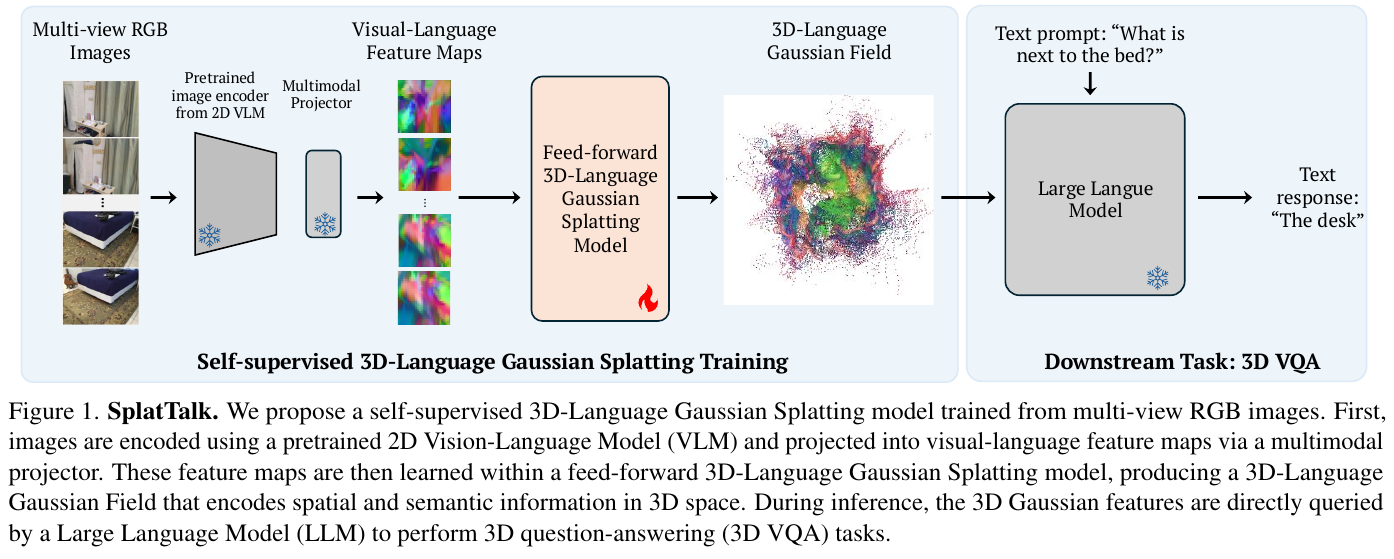
1. 引言
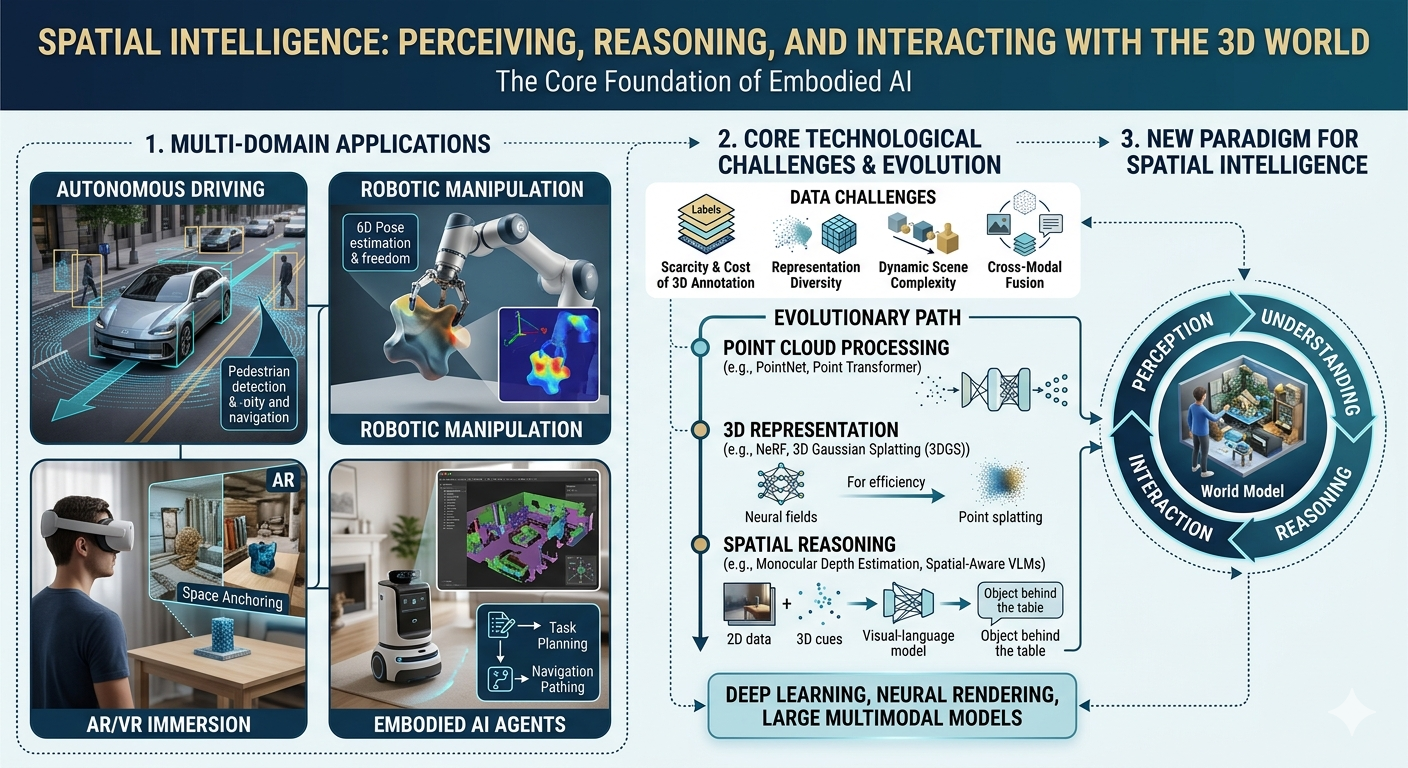
空间智能(Spatial Intelligence)是指 AI 系统感知、理解、推理和交互三维物理世界的综合能力。与人类从婴幼儿期便开始发展的空间认知类似,空间智能涵盖了对物体形状、场景布局、三维空间关系以及动态变化的全面理解。作为具身智能(Embodied AI)的核心基础,空间智能的研究近年来随着深度学习、神经渲染以及大型多模态模型的飞速发展而进入了全新阶段。
从应用价值来看,空间智能横跨多个高价值领域:在自动驾驶中,精确的三维感知与动态目标检测是安全行驶的前提;在机器人操控中,六自由度的空间理解决定了机械臂的抓取成功率;在增强现实与虚拟现实(AR/VR)中,实时高质量的三维重建与空间锚定是沉浸式体验的关键;在具身 AI 智能体中,空间记忆与三维场景图是任务规划与导航的基础。
研究空间智能面临的核心挑战来自三维数据的内在复杂性:三维标注数据的稀缺与昂贵、点云/体素/隐式表达之间的表示多样性、真实世界动态场景的时变性,以及三维几何与语义理解的跨模态融合难题。近年来,从 NeRF 到三维高斯溅射(3D Gaussian Splatting,3DGS),从 PointNet 到 Point Transformer,从单目深度估计到空间推理 VLM,空间智能领域正经历着技术范式的快速迭代。
本文旨在系统梳理空间智能研究进展,为学习和研究空间智能提供参考。
2. 空间智能基本概述
2.1 什么是空间智能?
空间智能是一个多层次的能力体系,从低层几何感知到高层空间推理,可划分为以下四个层次:
- 空间感知(Spatial Perception):获取三维几何信息,包括深度估计、点云获取与处理、三维形状重建。
- 空间重建(Spatial Reconstruction):从多视角图像或传感器数据建立场景的三维模型,包括 SLAM、MVS、NeRF、3DGS 等技术。
- 空间理解(Spatial Understanding):对三维场景进行语义解析,包括三维目标检测、三维实例分割、场景图生成与视觉定位。
- 空间推理(Spatial Reasoning):在三维空间中进行高阶认知,包括空间关系判断(物体 A 是否在 B 的左侧?)、视角变换推理,以及语言引导的三维交互。
这四个层次构成了空间智能的完整能力栈:感知为重建提供原始数据,重建为理解提供几何基础,理解为推理提供语义上下文。
2.2 感知硬件基础
空间智能的源头是多样的传感器,硬件特性直接决定了算法的选择与感知上限:
| 传感器类型 | 原理 | 优势 | 局限 | 应用场景 |
|---|---|---|---|---|
| 激光雷达 (LiDAR) | 激光飞行时间 (ToF) | 精度极高、抗光照干扰、直接 3D | 成本高、点云稀疏、无颜色 | 自动驾驶、地形测绘 |
| RGB-D 相机 | 结构光 / 局域 ToF | 像素级对齐、室内精度高 | 室外易受干扰、量程有限 | 机器人导航、AR/VR |
| 立体视觉 (Stereo) | 双目视差计算 | 成本低、室内外通用 | 依赖纹理、弱光表现差 | 工业视觉、避障 |
| 单目相机 | 透视投影 | 极其廉价、部署便捷 | 存在尺度歧义、需学习先验 | 消费级电子、广域监控 |
| 事件相机 | 像素级亮度变化 | 极高动态范围、低延迟 | 空间分辨率低、输出异构 | 高速运动捕捉、无人机 |
2.3 核心要素与技术体系
空间智能的技术体系围绕三维表示展开,主流形式对比如下:
| 表示形式 | 特点 | 硬件适配 | 代表技术 |
|---|---|---|---|
| 点云 (Point Cloud) | 稀疏、无序、直接采集 | LiDAR、RGB-D | PointNet, Point Transformer |
| 体素 (Voxel Grid) | 规则、密集、内存开销大 | 全局建模 | VoxNet, OccNet |
| 网格 (Mesh) | 面片表示、适合渲染 | 3D 扫描 | Marching Cubes |
| 隐式场 (Implicit Field) | 连续、可微、内存高效 | 多视角图像 | NeRF, SDF |
| 三维高斯 (3D Gaussian) | 显式、快速渲染、可优化 | 多视角图像 | 3DGS |
| 深度图 (Depth Map) | 像素对齐、计算友好 | 单目/双目 | Monocular Depth Estimation |
2.4 评价指标速查表
| 维度 | 指标 | 含义 | 适用任务 |
|---|---|---|---|
| 几何精度 | CD (Chamfer Distance) | 点集间的平均欧氏距离 | 点云配准、形状重建 |
| EMD (Earth Mover’s Distance) | 两个分布间的推土机距离 | 形状生成、点云生成 | |
| AbsRel / RMSE | 深度预测的绝对误差与均方根误差 | 深度估计 | |
| 理解精度 | mIoU (Mean IoU) | 预测框与真值的交并比均值 | 语义/实例分割、检测 |
| mAP (Mean Average Precision) | 平均精度均值(多阈值下的召回/精确度) | 三维目标检测 | |
| 推理/对话 | CIDEr / BLEU-4 | 生成文本与参考答案的共现相似度 | 3D Captioning / 3D VQA |
| EM (Exact Match) | 答案完全匹配的比例 | 3D 视觉问答 | |
| 重建质量 | PSNR / SSIM | 渲染图像的峰值信噪比与结构相似度 | 视角合成 (NeRF/3DGS) |
2.5 研究趋势与汇聚路径
graph TD
%% 路径 1: 点云/离散几何
subgraph Path_Point ["离散几何路径 (Discrete Geometry)"]
P1["PointNet (2017)"] --> P2["PointNet++ (2017)"]
P2 --> P3["Point Transformer (2021)"]
P3 --> P4["Uni3D / OpenShape (2024)"]
end
%% 路径 2: 深度/重建
subgraph Path_Recon ["深度与重建路径 (Depth & Reconstruction)"]
R1["DPT (2021)"] --> R2["Depth Anything (2024)"]
R1 --> R3["NeRF (2020)"]
R3 --> R4["Instant-NGP (2022)"]
R4 --> R5["3D Gaussian Splatting (2023)"]
R2 --> R6["DUSt3R / MASt3R (2024)"]
R6 --> R7["VGGT (CVPR 2025 Best Paper)"]
R7 --> R8["MapAnything (2026)"]
end
%% 路径 3: 空间语言模型
subgraph Path_Lang ["空间语言融合 (3D + Language)"]
L1["ScanRefer (2020)"] --> L2["3D-LLM (2023)"]
L2 --> L3["SplatTalk / GaussianVLM (2025)"]
end
%% 汇聚点
P4 & R8 & L3 --> F["通用空间智能基础模型 (Spatial Foundation Models)"]
style F fill:#f96,stroke:#333,stroke-width:4px
关键里程碑:
- 2015–2017:PointNet 奠定了直接在无序点云上进行深度学习的基础,开启了三维深度学习新纪元。
- 2018–2020:VoxelNet、SECOND、PointPillars 推动了自动驾驶 LiDAR 感知商业化;NeRF 的提出彻底改变了三维重建技术范式。
- 2021–2022:Transformer 架构被引入三维感知(Point Transformer、DETR3D、BEVFormer),性能大幅提升;Instant-NGP 将 NeRF 训练时间压缩至秒级。
- 2023:3D Gaussian Splatting 实现实时高质量渲染;3D-LLM、EmbodiedScan 将语言模型与三维场景理解结合。
- 2024–2025:Depth Anything、SpatialVLM、DUSt3R、Uni3D 等工作推动空间感知基础模型形成;VGGT(CVPR 2025 Best Paper)以单次前馈同时输出相机参数、深度、点图与点轨迹,标志空间智能正式进入”前馈三维基础模型”新阶段。
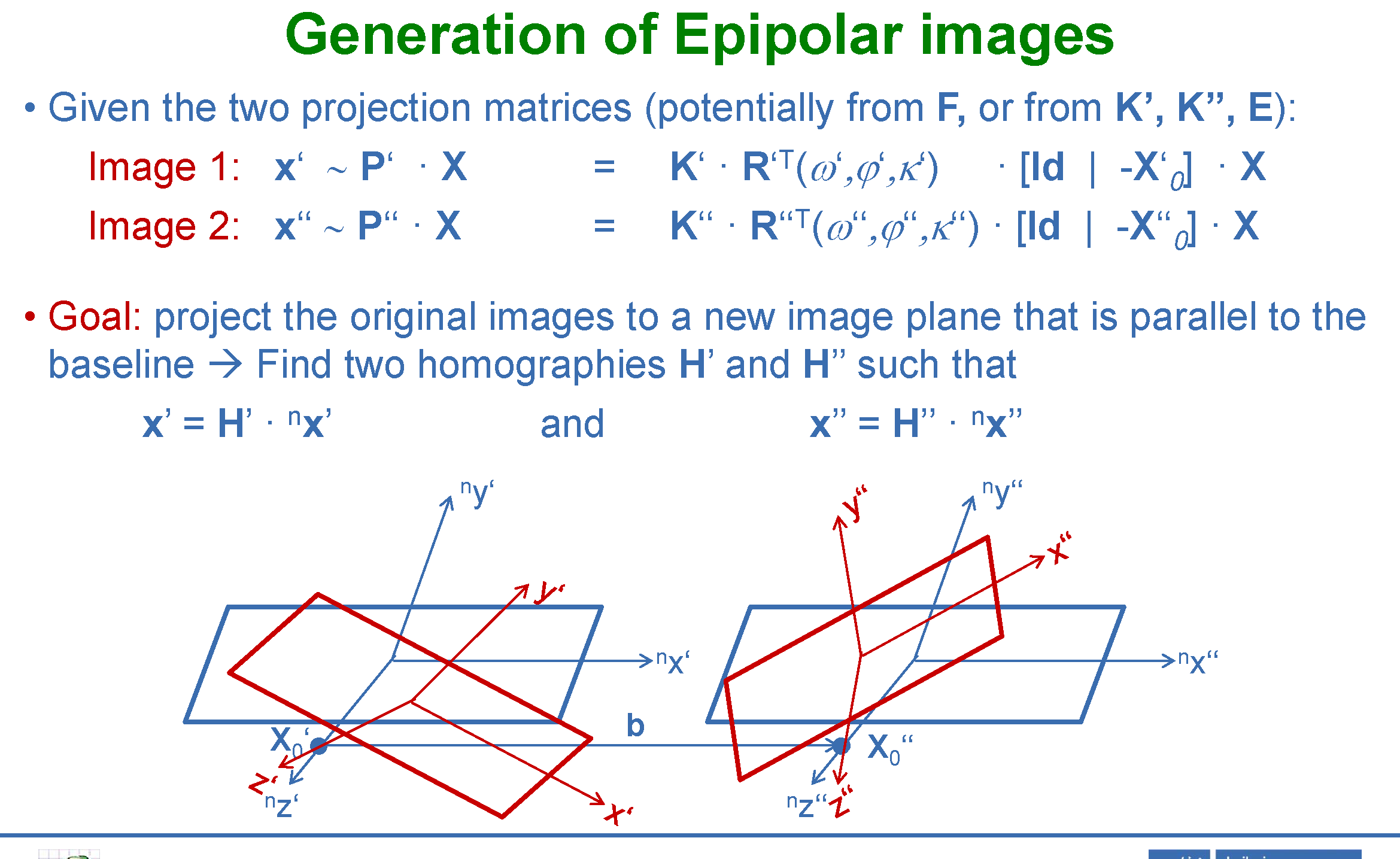
2.6 相机模型与投影几何基础
空间智能的数学基础之一是针孔相机模型(Pinhole Camera Model),它精确描述了三维世界中的点如何透过镜头中心投影到二维图像平面。理解相机投影是理解 SfM、立体视觉、NeRF 位姿输入以及 VGGT 相机参数输出的必要前提。

针孔相机投影
给定世界坐标系中的齐次点 $\widetilde{\mathbf{X}}_w = (X, Y, Z, 1)^T$,其图像齐次坐标 $\widetilde{\mathbf{x}} = (u, v, 1)^T$ 由完整投影矩阵 $P \in \mathbb{R}^{3\times4}$ 给出:
\[\lambda \begin{pmatrix} u \\ v \\ 1 \end{pmatrix} = P \, \widetilde{\mathbf{X}}_w = K [R \mid \mathbf{t}] \begin{pmatrix} X \\ Y \\ Z \\ 1 \end{pmatrix}\]其中 $\lambda$ 为尺度因子(深度),$K$ 为内参矩阵,$[R \mid \mathbf{t}]$ 为外参(旋转+平移)。
内参矩阵(Intrinsic Matrix) $K$ 描述相机的光学与几何特性:
\[K = \begin{pmatrix} f_x & s & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{pmatrix}\]- $f_x, f_y$:水平/垂直方向焦距(以像素为单位),对于方形像素 $f_x = f_y = f$
- $(c_x, c_y)$:主点(principal point),即光轴与像平面的交点
- $s$:像素倾斜系数(现代相机通常为零)
外参(Extrinsic Parameters) $[R \mid \mathbf{t}]$:旋转矩阵 $R \in SO(3)$ 和平移向量 $\mathbf{t} \in \mathbb{R}^3$ 描述相机坐标系相对于世界坐标系的位姿。
镜头畸变模型
真实镜头存在非线性畸变,在投影后需校正。最常用的径向畸变(Radial Distortion):
\[\begin{cases} x_d = x(1 + k_1 r^2 + k_2 r^4 + k_3 r^6) \\ y_d = y(1 + k_1 r^2 + k_2 r^4 + k_3 r^6) \end{cases}, \quad r^2 = x^2 + y^2\]其中 $(x, y)$ 为归一化相机坐标,$k_1, k_2, k_3$ 为径向畸变系数(负值产生桶形畸变,正值产生枕形畸变)。切向畸变由镜头安装偏心引起,额外引入参数 $p_1, p_2$。
相机标定
相机标定的目标是从已知三维—二维对应点中估计 $K$ 和畸变参数。
- 直接线性变换(DLT):将 $P\widetilde{\mathbf{X}} = \lambda\widetilde{\mathbf{x}}$ 线性化为 $A\mathbf{p} = 0$,通过 SVD 求解 $P$ 的 11 个自由度,至少需要 6 个点对,是最基础的标定方法。
- Zhang 标定法(Zhang, TPAMI 2000):使用多姿态平面棋盘格,先估计各姿态下的单应矩阵 $H$,再利用多个 $H$ 的约束分解内参 $K$,最后以 Levenberg-Marquardt 非线性优化联合精化内外参与畸变系数。已集成于 OpenCV
calibrateCamera(),是目前最主流的实用标定方法。
2.7 旋转表示
三维旋转是空间智能的核心数学工具,从 NeRF/3DGS 的相机位姿到机器人末端执行器的朝向,旋转无处不在。李群 $SO(3)$(Special Orthogonal Group)是旋转的代数结构,不同的参数化方式各有权衡:
| 表示 | 参数数 | 自由度 | 优点 | 局限 |
|---|---|---|---|---|
| 旋转矩阵 $R \in SO(3)$ | 9 | 3 | 运算直接,组合简单 | 需满足正交约束 $RR^T=I,\det R=1$;冗余 |
| 欧拉角 $(\phi,\theta,\psi)$ | 3 | 3 | 直观,便于人工设定 | 万向节锁(Gimbal Lock)问题,插值不稳定 |
| 轴角 $(\mathbf{n}, \theta)$ | 4 | 3 | 物理含义清晰(绕轴旋转) | 不适合梯度优化;$\theta$ 接近 0 时奇异 |
| 四元数 $\mathbf{q}=(w,x,y,z)$ | 4 | 3 | 插值平滑(SLERP)、无奇异性、数值稳定 | 存在双覆盖($\mathbf{q}$ 与 $-\mathbf{q}$ 表示同一旋转) |
万向节锁:欧拉角在特定配置(如俯仰角 $\theta=\pm 90°$)下,两个旋转轴重合,导致丢失一个自由度。这是 3D 动画和机器人控制中必须避免使用欧拉角插值的主要原因。
单位四元数旋转:$|\mathbf{q}|=1$ 的四元数 $\mathbf{q} = w + x\mathbf{i} + y\mathbf{j} + z\mathbf{k}$ 对应唯一旋转,旋转点 $\mathbf{p}$: \(\mathbf{p}' = \mathbf{q} \otimes \mathbf{p} \otimes \mathbf{q}^{-1}\)
3DGS 中每个高斯椭球的朝向用四元数参数化(确保梯度优化在旋转流形上的连续性),VGGT 输出的相机外参也使用四元数表示。Rodrigues 公式提供了旋转矩阵与轴角之间的转换桥梁,是 SfM 和 Bundle Adjustment 中常用的微分工具: \(R = I + \sin\theta [\mathbf{n}]_\times + (1-\cos\theta) [\mathbf{n}]_\times^2\)
其中 $[\mathbf{n}]_\times$ 为旋转轴 $\mathbf{n}$ 的反对称矩阵。
3. 任务分类体系
1. 几何感知类:以获取和处理三维几何信息为核心。典型任务包括单目/双目深度估计、点云配准(ICP、RANSAC)、法向量估计等。
2. 三维重建类:从图像序列或传感器数据恢复场景的三维结构。包括** SfM、MVS、SLAM、神经隐式重建(NeRF、3DGS)**等。
3. 三维检测与识别类:在三维空间中定位并分类物体。包括三维目标检测、三维实例/语义分割、三维场景图生成。
4. 空间理解与推理类:在三维语义层面建立高层理解。包括三维视觉定位、三维视觉问答、空间关系推理。
5. 具身空间导航类:在智能体主动探索的背景下使用空间智能。包括目标驱动导航、三维语义地图构建、空间记忆网络。
4. 空间智能技术演进范式
4.1 离散几何表示与点云处理
PointNet
PointNet(Qi et al., CVPR 2017)是第一个直接在无序三维点云上端到端学习的深度神经网络,彻底改变了三维深度学习的研究范式。其核心设计思想是:对点集的任意排列保持置换不变性,对刚体变换保持变换不变性。
核心设计:
- 对每个点独立应用共享 MLP,将点坐标映射到高维特征空间。
- 使用对称函数(max pooling)聚合全局特征,自然解决无序问题。
- T-Net(Transformer Network)学习输入点云的对齐变换($3\times3$)和特征对齐变换($64\times64$),提升旋转鲁棒性。
核心特点:
- 无需体素化,直接处理原始点云,计算高效。
- 可用于分类、部分分割、语义分割三类任务。
- 奠定了点云深度学习”点独立处理+对称聚合”的基本范式。

PointNet++
PointNet++(Qi et al., NeurIPS 2017)针对 PointNet 无法捕捉局部几何结构的缺陷,引入层级化的局部特征学习机制。
核心设计:
- 最远点采样(FPS):递归选取与已选点集距离最远的点,得到空间均匀分布的采样子集。
- Ball Query 分组:以采样点为中心,在球形邻域内收集局部点集。
- 层级化 PointNet:在局部点集上应用 PointNet 提取局部特征,再在更高层的局部区域上再次聚合,类比 CNN 的感受野逐层扩大。
- 多尺度分组(MSG):在不同半径球域内聚合特征,增强对点云密度变化的鲁棒性。
核心特点:
- 解决了 PointNet 对局部几何信息感知不足的问题。
- 自适应处理非均匀点云密度。
- 奠定了”采样+分组+聚合”的点云学习标准范式,后续工作(DGCNN、Point Transformer 等)均在此框架下扩展。

DGCNN
DGCNN(Dynamic Graph CNN,Wang et al., TOG 2019)将图神经网络(GNN)引入点云处理。不同于在欧氏空间中构建固定 k 近邻图,DGCNN 在特征空间中动态更新 k-NN 图,捕捉语义上相近但空间上未必相邻的点对关系。
EdgeConv 操作计算每个点与其 k 近邻之间的边特征: \(e_{ij} = h_\Theta(x_i,\ x_j - x_i)\) 通过聚合边特征获得节点新特征。每层 EdgeConv 后,图结构在特征空间重新计算(动态更新),使网络同时保留局部和非局部几何信息。
核心特点:
- 动态图结构能捕捉语义关联,而非仅依赖空间邻近性。
- EdgeConv 操作简洁高效,易于集成至各类点云架构。
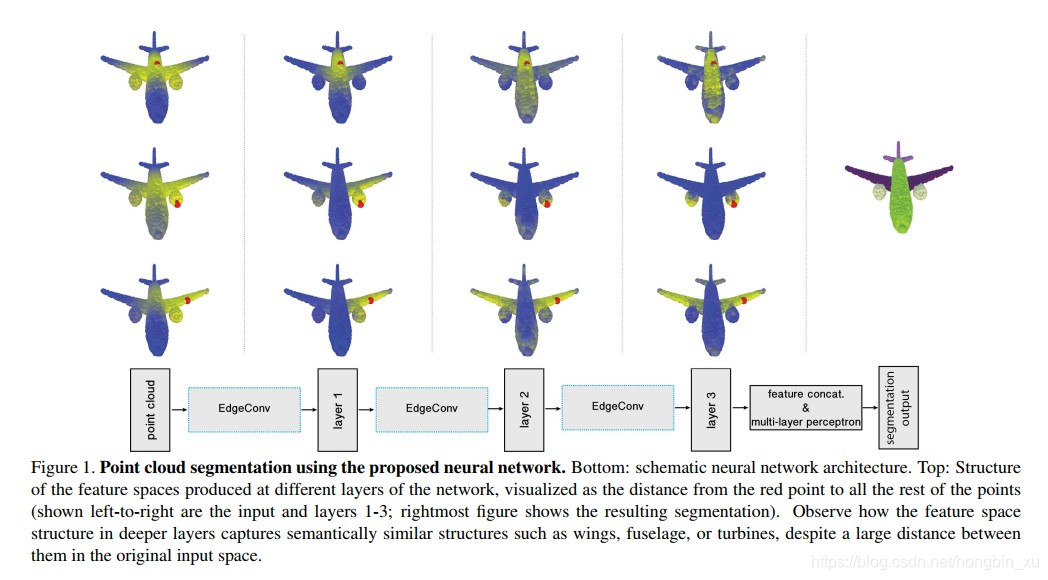
Point Transformer
Point Transformer v1(Zhao et al., ICCV 2021)将自注意力机制引入点云处理。其向量自注意力为每个特征维度分配独立的注意力权重(区别于标量注意力),并引入位置编码捕捉局部几何关系: \(y_i = \sum_{x_j \in \mathcal{N}(x_i)} \rho\!\left(\gamma\!\left(\phi(x_i) - \psi(x_j) + \delta\right)\right) \odot \left(\alpha(x_j) + \delta\right)\) 其中 $\delta$ 为点位置编码,$\rho$ 为 softmax 归一化,$\gamma$ 为关系网络。Point Transformer v2(Wu et al., NeurIPS 2022)引入分组向量注意力与多头机制,在 ScanNet 语义分割等基准上达到当时的最优性能。
核心特点:
- 基于 Transformer 的局部自注意力,捕捉细粒度局部几何特征。
- 位置编码设计使网络对点云几何结构具有明确的感知能力。
- 确立了点云 Transformer 的标准架构,后续 Point Transformer v3(2024)进一步在大规模数据上预训练。
三维感知基础模型 (2024-2025 最新进展)
Uni3D(Zhou et al., ICLR 2024)是首个大规模统一三维感知基础模型。通过在 1000 万以上三维对象上进行对比预训练,Uni3D 学习到跨类别、跨数据集的通用三维点云特征,在零样本三维理解和跨模态检索(点云↔图像↔文本)等任务上取得突破性进展。
OpenShape(Liu et al., NeurIPS 2023)利用文本-三维形状对进行大规模多模态对比学习,将 CLIP 的开放词汇理解能力迁移至三维领域,支持零样本三维分类(ModelNet40 上约 85% top-1 准确率,无需三维训练数据)。
Point-BERT(Yu et al., CVPR 2022)和 Point-MAE(Pang et al., ECCV 2022)将 BERT/MAE 自监督预训练引入点云领域,推动三维感知基础模型的形成。
4.2 密集几何感知与深度估计
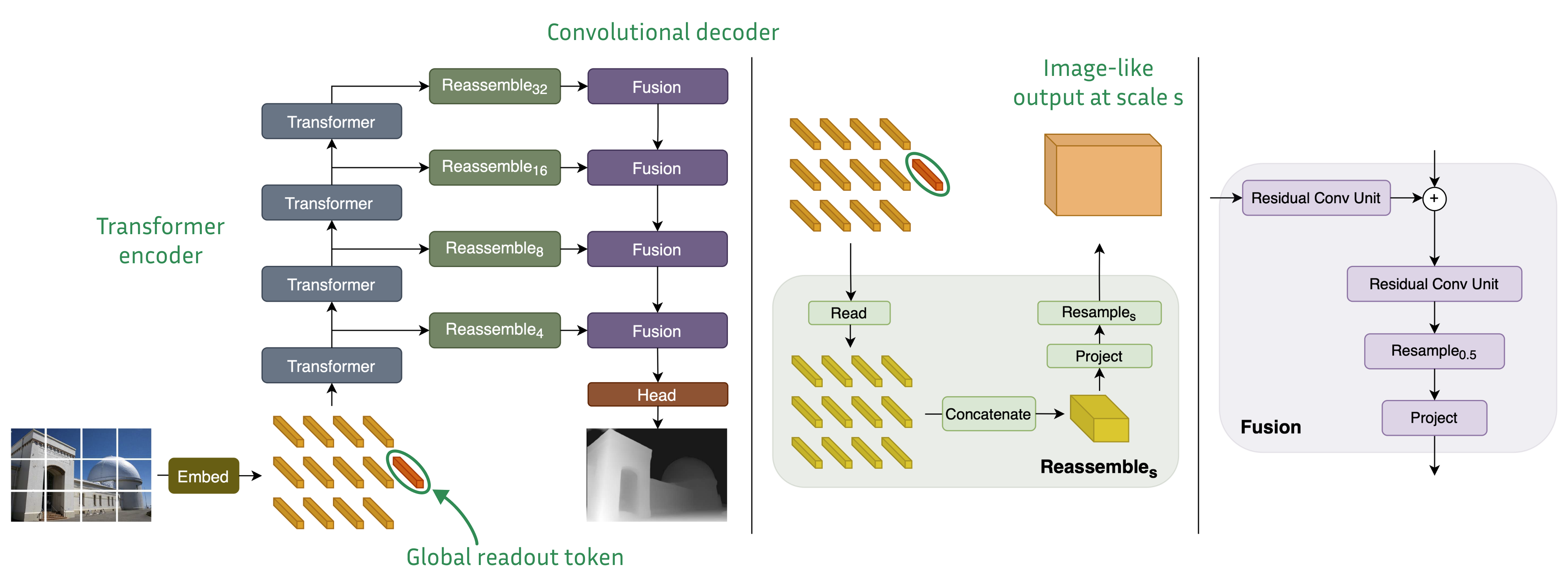
DPT
DPT(Dense Prediction Transformer,Ranftl et al., ICCV 2021)将视觉 Transformer(ViT)引入密集预测任务(深度估计与语义分割),将 ViT 各层 patch token 特征图融合进解码器,实现高分辨率密集输出。
DPT 训练采用尺度不变损失(Scale-Invariant Loss): \(\mathcal{L}_{si} = \frac{1}{n}\sum_i d_i^2 - \frac{\lambda}{n^2}\left(\sum_i d_i\right)^2\) 其中 \(d_i = \log \hat{y}_i - \log y_i\) 为预测值与真实值对数之差,$\lambda$ 控制全局尺度惩罚项的权重。该损失对绝对尺度不敏感,适用于单目深度估计的固有尺度歧义性。
核心特点:
- 首次在深度估计中使用纯 ViT 特征提取,利用大感受野捕捉全局场景结构。
- 多尺度特征融合,从粗到细捕捉不同层次的深度信息。
- 在相对深度零样本迁移中具有很强的跨数据集泛化性。
Depth Anything 系列
Depth Anything(Yang et al., CVPR 2024)是迄今最具代表性的单目深度估计基础模型。其核心创新在于大规模半监督数据引擎:以 150 万张有标注图像为种子,利用教师模型为 6200 万张无标注图像生成伪标签,再以强数据增强对学生模型进行强制泛化训练,突破了标注数据瓶颈。
Depth Anything V2(NeurIPS 2024)进一步引入高质量合成数据(Hypersim、Virtual KITTI)改善细粒度深度预测,并提供绝对尺度(Metric Depth)版本,适用于机器人导航等需要真实深度值的应用场景。
核心特点:
- DINOv2 作为骨干网络提供强大的语义先验。
- 零样本泛化能力显著优于前代模型,在未见场景上表现稳定。
- V2 版本的细节质量(边缘清晰度、薄结构)得到显著改善。

Marigold
Marigold(Ke et al., CVPR 2024)将扩散模型(Diffusion Model)引入深度估计,利用 Stable Diffusion 中蕴含的图像先验,通过在少量真实深度数据上微调实现强大的零样本深度估计。其核心洞察是:预训练扩散模型中编码了丰富的场景几何先验,可高效迁移至深度估计任务而无需大规模重新训练。
核心特点:
- 基于扩散模型的生成式深度估计框架,通过多步去噪生成深度图。
- 仅需在少量有标注数据上微调即可达到 SOTA 性能。
- 生成的深度图具有丰富的细节和清晰的边界,在弱纹理/重复纹理区域表现尤为突出。

