方向正确但位置偏差的像素目标具有鲁棒性,能通过实时RGB修正轨迹
- 点目标方法:直接将像素投影到世界坐标,对微小像素误差高度敏感
- 特例:当像素目标语义错误(如目标在障碍物上)或机器人靠近障碍物时,系统1的鲁棒性也会失效
- 避障能力:
- 系统1展现出强大的视觉避障行为(基于高频RGB输入)
- 点目标方法更依赖精确的几何信息,对传感器噪声更敏感
5.3 系统1的数据缩放规律
实验设计:
- 使用系统2轨迹数据的不同比例训练系统1:1%, 5%, 10%, 30%, 50%
- 评估SR和SPL在R2R Val-Unseen上的变化
结果曲线:
- 1%:SR ~54%, SPL ~54%(已具备竞争力)
- 10%:SR ~62%, SPL ~58%(接近饱和)
- 50%:SR ~64%, SPL ~58.5%(边际收益递减)
关键洞察:
- 系统1是轻量级的:
- 设计为快速、简单的轨迹生成器
- 目标跟踪任务本质上比语义理解简单
- 与系统2的数据缩放对比:
- 系统2遵循VLM的数据饥饿特性(更多多样化数据→更好泛化)
- 系统1快速饱和,表明其性能上限取决于系统2的质量
- 训练效率:
- 仅需系统2数据的10%即可训练出高性能系统1
- 进一步证明了解耦训练的优势
5.4 像素目标与轨迹的一致性分析
实验设计:
- 随机采样1000个样本,来自不同成功率的DualVLN模型(64.3%, 60.9%, 58.2%, 56.8%)
- 将预测轨迹投影到图像平面,计算与像素目标的:
- 像素距离:投影轨迹点到像素目标的欧氏距离
- 角度偏差:轨迹方向与像素目标方向的夹角
可视化结果(见Figure 10):
- 密度集中在左下角:大多数点的像素距离和角度偏差都很小
- 趋势一致:所有成功率模型都显示轨迹朝向像素目标并到达其附近区域
- 性能相关性:成功率越高的模型,密度集中度越高(轨迹-目标一致性越强)
结论:
- 系统1的轨迹预测强烈受像素目标引导
- 验证了双系统设计的有效性:系统2提供明确目标,系统1忠实执行
6. 注意力机制分析
可视化方法(见Supplementary Material Figure 11):
- 提取Qwen-VL不同层(第6、15、24层)的注意力图
- 关注两个模态:语言指令token 和 视觉token(历史帧+当前观察)
层级分析:
- 浅层(Layer 6):
- 注意力分散在整个场景和指令的多个词汇
- 关注通用的上下文和空间线索(如物体、场景布局、方向词)
- 中层(Layer 15):
- 注意力开始聚焦到目标相关区域
- 指令中的关键词(如”table”, “bridge”)获得更高权重
- 深层(Layer 24):
- 注意力高度集中在精确的像素目标区域
- 同时对STOP token分配显著权重(用于任务完成判断)
- 证明模型在最后阶段整合视觉和语言线索进行最终决策
关键发现:
- 逐层精化:从广泛的语义理解 → 逐步精确的空间定位
- 多模态融合:深层同时关注视觉目标和语言指令(特别是STOP信号)
- 任务完成感知:模型能自主判断何时到达目标(通过STOP token的注意力)
7. 推理效率分析
系统2优化:
- KV-cache复用:将轨迹token推理时间从1.1s降至0.7s(提速36%)
- 视角调整缓存:连续视角调整时重用已编码的历史图像特征
系统1优化:
- TensorRT加速:并行生成32个轨迹点仅需0.03s
- 异步推理:系统1持续运行在30Hz,不等待系统2更新
端到端延迟:
- 系统2更新周期:0.5s(2Hz)
- 系统1更新周期:0.033s(30Hz)
- 控制器频率:200Hz(MPC跟踪)
- 实际效果:机器人始终有最新轨迹可用,实现近实时、流畅的导航
局限性与未来方向
- 极端扰动鲁棒性:
- 在强烈相机抖动、光照剧变、遮挡等极端情况下性能下降
- 未来可引入更鲁棒的视觉编码器(如事件相机、多模态传感器融合)
- Sim-to-Real迁移效率:
- 虽然DualVLN展现出强大的零样本泛化能力,但仿真到真实的域差距仍存在
- 可探索域随机化、域自适应等技术进一步缩小差距
- 跨层表征对齐:
- 当前的潜在查询机制是单向的(系统2 → 系统1)
- 未来可探索双向反馈机制,让系统1的执行结果反馈到系统2的规划
- Social-VLN性能:
- 在动态场景中成功率仍有很大提升空间(37.2% vs 静态64.3%)
- 需要更多社交导航数据和显式的人-机器人交互建模
- 长视程泛化:
- 论文未详细评估超长指令(如跨楼层导航)的性能
- 未来可扩展到更大规模环境(如整栋建筑、园区级导航)
- 计算资源需求:
- 系统2(7B VLM)需要20GB显存,限制了边缘设备部署
- 可探索模型压缩、量化、知识蒸馏等技术实现轻量化
方法论贡献总结
- 首个双系统VLN基础模型:将认知科学的”双过程理论”引入具身导航
- 解耦训练范式:保留VLM泛化能力的同时,高效训练低级策略
- 显隐式目标协同:兼顾可解释性(像素目标)和表征丰富性(潜在特征)
- 异步推理架构:实现高频控制(30Hz)的同时保持低级别的感知-行动延迟
- Social-VLN基准:填补了VLN领域在动态场景评估上的空白
2. NavDP (2025)
——只用仿真数据训练,零样本迁移到真实机器人的导航扩散策略
📄 Paper: arXiv:2505.08712
一句话概括:NavDP 用纯仿真数据训练一个端到端导航网络,靠”扩散模型生成多条候选轨迹 + Critic 打分选最安全的一条“这一组合,做到零样本 sim-to-real、并能直接换装到 TurtleBot / Unitree Go2 / G1 / Galaxea R1 等不同形态的机器人上,全程不需要地图、不需要任何真机训练数据。
研究背景/问题
机器人要在动态、非结构化的开放世界里导航,理想状态是”换个机器人、换个场景都能直接用”。但现有两条路线都有硬伤:
- 传统模块化方法(感知 → 建图 → 定位 → 规划):系统延迟大、模块间误差层层累积,且要反复手调超参数;
- 学习型方法:受限于真实数据稀缺。靠真机遥操作采数据又慢又贵,难以 scale up。
NavDP(上海 AI Lab)的破题思路是全面拥抱仿真数据——仿真场景可以无限生成、自带”上帝视角”的特权信息(全局最优路径、全局 ESDF 距离场)。导航任务的物理交互远少于机械臂操作(manipulation),sim-to-real gap 本就更小,配合域随机化与高真实感渲染就能进一步弥合。问题随之变成两点:(1) 如何把仿真里的特权信息有效”蒸馏”进策略?(2) 如何保证策略在没见过的真实场景里安全?NavDP 的答案分别是模仿学习生成轨迹和对比式 Critic 评估轨迹。
NavDP 在双系统框架中的定位:NavDP 扮演快慢双系统(Fast-Slow System)里的 System 1——负责高频、实时的局部避障与路径规划,可无缝挂到 VLM 驱动的 System 2(负责语义理解、任务分解、长期记忆)之下,构成完整的开放世界导航能力。本文专注 System 1。
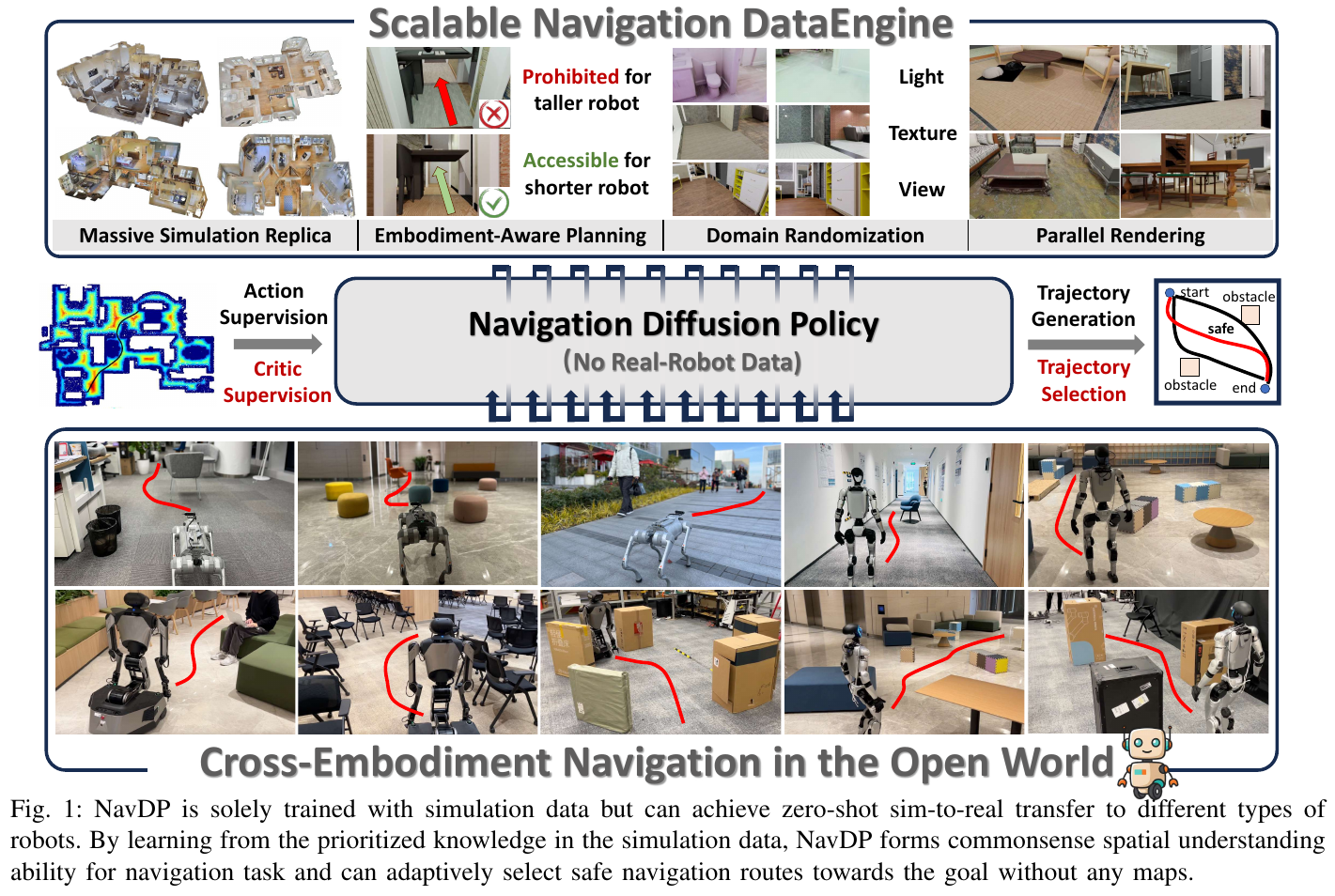
主要方法/创新点
NavDP 由两大支柱组成:(A) 可扩展的仿真数据引擎,负责高效造数据;(B) 统一的策略 Transformer,在一个共享网络里同时学”生成轨迹”(Actor 头)和”评估轨迹安全性”(Critic 头)。下面逐一拆解。
(A) 可扩展仿真数据引擎(DataEngine)
目标是把”造导航数据”做到又快又多样。流程是:
- 场景与本体建模:机器人简化为半径 $r_b=0.25\text{m}$ 的圆柱 + 两轮差速模型;为模拟不同机器人,随机化机器人高度(0.25–1.25 m)与相机俯仰角(−30°–0°),并提供两套相机 FOV(RealSense D435i 与 Zed 2)。高于相机配置高度的物体不计为障碍——这让”矮机器人能钻、高机器人要绕”成为数据里天然存在的常识。
- 生成无碰撞轨迹:把场景网格体素化(0.05 m)算出可通行区的 ESDF(欧氏符号距离场);A* 规划初始路径后,对每个路径点在局部做贪心搜索把它推离障碍更远,最后用三次样条插值平滑成连续轨迹。
- 域随机化 + 并行渲染:用 BlenderProc 渲染照片级 RGB-D,并施加光照 / 纹理 / 视角三类随机化提升多样性。
效率上达到 2500 条轨迹 / GPU / 天,比真机采集快约 20×;最终数据集覆盖 3154 个场景、约 1627 km、452 小时、4000 万张图片(见论文 Table I),在规模与多样性上全面超越以往导航数据集。
(B) 统一策略 Transformer(一个网络,两个任务)
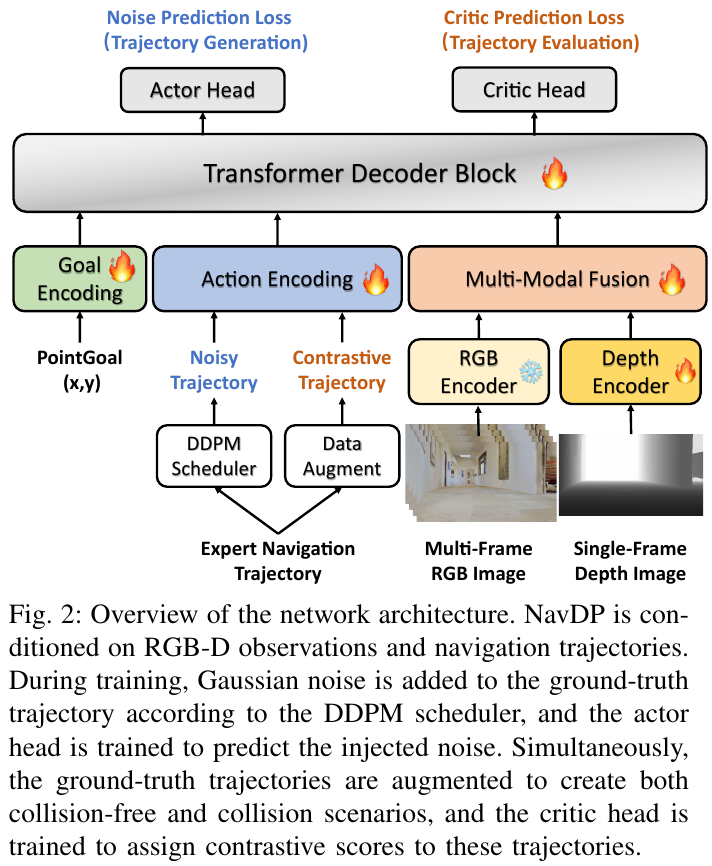
① 多模态编码(输入怎么进网络)
- RGB:取最近 $N=8$ 帧,用预训练并冻结的 DepthAnything 编码器,每帧抽 256 个 patch token(带入时序信息)。
- 深度:只取单帧深度,用一个从零训练的 ViT 编码(为对齐绝对物理尺度,利于轨迹生成);因深度图有 sim-to-real gap,只保留 (0.1 m, 5 m) 范围。
- 融合压缩:用带可学习 query 的轻量 transformer decoder,把 $(N+1)\times 256$ 个 token 压缩成 $N\times 16$ 个紧凑 token,降低后续计算量。
- 目标编码:遵循 PointGoal 定义,目标是相对当前位姿的 2D 坐标 $(x_g, y_g)$,经 MLP 投影到同一维度;无目标(NoGoal)探索任务则用全零张量当目标嵌入。
② Actor 头——扩散式轨迹生成 把专家轨迹按 DDPM 加噪,网络学习预测被注入的噪声,推理时从高斯噪声反复去噪得到一条由 $M=24$ 个密集路径点构成的轨迹。扩散过程天然能建模专家演示的多模态分布(同一处可能有”左绕”和”右绕”两条都对的路)。训练同时覆盖 PointGoal 与 NoGoal 两种目标,损失为两者噪声预测 MSE 的加权和(默认各 0.5)。
③ Critic 头——对比式轨迹评估(本文最关键创新) 这是 NavDP 区别于普通扩散策略的灵魂。纯模仿学习只见过”正确轨迹”,无法判断一条轨迹有多危险。NavDP 借用强化学习里的 Critic 价值函数思想:利用仿真里现成的全局 ESDF,给任意轨迹打一个”安全分”。具体地,对增广后的轨迹 $\hat\tau$,其在第 $m$ 个路径点上的 ESDF 值记作 \(d_{\hat\tau}^{m}\),标签价值定义为:
\[V(\hat\tau) = \gamma \cdot \sum_{m=0}^{M}(d_{\hat\tau}^{m+1} - d_{\hat\tau}^{m}) + \lambda \cdot \frac{1}{M}\sum_{m=0}^{M}\mathbb{I}(d_{\hat\tau}^{m} < d_{safe})\]直观理解:第一项奖励”越走离障碍越远”的趋势,第二项惩罚”靠得太近(小于安全阈值 $d_{safe}=0.5\text{m}$)”的路径点。训练时把专家轨迹做随机旋转增广,人为造出”碰撞 / 不碰撞”的对比样本喂给 Critic,让它学会区分安全与危险行为。
关键 insight:仿真专家轨迹因超参难调,常有轻微”贴边”现象。Critic 的真正价值不只是过滤碰撞,而是从一批候选里挑出安全裕度最大的那条,从而系统性提升 sim-to-real 的鲁棒性。
④ 推理流程:先生成、再选择 推理时 NavDP 先用 Actor 头一次性生成一批候选轨迹,再用 Critic 头给每条打分,选出价值最高(最安全)的一条执行。这就是”扩散生成多样性 + Critic 把关安全性”的两阶段闭环。下图把预测轨迹投影回图像、按 Critic 分值上色,蓝色=危险、红色=安全,直观展示 Critic 学到的空间常识:

训练配置:整个网络单阶段联合训练 Actor + Critic 两个损失之和;扩散步数 10、预测路径点 $M=24$、RGB 历史 $N=8$、安全阈值 0.5 m,用 32 张 A100、batch 2048 训练。
核心结果/发现
- PointGoal 点目标导航:仿真中 SR 67.2 / SPL 62.6,比此前最强的 ViPlanner(60.9 / 58.6)高 +6.3% SR;真机跨本体平均 SR 76.7%,比 ViPlanner(53.3%)高 +23.4%,在 TurtleBot 9/10、Go2 7/10、G1 7/10 上全面领先。
- NoGoal 无目标探索:仿真平均无碰撞时长是 NoMaD 的 2.9×、探索面积 3.1×;真机探索时长达 3.8×,展现极强的零样本泛化与避障一致性。
- 三类失败模式对比(Fig. 4):iPlanner/ViPlanner 用单帧输入导致时序不一致(相机过了障碍但机体没过,路径突变引发碰撞)、对深度噪声敏感、被带洞的不规则障碍几何”骗”而试图穿墙;NavDP 凭多帧时序 + Critic 把关都能稳健处理。
- 消融实验(Table V,验证三组因素):
- RGB-D 融合不可或缺:去掉深度 −10.3% SR,去掉 RGB −5.1% SR,单帧替代多帧 −2.8% SR。
- Critic 是安全性的关键:同权重下改用随机选轨迹(去掉 Critic 选择)−7.8% SR;去掉对比轨迹增广 −3.0% SR(家居场景)。
- NoGoal 是有用的辅助任务:联合训练 NoGoal 让 PointGoal 反而 +2.1% SR / +1.8% SPL。
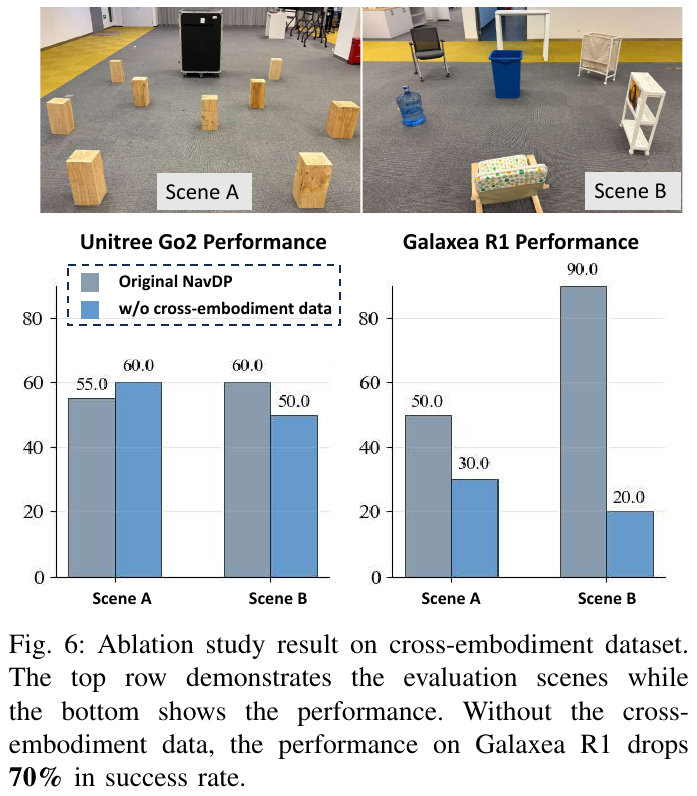
- 域随机化对跨本体至关重要(Q5 / Fig. 6):若只用矮机器人(< 0.5 m)数据训练,高个子 Galaxea R1 学不会”绕开桌子”的策略,成功率从 90% 暴跌到 20%(−70%),而矮个子 Go2 基本不受影响——证明跨本体数据的多样性才是泛化的根本。
局限性与未来方向
NavDP 性能高度依赖高质量仿真数据;扩散模型多步去噪虽带来轨迹多样性,但相比直接回归计算开销更大。作者点明三个未来方向:
- 显式本体信息编码:当前仅从数据分布隐式学习运动约束,无法明确感知自身体型;理想系统应能判断”这条缝我过不去”,即把机器人几何参数作为显式条件引入决策。
- 运动技能与路径规划联合设计:当前避障默认”只能行走绕行”;在极端地形(需跳跃 / 跨越)下,规划器应结合自身运动能力上限做更合理的通过 / 绕行决策。
- 高效后训练 + 语言目标 + 全局记忆:探索后训练策略提升真机表现,把目标扩展到自然语言指令,并引入全局记忆支持长时探索。
3. NoMaD (2023)
——目标掩码扩散策略实现统一导航
📄 Paper: arXiv:2310.07896 · 🏛️ ICRA 2024
研究背景/问题
传统机器人导航系统通常为探索(exploration)和目标导航(goal-conditioned navigation)分别训练独立的策略模型,这不仅增加了系统复杂度,也限制了跨任务的知识共享和泛化能力。NoMaD(Nomadic Multi-task Agent with Diffusion,伯克利,ICRA2024 Best Paper)提出通过统一的扩散策略框架,使用目标掩码机制同时建模任务特定行为(目标导向)和任务无关行为(探索),实现单一策略胜任多种导航任务。
主要方法/创新点
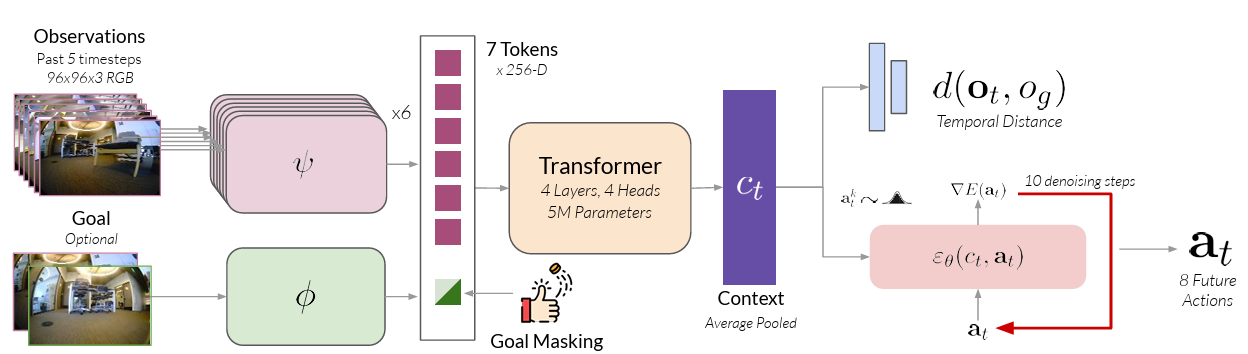
核心思路
通过统一的扩散策略,同时建模任务特定和任务无关行为
两个关键组件
目标掩码(Goal Masking)
- 通过二值掩码控制策略是否关注目标图像,实现任务条件的灵活切换
- 训练时:目标掩码以50%概率随机设置,使模型同时学习目标导向行为和探索行为
- 推理时:根据任务需要设置掩码(探索时掩盖目标,导航时提供目标)
扩散策略(Diffusion Policy)
- 利用扩散模型生成多模态、无碰撞的动作序列
- 从随机噪声逐步迭代生成预测动作序列
- 动作分布既可在无目标条件下表达探索行为,也可在提供目标条件下收敛到目标导向行为
统一框架设计
- 通过Transformer编码视觉观测并结合扩散模型生成未来动作序列
- 同时支持任务特定行为(目标导向)和任务无关行为(探索)
- 使用大规模多样化数据集(GNM和SACSoN)进行端到端监督训练
核心结果/发现
- 探索未知环境:成功率达到98%,平均碰撞数仅0.2,超过最优基线Subgoal Diffusion约25%,且参数量仅为其1/15
- 目标导航:在已知环境的目标导航任务中,成功率与最优基线相当,但计算资源需求更少
- 计算效率:比现有方法计算效率提升约15倍,是首个成功在物理机器人上部署的目标条件动作扩散模型
- 统一策略优势:联合训练能够学习共享表示和环境可操作性,单一策略即可胜任多种行为
- 编码器选择:ViNT编码器配合注意力目标掩码效果最佳,成功率98%,碰撞数最少
- 多场景验证:在6个复杂的室内外环境中表现优异
局限性
NoMaD的视觉编码器选择对性能影响较大,需要仔细调优以达到最佳效果。虽然ViT编码器具有更大的容量和表达能力,但其训练优化难度较高,收敛速度相对较慢。此外,目标掩码机制的随机采样比例(训练时50%)是一个关键超参数,在不同场景下可能需要针对性调整。尽管在多个室内外环境中表现优异,但在极端复杂、高度动态的场景(如密集人流、快速变化的障碍物)下的鲁棒性仍有进一步提升空间。
4. ODYSSEY (2025)
——Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
📄 Paper: arXiv:2508.08240 · 🏛️ AAAI 2026
研究背景/问题
在动态、非结构化环境中,机器人需要将移动性、操作和实时感知紧密结合才能执行复杂任务。现有研究大多局限于桌面场景,未能解决移动平台特有的感知受限和执行器范围有限的问题,且在开放世界环境中的泛化能力不足。
主要方法/创新点
ODYSSEY提出了一个统一的移动操作框架,包含分层规划和全身控制两大核心模块:
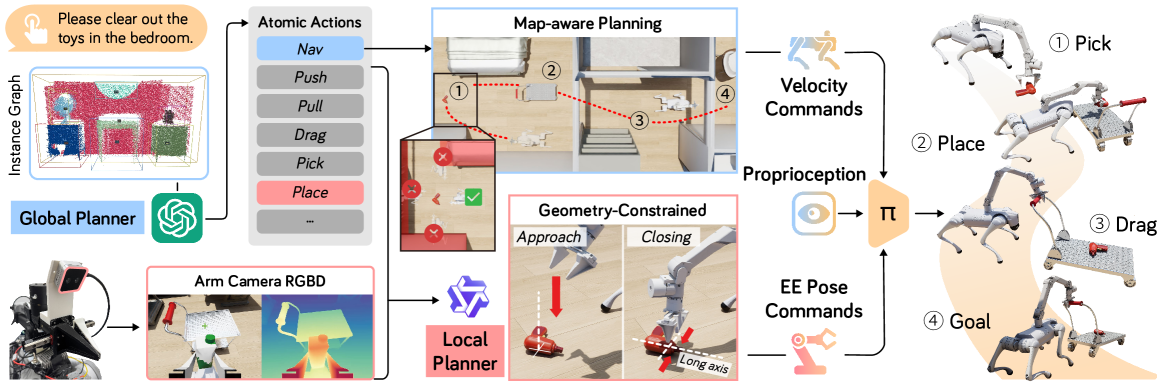
长期任务规划器:
- 全局任务级规划:融合RGB和LiDAR流构建场景的空-语义表示,利用预训练基础模型将实例图映射到场景中
- 使用GPT-4.1将自然语言指令分解为原子动作序列(导航、抓取、放置等),并输出粗略目标航路点
- 航路点投影到2D占用图,通过局部搜索确定无碰撞目标姿态
局部操作:
- 使用腕部安装的深度观测数据指导视觉-语言模型生成精确末端执行器姿态
- Qwen2.5-VL-72B-Instruct模型根据RGB观测和文本描述推断任务相关接触点
- 根据目标物体主轴和表面法线施加几何约束,确定末端执行器朝向
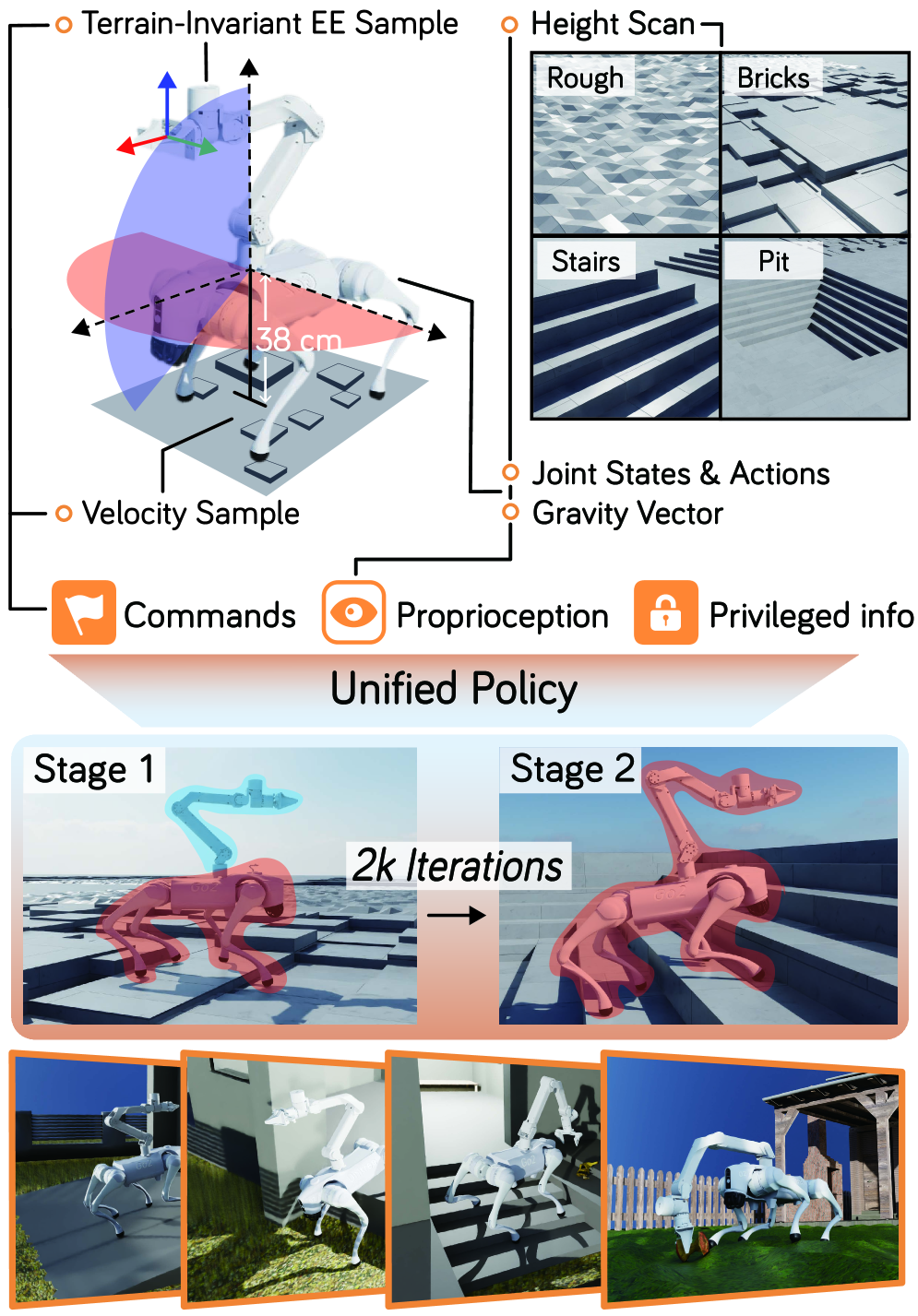
全身控制策略:
- 单一网络将观测向量(运动指令、末端执行器目标、地面高度图、重力向量、本体感知状态等)映射到目标动作
- 两阶段训练:第一阶段固定机械臂关节训练运动;第二阶段控制全部18个关节,采用地形不变末端执行器采样策略
- 引入步态奖励、频率奖励和末端执行器跟踪项,运用领域随机化增强适应性
模拟基准测试:
- 构建包含50个刚体物体、15个容器、30个关节结构、10个可拖动物体的多样化资产库
- 基准测试包括10个真实场景(室内家居、超市、餐厅、室外庭院等)
- 长期任务包含246个室内和58个室外变化,涉及抓取、重新定向、容器放置、关节操作等多种技能
核心结果/发现
- 短期任务:在ARNOLD基准测试上优于PerAct基线,仅依赖单个自我中心摄像头实现更强的泛化能力,在未见数据集上性能保持稳定
- 长期任务:在8个长期移动操作任务上实现40%以上整体成功率,每个原子技能类别保持60%以上成功率,展现出可靠的协调能力
- 低层策略:在基座速度跟踪方面优于RoboDuet基线,末端执行器姿态跟踪性能相当,且在不同地形上具有更强的适应性
- Sim-to-Real迁移:成功在Unitree Go2+Arx5平台上实现现实世界部署,在”导航到抓取”和”抓取和放置”任务中验证了框架的实用性
局限性
模型在物体几何形状的空间推理方面存在局限,导致夹爪对齐不佳和细长手柄或部分遮挡物品的定位不准确。此外,抓取小物体时偶尔失败,主要由于末端执行器跟踪和视觉感知精度不足。
5. PanoNav (2025)
——Mapless Zero-Shot Object Navigation
📄 Paper: arXiv:2511.06840 · 🏛️ AAAI 2026 (Poster)
研究背景/问题
现有目标导航方法大多依赖深度传感器或预建地图来构建2.5D场景表示,限制了在真实环境中的适用性和泛化能力。零样本目标导航要求机器人识别和导航到超出预定义类别范围的对象,现有方法在开放词汇场景中表现有限。无地图方法通常只基于当前观测进行决策,忽略历史轨迹信息,容易陷入局部死锁。
主要方法/创新点
PanoNav是一个无地图、仅使用RGB图像的零样本目标导航框架,包含两个核心模块:
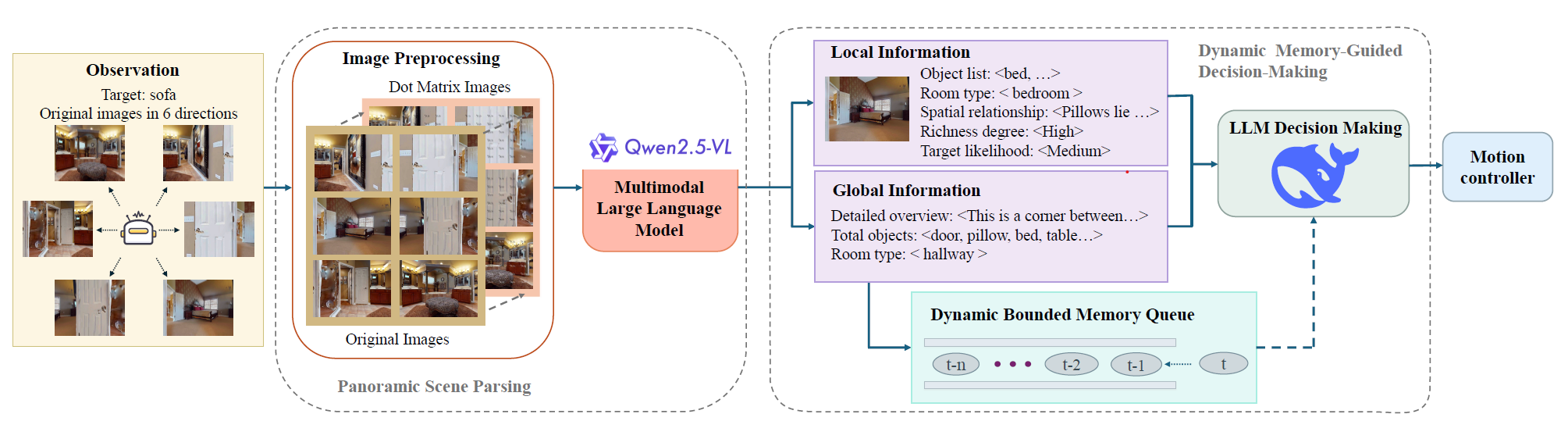
全景场景解析(Panoramic Scene Parsing):
局部方向解析:
- 点阵图像增强:将每个RGB图像转换为点阵图像,通过Scaffold方法增强平面位置理解,与RGB图像共同作为MLLM输入
- 空间关系图构建:MLLM利用几何距离关系和平面位置关系,构建空间关系图,生成每个方向的详细描述(物体存在、空间关系、房间类型等)
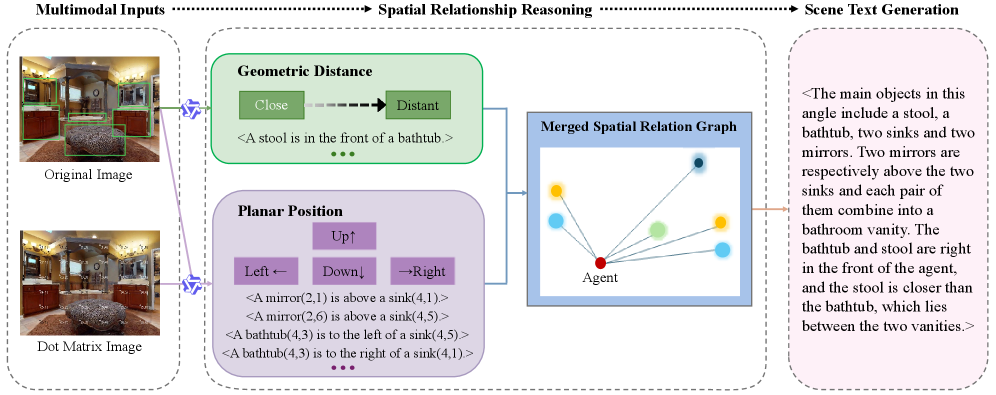
全局全景总结:
- 环境整体感知:对机器人周围环境进行整体分析,识别环境中存在的物体类型和当前房间类型(如厨房、走廊)
- 隐式自我定位:通过全局总结提供隐式自我定位信息,帮助机器人理解其在更大环境中的位置
动态记忆引导决策(Dynamic Memory-guided Decision-Making):
- 动态有界记忆队列:存储最近的全局场景总结,队列长度固定,当队列满时新元素加入会移除最旧元素
- 决策过程:
- 记忆队列未满时:决策仅基于当前的局部描述和全局总结
- 记忆队列满时:决策结合当前信息和历史记忆信息,避免重复探索已访问区域
- 动作选择:决策结果包括导航方向和是否找到目标的标志,由运动控制器执行相应动作
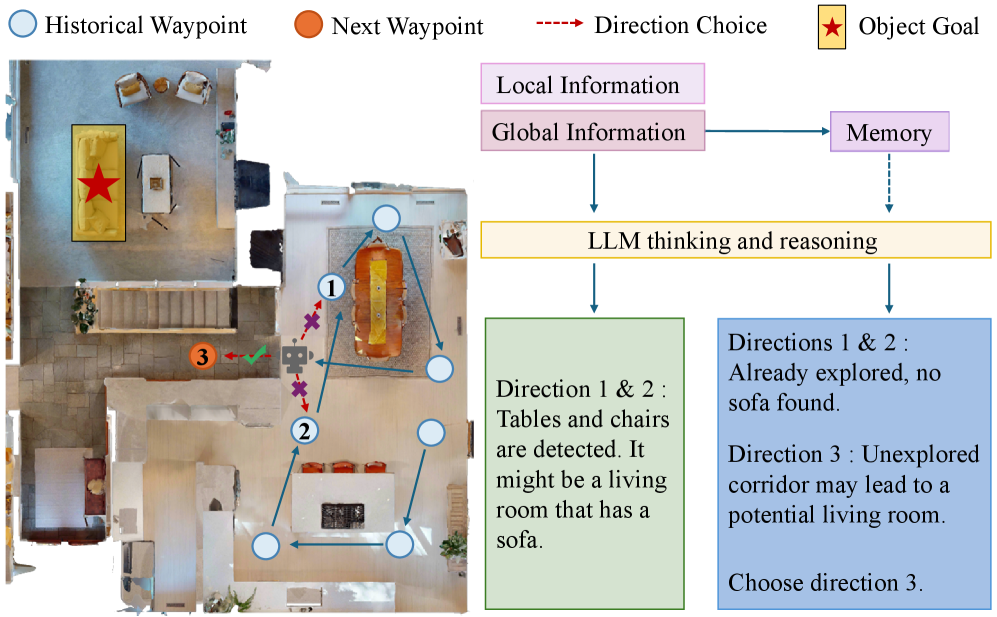
任务设置:
- 观测数据:每个时间步获取六个方向的RGB图像(间隔60度),形成全景视图,不依赖深度传感器或GPS
- 动作空间:停止、前进(0.25米)、左转/右转(30度)、抬头/低头
- 任务目标:在未见过的环境中根据语言指令找到目标对象,并导航至目标位置
核心结果/发现
- 性能优势:在HM3D数据集上,PanoNav的成功率(SR)达到43.5%,SPL达到23.7%,显著优于PixNav(SR=37.9%,SPL=20.5%)和ZSON(SR=25.5%,SPL=12.6%),甚至超过部分依赖地图和闭词汇表的方法
- 死锁避免:在高度欺骗性环境中,通过动态记忆机制实现48.0%成功率和19.2% SPL,逃离局部区域的逃逸率达82.0%
- 消融实验验证:
- 全景视图的重要性:仅使用三视图时性能显著下降(SR=19.5%,SPL=9.97%)
- 解耦解析与决策的优势:解耦方法(SR=43.5%,SPL=23.7%)优于直接从MLLM输出决策(SR=38.5%,SPL=22.57%)
- 动态记忆的关键作用:移除动态记忆后性能大幅下降(SR=38.5%,SPL=22.57%)
局限性
虽然PanoNav显著提升了无地图零样本导航性能,但未来仍需探索利用多模态信息(如语音、手势等)构建更强大的记忆队列,以进一步提高无地图目标导航的鲁棒性和泛化能力。
6. VLN-R1 (2025)
——基于GRPO与Time-Decayed Reward的端到端导航
📄 Paper: arXiv:2506.17221
研究背景/问题
VLN是具身人工智能领域的一项核心挑战,要求智能体根据自然语言指令在真实世界环境中进行导航。传统的导航方法通常依赖离散的拓扑图和预定义的节点连接,限制了智能体在连续环境中的泛化能力。
主要方法/创新点
VLN-R1提出了一种创新的端到端框架,利用大型视觉-语言模型(LVLM)直接处理自我中心视频流,生成连续的导航动作。
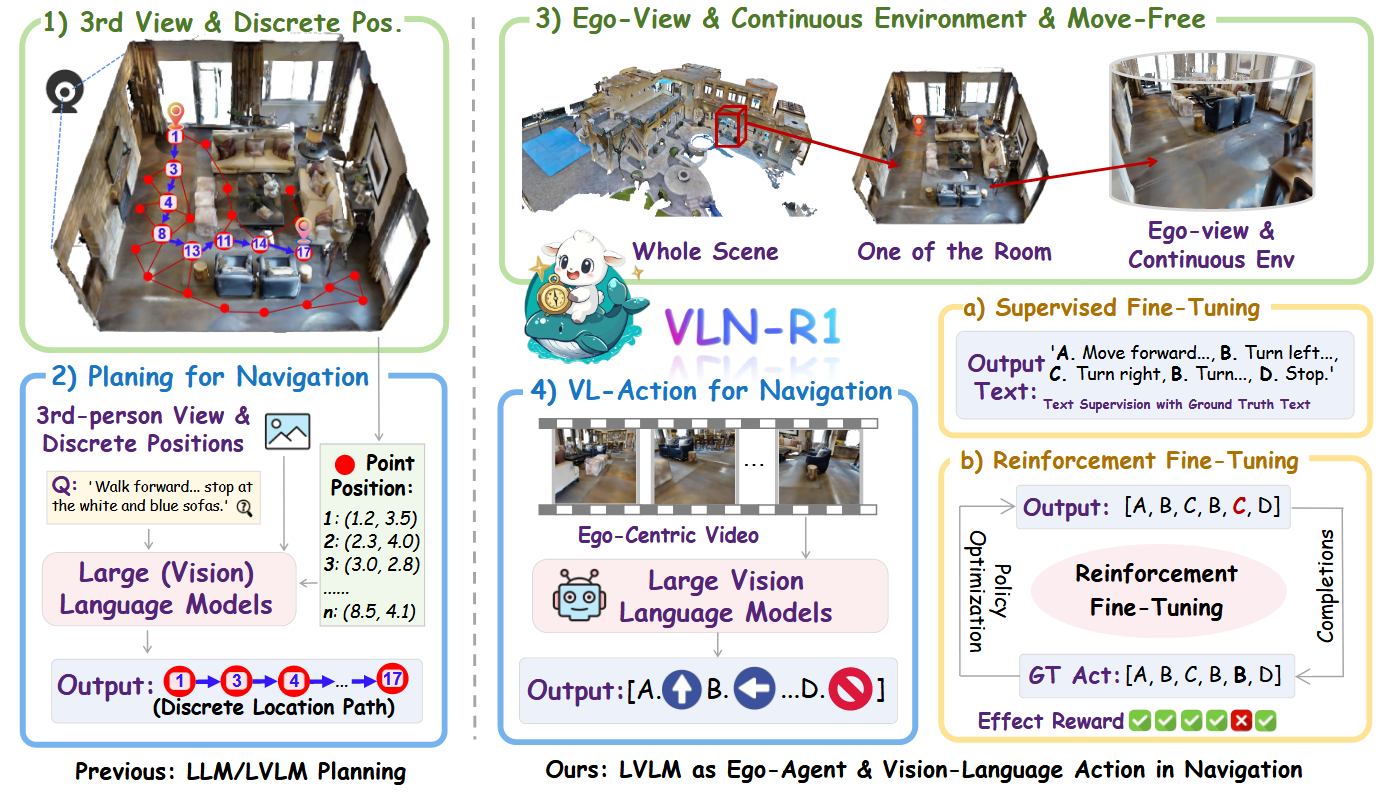
核心设计理念:
- 构建能够实时处理自我中心视频流并生成连续导航动作的端到端框架
- 与传统方法依赖导航图或额外传感器不同,VLN-R1直接将视觉输入和自然语言指令转化为动作输出
- 提高系统通用性,增强在未见过环境中的适应能力
主要组件:
VLN-Ego数据集:
- 数据生成:通过Habitat模拟器生成,包含自我中心视频流与未来动作预测的配对数据
- 三部分文本注释:
- 指令部分:自然语言导航指令(如”走到客厅的沙发旁”)
- 视觉部分:包括历史帧和当前观察,提供自我中心的视觉信息
- 动作部分:未来动作选择(前进、左转、右转、停止四种基本动作)
- 数据规模:
- 从Room-to-Room生成了60K个训练样本
- 从Room-Across-Room生成了1.2M个训练样本
- 覆盖了61个训练场景
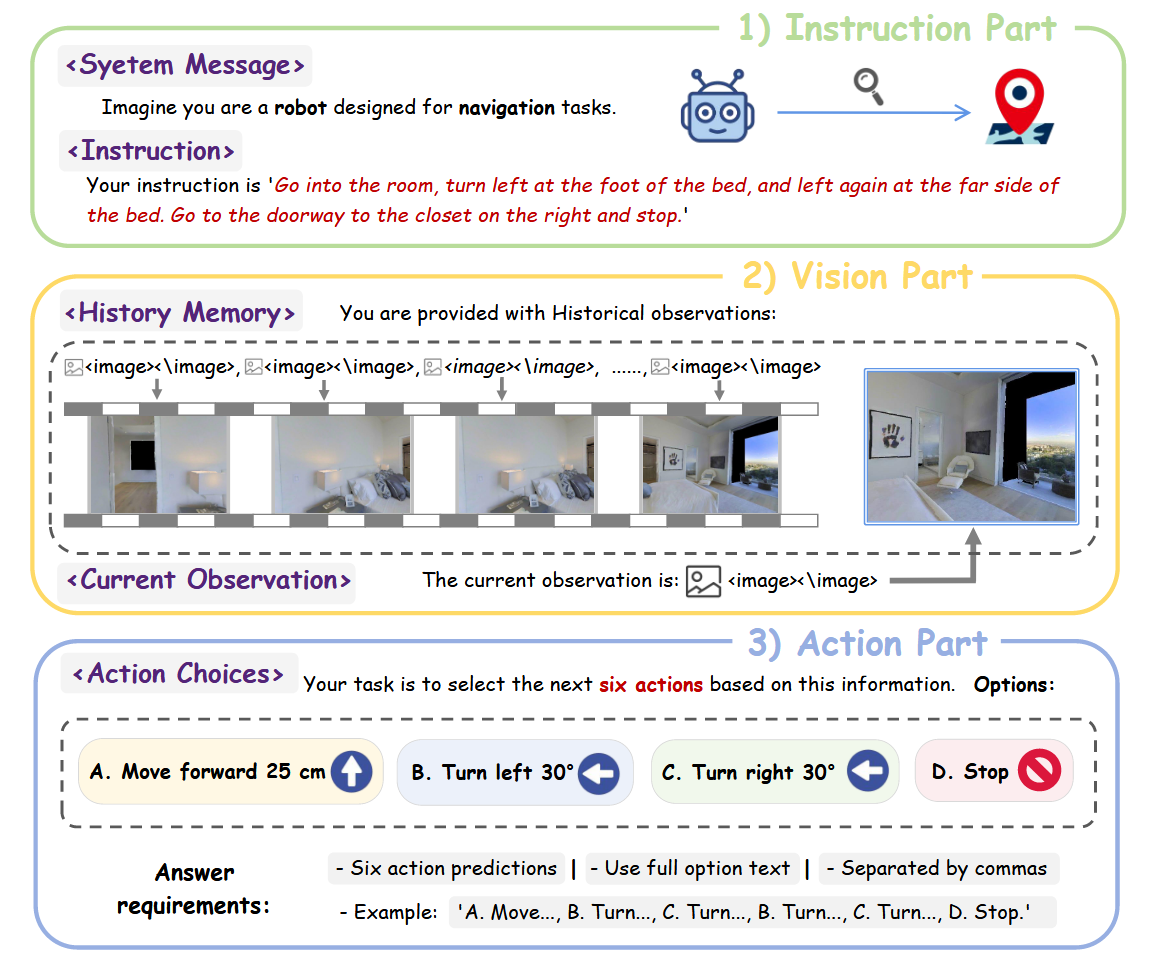
长短期记忆采样:
- 新颖的视频输入处理策略,用于动态平衡历史帧的重要性与当前观察的实时性
- 确保模型既能利用历史信息,又能快速响应当前环境变化
- 相比单一动作预测,多步动作预测结合历史上下文显著提升性能
两阶段训练策略:
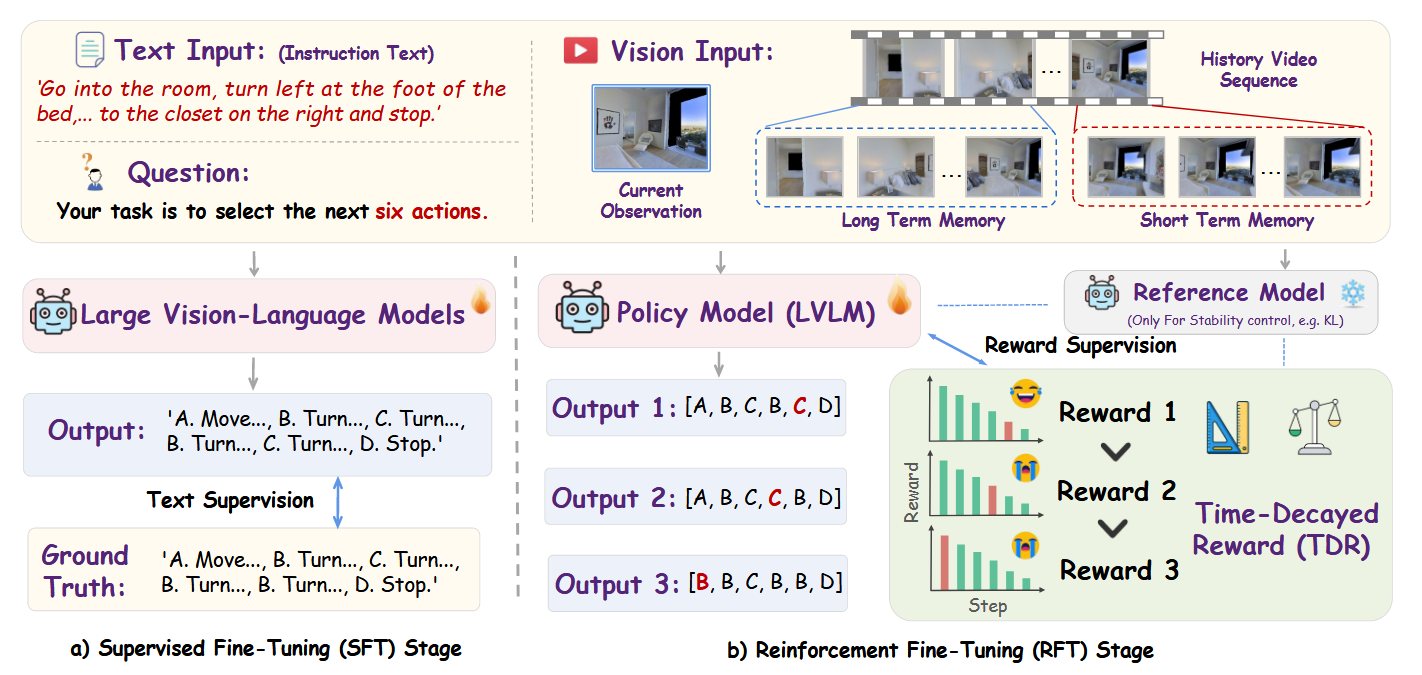
监督微调(SFT)阶段:
- 模型的动作序列预测与专家演示对齐,通过监督学习优化输出文本
- 模型生成的多步动作序列文本与地面真值对齐,通过交叉熵损失进行优化
- 给定历史观察序列H_t、指令Z和当前观察O_t,模型预测n步未来动作序列
强化微调(RFT)阶段:
- 引入基于GRPO(Group Relative Policy Optimization)的强化学习方法
- 结合时间衰减奖励机制(TDR),进一步优化模型在长时程导航中的性能
- 超参数经过消融实验确定,生成次数选择8作为默认值
时间衰减奖励机制(TDR):
- 核心思想:通过引入衰减因子,平衡短期和长期奖励
- 作用机制:使模型能够更关注近期的动作,同时考虑长期目标
- 优势:用于评估多步动作预测的长期效果,优化长时程导航性能
模型架构:
- 输入:自我中心视频流和指令
- 输出:多步未来动作序列
- 端到端设计:消除了对导航图的依赖,使其在连续环境中表现出色
核心结果/发现
VLN-R1在VLN-CE(视觉-语言导航连续环境)基准上进行了全面测试:
测试平台:
- Room-to-Room(R2R):要求智能体在单个房间内导航
- Room-Across-Room(R4R):要求智能体跨房间导航,任务更具挑战性
性能表现:
- R2R数据集:展现了高效的导航能力和准确的任务完成率
- R4R数据集:通过强化微调显著提升了跨域适应性,小型2B模型的性能甚至接近7B模型
- 模型可扩展性:证明了端到端框架在不同模型规模下的有效性
消融实验验证:
- 长短期记忆采样:多步动作预测结合历史上下文显著提升性能,优于单一动作预测
- TDR机制:与传统奖励函数相比,TDR显著提高了长时程任务的成功率
- 生成次数:从6增加到8时性能提升有限,因此选择8作为默认值
技术优势:
- 端到端设计实现了实时导航
- 结合LVLM的视觉-语言理解能力和强化学习的优化策略
- 展示了在任务特定推理中的潜力
局限性
论文内容相对简短,未详细说明具体的性能指标数值(如SR、SPL等)和与其他SOTA方法的详细对比。此外,对于Real-world部署的讨论较少,主要集中在仿真环境(Habitat)测试,缺乏真实机器人平台上的验证实验。
7. LagMemo (2025)
——Language 3D Gaussian Splatting Memory for Multi-modal Open-vocabulary Multi-goal Visual Navigation
📄 Paper: arXiv:2510.24118
研究背景/问题
传统视觉导航方法受限于单目标、单模态和封闭类别设置,无法满足实际应用中多模态开放词汇表多目标导航的需求。现有方法如端到端强化学习依赖隐式状态编码导致泛化能力差,而模块化方法基于2D语义地图仅支持预定义类别,无法适应开放词汇场景。
主要方法/创新点
LagMemo提出了首个将语言特征融入3D Gaussian Splatting(3DGS)的视觉导航系统:
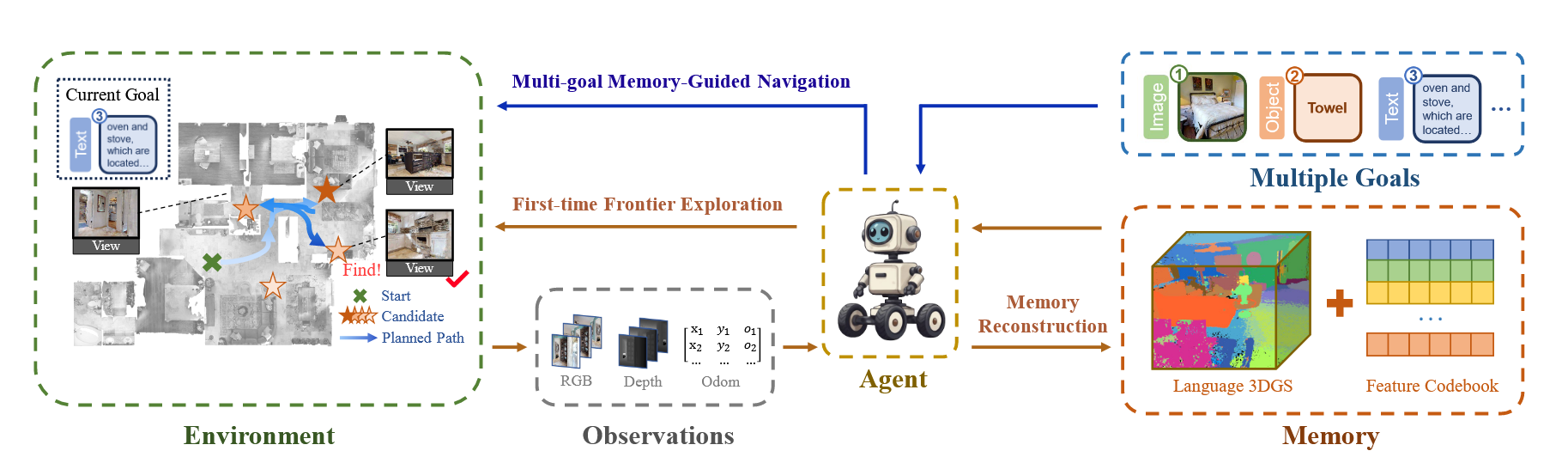
语言3DGS记忆重建:
前沿探索与几何重建:
- 前沿探索策略:智能体首先进行基于前沿的环境探索,收集RGB-D图像和姿态信息
- 3DGS几何重建:3D高斯由空间位置μ、颜色c、半径r和不透明度o参数化,通过颜色和深度渲染的几何损失优化
- 关键帧检索机制:针对导航场景中帧间重叠有限导致的遗忘和表面空洞问题,引入帧池存储历史帧,周期性渲染并按PSNR评估,优先优化低保真帧
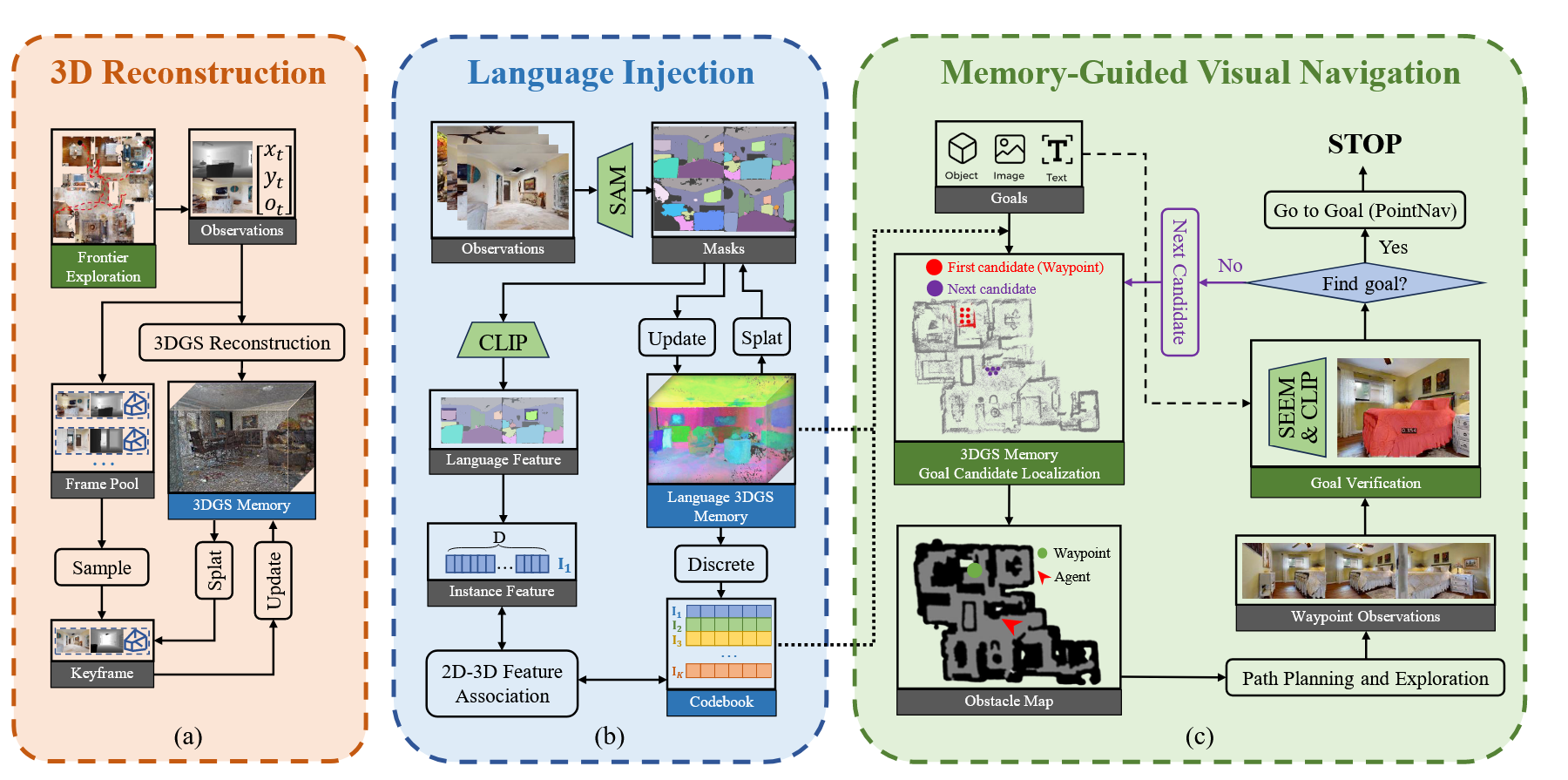
语言特征注入:
- 实例级特征提取:使用SAM生成实例掩码,通过特征splatting渲染逐像素语义特征,聚合掩码级特征并优化
- 两级码本量化:粗分区联合考虑3D位置和语言特征,细分区仅基于语言特征细化类别
- 2D-3D特征关联:对每个实例类别,渲染其高斯并评估与2D实例掩码的空间语义一致性,将高维CLIP实例特征分配给离散化的3D高斯语言类别
- 码本构建:每个码本条目对应一簇3D高斯,富含CLIP特征,支持多模态查询(文本/图像)
记忆引导的视觉导航:
- 目标定位:多模态输入目标(文本/图像)通过CLIP编码器编码,与码本计算余弦相似度定位候选实例,计算高斯质心并投影到2D障碍地图生成路径点
- 路径点导航:使用Fast Marching Method(FMM)从当前位置规划无碰撞路径至路径点
- 目标验证与匹配:到达路径点后全景扫描验证目标,对象/文本目标使用SEEM开放词汇实例分割和CLIP相似度二次验证,图像目标使用LightGlue特征匹配
- 终点导航:确认目标可见后,利用SEEM掩码和深度信息将目标点投影到障碍地图,再次使用FMM导航至终点并执行STOP
GOAT-Core基准数据集:
- 针对GOAT-Bench质量问题策划高质量核心子集:每集20个子任务(原7.88个),平均13.37个独特类别(原4.82个),子任务间平均距离6.89m(原5.18m)
- 手动修正不准确文本描述,优先语义清晰的对象,限制所有子任务在单层楼
- 包含480个多模态子任务(163图像、158对象、159文本目标)
核心结果/发现
目标定位任务:
- 在GOAT-Core上总体成功率70.8%,显著优于VLMaps(58.8%)
- 分模态性能:对象88.4% vs 69.7%,图像56.4% vs 43.3%,文本66.8% vs 61.0%
- 语言3DGS保留详细3D空间上下文,实现精确定位,而VLMaps的2D网格压缩丢失关键几何信息
多模态多目标视觉导航:
- 平均成功率SR=56.3%,SPL=35.3%,在所有四个场景中均取得最高成功率
- 相比次优基线CoWs*,SR提升10%,相比Modular GOAT提升18%
- 文本导航任务优势尤为显著,充分展现丰富3D语义表示的优势
- 消融实验验证:移除关键帧机制导致PSNR从27.20降至21.15,定位准确率从70.8%降至66.3%;移除码本定位准确率骤降至34.6%
- 目标验证机制至关重要:无验证SR=41.3%,通用CLIP验证SR=46.7%,模态特定验证SR=56.3%
局限性
当前方法依赖静态固定容量记忆,在动态环境(重新排列、增删物体)中适应性不足。全场景3D表示内存密集,需要层次化或多分辨率高斯、不确定性感知剪枝和特征压缩。此外,目标定位能力依赖几何保真度,视角覆盖不足会留下盲区,未来需开发记忆感知的主动探索策略。
8. GaussNav (2025)
——Gaussian Splatting for Visual Navigation
📄 Paper: arXiv:2403.11625 · 🏛️ IEEE TPAMI 2025
研究背景/问题
Instance ImageGoal Navigation (IIN)要求智能体在未探索环境中定位并导航至目标图像所描绘的特定对象实例,需要跨视角识别目标对象同时忽略干扰物。现有基于BEV地图的导航方法缺乏详细纹理表示,难以胜任实例级任务,无法保留场景的实例感知特征,不足以区分同类别的多个对象。
主要方法/创新点
GaussNav首次将3D Gaussian Splatting(3DGS)引入具身视觉导航,提出语义高斯地图表示:
前沿探索(Frontier Exploration):
- 智能体同时维护探索地图和障碍地图,探索地图标记已探索区域,障碍地图标记场景中的障碍物
- 检测探索地图轮廓并排除障碍地图区域,将最近的前沿点设为路径点,迭代覆盖整个环境
语义高斯构建(Semantic Gaussian Construction):
几何重建:
- 3DGS简化表示:每个高斯由9个参数特征化:RGB颜色向量c、质心µ∈R³、半径r、不透明度o∈[0,1]、类别标签l
- 可微渲染:通过alpha合成渲染RGB、深度和轮廓图像,支持新视角合成(NVS)
- 关键帧检索机制:针对导航场景帧间重叠有限问题,存储历史帧并周期性渲染评估PSNR,优先优化低保真帧,采用两阶段优化(p1=30迭代新视点,p2=60迭代关键帧视点)
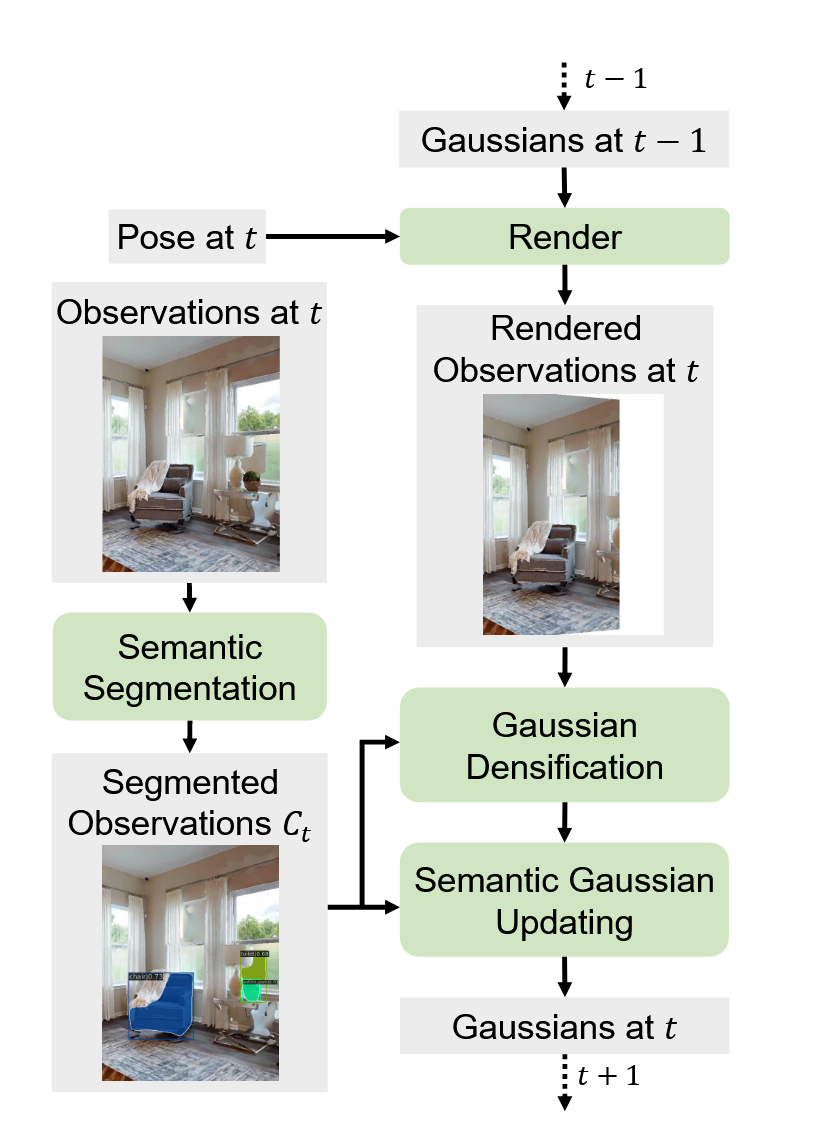
语义特征注入:
- 实例分割:使用Mask-RCNN为每个高斯分配语义标签
- 特征优化:通过特征splatting渲染逐像素语义特征,优化特征损失以鼓励实例内一致性和实例间可分性
- 高斯聚类:基于语义标签和3D位置聚类高斯,将场景中的对象分割为不同语义类别下的不同实例
高斯导航(Gaussian Navigation):
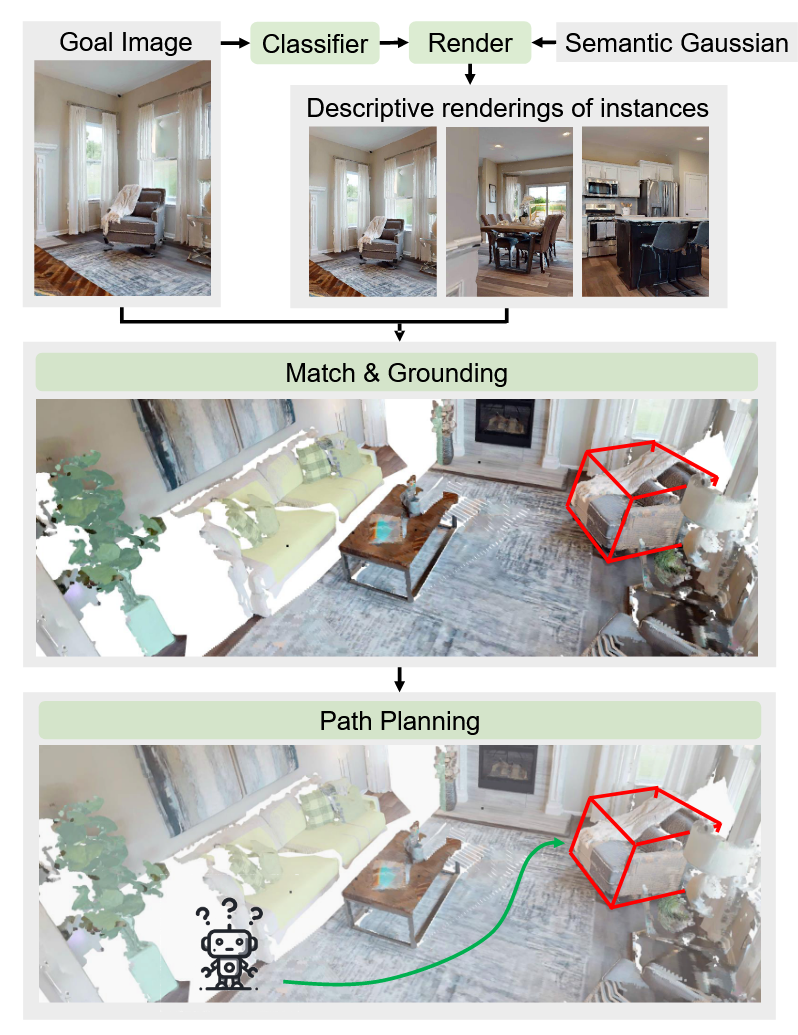
- 分类器:使用ResNet50对目标图像分类预测语义标签ˆlg,显著缩小搜索空间(如场景CrMo8WxCyVb从648个潜在观测减少到33个)
- 匹配与定位:
- 为每个候选实例通过NVS生成描述性图像(nv=1/3/5,θ=±15°/±30°水平和垂直旋转)
- 使用DISK提取关键点和特征描述符,通过LightGlue匹配,选择匹配关键点数最多的候选对象
- 使用DBSCAN聚类去除语义分割误差导致的离群点,精确定位目标实例
- 路径规划:将语义高斯转换为点云并体素化投影到2D BEV网格,使用FMM生成最短距离场并规划路径
创新要点:
- 统一几何、语义和实例感知特征的地图表示,首次将3DGS应用于具身视觉导航
- 通过渲染描述性图像直接定位目标对象,无需额外探索或验证步骤
- 关键帧检索机制有效缓解导航场景中的遗忘和表面空洞问题
核心结果/发现
- HM3D数据集性能:SPL从0.347大幅提升至0.578(提升66.6%),成功率达72.5%,显著超越所有基线方法
- 效率优势:运行帧率超过20 FPS,在模块化方法中效率最高,搜索空间优化显著(如CrMo8WxCyVb场景从648个观测点减少至33个)
- 消融实验验证:
- 移除分类器导致Success降至37.5%,SPL降至29.1%,但使用分类器后匹配时间减少2.5倍
- 移除匹配模块Success降至44.4%,SPL降至35.3%
- NVS对识别成功率有益,GT NVS可进一步提升性能(Success从72.3%升至74.7%)
- 使用GT匹配模块Success提升至85.0%,GT目标定位Success达94.6%
- 渲染质量分析:在HM3D验证集上PSNR最高可达40,深度渲染误差接近零,但部分高纹理场景重建质量欠佳
- 跨场景泛化:在36个验证场景中表现稳定,语义高斯可视化展示了对多种场景复杂度和对象组成的鲁棒性
局限性
当前方法在高纹理环境中重建质量欠佳,导致NVS可能产生孔洞等伪影。错误源分析显示匹配失败和目标定位不准确仍有改进空间。语义高斯不适合直接路径规划,需转换为2D BEV网格,增加了计算开销。
9. VLFM (2023)
——Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
📄 Paper: arXiv:2312.03275 · 🏛️ ICRA 2024
研究背景/问题 零样本语义导航要求机器人在未见环境中高效定位目标对象,现有方法(如ESC、SemUtil)依赖物体检测器将视觉线索转化为文本后再用LLM/BERT进行语义推理,存在计算瓶颈且无法充分利用视觉-语言联合表征。如何直接从RGB观测中提取语义价值以指导前沿探索成为关键挑战。
主要方法/创新点
VLFM提出语言驱动的前沿价值图框架,实现端到端视觉-语义推理:
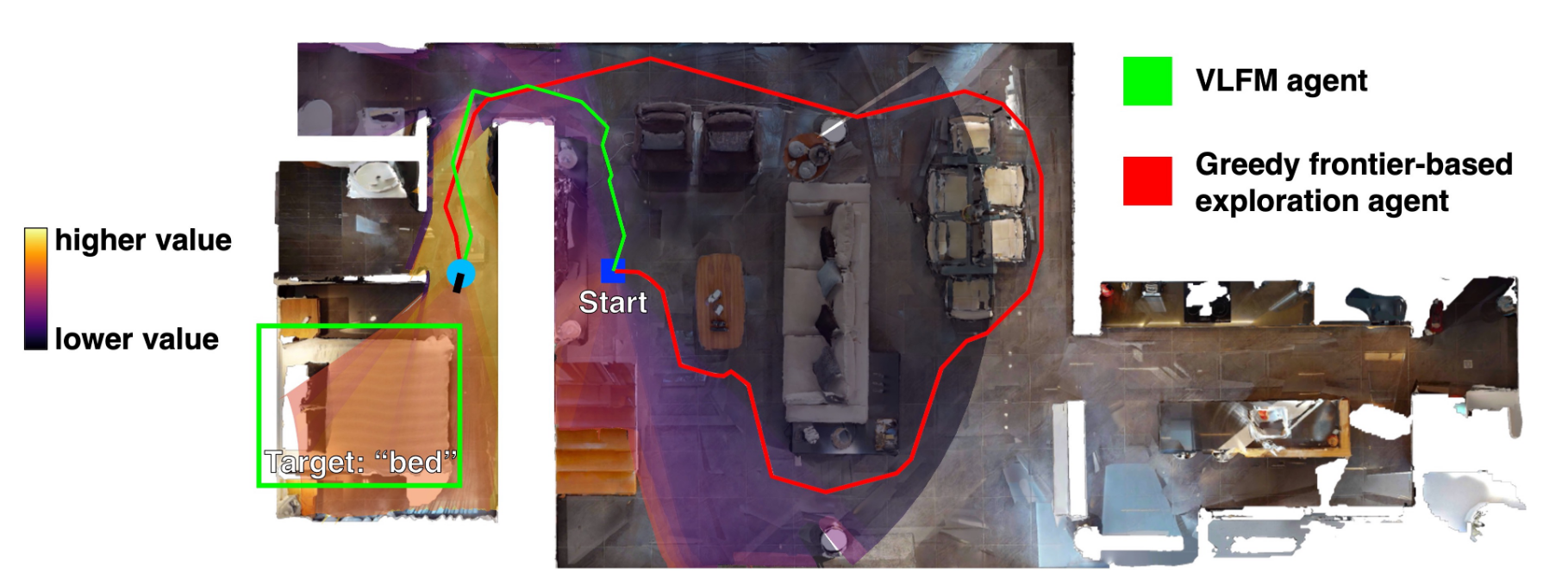
核心机制:
- 前沿航点生成(Frontier Waypoint Generation)
- 利用深度和里程计构建2D占用地图,识别已探索与未探索区域边界作为前沿候选点
- 每个前沿中点作为潜在导航航点
- 价值图生成(Value Map Generation)
- 使用预训练BLIP-2视觉-语言模型直接从RGB图像计算语义价值分数
- 文本提示:”Seems like there is a
ahead" - 输出余弦相似度分数并投影到俯视图价值图(双通道:语义分数+置信度分数)
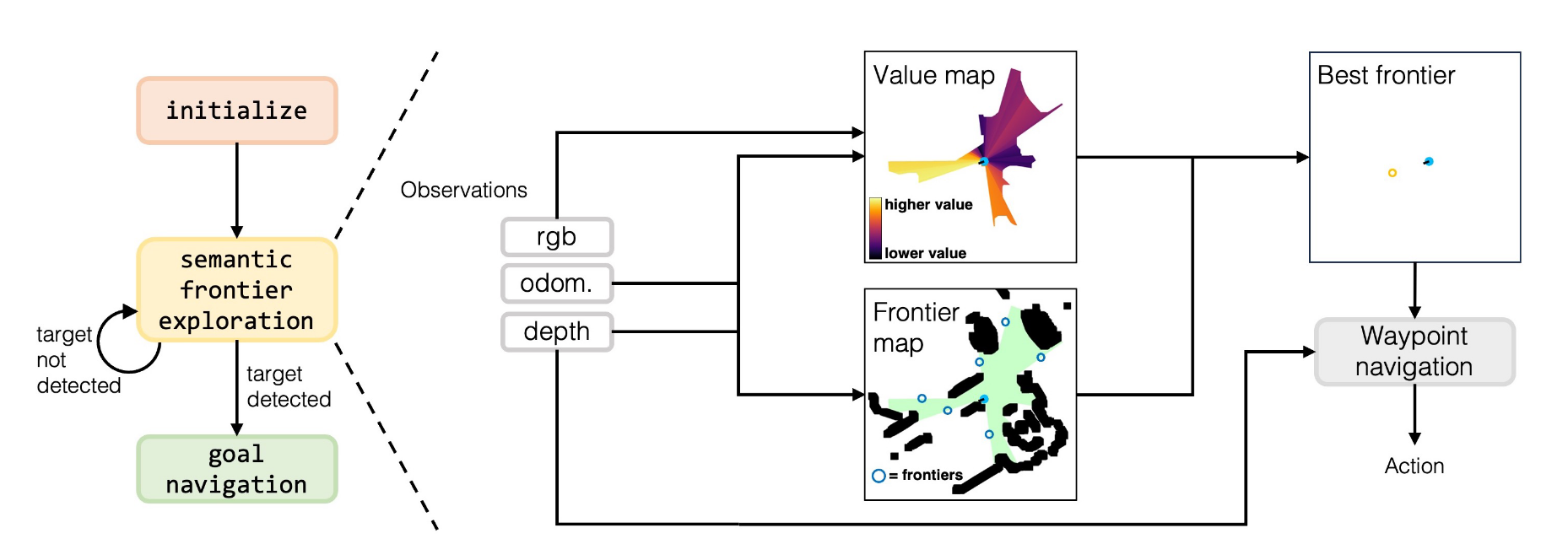
- 置信度加权更新(Confidence-Weighted Averaging)
- 置信度分数基于像素相对光轴位置:$c_{i,j} = \cos^2(\theta/(\theta_{fov}/2) \times \pi/2)$
- 重叠区域的语义值更新:$v_{i,j}^{new} = (c_{i,j}^{curr}v_{i,j}^{curr} + c_{i,j}^{prev}v_{i,j}^{prev})/(c_{i,j}^{curr} + c_{i,j}^{prev})$
- 置信度更新偏向高置信值:$c_{i,j}^{new} = ((c_{i,j}^{curr})^2 + (c_{i,j}^{prev})^2)/(c_{i,j}^{curr} + c_{i,j}^{prev})$
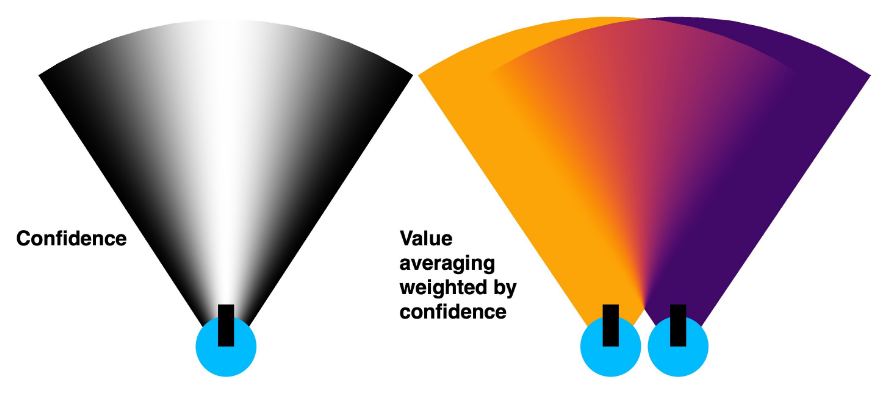
- 物体检测与导航
- YOLOv7用于COCO类别,Grounding-DINO用于开放词汇检测
- Mobile-SAM提取目标轮廓,确定最近点作为目标航点
- 使用VER训练的PointNav策略执行航点导航(纯几何理解,不依赖语义)
关键创新:
- 直接视觉-语义推理:绕过物体检测器,BLIP-2直接从RGB生成语义分数
- 空间化价值表征:将语义价值映射到俯视图网格,支持前沿选择
- 置信度驱动融合:动态平衡当前观测与历史信息
核心结果/发现
- 基准测试表现:在Gibson、HM3D、MP3D三个数据集上均达到SOTA零样本性能
- Gibson:SPL 52.2%、SR 84.0%(相比SemUtil提升+11.7% SPL、+14.7% SR)
- HM3D:SPL 30.4%、SR 52.5%(相比ESC提升+8.1% SPL、+13.3% SR)
- MP3D:SPL 17.5%、SR 36.4%(相比ESC提升+3.3% SPL、+7.7% SR)
- 超越部分有监督方法:在Gibson和MP3D数据集上优于SemExp、PONI等ObjectNav训练方法
- 消融实验:置信度加权平均(Weighted avg.)在所有数据集上均优于简单替换(Replacement)和无权平均(Unweighted avg.)
- 真实世界部署:成功在Boston Dynamics Spot机器人上部署,在办公楼环境中高效导航至未见目标对象,所有模型(BLIP-2、GroundingDINO、MobileSAM、ZoeDepth)实时运行于RTX 4090 MaxQ笔记本
局限性 仅支持单层楼导航(缺少z坐标里程计导致价值图重置困难),HM3D和MP3D中14.6%和9.6%的跨楼层任务失败;假定目标物体在默认相机高度可见,未来可探索主动相机控制、操作式搜索(如打开抽屉)及可复用的语义地图表征以支持长时程多任务规划。
10. LoGoPlanner (2025)
——定位接地的端到端导航策略:把度量尺度的视觉几何”植入”规划
📄 Paper: arXiv:2512.19629
研究背景/问题
现有”端到端”导航虽把感知、建图、规划合并,却仍依赖独立的定位模块(SLAM / 视觉里程计)做自状态估计,而定位模块需要精确的相机-底盘外参标定,泛化性差、在足式机器人抖动场景尤其不稳定。根因在于这些规划器大多只处理单帧或短片段,缺乏对长时序历史的总结能力,短期估计会随时间累积漂移;单帧感知也缺乏稳健度量推理所需的几何记忆,重建往往是局部或尺度模糊的。本文目标:仅用 RGB-D 观测,实现无需任何外部定位模块的点目标(point-goal)导航。
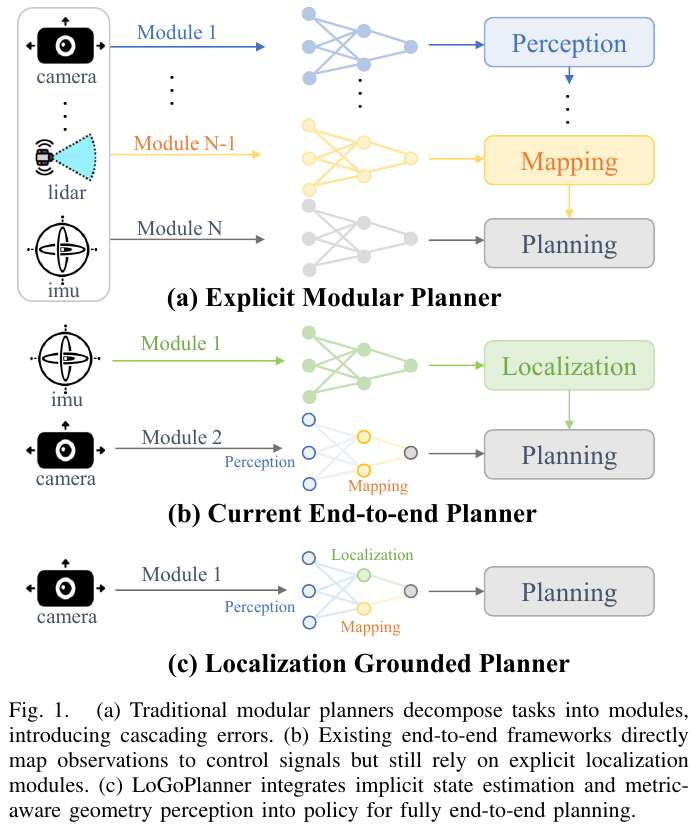
主要方法/创新点
LoGoPlanner 在一个统一网络里端到端协同三大部分:(A) 度量感知视觉几何学习——以预训练视频几何骨干 VGGT 为底,注入深度尺度先验,通过局部点 / 相机位姿两个 auxiliary head 产生世界点嵌入;(B) 定位接地的导航策略——解耦相机与底盘位姿,用 state query / geometric query 通过 cross-attention 把隐式状态与几何聚合成统一规划上下文;(C) Diffusion 策略头——以规划上下文为条件对噪声动作迭代去噪,输出无碰撞轨迹。整条链路把”定位”和”建图”从显式模块降格为网络内部的隐式特征,规划误差是唯一最终优化目标。
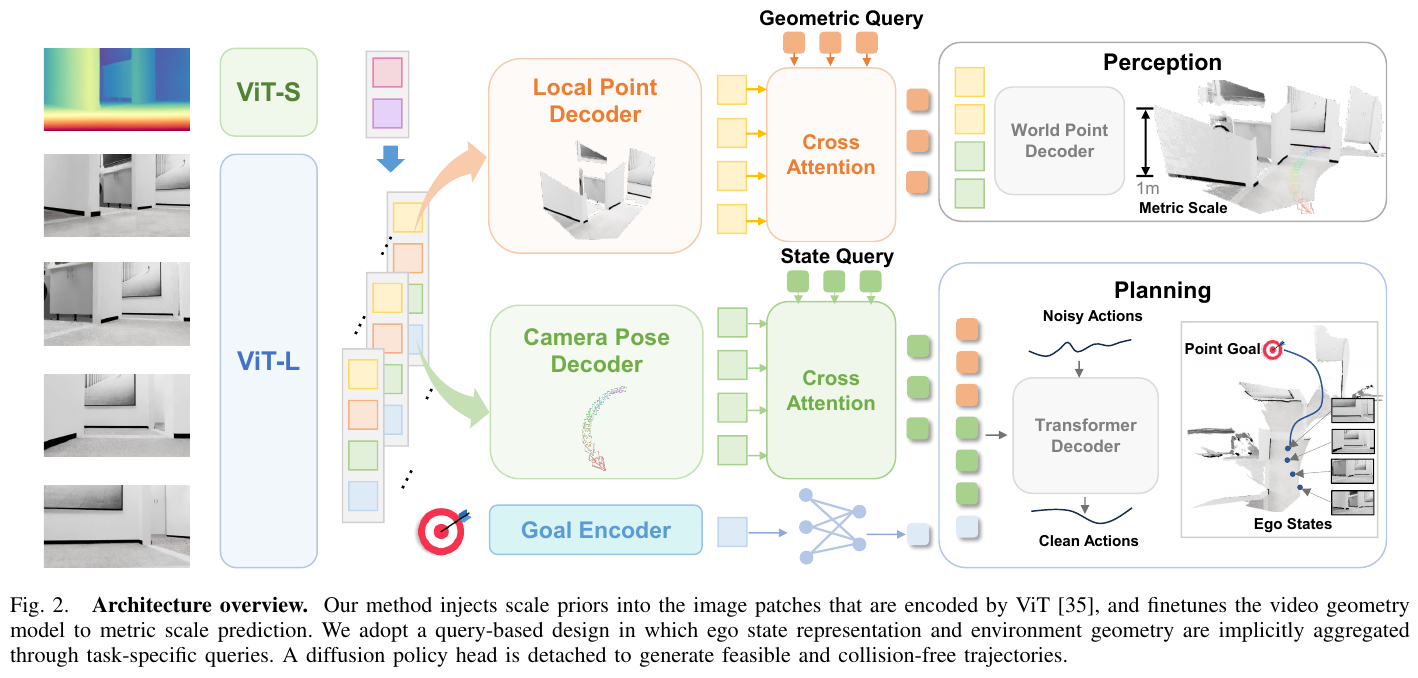
-
度量尺度注入(Metric-aware Geometry):VGGT 原生只给相对尺度重建,无法对齐规划轨迹。作者用一个轻量 ViT 把深度图编码成几何 token,在 patch 级与语义 token 融合,经带 RoPE 的 transformer decoder 得到带度量尺度的逐帧特征:
\[t_i^{metric} = \text{Attention}_{\text{RoPE}}((t_i^I, t_i^D), pos)\]再分支到局部点 head(由针孔模型监督相机系 3D 点)与相机位姿 head(解码相机到世界变换,世界系定义在最后一帧底盘系)。两个 head 的中间特征拼接后经 context fusion 与点云解码器,输出以机器人当前位置为原点的稠密度量尺度点云,覆盖被遮挡与后视区域。
-
相机/底盘外参解耦:感知绑定相机视角、控制执行在底盘坐标系。把相机位姿与底盘位姿拆成两个独立预测任务,假设相机相对底盘无 yaw 旋转,由位姿特征额外预测底盘位姿与当前帧相对目标,相机位姿经固定外参 \(T_{b,i}=T_{c,i}\cdot T_{ext}\) 换算。训练时在任意相机高度(0.25–1.25 m)与俯仰角(0°–30°)下构造数据,赋予跨本体鲁棒性。
-
Query-based 隐式聚合(借鉴 UniAD):state query 从位姿 token 抽自状态、geometric query 从世界点 token 抽环境几何,与目标 embedding 拼接送 transformer decoder 得规划上下文 query \(Q_P\)。关键:不把上游预测的外参/点云显式喂下游,避免级联误差,最终优化目标始终是轨迹规划误差。
-
Diffusion 策略头:以 \(Q_P\) 为条件,从高斯噪声对动作块 \(\{(\Delta x_t,\Delta y_t,\Delta\theta_t)\}\) 迭代去噪,生成可行、无碰撞轨迹。
训练采用两阶段:阶段一微调几何模型 decoder 与 task head(注入深度尺度先验,监督度量点云与外参);阶段二冻结骨干 decoder,联合训练 diffusion head 与 task head。
核心结果/发现
- 仿真(InternScenes 40 个未见场景):在完全无外部定位条件下,Home SR 57.3 / SPL 52.4、Commercial SR 67.1 / SPL 63.9,超过使用 oracle 定位的 ViPlanner——相对 ViPlanner,Home SR 提升 27.3 个百分点、SPL 提升 21.3%。
- 真实世界(3 平台 × 各 20 条轨迹,免 VO/SLAM 直接部署):TurtleBot(办公)SR 85% (17/20)、Unitree Go2(家居)70% (14/20)、Unitree G1(工业)50% (10/20),全面优于 iPlanner(10/15/0%)与 ViPlanner(50/45/0%);四足平台相机抖动下仍能准确自定位并避障。

- 消融(关键模块):Odometry / Goal / Point Cloud 三个 auxiliary task 逐项叠加,Home SR 从纯端到端的 49.5 提升到 51.3 → 52.4 → 57.3,证明点云监督带来超出 2D 语义的空间关系、显著提升避障。
- 消融(几何骨干):DepthAnything(单帧)→ Video DepthAnything → VGGT†(无度量尺度)→ VGGT(注入尺度先验)逐级提升;注入尺度先验后 PE 从 0.87 降到 0.55(Home),说明度量尺度监督对真实部署是必需的。

关键创新:
- 把”定位”吸收进网络:用长时序视觉几何骨干做隐式自状态估计,免标定、免外部 SLAM/VO,跨本体跨视角直接部署。
- 相对尺度→绝对度量尺度:注入深度先验校正 VGGT 的尺度模糊,得到可对齐规划坐标系的稠密点云。
- 隐式特征条件化而非显式传递:用 auxiliary task 把几何/位姿能力蒸馏成隐式特征供 diffusion 头条件化,切断级联误差,以规划误差为唯一优化目标。
局限性
受限于可用导航场景数量较少(约 2k),真实环境下的重建质量仍不理想;作者正在度量尺度的真实世界数据集上继续训练,以提升实际部署性能。
11. NavGPT (2024)
——利用大语言模型进行视觉语言导航的显式推理
📄 Paper: arXiv:2305.16986 · 🏛️ AAAI 2024
研究背景/问题
现有的视觉语言导航(VLN)方法虽然性能较好,但其决策过程是隐式的、不可解释的。大语言模型(LLMs)在训练中展现出强大的推理能力和知识储备,但其在具身导航任务中的推理能力尚未被充分探索。研究的核心问题是:LLMs能否理解以文本形式描述的交互世界、动作及其后果,并利用这些信息解决导航任务?
主要方法/创新点
NavGPT是一个完全基于LLM的指令跟随导航系统,通过零样本方式执行视觉语言导航任务。系统包含四个核心组件:
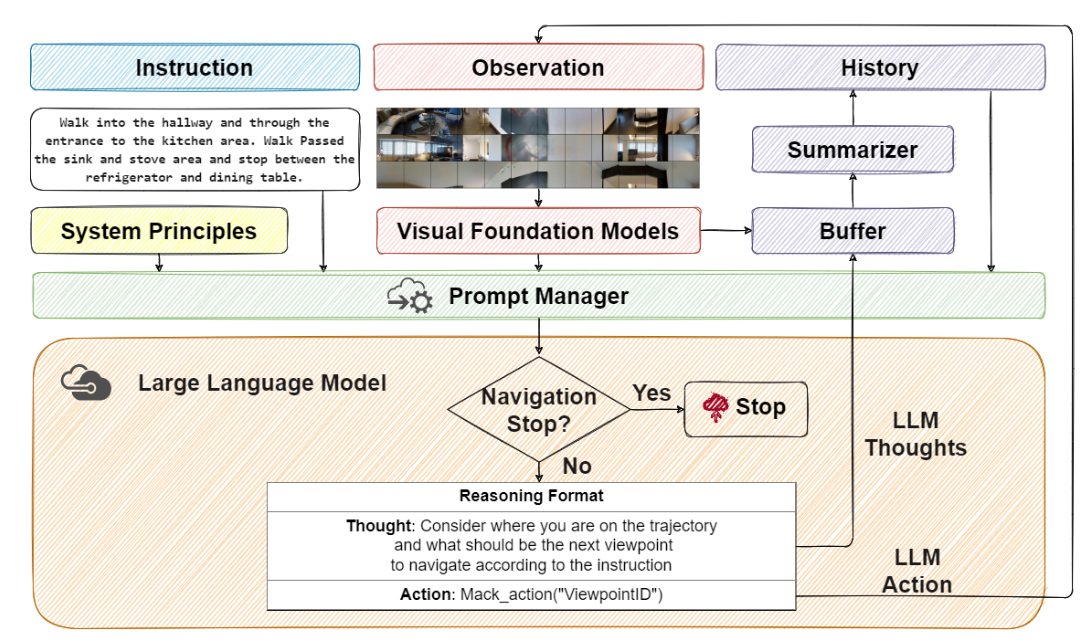
- 导航系统原则(Navigation System Principle): 定义VLN任务和LLM的基本推理格式与规则
- 视觉基础模型(Visual Foundation Models): 使用BLIP-2将视觉观察转换为自然语言描述,使用Faster-RCNN检测物体并提取深度信息
- 导航历史(Navigation History): 维护观察、推理和动作的三元组历史,使用GPT-3.5进行摘要以控制长度
- 提示管理器(Prompt Manager): 将所有信息整合为LLM可理解的自然语言提示
关键创新在于协同推理与动作(Synergizing Reasoning and Actions):
- 扩展动作空间为 A˜ = A ∪ R,其中R为推理轨迹
- 在每步导航前先生成推理(Thought),再做出动作决策(Action)
- 推理不触发环境交互,但能增强LLM的问题解决能力
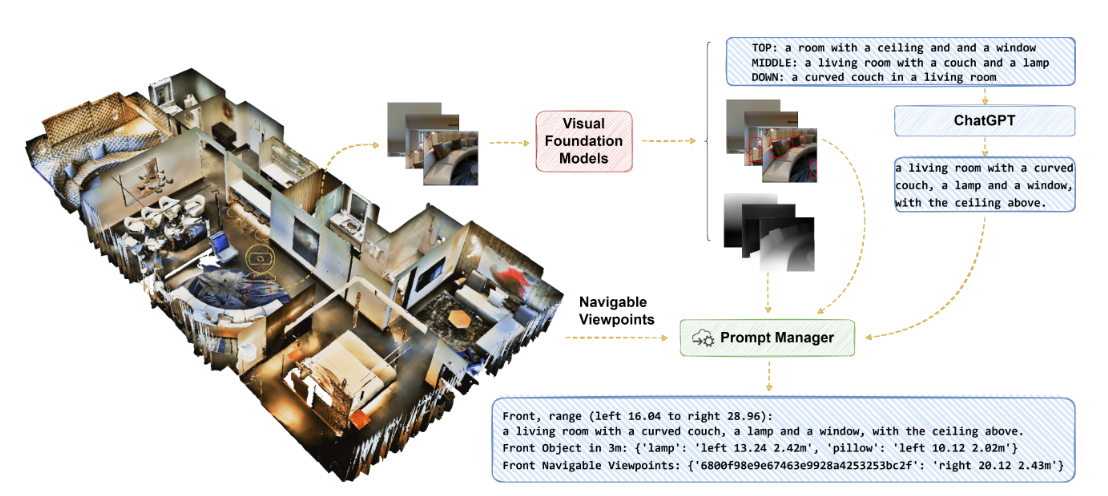
NavGPT展现出多种高级导航规划能力:
- 将指令分解为子目标
- 整合与导航相关的常识知识
- 从观察场景中识别地标
- 跟踪导航进度
- 处理异常情况并调整计划
核心结果/发现
在R2R val unseen数据集上的实验结果(使用GPT-4):
- Success Rate (SR): 34%
- SPL: 29%
- Oracle Success Rate (OSR): 42%
虽然与训练模型仍有约40%的性能差距,但NavGPT展示了LLM的强大能力:
- 高级规划能力: 能够分解指令、识别地标、跟踪进度、适应异常
- 生成能力: 可根据导航历史生成高质量的导航指令
- 空间意识: 能够绘制准确的俯视图轨迹
人类评估显示LLM生成的推理质量可接受但仍有提升空间(准确性1.66/3.0,信息量1.93/3.0,合理性1.78/3.0)。
局限性
主要瓶颈在于:(1)视觉信号转换为自然语言时的信息损失;(2)历史观察摘要时的信息损失;(3)零样本性能与训练模型相比仍有较大差距(SR差距约40%)。未来方向建议采用多模态输入的LLMs或利用LLMs的高级推理能力来增强基于学习的模型。
12. NavGPT-2 (2024)
——释放大型视觉语言模型的导航推理能力
📄 Paper: arXiv:2407.12366 · 🏛️ ECCV 2024
研究背景/问题
虽然有将LLMs集成到VLN任务的努力,但存在两个极端方法的局限:(1)零样本方法依赖复杂的提示工程,存在信息损失且性能差距大(约40% SR);(2)微调方法虽然使用大规模LLMs,但性能仍落后于VLN专用模型,且丧失了LLMs的语言能力和可解释性。研究目标是在保持LLMs解释能力的同时,消除LLM-based agents与SOTA VLN专用模型之间的性能差距。
主要方法/创新点
NavGPT-2采用冻结LLM + 导航策略网络的混合架构,分两阶段训练:
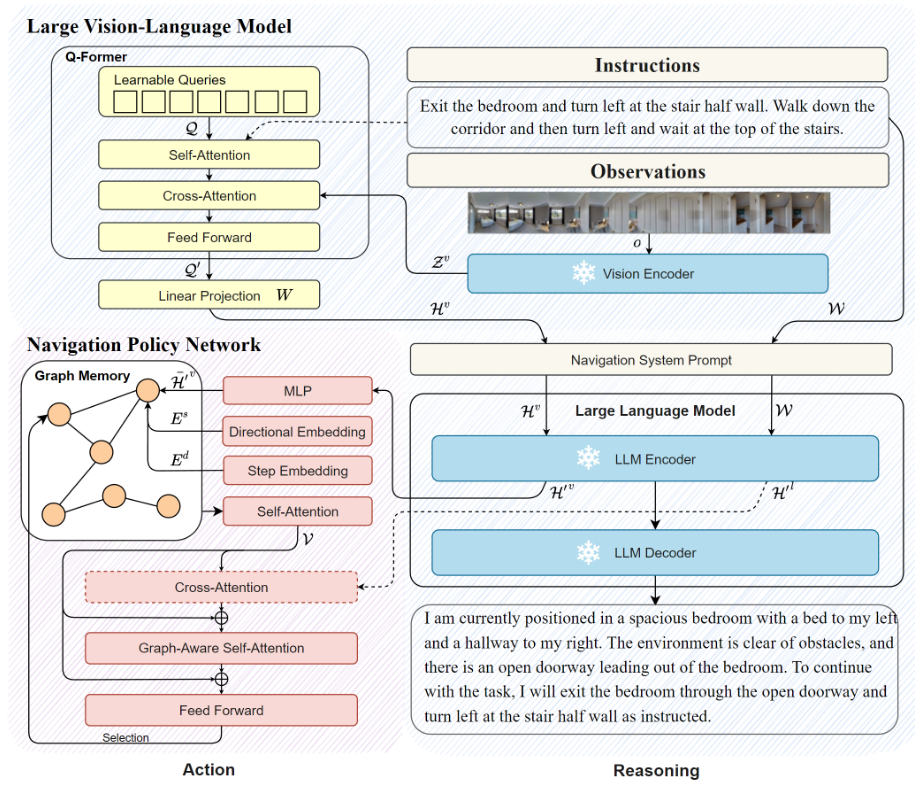
阶段一:视觉指令调优(Visual Instruction Tuning)
- 基于InstructBLIP架构,使用Q-former将多视图图像编码为固定长度的视觉tokens
- 使用GPT-4V自动生成10K导航推理数据
- 仅微调Q-former和投影层,保持LLM和视觉编码器(EVA-CLIP ViT-g/14)冻结

阶段二:图基础导航策略学习
- 提取LLM隐藏层表示作为视觉-语言表征
- 采用拓扑图导航策略网络(源自DUET),包含:
- 节点嵌入(Node Embedding):整合视觉特征、方向嵌入、步数嵌入
- 跨模态编码(Cross-Modal Encoding):图感知自注意力(GASA)机制
- 全局动作预测(Global Action Prediction):从整个构建的图中选择下一步
- 使用DAgger损失训练,保持VLM冻结
关键创新点:
- VLM隐表示作为视觉-语言表征:将视觉特征投影到LLM的语言空间,实现更强的跨环境对齐
- 数据高效:利用LLM预训练权重,在50%数据量下即可达到DUET全量数据的性能
- 保留语言能力:冻结LLM使其保持生成导航推理和与人类交互的能力
核心结果/发现
在R2R数据集上的性能(NavGPT-2FlanT5-XXL, 5B参数):
| Split | SR | SPL | NE | OSR |
|---|---|---|---|---|
| Val Unseen | 71% | 60% | 3.18 | 80% |
| Test Unseen | 72% | 60% | 3.33 | 80% |
主要发现:
- 消除性能差距:在相同训练规模下,超越所有LLM-based方法,与DUET(SOTA VLN专用模型)性能相当
- 数据效率:使用50% R2R数据即可达到DUET使用全量数据的性能
- 泛化能力:
- RxR数据集(细粒度指令):SR提升3.67%
- HM3D数据集(未见环境):SR提升21.6%(47.2% vs 25.6%)
- 可解释性:能够生成描述周围环境、识别导航进度、规划下一步的自然语言推理
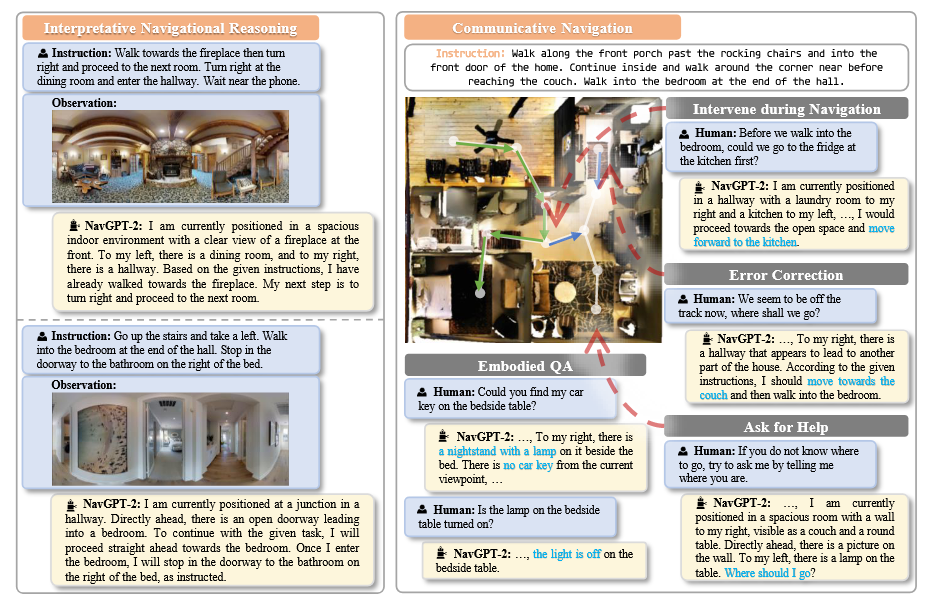
消融实验表明:
- 移除导航策略网络后性能大幅下降(SR从68%降至21%)
- FlanT5系列模型优于Vicuna系列(编码器-解码器架构优于纯解码器架构)
- 更强的视觉编码器对性能提升有限,主要增益来自LLM隐表示
局限性
(1)导航推理基于局部观察,未在VLM中建模历史,一致性有待提高;(2)推理与动作预测未严格同步;(3)存在幻觉问题(识别不存在的物体或误判方向);(4)交互能力未经充分评估。未来工作应聚焦于推理-动作同步机制、历史建模以及交互导航能力的开发。
系列对比总结
| 维度 | NavGPT (AAAI-2024) | NavGPT-2 (ECCV-2024) |
|---|---|---|
| 核心思路 | 纯LLM零样本导航 | 冻结LLM + 微调导航策略 |
| 训练方式 | 无需训练(零样本) | 两阶段训练(VLM微调+策略学习) |
| 性能(R2R SR) | 34% | 72% (test unseen) |
| 推理能力 | 显式,基于提示工程 | 显式,基于指令调优 |
| 主要贡献 | 揭示LLM导航推理能力 | 消除LLM-agent与SOTA的性能差距 |
| 局限 | 性能差距大,信息损失严重 | 推理-动作同步不足,存在幻觉 |
两篇工作共同展示了LLMs在具身导航中的巨大潜力,从探索性的零样本方法发展到实用的混合架构,为构建可解释、可交互的通用导航智能体指明了方向。
13. FSR-VLN (2025)
——基于层次化多模态场景图的快慢推理视觉语言导航
📄 Paper: arXiv:2509.13733
研究背景/问题
视觉语言导航(VLN)是具身智能中的基础任务,但现有方法在长距离空间推理方面存在严重局限,特别是在长距离导航任务中表现出较低的成功率和较高的推理延迟。关键瓶颈在于缺乏持久的长距离空间记忆来编码、组织和检索环境知识。现有几何语义地图和3D场景图依赖预提取的视觉特征,缺乏与VLM的直接交互;而基于图像的拓扑方法虽然成功率高,但由于依赖视频字幕处理长序列而效率低下。
主要方法/创新点
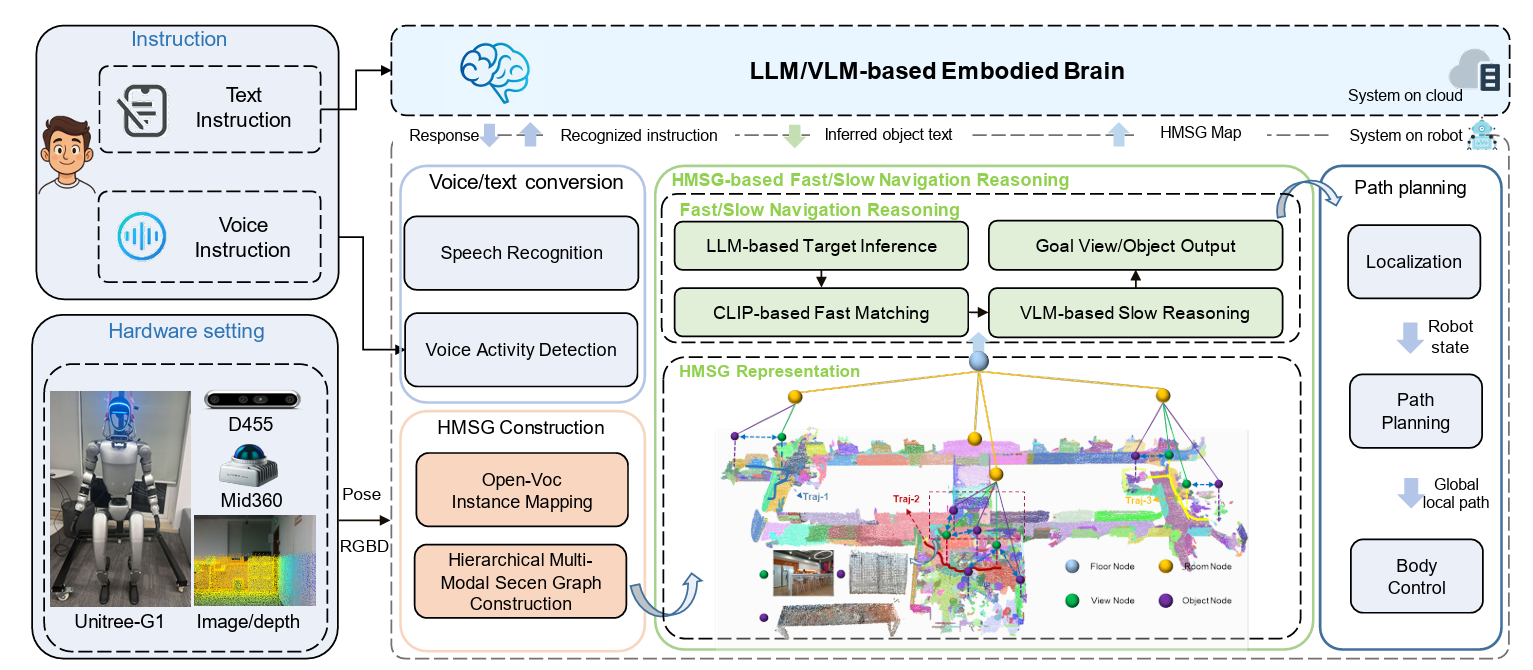
FSR-VLN提出了结合两大核心创新的新型导航系统:
1. 层次化多模态场景图(HMSG)表示
HMSG将环境组织为四个层级:
- 楼层节点(Floor nodes):存储楼层标识符、名称、最小/最大高度、PLY点云以及所含房间节点的引用
- 房间节点(Room nodes):包含ID、2D多边形边界、点云、语义属性(名称、CLIP嵌入)以及关联的视图和对象节点链接
- 视图节点(View nodes)(新颖贡献):表示房间内的特定视觉视角,存储CLIP嵌入、VLM生成的描述、相机位姿以及与对象的可见性关系。该层支持使用VLM对图像视图进行推理,同时增强对象级定位能力
- 对象节点(Object nodes):表示离散实例,具有几何属性(3D边界框、点云)、语义嵌入以及与父房间和可见视图的链接
每个节点编码多模态特征,包括几何属性、语义信息和拓扑连接。HMSG使用FAST-LIVO2 SLAM系统提取RGBD数据和位姿来构建,然后进行开放词汇实例映射。GPT-4o从图像视图推断房间名称,系统计算每个对象的平均深度以选择最佳代表视图。

2. 快慢导航推理(FSR)
受人类认知双过程理论启发,FSR分三个阶段运行:
阶段1:基于LLM的用户指令理解
- 对于空间指令(如”办公室里的蓝色圆柱形凳子”):LLM充当层次化概念解析器,将输入分解为楼层、区域和对象组件
- 对于非空间指令(如”我累了”):LLM充当目标推理代理,根据用户意图识别最相关的对象或区域
阶段2:快速匹配(直觉检索)
- 在查询文本与HMSG视图层嵌入之间进行基于CLIP的相似度匹配以识别目标视图
- 并行进行对象级匹配,使用查询文本与对象嵌入之间的CLIP特征
- 通过层次化特征匹配高效检索候选房间、视图和对象
阶段3:慢速推理(深思熟虑的精化)
- VLM(GPT-4o)验证匹配的对象是否出现在其最佳视图中
- 如果验证失败,系统会:
- 使用LLM对未匹配视图的文本描述进行推理
- 比较快速匹配视图与LLM选择的视图
- 应用VLM推理确定最终最优目标图像
- 通过重新计算与最终视图中对象的CLIP相似度来更新目标对象

这种多阶段架构无缝集成了高效的特征空间匹配与鲁棒的VLM驱动视觉验证。慢速推理仅在快速直觉失败时激活,大幅减少推理时间的同时提高准确性。
核心结果/发现
FSR-VLN在长距离真实室内环境中对87条机器人采集的指令进行评估,涵盖四个不同类别(无需推理、需要推理、小物体、空间目标):
- 成功率(SR):92%(80/87),显著优于基线方法:
- 比MobilityVLA(34.5%)高167%
- 比OK-Robot(60.9%)高51%
- 比HOVSG(51.7%)高77%
-
检索成功率(RSR@Top1):在4-5米距离阈值下达到96.6%,在所有距离阈值下始终保持最佳性能
- 响应时间:使用慢速推理平均5.5秒,仅使用快速匹配平均1.5秒
- 与MobilityVLM(30秒)相比响应时间减少82%
- 通过仅在快速匹配失败时激活慢速推理,实现高效实时性能
-
HM3D-SEM数据集:RSR@Top1在1米处达到87%,显著优于HOVSG(52%)和osmAG-LLM(28%)
- 消融实验:添加空间目标(ST)指令使RSR从72.4%提升到81.6%,结合导航推理(NR)进一步提升到92%,验证了两个组件的有效性
该系统已成功集成到Unitree-G1人形机器人的语音交互、规划和控制模块中,展示了具备自然语言交互能力的真实世界部署能力。
局限性
HMSG构建耗时,不适合实时建图。系统假设静态环境,限制了在动态场景中的适用性。未来工作将重点提高场景图构建效率、扩展对动态环境的鲁棒性,以及集成探索性导航能力以处理新颖或模糊的场景。
14. VLingNav (2026)
——Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
📄 Paper: arXiv:2601.08665
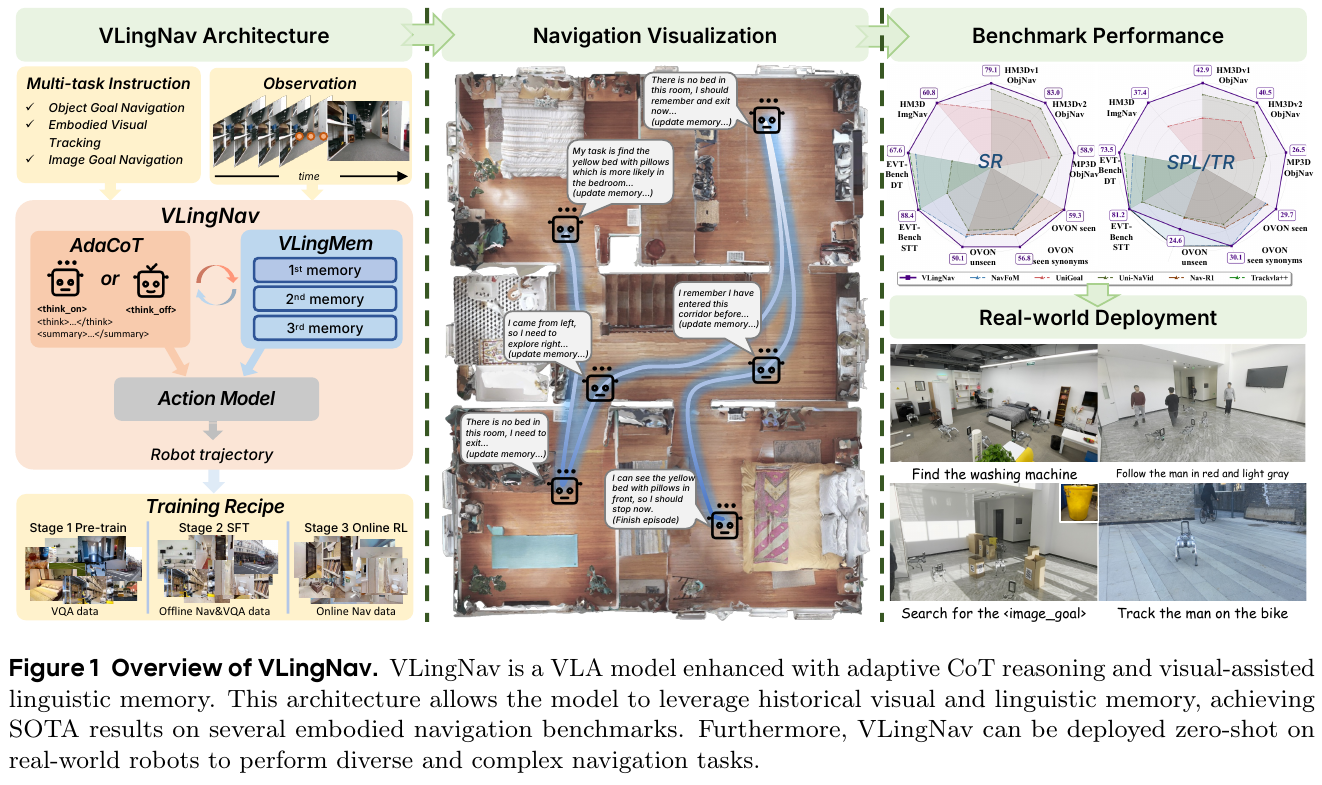
精华
该论文提出了VLingNav框架,通过自适应链式思考(AdaCoT)和视觉辅助语言记忆(VLingMem)赋予具身智能体认知能力,实现了高效且可解释的具身导航。其核心亮点在于动态推理机制和跨模态记忆,使其在各种具身导航基准测试中达到SOTA性能,并展示了强大的零样本迁移能力和跨任务泛化能力,为资源受限机器人平台上的智能导航提供了启发。
研究背景/问题
当前的具身导航VLA模型在复杂、长周期任务中缺乏明确的推理能力和持久性记忆,难以泛化到不同环境和任务变体。现有模型多为被动式系统,缺少自适应推理机制,并且依赖有限的上下文窗口,导致在复杂场景下无法有效规划和避免重复探索。
主要方法/创新点
本文提出了VLingNav,一个以语言驱动的VLA框架,旨在通过两个核心组件赋予具身智能体认知能力:
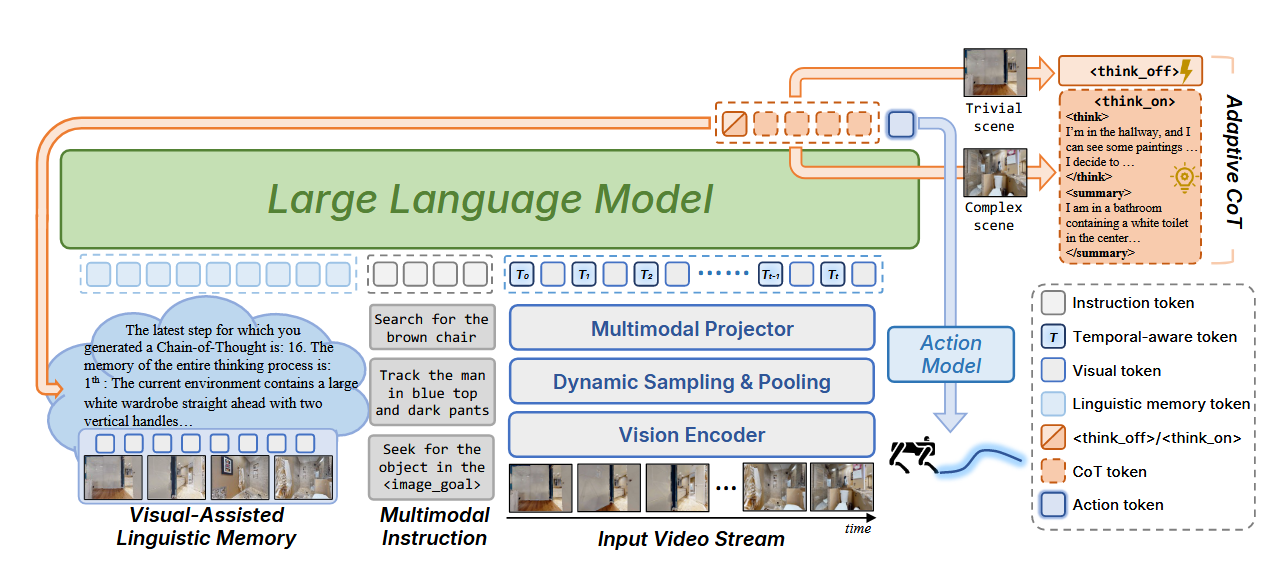
- 自适应链式思考 (Adaptive Chain-of-Thought, AdaCoT): 受人类双进程理论启发,AdaCoT机制在必要时动态触发显式推理,使智能体能够根据任务复杂性在快速、直观执行和缓慢、深思熟虑的规划之间灵活切换。这解决了现有CoT方法中推理频率固定导致效率低下的问题。
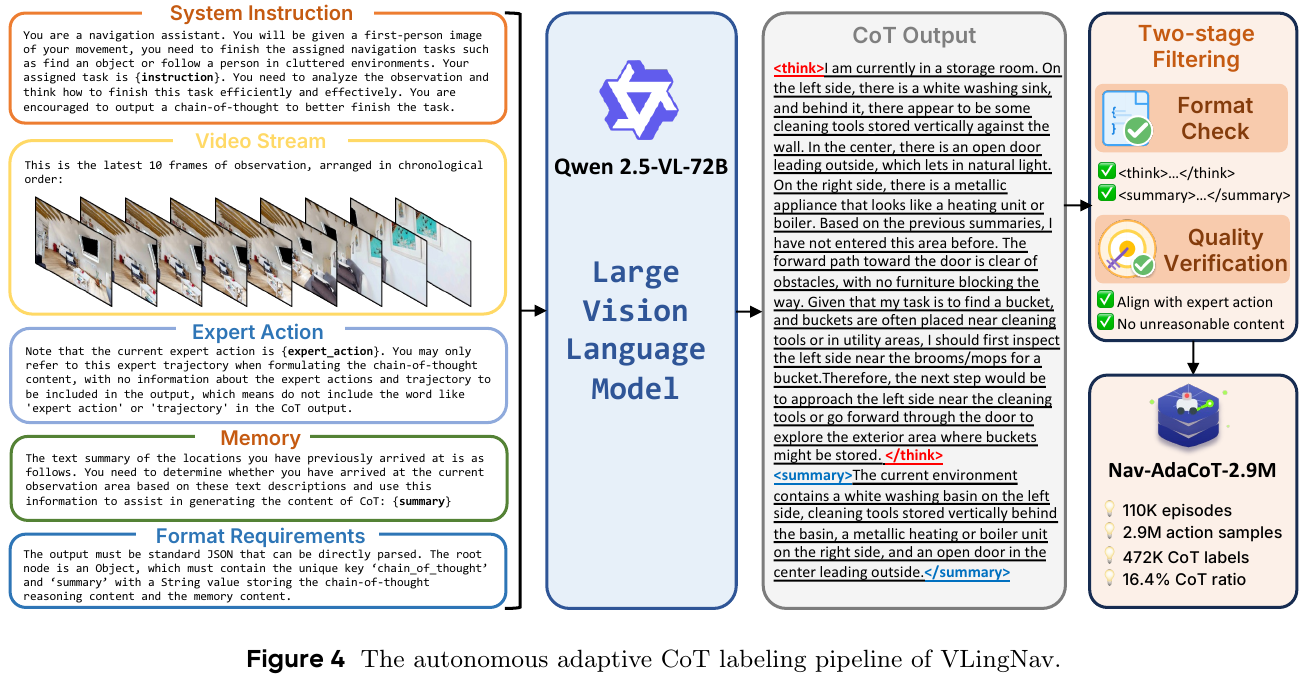
- 视觉辅助语言记忆 (Visual-Assisted Linguistic Memory, VLingMem): 为了处理长周期的空间依赖性,VLingMem构建了一个持久的、跨模态的语义记忆,使智能体能够回忆过去的观察结果,防止重复探索,并推断动态环境中的移动趋势,从而确保在长时间交互中的连贯决策。
训练数据和策略:
- Nav-AdaCoT-2.9M数据集:构建了目前最大的具身导航数据集,包含推理标注和自适应CoT标注。
- 在线专家引导强化学习 (Online Expert-guided RL):在模仿学习(SFT)之后引入了在线专家引导RL阶段,使模型能够获得更鲁棒、自探索的导航行为,超越监督演示的局限性。
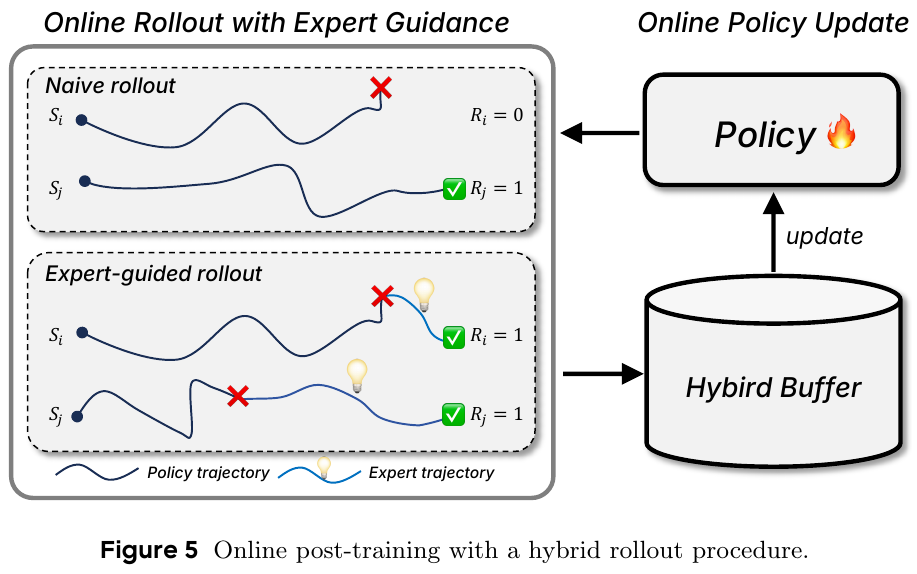
核心结果/发现
- VLingNav在多项具身导航基准测试(如ObjectNav, EVT, ImageNav)上实现了最先进的性能。
- 在HM3Dv1 ObjectNav上,SR和SPL显著优于Uni-NaVid,展现了强大的探索和记忆能力。
- 在HM3D OVON上,VLingNav在所有测试拆分中均表现最佳,证明了其强大的跨领域泛化能力。
- 在EVT-Bench上,VLingNav在单目标跟踪和分心跟踪任务中均达到SOTA性能,尤其在复杂混乱场景中优势明显。
- 在Image Goal Navigation上,VLingNav的成功率和导航效率显著高于UniGoal,表明其先进的推理和规划能力。
- 在真实世界机器人平台上实现了零样本迁移,成功执行了未见过的导航任务,展示了强大的真实世界泛化和实用性。
局限性
- 当前模型主要依赖单目自我中心观测,这限制了其感知能力。未来工作可以探索多视角观测以提高导航效率。
- 模型采用单系统架构,限制了预测频率,可能影响在高度动态环境中的快速决策和障碍物处理。未来可升级为双系统结构以支持高频动作输出。
- 当前方法仅使用基于MPC的路点控制器,缺乏更灵活的运动模型,未来可集成更多运动能力。
15. Slow4fast-VLN (2026)
——General Vision-Language Navigation via Fast-Slow Interactive Reasoning
📄 Paper: arXiv:2601.09111 · 🏛️ CVPR 2026
精华
这篇论文的核心借鉴价值在于其提出的动态交互式快慢脑(Fast-Slow Interactive Reasoning)导航框架。它通过模拟人类的“快思考”(直觉决策)和“慢思考”(深度反思),实现导航策略的持续优化。其亮点在于,慢脑系统能够从历史经验中提炼出可泛化的“导航知识”,并用其“赋能”快脑,从而有效提升了智能体在未知环境(OOD场景)中的泛化能力和决策效率,解决了传统方法中快慢系统割裂、经验无法沉淀的问题。
1. 研究背景/问题
传统的视觉-语言导航(VLN)方法在封闭环境下表现良好,但在面对环境和指令风格多变的开放世界时,其泛化能力严重不足。GSA-VLN任务通过引入多样化的场景和指令,对模型的场景适应性提出了更高要求。当前方法的主要挑战在于如何让智能体在导航过程中动态生成可泛化的策略,以应对前所未见的场景和指令。
2. 主要方法/创新点 (Core content, most detailed)
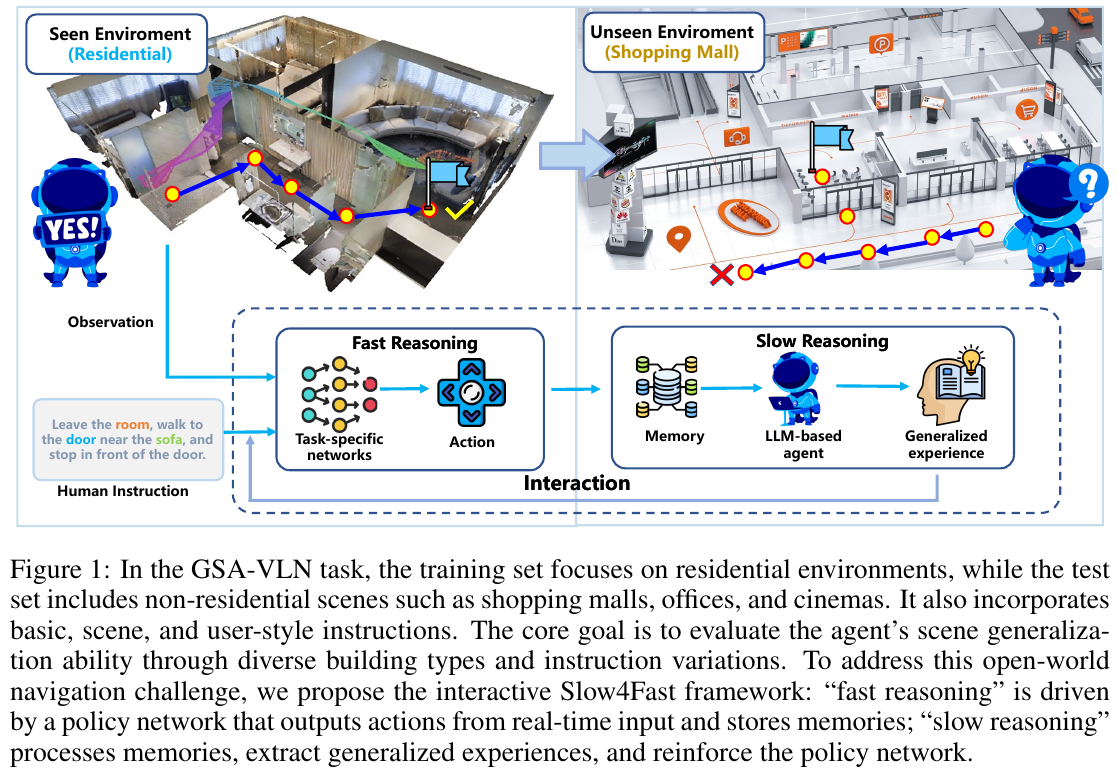
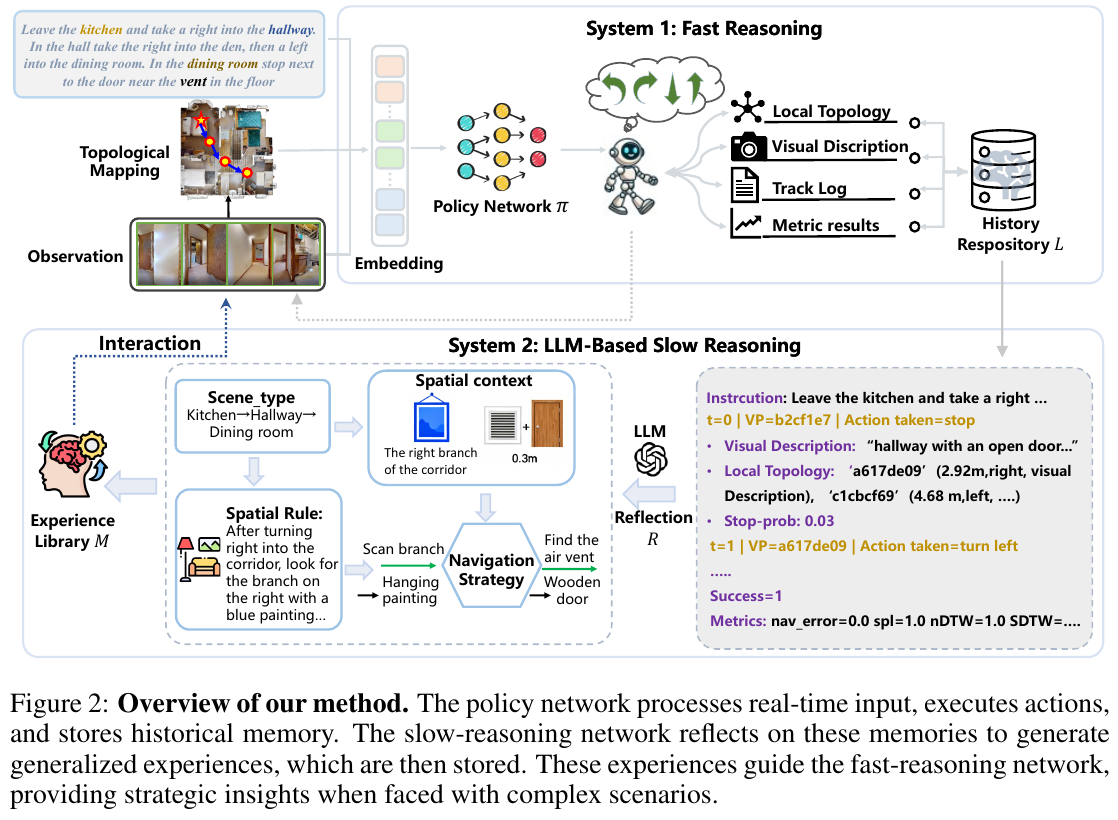
论文提出了一个名为 slow4fast-VLN 的动态交互式快慢推理框架,以应对开放环境下的视觉语言导航挑战。该框架包含快慢两个核心模块:
-
快推理模块 (Fast Reasoning):这是一个端到端的策略网络(基于DUET),负责根据实时的视觉和指令输入,快速生成导航动作。同时,它会记录导航过程中的所有执行记录(如观测、动作、度量等),形成历史记忆(History Repository)。
-
慢推理模块 (Slow Reasoning):该模块是整个框架的核心创新点。它利用大语言模型(LLM)对快推理模块产生的历史记忆进行深度“反思”(Reflection),从中提取出结构化、可泛化的导航经验(Structured Experience),并存入一个经验库(Experience Library)。这些经验包含了场景类型、空间上下文、空间规则、导航策略等关键信息。
-
快慢交互机制 (Interaction):这是区别于以往工作的关键。在导航决策时,快推理模块会从经验库中检索与当前场景最相关的经验,并将这些经验特征与实时视觉特征进行融合(通过Attention机制),从而“赋能”快脑,使其做出更精准、更泛化的决策。这种交互使得慢脑提炼的经验能够持续优化快脑的性能。
-
指令风格转换 (Instruction Style Conversion):为了应对多样的指令风格(如场景化、用户个性化),论文还设计了一个基于LLM的指令转换模块,通过CoT提示工程,将不同风格的指令实时转换为统一的“基础风格”指令,降低了模型对指令变化的敏感度。
3. 核心结果/发现 (Key findings)
- 环境适应性:在GSA-R2R数据集上,使用基础指令进行测试时,slow4fast-VLN在住宅(ID)和非住宅(OOD)场景中的成功率(SR)分别比基线方法GR-DUET提升了1.5%和2.2%,证明了快慢交互框架对于提升场景泛化能力的有效性。
- 指令适应性:在面对用户个性化指令和场景化指令时,该方法同样全面优于基线。例如,在用户指令测试中,其SR和SPL指标在多种角色(如Child, Keith, Moira等)下均达到SOTA水平。这得益于其指令风格转换模块和动态经验反馈循环。
- 消融实验:实验证明,快慢推理(FSR)框架和指令风格转换(ISC)模块都是有效的。当两者协同工作时,模型在最具挑战的Test-N-Scene任务上达到了最佳性能。
- 案例研究:通过可视化导航轨迹,论文展示了在引入慢脑反思后,智能体能够修正初始的错误路径,并基于经验(如“寻找蓝色画作”作为线索)更高效、更准确地完成导航任务,避免了不必要的探索。
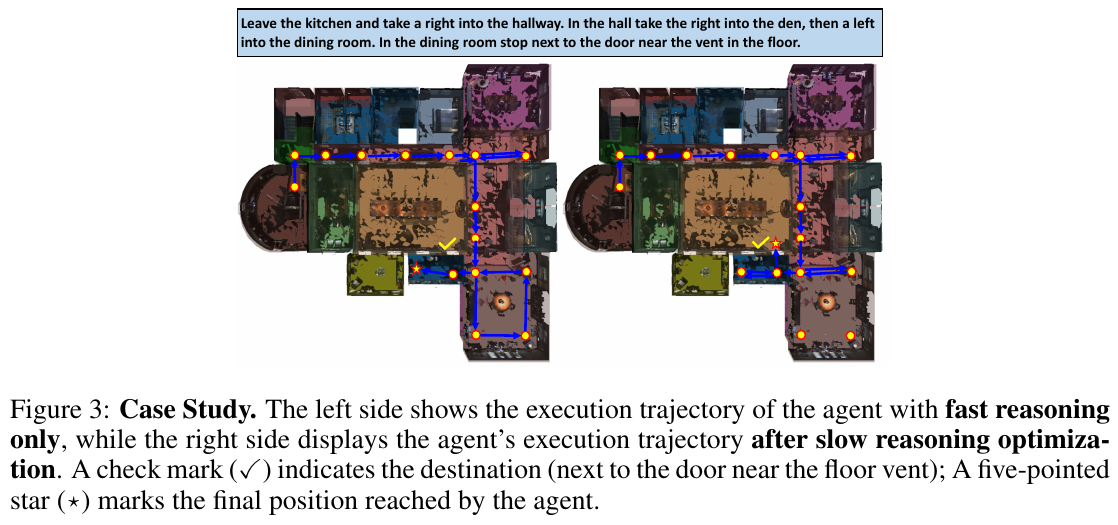
4. 局限性 (Brief, 1-2 sentences)
论文指出的一个局限是,慢脑推理产生的知识是隐式地编码在策略网络的权重中,这种“黑盒”形式使得学习到的经验难以解释和直接干预。未来的一个研究方向是让慢脑生成显式的、结构化的知识库(如语义地图或知识图谱),以供快脑在导航时直接查询。
16. FantasyVLN (2026)
———统一多模态Chain-of-Thought推理用于视觉-语言导航
📄 Paper: arXiv:2601.13976
精华 这篇论文展示了如何通过统一框架整合文本、视觉和多模态CoT推理模式,值得借鉴的点包括:(1) 训练时使用CoT监督、推理时直接预测的隐式推理范式,避免了显式CoT的token膨胀问题;(2) 使用预训练VAR模型将想象的视觉观测压缩到紧凑潜在空间,大幅降低序列长度;(3) 通过跨模态对齐约束统一不同推理模式,学习模态不变的推理表示;(4) 门控机制实现单一模型灵活切换多种推理模式。这种设计在保持推理能力的同时实现了实时导航,为具身智能任务提供了实用的解决方案。
研究背景/问题 现有VLN方法面临关键挑战:纯文本CoT缺乏空间理解且容易过拟合稀疏标注;多模态CoT通过生成想象的视觉观测引入严重的token膨胀,导致推理延迟增加数个数量级,无法实现实时导航。这在长时域、多阶段导航场景中尤为突出。
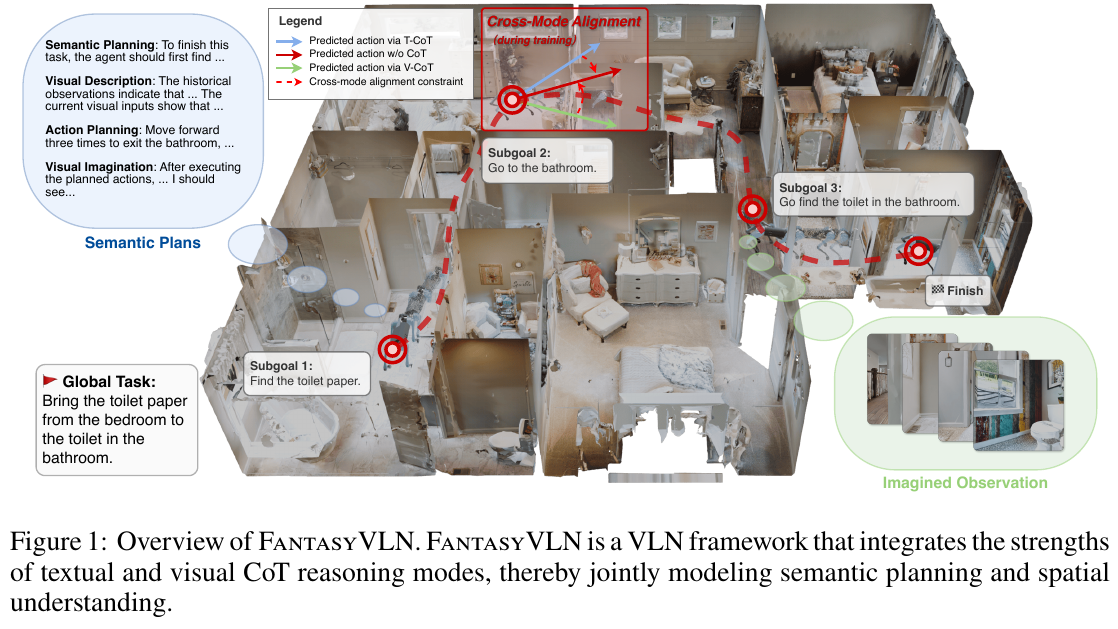
主要方法/创新点
FantasyVLN提出了统一的隐式推理框架,核心创新包括:
1. Compact Visual CoT (CompV-CoT)
- 使用预训练的Visual AutoRegressor (VAR)模型将想象的视觉观测编码到紧凑潜在空间
- VAR采用next-scale预测范式,256×256图像仅需30个视觉token即可精确重建,压缩比达1/2185
- 训练时VLM直接生成VAR潜在表示,推理时无需显式VAR解码,大幅提升效率
2. 统一多模态CoT (UM-CoT)框架
- 通过二元门控信号 gT 和 gV 控制文本和视觉推理的激活
- 四种推理模式:(a) Non-CoT (gT=0, gV=0) 直接预测动作;(b) T-CoT (gT=1, gV=0) 生成文本推理步骤;(c) V-CoT (gT=0, gV=1) 生成压缩视觉想象;(d) MM-CoT (gT=1, gV=1) 联合生成文本-视觉推理
- 单一模型共享参数,通过数据混合实现端到端联合训练
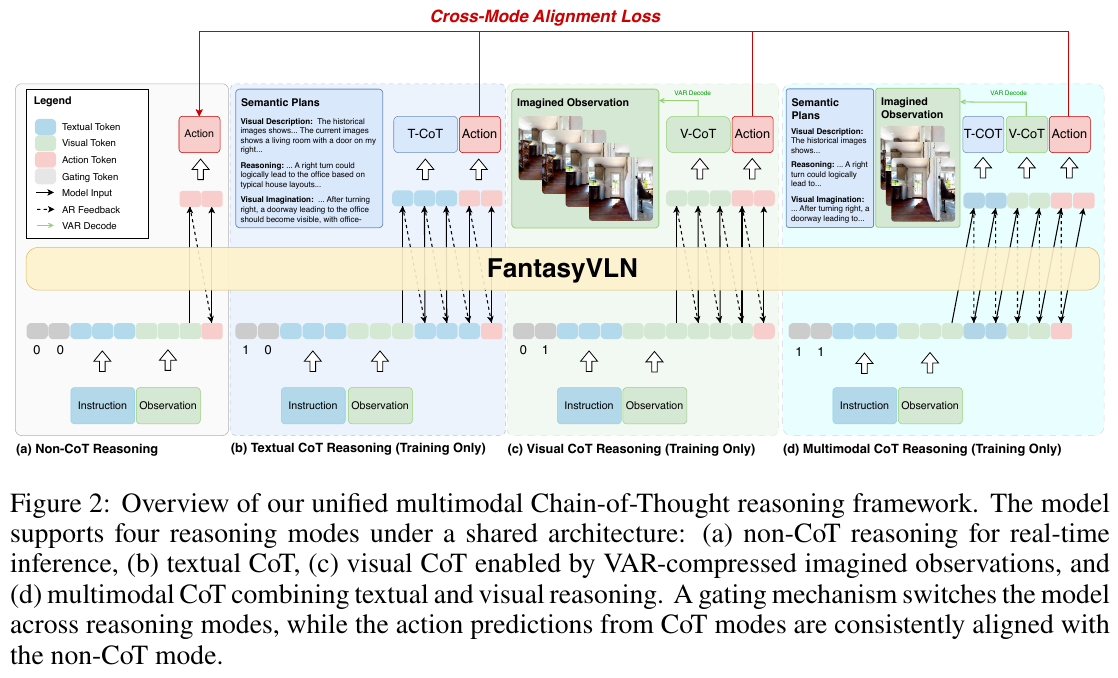
3. 跨模态对齐约束 (Cross-Mode Alignment)
- 将Non-CoT模式的动作预测作为软监督信号,对齐所有CoT变体的动作输出
- 交替优化Non-CoT目标和跨模态对齐的联合目标,嵌入多样化推理模式到统一潜在策略
- 防止不同推理模式间的冲突,学习一致的模态不变表示
4. 隐式推理机制
- 训练时:联合学习文本、视觉和多模态CoT模式
- 推理时:采用Non-CoT模式直接指令到动作映射,无需生成显式CoT序列
- 借鉴Aux-Think的”train-with-CoT, infer-without-CoT”范式,模型隐式保留推理感知表示
训练细节
- 基础模型:Qwen2.5-VL (7B参数)
- 数据:LH-VLN训练集18,554个导航轨迹切片(每5步一个切片)
- T-CoT标注:使用Qwen-VL-Max生成,包含语义规划、视觉描述、动作规划和视觉想象四部分
- 优化:LoRA微调,AdamW优化器,学习率1e-4,64×H20 GPUs,DeepSpeed ZeRO-2
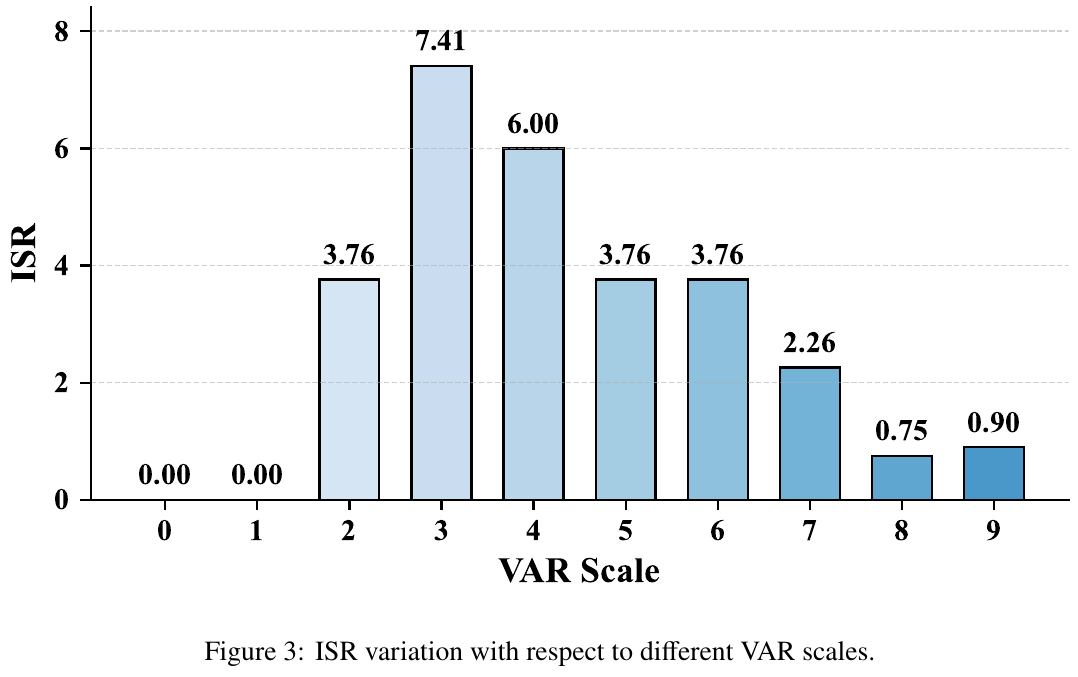

核心结果/发现
导航精度 (LH-VLN benchmark)
- SR (成功率): 2.44% (所有基线中最佳)
- ISR (独立成功率): 11.01% (显著优于所有方法)
- CSR (条件成功率): 9.64%
- CGT (加权CSR): 8.99%
- 显著超越次优方法Aux-Think (仅T-CoT): SR提升3.75×,ISR提升3.5×
推理效率
- APS (每秒动作数): 1.03,与WorldVLA (1.02)和Aux-Think (0.97)相当
- 比显式CoT方法CoT-VLA (0.19 APS)快5.4×,推理延迟降低一个数量级
- 隐式推理每次预测仅解码单个token,而显式CoT需生成3k-5k个token
训练效率
- FantasyVLN在few thousand迭代内快速收敛,token预测准确率达到1.0
- WorldVLA (像素级V-CoT)需10k+迭代才能达到0.5准确率,且训练不稳定
- CompV-CoT通过潜在空间推理提供更强梯度信号和更稳定的学习动态
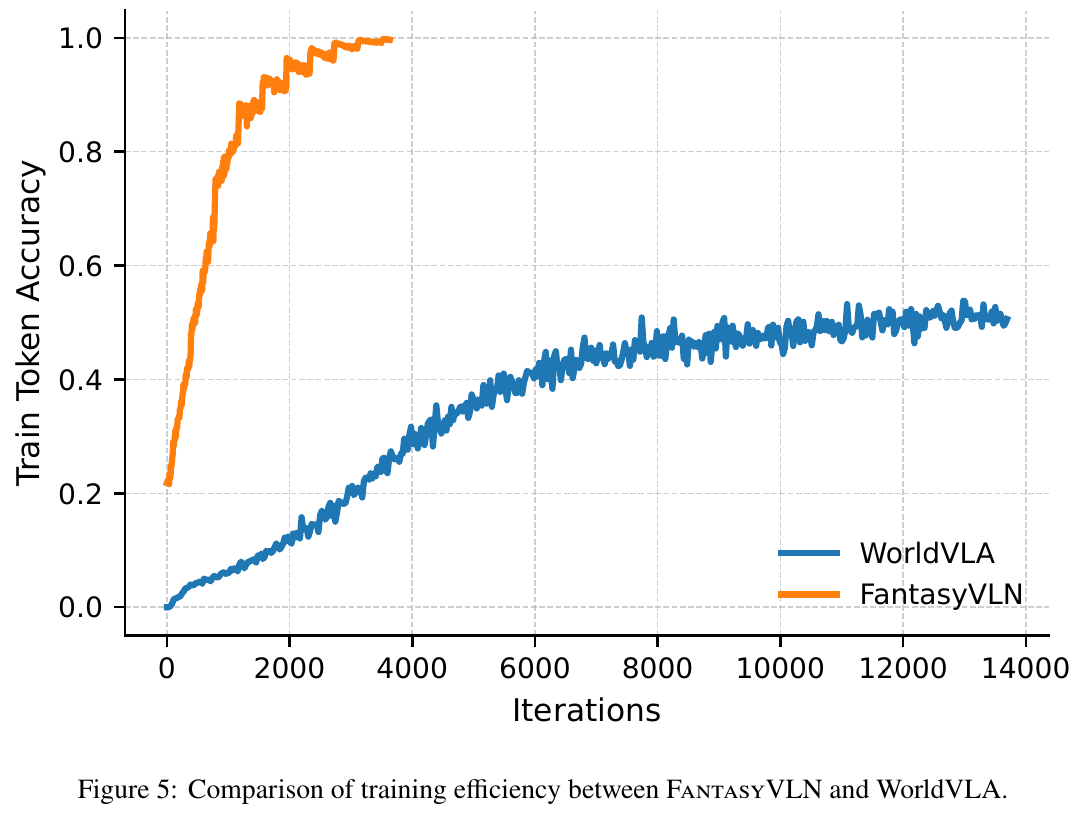
消融实验
- 各推理模式贡献:结合任何CoT模式与Non-CoT都能提升性能,四模式联合训练效果最佳
- VAR scale选择:scale 4最优(ISR 7.41%),更小scale信息不足,更大scale冗余
- 跨模态对齐:关键组件,移除后SR从2.44%降至0,ISR从11.01%降至2.39%
- 显式vs隐式推理:隐式推理在多模态设置下表现最佳(MM-CoT隐式:SR 2.44 vs 显式0.98)
局限性 该方法在LH-VLN这种小规模数据集(18k轨迹切片)上训练,显式CoT容易过拟合并产生累积误差;在更大规模数据集上的表现有待验证。此外,绝对成功率仍较低(SR 2.44%),表明长时域多阶段导航仍是极具挑战性的任务。
17. VL-Nav (2025)
——实时零样本 Vision-Language 导航系统,融合像素级视觉-语言特征与启发式空间推理
📄 Paper: arXiv:2502.00931
精华
这篇论文展示了如何将像素级 vision-language 特征与启发式探索策略结合,实现高效的零样本导航。值得借鉴的核心思想包括:(1) 使用 Gaussian 混合模型将像素级 VL 特征转换为空间分布,而非依赖单一图像级相似度分数;(2) 引入 instance-based target points 模拟人类搜索行为,允许机器人接近并验证潜在目标;(3) 通过 rolling occupancy grid 和 partial frontier detection 优化计算开销,使系统能在低功耗平台上实时运行;(4) 结合 distance weighting 和 unknown-area heuristic 避免反复移动,提升大规模环境中的导航效率;(5) 证明了模块化方法在真实世界中的泛化能力优于端到端学习方法。
研究背景/问题
当前的 vision-language navigation 系统面临三大挑战:难以解释像素级 vision-language 特征、在不同环境中泛化能力差、无法在低功耗平台上实时运行。现有方法如 VLFM 依赖计算密集型模型且仅使用单一图像级相似度分数进行目标选择,限制了其利用细粒度 vision-language 线索的能力。
主要方法/创新点
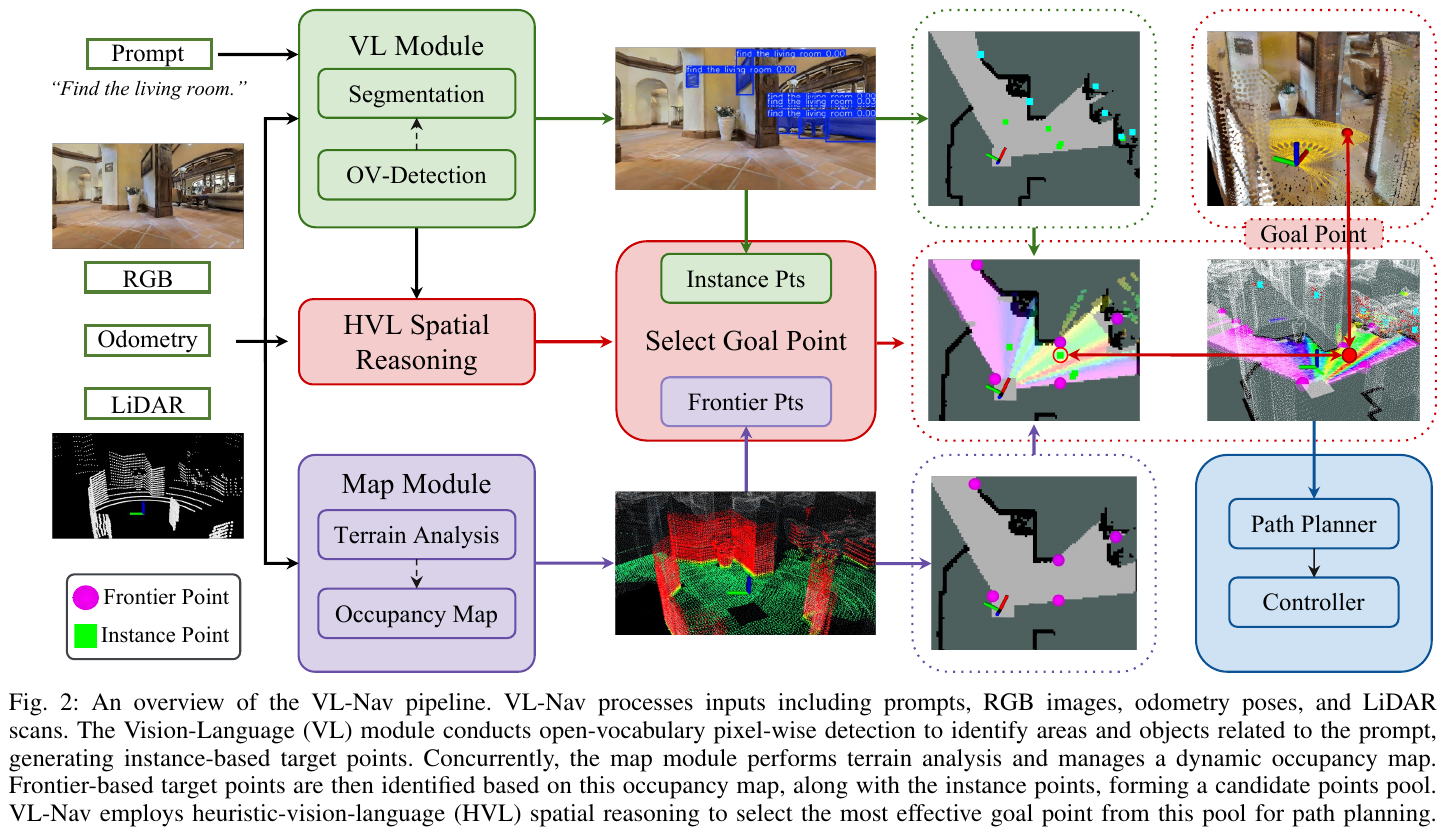
VL-Nav 提出了一个针对低功耗机器人优化的 vision-language navigation 框架,在 Jetson Orin NX 上实现 30 Hz 实时性能。核心创新在于 Heuristic-Vision-Language (HVL) 空间推理,将像素级 vision-language 特征与启发式探索策略相结合。
Rolling Occupancy Map:系统维护一个动态 2D 占用栅格地图,每个单元格标记为 free (0)、unknown (-1) 或 occupied (100)。与传统固定大小全局栅格不同,VL-Nav 采用 rolling grid,仅在新传感器数据需要时动态扩展,降低内存使用和 BFS/cluster 计算开销。更新过程包括:(1) 根据需要扩展地图;(2) 清除前向 FOV 内的过时障碍物;(3) 膨胀新障碍物;(4) 使用 raycasting 将 unknown cells 标记为 free。
Frontier-based 与 Instance-based Target Points:系统生成两类候选目标点。Frontier-based points 通过 partial frontier detection 在前向楔形区域内识别,仅测试满足角度和距离约束的单元格,并使用 BFS 聚类。Instance-based target points (IBTP) 来自 vision-language 检测器周期性报告的候选实例中心,保留置信度高于阈值 τdet 的检测结果。IBTP 模拟人类搜索行为:看到可能匹配的目标时会靠近确认,而非忽略中间检测结果。
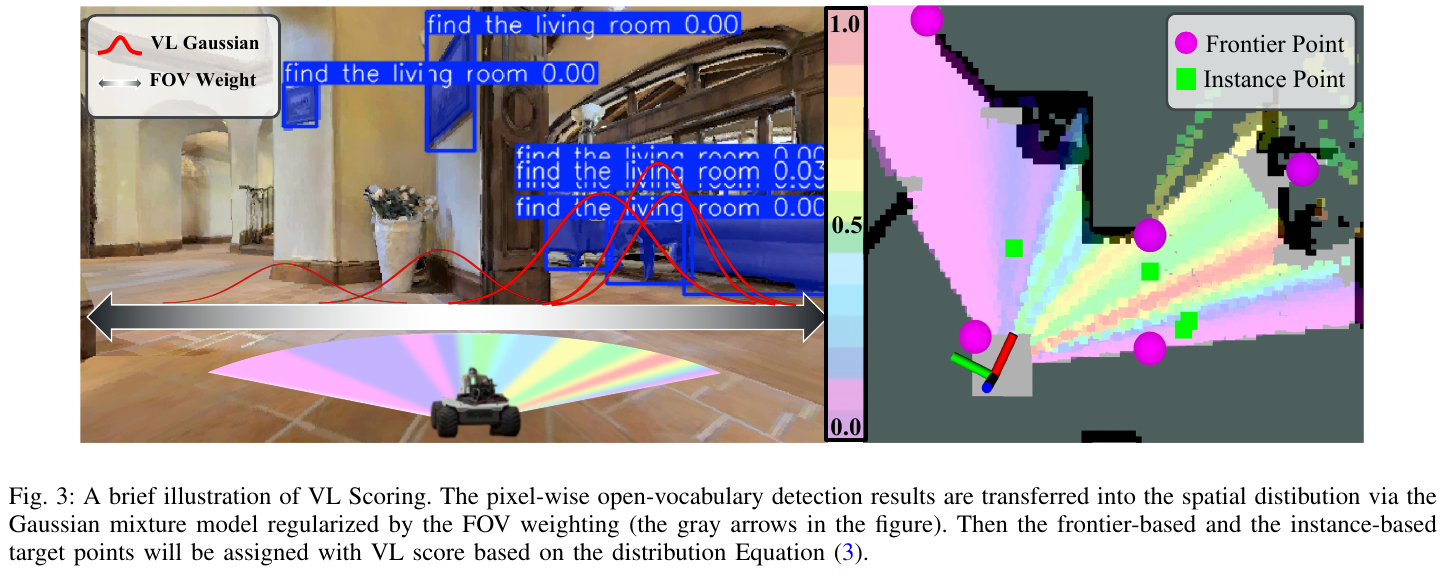
HVL 空间推理:这是 VL-Nav 的核心创新。对每个候选目标 g,系统计算 HVL score。VL Score 使用 Gaussian 混合模型将像素级 vision-language 特征转换为机器人水平 FOV 上的分布。假设开放词汇检测模型识别出 K 个可能方向,每个由 (μk, σk, αk) 参数化,其中 μk 表示 FOV 内的平均偏移角度,σk 编码检测的角度不确定性(固定为 0.1),αk 是基于置信度的权重。VL score 计算为:
S_VL(g) = Σ(k=1 to K) αk * exp(-1/2 * ((Δθ - μk)/σk)²) * C(Δθ)
其中 C(Δθ) = cos²(Δθ/(θ_fov/2) * π/2) 是视野置信度项,降低大角度偏移检测的权重。
Heuristic Cues 包括两个启发式项:(1) Distance Weighting: S_dist(g) = 1/(1+d(xr,g)),使较近目标获得更高分数,减少能量消耗和不必要的徘徊;(2) Unknown-Area Weighting: S_unknown(g) = 1 - exp(-k*ratio(g)),其中 ratio(g) 是局部 BFS 中 unknown cells 与可达 cells 的比率,鼓励探索可能揭示大量未知空间的目标。
最终 HVL score 为:S_HVL(g) = w_dist * S_dist(g) + w_VL * S_VL(g) * S_unknown(g)。系统优先选择 instance-based goals(基于 VL score),若无则选择得分最高的 frontier goal(基于 HVL score)。
Path Planning:选定 HVL goal 后,系统使用 FAR Planner 进行 point-goal 路径规划,以多边形表示障碍物并实时更新可见性图,支持部分未知环境中的高效重规划。局部规划器将 FAR Planner 的路径点细化为短时域速度命令,确保对新障碍物的快速反应。

核心结果/发现

VL-Nav 在四个真实世界环境(Hallway、Office、Apartment、Outdoor)上进行了全面评估,每个环境具有不同的语义复杂度(High、Medium、Low)和规模(Big、Mid、Small)。主要发现包括:
- 整体性能:VL-Nav 达到 86.3% 的总体成功率 (SR),比先前方法提升 44.15%。在所有四个环境中,VL-Nav 的 SR 和 SPL(Success weighted by Path Length)均为最高。
- Instance-based Target Points 的影响:去除 IBTP 后性能显著下降,特别是在复杂环境(Apartment 和 Office)中,证明了允许机器人接近并验证潜在检测结果的重要性。
- Heuristics 的贡献:去除启发式项后 SR 和 SPL 均下降,特别是在大规模环境中,表明 distance weighting 和 unknown-area heuristic 对提升效率至关重要。
- 相比 VLFM:VL-Nav 在所有环境中均超越 VLFM,特别是在语义复杂(Apartment)和开放区域(Outdoor)环境中,优势更加明显,证明了像素级 VL 特征和 HVL 空间推理的有效性。
- 环境规模影响:经典 Frontier Exploration 在大规模环境中性能急剧下降(Big 环境中 SR 仅 36.7%),而 VL-Nav 保持鲁棒(82.3% SR),证明了其在各种规模环境中的适应能力。
- 语义复杂度影响:所有方法在语义更丰富的环境中表现更好,因为结构化室内空间提供了更强的检测和分割线索。VL-Nav 能够充分利用语义上下文,在高复杂度环境中获得更显著的优势。
- 实时性能:VL-Nav 在 Jetson Orin NX 上以 30 Hz 运行,通过选择高效的 YOLO-World 模型变体(256×320 输入,标准 GPU runtime)和 rolling occupancy grid 实现了真实世界部署的可行性。
局限性
系统在处理包含隐藏对象引用和特定文本注释的复杂语言描述时存在困难。此外,系统依赖于手动定义的阈值(如光照条件等),这些阈值可能无法在不同环境和场景中很好地泛化,需要进一步研究自适应或基于学习的阈值调整方法。
18. StreamVLN (2025)
——— 通过慢-快上下文建模实现流式视觉-语言导航
📄 Paper: arXiv:2507.05240 · 🏛️ ICRA 2026
精华
这篇论文提出了一个适用于真实世界部署的流式 VLN 框架,值得借鉴的核心思想包括:(1) 采用慢-快双通道上下文建模策略,平衡全局场景理解和实时响应能力;(2) 利用 3D 几何信息进行智能 token 剪枝,在保持性能的同时显著降低计算开销;(3) 通过 KV cache 复用机制利用时间连贯性,支持长视频流的高效推理;(4) 将上下文大小和推理成本控制在有界范围内,为 embodied AI 的实际部署提供了可行方案;(5) 采用多源数据联合训练策略(VLA数据+通用VL数据+DAgger数据),同时保持通用推理能力和导航专业性能。这些设计思路可以迁移到其他需要处理长序列多模态输入的具身智能任务中。
研究背景/问题
现有的 Vision-and-Language Navigation 方法在处理真实世界连续环境时面临关键挑战:如何在长视频流中高效进行多模态推理,同时保持低延迟以支持实时交互。现有 Video-LLM 基于的 VLN 方法往往在细粒度视觉理解、长期上下文建模和计算效率之间存在权衡。本文旨在设计一个既能捕捉全局场景理解,又能快速响应的流式导航框架。
主要方法/创新点
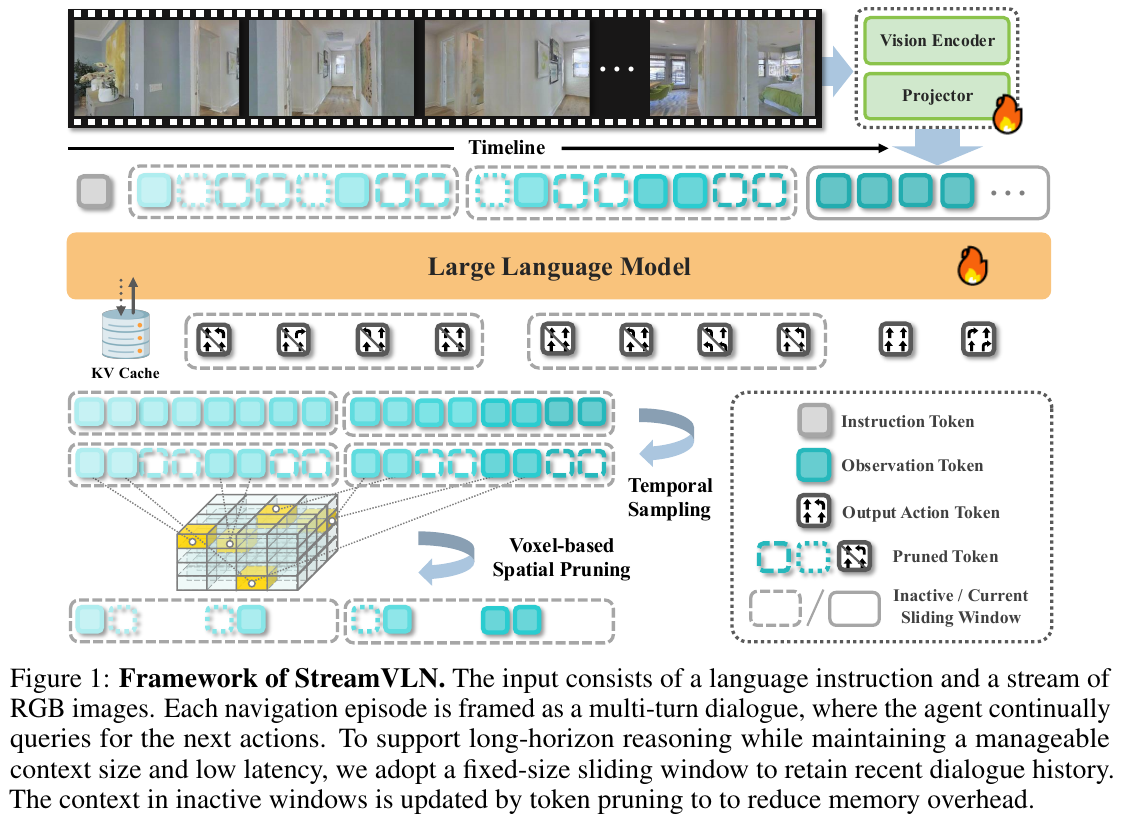
论文提出了 StreamVLN,一个基于慢-快上下文建模的流式视觉-语言导航框架,将 Video-LLM 扩展为交错的 vision-language-action 模型。
1. 连续多轮自回归生成
VLN 的多轮对话会话由一系列交错的观测和动作组成。在每个对话 $d_i = (o_i, a_i)$ 中,VLN 模型接收新观测 $o_i$ 并生成动作响应 $a_i$,条件于当前输入和对话历史。完整输入序列构造为:$o_1a_1o_2a_2…o_{i-1}a_{i-1}$。Transformer 基于 LLM 首先执行 prefill 阶段(预填充阶段)编码输入 token 并缓存 key/value(KV)状态,然后在 decoding 阶段使用缓存的 KV 对生成新 token。
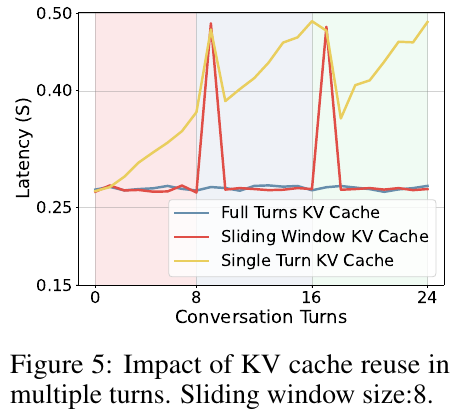
2. 快速流式对话上下文 (Fast-Streaming Dialogue Context)
虽然跨轮次复用 KV cache 可以消除超过 99% 的 prefilling 时间,但会引入巨大的内存开销。随着对话数量增加,KV cache 呈线性增长(例如 2K token 可能消耗约 5GB 内存),使长会话变得不切实际。此外,现有 Video-LLM 在处理过长上下文时推理性能会下降。
StreamVLN 采用 滑动窗口 KV cache 管理对话上下文,保留固定数量 $N$ 的最近对话在活跃窗口中:$W_j = [o_{(i-N+1)}a_{(i-N+1)}…o_ia_i]$。当窗口达到容量时,key/value 状态从 LLM 中卸载,非观测对话 token(如提示词和生成的动作)的状态立即丢弃。对于新的滑动窗口,来自过去窗口的 token 状态被处理为记忆 token 状态 ${M_0, …, M_j}$。
3. 慢速更新记忆上下文 (Slow-Updating Memory Context)
在有限的上下文长度内平衡时间分辨率和细粒度空间感知仍然是 Video-LLM 的关键挑战。StreamVLN 不在特征层面压缩视频 token(如通过平均池化),而是保留高图像分辨率的同时选择性地丢弃空间和时间冗余 token,以更好地保持 Video-LLM 的可迁移性。
- 时间采样: 采用简单的固定数量采样策略,避免不同长度的记忆 token 引入时间持续偏差
- 体素化空间剪枝 (Voxel-based Spatial Pruning): 使用深度信息将视频流中的 2D 图像patches 反投影到共享 3D 空间,离散化为均匀体素。通过跟踪 patch token 在时间上的体素索引,如果给定时长内的多个 token 投影到同一体素,仅保留最新观测的 token。该剪枝掩码用于选择保留的 token 状态(详见 Algorithm 1)。
4. 多源数据联合训练
- Vision-Language Action (VLA) 数据:
- 使用 Habitat 模拟器收集 450K 样本(来自 60 个 Matterport3D 环境的 R2R、R2R-EnvDrop 和 RxR 数据集)
- 额外 300K 样本来自 ScaleVLN(涵盖 700 个 HM3D 场景)以提高场景多样性
- 采用 DAgger 算法收集 240K 纠正示范样本以增强鲁棒性和错误恢复能力
- 通用Vision-Language数据: 为保持预训练 Video-LLM 的通用推理能力,引入:
- 248K 视频基础 VQA 样本(来自 LLaVA-Video-178K 和 ScanQA)
- 230K 交错图像-文本样本(来自 MMC4)以增强多轮视觉-语言交互能力
主要创新点:
- 首次提出针对实时 VLN 的慢-快上下文建模策略
- 设计了基于 3D 几何的智能 token 剪枝方法,优于通用的均匀剪枝
- 实现了低延迟、可扩展的流式多模态推理框架,支持 KV cache 高效复用
- 通过交错 vision-language-action 建模支持连贯的多轮对话
- 有界的上下文大小和推理成本,适合长视频流处理
核心结果/发现
- VLN-CE 基准测试上取得 state-of-the-art 性能:
- R2R Val-Unseen: SR 56.9%, SPL 51.9%(无额外数据)
- RxR Val-Unseen: SR 52.9%, SPL 46.0%, nDTW 61.9%
- 性能与 ETPNav 相当,但不依赖全景视图或航点监督
-
ScanQA 3D 问答基准测试:超越 NaVILA 和 NaviLLM,Exact Match达到 28.8%
- 真实世界部署验证:
- 在 Unitree Go2 机器狗上成功部署
- 平均推理延迟 0.27s(4个动作)+ 通信延迟 0.2s(室内)/ 1.0s(室外)
- 支持实时物理部署