4.2.5 经典立体视觉与密集匹配
在深度学习方法出现之前,立体视觉(Stereo Vision)是从图像中恢复深度的主流手段。理解其原理有助于把握 Depth Anything、Marigold 等方法究竟解决了哪些经典痛点。
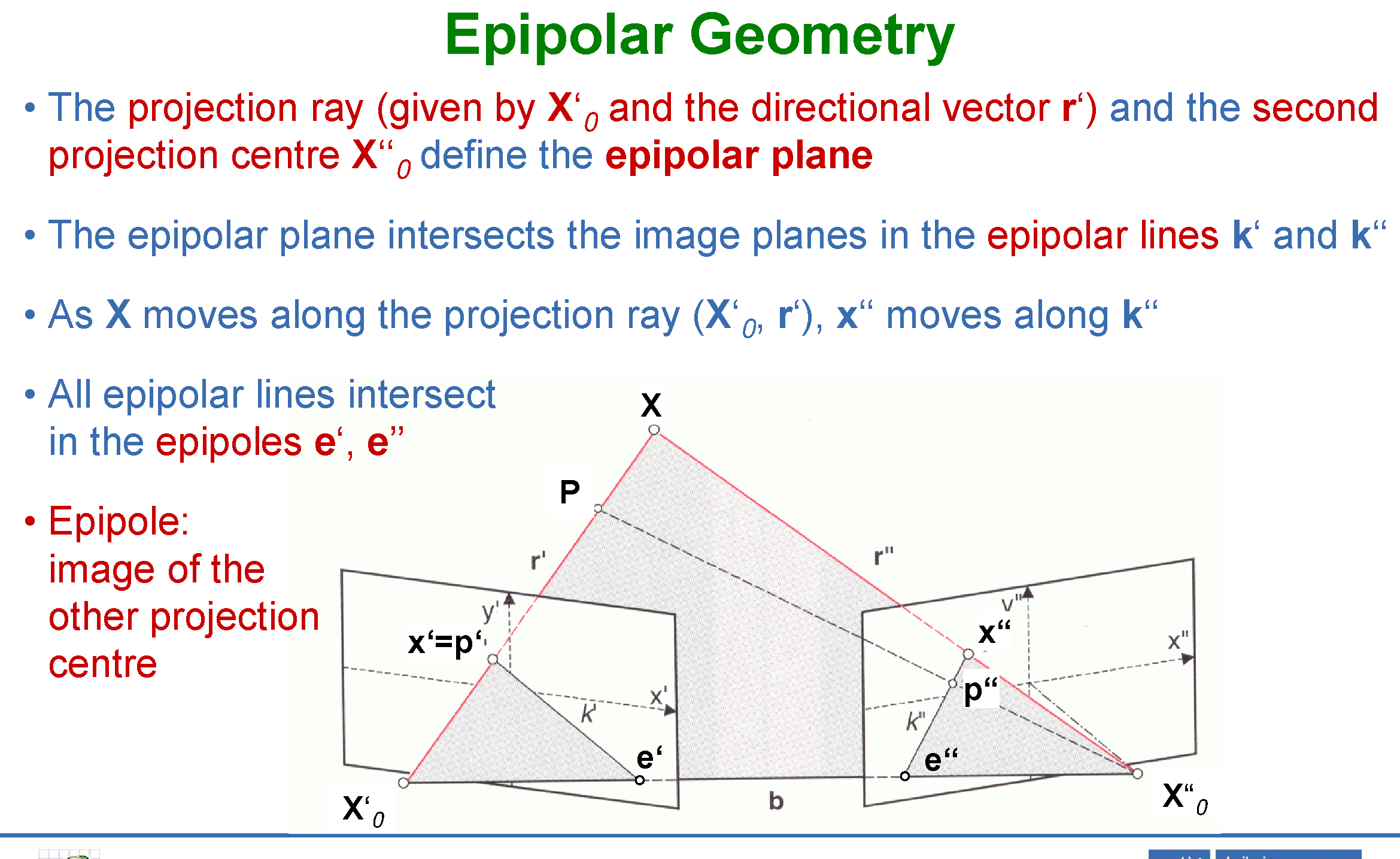
对极几何
对极几何(Epipolar Geometry)描述同一场景在两张图像中的几何约束关系,是立体匹配的理论基础。给定两幅图像中的对应点 $\mathbf{x}_1$ 和 $\mathbf{x}_2$(齐次坐标),它们满足:
\[\mathbf{x}_2^T F \mathbf{x}_1 = 0\]其中 $F \in \mathbb{R}^{3 \times 3}$(秩为 2)为基础矩阵(Fundamental Matrix),包含两相机的相对位姿与内参信息。若已知两相机内参 $K_1, K_2$,则对应的本质矩阵(Essential Matrix):
\[E = K_2^T F K_1 = [\mathbf{t}]_\times R\]$E$ 仅编码外参旋转 $R$ 和(归一化)平移方向 $\mathbf{t}$,可通过 SVD 分解恢复相对位姿。对极约束将二维搜索空间降至对极线(Epipolar Line)上的一维搜索,是所有立体匹配算法的核心加速手段。
立体纠正与视差深度
对图像对进行立体纠正(Stereo Rectification)后,两相机光轴平行,对极线变为水平扫描线,对应点仅在水平方向存在位移——视差(Disparity) $d = u_L - u_R$。由相似三角形:
\[Z = \frac{f \cdot B}{d}\]其中 $f$ 为焦距,$B$ 为基线(Baseline)(双目间距),$Z$ 为深度。视差越大,距离越近;视差趋向零,深度趋向无穷——这正是单目深度估计存在尺度歧义的几何本质。
半全局匹配(SGM)
SGM(Semi-Global Matching,Hirschmüller, TPAMI 2008)是经典密集视差估计的代表算法,至今仍是自动驾驶和航测领域的工业基线。其核心思路是将逐像素代价最小化问题近似为沿多方向一维路径积分,融合局部匹配代价与全局平滑约束:
\[E(D) = \sum_{\mathbf{p}} \left( C(\mathbf{p}, D_\mathbf{p}) + \sum_{\mathbf{q} \in N_\mathbf{p}} P_1 T[|D_\mathbf{p} - D_\mathbf{q}| = 1] + P_2 T[|D_\mathbf{p} - D_\mathbf{q}| > 1] \right)\]其中 $C(\mathbf{p}, d)$ 为像素 $\mathbf{p}$ 在视差 $d$ 下的匹配代价,$P_1, P_2$ 分别为小/大视差跳变的惩罚项。SGM 通过 8 个方向的路径累积(Left/Right/Top/Bottom 及对角线),以接近 $O(WH)$ 的线性复杂度逼近全局能量最小化。

Census 变换是 SGM 常用的匹配代价,将像素邻域中每个位置与中心像素的大小关系编码为二进制串,再以汉明距离度量相似性——对光照变化具有天然的鲁棒性,避免了直接使用像素灰度差(SAD/SSD)时对绝对亮度敏感的缺陷。
SGM 的局限性正是推动深度学习方法(如 Depth Anything、Marigold)兴起的原因:
- 无纹理区域(白墙、均匀地面)匹配代价退化,产生大片”空洞”;
- 透明/反射物体违反朗伯体假设,经典代价函数失效;
- 参数($P_1, P_2$)需针对场景手工调节,泛化性弱;
- 立体方法必须依赖已标定的双目相机,单目场景无法使用。
4.3 神经三维重建:从隐式到显式
4.3.0 经典 SfM/MVS 管线
在神经渲染出现之前,运动恢复结构(Structure from Motion, SfM)是从无约束图像集中重建三维场景的标准框架。理解经典管线是理解 DUSt3R、VGGT 等端到端前馈方法”革命性”的前提。
经典 SfM 流程:
- 特征提取:SIFT(Scale-Invariant Feature Transform,Lowe, IJCV 2004)通过高斯差分(DoG)检测尺度空间极值点,提取 128 维方向梯度直方图(HOG)描述子,实现尺度、旋转与光照不变性,是两十年来最稳健的图像匹配特征。
- 特征匹配 + RANSAC:对图像对进行描述子最近邻匹配,使用 RANSAC(Random Sample Consensus) 鲁棒估计基础矩阵 $F$,以迭代随机采样的方式自动剔除误匹配(outliers)。
- 相对位姿估计:从本质矩阵 $E = [\mathbf{t}]_\times R$ 通过 SVD 分解恢复两相机间的旋转 $R$ 和平移方向 $\mathbf{t}$(4个候选解,通过正深度约束确定唯一解)。
- 三角化(Triangulation):已知两相机位姿后,对匹配点对用线性最小二乘(DLT)恢复 3D 点坐标 $\mathbf{X}$,解方程组 $\mathbf{x}_i \times (P_i \mathbf{X}) = 0$。
- 增量式重建:以最佳匹配图像对为种子,通过 PnP+RANSAC 将新图像注册进已重建的点云,持续扩展稀疏 3D 结构。
- 光束法平差(Bundle Adjustment, BA):联合优化所有相机位姿 ${R_i, \mathbf{t}_i}$ 与 3D 点坐标 ${X_j}$,最小化重投影误差: \(\min_{\{R_i,\mathbf{t}_i\},\{X_j\}} \sum_{i,j} \rho\!\left(\left\|\mathbf{x}_{ij} - \pi(R_i X_j + \mathbf{t}_i)\right\|^2\right)\) 其中 $\pi(\cdot)$ 为透视投影,$\rho(\cdot)$ 为鲁棒核函数(Huber)。BA 是 SfM 精度的核心,通常用 Ceres Solver 实现。
- 稠密重建(MVS):在稀疏 SfM 位姿基础上,通过 PatchMatch MVS 等算法逐像素恢复稠密深度图,再融合为稠密点云或体素。
COLMAP(Schönberger & Frahm, CVPR 2016)是目前最主流的开源 SfM+MVS 系统,集成了上述全流程,DUSt3R、VGGT 等工作均以 COLMAP 重建结果作为位姿精度评测基准(AUC@5°/10°/20°)。
经典 SfM 的核心局限——正是推动神经渲染革命的根本动因:
- 速度极慢:大场景 BA 耗时数小时乃至数天;
- 稀疏输出:最终点云稀疏,需再跑 MVS 才能得到稠密结果;
- 弱纹理失败:SIFT 特征在低纹理区域(白墙、天空)匹配稀疏;
- 无语义:纯几何管线,无法感知物体类别与语义关系;
- 场景独立:无法跨场景泛化,每个新场景需重新运行完整管线。
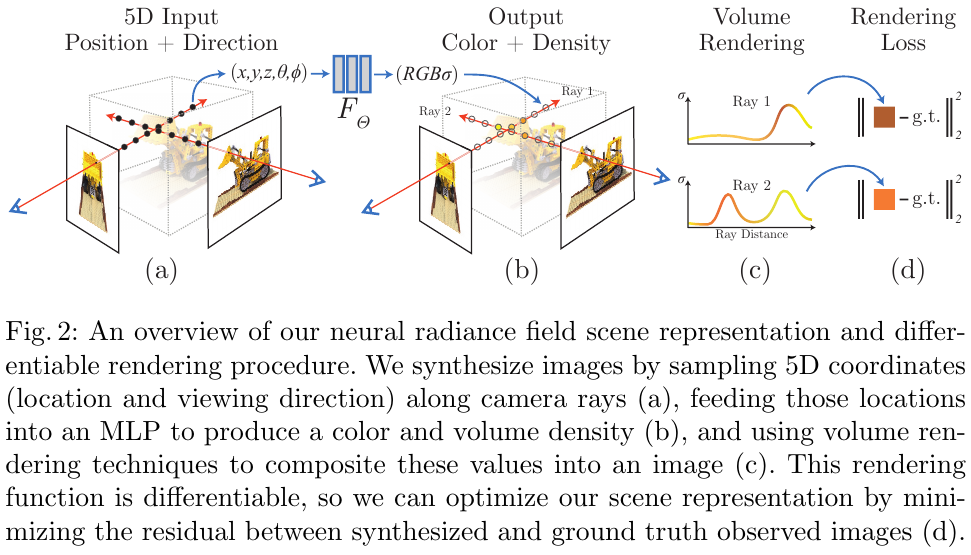
NeRF
NeRF(Neural Radiance Fields,Mildenhall et al., ECCV 2020)是近年来三维视觉领域最具影响力的工作之一。NeRF 用一个全连接网络 $F_\Theta: (\mathbf{x}, \mathbf{d}) \to (\mathbf{c}, \sigma)$ 将三维坐标 $\mathbf{x}$ 和视角方向 $\mathbf{d}$ 映射为颜色 $\mathbf{c}$ 和体积密度 $\sigma$,通过可微体积渲染方程合成图像: \(\hat{C}(\mathbf{r}) = \int_{t_n}^{t_f} T(t)\,\sigma\!\left(\mathbf{r}(t)\right)\mathbf{c}\!\left(\mathbf{r}(t),\mathbf{d}\right)\mathrm{d}t\) 其中 $T(t) = \exp!\bigl(-\int_{t_n}^{t}\sigma(\mathbf{r}(s))\,\mathrm{d}s\bigr)$ 为沿光线的累积透射率。以重建图像与真实图像的光度损失(MSE/SSIM)监督网络训练。
核心特点:
- 全隐式连续表示,内存高效,可渲染任意分辨率。
- 可微渲染支持端到端优化,无需显式三维监督。
- 高质量新视角合成,擅长细节纹理与镜面反射。
- 局限:训练缓慢(数小时/场景)、仅表示静态场景、不同场景间无泛化性。
重要扩展:Mip-NeRF(处理混叠)、Mip-NeRF 360(无界场景)、Instant-NGP(哈希编码,加速至秒级)、Block-NeRF(大规模城市场景)。
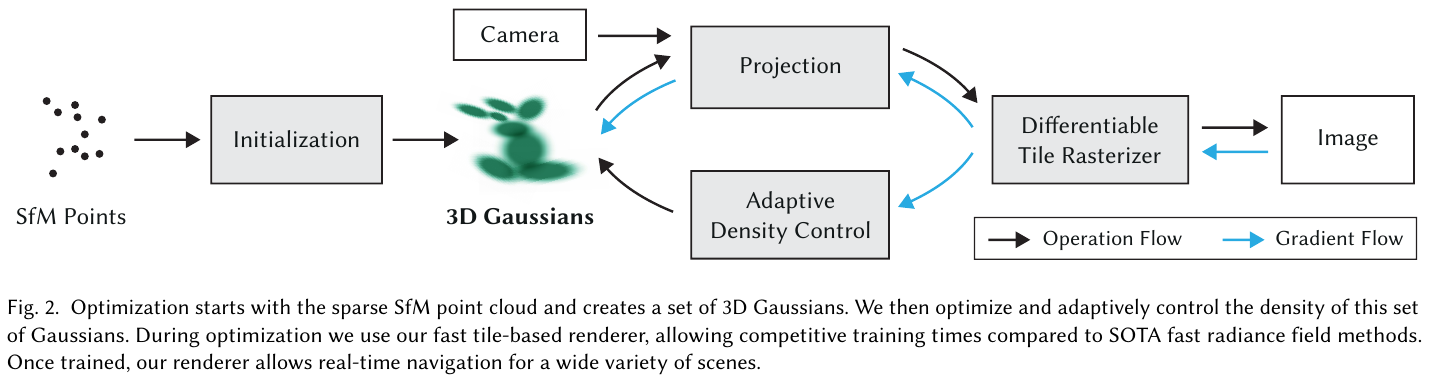
3D Gaussian Splatting
3D Gaussian Splatting(Kerbl et al., SIGGRAPH 2023)是 2023 年三维重建领域最重要的突破,以实时高质量渲染彻底改变了神经渲染领域格局。
3DGS 用一组各向异性三维高斯基元显式表示场景,每个高斯由以下参数描述:
- 位置(均值)$\mu \in \mathbb{R}^3$
- 协方差矩阵,通过旋转矩阵 $R$ 和缩放向量 $s$ 分解:$\Sigma = RSS^TR^T$
- 不透明度 $\alpha$
- 球谐函数(SH)系数,描述视角相关外观
渲染时将三维高斯投影到图像平面(Splatting),按深度排序后进行 $\alpha$-混合,得到最终像素颜色。自适应密度控制机制根据梯度信息自动克隆或删除高斯基元,实现几何细节的自动校准。
核心特点:
- 显式表示,避免 NeRF 的体积渲染开销,实现实时渲染(>30 FPS @ 1080p)。
- 可微分,支持端到端梯度优化。
- 训练速度远快于 NeRF(分钟级),且渲染质量更高。
- 局限:高斯基元数量庞大(数百万),存储开销较大;对无纹理平滑区域建模较弱。
端到端稠密三维重建 (2024-2025)
DUSt3R(Wang et al., CVPR 2024)提出端到端稠密三维重建新范式,将传统 SfM 管线(特征匹配→位姿估计→密集重建)统一为单一 Transformer 网络:输入任意图像对(无需已知相机参数),直接预测稠密点图(Pointmap),再通过全局优化融合多图。DUSt3R 突破了传统方法对高重叠度图像对的依赖,在极端视角变换下依然稳健。
MASt3R(Leroy et al., 2024)在 DUSt3R 基础上增加局部特征匹配能力,进一步提升多视角三维重建的鲁棒性与精度,同时支持稀疏匹配任务。两者共同代表了三维重建向”前馈基础模型”方向的重要转变。
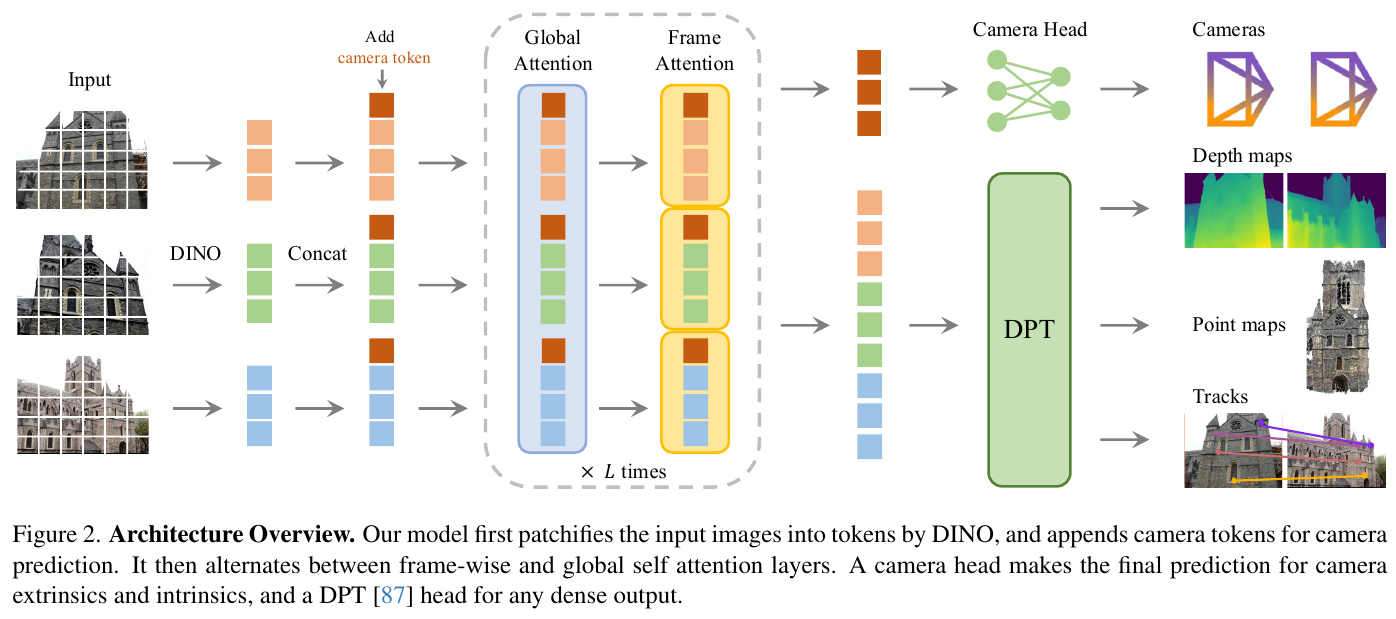
VGGT:通用三维视觉基础模型 (2025)
VGGT(Visual Geometry Grounded Transformer,Wang et al., CVPR 2025 Best Paper,arXiv:2503.11651)是 DUSt3R/MASt3R 路线的集大成者,也是首个真正意义上的”通用三维视觉基础模型”。其核心突破是用单个前馈 Transformer 在亚秒级一次推理中,同时预测一组图像(从单张到数百张)所对应的全部关键三维属性:
- 相机内参与外参(intrinsics + extrinsics)
- 每帧度量深度图(metric depth)
- 全场景一致的稠密点图(Pointmap)
- 跨帧的 3D 点轨迹(point tracks)
前馈范式的演进:从传统 SfM/MVS 多阶段几何流水线,到 DUSt3R/MASt3R 的成对前馈+全局对齐,再到 VGGT 的统一前馈,三维重建的”阶段数”在逐步收敛——下图直观对比三种范式:
graph TD
subgraph Trad ["① 传统 SfM/MVS 流水线(多阶段几何)"]
T1["多视图输入"] --> T2["特征提取与匹配"]
T2 --> T3["相机位姿估计"]
T3 --> T4["稀疏三角化"]
T4 --> T5["Bundle Adjustment"]
T5 --> T6["MVS 稠密重建<br/>(分钟~小时级)"]
end
subgraph Dust ["② DUSt3R / MASt3R(成对前馈 + 全局对齐)"]
D1["图像对 (2 张)"] --> D2["前馈 Pointmap 网络"]
D2 --> D3["全局对齐优化<br/>(多对融合)"]
D3 --> D4["相机参数 + 稠密点云<br/>(秒~十秒级)"]
end
subgraph Vggt ["③ VGGT(统一前馈基础模型)"]
V1["1 ~ 数百张图像"] --> V2["统一 Transformer<br/>(交替注意力, 单次前馈)"]
V2 --> V3["相机 + 深度 + 点图 + 点轨迹<br/>(亚秒级, 无需任何后处理)"]
end
style Trad fill:#fff5f5,stroke:#fca5a5
style Dust fill:#fffbeb,stroke:#fcd34d
style Vggt fill:#f0fdf4,stroke:#86efac
style V3 fill:#bbf7d0,stroke:#16a34a,stroke-width:2px
核心设计:
- 统一前馈架构:彻底抛弃了 DUSt3R 路线中仍依赖的全局对齐优化、bundle adjustment 等几何后处理步骤——所有几何量都直接由网络一次性输出,无需任何测试时优化。
- 交替注意力(Alternating Attention):网络主体由”逐帧自注意力(frame-wise self-attention)”与”跨帧全局自注意力(global self-attention)”层交替堆叠组成。前者提取单图局部细节,后者建立多视角间的几何一致性,避免了 DUSt3R 显式构造图像对带来的 $O(N^2)$ 复杂度,可平滑扩展到数百张输入视图。
- 多任务联合监督:通过多个轻量预测头同时回归相机参数、深度、点图与轨迹,并采用置信度(confidence)加权损失自适应处理动态物体与遮挡区域。
- 大规模混合训练:在多种真实与合成 3D-annotated 数据集(包含 ScanNet、CO3D、ARKitScenes、MegaDepth、BlendedMVS 等)上联合预训练,吸收跨域几何先验。
核心结果:
- 在相机位姿估计、多视角深度估计、稠密点云重建、3D 点跟踪等多个基准上同时达到 SOTA,全面超越仍依赖测试时优化的 DUSt3R / MASt3R / MonST3R 等方法。
- 推理速度达到秒级(典型几十张图像 < 1s),相比传统 SfM/MVS 与基于优化的前馈方法快 1–2 个数量级。
- 输出可直接作为下游任务(新视角合成、动态点跟踪、3DGS 初始化、视觉 SLAM、机器人空间感知)的高质量先验,验证了其作为通用”三维基础模型”的可迁移性。
意义与影响:
- 标志着三维重建正式从”先估位姿—再三角化—再稠密化”的多阶段几何管线,转向”前馈基础模型一步出几何”的新范式,与 NLP/2D 视觉的发展轨迹高度对应。
- 推动了 Fast3R、CUT3R 等多视角/流式前馈三维重建工作的快速涌现,形成了围绕 DUSt3R → VGGT 的”3D Foundation Model”研究热潮。
- 对具身智能与世界模型而言,VGGT 提供了一个可即插即用的统一几何先验,显著降低了空间感知模块的工程复杂度。
MapAnything:通用度量级前馈重建模型 (2026)
MapAnything(Keetha et al., Meta Reality Labs & CMU, arXiv:2509.13414)将 VGGT 的”统一前馈”范式进一步推向通用化与度量化。VGGT 只吃图像、输出 up-to-scale 几何,而 MapAnything 补上两个关键缺口:(1) 灵活接受任意几何先验(相机内参、位姿、深度)作为可选输入;(2) 直接输出度量级(metric-scale)三维与相机。单个模型由此覆盖无标定 SfM、标定 MVS、单目/多视角深度估计、相机定位、度量深度补全等 12+ 种任务、64 种输入组合。

核心设计——因子化场景表示(Factored Scene Representation):MapAnything 的关键洞察是不直接回归 pointmap,而是把每个视角的几何拆解为四个解耦分量——逐像素 ray 方向(等价相机标定)、沿 ray 的深度、视角在首帧系下的全局位姿(四元数 + up-to-scale 平移),以及全场景单一 metric scale 因子 $m$。由这些因子可逐级还原局部点图 \(\tilde{L}_i = R_i \cdot \tilde{D}_i\)、世界系点图直至度量三维 \(X_i^{\text{metric}} = m \cdot \tilde{X}_i\)。这套因子表示同时充当可选输入与最终输出:有先验时按同一参数化喂入,无先验时退化为纯图像重建。
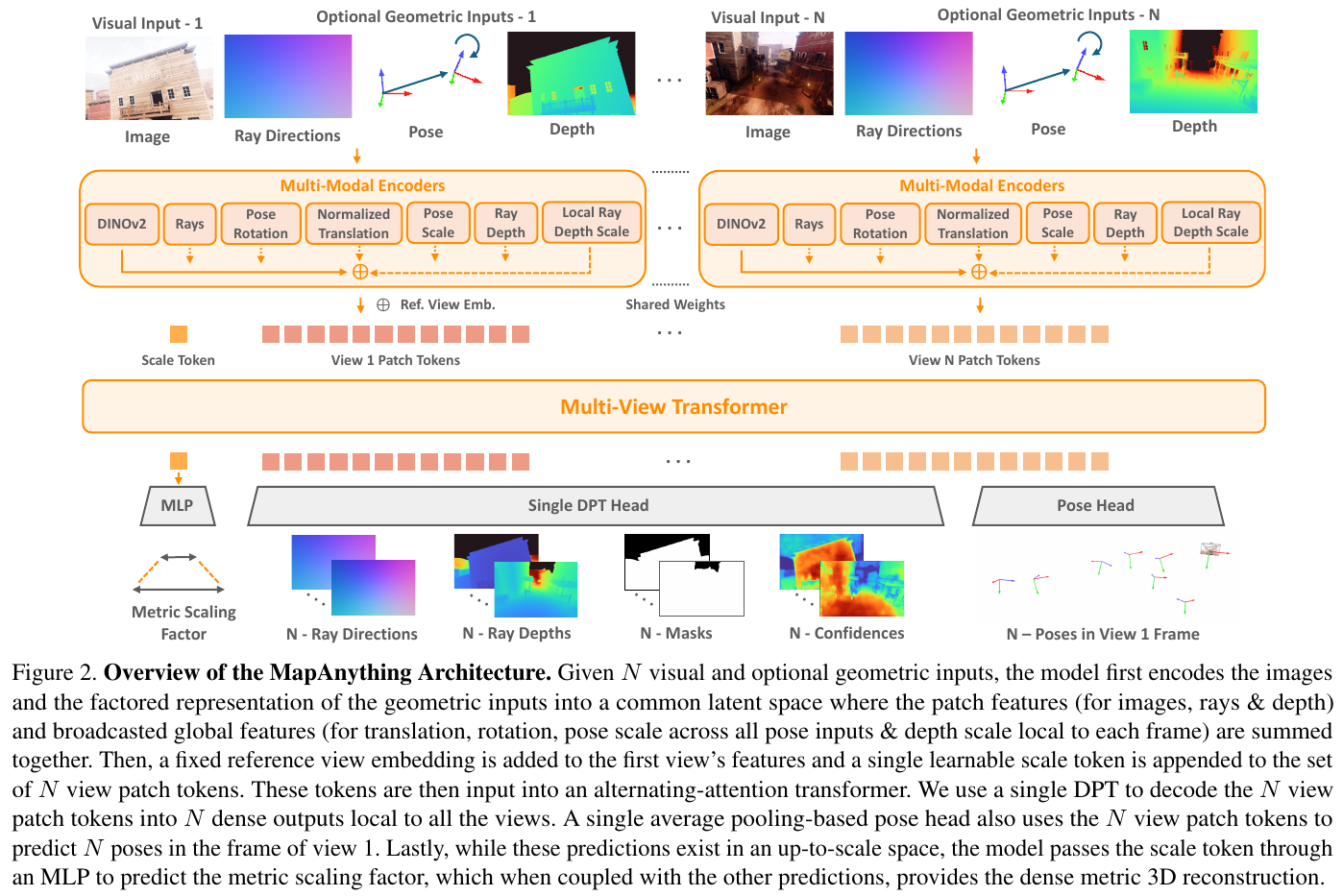
架构要点:
- 多模态编码器:图像走 DINOv2 ViT-G;ray 方向 / 深度等稠密量走浅层卷积编码器;旋转、平移、深度尺度、位姿尺度等全局量走 MLP 并广播到所有 patch。所有模态编码后经 LayerNorm 逐视角相加,进入共享隐空间。
- 交替注意力 Transformer:与 VGGT 同源,16 层逐帧 / 全局交替注意力,用 DINOv2 后 16 层初始化;首视角加 reference-view embedding,并额外拼一个可学习 scale token 专门预测全局度量尺度,使尺度预测与几何解耦(消融证明这是通用度量推理的关键)。
- 输入概率训练(input-probability training):训练时按概率随机给入各几何模态(ray、深度、位姿各约 0.5),让单一通用模型自然支持 64 种输入组合,并能从”只有 up-to-scale 标注”的数据集学习——这是实现通用度量推理的另一关键。
核心结果:
- 仅用图像即在 ETH3D / ScanNet++ v2 / TartanAirV2 上取得多视角密集重建 SOTA,超过 VGGT;提供内参 / 位姿 / 稀疏深度等先验后精度进一步显著提升(全先验下点图 rel 低至 0.01)。
- 单视角标定(平均角误差 1.06°,优于 VGGT 4.00、MoGe-2 1.95)、两视角重建、Robust-MVD 度量深度等多项基准上达到或逼近专家模型。
- 用等同两个专用模型的算力一次训成 12+ 任务,性能却媲美甚至超过多个 bespoke 专家模型,验证多任务训练的高效性;在 2–500 视角下推理速度与峰值显存均优于 VGGT、Depth-Anything-3 等并发模型。