- 关键消融实验发现:
- KV cache 复用在多轮对话中消除超过 99% 的 prefilling 时间
- 滑动窗口大小为 8 个对话轮次时实现最佳平衡
- 记忆上下文大小从 2×196 增加到 8×196 tokens 时,SR 从 37.3% 提升到 45.5%
- 体素化空间剪枝减少约 20% 的输入 token,同时提升性能(R2R +1.2% SR,RxR +1.1% SR)
- DAgger 数据对性能提升至关重要(+5.5% SR / +3.8% SPL)
- 通用 VL 数据(VideoQA + MMC4)的联合训练带来显著增益(+7.3% SR / +5.6% SPL)
局限性
- 直接从原始视觉观测生成低级动作对视点和遮挡变化的鲁棒性较弱,在真实世界环境中可能导致次优控制
- 当前的混合上下文建模策略在更长视野的导航场景中仍然面临挑战,保持扩展序列上的一致推理较为困难
- 依赖显式动作历史作为对话上下文的一部分,为异步推理和部署带来额外复杂性,需要同步过去的动作以保持对话连贯性
19. NavFoM (2025)
——Embodied Navigation Foundation Model
📄 Paper: arXiv:2509.12129 · 🏛️ ICLR 2026
精华
这篇论文展示了如何构建跨任务、跨具身体的导航基础模型,值得借鉴的核心思想包括:(1) 引入 Temporal-Viewpoint Indicator (TVI) tokens 来统一编码不同相机配置和时间信息,使模型能够处理多视角输入;(2) 提出 Budget-Aware Temporal Sampling (BATS) 策略,通过遗忘曲线动态采样历史帧,平衡性能和推理速度;(3) 在 8.02M 导航样本(包括四足机器人、无人机、轮式机器人、汽车等多种具身体)上联合训练,展示了大规模多任务训练对泛化能力的提升;(4) 采用视觉特征缓存机制加速训练 2.9 倍;(5) 证明了无需针对特定任务微调即可在多个基准测试上达到 SOTA 或竞争性能。
研究背景/问题
当前导航系统主要聚焦于特定任务设定和具身体架构,缺乏跨任务和跨具身体的泛化能力。现有 VLM 虽然在零样本任务上表现出色,但导航任务仍然局限于狭窄的任务领域、固定的相机配置和特定的具身体平台。本文旨在构建一个统一的导航基础模型,能够处理来自不同具身体(四足机器人、无人机、轮式机器人、汽车)的多视角输入,并跨越多个导航任务(VLN、目标搜索、目标追踪、自动驾驶)。
主要方法/创新点
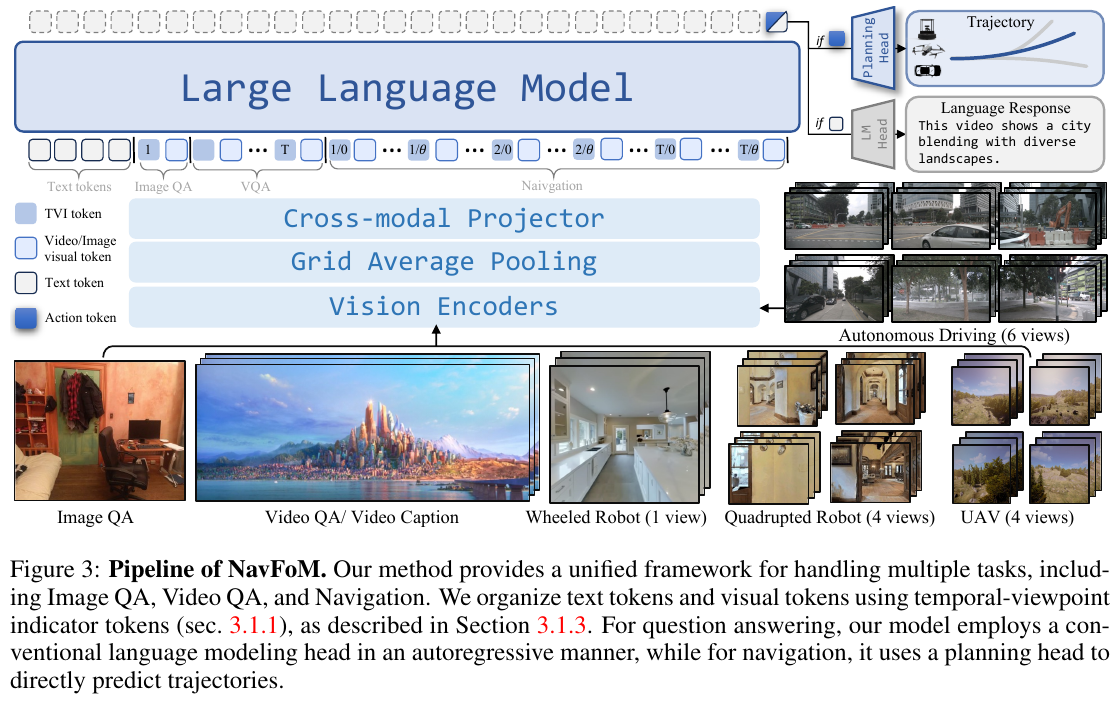
NavFoM 基于 Vision-Language Model 架构,扩展为双分支系统:一个用于导航,一个用于问答。核心创新包括:
1. Temporal-Viewpoint Indicator (TVI) Tokens
- 引入特殊 indicator tokens 来编码相机视角和时间信息,每个 TVI token 由三部分组成:
- 可学习的 base embedding (E_Base)
- 时间编码 (Time PE): 使用正弦位置编码标识帧的时间顺序
- 视角编码 (Angle PE): 使用正弦/余弦编码保持方位角的循环连续性
- 对于导航任务,使用: E_TVI = E_Base + Time PE + Angle PE
- 对于 Video QA,仅使用时间信息;对于 Image QA,仅使用 base embedding
- TVI tokens 使 LLM 能够区分不同时间步和不同视角的 tokens,实现多视角导航
2. Budget-Aware Temporal Sampling (BATS)
- 解决在线导航时视觉 tokens 数量激增的问题
- 基于遗忘曲线(exponential decay)的采样概率: P(t) = (1 - ε)e^(k(t-T)/T) + ε
- 动态调整历史帧采样,越近的帧采样概率越高
- 在 token budget 约束下,平衡短期上下文和长期历史信息
- 相比 Uniform Sampling,BATS 在保持性能的同时显著降低推理时间
3. 观测编码
- 使用预训练 vision encoders (DINOv2, SigLIP) 提取视觉特征
- 采用 Grid Average Pooling 策略生成两种分辨率的视觉 tokens:
- Fine-grained (64×C): 用于当前最新观测和 Image QA
- Coarse-grained (4×C): 用于导航历史和 Video QA
- 通过 cross-modality projector 将视觉特征映射到 LLM latent space
4. Token 组织策略
- 不同任务采用不同的 token 组织方式:
- Image QA: fine-grained visual tokens + base TVI embedding
- Video QA: coarse-grained visual tokens + base + time embedding
- Navigation: coarse-grained + fine-grained tokens + base + time + angle embedding
- 这种设计实现了导航和 QA 数据的联合训练
5. 轨迹预测
- 使用三层 MLP 作为 planning head 从 LLM 隐藏状态预测轨迹
- 轨迹归一化到 [-1, 1] 分布,针对不同具身体(室内导航 vs 户外驾驶)采用不同的 scaling factor
- 对于室内机器人,预测 8 个航点;对于汽车和无人机,预测更长的轨迹
6. 数据规模与来源
- 导航数据 (8.02M): VLN-CE R2R/RxR (2.94M), OpenUAV (429K), 目标导航 (1.02M), 主动视觉追踪 (897K), 自动驾驶 (681K), Web 导航伪标签 (2.03M)
- QA 数据 (4.76M): Image QA (3.15M) + Video QA (1.61M)
- 总计 12.7M 训练样本,覆盖四足机器人、无人机、轮式机器人、汽车等多种具身体
7. 训练优化
- 视觉特征缓存: 预先计算并缓存 coarse-grained visual tokens,训练加速 2.9 倍,GPU 内存减少 1.8 倍
- 使用 Qwen2-7B 作为 LLM backbone
- 单次训练所有参数(仅 designated trainable parameters),无需多阶段训练
核心结果/发现
VLN 性能:
- VLN-CE R2R (single-view): SR 5.01% → 64.9%, SPL 56.2%,无需任务特定微调即达到 SOTA
- VLN-CE RxR (four-view): SR 5.51% → 57.4%, SPL 49.4%,超越所有基线方法
- OpenUAV (四视角,UM split): SR 6.38% → 14.05%, OSRL 5.68% → 18.65%,显著优于 TravelUAV
目标搜索:
- HM3D-OVON (zero-shot): VAL SEEN SR 55.0%, VAL UNSEEN SR 45.2%,超越 MTU3D baseline
主动视觉追踪:
- EVT-Bench (four-view, zero-shot): Single Target SR 85.1%/TR 80.5%, Distracted Target SR 62.0%/TR 67.9%
自动驾驶:
- NAVSIM (eight-view): PDMS 84.3%, 与 SOTA 方法竞争性能
- nuScenes (six-view): CR 93%, 接近 SOTA
Ablation 研究:
- 多任务训练带来显著增益:联合训练使 VLN SR 从 57.3% 提升到 64.4%
- 相机数量对性能的影响:从单视角到四视角,SR 从 58.3% 提升到 65.8%,但增加到六视角略有下降
- BATS 相比 Uniform Sampling,在 RxR 上 nDTW 仅下降 1.4%,但保持稳定推理速度
- TVI tokens 相比其他替代方案(learned special tokens, handcraft tokens)显著提升性能
实际部署:
- 在 110 个真实世界测试场景(50 VLN + 30 搜索 + 30 追踪)中验证,成功率达到 72%~93%
- 支持跨具身体部署:四足机器人(Unitree Go2)、类人机器人、无人机、轮式机器人
- 0.5 秒内生成 8 航点轨迹(1600 token budget)
局限性
该方法在训练时需要大量计算资源(56 NVIDIA H100 GPUs,72 小时)。尽管引入了视觉特征缓存等优化策略,大规模训练仍然是资源密集型任务。此外,在需要遍历 300 米复杂邻域的 Unseen-Map 场景中表现较差,表明模型在大规模环境探索和长距离规划方面仍有改进空间。作者也指出 NavFoM 只是一个起点,未来需要更高质量的数据、更先进的技术以及新一代基准测试来推动泛化导航研究的发展。
20. DGNav (2026)
———动态拓扑感知:打破视觉-语言导航中的粒度刚性
📄 Paper: arXiv:2601.21751
精华
这篇论文解决了 VLN-CE 中的”粒度刚性”问题,值得借鉴的核心思想:
- 自适应结构调整:不仅调整模型参数,还动态调整数据结构本身(拓扑图的节点密度),实现”简单场景保效率、复杂场景保安全”的自适应平衡,这一思路可迁移到其他需要精度/效率权衡的规划任务(如 SLAM、点云处理)。
- 条件干预设计:引入”稳定性门槛”(中位数离散度 σ_med),只在高不确定性场景触发动态调整,而非全局自适应,有效避免了在简单场景引入不必要的噪声——这是一种极具工程实用性的设计思想。
- 多模态软硬约束融合:将几何硬约束(物理可达性)与视觉语义和语言指令软约束通过可学习权重动态融合,使图连接从”物理近邻关系”升级为”语义近邻关系”,为多约束优化提供了优雅解法。
- 线性映射的理论优越性:基于信息论论证了线性映射是保持最大熵属性的最优一阶近似,既优于 Sigmoid 的梯度饱和,又优于 Exponential 的保守偏差——理论驱动设计的典范。
- 结构与训练解耦:Scene-Aware Adaptive Strategy 仅在推理阶段激活,训练阶段使用固定阈值,实现了稳定的特征学习与灵活的测试时推理之间的解耦。
1. 研究背景/问题
VLN-CE(连续环境中的视觉-语言导航)中,现有拓扑规划方法(如 ETPNav)依赖固定的图构建阈值 γ 和静态欧式距离边权重,导致”粒度刚性”问题:在简单低不确定性区域产生大量冗余节点,在复杂高不确定性区域图过于稀疏导致导航失败。更严重的是,纯几何边权重使智能体优先连接物理距离近但语义无关的节点(”导航性近视” Navigational Myopia),无法遵从指令中的语义意图。
主要方法/创新点
论文提出 DGNav (Dynamic Graph Navigation) 框架,包含两大核心模块:
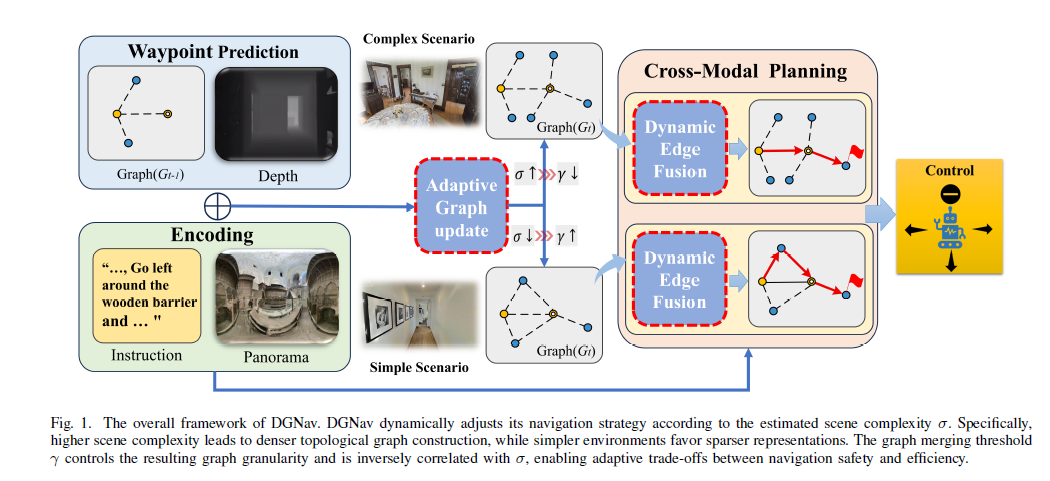
1. 场景感知自适应策略 (Scene-Aware Adaptive Strategy)
针对物理结构层面的粒度刚性问题,提出动态调整图构建阈值的方法:
- 场景复杂度度量:通过分析预测路径点的角度离散度 (angular dispersion) σ 来量化局部场景复杂度:
σ_t = sqrt(1/N_c * Σ(θ_i - θ̄)²)其中 θ_i 是候选节点相对于智能体朝向的角度。高 σ 表示复杂决策边界(如交叉路口),低 σ 表示简单几何结构(如走廊)。
- 条件线性映射控制律:基于统计校准的高斯分布特性,采用线性映射动态调整合并阈值 γ:
γ_t = γ_fix if σ_t ≤ σ_med γ_t = γ_fix - (σ_t - σ_med)/(σ_max - σ_med) * (γ_fix - γ_min) if σ_t > σ_med

- 理论依据:选择线性映射而非 Sigmoid/指数映射的原因是线性变换保持高斯源分布的最大熵特性。非线性映射会在分布尾部引入饱和区域(梯度消失),导致高不确定状态的信息丢失。条件映射策略仅在 σ > σ_med 时激活自适应机制,在稳定场景中保持拓扑稳定性。
2. 动态图 Transformer (Dynamic Graph Transformer)
针对语义逻辑层面的导航近视问题,融合多模态线索动态重构图连接性:

1.Scene-Aware Adaptive Strategy(场景感知自适应策略)
通过计算当前时刻候选节点的角度离散度 $\sigma_t$ 来量化场景复杂度:
\[\sigma_t = \sqrt{\frac{1}{N_c} \sum_{i=1}^{N_c} (\theta_i - \bar{\theta})^2}\]基于 $\sigma_t$,采用条件线性映射动态调整图合并阈值 $\gamma_t$:
\[\gamma_t = \begin{cases} \gamma_{fix} & \text{if } \sigma_t \leq \sigma_{med} \\ \gamma_{fix} - \dfrac{\sigma_t - \sigma_{med}}{\sigma_{max} - \sigma_{med}}(\gamma_{fix} - \gamma_{min}) & \text{if } \sigma_t > \sigma_{med} \end{cases}\]- 简单场景($\sigma_t \leq \sigma_{med}$):$\gamma_t = \gamma_{fix} = 0.5\text{m}$,保持稀疏效率
- 复杂场景($\sigma_t > \sigma_{med}$):线性降低 $\gamma_t$(最低至 $\gamma_{min} = 0.1\text{m}$),生成密集拓扑
$\sigma_{med}$ 和 $\sigma_{max}$ 通过在 ETPNav 基线模型上统计推断得到(数据驱动校准),线性函数的选择基于信息论证明其是保最大熵的最优一阶近似。
2.Dynamic Graph Transformer(动态图 Transformer)
Dynamic Edge Fusion:融合三种信息流构造动态邻接矩阵:
\[\mathbf{E}_{dynamic} = \mathbf{E}_{geo} + \omega_1 \cdot \mathbf{E}_{sem} + \omega_2 \cdot \mathbf{E}_{inst}\]- $\mathbf{E}_{geo}$:归一化欧式距离(物理可达性硬约束)
- $\mathbf{E}_{sem}$:CLIP-ViT 提取的视觉特征通过 MLP 计算的成对相似度
- $\mathbf{E}{inst}$:节点特征与全局指令 token $\mathbf{W}_L$ 的外积相关性分数,即 $w_i = \text{MLP}([v_i; \mathbf{W}_L])$,$E{inst}^{(i,j)} = w_i \cdot w_j$
Graph-Aware Self-Attention (GASA):
\[\text{GASA}(\mathbf{H}^l, \mathbf{E}_{dynamic}) = \text{Softmax}\!\left(\frac{(\mathbf{H}^l \mathbf{W}_Q)(\mathbf{H}^l \mathbf{W}_K)^\top}{\sqrt{d_k}} + \mathbf{E}_{dynamic}\right)\!(\mathbf{H}^l \mathbf{W}_V)\]将 $\mathbf{E}{dynamic}$ 直接叠加到注意力分数上,强制模型关注语义相关($\omega_1 \cdot \mathbf{E}{sem}$)且指令对齐($\omega_2 \cdot \mathbf{E}{inst}$)的节点,同时 $\mathbf{E}{geo}$ 保证物理约束不被完全忽略,实现从纯几何到语义驱动的平滑过渡。
训练策略:采用两阶段训练,Adaptive Strategy 仅在推理阶段激活,训练阶段固定 $\gamma = 0.5\text{m}$ 确保稳定的特征学习。
3. 核心结果/发现
R2R-CE 数据集:
- Val-Unseen:SR 64.82%,SPL 50.08%,超越 ETPNav 基线(+4.66% SR,+2.21% SPL)
- Test-Unseen:SR 64%(+1% vs ETPNav),SPL 47%,NE 下降 0.2m
- 超越所有 End-to-End 方法和显式地图方法(含 GridMM, Safe-VLN, OVL-MAP)
RxR-CE 数据集(多语言,更长路径):
- Val-Unseen:SR 53.78%,nDTW 62.04%(+0.55%),SDTW 44.49%(+0.57%)
- 路径保真度指标全面超越 ETPNav,证明在长时域细粒度指令遵从上的优越性
消融实验关键发现:
- 条件线性映射 vs 全局线性映射:SR +1.52%(稳定性门槛机制的贡献)
- 动态 $\gamma$ vs 固定 $\gamma$(0.25/0.40/0.50m):SR 最高提升 +1.63%,且计算开销仅增加 0.4 个节点
- 完整 $\mathbf{E}_{dynamic}$ vs 仅几何:SR 大幅提升,验证语义软约束的关键作用
- 定性分析(Fig.9):在”绕过木质围栏”场景中,仅几何模型因物理距离过近而提前错误转向,DGNav 正确识别指令语义并忽略了几何干扰,成功到达目标
4. 局限性
自适应策略的核心参数($\gamma_{fix}, \gamma_{min}, \sigma_{med}, \sigma_{max}$)通过在 R2R-CE 训练集上进行统计校准获得,在分布外场景(如户外环境、高度动态场景)中的泛化能力尚未验证;同时,随着导航轨迹增长,拓扑图规模持续膨胀,论文未讨论图压缩和历史节点管理策略,在超长路径任务中可能面临内存和计算的挑战。
21. MapNav (2025)
———A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
📄 Paper: arXiv:2502.13451 · 🏛️ ACL 2025
精华
MapNav 的核心创新在于用轻量级的 Annotated Semantic Map (ASM) 替代传统的历史 RGB 帧序列作为记忆表示,实现了恒定 0.17MB 的内存占用(与步数无关),推理速度提升 79.5%。值得借鉴的关键思想:将语义地图与自然语言标注相结合,使 VLM 能够直接理解空间信息,而无需额外的解码器;用结构化的 top-down 地图取代时序帧,把”历史信息”从时间维度转移到空间维度,大幅降低计算开销。这种”语言化地图”的思路为 VLM 赋能导航提供了一个清晰且高效的范式。
研究背景/问题
Vision-and-Language Navigation (VLN-CE) 要求 agent 在连续三维环境中跟随自然语言指令导航。现有方法大量依赖历史 RGB 帧作为时序上下文,导致内存随轨迹长度线性增长(Navid 在 300 步时高达 276MB),且无法充分利用 VLM 对语言的理解能力。设计一种高效的记忆表示以替代历史帧,成为本工作的核心动机。
主要方法/创新点
MapNav 提出一个端到端的 VLM-based VLN 框架,核心组件是在线更新的 Annotated Semantic Map (ASM)。
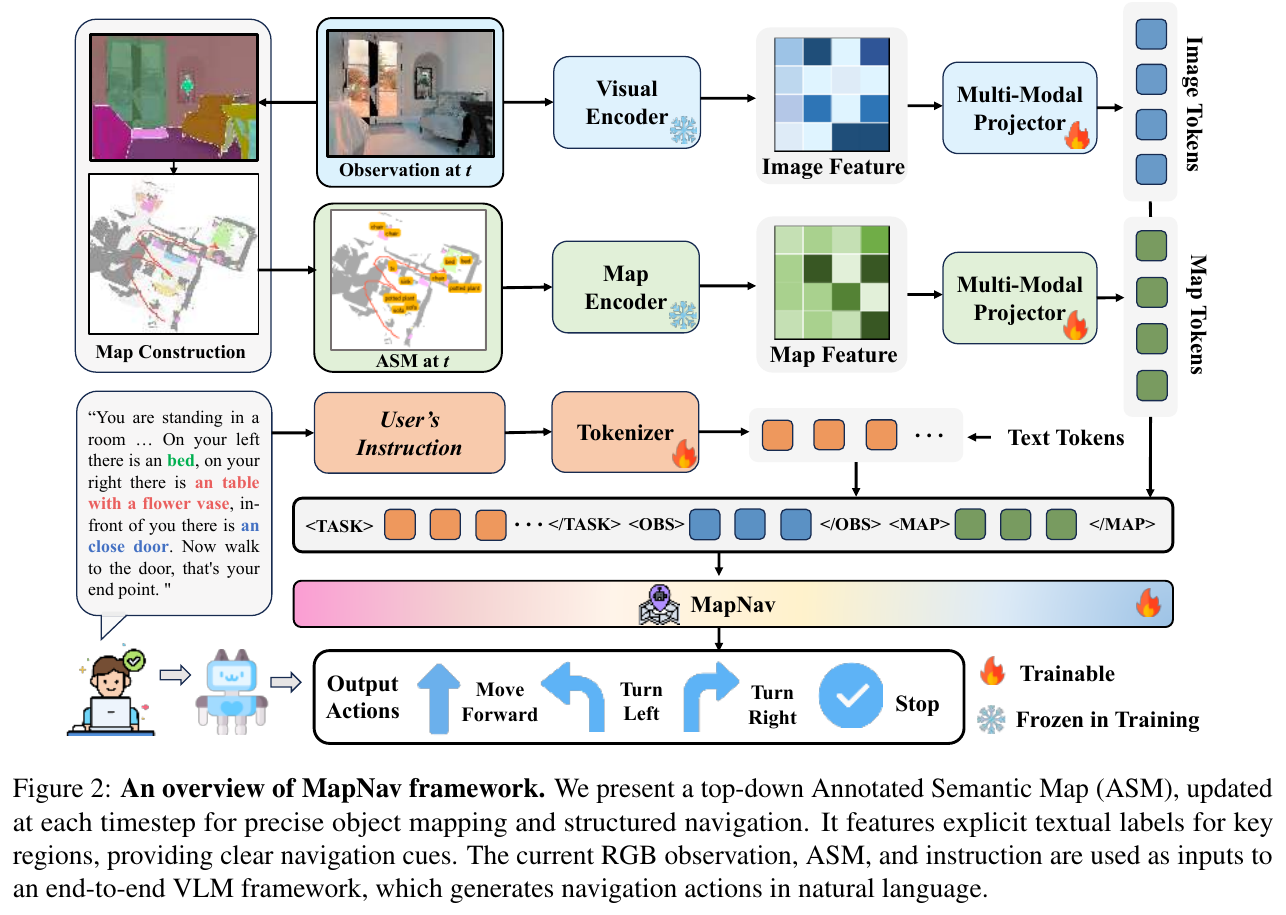
ASM 生成流程
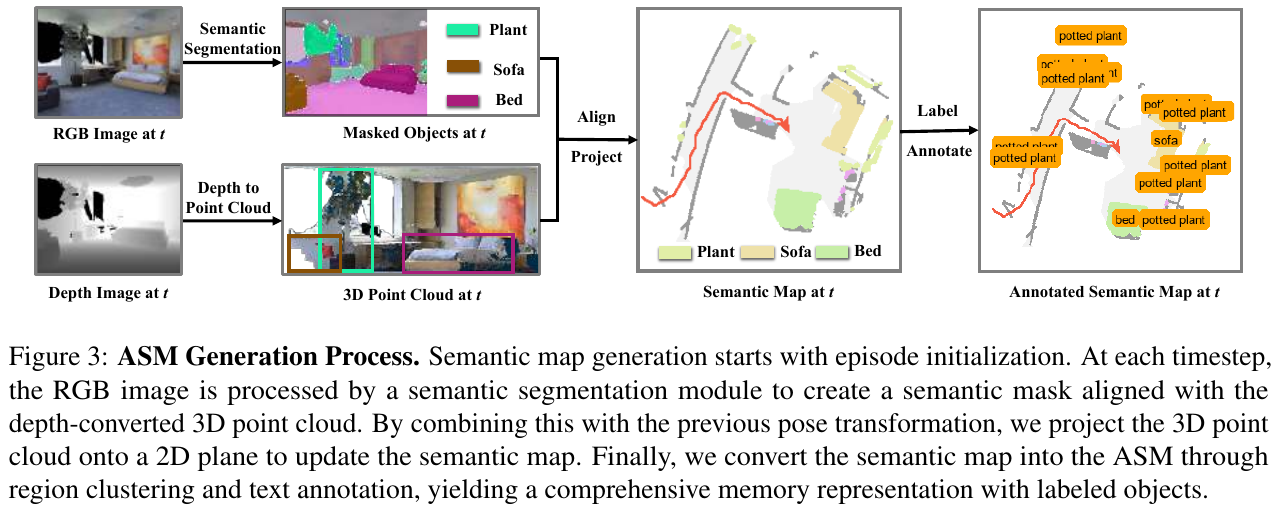
ASM 是一个多通道张量 M(维度 $C \times W \times H$,$C = C_n + 4$),其中:
- 基础通道(1-4):编码障碍物分布、已探索区域、agent 当前位置、历史轨迹
- 语义通道(n个):存储各目标物体的空间分布
生成流程:
- 用 Mask2Former 对当前 RGB 帧做语义分割,提取目标 mask
- 结合深度图将 3D 点云投影到 2D 俯视平面,对齐语义 mask
- 对每个语义区域做连通分量分析,计算区域质心并在地图上添加文字标签(如 “chair”、”potted plant”)
- 生成最终 ASM,包含物体位置、轨迹、障碍物等结构化信息
为什么 ASM 优于普通语义地图?

实验证明,VLM(GPT-4o 和 MapNav)处理 ASM 时表现出对物体位置的精准理解(注意力峰值 > 0.8),而处理原始 top-down 地图(峰值 < 0.3)或语义地图(峰值 < 0.4)时注意力极为分散。ASM 通过显式文字标注将抽象语义转化为语言基础,充分激活 VLM 预训练的语言理解能力。
双流编码器架构
MapNav 基于 LLaVA-Onevision 框架,使用 SigLIP-so400m 视觉编码器:
\[\mathbf{F}_t = \Phi_{spatial}(\mathbf{X}_t, \mathcal{G}), \quad \mathbf{F}_t^M = \Phi_{spatial}(\mathbf{X}_t^M, \mathcal{G})\]两路特征分别通过 MLP 投影对齐到语言空间,最终拼接为统一表示:
\[\mathbf{V}_t = [\text{TASK}; \mathbf{E}_t; \text{OBS}; \mathbf{E}_t^M; \text{MAP}]\]动作预测
VLM 直接输出自然语言动作,通过正则表达式匹配解析为 {前进, 左转, 右转, 停止} 四类动作,无需额外动作解码器。
训练数据(~1M 样本)
三阶段数据收集:
- Phase I:来自 R2R + RxR 的 GT 轨迹(~300k × 2)
- Phase II:DAgger 在线交互采集(~200k × 2)
- Phase III:碰撞恢复专项数据(~25k × 2)
历史帧数量的消融
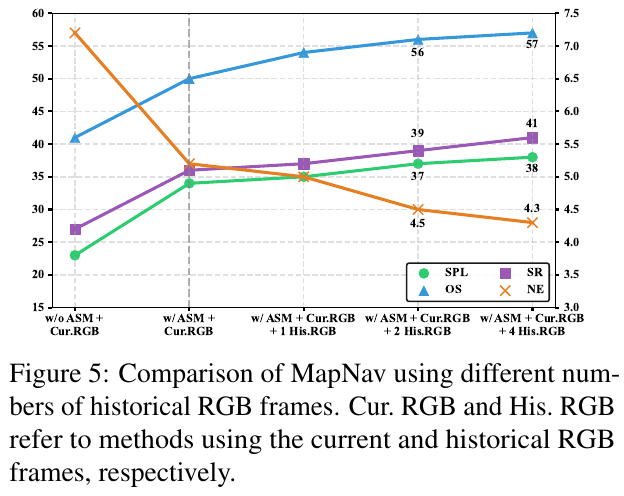
加入 ASM 后,SR 从 27% 提升至 36%,SPL 从 23% 提升至 34%;继续增加历史 RGB 帧带来的提升则相当有限,说明核心增益来自 ASM 的空间表示能力,而非时序帧累积。
核心结果/发现
模拟环境(R2R-CE & RxR-CE Val-Unseen)
| 方法 | R2R SR↑ | R2R SPL↑ | RxR SR↑ | RxR SPL↑ |
|---|---|---|---|---|
| NaVid (All RGB Frames) | 49.1 | 37.4 | 23.8 | 21.2 |
| MapNav (w/o ASM + Cur. RGB) | 41.2 | 27.1 | 15.6 | 12.2 |
| MapNav (w/ ASM + Cur. RGB) | 50.3 | 36.5 | 22.1 | 20.2 |
| MapNav (w/ ASM + Cur. + 2 His. RGB) | 53.0 | 39.7 | 32.6 | 27.7 |
- 仅用 ASM + 单帧 RGB,性能即可媲美使用全部历史帧的 NaVid
- 加入 2 帧历史 RGB 后超越所有 SOTA,R2R SPL 提升 1.3%,RxR SPL 提升 6.5%
效率对比(关键优势)
| 方法 | 1步 | 10步 | 100步 | 300步 | 平均推理时间 |
|---|---|---|---|---|---|
| Navid | 0.92MB | 9.2MB | 92MB | 276MB | 1.22s |
| MapNav | 0.17MB | 0.17MB | 0.17MB | 0.17MB | 0.25s |
- 内存占用恒定 0.17MB,与轨迹长度完全解耦
- 推理速度提升 79.5%(1.22s → 0.25s)
真实世界(5种室内场景)
在 Office、Meeting Room、Lecture Hall、Tea Room、Living Room 中,MapNav 在简单指令和语义指令下均全面超越 WS-MGMAP 和 Navid,SR 提升最高达 30%。
局限性
语义分割模块在遮挡或光照变化等复杂条件下可能产生不准确的物体标签,从而影响 ASM 质量。未来计划扩展到更复杂的具身 AI 任务(如交互导航和操作),需将物体可供性和物理交互能力整合进 ASM 表示。
22. Hydra-Nav (2026)
——Object Navigation via Adaptive Dual-Process Reasoning
📄 Paper: arXiv:2602.09972
精华
Hydra-Nav 最值得借鉴的核心思想是:将”慢思考”(CoT 推理)与”快行动”(低级反应控制)统一在单个 VLM 内,避免了多模型架构的碎片化问题。其关键创新在于通过 Iterative Rejection Fine-Tuning (IRFT) 让模型自主学习”何时触发推理”,而非固定频率触发,从而在成功率与推理开销之间取得最优平衡。三阶段课程训练(空间-动作对齐 → 记忆-推理集成 → 自适应推理)的渐进式设计,为构建具身导航智能体提供了可复用的训练范式。新提出的 SOT 指标(Success weighted by Operation Time)将推理延迟纳入评估,比 SPL 更贴近实际部署需求,值得在其他具身任务中推广使用。
研究背景/问题
Object goal navigation 要求机器人仅凭自我中心感知在真实环境中主动探索并定位目标物体。当前 VLM-based 方法存在两大核心缺陷:(1)时空推理能力不足,导致对已探索区域的记忆维护失效,引发重复探索;(2)在每步推理(chain-of-thought)的做法带来大量不必要的计算开销,而在关键”停滞点”又未能及时触发推理。现有双系统架构(slow-fast paradigm)依赖独立模型,存在架构割裂和切换灵活性不足的问题。
主要方法/创新点
Hydra-Nav 将高层规划与低层元动作统一在单一 VLM(基于 Qwen2.5-VL-7B)内,通过输出特殊 transition token obs 自主触发从快系统到慢系统的切换。
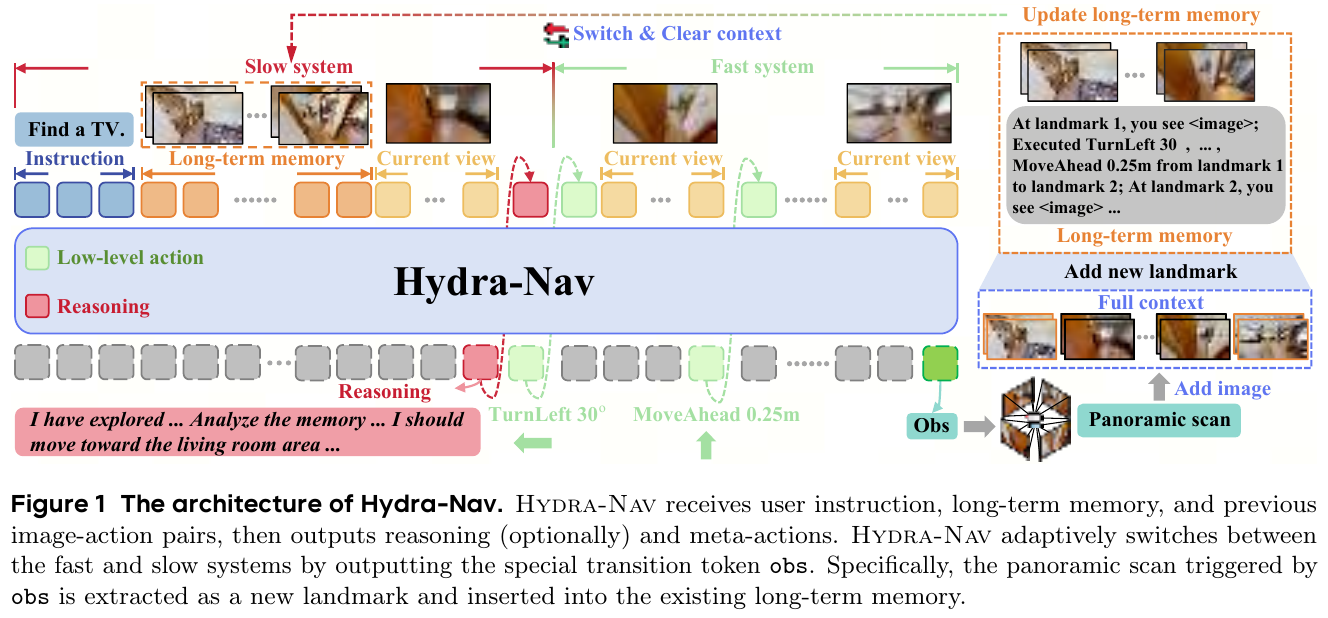
双过程系统(Dual-process System)
- 慢系统(Slow system):接收目标指令、当前全景观测(4 张 90° 间隔 RGB 图)和结构化长期记忆,生成 CoT 推理文本与高层计划,随后输出第一个元动作。
- 快系统(Fast system):基于上一慢系统的对话历史,利用 KV-caching 仅编码最新自我中心帧,自回归解码低级原子动作(MoveAhead 0.25m、TurnLeft/Right 30°),避免重复处理完整历史上下文。
- 自适应切换机制:当智能体完成子目标或当前观测与现有计划矛盾时,输出
obs触发全景扫描,构建新的地标节点并更新长期记忆,随后重新进入慢系统。
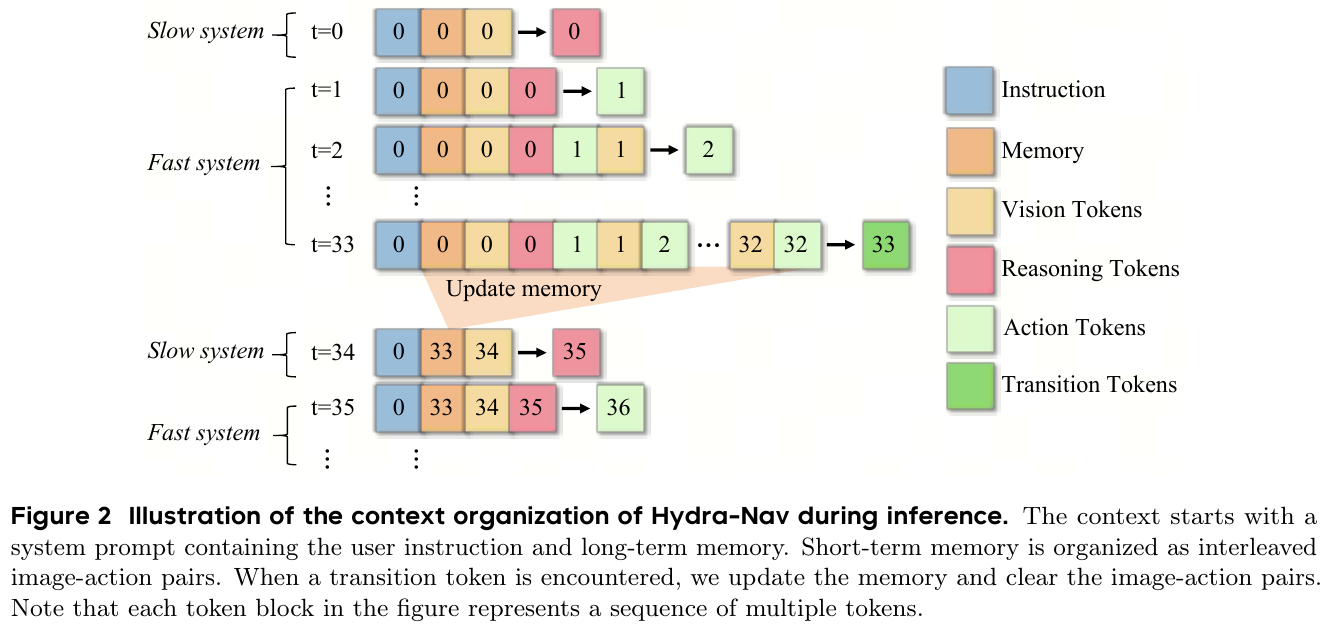
三阶段课程训练(Curriculum Training Pipeline)
Stage 1 — 空间-动作对齐(Spatial-Action Alignment)
使用 A* planner 在 HM3D、MP3D、OVON 训练集上生成 500K 条轨迹(20.1B tokens),训练 Qwen2.5-VL-7B 学习基本导航动作执行。每条轨迹格式化为多轮对话,通过单次前向-反向传播完成梯度计算。
Stage 2 — 推理-记忆集成(Reasoning-Memory Integration)

- 使用启发式路点选择策略生成包含探索行为的轨迹(而非仅最短路径),每条轨迹选取分数最高的两个探索路点。
- 将轨迹分段(固定长度 16 步),在每段开头插入长期记忆和推理文本,段尾插入
obstoken。 - 推理文本合成:先用 Qwen3-VL-235B-Thinking 对历史图像进行记忆摘要,再结合当前视图与”未来正确视图”(信息泄漏防止)生成前瞻性规划文本。
- 共生成 565K 条混合样本(8.3B tokens),同时混入 VQA 数据防止过拟合。
Stage 3 — 自适应推理(Adaptive Reasoning via IRFT)
定义两类停滞点(Stagnation Points):
- 重复探索:智能体在过去 $T_{stag}=20$ 步内回到距离 $\delta_{stag}=0.5$m 内的位置。
- 缺乏进展:在随机时间窗口 $\Delta t \sim \mathcal{U}(20,35)$ 内到目标距离未缩短。
IRFT 流程:在快系统模式下运行,于停滞点触发慢系统;对失败轨迹(超时或目标误识别)进行”拒绝-修复”——找到干预时间戳 $t^$,用 A 最优路径替换后续轨迹,重新合成修正段的推理文本;使用最新 checkpoint 迭代执行,每轮生成约 60K 条轨迹(4.5B tokens)。
核心结果/发现
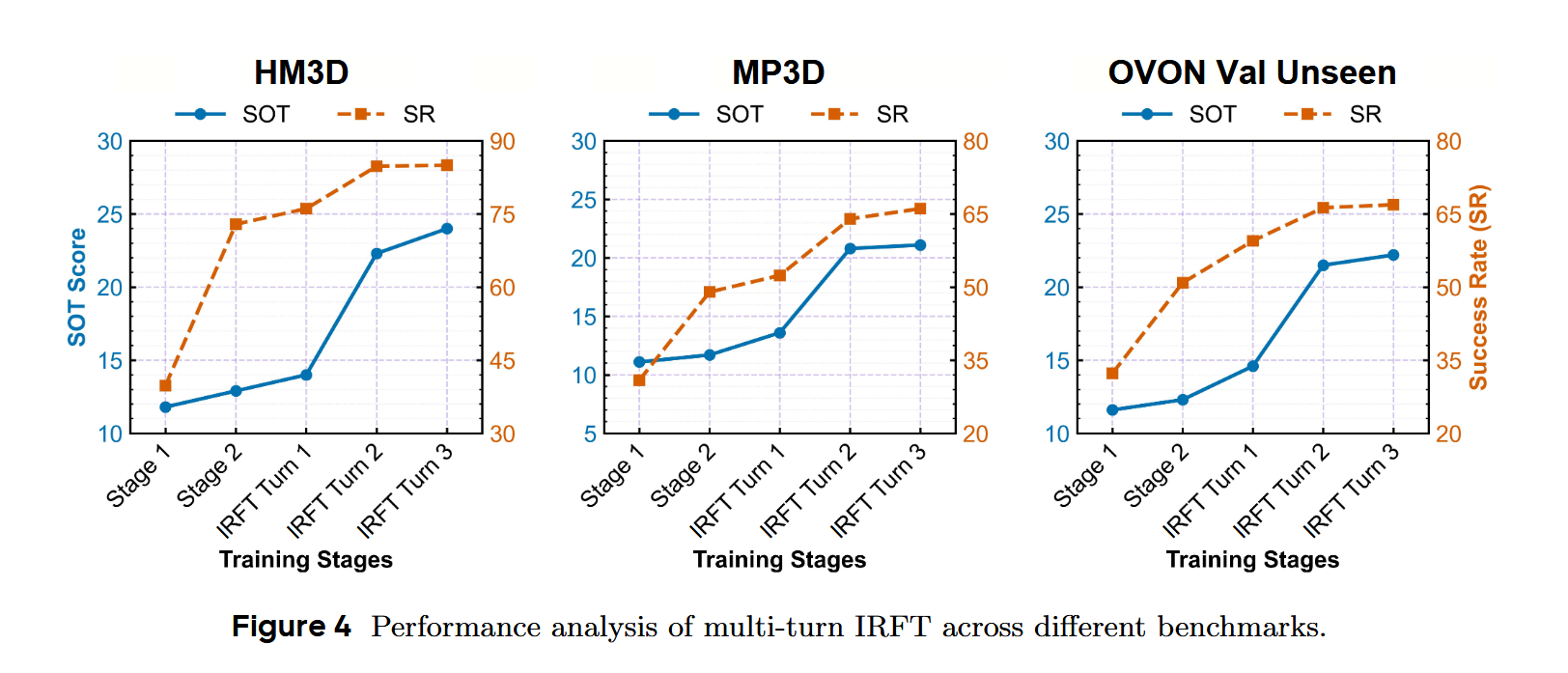
与 SOTA 对比(Table 2):
| Benchmark | 指标 | Hydra-Nav-IRFT | 第二名 | 提升 |
|---|---|---|---|---|
| HM3D Val | SR | 84.8% | 73.7% | +11.1% |
| MP3D Val | SR | 64.0% | 46.6% | +17.4% |
| OVON Val-Unseen | SR | 66.3% | 45.2% | +21.1% |
SOT 指标分析(Table 5):
- Hydra-Nav-IRFT 推理触发比例仅 3.0%(HM3D),而 VLMnav/Nav-R²/WMNav 均为 100%。
- SOT 得分:Hydra-Nav-IRFT 24.0(HM3D)vs Nav-R² 1.9(最高 SR 竞争者),提升约 12×。
- 说明频繁推理虽提高 SR,但严重拖累效率;自适应推理是实际部署的关键。
消融实验关键发现:
- 记忆模块对 SPL 提升显著(无记忆 SPL=13.9 vs 有记忆 28.8),说明长期空间记忆是路径效率的核心。
- 探索性轨迹数据 vs 最短路径数据:SR 下降 25.4%(HM3D),说明探索能力对高成功率不可或缺。
- Co-training with VQA 防止导航专有数据过拟合,维持泛化性(SR: 69.1→72.9,HM3D)。
局限性
评估仅在 Habitat 模拟器(HM3D/MP3D/OVON)中进行,缺乏在 Isaac Sim 等更高保真度仿真环境中的验证;当前框架专为 object navigation 设计,向移动操作等更复杂具身任务的扩展有待探索。
23. 3DGSNav (2026) {#3dgsnav}
———用主动 3DGS 记忆增强 VLM 空间推理,实现零样本目标导航
📄 Paper: arXiv:2602.12159
精华
3DGSNav 最值得借鉴的核心思想:
- 将 3DGS 作为持久记忆替代语义地图/文字描述,让 VLM 直接”看”到几何连续的场景,而非依赖中间抽象层,从而释放 VLM 本身的视觉空间推理能力。
- 主动感知(Active Perception)+ 自由视角优化:代理不被动旋转扫描,而是通过不透明度场(opacity field)主动定位视觉盲区,再利用 3DGS Novel View Synthesis 渲染最优视角——这种”按需生成观测”的模式可推广到其他需要视角控制的具身任务。
- 结构化视觉提示(Structured Visual Prompts)+ CoT 融合:在渲染图像上叠加注释(gaze point、未探索区域标注),配合 Chain-of-Thought,让 VLM 的长程规划推理能力得到充分激活,无需额外训练。
- 实时检测 + VLM 重验证(Re-verification):先用轻量检测器初筛候选目标,再用 VLM 主动切换视角确认——分两阶段解耦效率与可靠性,是目标确认模块的通用设计范式。
研究背景/问题
现有零样本目标导航(ZSON)方法通常将环境转换为语义地图或文字描述,导致高层决策被低层感知精度所制约,VLM 的视觉空间推理能力无法充分发挥。如何让 VLM 直接基于高质量视觉观测进行空间推理,而非依赖降维后的语义抽象,是本文解决的核心问题。
div align=”center”>
</div>
主要方法/创新点
3DGSNav 是一个基于 3D Gaussian Splatting 的 ZSON 框架,核心由三个模块组成:
1. 主动感知(Active Perception)模块
- 使用虚拟相机渲染全景不透明度场(panoramic opacity field),定量估计当前观测完整性
- 利用 DBSCAN 聚类低不透明度区域,识别视觉盲区,计算最优俯仰角 θ* 和偏航角 ϕ*,驱动真实相机主动补偿缺失视角
- 避免机械旋转带来的定位误差与冗余观测
2. 自由视角规划(Free-Viewpoint Planning)模块
- 前沿点提取与聚类:在 3DGS 空间构建探索地图,提取 frontier points(已探索与未探索边界),通过距离场 + 分水岭分割(watershed segmentation)自适应聚类冗余前沿点,选代表性点降低 VLM 分析开销
- 引导轨迹(Guidance Trajectory):基于 Dijkstra + 指数惩罚障碍物距离的代价函数,为每个前沿点生成安全路径,作为自由视角优化的参考基准
- 虚拟视角初始化:利用轨迹曲率 κ 和距离 d 加权得分选最优初始位置,确保既不过近(优化不稳定)也不过远(信息量低)
- 多约束视角优化:最小化复合损失函数 ℒ = λ_opa·ℒ_opa + λ_vis·ℒ_vis + λ_cos·ℒ_cos + λ_traj·ℒ_traj,包含:
- Opacity Loss:控制可见/不可见区域比例
- Ray Occlusion Loss:确保虚拟相机视线直达前沿点(无遮挡)
- Cosine Loss:约束视角方向与前沿点方向一致
- Trajectory Loss:约束相机位置在轨迹附近
3. 结构化视觉提示 + VLM 推理
- 渲染 Bird’s-Eye View(BEV)+ 多个前沿点的 First-Person Views(FPVs)
- 在图像上叠加结构化注释:注视点(gaze point)、未观测区域表示(unobserved region)
- 配合 Chain-of-Thought(CoT)提示,驱动 planner VLM(Gemini 3)对候选前沿点进行空间语义推理,选择最优探索目标
4. 实时检测 + VLM 主动重验证(Re-verification)
- 导航过程中使用轻量实时检测器(YOLOE)初步筛选候选目标
- 当检测置信度不足时,action-decision VLM(GLM-4.1V-Thinking)主动切换视角——将所选动作投影回 3DGS 渲染新视角,获取更具判别力的观测,完成目标二次确认
- 有效降低漏检率和误停率
核心结果/发现
div align=”center”>
</div>
- 在 HM3D、MP3D、Gibson 等多个 ObjectNav 标准 benchmark 上取得 SOTA 或竞争性性能
- 消融实验验证:自由视角优化、结构化注释、CoT、Re-verification 模块均对最终 Success Rate 有显著贡献
- 不同 VLM(Gemini 3、GPT-4V、GLM-4.1V 等)可灵活替换,框架具备良好兼容性
- 在四足机器人真实环境实验中成功复现(定位厕所等目标),验证了 sim-to-real 迁移能力
- Runtime 分析显示主动感知显著优于被动旋转扫描,探索效率更高
局限性
3DGS 的在线增量重建和自由视角优化带来一定计算开销,在计算资源受限的嵌入式平台上实时性仍有挑战;此外,真实场景的动态物体、运动模糊和视觉感知噪声会影响 3DGS 质量,进而影响导航可靠性。
24. BudVLN (2026)
———Nipping the Drift in the Bud: Retrospective Rectification for Robust Vision-Language Navigation
📄 Paper: arXiv:2602.06356
精华
- 核心思想:通过“回顾式纠偏”(Retrospective Rectification)解决 Vision-Language Navigation (VLN) 中的指令-状态不一致问题。
- 训练范式:引入了 Adaptive Mutual Exclusion Strategy,将样本动态分流为效率路径和鲁棒性路径,实现了精准训练。
- 纠偏机制:利用“回锚”机制合成语义一致的修正轨迹,避免了传统方法中强制回归导致的语义冲突。
- 极致效率:采用 GRPO 算法(借鉴自 DeepSeek-R1),无需价值网络,训练成本仅为传统 DAgger 的约 25%。
- 性能卓越:在 R2R-CE 和 RxR-CE 基准测试上刷新 SOTA,尤其在处理偏差和鲁棒性方面表现突出。
1. 研究背景/问题
当前的视觉-语言导航(VLN)系统面临严重的曝光偏差(Exposure Bias)问题:推理时的细微偏差会导致严重的累积误差。虽然 DAgger 类方法尝试通过纠正错误状态来缓解这一问题,但论文指出这些方法存在指令-状态不一致(Instruction-State Misalignment)的致命局限。如图 1 所示,强制智能体从离群状态回归往往会生成与其原始语言指令相冲突的监督信号(例如:指令要求直行,但为回归正轨必须掉头),这会损害智能体的指令遵循能力。
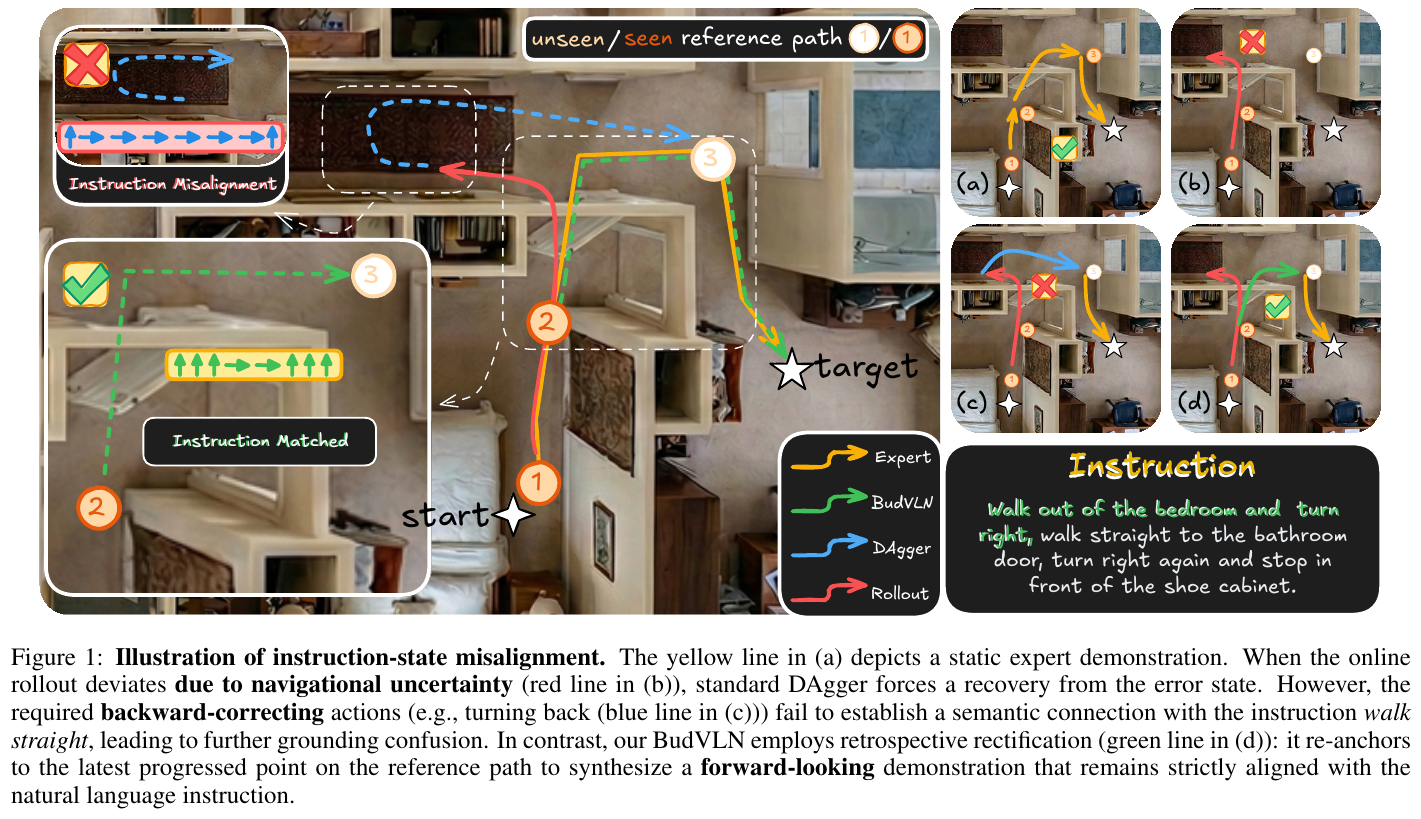
2. 主要方法/创新点
论文提出了 BudVLN,一个旨在通过统一的在线回顾式纠偏框架解决上述挑战的系统。
Adaptive Mutual Exclusion Strategy (自适应互斥策略)
BudVLN 并不对所有样本一视同仁,而是采用一种自适应策略进行动态路由:
- Proficiency Pathway (效率路径):通过 Greedy Probe 评估。若智能体已能熟练完成任务,则利用 GRPO (Group Relative Policy Optimization) 进行组内相对优势学习,进一步优化路径效率。
- Rectification Pathway (纠偏路径):若智能体在任务中失败,则触发回顾式纠偏。
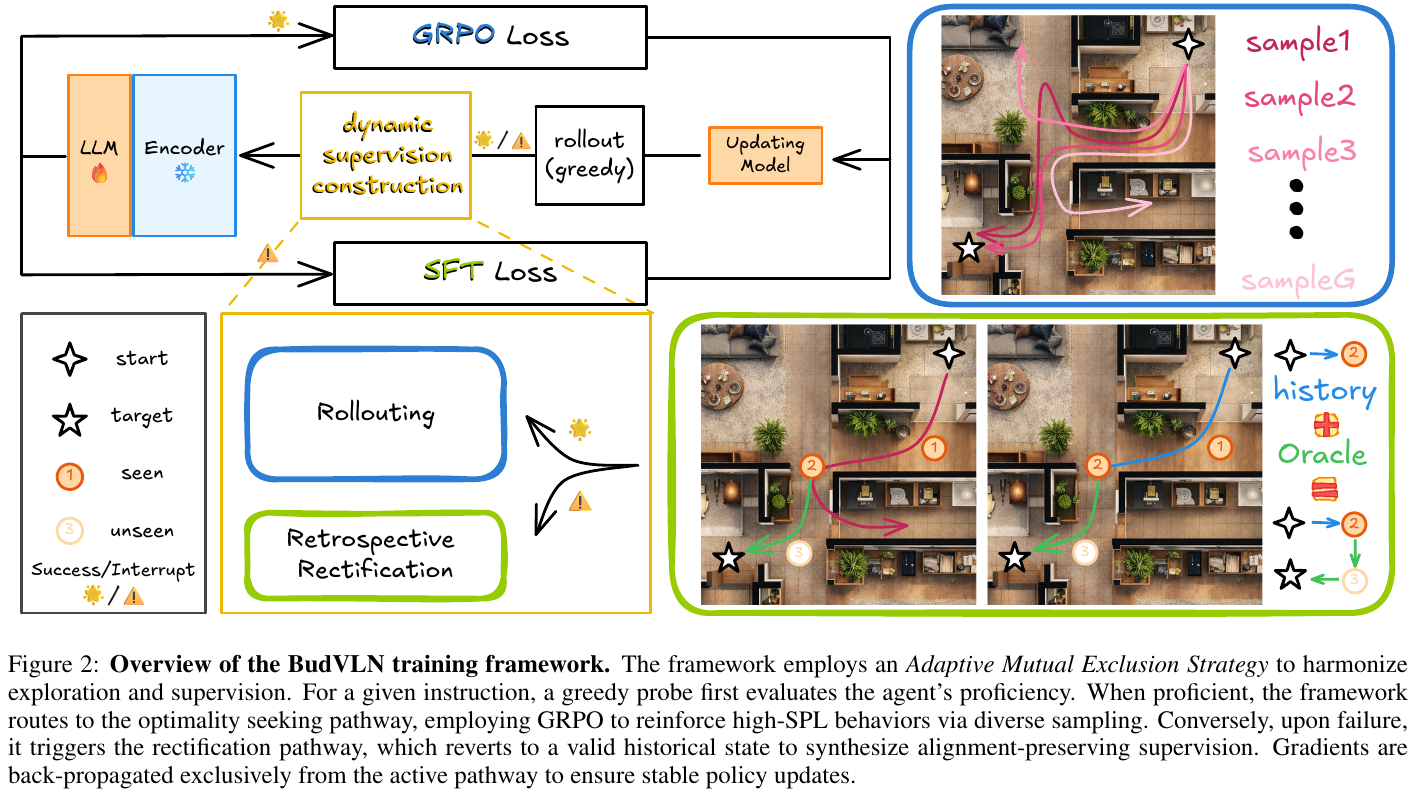
Retrospective Rectification (回顾式纠偏)
针对失败样本,BudVLN 执行以下操作:
- 回锚(Anchor Identification):将状态回溯到发生偏差前的最后一个有效路径点(Valid Anchor)。
- 语义一致性合成:利用 Oracle 合成从该锚点出发的正确轨迹,以此作为 SFT 的监督信号。 这种方法确保了监督信号与原始指令的语义一致性,彻底解决了 DAgger 的语义冲突问题。
GRPO 优化
受到大规模推理模型成功的启发,BudVLN 引入了 GRPO 算法。它通过在一个采样组内计算相对优势,摆脱了对昂贵价值网络(Value Network)的依赖,极大地降低了计算开销,同时提升了探索效率。
3. 核心结果/发现
- SOTA 性能:在 R2R-CE 和 RxR-CE 两个主流基准测试中,BudVLN 全面超越了现有模型。在 R2R-CE 上,成功率 (SR) 达到 57.6%,SPL 达到 51.1%。
- 训练效率:得益于 GRPO 算法和高效的纠偏机制,BudVLN 仅需 27 GPU 小时 即可完成训练,相比 DAgger 的 114 小时,效率提升了近 4 倍。
- 消融研究:实验证明,单独添加纠偏机制能显著提升 SR,而 GRPO 算法则对 SPL 的提升和训练效率的优化起到了关键作用。

4. 局限性
虽然 BudVLN 在离散和连续环境中均表现出色,但其鲁棒性目前仍受限于预定义 Oracle 的质量。在极度复杂的极端环境下,如何自主生成更高质量的“回顾性”知识仍是未来研究的方向。
25. Open-Nav (2025)
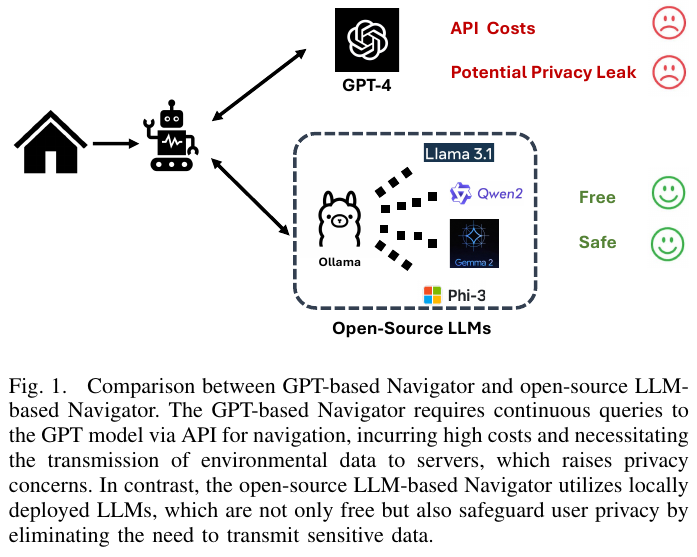
———Zero-Shot VLN in Continuous Environment with Open-Source LLMs
📄 Paper: arXiv:2409.18794 · 🏛️ ICRA 2025
精华
Open-Nav 的核心贡献在于将昂贵的 GPT-4 API 替换为本地部署的开源 LLM,同时维持竞争力性能,这对隐私敏感的真实场景机器人部署有重要意义。论文设计的三阶段空间-时序 CoT(指令理解 → 进度估计 → 决策制定)是一种可复用的 LLM 导航推理框架,值得借鉴。用 SpatialBot + RAM 联合增强视觉感知的思路——一个负责空间关系理解,一个负责细粒度目标识别——有效弥补了开源 LLM 相比 GPT-4 在视觉感知上的差距。真实世界评估结果显示,无训练的 Open-Nav 甚至超越了有监督训练的 SOTA 方法,说明 LLM 的泛化能力在分布外场景中优势显著。
1. 研究背景/问题
Vision-and-Language Navigation in Continuous Environments (VLN-CE) 要求 agent 在未见过的 3D 室内环境中,根据自然语言指令进行导航。现有基于 LLM 的零样本方法(如 NavGPT、DiscussNav)严重依赖 GPT-4 API,存在高昂 token 费用和用户环境数据隐私泄露风险,且主要在离散环境中验证,难以直接应用于连续真实场景。
2. 主要方法/创新点
Open-Nav 框架由三个核心模块组成:
1. Waypoint Prediction 模块
使用基于 Transformer 的路径点预测模型,融合 RGB 和深度图像特征(两个专用 ResNet50 分支):
\[v_i^{rgbd} = W_m(f_{\text{ResNet-RGB}}(I_i^{rgb}) \| f_{\text{ResNet-Depth}}(I_i^d))\]经 Transformer 处理后生成候选路径点热力图,再通过 NMS 筛选出 K 个候选方向点 $\Delta W = {\Delta w_i}_{i=1}^K$,每个候选点由角度和距离表示。
2. Scene Perception 模块
针对连续环境中需要精确空间理解的挑战,使用两个互补模型增强场景描述:
- SpatialBot:空间理解 VLM,输入 RGB+深度图,输出包含物体间距离和空间关系的文本描述
- RAM(Recognize Anything Model):细粒度目标检测,识别场景中所有物体的类别和三维位置
两者输出合并为统一的文本化场景观测 $O_{text} = \langle D_{spatial}, {o_i}\rangle$,为 LLM 提供丰富的空间语境。

3. LLM Navigator:三阶段空间-时序 Chain-of-Thought
这是 Open-Nav 的核心创新。每个导航步骤,LLM 按顺序完成三个推理阶段:
- 指令理解(Instruction Comprehension):将导航指令分解为动作序列和地标列表,使用专用 prompt 提取结构化信息
- 进度估计(Progress Estimation):综合历史轨迹和当前观测,通过地标验证、方向分析、动作完成度评估四步判断已完成哪些子任务
- 决策制定(Decision Making):整合当前候选路径点的空间描述、历史轨迹摘要和进度估计结果,生成推理过程并选择最优方向点
框架通过 Ollama 在本地部署四种开源 LLM:Llama3.1-70B、Qwen2-72B、Gemma2-27B、Phi3-14B。
3. 核心结果/发现
模拟环境(R2R-CE 数据集):
| 方法 | SR↑ | SPL↑ | nDTW↑ |
|---|---|---|---|
| DiscussNav-GPT4 | 15 | 10.51 | 42.87 |
| Open-Nav-Llama3.1(本文) | 16 | 12.90 | 44.99 |
| Open-Nav-GPT4(本文) | 19 | 16.10 | 45.79 |
Open-Nav 使用开源 LLM 在 SR 和 SPL 上均超过 DiscussNav-GPT4,证明开源 LLM 配合良好的感知增强可媲美闭源方案。
真实世界环境(Office / Lab / Game Room):

在全部真实场景中:Open-Nav-Llama3.1 达到 SR=35, NE=2.39,超越有监督训练的 CMA(SR=23)、RecBERT(SR=27)、BEVBert(SR=20),验证了 LLM 泛化能力在分布外场景的优越性。
不同开源 LLM 对比(模拟环境导航性能):

4. 局限性
当前开源 LLM 的推理速度较慢,在真实环境中计算效率仍有待提升;论文未探索针对导航任务微调开源 LLM 的潜力,未来可进一步缩小与 GPT-4 的性能差距。
26. CausalNav (2026)
———First Scene Graph-based Semantic Navigation for Dynamic Outdoor Environments
📄 Paper: arXiv:2601.01872 · 🏛️ IEEE RA-L
精华
CausalNav 的核心亮点在于将多层级场景图(Embodied Graph)与 RAG 机制深度结合,实现了支持开放词汇查询的长程语义导航——”图即知识库”的设计范式值得借鉴。其次,层次化 Embodied Graph 构建策略(从细粒度对象节点到粗粒度建筑物与聚类节点)展示了如何在多空间尺度上统一语义表示与检索。第三,基于时空走廊(Spatial-Temporal Corridor)的动态对象过滤机制,无需额外标注即可区分静态、准静态与动态障碍物,是处理室外动态场景的实用方案。第四,使用本地开源 LLM 替代商业 API 完成层次语义检索,证明了在自主平台上脱离云端仍可实现高质量语义推理。
1. 研究背景/问题
室外大规模动态环境中的自主语义导航面临三大挑战:开放词汇的语义理解、动态环境适应(行人、车辆等移动障碍物)以及长期稳定性。现有 VLN 研究主要聚焦于静态室内场景,依赖高精度地图或大规模训练数据,在真实室外动态场景中的长程导航鲁棒性未得到充分验证。
2. 主要方法/创新点
CausalNav 提出了一个由三个核心模块构成的语义导航框架:
模块一:开放词汇目标跟踪与自我运动估计
使用 YOLO-World 从 RGB 图像中提取开放词汇的 2D 检测框和分割掩码,通过 ByteTrack 进行多目标跟踪。结合 LiDAR 点云将 2D 检测投影至 3D 空间,获得目标的 3D 姿态 $^w\mathbf{T}_{obj}$。自车运动通过 LiDAR-IMU 里程计(FAST-LIO2)估计,提供精确的定位与坐标变换基础。
模块二:动态对象过滤与 Embodied Graph 构建
-
时空走廊过滤:将每个目标的历史轨迹编码为时空走廊 $\mathcal{T} = {^w\mathbf{T}^n_{obj}, \text{3DBBox}i, t_i}{i=1}^n$。若目标在 $k$ 步内位移超过阈值,则认定为动态目标并从图中移除,有效消除运动引起的虚假节点。
-
Embodied Graph 层次构建:静态环境由两类节点组成——建筑物节点 $\nu_i^{build}$ 来自离线地图,对象节点 $\nu_i^{obj}$ 来自实时感知。使用 LLM 对节点进行层次聚类(spatial-semantic similarity),形成多级抽象:对象层(Level $L-1$)→ 建筑物/Place 层(Level $L$)→ 聚类节点(Clustering Node)。每次自车移动超过距离阈值 $d$,新增自车节点 $\nu_i^l$ 记录历史轨迹。
-
RAG 语义检索:基于 LLM 打分的层次化检索,结合空间相似性 $\kappa^{spatial}$ 和语义相似性 $\kappa^{semantic}$,在图中逐层选择最匹配查询的节点路径,支持开放词汇目标定位。
模块三:Embodied Graph 动态更新与自然语言导航
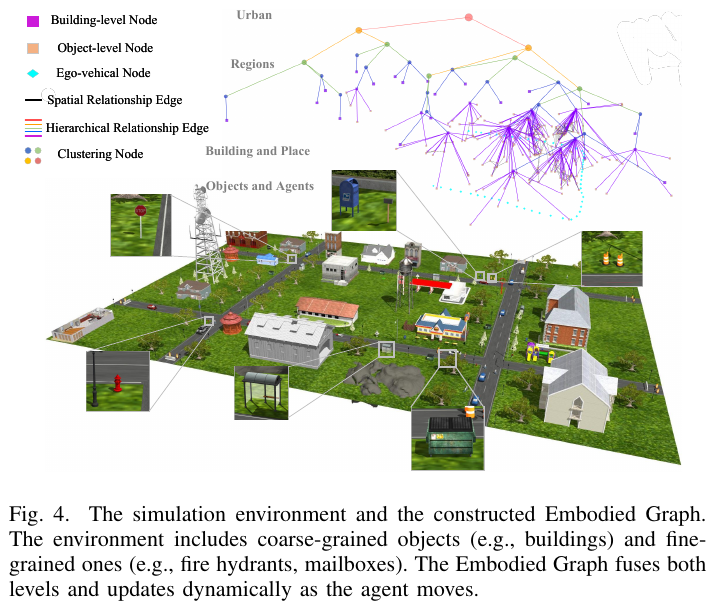
-
全局规划:解析自然语言指令,通过 RAG 检索 Embodied Graph 推断目标位置,优先使用历史轨迹中的 Dijkstra 最短路径;若目标不可达,则调用离线地图或 Google Maps 生成粗粒度路线,结果表示为路点序列 $\mathcal{W} = {w_1, w_2, \ldots, w_n}$。
-
局部规划:采用 RH-Map 进行实时动态局部地图构建,通过 Informed-RRT* 生成初始轨迹,再使用 NMPC-CBF(Nonlinear Model Predictive Control with Control Barrier Function)进行轨迹跟踪与动态避障,保证对移动行人/车辆的安全性。
3. 核心结果/发现
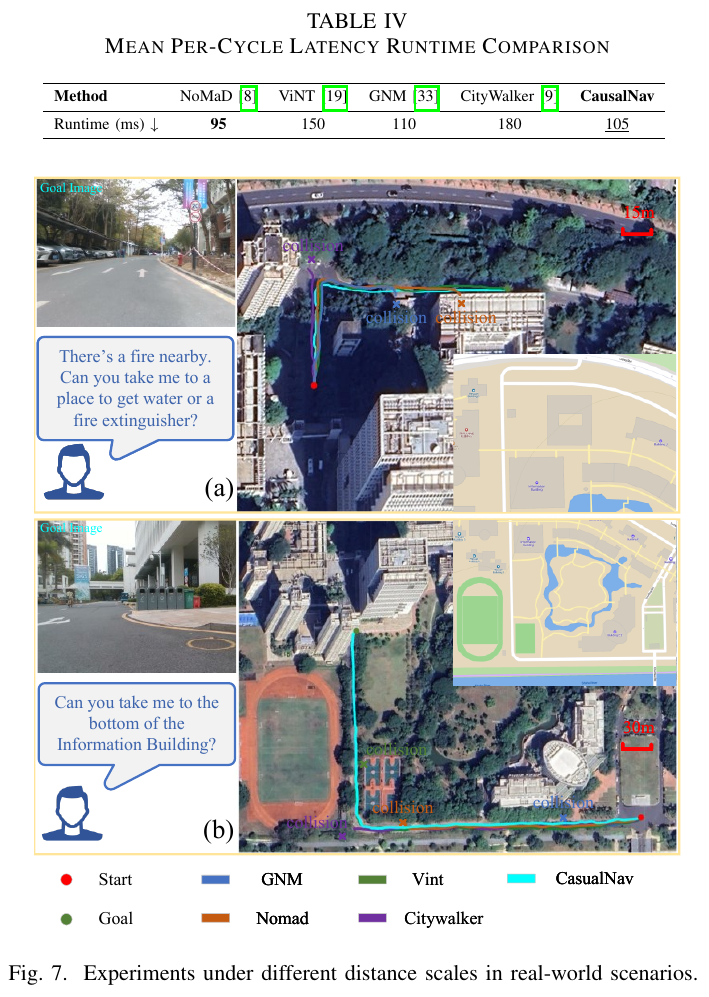
仿真实验(对比 ViNT、NoMaD、GNM、CityWalker):
- Small 任务:SR 100%,SPL 88.9%,CC 0.2(所有方法中最优)
- Medium 任务:SR 92%,SPL 82.2%
- Large 任务:SR 80%,SPL 66.0%,CC 1.2,TL 141.82m
真实世界实验:
- 短程(130m):ViNT 和 CausalNav 均成功,其他方法失败
- 长程(512m):仅 CausalNav 成功完成任务,其他方法因碰撞失败
- CityWalker 在真实世界表现显著差于仿真,对光照变化和动态障碍物敏感
消融实验:
- 启用 Embodied Graph 动态更新:SR 从 78% 提升至 90%,SPL 从 54.7% 提升至 80.1%
- 最优超参数:$\alpha=\beta=0.5$,$\gamma=1.5$(空间-语义平衡点)
- 运行时延:105ms/cycle(10Hz),比 NoMaD 仅多 11% 开销
4. 局限性
CausalNav 在极端光照/天气条件下的鲁棒性有待提升,且长程图记忆的压缩与遗忘机制尚未完善,可能在超长时间运行后出现图膨胀和检索精度下降问题。
27. SparseVideoNav (2026)
———Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
📄 Paper: arXiv:2602.05827
精华
SparseVideoNav 最值得借鉴的核心思想:视频生成模型(VGM)天然具备长视野预测能力,可以替代 LLM 作为导航的”大脑”,彻底解决 LLM 短视野导致的短视行为。稀疏化(sparse video generation)是兼顾长预测视野与计算效率的关键设计——不需要预测连续帧,只需关键时间戳处的帧即可提供有效导航指引。四阶段渐进式训练(T2V→I2V→历史注入→扩散蒸馏→动作学习)将大规模预训练视频模型迁移到导航领域,是一套通用的 VGM 适配范式。Diffusion Distillation 将推理步数从 50 步压缩到 4 步(9.6× 加速),使实时部署成为可能。此外,Q-Former + Video-Former 的历史压缩策略解耦了推理延迟与历史长度的关系,保证了稳定的推理效率。
1. 研究背景/问题
现有视觉-语言导航(VLN)系统依赖 LLM,受限于短视野监督(4-8步),在 Beyond-the-View Navigation(BVN)任务中表现欠佳:智能体需要在没有逐步指引的情况下,仅凭高层语义指令(如”找一张桌子并停在旁边”)定位远处不可见目标,LLM-based 方法因此频繁出现意外转向和死路困陷。简单延长监督视野会破坏 LLM 训练稳定性,而视频生成模型天然对齐长视野语言理解,成为解决 BVN 的关键突破口。
2. 主要方法/创新点
核心思路: 利用视频生成模型(VGM)预测未来稀疏帧序列作为导航预见,将预测视野延伸到 20 秒(20s × 4FPS = 80帧),而非 LLM 仅能处理的 4-8 步。稀疏间隔设为 3 时(sparse interval = 3),在预测视野与视觉保真度之间取得最优平衡。
整体架构:
架构由三个核心组件构成:
- VGM Backbone(Wan 2.1-1.3B):接收当前帧、历史嵌入(h_T)和语言指令(umT5),输出未来稀疏视频 latents
- Former 模块:Q-Former 处理时间维度历史压缩,Video-Former 处理空间维度,联合生成固定维度的历史嵌入,使推理延迟不随历史长度增长
- DiT Action Head:以生成的稀疏未来 latents 和语言指令为条件,通过 cross-attention 预测连续动作序列(DDIM 重建)
四阶段训练流程:
-
Stage 1 — T2V → I2V 适配:保留 Wan 的 flow matching 目标,将文本到视频模型适配为图像条件的视频生成(Image-to-Video),引入稀疏帧监督,以稀疏 chunk latents
[c_{T+1}, c_{T+2}, c_{T+5}, c_{T+8}, ..., c_{T+20}]作为训练目标 -
Stage 2 — 历史注入:在 Wan backbone 每个 transformer block 中新增 cross-attention block,注入历史信息 h_T(Q-Former + Video-Former 编码);新增层以零初始化保留预训练生成先验
-
Stage 3 — Diffusion Distillation:采用 PCM(Phased Consistency Models)进行蒸馏,以 history-injected I2V 模型为 teacher,训练结构相同的 student 模型,将推理步数从 N=50 压缩至 M=4,实现 9.6× 推理加速,同时保持视觉保真度
-
Stage 4 — 动作学习:冻结蒸馏后的 I2V 模型,采用逆动态范式(inverse dynamics paradigm),利用 DA3 对生成的稀疏未来帧重新标注动作标签,确保动作监督与合成动态精确对齐;训练 DiT action head 以去噪方式预测连续动作
数据采集: 使用手持 DJI Osmo Action 4(RockSteady+ 稳像)采集 140 小时真实室外导航视频,处理为约 13,000 条轨迹(均值 140 帧 × 4FPS),使用 DA3 估计相机位姿提取连续动作标签;语言指令由人工专家标注——构建了目前最大规模的真实世界 VLN 数据集。
3. 核心结果/发现

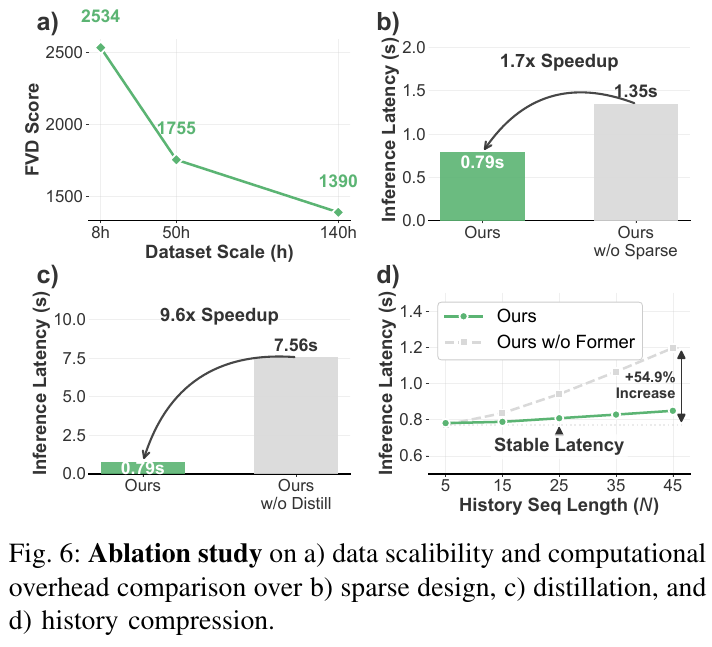
零样本真实世界性能:
- SparseVideoNav 在 6 种真实场景(室内 Room/Lab、室外 Yard/Park、夜间 Square/Mountain)上全面超越所有 LLM-based 基线
- IFN 任务平均成功率 50.0%(vs StreamVLN 35.0%、UniNavid 10.0%)
- BVN 任务平均成功率 25.0%(vs 所有基线几乎为 0%,StreamVLN 仅 10.0%)
- 夜间场景成功率 17.5%(LLM 基线在夜间 BVN 全部失败)
效率提升:
- 推理延迟 9.8s vs 基线 21.6s(27× 加速对比未优化版本)
- Stage 1+2 训练时间 32h vs 从头训练 64h(2× 加速)
- 稀疏设计带来 1.7× 推理加速,Distillation 带来 9.6× 加速
鲁棒性: 在训练高度(1m)与部署高度(50cm)不一致时仍能正确导航,展示出对相机高度变化的强鲁棒性;能够动态规避行人障碍(emergent ability,非显式训练)。
4. 局限性
当前 140 小时数据集相较于网络规模数据仍然有限,数据扩展是进一步提升的关键方向;推理延迟(9.8s)仍略高于现有 LLM-based 导航范式(StreamVLN),加速蒸馏与 VGM 量化是未来研究的重要课题。
28. AgentVLN (2026)
———Towards Agentic Vision-and-Language Navigation
📄 Paper: arXiv:2603.17670
精华
AgentVLN 最值得借鉴的思想是 VLM-as-Brain 范式:将 VLM 作为大脑纯做高层语义推理与技能调度,把感知、规划、控制等低层能力封装成模块化、即插即用的技能库,彻底解耦了认知与执行。跨空间表示映射(将 3D 拓扑路点反投影为像素对齐的 2D 视觉提示)是一个无需额外参数就能弥合 2D VLM 与 3D 物理世界之间鸿沟的精妙设计。QD-PCoT 展示了如何赋予模型元认知能力:当面对空间歧义时主动提问、调用感知技能获取深度信息,而非盲目输出坐标。3B 参数量在 R2R/RxR 双榜均超越 7B+ 的先前 SOTA,证明结构化分层推理远比暴力扩参数更高效。该框架可直接部署于 Jetson 嵌入式边缘平台,具备极强的落地价值。
1. 研究背景/问题
Vision-and-Language Navigation (VLN) 要求具身智能体将复杂自然语言指令转化为长时域、连续空间的导航行为。当前 VLN 系统面临三大核心瓶颈:VLM 固有的 2D 语义理解与 3D 几何感知之间的跨空间失配;单目 RGB 图像引起的尺度歧义导致局部目标定位失败;以及大参数量模型无法满足边缘设备实时推理需求。
2. 主要方法/创新点
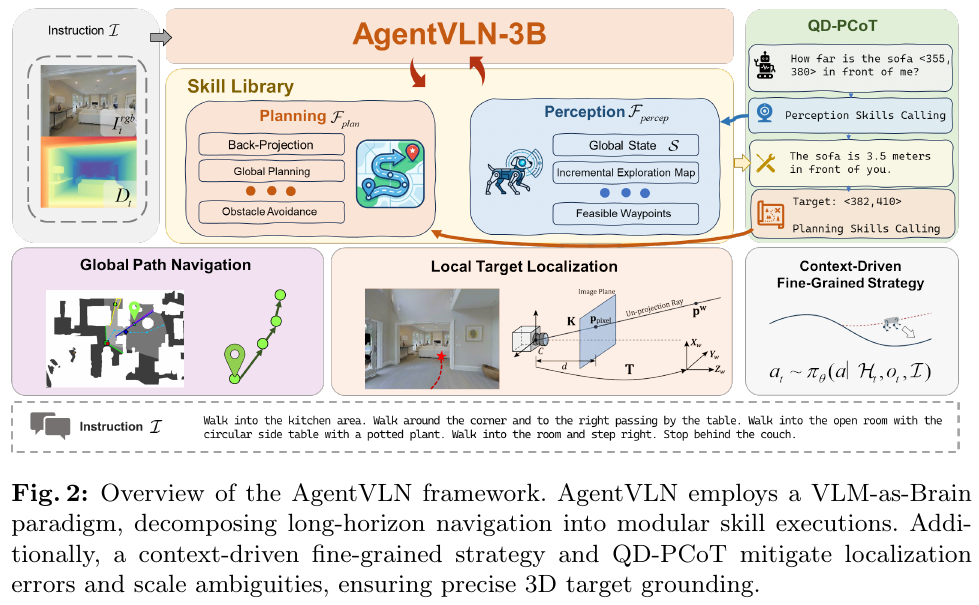
VLM-as-Brain 范式与 POSMDP 建模
AgentVLN 将 VLN 任务形式化为 Partially Observable Semi-Markov Decision Process (POSMDP) $\mathcal{M} = \langle \mathcal{S}, \mathcal{O}, \mathcal{F}, \mathcal{T}, \mathcal{I}, \mathcal{H} \rangle$。VLM 作为中央控制器,在每个决策步 $t$ 基于历史上下文 $\mathcal{H}_t$、视觉观测 $o_t$ 和自然语言指令 $\mathcal{I}$ 生成技能调用指令:
\[c_k \sim \pi_\theta(f \mid \mathcal{H}_{t_k}, o_{t_k}, \mathcal{I}), \quad f \in \mathcal{F}\]技能库 $\mathcal{F}$ 分为两类:感知技能 $\mathcal F_{percep}$($\tau=0$,无延时地从环境提取几何/语义特征,更新全局状态 $\mathcal{S}$)和规划技能 $\mathcal F_{plan}$($\tau>0$,执行多步物理动作序列)。具体包括:Back-Projection、Global Planning、Obstacle Avoidance、Incremental Exploration Map、Feasible Waypoints 等模块。这种分层设计使 VLM 完全不接触低层运动细节,专注高层语义-空间匹配。
跨空间表示映射(Cross-Space Representation Mapping)
为解决 VLM 无法直接感知 3D 几何的问题,AgentVLN 设计了一套逆透视投影机制。感知技能首先将 RGB-D 观测通过反投影构建全局占据栅格地图,生成三维路点 $\mathbf{P}^w_{path} = [X_{path}, Y_{path}, 0]^T$;随后通过相机内参矩阵 $K$ 和当前位姿 $T_t$ 将 3D 路点投影回像素坐标:
\[s \cdot \mathbf{p}^{img}_{path} = KR_t^{-1}(\mathbf{P}^w_{path} - \mathbf{t}_t)\]这样 VLM 只需在 2D 像素空间中根据语义选择最匹配的路点,再由规划技能将其恢复为 3D 控制信号,实现了 2D 视觉语义与 3D 物理结构的无缝桥接。
上下文感知的细粒度自校正与主动探索
当当前观测 $o_t$ 中不存在满足指令语义的可行路点时(如遮挡、盲区、轨迹偏差),AgentVLN 不强制执行长距离盲位移,而是输出细粒度原子动作 $a_t \sim \pi_\theta(a \mid \mathcal{H}_t, o_t, \mathcal{I})$,$a \in {\text{Forward, Left, Right}}$,自主环顾恢复可见路点后切回宏观技能调用,有效抑制长轨迹误差累积。
Query-Driven Perceptual Chain-of-Thought (QD-PCoT)
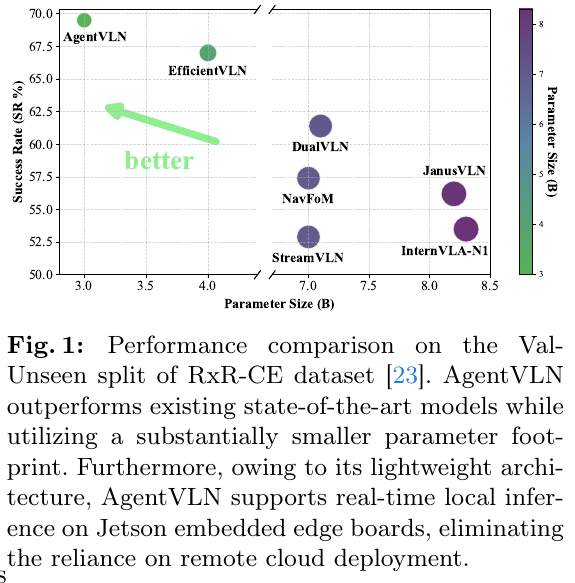
针对局部目标定位阶段的单目尺度歧义,AgentVLN 引入 QD-PCoT 机制。当模型检测到空间歧义时,不盲目回归像素坐标,而是生成中间自然语言查询(如 “How many meters is the chair in front of me?”)并调用感知技能 $\mathcal F_{percep}$ 获取精确深度反馈。该反馈以增量文本提示形式注入上下文,引导模型最终输出准确的目标像素坐标 $\mathbf p_{target}^{img} = [u_{target}, v_{target}, 1]^T$,再经深度图反投影转换为 3D 目标坐标 $\mathbf{P}^w_{target}$,实现精准对接。
AgentVLN-Instruct 数据集
构建了大规模指令调优数据集 AgentVLN-Instruct(基于 Habitat 仿真器),包含四个关键组件:目标可见性驱动的动态阶段路由机制(模拟人类”先粗导航、再精定位”的认知模式)、可泛化技能调用标注、局部化推理数据,以及主动问答交互对。基础模型为 Qwen2.5-VL-3B,训练时冻结视觉编码器,以 AdamW 优化,使用 32 块 NVIDIA A100 GPU。
3. 核心结果/发现