意义:MapAnything 把 DUSt3R → VGGT 的前馈三维基础模型路线,从”纯图像、up-to-scale”扩展到”任意几何先验、度量级”,并以开源(Apache 2.0 / CC BY-NC)的模型与训练框架,朝”通用三维重建主干(Universal 3D Reconstruction Backbone)”又迈进一步。
三维生成与单图重建
Zero-1-to-3(Liu et al., ICCV 2023)利用扩散模型从单张 RGB 图像生成任意视角下的新视角图像,为单图三维重建提供了新思路。Zero123++(Shi et al., 2023)、One-2-3-45(Liu et al., 2024)进一步提升了多视角一致性和生成速度。
LRM(Large Reconstruction Model,Hong et al., ICLR 2024)基于大型 Transformer 的前馈三维重建模型,从单张图像在数秒内生成三维 NeRF,代表了三维重建从基于优化到前馈推理的范式转变。CAT3D(Google DeepMind,2024)利用扩散模型从极少量输入图像(1–3 张)生成多视角一致的三维场景,进一步放宽了对输入数量的要求。
动态场景建模 (4D)
静态 3DGS 在动态场景建模上存在局限。Dynamic 3D Gaussians(Luiten et al., 3DV 2024)为每个高斯引入时间轨迹,追踪多帧场景中粒子的动态运动;4D Gaussian Splatting(Wu et al., CVPR 2024)通过时间维度的高斯变形场实现动态场景实时渲染;Deformable 3D Gaussians(Yang et al., CVPR 2024)则专注于非刚体形变建模,为机器人交互场景动态建模打开了新方向。
4.4 三维目标检测与场景理解
VoxelNet, SECOND 与 PointPillars
VoxelNet(Zhou & Tuzel, CVPR 2018)是第一个端到端直接从激光雷达点云学习三维目标检测的框架。它将点云体素化,在每个非空体素内用 VFE(Voxel Feature Encoding)层提取局部特征,再通过三维卷积骨干网络和 RPN 完成检测,消除了人工特征工程。然而,由于使用常规稠密三维卷积,其计算与显存开销极大,限制了其实时性。
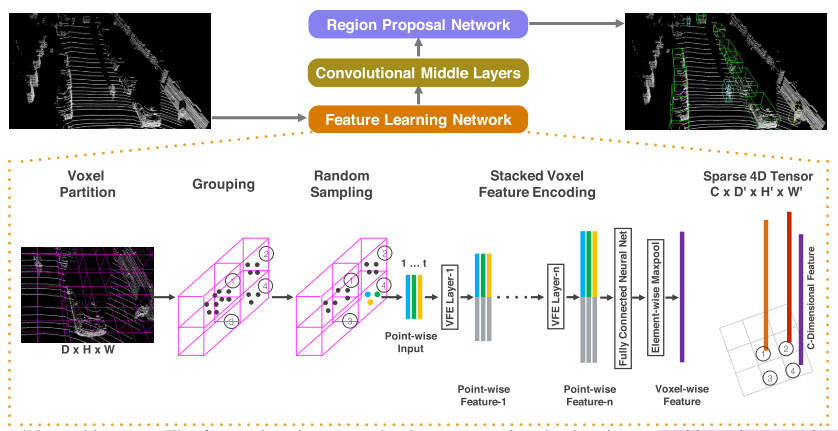
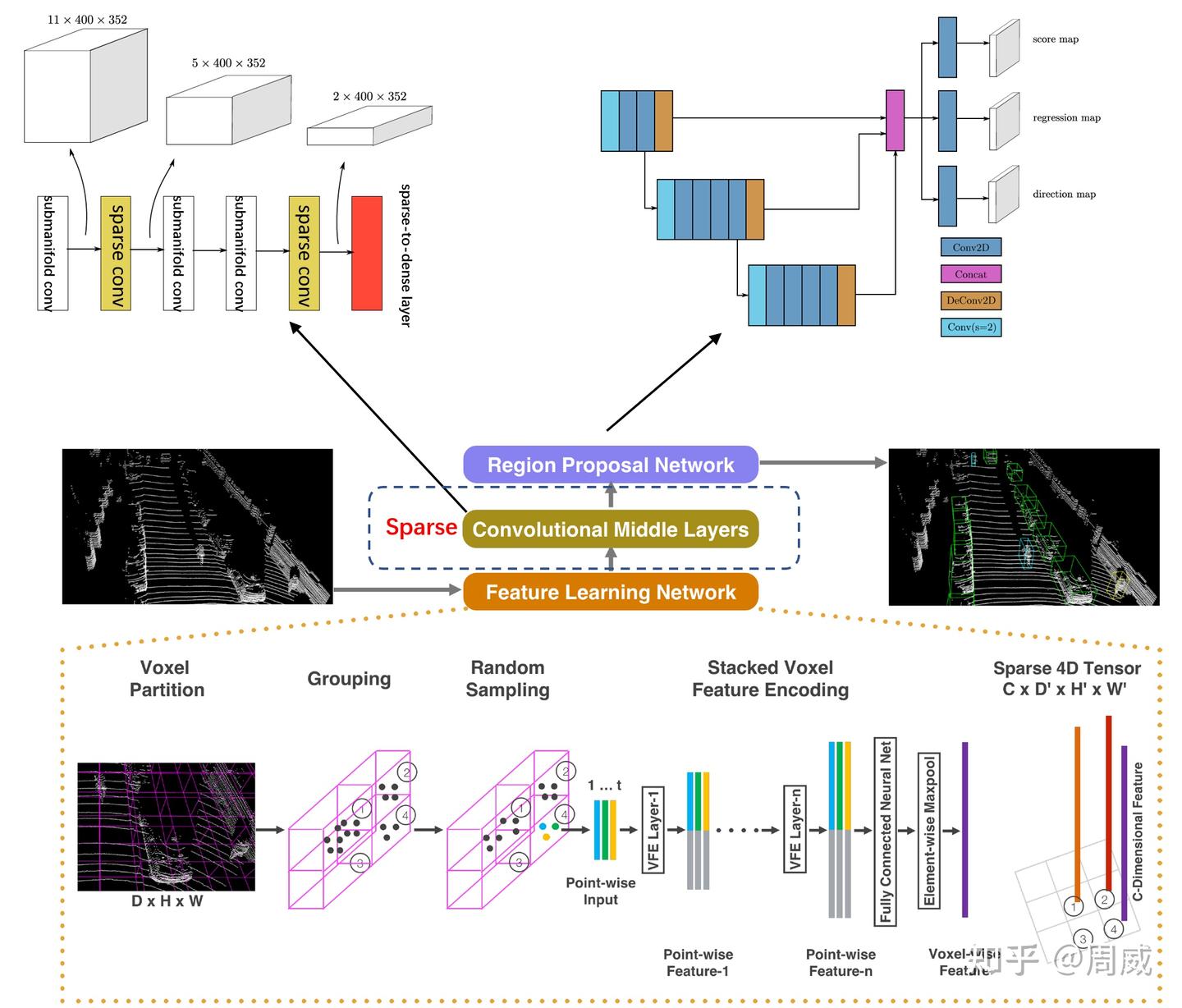
SECOND(Sparsely Embedded Convolutional Detection,Yan et al., Sensors 2018)针对 VoxelNet 常规三维卷积的高昂开销,引入了稀疏卷积(Sparse Convolution)与流形稀疏卷积(Submanifold Sparse Convolution),仅在非空体素上进行卷积计算,大幅提升了训练和推理速度,并改进了角度回归损失函数,使基于体素的方法真正具备了实用价值。
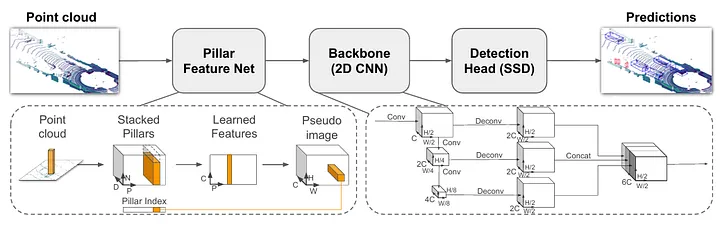
PointPillars(Lang et al., CVPR 2019)则更进一步,将体素化简化为”柱状(Pillar)”编码——沿高度方向将点云压缩为二维伪图像,从而用高效的 2D CNN 代替了 3D 卷积(无论是稠密还是稀疏),推理速度提升至 62 FPS(GPU)。PointPillars 在速度与精度之间取得了极佳的工程平衡,成为自动驾驶 LiDAR 感知领域经典的工业界基线。
核心特点:
- 体素/柱状编码将无序点云转化为规则特征图,兼容成熟的 2D/3D CNN 框架。
- PointPillars 推动了三维检测系统在嵌入式硬件上的实时部署。
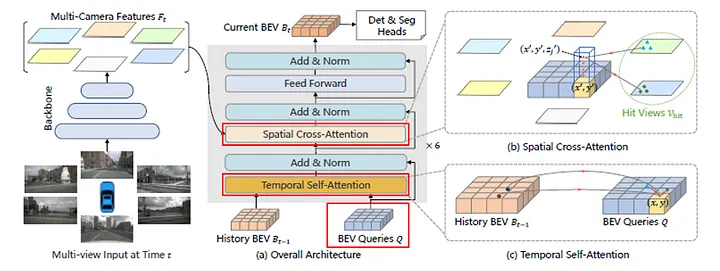
BEVFormer
BEVFormer(Li et al., ECCV 2022)是纯视觉(无 LiDAR)三维感知的里程碑工作。其核心思路是通过可变形注意力(Deformable Attention)将多相机图像特征查询到统一的鸟瞰图(Bird’s Eye View, BEV)空间,并引入时序 BEV 特征融合捕捉运动信息。
核心设计:
- BEV 平面上预设 Query,通过空间交叉注意力从多视角图像中采样特征(避免稠密特征变换的计算开销)。
- 时间自注意力将历史 BEV 特征与当前帧对齐,隐式编码速度和运动信息。
- 在 nuScenes 数据集上显著超越前代纯视觉方法,触发了”纯视觉自动驾驶感知”研究热潮。
核心特点:
- 无需昂贵 LiDAR,仅用摄像头实现接近 LiDAR 水平的 3D 感知。
- BEV 统一表示支持检测、跟踪、地图分割等多任务联合训练。
语义占用预测与表示演进
语义占用预测(Semantic Occupancy Prediction)近年在自动驾驶中受到广泛关注。与 3D 目标检测输出有限数量的边界框不同,占用预测为场景中每个区域(体素)分配语义标签,能更自然地处理任意形状的异型障碍物与长尾目标(如倒地的纸箱、施工护栏、悬挂的线缆),因而被视为通往”通用障碍物感知”的关键路径。然而,稠密体素表示天然面临 $O(N^3)$ 的内存与计算爆炸问题,整个领域的技术演进,本质上是一条不断逼近”高分辨率 × 低算力 × 时序一致”三角约束的优化轨迹:
graph LR
A["① 稠密 Transformer<br/>(2022-2023)<br/>TPVFormer / OccFormer / SurroundOcc"] --> B["② 稀疏 & 自适应分辨率<br/>(2023-2024)<br/>AdaOcc / SparseOcc / GaussianFormer"]
B --> C["③ 线性复杂度 & 世界模型<br/>(2025-)<br/>OccMamba / OccRWKV / GaussianWorld"]
style A fill:#fff5f5,stroke:#fca5a5
style B fill:#fffbeb,stroke:#fcd34d
style C fill:#f0fdf4,stroke:#86efac
1)稠密 Transformer 范式(2022–2023):TPVFormer(Huang et al., CVPR 2023)将 BEV 扩展为三平面(Tri-Perspective View, TPV)表示,用三个正交平面而非完整体素网格近似 3D 空间,在计算效率与感知完整性之间取得平衡;OccFormer、SurroundOcc 则通过 3D / 双路注意力进一步提升重建质量。这一阶段确立了”环视图像 → 3D 体素语义”的端到端范式,但稠密注意力带来的显存与延迟开销,成为车端实时部署的主要瓶颈。
2)稀疏与自适应分辨率表示(2023–2024):核心思想是”好钢用在刀刃上”,不再对所有体素一视同仁地计算。AdaOcc(Adaptive-Resolution Occupancy Prediction)引入自适应分辨率机制——在近处、复杂障碍物等安全关键的兴趣区域(ROI)使用高分辨率,在远处空旷区域使用低分辨率,打破效率与精度的 Trade-off;SparseOcc / Fully Sparse Occupancy 将稀疏性推向极致,在整条流水线中仅对非空区域进行计算,大幅压缩延迟;甚至有工作(Occupancy as Set of Points)彻底摒弃规则体素网格,改用点集灵活表示占用,对薄结构与边缘有更好的刻画。受 3DGS 启发,GaussianFormer(Wang et al., ECCV 2024)/ GaussianFormer-2(CVPR 2025)则用一组 3D 高斯体替代稠密体素,以”概率叠加”建模占用,在显著压缩内存的同时保留细粒度几何。
3)线性复杂度架构与时序世界模型(2025–):Transformer 的二次复杂度在高分辨率 3D 空间中成为致命弱点,新一代工作转向线性复杂度骨干。OccMamba(CVPR 2025)是首个将状态空间模型(SSM / Mamba)引入占用预测的网络,通过希尔伯特曲线等 3D-to-1D 展开保持空间局部性,配合层次化 Mamba 模块实现 $O(N)$ 复杂度;OccRWKV 则借助线性 RNN 架构探索端侧实时部署。与此同时,占用预测正从”单帧感知”迈向”时序世界模型”:GaussianWorld(CVPR 2025)在流式输入中不仅预测当前占用状态,更预测未来的 3D 占用演变,强调时序一致性;面向遮挡难题,Collaborative Semantic Occupancy Prediction 通过车路 / 车车协同(V2V)融合多视角特征”看透”遮挡,显著提升 IoU。
演进脉络小结:占用预测沿”稠密计算 → 自适应 / 稀疏表示 → 线性复杂度 → 时序世界模型”逐级演进,背后是同一条主线——在有限车端算力下,把感知分辨率、计算效率与时序预测能力推向新的帕累托前沿。
三维场景图(3D Scene Graph)则从另一视角组织空间语义:将场景表示为图结构,节点表示物体实例,边表示空间关系(上方 / 下方、左侧 / 右侧、支撑等),支持语言查询与逻辑推理。3DSSG(Wald et al., CVPR 2020)是该方向的代表性数据集与基线工作。占用预测提供”稠密几何 + 语义”,场景图提供”稀疏结构 + 关系”,二者在具身导航与任务规划中常互为补充。
4.5 空间感知语言模型
ScanRefer & ScanQA
ScanRefer(Chen et al., ECCV 2020)提出了三维视觉定位(3D Visual Grounding)任务:给定自然语言描述(如”靠近门口的那张棕色椅子”),在三维点云场景中定位目标物体(输出三维边界框)。ScanRefer 数据集包含 51,583 条对 ScanNet 扫描中物体的语言描述,是三维语言定位方向的核心基准。ScanRefer 之后,Nr3D/Sr3D(Achlioptas et al., 2020)和 ScanQA(Azuma et al., CVPR 2022)进一步扩展了三维语言理解的评测维度。

3D-LLM
3D-LLM(Hong et al., NeurIPS 2023)首次将大型语言模型(LLM)扩展至三维感知任务。通过将三维点云特征注入 LLM 的上下文(使用基于扩散模型的三维特征提取器,将点云映射为 token 序列),3D-LLM 支持三维场景问答、三维视觉定位、三维对话等多类任务,无需为每个任务设计专用模块。
核心特点:
- 将 LLM 的开放式语言理解能力迁移到三维场景感知,赋予模型三维感知能力。
- 支持多样化三维-语言任务,展示了统一框架的可行性。
- 为后续三维多模态大模型(3D MLLM)奠定基础。
SpatialVLM
SpatialVLM(Chen et al., CVPR 2024)专门针对视觉语言模型(VLM)的空间推理短板而设计。现有 VLM(如 GPT-4V)在”物体 A 距离物体 B 有多远?”此类定量空间推理问题上表现较差。SpatialVLM 通过构建大规模空间推理问答数据集——利用三维传感器自动生成涵盖距离估计、方位判断、大小比较等类型的定量标注问答对——对 VLM 进行空间推理专项微调。
核心特点:
- 首个系统性提升 VLM 定量空间推理能力的工作。
- 自动化数据生成管线可扩展至大规模,不依赖人工标注。
- 在机器人操控等空间推理密集型下游任务中显著提升性能。
EmbodiedScan
EmbodiedScan(Wang et al., CVPR 2024)提出了全面的具身三维场景理解基准,覆盖三维目标检测、三维视觉定位、三维问答等多任务,强调从智能体的主动探索视角理解三维场景(第一人称视角的 RGB-D 流输入),而非离线的完整点云扫描。EmbodiedScan 包含 5000+ 场景、146 万+ 实例标注,是当前规模最大的具身三维场景理解数据集之一。
核心特点:
- 统一的多任务具身三维理解框架,贴近真实机器人部署的感知模式。
- 强调实时、增量式的三维场景理解,而非离线离线处理完整点云。
- 引入多粒度空间语言对齐,支持细粒度物体级和场景级描述。
空间智能大模型进展 (2024-2025)
SpatialBot(Cai et al., 2024)专门针对机器人空间理解任务,整合深度图与 RGB 图像,增强 VLM 在物体空间布局与距离估计等任务上的能力,并构建了相应的评测基准。RoboSpatial(2024)提出面向机器人操控的空间理解数据集与模型,系统研究了 VLM 空间推理能力与机器人任务成功率之间的关联。Chat-3D v2(Wang et al., 2024)通过对象感知的三维特征注入,支持多轮对话式三维场景理解,可回答”帮我找一把椅子放在桌子旁边”等具身交互指令。
近期对 Gemini 1.5 Pro 和 GPT-4V 的系统评测表明,当前通用 VLM 在定量空间推理任务(度量距离、方向估计、体积比较)上仍存在明显缺口,与人类空间认知能力相比存在系统性偏差,这成为空间智能基础模型研究的重要驱动力。
多视角图像驱动的 3D 场景 MLLM 与重建式监督
前述 3D-LLM(§6.7)、PointLLM-V2(§6.8)以点云为输入,GaussianVLM(§6.6)、SplatTalk(§6.3)以3DGS为载体。但这两类都依赖额外的三维重建或扫描预处理。另一条更贴近实际部署的路线是直接复用为 2D 内容设计的大型多模态模型(LMM),仅以带位姿的多视角图像/视频帧为输入,把三维感知作为隐式能力注入,从而无需显式点云。LLaVA-3D(2024)将 2D patch 特征按相机位姿”提升”为 3D patch,Video-3D LLM(2025)则把视频帧与三维位置编码绑定,二者均验证了”视频帧 + 位姿”即可支撑 ScanQA、SQA3D 等三维问答任务。
Ross3D(Reconstructive Visual Instruction Tuning with 3D-Awareness,Wang et al., 2025,arXiv:2504.01901)在这条路线上给出了一个独特的自监督视角。它指出适配 2D LMM 到三维场景的最大障碍是大规模三维视觉-语言数据的稀缺,于是不去堆叠三维标注,而是在指令微调中额外引入两类 3D 感知重建目标:
- 跨视角重建(Cross-view Reconstruction):随机掩码部分视角,强迫模型聚合相互重叠的其他视角信息来恢复被掩码视图,从而学会跨帧几何对应关系;
- 全局视角重建(Global-view Reconstruction):聚合全部可用视角,重建出场景的鸟瞰图(BEV),迫使模型形成全局一致的空间布局表征。
这两个重建头与文本监督联合训练,使模型在不改变输入形态(仍是视频帧 + 指令)的前提下获得三维感知能力。Ross3D 在多个三维场景理解基准上取得当时的 SOTA;更关键的是其半监督实验表明,借助大量”纯视觉、无语言标注”的三维数据即可显著提升性能——这为缓解三维视觉-语言数据瓶颈提供了一条可扩展的路径,与 Depth Anything(§4.2)”用海量无标注数据驱动基础模型”的思路一脉相承。

HiSpatial:分层式三维空间理解 (CVPR 2026)
HiSpatial(Microsoft,CVPR 2026,arXiv:2603.25411)是当前 VLM 空间推理方向最系统的标杆工作。其核心主张是:三维空间理解应像人类认知发育一样逐级搭建——缺乏底层几何与度量基础,高阶抽象推理几乎无法习得。为此它将空间理解显式拆解为 Level 0(基础几何感知)→ Level 1(物体级理解)→ Level 2(物体间关系)→ Level 3(抽象推理)四个层层依赖的层级,配合无人工标注的自动化数据引擎(约 500 万图像 / 20 亿 QA)与注入度量尺度点图的 RGB-D VLM,以仅 3B 参数在 SpatialRGPT、QSpatial、RoboSpatial 等多个基准上超越 Gemini-2.5-Pro、GPT-5。作为本综述”具身 / VLM 空间推理”主线的代表性工作,完整解析详见 §6.10。
语言高斯溅射 (Language Gaussian Splatting)
这是 2025 年最新的研究前沿,将语义特征”喷涂”到 3DGS 高斯基元上,使三维场景兼具几何精度与语义可查询性。代表作包括 SplatTalk (2025)、LangSplatV2 (2025)、4D LangSplat (2025) 和 GaussianVLM (2025)。这些工作共同推动了三维场景表示与语言交互的深度融合。
5. 主流数据集与评测基准
本节按任务与应用维度对常用数据集与评测基准进行整理,并指出每类数据集的适用场景、常用评价指标与使用注意事项,便于选型与横向比较。
5.1 按任务分类的数据集概览
- 形状与合成三维数据(用于三维生成、形状检索、点云分类)
- ShapeNet:大规模 CAD 模型库,类别丰富(~55 类),常用于形状重建、生成与分类基线测试。优点是样本整洁、无噪声;缺点是与真实感知场景分布有域差异。
- ModelNet(ModelNet10 / ModelNet40):经典三维分类基准,ModelNet40 常用于点云分类的基线验证与 ablation。
- 室内扫描与语义理解(用于语义分割、实例分割、3D 帧跟踪、场景图)
- ScanNet v2:真实室内 RGB-D 扫描,提供逐帧 RGB、深度、相机位姿、全景点云与语义/实例标注。适合三维语义分割、场景重建与ScanRefer 等语言对齐任务。
- Matterport3D / HM3D:高质量室内重建,尺度大、场景复杂,常用于视觉导航、语义地图和 VLM 对齐任务。
- S3DIS:室内点云语义分割基准,面向屋内大场景的语义重建与分割评测。
- 深度估计与稠密几何(用于单目/双目深度、重建质量评估)
- NYU Depth V2:室内 RGB-D 深度图与语义标注,长期作为单目深度估计与室内重建的标准数据集。
- KITTI Depth / Eigen split:用于室外单目深度估计和立体匹配评测(驾驶场景)。
- DTU / Tanks and Temples / BlendedMVS / Mip-NeRF360:传统与神经渲染领域用于新视角合成与多视图重建的评测集。
- 自动驾驶与户外三维感知(检测、跟踪、BEV、占用预测)
- KITTI 3D / KITTI Odometry:早期自动驾驶基准,包含 LiDAR、立体/单目图像与位姿;适用于三维检测与里程计评测。
- nuScenes:多传感器(LiDAR + 多相机 + radar)大规模数据集,支持检测、跟踪、场景分割与行为分析,常用于 BEV 任务评测。
- Waymo Open Dataset:更加规模化的自动驾驶基准,提供高密度标签、长尾物体类别与丰富场景分布。
- Argoverse / Lyft Level 5:行业级别别的补充基准,侧重地图级任务与轨迹预测。
- 具身智能与导航(用于模拟器训练、长期交互与导航评测)
- Gibson / Habitat / Replica:提供与真实场景对齐的 3D 环境与物理交互接口,常用于导航、视觉导航(VLN)、目标驱动探索的训练与评测。
- Habitat-Matterport / Habitat-Geo:用于大规模具身代理的长期导航与语义任务。
- 三维-语言与问答(用于三维定位、3D VQA、三维描述)
- ScanRefer:点云+语言定位基准,含三维边界框与语言描述,常用于 3D Visual Grounding。
- Nr3D / Sr3D:Nr3D(自然语言)与 Sr3D(模板化语言)用于 3D 指称与定位评测。
- ScanQA / MSR3D / SQA3D:针对三维视觉问答与具身场景问答的扩展基准。
- 三维生成与合成渲染(用于 NeRF / 3DGS 等新视角合成)
- Synthetic-NeRF / Blender scenes:用于渲染与新视角合成的合成数据集,方便复现并量化 PSNR/SSIM/LPIPS 指标。
- Tanks and Temples / DTU:用于传统 MVS 与新视角合成的高质量真实场景基准。
5.2 常用评测指标(按任务)
- 形状重建 / 生成:Chamfer Distance (CD), Earth Mover’s Distance (EMD)
- 点云 / 语义分割:mean IoU (mIoU), per-class IoU, mAcc
- 三维目标检测:mAP (IoU thresholds), Average Translation Error, BEV mAP
- 深度估计与重建:AbsRel, RMSE, SILog(尺度不变误差),PSNR/SSIM/LPIPS(视图合成)
- 文本生成与问答:CIDEr, BLEU, ROUGE, Exact Match (EM)
- 具身导航:Success Rate (SR), Success weighted by Path Length (SPL), Coverage
5.3 选型建议与常见陷阱
- 数据域匹配:合成 CAD 数据(ShapeNet / ModelNet)适合算法设计与快速迭代,但与真实传感器噪声和遮挡差距大;研究真实感知能力请优先选择 ScanNet / Matterport3D / HM3D 等真实扫描集。
- 任务对齐:若目标是自动驾驶感知(BEV、跟踪),优先使用 nuScenes / Waymo / KITTI;若目标是室内语言理解与具身交互,优先选用 ScanRefer / ScanQA / Gibson / Habitat 数据。
- 标注一致性:不同数据集对类别定义、坐标系、度量单位可能不同(例如 Metric depth 的尺度),实验前需对数据预处理(坐标变换、分辨率、语义类映射)做严格统一。
- 训练/测试泄露:使用大规模预训练(3D/2D)模型时,注意数据集交叉包含的场景/对象可能导致评测偏高,应采用严格的场景分割(scene-level split)。
5.4 推荐基准组合(研究者/工程师视角)
- 原型研究(快速验证算法想法):ModelNet / ShapeNet(小样本、合成、训练快)
- 室内三维感知与语义:ScanNet v2 + S3DIS + ScanRefer(语义+定位)
- 新视角合成与神经渲染:DTU + Tanks&Temples + Mip-NeRF360(涵盖合成与真实场景)
- 自动驾驶端到端:nuScenes + Waymo(多传感器、场景多样、长尾)
- 具身智能与导航:Habitat/Gibson + Matterport3D(与实际部署场景更贴近)
5.5 结语与未来展望
近年来随着多模态与大模型的发展,三维数据集逐渐从孤立任务基准向多任务、跨模态、具身交互的综合基准演化(如 EmbodiedScan、HM3D 扩展集)。未来优先方向包括:
- 标注尺度化(更细粒度的物体属性、物理状态与关系标注);
- 动态场景与时序标注(4D 数据集、动作/状态标注);
- 开放词汇/长尾语义覆盖(结合大模型自动标注管线的弱监督数据扩充);
- 标注互操作性(统一坐标系、语义词表与评测套件),以便可重复、可比较的跨工作评测。
6. 经典论文深度解析
6.1 NeRF (2020)
———Representing Scenes as Neural Radiance Fields for View Synthesis
📄 Paper: https://arxiv.org/abs/2003.08934
精华
NeRF 是神经渲染(Neural Rendering)领域的开创性工作,其核心贡献和启发包括:
- 隐式场景表示:不再使用显式的点云或网格,而是将 3D 场景编码为 MLP 网络的权重,实现极高精度的连续场景表示。
- 5D 辐射场函数:通过输入空间坐标 $(x, y, z)$ 和观测视角 $(\theta, \phi)$,输出颜色和体积密度,完美捕捉了与视图相关的材质光泽(如 Specular 效应)。
- 位置编码(Positional Encoding):发现并解决了深度网络偏向学习低频信号的问题,通过傅里叶变换将坐标映射到高维空间,从而还原复杂的纹理细节。
- 层次化体采样:设计了 Coarse-to-Fine 的采样策略,通过两个 MLP 同时优化,将计算资源集中在场景中有内容的区域,显著提升了渲染效率和质量。
- 端到端可微体渲染:结合经典体渲染公式,使得整个管线仅需带位姿的 2D 图像即可进行端到端训练。
1. 研究背景/问题
视角合成(View Synthesis)是计算机图形学的长期难题。传统方法(如离散体素、多平面图像或网格渲染)在处理复杂几何边缘和非朗伯体(Non-Lambertian)反射材质时,往往存在存储成本高或渲染不自然的问题。NeRF 旨在通过连续的神经场表示,在仅使用稀疏 2D 图像作为输入的情况下,实现照片级真实感的 3D 场景重建和视角合成。
2. 主要方法/创新点

NeRF 的核心管线包含以下关键技术:
- 5D 神经场景表示:
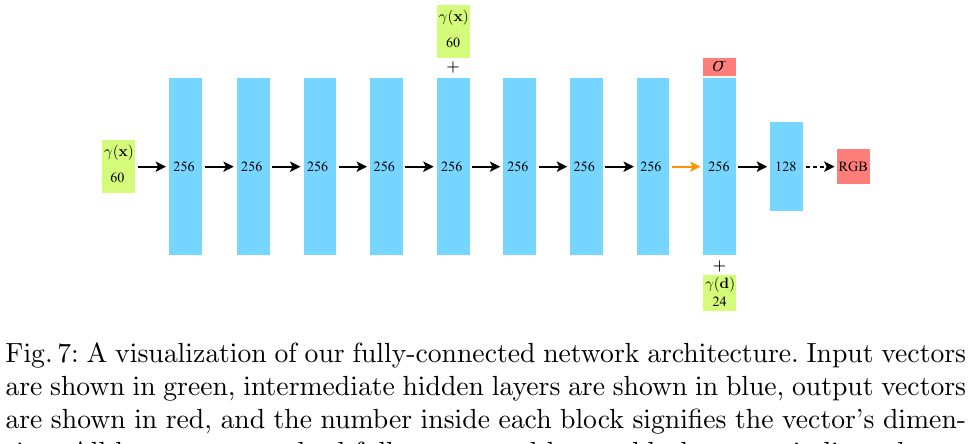
通过限制体积密度仅取决于位置,而颜色取决于位置和方向,模型能够保证在不同视角下观察到的几何结构一致,同时捕捉到随视角变化的光影。
- 可微渲染管线:
利用数值积分近似体渲染方程,使得像素颜色成为网络权重的可微函数。
- 捕捉高频细节: 引入了位置编码 $\gamma(p)$,将原始坐标映射为一系列正余弦函数: \(\gamma(p) = \left( \sin(2^0\pi p), \cos(2^0\pi p), \dots, \sin(2^{L-1}\pi p), \cos(2^{L-1}\pi p) \right)\) 这使得 MLP 能够拟合高频变化的颜色和几何细节,避免了渲染结果过于平滑(Oversmoothed)。
3. 核心结果/发现
- 定量与定性超越:在合成数据集(如 Lego, Drums)和真实场景中,NeRF 的 PSNR 和 SSIM 指标均大幅超越了当时的 SOTA(如 LLFF, SRN)。