- R2R-CE Val-Unseen: AgentVLN-3B 达到 SR=67.2%, SPL=64.7%,超越同类 SOTA InternVLA-N1-8.3B(SR+9.0%,SPL+10.7%),以不到一半的参数量实现全面超越
- RxR-CE Val-Unseen: SR=69.5%, SPL=61.3%, nDTW=74.6%,同样刷新 SOTA
- 消融分析:仅引入 VLM-as-Brain + 跨空间映射,SR 从基线 38.6% 提升至 59.7%;加入 CDFG 细粒度自校正后达 65.6%;最终集成 QD-PCoT 达 67.2%
- 时序上下文:最优历史帧数 K=8(SR=67.2%,SPL=64.7%),过短则短视,过长则注意力稀释
- 真实世界部署:基于 Unitree Go2 四足机器人 + Intel RealSense D455,结合 RTAB-Map SLAM,在室内外场景均实现准确导航,支持 Jetson 边缘实时推理
4. 局限性
AgentVLN 当前依赖深度传感器(RGB-D)支持精确的 3D 反投影,在纯 RGB 单目场景下的尺度歧义处理能力仍受限;此外,技能库的扩展和维护需要一定的工程成本,对全新场景的零样本适配能力尚待系统评估。
29. Skill-Nav (2025)
———Enhanced Navigation with Versatile Quadrupedal Locomotion via Waypoint Interface
📄 Paper: arXiv:2506.21853 · 🏛️ Vicinagearth (Springer) 2025
精华
Skill-Nav 的核心贡献在于用 waypoint(路标点) 作为高层规划器与低层运动控制器之间的接口,相比速度命令接口,waypoint 对追踪误差更不敏感,且天然兼容 LLM 和经典路径规划算法。两阶段训练策略(WP-Fixed 先学技能、WP-Random 再强化泛化)解决了单阶段训练的跌步或过度跳跃问题,值得在其他层级化机器人控制任务中借鉴。Teacher-Student 蒸馏架构通过在 Student 训练时引入膨胀虚拟障碍(inflated virtual obstacles),使 Student 策略在不接触特权信息的条件下保持安全导航能力。
1. 研究背景/问题
四足机器人通过 RL 已能完成极限 parkour 等高难度运动,但将丰富的运动技能集成到长距离导航任务中仍未充分探索。现有方法大多以速度命令为接口,高层规划器难以精确跟踪,且与多样化通用规划工具(LLM、A*)耦合困难。
2. 主要方法/创新点
Waypoint 接口设计
Skill-Nav 以 2D 相对位置(相对于机器人 base frame 的坐标)作为 waypoint 命令替代速度命令。高层规划器通过 $\mathcal{W} = \mathcal{H}(\mathbf{M}, p_e, p_s)$ 生成从起点到终点的 waypoint 序列,$\mathcal{H}$ 可以是 A* 算法或 LLM,$\mathbf{M}$ 为粗粒度环境信息(如占用地图或房间布局)。
两阶段训练策略
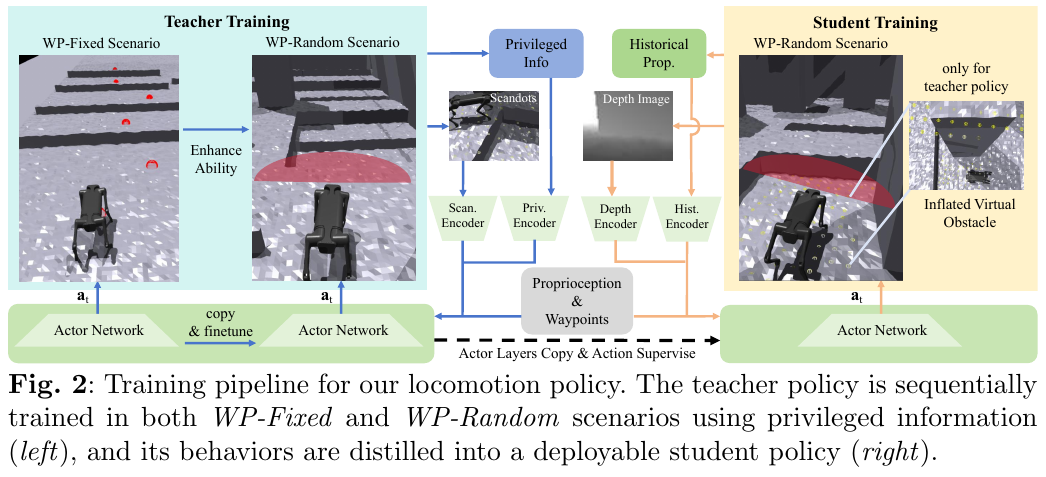
-
WP-Fixed 场景(技能学习):障碍物按行排列,waypoint 预置。策略从零开始学习攀爬箱体、跨越间隙、越过护栏等基础运动技能。设计 $r_{\text{reach}} = n_p/(t + \epsilon)$ 鼓励机器人快速到达更多 waypoint,同时引入 $r_{\text{stay}}$ 使机器人在到达 waypoint 后等待下一条指令。
-
WP-Random 场景(泛化增强):障碍物以矩阵形式随机分布,waypoint 根据机器人位置和偏航角动态选取。引入修改后的 $r_{\text{track}}$,当速度方向与 waypoint 方向余弦相似度 $< 0.1$ 时给予 $-1$ 惩罚,鼓励机器人向目标前进。Student 训练时在深度图中加入虚拟膨胀障碍,使学生策略保持安全距离。
双规划器高层架构
- 经典规划(A*):输入仅含墙体标注的占用地图,输出连续路径点序列,以 0.5–3m 间隔采样为 waypoint 输入低层控制器。
- LLM 规划:向 LLM 提供任务描述、粗粒度地形图、机器人运动能力(最高攀爬 0.45m、最大跨越 0.7m 间隙)等信息,由 LLM 生成 waypoint 索引序列(以 GPT-4 验证)。
3. 核心结果/发现
- Single-traverse 任务:在有无高障碍物场景中,Skill-Nav 均达到 SR=1.00、ATD=15.8m,是唯一在两种条件下均成功的方法。
- Omni-traverse 任务:SR=0.89、ATD=8.2m,超越所有对比方法(RMA SR=0.00,Extreme Parkour SR=0.44/0.28)。
- 消融分析:仅 WP-Fixed 训练(Ours-s1)因 waypoint 分布规则,泛化能力差;仅 WP-Random 训练(Ours-s2)导致过度跳跃步态,实际部署困难;两阶段结合效果最优。
- 真实机器人部署:在 Unitree AlienGo 上成功验证,可应对深度相机未检测到的低矮障碍,并在受到外力干扰后恢复平衡继续导航。
4. 局限性
高层规划器(尤其是 LLM)可能生成位于间隙中央或箱体边缘等异常 waypoint,低层控制器难以从这类极端位置恢复;未来工作将设计边缘无碰撞低层控制器,并探索运动与导航的端到端统一策略。
30. VLN-Cache (2026)
———Enabling Token Caching for VLN Models with Visual/Semantic Dynamics Awareness
📄 Paper: arXiv:2603.07080
精华
VLN-Cache 的核心洞见是:现有 token caching 方案在 VLN 场景下失效的根本原因有两个相互独立的维度——视觉动态(视角偏移导致空间位置错配)和语义动态(任务阶段推进导致缓存 token 语义过时)。将 “视图对齐重映射” 与 “任务相关性语义门控” 分别针对这两种动态进行正交设计是本文最值得借鉴的思路:先用几何对应恢复可复用集合,再用语义相关性做一票否决,二者缺一不可。层自适应熵策略(layer-adaptive entropy policy)将每层的复用预算与注意力分布的不确定性挂钩,也为其他需要跨层差异化处理的 inference 优化工作提供了参考范式。整个框架训练自由、无需架构修改,可作为即插即用的推理加速包裹层,具有很强的实用价值。
1. 研究背景/问题
现代 VLN 系统依赖大型视觉-语言模型(VLM)作为规划器,每个导航步骤都需完整的前向推理,导致每步延迟成为实时部署的瓶颈。Token caching 是一种无需训练的推理加速策略,通过复用帧间稳定 token 的 KV 表示来跳过冗余计算;然而现有方法基于静态相机和固定语义的假设,在 Agent 连续平移旋转的 VLN 场景下会出现两类系统性失效:视角偏移导致位置对齐失效,任务阶段推进导致语义相关性突变,使得缓存 token 在视觉上”看起来稳定”但语义上已经过时。
2. 主要方法/创新点
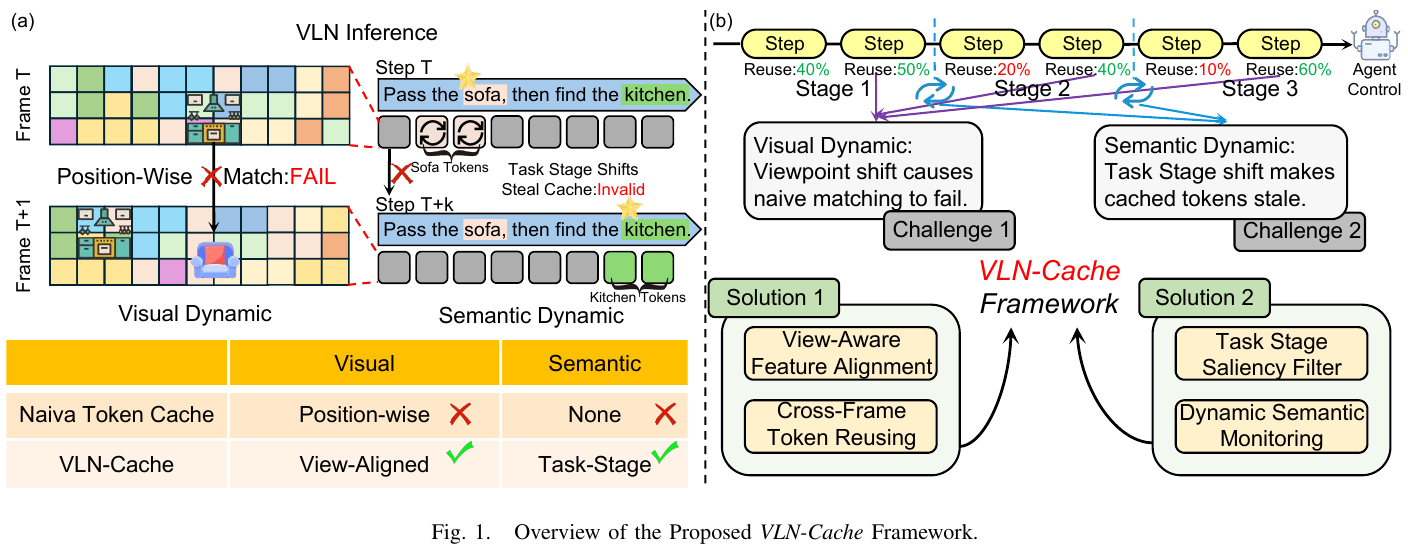
VLN-Cache 是一个双感知 token caching 框架,针对视觉动态和语义动态分别设计了正交的处理机制:
A. 视觉动态感知 Token Caching
由于 Agent 连续移动,帧 t 中位置 i 的 token 对应的物理表面与帧 t-1 中同一位置 i 的表面完全不同。VLN-Cache 通过 视图对齐重映射(View-Aligned Remapping) 解决这一问题:
- 利用深度图将每个 token 中心 $u_t^{(i)}$ 反投影到 3D 空间,结合相机相对位姿变换矩阵 $T_{t \to t-1}$,重新投影到上一帧图像平面,得到对应位置 $\pi_t(i)$
- 通过 3×3 邻域细化($\mathcal{N}$)处理连续坐标到离散 patch 索引的量化误差
- 仅当重映射后的 token 对余弦相似度超过阈值 $\tau_{vis}$ 且在有效视野内时才标记为可复用
B. 语义动态感知 Token Caching
即便两帧间 token 在几何上完美对齐、视觉上高度相似,若 Agent 已完成当前子目标并转向下一阶段,该区域的任务相关性可能已骤降,复用其缓存状态会向语言解码器注入过时的注意力模式。VLN-Cache 引入 任务阶段显著性过滤器(Task-Stage Saliency Filter):
- 为每个 token 计算指令条件相关性分数 $s_t^{(i)}$(top-k 注意力集中区域的 Jaccard 距离衡量语义转变幅度 $D_t^{sem}$)
- 满足以下任一条件则强制刷新:当前相关性过高($s_t^{(i)} > \tau_{abs}$,缓存版本无法代表该区域重要性)或相关性快速变化($\lvert s_t^{(i)} - s_{t-1}^{(i)} \rvert > \tau_\Delta$,正在经历语义转变)
- 语义门控为 一票否决(hard veto):视觉稳定性是复用的必要条件但不充分,语义过时则无条件刷新
C. 双感知融合与层自适应缓存策略
最终复用掩码采用乘法形式 $m_t^{(i)} = m_{vis,t}^{(i)} \cdot (1 - m_{sem,t}^{(i)})$,仅当几何稳定且无语义转变时才复用。
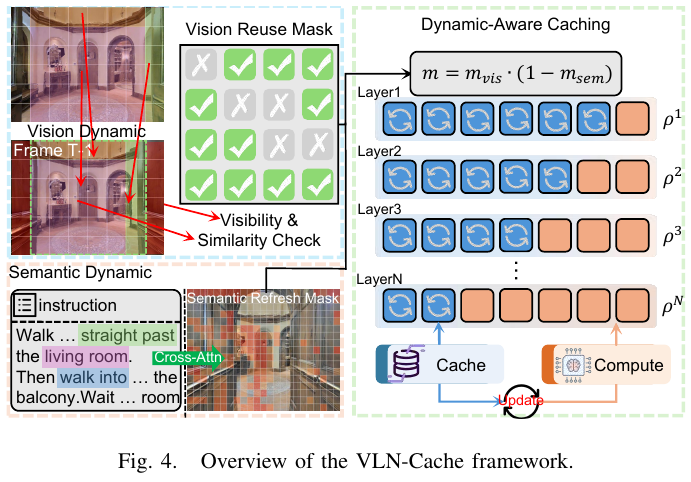
对于 Transformer 不同层,早期层处理低层次视觉特征(变化较慢),深层编码任务相关表示(在指令转变时变化更剧烈)。VLN-Cache 通过 层自适应熵策略 调节每层复用预算: \(\rho_t^\ell = \text{clip}(\rho_{max} - \alpha H_t^\ell, \rho_{min}, \rho_{max})\) 其中 $H_t^\ell$ 是从现有注意力 softmax 读取的层熵代理,高熵层(不确定层)分配更保守的复用预算,低熵层可更激进地复用。
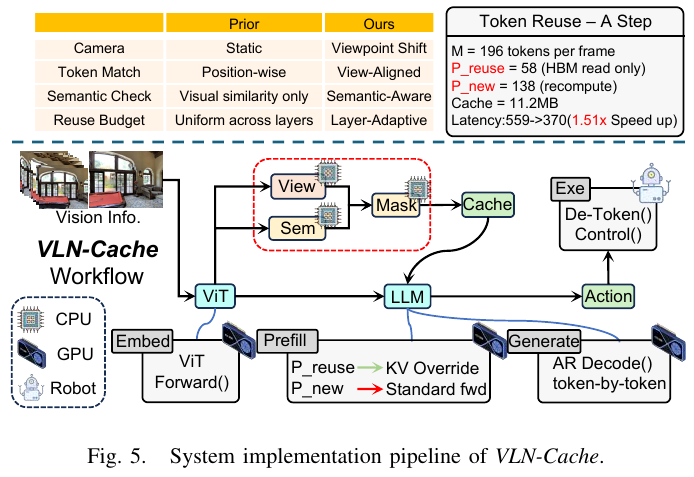
在系统实现上,VLN-Cache 不修改模型权重或注意力核,作为 drop-in 包裹层集成到任意基于 Transformer 的 VLA backbone:复用 token 从视图对齐缓存位置 $\pi_t(i)$ 直接拼接 KV 状态,新 token 经标准投影;RoPE 位置编码仅对新 token 更新,复用 token 继承原有编码。每帧缓存占用约 85.8 MB(A100 VRAM 的 0.21%),无需 CPU 卸载。
3. 核心结果/发现
在 R2R-CE val_unseen 基准(1,839 个 episode,基于 InternVLA-N1 / QwenVL-2.5 7B backbone)上:
- 推理加速:每步延迟从 637 ms 降至 419 ms,实现 1.52× 步级加速,episode 级别同样达到 1.52× 加速(114.7s → 75.5s)
- 导航精度保持:SR = 63.1(vs. 基线 64.3),SPL = 57.6(vs. 基线 58.5),SR 下降仅 1.2%
- Token 复用率:平均每步 31% 的 VLA token 从缓存复用;83% 的帧完全绕过 ViT 视觉编码器
- 消融分析:移除视图对齐重映射后 SR/SPL 显著下降(回退到位置对齐方案),移除语义门控后精度下降(视觉相似但语义过时的 token 被错误复用),二者均为不可或缺的正交贡献
- 效率-精度帕累托最优:在所有 RGB-only VLN 方法(NaVid, MapNav, UniNaVid, NaVILA, StreamVLN, DualVLN)中,VLN-Cache 达到最低 NE(3.93)和最高 OS(71.4),同时具备最快推理速度
4. 局限性
VLN-Cache 目前仅针对 RGB-based 连续 VLN,不支持深度传感器或地图导航设置;四个超参数($\tau_v, \tau_s, k, \rho_{max}$)缺乏自动调节方法,需在小型保留轨迹集上手动校准,自动超参确定方案留作未来工作。
31. SysNav (2026)
———Multi-Level Systematic Cooperation Enables Real-World, Cross-Embodiment Object Navigation
📄 Paper: arXiv:2603.06914
精华
SysNav 将 ObjectNav 重新定义为系统级问题,将语义推理、导航规划、运动控制三层彻底解耦,值得借鉴。核心洞见是:VLM 不应被用于细粒度的 frontier 级别决策,而应限制在房间级别的高层规划,从而在推理能力与空间可靠性之间取得最佳平衡。三层场景图(Room→Viewpoint→Object)为 VLM 提供了结构化上下文,是 VLM 高效推理的关键基础设施。Early-stop 和 Room-query 两种 VLM 调用模式按需触发,有效避免了 VLM 的冗余调用。该系统在三种机器人平台上部署,验证了模块化设计对跨平台泛化的价值。
1. 研究背景/问题
Object Navigation(ObjectNav)要求机器人在未知室内环境中自主找到目标物体,需同时处理复杂空间结构、长程规划和语义理解。现有方法将 ObjectNav 作为单一策略学习问题,端到端模型难以兼顾多个子挑战;而过度依赖 VLM 进行 frontier 级别决策会因 VLM 缺乏精确 3D 空间理解而导致频繁回溯和低效行为。
2. 主要方法/创新点

SysNav 是一个三层解耦的 ObjectNav 系统,各层专注于不同粒度的子问题:
高层——语义推理(Semantic Reasoning)
构建三层场景图表示 $\mathcal{R}$:
- Room Node $v^r$:通过点云垂直分布拟合墙面并划分独立房间,每个节点存储房间类别、2D 顶视图和代表性 RGB 图像
- Viewpoint Node $v^v$:在覆盖范围发生显著变化时新增,存储位置、覆盖区域和全景图像,实现高效语义存储
- Object Node $v^o$:使用开放词汇检测(YOLOv8x + SAM2)实例化,每个节点存储类别、置信度、3D 点云、bounding box 及自属性
边类型包括:Room-Room(门道连通)、Room-Viewpoint(包含关系)、Room-Object(包含关系)、Viewpoint-Object(可见性)、Object-Object(空间约束,按需添加)。
VLM Reasoning 组件(Gemini-2.5-flash)基于上述场景图进行语义推理,提供房间级别导航指导。
中层——基于房间的导航(Room-based Navigation)
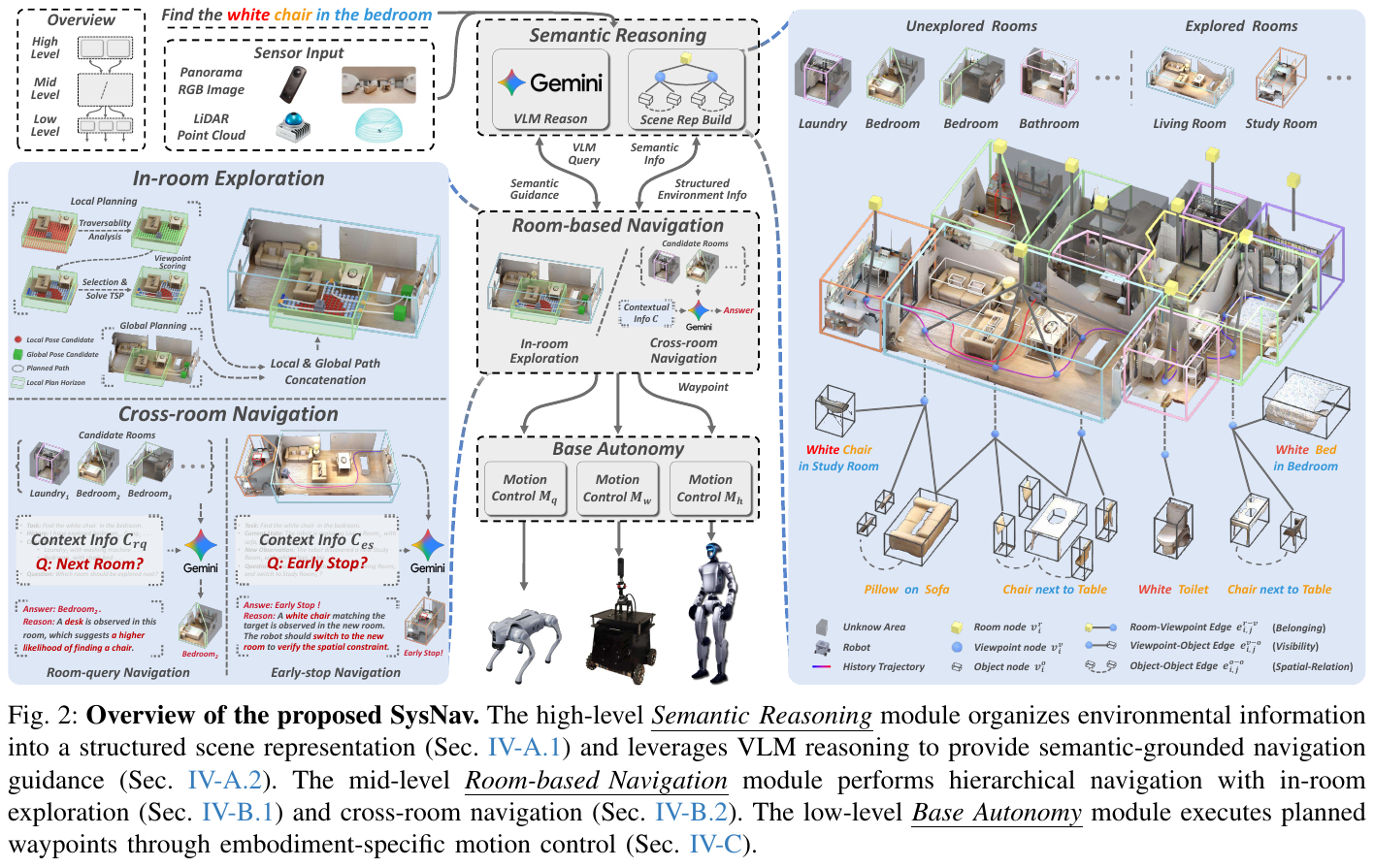
将房间作为最小语义规划单元,在房间内使用高效经典探索算法,仅在房间切换时调用 VLM:
- In-room Exploration:两级规划(局部 + 全局),以覆盖分数 $w_{cov}(c_i) = \lvert \mathcal S_{cov}(c_i) \cap \hat{\mathcal S} \rvert$ 选取位姿候选,用 TSP 生成探索路径,滚动窗口机制协调局部与全局计划
- Early-stop 模式:进入新房间时,VLM 根据上下文信息 $\mathcal C_{es}$(房间属性、已观测物体、任务目标)判断是否提前终止当前房间探索并切换到新房间
- Room-query 模式:当前房间探索完毕仍未找到目标时,VLM 基于未探索房间信息 $\mathcal C_{rq}$ 推理最可能包含目标的下一个房间
低层——基础自主(Base Autonomy)
设计跨平台基础自主模块,将路径点转换为各平台(轮式机器人、四足 Unitree Go2、人形 Unitree G1)的具体运动控制指令,包含路径点跟随、碰撞回避和地形可通行性分析。
3. 核心结果/发现
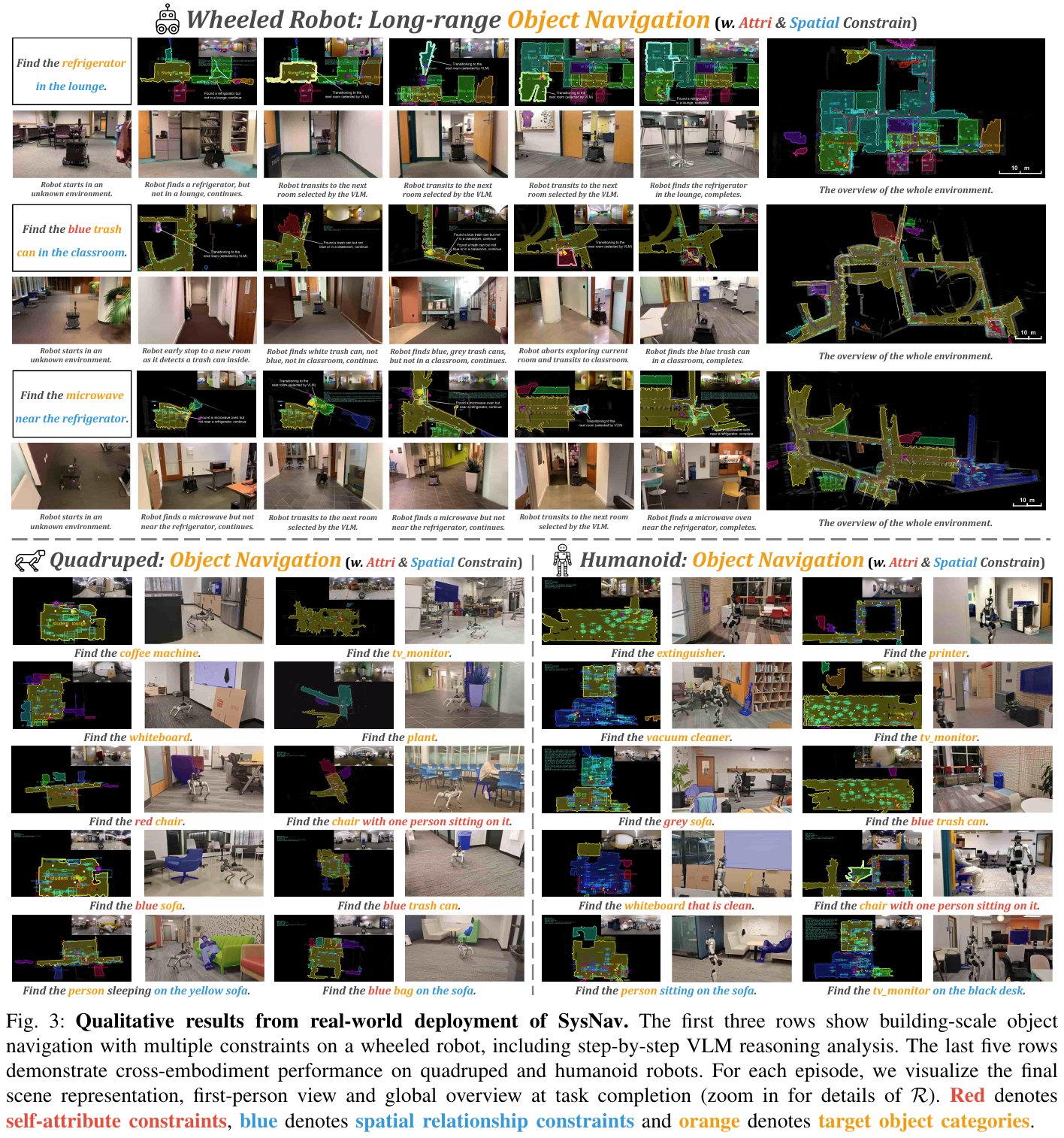
仿真基准(4个benchmark,与 SOTA 对比):
- HM3D-v1:SR 63.7%,SPL 30.5%(大幅领先次优 ApexNav 的 59.6%/33.0%)
- HM3D-v2:SR 80.8%,SPL 37.2%(次优 ApexNav 76.2%/38.0%)
- MP3D:SR 50.7%,SPL 18.1%
- HM3D-OVON:SR 54.9%,SPL 26.1%(次优 MTU3D 40.8%/12.1%,提升 14.1%/6.5%)
真实环境(190 次实验,对比 VLFM 和 InstructNav):
- Hard 设置(目标在不同房间):SR 97.5%,SPT 71.8,AT 67.6s(Hard setting SR 较次优提升 61.1%,SPT 提升 51.1%,AT 减少 29.8s)
- 导航效率较现有 ObjectNav 基线提升 4-5×
4. 局限性
仿真中 SPL 提升幅度小于 SR,原因是面向真实场景设计的严格覆盖策略在仿真中会造成轻微过度覆盖;此外,多房间布局对系统的额外挑战有限,因为中等难度场景中障碍物更密集反而会降低速度。
32. VLN-Imagine (2025)
———用文本生成图像模型为导航智能体构建”视觉想象”
📄 Paper: arXiv:2503.16394 · 🏛️ CVPR 2025
精华
- 利用现成的 text-to-image 扩散模型(SDXL)为导航指令中的地标名词短语生成”视觉想象”,将跨模态对齐从隐式学习转化为显式的图像-图像匹配,思路简洁且可迁移。
- 方法设计为 model-agnostic:通过独立的 imagination encoder + 辅助对齐损失即可嵌入任意 VLN 模型,无需修改原有架构。
- 子指令过滤策略(FG-R2R 分割 + 名词短语黑名单)有效控制了生成图像的质量与相关性,是低成本数据增强的好范例。
- 实验表明 imagination 在训练和推理阶段均有增益,且训练阶段的正则化效应独立于推理时的输入增益,说明多模态辅助信号可提升模型泛化。
- cosine similarity 辅助损失足以对齐 imagination 与指令表征,无需更复杂的对比损失(InfoNCE),体现了”够用即可”的工程哲学。
1. 研究背景/问题
Vision-and-Language Navigation(VLN)任务中,智能体需要根据自然语言指令在未见过的环境中导航。指令常引用视觉地标(如”pool table”“kitchen”),但现有方法依赖隐式跨模态对齐来关联名词短语与实际观察。本文探索是否可以在导航前先用 text-to-image 模型为地标生成”视觉想象”,将语言-视觉对齐转化为更容易的图像-图像匹配任务。
2. 主要方法/创新点
2.1 Visual Imagination 生成管线

- 指令分割:使用 FG-R2R 将完整导航指令分割为子指令序列 $S = (S_0, \cdots, S_m)$,R2R 训练集平均每条指令 3.66 个子指令。
- 子指令过滤:通过 SpaCy 过滤无名词短语的子指令,再用黑名单排除非视觉名词(如计数词、方向词、代词),保留有效子指令集 $S’ \subset S$。
- 图像生成:使用 SDXL 扩散模型,以正向提示词(indoor, house, realistic, real estate)和负向提示词(outdoor, text, humans 等)引导生成室内场景图像。最终构建 R2R-Imagine 数据集,包含超过 41k 张 1024×1024 想象图像。
2.2 Model-Agnostic 集成方法
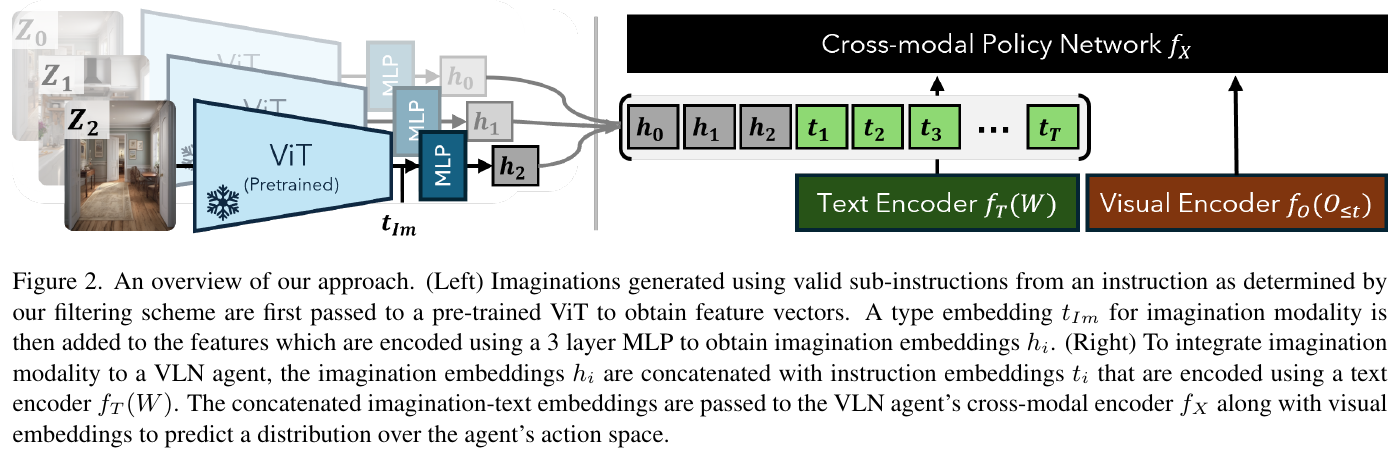
- Imagination Encoder:使用预训练 ViT-B/16 编码想象图像,加上 imagination modality 的类型嵌入 $t_{Im}$,再通过三层 MLP(768→512→768,ReLU + Dropout 0.15)得到 imagination embedding $h_i = \text{MLP}(\text{ViT}(Z_i) + t_{Im})$。
- 模态融合:imagination embedding 与指令的文本编码拼接后,一起送入 VLN 智能体的跨模态编码器。本文在 HAMT 和 DUET 两个代表性模型上验证了该方法。
- 辅助对齐损失:计算 imagination embedding $h_i$ 与对应子指令名词短语的平均文本嵌入 $\bar{S}i$ 之间的 cosine similarity 损失 $\mathcal L{cos}$,总损失为 $\mathcal L_{\text{base}} + \lambda \mathcal L_{cos}$($\lambda=0.5$)。
- 三阶段微调:为缓解灾难性遗忘,先训练 MLP + 类型嵌入(25% 迭代)→ 联合训练所有模块(25%)→ 统一学习率训练(50%),总计 100k 迭代。
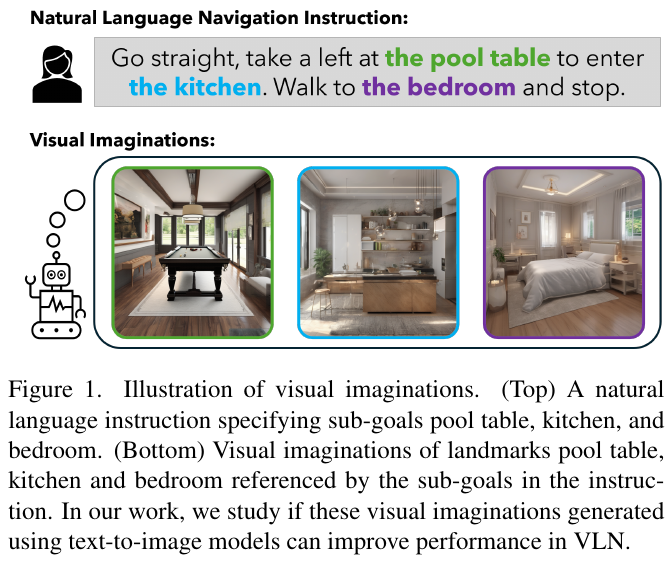
3. 核心结果/发现
- R2R 数据集:在 HAMT 和 DUET 基础上,VLN-Imagine 在 val-unseen 上分别提升约 1.0 SR 和 0.5 SPL(HAMT: 67.26 SR / 62.02 SPL;DUET: 79.9 SR / 73.75 SPL)。DUET 在 test split 上 SR 提升 2 个点。
- REVERIE 数据集:DUET-Imagine 在粗粒度指令设置下 SR 提升 1.3 点,RGS 提升 0.82 点,说明想象对目标定位也有帮助。
- 训练与推理双重增益:即使在推理时 nullify imagination(置零注意力掩码),模型仍优于 baseline,暗示 imagination-based 训练具有正则化效果。
- 对齐是关键:随机 imagination 反而降低性能;正确对齐的 imagination 才能带来提升。
- 视觉优于文本:用子指令文本嵌入代替 imagination embedding 效果不如视觉想象,说明视觉表征与语言起互补作用。
- Imagination 高保真度:通过 LangSAM 开放词汇检测器验证,98.78% 的子指令至少有一个名词短语被检测到。
4. 局限性
生成和编码想象图像增加了计算开销,对实际机器人部署尤为不利(H100 上单张 3.2 秒,微调需 V100 约 1.5 天)。此外,想象图像无法捕捉环境中物体和位置的个性化命名,终身学习的持久化视觉 grounding 仍是开放问题。
33. R³: Run, Ruminate, and Regulate (2026)
———一个面向视觉语言导航的双过程思考框架
📄 Paper: arXiv:2511.14131 · Code · 🏛️ AAAI 2026
精华
- 将 Kahneman 双过程理论落到 VLN:Runner(快系统)处理常规导航,Ruminator(慢系统)处理异常情境,Regulator在两者间做监督切换——解决 “LLM 方法慢但泛化强 vs. 专家模型快但迁移差” 的取舍。
- Runner 用轻量级 transformer VLN 专家(~160 M 参数、沿用 GridMM)做反应式高频动作预测;Ruminator 用 GPT-4o + CoT 做感知-规划-预测三步推理;二者共享一个grid-based topological memory bank,使慢系统能直接继承快系统的历史上下文。
- Regulator 的切换信号来自三路critical evaluation(looping 视点重访阈值 + scoring GNN 对轨迹图做自监督打分 + ending 对 STOP 的校验),切换后进入critical formulation清空误导性历史,避免 LLM 被错误上下文污染。
- Scoring 的自监督标注策略值得借鉴:以”是否最终到达目的地 / 路径是否属于 GT 子集”作为二分类伪标签,GNN 用图注意力做消息传递,从而无需人工标注就能早期识别失败前兆。
- R³ 在 REVERIE Val-Unseen 上 SPL/RGSPL 比 SOTA 高 3.28 / 3.30,推理时间仅为其他 LLM-assisted 方法的 1/5(1.10 s vs. 5~11 s),展示了”大部分步数走快系统、异常步数才调 LLM”这一思路在效率与性能上的双赢。
1. 研究背景/问题
VLN 需要智能体根据自然语言指令在复杂 3D 环境中动态导航。两条主流路线各有短板:(1)基于 BC 的 VLN 专家(DUET、GridMM 等)效率高但常识缺失、对未见环境泛化差;(2)LLM-assisted 零样本方法(NavGPT、MapGPT、DiscussNav 等)泛化好但每步调 LLM 导致延迟高(5~11 s/step),且对空间几何与场景布局的理解不够精确。作者目标是把两者的长处糅合在同一框架下——而不是简单地把 LLM 插进每一步。
2. 主要方法/创新点
2.1 整体思想:双过程思考
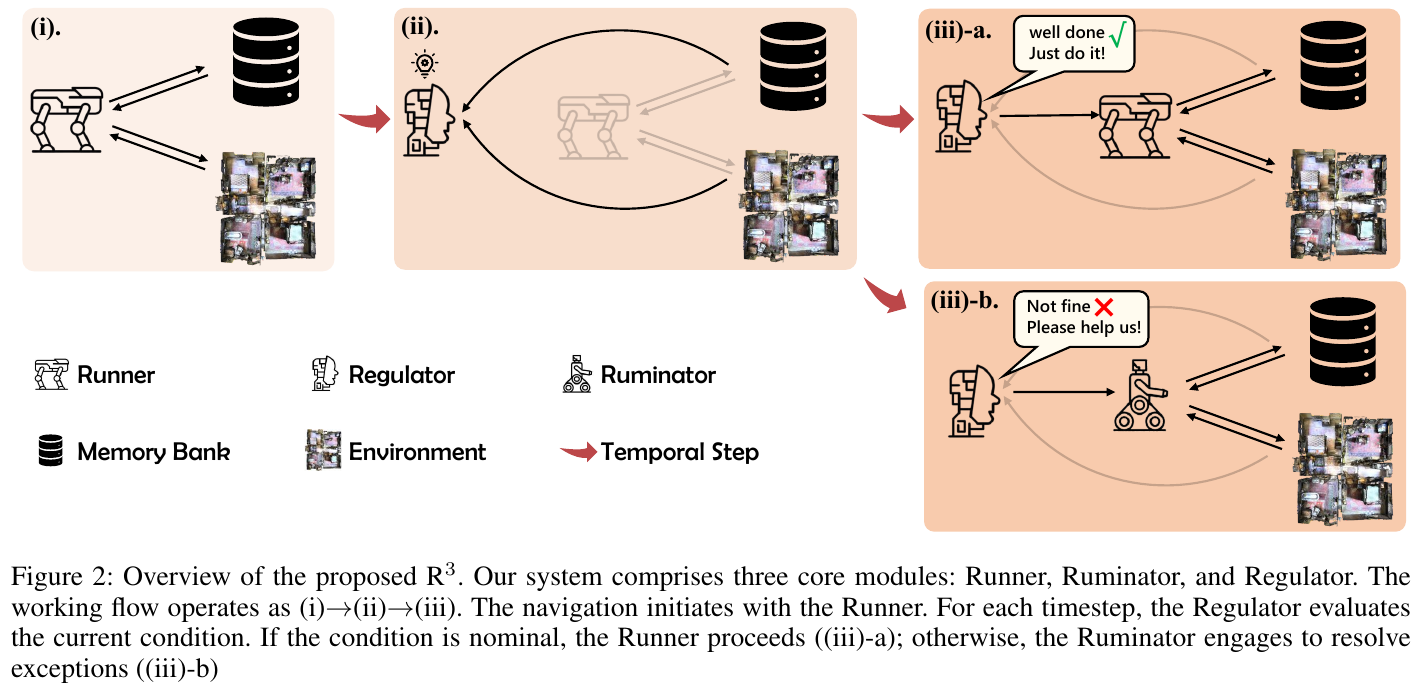
R³ 由三个模块组成:
- Runner(快系统):反应式 VLN 专家,常规步骤下主导。
- Ruminator(慢系统):多模态 LLM + CoT,仅在检测到异常时激活,接管直到该异常消除或片段结束。
- Regulator(监督者):每个时间步评估当前状态,决定是否切换到 Ruminator,并在切换时清洗历史。
2.2 整体 Pipeline
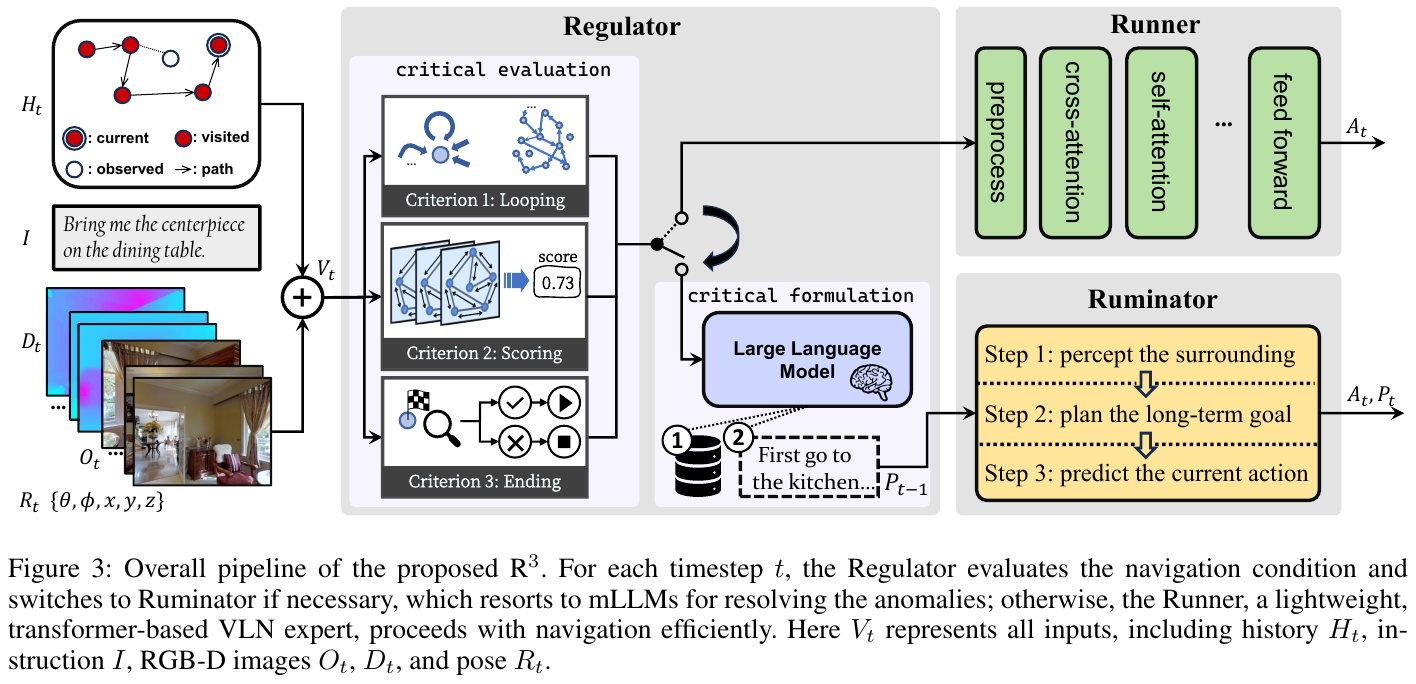
问题形式化:VLN 建模为 POMDP,智能体在时刻 $t$ 观察到位姿 $R_t$ 与全景 $O_t={o_t^i}{i=1}^{36}$(36 个相对 heading/elevation 的透视图),从可导航视点集合中选一个作为动作 $A_t$。策略 $\pi(A_t \mid I, O_t, H_t; \Theta)$ 基于指令 $I$、历史 $H_t={O_0, A_0, …, O{t-1}, A_{t-1}}$ 与当前观察预测动作,直到智能体输出 [STOP] 或超步数上限。
2.3 Runner:轻量 transformer 快速响应
Runner 接收 RGB-D $O_t, D_t$ 与位姿 $R_t$,通过投影提取细粒度特征并写入egocentric grid memory;随后与指令嵌入一起走 cross-modal transformer encoder,最终由两层 FFN 预测动作。Runner 仅 160 M 参数,保证实时推理。其实现直接复用 GridMM 官方仓库。作者指出 Runner 的两类固有缺陷:(1)训练 teacher-forcing 分布有限导致未见场景下容易出现短视决策(aimless wandering / 重复徘徊);(2)BC 学习使其进入错误视点后难以自我纠错——这正是 Ruminator 要补的。
2.4 Ruminator:GPT-4o + CoT 三步慎思
Ruminator 的输入通过一段结构化文本模板拼接(论文 Fig. 4):Instruction + 36 张全景 Observation + Trajectory(”你从 $id_0$ 出发看到 $M_0$;step 1 到 $id_1$ 看到 $M_1$…“)+ Map(视点连通关系)+ Option(候选动作)。这种系统化格式化让 LLM 能显式感知环境拓扑与历史。
Ruminator 以 GPT-4o 为底座,用 CoT 组织三步:
- Perception:根据指令 $I$ 与全景 $O_t$ 生成细粒度环境文字描述,突出指令涉及的对象。
- Planning:结合历史 $H_t$、上一步规划 $P_{t-1}$ 做长视野重规划,生成新 plan $P_t$。历史在 Ruminator 状态下以”taken action + target destination“形式表达——动作从
{go forward to, turn left to, turn right to, turn back to}根据当前朝向与目标视点的夹角生成。 - Prediction:基于 $I, P_t, O’_t$(可导航视点的子集)从候选中选动作。执行后更新 $H_t$ 与相邻视点。
2.5 Regulator:双阶段切换机制
Stage 1 — Critical Evaluation(何时切换) 三条互补准则:
- Looping:当任一视点的重访次数超过 $\tau_r$,或轨迹长度超过 $\tau_l$,判定为陷入循环。
- Scoring:用 GNN(两层 graph attention + edge encoding)给当前轨迹打分,输入是以”位置 / 最后到达时间戳 / 视觉 embedding”为节点特征、视点连通关系为边的拓扑图,未访问节点用邻居视觉嵌入均值近似。训练用自监督伪标签——成功到达或所有视点都属于 GT 路径的 $\mathcal T_t$ 标 0,否则标 1。推理时分数 $>\tau_g=0.35$ 触发切换。
- Ending:Runner 预测
[STOP]时再由 GPT-4o 根据 $I, O_t$ 判断是否真的到达目的地,避免早停。
Stage 2 — Critical Formulation(如何切换) 切换到 Ruminator 前,Regulator 额外用 LLM 判断”从起点重启是否更可取”——这一步重置 memory bank以模拟真实部署;同时在其它触发下也会剔除 Runner 积累的误导历史,再让 Ruminator 重新推理,避免错误上下文污染 LLM。
2.6 共享 Memory Bank
这是效率关键:Runner 的 grid-based topological memory 不仅服务快系统的长上下文决策,在切换时也直接继承给 Ruminator,使 LLM 无需从零重建历史(消融显示 w/o memory bank 时 SR 下降 0.87)。
3. 核心结果/发现
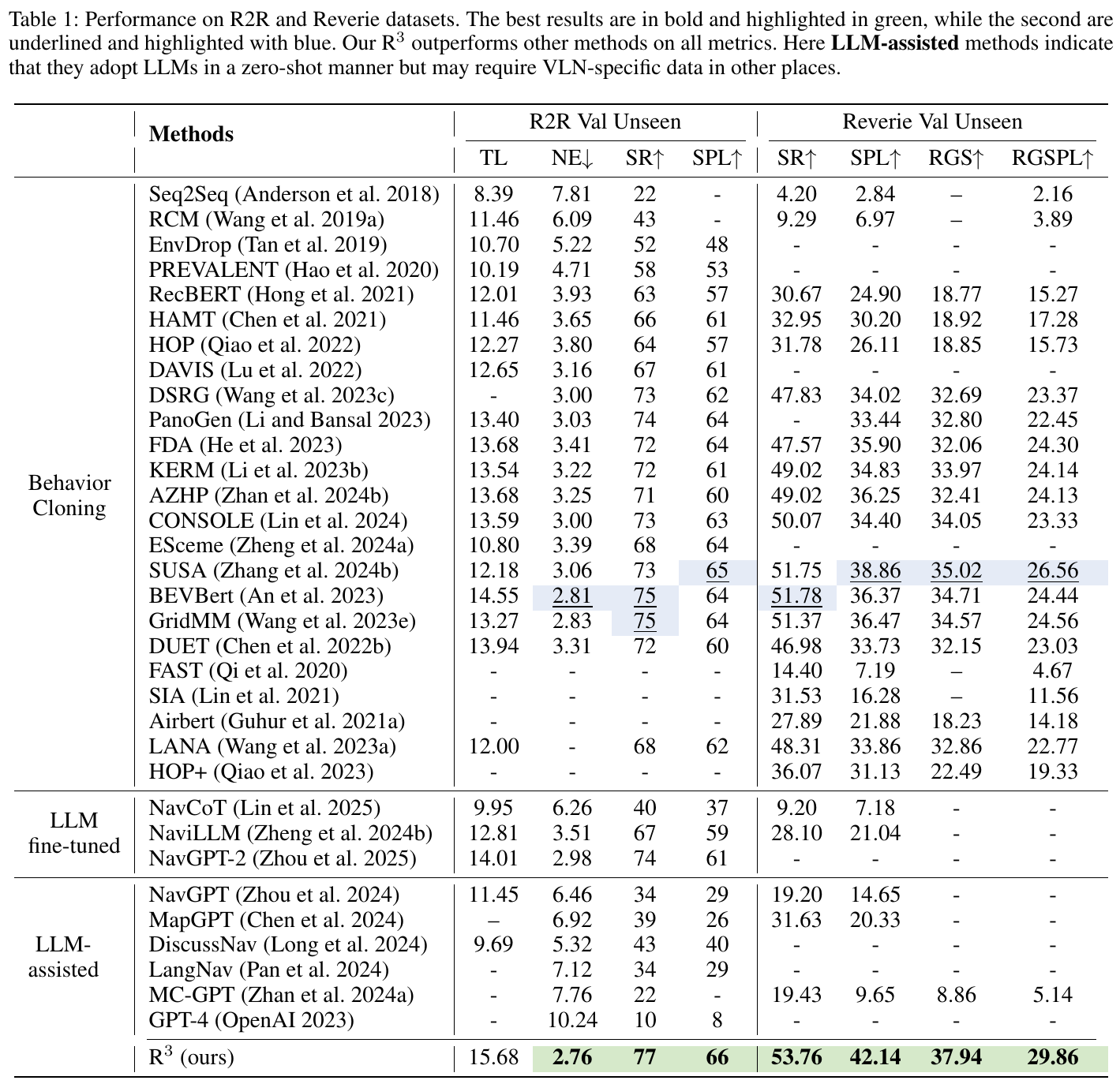
- R2R Val-Unseen:SR 77 / SPL 66,较最佳 BC 基线(GridMM 75 / 64、BEVBert 75 / 64)提升 2 / 1.5 个点;NE 2.76(最低)。
- REVERIE Val-Unseen:SR 53.76 / SPL 42.14 / RGS 37.94 / RGSPL 29.86,较次优方法(SUSA 51.75 / 38.86 / 35.02 / 26.56)分别 +2.01 / +3.28 / +2.92 / +3.30;REVERIE 上提升显著大于 R2R,表明 R³ 对高层语义理解与慎思分析要求更高的”粗粒度”指令更有优势。
- 效率(Fig. 1):R³ 1.10 s/step vs. 其他 LLM-assisted 方法 5~11 s,约 1/5;且 SR 77 远超所有 LLM-assisted 基线(最高 DiscussNav 40)。证明”异常步才调 LLM”的策略可同时获得效率与性能。
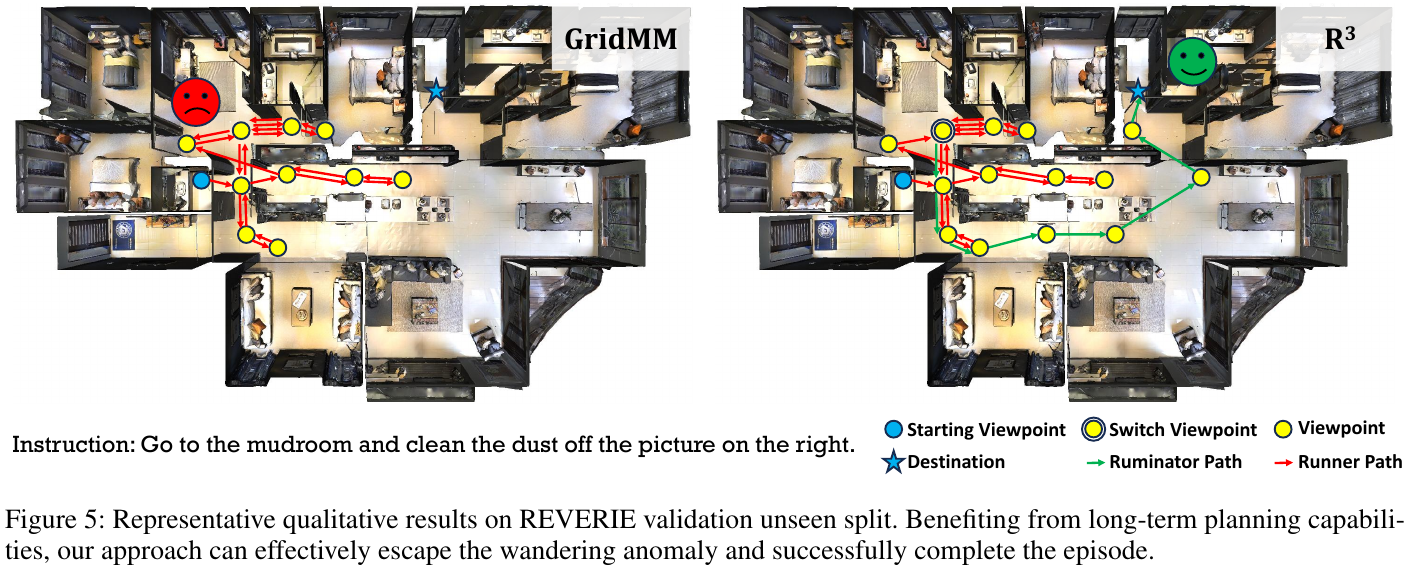
消融要点(Table 2/3,略图):
- Regulator 三准则互补:去掉 Scoring 掉 SR 2.05 / SPL 2.76(最大降幅),说明 GNN 打分是主要的失败早期信号;去掉 Ending 掉 RGS 2.33 / RGSPL 4.01(RGS/RGSPL 最大降幅),对物体定位影响最大;去掉 Looping 与 Critical Formulation 也都有 0.37~0.39 的 SR 下降,全部非冗余。
- LLM 能力 × 性能正相关:GPT-4o > GPT-3.5 Turbo » MiniGPT-4;有趣的是不接 Ruminator(w/o LLM)的 R³ 仍比接 MiniGPT-4 好 1.98 SR,说明能力不足的 LLM 会破坏系统,预示未来更强 LLM 可直接放大 R³ 收益。
- 共享 memory 的必要性:w/o memory bank 时 SR 52.89(-0.87)、RGSPL 28.06(-1.80),说明 Ruminator 真的依赖 Runner 积累的上下文。
4. 局限性
- Ruminator 依赖 GPT-4o API,部署成本与网络延迟仍是瓶颈(Fig. 1 中 NavGPT-2 本地部署效率更好);在真实机器人上需要等价的本地 MLLM。
- 仅在 Matterport3D(R2R / REVERIE)上评测,连续动作空间(R2R-CE、RxR-CE)与真实机器人泛化尚未验证。
- Scoring GNN 的自监督伪标签依赖”GT 路径子集”这一先验,迁移到无明确路径标注的任务(如 ObjectNav)可能需要重新设计。
34. Uncertainty-Aware Gaussian Map for VLN (2026)
———三类感知不确定性 × Semantic Gaussian Map,赋予 VLN 智能体可靠决策能力
📄 Paper: github.com/Gaozzzz/Uncertainty-Aware-VLN
精华
- 将环境表征(3D Gaussian Map)与感知不确定性(几何/语义/外观)统一到同一空间,是比单纯 map-based 方法更稳健的设计范式。
- 几何不确定性用变分推断建模位置/尺度扰动,语义不确定性用语义属性扰动揭示歧义解释,外观不确定性用 Fisher Information 衡量渲染敏感度——三条路径正交互补,可迁移到其他 3DGS 场景表征任务。
- 用”3D Value Map”将不确定性从特征维度编码为可导航的 affordance / constraint,是将感知置信度转化为行动先验的优雅工程。
- 训练时让 SGM 的渲染损失和导航损失联合优化,使场景表征与决策策略协同提升,避免了两阶段分离设计的 representation gap。
- REVERIE RGS 提升 2.94%、R2R SR 提升 2% 的边际增益表明:当前 VLN 瓶颈已从”语言理解”转移到”感知可靠性”,不确定性建模是下一个值得深耕的方向。
1. 研究背景/问题
VLN 要求智能体在 3D 环境中依据自然语言指令导航。现有智能体在推理时普遍忽略感知不确定性(如相似门洞的视觉歧义、遮挡导致的路径可通行性不确定),训练目标迫使模型对每个 step 输出确定动作,无法表达”不确定”。这在遮挡多、结构重复的场景中易造成错误停止或路径偏移。
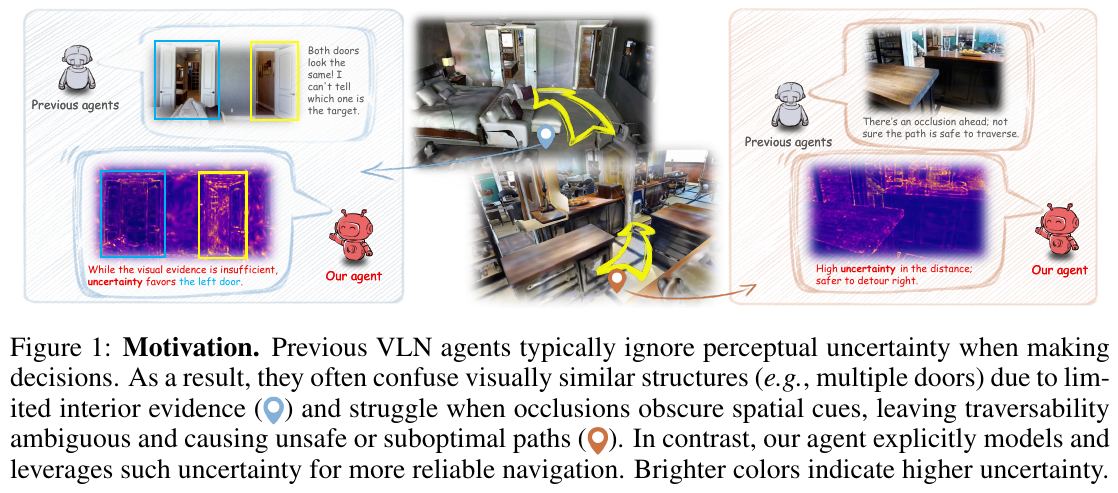
2. 主要方法/创新点
整体框架:SGM 构建 → 不确定性估计 → 3D Value Map → 多层 Transformer 预测动作。
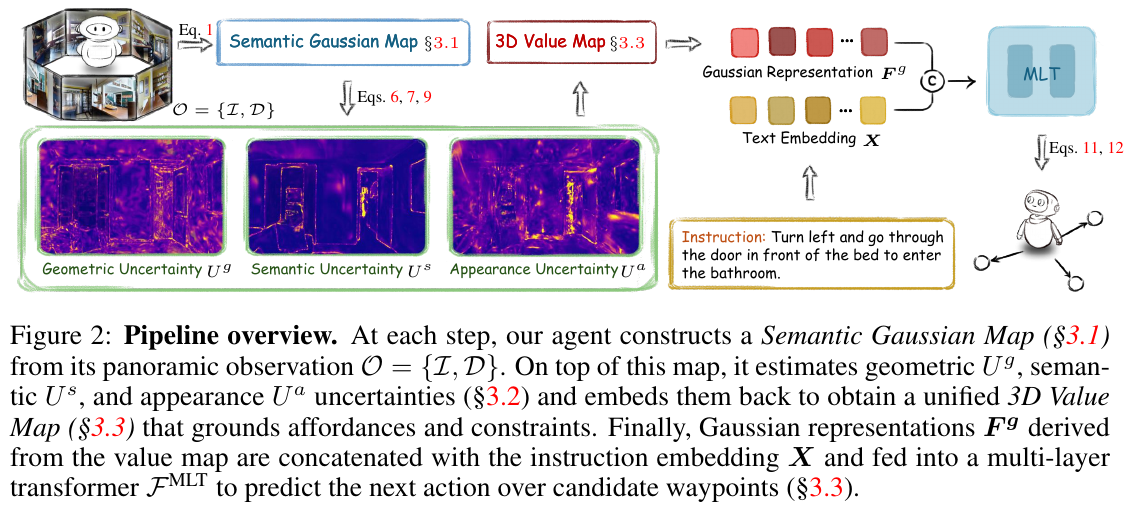
3.1 Semantic Gaussian Map (SGM)
每个导航点处,将多视角 RGB-D 观测反投影为稀疏伪激光点云,每个点初始化为一个可微 3D Gaussian primitive \(g_i\),包含:均值 \(\boldsymbol{\mu}_i \in \mathbb{R}^3\)(位置)、协方差 \(\boldsymbol{\Sigma}_i\)(形状/尺度)、不透明度 \(\alpha_i\)、颜色球谐系数 \(c_i\),以及语义属性 \(s_i\)(由 SAM2 分割区域 + CLIP 特征附加而来)。通过可微渲染优化使 SGM 与当前观测一致,并裁剪低尺度(\(\lVert e_i \rVert_2 < \tau_e\))和低不透明度(\(\alpha_i < \tau_\alpha\))的冗余 Gaussian。
3.2 不确定性估计(三类)
| 类型 | 建模方式 | 含义 |
|---|---|---|
| 几何不确定性 \(U^g\) | 对位置/尺度施加变分扰动,最小化 ELBO,提取变分分布标准差 | 结构可靠性:Gaussian 是否在多种几何假设下保持稳定 |
| 语义不确定性 \(U^s\) | 对语义属性施加可学习偏移,同样 ELBO 优化 | 语义歧义程度:同一区域的语义解释有多不稳定 |
| 外观不确定性 \(U^a\) | 用 Fisher Information(渲染 Jacobian 的 log-determinant)近似 Hessian | 外观敏感性:纹理复杂/遮挡/光照变化是否导致渲染剧变 |
3.3 3D Value Map 与动作预测
将 \((U^g, U^s, U^a)\) 附加到每个 Gaussian 的属性向量,扩展为 \(g_i \in \mathbb{R}^{20}\)。再通过非线性投影得到每个 Gaussian 的特征 \(F^{g_i} \in \mathbb{R}^{768}\),聚合后与语言嵌入 \(X\) 拼接,输入多层 Transformer \(\mathcal{F}^{\text{MLT}}\) 预测候选 waypoint 的导航概率。

3. 核心结果/发现
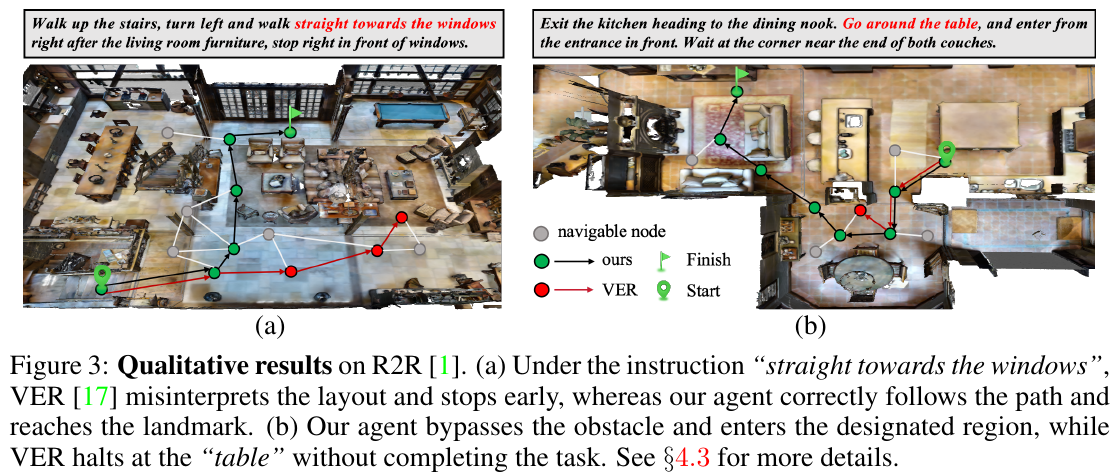
- R2R val unseen:SR 78%(vs VER 76%,+2%),SPL 66%(vs 65%,+1%)
- RxR val unseen:SR 65.2%(vs BEVBert 64.1%,+1.1%),nDTW 65.6%(vs 63.9%,+1.7%)
- REVERIE val unseen:RGS 37.65%(vs BEVBert 34.71%,+2.94%),RGSPL 27.01%(vs 24.44%,+2.57%)——远程目标定位能力显著提升
- 消融:SGM 单独带来结构理解增益(REVERIE RGS 32.15% → 35.48%),不确定性单独将 R2R SR 从 72.22% 提升至 74.20%,两者叠加达到最优 78.32%
- 三类不确定性均有独立贡献,全部使用时最优,几何+语义的提升幅度大于外观
4. 局限性
SGM 构建(尤其是 SAM2 语义抽取与不确定性估计)推理开销较大,训练阶段采用离线预计算缓解,但实时部署仍需轻量化替代(论文建议以轻量 SAM2 变体替换);此外,框架在 Matterport3D 室内场景验证,对室外或动态环境的泛化性未知。
35. GSMem (2026)
———3D Gaussian Splatting 作为具身探索与推理的持久空间记忆
📄 Paper: arXiv:2603.19137
精华
GSMem 的核心洞察是将 3D Gaussian Splatting(3DGS)作为一种具备”事后重新观察”能力(post-hoc re-observability)的持久空间记忆,使 agent 无需物理回访即可从任意最优视点重新渲染已探索区域,从根本上突破了离散检测失败导致记忆永久缺失的固有瓶颈。双层检索机制(对象级场景图 + 语义级 CLIP 语言场)互为补充:场景图提供结构化定位,语言场在检测缺失时兜底召回,两者共同驱动最优视点渲染为 VLM 提供高保真视觉证据。混合探索策略将 VLM 语义相关性与基于 Fisher 信息矩阵迹近似的 3DGS 几何信息增益动态结合,在任务导向探索与全局覆盖之间自适应切换,兼顾效率与鲁棒性。将连续辐射场引入具身导航记忆是一次重要范式转移,其”写入即可重渲染”的特性对长时导航任务尤为关键。
1. 研究背景/问题
具身导航要求 agent 在未知环境中主动探索并持续积累空间知识。现有方法依赖两类表示:离散的 3D 场景图(如 ConceptGraphs)因依赖检测模块,目标漏检将导致不可恢复的记忆空洞;基于视图快照的方法(如 3D-Mem)则因视角固定、稀疏,无法从最优视角重新观察已探索区域,给 VLM 推理提供的视觉证据质量受限。上述方法均缺乏 post-hoc re-observability:agent 被锁定在初始探索时的固定观测中,无法如人类一样”从新角度回忆”过去场景。
2. 主要方法/创新点
整体框架概览
GSMem 在主动探索过程中实时维护三个并行结构:3DGS 几何与外观地图、每个 Gaussian 附带的 CLIP 语言嵌入场、对象级场景图。查询到来时,多层检索-渲染机制定位相关区域并渲染最优视点图像,VLM 据此推理;当没有 frontier 提供足够语义线索时,切换至基于信息增益的几何探索。
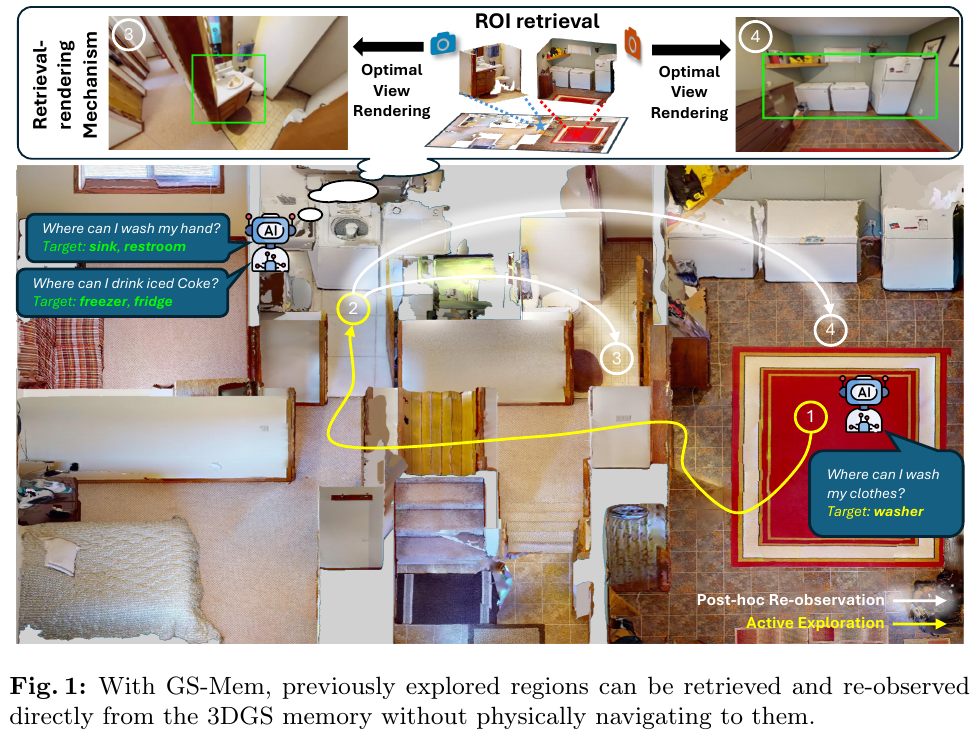
3DGS 建图与在线语言场
每个 3D Gaussian \(g_i\) 额外携带 32 维语言嵌入(由 768 维 CLIP 特征经自编码器压缩得到)。为避免高维语言特征的优化开销,提出”权重一致逆聚合”:forward 渲染中 2D 像素特征由 3D Gaussian alpha-blending 生成,逆向时以完全相同的混合权重将 2D CLIP 特征反向分配给各 Gaussian,实现零优化开销的在线语义更新:
\[\mathbf{f}_i^t = \frac{W_i^{t-1}\mathbf{f}_i^{t-1} + \sum_{k \in \mathcal{T}_t} \sum_p w_{i,p,k}^t \mathbf{f}_{p,k}^{2D}}{W_i^t}\]同时维护对象级场景图(含 3D 位置、语义标签、最高置信度检测视角)、TSDF 地图和 frontier 地图。
多层检索-渲染机制
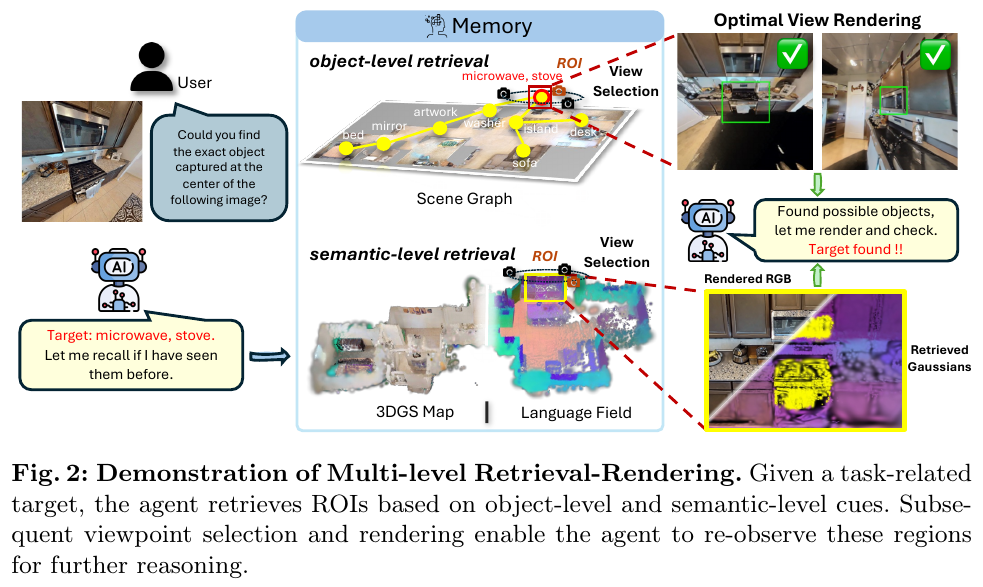
给定任务查询,同时触发两条互补检索路径:
- 对象级检索:VLM 对场景图全部对象按语义相关性排序,选 top-$K_\text{obj}$ 候选作为 ROI
- 语义级检索:将查询编码为 CLIP 嵌入,在语言场中以余弦相似度 $> \tau_\text{clip}$ 召回相关 Gaussian,经 KD-Tree 聚类后保留 top-$K_\text{cluster}$ 个空间连贯群组作为 ROI
对每个 ROI,在水平圆形轨迹上均匀采样 108 个候选视点(36 方位角 × 3 仰角),经两阶段打分筛选:Phase 1 以能见度分 $S_\text{vis}$(TSDF 光线投射)+ 投影面积分 $S_A$(高斯惩罚鼓励适当观察距离)选出 top-10;Phase 2 进一步以 3DGS 不透明度分 $S_\text{opa}$ 评估实际渲染质量,综合分 $S_\text{final} = S_\text{vis} + S_A + S_\text{opa}$ 选出最优视点。最终通过单步扩散模型提升渲染图像质量后送入 VLM 推理。
混合探索策略
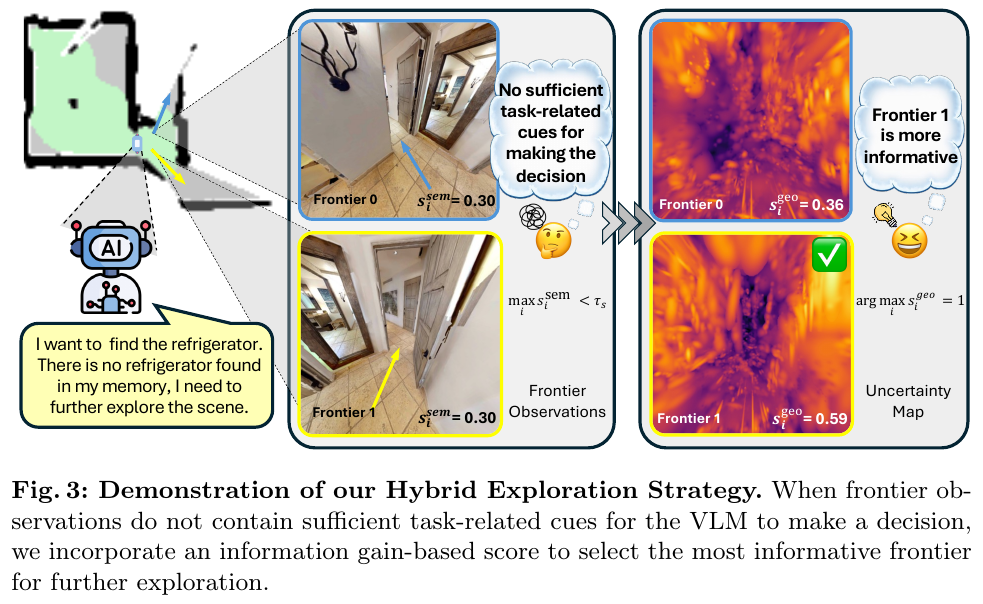
对每个候选 frontier 计算两类分数:
- 语义相关分 $s_i^\text{sem} \in [0,1]$:VLM 评估 frontier 观测图像与任务查询的相关程度
- 几何覆盖分 $s_i^\text{geo}$:基于 Fisher 信息矩阵(FIM)的信息增益,以 T-optimality 代理近似为 FIM 增量的迹 \(s_i^\text{geo} \approx \text{Tr}(\mathbf{I}_i)\),可直接由渲染 Jacobian 计算,无需真值监督
探索决策规则:
\[i^* = \begin{cases} \arg\max_i \, s_i^\text{sem}, & \text{if } \max_i s_i^\text{sem} > \tau_s \\ \arg\max_i \, s_i^\text{geo}, & \text{otherwise} \end{cases}\]3. 核心结果/发现
Active Embodied QA (A-EQA) on OpenEQA(63 个 HM3D 场景,184 问题,GPT-4o 作为 VLM):
| 方法 | LLM-Match ↑ | LLM-Match SPL ↑ |
|---|---|---|
| Explore-EQA | 46.9 | 23.4 |
| ConceptGraphs w/ Frontier | 47.2 | 33.3 |
| 3D-Mem | 52.6 | 42.0 |
| GSMem (Ours) | 55.4 | 43.8 |
GOAT-Bench 多模态长时导航(36 场景 val-unseen,2600+ subtasks):
| 方法 | SR ↑ | SPL ↑ |
|---|---|---|
| TANGO | 32.1 | 16.5 |
| MTU3D | 47.2 | 27.7 |
| 3D-Mem | 62.9 | 44.7 |
| GSMem (Ours) | 67.2 | 46.9 |
GSMem 在长时导航任务中的优势比 A-EQA 更显著(SR +4.3 vs LLM-Match +2.8),验证了持久记忆对长时累积任务的特殊价值。消融研究显示:去除 CLIP 语言场 −4.5 SR、去除最优视点选择 −2.7 SR、去除混合探索时 SPL 下降 −4.1,表明几何覆盖策略对探索效率贡献显著。

4. 局限性
当前系统依赖 RGB-D 输入,深度噪声或高遮挡场景将影响 3DGS 建图质量,进而降低检索与渲染精度;单步扩散增强引入额外推理延迟,实时部署(当前约 1.2 s/step)仍有优化空间。
36. WorldVLN (2025)
———Autoregressive World Action Model for Aerial Vision-Language Navigation
📄 Paper: arXiv:2605.15964
精华
WorldVLN 将航空 VLN 重新定义为”预测驱动的世界-动作”问题:Agent 不直接从观测映射到动作,而是先在隐空间预测世界状态演化,再从预测的隐表示解码出可执行路径点。其核心启发是:空间导航本质上是预期性的,如同人脑预测移动后的状态变化。将视频生成模型的时序先验迁移至导航,并通过 Action-aware GRPO 强化学习直接优化动作后果而非视觉合成质量,这两个设计使 WAM 范式在有限训练步数下超越 VLA 基线 12+ 个百分点。闭环自回归更新(用真实观测替换模型生成的隐状态)解决了长程隐预测的漂移问题。零样本迁移到真实无人机验证了隐式预测架构的潜在泛化能力。
1. 研究背景/问题
现有 VLA 模型将 VLN 视为从指令和观测到动作的条件映射,虽具备语义理解能力,但缺乏对”Agent 自身动作如何改变世界状态”的显式时序因果建模,导致在空间推理和几何精度上存在明显短板。视频生成模型虽拥有强大的时空先验,但其生成目标(视觉真实性)与 VLN 目标(动作导向的状态预测)之间存在结构性错配:大多数视频骨干以双向方式生成整段视频,而 VLN 需要因果性的”观测—行动—更新”闭环;此外,生成模型的隐表示未被优化为可动作解码的形式。
2. 主要方法/创新点
整体框架: WorldVLN 由三大模块构成——(1)潜空间时空自回归 Transformer(世界骨干)负责预测短时域世界状态转变;(2)动作解码器(Action Decoder)将隐状态转变解码为可执行路径点;(3)两阶段训练框架,先通过监督学习对齐视频先验与导航动态,再通过 Action-aware GRPO 强化学习优化动作后果。
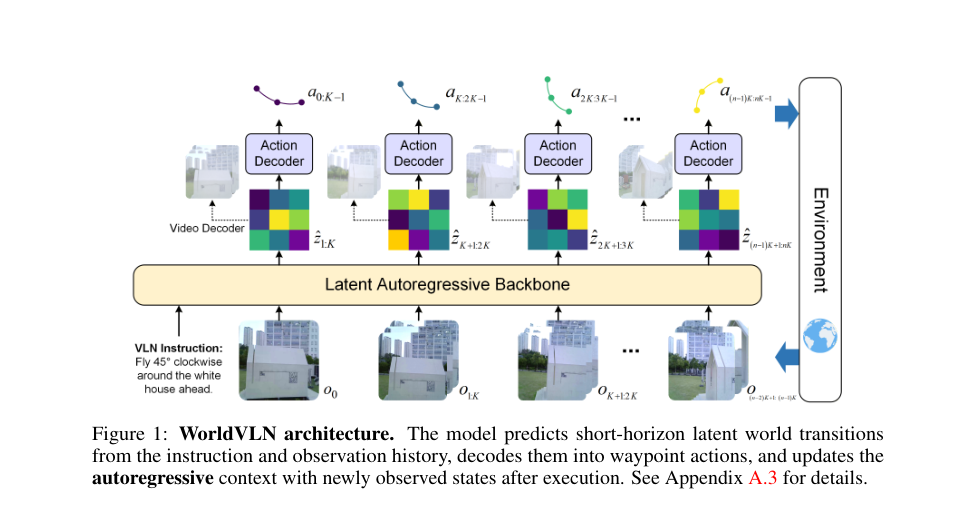
① 世界骨干(Latent Autoregressive Video Transformer)
- 输入:文本编码器输出指令嵌入 $e_\ell = \psi(\ell)$,以及历史真实自中心观测编码后的隐状态序列 $z_{\leq t}$
- 处理:时空自回归 Transformer 按从粗到细的尺度预测多尺度 token 块(先全局低分辨率,再局部高分辨率),并沿时间维度按片段顺序自回归生成
- 输出:短时域隐状态预测 $\hat{z}{t+1:t+K} \sim p\theta(\cdot \mid e_\ell, z_{\leq t})$
- 设计动机:借用视频生成模型的时序先验而非从头学习,同时将生成架构改造为因果自回归以支持闭环
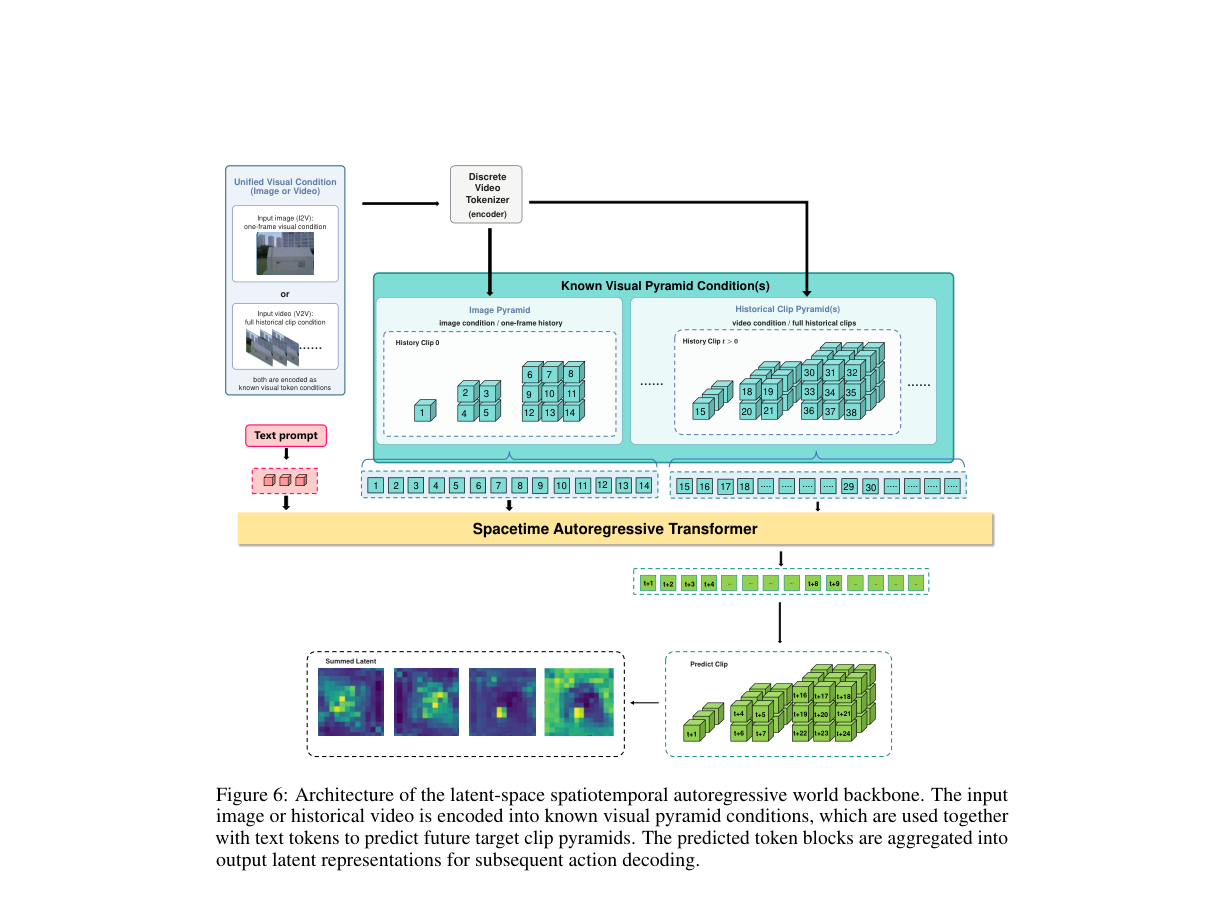
② 动作解码器(Action Decoder)
- 输入:世界骨干输出的未来隐表示 $\hat{z}_{t+1:t+K}$(紧凑时空表示,编码了视角变化、空间结构变化和运动趋势)
- 处理:Vision Embedding 模块将隐表示转换为时空嵌入 token;多层 Transformer Block 采用分解时空注意力——时间注意力捕捉跨帧运动演化,空间注意力建模每帧内的几何结构;MLP 动作头将聚合特征回归到连续动作向量
- 输出:连续路径点动作 $a_{t:t+K-1} = D_\phi(\hat{z}_{t+1:t+K})$,对应 UAV 的相对 3D 位移和偏航角变化
- 设计动机:避免将隐状态解码为视频帧再估计运动(有误差累积),直接从隐表示推理动作更简洁高效
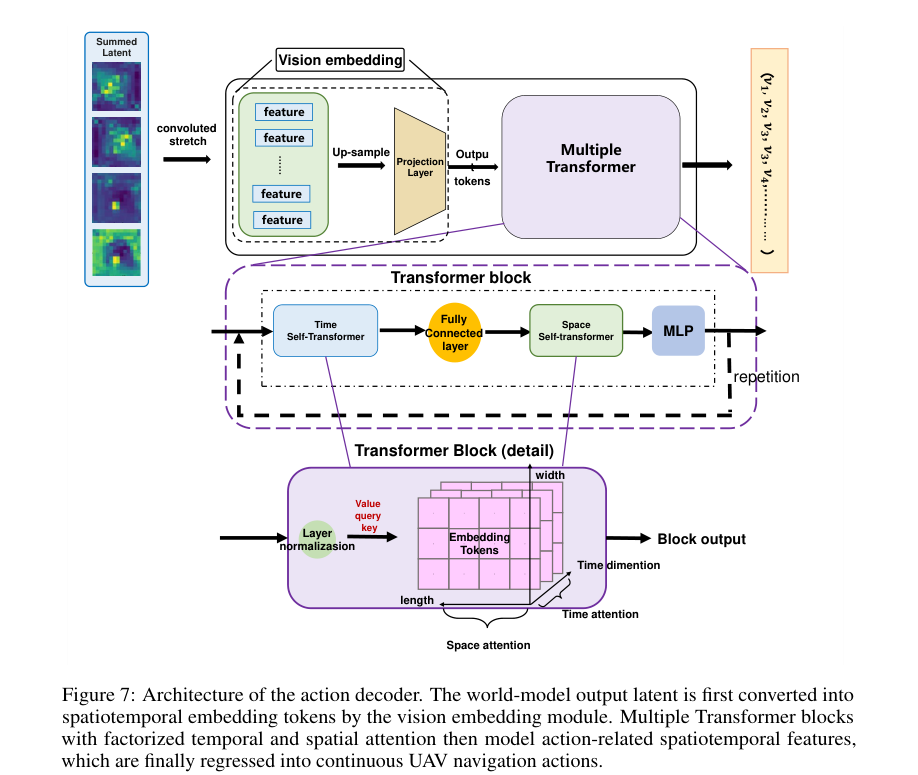
③ 闭环自回归更新
完整推理循环为: \((e_\ell, z_0) \to \hat{z}_{1:K} \to a_{0:K-1} \to o_{1:K} \to z_{1:K} \to \hat{z}_{K+1:2K} \to \cdots\) 关键在于执行动作后,将真实观测重新编码 $z_{t+1:t+K} = E_\text{vid}(o_{t+1:t+K})$ 替换模型预测的隐状态,防止隐预测漂移积累。
④ 两阶段训练框架
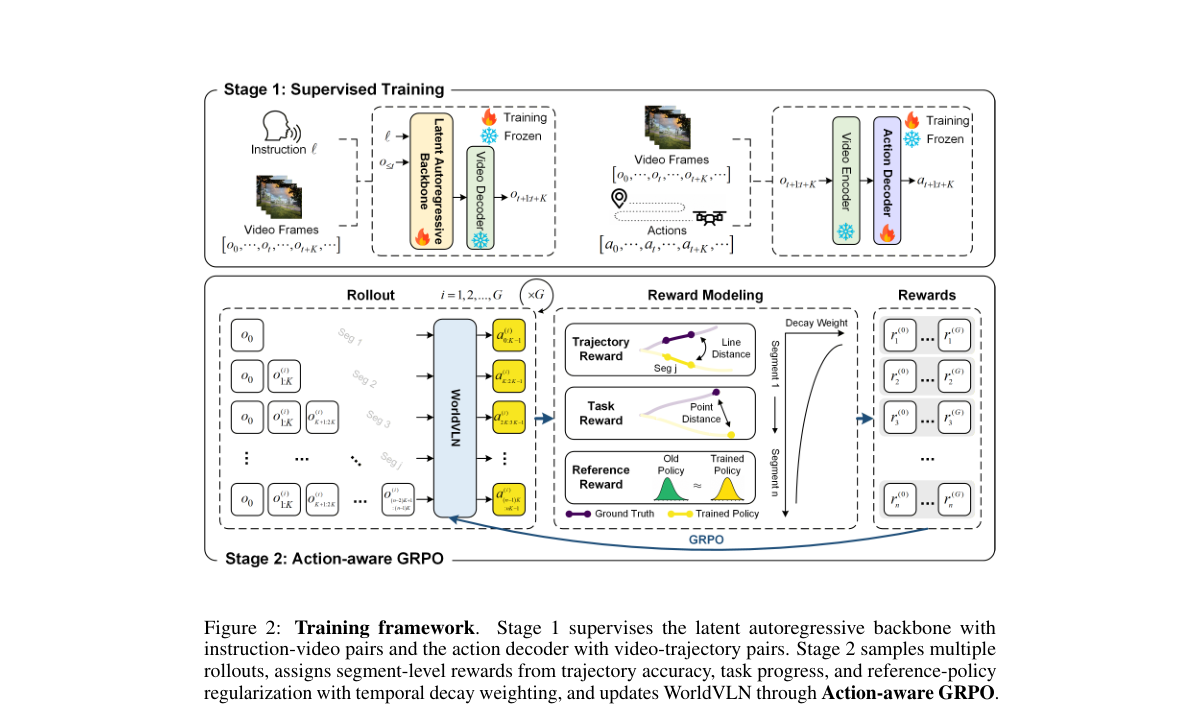
Stage 1 — 监督训练(世界先验对齐)
世界骨干目标: \(\mathcal L_\text{wm} = -\sum \log p_\theta(z_{t+1:t+K} \mid e_\ell, z_{\leq t})\)
动作解码器目标(通过视频-动作教师模型蒸馏初始化): \(\mathcal L_\text{act} = \sum \lVert D_\phi(E_\text{vid}(o_{t+1:t+K})) - a^*_{t:t+K-1} \rVert\)
Stage 2 — Action-aware GRPO(动作后果对齐)
对每条导航案例采样 $G$ 条在线轨迹,每条包含 $n$ 个自回归决策段,对第 $j$ 段分配奖励:
\[r^{(i)}_j = \gamma^{j-1}\left(\lambda_\text{traj} r^{(i)}_{\text{traj},j} + \lambda_\text{task} r^{(i)}_{\text{task},j} + \lambda_\text{ref} r^{(i)}_{\text{ref},j}\right)\]- 轨迹奖励 $r_\text{traj}$:局部几何监督,衡量预测动作与专家动作的接近程度
- 任务奖励 $r_\text{task}$:全局终点评估,衡量轨迹终点与目标的距离
- 参考奖励 $r_\text{ref}$:KL 正则化,保持更新策略与参考策略(Stage 1 产物)的一致性,防止世界先验退化
- 时序衰减 $\gamma^{j-1}$($\gamma=0.9$):早期决策权重更大,因其影响后续更长的动作链
优势归一化后以 GRPO 截断目标更新策略。
3. 核心结果/发现
UAV-Flow-Sim(室外):WorldVLN 达到 79.12% / 78.02% 平均 SR(固定/开放语言模板),分别比最强基线提升 13.51 / 12.24 个百分点。在 Approach(97.62%)、Land(98.15%)、Move(100%)等精细动作上表现尤为突出。
IndoorUAV-VLA(室内):Full-set SR 达 41.76%,比最强基线(π0,27.16%)提升 14.60 个百分点;Hard 难度下 SR 从 7.55% 提升至 41.19%,显示对复杂多步动作组合的强适应能力。
消融分析:
- 与 OpenVLA 对比:相同步数下,Stage 1 后的 WorldVLN 已超越 OpenVLA-SFT,表明 WAM 范式学习效率更高
- 自回归 vs 全序列预测:自回归提升 SR 5.7+ 个百分点,隐预测可视化显示全序列预测存在语义漂移,而自回归因持续融合真实观测保持了连贯的视觉空间表示
- Action-aware GRPO:在 Stage 1 接近饱和后额外提升 10+ 个百分点,轨迹可视化显示 RL 后模型能正确执行”环绕”等几何精确动作
零样本真实机器部署:在仅用仿真数据训练的情况下,WorldVLN 在 250 mm 轴距四旋翼无人机上实现室内和室外的语言指令跟随,机载 Jetson Orin NX + 远程服务器推理架构验证了实际可部署性。
4. 局限性
当前实验主要针对短程低时域导航,长距离多阶段 VLN 尚未充分验证;受骨干计算量限制,真实部署仍依赖服务器端推理,无法完全机载运行。
37. AwareVLN (2026)
———Reasoning with Self-awareness for Vision-Language Navigation
📄 Paper: arXiv:2605.22816 · Project Page · 🏛️ CVPR 2026
精华
- 现有 VLM-based VLN 方法把 VLM 当成”指令→动作”的端到端映射器,浪费了 VLM 本身的推理能力,导致导航过程不可解释、缺乏纠错能力。
- AwareVLN 的核心思想是自我感知(self-awareness)推理:让 agent 在导航中显式分析”自己当前在哪、任务完成到哪、是否偏离了指令”,而不仅仅预测下一步动作。
- 关键设计是稀疏触发的结构化推理——用一个 special token(
[REASON]/[ACT])让模型自主决定”何时该想一想”,只在子任务边界、路径偏离、停止误差这些关键节点触发推理,兼顾效率与有效性。 - 推理采用固定的三元结构:场景描述 → 进度评估 → 下一步规划,并把上一次推理结果回灌给模型,形成因果链式的自我对话。
- 配套一个全自动数据引擎:利用模拟器的房间级语义 + ground-truth 路点自动定位关键推理节点,再用通用 VLM(Qwen-VL-Max)生成结构化推理监督,无需人工标注即可规模化造数据。
1. 研究背景/问题
VLN(Vision-Language Navigation)要求 agent 在未知环境中跟随自然语言指令导航。传统方法依赖显式拓扑图 + SLAM/3D 传感器做规划,部署受限;近期端到端 VLM-based 方法(NaVid、NaVILA、StreamVLN 等)直接把指令和 RGB 观测映射为动作,摆脱了对深度/位姿的依赖。但这些方法只”驯化 VLM 去预测动作”,忽视了 VLM 的内在推理能力,导致导航过程像黑盒、缺乏自我感知,难以做精确的子任务规划和错误纠正。已有的 Nav-R1 虽尝试以固定间隔的双系统机制做推理,但其监督数据来自通用 VLM 对历史观测的泛化查询,缺乏真正的自我感知知识,推理只是文本输出而无法指导后续动作。核心问题是:如何根据观测历史准确推理 agent 当前状态与任务进度,并让推理真正服务于行动?
2. 主要方法/创新点
AwareVLN 在一个统一的 VLM 中同时承担动作预测与自反思推理。相比用两个独立模型,统一架构让”推理”和”行动”两个维度的知识在模型内部相互交互、彼此增强。
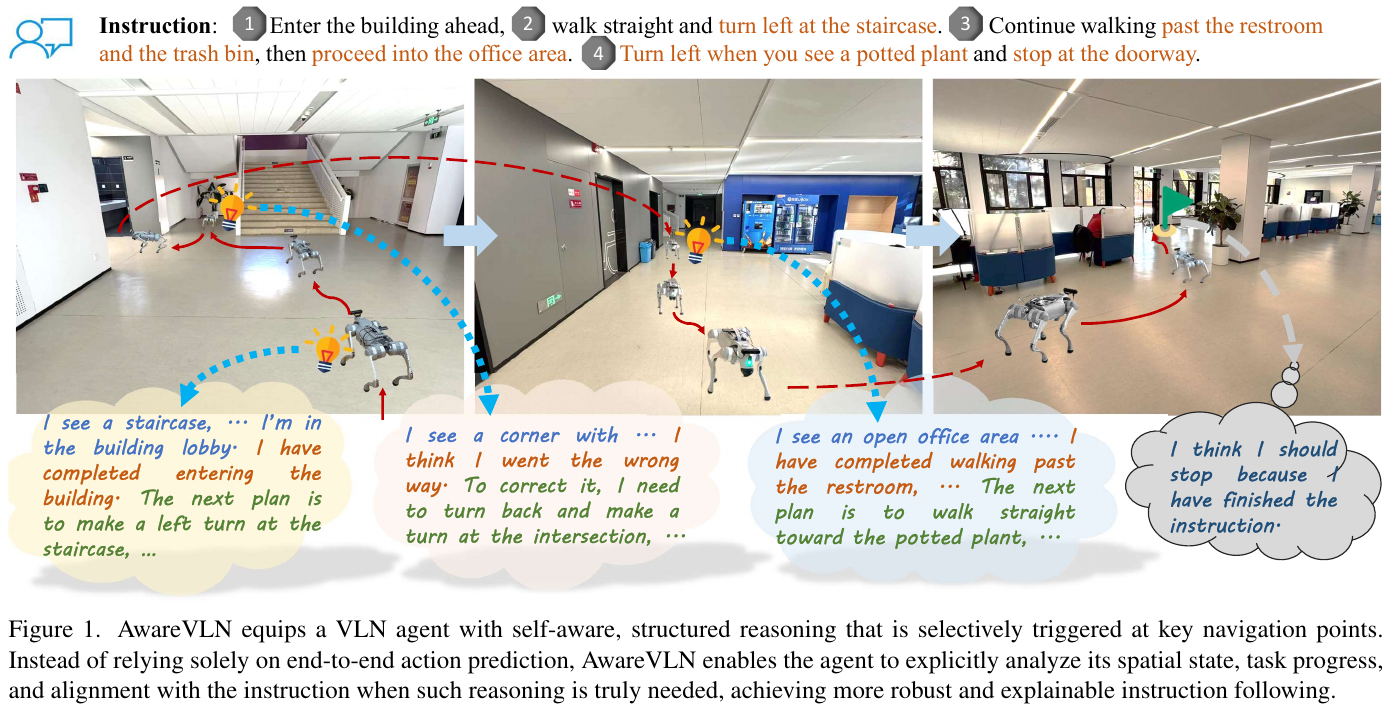
① 整体框架概述
AwareVLN 由三大部分构成:(a) 统一的 Reason-Act 框架(一个 VLM 同时输出动作和推理)、(b) 结构化的三元推理格式(场景描述 / 进度评估 / 下一步规划)、以及 (c) 稀疏触发机制(由 special token 在关键节点决定是否推理)。视觉观测经 Vision Encoder & Projector 编码,与指令、上一次推理文本一起送入 LLM,模型先输出一个 special token 决定进入”行动模式”还是”推理模式”,再生成相应的文本。
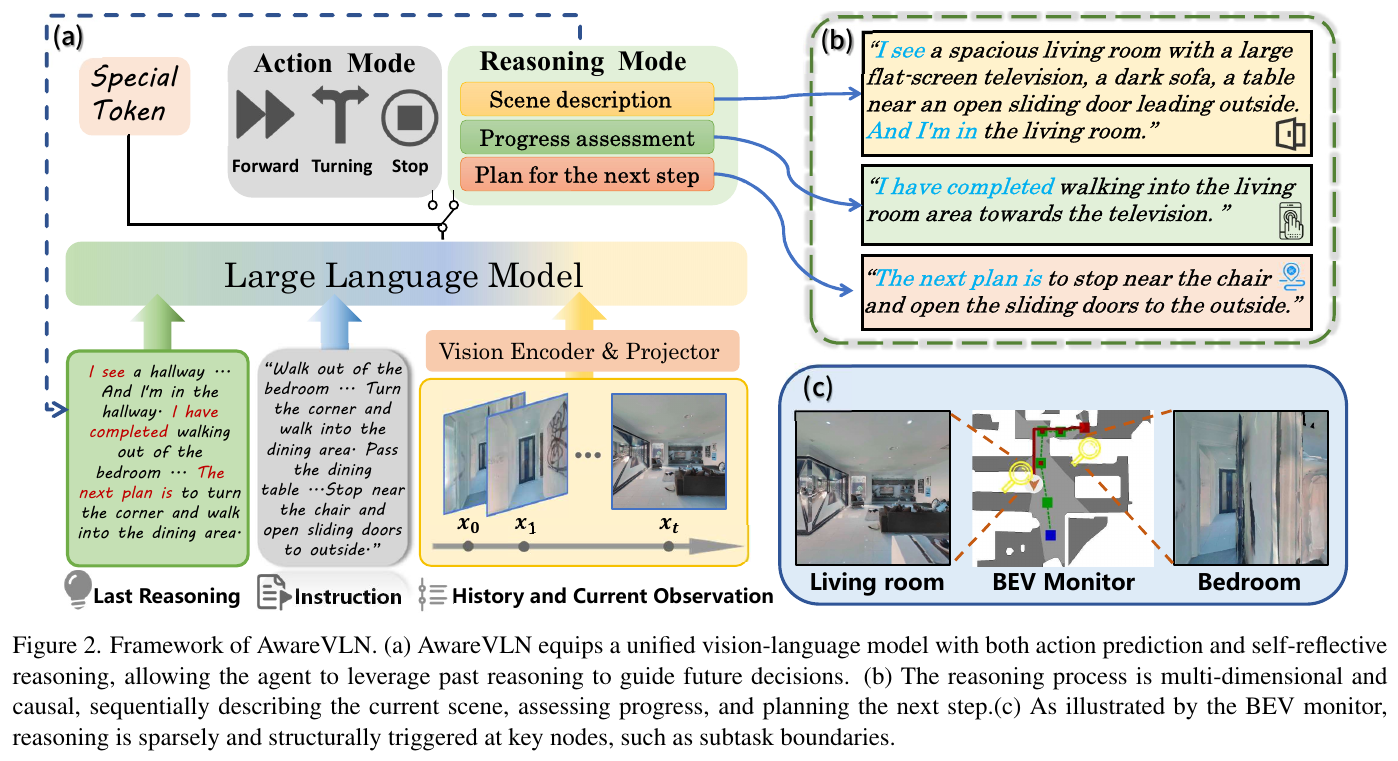
② 逐模块讲解
统一 Reason-Act 框架(Unified Reason-act Framework)
- 输入:导航指令 $I={w_1,\dots,w_l}$、视觉观测序列 $O_t={x_0,\dots,x_t}$(为效率均匀采样 8 帧),以及最近一次推理输出 $R$。
- 处理:tokenizer $f_{tok}(\cdot)$ 把指令和上次推理转成 token,vision encoder $f_{vis}(\cdot)$ 提取视觉嵌入。一个关键细节是把”当前帧与上次推理帧之间的步数差”作为相对位置线索编码进去,与推理文本融合以提供显式的时间上下文:
其中 $t_{prev}$ 是上一次推理输出的时间步。统一策略 $\pi_\theta$ 基于该上下文产生一个 logit $d$(决定 special token)和文本输出 $y_t$:
\[d, y_t = \pi_\theta\big(f_{tok}(I), f_{tok}(R'), f_{vis}(O_t)\big)\]special token 的选择规则为:当 $d_{[\text{REASON}]} > d_{[\text{ACT}]}$ 时取 [REASON],否则取 [ACT]。
- 输出:若为
[REASON],模型进入推理模式,产生总结自身理解与进度的文本,并更新 $R$、记录 $t_{prev}$;若为[ACT],进入行动模式,生成动作命令(如”move forward 75 cm”),经 PARSE 解析为底层离散动作 $a_{t+1:t+k}$(动作集 $A={$FORWARD, TURN-LEFT, TURN-RIGHT, STOP$}$)执行。 - 设计动机:这种”语言驱动”的统一形式让感知、推理、控制无缝衔接;通过递归地以上一次推理和相对步数为条件,模型在长程导航中保持时间感知与自适应决策。
结构化自我感知推理(Structural Reasoning for Self-awareness)
- 触发时机(关键节点):不在每一步都推理,而只在三类关键状态触发——(i) 子任务完成:检测到某条子指令(如”走到门口”)已完成时,总结进度、确认子目标、规划下一步;(ii) 路径偏离:发现期望与观测的视觉线索不一致(地标缺失、空间错位)时,进入推理分析错误并提出纠正动作;(iii) 停止误差:导航末段当前视觉上下文与目标描述不符时,触发推理分析偏差、调整后续计划以精确定位终点。
- 三元推理格式:每次推理强制产出三个组件——(1) Scene description(对关键节点视觉上下文的简洁描述)、(2) Progress assessment(分析指令完成到哪、是否偏离)、(3) Plan for the next step(下一阶段的高层意图/策略)。这套结构在统一语言空间里把感知、推理、规划连成一体,为模型提供显式的自我感知。
③ 自动数据引擎(Automatic Data Engine)
为规模化获得高质量推理监督且不依赖人工标注,AwareVLN 设计了一个全自动数据引擎。
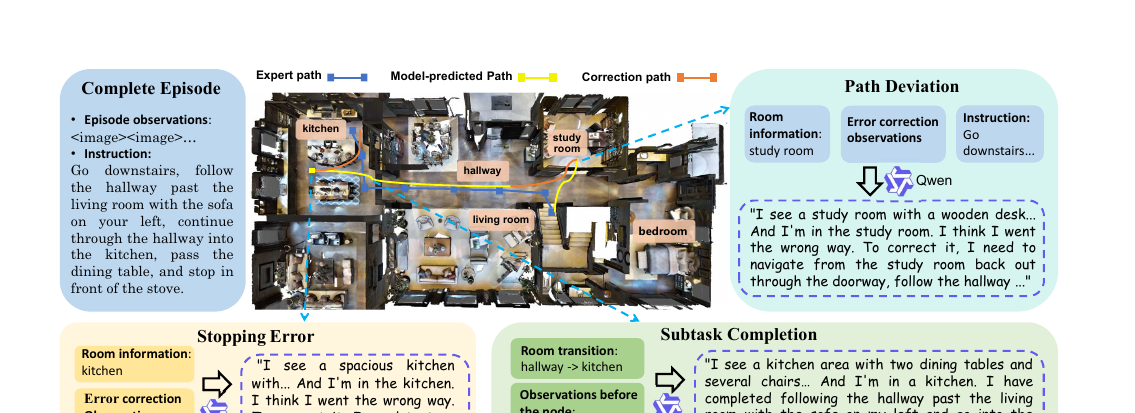
- 轨迹采集:两种互补策略。其一是 ground-truth following(严格跟随参考轨迹,得到指令对齐的”正确推理”样本);其二是 DAgger-based collection(用早期模型执行预测动作,一旦偏离 ground-truth 就纠正回下一个路点,产生含真实预测错误与纠正行为的轨迹,对训练”错误识别与恢复”推理尤为宝贵)。
- 关键节点识别:利用模拟器场景语义 + 数据集标注路点自动定位。子任务完成通过轨迹上房间类别的变化判定(并把纠正过程的完成也当作子任务边界);路径偏离/停止误差通过计算执行轨迹与 ground-truth 路点的空间偏差,超过阈值即标记为偏离节点并记录后续纠正观测。
- 推理监督生成:用通用 VLM(Qwen-VL-Max)以多轮对话流水线把上下文转成结构化推理。第一轮输入完整 episode 观测序列 + 指令,让 VLM 建立全局理解;后续每个关键节点再输入节点类型、节点前的降采样观测、房间转移信息、估计的导航进度(已行进距离/总路径长度);对偏离节点额外提供纠正过程观测,使 VLM 能推断”错误—恢复”的因果关系。最终为每个节点生成上述三元结构的推理文本。
④ 训练与推理
- 训练:分两阶段。预训练遵循 NaVILA,纳入常规导航数据 + 大规模 VQA 数据;微调使用数据引擎产出的”推理增强导航轨迹”,并混入无推理监督的人类视频以提升泛化。这使模型在获得自我感知推理能力的同时保留强视觉对齐与语言对齐。训练在 4 节点 NVIDIA H20 GPU 上完成。
- 推理:见 Algorithm 1——循环中先融合相对步数与上次推理 $R’ = R \oplus (t-t_{prev})$,再由 $\pi_\theta$ 输出首个 logit 与文本;据 special token 决定更新推理(
[REASON])还是解析并执行动作([ACT]),然后追加新帧。单卡 NVIDIA RTX 4090 上推理速度约 1 FPS。
3. 核心结果/发现
- 仿真主结果(R2R-CE / RxR-CE Val-Unseen,纯单目 RGB 输入):AwareVLN 在 R2R-CE 上 SR 65.4、SPL 55.1、OS 73.5、NE 4.02;RxR-CE 上 SR 67.6、SPL 56.1、nDTW 65.7,全面超越所有不依赖模拟器预训练 waypoint predictor 的方法(包括 NaVILA、StreamVLN、Uni-NaVid、OctoNav 等),甚至优于很多使用深度、全景、里程计等额外输入的方法。例如相比 StreamVLN,R2R-CE SR 从 56.9 提升到 65.4,OS 从 64.2 提升到 73.5。
- 真实世界评测:在 Corridor / Home / Office 三类环境、简单与复杂任务共 18 条指令上,AwareVLN 的 NE 和 SR 一致优于 NaVid、NaVILA,复杂任务下优势尤为明显(多个复杂场景 SR 从 0.33 提升到 0.67–1.00),验证了自我感知推理对 sim-to-real 泛化的增益。
- 消融——数据引擎关键节点(Table 3):去掉任一节点都会掉点;去掉 Subtask Completion 掉点最严重(R2R SR 65.4→52.3),因为模型失去对整体指令进度的跟踪;去掉 Path Deviation 削弱纠错能力,去掉 Stopping Error 影响终点判定。
- 消融——架构与推理调度(Table 4):去掉 special token 强迫模型直接预测会掉点(结构化输出对任务分解很关键);”每帧都密集推理 + 动作”(Reason with action densely)反而明显变差,证明稀疏推理既更有效又更高效(昂贵的推理只在必要时触发)。
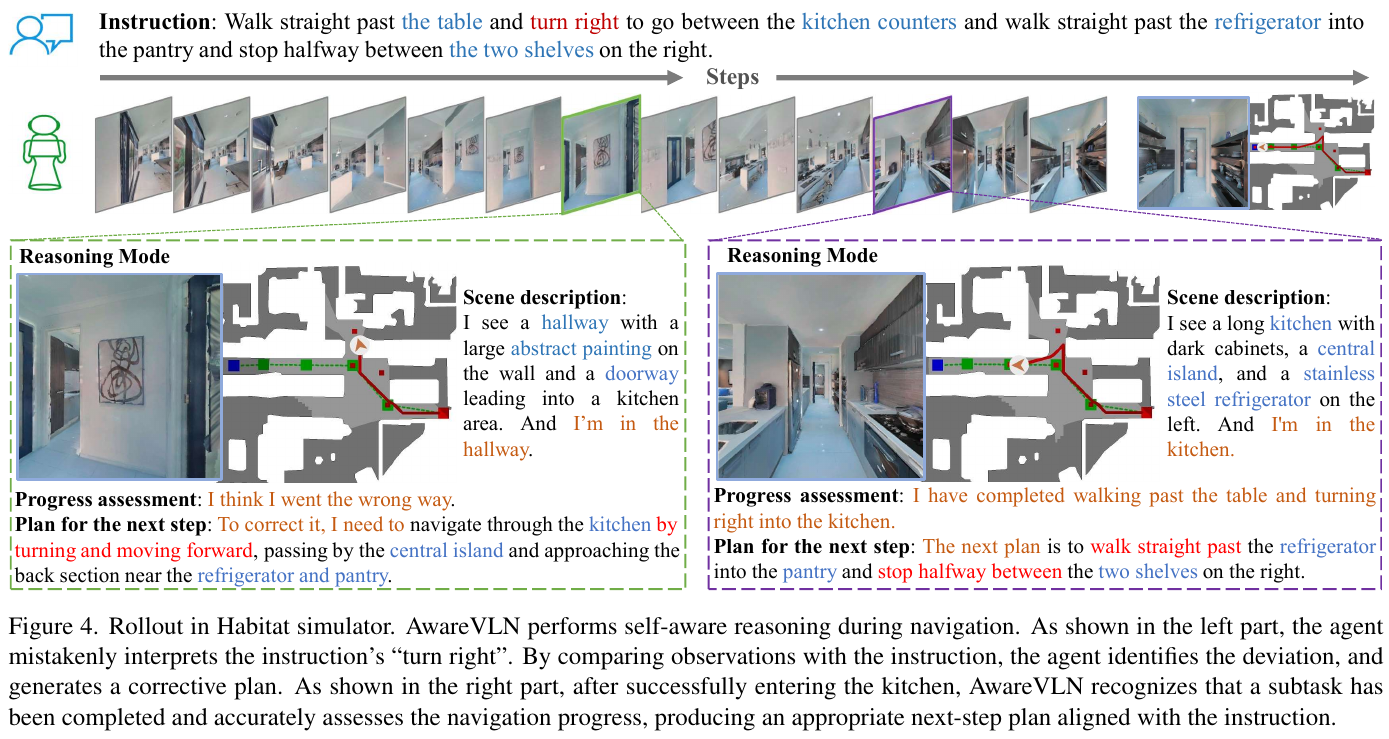
4. 局限性
推理监督的质量受限于通用 VLM(Qwen-VL-Max)和模拟器语义/路点标注的准确性;关键节点的检测依赖房间级语义与阈值规则,迁移到无此类标注的开放环境时数据引擎的可用性有待验证。此外约 1 FPS 的推理速度对高动态实时场景仍有压力。
38. Dual-Anchoring (2026)
———用”指令进度”与”地标记忆”双重锚定,对抗 VLN 中的状态漂移(State Drift)
📄 Paper: arXiv:2604.17473v2
精华
- 提出 State Drift(状态漂移) 概念:基于 Video-LLM 的 VLN agent 在长程任务中,内部状态会逐渐脱离真实任务状态,表现为进度漂移(Progress Drift,搞不清走到指令哪一步)和记忆漂移(Memory Drift,忘记已经过的地标)。
- 核心洞见:纯 next-action prediction 是”结果导向”的弱监督,只保证局部动作正确,却不约束内部认知过程,长程下必然与物理现实解耦。解法是给内部状态加显式锚点。
- 双锚定框架两条互补支路:① 指令进度锚定——让 agent 在动作前先用结构化文本写出”已完成 vs 未完成”的子目标清单(语义稳定器);② 记忆地标锚定——用 Landmark-Centric World Model 回溯重建最近经过地标的 SAM 特征(视觉”后视镜”)。
- 方法论启发:用”语言化心智清单”显式表征任务进度,用”回溯式(hindsight)而非前瞻式(foresight)世界模型”锚定历史记忆——两者都是给隐状态加可监督的显式约束,且推理时可丢弃辅助头,零额外开销。
- 配套构建两个大规模数据集(360 万进度描述 + 93.7 万地标 SAM 特征),在 R2R-CE / RxR-CE 上达到 SOTA,长程轨迹 SPL 相对提升高达 +33.2%。
1. 研究背景/问题
VLN 要求 agent 在未见 3D 环境中按自然语言指令导航。主流 perception-to-action 流水线对短指令有效,但在长、组合性指令下脆弱:随导航推进,agent 的任务状态逐渐不可靠,丧失对”我在指令的哪一步”和”我去过哪里”的一致感知,即 State Drift。近期 Video-LLM 虽借助强预训练表征推进了 VLN,但其 next-action prediction 目标只约束局部动作、不约束内部状态,长程下内部表征不可避免地与物理现实解耦。作者将其归因为两种耦合的失败模式:Progress Drift(指令阶段误判,已完成/未完成边界模糊)与 Memory Drift(历史表征退化,丢失已访问地标)。
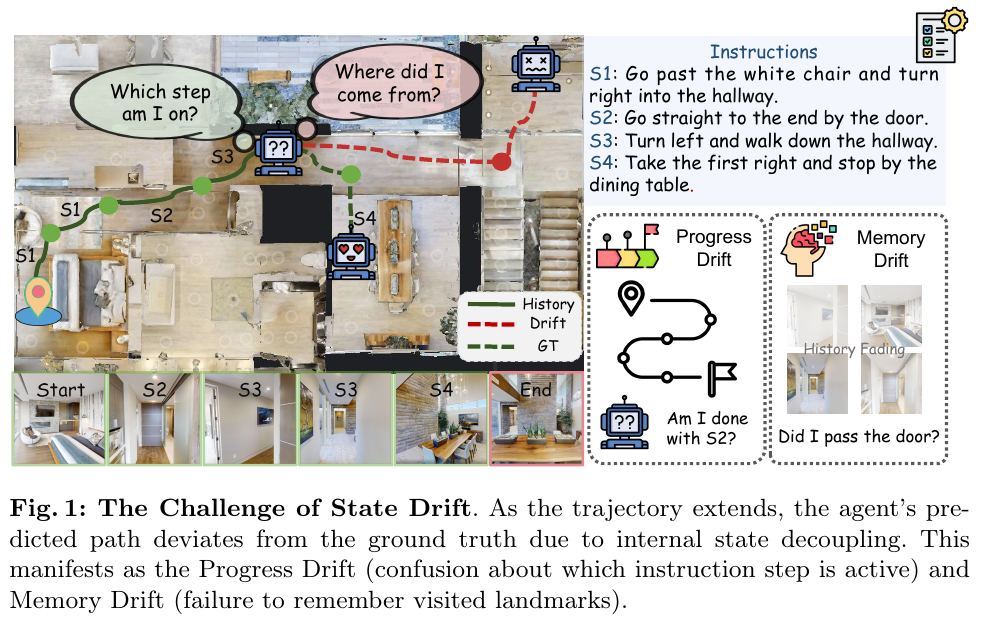
2. 主要方法/创新点
① 整体框架概述
Dual-Anchoring Framework 以 StreamVLN(LLaVA-Video 为骨干的流式 Video-LLM)为 backbone,在标准动作预测之外,叠加两个仅训练期生效的辅助任务来正则化内部状态:Instruction Progress Anchoring(指令进度锚定,作为 Co-Training 任务) 负责语义对齐,Memory Landmark Anchoring(记忆地标锚定,作为辅助头) 负责视觉记忆锚定。两个辅助头在部署时被丢弃,对推理零额外计算开销。
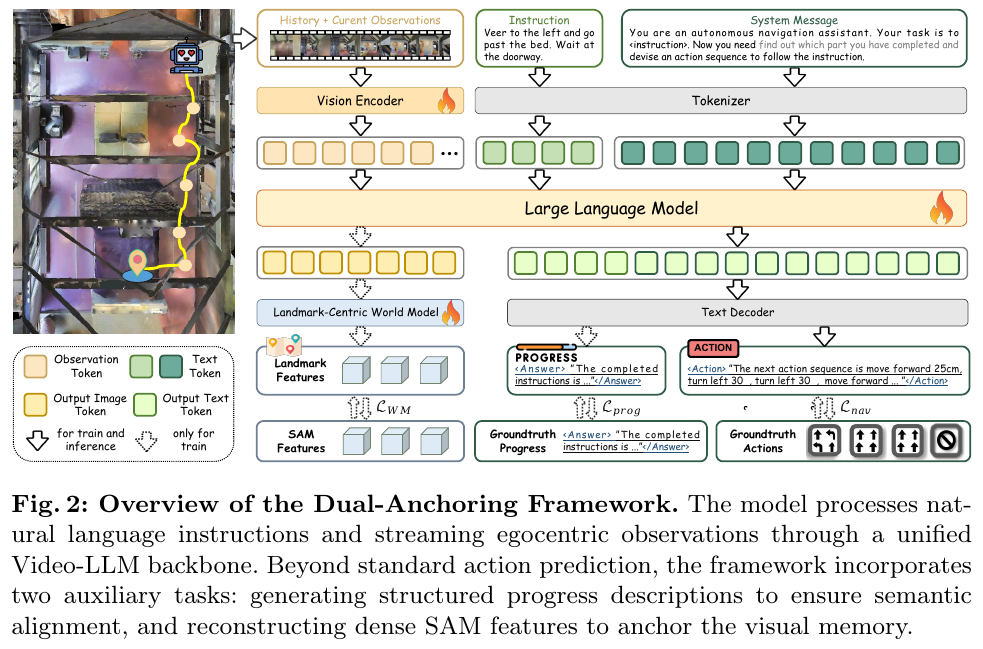
② 逐模块讲解
模块一:Instruction Progress Anchoring(指令进度锚定)
- 目标:缓解 Progress Drift,让 agent 显式维护一份”已完成 vs 待完成”的心智清单(mental checklist),而非依赖隐式 attention 推断进度。
- 数据生成(Progress Annotation Generation):用 Qwen3-VL 作离线标注器,给定 GT 轨迹与指令,按四步流水线合成 360 万条进度描述:
- Visual Kinematics Prompting:把帧序号与已执行动作文本(如 “Turn Left 15°”)叠印到每帧左上角,弥合静态帧与动态导航的鸿沟,让标注器感知帧间运动学。
- Interval Sampling:以步长 n 沿轨迹间隔采样。
- Dual-Step Reasoning:先让模型对比视觉证据与指令做分析(CoT),再用原文措辞总结”已完成子目标”。
- Instruction-Aligned Refinement:把分析蒸馏成一句话,严格约束输出为指令的逐字前缀(verbatim prefix),消除中间推理与幻觉。
- 输入 → 处理 → 输出:输入指令 + 历史观测 → 模型先输出结构化进度文本,再输出动作序列。
- 训练(Instruction-Aware Co-training):把 GT 动作前缀以合成的进度描述,并在 Prompt 中加入”find out which part you have completed”。目标改为最大化 \(P(y^{prog}_t, a_t \mid \mathcal I, \mathcal H_t)\),强制 agent 在执行任何控制前先用语言articulate自身状态。
模块二:Memory Landmark Anchoring(记忆地标锚定)
- 目标:缓解 Memory Drift(遗忘地标、感知混淆 perceptual aliasing),强制 Retrospective Grounding(回溯式接地)。
- 数据生成(Landmark Frame Mining):两阶段挖掘 93.7 万条地标数据:
- Decomposition:用 Qwen3 把复杂指令拆成原子子目标 \(\mathcal S = \{s_1, \dots, s_K\}\),每个 \(s_k\) 含一个动作或地标。
- Temporal Grounding:把完整视频 + \(\mathcal S\) 喂给 Qwen3-VL,定位每个地标首次出现的帧 \(t^{(k)}_{lm}\);并施加严格递增约束(\(t^{(i)}_{lm} < t^{(j)}_{lm}\) 对 \(i<j\)),违反时序逻辑的标注被过滤以消除幻觉。
- 对任意导航时刻 \(t\),可检索最近经过的地标帧 \(t^*\)(\(t^* \le t\)),用 SAM 抽取其高分辨率空间特征图 \(F_{SAM}(o_{t^*})\) 作为回溯监督的 ground truth。
- Landmark-Centric World Model(回溯式世界模型):用 Learnable Spatial Query Decoder 让 agent 重建最近经过地标的稠密空间特征。
- 输入:Video-LLM 在第 \(t\) 步的输出序列 \(X_t \in \mathbb R^{N \times d_{llm}}\)(含历史与当前视觉语义)。
- 处理:先经线性层 + LayerNorm 投影到紧凑潜空间 \(\hat X_t = \text{LayerNorm}(X_t W_{in})\);初始化一组可学习空间查询 \(Q_{spa}\)(每个 query 是对应 \(H\times W\) 分辨率的像素级锚点),通过 cross-attention 从 \(\hat X_t\) 检索局部空间线索:\(Z = \text{Softmax}(Q_{spa}\hat X_t^T / \sqrt{d_{attn}})\hat X_t\);再线性投影到 \(d_{sam}\) 维并 reshape 成 2D 特征图 \(F_t\)。
- 输出:预测特征图 \(F_t\),与冻结的 SAM 特征做 MSE 对齐。
- 设计动机:充当”后视镜(rear-view mirror)”,逼迫内部状态保留过去轨迹的稠密、可区分的物体信息,防止记忆衰减;区别于 NWM 等前瞻式(foresight)像素级世界模型(计算昂贵、且忽视历史维护),本文是回溯式(hindsight)特征级,更适合实时 onboard 推理。
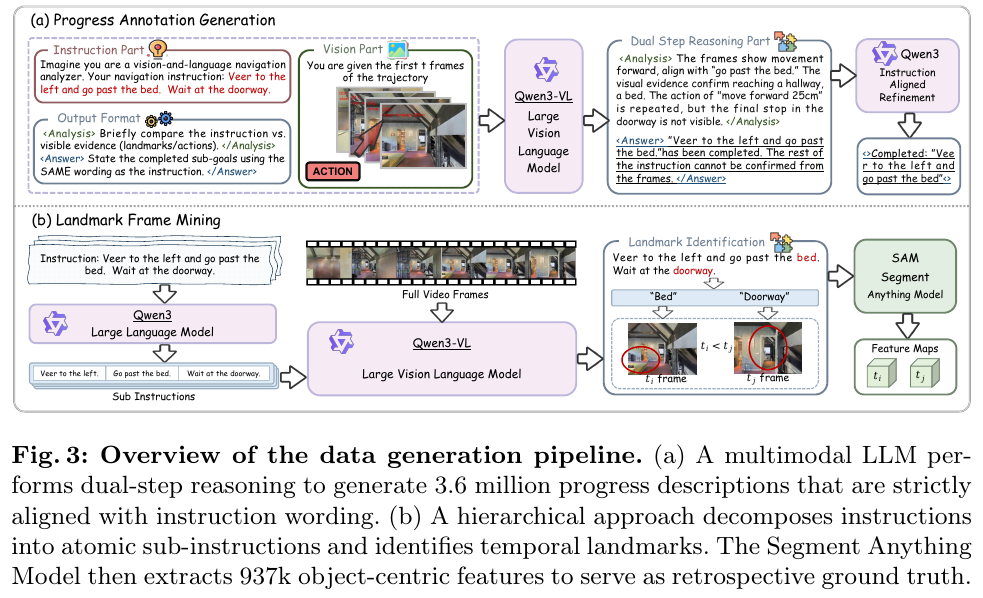
③ 训练目标 / 损失函数
Stage 1(导航数据预训练) 的总损失是三项加权和:
\[\mathcal{L}_{Stage1} = \mathcal{L}_{nav} + \lambda_{prog}\mathcal{L}_{prog} + \lambda_{WM}\mathcal{L}_{WM}\]- \(\mathcal L_{nav}\):标准导航动作损失。
- \(\mathcal L_{prog}\):进度描述生成损失。
- 世界模型 MSE 损失:\(\mathcal{L}_{WM} = \lVert F_t - F_{SAM}(o_{t^*}) \rVert_2^2\)。
④ 两阶段训练与数据组成
- 数据组成:Base Navigation(R2R/RxR/EnvDrop 180K + ScaleVLN HM3D 子集 155K)+ State Anchoring(360 万进度描述 + 93.7 万地标 SAM 特征)+ 240K DAgger rollouts + 400K VideoQA + 230K 图文对(MMC4,保留通用 VL 能力)。
- Stage 1:在导航数据 + 双锚定目标上预训练。
- Stage 2(DAgger + Generalist Fine-tuning):用 Stage 1 策略采样轨迹、收集纠正性专家动作构成 ~240K DAgger 数据,混合导航数据与通用 VL 数据共训以缓解 exposure bias 并防灾难性遗忘;双锚定目标(\(\mathcal L_{prog}\)、\(\mathcal L_{WM}\))在所有导航批次上保持激活。
3. 核心结果/发现
仿真 SOTA(R2R-CE / RxR-CE val unseen):仅用单目 RGB(S-RGB),在 R2R-CE 上 SR 从 StreamVLN 基线的 56.9% → 65.6%、SPL 51.9% → 62.1%;RxR-CE 上 SR 52.9% → 61.7%(绝对 +8.8%),SPL → 53.3%。相比同期强方法 DualVLN,SR/SPL 多项指标领先。
长程增益尤为显著:按轨迹测地距离分 Short/Medium/Long 三档,基线随距离增大急剧退化;本文方法的相对增益随轨迹变长而扩大——SR 相对提升从 Short 的 +10.7% 升到 Long 的 +24.7%,SPL 相对提升从 +12.6% 升到 Long 的 +33.2%,验证显式状态锚定对长程导航的关键作用。
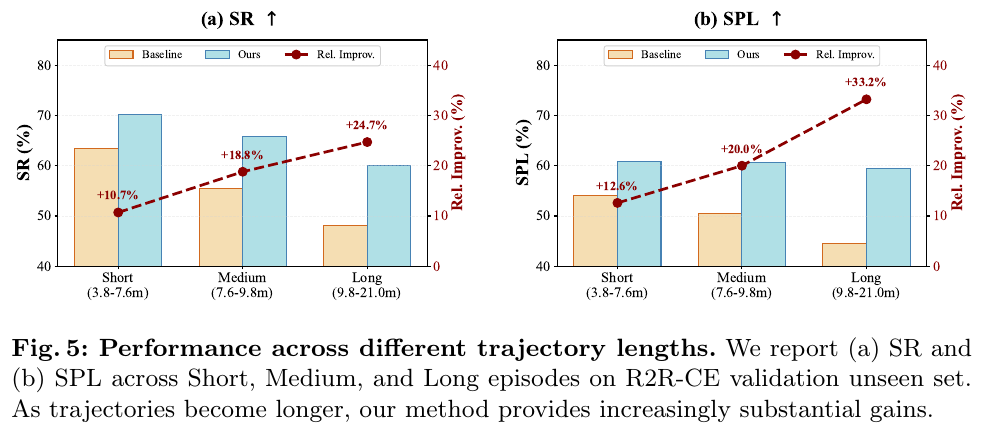
消融(Table 3):在两种数据规模下,IPA 单独把 SR 从 40.8%→45.4%(语义对齐有效);MLA 单独显著提升 SPL 并降低 NE(6.49→6.01,回溯重建抑制轨迹漂移);二者组合(双锚定)在所有设置下最优,证明两种正则互补且在数据扩展后依然有效。
数据质量(Table 4,参考无关指标):Visual Kinematics Prompting 使进度描述的 Logical Consistency Score 从 1.71→4.26(+149%)、Hallucination Rate 8.13%→6.04%(-25.7%);地标挖掘相对随机采样,Landmark Presence Rate 从 13.9%→75.6%(+444%)。
定性与真机:仿真中(图4)面对欺骗性开口,基线因 Progress Drift 提前左转失败,而本文 agent 的进度锚定明确指示”go straight 仍在进行”以抑制干扰动作,记忆锚定回溯重建出发”bathroom”特征接地当前位置。真机部署在 Unitree Go2 + RealSense D435i 上,纯 Matterport3D 仿真训练、零微调直接迁移,实时生成的进度描述准确反映完成状态。
4. 局限性
- 仍依赖自采集合成数据(Qwen3-VL/SAM 标注),其质量与覆盖度受标注器能力限制(进度描述仍有 ~6% 幻觉率);地标锚定假设可从指令显式分解出离散地标,对缺乏明确地标的指令收益可能受限。
39. WAM-Nav (2026)
———非对称隐空间「世界-动作」联合建模,用一个 DiT 统一三类视觉导航
📄 Paper: arXiv:2606.04907 — WAM-Nav: Asymmetric Latent World-Action Modeling for Unified Visual Navigation
精华
- 把”想象未来画面”与”生成动作”塞进同一个共享 DiT 里联合扩散,而不是先想象再用逆动力学解算动作的解耦式 pipeline,从根上消除了模块间的状态-动作错配与误差累积。
- 核心 insight 是非对称视界(asymmetric horizon):动作用长视界($H_{act}=24$)保证轨迹连续,视觉前瞻只用极短视界($H_{vis}=1$)。因为导航的视角变化剧烈,长自回归视觉 rollout 既慢又容易误差爆炸,短视界恰好提供可靠的近未来几何约束。
- 视觉前瞻全部在 Stable Diffusion VAE 的隐空间里预测(不解码成像素),让”未来感知”以低成本反过来约束动作生成(视觉速度匹配损失惩罚动作-场景不一致)。
- 双流上下文条件(DSCC):视觉记忆流管空间避障,自我运动历史流管运动学动量(平滑性),用运动 token 去 query 视觉空间,兼顾几何安全与轨迹顺滑。
- 统一目标对齐:把 Image-Goal / Point-Goal / No-Goal 都编码成”视觉语义查询 $g_V$ + 几何查询 $g_G$”两路互补 embedding,一个策略零样本支持三类任务且性能均衡,无需切换架构。
1. 研究背景/问题
视觉导航要在复杂几何与物理约束下生成平滑、无碰撞的轨迹。现有范式各有硬伤:反应式端到端策略(GNM/ViNT/NoMaD)直接把观测映射到动作,缺乏预测性推理,在杂乱环境里容易陷入局部最优和碰撞;模块化解耦的世界模型方法(先想象未来子目标,再用逆动力学/轨迹打分)虽有前瞻能力,但预测与决策分离训练,带来高延迟和累积误差。已有的「世界-动作模型」在机器人操作上验证了联合建模的价值,但其自回归生成范式在导航大视角变化下实时性差、误差累积严重。此外多数方法只支持单一目标类型,换任务就得重新设计训练;即便 NavDP 支持多目标,其单模态对齐也导致跨任务性能不均衡。
2. 主要方法/创新点
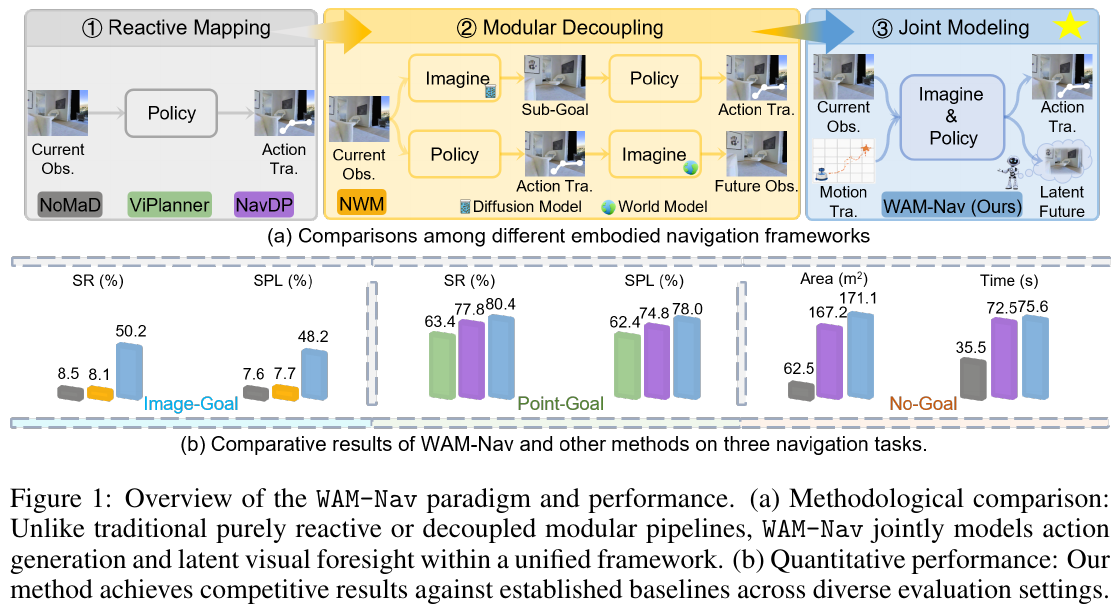
① 整体框架概述
如图 2,WAM-Nav 由三个核心组件构成:(1) 统一目标对齐(Unified Goal Alignment),把异构目标投影到统一空间,产出视觉语义查询 $g_V$ 与几何查询 $g_G$;(2) 双流上下文条件(DSCC),分别编码序列视觉观测和自我运动历史,经目标调制后融合成紧凑条件上下文 $C$;(3) 非对称动作-前瞻生成(Asymmetric Action-Foresight Generation),以 $C$ 为条件,用一个共享 DiT 通过非对称去噪同时生成未来动作轨迹与隐空间视觉前瞻。
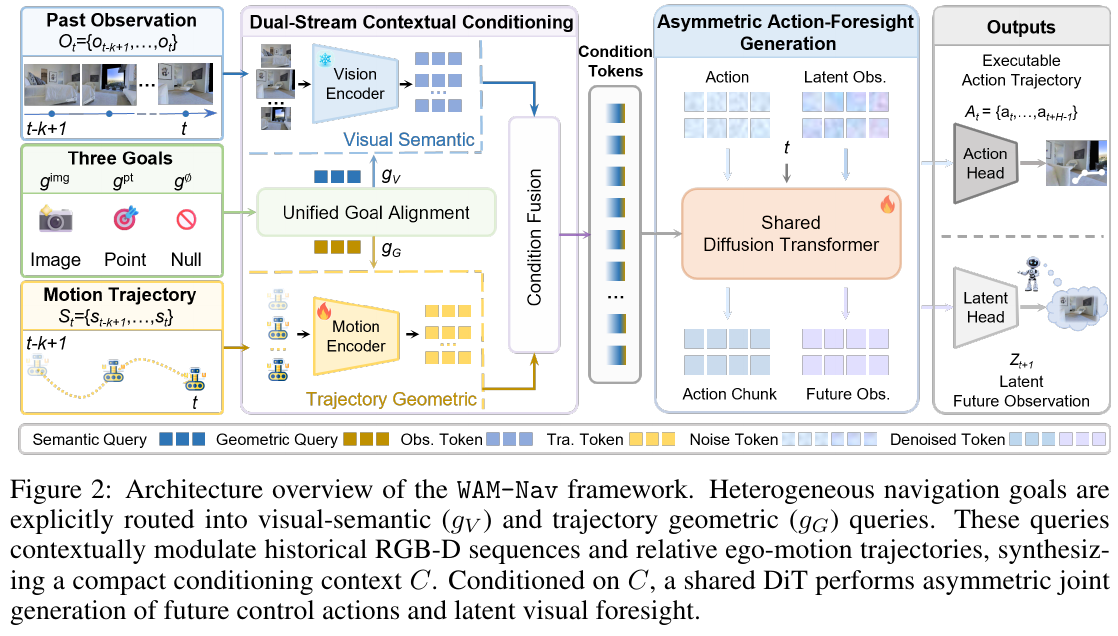
② 逐模块讲解
模块一:统一目标对齐(Unified Goal Alignment)
- 输入:一个目标 $g$,可能是目标图像(Image-Goal)、相对坐标(Point-Goal)或空目标(No-Goal)。
- 处理:先用模态专属特征提取器 $E_\phi(\cdot)$ 把 $g$ 转成基础 embedding $e_g$(图像目标用从零训练的 ViT,相对坐标用正弦位置编码,无目标用 masked 零状态);再通过两个可学习线性映射 $\psi_V,\psi_G$ 投到两路功能 token 空间:$g_V=\psi_V(e_g)$、$g_G=\psi_G(e_g)$。
- 输出:视觉语义查询 $g_V$(用于视觉记忆检索)与几何查询 $g_G$(用于轨迹级方向引导)。
- 设计动机:与 NavDP 等”把所有任务都重写成 point-goal”的做法不同,本设计保留模态特异性信息,又提供统一接口,从而在三类目标上性能均衡。
模块二:双流上下文条件 DSCC(Dual-Stream Contextual Conditioning) 仅靠视觉条件会因缺乏显式动量约束而生成抖动、运动学不一致的轨迹。DSCC 在 $t-k+1$ 到 $t$ 的滑动窗口上融合两条流:
- 目标调制视觉记忆流:历史 RGB 观测 $O_t$ 经 DINOv2 编码成记忆张量 $V$;用视觉查询 $g_V$ 对每个 patch token 算缩放点积相关性分数 \(\alpha=\sigma\!\left(\tfrac{g_V V^\top}{\sqrt D}\right)\),再残差强化与目标相关的空间 token:\(\tilde V = V + \alpha \odot V\)。输出:被目标”点亮”的视觉空间记忆。
- 轨迹感知运动历史流:把执行过的位姿序列 $S_t$ 转成坐标无关的相对位移与朝向变化 \(\tilde S_t=\{(\Delta x_i,\Delta y_i,\Delta\theta_i)\}\)(在当前自我中心坐标系下,见 Algorithm 1),经因果 Transformer 编码为 $H$;再用几何目标 $g_G$ 通过 cross-attention query 出一个浓缩的运动学向量 \(o_{kin}=\mathrm{CrossAttn}(g_G,H,H)\)。输出:相对目标方向的历史运动连续性摘要。
- 跨注意力条件融合:用运动学 token $o_{kin}$ 去偏置一组可学习 query $Q_c$,再用多层 Transformer Decoder 让”运动动量”主动 query “目标调制后的视觉空间”:\(C=\mathrm{TransformerDecoder}\big(Q_c+\phi(o_{kin}),\,\tilde V,\,\tilde V\big)\)。输出:统一条件上下文 $C$,同时编码几何安全(避障)与执行平滑(动量)。
模块三:非对称动作-前瞻生成(Asymmetric Action-Foresight Generation) 这是全文最关键的设计。在 $C$ 条件下,模型联合建模:长视界动作轨迹 $A_t={a_t,\dots,a_{t+H_{act}-1}}$ 与短视界隐空间视觉前瞻 \(Z_{t+1:t+H_{vis}}=\{z_{t+1},\dots,z_{t+H_{vis}}\}\),其中 $H_{vis}\le H_{act}$。未来视觉状态 $z_i=\mathcal E(o_i)$ 由预训练 SD-VAE 压成 $N$ 个隐 patch 的紧凑网格。
- 训练用 flow-matching:把高斯先验 $(A_0,Z_0)$ 到数据流形的概率路径建成直线,任意流时刻 $\tau$ 的插值态为 $A_\tau=(1-\tau)A_0+\tau A_1$、$Z_\tau=(1-\tau)Z_0+\tau Z_1$,目标速度场 $u_A=A_1-A_0$、$u_Z=Z_1-Z_0$。
- 共享 DiT:$A_\tau$ 与 $Z_\tau$ 被 token 化后拼接,送入多层 DiT。每个 block 内两类异构 token 先做共享 self-attention(让动作路径与视觉表征逐层交换时空约束),再各自 cross-attend 到条件 $C$,时间步 $\tau$ 经 adaLN 注入,回归联合速度场 $\hat u_A,\hat u_Z=f_\theta(A_\tau,Z_\tau,\tau,C)$。共享参数让隐空间前瞻成为”感知接地”的约束,通过视觉速度匹配损失惩罚动作-场景不一致。
- 为何非对称:操作类 WAM 的未来视觉变化局部、以物体为中心;而导航涉及大幅自我中心视角变化,长自回归视觉 rollout 会同时带来推理延迟和累积视觉误差,反而误导动作。故采用”动作长视界保连续 + 视觉短视界给可靠近未来几何约束”的非对称设计。
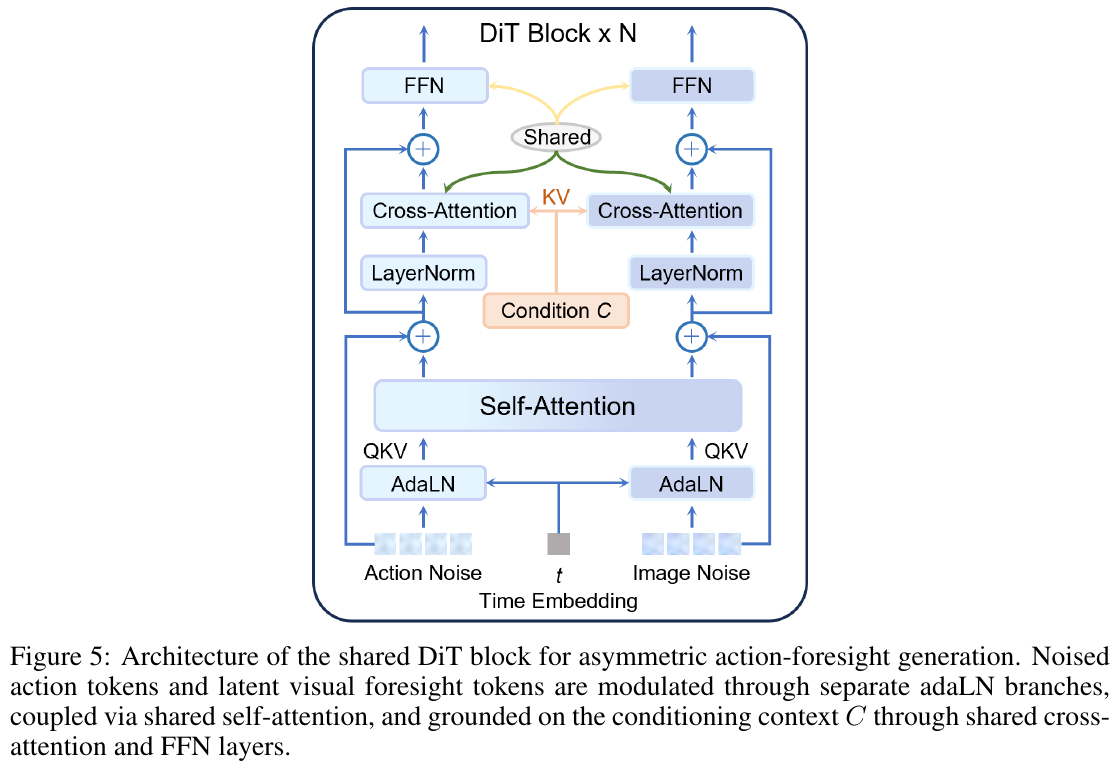
③ 端到端数据流:单步样本流经路径为——目标 $g$ → 对齐成 $g_V,g_G$;历史观测 $O_t$、运动历史 $S_t$ → 经 DSCC 双流调制融合成 $C$;高斯噪声 $(A_0,Z_0)$ → 在 $C$ 条件下经共享 DiT 的 10 步 Euler 积分去噪 → 输出执行动作轨迹 $A_t$ 与隐空间未来观测 $Z_{t+1}$。
④ 训练目标:端到端最小化联合损失 \(\mathcal L_{total}=\mathbb E\big[\lVert\hat u_A-u_A\rVert_2^2+\lambda_{img}\lVert\hat u_Z-u_Z\rVert_2^2\big]+\lambda_{align}\mathcal L_{align}\) 其中第一项为动作流速度回归,第二项为视觉前瞻速度匹配($\lambda_{img}=0.25$),第三项 $\mathcal L_{align}$ 为对称对比 InfoNCE 损失($\lambda_{align}=0.1$),通过最大化跨空间投影的互信息保证多目标模态一致性。训练时 DINOv2 ViT-S/14 与 SD-VAE 冻结,目标图像编码器、融合解码器、因果运动编码器与共享 DiT 从零训练。
⑤ 推理流程:采用 receding-horizon 控制循环。与 NavDP 一致,每步在当前 $C$ 下采样 16 条候选轨迹,按 NoMaD 做法选第一条执行;flow-matching ODE 求解器跑 10 步 Euler 积分,平衡生成质量与实时性。
3. 核心结果/发现
主结果(零样本,IsaacSim,ClutterScenes + InternScenes,6000 episodes):WAM-Nav 在三类任务上平均最优——Image-Goal 达 50.2% SR / 48.2% SPL(较 NavDP 提升 15.7% SR),Point-Goal 80.4% SR / 78.0% SPL(提升 3.3%),No-Goal 探索面积 171.1 m²。
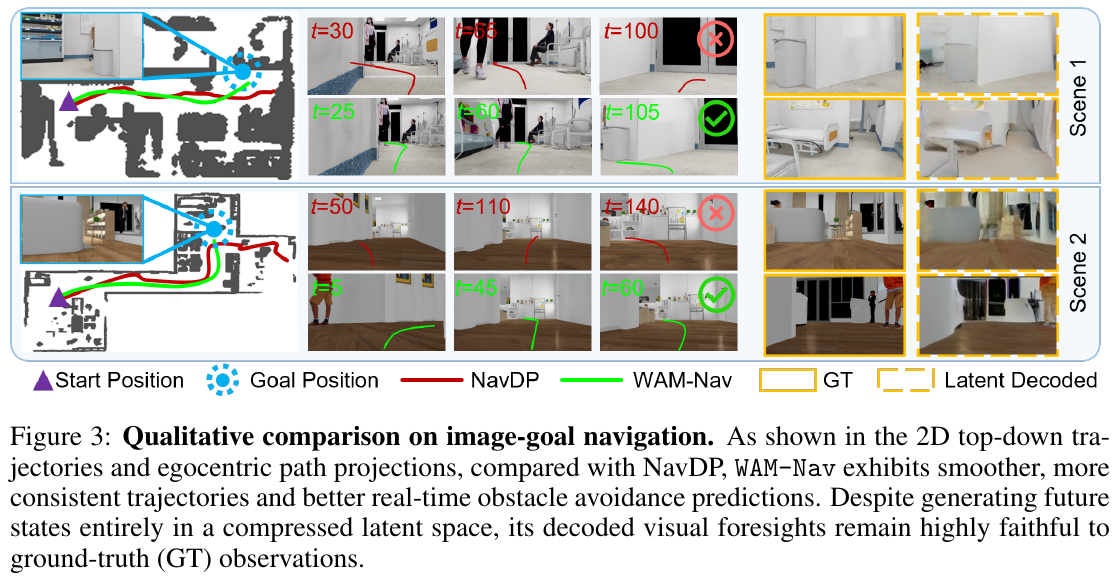
- 效率(Q3):推理延迟 0.26s,每决策仅 0.7 TFLOPs(NavDP 1.3、NWM 8.3),可训练参数与 NavDP 相当;避免了 NWM 那种 1.43s 的多候选视觉 rollout,满足实时导航。
- 消融(Q4):纯隐空间前瞻把 SR 从 42.1%→45.7%;纯运动轨迹在 ClutterScenes 有益但在语义更复杂的 InternScenes 反而下降;两者结合最佳(50.2% SR)——印证 DSCC 设计:运动历史稳定轨迹生成、隐空间前瞻提供安全所需几何约束。
- 非对称视界验证:$H_{vis}=1$ 最佳(50.2 SR),随视觉视界拉长(4/8/24)性能单调下降(直至 30.4 SR),强力支撑”视觉前瞻应给近未来约束而非长自回归 rollout”的核心动机。
- 耦合架构:完全共享 DiT 优于解耦/部分共享变体,说明隐空间前瞻在直接通过共享表征正则化动作生成时最有用。
- 跨本体 & 真实世界:单策略零样本迁移到 Dingo 轮式、Unitree G1/H2 人形机器人均稳定领先 NavDP;真实部署(G1 + RealSense D455,会议室/仓库/大厅/停车场四场景)平均 85% 成功率,验证有效的 sim-to-real 零样本迁移。难度越高(长程)相对 NavDP 优势越大(Hard 子集 +7.6% SR)。
4. 局限性
真实部署发现两类失败:(1) 相机高度与视野受限,对近场低矮障碍感知弱,易漏看导致碰撞或避障延迟;(2) 当前策略未显式建模机器人本体形状,轨迹规划只保证相机能通过,导致身体与侧方障碍碰撞。未来方向:自适应视角控制、以及融入多形态本体的 embodiment-aware 训练。
40. JanusVLN (2026)
——— 解耦语义与空间:使用双隐式神经内存的视觉语言导航
📄 Paper: arXiv:2509.22548v2 · 🏛️ ICLR 2026
精华
- 脑区分工启发:首次将人类左右脑的语义理解和空间认知分工应用到具身智能导航中,解耦视觉语义与 3D 空间几何信息。
- 双隐式神经内存:抛弃显式文本认知地图或历史帧图片缓存,使用 Transformer 的深层 KV cache 缓存,并结合初始窗口(全局锚点)与滑动窗口(局部细节)进行混合增量更新。
- 强大的 3D 几何特征:引入在像素-3D 点云对上预训练的 3D 几何模型 VGGT,仅通过单目 RGB 输入即可推断隐式 3D 几何,极大地增强了纯 2D 模型的空间推理能力。
- 低延迟与高效率:增量内存更新方式规避了传统方法随时间增长的内存和计算复杂度膨胀,在测试中将单帧推理延迟从 268ms 大幅降低至最少 82ms。
- 多基准 SOTA:在 VLN-CE(R2R-CE, RxR-CE)和更复杂的 HM3D-OVON 开放词汇导航上均刷新了成功率与路径效率 of SOTA 记录。
1. 研究背景/问题
近年来,基于多模态大语言模型(MLLMs)的具身导航(VLN)系统取得了很大进展。然而,现有模型大多面临两大痛点:
- 显式语义记忆的局限性:许多方法通过构建基于文本的显式语义地图或直接保存历史观察帧来做决策。这不仅造成 3D 空间物理信息的丢失,而且会导致随着时间序列增长,模型出现严重的计算冗余和内存膨胀(Memory Bloat),在长程任务中推理效率低下。
- 缺乏 3D 几何结构理解:现有视觉语言动作模型(VLA)几乎完全继承了以 CLIP 为代表的 2D 图像-文本预训练视觉编码器。由于 2D 训练数据的性质,这些编码器非常擅长高层语义识别,但对三维空间物理结构、景深、透视以及遮挡关系的理解却极为匮乏。而这正是 3D 实地导航所必需的。
2. 主要方法/创新点
整体框架概述
针对上述局限性,论文提出了 JanusVLN 框架。它利用双隐式神经内存,将 3D 空间几何信息(负责“在哪里,如何关联”)与 2D 视觉语义信息(负责“是什么”)进行分离编码,并使用混合增量策略对神经内存进行高效更新。系统主要由 2D 视觉语义编码器、3D 空间几何编码器、双隐式神经内存以及空间感知特征融合模块组成,最后将多模态表征输入大语言模型以预测离散动作。
逐模块讲解
① 2D 视觉语义编码器 (Visual-Semantic Encoder)
- 输入:当前帧 RGB 图像 $x_t \in \mathbb{R}^{3 \times H \times W}$。
- 处理:直接采用多模态大语言模型(Qwen2.5-VL)的原始视觉编码器,提取输入图像的二维语义特征。为了减少视觉标记(Tokens)带来的计算量,Qwen2.5-VL 将空间上相邻 of $2 \times 2$ 特征小块(Patches)进行级联融合,形成单个语义标记。
- 输出:降采样后的 2D 视觉语义标记 $S’_t \in \mathbb{R}^{\lfloor \frac{H}{2p} \rfloor \times \lfloor \frac{W}{2p} \rfloor \times C}$,其中 $p$ 为 patch 大小。
- 设计动机:负责提取场景中强有力的语义物体感知(例如床、台灯、拐角的位置与语义属性)。
② 3D 空间几何编码器 (Spatial-Geometric Encoder)
- 输入:当前帧 RGB 图像 $x_t$。
- 处理:引入预训练的 3D 视觉几何基础模型 VGGT 的编码器部分。VGGT 在大量“像素-3D 点云”对上进行过训练,因此蕴含了极强的 3D 空间深度感知和三维布局先验。VGGT 将输入图像提取的初始特征与 3D 几何隐式内存中的历史 KV 缓存相结合,再输入到 Fusion Decoder 中进行跨帧交互处理。
- 输出:包含了 3D 空间结构的几何 Token 序列 $G_t \in \mathbb{R}^{\lfloor \frac{H}{p} \rfloor \times \lfloor \frac{W}{p} \rfloor \times C}$。这些 Token 也可以用一个轻量级的小头部重建高保真的单目深度图和局部 3D 点云。
- 设计动机:直接从纯 RGB 视频流中,以在线和流式(Online & Streaming)的方式获取 3D 深度、几何和空间关系,避免了对昂贵且难以获取的 3D 实地数据(如激光雷达、实时 RGB-D 相机)的硬件依赖。
③ 双隐式神经内存 (Dual Implicit Neural Memory)
- 输入:历史帧在语义编码器与几何编码器内的 Key-Value (KV) 缓存。
- 处理:不再保存原始图像或冗余的多级地图,而是通过混合增量更新策略管理内存容量:
- 滑动窗口队列 $M_{\text{sliding}}$:一个固定容量为 $n$(如 48 帧)的先进先出(FIFO)队列,只保留最近 $n$ 帧的特征 KV 缓存。这保证了模型对近期局部环境细节的敏感性。
- 初始窗口 $M_{\text{initial}}$:永久保留导航任务开始前几帧的特征 KV 缓存。其充当“注意力汇(Attention Sinks)”,为长距离导航提供全局任务指引和恒定的地理起始锚点。 对于新的输入帧,编码器通过注意力交互融合 $M_{\text{sliding}}$ 和 $M_{\text{initial}}$ 内的历史信息: \(G_t = \text{Decoder}(\text{CrossAttn}(\text{Encoder}(x_t), \{ M_{\text{initial}}, M_{\text{sliding}} \}))\)
- 输出:更新后的当前帧几何 Token 和语义 Token。
- 设计动机:实现定长、紧凑的特征存储,彻底消除记忆空间随着时间无限拉长而膨胀的问题,且只增量计算当前帧,避免了 reprocess 历史所有图像造成的计算开销。
④ 空间感知特征融合 (Spatial-aware Feature Fusion)
- 输入:语义标记 $S’_t$ 与 3D 几何标记 $G_t$。
- 处理:
- 空间融合对齐:对 VGGT 提取的几何特征 $G_t$ 实施相同的空间合并(Spatial Merging)降采样,将其 $2 \times 2$ 的特征区域拼接对齐,产生 $G’_t \in \mathbb{R}^{\lfloor \frac{H}{2p} \rfloor \times \lfloor \frac{W}{2p} \rfloor \times C}$。
- 加权残差融合:利用轻量级的双层 MLP 投影层将两个域的特征融合成统一的、强空间感知的多模态视觉特征 $F_t$: \(F_t = S'_t + \lambda \cdot \text{MLP}(G'_t)\) 其中 $\lambda$ 为几何特征的权重,设定为 0.2。
- 输出:融合后的特征 $F_t$。
- 设计动机:在保证大模型主要关注语义指令对齐的前提下,将隐式 3D 几何特征低成本地无缝整合进大语言模型输入中。
训练目标与推理流程
- 训练目标:系统使用模仿学习(Behavior Cloning)对智能体进行端到端优化,优化过程中将 2D 视觉语义编码器(Qwen2.5-VL 视觉部分)和 3D 空间几何编码器(VGGT)的参数全部冻结(Frozen),仅微调 LLM 主干(7B)以及特征融合投影层(MLP)。使用 DAgger 算法在连续模拟环境中通过人类或专家轨迹对策略进行微调,显著减轻“漂移”带来的误差累积。
- 推理流程:每个时刻 $t$,智能体从 RGB 摄像头提取当前帧 $x_t$,通过双编码器与内存模块提取并更新隐式内存,融合成 $F_t$;接着将 $F_t$ 与自然语言指令嵌入 $\mathcal{I}$ 连接,直接由 LLM 的 KV cache 机制增量推理出下一个离散控制动作 $a_{t+1}$,直到输出
Stop。

3. 核心结果/发现
- VLN-CE 基准表现(R2R-CE & RxR-CE):
- 在 R2R-CE 未见场景测试集(Val-Unseen)中,JanusVLN 刷新了 SOTA 成绩,取得了 成功率 (SR) 60.5% 和 路径长度加权成功率 (SPL) 56.8% 的杰出表现,相比此前最好的模型 StreamVLN,SR 提升了 3.6%,SPL 提升了 4.9%。
- 在不使用任何外部轨迹辅助训练的设置下(JanusVLN*),成功率依然达到 52.8%,超越了其他使用大量额外多模态数据的框架。
- 在 RxR-CE 基准中,其表现同样刷新 SOTA,取得了 SR 56.2% 和 SPL 47.5% 的优异成绩。
- HM3D-OVON 表现:
- 在面向开放词汇的目标导航测试(HM3D-OVON)中,JanusVLN 取得了 SR 44.9% 和 SPL 31.7%,遥遥领先于之前的算法(如 MTU3D 的 SR 40.8% 和 SPL 12.1%),展现出强劲的场景泛化力与指令理解力。
- 推理耗时对比:
- 引入了 Cached Memory 机制后,模型单帧的图像特征处理延迟(VGGT)被降至极低的 82ms(缓存 8 帧)与 195ms(缓存 48 帧),而如果不使用缓存、直接重计算全长序列特征,耗时则随着帧数呈指数级上升,很快会在 GPU 上发生内存溢出(OOM)。
- 消融实验关键结论:
- 3D 几何特征是路径规划的关键:去掉 3D 空间几何隐式内存后,模型在 R2R-CE 上的 SPL 表现从 49.2 急剧下滑至 40.9。
- 初始锚点不可或缺:若从内存中去除初始窗口(w/o initial’s KV),性能将下降近 2%,证明了 Attention Sinks 为导航任务提供全局参照的必要性。
4. 局限性
- 偏差自纠错能力仍然脆弱:统计表明,虽然系统利用 DAgger 算法收集了非最优路线数据进行微调,但当智能体在大范围、长程导航中严重偏离预设路线时,它依然很容易由于误差在时间上的逐步累积而彻底迷失,难以主动退回最优路径。
- 缺乏真实尺度引起的提前停止:由于 3D 几何编码器(VGGT)本身在没有真实物理标定的前提下仅提取隐式的相对几何特征,其输出在一定程度上缺乏真实的绝对尺度(Real-world Scale)。这导致智能体在距离目标物体还有一段距离(尚未到达 3 米判定半径)时,容易由于视觉上的“已看清目的地”而错误地提前停下来。
41. HSGM (2026)
——— 层级式语义-几何地图,填补 VLM 2D 视觉与 3D 空间推理及运动规划的鸿沟
📄 Paper: arXiv:2606.00095
精华
- 针对大视觉语言模型(VLM)在连续环境导航(VLN-CE)中缺乏 3D 几何常识与底层运动规划能力(即语义-几何鸿沟)的问题,提出无须训练的层级式语义-几何地图(HSGM)。
- HSGM 在三维空间中维护层级场景表示,包含用于记录可通行性的几何地图、表征物体实例的语义地图以及用于采样航点与轨迹的决策地图。
- 通过将 3D 点云栅格化为 2D BEV 鸟瞰图,并在其上叠加可视化的离散航点标记,成功使 VLM 的 2D 视觉推理能够直接关联并操纵三维空间。
- 采用规划与控制解耦的设计,VLM 仅作为高层语义规划器选择离散的目标航点,而具体的无碰撞连续轨迹则交由经典的 A* 算法和底层 PID 控制器执行。
- 引入子任务管理机制将长程复杂指令解耦,并结合失败回溯(Backtracking)策略,显著降低了 VLM 的记忆与推理开销,大幅提升了导航的成功率。
1. 研究背景/问题
在连续三维环境中的视觉语言导航(VLN-CE)要求具身智能体基于第一人称视角(RGB-D)和相机位姿,按照复杂的自然语言指令运动并寻找目标物。尽管预训练的 VLM(如 GPT-5 等)具有强大的通用语义推理和 2D 视觉常识,但在将其应用于 VLN-CE 时,遇到了明显的 “语义-几何鸿沟” (Semantic-Geometric Gap):
- 三维几何理解贫瘠:VLM 虽然可以识别图像中的物体,但由于仅在 2D 图文对上进行训练,它们很难跨多视角重建全局 3D 拓扑布局,无法理解复杂的 3D 空间相对关系。
- 底层动作控制脱节:将语义级的目标描述(例如“穿过走廊,在沙发旁停下”)转化为精确的厘米级底层连续运动指令(如左转 $15^\circ$,前进 $0.5\text{ m}$)非常困难,容易导致避障失败和过度碰撞。
2. 主要方法/创新点
HSGM 通过显式地在三维空间中构建层级语义-几何表征,并将高层语义决策与低层控制解耦,彻底解决了上述鸿沟。
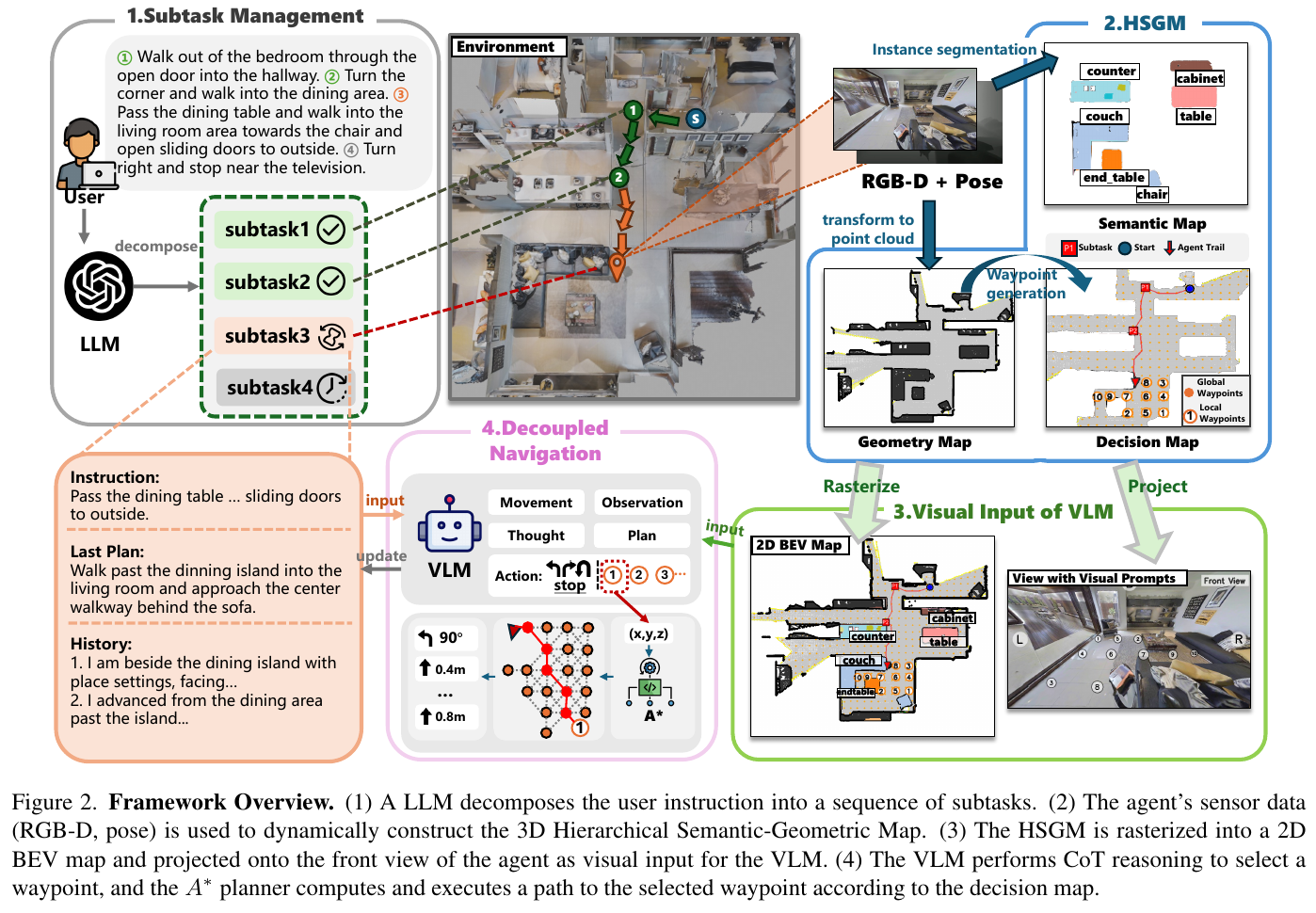
① 整体框架概述
如图 2 所示,HSGM 框架包含三大支柱:首先利用大模型对复杂的长句导航指令进行子任务解耦(Subtask Management);其次智能体在运行中动态构建层级语义-几何地图(HSGM);最后,系统基于该地图将 VLM 的高层语义航点选择(High-Level Planning)与 A* 经典路径规划算法的低层运动控制(Low-Level Control)进行完全解耦。
② 逐模块讲解
A. 动态层级建图 (Hierarchical Mapping) HSGM 包含三个并行的层级,以维持高精度、长期稳定的 3D 环境模型:
- 几何地图 (Geometry Map, $M_{geo}$):
- 输入:智能体采集的多视角 RGB-D 图像 $O_t$ 以及实时位姿 $\xi_t$。
- 处理:将图像像素通过对应的深度图与位姿反投影回 3D 空间,汇聚成场景点云 $P_{scene}$。点云中高于地面的部分识别为障碍物 $P_{obs}$,其余提取为初始可通行面 $P_{nav}^{init}$。针对可能遇到的跨楼层情况,通过法向量估计和倾斜面滤波专门提取楼梯区域点云 $P_{stair}$。
- 输出:最终的几何地图为两者并集: \(M_{geo} = P_{nav} \cup P_{obs}\) 其中 $P_{nav} = P_{nav}^{init} \cup P_{stair}$。
- 语义地图 (Semantic Map, $M_{sem}$):
- 输入:egocentric RGB 图像。
- 处理:利用 YOLO-E 进行 2D 目标检测与实例分割,提取物体的 2D Mask 和类别信息。随后利用深度图与相机位姿将 Mask 投影至 3D 空间生成物体点云。新生成的物体点云会根据 3D IoU 和类别标签的一致性,与已有物体特征相融合,并设定阈值剔除噪声点。
- 输出:包含 N 个语义物体的 3D 点云与标签集合: \(M_{sem} = \{(P_{obj, j}, c_j)\}_{j=1}^{N_{obj}}\)
- 决策地图 (Decision Map, $M_{dec}$):
- 输入:几何地图 $M_{geo}$、障碍点云 $P_{obs}$ 和智能体当前位置 $p_{agent}$。
- 处理:由两部分组成:全局航点图 $G = (V, E)$ 和局部航点集 $A_{curr}$。
- 全局图 $G$:对可通行点云进行下采样,通过柱状碰撞体检查(Cylindrical Occupancy Check,智能体高 $h$ 宽 $r$ 范围内无障碍点)确定安全节点。相邻节点如果在水平距离($\le 1.0\text{ m}$)和高度差($\le 0.3\text{ m}$,针对楼梯)内满足连通,则建立无碰撞边。
- 局部航点集 $A_{curr}$:在当前视野的可通行区域进行较粗粒度的采样,通过 cylindrical check 后,结合距离($0.3\text{ m} \sim 3.0\text{ m}$)及语义接近度进行筛选,并过滤掉在全局图上与当前位置不可达的悬空或隔离点。
- 输出:当前可用的决策图表示: \(M_{dec} = \{G, A_{curr}\}\)
B. 2D 栅格化与航点可视化投影 (2D Rasterization & Prompting)
- 输入:3D HSGM 各层信息。
- 处理:将三维点云进行高度投影并栅格化为 Top-down 的 2D BEV 图像(几何通道标记障碍和路,语义通道以特定标记代表各类物体,状态通道包含轨迹线与子任务终点等)。同时,将 $A_{curr}$ 的三维坐标转化为带有编号的彩色圆圈(未访问为灰色,已访问为红色),直接投影到 top-down BEV 图和 egocentric 第一人称前向视图上。
- 输出:直观的 2D 视觉提示图,将连续 3D 规划转化为 2D 离散的选择题。
C. 高低层解耦规划与控制 (Decoupled Navigation)
- 高层语义规划:VLM 作为决策核心,其输入包括当前的 2D BEV 图像、第一人称视角图(二者均叠加密集航点提示)以及系统提示和历史 Chain-of-Thought (CoT) 轨迹。VLM 运用 CoT 依次分析先前的进度、当前的环境、当前的子目标与接下来的路线,最后输出要跳转的航点序号 $a_t \in A_{curr}$,或原地转弯的姿态,或触发子任务完成的 STOP 信号。
- 低层控制执行:当 VLM 决策了目标航点后,经典的 A* 路径规划算法以欧几里得距离为代价函数,在全局航点图 $G$ 上检索出无碰撞的最短拓扑路径,再由 PID 控制器转化为一连串的“转弯 - 直行”物理动作指令驱使机器人移动。
③ 训练与推理细节
- 训练:本框架为 完全零样本(Zero-shot)、免训练 (Training-free) 架构。它不需要任何针对导航任务的大规模模仿学习或强化学习。
- 推理:VLM 使用了 GPT-5 的多模态 API。子任务管理模块通过大模型预先将用户输入分解为若干语义独立的阶段,并利用双重确认(两轮连续 STOP)防止过早停止。同时,如果在单一子任务上耗费步数过多,会自动回退至子任务的起点,实现路径纠偏与回溯(Automatic Backtracking)。
3. 核心结果/发现
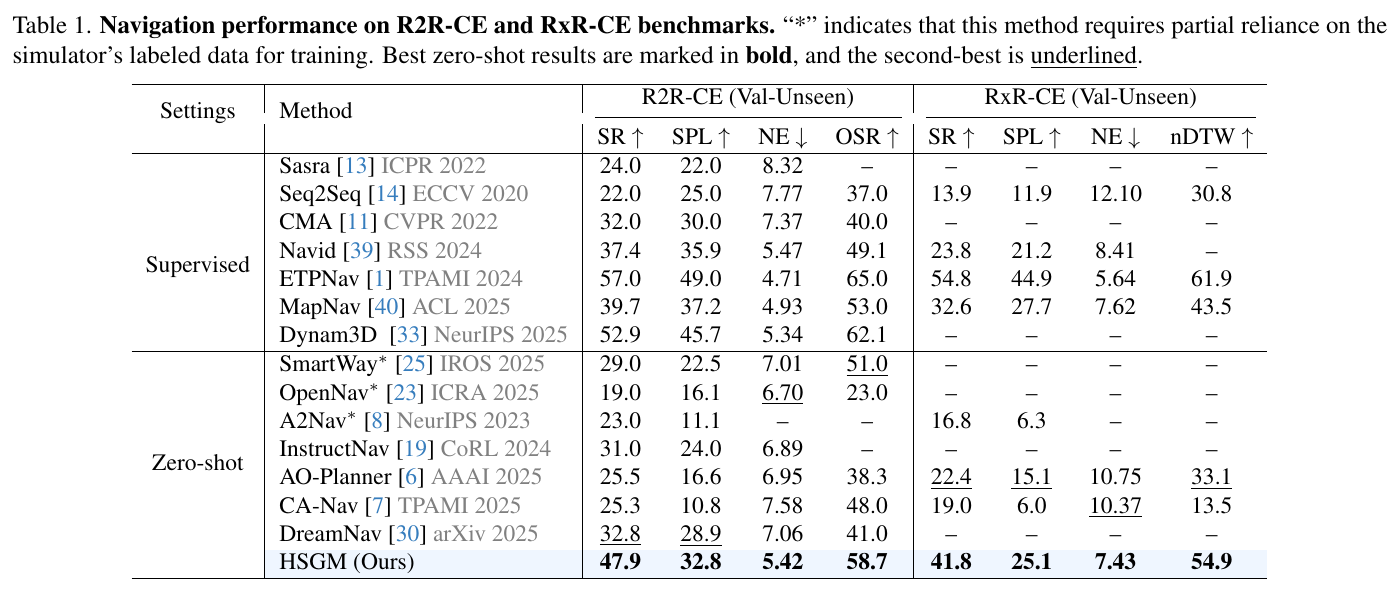
- 卓越的零样本性能: 在 R2R-CE(Val-Unseen)上,HSGM 取得了 47.9% 的成功率 (SR) 和 32.8% 的 SPL,优于当前最佳的零样本 baseline(DreamNav 32.8% SR,15.1% 领先)。更重要的是,它大幅打败了 CMA、NaVid (37.4% SR) 以及 MapNav (39.7% SR) 等使用了大量 Habitat 数据训练的监督学习模型。 在长程、多语言的 RxR-CE(Val-Unseen)上,其表现更为明显,SR 达到 41.8%,相较于先前最佳的零样本方法 AO-Planner (22.4% SR) 直接实现翻倍,且衡量路径逼真度的 nDTW 达到 54.9% (远高于 33.1%),这表明生成的轨迹极好地契合了人类指令。
- 建图层级的增量消融: 如表 2 所示,在不提供 BEV 图的基线下成功率为 46.0%。逐步加入几何地图后,成功率提升至 47.3%;加入语义通道可辅助物体寻找,将成功率拉升至 49.2%;最后加入包含了历史轨迹和航点指示的决策层地图,使系统达到 51.0% (注:300 episode 子集)。证明了三层地图信息的互补性。