- 存储优势:相比于需要数 GB 存储的体素网络,一个复杂的 NeRF 模型仅需约 5MB 的网络权重即可表示整个场景。
4. 局限性
NeRF 的主要局限在于训练和推理速度极慢(训练单个场景需一两天,渲染一张图需几十秒)。此外,原始 NeRF 仅适用于静态场景,无法处理动态物体或由于光照变化导致的一致性问题。
6.2 3D Gaussian Splatting (2023)
———Real-Time Radiance Field Rendering via Differentiable Gaussian Primitives
📄 Paper: https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
精华
3DGS 证明了显式、非连续的场景表示(无需神经网络)同样可以达到 SOTA 的 novel view synthesis 质量,打破了 NeRF 系隐式连续表示是高质量渲染必须条件的固有认知。各向异性协方差(通过旋转矩阵 R 和缩放矩阵 S 分解 \(\Sigma = RSS^T R^T\))使每个 Gaussian 能够自适应地拟合场景中任意形状的几何结构,是高质量紧凑表示的关键。自适应密度控制中的 Clone(欠重建)+ Split(过重建)策略提供了一个简洁有效的几何增殖机制,可迁移应用于其他点云优化场景。Tile-based GPU Radix sort 排序 + \(\alpha\)-blending 的渲染流水线完全可微,实现了无限制梯度回传,是实现实时渲染同时保持训练质量的工程核心。
1. 研究背景/问题
Neural Radiance Field(NeRF)方法通过体积光线投射实现了高质量 novel view synthesis,但需要大量采样查询,渲染速度极慢(Mip-NeRF360 仅 0.07 fps),训练时间长达 48 小时。现有快速方法(InstantNGP、Plenoxels)在速度上有所改进但质量存在妥协,且无法实现 1080p 分辨率下真正的实时渲染(≥30 fps)。
2. 主要方法/创新点
3D Gaussian 表示
场景由一组 3D Gaussian 基元表示,每个 Gaussian 由以下参数描述:
- 位置(均值) \(\mu \in \mathbb{R}^3\)
- 各向异性协方差 \(\Sigma = RSS^T R^T\),其中 R 为旋转矩阵(四元数 q 参数化),S 为缩放矩阵(向量 s 参数化)
- 不透明度 \(\alpha \in [0,1]\)(sigmoid 激活)
- 球谐函数(SH)系数 表示与视角相关的颜色外观(4 bands,共 48 个系数)
3D Gaussian 函数定义为:
\[G(x) = e^{-\frac{1}{2}x^T \Sigma^{-1} x}\]从 3D 投影到 2D
渲染时将 3D Gaussian 投影到图像平面,利用仿射近似的 Jacobian J 计算相机坐标系下的 2D 协方差 \(\Sigma' = JW\Sigma W^T J^T\)(去掉第三行列后为 2×2 矩阵),从而支持高效的各向异性 splatting。
可微 Tile-based Rasterizer
渲染器将图像分割为 16×16 的 Tile,对每个 Gaussian 计算其覆盖的 Tile 数量并分配 64-bit key(低 32 位为深度,高 32 位为 Tile ID),通过单次 GPU Radix Sort 全局排序后进行 front-to-back \(\alpha\)-blending:
\[C = \sum_{i \in \mathcal{N}} c_i \alpha_i \prod_{j=1}^{i-1}(1 - \alpha_j)\]反向传播时通过从最后一个影响像素的点开始 back-to-front 遍历重建中间 \(\alpha\) 值,无需显式存储每像素的混合列表,内存开销仅为常数级别。
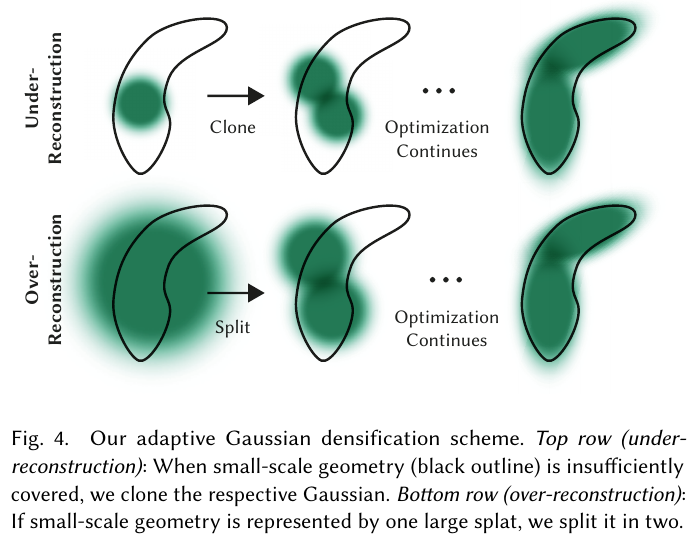
自适应密度控制
每 100 次迭代执行一次密度控制:
- 欠重建(位置梯度 \(\lVert \nabla_p L \rVert > \tau_{pos} = 0.0002\),且 Gaussian 体积小)→ Clone:复制 Gaussian 并沿位置梯度方向移动
- 过重建(位置梯度大,且 Gaussian 体积大)→ Split:替换为 2 个缩小 \(\phi=1.6\) 倍的子 Gaussian
- 每 N=3000 次迭代将 \(\alpha < \epsilon_\alpha\) 的 Gaussian 剪枝
训练损失结合 \(\mathcal{L}_1\) 和 D-SSIM:
\[\mathcal{L} = (1-\lambda)\mathcal{L}_1 + \lambda \mathcal{L}_\text{D-SSIM}, \quad \lambda=0.2\]3. 核心结果/发现
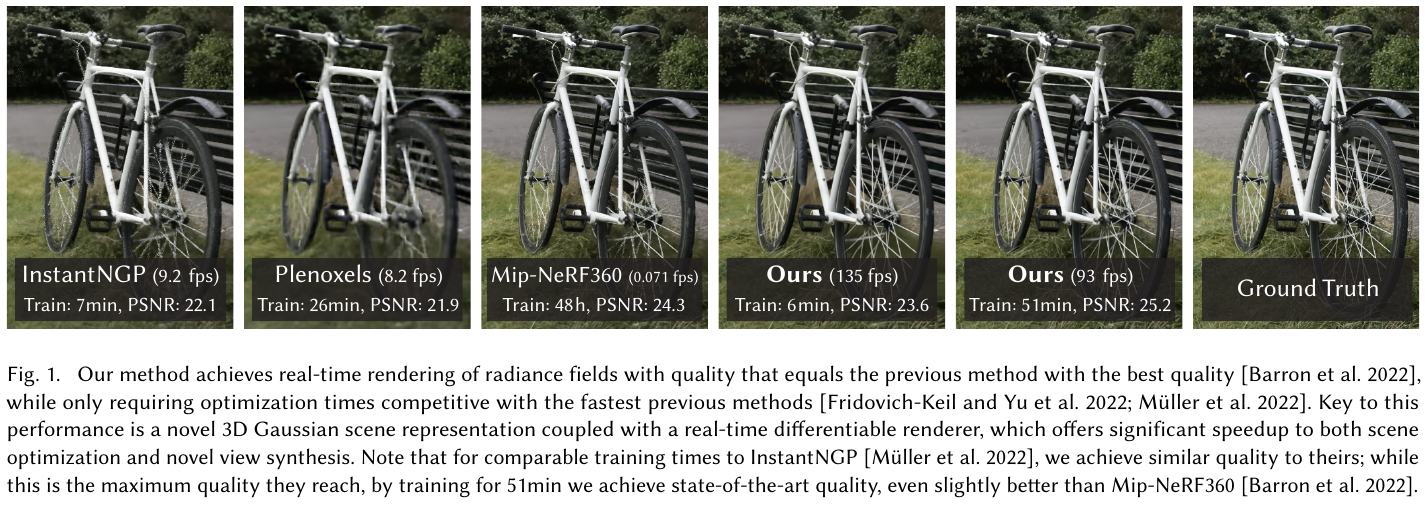
- 实时渲染:1080p 分辨率下达到 93-135 fps,远超 Mip-NeRF360(0.07 fps)
- 训练效率:7K 迭代(~6min)可媲美 InstantNGP,30K 迭代(~35-45min)超越 Mip-NeRF360(48h)
- Mip-NeRF360 数据集(30K iters):PSNR 27.21,SSIM 0.815,LPIPS 0.214
- Tanks&Temples(30K iters):PSNR 23.14,SSIM 0.841,LPIPS 0.183
- 消融实验:各向异性协方差、Clone/Split 两种密度化策略、SH 表示均对最终 PSNR 有显著贡献(见 Table 3)
- 模型规模:1-5M Gaussians 表示完整场景,内存占用 200-500 MB
4. 局限性
在场景观测不足的区域(如训练视角盲区、强反射/高光表面)可能产生伸长的”splotchy” Gaussian 伪影和深度排序跳变导致的 popping 现象;当前不对优化添加正则化,在非常大的场景(如城市级别)中可能需要降低学习率才能收敛。
SplatTalk、LangSplatV2、4D LangSplat、GaussianVLM 共同开辟了语言高斯溅射(Language Gaussian Splatting)这一新兴方向:将语义特征”喷涂”到 3DGS 高斯基元上,再通过多视角渲染蒸馏,使三维场景兼具几何精度与语义可查询性。其本质是将 PointPainting 思路迁移至 3DGS——将语言特征 attach 到高斯球上再渲染蒸馏;3DGS 在此扮演空间记忆(Spatial Memory)的角色,聚合多视角信息,支持下游语言推理,而非仅用于新视角合成。
6.3 SplatTalk (2025)
———用 3D Gaussian Splatting 做零样本 3D 视觉问答
📄 Paper: arXiv:2503.06271
精华
将语言特征嵌入 3D Gaussian 表示,可以绕开点云、深度图等显式 3D 输入,仅凭多视角 RGB 图完成 3D 空间推理。用 LLaVA-OV projector 后的 visual token(而非原始图像特征)作为伪真值,使 Gaussian 语义特征天然与 LLM 隐空间对齐。对高维稀疏 LLM 特征先训练一个统一 autoencoder 压缩至 256 维紧致超球面,再联合优化 RGB 和语义两路渲染,同时保持泛化性。推理时从 3D Gaussian 均值直接读取语言特征,以熵自适应采样选出信息量最大的 token 集合,无须额外训练即可提升性能。方法对比 2D LMM 基线(LLaVA-OV)在 ScanQA 上 CIDEr 提升 23%,并与需要点云输入的 3D LMM 达到竞争水平。
1. 研究背景/问题
3D VQA 要求模型理解场景内物体的空间位置与关系,但现有 3D LMM 依赖点云、深度图等昂贵 3D 输入,而纯 2D LMM 缺乏显式 3D 表示,难以回答跨物体的空间关系问题(如”桌子旁边是什么?”)。如何仅凭多视角 RGB 图像构建一个可被 LLM 直接查询的 3D 语言场,是本文解决的核心问题。
2. 主要方法/创新点
SplatTalk 的流水线分三阶段:特征 autoencoder 训练、自监督 3D-Language Gaussian Splatting 训练、3D VQA 推理。
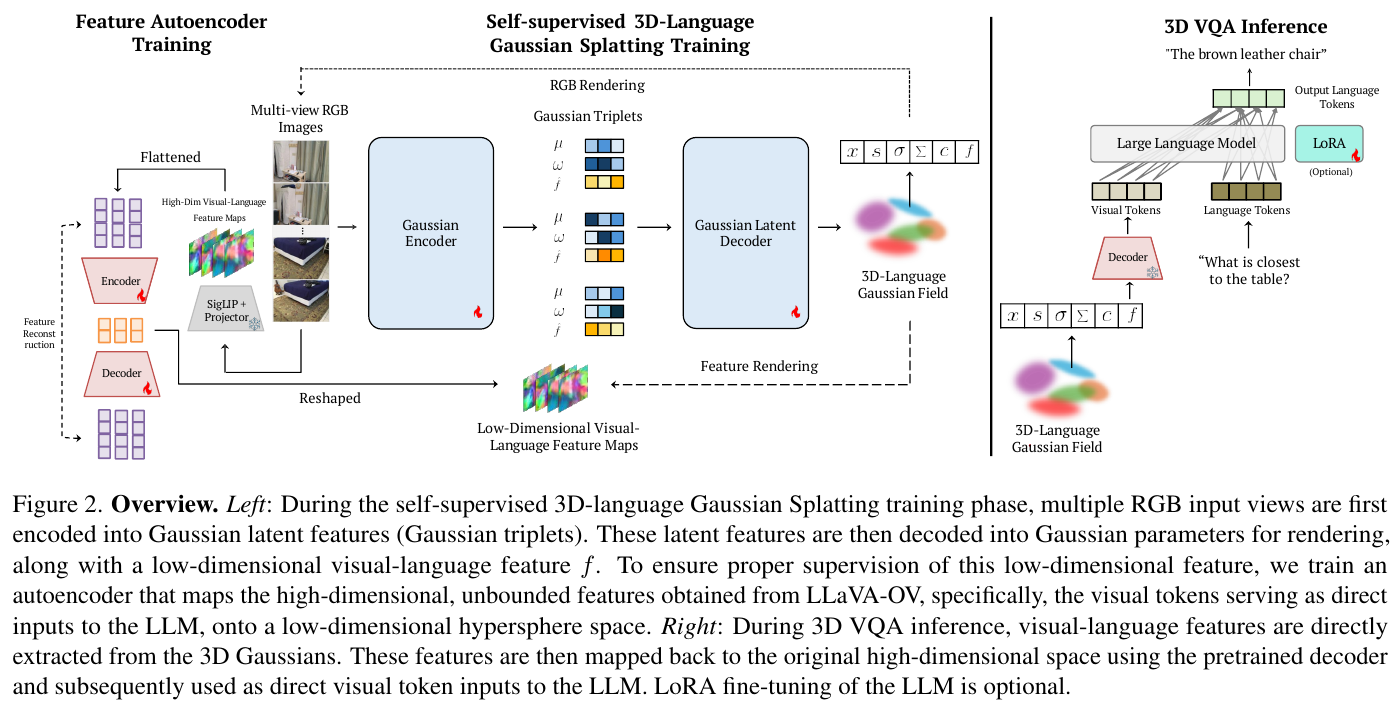
Visual Tokens 作为伪真值特征:从 LLaVA-OV 的 multimodal projector 之后提取 visual token,而非图像编码器原始输出。这样特征已与 LLM 隐空间对齐,Gaussian 学到的语义特征可直接被 LLM 解读。
特征降维:将 3584 维稀疏 LLM 特征通过单一全局 autoencoder 压缩至 256 维超球面(归一化约束),显著优于先前工作压缩至 3–16 维的有损方案,同时避免高维特征在 CUDA 可微渲染中的不稳定性。Encoder/Decoder 结构均为多层线性 + BatchNorm + GeLU。
联合训练 RGB 与语言:在 FreeSplat 前馈框架基础上,Gaussian decoder 新增一个语义特征预测头,与 RGB 渲染参数共同优化。训练损失为光度损失(MSE + LPIPS)与语义损失(MSE + cosine distance)之和:\(\mathcal{L} = \lVert I - \hat{I} \rVert^2 + 0.05 \cdot \text{LPIPS} + \lVert F - \hat{F} \rVert^2 + 1 - \cos(F, \hat{F})\)
均值特征提取(EM 对应):推理时每个 Gaussian 的语义特征 \(f_i^*\) 定义为其对所有视图渲染贡献的加权平均,与 EM 算法的 E-step 对应,理论上保证场景语义被全局捕获而非局部点。
熵自适应采样:对每个 Gaussian 计算语言特征熵,优先选择熵最高(信息量最大)的 top-k Gaussians 送入 LLM,无需额外训练即可提升空间推理质量(对比随机采样、点密度采样、FPS 均有优势)。
3. 核心结果/发现
ScanQA(3D 室内 QA):SplatTalk 零样本 CIDEr 61.7(vs LLaVA-OV 50.0);微调后 SplatTalk-3DVQA-FT 达到 77.5 CIDEr / EM@1 22.4 / EM@1-R 38.3,超越所有 Specialist 和 Generalist 3D LMM 基线(包括依赖点云的 LEO、Chat-Scene 等)。
SQA3D(具身 agent 状态问答):零样本 EM@1-R 32.2,微调后 SplatTalk-3DVQA-FT 为 41.3,达到 SOTA 2D LMM 水平,并接近点云 3D LMM。
MSR3D(多模态情境推理):零样本 Overall 41.8,约为 LLaVA-OV(24.0)的 1.7 倍,Spatial 类问题 35.8(vs LLaVA-OV 19.5),全面领先。
消融:熵采样在所有指标上优于随机/FPS/点密度采样;增大 visual context(从 729 token 到 32,076 token)在 MSR3D 上 EM@1 几乎翻倍,说明空间推理从更多场景上下文中显著受益。
4. 局限性
方法依赖 FreeSplat 的多视角前馈推断,对视角数量和覆盖范围有一定要求,单视图场景不适用。计数类任务(Counting)仍是短板,可能受限于 Gaussian 表示的物体粒度与 LLM 计数能力。
6.4 LangSplatV2 (2025)
——— 彻底告别解码器:基于稀疏系数场的超高速 3D 语言场
📄 Paper: arXiv:2507.07136
精华
LangSplatV2 解决了 3D 语言场在高分辨率下推理慢的核心痛点。其关键突破在于将 3D 高斯点表示为“全局码本”的“稀疏系数组合”,从而完全去除了沉重的 MLP 解码器。配合 CUDA 优化的稀疏 Splatting 技术,该方法在 A100 上实现了惊人的 450+ FPS 渲染速度(比 LangSplat 快约 42 倍),且在 3D 定位和语义分割精度上均有提升,真正实现了超高分辨率下的实时开放词汇查询。
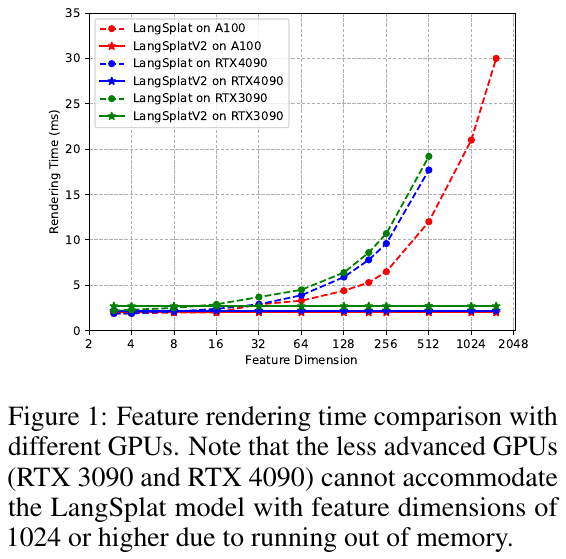
1. 研究背景/问题
尽管 LangSplat 相比之前的 NeRF 方法大幅提升了速度,但在处理高分辨率图像时,其推理速度仅为 8.2 FPS(A100),远未达到实时性要求。分析发现,其瓶颈在于必须使用一个重量级的 MLP 解码器,将渲染出的低维潜变量还原为高维 CLIP 特征。直接渲染高维特征又会导致内存崩溃和渲染效率直线下降,这种“精度与速度”的矛盾限制了 3D 语言场在实时机器人交互中的应用。
2. 主要方法/创新点
LangSplatV2 的核心思想是利用语义分布的稀疏性(一个场景中的唯一语义远少于高斯点数量)。
- 3D 稀疏系数场 (3D Sparse Coefficient Field):不再为每个高斯点学习完整的高维特征,而是学习一个共享的全局码本 (Global Codebook) 和每个点的稀疏系数 (Sparse Coefficients)。每个高斯点仅由码本中 $K$ 个基向量线性组合而成(实验中 $K=4, L=64$),完全绕过了 MLP 解码器。
- 高效稀疏 Splatting (Efficient Sparse Splatting):开发了专门的 CUDA 内核,利用系数的稀疏性,仅对非零通道进行 Alpha-blending。这使得渲染 1536 维特征图的成本等同于渲染极低维特征,极大地降低了计算复杂度。
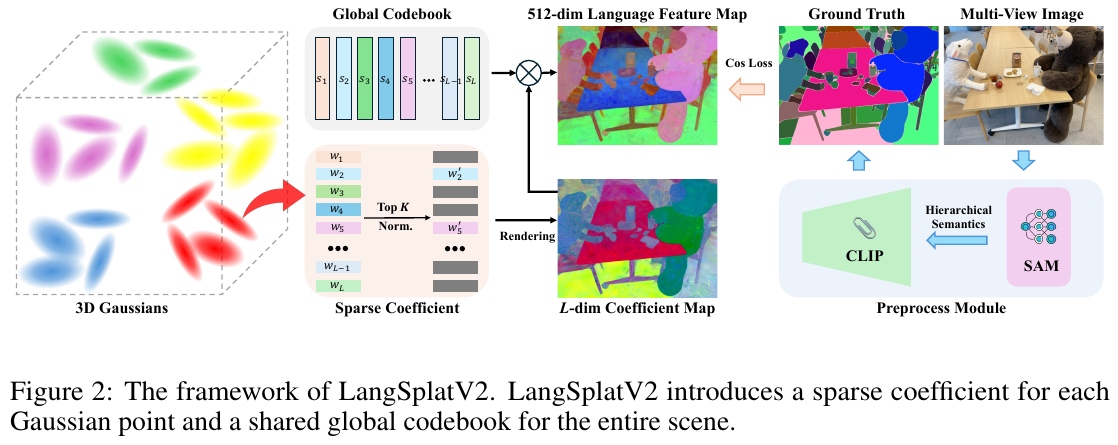
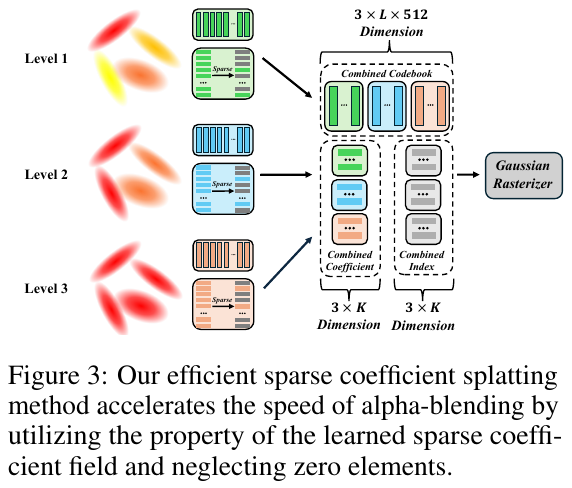
============================== 阶段 1: 离线预处理 (Data Prep) ==============================
[ 输入图像 I ] ----> ( SAM 分割 ) ----> [ 掩码 Masks ]
(H, W, 3) (H, W, 1) x M个物体
|
v
[ 输入图像 I ] ----> ( CLIP 编码 ) ----> [ 语义特征 F_gt ]
(H, W, D) <-- D=512 (真值“靶子”)
============================== 阶段 2: 3D 空间建模 (Modeling) ==============================
1. 全局资源 (Global):
[ Codebook B ] 维度: (L, D) <-- 场景共享的“语义字典”,L=512, D=512
2. 每个 3D 高斯点 i 存储的参数 (Point-wise):
[ 查询向量 q_i ] 维度: (1, d) <-- 用于寻找索引,d 通常较小 (如 32)
[ 其它参数 ] 维度: (1, 11) <-- 位置、旋转、缩放、不透明度
============================== 阶段 3: 训练迭代 (Training Loop) ==============================
步骤 A: 索引与权重生成 (Sparse Coding)
--------------------------------------
[ q_i (1,d) ] x [ B (d,L) ] --> [ 得分 S (1,L) ] (计算该点与字典各基准的相关性)
|
v (取 Top-K, 常用 K=3)
[ 索引 Idx (1,K) ] <----------- [ Top-K 操作 ] -----------> [ 原始权重 W (1,K) ]
(选出的 K 个基向量编号) | (Softmax 归一化)
v
[ 概率 P (1,K) ] (和为 1)
步骤 B: 特征合成 (Feature Composition)
--------------------------------------
[ P_i (1,K) ] ⊙ [ B[Idx_i] (K,D) ] --> [ 合成特征 F_i (1,D) ]
(概率点乘对应的基向量) (该 3D 高斯点的最终语义特征)
步骤 C: 微分渲染 (Differentiable Rendering)
------------------------------------------
[ 所有 F_i (N,D) ] + [ 几何参数 ] --(3DGS 渲染器)--> [ 渲染语义图 S_render (H,W,D) ]
步骤 D: 损失计算与回传 (Loss & Backprop)
---------------------------------------
计算误差: Loss = || S_render - S_gt ||
|
v (梯度反向传播)
1. 更新 Codebook B ------> 优化字典里的“词汇”
2. 更新查询向量 q_i ------> 改变该点“倾向于”选哪几个基向量 (即更新索引)
3. 更新其它几何参数 ------> 优化物体的形状和位置
============================== 阶段 4: 推理查询 (Inference) ==============================
用户输入: "红色椅子" --> CLIP 编码 --> [ 文本特征 T (1,D) ]
|
[ S_render (H,W,D) ] <---(相似度计算)--- [ T (1,D) ]
|
v
[ 语义热力图 (H,W,1) ] --> 瞬间定位目标物体!
3. 核心结果/发现
- 速度突破:在 LERF 数据集上,特征渲染达到 476.2 FPS,开放词汇文本查询达到 384.6 FPS,分别比 LangSplat 提升了 42 倍和 47 倍。
- 精度提升:由于直接在 CLIP 空间建模而无编解码损失,在 LERF 上的 3D 物体定位精度提升至 84.1%,语义分割 IoU 提升至 59.9%,显著优于 LangSplat 和 LEGaussian 等 baseline。
- 显存友好:成功在 RTX 3090/4090 等消费级显卡上运行高维 3D 语言场建模。

4. 局限性
- 训练成本:虽然推理极快,但由于需要构建和优化稀疏语义场,训练时间(约 3 小时)和训练显存(约 21.2 GB)略高于原始 LangSplat。
- 语义源限制:其性能上限仍受限于预训练 CLIP 模型的表示能力及其内在偏见。
6.5 4D LangSplat (2025)
———4D Language Gaussian Splatting via Multimodal Large Language Models
📄 Paper: https://arxiv.org/abs/2503.10437
精华
- 用 MLLM(Qwen2-VL)生成逐帧、逐对象的文本描述,绕过 CLIP 对动态语义理解的限制——”用语言描述视觉变化”比”用视觉模型建模变化”更鲁棒,是处理时序语义的关键思路转换。
- Status Deformable Network 将语义特征约束为 $K$ 个状态原型的线性组合,强制语义在有限状态间平滑过渡,避免了无约束形变场的时序不一致问题——用”状态空间投影”替代”任意形变”是设计上的核心 insight。
- 同时维护 time-agnostic(时不变)和 time-varying(时变)两个语义场,将”这是什么”与”现在处于什么状态”解耦,分别服务不同类型的 open-vocabulary 查询。
- 视觉 prompt 三件套(轮廓高亮 + 背景灰化 + 模糊)有效引导 MLLM 聚焦目标对象;全局运动描述 $\mathcal D_i$ 作为时序 context 可提升逐帧 caption 的一致性——这套 prompt 工程设计对其他多模态视频理解任务同样可迁移。
- 先用时不变场确定空间位置(”哪个对象”),再用时变场确定时间位置(”哪些帧”),两场解耦的查询策略使 time-sensitive 查询精度大幅超越纯 CLIP 方法。
1. 研究背景/问题
LangSplat 通过将 CLIP 特征 splatting 到 3D Gaussian 上实现了精确的静态场景 open-vocabulary 查询,但无法处理动态场景中物体状态随时间变化的情形(如”正在奔跑的狗”vs”静止的狗”)。CLIP 设计用于静态图文匹配,难以捕捉视频中的时序语义变化;直接将 4D-GS 扩展为语义场又面临”如何获得像素对齐的 object-level 时序特征”的困难——现有视觉模型主要提取 global video-level 特征,裁剪后带背景噪声,不足以支持精确的时空查询。
2. 主要方法/创新点

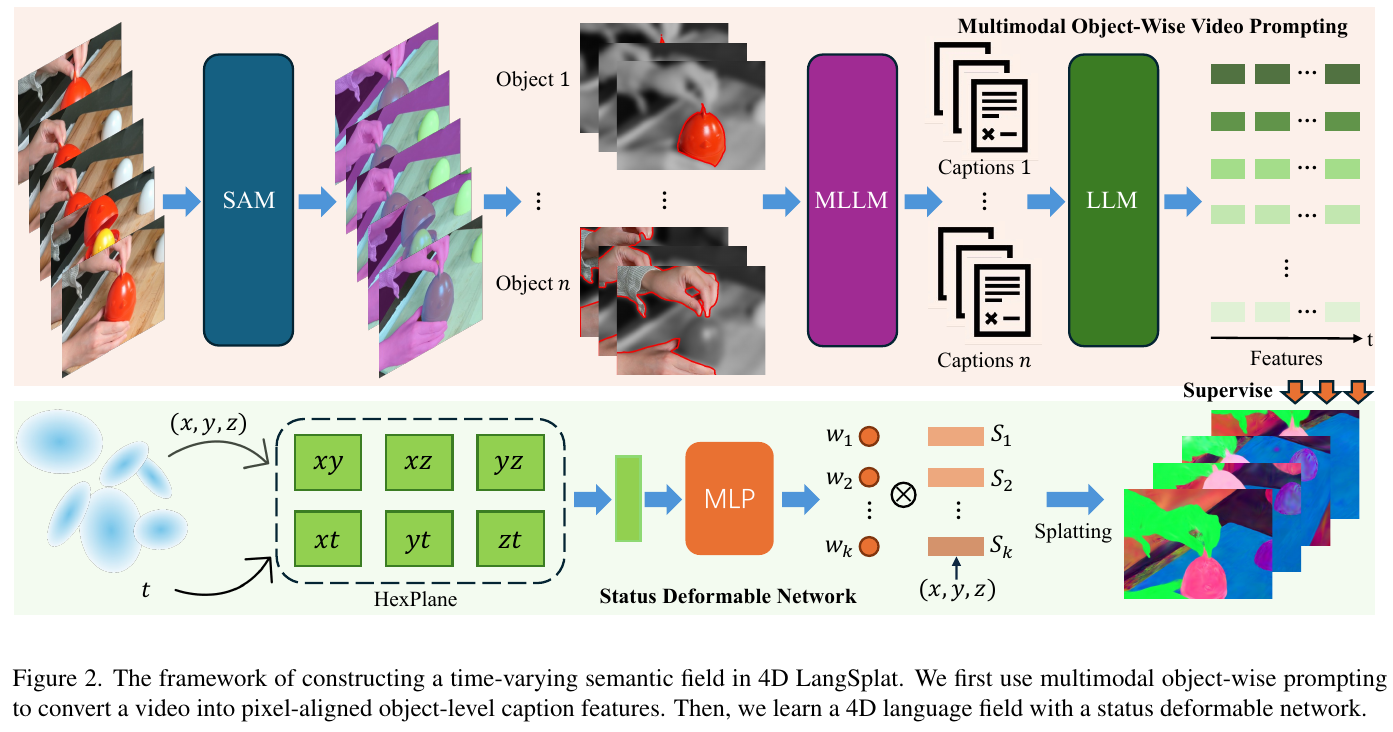
① 整体框架概述
4D LangSplat 由三个核心模块构成:Multimodal Object-Wise Video Prompting 模块从视频中提取像素对齐的逐对象语言特征;时不变语义场(继承 LangSplat 的 CLIP 三级语义)捕获不随时间变化的语义;Status Deformable Network 建模时变语义场,三者共同支持 time-agnostic 和 time-sensitive 两类 open-vocabulary 查询。
② 逐模块讲解
Multimodal Object-Wise Video Prompting
- 输入:视频帧序列 $V = {I_1, \ldots, I_T}$
- 处理:① 用 SAM + DEVA 追踪获得各帧中 $n$ 个对象的一致分割掩码 ${M_1, \ldots, M_n}$;② 构建视觉 prompt
用红色轮廓高亮目标、灰化非目标区域、模糊背景像素,保留背景参考同时聚焦目标;③ 先提示 MLLM 生成对象 $i$ 的全局运动描述 $\mathcal D_i$,再以此为时序 context 逐帧生成 caption
\[C_{i,t} = \text{MLLM}(\mathcal D_i, \mathcal P_{i,t}, \mathcal T_{frame}, V_t)\]④ 用微调后的 e5-mistral-7b 提取句子嵌入,作为每像素的 2D 监督信号 $\mathbf F_{x,y,t} = \mathbf e_{i,t}$
- 输出:像素对齐的、时序一致的 object-level 语言嵌入,作为时变语义场的训练标签
- 设计动机:CLIP 无法区分动态语义状态,而 MLLM 天然理解 action、物体条件与时序变化;text 特征比 vision 特征更善于捕捉”液体变暗”、”容器开/关”等动态语义
Status Deformable Network
- 输入:HexPlane 编码的时空特征(来自 $(x, y, z, t)$),以及 $K$ 个可学习的状态原型 ${\mathbf S_{i,1}, \ldots, \mathbf S_{i,K}}$
- 处理:MLP 解码器 $\phi$ 预测每个 Gaussian 点 $i$ 在时刻 $t$ 的权重系数 $w_{i,t,k}$(满足 $\sum_{k=1}^K w_{i,t,k} = 1$),语义特征为
MLP 与状态原型联合训练,同时利用 HexPlane 的空间和时间维度,确保权重随时空上下文自适应调整。
- 输出:在有限状态空间内平滑过渡的时变语义特征,用于语义场的 Splatting 渲染
- 设计动机:直接学习无约束的语义形变场 $\Delta \mathbf f$ 会导致复杂度爆炸且时序不一致;将语义约束在 $K$ 个原型之间,建模”状态机式”的平滑过渡,既降低学习难度又提升时序一致性
③ 端到端数据流
视频输入 → SAM+DEVA 分割追踪 → 视觉 prompt 构建 → Qwen2-VL-7B 生成逐帧逐对象 caption → e5-mistral-7b 提取嵌入作为 2D 监督 → 4D-GS 预训练 RGB 重建(固定) → 在 Deformable Gaussian 上联合训练时不变场(CLIP 三级语义)与 Status Deformable Network(时变语义场)。
④ 训练目标
- 时不变语义场:渲染特征与 CLIP 特征的 L2 损失(三个语义粒度各自独立)
- 时变语义场:渲染特征与 e5-mistral-7b caption 嵌入的 L2 损失
- CLIP 特征和 text 特征分别通过 autoencoder 压缩至 3 维和 6 维以降低显存开销
⑤ 推理 / 查询
- time-agnostic 查询:仅使用时不变语义场,渲染特征图后计算与文字 query 的 relevance score,按 LangSplat 后处理策略得到各帧分割掩码
- time-sensitive 查询:① 先用时不变场对全帧生成候选空间掩码(确定”哪个对象”);② 在掩码区域内逐帧计算时变特征与 query 的余弦相似度;③ 取均值相似度超过全视频均值阈值的帧段作为相关时间区间,并以时不变掩码作为最终空间分割结果
3. 核心结果/发现
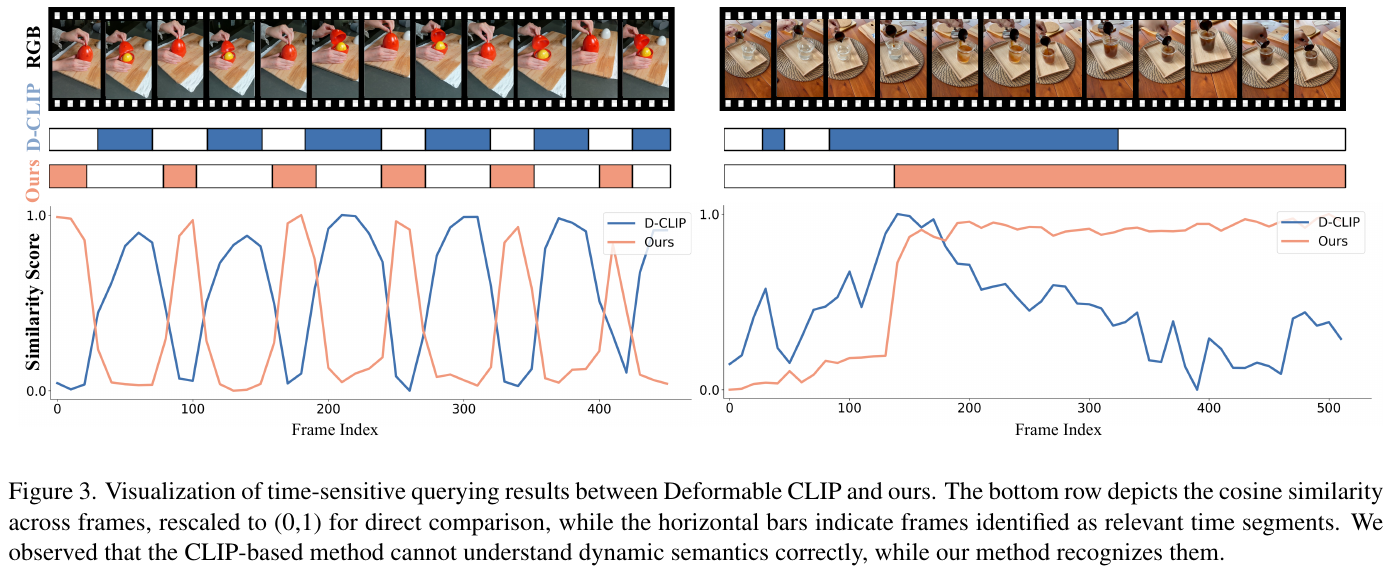

time-sensitive querying(HyperNeRF 数据集):
| 方法 | Acc (%) | vIoU (%) |
|---|---|---|
| LangSplat | 54.01 | 22.65 |
| Deformable CLIP | 61.80 | 44.72 |
| Non-Status Field | 87.58 | 68.57 |
| 4D LangSplat (Ours) | 90.83 | 72.26 |
time-agnostic querying(HyperNeRF / Neu3D):
| 方法 | HyperNeRF mIoU | HyperNeRF mAcc | Neu3D mIoU | Neu3D mAcc |
|---|---|---|---|---|
| Feature-3DGS | 36.63 | 74.02 | 34.96 | 87.12 |
| Gaussian Grouping | 50.49 | 80.92 | 49.93 | 95.05 |
| LangSplat | 74.92 | 97.72 | 61.49 | 91.89 |
| 4D LangSplat (Ours) | 82.48 | 98.01 | 85.11 | 98.32 |
消融关键发现:三种视觉 prompt 全部使用时 $\Delta_{sim}=3.32$ 最高;加入视频级运动描述 $\mathcal D_i$ 相比纯 image prompt 提升 +0.87 $\Delta_{sim}$;状态数 $K=3$ 达最优,过大或过小均导致性能下降。
4. 局限性
方法依赖 SAM+DEVA 的对象追踪质量,追踪失败时 caption 特征会出现时序错位,影响时变语义场的精度。Qwen2-VL-7B 的视频推理和 e5-mistral-7b 的嵌入提取引入显著的训练前预处理开销,整体计算成本高于纯视觉特征方法。
6.6 GaussianVLM (2025)
———Scene-centric 3D VLM using Language-aligned Gaussian Splats for Embodied Reasoning
📄 Paper: https://arxiv.org/abs/2507.00886
精华
- 将语言特征直接嵌入每个 3D Gaussian 基元(而非先检测物体再编码),实现 early modality alignment,彻底摆脱物体检测器依赖。
- 双稀疏化器将 40k 密集 token 压缩为 128 个任务感知 scene token + 4 个 ROI token,使冻结的 LLM 可以高效处理密集 3D 表示。
- Scene-centric 设计的核心价值:保留全局空间上下文,使模型在需要多物体推理的 embodied 任务(对话、规划)中大幅超越 object-centric 方法。
- Gaussian Splat 天然融合几何与外观(颜色、纹理),赋予模型识别细粒度视觉属性的能力,点云表示缺乏这类信息。
- 使用 RGB 图像驱动的 3DGS pipeline 打通了易获取数据→3D VLM 的路径,在 out-of-domain ScanNet++ 场景中相较点云方法 LL3DA 精度提升 474%。
1. 研究背景/问题
当前 3D VLM 主流方法依赖物体检测器提取 object-centric tokens,这引入了检测瓶颈、限制了开放词汇泛化,并忽略了全局空间上下文与多物体关系——而这恰恰是 embodied reasoning(situated QA、规划、多轮对话)的核心需求。此外,每个场景的 Gaussian Splat 包含数万个基元,将全部密集语言特征送入 LLM 面临巨大计算压力,需要高效的任务感知压缩机制。
2. 主要方法/创新点
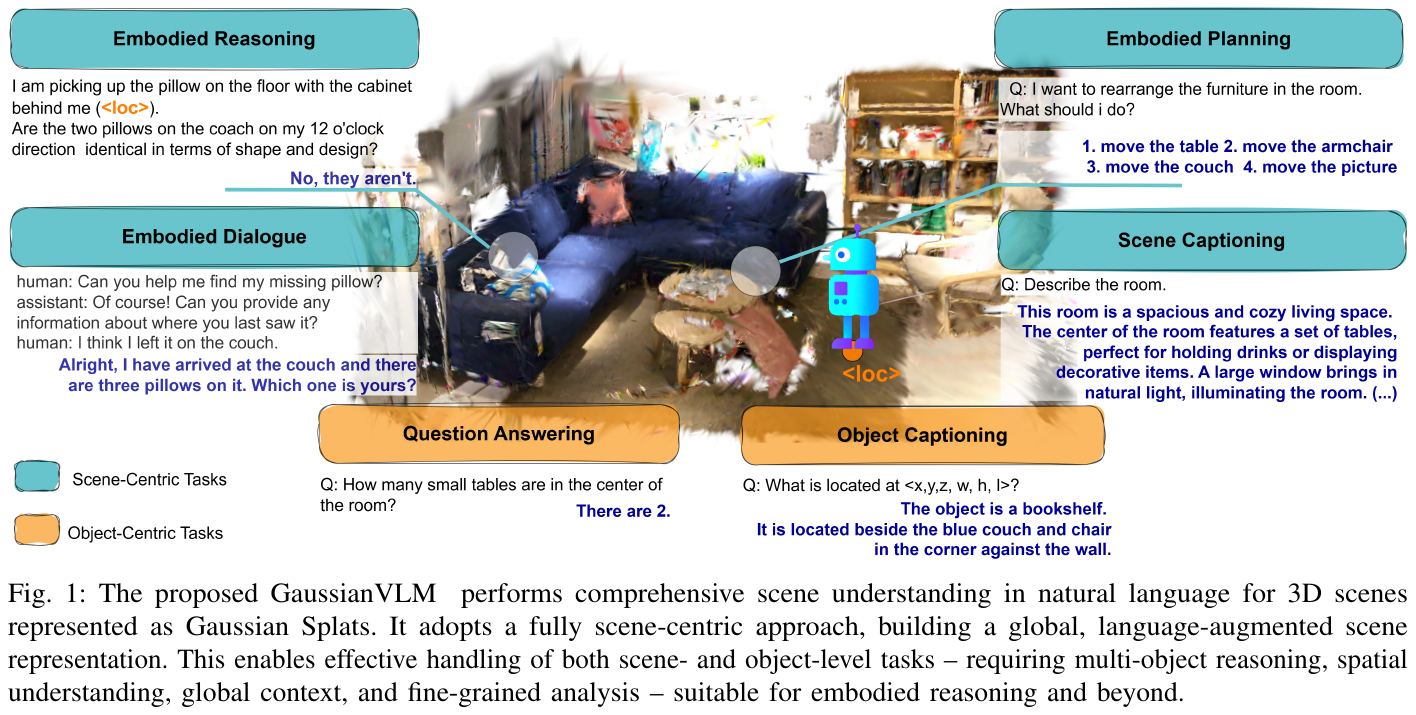
① 整体框架概述
GaussianVLM 由三个核心模块构成:(A) Language-aligned Gaussian Backbone(SceneSplat)将 3D 场景编码为 40k 密集语言特征;(B) Dual Sparsifier(位置引导 + 任务引导)将密集表示压缩为稀疏 token;(C) LLM(OPT-1.3B + LoRA)接收稀疏 token 与任务文本并生成回复。
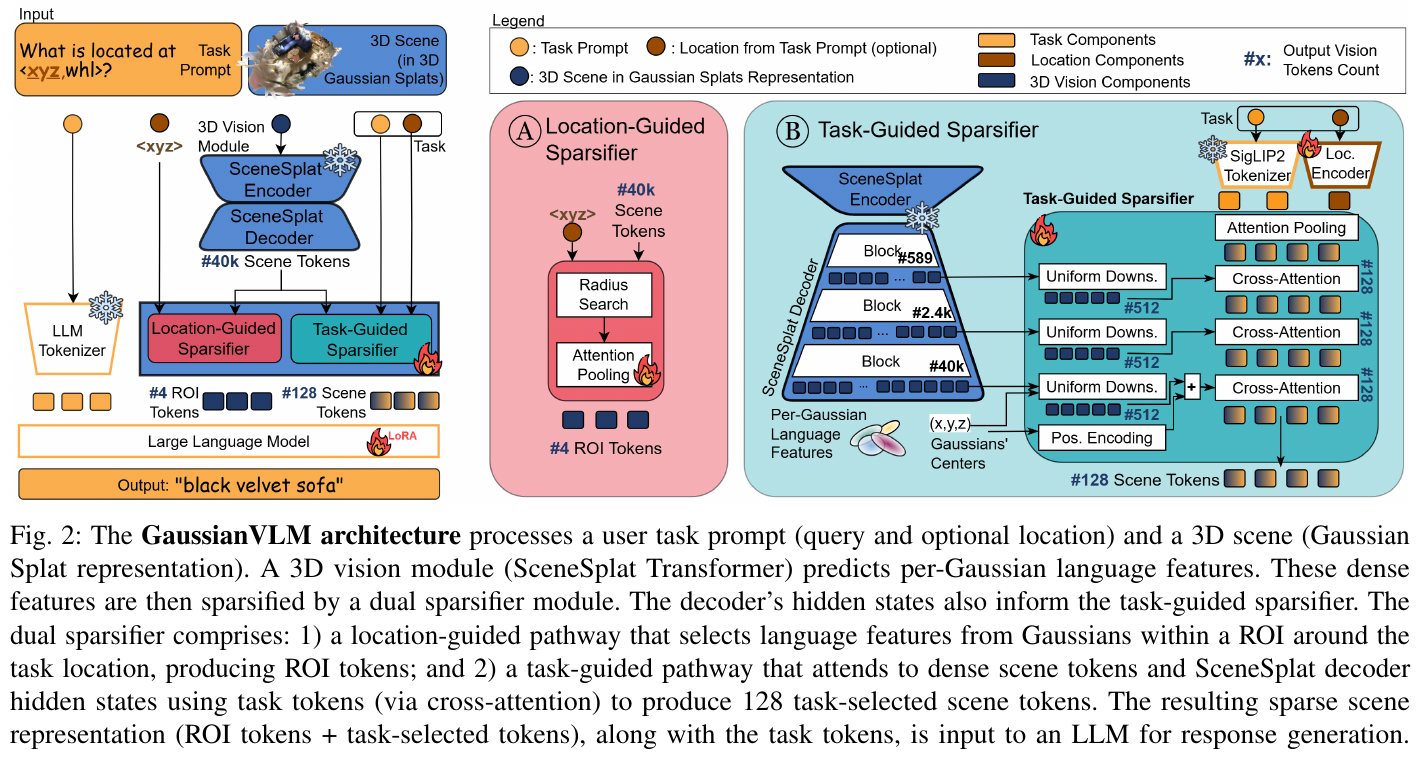
② 逐模块讲解
SceneSplat Backbone(3D Vision Module)
- 输入:从场景中随机采样的 40k 个 Gaussian Splat(含位置、颜色、不透明度、协方差等属性)
- 处理:Transformer 编码器 + 解码器;不同解码器 block 的隐状态分别携带粗粒度(block 589)到细粒度(block 40k)的特征
- 输出:每个 Gaussian 对应一个 SigLIP2 空间的语言特征向量,密集特征序列长度为 40k
- 动机:直接在几何-外观联合表示上预测语言特征,实现语言与 3D 结构的 early alignment,无需检测器中介
Location-Guided Sparsifier(位置引导稀疏化,图A)
- 输入:40k 密集语言特征 + 任务 prompt 中提取的位置坐标
<xyz> - 处理:以
<xyz>为中心做半径搜索(初始 15cm,若为空则递增 15cm 直至非空),对选中 Gaussian 的语言特征做 Attention Pooling - 输出:4 个 ROI token,聚合局部区域信息
- 动机:为物体级任务(captioning、grounding)提供局部细粒度信息,补充全局 scene token 的不足;无需显式检测器即可实现位置敏感的特征提取
Task-Guided Sparsifier(任务引导稀疏化,图B)
- 输入:每个 SceneSplat decoder 层输出 of per-Gaussian 特征(589 / 2.4k / 40k token)+ 任务 token(由用户 prompt 经 SigLIP2 tokenizer 编码并 Attention Pooling 得到)
- 处理:
- Uniform Downsampling:将每层特征均匀下采样至 512 token
- Depth-wise Cross-Attention:对每个下采样后的 decoder 层,以任务 token 为 query 对视觉 token 做 cross-attention,依次聚焦任务相关区域
- 位置编码注入:在最终层将 512 个 Gaussian 的中心坐标用可学习 Fourier 嵌入编码后加入,赋予 token 位置感知能力
- 输出:128 个任务感知 scene token(从三层 decoder 特征动态蒸馏而来)
- 动机:固定粒度的 region-based tokenization 无法动态聚焦任务相关区域;depth-wise CA 使不同层级的语义(全局布局 vs 实例细节)均能参与稀疏化
LLM(OPT-1.3B + LoRA)
- 输入:4 ROI token + 128 scene token(经线性投影到 LLM 空间)+ 任务文本 token
- 处理:自回归生成,LoRA 微调,其余参数冻结
- 输出:自然语言回复(caption、answer、plan 等)
③ 端到端数据流
给定任务 prompt(如”What is at <x,y,z>?”) and 40k Gaussian 场景:SceneSplat 编码器提取 per-Gaussian 语言特征 → 解码器逐层精化(589→2.4k→40k token)→ 位置引导稀疏化在 <xyz> 周围提取 4 个 ROI token → 任务引导稀疏化对三层 decoder 输出逐层 cross-attend 压缩至 128 scene token → 两路 token 与任务 token 拼接送入 LLM → LLM 自回归生成回复。
④ 训练目标 / 损失函数
主要训练目标为 prefix language modeling(以任务 prompt 与视觉 token 为前缀,自回归预测回复序列):
\[\mathcal{L}(\theta, \mathcal{B}) = -\sum_{\{s_\text{prefix},\, s_p\} \in B} \sum_{t=1}^{|s_\mu|} \log p_\theta\!\left(s_\text{gt}^{(t)} \mid s_\text{gt}^{(<t)},\, s_\text{prefix}\right)\]两阶段训练:Alignment 阶段冻结 3D backbone 和 LLM tokenizer,训练 sparsifier 与 transformer 实现跨模态对齐;Fine-tuning 阶段用 LoRA 适配 LLM 并在多任务数据上联合训练。
任务引导稀疏化器预训练使用对比损失,鼓励 sparsifier 输出 $s_i$ 匹配对应标签的 SigLIP2 嵌入 $l_i$:
\[\mathcal{L}_\text{contrast} = -\log \frac{\exp(s_i^\top l_i / \tau)}{\sum_{j=1}^{N} \exp(s_i^\top l_j / \tau)}\]其中温度超参数 $\tau = 0.07$。
3. 核心结果/发现
场景级任务(LL3DA 协议,ScanNet)
| 任务 | GaussianVLM | LL3DA | 提升 |
|---|---|---|---|
| Embodied Dialogue CIDEr | 270.1 | 145.9 | +124.2 |
| Embodied Planning CIDEr | 220.4 | 65.1 | +155.3 |
| Scene Captioning CIDEr | 65.8 | 66.4 | 相当 |
场景级任务(LEO 协议,SQA3D)
| 方法 | EM1 | CIDEr |
|---|---|---|
| LEO | 47.0 | 124.7 |
| GaussianVLM | 49.4 | 129.6 |
物体级任务(LL3DA 协议):ScanRefer Sim 59.1(LL3DA: 55.9),Nr3D METEOR 20.8(LL3DA: 5.8)。无检测器的 GaussianVLM 在物体级任务上同样有竞争力。
Out-of-domain 泛化(ScanNet++,RGB 图像生成 3DGS):GaussianVLM 准确率 24.1% vs LL3DA 4.2%,提升 474%,验证了 Gaussian Splat 表示相较点云在真实世界场景中的泛化优势。
消融研究表明:去除任务引导 sparsifier(改用无文本指导的可学习 query)或去除 depth-wise cross-attention(仅用最终解码器输出)均导致性能大幅下降,证明这两个设计是性能增益的主要来源。