- 子任务与 CoT 推理的必要性:
- 去除子任务管理:SR 骤跌 8.9%。说明长任务中极易发生进度遗忘,而将其切分为离散目标可降低 VLM 的长上下文记忆负荷。
- 去除 A* 解耦规划(直线前进):SR 下降 6.7%。说明仅仅输出航点不够,若无经典几何规划避障,机器人在连续环境中极易因障碍物阻隔导致路线偏移或陷入局部极小。
-
去除 Chain-of-Thought:导航性能灾难性下滑(SR 下降 17%,跌至 34.0%),这表明长程三维导航是一个非常复杂的时空逻辑决策过程,需要显式的思维链过渡。
- 回溯机制的作用:
- 如表 4,在 R2R-CE 和 RxR-CE 中分别触发了 18.3% 与 19.0% 的自动回退,得益于此,分别挽救并纠正了其中 30.8% 和 26.8% 的失败回溯案例(Recovery SR),极大地提升了系统的运行鲁棒性。
4. 局限性
- 传感器精度依赖度高:3D 点云建图严重依赖深度相机的精度以及位姿传感器的估计。如果发生相机遮挡、剧烈抖动或黑暗导致 2D 目标检测器失效,则生成的语义-几何地图会出现漂移或穿模。
- 高频推理与高昂延迟:采用强大的 GPT-5 等 VLM 进行高频 API 交互推理,在线推理开销和通信延迟十分明显,在对实时动态避障要求极高的超高速机器人任务上难以直接应用。
- 复杂动态场景适应性弱:当前航点生成与 A* 碰撞检测针对的是静态环境下的三维障碍,面对移动障碍物(如行人、宠物等)时,其建图更新机制和航点更新率可能无法及时应对。
42. OneVLA (2026)
OneVLA: A Unified Framework for Embodied Tasks ———首个在单一网络与动作头下统一具身导航和操作的 VLA 模型
📄 Paper: arXiv:2606.01241
精华
- 提出了 OneVLA,这是首个在单一网络架构与单个动作输出头(Action Head)下,同时解决具身导航(Navigation)与机械臂操作(Manipulation)任务的统一 VLA 框架,无需任何任务特定的模型变体。
- 核心创新在于设计了 11 维统一动作输出头,创造性地将离散的导航命令分布与连续的 7-DOF 机械臂末端控制量进行拼接,并通过任务特定维度掩码(task-specific weight masks)解决了不同动作空间带来的梯度干扰问题。
- 提出了多阶段渐进式混合训练策略(操作基础建立 $\rightarrow$ 导航能力融入 $\rightarrow$ 思维链 CoT 强化),使模型逐步掌握复杂的多模态知识,促进了跨任务域的表征学习和正向知识迁移。
- 仿真与实物实验表明,3B 参数 of OneVLA 在 VLN-CE 和 SimplerEnv 等多项导航和操作基准上均达到了 SOTA 性能,显著超越了现有的 7B 跨任务模型(如 UniVLA)和专门的单任务模型(如 StreamVLN、π0-Fast)。
- 提供了强有力的实证证据,证明导航与操作这两类截然不同的具身任务进行混合联合训练,可以实现性能上的互惠与相互增强(mutual reinforcement)。
1. 研究背景/问题
当前的具身智能机器人系统主要依赖专用的视觉-语言-动作(VLA)模型,通常局限于单一领域:
- 领域割裂:模型要么专注于导航(如 NaVid、MapNav),要么专注于机械臂操作(如 OpenVLA、π0),导致无法构建通用型的机器人智能体。
- 架构依赖变体:现有的跨任务 VLA 模型(如 UniVLA)虽然尝试同时处理两类任务,但仍需要为不同任务设计独立的动作头或特定任务的模型变体,无法实现真正的无缝切换。
本文旨在解决两个核心问题:
- 是否能设计一个完全统一的 VLA 架构,在没有任何任务特定变体的情况下,同时生成导航与操作动作?
- 导航和操作这两个根本不同的具身任务,在联合训练时能否实现知识的正向迁移与性能的相互增强?
2. 主要方法/创新点
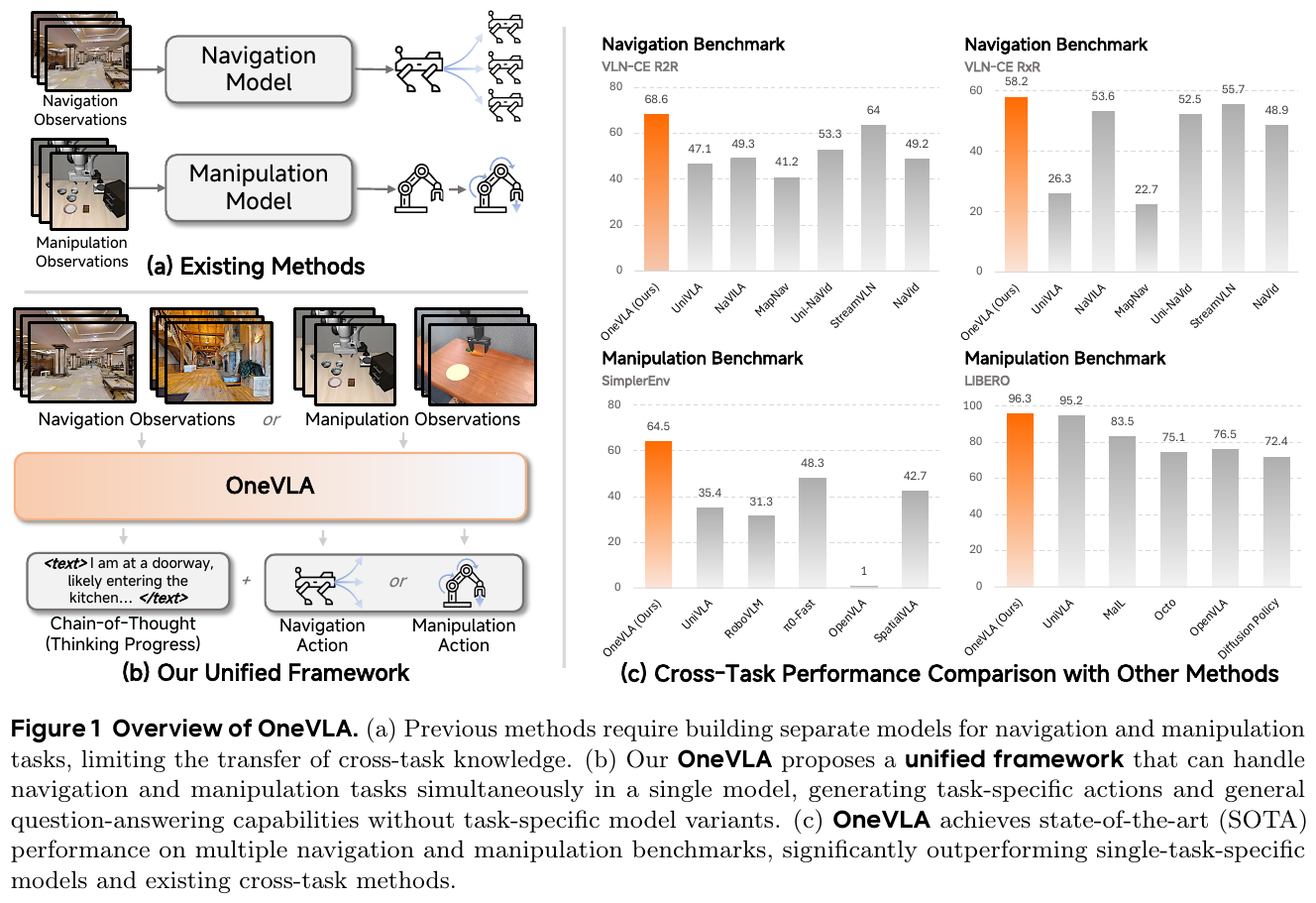
① 整体框架概述
OneVLA 在每个时间步 $t$ 接收包含多视角 RGB 图像($o_t$)、自然语言指令($l_t$)和可选的机器人状态($r_t$)在内的多模态输入。在单个 Forward Pass 中,模型先以文本自回归方式输出对指令的推理理解($y_t$),接着输出对应的动作序列($a_{t:t+T}$)。整体流程公式化表示为: \(OneVLA: (o_t, l_t, r_t) \rightarrow (y_t, a_{t:t+T})\) 动作输出会根据当前的任务自适应映射到离散导航命令或连续操作指令,而无需任何架构修改。
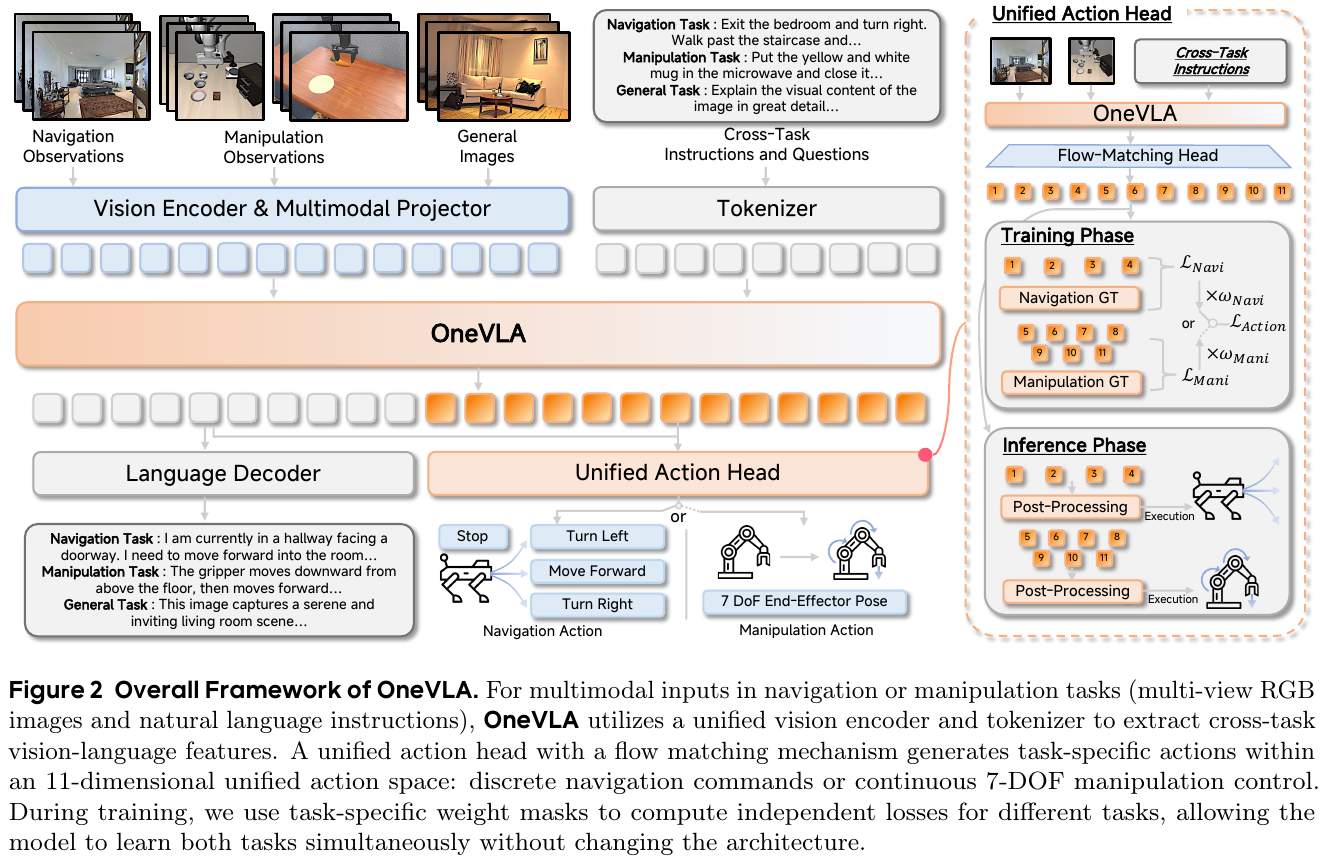
② 逐模块讲解
统一视觉-语言编码器(Unified Vision-Language Encoder)
- 输入:多视角观测 $o_t = {I_1, I_2, …, I_M}$($M$ 为摄像头视角数,如主相机与手眼相机)及文本指令 $l_t$。
- 处理:
- 每张图像 $I_i$ 被分割为 $14 \times 14$ 的图像块(Patches)。
- 通过 32 层的 Vision Transformer(隐藏维度 $d_v = 1280$)提取特征,并使用空间合并(merge size = 2)来捕获分层视觉特征。
- 通过线性投影层将提取的视觉特征映射到语言模型的隐藏空间($d_h = 2048$): \(V = \text{Proj}(\text{VisionEncoder}(o_t)) \in \mathbb{R}^{N_v \times d_h}\)
- 文本指令 $l_t$ 被 Tokenizer 编码到相同的 $d_h$ 空间。
- 将视觉 Token $V$ 与文本 Token $T$ 拼接后输入 36 层、具有 16 个注意力头的 Qwen2.5-VL-3B-Instruct 模型中进行深度跨模态融合。
- 输出:生成上下文感知的高维多模态表征 $H \in \mathbb{R}^{(N_v + N_t) \times d_h}$。
输出生成与 Token 解码(Output Generation)
- 核心机制:在词表中引入四种特殊 Token(
<text>,</text>,<action>,</action>),在单次前向传播中显式分离文本推理和动作生成两个阶段: \(\text{sequence} = \langle\text{text}\rangle y_t \langle/\text{text}\rangle \langle\text{action}\rangle \hat{a}_{t:t+T} \langle/\text{action}\rangle\) - 这种 Chain-of-Thought(CoT)式的设计允许模型先进行语言层面的物理推理与子目标规划,然后再条件化地生成执行动作,极大提升了多步任务下的可靠性与可解释性。
统一动作头与掩码流匹配(Unified Action Head)
- 11 维统一动作空间:拼接两个任务的动作输出:
\(a_{\text{unified}} = [a_{\text{navi}}, a_{\text{mani}}] \in \mathbb{R}^{11}\)
- $a_{\text{navi}} \in \mathbb{R}^4$:对应 discrete 导航指令的概率分布 $[p_{\text{forward}}, p_{\text{turn-left}}, p_{\text{turn-right}}, p_{\text{stop}}]$。
- $a_{\text{mani}} \in \mathbb{R}^7$:对应机械臂操作的 7-DOF 连续控制量 $[\Delta x, \Delta y, \Delta z, \Delta roll, \Delta pitch, \Delta yaw, g]$。
- 动作预测机制:采用基于 Transformer 的扩散模型(DiT-B)和流匹配(Flow Matching)。在去噪过程中,模型接收高维表征 $H$、时间步 sinusoidal 编码以及动作噪声 $a_t$,通过 Euler 积分迭代 $N$ 步预测速度场 $v_\theta$,最终生成连续的动作序列。
- 任务特定权重掩码(Loss Masking):为了消除离散导航概率与连续操作姿态之间的相互梯度干扰,对样本 $i$ 设计了掩码 $w_{\tau_i} \in {w_{\text{navi}}, w_{\text{mani}}}$。对于导航任务,操作相关的 7 维 loss 权重设为 0,反之亦然。关键维度(如 Stop 命令)被分配更高权重以缓解类别不平衡。 \(L_{\text{action}}^i = \text{mean}(w_{\tau_i} \odot (\hat{v}_{\theta}^i - v^i)^2)\)
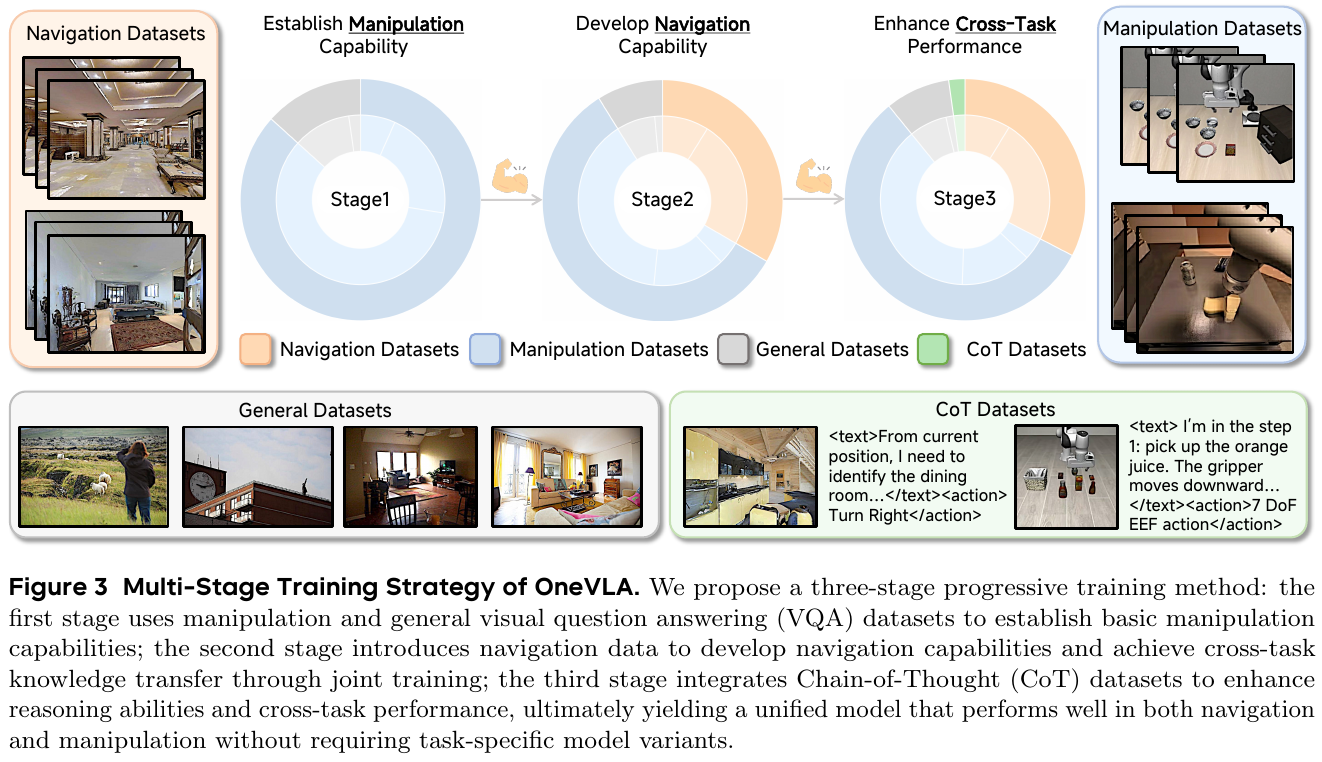
③ 多阶段渐进式训练策略
为了使单一模型平滑掌握如此异构的动作与理解空间,OneVLA 设计了三阶段训练方案:
- Stage 1 (操作基础建立):仅在机械臂操作数据集和通用视觉问答(VQA)数据集上进行预训练,只更新操作相关维度。
- Stage 2 (导航能力融入):引入 VLN 导航数据进行跨任务联合训练。此时两个通道的损失同时计算(使用各自的任务特定 Mask 隔离),使得 Vision-Language 骨干网开始学习融合两者的共享表示。
- Stage 3 (思维链 CoT 强化):最后阶段加入 Chain-of-Thought(CoT)推理数据,对语言和动作头进行端到端的联合微调,以极大强化模型在长程交互中的高层规划与理解能力。
3. 核心结果/发现
① 仿真基准对比(SOTA 性能)
OneVLA 在导航基准 VLN-CE (R2R & RxR) 以及操作基准 SimplerEnv 上均表现卓越:
| 类别 / 模型 | 统一架构 | R2R OSR ↑ | RxR OSR ↑ | SimplerEnv Avg. Success Rate ↑ |
|---|---|---|---|---|
| 导航专用 VLA | ||||
| NaVid (7B) | ❌ | 49.2% | 48.9% | - |
| Uni-NaVid (7B) | ❌ | 53.3% | 52.5% | - |
| StreamVLN (7B) | ❌ | 64.0% | 55.7% | - |
| 操作专用 VLA | ||||
| $\pi_0$-Fast (3B) | ❌ | - | - | 48.3% |
| OpenVLA-OFT (7B) | ❌ | - | - | 41.8% |
| 多任务跨域 VLA | ||||
| UniVLA (7B) | ❌ | 47.1% | 26.3% | 35.4% |
| OneVLA (Ours, 3B) | ✓ | 68.6% | 58.2% | 64.5% |
| 相比 UniVLA 提升 | - | +21.5% | +31.9% | +29.1% |
- 跨构型碾压:作为一个参数量仅 3B 的完全统一模型,OneVLA 击败了所有 7B 的专用单任务模型(如 StreamVLN 7B)和多任务模型(如 UniVLA 7B),且不需要为每个任务维护独立的动作头。
② 消融实验与互惠实证
- 渐进式训练的价值:多阶段训练相比单阶段混合训练,在导航和操作上的性能分别提升了 12.5%、15.3% 和 18.3%(见下表),证明了逐步引入任务复杂性的必要性。
| 训练策略 | R2R OSR | RxR OSR | SimplerEnv Avg |
|---|---|---|---|
| OneVLA (单阶段直接训练) | 56.1% | 42.9% | 46.2% |
| OneVLA (多阶段渐进训练) | 68.6% | 58.2% | 64.5% |
- 跨任务互惠效应(Mutual Reinforcement):将导航与操作进行联合训练后,相比于单独训练导航(Navi. Only)或单独训练操作(Mani. Only),模型在 R2R 导航上提升了 7.3%,在 RxR 导航上提升了 9.3%,在操作上提升了 5.5%(见下表)。这强有力地证实了:不同的具身任务在共享特征网络下,能学到更好的通用空间与多模态表征,从而互利共赢。
| 训练设置 | R2R OSR | RxR OSR | SimplerEnv Avg |
|---|---|---|---|
| OneVLA (单独任务训练) | 48.8% | 33.6% | 40.7% |
| OneVLA (跨任务联合训练) | 56.1% | 42.9% | 46.2% |

- 动作跨度(Action Horizon)消融:评估表明,预测步数 $T = 5$ 最优。过短的步数缺乏时序建模,过长的步数(如 8 步)由于累积误差,会导致操作性能急剧下降。
③ 真实世界实物评估
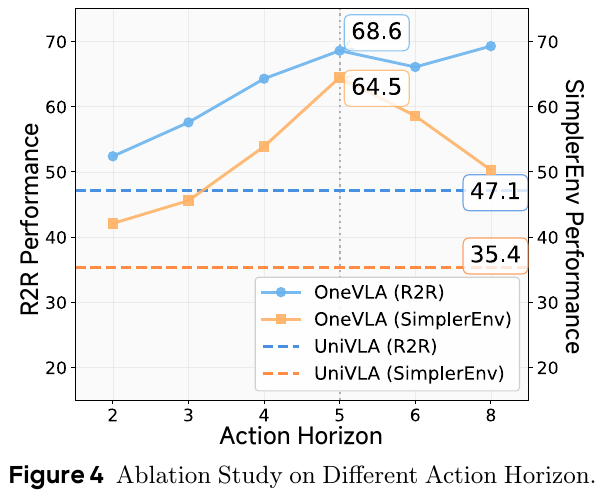
- 移动导航真机:四种典型场景中,导航成功率达 77.5%,相比 UniVLA 提升 35.0%。
- Franka 机械臂操作:四种代表性灵巧任务中,成功率达 78.8%,相比 UniVLA 提升 16.3%。证明了从仿真到现实(Sim-to-Real)的极强迁移与泛化能力。
4. 局限性
- 真实世界极端长程任务的漂移:在极长程或多障碍物的复杂动态真机导航中,偶尔会出现因推理步数过多导致的动作偏差累积。
- 离散动作维度的稀疏性:统一动作空间中,虽然有 Loss Mask 屏蔽梯度,但在模型前向传播中导航动作依然以离散概率输出,无法直接表征更精细、连续的转弯控制。
- 计算延迟限制:自回归的 CoT 文本推理(
<text>...</text>)虽然能大幅增加准确率,本模型生成时间也随之增加,带来了额外的推理延迟,对于高频闭环机械臂控制(如 > 20Hz)具有一定的部署压力。
43. CA-VLN (2026)
——— 基于双智能体协作的多模态大模型具身导航框架
📄 Paper: Sensors 2026
精华
- 双智能体协作机制:将高层常识认知与底层情景记忆解耦,通过知识推理智能体(Knowledge Agent)和分层历史智能体(History Agent)的协作,有效提升了具身导航智能体在未见环境(unseen environments)中的泛化与回溯能力。
- 渐进式在线知识生成:在推理时,智能体根据原始指令和实时视觉观测动态生成并检索 Top-K 相关的语义知识事实,降低了对静态离线知识库的依赖。
- 分层拓扑记忆设计:通过视角层与路径层的分层描述构建情景记忆拓扑图,既保留了时序连续性,又有效防止了徘徊或往复运动引起的记忆爆炸。
- 两阶段参数高效微调:利用 LoRA 约束可训练参数在 10M 以内,先后微调双智能体及多模态融合模块,实现了对大模型在具体导航任务中的低成本领域自适应。
- 解耦泛化的 Sim-to-Real 启示:将导航策略绑定在相对稳定的语义概念和连通关系上,而非脆弱的低层视觉纹理,这为克服 Sim-to-Real 的领域偏移提供了极佳的可迁移设计。
1. 研究背景/问题
视觉语言导航(VLN)要求智能体依据自然语言指令在复杂 3D 环境中寻路。然而,传统端到端方法在面临未见环境时泛化性能较差,且在大规模场景中由于缺乏长程历史语境而容易迷失或陷入循环。虽然近年来多模态大模型(MLLM)被引入具身导航,但大模型的庞大参数直接输出导航动作会带来巨大的“域差距”(Domain Gap)和极高的计算延迟,如何巧妙地将大模型的常识推理优势与精细的底层局部决策及空间拓扑记忆融合,依然是个亟待解决的难题。
2. 主要方法/创新点
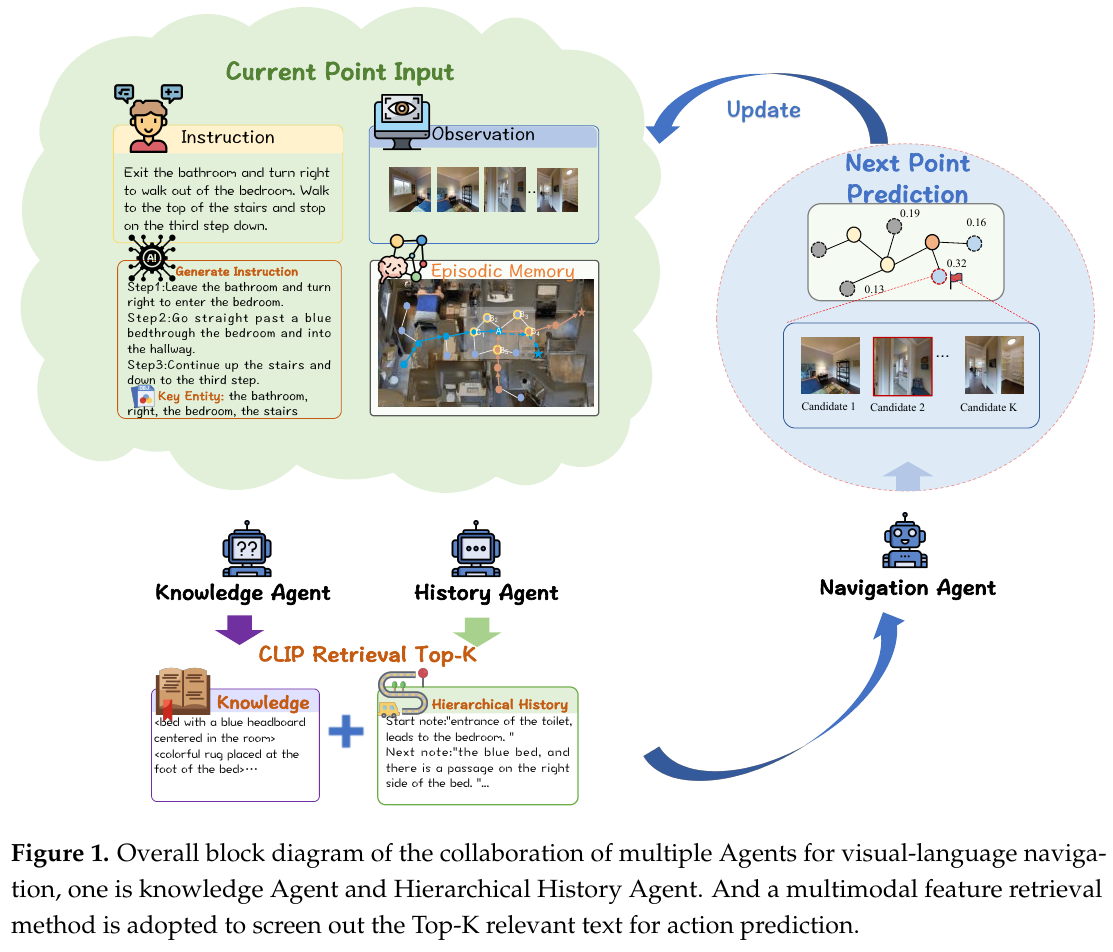
① 整体框架概述
CA-VLN 提出了一个由知识推理智能体(Knowledge Reasoning Agent)和分层历史智能体(Hierarchical History Agent)组成的双智能体协作框架,并通过专门的多模态融合模块对视觉、文本、常识及记忆特征进行深度交互,最终输出动作决策。
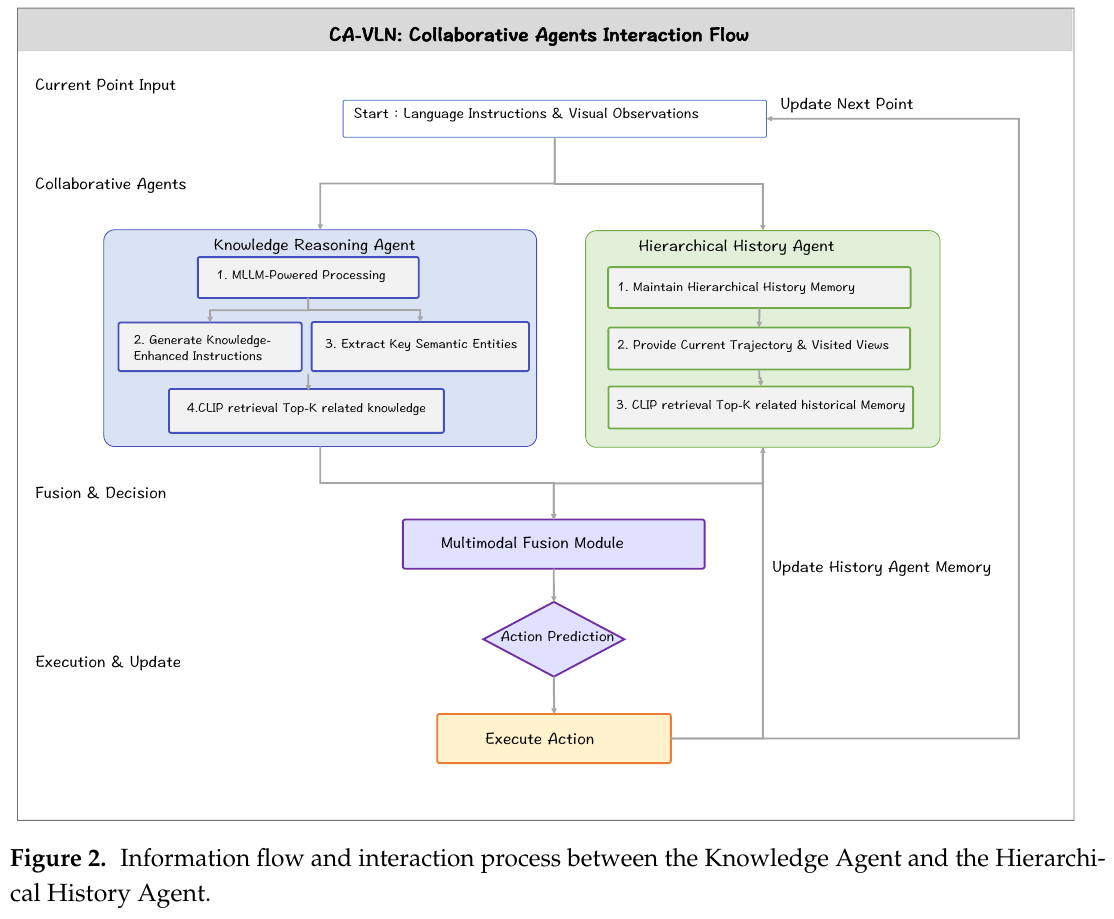
② 逐模块讲解
- 知识推理智能体 (Knowledge Reasoning Agent)
- 输入:原始自然语言指令、当前视角下的实时多视角图像。
- 处理:训练期间,将原始指令与真值轨迹拼接,由 MLLM 生成精确的逐步指令并提取关键实体;推理期间,在无真值情况下,大模型采用逐步提示策略,从颜色、形状、尺寸识别场景中的可见物体属性,描述空间布局,并利用 CLIP 文本编码器在当前指令与预设事实之间进行检索,获取 Top-K 最相关的语义事实(如“Dining table is near the kitchen”)。
- 输出:提取的关键语义实体特征向量和检索到的 Top-K 语义事实特征向量。
- 设计动机:为了桥接 MLLM 与下游导航动作决策之间的语境鸿沟,将大模型作为“高级规划器与常识检索器”,用自然语言描述辅助多模态对齐。
- 分层历史智能体 (Hierarchical History Agent)
- 输入:当前时刻的图拓扑结构、历史遍历节点的局部场景描述以及图像的 CLIP 特征。
- 处理:维护两层分层结构:一是视角层(Viewpoint Hierarchy),利用 LLaVA 针对每一个新访问的观测点生成包含位置类型、显著视觉特征和连通区域关系的三元组描述;为了避免徘徊往复运动引起记忆爆炸,仅在智能体前进到新观测点时追加新节点。二是路径层(Path Hierarchy),按时间轴级联已访问视角的描述,利用 MLLM 进行全局路径的语义增强。
- 输出:分层历史特征向量 $H_{hist}$ 及拓扑节点的连接描述。
- 设计动机:克服了传统图神经网络在长距离依赖 and 长程回溯时因缺乏高层时序语义而迷失的缺点。
- 历史增强模块 (History Enhancement Module, HEM)
- 输入:未增强的局部节点特征向量 $V_t$、候选节点特征向量 $v_i$ 以及情景记忆中检索出的相关记忆向量 $m_s$。
- 处理:首先通过 MLP 对节点特征与记忆特征进行非线性融合: \(\tilde{V}_t = \text{MLP}([V_t; m_s]), \quad \tilde{v}_i = \text{MLP}([v_i; m_s])\) 随后通过图注意力网络(Graph-Aware Transformer, GAT)建立全局依赖关系。GAT 内部包含交叉注意力层(用于建模节点特征关系)和自注意力层(用于编码拓扑布局),计算公式为: \(\tilde{h}'_t = \text{GAT}(\tilde{h}_t) = \text{softmax}\left(\frac{(\tilde{h}_t W_q)(\tilde{h}_t W_k)^T}{\sqrt{d}} + M\right)\tilde{h}_t W_v\) 其中偏置矩阵 $M = D W_a + b_d$ 用于整合拓扑距离图,限制不可达节点间的影响。
- 输出:增强后的全局历史轨迹特征表示 $\tilde{H}t = {\tilde{h}’_1, \tilde{h}’_2, \dots, \tilde{h}’{t-1}}$。
- 设计动机:使历史表征既富有时序和语义信息,又兼备精确的几何结构约束,从而提升回溯决策的准确性。
- 多模态融合与动作预测模块
- 该模块包含指令引导特征融合 (IGFF) 和 知识感知视觉语义交互器 (KVSI) 两个子部分。
- IGFF 模块:提取指令
[CLS]Token 的全局语义特征,通过交叉注意力计算各视觉区域特征 $o_i$ 的响应权重,使智能体聚焦在指令相关的地标上: \(\eta_i = \text{softmax}\left(\frac{o_i W_q \hat{W}_0^T}{\sqrt{d}}\right), \quad \bar{o}_i = \eta_i o_i\) - KVSI 模块:融合视觉与知识特征。首先通过交叉注意力计算视觉查询与知识键之间的对齐分数 $a_{ij}$,并得到融合语义知识的局部特征: \(a_{ij} = \text{softmax}\left(\frac{Q K^T}{\sqrt{d}}\right), \quad o'_i = \sum_{j} a_{ij} \cdot V_j\) 此后通过自注意力精炼空间关系,并引入自适应视角加权机制(Adaptive View Weighting),结合历史语境为各候选视角计算重要性得分,最终通过 Softmax 归一化计算出加权后的上下文表征。
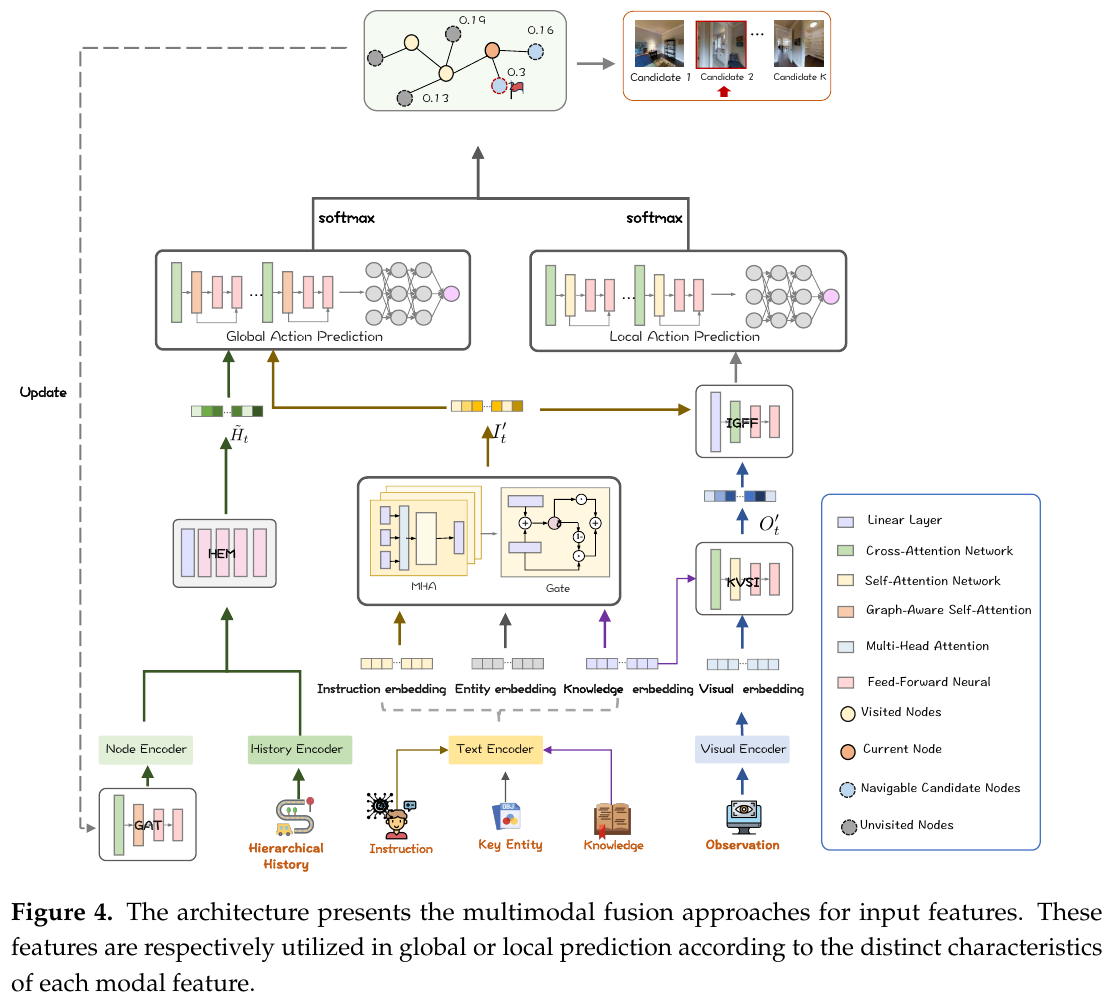
③ 端到端数据流
在每一个决策步骤 $t$:
- 智能体从当前环境获取全景视觉观测 $O_t$。
- 知识推理智能体结合当前指令与多模态模型在线生成的描述,检索出 Top-K 的语义事实知识 $K_{emb}$。
- 分层历史智能体更新图拓扑结构并利用 HEM 得到增强后的全局轨迹特征 $\tilde{H}_t$。
- 将提取的视觉特征、知识特征、指令特征和实体特征分别输入多模态融合模块,通过 KVSI 进行知识-视觉对齐,通过 IGFF 进行指令-视觉对齐,得到精炼的局部候选特征表示。
- 全局动作预测分支利用图注意力对全局拓扑图和指令交叉建模输出全局候选得分,局部动作预测分支则针对当前节点的相邻导航候选进行局部打分。
- 二者经过自适应加权融合,利用 Softmax 决策出概率最大的下一步动作(执行移动或停止),并更新下一时刻的历史和拓扑。
④ 训练目标 / 损失函数
模型采用两阶段微调。首先采用 LoRA 对 LLaVA-7B 进行指令微调,将可训练参数限制在 10M 以内,优化其生成 stepwise 指令与分层历史描述的能力。随后冻结智能体,联合微调融合与动作预测模块。动作预测分支使用行为克隆(Imitation Learning)与强化学习的混合损失进行优化。
3. 核心结果/发现
- R2R 数据集表现:在 unseen validation 集合上,CA-VLN 达到了 73.31% 的 Success Rate (SR)(相比基线 DUET 提升了 +1.79%)和 61.95% 的 SPL(提升 +1.53%);在 unseen test 集合上,SR 达到 70.27%,SPL 达到 60.31%,超越了 HAMT 和 KERM 等 SOTA 方法。
- REVERIE 与 SOON 表现:在包含丰富物体定位要求的 REVERIE 数据集上,未见场景下的 SR 达到 50.99%,物体定位指标 RGSR 提升了 +2.85%;在路径更长、空间结构更复杂的 SOON 数据集上,unseen validation 上的 SR 达到 37.32%(+1.02%),表明分层历史与知识增强对于大范围探索有明显增益。
- 消融实验与超参分析:分层历史、实体引导、大模型逐步指令等均提供了正向增益。对于 Top-K 的敏感度分析表明,知识检索的 Top-K 设定在 3 至 5 之间为最佳,过高(Top-K > 5)会因引入冗余或幻觉信息导致性能骤降。
4. 局限性
- 视觉稀疏场景敏感:在缺乏显著地标和物体纹理的视觉极简场景下,知识推理智能体由于无法捕捉丰富的实体属性,对导航指令的语义增强效果会有所下降。
- 计算与推理延迟:由于引入了在线 MLLM 的文本描述检索和图注意力计算,每步导航决策的推理耗时相比 baseline 增加了约 15%(但更优的路径规划即更高的 SPL 减少了总导航步数,在总耗时上提供了部分补偿)。
44. VLN-CE (2020)
——Beyond the Nav-Graph: 在连续环境中的视觉-语言导航
📄 Paper: arXiv:2004.02857 · 🏛️ ECCV 2020
精华
这篇论文通过将 VLN 任务从离散导航图迁移到连续 3D 环境,揭示了基于导航图的设定中隐含的强假设对性能的巨大影响。值得借鉴的核心思想包括:批判性地审视任务设定中的隐含假设、通过消除不现实的简化来提高任务的实际应用价值、深度信息在具身导航中的关键作用、以及端到端学习与低层控制结合的必要性。这种”去简化”的研究思路对构建更接近真实机器人应用的 AI 系统具有重要指导意义。
研究背景/问题
现有的 Vision-and-Language Navigation (VLN) 任务基于导航图 (nav-graph) 表示,引入了三个不现实的假设:已知环境拓扑、短距离 oracle 导航、以及完美的智能体定位。这些假设使得任务本质上退化为视觉引导的图搜索问题,与真实机器人导航场景存在巨大差距,限制了向实际机器人平台迁移的可能性。
主要方法/创新点
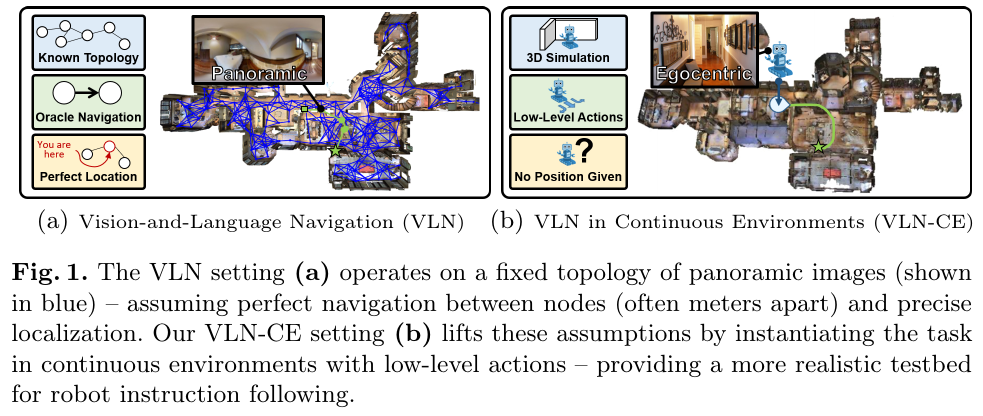
论文提出了 Vision-and-Language Navigation in Continuous Environments (VLN-CE) 任务,在 Habitat 模拟器中实例化连续的 Matterport3D 环境。主要创新包括:
-
连续环境设定:智能体通过低层动作(前进 0.25m、左转/右转 15°、停止)在连续 3D 空间中自由导航,而非在固定节点间传送。
-
轨迹迁移方法:设计了将 Room-to-Room (R2R) 数据集的导航图轨迹转换为连续环境路径的算法。通过向下投射射线找到最近的可导航点,并使用 A* 算法验证路径可达性,成功转换了 77% 的 R2R 轨迹(4475 条)。
- 模型架构:
- Seq2Seq Baseline: 使用 GRU 处理 RGB 和 Depth 观察的均值池化特征以及 LSTM 编码的指令
- Cross-Modal Attention Model: 采用双 GRU 架构,一个处理视觉观察,另一个基于注意力机制融合指令和视觉特征进行决策。使用预训练的 ResNet50 (ImageNet) 提取 RGB 特征,使用预训练的 ResNet50 (Point-Goal Navigation) 提取深度特征。
- 训练策略:
- 基础模仿学习 with inflection weighting
- DAgger 应对 exposure bias
- Progress Monitor 辅助损失
- Speaker 模型生成的合成数据增强(~150k 条轨迹)
核心结果/发现
-
任务难度显著增加:VLN-CE 中平均轨迹长度为 55.88 个动作,而 VLN 仅需 4-6 个节点跳转。最佳模型在 val-unseen 上达到 32% 成功率 (SR) 和 0.30 SPL,显著低于 VLN 中的表现。
-
深度信息至关重要:移除深度输入导致模型性能崩溃(成功率 ≤1%),而移除 RGB 或指令的影响相对较小。深度使智能体能够快速学会有效遍历环境(避免碰撞),是引导学习的关键信号。
-
训练技术的混合效果:Cross-Modal Attention 优于 Seq2Seq;DAgger 带来 3-5% SPL 提升;但 Progress Monitor 和数据增强单独使用时效果不佳,需要组合使用(预训练 + DAgger 微调)才能达到最佳性能。
-
导航图的强先验:将 VLN-CE 训练的智能体路径转换回导航图并在 VLN 测试集上评估,SPL 为 0.21,远低于利用导航图训练的 SOTA 方法(0.47 SPL)。这表明现有 VLN 结果可能因导航图的强先验而被高估。
-
单模态消融:无指令模型达到 17% SR,无图像模型也达到 17% SR,表明轨迹存在共同的规律性;但完整多模态模型(20% SR)仍明显优于单模态基线。
局限性
约 23% 的 R2R 轨迹无法在连续环境中导航(环境重建的不连续性、物体移动等)。当前端到端方法的绝对性能仍较低,未来需要探索模块化方法,如将学习到的智能体与运动控制器集成。论文未详细探索所有可能改善 VLN-CE 性能的技术(如更多应对 exposure bias 和数据稀疏性的方法)。
45. VLN-PE (2025)
———重新思考视觉-语言导航中的具身化差距:物理和视觉差异的全面研究
📄 Paper: arXiv:2507.13019 · 🏛️ ICCV 2025
精华
这篇论文通过构建物理真实的VLN平台,系统性地揭示了理想化仿真与物理部署之间的巨大差距。核心启示包括:(1) 跨具身数据融合训练可以显著提升模型泛化能力,为统一的跨机器人导航模型奠定基础;(2) 多模态感知(RGB+Depth)比单一RGB更鲁棒,尤其在光照变化环境下;(3) 物理控制器的引入对于腿足机器人至关重要,训练和评估阶段的控制器一致性直接影响性能;(4) 现有MP3D风格数据集的泛化能力有限,小规模域内数据微调即可超越大模型零样本性能;(5) diffusion policy作为连续路径点预测的新范式在VLN任务中展现潜力。
研究背景/问题
现有的VLN方法在理想化仿真环境中表现优异,但在部署到真实物理机器人时面临巨大挑战。主要问题包括:当前VLN平台忽视了机器人的物理具身特性(如视点高度、运动动力学、碰撞和跌倒等),并且缺乏对不同机器人类型(轮式、人形、四足)的跨具身支持。研究核心问题是:物理具身约束和视觉环境变化对现有VLN方法的性能影响究竟有多大?
主要方法/创新点
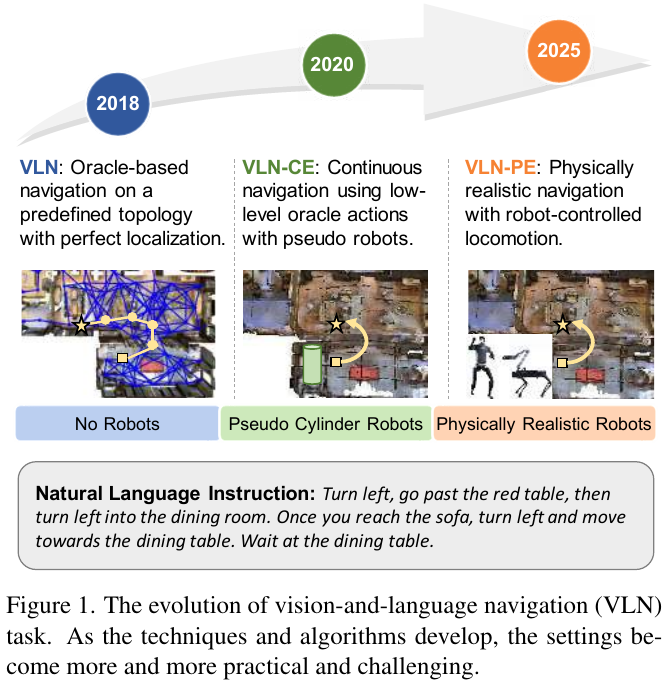
论文提出了VLN-PE平台,一个基于GRUTopia构建的物理真实VLN基准测试平台,具有以下核心特性:
-
跨具身支持:支持人形机器人(Unitree H1, G1)、四足机器人(Unitree Aliengo)和轮式机器人(Jetbot),并提供基于RL的物理控制器API,实现真实的运动动力学模拟
-
场景多样性:除了90个MP3D场景外,新增10个高质量合成家居场景(GRScenes)和3DGS在线渲染实验室场景,支持无缝集成更多环境
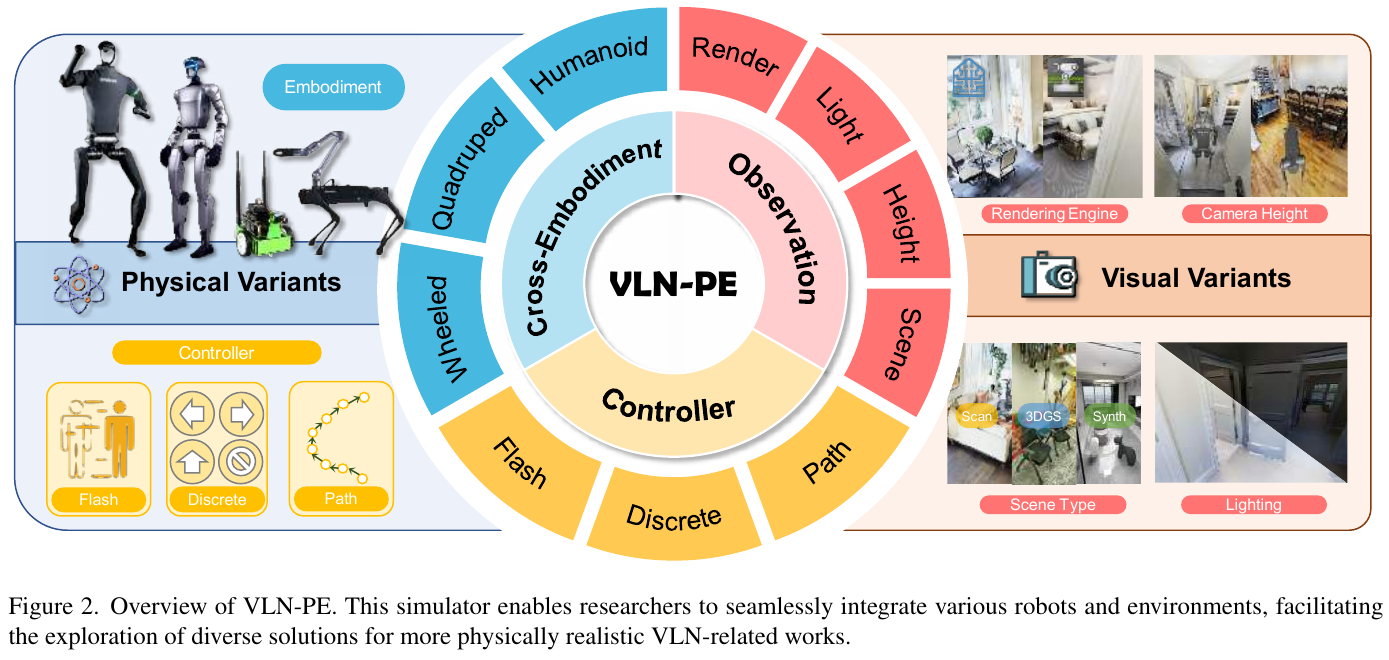
- 系统性评估框架:评估三类ego-centric VLN方法
- 单步端到端方法:Seq2Seq、CMA(约36M参数)和NaVid(7B参数的视频MLLM)
- 多步端到端方法:首次提出RDP(Recurrent Diffusion Policy),使用transformer-based diffusion模块预测连续轨迹路径点
- 地图基零样本方法:改进的VLMaps,结合LLM和语义地图进行路径规划
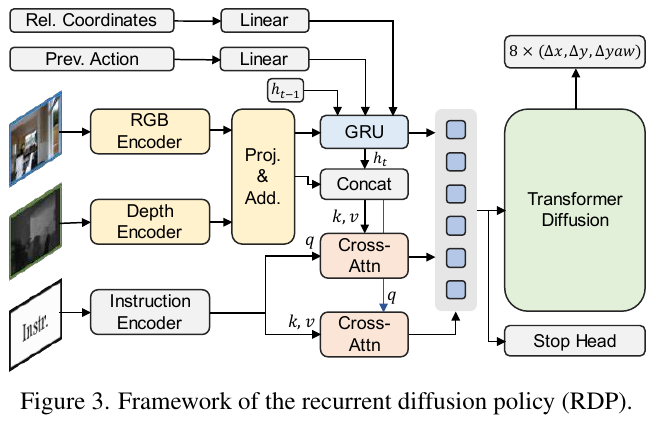
- 新数据集:
- R2R-filtered:过滤楼梯场景后保留8,679/658/1,347个训练/val-seen/val-unseen episodes
- GRU-VLN10:10个合成场景,441/111/1,287个episodes
- 3DGS-Lab-VLN:3DGS渲染实验室环境,160训练/640评估episodes
- 新评估指标:除了传统的TL、NE、SR、OS、SPL外,新增Fall Rate (FR)和Stuck Rate (StR)来衡量物理真实性挑战
核心结果/发现
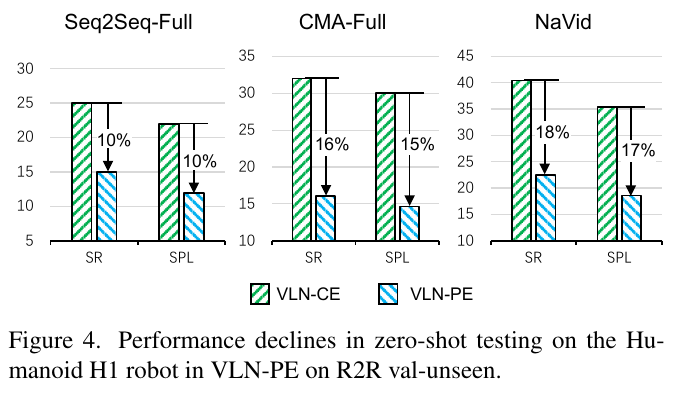
零样本迁移性能大幅下降:
- VLN-CE模型直接迁移到VLN-PE时,SR相对下降约34%
- Seq2Seq-Full、CMA-Full和NaVid的SR分别下降10%、16%和18%
- 这表明现有模型严重过拟合特定仿真平台
域内微调显著提升:
- 在VLN-PE上从头训练的CMA(无数据增强)超越了使用175K增强数据训练的CMA-Full
- 小模型CMA+经过微调后,在val-seen上达到SR 28.72,SPL 24.24,超越NaVid的零样本性能
跨具身敏感性:
- 四足机器人(相机高度约0.5m)在迁移时几乎完全失败
- 调整相机高度到1.8m可改善人形机器人的迁移性能
- 跨具身联合训练使单一模型在所有机器人类型上达到SoTA性能
物理控制器的重要性:
- 训练和评估使用相同控制器时性能最佳
- 使用物理控制器收集数据可降低Fall Rate和Stuck Rate
多模态鲁棒性:
- 仅RGB的NaVid在低光照下SR下降12.47%
- RGB+Depth的CMA和RDP受光照影响较小(下降约1-2%)
MP3D数据集泛化能力有限:
- 在GRU-VLN10上,RDP用6M参数仅441个训练样本,零样本超越NaVid大模型
- 在3DGS-Lab-VLN上,NaVid完全失败(SR仅5.81),可能是3DGS渲染噪声导致
扩散策略的潜力:
- RDP作为首个VLN扩散策略基线,在从头训练时优于Seq2Seq和CMA
- 预测连续密集路径点,可与MPC等控制理论方法结合
真机实验验证:
- 使用Unitree Go2机器人进行14个室内场景测试
- VLN-PE微调模型在真实环境中OS达到57.14,SR达到28.57,显著优于VLN-CE训练模型
局限性
当前RL-based运动控制器无法可靠处理复杂环境中的楼梯导航,需要过滤相关场景。论文主要聚焦ego-centric视角,未评估panoramic VLN方法。MLLM在精确目标识别和停止决策上仍存在挑战。3DGS渲染引入的像素级噪声可能干扰纯RGB模型,需要进一步研究图像扰动的鲁棒性。
46. RynnBrain (2026)
———Open Spatiotemporal Foundation Model for Embodied Intelligence
📄 Paper: arXiv:2602.14979
精华
RynnBrain 最值得借鉴的核心思想包括:统一输出空间设计——将 bounding box、轨迹点、区域点等空间量编码为离散 coordinate token,与语言 token 共享同一 autoregressive 解码器,优雅地将定位任务转化为分类问题;Chain-of-Point (CoP) 推理——在文本推理链中交替插入显式空间定位步骤,使推理过程”扎根”于物理环境,避免幻觉;层级式 Plan-VLA 架构——高层 RynnBrain-Plan 生成带精确坐标的子任务计划,低层 RynnBrain-VLA 执行动作,两者分工明确;人模协作数据飞轮——仅在关键节点引入人工标注,结合模型辅助生成,以有限预算构建出 2000 万样本的高质量语料;多维度 Spatio-temporal Memory——将图像和视频统一为帧序列,用 temporal positional embedding 编码时序信息,赋予模型跨帧的全局空间感知能力。
1. 研究背景/问题
当前多模态基础模型在具身智能场景中存在三大缺口:自我中心认知范围狭窄(通常仅覆盖有限任务类别);空间推理局限于静态图像、缺乏时序一致的 spatio-temporal 表征;高层规划停留在纯文本空间、与物理约束脱节导致幻觉和执行失败。现有具身模型与通用 VLM 各有偏废,尚无统一框架同时具备宽泛语义泛化与精确物理定位能力。
2. 主要方法/创新点
RynnBrain 是阿里巴巴 DAMO Academy 提出的开源具身基础模型系列,基于 Qwen3-VL 构建,强化四大核心能力:
① 综合自我中心理解 (Egocentric Cognition) 涵盖物体理解、空间理解、计数、OCR、自我中心任务问答等,新增细粒度视频理解能力。
② 多样化时空定位 (Spatio-temporal Localization) 输出涵盖 Object Location(bounding box)、Area Location(区域点集)、Affordance Location(可交互热点)、Trajectory Location(最多 10 个轨迹航点)、Grasp Pose(4 角点抓取矩形),所有坐标归一化到 [0, 1000] 编码为整数 token。

③ 物理扎根推理 (Chain-of-Point Reasoning) RynnBrain-CoP 在推理链中交替生成文本步骤与空间定位 token,将抽象推理锚定到可观测的物理证据。训练数据由 Qwen3-VL-235B 生成初始推理链,再经人工标注关键帧精确空间实体。
④ 物理感知规划 (Physics-aware Planning) RynnBrain-Plan 输出的子任务计划直接嵌入 affordance/区域坐标,供下游 RynnBrain-VLA 执行;使用多轮对话数据微调,维持任务执行中的历史状态一致性。
模型规模:提供 RynnBrain-2B、8B(Dense)和 30B-A3B(MoE)三个尺度,预训练语料约 2000 万样本,涵盖 General MLLM、Cognition、Localization、Planning 四大类别。
训练优化:在线负载均衡流水线(按序列长度动态分配 DP worker),per-sample loss reduction 消除全局 token 计数同步开销,训练效率提升 2×。
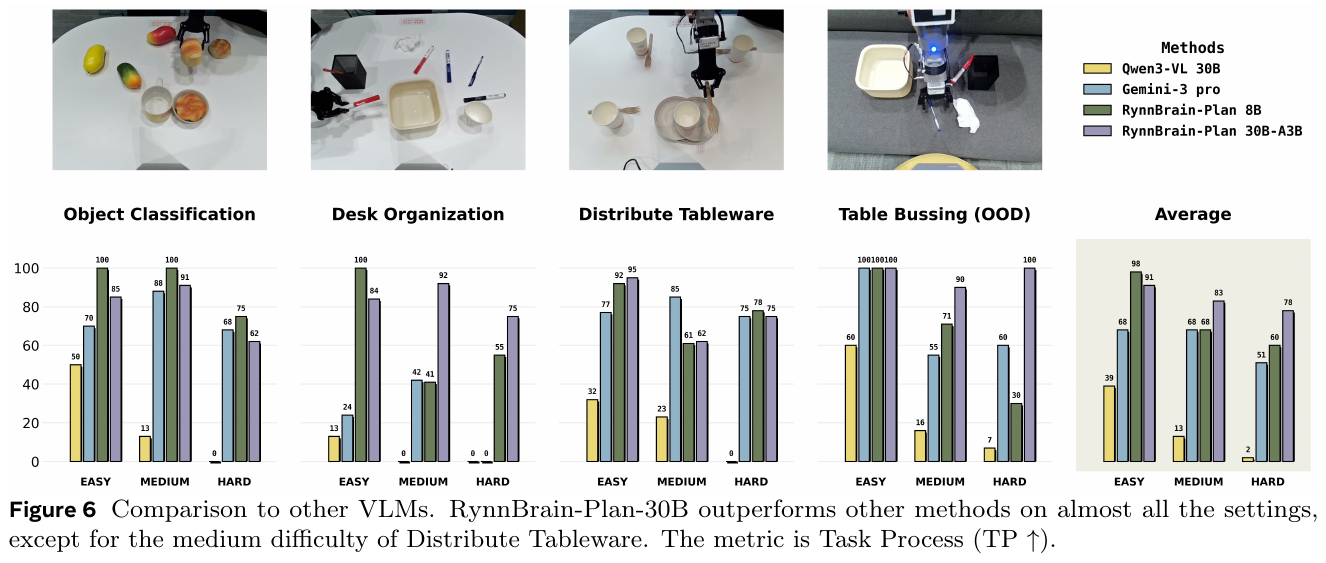
3. 核心结果/发现
- VLN 导航:RynnBrain-Nav-8B 在 R2R 基准达到 SOTA(SR 56.1%、NE 4.92),在 R2R 和 RxR 上全面超越同尺度 Qwen3-VL 基线;2B 模型相比 Qwen3-VL-2B 提升 7.2% SR / 7.6% SPL;DAgger 迭代训练将 SR 从 50.6% 提升至 58.5%。
- 操作规划:RynnBrain-Plan-30B 在 OOD 任务 Table Bussing Hard 难度达到近 100% Task Progress,而 Qwen3-VL 30B < 10%、Gemini-3 Pro ~60%;多轮对话微调相比单轮基线在 Hard 任务提升显著(单轮几乎为 0)。
- VLA 抓取:RynnBrain-VLA 整体 SR 为 0.77,超越 π₀.₅(0.47)和 Qwen3-VL-Finetuned(0.60);RSR 0.97,体现出强的目标识别精度。
- 综合评测:在 28 个基准(20 个具身 + 8 个通用视觉理解)上,RynnBrain 全面超越现有开源具身基础模型,同时保留竞争力的通用 VLM 能力。
4. 局限性
MoE 架构(30B-A3B)在 VLN 任务上未能超越 8B Dense 模型,稀疏激活机制在此类任务中的潜力尚未充分释放,需要进一步探索专门的训练策略;DAgger 迭代在第 3 轮后呈现明显收益递减,导航策略收敛后的持续提升路径有待研究。
47. EvoMemNav (2026)
——— 零样本具身导航中基于轻量化图先验与多视图反思的高效自进化细粒度拓扑记忆框架
📄 Paper: arXiv:2606.03509
精华
- 纯视觉记忆设计:提出视觉-语义记忆图(VSMGraph),将原始视觉视图(View)作为一等公民(first-class)存储在图节点中,避免了传统检测中心化场景图的信息压缩与噪声积累,且无需高昂的 3D 重建开销。
- 预算受限的粗到细决策(Budgeted Coarse-to-Fine):将决策分解为粗阶段(Explore,过滤并路由至前沿或锚点)和细阶段(Search+Verify,仅针对短名单进行 VLM 决策和多视图 Stop 验证),在降低 VLM 延迟与 Token 数的同时,解决了同类多实例歧义和过早停止(premature stop)问题。
- 反思驱动的自进化记忆(RDCMA):设计了一种无需训练的在线先验更新机制,在子任务结束后通过评估轨迹事件与停止结果,更新附着于图节点上的轻量级目标条件先验(Episode-STM 和 Scene-LTM),指导后续决策。
- 开箱即用且高效通用:在 GOAT-Bench 和 HM3D 上取得显著的 SR/SPL 提升,相比 3D-Mem 表现更佳,同时 VLM 调用次数减少了 41%,总耗时缩短了 39%,且无需任何权重训练或微调。
1. 研究背景/问题
在长程零样本具身导航(Zero-Shot Embodied Navigation)中,建立能够支撑长期规划的记忆系统至关重要。然而,现有的记忆表征方案存在以下局限性:
- 基于检测器的场景图(Detector-centric Scene Graphs):将观测压缩成稀疏的对象节点,会丢弃纹理、空间布局等细粒度视觉线索,且检测器的错误(如类别噪声)会在下游推理中累积,导致决策失误。
- 基于 3D 重建的记忆方法(3D-reconstruction-based Memory):在运行时会产生高昂的计算和存储开销,且与只能直接推理图像的强大 VLM 不兼容。
- 基于图像的拓扑图缓存(Image-based Topological Graphs):缺乏房间、前沿或可达性的结构化组织,容易在同类别物体的多实例场景中混淆,导致在错误的实例前过早停下(Premature Stop),且记忆缺乏演进能力,失败教训无法复用。
2. 主要方法/创新点
整体框架概述
EvoMemNav 由三个核心部分构成:构建于 occupancy grid 上的层次化拓扑记忆图(VSMGraph)、双阶段“粗到细”导航控制器(Coarse-to-Fine Policy)以及无训练的反思驱动在线自进化先验模块(RDCMA)。系统在每个时间步接收 posed RGB-D 观测,更新拓扑图;导航决策时,由粗决策进行候选过滤并导航,随后利用 VLM 进行细粒度的精确路由与多视图 Stop 验证;子任务结束时,反思机制将结果写回图中的轻量化统计量(STM/LTM),以指导未来的导航。
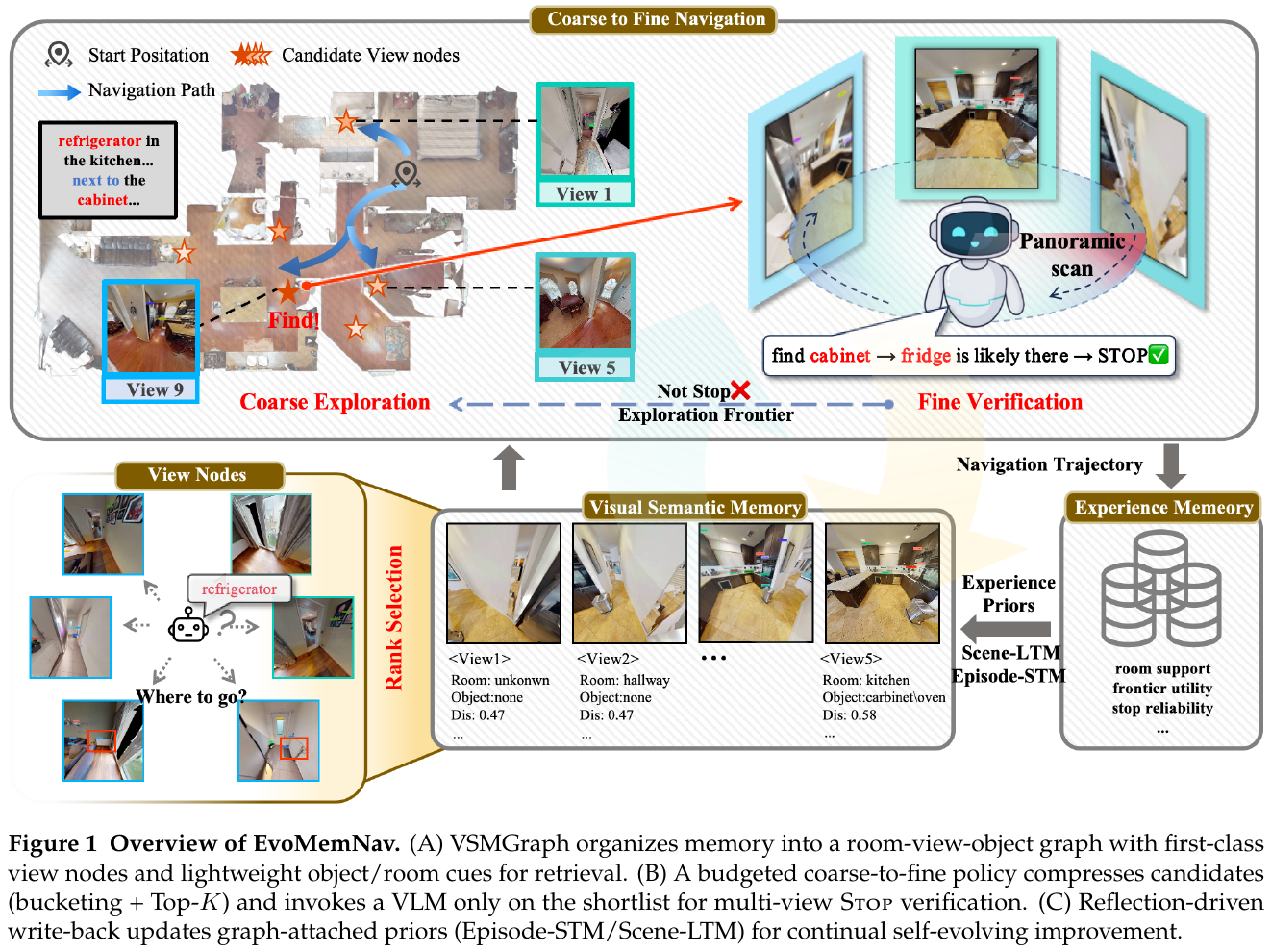
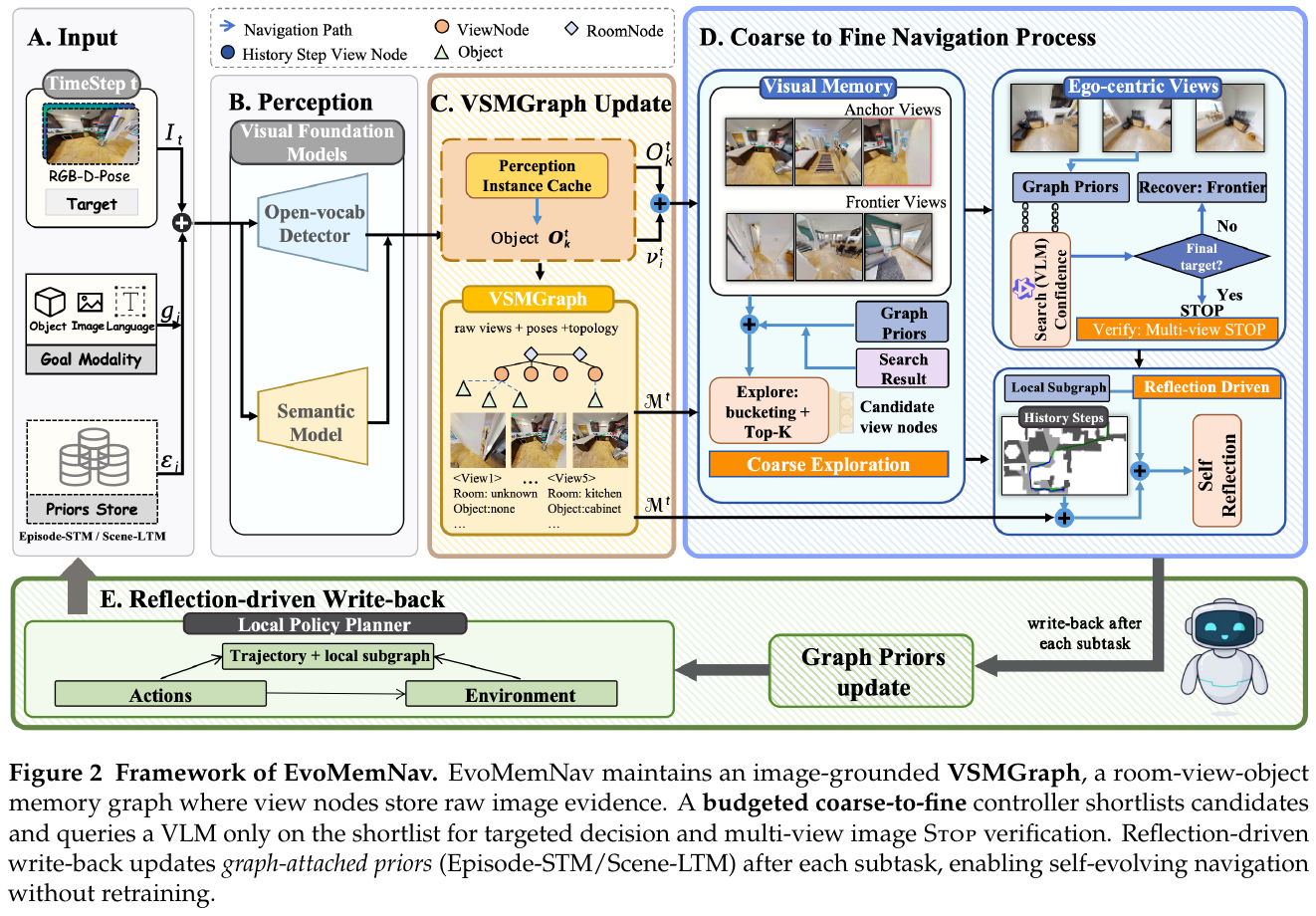
逐模块讲解
① 视觉-语义记忆图 (VSMGraph) 构建
- 输入:posed RGB-D 观测流 $I_t = \langle I_t^{rgb}, I_t^{depth}, p_t \rangle$ 和作为度量支撑的二维占用网格(occupancy grid)$M_t$。
- 处理:在线在占用网格上添加沿着机器人运动轨迹的视图节点,并根据无碰撞路径建立可达性边(navigability edges)。通过轻量级目标检测模型(YOLOv8-World & SAM)维护一个 3D 目标候选缓存 $O_{map}$,但它仅用于给视图节点添加“目标可见性”的弱标签(visibility edges),并不用于压缩图像信息。视图节点被划分为:
- 锚点视图 (Anchor Views) $V_{A,t}$:富含物体观测的已探索区域,存储原始图像、位姿及可见的目标弱标签。
- 前沿视图 (Frontier Views) $V_{F,t}$:位于探索边界的未探索区域,连接至最近的已探索视图,代表可探索的前沿方向。 同时,利用 CLIP 提取房间类别对每个视图进行分类 $\rho_v$,形成“房间-视图-物体”(Room-View-Object)的层次化拓扑图。
- 输出:图结构 $G_t = (R_t, V_t, O_t, E_t)$。
- 设计动机:以原始视图作为一等公民记忆,完全保留细粒度细节供 VLM 进行直接的图像级分析验证,避免检测误差引起的硬分类错误;同时,利用拓扑边和房间类别软标签加速检索。
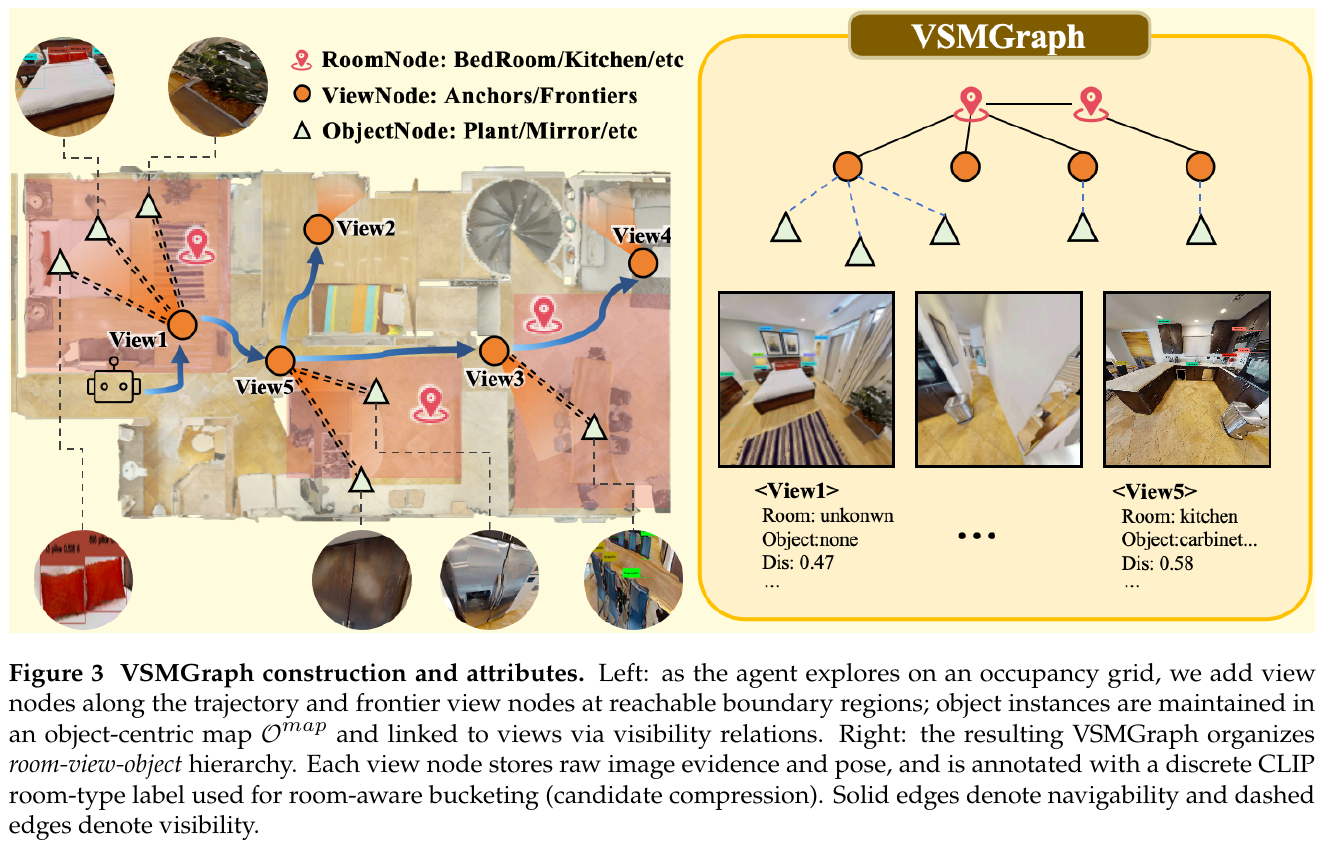
② 预算受限的粗到细导航决策(Coarse-to-Fine Policy)
- 输入:多模态目标 $g$、当前拓扑图 $G_t$。
- 处理:
- 粗阶段 (Explore - 候选压缩与路由):从大量的锚点和前沿视图中过滤,仅保留最相关的 Top-K 个候选(锚点候选集 $C_t^A$ 预算限制为 $K_A$,前沿候选集 $C_t^F$ 预算限制为 $K_F$)。候选通过房间类别关联和轻量目标命中进行初步筛选。如果锚点集为空,则直接路由至前沿;若不为空,则进入细阶段。
- 细阶段 (Search+Verify - 局部选择与验证):将过滤后的候选池 $C_t = C_t^A \cup C_t^F$ 输入给 VLM(Qwen3-VL-8B),VLM 只需对这个精简的短名单进行单步推理:
\(a_t, \sigma_t = \text{VLM}(g, C_t)\)
其中 $a_t$ 是选择的目标点,$\sigma_t \in {\text{certain}, \text{uncertain}, \text{unknown}}$ 为置信度。若 VLM 选择锚点视图但置信度不足(
uncertain/unknown),系统会强制降级为前沿探索以避免盲目决策。 - 验证步骤 (Verify - 多视图停止验证):当智能体抵达选择的锚点视图时,不立即停止,而是调用 VLM 结合智能体在当前位置的多角度视图进行最终的多视图 Stop 验证,返回
STOP或RESELECT。如果判定为RESELECT,则将当前锚点拉入冷却队列并重新回到粗阶段,防止由于局部视野限制而产生的过早停止错误。 - 恢复机制 (Recover):如果检测到死锁或多次冷却,会触发 Recover 机制,强制智能体进行一段时间的纯前沿探索。
- 输出:下一个运动路径终点或
STOP指令。 - 设计动机:用粗筛选控制 VLM 的计算开销(避免对全图检索的 Token 爆炸),同时在局部进行多视角图像级的细粒度对比,提高多实例判别的准确度。
③ 反思驱动在线记忆自适应 (RDCMA)
- 输入:历史子任务的运动轨迹事件(如常去的房间、探索受阻的前沿、环路检测等)以及多视图验证结果(STOP / RESELECT)。
- 处理:任务结束时,将结果以目标条件签名 $s_g$(类别或模态)归纳为轻量化统计先验,写回图结构中附着于对应的房间/视图/前沿节点:
- 短时记忆 (Episode-STM):缓存当前 episode 内的避障与路径惩罚信息,避免在一个任务中反复打转,在 episode 结束时重置。
- 长时记忆 (Scene-LTM):记录房间中特定物体的支持概率(例如,厨房更容易有冰箱)和特定锚点的停止可靠度,长效留存,跨子任务复用。 在 Explore 阶段,这些先验以“加权平局决胜(tie-breakers)”的方式调整过滤后的候选排序,指导探索方向;在 Verify 阶段,作为 hint 输入给 VLM 提示当前区域此前是否曾被成功验证过。 通过指数衰减(exponential decay)来淘汰陈旧先验,且仅保留 Top-K 项并对冲突先验进行抑制。
- 输出:图附着的记忆先验。
- 设计动机:实现非参数化的轻量自适应,使得智能体在未知的终身学习任务中能够随着时间“越走越聪明”,越熟悉当前环境,导航成功率越高。
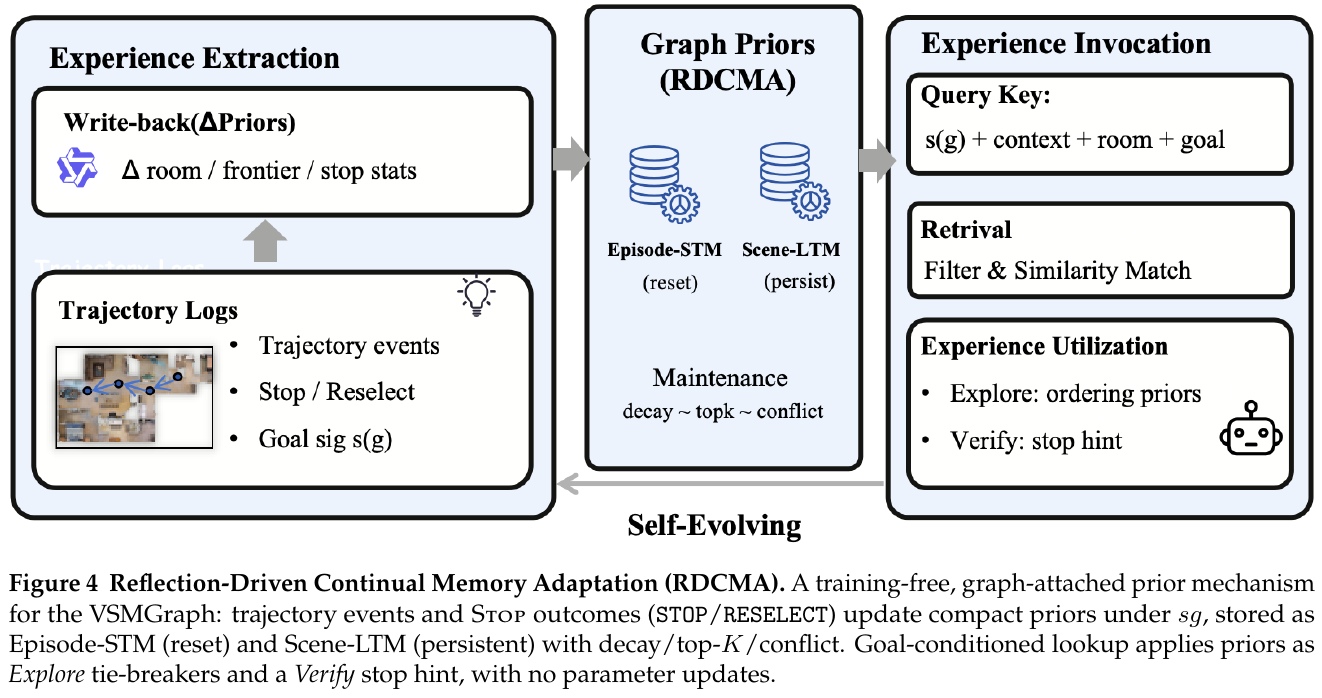
3. 核心结果/发现
- GOAT-Bench 终身多模态导航: 在 GOAT-Bench VAL-UNSEEN 验证集上,EvoMemNav 取得了 59.6% SR 和 38.9% SPL 的最佳结果(见下表),大幅领先于先前的图像级拓扑记忆方法 3D-Mem(42.6% SR / 22.8% SPL)和 MSGNav(52.0% SR / 29.6% SPL)。
| 方法 | 类别 | 是否无需训练 | SR (%) ↑ | SPL (%) ↑ |
|---|---|---|---|---|
| SenseAct-NN Monolithic [20] | 单体学习型 | ❌ | 12.3 | 6.8 |
| CLIP on Wheels [20] | 模块化零样本 | ✓ | 16.1 | 10.4 |
| Modular GOAT [20] | 模块化零样本 | ✓ | 24.9 | 17.2 |
| TANGO [28] | 模块化零样本 | ✓ | 32.1 | 16.5 |
| 3D-Mem [46] | 模块化拓扑 | ✓ | 42.6 | 22.8 |
| MSGNav [17] | 模块化拓扑 | ✓ | 52.0 | 29.6 |
| EvoMemNav (Ours) | 模块化拓扑 (自进化) | ✓ | 59.6 | 38.9 |
-
HM3D ObjectGoal 导航: 在纯目标导航(ObjectGoal)的 HM3D 任务上,EvoMemNav 在 HM3Dv1(59.2% SR / 33.6% SPL)和 HM3Dv2(63.8% SR / 39.4% SPL)上均创下或逼近了免训练方法的最高水准。
-
消融实验与效率分析:
- 相比于完全不带有 coarse 筛选的拓扑 baseline,加入 VSMGraph 使 SR 提升了 7.2%,而粗筛选(Coarse)模块直接带来了 +11.6% 的巨大 SR 跃升,是性能提升的主要因素。
- 反思模块 RDCMA 使整体 SR 进一步提升了 4.0%(从 60.8% 提升至 64.8%),并且这种增益在第 3 至第 5 个子任务(Mid subtasks)中最为明显,说明随着记忆在场景中的不断写入和演进,智能体表现越发稳健。
- 相比于 3D-Mem,得益于粗阶段的决策短名单机制,VLM 调用次数从 10.7 次降至 6.5 次(减少 39%),单次子任务的耗时从 102.2s 骤降至 58.7s(降低 42.5%),实现了性能与效率的完美兼顾。
4. 局限性
- 多模态目标识别依然受限于感知模块:尽管使用 VSMGraph 规避了下游推理对目标检测框的绝对依赖,但粗筛选阶段生成 soft tags 仍需依靠 YOLOv8-World 和 SAM 等 2D 检测器。在极其嘈杂或低光照环境下,若检测标签完全丢失或偏离,可能导致过滤时的 Top-K 列表中漏掉正确的锚点,从而拖累粗筛选的准确性。
- 反思先验的表达与检索粒度仍可优化:目前的 RDCMA 先验写入是通过对离散的 CLIP 房间类型和停止事件做简单的支持度与错误率计数来实现的。对于极其复杂、分布非常离散的房间结构或者开箱即用的大规模开放世界,简单的图计数可能会面临记忆冲突问题,未来可考虑融入基于小规模向量嵌入的非参数化情境记忆检索。
48. Goal2Pixel (2025)
———将导航目标接地到图像像素,以像素预测统一 VLN-CE 的决策空间
📄 Paper: arXiv:2606.01621
精华
- 图像平面即决策空间:将 VLN-CE 的高层决策从离散动作预测重新定义为像素预测——VLM 只需输出一个像素坐标,消除了动作标签的歧义性,并与 VLM 的原生输出空间对齐。
- 辅助指令区域设计:将转向/停止等非前进动作编码为图像平面扩展区域中的像素,使所有决策在同一坐标空间内统一处理,无需两阶段切换。
- ViKeyMem 以可见性驱动关键帧:以”未来路点可见性变化”为关键帧选取标准,仅需 3–4 帧即可编码 100+ 步轨迹,训练成本从 156 降至 70 H100 GPU 小时。
- 减少 VLM 调用次数:像素预测粒度更粗(一次预测对应 5 步低层动作),使 VLM 调用次数从 46.62 降至 7.75,同时性能从 32.9% SR 提升至 54.1% SR。
- 跨平台可迁移性:像素输出将高层 VLM 推理与机器人底层控制器解耦,同一模型可跨不同硬件平台复用。
1. 研究背景/问题
VLN-CE(连续环境视觉语言导航)中,现有 VLM-based 方法多以低层动作预测(前进/左转/右转/停止)为输出接口,存在三个缺陷:监督信号模糊(同一空间目标对应多个合法动作序列)、决策视野短(每步只移动 25cm)、VLM 调用次数过多(每集需 30–47 次)。如何为 VLM 推理与机器人执行之间找到更合适的接口,成为核心问题。
2. 主要方法/创新点
① 整体框架概述
Goal2Pixel 由三个核心部分构成:像素预测 VLM(InternVL3 微调)、几何反投影模块、本地规划器。VLM 输出坐标字符串 → 反投影为 3D 路径点 → 规划器执行至多 5 步低层动作后再次查询 VLM,形成闭环。
② 纯像素输出接口(Pure Pixel Paradigm)
- 输入:正方形填充的当前 RGB 图像(含三侧辅助指令区域)+ 语言指令 + ViKeyMem 历史(最多 8 帧)
- 处理:VLM 自回归生成 “XXX,YYY” 格式坐标字符串,坐标归一化至 [000, 999]
- 输出判断:坐标落在 RGB 区域 → 经相机内参反投影为 3D 路径点,由本地规划器跟踪执行;坐标落在辅助区域 → 直接执行 Turn_Left / Turn_Right / Stop
- 设计动机:像素坐标是 VLM 的原生输出空间,监督信号更明确;所有决策统一在同一接口,无需两阶段 action-then-pixel 切换
辅助指令区域规则:
- 底部区域 → Stop(距终点 ≤1m 时,GT 像素指向此区域)
- 左/右区域 → Turn_Left / Turn_Right(当前进路点不可见时,根据接下来 5 个路点的平均自中心方向决定)
GT 像素定义:沿 oracle 轨迹,当前帧中最远可见可行驶像素——鼓励更长视野决策,去除短程动作的模糊歧义。
③ ViKeyMem 关键帧历史记忆
ViKeyMem 以未来路点可见性变化为关键帧选取标准,候选帧满足以下三个条件时加入关键帧集合:
- 候选帧视点不再被最近关键帧覆盖(核心可见性条件)
- 候选帧自中心图像中至少有一个后续路点可见
- 至少两个不同后续路点落在候选帧 45° 前向视场内
每个选取的关键帧上叠加蓝色轨迹点(trajectory overlay),提供轻量级过去运动提示。R2R-CE 上平均每 100 步仅选 3–4 帧,推理时间从 0.224s 降至 0.121s,训练时间从 156 H100 小时降至 70 小时。
④ 视觉语义嵌入(Visual Semantic Embeddings)
预训练 VLM 对导航特有的视觉模式(辅助指令区域、轨迹叠加点)识别能力不足,因此引入两类可学习嵌入:
- 指令区域嵌入(directive embedding):叠加在与辅助指令区域重叠的当前帧 visual token 上
- 轨迹嵌入(trajectory embedding):叠加在含蓝色轨迹点的历史帧 visual token 上
- 普通 RGB token 保持不变,参数量极小
⑤ 训练目标与坐标感知损失
\[\mathcal{L} = \mathcal{L}_{CE} + \lambda_{num}\mathcal{L}_{num} + \lambda_{ang}\mathcal{L}_{ang}\]- \(\mathcal{L}_{CE}\):标准 token 级交叉熵,主要监督信号;\(\lambda_{CE}=1\)
- \(\mathcal{L}_{num}\):数值损失,通过 softmax logits 推导可微 soft 坐标,鼓励预测数值接近 GT;\(\lambda_{num}=0.3\)
- \(\mathcal{L}_{ang}\):角度损失,鼓励预测像素保持与 GT 相同的自中心方向;\(\lambda_{ang}=0.03\)
⑥ 推理流程
每次 VLM 调用后,本地规划器最多执行 t=5 步低层动作;若出现连续 20 步左右震荡,自动 fallback 到固定前进像素 (500,970) 以脱困。
3. 核心结果/发现
R2R-CE Val-Unseen 主要结果(2B 模型,零外部数据):
- SR 54.1%,SPL 52.5%,每集仅需 7.75 次 VLM 调用
- 直接动作预测:SR 32.9%,需 46.62 次调用(SR 差 21.2 点,调用多 6×)
- 与 JanusVLN 7B(SR 52.8%)相比,2B Goal2Pixel SR 高 1.3 点,参数规模仅 2/7
输出范式消融(Table 2):
| 输出范式 | SR | SPL | # VLM Calls |
|---|---|---|---|
| 1 动作预测 | 32.9% | 31.5% | 46.62 |
| 4 动作预测 | 37.0% | 36.0% | 15.77 |
| 混合 Action-Pixel (Seq) | 43.7% | — | ~10 |
| 纯 Pixel(本文) | 54.1% | 52.5% | 7.55 |
ViKeyMem 消融(Table 3a):
- 对比 5-step 固定间隔采样:SR/SPL +8.0/+7.4(R2R),+5.1/+5.0(RxR)
- 推理时间:0.243s → 0.121s(−50%);训练时间:173h → 70h(−60%)
RxR-CE Val-Unseen(2B):SR 43.8%,SPL 40.4%,nDTW 61.1%
实物机器人:16 次室内导航测试,Goal2Pixel 能将语言指令(门、沙发、冰箱、楼梯等)接地到有意义的像素目标,并通过本地控制器完成实际导航。
4. 局限性
ViKeyMem 以可见性为标准可能遗漏短暂出现或远距低分辨率的细粒度地标;soft 坐标期望值在多峰数字分布下可靠性有限(但主监督仍为 token 级 CE loss,已起缓解作用)。
49. OmniNav (2026)
———用快慢双系统统一点目标、物体目标、指令目标导航与前沿探索
📄 Paper: arXiv:2509.25687 · 🏛️ ICLR 2026 (Poster)
精华
- 导航任务的瓶颈往往不在策略学习本身,而在于对通用指令和开放词汇物体的理解能力,这一发现指导了训练数据设计而非单纯堆叠导航算法。
- 用”快系统(连续路标点 + flow-matching)+ 慢系统(前沿探索 + 视觉记忆 + CoT 推理)”的双系统架构,把局部高频控制和全局长程规划解耦,二者通过 KV 缓存共享的中心记忆耦合。
- 用流匹配(flow matching)生成连续坐标路标点而非离散动作 token,避免了离散化带来的精度损失和误差累积,同时支持 5Hz 实时闭环控制。
- 把图像描述、OCR、grounding/referring 等通用视觉语言数据和导航数据联合训练,能显著提升指令理解和开放词汇物体识别能力,进而提升导航成功率——通用数据对导航任务的收益甚至超过任务本身数据。
- 前沿(frontier)+ 历史图像记忆的轻量记忆机制,比场景图或语义地图等复杂记忆结构更易实现,同样能支撑语义感知的探索决策。
1. 研究背景/问题
具身导航研究长期分裂为点目标、指令目标、物体目标三种范式,各自依赖任务定制数据,难以互相迁移;现有 VLM/VLA 方法普遍存在离散动作建模精度不足、长上下文管理困难、推理延迟高的问题,且实践中失败的主要原因往往是模型对通用指令和开放词汇物体理解不足,而非导航策略学习本身的缺陷。
2. 主要方法/创新点
OmniNav 整体由两个互补模块构成:快系统负责基于短时视觉上下文和当前子任务,以高频生成连续路标点,支持直接部署;慢系统负责基于长时记忆(前沿点 + 历史图像)进行审慎规划,决定下一个子目标/子任务。两者通过 KV 缓存共享的中心记忆模块耦合,实现局部敏捷与全局一致的统一。
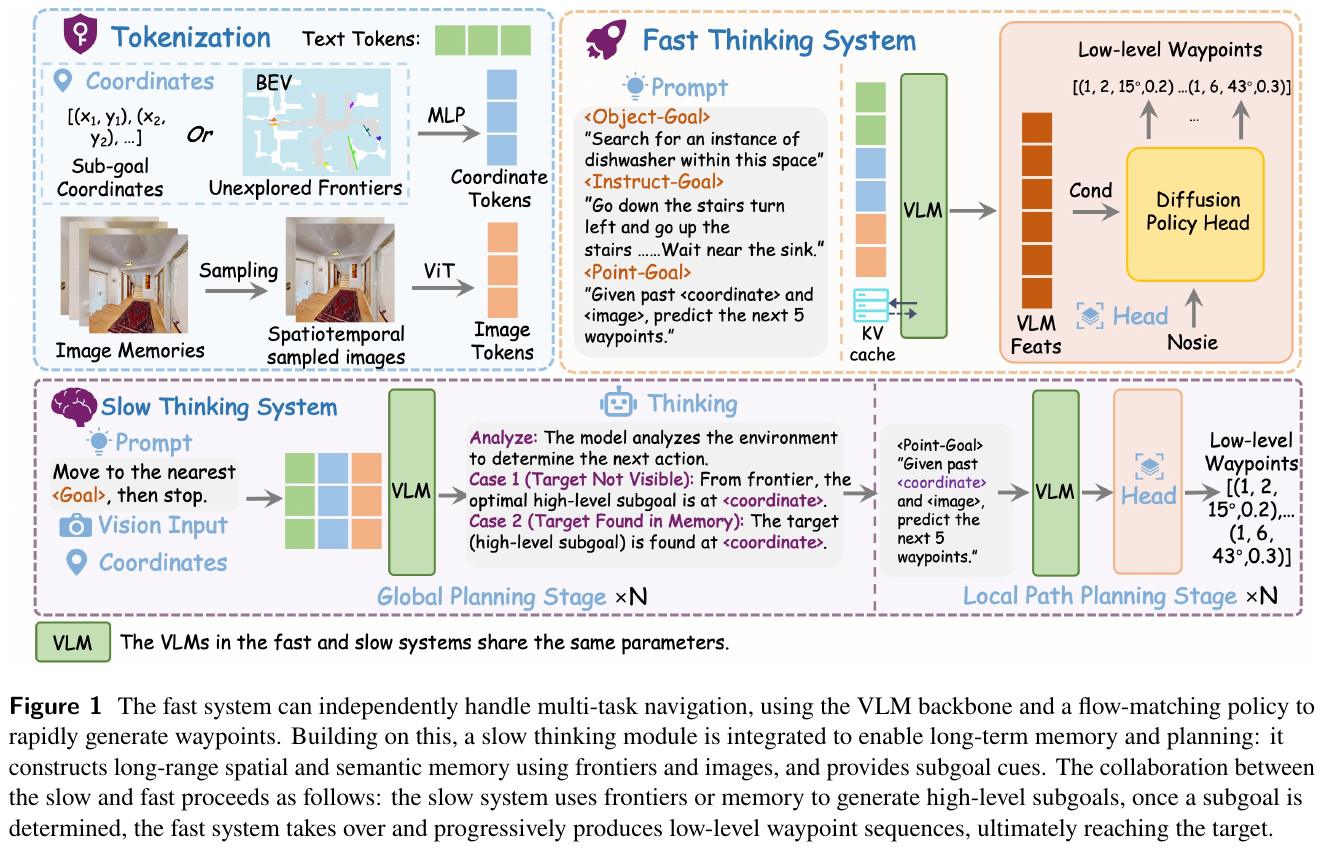
① 多模态输入分词:以 Qwen2.5-VL-3B-Instruct 为基座并扩展坐标模态。文本 token 来自指令、物体类别、点目标坐标等统一指令序列;坐标 token 将候选区域的2D坐标和朝向角经 MLP 编码为稀疏嵌入;图像 token 由中心记忆环形缓冲区中按时空采样得到的历史图像经 ViT 编码而成(快系统采样最近的若干帧,慢系统采样与候选前沿点空间邻近的帧)。
② 快系统(Fast Thinking System):输入为 VLM 融合后的多模态特征 O_VLM,输出为 H=5 个连续空间路标点 w∈R^(H×5),每个路标点编码为位置 (x,y)、朝向 (sinθ, cosθ) 和到达标志 c。采用 DiT 变体作为流匹配(flow matching)策略头:自注意力块捕捉路标点序列内部的时空依赖,交叉注意力块对接 VLM 融合特征作为条件。训练时对真实路标点序列加噪并回归去噪残差;推理时通过 S=5 步欧拉积分从纯噪声逐步还原出路标点序列。相比离散动作分块(action chunk)方法,该设计精度更高,支持最高 5Hz 的实时闭环控制,且轨迹更平滑。
③ 慢系统(Slow Thinking System):负责长程探索的审慎规划,核心任务是判断目标是否已出现在当前或历史视野中——若已出现,直接定位目标坐标驱动快系统逼近;若未出现,则结合语义先验选择探索价值最高的前沿点作为下一子目标(如找浴缸时优先朝浴室方向探索)。系统维护一个3D占据地图来识别已探索/未探索边界(前沿点),并构建记忆库存储历史观测的位姿与图像;通过采样策略为每个候选前沿点匹配一张最贴合其空间位置的历史图像作为”视觉代理”。

慢系统显式引入链式思维(CoT)推理,使前沿选择的依据透明化,支持过程级自检与纠错,减少长链推理和复杂语义任务中的累积误差。
④ 数据构成与联合训练:训练数据遵循”通用网络数据 - 仿真数据 - 真机数据”金字塔结构,包含导航任务数据(4M:物体目标/点目标/指令目标/前沿探索)、Embodied QA 数据(0.2M)、通用 MLLM 数据(5M:caption/通用QA/OCR/图表/代码数学)和 grounding & referring 数据(3M)。实验发现模型学习导航范式相对容易,但通用能力(指令理解、开放词汇物体识别)才是真正瓶颈,因此引入大规模通用视觉语言数据联合训练,显著提升指令理解、视觉语义和常识先验(如”浴巾通常在浴室”)。
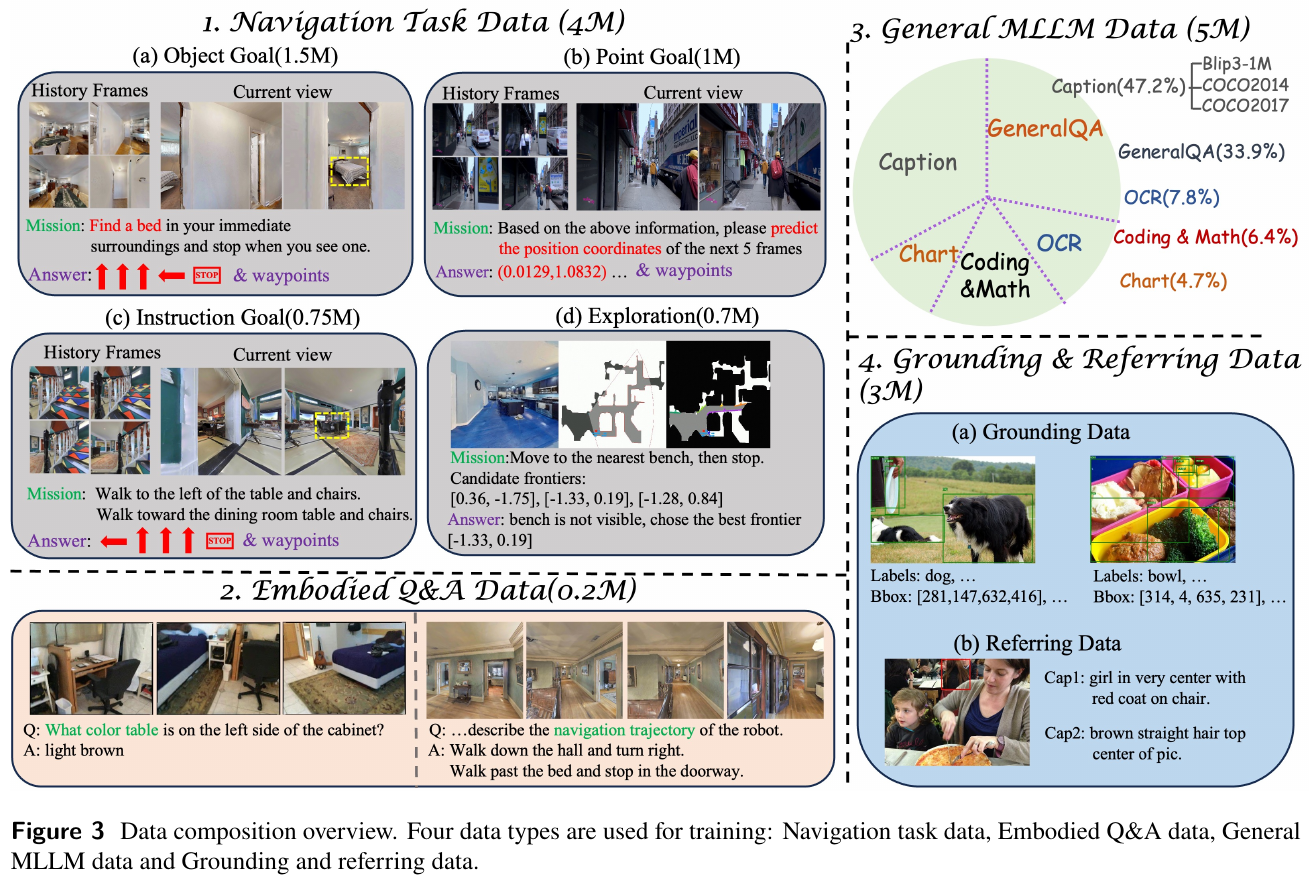
训练目标:采用两阶段训练范式。Stage 1 用自回归目标预测离散变量(导航动作块、通用语义数据、Embodied QA、grounding/referring 数据),实现语言-视觉-动作对齐;Stage 2 在共享主干上接入流匹配策略头预测连续路标点,并混入20%的 Stage-1 离散数据联合训练,防止连续控制微调侵蚀基座 VLM 的通用能力。连续坐标采用 min-max 归一化以稳定训练。Stage 1 用96张 H20 训练120小时,Stage 2 用64张 H20 以更低学习率训练48小时。
⑤ 推理流程:慢系统与快系统协同——慢系统利用前沿或记忆生成高层子目标后,快系统接管并持续生成低层路标点序列逐步逼近目标;若直线路径被障碍物阻挡,快系统会依据实时视觉线索绕行调整,体现其并非单纯的预设坐标跟随器。
3. 核心结果/发现
- 指令目标导航(R2R-CE / RxR-CE Val-Unseen):仅用快系统和纯 RGB 输入即取得 SOTA,成功率分别比此前最优方法提升 4.4% 和 4.3%(SR 69.5% / 62.0% SPL)。
- 物体目标导航(HM3D-OVON):纯视觉输入下已超越此前最优方法 2.7%;加入慢系统(前沿推理 + CoT)后整体性能超过此前最强方法 18.4%(Val-Unseen SR 59.2%,SPL 33.2%)。
- 点目标导航(CityWalker 基准,开放集 MAOE 指标):OmniNav 11.53% 优于 CityWalker 的 15.23%。
- 消融研究:策略头(连续路标点 vs 离散动作块)、慢系统、通用数据、CoT 四个组件均带来稳定且可叠加的增益,全部启用时性能最佳;其中慢系统在长程探索任务上的提升最大。
- 真机部署:在四足机器人上以云端 RTX 3090 实现 5Hz 以上闸环控制,验证了零样本场景下物体目标、点目标(视觉避障)、指令目标三类任务的有效性。

4. 局限性
完整慢系统的真实物理部署仍需额外工程(如 LiDAR/深度估计的鲁棒实时集成),本文真机实验仅验证了快系统组件;复杂纹理物体(如毛毯、衣物)的识别在任何模型规模下仍不稳定,且模型规模(3B vs 7B)在数据充分时收益趋同,尚未进行系统性的 scaling law 研究。
50. AstraNav-World (2025)
———将”想象未来”与”规划未来”统一进同一个生成式概率框架
📄 Paper: arXiv:2512.21714
精华
- 把”先想象未来场景、再据此规划动作”的松耦合 envision-then-plan 范式,改造为视觉预测与动作生成在同一概率框架内联合建模、同步 rollout 的紧耦合范式,从根本上抑制误差累积。
- VLM 不再只做语言理解,而是同时作为视频生成器和动作策略头的统一条件编码器,用同一份”语言-视觉嵌入”驱动两条分支。
- 双向约束是关键:动作要以可执行的未来视觉证据为依据,预测的未来画面也要被动作意图反向约束,两者互相校正而不是单向传递误差。
- 引入 Sparse Foresight Scheduling,按固定间隔而非逐帧触发”视觉预测+动作生成”的联合推理,在几乎不掉点的情况下把推理速度提升一个数量级。
- 消融证明:性能提升主要来自世界模型的双向约束机制,而非单纯堆参数量(3B 联合模型优于纯放大到 7B 的 VLA-only 基线)。
1. 研究背景/问题
具身导航失败的一个核心原因是模型缺乏对物理规律和时间动态的建模:微小的预测偏差会随时间累积,最终破坏全局规划的有效性。现有方法通常把”想象未来”(world model 生成未来画面)和”规划未来”(VLA 输出动作)做成两个松耦合的串行模块,这种 envision-then-plan 流水线会放大物理不确定性和因果歧义,导致视觉预测和实际动作彼此不一致。
2. 主要方法/创新点
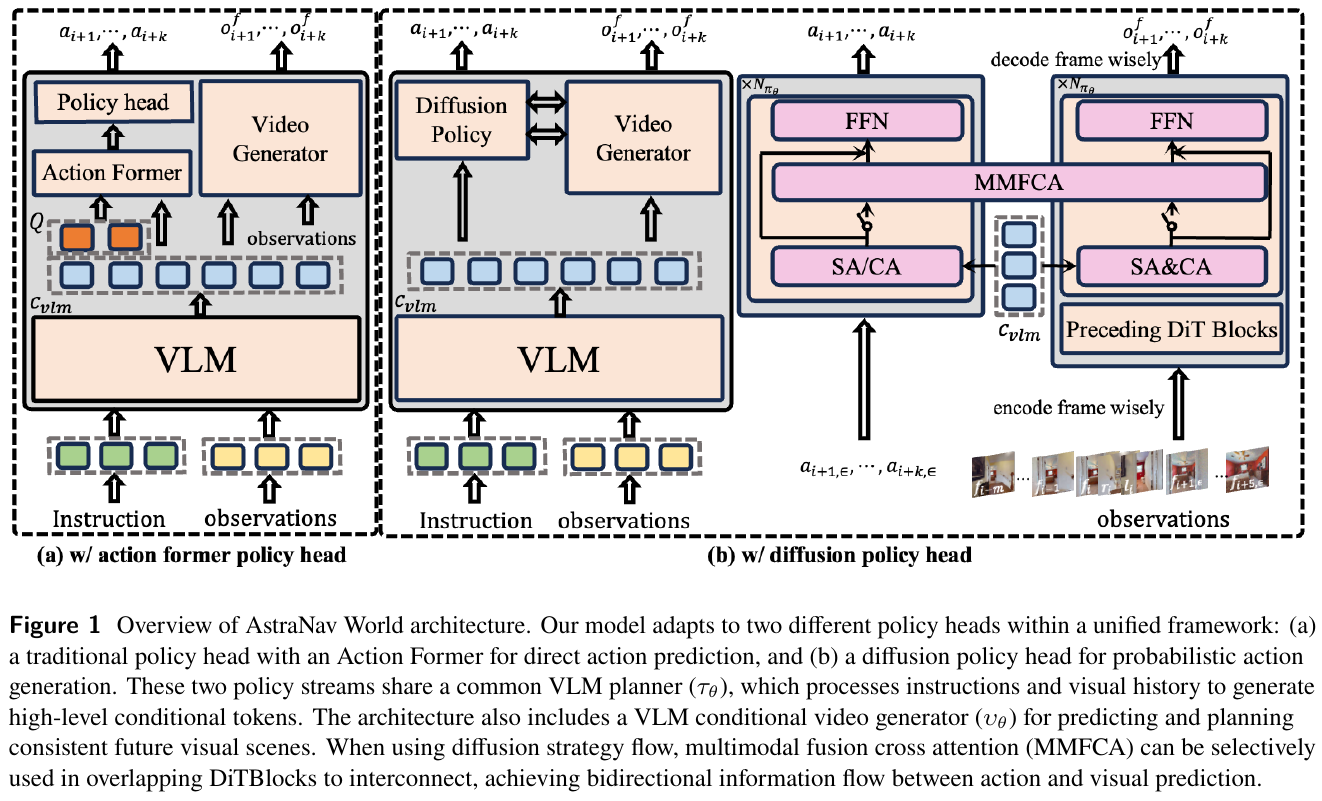
① 整体框架概述:AstraNav-World 由三个核心模块构成——VLM 规划器(高层语义推理)、基于 DiT 的视频生成器(预测未来视觉观测)、动作策略头(生成未来动作序列,有 Action Former 和 Diffusion Policy 两种实现)。VLM 编码指令和历史/当前多视角观测,生成统一的视觉-语言嵌入,同时作为视频生成器和策略头的条件输入,取代了传统视频扩散模型里的文本编码器。
② 逐模块讲解
- VLM 规划器(τθ):输入是自然语言指令 I 和历史观测序列 O_hist;内部用 Qwen2.5-VL-3B 做全参数微调;输出是 C ∈ R^(L×D)(D=2048)的视觉-语言嵌入,同时包含”目标导向语义特征”(指令编码)和”空间上下文特征”(历史/当前视觉语义与空间信息)。这一表示让模型既能保持对长时序任务的整体理解,又能灵活响应环境的即时变化。
- VLM 条件视频生成器:基础架构是 Wan2.2-TI2V-5B(ST-VAE + 30 层 DiT),用 LoRA(rank=128)微调。把 VLM 的视觉-语言嵌入通过 cross-attention 注入 DiT,替代原本的 umT5 文本编码器,使生成的未来帧在语义上与 VLM 的高层规划保持一致。训练时对历史/当前帧加极小噪声(σ_obs≈0.05)当作”干净”条件,对未来帧用 Flow Matching 方式加噪并学习速度场 u_t=ϵ−z_future,损失只在未来帧上计算(L_VG,式 4)。
- 3D-RoPE 重排:为了把当前时刻的 left/front/right 三个视角和历史帧统一编码进同一套 3D 旋转位置编码,作者把三个视角沿宽度轴”虚拟拼接”——front 保持原坐标,right 在宽度上偏移 W,left 偏移 2W,同时共享相同的时间和高度索引(式 1–3),从而显式编码多视角间的空间-时间关系,而不打乱时序对齐。
- 动作策略头(两种实现):
- Action Former:用一组可学习 query 向量通过若干层 Transformer 与 VLM 嵌入交互,再经 MLP 输出确定性动作序列 A=(X,Y,cosθ,sinθ,α),分别用 L1 位置损失、余弦角度损失、二元到达损失加权组合(式 5–8)。
- Diffusion Policy:用 Flow Matching 在噪声动作序列上做去噪生成,提供概率化的动作预测。关键创新是 Multimodal Fusion Cross-Attention(MMFCA):在 Diffusion Policy 和视频生成器最后 8 个重叠的 DiT 块之间引入双向 cross-attention——动作表征作 query 去 attend 视频隐表征(确保动作以可信的未来视觉为依据),同时视频隐表征也作 query 去 attend 动作表征(确保生成画面与已规划动作保持因果一致)。MMFCA 受二元开关 γ 控制:γ=1 时两路双向融合、同步 rollout;γ=0 时两路独立运行,推理时甚至可以完全跳过视频生成器只跑策略头,大幅降低算力开销。
- 设计动机:核心 gap 是松耦合流水线里视觉预测和动作规划互不感知,容易各自漂移。MMFCA 和共享 VLM 条件正是为了让两条分支在训练和推理阶段都能”互相看见对方”,把误差互相校正而不是单向累积。
③ 端到端数据流:一条样本先经 VLM 编码指令+历史/当前三视角观测得到统一嵌入;该嵌入同时条件化视频生成器(预测未来 N 步前视帧)和策略头(预测未来 N 步动作);若启用 MMFCA,两路在重叠 DiT 块内做双向 cross-attention 实现同步 rollout;最终输出未来视觉帧序列和对应的动作(路径点)序列。
④ 训练目标:总损失 L_Total = L_VG + λ·L_PH(λ=1.0,式 10),L_VG 是视频生成的 Flow Matching 损失(式 4),L_PH 根据策略头类型为式 8(Action Former 的位置+角度+到达损失组合)或式 9(Diffusion Policy 的 Flow Matching 损失)。训练分两阶段:Stage 1 冻结 VLM,先独立预训练视频生成器(L_VG)、再独立预训练策略头(L_PH),避免两个模块过早互相干扰;Stage 2 解冻全部组件用 L_Total 联合微调,对 Diffusion Policy 以 50% 概率随机启用 MMFCA,防止策略头过度依赖视觉反馈,保证视频生成器关闭时策略头仍能独立工作。
⑤ 推理流程(Sparse Foresight Scheduling, SFS):视频生成是推理速度的瓶颈,因此不在每一步都联合生成”未来帧+动作”,而是按固定间隔触发联合生成——大量导航场景里直行等简单一致行为并不需要逐帧更新世界模型。使用 Action Former 时,推理阶段直接完全关闭视频生成器,只用 query Transformer 出动作;使用 Diffusion Policy 时,视频生成器仅在固定间隔步(实现中每 10 步)激活一次,中间步骤保持关闭,在预测精度和推理速度间取得最优折中。
3. 核心结果/发现

- 在 R2R-CE / RxR-CE Val-Unseen 上,AstraNav-World 全面超越此前 SOTA:Action Former 版本相对此前最佳方法 SR 绝对提升 2.1%(R2R-CE)/1.1%(RxR-CE);Diffusion Policy + MMFCA 版本进一步在 Action Former 基础上再提升 0.7%(R2R-CE)/2.5%(RxR-CE),最终 R2R-CE SR=67.9%、SPL=65.4%,RxR-CE SR=72.9%。
- 在 HM3D-OVON 开放词表物体导航上,Diffusion Policy 相对此前最佳 MTU3D 提升 SR 4.9% 绝对值(45.7% vs 40.8%)。
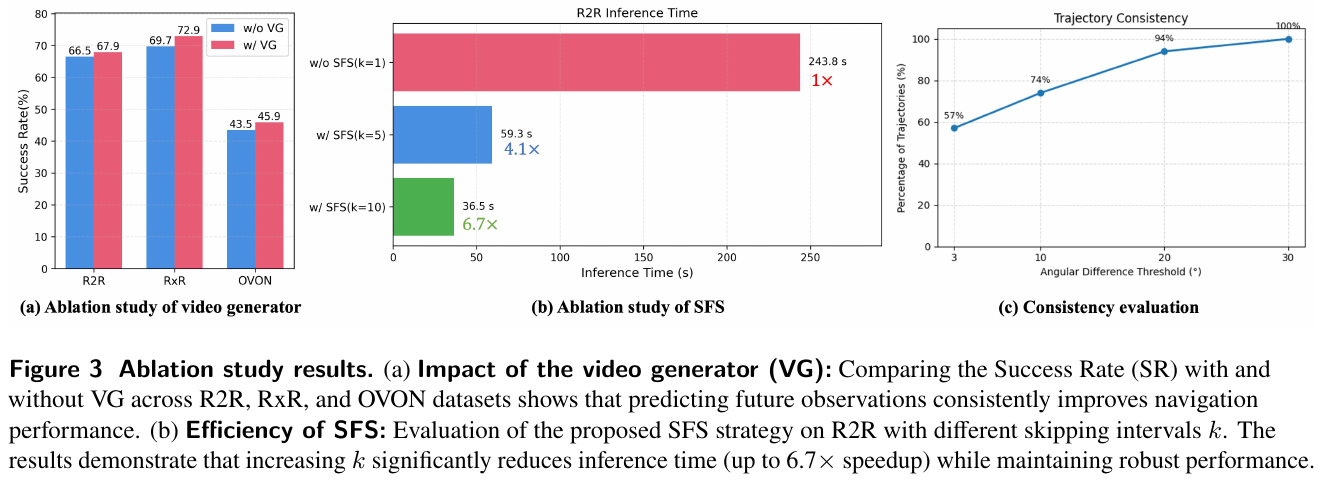
- 去掉视频生成器分支会在 R2R、RxR、OVON 三个数据集上一致地降低 SR,证明显式预测未来观测确实为规划提供了关键的视觉引导,并非冗余分支。
- 缩放 vs. 世界建模:把 VLA-only(无视频生成)基线的 VLM 从 3B 放大到 7B,R2R-CE SR 几乎不变(66.5%→66.6%),已触及参数缩放的天花板;而 3B 模型加上视频生成分支(L_VG 正则化)就能把 SR 推到 67.9%,说明性能增益主要来自世界模型的双向约束机制,而不是单纯堆参数。
- 一致性分析:用开源 VGGT 模型估计生成图像序列的相对相机位姿变化,与仿真器真实渲染的相对位姿对比,角度差 δ_a 的分布显示生成的未来视觉预测与规划动作具有很高的几何一致性。
- 真实世界零样本迁移:未做任何真实世界数据微调,AstraNav-World 直接部署在物理机器人上完成自然语言指令导航任务,在过门、转角等关键过渡场景上表现出对未来场景的预判能力,显著优于通常需要域适应的现有方法,验证了世界模型学到的是可迁移的物理/导航规律而非仅过拟合仿真数据分布。
4. 局限性
视频生成本身的推理延迟和复杂场景下的算力开销仍是瓶颈(尽管 SFS 已大幅缓解);论文也指出未来工作需要扩展到更长时间跨度和更难的任务,进一步加强物理与因果一致性建模,并提升闭环一致性与实时推理/规划能力。
51. ABot-N0 (2026)
———统一具身导航的”大脑-行动”VLA基础模型:5大任务、16.9M轨迹、Agentic部署
📄 Paper: arXiv:2602.11598
精华
- 把 Point-Goal、Object-Goal、Instruction-Following、POI-Goal、Person-Following 五类历来彼此独立架构的导航任务,统一进同一个”Brain-Action”VLA 模型,用同一套 token 化输入接口和同一个 Flow Matching 动作头输出轨迹。
- 高层语义推理(LLM Brain)与底层连续运动控制(Flow Matching Action Expert)解耦为”If-Else”双头并行结构,而不是串行 CoT,推理时按任务直接走对应分支,省去不必要的链式生成开销。
- 数据是工程重点:16.9M 专家轨迹 + 5.0M 推理样本,来自 7,802 个高保真 3D 场景(10.7 km²),三种轨迹来源(网络视频伪轨迹、3D 场景合成、真实机器人遥操作)互补,解决”标注成本 vs 真实物理动态”的矛盾。
- 三阶段课程学习(认知预热 → 统一感知运动 SFT → SAFE-GRPO 价值对齐后训练)先让模型学会”看懂、想懂”,再学”怎么动”,最后用强化学习专门纠正社会合规性,而不是一股脑端到端硬训。
- 工程落地上用 Agentic Planner + 分层 Topo-Memory 把基础模型包装成可执行长程复合任务的系统,并通过云端规划 + 端侧 VLA/控制器的混合部署,在 Jetson Orin NX 上做到 2Hz VLA 推理 + 10Hz 闭环控制。
1. 研究背景/问题
具身导航长期处于”碎片化范式”:Point-Goal、Object-Goal、Instruction-Following 等任务各自使用专门架构,彼此难以共享数据与能力,模型无法从异构大规模数据中提炼统一的物理先验,也限制了跨任务泛化。同时,现实世界的用户指令往往是模糊、复合的(如”带我去奶茶店并占个座”),单一任务原语无法直接执行,需要更高层的任务分解与记忆机制配合。
2. 主要方法/创新点
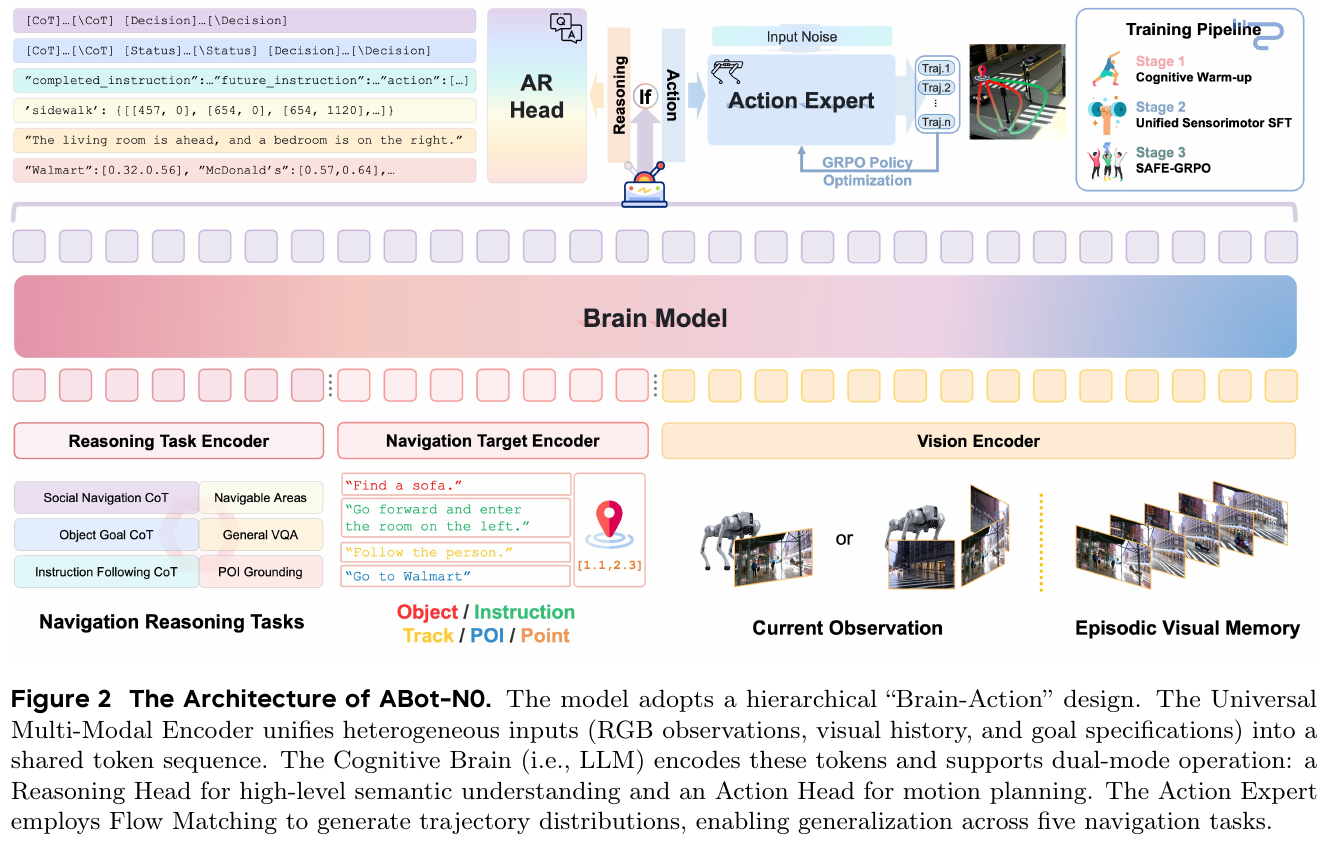
① 整体框架概述
ABot-N0 由三大支柱构成:统一多模态编码器(Universal Multi-Modal Encoder)负责把异构的视觉观测、历史记忆、目标描述统一编码进共享 latent 空间;认知大脑(Cognitive Brain,基于 Qwen3-4B)做语义理解与空间推理;行动专家(Action Expert)基于 Flow Matching 生成连续轨迹。三者串联成”先理解、再决策、再执行”的层级流水线,但 Reasoning Head 和 Action Head 在推理时是按任务类型二选一的并行分支,而非强制串行的 CoT。
② 逐模块讲解
- 统一多模态编码器:
- 输入:当前观测 $O_t$(支持全景三视角或单前视两种模式,分别用专属 view token 区分,避免拼接畸变)、历史视觉记忆 $M_S$(应对 POMDP 下的部分可观测性)、以及目标描述——语义目标(指令文本、物体类别、POI 名称、人物描述,统一走 LLM 文本 tokenizer)或几何目标(Point-Goal 的 BEV 坐标,经 MLP 投影为伪 token)。
- 处理:ViT 编码 RGB,MLP 投影几何坐标,文本目标直接复用 LLM 词表,三类输入统一拼接进同一个 token 序列。
- 输出:跨任务统一的 token 序列,供 LLM Brain 消费。
- 设计动机:解决”任务专属架构无法共享数据”的核心 gap——把所有任务的目标表示压成同一种接口,模型才能在异构数据上联合训练。
- 此外还引入 Reasoning Task Encoder,注入具体任务描述(如”Where is Luckin Coffee?”)来激活 LLM 内部对应的推理回路,作为训练期辅助监督信号。
- Cognitive Brain(认知大脑):
- 输入:上述统一 token 序列。
- 处理:基于预训练 LLM(Qwen3-4B),按任务 token 走 Reasoning Head(场景可通行性分析、社会规范判断、POI grounding 等显式推理)或 Action Head(为下游动作生成提供语义条件)。
- 输出:要么是自然语言推理结果(NTP 监督),要么是供 Action Expert 使用的语义条件向量。
- 设计动机:传统端到端策略缺乏显式中间推理,容易过拟合训练分布中的隐式偏置;显式推理监督能让高层语义表示与物理世界约束对齐。
- Action Expert(行动专家):
- 输入:Cognitive Brain 提供的语义条件。
- 处理:用 Flow Matching(而非确定性回归)建模轨迹分布,因为同样的输入条件下专家行为往往是多模态的(绕障可以向左也可以向右),确定性回归会把这些模式平均成无效路径。
- 输出:未来 5 个 waypoint 的连续轨迹 $W={(x_1,y_1,\theta_1),…,(x_5,y_5,\theta_5)}$,同时给出位置与朝向角,保证机器人姿态的完全可控性。
- 设计动机:连续高精度的平移/旋转控制 + 多模态分布建模,两者都是确定性回归难以兼顾的。
③ 端到端数据流
一个样本的流转路径:原始 RGB/历史帧 + 目标描述 → 统一多模态编码器编码为共享 token 序列 → Cognitive Brain 按任务类型路由:若为推理任务则走 Reasoning Head 输出文本,若为导航任务则用语义条件去驱动 Action Expert → Action Expert 通过 Flow Matching 采样生成 5 步 BEV 轨迹 → (部署时)轨迹交给 Neural Controller 转换为机体速度指令。
④ 训练目标 / 损失函数
三阶段课程学习:
- Phase 1 认知预热:冻结 Vision Encoder 和 Action Expert,仅用 ABot-N0 Reasoning Dataset 以 Next Token Prediction(NTP)损失微调 LLM 主干,让模型先学会”看懂场景、对齐语言与实体”。
- Phase 2 统一感知运动 SFT:引入轨迹数据集,联合优化 AR Head 和 Action Expert(Dual-Head Optimization),并以约 20% 比例混入推理数据防止遗忘: \(\mathcal{L}_{Phase2} = \lambda_{txt}\mathcal{L}_{NTP}(\theta_{brain}) + \lambda_{flow}\mathcal{L}_{CFM}(\theta_{action}|\theta_{brain})\) 其中 $\mathcal{L}{NTP}$ 是文本生成交叉熵损失,$\mathcal{L}{CFM}$ 是条件 Flow Matching 轨迹生成损失。
- Phase 3 SAFE-GRPO 后训练价值对齐:冻结 Brain,仅微调 Action Expert,用 SocCity 环境中的专家轨迹做强化学习,优化复合奖励:
\(R = w_{soc}R_{social} + w_{exp}R_{expert} + w_{sm}R_{smooth} + w_{eff}R_{eff}\)
- $R_{social}$:依据语义占据图,若轨迹经过非通行/社会受限区域(草坪、限行车道、行人占用区)则重罚;
- $R_{expert}$:约束策略不偏离专家分布太远,防止 reward hacking;
- $R_{smooth}/R_{eff}$:惩罚抖动动作、鼓励朝目标推进。
动机:模仿学习只能学到专家行为的表面统计,无法掌握”为什么不能走草坪”这种因果层面的社会规范,需要 RL 显式纠正。
Agentic Navigation System(应用层包装)
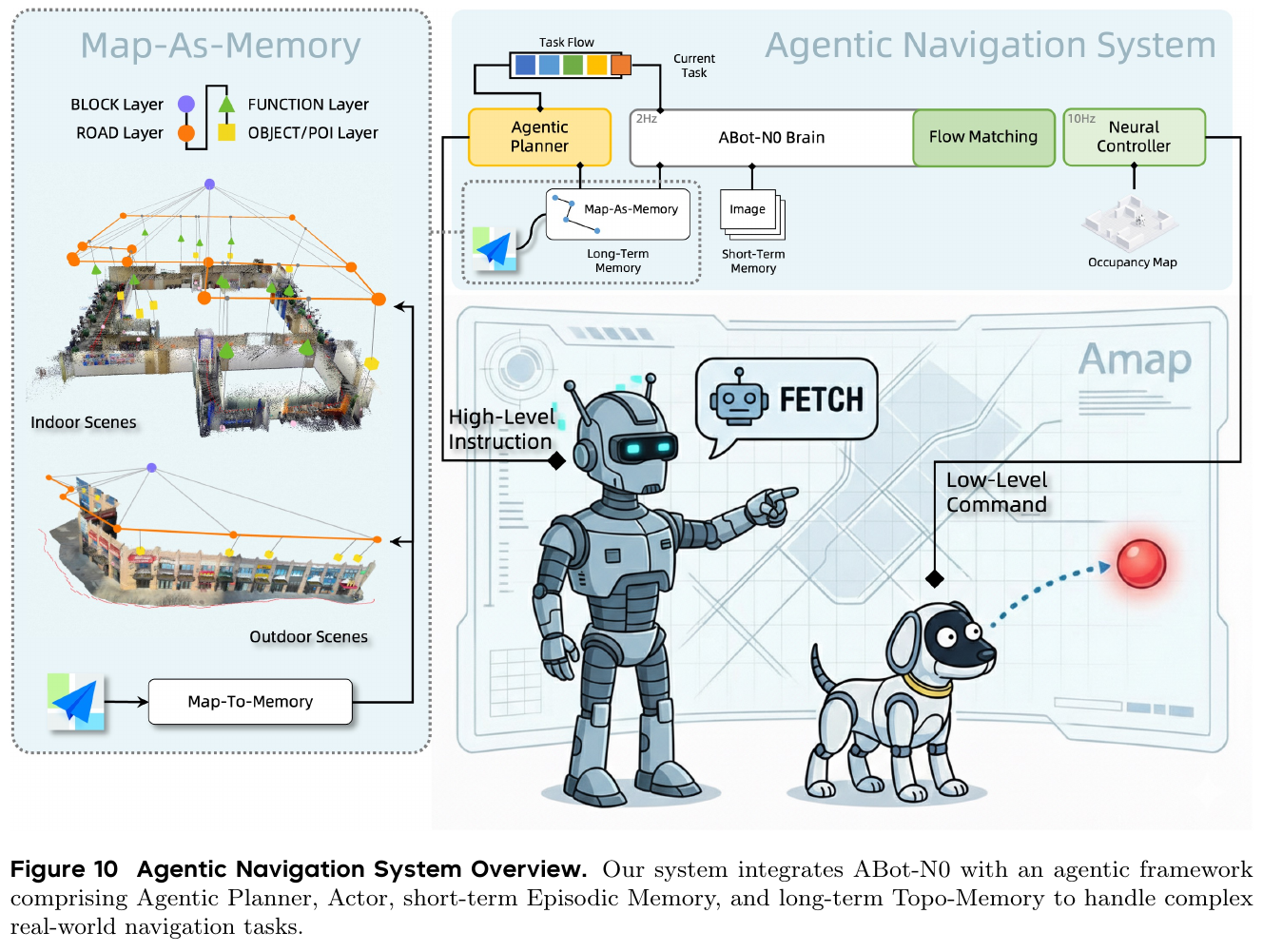
为弥合基础模型能力与实际部署之间的差距,论文在 ABot-N0 之上包装了一套 Agentic 系统,包含四个模块:Agentic Planner(高层规划器,把模糊用户指令分解为可执行子任务序列 $G={g_1,…,g_n}$,$G=P(I,M_L,M_S,O_t)$)、Actor(ABot-N0 + Neural Controller,负责执行具体子任务)、短期 Episodic Memory(维持当前 episode 内的近期观测,支持即时错误恢复)、长期 Topo-Memory(持久化的分层拓扑空间记忆,支持跨尺度导航与经验积累)。
Topo-Memory 按 Block(房间/街区)、Road(路口/门连通性)、Function(休息区/厨房等功能节点)、Object/POI(具体实体/店铺)四层组织空间知识,并采用”维护在环”机制:每次任务执行的观测、轨迹、交互结果都会反馈更新拓扑图,应对道路封闭、拥堵等动态环境变化。
Planner 的三个关键能力:
- 歧义消解:利用 LLM/VLM 的常识知识把模糊自然语言指令解析为结构化子任务序列;
- 记忆感知规划:若 Topo-Memory 中已知”厨房在 (x,y)”,则直接生成确定性 Point-Goal(x,y) 而非盲目 Object-Goal 搜索,到达后再切换局部 Object-Goal 精确定位;
- 由粗到细分解:鉴于 Reaching 类任务(Object/POI-Goal)随距离增加性能衰减明显、而 Approaching(Point-Goal)更稳健,规划器把任务拆成”远程用 Point-Goal 接近 → 局部用 Object/POI-Goal 精确到达 → 最后用 Instruction-Following/Person-Following 完成交互”的可靠序列: \(P(W|I,M_L,M_S) = \underbrace{P(G|I,M_L,M_S)}_{\text{Agentic Planning}} \cdot \prod_{j=1}^N \underbrace{P(W_j|g_j,M_L,M_S)}_{\text{ABot-N0}}\)
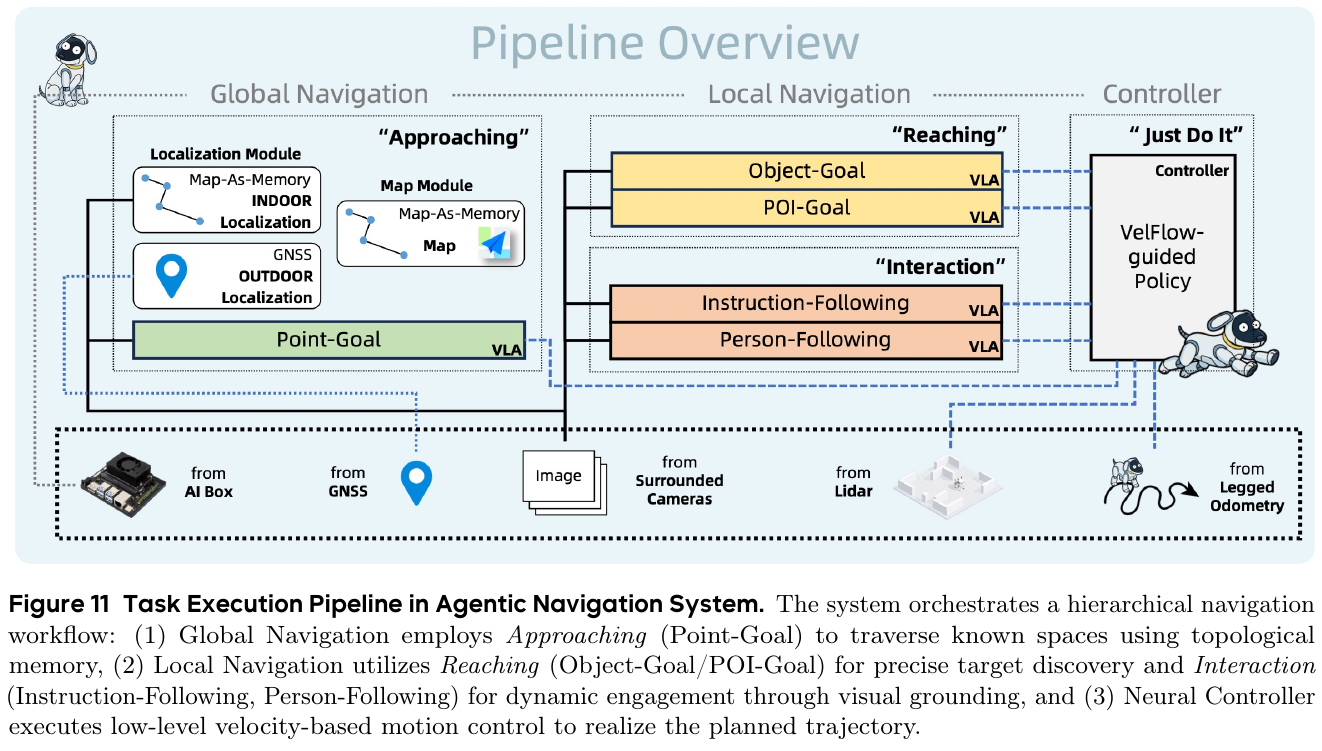
此外还有闭环自我反思与重规划机制:子任务结束后,基于 VLM 的 Self-Reflector $S$ 根据记忆判断完成状态与反馈 $(r,f) = S(M_L,M_S,g_i)$,若失败则用反馈触发重规划 $G’ = P(I,M_L,M_S,O_t,f)$(例如货架找不到可乐则改去自动售货机)。
⑤ 推理 / 部署细节
为适配边缘端实时推理,视觉骨干换成轻量的 93M SigLIP-B/16 + MLP projector,并引入 merge size=4 的视觉 token 合并机制压缩 token 数,端侧推理速度达 2Hz、性能仅下降约 3%。高层 Agentic Planner 部署在云端 RTX 4090 服务器做复杂意图分解与自反思,ABot-N0 与基于 CE-Nav 的 Neural Controller 部署在本地 NVIDIA Jetson Orin NX 上,运行在 10Hz+ 实现高速反应式避障,这种云-边混合架构兼顾复杂推理能力与离网安全性。

3. 核心结果/发现
ABot-N0 在 7 个权威基准上全面刷新 SOTA:
- Point-Goal:CityWalker 开环 MAOE 11.2(前 SOTA CityWalker 15.2);SocNav 闭环 Success Rate 88.3%(基线 47.8%),社会合规 DCR 达 85.1%(基线 36.1%),证明模型不只是”到达目标”,而是真正遵守社会规范。
- Instruction-Following:VLN-CE R2R-CE Val-Unseen SR 66.4%(较 NavFoM 提升 4.7%),SPL 提升 8.6%;RxR-CE SR/SPL 达 69.3%/60.0%。
- Object-Goal:HM3D-OVON Val-Unseen SR 比 MTU3D 高 13.2%,且从 Val-Seen 到 Val-Unseen 性能仅下降 1.3%(MTU3D 下降 14.2%),泛化差距显著更小。
- POI-Goal:BridgeNav 最严格 0.1m 阈值下 SR 提升 70.1%(相对基线),平均轨迹偏差降低 30.5%。
- Person-Following:EVT-Bench 全部三档(STT/DT/AT)均创新 SOTA,最难的 Ambiguity Tracking 档 SR 与 TR 均提升 16.1%。
真实部署方面,模型在 Unitree Go2 四足机器人上验证了单任务执行(Point/Object/POI-Goal、Instruction-Following、Person-Following)以及室内外跨域长程复合任务(如”去最近的公园放松”、”去奶茶店买茶并占座”),并在 Self-Reflector 驱动下展示了失败后自动重规划的能力。
4. 局限性
论文未设独立的局限性章节讨论。从内容看,潜在局限包括:高层 Agentic Planner 依赖云端大模型推理,离网或弱网环境下的规划能力会受限;Person-Following 在 Ambiguity Tracking 等高难场景下 Collision Rate 仍高于多数基线(如 8.54% vs TrackVLA 的 1.65%),说明在复杂遮挡追踪场景下安全性与追踪性能之间仍存在权衡。
52. Qwen-RobotNav (2026)
———首个统一的多任务、时空可重构具身导航大模型
📄 Paper: arxiv:2606.18112
精华
- 统一建模:Qwen-RobotNav 是首个将多任务导航(指令遵循、目标搜索、主动追踪、自动驾驶)统一为参数化观测上下文建模的通用导航底座大模型。
- 时空可重构:提出任务自适应观测编码(Task-Adaptive Observation Encoding),在推理时可通过调节 Token 预算、时间衰减和相机权重动态重新配置时空上下文策略。
- 架构零修改:采用自然语言标签对相机视角与时间戳进行交错标记,并使用具身前缀区分平台角色,无需修改预训练 Qwen3-VL 架构即可跨平台泛化。
- 联合训练:采用 15.6M 规模的混合数据集,将导航轨迹与 15% 的通用及导航特定视觉语言推理数据进行联合训练(Co-training),有效防止模型发生纯动作轨迹映射退化。
- 高效协同:在层次化 Agent 导航中,它与上层规划器通过“单回合证据+跨回合记忆本”的双层记忆机制无缝配合,在 EQA 等长程任务上实现显著的步数精简与 SOTA 表现。
1. 研究背景/问题
具身智能导航任务(如指令遵循、目标搜索、主动追踪和自动驾驶)多种多样,各自对视觉时空上下文的需求存在本质差异。例如,指令遵循需要长程的全局记忆来重定远期地标,而主动追踪则高度依赖最新几帧的近况画面进行实时反应。现有的统一导航模型大都使用固定的下采样或滑动窗口策略,无法在部署推理时因地制宜地调整,且在大大规模轨迹训练中极易丢失大模型的多模态通用理解与常识,退化为被动作的动作生成器。因此,如何在单一底座模型上暴露一个参数化、可重构的观测编码接口,并构建能与高层 Agent 协同运作的通用导航系统,是目前具身导航领域的核心挑战。
2. 主要方法/创新点
整体框架概述
Qwen-RobotNav 继承自 Qwen3-VL 多模态大模型,并在其基础上设计了一个极其轻量化的 4 层 MLP 动作预测头。该框架的核心思想是将多任务导航统一建模为回归预测 8 个未来路点的轨迹规划任务。在数据流的输入端,系统暴露出由 Token 预算 $B$、时间衰减系数 $\gamma$ 和相机权重 $w_c$ 组成的参数化接口,用以自适应控制输入图像的分辨率和时空 Token 占比,从而实现无缝的推理期策略重构。
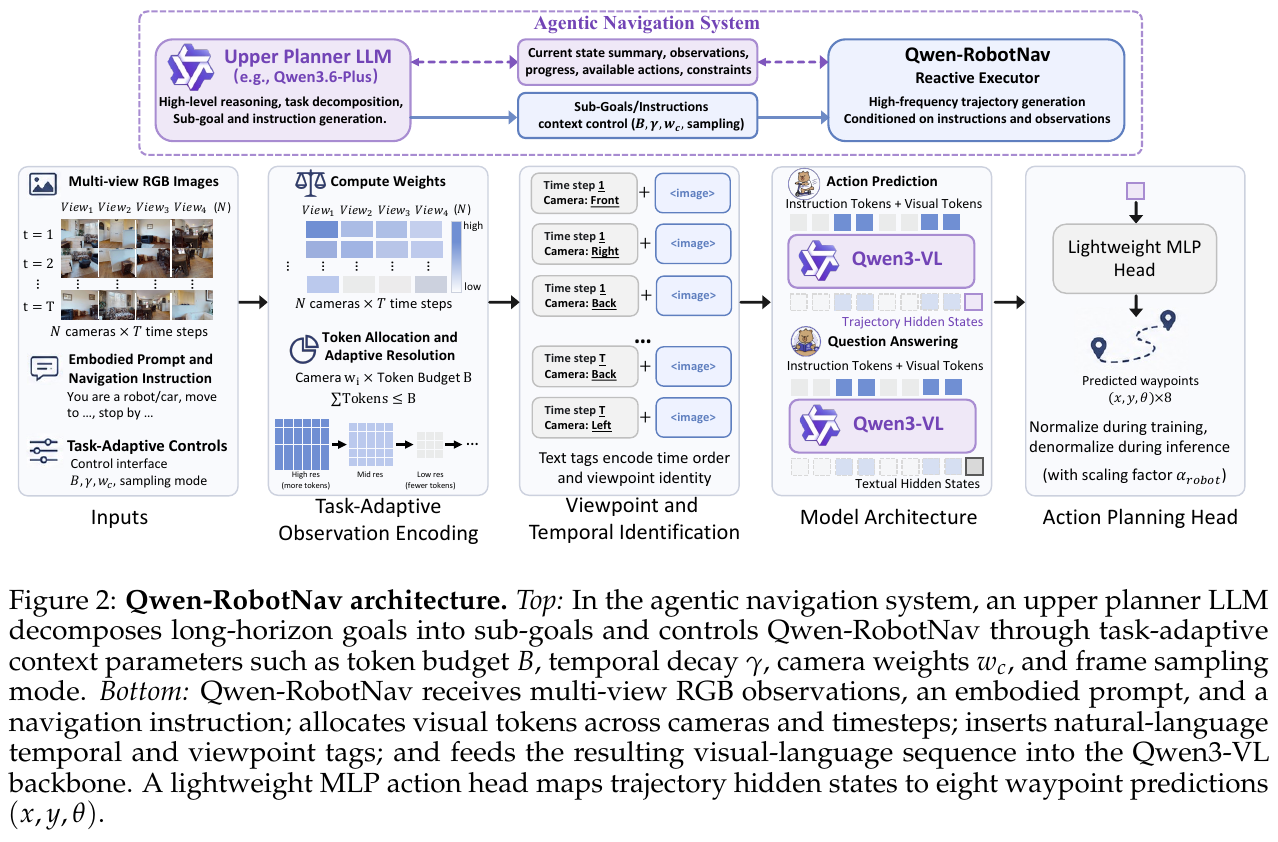
逐模块讲解
① 参数化观测编码与 Token 动态分配
- 输入:多视角图像序列 $I_{1:T}^{1:N}$(由 $N$ 个相机在 $T$ 个时间步捕获)、Token 预算 $B$、时间衰减因子 $\gamma$、相机权重向量 $w_c$。
- 处理:系统首先根据时间步 $t$ 计算每个保留帧的临时衰减权重: \(\omega_t = \exp\left(\gamma \cdot \frac{t}{T' - 1}\right)\) 其中 $\gamma=0$ 时退化为均匀分配,$\gamma > 0$ 时权重更偏向最新帧。随后,结合各视角的相机权重(如前向相机 $w_{\text{front}}=2.0$,后向相机 $w_{\text{rear}}=0.5$),生成联合时空权重矩阵 $W[t,c] = \omega_t \cdot w_c$。最后,通过受限分配算法(CONSTRAINEDALLOC),在满足单图 Token 上下限 $[b_{\min}, b_{\max}]$ 约束的前提下,将总 Token 预算 $B$ 分配给对应的画面。这些分配到的 Token 决定了输入图像的像素分辨率,以便使用 dynamic-resolution ViT 进行大小缩放与 patch 合并。
- 输出:经过动态分辨率缩放的图像序列特征 Token。
- 设计动机:实现推理时无需微调即可切换上下文倾向。例如,在局部的反应式追踪中,可以使用大 $\gamma$ 和小预算快速处理最新画面;在全局搜索中,则调小 $\gamma$ 并调大 $B$ 以保留更多的历史帧信息。
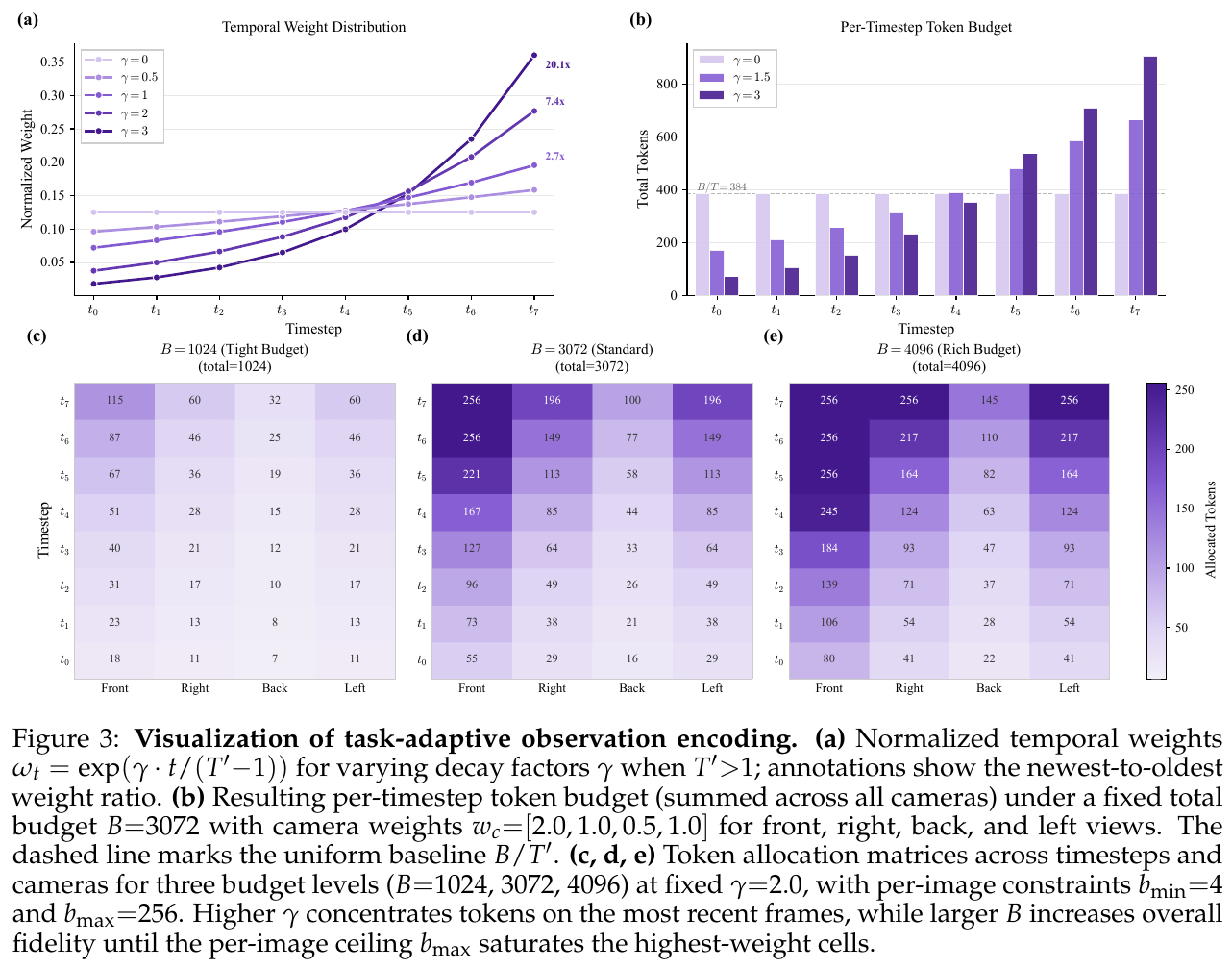
② 时空视图标识与具身提示
- 输入:动态分辨率的图像特征 Token、当前自然语言指令、具身提示前缀(如 “Imagine you are a robot…” 或 “Imagine you are a car…“)。
- 处理:系统将自然语言的相机视点标识(如 “Front View”、”Left View”)和时间步头(”Time step t”)直接交错拼插在对应的图像 Token 之前。同时,将具身类型置于 Prompt 的系统前缀中。
- 输出:输入给 Qwen3-VL 语言底座的统一图文交错 Token 序列。
- 设计动机:通过在普通的文本词表中插值时空标识,避免了引入额外的空间/时间位置编码层,最大程度保留了预训练大模型的语言 grounding 和空间推理能力,从而能够零样本支持新型机器人底盘或传感器配置。
③ 动作规划头与轨迹规划
- 输入:Qwen3-VL 在对应路点特征上的最后隐藏层状态 $E_A \in \mathbb{R}^d$。
- 处理:隐藏状态通过一个 4 层的高维 MLP(隐藏单元 512,使用 GELU 激活函数),在训练时使用每个数据集的第 99 百分位数作为尺度因子将真实路点坐标归一化到 $[-1, 1]$ 之间进行回归。
- 输出:$K=8$ 个带有航向角的未来 2D 轨迹路点 $W = {(x_k, y_k, \theta_k)}_{k=1}^8$。
- 设计动机:动作头被设计得尽可能轻量,确保几乎所有的时空建模与常识推理都在大语言底座内部进行,从而保证强大的跨场景泛化能力。
端到端数据流与 Agent 协作
当部署在多任务长程场景(如 EQA)中时,系统由上层规划器(如 Qwen3.6-Plus)和底层的 Qwen-RobotNav 共同构成。上层规划器根据全局目标进行高层推理与拆解,下发包含具体任务模式 $\tau_i$ 和观测参数 $\Phi_i$(如 $B$, $\gamma$)的导航 Tool 调用。Qwen-RobotNav 作为高频执行器输出轨迹并执行。每次执行完毕,导航 Harness 会自动将执行过程提炼为 compact 的轨迹证据(Trajectory Evidence)(记录关键的 landmark 和目标状态),并用来更新全局的证据笔记本(Evidence Notebook)。该机制实现了层次化的端到端闭环控制,成功避免了将 dense 视频流反复塞入大模型导致的上下文爆炸。
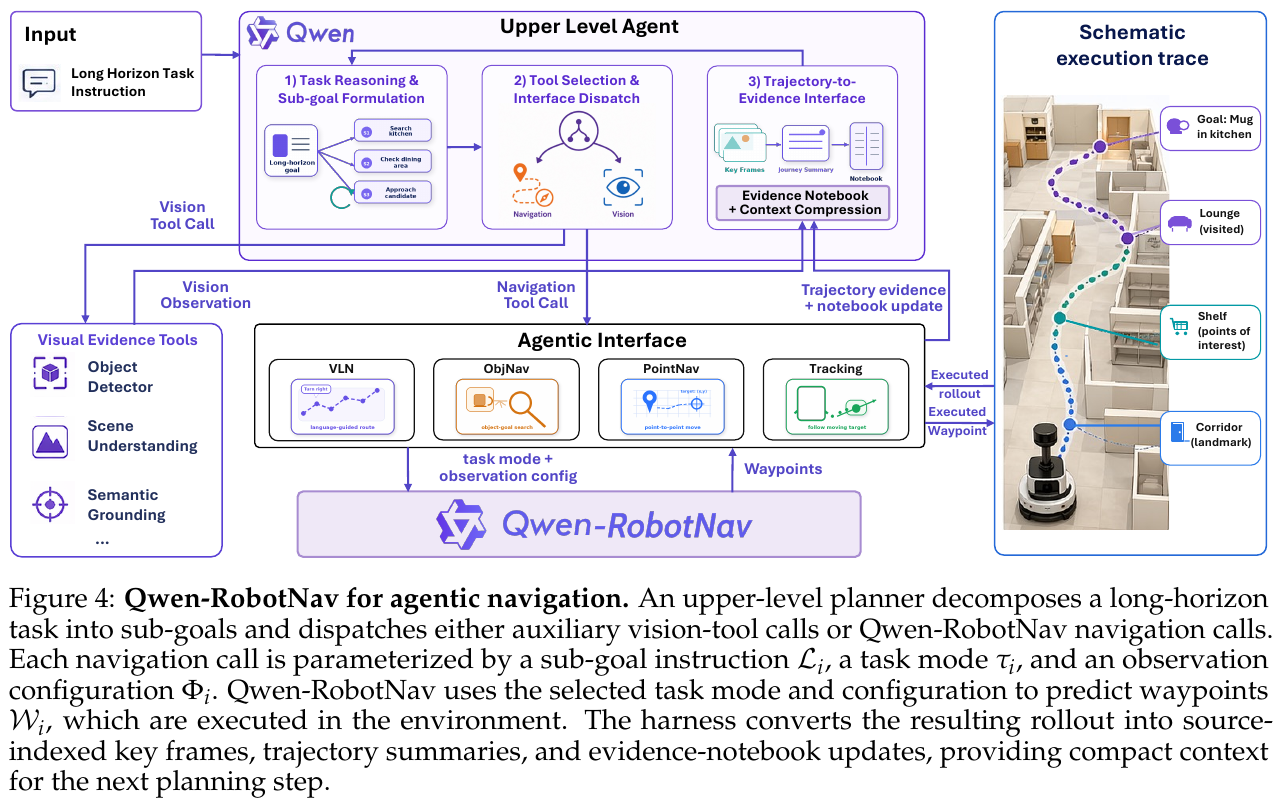
训练策略与联合训练
联合优化的损失函数定义为: \(L = L_{\text{traj}} + \lambda L_{\text{VL}}\) 其中 $L_{\text{traj}}$ 为预测轨迹相对于 ground-truth 的 MSE 损失;$L_{\text{VL}}$ 是基于 vision-language samples 的自回归 Next-Token 交叉熵损失,用于防止大模型的语言理解与开世界视觉感知能力在纯轨迹微调中发生退化崩溃。在训练过程中,所有观测配置($B$, $\gamma$, $w_c$, $b_{\min}$, $b_{\max}$)在每个 batch step 均会被进行独立随机采样,使模型自然适应任何推理时的配置变化。

3. 核心结果/发现
实验基准概览
Qwen-RobotNav-4B 和 8B 在多项基准测试中均展现出了 state-of-the-art(SOTA)的水平,覆盖了指令遵循、目标探索、主动追踪、自动驾驶等多个维度。
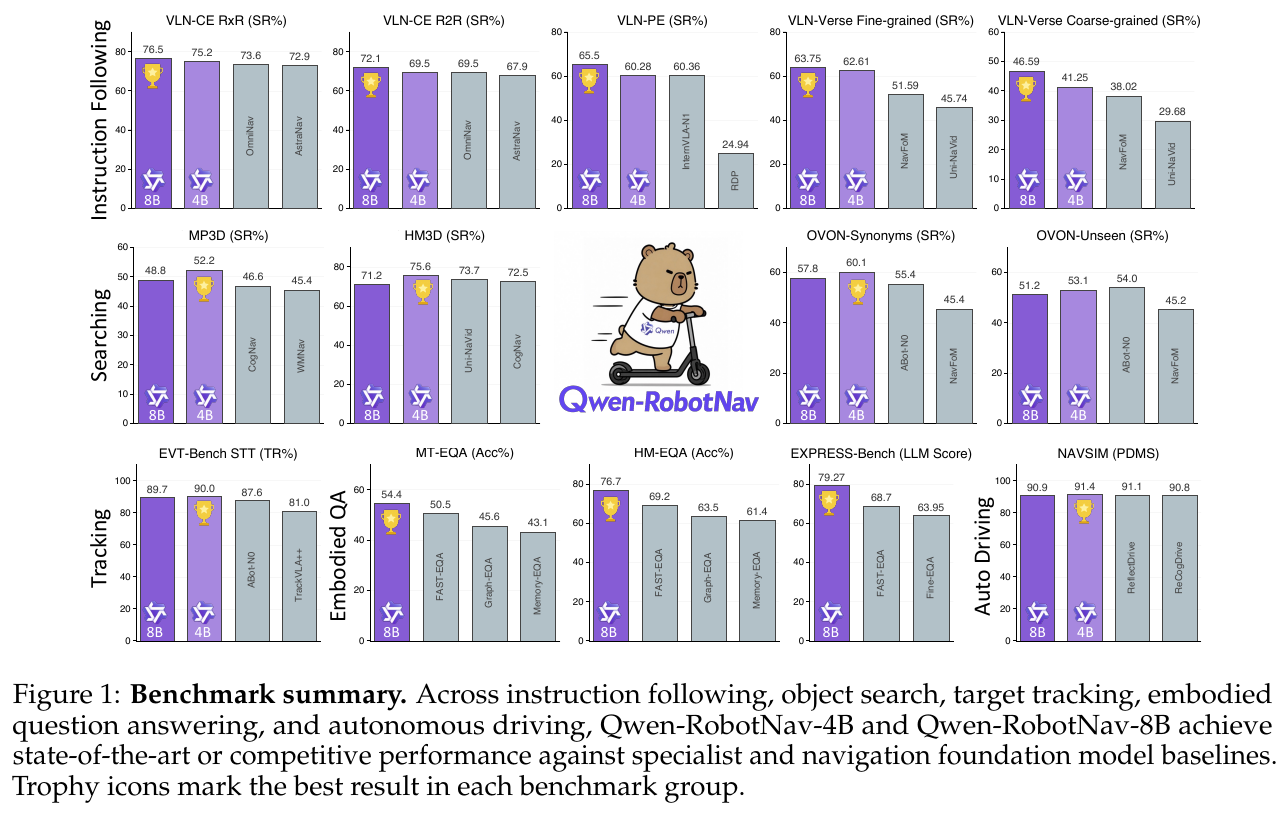
- 指令遵循 (VLN-CE): 在 R2R 基准上,Qwen-RobotNav-8B 达到 72.1% 的成功率(SR)和 66.6% 的 SPL;在长程的 RxR 基准上达到 76.5% 的 SR,超出强基线 NavFoM达 12.1% SR。在仅有单前向相机的 monocular 设定下,依然在 R2R 取得 66.9% SR,RxR 取得 73.4% SR,超越了专业的单目模型。
- 主动追踪 (EVT-Bench): 在 EVT-Bench 单目标追踪任务中,Qwen-RobotNav 取得了 90.0% 的追踪率(TR),是通用大模型及专用追踪模型(如 TrackVLA++)中的最高值,且碰撞率仅为 5.70%。
- 自动驾驶 (NAVSIM & AlpaSim): 在 NAVSIM 基准上,引入前三帧的历史自我状态(Ego-Status)后,Qwen-RobotNav-4B 取得了 91.4 PDMS(PDM Score),NC(导航合规率)高达 99.8%,超越了 WoTE、LAW 等专用多模态驾驶模型。此外,模型在 AlpaSim 上展现了出色的零样本跨领域闭环控制泛化能力。
- 具身问答 (EQA): 在与 Qwen3.6-Plus Agent 架构协同测试中,该系统在 HM-EQA 取得 76.7% SR,MT-EQA 取得 54.4% SR,而在导航所需的折算等效步数(Steps)上,比此前的 SOTA 方法(如 FAST-EQA)精简了 77%。
数据规模与接口控制消融
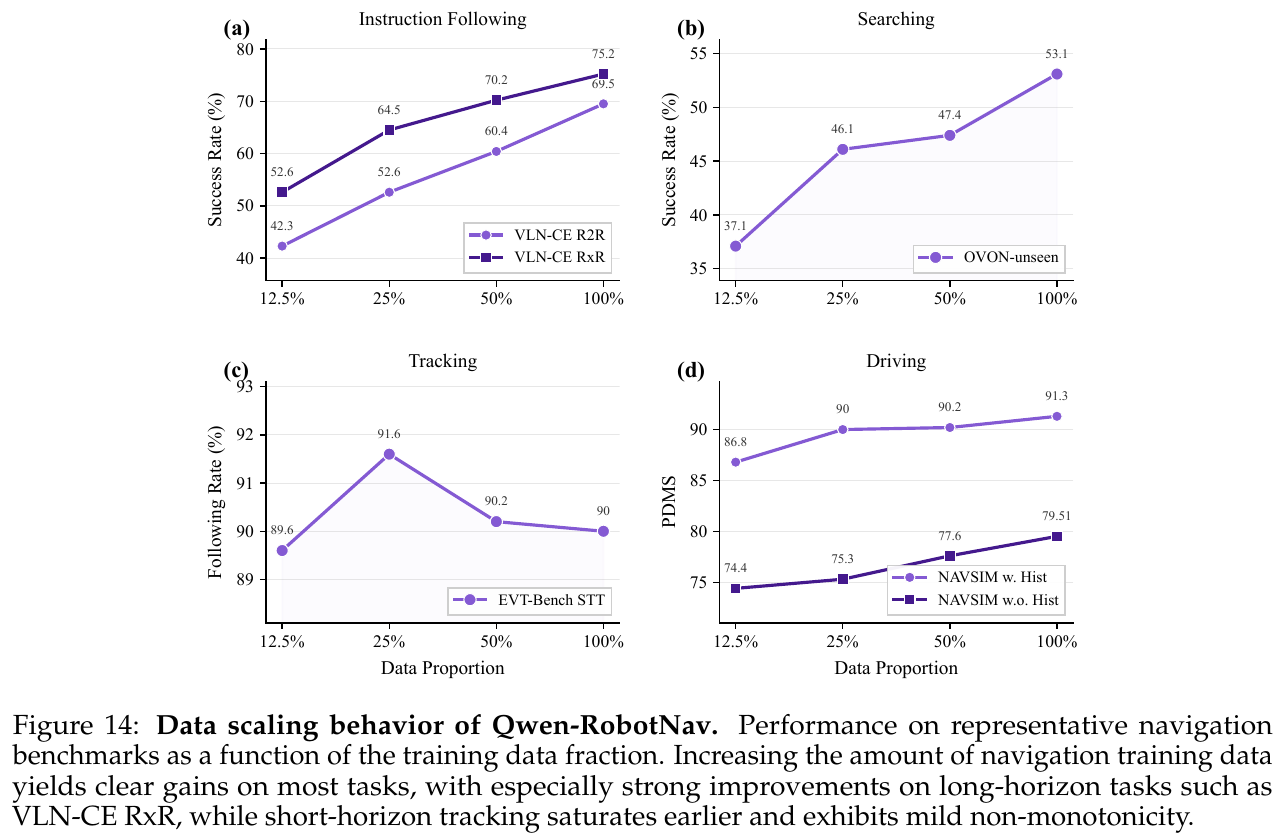
- 数据量消融:将导航轨迹数据占比从 12.5% 扩展到 100% 后,指令遵循(RxR)与自动驾驶(NAVSIM)的表现提升尤为显著,而短程追踪任务则在较少的数据下即快速饱和。
- 控制参数消融:
- Token 预算 $B$:预算从 2048 提升到 4608 时,R2R 的 SR 从 70.8% 攀升至 74.6%,但超过 3584 后 OSR 指标表现出边际效应递减,说明过量多余视觉特征可能引入负面噪声。
- 衰减系数 $\gamma$:$\gamma$ 从 0.5 提升到 3.5 的扫参中,SR 指标在 $\gamma=3.0$ 时达到峰值(72.5%),显示了对于局部导航,强化最新帧权重的 Recency Bias 非常重要,但过大的衰减会导致历史丢失,从而略微损害整体路径规划的高效性。
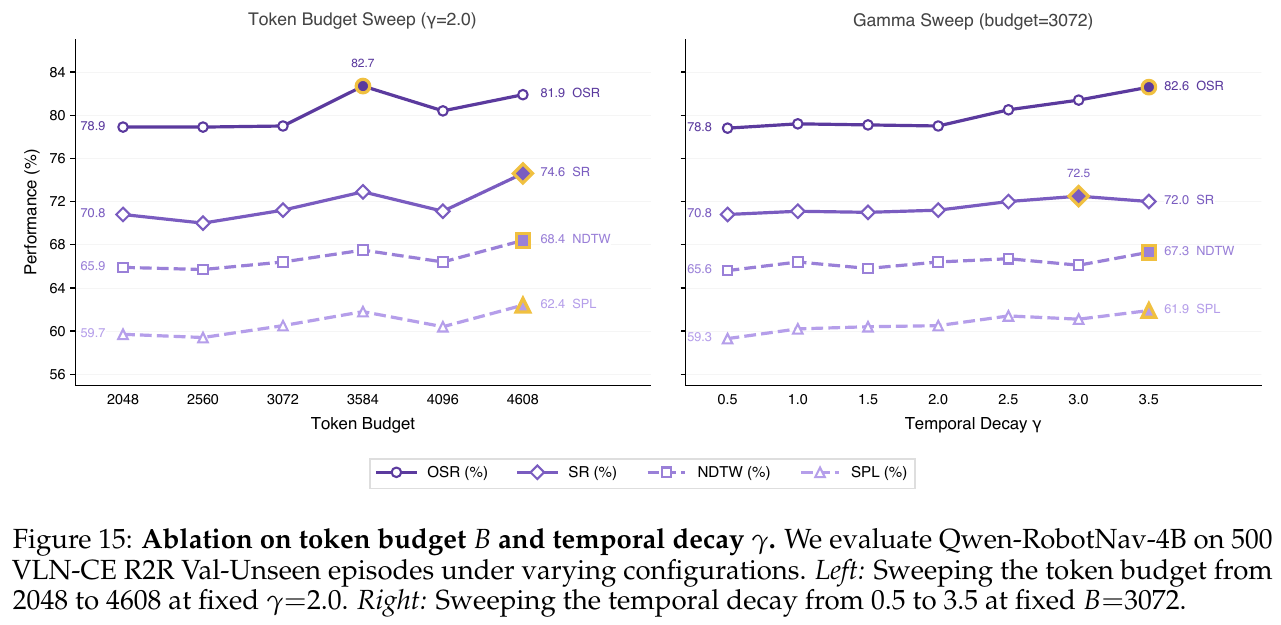
真实世界机器人部署
Qwen-RobotNav 部署在宇树 Unitree Go2 四足机器人以及移动底座上,在从未见过的展厅、复杂公寓等真实场景中展示了非凡的零样本落地能力。