4. 局限性
GaussianVLM 依赖 3DGS pipeline 重建场景,在光照不均或反射材质场景中 Gaussian 质量可能下降,影响语言特征的准确性。此外,对于需要精确位置查询的任务(SQA3D “Where” 类),仍弱于内置物体检测器的 LL3DA,这是位置引导稀疏化半径搜索的局限。
四项工作演进脉络:
| 论文 | 核心任务 | 关键创新 | 密集-稀疏问题解法 |
|---|---|---|---|
| SplatTalk | 3D VQA(静态) | 2D VLM 特征提升至 3DGS | 特征自动编码器 |
| LangSplatV2 | 实时语言查询(静态) | 解决推理速度瓶颈 | 稀疏编码 + 全局字典 |
| 4D LangSplat | 动态场景查询(4D) | MLLM 生成时序文本监督 | 双语言场 + 状态可变形网络 |
| GaussianVLM | 场景中心 VQA(静态) | 避免检测器依赖 | 双路径稀疏化器(任务/位置引导) |
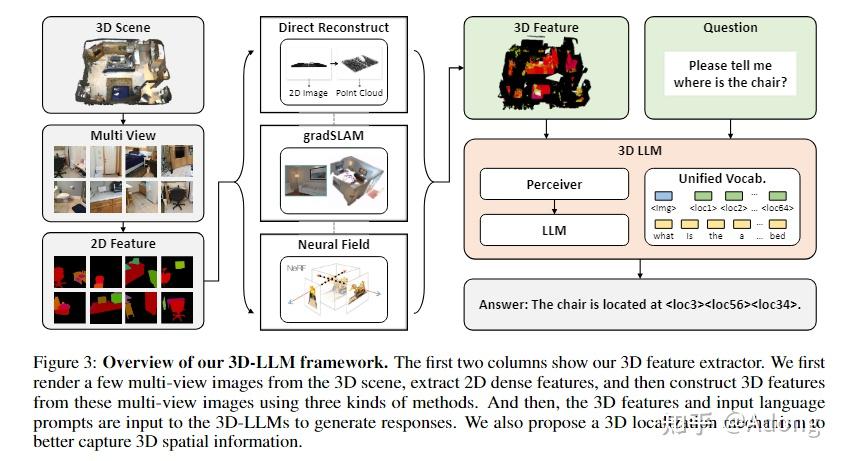
6.7 3D-LLM: Injecting the 3D World into Large Language Models (2023)
——— 将 3D 物理世界注入大语言模型
📄 Paper: https://vis-www.cs.umass.edu/3dllm/
精华
3D-LLM 提出了一套将 3D 世界注入大语言模型(LLMs)的完整范式。其核心在于利用 2D 预训练 VLMs 的强大理解能力,通过 2D-3D 特征对齐和位置编码实现 3D 空间感知。通过设计三套自动数据生成管线,构建了包含 300k+ 样本的 3D-语言数据集,使模型能够处理从 3D 描述到具身导航的多样化任务。
1. 研究背景/问题
现有的 LLMs 和 2D VLMs 虽然具备强大的常识推理能力,但由于缺乏对 3D 物理世界的直接建模,难以理解复杂的 3D 空间关系(如方位、距离)、物体物理属性和环境布局。这限制了它们在机器人具身智能和真实感 3D 交互中的应用。
2. 主要方法/创新点
3D-LLM 的核心思想是:不从头训练 3D 模型,而是将 3D 特征映射到 2D 预训练 VLMs 的对齐特征空间中,并引入 3D 定位机制。
① 3D-语言数据生成管线
为了解决 3D-语言数据稀缺的问题,作者设计了三种基于 GPT 的数据生成方式:
- Box-Demonstration-Instruction based Prompting: 输入房间内物体的 AABB 框及其语义信息,让 GPT 生成任务分解和对话。
- ChatCaptioner based Prompting: 利用多视图 BLIP-2 对 3D 场景进行问答,汇总信息后由 GPT 生成详细描述。
- Revision based Prompting: 将已有的粗略 3D 描述进行重写和优化,提升语义丰富度。

② 3D 特征提取与对齐
系统首先从 3D 场景渲染多视图图像,利用预训练 2D 编码器(如 CLIP)提取特征。随后通过三种方式将 2D 特征映射回 3D 空间:
- Direct Reconstruction: 基于相机参数直接映射到点云。
- Feature Fusion: 使用 gradSLAM 等工具将特征融合到 3D 映射中。
- Neural Field: 利用类似 Neural Voxel Field 的方法构建紧凑的 3D 表示。
③ 3D-LLM 架构设计
- 底座模型: 采用 Flamingo 或 BLIP-2 等成熟的 2D VLM,冻结其视觉编码器和 LLM 部分。
- 特征聚合: 引入 Perceiver Resampler,将变长的 3D 特征映射为固定数量的 visual tokens。
- 3D 定位机制 (3D Localization):
- 位置编码: 为 3D 特征点添加 sin/cos 位置编码。
- 位置 Token: 在词表中增加数个离散的位置 token(如
<loc123>),表示 AABB 框的坐标。LLM 通过输出这些 token 实现物体的定位(Grounding)。
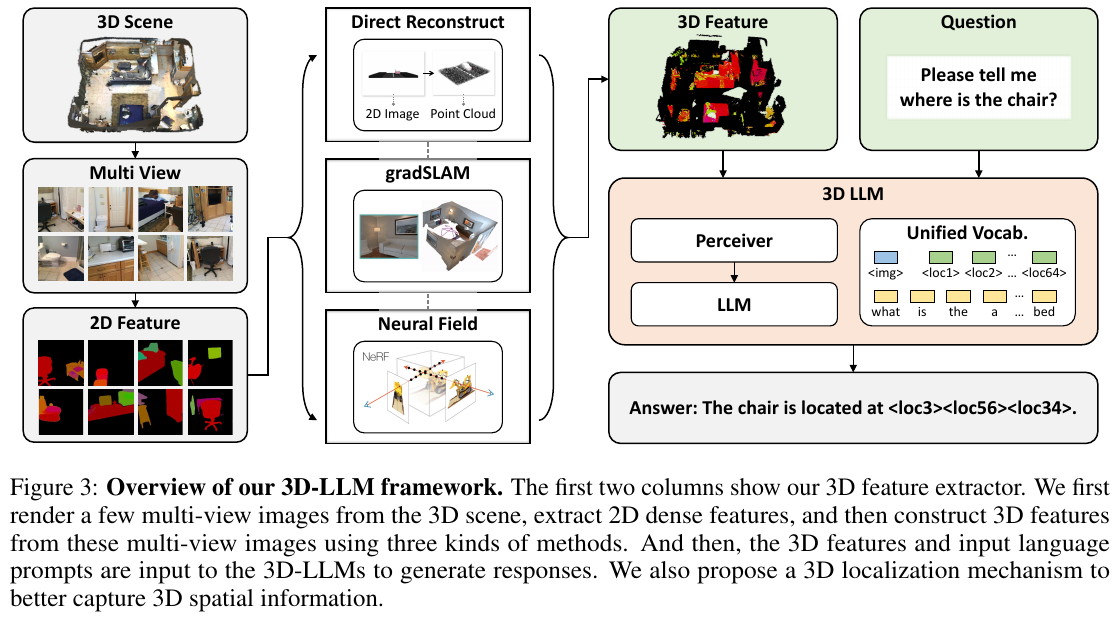
④ 多任务能力展示
生成的 300k+ 数据涵盖了 3D Captioning, Grounding, QA, Task Decomposition, 3D-Assisted Dialog 以及导航等。

3. 核心结果/发现
- ScanQA 性能: 在 ScanQA 基线测试中,3D-LLM 显著优于仅使用 2D 视图或显式物体表示的方法(BLEU-1 在验证集上提升了约 9%)。
- 多任务泛化: 模型在未见过的 3D Captioning 和 任务分解任务上表现出色,证明了 3D 特征对齐的有效性。
- 定性分析: 模型能够根据 3D 场景提供合理的导航路径建议 和 任务执行步骤,展现出初步的具身智能潜力。

4. 局限性
- 计算开销: 3D 特征提取器依赖于多视图渲染,这在训练阶段会产生较大的计算负担。
- 特征融合瓶颈: 现有的特征映射方法在处理极大规模或极细碎的 3D 场景时,特征的紧凑性和完整性仍有待优化。
6.8 PointLLM-V2 (2025)
———赋能大语言模型更好地理解点云
📄 Paper: https://github.com/OpenRobotLab/PointLLM (TPAMI 2025)
精华
PointLLM-V2 通过引入首个自动化的点云指令微调数据生成流水线,解决了 3D 领域指令数据匮乏的问题。它利用多视图投影和 GPT-4o 的强大视觉能力,生成了约 1.8M 条高质量的点云-文本对,涵盖了物体属性、几何特征及精细的局部坐标感知。模型架构上采用简洁的 Tokenizer-Projector-LLM 范式,在物体分类和描述任务上显著超越了现有 2D 和 3D 基线,甚至在描述任务中超过了人类标注员的表现。
1. 研究背景/问题
尽管大语言模型(LLM)在文本和图像领域取得了巨大成功,但在 3D 点云理解方面仍处于起步阶段。核心瓶颈在于:1)缺乏大规模、高质量的点云-指令对齐数据;2)缺乏能够评估 3D 多模态模型生成能力的基准测试。现有 3D 基础模型多依赖于合成数据的文本描述,难以捕捉点云中丰富的几何和外观细节。
2. 主要方法/创新点
① 整体概览
PointLLM-V2 是一个能够理解彩色点云的多模态大语言模型,具有强大的物体类别、几何形状、外观特征理解能力,并支持精细的局部坐标感知。
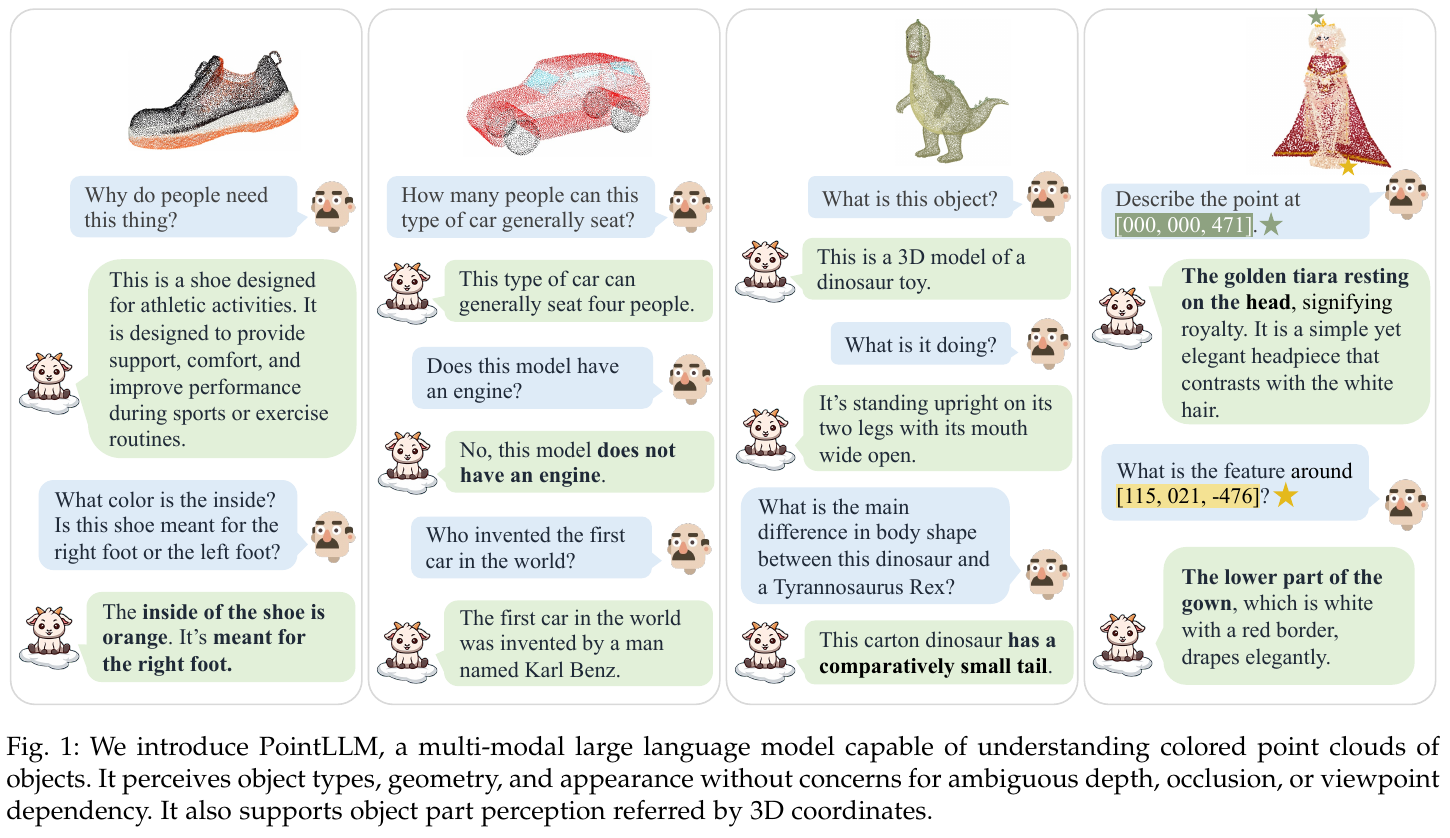
② 自动化数据生成流水线(Data Generation Pipeline)
作者提出了一种创新的数据生成流程,将 3D 点云转化为 LLM 可理解的指令数据。

流程详情:
- 多视图投影:从 20 个不同视角对 3D 物体进行投影,生成渲染图。
- 锚点视图采样与标注:利用 SAM (Segment Anything Model) 生成掩码,并选择具有代表性的点作为锚点。
- 点云传播(Point Propagation):利用相机参数将锚点投影回 3D 空间,并进一步传播到所有 20 个视图中,实现 3D 坐标与多视图像素的精确对应。
- GPT-4o 提问与过滤:将渲染图输入 GPT-4o,结合点云对应的局部描述生成问答对。通过专门的过滤机制剔除幻觉内容,确保数据质量。
② 模型架构(Architecture)
PointLLM-V2 采用了典型的端到端训练架构。
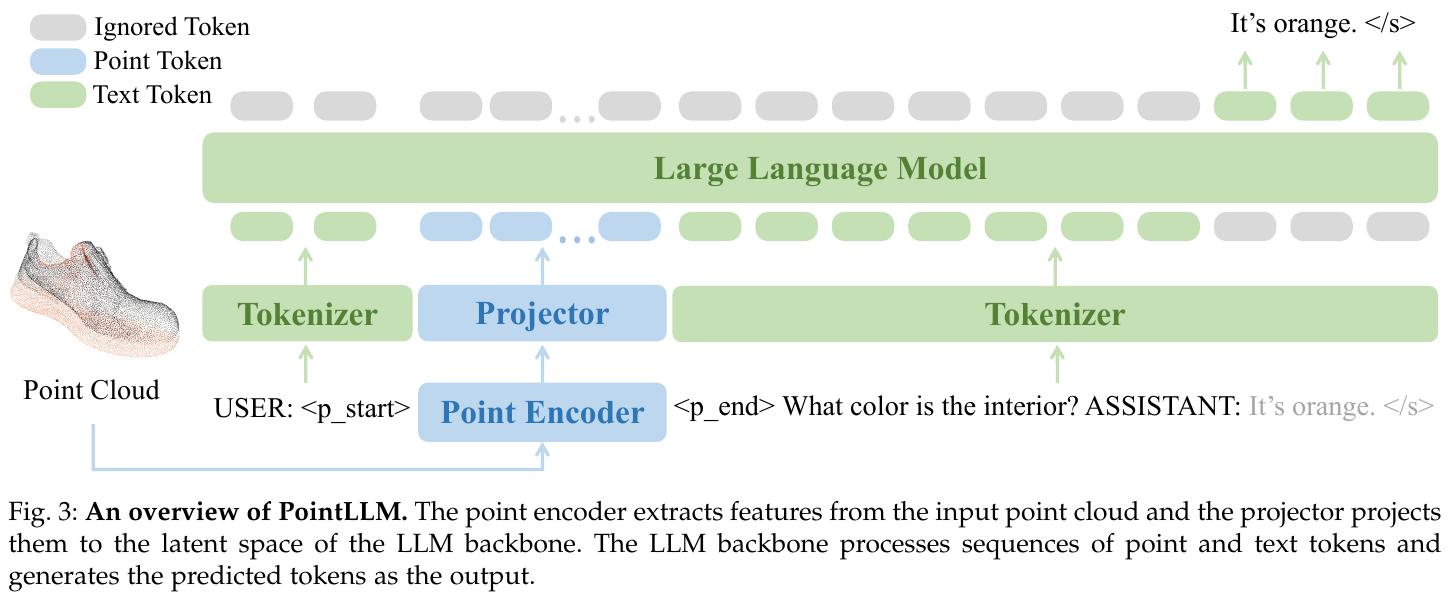
- 输入:包含 $N$ 个点的彩色点云 $P \in \mathbb{R}^{N \times 6}$。
- Point Encoder:采用预训练的点云编码器(如 Point-BERT),将点云转换为特征向量。
- Projector:一个简单的 MLP,将点云特征映射到 LLM 的特征空间。
- LLM Backbone:采用 Llama-3-8B-Instruct 作为核心推理引擎,接收点云 token 和用户指令 token,输出文本响应。
③ 训练策略
采用两阶段训练方案:
- 特征对齐阶段:冻结点云编码器和 LLM,只训练 Projector,使模型学会将点云特征与语言空间对齐。
- 指令微调阶段:联合微调 Projector 和 LLM,使其能够遵循复杂的人类指令进行交互。
3. 核心结果/发现
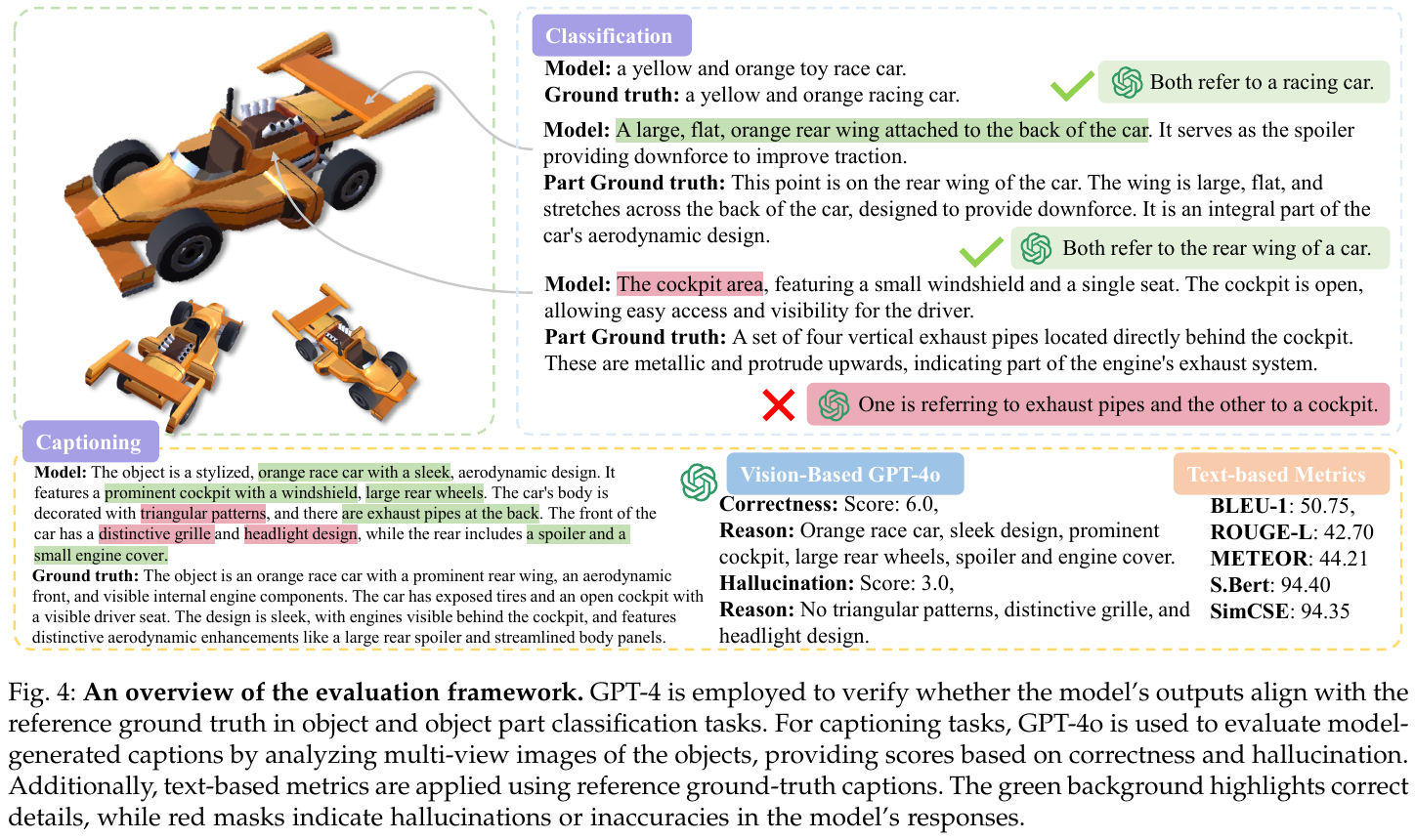
- 性能飞跃:在 Generative 3D Object Classification 和 3D Object Captioning 两个新提出的基准上,PointLLM-V2 均取得了 SOTA 性能。
- 超越人类标注:在物体描述(Captioning)任务中,GPT-4o 评估结果显示 PointLLM-V2 的描述质量在 50% 以上的样本中优于人类标注。
- 幻觉降低:通过高质量的数据对齐 and 过滤,模型在描述中的幻觉显著减少,得分(Hallucination Score)优于 3D-LLM 等竞争对手。
4. 局限性
- 场景理解受限:目前训练数据主要集中在物体级(Object-level)点云,对复杂室内/室外大场景(Scene-level)的理解仍有提升空间。
- 计算效率:随着点云规模增加(如超过 8192 个点),计算开销 and 内存占用会显著增长。
6.9 OpenGaussian (2024)
———迈向点云级 3D Gaussian 开放词汇理解
📄 Paper: arXiv:2406.02058
精华
- 点云级理解:不同于以往将 3D 特征渲染到 2D 像素进行理解的方法,OpenGaussian 实现了真正的 3D 点云级开放词汇理解。
- 3D 一致性特征学习:利用视角无关的 SAM 掩码作为监督,通过内部平滑和间对比损失,训练出具有 3D 空间一致性的实例特征。
- 两级量化码本:引入 coarse-to-fine 的两级码本,coarse 级结合位置信息解决远端物体特征冲突,fine 级精细化特征,显著提升特征判别式。
- 无深度测试的关联:提出一种基于 IoU 和特征相似度的 3D-2D 关联方法,无需深度测试即可将 2D CLIP 特征无损关联至 3D 高斯点。
- 高效且无损:不需要额外的特征降维或蒸馏网络,保留了原始 CLIP 特征的强大泛化能力。
1. 研究背景/问题
现有的基于 3D Gaussian Splatting (3DGS) 的开放词汇方法(如 LangSplat、LEGaussians)主要侧重于 2D 像素级 的解析,即通过渲染特征图并在 2D 空间进行匹配。这种方法在处理 3D 点云级任务(如物体定位、交互)时存在以下局限:
- 特征表现力弱:受限于显存和速度,高维语言特征往往需要降维或量化,导致区分度下降。
- 2D-3D 对应不准确:Alpha-blending 渲染过程累积了多个点的值,无法建立 3D 点与 2D 像素之间的一对一准确映射。
- 无法处理遮挡:仅靠 2D 渲染难以识别被遮挡的物体部分。
2. 主要方法/创新点

① 整体框架概述
OpenGaussian 放弃了直接在 3D 空间训练高维 CLIP 特征的思路。它首先训练低维的、具有 3D 一致性的实例特征,然后通过两级码本对其进行离散化,最后通过一种新颖的关联机制将 2D CLIP 特征映射到 3D 实例上,从而实现点云级的开放词汇查询。
② 3D 一致性实例特征学习 (Sec 3.1)
为了让 3D 点在不同视角下表现出一致的物体属性,作者为每个高斯点增加了低维特征 $f \in \mathbb{R}^6$。
- 输入:RGB 图像和由 SAM 生成的视角无关布尔掩码(Boolean Mask)。
- 处理:将 3D 特征渲染成 2D 特征图 $M$,并利用掩码 $B_i$ 计算:
- Intra-mask smoothing loss ($L_s$):强制同一掩码内的像素特征接近其均值,保证物体内部一致性。
- Inter-mask contrastive loss ($L_c$):增大不同掩码均值特征之间的距离,保证物体间判别性。
- 输出:具有 3D 空间一致性和判别性的连续实例特征。
③ 两级离散化码本 (Sec 3.2)
连续特征在大型场景中容易出现噪声和远端物体特征重合。
- Coarse Level:将特征 $F$ 与 3D 坐标 $X$ 拼接进行聚类。通过引入位置信息,确保空间上相距较远的物体(即使特征相似)也被分到不同簇。
- Fine Level:在每个 coarse 簇内,仅根据特征进一步精细化聚类。
- 效果:确保了同一个实例内的高斯点具有完全相同(而非仅仅相似)的特征,极大地提高了交互式分割和定位的鲁棒性。
④ 实例级 3D-2D 特征关联 (Sec 3.3)
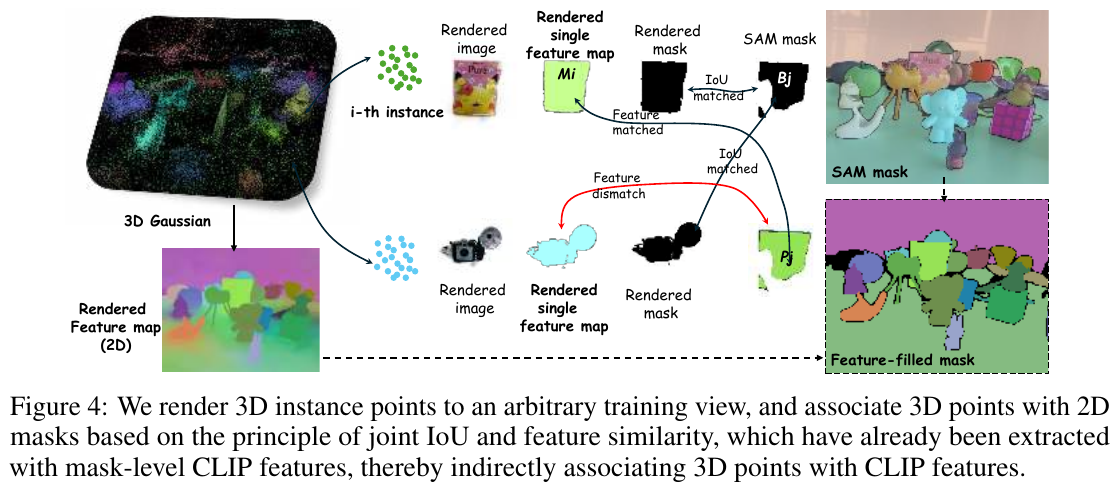
为了将 CLIP 特征赋予 3D 点,作者提出了一种无需深度测试(Depth Test)的关联方法:
- 渲染单实例图:将某个 3D 实例 $i$ 的点单独渲染到当前视角,得到 $M_i$。
- 计算匹配分 $S_{ij}$:结合渲染掩码与原始 SAM 掩码 $B_j$ 的 IoU,以及 3D 特征与预提取的 2D 掩码特征的距离。
- 多视角聚合:将匹配得分最高的 2D CLIP 特征关联至该 3D 实例。这种方法绕过了复杂的遮挡处理,实现了特征的无损传递。
3. 核心结果/发现
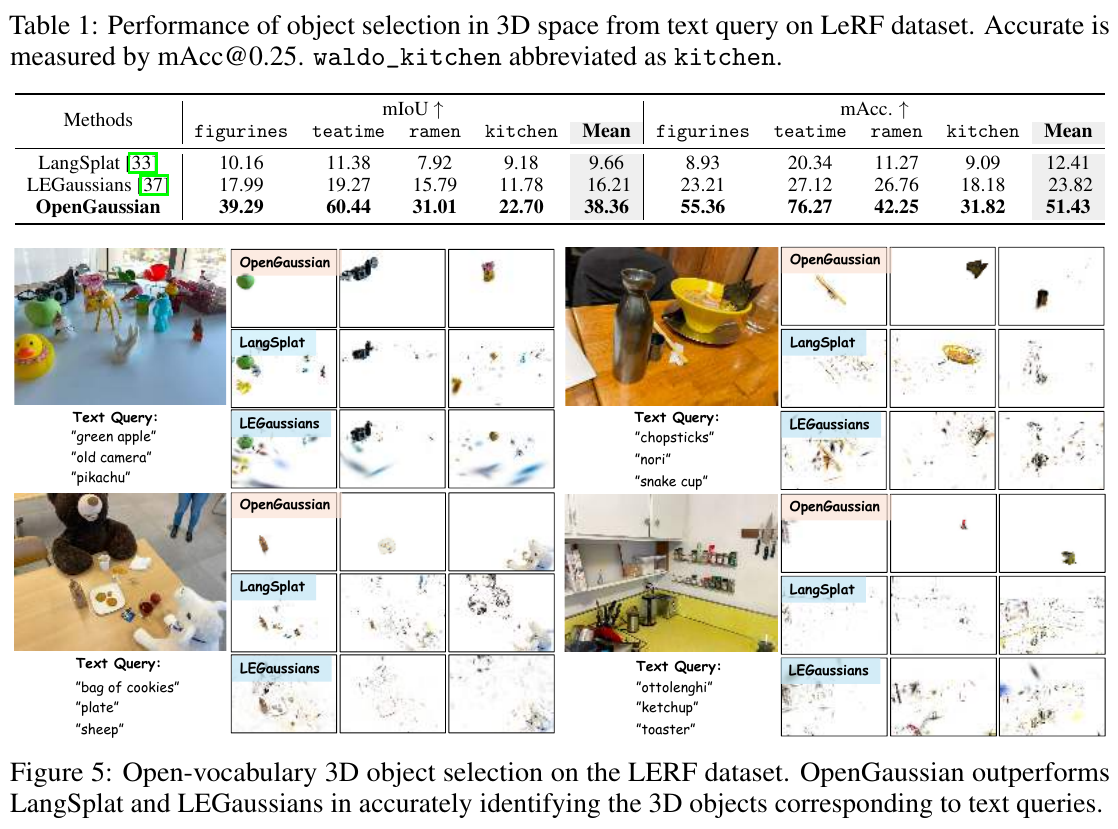
- SOTA 性能:在 LERF 评估中,mIoU 达到 38.36%,准确率 mAcc 达到 51.43%,相比 LangSplat(9.66% / 12.41%)有质的飞跃。
- 特征区分度:通过可视化发现,OpenGaussian 的 3D 特征具有极高的边界清晰度和语义一致性,能够精确区分细小物体。

4. 局限性
- 几何固定:目前特征学习不改变高斯点的几何属性(位置、缩放等),未来可考虑联合优化。
- 码本超参数:簇数量 $k$ 仍需根据经验设定,缺乏自适应性。
- 动态场景:尚未考虑 4D 动态因素,与 4DGS 的结合是未来的方向。
6.10 HiSpatial (2026)
———Taming Hierarchical 3D Spatial Understanding in Vision-Language Models
📄 Paper: arXiv:2603.25411 | Code: github.com/microsoft/HiSpatial(CVPR 2026)
精华
- 把”空间智能”做成可检验的能力分层:将三维空间理解拆解为 Level 0(几何感知)→ Level 1(物体级)→ Level 2(物体间关系)→ Level 3(抽象推理)四级,并用消融实验证明”层级依赖”——去除低层任务会使高层性能下降最多 14.51%。这给”为什么通用 VLM 不会做定量空间推理”一个结构性答案:缺的不是参数,而是底层的几何与度量地基。
- 度量尺度点图作为辅助模态:区别于以往只用相对深度的工作,HiSpatial 把 metric-scale point map(真实尺度 XYZ)注入 VLM,让模型直接拿到”以米为单位”的 3D 信息,而非仅靠 RGB 隐式推断。
- 可规模化的数据飞轮:用一条全自动、无人工标注的流水线,从约 500 万图像 / 4500 万物体生成 20 亿+ 条空间 VQA,并开源 120 万图像子集——把”空间 SFT”从手工标注瓶颈中解放出来。
- 小模型打大模型:仅 3B 参数即在多个空间基准上超越 GPT-5、Gemini-2.5-Pro,印证了空间推理更多是”数据与训练范式”问题,而非”参数规模”问题。
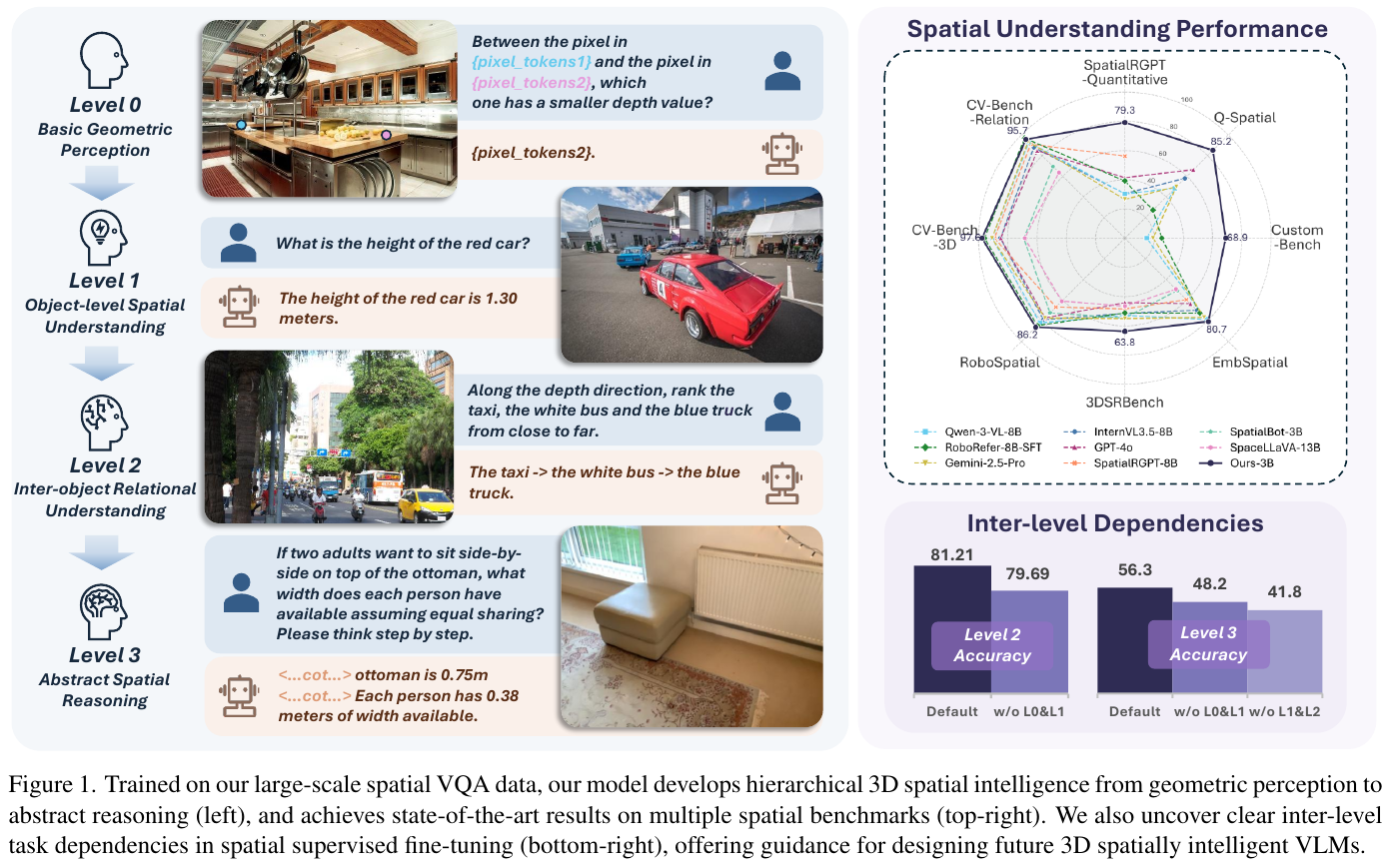
1. 研究背景/问题
通用 VLM(GPT-4V/5、Gemini)在”物体 A 距 B 多远”“从门口看冰箱在左还是右”这类定量 / 自我中心空间推理上系统性偏弱。已有改进(SpatialVLM、SpatialRGPT、RoboRefer)大多沿”自动生成空间 QA → 微调 VLM”思路,但普遍把”判断方位”和”多步空间问题求解”混在同一难度层级直接训练,导致模型在简单感知与复杂推理之间顾此失彼。HiSpatial 的出发点是:空间认知本质上是分层的,应当先打牢几何与度量的地基,再逐级构建关系理解与抽象推理。
2. 主要方法/创新点
(1)四层级能力体系:HiSpatial 将空间理解显式组织为由易到难、层层依赖的四级,每级又细分为若干原子任务:
graph TD
L0["<b>Level 0 · 基础几何感知</b><br/>逐像素 3D 点查询(度量坐标)、成对深度排序"] --> L1["<b>Level 1 · 物体级空间理解</b><br/>3D 定位、朝向(yaw)估计、物理尺寸估计"]
L1 --> L2["<b>Level 2 · 物体间关系理解</b><br/>相对方向、相对距离、关系比较/排序"]
L2 --> L3["<b>Level 3 · 抽象空间推理</b><br/>视角变换、带空间约束的计数、多步问题求解"]
style L0 fill:#eff6ff,stroke:#93c5fd
style L1 fill:#ecfeff,stroke:#67e8f9
style L2 fill:#fefce8,stroke:#fde047
style L3 fill:#fef2f2,stroke:#fca5a5,stroke-width:2px
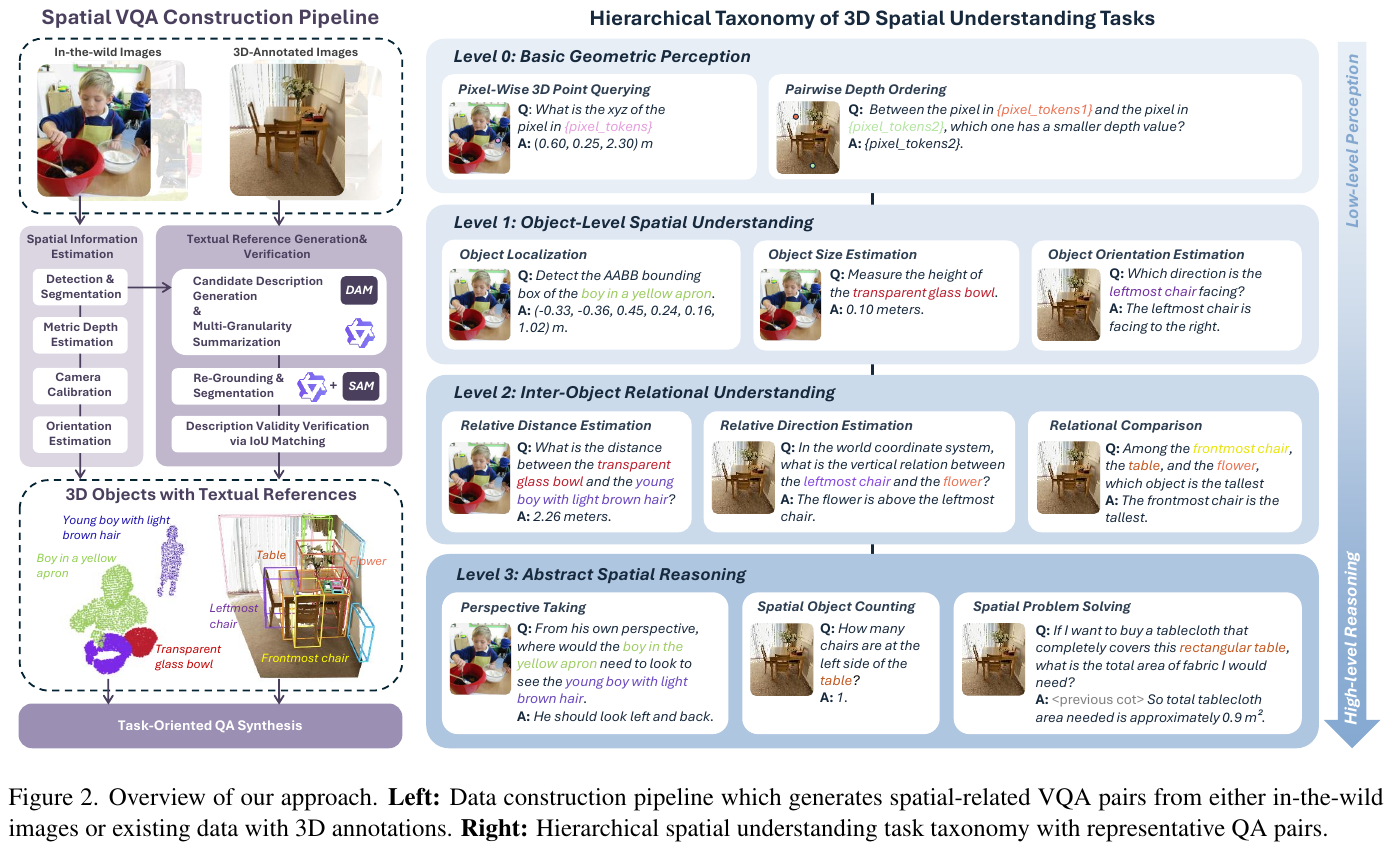
(2)全自动数据引擎:无需人工标注,从约 500 万图像 / 4500 万+ 物体(KosMos-2、Objects365、CA-1M)自动合成 20 亿+ 条空间 VQA,覆盖自由问答、选择题、判断题三种形式(Level 3 的问题求解改用 GPT 生成而非模板)。流水线分三步:先用 MoGe-2 估计逐像素点图、RAM/GroundingDINO/SAM 完成检测分割、OrientAnything-v2 估朝向、Perspective Fields 建立重力对齐世界坐标,得到结构化空间信息;再由 Describe Anything + Qwen2.5/3-VL 生成带 VLM 校验的文本引用;最后按各层级任务模板合成 QA:
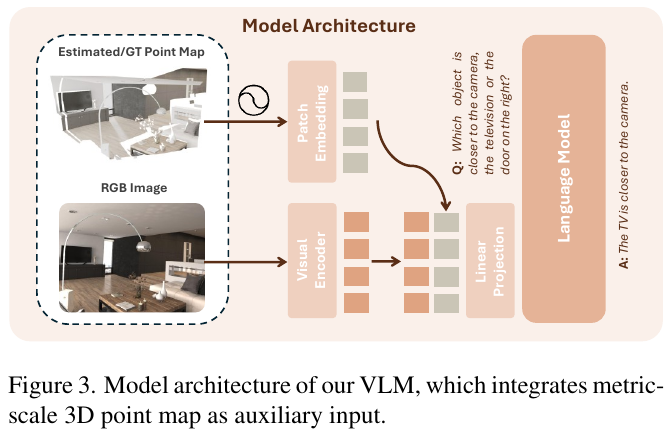
(3)注入度量点图的 RGB-D VLM:以 PaliGemma-2(SigLIP 视觉编码器 + Gemma-2,约 3B 参数)为底座。除 RGB 外,额外输入一张度量尺度 3D 点图($H\times W\times4$:XYZ 坐标 + 有效性掩码,由 MoGe-2 估计或深度传感器提供),经正弦位置编码与可学习 Conv2D patchify 后得到与图像 patch 对齐的特征,与 RGB token 拼接、投影为融合 token 送入 LLM。关键区别在于使用度量尺度而非相对深度,从而提供绝对距离、真实物体尺寸等量纲信息。
3. 核心结果/发现
仅 3B 参数的 HiSpatial 在多个空间理解与推理基准上全面领先大型闭源系统:
| 基准 | 任务层级 | HiSpatial-3B | Gemini-2.5-Pro | GPT-5 |
|---|---|---|---|---|
| SpatialRGPT | L1–L2(定量) | 79.28% | 26.57% | 40.47% |
| QSpatial | L1–L2(定量) | 85.16% | — | 68.45% |
| EmbSpatial | L1–L3 | 80.71% | 76.67% | — |
| RoboSpatial | L1–L3 | 86.18% | 77.24% | — |
| CV-Bench-3D | L1–L2 | 97.58% | 90.80% | — |
| 3DSRBench | L1–L3 | 63.81% | 48.47% | — |
- 层级依赖被实证:移除低层(Level 0–2)训练任务后,高层任务性能下降最多 14.51%——没有几何与度量地基,抽象推理(Level 3)几乎无法掌握。这是全文最有价值的结论,把”分层”从叙事变成可检验的假设。
- 不牺牲通用能力:在 MMBench 等通用 VQA 上不退反升(69.67% vs 基座 PaliGemma-2 的 49.86%),说明空间专项训练未损伤底座的通用多模态能力。
- 难任务上的优势更明显:在多步空间问题求解上达到 47.44%(vs RoboRefer 的 26.92%),抽象推理层的提升幅度最大。
4. 局限性
- 依赖单目几何估计:整条链路建立在 MoGe-2 点图质量之上,几何 / 度量估计的误差会向上传导至关系理解与抽象推理,论文对此讨论较简略。
- 静态图像、缺时序:仅处理单帧图像输入,未覆盖视频 / 4D 动态空间推理(如运动物体的轨迹与碰撞预测)。
- 基准的”主场”成分:多数评测格式与其数据引擎同源,对未在此类格式上对齐过的闭源模型(GPT-5、Gemini)并不完全公平,79% vs 27% 这类悬殊数字宜打折看待。
- 方法论增量偏工程:核心是”分层数据体系 + 度量点图 + 大规模 SFT”,每一块均非首创,更多是 scaling 与系统工程的胜利,而非范式级突破——但它确实为”如何系统训练 VLM 空间智能”提供了可复现、可扩展的蓝本。
6.11 LLaVA-3D (2024)
——— 简单高效地为多模态大模型赋予三维空间感知能力
📄 Paper: arXiv:2409.18125
精华
- 证明了直接在成熟的 2D 多模态大模型上通过添加 3D 位置编码与联合微调,即可高效实现强大的 3D 场景理解,无需从头训练 3D 编码器。
- 巧妙利用 RGB-D 深度图与相机内外参,将 2D视觉特征(CLIP Patches)与 3D 空间绝对坐标进行加法融合,构建极简的 “3D Patches” 表征。
- 验证了视频预训练多模态大模型(如 LLaVA-Video)在多视图 3D 表征上的天然亲和力,使其在收敛速度和 3D 问答上表现出卓越性能。
- 设计了轻量级的 Grounding Decoder 结构,解耦了高阶语义推理与低阶几何框预测,成功避开了 LLM 不擅长生成精确坐标文本的问题。
- 采用 2D 与 3D 数据的联合微调策略,在显著提升 3D 空间智能的同时,完全保留了原始模型优异 2D 理解与对话能力。
1. 研究背景/问题
- 核心问题:现有的 3D 多模态大模型(3D LMMs)发展受限于大规模 3D 视觉-语言数据集的稀缺,以及缺乏类似 2D CLIP 那样强大且通用的 3D 点云预训练编码器。
- 研究动机:现实世界的具身智能体主要依赖多视角图像(Ego-centric images)进行观测,但现有的 3D LMM 通常依赖复杂的离线 3D 实例分割来提取物体特征,流程繁琐且难以端到端应用。作者旨在利用 2D LMM 的强语义先验,以极简且高效的方式赋予模型 3D 空间智能。
2. 主要方法/创新点

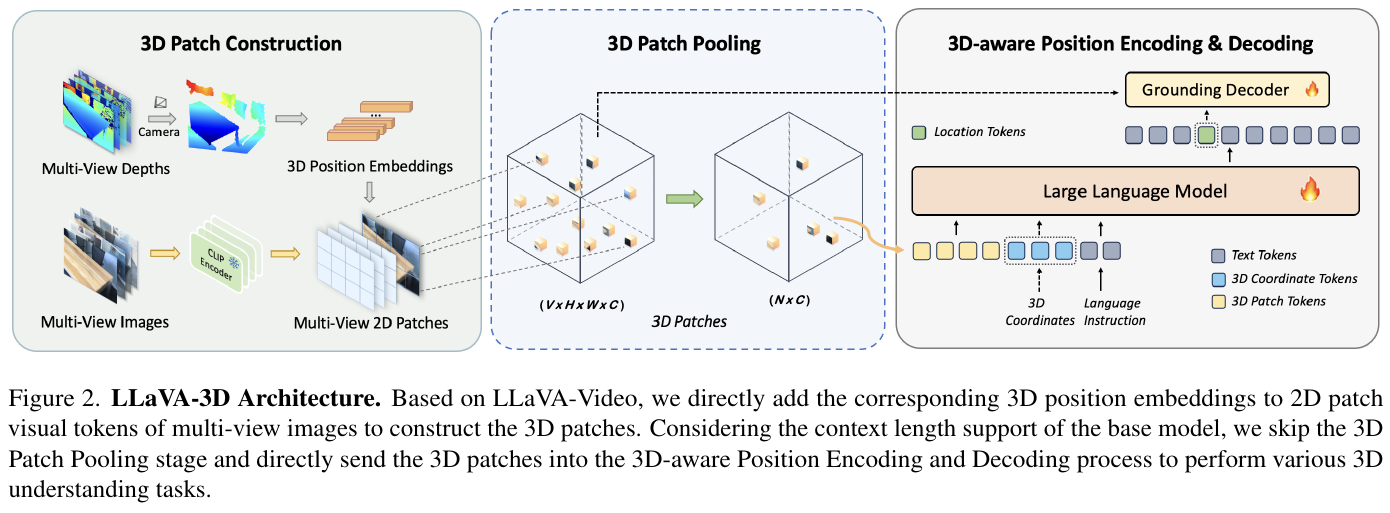
① 整体框架概述 LLaVA-3D 框架基于 LLaVA-Video 改进,由 CLIP 图像编码器、2D-to-3D 投影与可学习 3D 位置编码层、免训练的 Token 压缩池化层、LLM 主干网络以及专门的 Grounding Decoder 组成。通过多视图特征与 3D 坐标编码的融合,将 2D 视觉 Token 升级为 3D Patches,在输入 LLM 进行语义推理的同时,使用 Grounding Decoder 解码出高精度的 3D 边界框。
② 逐模块讲解
- 3D Patch 的构建:
- 输入:多视角 RGB-D 图像及相机内外参。
- 处理:基座模型(LLaVA-Video)使用 CLIP 视觉编码器提取各帧/视图的 2D Patch 特征,并通过线性层投影到 LLM 嵌入空间。同时,根据对应的深度图和相机参数,将每个 2D 像素 Patch 投影到 3D 空间,得到其 3D 世界坐标 $P \in \mathbb{R}^{V \times 3 \times w \times h}$。接着,使用一个由两层 MLP 构成的可学习 3D 位置编码层,将 3D 坐标转换为 3D 位置嵌入 $P’ \in \mathbb{R}^{V \times d \times w \times h}$。最后,将 3D 位置嵌入与投影后的 2D 视觉 Token 直接相加,输出 3D Patches $X’_{3D} = X’_p + P’$。
- 设计动机:在保留 2D CLIP 强视觉-语义对齐特性的同时,赋予其显式的 3D 空间几何信息,避免了构建繁重的三维点云或体素网格的开销。
- 3D Patch Pooling 机制:
- 输入:多视角图像生成的高密度 3D Patches(其数量随视图数线性增长)。
- 处理:为了降低输入 LLM 的 Token 数量,引入了两种免训练的池化策略:
- 体素化池化(Voxelization Pooling):将 3D 空间离散化为三维网格,将落在同一占用体素内的 3D Patches 进行均值池化,仅保留被占用体素的 Token。
- 最远点采样池化(FPS Pooling):使用最远点采样算法,从所有 3D Patches 中均匀采样固定数量(如 $N$ 个)的代表性 Token。
- 设计动机:有效降低 LLM 上下文长度,保障计算效率,同时通过 3D 空间分布规律最大程度地保留场景的几何和空间结构。
- 3D 坐标的编码与解码:
- 输入:用户指令中包含的 3D 坐标(如密集物体描述任务),或 LLM 用于指导预测的隐状态。
- 处理:
- 编码端:用户指令中的 3D 坐标通过 3D 位置编码层转化为 3D Coordinate Token,与 text tokens、3D patch tokens 共同输入 LLM,协助空间敏感的文本生成。
- 解码端(Grounding Decoder):直接让 LLM 输出 3D 边界框文本坐标极其困难。因此,LLaVA-3D 设计了 Grounding Decoder。首先从 3D Patches 中通过 FPS 采样一组 Instance Queries。在每个 Decoder 层中,Instance Queries 与 3D Patch 特征进行 Cross-Attention,并使用多尺度 3D k-NN 注意力和相对位置编码建模局部几何。随后,更新后的 Queries 与 LLM 提取的 Location Token 拼接,利用距离自适应自注意力(Distance-adaptive Self-Attention)捕获相对位置,最终输入 Grounding Head 预测 3D 边界框。
- 设计动机:解耦高级语义理解与低级边界框预测,让 LLM 专注文本推理,Decoder 专注三维几何预测,解决 LLM 直接预测坐标时精度低下的难题。
③ 端到端数据流 输入的多个视角 RGB 帧及其深度图首先输入视觉模块,结合相机投影几何提取出对应的 3D Patches。接着,根据需要执行 3D Patch Pooling 以压缩序列长度。将压缩后的 3D 视觉 Token 与文本 Token 拼接,输入 LLM 进行自回归语言推理。若当前任务包含 3D 定位输出,LLM 输出的特定位置隐状态将与 3D Patches 共同被送入 Grounding Decoder,并最终解码出 3D 边界框。
④ 训练目标 / 损失函数
- 训练分为两阶段:
- 第一阶段:多任务联合微调(Multi-Task Instruction Tuning):混合 3D QA、3D Captioning 等 3D 数据(LLaVA-3D-Instruct-86K)与原 LLaVA-Video 的 2D 视频微调数据。整体损失包含文本自回归损失 $\mathcal{L}{text}$ 以及 3D 边界框预测损失(GIoU 损失与 $L_1$ 框回归损失之和 $\mathcal{L}{box}$): \(\mathcal{L} = \mathcal{L}_{text} + \lambda \mathcal{L}_{box}\)
- 第二阶段:仅微调解码器(Decoder-only Fine-tuning):冻结 LLM 和位置编码层,仅在 3D 视觉定位数据上继续训练 Grounding Decoder 几个 epoch,以加速边界框预测部分的收敛。
⑤ 推理流程 推理时除了支持标准的文本和图像问答外,模型还支持交互式理解。用户可在 2D 图像或视频帧中点击特定像素,点击位置通过相机几何投影至 3D 空间生成 3D Coordinate Token,指导模型对特定物体生成 3D 边界框及详细的描述文本。

3. 核心结果/发现
- 极快的训练收敛速度:相比于从头训练 3D 编码器并进行对齐的 3D LMM,得益于强大的 2D 大模型先验,LLaVA-3D 在 3D 数据集上的收敛速度提升了 3.5 倍。
- 各项 3D 任务显著超越 SOTA:
- 在 3D QA 上,ScanQA (103.1 CIDEr)、SQA3D (60.1 EM@1) 分别创造了全新纪录,显著优于 LEO (101.4/50.0) 和 LL3DA (76.8/-).
- 在 3D Dense Captioning 上,Scan2Cap (84.1 C@0.5) 和 MMScan Captioning (78.8 Overall) 达到最先进水平,其中在颜色和设计维度的描述精度分别提升了 49.5% 和 43.3%。
- 在 3D 视觉定位上,单阶段模式的 ScanRefer (50.1 Acc@0.25) 和 Multi3DRefer (49.8 Acc@0.25) 表现极为优异,逼近复杂的两阶段模型。
- 保留原始 2D 理解能力:联合训练使模型在 MVBench (58.1 vs. 58.6) 和 VideoMME (62.8 vs. 63.3) 2D 视频测试中几乎与 LLaVA-Video 保持一致,有效避免了严重遗忘。
4. 局限性
- 高度依赖高质量的 RGB-D 深度图以及精确的相机标定参数。在复杂未知的现实场景中,深度估计的累积误差或粗糙的标定会导致 3D Coordinate 映射偏移,进而影响 3D Patches 构建的准确度。
- Grounding Decoder 的收敛无法在第一阶段单 epoch 训练中完美解决,当前仍需要分阶段的独立微调步骤。
6.12 LLaVA-Video (2024, TMLR 2025)
———用高质量合成数据做视频指令微调:LLaVA-Video-178K 数据集 + SlowFast 视频表示
📄 Paper: arXiv:2410.02713
精华
- 数据质量 > 数据数量:178K 高动态、未剪辑视频的密集标注,胜过 900K 静态视频的稀疏标注——训练视频 LMM 时,选”剧情完整、时序动态强”的视频源比堆量更关键。
- 递归式分层字幕生成是为任意长度视频做密集描述的可迁移范式:以 10s/30s/全片三个时间粒度递归生成,每层都以历史描述为上下文,保证跨时段的人物与事件指代一致。
- 密集采样(1 FPS)喂给标注模型:稀疏采样(如 0.008–0.15 FPS)的字幕只能描述大场景、丢失细微动作,是下游模型幻觉的根源之一。
- SlowFast token 分配:对视频帧分组施加不同空间池化率(slow 帧多 token、fast 帧少 token),在固定 LLM 上下文/显存预算内塞进最多 3 倍帧数,是”帧数 vs 每帧 token 数”权衡的简洁解法。
- 用 16 类问题模板引导 GPT-4o 生成 QA 对,可系统性覆盖时序、因果、计数、相机方向等真实查询分布,避免模板 QA 的低质重复。
1. 研究背景/问题
视频 LMM 的发展受限于高质量视频-语言指令数据的匮乏:现有数据集(LLaVA-Hound、ShareGPT4Video 等)的视频源大多静态、按场景切分成短片段导致剧情简化,且标注时帧采样极稀(平均 0.008–0.15 FPS),无法捕捉细微动作变化,导致模型在需要细节描述时产生幻觉。本文走”合成数据”路线,用 GPT-4o + 人工流程构建高质量视频指令微调数据集,并探索在有限显存下最大化帧数的视频表示。
2. 主要方法/创新点
2.1 LLaVA-Video-178K 数据集构建
整个数据合成 pipeline 由三个环节构成:动态视频筛选(从 10 大视频源选取高动态、未剪辑视频)、递归式三层详细字幕生成(1 FPS 密集采样 + GPT-4o)、16 类问题引导的 QA 生成(开放式 + 多选)。最终得到 178K 视频、1.3M 指令样本(178K 字幕、960K 开放式 QA、196K 多选 QA)。
① 视频源与动态筛选

- 输入:调研 40+ 视频-语言数据集后归纳出的 10 大视频源(HD-VILA-100M、InternVid-10M、VidOR、VIDAL/YouTube Shorts、YouCook2、Charades、ActivityNet、Kinetics-700、Sth-sth v2、Ego4D),覆盖活动、烹饪、TV、第一视角等领域。
- 处理:用 PySceneDetect 统计场景数作为”动态程度”指标,过滤逻辑包括:按播放量排序、场景数 > 2、时长 5–180s、场景数/时长 ≤ 0.5(剔除 PPT 式幻灯片视频)、分辨率 > 480p、每类别采样 50 条。
- 设计动机:除 YouCook2 和 Kinetics-700 外全部使用未剪辑原始视频——切片会破坏剧情连续性,而完整剧情正是视频理解区别于图像理解的核心价值。
② 递归式三层详细字幕生成
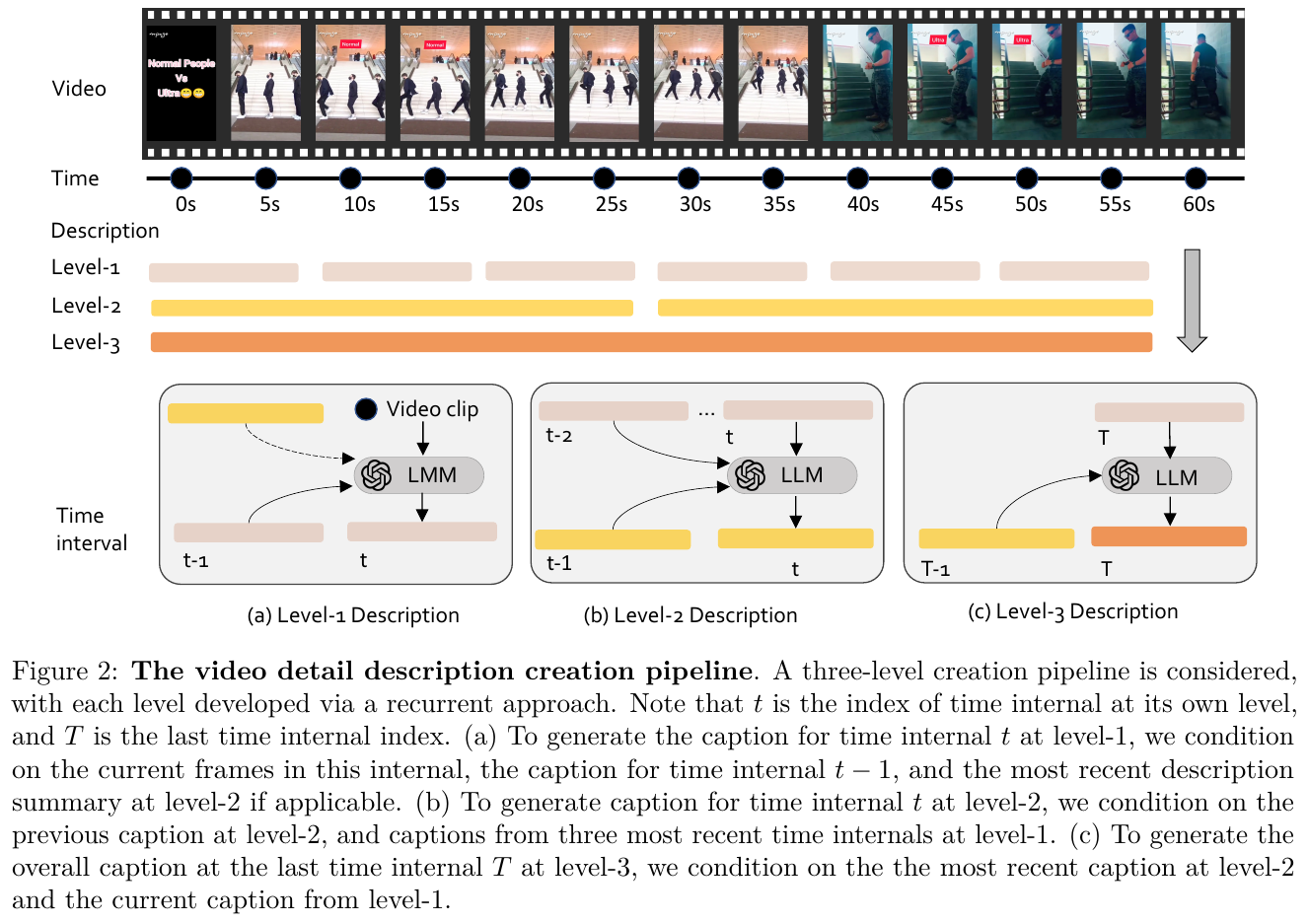
以 1 FPS 密集采样帧,按三个时间粒度递归调用 GPT-4o:
- Level-1(每 10s):输入当前片段的帧 + 历史上下文(尚未被汇总的近期 level-1 描述 + 最新 level-2 描述),输出该 10s 片段的事件描述;
- Level-2(每 30s):输入最近三条 level-1 描述 + 上一条 level-2 描述,输出到当前为止的剧情摘要;
- Level-3(视频结束时):输入最新 level-2 描述 + 尚未汇总的 level-1 描述,输出整段视频的完整描述。
设计动机:与 Video ReCap 等先逐段独立描述再汇总的方案不同,这里每条 level-1 描述生成时就携带历史上下文,保证时间线上前后事件的关联(如跨时段识别同一人物)。下图消融展示了历史上下文的作用:

③ 16 类问题引导的 QA 生成
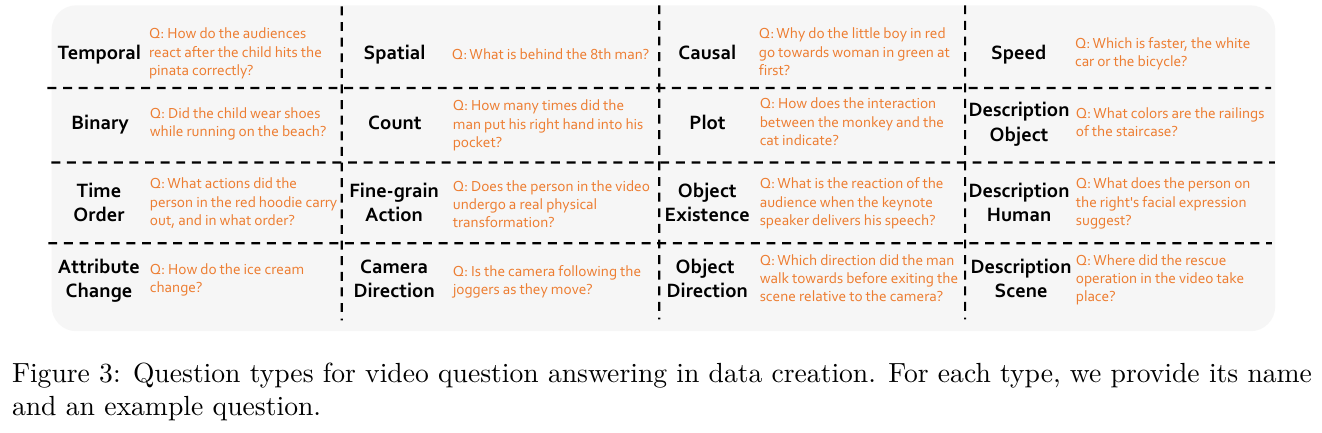
- 输入:每个视频的详细描述(level-3)+ 当前问题类型的任务定义 + 3 个同类型 in-context 示例。
- 处理:GPT-4o 对每种类型最多生成一个 QA 对,无法生成则返回 None;随后用 sentence-transformer 去重,并丢弃以 “does not specify/mention/show” 等开头的无效答案。
- 设计动机:16 类问题(时序、空间、因果、计数、属性变化、相机方向等)参考公开视频 QA 基准定义,确保覆盖真实用户查询分布,避免模板生成 QA 的低质与单一。
一条视频数据最终包含三种标注:

与同类合成数据集相比:LLaVA-Hound 900K 视频但 44% 来自静态的 WebVid 且仅 0.008 FPS 标注;ShareGPT4Video 40K 视频多为剪辑短片且 0.15 FPS;LLaVA-Video-178K 以 1 FPS 标注 178K 动态未剪辑视频,且同时覆盖字幕、开放式 QA、多选 QA 三种任务。
2.2 LLaVA-Video 模型与 SlowFast 视频表示
模型沿用 LLaVA-OneVision 架构:SigLIP 视觉编码器 + 两层 MLP projector + Qwen2 LLM,从 LLaVA-OneVision 单图(SI)阶段 checkpoint 出发微调。核心问题是 token 预算:T=100 帧、每帧 M=729 token 时共 67,600 个视觉 token,72B 模型在 128 张 H100 上也只能塞 8 帧。
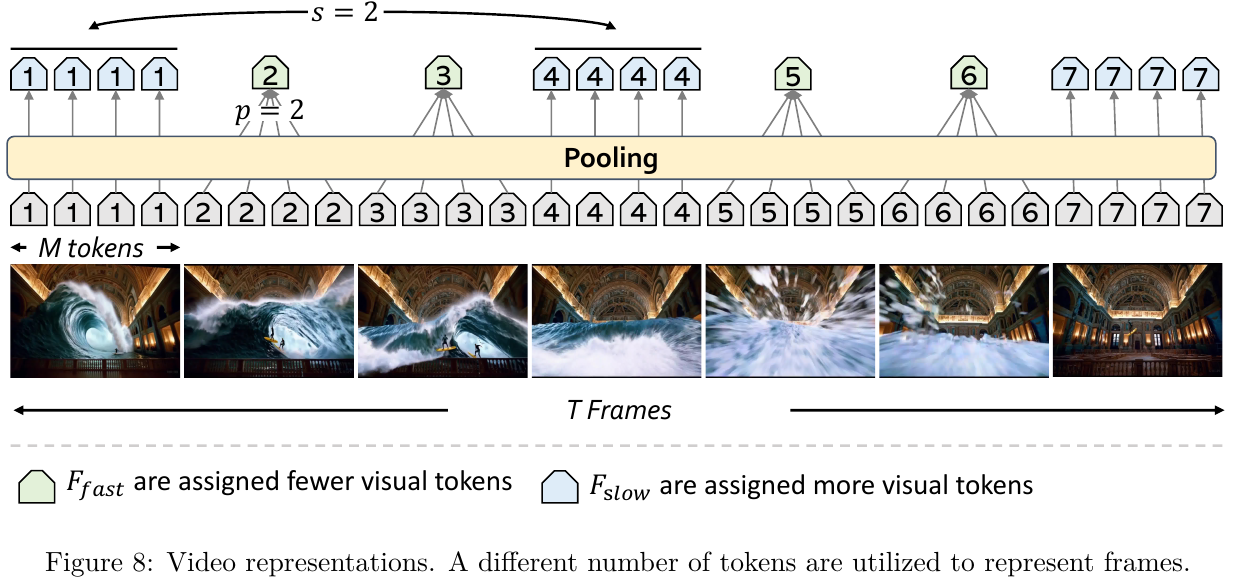
- 输入:最多 T 帧的视频序列,每帧经 SigLIP + MLP 得到 M 个视觉 token。
- 处理:按 stride $s$ 将帧分为两组——每隔 $s$ 帧均匀选出的帧构成 slow 组,施加 $p \times p$ 平均池化;其余帧构成 fast 组,施加 $2p \times 2p$ 池化(token 数为 slow 的 1/4)。slow 与 fast 帧按原时间顺序交错排列。$s = 1$ 时退化为所有帧等量 token 的普通表示。
- 输出:视频表示由四元组 $V = (T, M, s, p)$ 参数化,总 token 数为
- 设计动机:与 LITA、SlowFast-LLaVA 先把所有帧压成极少 token 再对部分帧补充细粒度 token(导致部分帧被表示两次)不同,本文每帧只属于一组、不重复表示;相比所有帧等量分配 token,可在同等预算下纳入最多 3 倍帧数。LLaVA-Video-7B 用 $V = (64, 679, 1, 2)$,72B 用 $V = (64, 679, 3, 2)$。
训练:在 LLaVA-Video-178K + 四个公开数据集(ActivityNet-QA、NExT-QA、PerceptionTest、LLaVA-Hound-255K,只取 <3 分钟视频)共 1.6M 视频-语言样本上,联合 1.1M LLaVA-OneVision 图像数据微调;其中 92.2% 字幕、77.4% 开放式 QA、90.9% 多选 QA 为新标注。
3. 核心结果/发现
- 总体性能:在 11 个视频基准上,LLaVA-Video-7B 在 10 个数据集中的 7 个超越此前最强开源 LLaVA-OV-7B;LLaVA-Video-72B 达到与商用 Gemini-1.5-Flash 相当的水平(VideoMME 70.5/76.9 w-subs,MLVU 74.4,NExT-QA 85.4)。
- 数据集消融:在 LLaVA-Hound 基线上加入 LLaVA-Video-178K,NExT-QA 提升 31.9 点(64.4→80.1)、VideoMME 提升 9.1 点(54.1→63.2),zero-shot 任务同样显著受益。
- 质量 vs 数量:等量对比下(900K 开放式 QA),178K 视频的 LLaVA-Video-178K 全面超过 900K 视频的 LLaVA-Hound(NExT-QA 73.2 vs 39.8),印证视频指令数据质量比数量更重要;与 ShareGPT4Video 的 40K 等量对比同样占优。
- 改进幅度与基准的视频来源相关:MLVU、LongVideoBench、VideoMME 等 YouTube 系基准提升明显;ActivityNet-QA 提升小(其问题多数看单帧即可回答)。
4. 局限性
视频源自多个平台,继承了来源平台的固有偏差;QA 对由 GPT-4o 生成,可能受标注者(prompt 设计者)视角影响而产生分布偏斜。
参考
- Paper: LLaVA-Video: Video Instruction Tuning With Synthetic Data (TMLR 2025)
- OpenReview: https://openreview.net/forum?id=EElFGvt39K
6.13 ROSS3D (2025)
———用”重建视觉信号”取代”堆3D输入”,给2D LMM注入真正的3D空间感
📄 Paper: arXiv:2504.01901
精华
- 3D LMM 的瓶颈不在”输入里塞多少3D信息”,而在缺乏让模型真正学会3D空间关系的训练信号——这是本文最值得迁移的论点。
- 解法是把”视觉输出”也纳入监督:用一个轻量去噪网络,让 LMM 的视觉 token 学会重建被遮挡视角(cross-view)和俯视图(global-view),而不只是预测文本。
- 两个重建任务分管不同能力——cross-view 重建强化细粒度跨视角对齐(利于 visual grounding),global-view 重建强化全局布局理解(利于 QA),两者叠加效果可叠加增强。
- 该视觉监督信号不需要文本标注,因此可以直接用在无标注的3D视频数据上做半监督训练,且效果能超过全量文本监督的上界,说明这是一条低成本扩大3D数据规模的路径。
- 这种”reconstructive supervision”思路具有通用性:把2D下的 Reconstructive Visual Instruction Tuning(ROSS, ICLR 2025)的目标函数,针对任务特性重新设计输入/输出变换,就能迁移到新模态(3D场景)。
1. 研究背景/问题
3D LMM 想要让2D视觉语言模型理解3D场景,但高质量3D视觉-语言配对数据极度稀缺,也没有像CLIP那样强大的预训练3D点云编码器。已有方法(点云特征融合、3D patch pooling、多视角当视频处理)都只是在输入层面做3D感知设计,本质上仍然只用文本交叉熵监督视觉输出,导致模型对2D数据的归纳偏置难以纠正,3D空间理解依然不充分。
2. 主要方法/创新点
① 整体框架概述
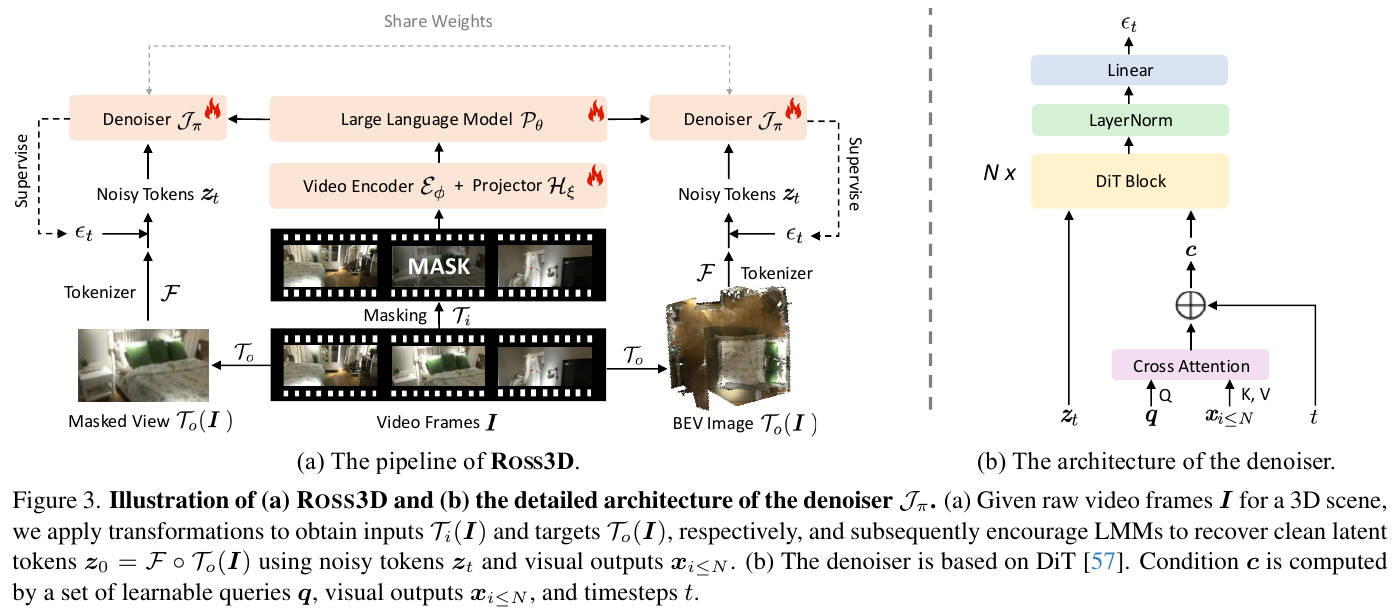
ROSS3D 由三部分构成:视频编码器 $\mathcal E_\phi$(提取多视角视频帧特征)、大语言模型 $\mathcal P_\theta$(处理视觉token+文本指令,自回归输出)、去噪器 $\mathcal J_\pi$(一个轻量的基于 DiT 的去噪网络,负责把 LMM 的视觉输出”翻译”回图像潜在空间,从而对视觉输出施加监督)。三者协作:视频编码器产生视觉前缀 token 输入 LLM,LLM 在生成文本的同时也输出一段”视觉token”,去噪器以这些视觉token为条件,去噪重建出指定的目标图像(被遮挡视角或BEV图)。
② 逐模块讲解
- Cross-view 重建(细粒度跨视角建模)
- 输入:把多视角视频帧 $I \in \mathbb R^{M\times H\times W\times 3}$ 按比例 $\gamma$(默认25%)随机mask掉一部分视角,被mask的视角特征替换成可学习的mask token。
- 处理:LLM 正常自回归处理所有视觉token(包括mask token位置),去噪器以”masked位置对应的视觉输出”为条件,去噪恢复这些视角原始图像的VAE潜在编码。
- 输出:被mask视角的重建潜在表示,用扩散损失 $\mathcal L_{3D}^{cross}$ 监督。
- 设计动机:迫使模型学会从其它视角的重叠信息推断某一视角内容,直接对应3D visual grounding等需要跨视角精确对齐的任务。
- Global-view 重建(全局布局理解)
- 输入:同样使用cross-view mask后的视频帧作为输入($\mathcal T_i$相同)。
- 处理:用3D重建技术(结合相机外参、内参、深度)把全部视角的视觉信息聚合,渲染出一张俯视BEV图像作为重建目标,去噪器同样以LLM视觉输出为条件去噪重建这张BEV图(稀疏点云渲染产生的黑色空白区域会被过滤掉,不计入损失)。
- 输出:BEV图像的重建潜在表示,用扩散损失 $\mathcal L_{3D}^{global}$ 监督。
- 设计动机:BEV图天然汇聚了整个场景的空间布局,能强化模型对全场景整体结构的理解,对3D QA等需要综合场景信息的任务最有效。
- 去噪器 $\mathcal J_\pi$(共享架构,基于DiT)
- 输入:噪声token $z_t$、LLM输出的视觉条件 $x_{i\le N}$、时间步 $t$。
- 处理:可学习查询 $q$ 与视觉输出 $x_{i\le N}$、时间步嵌入通过cross-attention融合得到条件 $c$,再经过 N 个 DiT block、LayerNorm、Linear层预测噪声 $\epsilon_t$。
- 输出:预测的噪声,用于和真实噪声计算 MSE,从而反传梯度优化LLM的视觉输出。
③ 端到端数据流
一个3D场景的32帧视频先按25%比例随机mask部分视角,连同深度图编码成position-aware的视觉token输入视频编码器+projector,前缀给LLM;LLM自回归生成(部分位置对应文本指令的回答,部分位置对应视觉输出);视觉输出位置每隔 $\Delta t=4$ 步被取出,分别送入共享权重的去噪器,一路重建被mask掉的原始视角,一路重建整个场景的BEV俯视图;文本输出位置正常用交叉熵监督。三个损失(文本交叉熵 + cross-view重建 + global-view重建)联合训练同一组LLM参数。
④ 训练目标 / 损失函数
\(\mathcal L_{text} = -\frac{1}{T-N}\sum_{i=N+1}^{T} \log p_\Theta(x_i \vert x_{<i}, v)\) 标准文本交叉熵,仅监督文本token。
\(\mathcal L_{3D}^{cross} = \frac{1}{\gamma M}\sum_{j=1}^{M}(1-M_j)\cdot \mathcal D(\mathcal J_\pi \circ \mathcal P_\theta(v), \mathcal F(I_j))\) 仅对被mask的视角计算重建损失。
\(\mathcal L_{3D}^{global} = \mathcal D(\mathcal J_\pi \circ \mathcal P_\theta(v), \mathcal F(I_{BEV}))\) 对BEV重建目标计算损失。
距离度量 $\mathcal D$ 默认采用扩散去噪过程:\(\mathcal D = \mathbb E_{t,\epsilon}\left[\Vert \mathcal J_\pi(z_t \vert \mathcal P_\theta(v), t) - \epsilon \Vert^2\right]\),其中 $z_t = \sqrt{\bar\alpha_t} z_0 + \sqrt{1-\bar\alpha_t}\,\epsilon$,$z_0$ 由FLUX提供的连续VAE(KL正则)编码得到。3D visual grounding任务额外使用InfoNCE grounding损失(基于物体级特征与<ground> token的相似度)。
⑤ 推理流程
推理时不再进行masking或重建,去噪器不参与,LLM直接根据完整多视角视频输入自回归生成文本答案(QA/captioning用greedy decoding;grounding任务通过<ground> token隐状态与候选物体特征的相似度选择/排序候选框)。
3. 核心结果/发现
ROSS3D 基于 LLaVA-Video-7B 微调,在五个ScanNet系3D基准上全面超越此前SOTA Video-3D-LLM:SQA3D达63.0 EM(+4.4)、ScanQA达107.0 CIDEr(+4.9)、Scan2Cap达66.9 ROUGE(+4.6)、ScanRefer达61.1 Acc@0.25(+3.0)、Multi3DRefer达59.6 F1@0.25(+1.6)。消融实验证实:无3D感知的”vanilla重建”几乎无收益,而cross-view和global-view重建分别有效且能叠加增强,二者还能迁移到不同输入表示(点云特征 3D-LLM、视频特征 Video-3D-LLM)上均有效。额外训练成本很小(速度仅增加1.12×,显存增加1.02×)。更重要的是,半监督实验显示:50%文本数据 + 50%无标注数据上应用 $\mathcal L_{3D}$,效果超过100%全量文本监督基线(ScanQA上103.2 vs 102.1 CIDEr),证明该视觉监督信号能有效从无标注3D视觉数据中学习。
4. 局限性
论文未专门讨论局限性章节,但从设计看:(1) global-view重建依赖额外的3D重建/渲染流程(生成BEV图需要深度、外参、内参及点云渲染),增加了数据预处理复杂度;(2) masking机制存在训练/测试不一致的问题,需要通过较小mask比例(25%)和较大重建间隔(每4步一次)来缓解,调参敏感性仍需权衡。
参考
- Paper: ROSS3D: Reconstructive Visual Instruction Tuning with 3D-Awareness
- Project Page: haochen-wang409.github.io/ross3d
6.14 VGGT (2025)
———用一个前馈 Transformer,一次推理同时输出相机、深度、点图与点轨迹
📄 Paper: arXiv:2503.11651 (Visual Geometry Grounded Transformer, CVPR 2025 Best Paper)
精华
- 神经优先、去几何归纳偏置:不为三维任务设计特殊结构,而用接近标准的大型 Transformer + 海量带三维标注数据,复刻 GPT / DINO / CLIP 式「通用骨干」范式,把传统需迭代优化(SfM / BA / 全局对齐)的三维重建彻底改写成一次前馈推理。
- 交替注意力(Alternating-Attention):逐帧自注意力与全局自注意力交替堆叠,在「跨图信息融合」与「单帧激活归一化」间取得平衡,全程不用 cross-attention;消融证明其优于「仅全局注意力」与「cross-attention」两种变体。
- 过完备多任务监督:相机、深度、点图之间虽存在闭式关系,仍同时显式预测;多任务联合训练反而提升整体精度。
- 反直觉推理发现:推理时由「深度 + 相机反投影」得到的点云,比专用点图头更准——把复杂任务拆解为更简单的子问题带来收益。
- 特征可迁移:预训练 VGGT 特征可即插即用迁移到动态点跟踪、前馈新视角合成等下游任务,验证其作为「三维基础模型」骨干的价值。
1. 研究背景/问题
三维重建长期由「视觉几何 + 迭代优化」主导:经典 SfM/MVS 管线(COLMAP 等)依赖特征匹配、三角化与 Bundle Adjustment,复杂且计算昂贵。近年 DUSt3R / MASt3R 用前馈网络直接回归对齐点图,迈出去优化的一步,但它们一次只能处理两张图像,多图必须靠成对重建 + 全局对齐(global alignment)融合,仍残留昂贵的测试时优化。本文要回答的核心问题是:网络能否足够强大,以至于直接、一次性地预测一组图像的全部三维属性,几乎完全抛弃几何后处理?

2. 主要方法/创新点
① 整体框架概述
VGGT(约 1.2B 参数)整体由一个共享主干(Alternating-Attention Transformer) 加四个轻量预测头构成:DINOv2 先把每帧图像 Patchify 成视觉 token,主干在「逐帧 / 全局」两种自注意力间交替融合多视角信息,随后 Camera Head 输出相机内外参,DPT Head 输出稠密的深度图、点图与跟踪特征,Tracking Head 再据跟踪特征回归 2D 点轨迹。形式化地,网络是一个映射
\[f\,(I_i)_{i=1}^{N} = (g_i, D_i, P_i, T_i)_{i=1}^{N}\]把 N 张 RGB 图映射为每帧的相机参数 $g_i$、深度图 $D_i$、点图 $P_i$ 与跟踪特征 $T_i$。
② 逐模块讲解
(a) DINOv2 图像 Tokenizer
- 输入:每张图像 $I \in \mathbb{R}^{3\times H\times W}$。
- 处理:用预训练 DINOv2 把图像 Patchify 为 K 个 token(K 随分辨率而变),并加位置编码。论文实验表明,相比 14×14 卷积,DINOv2 不仅性能更好,训练(尤其初期)也更稳定、对学习率/动量更不敏感。
- 输出:所有帧的图像 token 集合 \(t^I = \bigcup_{i=1}^{N}\{t^I_i\}\)。
- 动机:用自监督视觉基础模型提供强语义先验,避免从零学习低层特征。
(b) 相机 token 与 register token 增强
- 输入:每帧图像 token $t^I_i$。
- 处理:为每帧追加 1 个可学习的相机 token 和 4 个 register token。关键设计是——第一帧使用一套独立的可学习 token(与其余帧不同),从而让模型区分「参考帧 / 世界坐标系原点」与其它帧。
- 输出:拼接后的 token 序列送入主干。
- 动机:所有相机、点图、深度图都定义在第一帧相机坐标系下(第一帧外参固定为单位旋转 $q_1=[0,0,0,1]$、零平移)。除首帧外,架构对输入顺序是置换等变的。
(c) Alternating-Attention(AA)主干
- 输入:全部帧的(图像 + 相机 + register)token。
- 处理:交替进行两种自注意力——逐帧自注意力(Frame Attention) 只在单帧内部 token 间做注意力;全局自注意力(Global Attention) 在所有帧的 token 间联合做注意力。默认 L=24 层交替堆叠(共 2L 个注意力层),完全不使用 cross-attention。每层配 QKNorm 与 LayerScale 稳定训练。
- 输出:精炼后的图像 / 相机 / register 输出 token(register token 用后丢弃)。
- 动机:全局注意力负责跨视角信息融合(隐式完成多视三角化推理),逐帧注意力负责单帧内 token 激活的归一化;二者交替在「融合」与「稳定」间取得平衡。消融显示 AA 明显优于「仅全局注意力」和「cross-attention」两种变体。
(d) Camera Head
- 输入:每帧的相机输出 token \(\hat{t}^g_i\)。
- 处理:4 层额外自注意力 + 1 个线性层。
- 输出:相机参数 $g=[q,t,f]$,即旋转四元数 $q\in\mathbb{R}^4$、平移 $t\in\mathbb{R}^3$、视场角 $f\in\mathbb{R}^2$(假设主点在图像中心)。
- 动机:以回归方式直接得到内外参,免去 PnP / BA。
(e) DPT 稠密预测头
- 输入:每帧图像输出 token \(\hat{t}^I_i\)(取主干第 4/11/17/23 层特征)。
- 处理:DPT 上采样为稠密特征图,再经 3×3 卷积分别映射。
- 输出:深度图 $D_i$、点图 $P_i$、跟踪特征 $T_i$,并额外预测偶然不确定性(aleatoric uncertainty) 图 $\Sigma^D_i$、$\Sigma^P_i$(训练后正比于模型置信度)。点图与 DUSt3R 一样是视点不变的——所有 3D 点都表达在第一帧坐标系中。
- 动机:把「几何量」与「置信度」一并输出,置信度进入损失加权,也可用于下游过滤。
(f) Tracking Head
- 输入:DPT 输出的稠密跟踪特征 $T_i$ 与查询点 $y_q$。
- 处理:采用 CoTracker2 架构——在查询图特征 $T_q$ 上双线性采样查询点特征,与其它帧特征图做相关,得到相关图后经自注意力回归各帧 2D 对应点。
- 输出:查询点在所有帧的 2D 轨迹。不假设输入帧的时间顺序,故可用于任意无序图像集。
③ 端到端数据流
一张样本的流经路径:N 张图 →(DINOv2)视觉 token →(拼接相机/register token,首帧特殊)→(L 次交替的逐帧/全局自注意力)精炼 token → 分流到 Camera Head(出内外参)与 DPT Head(出深度、点图、跟踪特征、不确定性)→ Tracking Head 据跟踪特征 + 查询点出 2D 轨迹。全部在一次前馈内完成。
④ 训练目标 / 损失函数
多任务联合损失:
\[L = L_{camera} + L_{depth} + L_{pmap} + \lambda L_{track}\]- 相机损失 $L_{camera}$:对预测相机参数与真值用 Huber 损失。
- 深度损失 $L_{depth}$:沿用 DUSt3R 的偶然不确定性加权损失,并加入单目深度常用的梯度项,用预测不确定性 $\Sigma^D_i$ 加权深度残差与梯度残差。
- 点图损失 $L_{pmap}$:与深度损失同构,用点图不确定性 $\Sigma^P_i$ 加权。
- 跟踪损失 $L_{track}$:各查询点预测与真值 2D 对应点的距离,并按 CoTracker2 加二元可见性损失(BCE);权重 $\lambda=0.05$。相机/深度/点图三项量级相近,无需相互加权。
真值坐标归一化(关键 trick):先把所有量表达到第一帧坐标系,再用「所有 3D 点到原点的平均欧氏距离」作为尺度,归一化平移、点图与深度。与 DUSt3R 不同,VGGT 只归一化真值、不归一化网络预测——强制模型从数据中学到这一规范化选择,这样既无损收敛,又避免额外训练不稳定。
训练配置:DINOv2/ViT-L 主干(特征维 1024、16 头),约 1.2B 参数;AdamW,峰值 LR 2e-4,cosine 调度,8K 步 warmup,共 160K 步;每 batch 随机采 2–24 帧、固定总计 48 帧;图像最长边 518px,长宽比随机;64 张 A100 训练 9 天;bfloat16 + 梯度检查点 + 梯度裁剪。训练数据为 Co3Dv2、BlendMVS、DL3DV、MegaDepth、ScanNet、HyperSim、Habitat、Aria 等 17+ 个室内外、合成/真实数据集。
⑤ 推理特性:过完备预测
相机、深度、点图三者并非独立(点图可由深度+相机闭式导出,相机也可由点图 PnP 反解)。但训练时全部显式预测反而带来显著增益;推理时一个反直觉发现是:用「深度图 + 相机参数反投影」得到的点云,比直接用专用点图头更准——把复杂任务(点图)拆解为更简单子问题(深度 + 相机)带来好处。若进一步配 Bundle Adjustment,VGGT 直接预测的近似点/深度图可作为优质初始化,免去三角化与迭代精炼,使 VGGT+BA 仍只需约 2 秒。
3. 核心结果/发现
- 相机位姿估计(RealEstate10K / CO3Dv2,10 帧):前馈版 AUC@30 达 85.3 / 88.2,在 0.2 秒内超过 DUSt3R、MASt3R、VGGSfM 等需 7–10 秒后处理的方法;配 BA 升至 93.5 / 91.8。在从未训练过的 Re10K 上优势更大,验证泛化性。
- 多视角深度估计(DTU):Overall(Chamfer)从 DUSt3R 的 1.741 大幅降到 0.382,且逼近「已知真值相机」的 MVS 方法。
- 点图估计(ETH3D):「深度+相机」版 Overall 0.677,仅 0.2 秒/场景,显著优于需约 10 秒全局对齐的 DUSt3R/MASt3R。
- 两视角匹配(ScanNet-1500):尽管未针对两视角专门训练,仍超过 SOTA 匹配方法 Roma。
- IMC phototourism:VGGT+BA 取得 SOTA(AUC@10 84.91),超越曾居 CVPR’24 IMC 冠军的 VGGSfMv2。
- 下游迁移:(1) 前馈新视角合成(GSO)——在不输入相机参数、仅用 20% 训练数据下,PSNR 30.41 媲美需已知相机的 LVSM;(2) 动态点跟踪(TAP-Vid)——用 VGGT 预训练特征替换 CoTracker 主干,多项指标全面提升。
- 效率:特征主干处理 1→200 帧,从 0.04 秒/1.88GB 扩展到 8.75 秒/40.63GB;Camera Head 仅占约 5% 运行时与 2% 显存。

4. 局限性
不支持鱼眼 / 全景图像;在极端输入旋转下重建质量下降;仅能处理轻微非刚性运动,大幅非刚性形变场景会失败。作者指出这些可通过在目标数据上微调、几乎不改架构地缓解,这正是相对「需大量测试时优化重工程」方法的优势。
参考
6.15 MapAnything (2026)
———一个前馈主干,单次推理统一 12+ 种度量级三维重建任务
📄 Paper: arXiv:2509.13414
精华
- 核心思想——因子化场景表示(Factored Scene Representation):不直接回归 pointmap,而是把多视角几何拆成「每像素 ray 方向 + 沿 ray 的深度 + 每视角全局位姿 + 全场景单一 metric scale 因子」四个解耦分量,再组合还原出全局度量一致的三维。
- 因子化同时统一了输入与输出:任意可得的几何先验(内参/位姿/深度)都能按同一套因子表示喂进模型,于是单个模型支持 SfM、MVS、单目深度、相机定位、深度补全等 12+ 任务、64 种输入组合。
- 尺度解耦是实现通用度量推理的关键:用一个可学习的 scale token 经 MLP 单独预测 metric scale 因子,使模型既能吃「只有 up-to-scale 标注」的数据集训练,又能在有度量先验时输出精确尺度。
- 输入概率训练(input-probability training):训练时以一定概率随机给入各几何模态,一个通用模型即可媲美甚至超过为单一任务专门训练的专家模型,且训练算力更省。
- 可迁移启发:当一个任务族共享底层物理量但输入条件各异时,「把表示因子化 + 随机 drop 输入模态」是用一个前馈模型吃下整族任务的有效范式。
1. 研究背景/问题
传统 image-based 3D 重建被拆成特征匹配、两视图位姿、相机标定、BA、MVS、单目深度等一系列独立子任务串联求解。近期前馈方法(DUSt3R、MASt3R、VGGT、π³ 等)虽把部分子任务统一进一个 transformer,但仍有三大局限:(a) 只吃图像输入、无法利用机器人场景常有的内参/位姿先验;(b) 多预测耦合的 pointmap,需昂贵后处理才能恢复相机与几何,且常有冗余分支;(c) 视角数受限、只建模简单针孔相机、且多数无法输出 metric scale。本文要解决的核心问题是:能否用一个前馈主干,吃任意数量视角 + 任意几何先验子集,直接输出度量级三维重建与相机?
2. 主要方法/创新点
① 整体框架概述
MapAnything 由三大部分构成:多模态编码器把图像与几何先验统一编码进同一隐空间,多视角交替注意力 transformer 在所有视角间传播信息,多个轻量预测头 + scale token 解码出因子化的度量三维输出。其设计动机是:用一套「因子化表示」同时承载可选输入与最终输出,从而既能利用任意几何先验,又能在缺先验时退化为纯图像重建。
② 因子化表示(方法基石)
模型不直接预测 pointmap,而是把每个视角 $i$ 的几何拆成四个分量:局部 ray 方向 $R_i$(等价于相机标定)、沿 ray 的 up-to-scale 深度 \(\tilde{D}_i\)、视角在首帧坐标系下的位姿 \(\tilde{P}_i\)(四元数 $Q_i$ + up-to-scale 平移 \(\tilde{T}_i\)),以及全场景单一的 metric scale 因子 $m$。由这些因子可逐级还原:局部点图 \(\tilde{L}_i = R_i \cdot \tilde{D}_i\),世界系 up-to-scale 点图 \(\tilde{X}_i = O_i \cdot \tilde{L}_i + \tilde{T}_i\)($O_i$ 为 $Q_i$ 对应的旋转矩阵),最终度量三维 \(X_i^{\text{metric}} = m \cdot \tilde{X}_i\)。设计动机:把「计算标定」(ray 方向)和「沿 ray 深度」做成逐视角任务,可由单个稠密头预测;把尺度抽成独立标量,使模型能从只有 up-to-scale 标注的数据集学习。
③ 多模态编码器(输入 → 处理 → 输出)
- 图像分支:用 DINOv2 ViT-G 第 24 层归一化 patch 特征 \(F_I \in \mathbb{R}^{1536 \times H/14 \times W/14}\)。作者对比 CroCov2、DUSt3R encoder、RADIO 等后发现 DINOv2 在下游性能、收敛速度与泛化上最优。
- 稠密几何分支(ray 方向、归一化 ray 深度):用浅层卷积编码器 + pixel-unshuffle(步长 14)投影到与 DINOv2 同样的空间与隐维度。
- 全局非像素量(旋转、平移方向、深度尺度、位姿尺度):用 4 层 GeLU-MLP 投到 \(\mathbb{R}^{1536}\) 后广播到所有 patch。
- 关键解耦:旋转与平移分开编码(兼容只有 IMU/GPS 单独先验的情形);深度与位姿的归一化分开(不假设二者总是成对给入)。尺度因可能极大且跨场景剧变,先做 log 变换再编码。只有当给入的位姿/深度本身是 metric 时才使用其尺度信息。
- 输出:所有编码量经 LayerNorm → 求和 → LayerNorm,得到每视角 token \(F_E \in \mathbb{R}^{1536 \times (HW/256)}\)。
④ 多视角交替注意力 Transformer
把 N 视角 patch token 拼上单个可学习 scale token 后,送入 16 层交替注意力(alternating-attention)transformer(24 头、隐维 1536、MLP ratio 4),用 DINOv2 ViT-G 的后 16 层初始化。首视角 token 额外加一个固定的 reference-view embedding 以标识参考系。作者发现 DINOv2 自带的 patch 位置编码已足够,刻意不用 RoPE(认为它会引入不必要的偏置)。
⑤ 因子化输出预测头
- 单个 DPT 头解码 N 视角 patch token,输出每视角稠密量:ray 方向 $R_i$(归一化为单位长)、up-to-scale ray 深度 \(\tilde{D}_i\)、非歧义深度类别 mask $M_i$、点图置信度 $C_i$。
- 平均池化卷积 pose 头用 N 视角 token 预测各视角在首帧系下的单位四元数 $Q_i$ 与 up-to-scale 平移 \(\tilde{T}_i\)。
- scale token 经 2 层 ReLU-MLP 预测一个标量,再指数化得到 metric scale 因子 $m$。消融(Table 5a)证明这种尺度解耦预测是实现通用度量前馈推理的关键。
⑥ 端到端数据流
一个样本流经路径为:N 张图像(及可选几何先验)→ 各模态编码并逐视角相加 → 拼 scale token → 交替注意力 transformer 融合跨视角信息 → DPT 头出逐视角 ray/深度/mask/置信度、pose 头出逐视角位姿、scale token 出 $m$ → 按因子公式组合还原全局度量三维点云与相机。
⑦ 训练目标
ray 方向与四元数不依赖尺度,直接回归(四元数取 \(\min(\lVert \hat{Q}_i - Q_i \rVert,\ \lVert -\hat{Q}_i - Q_i \rVert)\) 以处理双覆盖)。对 up-to-scale 的深度、平移、点图,沿用 DUSt3R 的尺度归一化做 scale-invariant 监督,并对深度/点图/尺度施加 log 空间损失 \(f_{\log}: x \mapsto (x/\lVert x \rVert)\cdot \log(1+\lVert x \rVert)\)。为防尺度梯度污染几何,用 stop-grad 把度量范数因子写成 $z^{\text{metric}} = m \cdot \text{sg}(\tilde{z})$。总损失(上调全局点图、下调 mask):
\[\mathcal{L} = 10\,\mathcal{L}_{\text{pointmap}} + \mathcal{L}_{\text{rays}} + \mathcal{L}_{\text{rot}} + \mathcal{L}_{\text{translation}} + \mathcal{L}_{\text{depth}} + \mathcal{L}_{\text{lpm}} + \mathcal{L}_{\text{scale}} + \mathcal{L}_{\text{normal}} + \mathcal{L}_{\text{GM}} + 0.1\,\mathcal{L}_{\text{mask}}\]其中 normal 损失与多尺度梯度匹配损失 \(\mathcal{L}_{\text{GM}}\) 只施加于合成数据集(真实数据几何偏粗糙)。所有回归项用自适应鲁棒损失($c=0.05,\ \alpha=0.5$)。
⑧ 输入概率训练(让一个模型吃下整族任务)
训练时以总几何输入概率 0.9 给入先验,其中 ray 方向、ray 深度、位姿各以 0.5 概率独立给入;选中深度时一半概率给稠密、一半给 90% 随机稀疏化的深度;每视角 0.95 概率拥有几何信息;对 metric 数据集以 0.05 概率不给 metric scale。这种随机 drop 输入模态的训练让单模型自然支持 64 种输入组合。模型在 13 个高质量数据集(约 72K 场景的 MPSD 等,覆盖室内/室外/in-the-wild)上以两阶段课程训练(64×H200,约 420K 步)。开源两个权重:6 数据集的 Apache 2.0 版与额外 7 数据集的 CC BY-NC 版。
3. 核心结果/发现
- 多视角密集重建(2–100 视角):仅用图像即在 ETH3D / ScanNet++ v2 / TartanAirV2-WB 上取得 SOTA,超过 VGGT;加入内参/位姿/稀疏深度等先验后,pointmap、位姿、深度、ray 误差进一步显著下降。
- 两视角重建:仅图像输入即 SOTA;加先验后大幅超过唯一同类利用先验的两视图方法 Pow3R(含其 BA 变体)。给全先验(图像+内参+位姿+深度)时点图 rel 低至 0.01。
- 单视角标定:虽未专门为单图训练,平均角误差 1.06° 优于 VGGT(4.00)、MoGe-2(1.95)、AnyCalib(2.01)。
- 度量深度估计(Robust-MVD):多视角仅图像即超过 MASt3R-BA、MUSt3R;加内参/位姿后与专家模型相当。
- 关键消融:① 因子化 RDP & Scale 表示是强重建性能的关键(优于直接 local pointmap、优于 π³ 式解耦设计);② 通用训练 ≈ 专家训练——用等同两个专用模型的算力一口气训 12+ 任务,性能却媲美甚至超过三个分别定制的 bespoke 模型,说明多任务训练高效;③ log 缩放与交替注意力对 50 视角外推至关重要。
- 速度/显存:相比 VGGT、Depth-Anything-3 等并发模型,MapAnything 在 2–500 视角下速度与峰值显存均最优;mem-efficient 变体把稠密头按视角小批循环,几乎不损速度而大幅降显存。
4. 局限性
模型不显式建模几何输入中的噪声/不确定性;当前架构尚未支持「部分视角无图像」(如新视角合成中目标视角只有相机)的情形;输入像素与输出场景表示是一对一映射,限制了对超大场景的可扩展性(场景需更高效的内存表示与按需解码);当前参数化不建模动态运动 / scene flow。
参考
- Paper: MapAnything: Universal Feed-Forward Metric 3D Reconstruction
- Project Page: map-anything.github.io
6.16 Depth Anything 3 (2025)
——— 从任意视角恢复一致的三维几何空间
📄 Paper: arXiv:2511.10647
精华
- 抛弃特化架构的极简建模:DA3 证明了无需复杂的多阶段/多分支流水线或特化网络,仅使用单个 Plain Transformer (DINOv2) 配合双 DPT 头,即可实现任意视图下端到端的位姿与深度联合估计。
- 深度-射线 (Depth-Ray) 极简表征:将相机外参以逐像素三维射线方向和起点隐式建模,通过这种极简表征将场景几何与相机运动完美结合,极大地降低了多任务学习的优化难度。
- 教师-学生蒸馏范式:针对真实世界 3D 传感器捕获的数据中常见的噪声和缺失问题,先在大规模合成数据集上训练单目指数深度教师模型(DA3-Teacher),进而生成高品质伪深度标签,用 RANSAC 尺度-偏移量对齐技术去监督学生模型,极大提升了模型的三维细节还原度。
- 度量级与一致性重建:在位姿估计和几何重建上展现出超越 VGGT 和 Pi3 的优异表现。此外,微调后的前馈 3D 高斯泼溅 (FF-NVS) 头能直接产生高保真得新视角渲染,证明了其作为三维几何骨干的优越性。
1. 研究背景/问题
传统的 3D 几何重建任务(如单目深度估计、多视图立体视觉 MVS、运动恢复结构 SfM、视觉 SLAM 等)通常依赖高度特化的独立模型或复杂的级联架构。尽管有研究尝试多任务统一,但其架构往往存在分支冗余、优化冲突且难以直接复用大规模预训练视觉基础模型(如 DINOv2)的强特征。本文旨在探讨:
- 是否存在一个最小的几何表征目标集,能够同时捕获三维场景结构和相机相对运动,而无需复杂的交织目标?
- 一个没有任何架构定制的 plain transformer 骨干,是否足以胜任这一通用的任意视角几何恢复任务? DA3 通过引入“深度-射线(Depth-Ray)”表征与输入自适应自注意力机制,对这两个问题给出了肯定的回答。
2. 主要方法/创新点
① 整体框架概述
DA3 主要由三部分构成:单个 DINOv2 Vision Transformer 骨干网络、相机条件注入编码器,以及联合输出深度图和射线图的双预测头(Dual-DPT Head)。输入任意视角图像后,网络直接前馈生成像素级对齐的深度图与射线方向/起点,最后通过简单的逐像素计算直接恢复出全局一致的三维度量点云,整体流程极简且计算高效。
② 深度-射线(Depth-Ray)隐式位姿表征
为了避免回归具有严格正交约束的旋转矩阵 $R_i$,DA3 采用了一种新颖的逐像素射线图(Ray Map) $M_i \in \mathbb{R}^{H \times W \times 6}$ 来隐式表达相机位姿。每一像素的射线定义为 $r = (t, d)$,其中平移起点 $t \in \mathbb{R}^3$ 和方向向量 $d \in \mathbb{R}^3$ 均为三维向量,且未归一化的方向向量其模长本身也蕴含了投影尺度。结合对应的深度 $D(u, v)$,物体的三维点坐标直接由下式算出: \(P = t + D(u, v) \cdot d\) 在推理阶段,若需要显式恢复相机参数,则通过求 ray 起点的均值来估计相机中心 $t_c$,并建立与单位相机射线的 homography 矩阵 $H = KR$,使用直接线性变换(DLT)算法求解并进行 RQ 分解,即可高效地分离出相机的内参 $K$ 与旋转矩阵 $R$。
③ 视图自适应交替自注意力
为了适配从单张(单目)到十数张(多视角)不等的输入视图数量,DA3 采用了一种输入自适应的 Token 排列策略。网络分为 $L_s$ 层内部注意力模块(Within-view Attention,捕获单图细节) and $L_g$ 层交替注意力模块(交替在所有视图 of tokens 间进行 Cross-view Attention),通过简单的张量轴置换实现了跨视图的信息交换。若输入只有单张图像,则跨视图模块自动退化,没有额外开销。
④ 共享特征的双 DPT 头(Dual-DPT Head)
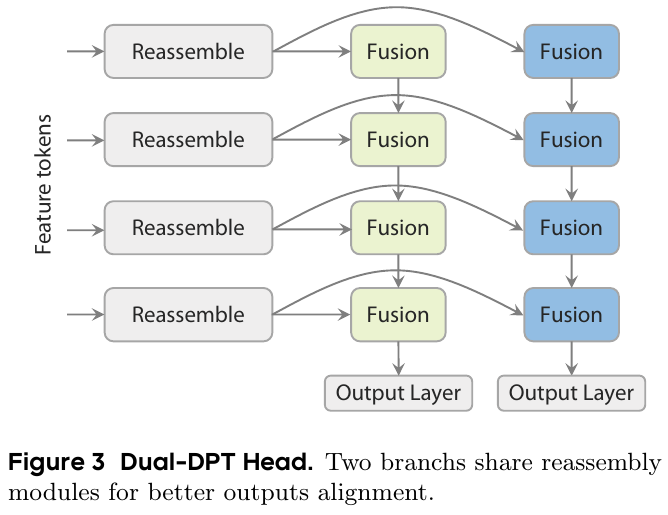
Dual-DPT 头包含共享的 Reassemble 模块与两个独立的融合解码分支。这种共享特征通道的架构促成了深度估计与射线估计之间的强几何共鸣与约束,同时极大地避免了分别使用两个完整 DPT 头所带来的冗余计算和不一致现象。
⑤ 教师-学生蒸馏与 RANSAC 对齐
真实数据(如 LiDAR 和 COLMAP 点云)常包含噪点和空洞。DA3 首先使用纯合成数据集(包含 Hypersim、TartanAir 等 20 个高品质数据集)训练出单目指数深度教师模型(DA3-Teacher),对所有的真实多视图序列预测出稠密的相对深度伪标签。再利用 RANSAC 最小二乘法估计出尺度参数 $s$ 与平移参数 $t$,对齐到真实稀疏/嘈杂深度上: \((s^*, t^*) = \arg\min_{s > 0, t} \sum_{p \in \Omega} m_p \left\lvert s \tilde{D}_p + t - D_p \right\rvert^2\) 最后用对齐后的稠密标签 $D_{T \to M}$ 监督学生网络,使学生模型不仅继承了真实位姿的准确性,还获得了极致清晰的深度边缘细节。