- 长程轨迹与运动原语:在长达 21.78 米的真实走廊中,四足机器人完全依靠自然语言指令成功穿越多个混合场景。令人瞩目的是,当接收到“向后退”的语言原语时,模型能够在完全没有里程计或目标图输入的情况下,以倒退姿态精准重走前行路线,验证了其在复杂物理环境下的精确空间闭环理解。
- 精细化控制与动态规划:在真实的公寓中,机器人精确地执行诸如“绕着床走”、“在夜视台的左侧停下”、“在出门前先转个身”等精细的空间细节逻辑。在更高级 of Agent 任务中,机器人可以自主探索寻找“Cotti Coffee”里落下的绿色雨伞,并在行进中自动汇报显著的路标标志。
4. 局限性
- 边缘部署的算力壁垒:虽然 remote-server 模式延迟表现优秀(196 ms, 5.1 Hz),但对网络稳定性和传输带宽存在天然的依赖,这在高速移动或网络信号死角中容易发生延迟突刺。而使用 NVIDIA Jetson Thor 进行 FP8 量化部署时,尽管延迟相对平稳(204 ms, 4.9 Hz),但其仍然受到端侧显存与计算带宽的严格物理限制,极大地约束了多视角和高频决策的上限。
- 基于 Skeleton 路径的效率损耗:由于在 ObjectNav 数据生成中广泛采用了基于 skeleton 的 medial-axis 探索算法,它虽然成功教会了模型如何在未知的场景中进行彻底的“房间-走廊-死角”回溯搜索,极大地提高了最终的寻物成功率(Reach-first),但这也导致模型在面对已知路径时,行为偏向于过分谨慎的安全避障与大范围搜寻,致使最终在某些特定路径上的 SPL 指标偏低。
53. GA-VLN (2026)
——— Geometry-Aware BEV Representation for Efficient Vision-Language Navigation
📄 Paper: arXiv:2605.22036
精华
- 提出了一种面向连续环境视觉语言导航(VLN-CE)的新型几何感知鸟瞰图(GA-BEV)特征表示方法。
- GA-BEV 将显式的基于深度图的 3D 投影与来自 3D 基础模型(VGGT)的隐式 3D 几何先验相结合,构建出紧凑且富含空间结构的智能体中心 BEV 地图。
- 采用网格化 BEV 聚合(Grid-Based BEV Aggregation)大幅压缩了历史视觉 token 数量,在提升导航成功率的同时将每步推理的平均 token 数从约 4000 降至 514。
- 结合多模态大语言模型(MLLM,如 LLaVA-Video),设计了高效的双阶段对话式动作预测框架,实现 BEV 特征每 8 步仅更新一次的高效运行机制。
- 在 R2R-CE、RxR-CE 和 NavRAG-CE 等连续 VLN 基准上刷新了 SOTA,并且不依赖 labor-intensive 的 DAgger 增强或通用 VQA 混合训练,展现出极高的数据效率和零样本泛化能力。
1. 研究背景/问题
现有的视觉语言导航(VLN)方法在处理连续环境时,大多直接将密集历史 RGB 视频块(patch tokens)送入多模态大语言模型(MLLM)进行动作决策。这种做法存在两个核心局限:
- 高计算开销:随着时间步增长,密集的 RGB 视频块会产生极其庞大的 token 数量($t \times H_p \times W_p$ 级别的 token),带来巨大的推理延迟与计算负担。
- 缺乏显式空间结构:纯图像特征缺乏显式的 3D 几何和空间结构,导致智能体在多视角空间推理(如“左转并寻找身后的电视”)上面临严重挑战,导航表现受限。
2. 主要方法/创新点
为了克服上述局限,本文提出了 GA-VLN 框架,其核心是构建一个几何感知鸟瞰图(GA-BEV)表示,该表示融合了显式深度几何与隐式 3D 先验,并在 MLLM 导航决策中重用,极大地平衡了表现与效率。
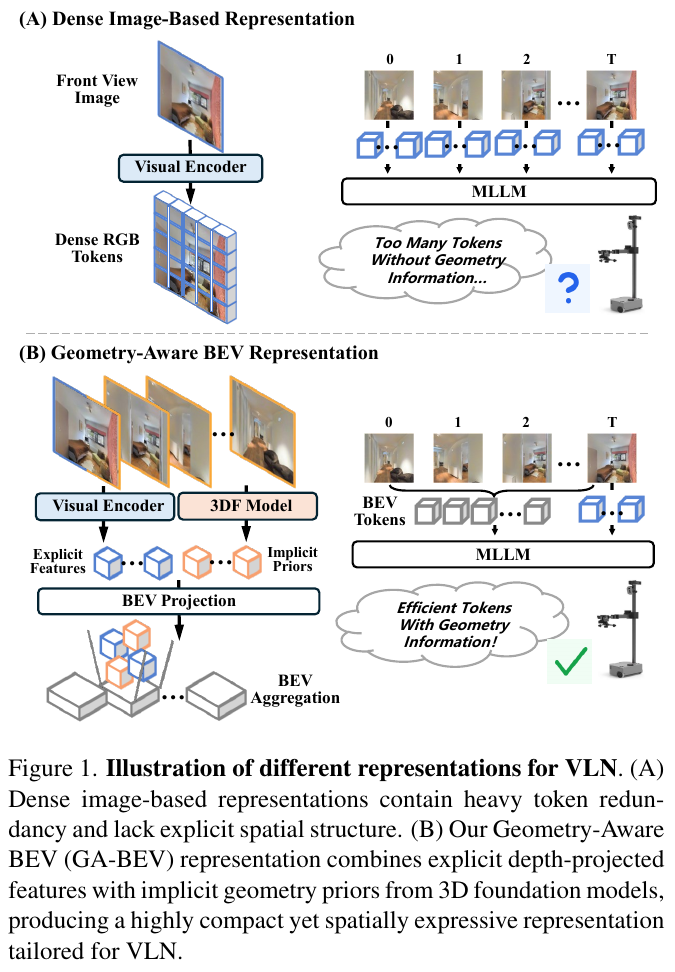
GA-BEV 表征构建流程
GA-BEV 的构建流程主要包含以下三个步骤:
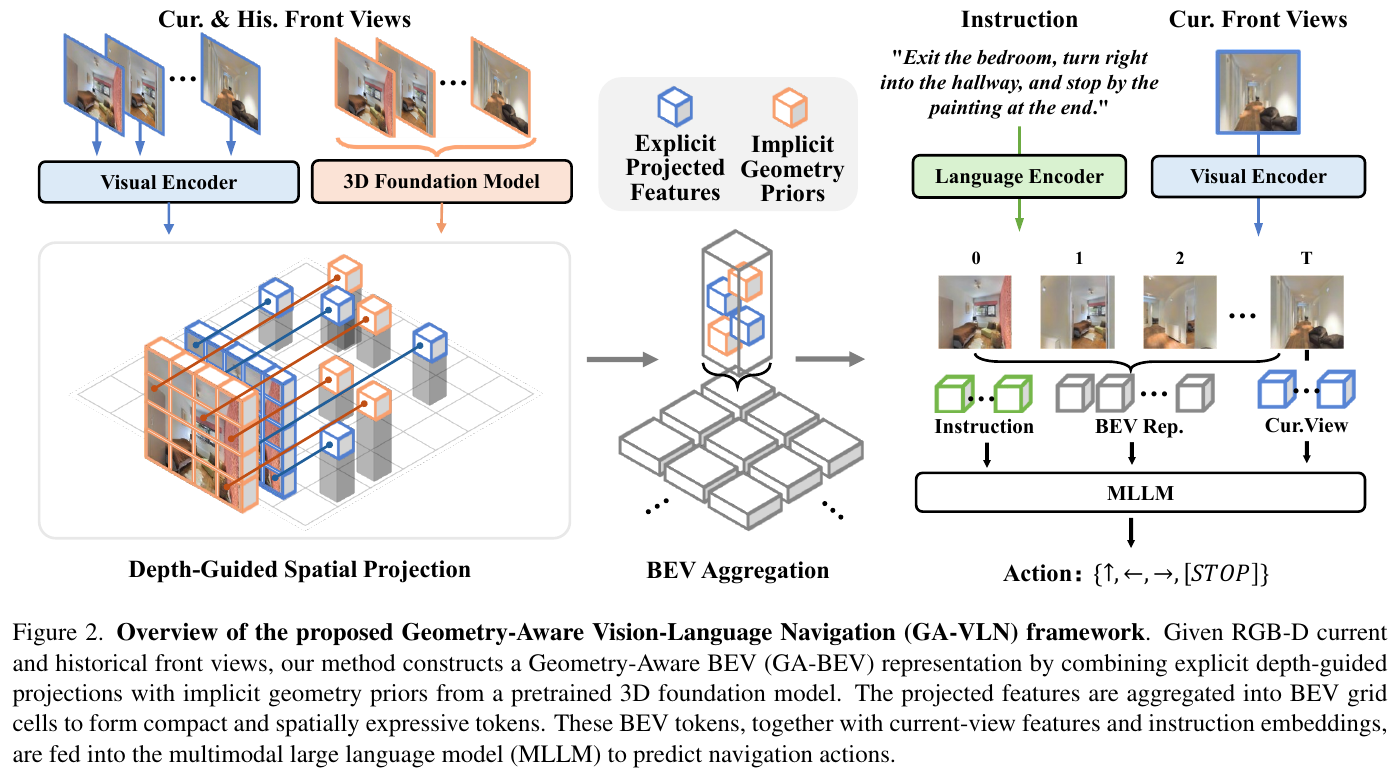
① 显式深度引导空间投影(Explicit Depth-Guided Spatial Projection)
- 输入:当前时间步的 RGB patch 特征 $V_t \in \mathbb{R}^{H_p \times W_p \times d_p}$,以及通过双三次插值(bicubic interpolation)缩放到相同分辨率的深度图 $D_t \in \mathbb{R}^{H_p \times W_p}$。
- 处理:利用当前时间步智能体的位置 $p_t$、相机旋转矩阵 $R_t$ 以及相机内参矩阵 $K$,根据针孔相机模型,将每个 2D 像素块中心反投影到 3D 世界坐标系中: \(\hat{p}_t(u, v) = R_t K^{-1} \begin{bmatrix} u \\ v \\ 1 \end{bmatrix} D_t(u, v) + p_t\)
- 输出:映射到 3D 空间的点云特征,这在输入阶段就为智能体显式注入了 3D 物理世界的空间几何一致性。
② 隐式 3D 几何先验融入(Implicit 3D Geometry Priors)
- 输入:智能体经历的历史图像序列 ${I_1, \dots, I_t}$。
- 处理:将历史序列输入 to 冻结参数的 3D 基础模型 $f_{3DFM}$(如 VGGT-1B)中,该模型经过大规模 3D 重建任务预训练,具备出色的多视角几何感知与形状先验: \(V^g = f_{3DFM}(\{I_1, \dots, I_t\}) \in \mathbb{R}^{t \times H_g \times W_g \times d_g}\) 通过一个 2 层 MLP(Linear-GeLU-Linear)投影层 $f_{project}$ 调整特征维度以匹配 SigLIP 特征: \(\tilde{V}^g = f_{project}(V^g) \in \mathbb{R}^{t \times H_g \times W_g \times d_p}\) 随后,使用与步骤 ① 相同的空间投影方式,将其投射到 3D 空间,得到对应的 3D 坐标 $\hat{p}_g \in \mathbb{R}^{t \times H_g \times W_g \times 3}$。
- 输出:富含隐式形状结构与多视角几何一致性的 3D 基础特征。
③ 网格化 BEV 聚合(Grid-Based BEV Aggregation)
- 输入:统一的 3D 空间特征集 $V = V \cup \tilde{V}^g$ 及其对应的 3D 物理位置 $\hat{P} = {\hat{p}} \cup {\hat{p}_g}$。
- 处理:由于室内空间物体在高度方向较矮,而智能体的动作主要约束在 2D 地面上,因此将所有 3D 特征投影到当前的以智能体为中心的 $(x, z)$ Bird’s-Eye-View (BEV) 平面上。
- 将 BEV 平面离散化为以智能体为中心、感知范围为 $[-R, R]$(取 $[-10\text{m}, 10\text{m}]$)、网格大小为 $\Delta \times \Delta$(取 $0.25\text{m} \times 0.25\text{m}$)的 $N \times N$ 网格。
- 对于每个非空网格 $(i, j)$,收集落入该网格的所有 3D 特征集 $S_{i, j}$。
- 对网格内的特征进行均值池化(mean pooling),并加上 2D 正弦位置编码(position embedding) $e_{i, j}$: \(B = \left\{ \frac{1}{\lvert S_{i,j} \rvert} \sum_{v \in S_{i,j}} v + e_{i,j} \;\middle|\; \lvert S_{i,j} \rvert > 0, i,j \in [1, N] \right\}\)
- 只保留非空网格,从而最大化地压缩冗余 token。
- 输出:高密度、紧凑的智能体中心 BEV 几何地图特征 $B$。
导航决策与推理流程:双阶段对话框架
为了最大化推理效率,GA-VLN 将动作决策表述为一个双阶段的对话式生成过程:
- 第一轮对话(Round 1):智能体接收语言指令 $L$、当前的正面视角图像 $IMAGE$(使用 SigLIP 编码)以及聚合了最近多达 32 个历史步观察的 GA-BEV 特征 $BEV$。MLLM(LLaVA-Video-7B)一次性预测 4 个动作(如
move forward,turn left,turn left,move forward)。 - 第二轮对话(Round 2):在执行完这 4 步后,智能体无需重新投影和更新 BEV 特征,仅获取新位置 of 正面视角图像 $IMAGE$,继续重用第一轮的 BEV 特征输入给 MLLM,再预测 4 个动作(如
turn left,turn right,move forward,STOP)。 - 更新周期:仅在每 8 步动作(即完成两轮对话)后,智能体才会重新构建并更新一次 BEV 特征。这样显著降低了 3D 基础模型前向传播和空间投影的调用频次。
3. 核心结果/发现
GA-VLN 在 Habitat 仿真环境中的多个连续导航数据集上进行了评估:
- 基准测试超越 SOTA(如 Table 1 所示):
- 在 R2R-CE 上,成功率(SR)达到 61.0%,SPL 达到 55.2%,均超过了此前最先进的 Image-based MLLM 智能体(如 StreamVLN: SR 56.9%, SPL 51.9%)。
- 在 RxR-CE 上,成功率(SR)达到 55.4%,SPL 达到 45.2%。
- 在 NavRAG-CE 上,成功率(SR)为 22.2%,SPL 为 18.2%。
- 重要特性:GA-VLN 在完全不使用 DAgger 数据增强与通用 VQA 数据联合训练的情况下,依靠高质数据集在少量 Epoch 下即取得了这些佳绩,验证了其极高的训练效率。
- 消融实验与效率分析:
- 显式深度投影与隐式 3D 先验的互补性(Table 2):
- 仅使用深度投影的 BEV 表征(w/o VGGT),SR 从 baseline 的 51.49% 提升至 59.21%,且 Latency 从 342.9ms 降至 212.9ms(归功于 token 的极度压缩)。
- 进一步融合 VGGT 的 3D 隐式先验后,成功率(SR)进一步攀升至 60.96%,虽然由于 3D Foundation Model 带来轻微的额外开销,但整体 Total Latency (258.7ms) 依然远低于 Baseline (342.9ms)。
- 最佳 BEV 超参数:网格分辨率设为 $0.25\text{m} \times 0.25\text{m}$ 最具性价比(Table 3);历史步长选为 32 最优,过长会引入累积误差与物理漂移。
- 抗噪稳健性强(Table 4):在模拟 Stretch 3 机器人的深度抖动($\sigma = 0.05\text{m}$)、位移漂移($\sigma = 0.05\text{m}$)和旋转偏差($\sigma = 5^{\circ}$)的传感器噪声测试下,GA-VLN 的 SR 下降均小于 2%,说明网格化均值池化和多视角 3D 特征的加入极大增强了鲁棒性。
- 显式深度投影与隐式 3D 先验的互补性(Table 2):
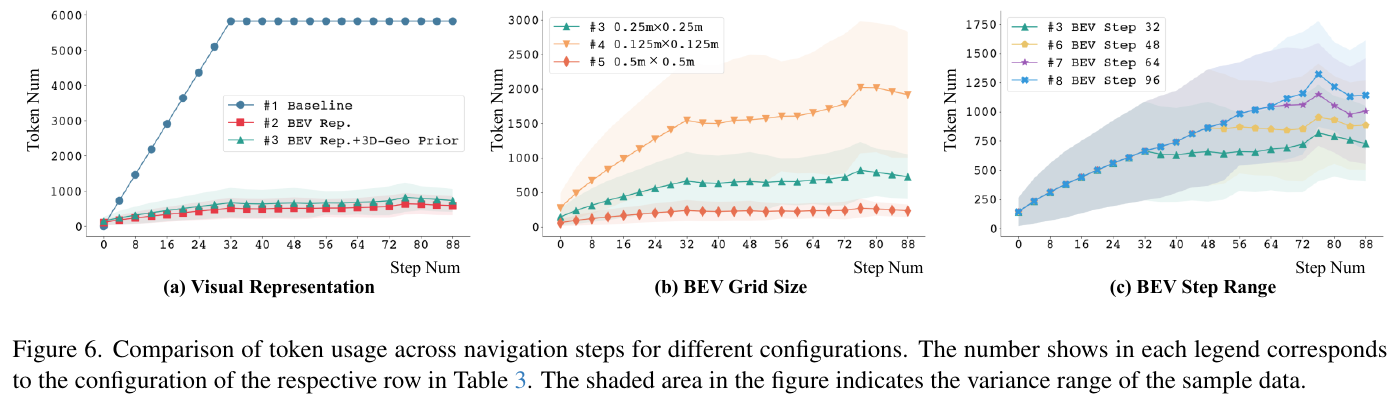
4. 局限性
- 实时深度图强依赖:显式投影环节非常依赖输入深度图的质量。在完全丢失深度或深度图质量极度恶化(例如镜面反射、强光直射)的情况下,三维重建的 BEV 地图可能会出现较大形变,进而影响导航性能。
- 历史滑窗限制:尽管 32 步的历史滑窗在大多数场景表现优秀,但当在超大规模或多楼层长程复杂场景中导航时,滑窗可能会丢弃较早前的关键地标,导致回溯困难。
5. 真实世界机器人部署
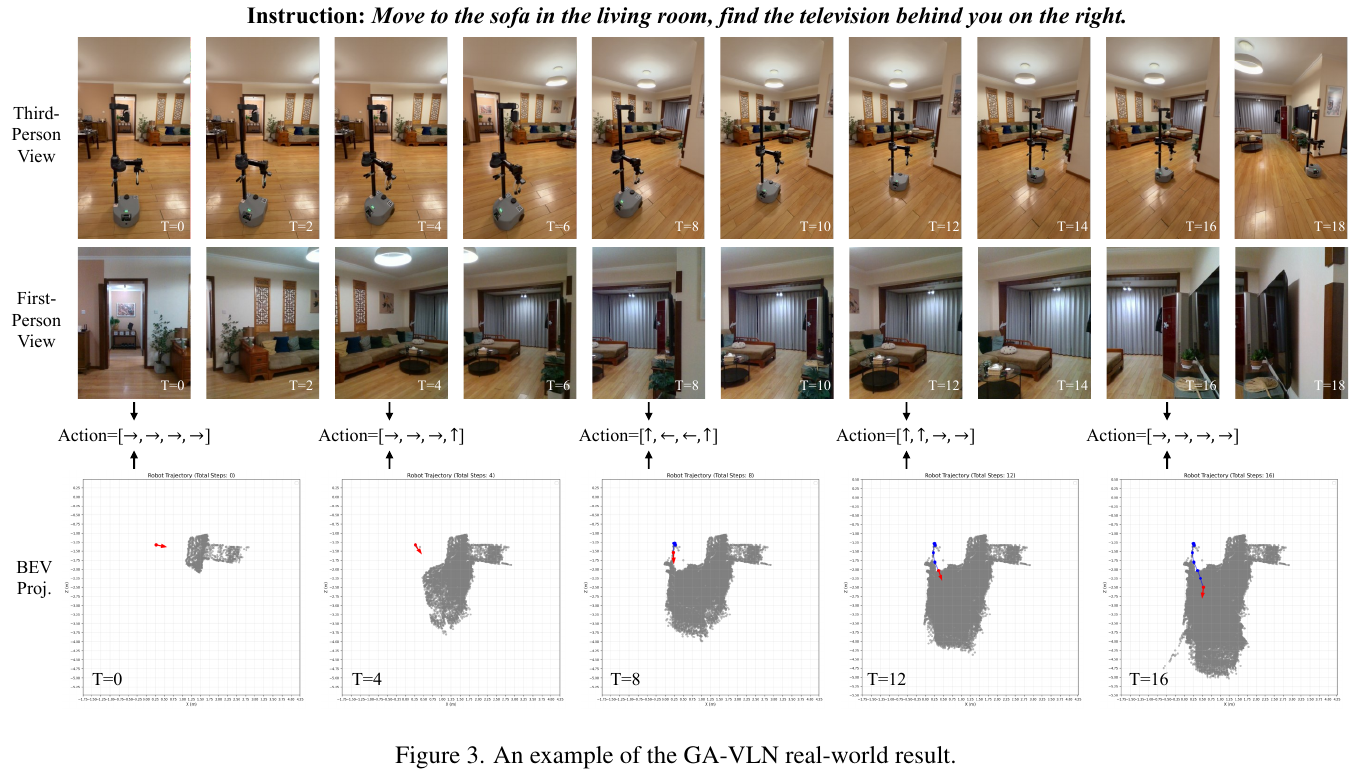
54. SEDualVLN (2026)
———空间增强的双系统连续环境视觉语言导航框架
📄 Paper: arXiv:2605.17249
精华
- 快慢协调决策:将导航任务分解为系统 1(轻量 VLM 原子动作预测器,高频)和系统 2(通用 MLLM 全局边界路径规划器,低频),兼顾了执行效率与全局规划能力。
- 多尺度空间增强:对系统 1 分别实施全局 3D 几何隐式监督和局部通道连通性显式提取,显著降低了 VLM 在岔路口走错方向的概率。
- 物理一致的 3D 路径渲染:系统 2 通过在线 3D 建图和沿路径插值渲染虚拟视图,为通用大模型提供高保真的空间感知,有效减少了纯文本或 2D 视角带来的空间幻觉。
- 性能新高度:在 continuous 视觉语言导航(VLN-CE)基准测试(R2R-CE 和 RxR-CE)上取得了最新的 State-of-the-Art 表现。
1. 研究背景/问题
现有的视觉语言导航(VLN)方法主要分为两类:一是基于轨迹数据微调的端到端视觉语言模型(VLM)策略,其动作执行快但缺乏动态推理能力,且在长距离导航中易因历史上下文累积而退化;二是零样本(Zero-Shot)模块化方案,其利用通用多模态大模型(MLLM)作为规划器,虽然泛化能力强,但由于缺乏精确的空间定位和几何推理能力,极易产生空间幻觉,且推理延迟巨大。
虽然最近有一些双系统(Dual-System)的尝试,但它们多是简单拼凑两种范式,未从根本上解决底层模型空间感知薄弱的问题。本论文提出 SEDualVLN,重点通过全局和局部等多尺度的空间增强(Spatial Enhancement)策略,赋予智能体极强的方向感,以提升其在连续未见环境(Unseen continuous environments)下的长周期导航鲁棒性。
2. 主要方法/创新点
① 双系统整体框架
SEDualVLN 由两个子系统以及一个协同调度器构成:
- 系统 1(快系统/动作生成器):高频运行,基于微调的 VLM 直接从当前第一视角 RGB 图像流和指令预测离散原子动作(前进、左转、右转、停止)。
- 系统 2(慢系统/路径规划器):低频运行,基于 3D 实时建图、路径插值渲染与通用 MLLM(如 GPT-4o),在全局地图上选择最佳的边界航点(waypoint)。
两个系统协同工作:系统 2 负责指引大方向,系统 1 负责执行到达航点所需的微观原子动作。通常,系统 1 执行约 20 步原子动作时,系统 2 才进行一次全局航点重新规划(频率比 20:1),这种“快慢协同”的设计不仅保证了实时响应,还兼顾了全局空间信息的整合。
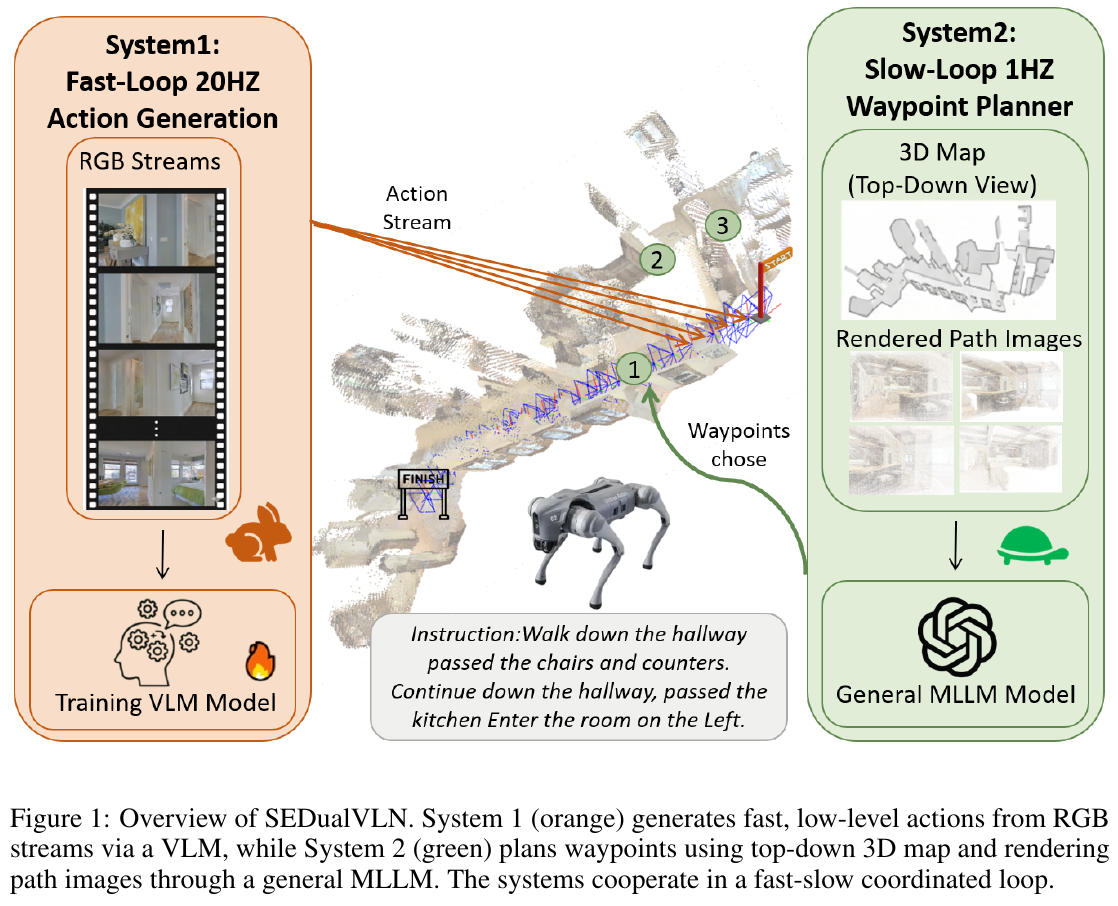
② 系统 1:空间增强的 VLM 模型
系统 1 基于 StreamVLN 骨干网络,通过多轮对话机制和 KV cache 实现高效推理。本论文引入了全局与局部双重空间增强策略来克服传统 VLM 空间表征隐式、易在长距离漂移的问题:
-
全局空间增强策略 (Global Spatial Enhancement Strategy): 不依赖额外的深度图传感器或显式 3D 重建模型,而是采用隐式对齐的策略。作者利用预训练的 3D 基础模型 VGGT 来提取当前帧 of 3D 空间结构特征。然后在 LLaVA-Video 中间的注意力融合层(第 24 层)上接入一个两层的 MLP,将 VLM 的视觉 Token 投影并与 VGGT 提取的 3D 空间特征进行对齐。
训练时,通过最小化两者的余弦距离来引导 VLM 隐式学习 3D 空间几何与结构信息。其联合训练损失函数 $L_{\text{SE}}$ 定义如下: \(L_{\text{SE}} = L_{\text{action}} + \alpha \cdot \frac{1}{N} \sum_{t=1}^{N} \left[ 1 - \cos\left(V_t, S_t + p_t\right) \right]\) 其中, $V_t$ 表示投影后的视觉 Token, $S_t$ 表示来自 VGGT 的 3D 空间表征, $p_t$ 为位置编码, $\alpha$ 是损失权重系数。
-
局部空间增强策略 (Local Spatial Enhancement Strategy): 在实际导航中,通道(如走廊、门口)是连接不同区域的关键拓扑结构,而 VLM 极易在这些决策岔路口选错分支。为此,作者设计了通道连通性提取模块(Channel Connectivity Extraction Module)。该模块首先使用开放词汇表目标检测模型 Grounding DINO 自动识别当前视野中的通道区域,随后利用 SAM 对这些区域进行分割以获取二值遮罩(通道区域像素设为 1,非通道设为 0),再经由 MLP 投影为与全局视觉 Token 维度相同的局部拓扑 Token 输入给 VLM。该策略使 VLM 能够显式地关注通道的连通性,显著减少了岔路口决策失误。
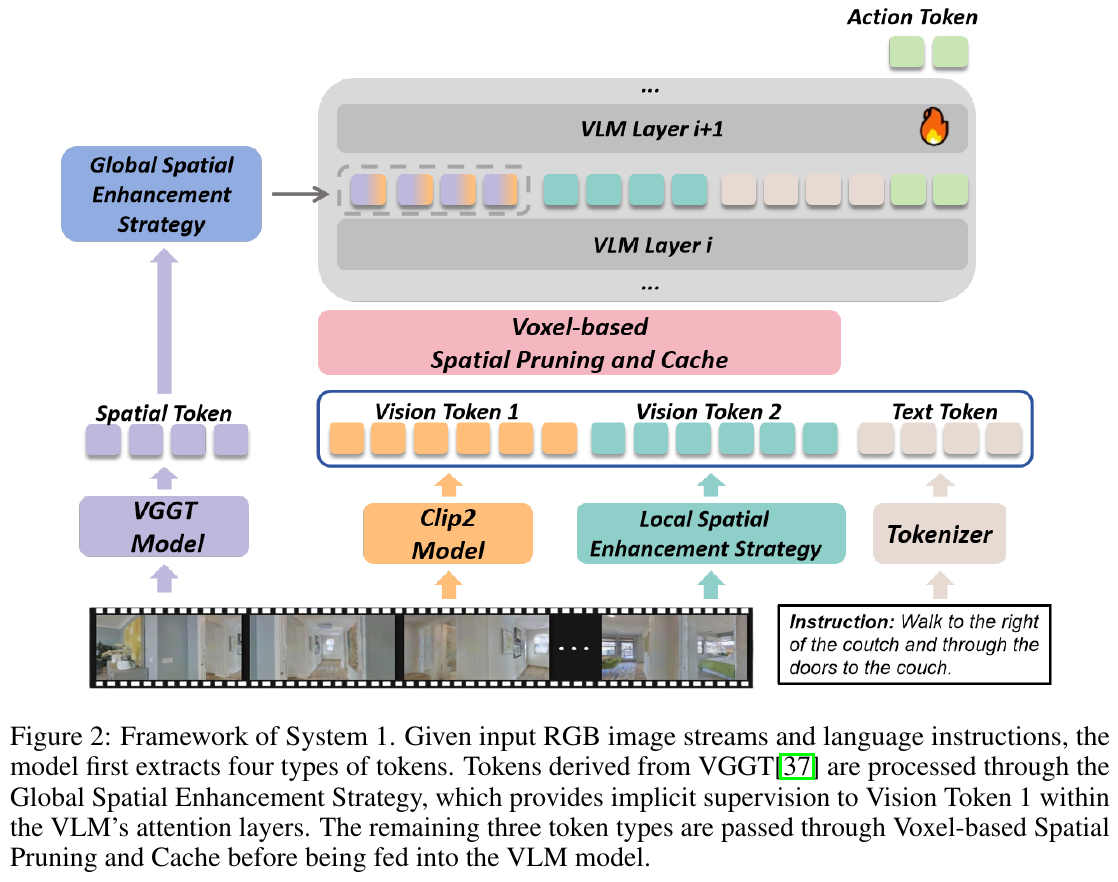
③ 系统 2:基于“建图-渲染-推理”的 MLLM 规划器
系统 2 旨在利用通用 MLLM(如 GPT-4o)强大的常识推理和零样本能力,并结合物理一致的 3D 地图克服其空间幻觉。其规划流程分为以下三步:
- 实时建图 (Mapping): 基于 LingBot-Map 算法,智能体在导航时实时在线构建轻量级的 3D 点云地图,并同时生成用以指引未探索区域的 2D 边界(frontier)地图。
- 路径虚拟渲染 (Rendering): 假设当前的候选边界点集合为 $F = {f_1, …, f_n}$。系统首先利用 A* 算法计算当前位置到各边界点在拓扑地图上的无碰撞路径: \(P_i = \text{A}^*(x_0, F_i)\) 为了向大模型直观呈现沿途视角,系统在路径的相邻节点间进行线性插值(若欧氏距离超过阈值 $d$ 则插入虚拟位姿点),并基于插值位姿渲染出虚拟的相机 RGB 视图。随后,为了减少大模型的输入 Token 消耗,使用 CLIP 编码器的余弦相似度进行冗余帧剪枝,仅保留场景变化明显的关键路径帧 ${I_1, …, I_m}$: \(s(I_k, I_{k+1}) = \frac{\langle \phi(I_k), \phi(I_{k+1}) \rangle}{\lVert \phi(I_k) \rVert \lVert \phi(I_{k+1}) \rVert} < \tau \implies \text{keep } I_{k+1}\)
- 两阶段多模态推理 (Reasoning):
- 第一阶段(环境自我感知增强):向 GPT-4o 输入 3D 自顶向下地图,令其总结和描述智能体当前所处位置和周遭环境(提取位置、空间关系与可行方向)。
- 第二阶段(模拟运动航点评估):向 GPT-4o 输入每个候选路径渲染出的视图序列,让其通过视觉与指令的契合度,评估并选择下一步的最佳边界航点 $F_i$。
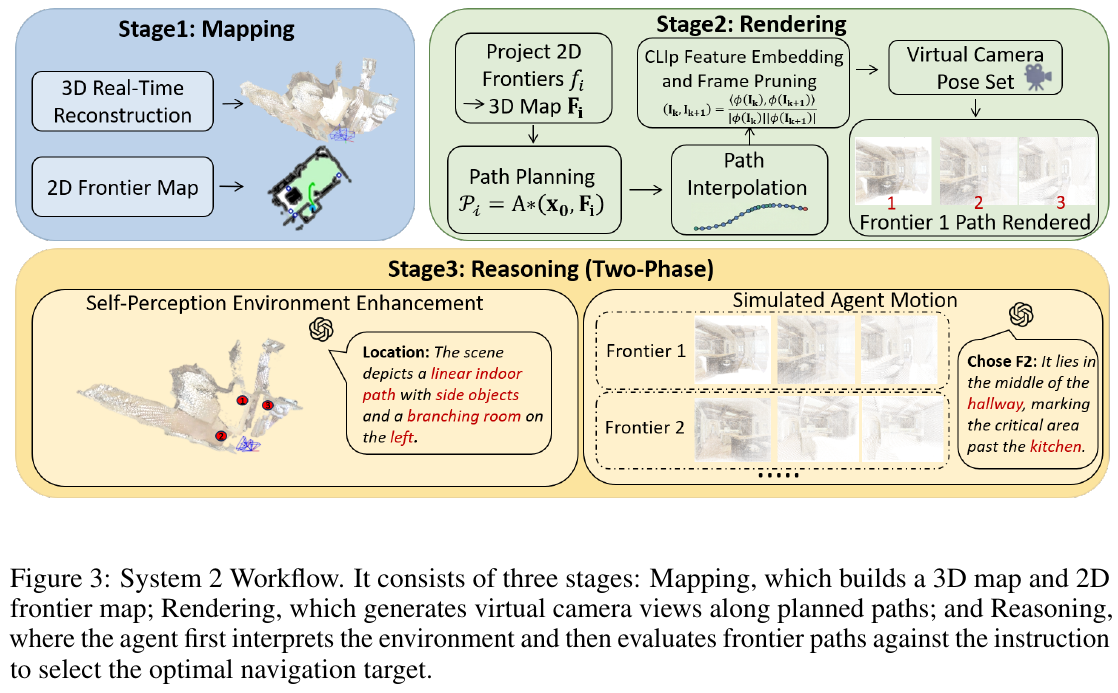
3. 核心结果/发现
-
SOTA 性能表现: 在连续视觉语言导航基准 R2R-CE 和 RxR-CE 的 Val-Unseen 验证集上,SEDualVLN 相比于之前最先进的双系统方法 DualVLN,在成功率(SR)上分别取得了 3% 和 2.5% 的绝对提升,且无需依赖任何额外的深度或全局传感器信息,仅用单目 RGB 输入即达到了新的基准高度。
-
岔路口避错能力: 消融实验与定性分析表明,在复杂的岔路口或房间交界处,引入通道连通性提取(LSES)能够极大地纠正智能体因视觉混淆引起的错误转向。
-
快慢协同的高效性: 单独运行系统 2 时,由于 GPT-4o 接口延迟和密集计算,单次导航的平均时间极其漫长(AT 接近 300秒)。而通过引入 20:1 的快慢频率比,双系统协同工作不仅使成功率高于单独的系统 1 或系统 2,更是将平均导航耗时(AT)降低了 5 倍以上,完美平衡了计算效率与决策准确度。

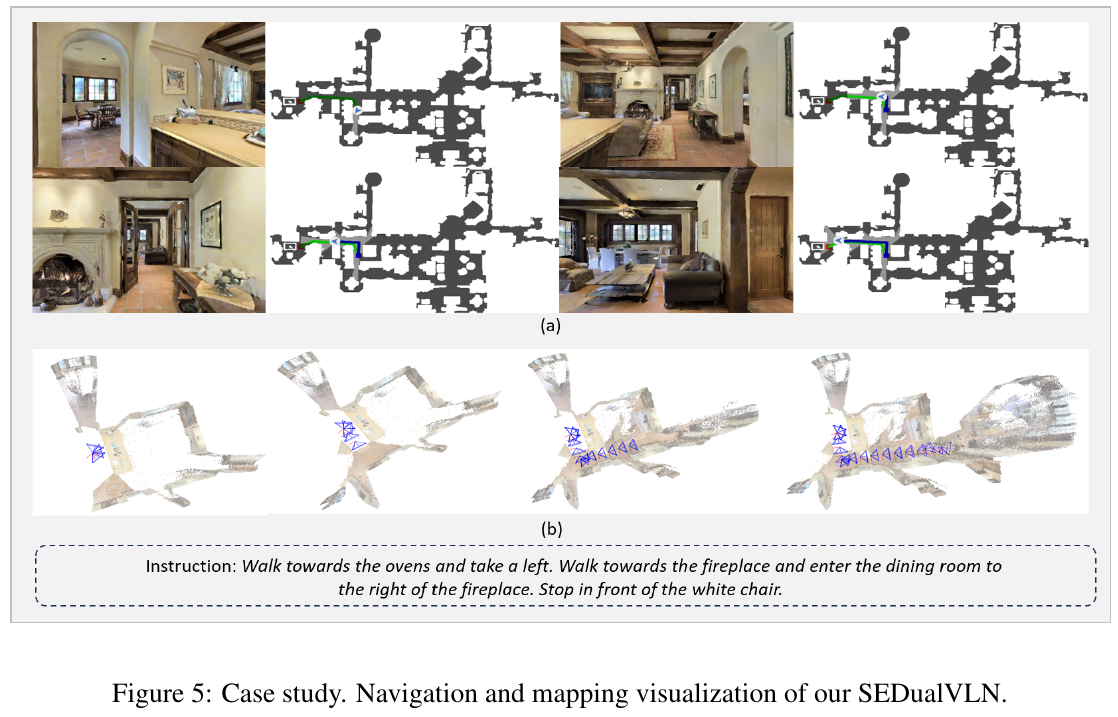
4. 局限性
- 真实物理设备部署难度:该框架严重依赖实时 3D 建图的表现。而在真实物理机器人设备上部署时,目前的实时三维重建特征提取仍存在较大的计算开销与噪声变形,建图的畸变可能会直接干扰系统 2 路径规划的准确度。
附录:系统 2 推理过程案例与 Prompt 模板
在系统 2 的推理机制中,GPT-4o 的决策包含两个阶段:
- 环境理解阶段:引导模型根据 3D 顶视图提取核心空间信息,输出当前 Location(位置环境)、Relationship(家具或障碍的空间关系)与 Possible directions(潜在的正确路径取向)。
- 规划决策阶段:输入各边界点路径的虚拟相机渲染流,评估 F1、F2、F3 等边界点中哪一个最符合导航指令,并生成具体原因。
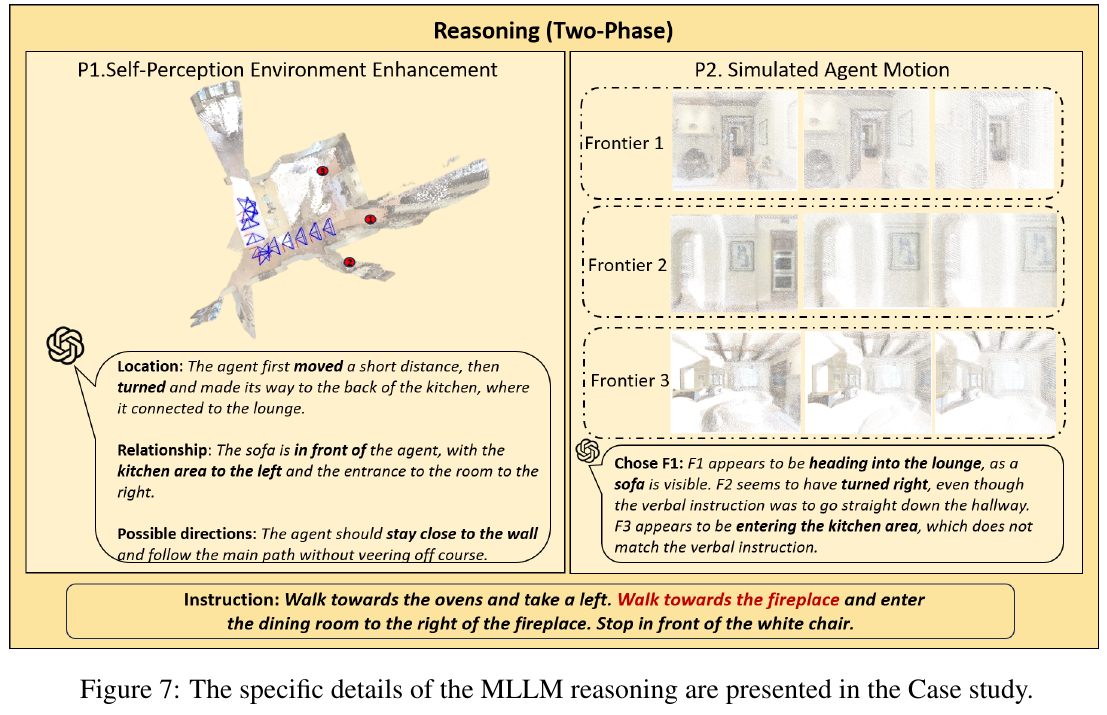
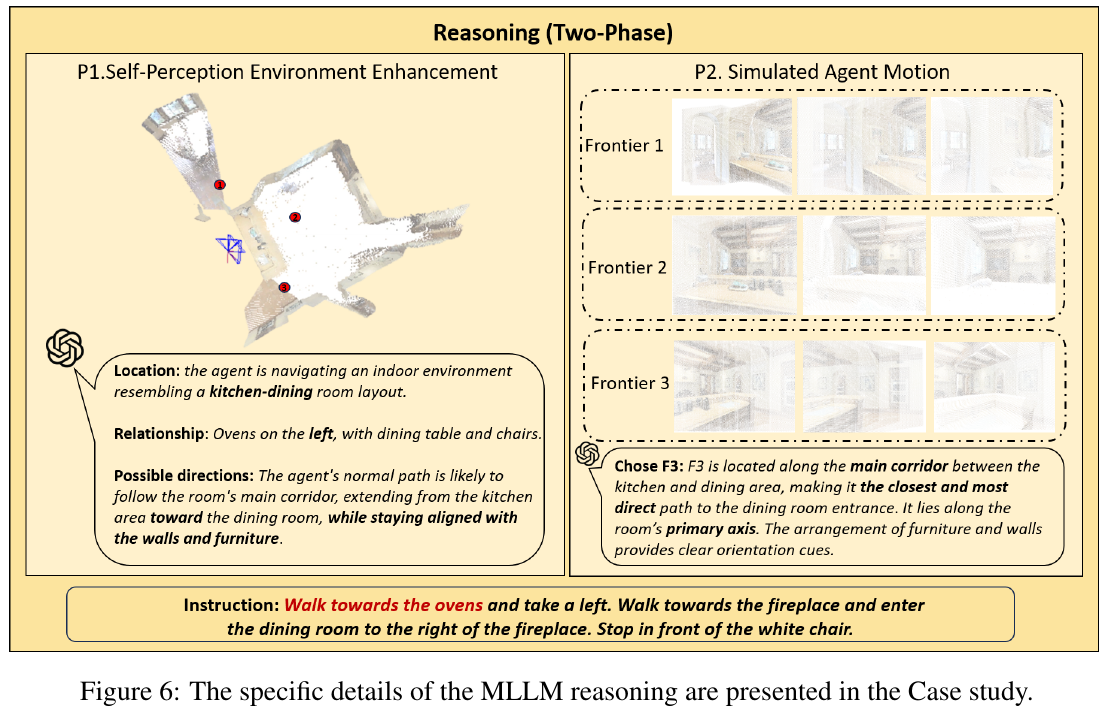
55. TopoGraph-VLN (2025)
——— 基于抽象障碍物地图航点预测与拓扑图-历史访问信息感知提示的零样本连续环境视觉语言导航
📄 Paper: arXiv:2509.20499
精华
- 输入特征抽象化:直接从深度图投影并计算高度梯度,构建 2D 抽象障碍物地图作为航点预测模型的唯一输入,剔除无关语义噪声,训练仅需 30 epochs 即可显著提升航点在开放空间中的可行性与线性可达性。
- 拓扑结构化记忆:提出一种动态更新的拓扑图,分类跟踪节点访问状态(Visited/Unvisited),并通过欧氏距离合并相近节点,解决 MLLM 导航时的局部环路死锁问题。
- 闭环容错纠错:利用拓扑图的连通性在提示词中进行自然语言描述,赋予 MLLM 局部路径规划与多步回溯重探索能力,使其能高效地纠正导航偏差。
- 零样本性能 SOTA:在 R2R-CE 和 RxR-CE 连续环境数据集上分别实现 41% 和 36% 的成功率,显著刷新了零样本方法的性能上限,并逼近有监督方法。
1. 研究背景/问题
vision-language navigation (VLN) 是机器人具身智能的核心任务之一,要求智能体理解语言指令并在 continuous environments (VLN-CE) 中进行导航。 以往基于航点预测(waypoint prediction)的 VLN-CE 方法主要面临三个局限:
- 感知特征冗余与不可行航点:常用的航点预测器输入高维的 RGB-D 图像,引入大量与空间可达性无关的语义噪点,且模型复杂;此外,生成的航点可能处于物理不可达区域或被中间障碍物遮挡。
- 缺乏结构化空间记忆:LLM/MLLM 导航器在连续环境中仅使用单线性的历史轨迹表示,容易在局部区域陷入死锁循环。
- 纠错能力不足:当导航发生偏差时,缺乏空间拓扑连通性认知的 MLLM 无法进行精准的局部路径规划和多步回溯重探索。
2. 主要方法/创新点
智能体的整体架构流程如图 1 所示:
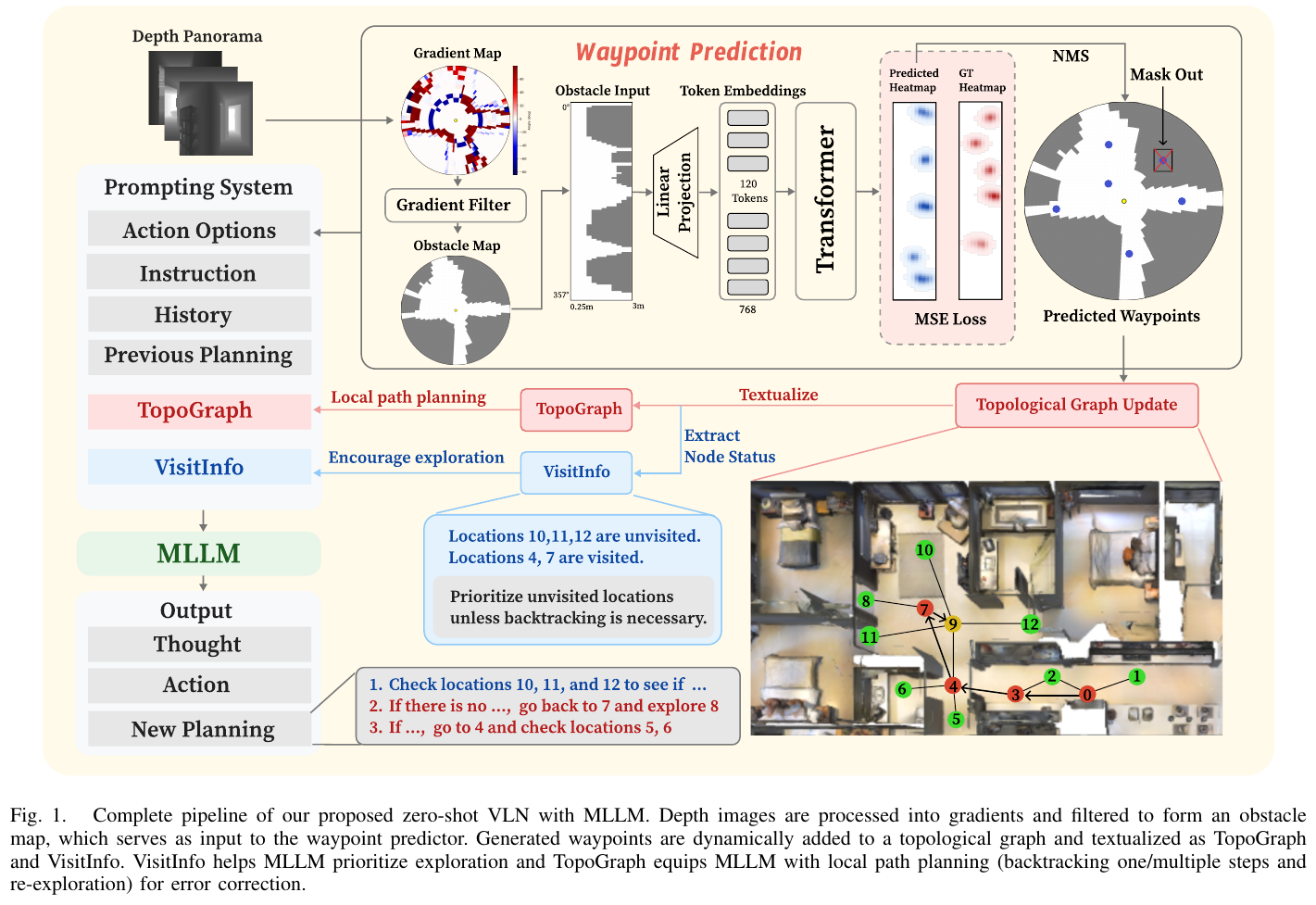
① 整体框架概述 整个系统主要由三个核心模块构成:基于高度梯度投影的抽象障碍物地图构建与轻量化航点预测模块、动态更新的拓扑图维护模块以及拓扑与访问状态感知的 MLLM 规划器。深度图像首先被转换为 3D 点云并投影构建出局部的 2D 障碍物地图,航点预测器基于该地图生成候选航点,随后这些航点被动态整合进带有访问状态标记的拓扑图中,最后 MLLM 根据当前多视角感知、指令和拓扑提示进行下一步的动作决策。
② 逐模块讲解
- 抽象障碍物地图构建与轻量化航点预测(Abstract Obstacle Map-Based Waypoint Prediction):
- 输入:智能体在当前位置采集到的全景深度图像 $O_t^{\mathrm{depth}}$。
- 处理:首先将深度图转换为 3D 点云,投影至 $120 \times 12$ 的径向 2D 网格中(对应角分辨率 $3^\circ$,径向步长 $0.25\text{m}$,最大探测半径 $3.0\text{m}$)。在网格中计算各网格的局部最大高度,并沿径向计算高度梯度(模拟智能体“爬坡”的物理过程)。若梯度超过预设阈值则判定为障碍物($1$),其余为自由空间($0$)。这比单纯的绝对高度阈值能更准确地识别楼梯或斜坡。接着,将该二值障碍物地图作为唯一输入,送入一个轻量化的自注意力模型(两层 Transformer 编码器),输出候选航点热力图。最后,应用线性可达性屏蔽,将每个方向上第一个障碍物之外的网格置零,并使用非极大值抑制(NMS)提取前 $K$ 个可行候选航点。
- 输出:一组在线性可达空间内的候选航点。
- 设计动机:高级的 RGB-D 交叉注意力模型较为复杂,本项目直接用纯 2D 几何信息对齐航点空间与输入特征,大幅降低参数量,仅通过 30 epochs 的训练便可学到避障模式,保证生成的航点都在自由且可达的空间中。
- 动态拓扑图构建与合并(Dynamic Topological Graph Updating):
- 输入:前一时刻的拓扑图 $G_{t-1}$、当前节点位置 $n_t$ 以及当前观测到的候选航点。
- 处理:系统在当前节点 $n_t$ 判断其是否曾被访问。如果是,则直接重用以往生成的航点(不重复生成航点,保证动作一致性)。如果未被访问过,则通过合并模块(Merging Module)将新预测的航点融入拓扑图 $G_t = (N_t, E_t)$:计算新航点与已有节点的欧氏距离,若小于指定阈值(如图 2 所示),则将其与已有节点合并,或将相近的多个新航点合并为一个,避免网格冗余。节点被分为 visited(已探索)和 unvisited(已观察但未去过)两类,两节点间若直线无阻碍,则建立连通边 $e_{ij}$。
- 输出:更新后的拓扑图 $G_t$。
- 设计动机:通过合并机制和分类跟踪节点访问状态,提供无冗余的、一致的空间拓扑结构,从而大大减少了 MLLMs 决策的推理开销。
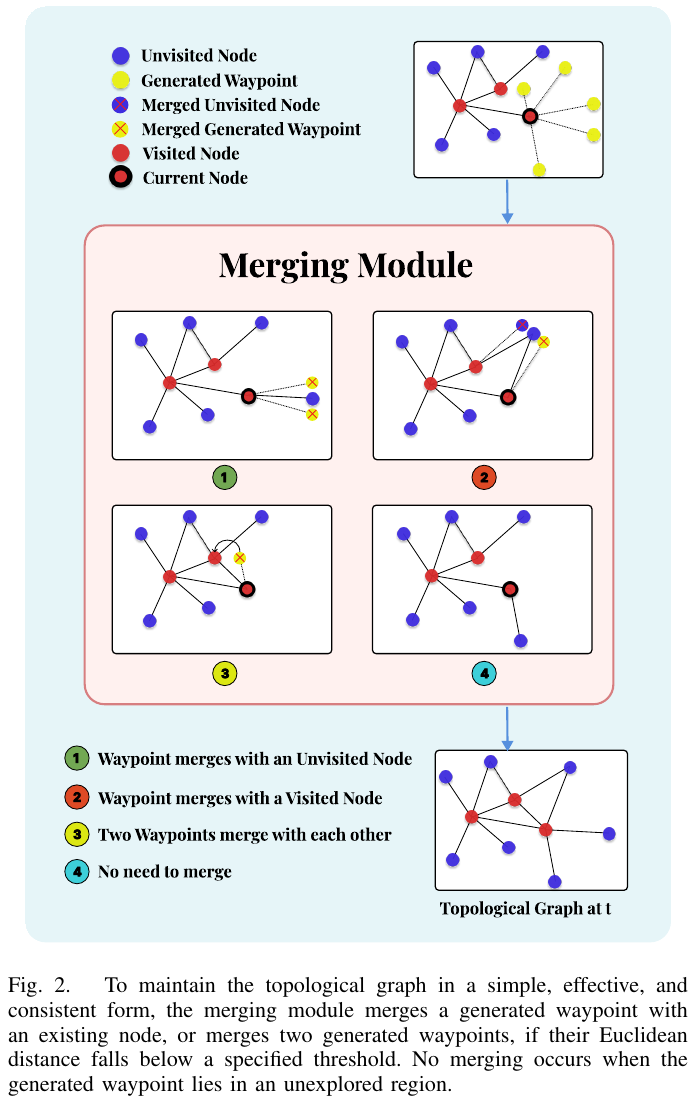
- 拓扑图与访问状态感知的提示系统(TopoGraph-and-VisitInfo-Aware Prompting):
- 输入:包括自然语言导航指令 $I$、由历史访问图像组成的视觉历史 $H_t$、访问节点 ID 序列构成的轨迹 $Tr_t$、表示空间连通性的拓扑图文本描述 $G_t$、当前可选动作的访问状态 $V_t$、未访问过的观察节点图像 $S_t$ 以及带四向图像的可选动作选项 $A_t$。其具体术语定义如图 3 所示:

- 处理:将上述结构化记忆和感知信息通过模板拼接生成 Prompt,送入 MLLM(如 GPT-5-mini API)进行推理。
- 输出:下一步决定前往的节点 ID 及思考过程 $T_t, a_t$。
-
设计动机:将 3D 预测航点通过相机内参反向投影回 2D 图像中,避免了像以往方法那样做耗时的 3D 像素反投影;同时,用连通图和明确的访问标志弥补单线历史轨迹记忆的不足,使智能体拥有全局和局部的空间拓扑概念。
- 多步回溯重探索与避圈决策:
- 处理:在提示中明确 VisitInfo 能让智能体主动避开已访问节点以减少死循环;如果智能体根据当前图像发现走错了(如偏离指令),它能够基于 TopoGraph 的连通性,选择先回溯(Backtrack)到一个甚至多个步骤之前的节点,再尝试其他未探索的分支(如图 4 所示)。
- 设计动机:为 MLLM 提供局部路径规划与重探索图谱,解决了无监督 VLN 极易陷入歧路、无法回头纠错的顽疾。
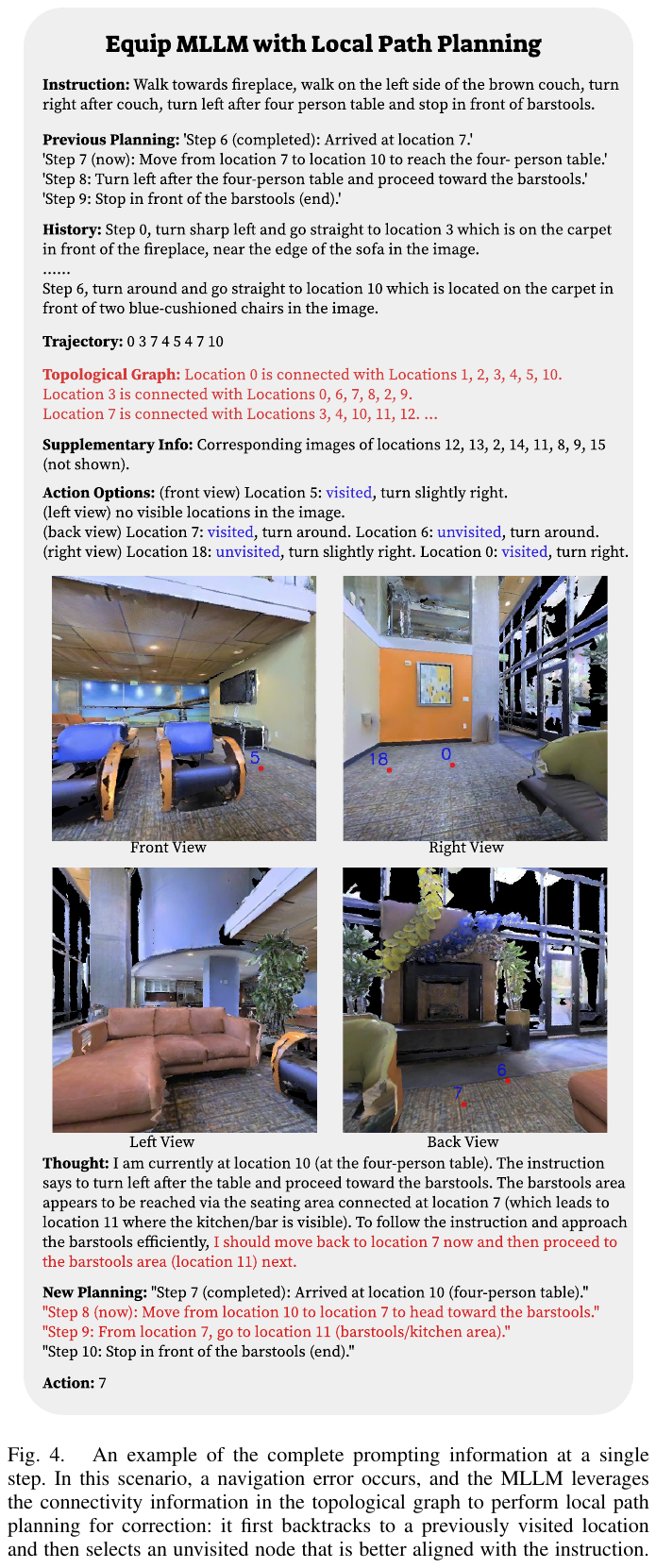
3. 核心结果/发现
- 零样本导航性能:
- 在 R2R-CE 数据集上,该方法在 val-unseen 划分中取得了 41% 的成功率(SR)和 25.4 的 SPL,全面超越先前的零样本 SOTA(如 SmartWay 的 29% 和 AO-Planner 的 25%)。
- 在 RxR-CE 数据集上取得 35.7% 的成功率(SR)和 21.7 的 SPL,相较 A2Nav (16.8%) 和 AO-Planner (22.4%) 具有明显优势,甚至逼近部分有监督方法。
- 航点预测器质量评估:
- 如 Table III 所示,在 MP3D ground-truth 连通图测试中,基于纯 2D 障碍物地图输入的预测器获得了最高的自由空间落点占比(%Open = 90.18%,比 baseline 提升近 3-10%)以及最佳的 Chamfer 距离($d_C = 1.02$),证明去除高维 RGB 语义噪声后,模型能更好地感知几何障碍并生成可行路线。
- 消融实验与分析:
- 记忆机制消融:去除 VisitInfo 会导致成功率下降 6%,去除 TopoGraph 会导致成功率下降 9%(Table IV),证明结构化图记忆对避圈和纠错至关重要。
- 预测器消融:若将本文的障碍物地图预测器替换为 DC-VLN 预测器(Table V),碰撞率由 3.85% 陡增至 9.98%,成功率降低 4%,验证了障碍物梯度地图和线性可达屏蔽的作用。
4. 局限性
- 依赖高精度的深度感知来构建 2D 障碍物地图,在深度噪声极大或传感器缺失的环境中,地图质量下降会直接导致航点预测失效。
- 目前的闭环多步回溯重探索高度依赖外部大模型(如 GPT-5-mini)的逻辑推理能力,在实际边缘端部署时面临 API 延迟和成本问题。
56. R2RIE-CE & IEDL (2024)
——— 首个连续导航指令错误基准测试,以及结合指令-轨迹兼容性的多模态错误检测与定位框架
📄 Paper: arXiv:2403.10700 · Project Page · 🏛️ ROMAN 2024
精华
- 指令容错新视角:首次指出现有 Vision-and-Language Navigation (VLN-CE) 研究默认指令完全正确的假设在现实中极易失效,人类常因记忆模糊或混淆给出带错指令。
- 基准测试构建:构建了首个包含指令错误的连续导航基准测试 R2RIE-CE,涵盖方向、房间、物体、复合及全错误五类扰动。
- 脆弱性验证:实验表明,指令中仅注入至多3个错误就会导致 SOTA 导航模型的 Success Rate (SR) 发生高达 25%–30.64% 的断崖式下跌。
- 定位与检测框架:提出 IEDL 框架,通过跨模态 Transformer 融合视觉轨迹与文本指令特征,实现高效的错误检测(AUC 0.79)与词级定位。
- 标注纠错价值:作为半自动数据清洗工具,成功在经典的 R2R-CE 和 RxR-CE 验证集中筛查出 8 个 and 10 个存在真值标注错误或歧义的路径样本。
1. 研究背景/问题
现有的视觉语言导航(VLN)方法均建立在“人类给出的指令是 100% 正确”的理想假设之上。然而在实际的人机交互中,由于人类记忆不精确、空间概念混淆(如左右不分)或认知障碍,给出的导航指令往往包含错误。
如果在这种情况下智能体盲目服从指令,会导致严重的导航失败。目前缺乏在连续三维环境(VLN-CE)下评估智能体对“错误指令”鲁棒性的基准测试。因此,本文提出了以下核心问题:
- 现有的 SOTA 导航模型在面对带有错误的人类指令时有多脆弱?
- 如何有效地检测输入指令中是否包含错误,并精确定位错误发生的单词位置,以便后续采取容错或澄清机制?
2. 主要方法/创新点
A. R2RIE-CE 基准测试构建
本文基于 R2R-CE 验证集(Val Unseen),通过人工引入具有常识先验和人类混淆特征的错误,构建了 R2RIE-CE (R2R with Instruction Errors in Continuous Environments) 基准测试。

错误类型分为以下五类:
- Direction Error (方向错误):将高频方向词(如 left/right、go down/go up、forward/backward 等)替换为其反义词。
- Object Error (物体错误):考虑常识共现性,将指令中的物体词(如 sofa)随机替换为通常在同个房间共现的另一物体(如 chair)。
- Room Error (房间错误):根据房间邻接先验,将目标房间(如 bathroom)随机替换为相邻的房间类型(如 bedroom)。
- Room & Object Error (房间与物体双重错误):在指令中同时注入房间错误和物体错误。
- All Error (全类型错误):在指令中同时引入方向、房间和物体三类错误(平均每个样本包含3个错误)。
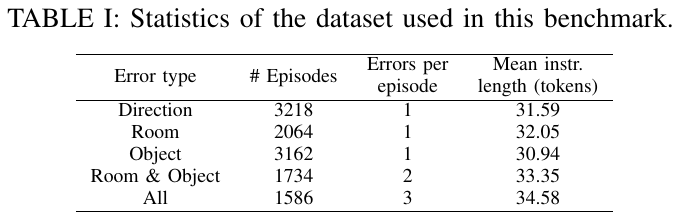
B. IEDL 错误检测与定位框架
为了解决上述挑战,本文提出了 IEDL (Instruction Error Detector & Localizer) 框架。该框架是一个与底层导航策略解耦的模块,其核心思路是通过对比智能体执行导航后的“轨迹视觉特征”与“输入文本指令”的语义兼容性来捕捉不一致的错误。
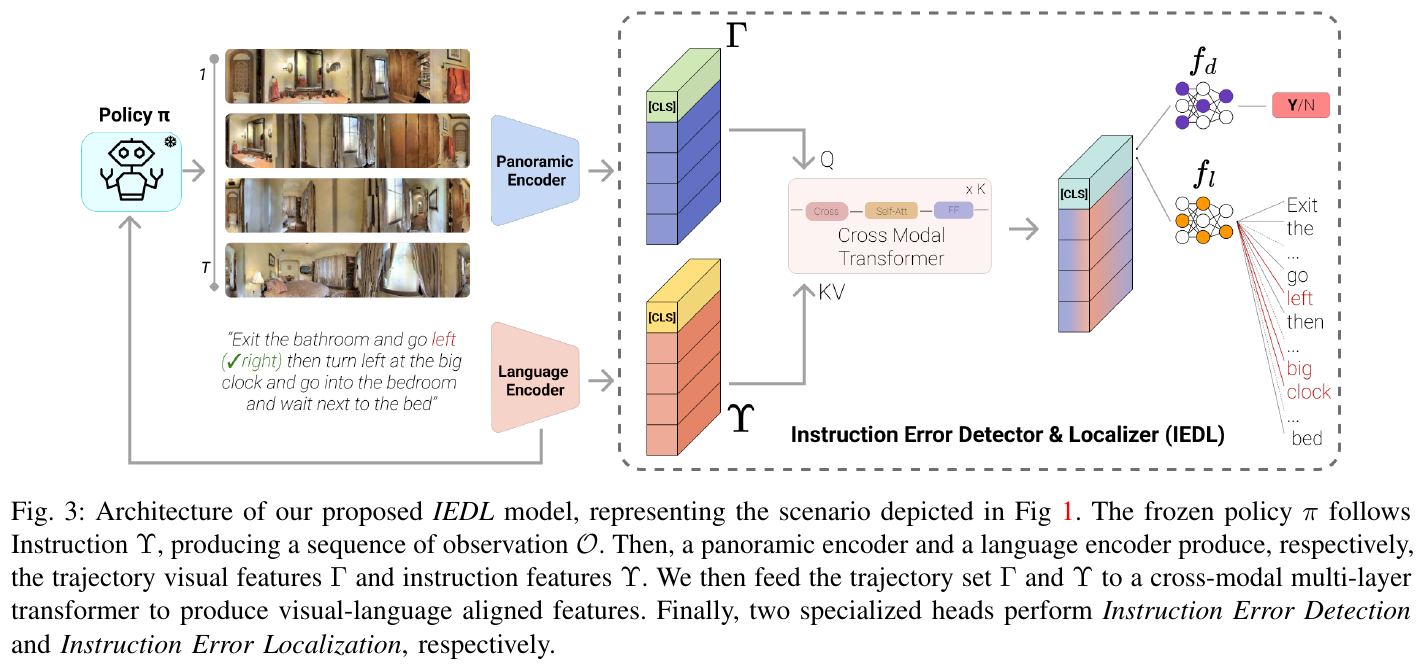
-
整体框架概述: IEDL 模型由指令编码器、全景轨迹编码器、跨模态融合 Transformer,以及两个并行的分类预测头构成。它利用智能体的动作历史和视觉观测序列作为真值轨迹,去检验指令的语义是否与其吻合。
- 逐模块讲解:
- 指令编码器 (Language Encoder):接收包含 $W$ ($W=80$) 个词的自然语言指令 $\mathcal{I}$。利用分词与填充后,送入预训练的 BERT 模型提取其词嵌入特征 $\Upsilon \in \mathbb{R}^{W \times D}$。
- 轨迹编码器 (Trajectory Encoder):导航智能体基于某策略 $\pi$ 在环境中导航 $T$ 步,得到图像观测序列 $\mathcal{O} = {O_1, …, O_T}$。每个 $O_t$ 提取 ViT-B/16-CLIP 全景特征,再经过 Panoramic Encoder 进行时空建模,得到轨迹表示 $\Gamma = {V_1, …, V_T} \in \mathbb{R}^{T \times D}$。为了引入轨迹时序,对 $\Gamma$ 加入 sine/cosine 位置编码,并在其头部拼接一个可学习的
[CLS]embedding。 - 跨模态多层 Transformer (Cross-Modal Transformer):包含 $k$ ($k=4$) 个堆叠层。在每一层,轨迹特征 $\Gamma$ 作为 Query ($Q$),文本指令嵌入 $\Upsilon$ 作为 Key-Value ($KV$) 进行交叉注意力 (cross-attention) 计算,将视觉特征对齐到文本;接着用 Self-Attention 和 FFN 充分交互以融合多模态特征。
- 轨迹-指令匹配预测头 (Trajectory-Instruction Matching Head, $f_d$):输入融合后的
[CLS]token,通过一个多层感知机(MLP,由 $\mathbb{R}^D \to \mathbb{R}$)和 Sigmoid 函数输出匹配概率 \(d_{\pi} \in [0, 1]\),用以识别当前指令是否包含错误。 - 错误定位预测头 (Error Localization Head, $f_l$):输入融合后的文本 token 序列,利用独立的 MLP(由 $\mathbb{R}^D \to \mathbb{R}^W$)预测每一个 token 为错误词的概率,实现细粒度的错误词定位。
- 训练目标 / 损失函数: 采用多任务联合训练,损失函数由匹配分类损失 $\mathcal{L}_d$(采用二元交叉熵损失)与词级定位损失 $\mathcal{L}_l$(对指令中每个 token 计算标准交叉熵并求和)加权组成: \(\mathcal{L} = \lambda_1 \mathcal{L}_d + \frac{\lambda_2}{E} \sum_{i=1}^{E} \mathcal{L}_l\) 其中 $E$ 是指令中实际含有的错误词数量,$\lambda_1$ 和 $\lambda_2$ 为平衡权重参数(实验中均设为 1)。
3. 核心结果/发现
A. 现有导航模型在错误指令下的脆弱性
研究人员在 R2RIE-CE 基准上测试了六种主流 VLN-CE 模型(包括 BEVBert, ETPNav 等 SOTA 算法)。
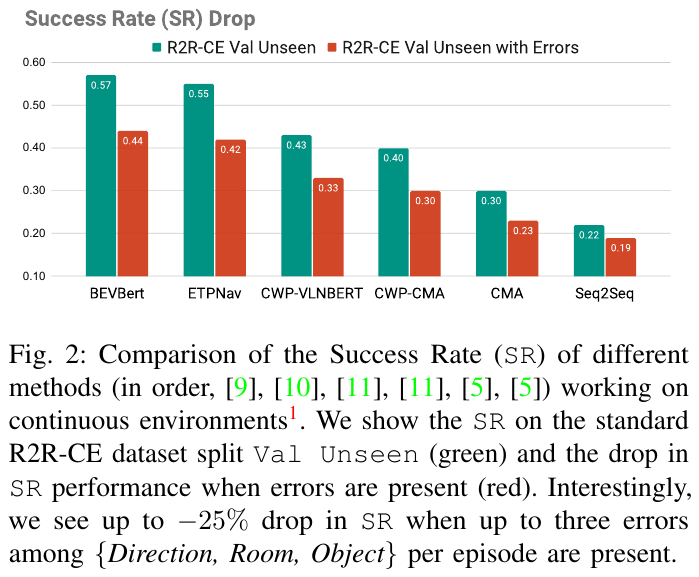
- 性能大跌:当指令中混入错误时,所有模型的 Success Rate (SR) 均有明显的断崖式下降。在 Room & Object 错误类型下,各模型表现平均下降约 11.47%;在包含所有错误的 All 模式下,SR 下降达到 30.64%。
- 错误类型敏感度差异:方向错误 (Direction) 对导航的负面影响最大,会导致 SR 平均相对大跌 18.64%。智能体对方向词(如 left/right)极度依赖,一旦方向写反,智能体会迅速走偏并提前终止。
B. IEDL 的检测与定位表现
作者将 IEDL 与 Random (随机预测) 和 CLIP Alignment (基于词组匹配的零样本对齐基准) 进行了比较:
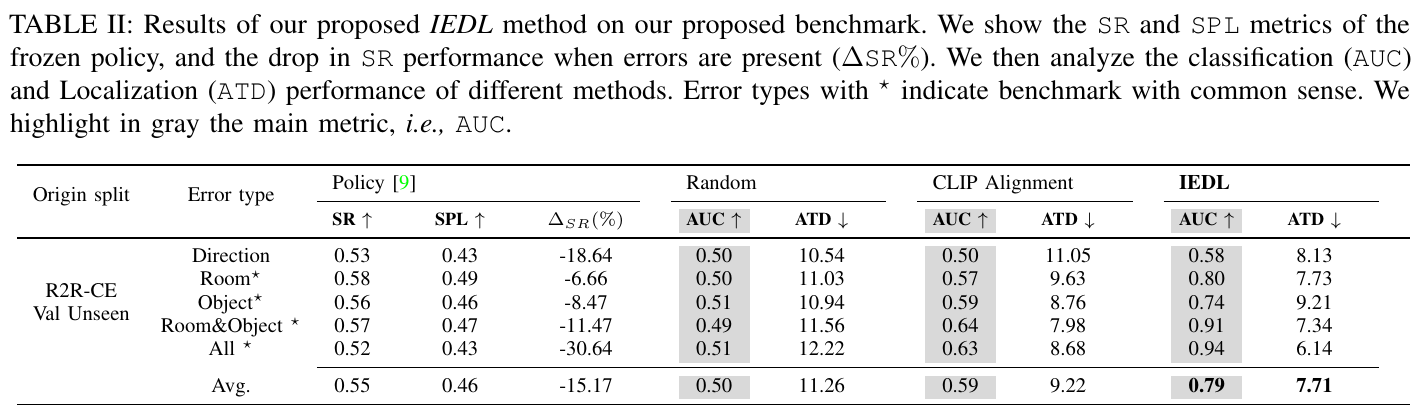
- SOTA 级的检测与定位:在所有类型下,IEDL 均显著优于基线模型。尤其在全类型错误 (All) 下,IEDL 的检测 AUC 达到了 0.94,平均定位距离 (ATD) 缩短至 6.14 个 token。
- 数据集纠错的实用价值:作者将训练好的 IEDL 应用于经典的 R2R-CE 和 RxR-CE 原始验证集,在分类置信度超过 0.99 的样本中,通过人工复核成功识别出 8个 R2R-CE 样本 和 10个 RxR-CE 样本 的地面真值(Ground-Truth)指令本身就存在明显的人类标注错误。
4. 局限性
- 离线检测限制:目前 IEDL 属于离线(Post-hoc)检测器,即必须等到智能体导航策略执行完毕、生成完整轨迹后才能进行错误检测。未来需要探索如何在导航执行过程中进行在线(Online)实时错误识别与纠偏。
- 纠错后的闭环策略缺失:论文主要聚焦于“检测”与“定位”错误,但未详细构建智能体发现错误后,如何主动向人类用户发起交互澄清或自主尝试重新规划路线的闭环控制策略。
57. NAVCON (2024)
——— 认知启发与语言落地的首个大规模 Vision-Language Navigation 概念数据集
📄 Paper: arXiv:2412.13026
精华
- 提出了首个基于认知科学与语言学理论的视觉语言导航(VLN)概念数据集 NAVCON,包含对 R2R 和 RxR 约 30,000 条指令的 23.6 万个高层导航概念标注。
- 定义了四种核心导航概念:定位自身(SIT)、移动路径(MOVE)、改变方向(CD)和改变区域(CR),构成了完备的导航语言原语。
- 利用 RxR 的时间戳信息,通过 Habitat 模拟器实现了 270 万帧图像/视频片段与导航概念词组的跨模态时间对齐。
- 基于该语料库微调的轻量级序列标注模型 NCC,达到了 96.53% 的概念和文本跨度预测准确率,展现出极强的泛化与落地潜力。
- 这一工作为打破 VLN 端到端黑盒设计提供了结构化的语义解析工具,有助于提高跨模态对齐的可解释性与实时运行效率。
1. 研究背景/问题
传统的视觉语言导航(VLN)模型多采用黑盒端到端架构,存在视觉与文本 token 对齐不平衡、缺乏可解释性等问题。此外,现有的句法解析方法过于依赖外部嘈杂的依存句法分析器,导致在下游机器人导航任务中泛化性能差、可解释性低。因此,如何定义完备的导航概念并实现低成本、高精度的细粒度文本-视频对齐,是实现可信、透明且高效的具身智能体导航的关键瓶颈。
2. 主要方法/创新点
NAVCON 提出了一套完整的视觉-语言导航概念自动化构建与标注流水线,实现了自然语言指令到核心导航概念(标签 + 文本跨度)以及视频片段的端到端对齐。
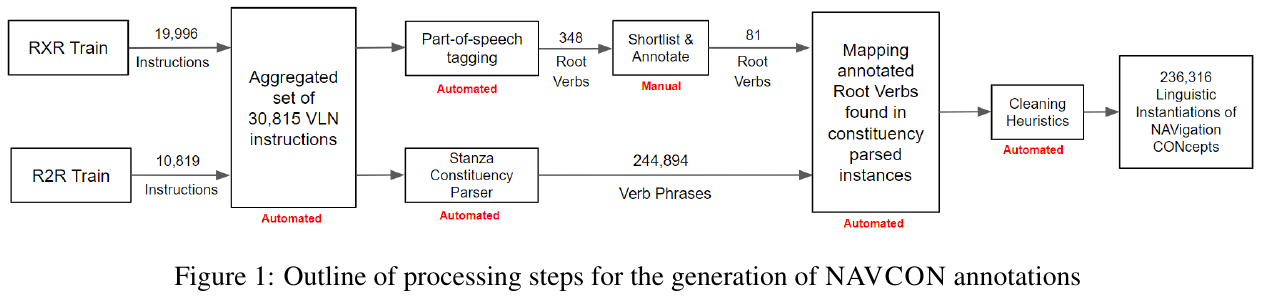
① 整体框架概述
整个构建框架由导航概念定义、语言概念提取与人工评估以及视频剪辑对齐与时序窗口微调三个核心阶段组成。它通过自然语言处理管线提取指令中的动作谓词及修饰词组,并与 Habitat 模拟器导出的智能体第一视角视频流进行多模态时序关联。
② 逐模块讲解
- 导航概念定义模块:
- 输入:无标注的导航指令文本。
- 处理:基于动物与人类大脑空间建图的认知科学研究(如海马区位置细胞、边缘系统头部方向细胞、内嗅皮层边界细胞和自主运动系统),系统定义了四种核心导航概念:
- 定位自身(Situate Yourself, SIT):标识当前所处的位置与环境特征(如 “standing in front of that pillar”)。
- 移动路径(Move along a Path, MOVE):表示沿特定物理通道的位移(如 “step into this area with a large pool”)。
- 改变方向(Change Direction, CD):描述朝向的转动(如 “turn around from the bench”)。
- 改变区域(Change Region, CR):刻画越过物理边界进入新空间的动作(如 “enter the room that is in front of you”)。
- 输出:导航概念的分类体系。
- 设计动机:提供符合认知科学、且覆盖主流 VLN 指令所需的完备导航语言原语。
- 语言概念提取管线:
- 输入:来自 R2R 和 RxR 数据集的 30,815 条训练指令。
- 处理:利用 Stanza constituency parser 等 NLP 工具进行分词、词干化、词性标注与句法分析。首先检索出 348 个候选根动词,通过人工筛选保留 81 个无歧义映射到上述四大概念的导航根动词;然后提取这 81 个根动词的所有句法子节点,形成代表导航概念的完整谓词短语。
- 输出:236,316 个自动生成的“银标(silver)”导航概念短语标注(包含概念类别与对应的文本跨度)。
- 设计动机:降低人工标注的成本,同时利用 constituency trees 保证提取出的概念词组的句法完整性(包含修饰语和地标名词)。
- 视频剪辑对齐与微调模块:
- 输入:带有单词级时间戳的 RxR 导航指令、 Matterport 3D 场景以及智能体运动轨迹姿态(pose traces)。
- 处理:利用 Habitat 模拟器以 10 倍下采样率渲染智能体视角图像(320x240 像素),提取了 760 万帧图像。通过 RxR 词级时间戳,将提取的语言概念短语在时序上投影到对应的智能体运动视频剪辑中。针对 RxR 部分单词时间戳不准导致动作未开始或已结束的对齐偏移问题,引入了时序窗口微调策略:将每个剪辑的提取时间窗口向后延伸视频总长度的 5%。
- 输出:270 万帧已实现概念-视频对齐的图像数据,覆盖 19,074 条指令。
- 设计动机:解决跨模态细粒度对齐的时间错位问题,提供大规模的高质量视频-语言导航原语对齐数据。

③ 训练目标与分类器
基于生成的银标数据集,论文训练了一个导航概念分类器 (Navigation Concept Classifier, NCC)。模型基于轻量级的 distilbert-base-uncased,在输入端接收分词后的指令,在输出端使用 BIO 格式进行 Token 级别分类(共 5 类:SIT、MOVE、CD、CR 的 B/I 标记,以及 O 外部词)。训练采用标准的交叉熵损失函数进行序列标注:
\(\mathcal{L} = -\sum_{i=1}^{N} \sum_{j=1}^{C} y_{i,j} \log p_{i,j}\)
其中 $N$ 为序列长度,$C$ 为分类类别数($C=9$,包括 B- 和 I- 标记及 O),$y_{i,j}$ 为真实标签,$p_{i,j}$ 为预测概率。
3. 核心结果/发现
- 数据集特征:NAVCON 概念分布中,MOVE(移动路径)占比最大,达 42%;SIT(定位自身)占 28%;CD(改变方向)占 22%;CR(改变区域)占 9%。
- 标注质量评估:人工评估表明,银标概念分类正确率达 95.82%,对应的文本跨度覆盖正确率达 95.49%,漏检率低于 4%。在引入时序窗口延伸 5% 后,视频剪辑的精确对齐率从 73.63% 大幅提升至 88.62%。
- NCC 分类器表现:NCC 分类器在 unseen 测试集上表现极佳,实现概念类别与文本跨度 100% 完美匹配(Exact Match)的比例高达 96.53%。
- LLM 少样本泛化能力:使用 GPT-4o 进行 3-shot 上下文学习(In-Context Learning)进行概念提取,在 unseen 数据上实现了 82.12% 的 Exact Match,说明该导航概念对 LLM 具有高度的可学习性与泛化性。
4. 局限性
- 解析器依赖性:对语言概念的提取极度依赖 Stanza constituency parser 的句法解析准确率,句法树错误会直接导致概念跨度提取不完整。
- 多模态对齐误差:视频-文本对齐质量受限于原始 RxR 数据集 word-timestamp 标注的准确性,尽管采用了窗口延展,仍有约 11% 的视频片段对齐不完整。
58. NavWAM (2026)
———首个将未来预测、价值评估与动作决策集成于单一具身世界模型的导航模型
📄 Paper: arXiv:2606.13494 · Project Page
精华
- 一体化整合:NavWAM 将传统导航世界模型(NWM)中分离的“未来预测”与“动作规划(如 CEM 搜索)”整合进单一的视频扩散 Transformer 网络中。
- 共享 Latent Canvas:将当前状态、目标图像、当前视觉观测、可执行动作 Chunk、未来状态、未来视觉预测和进度价值评估(Value)统一表征为固定 9 帧的潜在画布(Latent Canvas)序列,通过联合去噪实现多任务输出。
- 消除在线规划开销:在测试时直接以 Policy 模式进行单次推理去噪即可输出动作 Chunk,避免了传统世界模型繁重的在线轨迹采样与优化,控制频率可达 5Hz,计算量降低数千倍。
- 提升表征质量:通过引入未来视觉预测的 dense 自监督重构损失,为动作选择提供了强有力的“未来观测锚定”,显著降低了局部可观测下的策略漂移。
1. 研究背景/问题
在局部可观测的图像目标导航中,传统的基于规划的导航世界模型(NWM)通过预测动作序列条件下的未来视觉变化来辅助决策。然而,这些方法通常将“世界预测”和“动作选择”分为两个独立的步骤:模型仅作为一个单纯的预测器,而在推理时必须依靠外在的规划算法(如交叉熵方法 CEM)在大量的随机候选动作序列中进行耗时的闭环生成与评分。这导致了巨大的在线计算开销(通常低至 sub-Hz 级别)。为了消除这一瓶颈,本研究致力于构建一个世界动作模型,将未来感知预测、价值估计和连续动作生成直接统一在单个网络表征中。
2. 主要方法/创新点
整体框架
NavWAM 使用预训练的视频世界模型 Cosmos Predict2 (2B) 作为网络底座,将当前观测、图像目标、机器人状态、未来动作序列(Action Chunk)、未来视觉观测和目标进度价值(Goal-Progress Value)融合成一个统一的 9 帧“世界-动作潜在画布(World-Action Latent Canvas)”。通过这种表征,导航任务被建模为在潜在画布上的联合去噪问题。
Latent Canvas 帧布局
画布中的 9 个帧被定义如下:
- 帧 0 (Observed):Causal VAE temporal pad(全零帧),为时空 VAE 压缩提供边界。
- 帧 1 (Observed):当前机器人状态 $s_t = [x_t/100, y_t/100, \psi_t/\pi] \in \mathbb{R}^3$,在局部坐标系中标准化。
- 帧 2 (Observed):目标图像 $g$(Image Goal)。
- 帧 3 (Observed):当前第一人称视觉观测 $o_t$。
- 帧 4 (Predicted):待预测的可执行动作 Chunk $a_{t:t+H-1} \in \mathbb{R}^{3H}$,其中 $H=4$(表示局部航向点增量 $[\Delta x_i, \Delta y_i, \Delta \psi_i]$)。
- 帧 5 (Predicted):未来状态预测 $s_{t+H} \in \mathbb{R}^3$。
- 帧 6 & 7 (Predicted):未来的两个自车视角图像预测 $o_{t+H-1}, o_{t+H}$。
- 帧 8 (Predicted):目标进度估计值 $v_{t+H} \in [0, 1]$。
对于动作、状态、价值等非图像标量/向量,NavWAM 首先对其进行归一化,然后将其在空间网格(Spatial Grid)上进行广播(Broadcast)填充为整帧;解码时则通过空间平均(Spatial Averaging)将对应通道的去噪特征恢复为标量/向量值。
训练目标与混合模式
网络损失函数基于潜在画布上的加权去噪得分匹配: \(\mathcal{L}_{\text{diff}} = \mathbb{E}_{\sigma, \epsilon} \left[ w(\sigma) \lVert x_0 - F_\theta(x_\sigma, \sigma, c) \rVert_2^2 \right]\) 为了防止低维的动作信号淹没在图像重构的高维像素损失中,动作帧损失被乘以权重系数 $\lambda = 5$ 进行了上采样增强。
在训练阶段,样本被划分为三种不同的条件模式以促使网络联合学习不同的导航子任务(比例为 50/25/25):
- Policy 模式 (50%):给定观测帧 0–3,预测帧 4–8。
- World-Model 模式 (25%):给定观测帧 0–4,预测帧 5–8。训练模型在动作条件下的物理演化预测。
- Value 模式 (25%):给定观测帧 0–7,预测帧 8(当前轨迹下的目标进度价值)。
目标进度价值设计
价值目标 $v_{t+H}$ 被显式定义为反映机器人局部到终点精度的归一化距离进度: \(v_{t+H} = \text{clip}\left( 1 - \frac{\lVert p_{\text{end}} - p_t \rVert_2}{d_{\text{max}}}, 0, 1 \right)\) 其中 $p_t$ 为当前 2D 位置,$p_{\text{end}}$ 为目标 2D 位置,$d_{\text{max}}$ 为轨迹最大长度上限。
推理流程
在部署阶段,机器人获取当前图像 $o_t$ 和目标 $g$,在 Policy 模式下运行,通过单次去噪过程直接输出 $\hat{a}_{t:t+H-1}$。随后以 Receding-Horizon 的方式执行这组动作 Chunk,执行完毕后重新请求网络,实现大约 5Hz 的高频闭环响应。
3. 核心结果/发现
- 更优的导航表现:在 GO STANFORD 离线图像目标导航上,NavWAM 在无需推理时 CEM 动作搜索的前提下,其 zero-shot(ATE 0.324)和微调版(ATE 0.192 / RPE 0.070)均优于传统的 NWM(ATE 0.453)。同时,模型保持了卓越的未来视觉预测一致性(Consistency 达 0.635–0.668,明显好于 NWM 的 0.524)。
- 极其低廉的推理开销:单次去噪推理代替 CEM 轨迹优化,使得 NavWAM 的 FLOPs 仅为 4.45 TF,推理延迟仅为 205.7 ms,而同底座的 NWM 延迟达 233.8 秒,FLOPs 高达 14,521 TF,推理成本相差数千倍。
- 多任务监督的作用:消融实验证明,未来视觉预测监督能够为决策系统带来长程路标锚定,是不可或缺的自监督信号(相比去掉未来图像的策略,ATE 从 0.090 降低到 0.076)。
- ** Diablo 机器人实机闭环成功率**:在真实室内环境(Office, Storage, Meeting, Hallway)的 24 次部署测试中,NavWAM 取得了 79.2% 的高成功率,远超 OmniVLA (58.3%) 和传统 NWM (16.7%),证明了极强的鲁棒性。

4. 局限性
- 测试场景局限:实机评估主要集中在静态的室内环境中,面对含有行人和移动物体的动态障碍物场景未做验证。
- 目标形态局限:主要针对图像目标导航(Image-Goal Navigation),对于自然语言指令导航、物体类别导航(Object-Goal)以及具身问答尚未开展系统验证。
- 长程瓶颈:面对跨楼层、多房间的大范围、极长程导航场景(需要频繁的子任务规划与重规划),由于上下文帧数限制,依然存在表现衰退的风险。
参考资料
已发表论文(会议 / 期刊)
下表汇总本文中已正式发表于会议或期刊的论文,其余条目为 arXiv 预印本:
| 会议 / 期刊 | 论文 |
|---|---|
| ECCV | VLN-CE (2020)、NavGPT-2 (2024) |
| ICRA | NoMaD (2024)、VLFM (2024)、Open-Nav (2025)、StreamVLN (2026) |
| AAAI | NavGPT (2024)、ODYSSEY (2026)、R³ (2026)、PanoNav (2026, Poster) |
| CVPR | VLN-Imagine (2025)、Slow4fast-VLN (2026)、AwareVLN (2026) |
| ICLR | NavFoM (2026)、JanusVLN (2026)、OmniNav (2026, Poster) |
| ICCV | VLN-PE (2025) |
| ACL | MapNav (2025) |
| 期刊 | GaussNav (IEEE TPAMI 2025)、CausalNav (IEEE RA-L)、Skill-Nav (Vicinagearth / Springer 2025)、CA-VLN (Sensors 2026)、R2RIE-CE & IEDL (ROMAN 2024) |
论文
- DualVLN/InternVLN (2025). Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation. arXiv: 2512.08186
- NavDP (2025). Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance. arXiv: 2505.08712
- NoMaD (2023). Goal Masked Diffusion Policies for Navigation and Exploration. arXiv: 2310.07896
- ODYSSEY (2025). Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks. arXiv: 2508.08240
- PanoNav (2025). Mapless Zero-Shot Object Navigation with Panoramic Scene Parsing and Dynamic Memory. arXiv: 2511.06840
- VLN-R1 (2025). Vision-Language Navigation via Reinforcement Fine-Tuning. arXiv: 2506.17221
- LagMemo (2025). Language 3D Gaussian Splatting Memory for Multi-modal Open-vocabulary Multi-goal Visual Navigation. arXiv: 2510.24118
- GaussNav (2025). Gaussian Splatting for Visual Navigation. arXiv: 2403.11625
- VLFM (2023). Vision-Language Frontier Maps for Zero-Shot Semantic Navigation. arXiv: 2312.03275
- Motus (2025). A Unified Latent Action World Model. arXiv: 2512.13030
- NavGPT (2024). Explicit Reasoning in Vision-and-Language Navigation with Large Language Models. arXiv: 2305.16986
- NavGPT-2 (2024). Unleashing Navigational Reasoning Capability for Large Vision-Language Models. arXiv: 2407.12366
- FSR-VLN (2025). Fast and Slow Reasoning for Vision-Language Navigation with Hierarchical Multi-modal Scene Graph. arXiv: 2509.13733
- VLingNav (2026). Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory. arXiv: 2601.08665
- Slow4fast-VLN (2026). Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning. arXiv: 2601.09111
- FantasyVLN (2026). Unified Multimodal Chain-of-Thought Reasoning for Vision-Language Navigation. arXiv: 2601.13976
- VL-Nav (2025). A Neuro-Symbolic Approach for Reasoning-based Vision-Language Navigation. arXiv: 2502.00931
- StreamVLN (2025). Streaming Vision-and-Language Navigation via SlowFast Context Modeling. arXiv: 2507.05240
- NavFoM (2025). Embodied Navigation Foundation Model. arXiv: 2509.12129
- DGNav (2026). Dynamic Topology Awareness: Breaking the Granularity Rigidity in Vision-Language Navigation. arXiv: 2601.21751
- MapNav (2025). A Novel Memory Representation via Annotated Semantic Maps for VLM-based Vision-and-Language Navigation. arXiv: 2502.13451
- Hydra-Nav (2026). Object Navigation via Adaptive Dual-Process Reasoning. arXiv: 2602.09972
- 3DGSNav (2026). Enhancing Vision-Language Model Reasoning for Object Navigation via Active 3D Gaussian Splatting. arXiv: 2602.12159
- BudVLN (2026). Nipping the Drift in the Bud: Retrospective Rectification for Robust Vision-Language Navigation. arXiv: 2602.06356
- Open-Nav (2025). Exploring Zero-Shot Vision-and-Language Navigation in Continuous Environment with Open-Source LLMs. arXiv: 2409.18794
- CausalNav (2026). A Long-term Embodied Navigation System for Autonomous Mobile Robots in Dynamic Outdoor Scenarios. arXiv: 2601.01872
- SparseVideoNav (2026). Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation. arXiv: 2602.05827
- AgentVLN (2026). Towards Agentic Vision-and-Language Navigation. arXiv: 2603.17670
- GSMem (2025). 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning. arXiv: 2603.19137
- Skill-Nav (2025). Enhanced Navigation with Versatile Quadrupedal Locomotion via Waypoint Interface. arXiv: 2506.21853
- VLN-Cache (2026). Enabling Token Caching for VLN Models with Visual/Semantic Dynamics Awareness. arXiv: 2603.07080
- VLN-CE (2020). Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments. arXiv: 2004.02857
- VLN-PE (2025). Rethinking the Embodied Gap in Vision-and-Language Navigation: A Holistic Study of Physical and Visual Disparities. arXiv: 2507.13019
- RynnBrain (2026). Open Embodied Foundation Models. arXiv: 2602.14979
- LingBot-World (2026). Advancing Open-source World Models. arXiv: 2601.20540
- WorldVLN (2025). Autoregressive World Action Model for Aerial Vision-Language Navigation. arXiv: 2605.15964
- AwareVLN (2026). Reasoning with Self-awareness for Vision-Language Navigation. arXiv: 2605.22816
- Dual-Anchoring (2026). Addressing State Drift in Vision-Language Navigation. arXiv: 2604.17473
- LoGoPlanner (2025). Localization Grounded Navigation Policy with Metric-aware Visual Geometry. arXiv: 2512.19629
- WAM-Nav (2026). Asymmetric Latent World-Action Modeling for Unified Visual Navigation. arXiv: 2606.04907
- JanusVLN (2026). Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation. arXiv: 2509.22548
- HSGM (2026). Bridging the 2D-3D Gap: A Hierarchical Semantic-Geometric Map for Vision Language Navigation. arXiv: 2606.00095
- OneVLA (2026). A Unified Framework for Embodied Tasks. arXiv: 2606.01241
- CA-VLN (2026). Collaborative Agents in MLLM-Powered Visual-Language Navigation. Sensors 2026
- EvoMemNav (2026). Efficient Self-Evolving Fine-Grained Memory for Zero-Shot Embodied Navigation. arXiv: 2606.03509
- Goal2Pixel (2025). Grounding Goals to Pixels for Vision-Language Navigation. arXiv: 2606.01621
- OmniNav (2026). A Unified Framework for Prospective Exploration and Visual-Language Navigation. arXiv: 2509.25687
- AstraNav-World (2025). World Model for Foresight Control and Consistency. arXiv: 2512.21714
- ABot-N0 (2026). Technical Report on the VLA Foundation Model for Versatile Embodied Navigation. arXiv: 2602.11598
- Qwen-RobotNav (2026). Technical Report: A Scalable Navigation Model Designed for an Agentic Navigation System. arXiv: 2606.18112
- GA-VLN (2026). Geometry-Aware BEV Representation for Efficient Vision-Language Navigation. arXiv: 2605.22036
- SEDualVLN (2026). 空间增强的双系统连续环境视觉语言导航框架. arXiv: 2605.17249
- TopoGraph-VLN (2025). 基于抽象障碍物地图航点预测与拓扑图-历史访问信息感知提示的零样本连续环境视觉语言导航. arXiv: 2509.20499
- R2RIE-CE & IEDL (2024). 首个连续导航指令错误基准测试,以及结合指令-轨迹兼容性的多模态错误检测与定位框架. arXiv: 2403.10700
- NAVCON (2024). 认知启发与语言落地的首个大规模 Vision-Language Navigation 概念数据集. arXiv: 2412.13026
- NavWAM (2026). 首个将未来预测、价值评估与动作决策集成于单一具身世界模型的导航模型. arXiv: 2606.13494