⑥ 联合训练目标
DA3 采用多分支加权联合监督进行优化: \(L = L_D(\hat{D}, D) + L_M(\hat{R}, M) + L_P(\hat{D} \odot d + t, P) + \beta L_C(\hat{c}, v) + \alpha L_{\mathrm{grad}}(\hat{D}, D)\) 其中针对深度的边缘平滑,引入了深度梯度损失: \(L_{\mathrm{grad}}(\hat{D}, D) = \lVert \nabla_x \hat{D} - \nabla_x D \rVert_1 + \lVert \nabla_y \hat{D} - \nabla_y D \rVert_1\)
3. 核心结果/发现
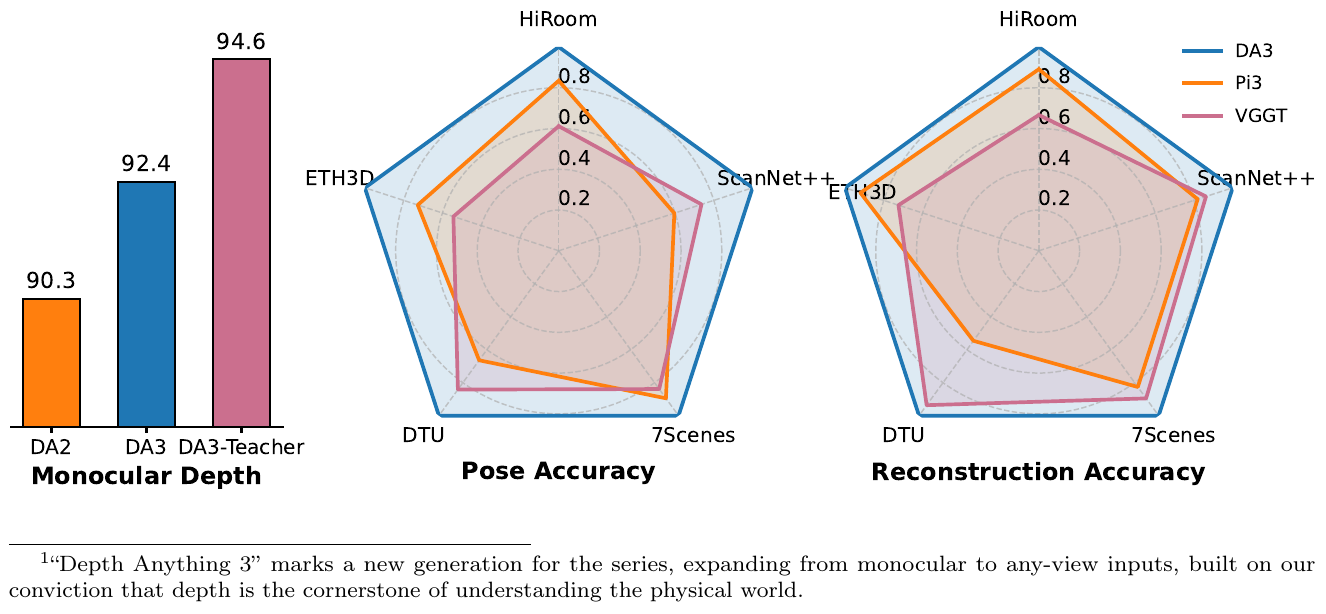
- 更强的相机位姿估计:在 HiRoom、ETH3D、DTU、7Scenes 和 ScanNet++ 五大评测数据集上,DA3-Giant 的位姿 AUC 指标显著超越 DUSt3R、MapAnything、Pi3、VGGT 等基线。在 ScanNet++ 室内场景中,其 Auc3 比 VGGT 领先约 35.7%。
- 极高的重建质量与效率:DA3 在有/无相机位姿输入下均取得了 SOTA 重建 F1 评分。且其参数仅 0.36B 的 DA3-Large 在多个基准上击败了 1.19B 参数量的 VGGT,推理吞吐量(A100 上 78 FPS 对比 VGGT 的 34 FPS)快了 2 倍以上。
- 向下游 3DGS 强力泛化:在大大规模前馈 3D 像素级高斯预测(FF-NVS)任务中,以 DA3 为先验骨干微调的 GS-DPT 头,在 DL3DV、Tanks and Temples 以及 MegaDepth 上的 PSNR/SSIM 渲染质量全面击败了专门设计的端端新视角合成模型。


4. 局限性
对于存在剧烈非刚体变形或大面积动态运动的场景,其像素射线的时序一致性难以得到完美保证;另外,因其纯粹聚焦于物理几何的重建,对跨模态高级语义及控制规律的感知仍需依靠额外的外部网络进行耦合。
参考
- Paper: Depth Anything 3: Recovering the Visual Space from Any Views
- Code: depth-anything-3.github.io
6.17 MuM: Multi-View Masked Image Modeling for 3D Vision (2025)
———多视角掩码图像建模:专为三维视觉任务打造的自监督多视几何特征表征模型
📄 Paper: arXiv:2511.17309
精华
- MuM(Multi-View Masked Image Modeling)将单视图掩码自编码器(MAE)直接推广至同一场景的任意多视角图像序列,是专为三维匹配、深度估计、三维重建等几何任务设计的自监督视觉表征模型。
- 相比依赖“无掩码参考图”的双目 CroCo 模型,MuM 对序列中所有视图执行统一比例的随机掩码(75%),利用交替“帧内注意力”与“跨帧全局注意力”的轻量解码器重建丢失像素,实现了对称且不显式锚定参考帧的简洁架构。
- 这种多视角与单视角混合训练性能,巧妙避开了 CroCo 在数据采样中对重合度(co-visibility)和真值三维几何的严格依赖,使预训练流程更加鲁棒且易于扩展。
- 实验表明,MuM 在前馈三维重建、稠密特征匹配和相对姿态估计等 3D 视觉下游任务中全面超越了 DINOv3 和 CroCo v2,且其预训练所需的计算资源仅为 DINOv3 的 1/30(4,608 A100 小时 vs 161,440 H100 小时)。
- 这一工作的重要启发是:对于需要高精度几何空间特征的三维视觉而言,简单的像素级掩码重建目标在几何特征学习上依然比复杂的语义自监督(如 DINO 系列的对比学习/自蒸馏)更加高效且表现更佳。
1. 研究背景/问题
自监督学习(SSL)在视觉表征上取得了巨大成功(如 DINO 系列),但大多数现有模型的优化目标倾向于高层语义理解,难以有效保留像素级的几何空间结构,在稠密特征匹配和三维重建中表现不佳。为引入三维意识,先前的工作 CroCo 提出了预测“跨视角补全”的策略,但它被严格限制在双目范围且面临苛刻的视场重合采样瓶颈。如何构建一个简单、高效且能自然拓展到任意视角数量的 3D 自监督表征学习模型,成为推动前馈三维重建等下游任务走向通用的关键挑战。
2. 主要方法/创新点
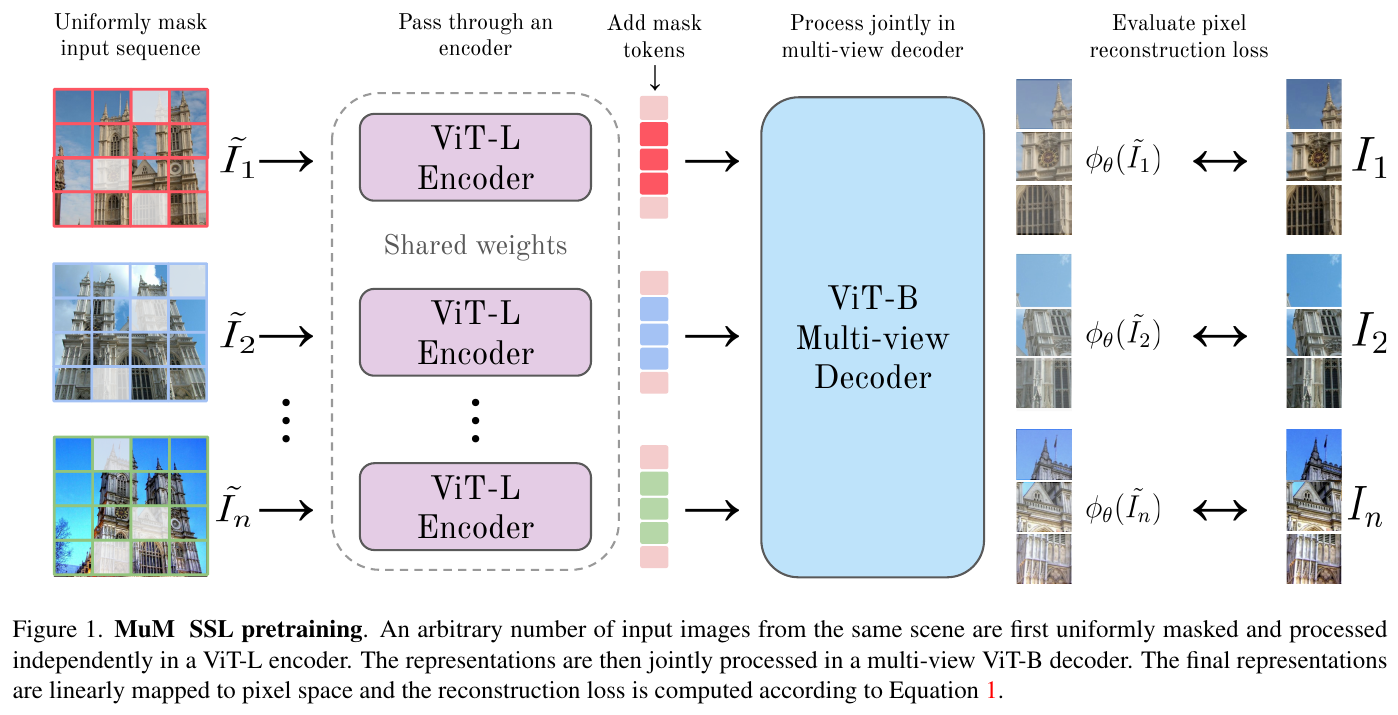
① 整体框架概述
MuM 将经典的单图掩码自编码器(MAE)直接推广到了包含任意数量视图的图像序列。在预训练阶段,对属于同一场景的 $n$ 张图像分别进行独立且对称的随机掩码(75%),其余可见的 Token 分别通过参数共享的 ViT-L 编码器,再将所有视图的掩码 Token 与可见 Token 共同送入一个轻量化的 ViT-B 多视图解码器,通过交替执行的“帧内自注意力”与“跨帧全局自注意力”实现信息融合与多视角联合像素重建。
② 逐模块讲解
-
统一掩码与 ViT-L 编码器: 对于属于同一三维场景的 $n$ 张输入图像序列 \(I = \{I_1, I_2, \dots, I_n\}\),每一张图均被划分为 $N$ 个不重合的 Patch。设定掩码比例 \(\gamma = 0.75\)(即保留 25% 的可见 Token),对所有视图独立地进行掩码处理,仅将可见 Token 送入 ViT-L 编码器(层数 24,通道宽 1024)。所有的视图在编码器阶段使用完全相同的共享权重进行独立前向计算,在此阶段没有跨视图的信息交互。
-
多视图 ViT-B 解码器(Multi-view Decoder): 进入解码器前,将包含可见 Token 特征的序列与对应丢失位置的可学习掩码 Token(Mask Tokens)重新按原空间顺序拼接,并加入现代的二维轴向旋转位置编码(Axial RoPE)。解码器为轻量化的 ViT-B 结构(层数 6,通道宽 768),核心在于其使用的交替注意力机制(Alternating Attention):每一个交替注意力块内,模型先进行帧内自注意力(Frame-wise Attention)(仅在单张视图内部的 Token 之间进行自注意力,限制了跨帧信息的盲目混淆,利于单帧细节保留),紧接着进行全局自注意力(Global Attention)(允许序列中所有视图的所有 Token 进行联合自注意力交互,实现跨视角几何约束传播和多视距离解算)。这种对称式的注意力机制避免了像 CroCo 那样显式指定或锚定某一个“参考帧”,对帧的输入顺序满足置换等变性。
-
线性预测头与重建目标: 在解码器最后一层,所有 Token 被输入到一个简单的线性预测头中,用以回归每个 Patch 对应的归一化 RGB 像素值。相较于未归一化的像素,重建目标采用每个 Patch 局部均值和方差进行归一化,使得重建对局部光照变化更加鲁棒,促使模型专注于几何与纹理结构的恢复。
③ 端到端数据流
在训练阶段,每个批次(Batch)内随机采样一个序列长度 $n \in [2, 24]$(且有 10% 的概率回退至单视角 $n=1$ 的普通 ImageNet-1K 数据)。将序列送入编码器进行特征压缩后,再在解码器中利用交替自注意力将多视图的未掩码 Patch 信息“广播”至其他视图的掩码区域,利用跨视角相似度和视差线索补全丢失的纹理,最后由预测头输出重建图像并计算损失。

④ 训练目标与损失函数
MuM 的自监督预训练损失是定义在各视图掩码区域上的 L2 像素重建损失。形式化地,对于掩码向量记为 $M^i$(掩码区域为 1,可见区域为 0)的第 $i$ 张图,损失函数为: \(L(\theta) = \sum_{i=1}^{n} \lVert M^i \odot (\phi_\theta(\tilde{I}^i) - f(I^i)) \rVert^2\) 其中 \(\tilde{I}^i\) 表示第 $i$ 张图的可见补丁,\(\phi_\theta\) 为 MuM 模型,\(f(I^i)\) 为归一化的真实 Patch 目标。 在下游任务的蒸馏微调中,模型通过监督 VGGT 输出的 3D 世界点坐标 $P$、相机参数 $C$ 和深度图 $D$ 进行学习,损失函数定义为: \(L_{\text{distill}}(\theta) = \sum_{i=1}^{n} ( \lVert P_i^t - P_i^s \rVert^2 + \lVert C_i^t - C_i^s \rVert^2 + \lVert D_i^t - D_i^s \rVert^2 )\) 其中上标 $t$ 和 $s$ 分别表示教师模型(VGGT)和学生模型(MuM-distilled)。
⑤ 推理流程
在应用于特征匹配(如 RoMa 框架)或相对姿态估计等下游任务时,我们通常只保留预训练好的 ViT-L 编码器作为冻结的几何特征提取器,并丢弃解码器部分。直接将 high 分辨率图像送入编码器提取局部稠密特征,即可即插即用地输送给下游的轻量化预测头(如匹配解码器或姿态解算器)。

3. 核心结果/发现
- 多视图前馈重建(Feedforward 3D Reconstruction):
- 冻结编码器评测:在 CO3Dv2、Re10K 和 MegaDepth 等多个数据集上,MuM 作为冻结编码器表现出色。在 Re10K 上的相机姿态估计 AUC@30 达到 50.8%,远超 CroCo v2(27.7%)和 DINOv3(36.7%)。在 MegaDepth 上达到 73.0%(DINOv3 仅 59.3%,CroCo v2 为 60.7%)。
- 蒸馏微调表现:MuM 在 DTU 和 ETH3D 点云估计任务上表现出卓越精度与完整度。
- 双目特征匹配(Dense Image Matching):
- 在 MegaDepth-1500 稠密特征匹配评测中(采用 Linear Probe),MuM 的端到端均方误差(EPE)大幅降至 10.2(DINOv3 为 19.0,CroCo v2 为 27.3),匹配鲁棒性达到 94.2%。
- 在 ScanNet-1500 上,EPE 达到 27.9,优于 DINOv3(28.7)和 CroCo v2(39.0)。
- 结合 RoMa 框架进行全模型训练时,MuM 作为粗特征编码器在 MegaDepth-1500 上的 100-PCK@3px 指标达到 4.0,同样超越了经典的 DINOv2 (4.6) 和 DINOv3 (5.2)。
- 相对姿态估计(Relative Pose Estimation):
- 虽然评测框架略微偏向了拥有双目预训练先验的 CroCo v2,但 MuM 在 MegaDepth、Re10K、BlendedMVS 数据集上的 AUC@5°/10°/20° 均全面优于 DINOv3,并在多数指标上优于或持平 CroCo v2(例如 MegaDepth AUC@5°/10°/20° 分别为 26.7% / 47.0% / 65.0%,而 CroCo v2 仅为 13.9% / 30.0% / 48.0%)。
- 单视图任务(单目深度/法线估计/分类):
- 在单目深度估计(NYUd/KITTI)与表面法线估计(NYUv2)中,MuM 超过了 CroCo v2 和 MAE,但落后于拥有强语义先验的 DINOv3(如 NYUd 深度 RMSE:MuM 0.41 vs DINOv3 0.34)。这说明像素重建目标有利于几何对应,但高层语义分类任务(如 ImageNet 图像分类)依然是语义蒸馏模型(DINOv3)占优(ImageNet 准确率:DINOv3 86.9% vs MuM 70.8%)。

4. 局限性
- 目前 MuM 采用的像素级重建损失在语义特征的刻画上依然偏弱,未来与类似于 DINOv3 的特征自蒸馏(Self-Distillation)目标相结合是进一步提升单目语义理解的有前景的方向。
- 受到计算资源限制,该工作尚无法对预训练数据 and 网络规模做进一步放大,且未能全尺寸复刻 VGGT 或 MapAnything 的前馈重建训练规模。
参考
6.18 VLM³: Vision Language Models Are Native 3D Learners (2026)
———首个仅用标准文本 SFT 让 VLM 掌握高精度单目/多目 3D 空间理解能力的极简框架
📄 Paper: arXiv:2605.30561
精华
- 去特化 3D 设计:证明了标准 VLM(如 Qwen3-VL-4B)在没有任何架构修改、辅助编码器、重度数据增强以及回归损失的前提下,仅依靠纯文本 SFT 就能成为极具竞争力的 3D 学习器。
- 焦距统一机制:通过在输入端统一图像焦距(缩放到相当于 1000 像素焦距),完美解决了传统单目 3D 理解中的相机内参歧义(Camera Ambiguity)问题。
- 高效文本像素参考:将像素坐标归一化到
[0, 2000)空间,避免了 DepthLM 的视觉标记(Visual Prompting)渲染开销,支持在单次推理中打包多点/多区域的查询。 - 数据混合与配比:指出在模型缩放前,合理的混合数据集加权配比对多任务 3D VLM 至关重要,过小的简易数据集在 naive scaling 时极易导致模型过拟合。
1. 研究背景/问题
当前的 3D 空间理解(如单目深度估计、像素匹配、相机位姿估计等)仍主要依赖于专家视觉模型(Expert Vision Models)。这些专家模型通常采用复杂的、任务特异性的网络架构(如多分支解码器、三维高斯过程等)、重度图像几何增强以及复杂的平衡多任务损失(如 L1/MSE 回归损失配合置信度加权等)。虽然 DepthLM 首次展示了 VLM 学习像素级度量深度估计的潜力,但其仍需要对图像进行视觉标记渲染(Visual Prompting),不仅计算开销高,而且难以扩展到多像素查询及多视图空间几何任务(如对应点匹配等)。
本文旨在探究:标准 VLM 是否能在不引入任何特化架构、不改动损失函数和不依赖复杂几何数据增强的条件下,仅通过文本 SFT 并在统一的输入/输出界面下匹配甚至超越专家 3D 视觉模型? 研究表明,只要解决相机内参歧义和高效像素参考机制,并匹配合理的混合数据配比,标准 VLM 即可成为原生且极具可扩展性的 3D 学习器。
2. 主要方法/创新点
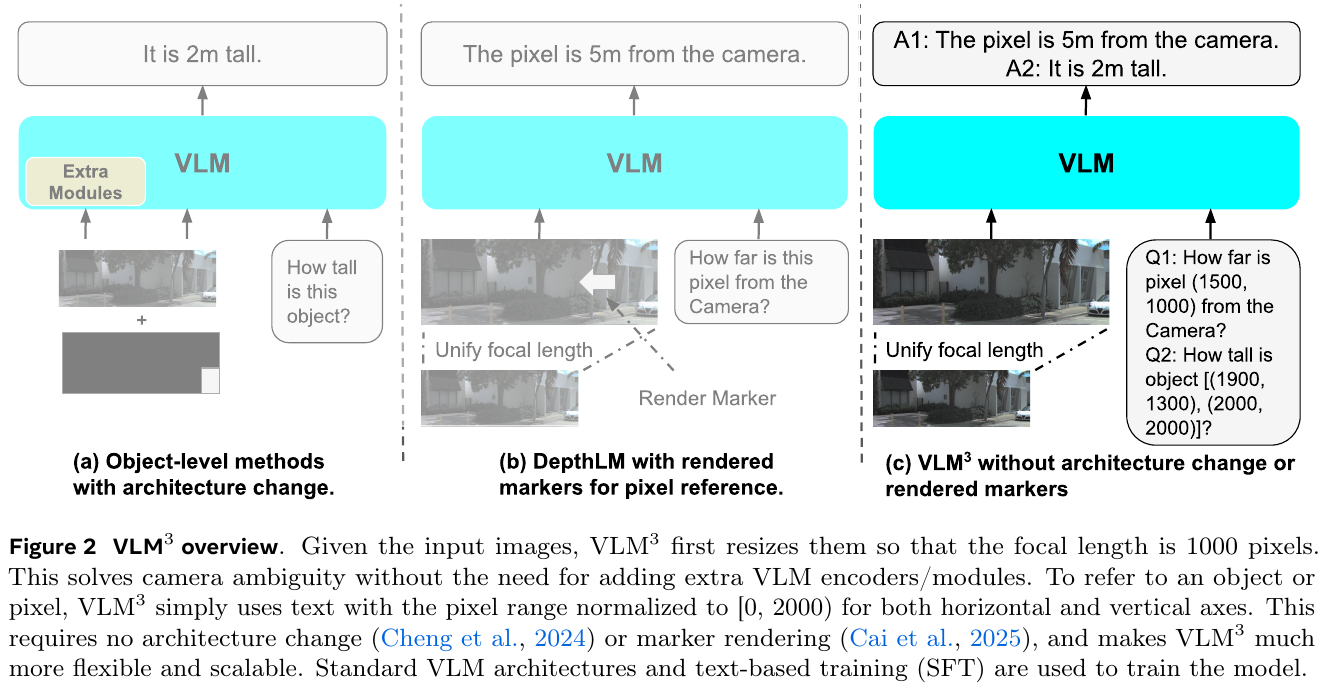
① 整体框架概述
VLM³ 是一个极简且高度可扩展的 3D 空间理解框架。整个系统不改变标准 VLM(如 Qwen3-VL-4B)的任何模型 structure 与预测头,而是将所有单视图/多视图 3D 空间任务统一在焦距统一(Focal Length Unification)、文本像素参考(Text-based Pixel/Region Reference)与多任务数据混合(Data Mixture & Weighting)三大核心设计中,以自回归式的文本生成方式(Next-token Prediction)端到端地解决所有细粒度和粗粒度 3D 空间任务。
② 逐模块讲解
A. 焦距统一模块(Focal Length Unification)
- 输入:包含或不包含相机内参信息的 2D 图像输入。若来自互联网的 unknown source 图像,则先通过预训练的单图相机自标定模型 Anycalib 估计其相机内参。
- 处理:通过双线性插值缩放图像尺寸,使得缩放后图像的等效焦距(Focal Length)精确统一为 1000 像素。
- 输出:焦距被统一归一化后的图像输入送入 VLM 的 ViT 编码器。
- 设计动机:单目 3D 任务(如度量深度估计)在本质上存在尺度歧义(即同一张图,相机焦距不同,对应的物理尺度完全不同)。由于标准 VLM 的 Vision Encoder 无法直接感知内参,若直接混入不同相机的多源数据训练,模型会产生严重混淆。焦距统一将所有内参归一化,彻底消除了相机内参歧义,使混合多源数据集训练变得可行。
B. 文本像素/区域参考模块(Text-based Pixel/Region Reference)
- 输入:在文本 Prompt 中指定需要查询的像素或区域,例如 “How far is the pixel at (x, y) from the camera?”。
- 处理:将图像的分辨率在水平 and 垂直方向均独立归一化到
[0, 2000)的整数坐标空间。无论是输入的像素 $(x, y)$,还是目标的匹配像素 $(x_2, y_2)$,均直接表示为该空间下的文本数字 token。 - 输出:将点坐标或目标框直接在文本 Prompt 中表征或由模型直接生成对应的坐标 token。
- 设计动机:先前的 DepthLM 使用了在图像上画标记(visual prompting)的方案,这意味着每询问 2 个不同的像素深度,就需要把同一张图像复制多份并分别画上不同标记输入模型,这导致训练 16M 样本时极其昂贵。而 VLM³ 采用
[0, 2000)像素空间归一化的文本坐标指示法,移除了视觉标记渲染,支持在单个 Prompt 中打包数十个问题(如同时询问 10 个像素的深度),将图像编码开销降低了数个数量级,使其能轻松扩展到多像素、多任务的大规模 SFT。
C. 多任务数据混合与加权策略(Data Mixture and Weighting)
- 输入:包含单目度量深度估计、3D 物体空间关系、双目/多视图像素匹配、两视图相机位姿估计等多元数据集。
- 处理:研究发现,当训练数据规模从 8M 扩展到 32M/80M 时,如果对各数据集使用均匀权重(Uniform Weights)进行混标训练,会导致模型在较小的简易数据集上极度过拟合,从而导致总体性能出现饱和甚至倒退。VLM³ 引入了基于数据集规模的加权基准(Dataset-size Based Weighting)以及人工精细调整的加权配比(VLM³ Weighting),为易过拟合的数据集分配较小权重。
- 输出:高质量、多任务均衡的训练集数据流。
- 设计动机:VLM³ 并不依赖传统的复杂数据增强(如随机裁剪、亮度及伽马变换等)或架构特化,而是发现数据配比和混合缩放才是提升 3D 通用能力的决定性因素。
③ 任务分支与端到端数据流

- 单视图度量深度估计:
- 输入:单张图像 + 10 个归一化坐标点查询。
- 模型处理:单次前向传播,依次生成 10 个对应像素的度量深度(以米为单位,以文本形式输出)。
- 3D 物体空间几何理解:
- 输入:图像 + 物体 2D 边界框坐标
[xMin, yMin, xMax, yMax]作为文本参考。 - 模型处理:推理输出物体的相对方位(如前后左右)、绝对高度与中心 3D 距离等。
- 输入:图像 + 物体 2D 边界框坐标
- 多视图像素匹配(Pixel Correspondence):
- 输入:左图与右图 + 左图中的查询像素坐标 $(x_1, y_1)$。
- 模型处理:直接以文本形式生成右图中对应的归一化匹配像素坐标 $(x_2, y_2)$。
- 相机位姿估计(Camera Pose Estimation):
- 输入:输入两张视角相近的图像。
- 模型处理:打包预测并输出:① 平移距离(米);② 平移方向(三维单位向量 $[x, y, z]$);③ 旋转方向(自底向上的 Roll、Pitch、Yaw 角,由文本 token 直接表达)。
④ 训练目标 / 损失函数
VLM³ 的一大突出特点是彻底摒弃了 3D 预测常用的 L1、MSE 等连续值回归损失,也没有使用任何特定任务的多损失平衡权重。其训练仅使用标准的自回归文本交叉熵损失函数(Cross-Entropy Loss):
\[L_{\text{SFT}} = -\sum_{i=1}^M \log P(t_i \mid t_{<i}, I)\]其中 $t_i$ 表示第 $i$ 个生成的文本 Token,$I$ 表示输入的归一化图像。所有连续的 3D 数值(如深度、三维向量、角度)都在文本层面表示为数字字符,模型通过离散的文本生成完全拟合出了高精度的连续 3D 结构,开辟了自回归预测 3D 信息的新范式。
⑤ 推理流程
推理时无需任何迭代重投影优化、多级 Warp 匹配或视觉标记多遍编码,仅需按照对应的任务 Prompt 格式将归一化后的图像与问题文本输入 VLM,即可直接在自回归解码中一步获得 3D 空间预测结果。
3. 核心结果/发现

- 单目深度估计比肩专家级模型: 在 NuScenes、ETH3D、SUNRGBD 等 9 个跨域数据集的评测中,VLM³-4B 的平均准确率 $\delta_1$ 达到了 0.904,相较于先前最强的 DepthLM-7B(0.838)取得了巨大突破,并在 NuScenes 和 iBims1 等数据集上超越或匹配了如 MoGe-2、UnidepthV2 等重度优化的专家级深度估计模型,且模型体量更小(仅 4B)。
- 像素对应点匹配(Pixel Correspondence)表现惊艳: VLM³-4B 的终点平均误差(EPE)相比 Qwen3-VL-4B 基准模型下降了 10 倍以上(从 153.28 降至 15.37),性能显著优于传统专家模型 DKM(41.30)和 RoMa(21.88)。
- 相机位姿估计达到 SOTA 级别: 在 ETH3D 和 ScanNet++ 上的 AUC30° 指标从基线 VLMs 的 5.4% 暴涨至 94.0%,在保持标准文本生成接口的情况下,表现直逼专门设计的相机位姿专家模型 DA3-Giant(94.7%),大幅领先 VGGT(88.0%)与 DUSt3R(30.6%)。
- 模型与数据规模的有趣发现:
- 文本坐标不输视觉 Prompt:在 8M 样本下的对比实验表明,采用归一化文本像素参考的深度估计准确率(0.853)甚至略微高于在图像上渲染标记的方案(0.849),且效率极高。
- 小模型性价比极高:在相同训练量下,4B 模型性能(0.904)强于 8B(0.880)和 32B 模型(0.873),表明在当前数据规模下,较大 VLM 模型极易在 3D 特征上发生过拟合,更小、更轻量的 VLM 足以充当高水准的 3D 原生学习器。
4. 局限性
- 对微调数据配比高度敏感:由于不使用特化的几何损失约束,VLM³ 极度依赖精心加权的数据混合比例,如果直接进行均匀的数据量缩放,模型极易发生过拟合,导致性能发生灾难性下降。
- 多视图一致性仍待增强:对于极其复杂或弱纹理的大尺度场景,由于缺乏传统显式 3D 几何投影(如三维重建中的多视图重投影误差约束)或 3D 点云匹配损失的几何强约束,其在严格物理一致性上相比部分定制的多视图专家重建模型(如 UFM)仍有微弱差距(在 TA-WB 上 EPE 为 20.21,弱于 UFM 的 12.56)。
参考
6.19 DepthLM (2025)
———首个与专家级纯视觉模型精度媲美的视觉语言三维深度估计模型
📄 Paper: arXiv:2509.25413
精华
- 打破密集预测头/复杂损失迷信:证明了视觉语言模型(VLM)在不需要任何特定的密集预测头或复杂的深度回归/正则化损失的情况下,仅靠标准的自回归文本生成和极稀疏标注即可达到专家级的绝对深度估计精度。
- 视觉提示(Visual Prompting)解决像素对齐:放弃文本坐标对齐方式,改在图像上直接渲染像素级视觉标记(如微小箭头),显著提升了 VLM 定位特定像素并准确推理其深度的能力。
- 重采样焦距(Intrinsic-conditioned Augmentation)去相机歧义:通过将图像缩放到统一的焦距($f_{uni} = 1000$),解决了跨数据集相机内参不一致导致的绝对尺度歧义,从而具备强大的零样本泛化能力。
- 极稀疏监督微调(SFT)的高效性:发现 VLM 对标注密度的要求极低,即便每张训练图像仅提供 1 个标注像素(16M 样本),其学习到的 3D 理解精度已能抗衡纯视觉模型,说明图像多样性比标注密度更为关键。
- 天然抗边界过度平滑:因为是逐像素独立预测,在不需要任何平滑正则化的前提下,DepthLM 生成的点云天然避免了纯视觉模型中常见的边界飞点(flying points)和物体粘连现象,物体边界极为清晰。
1. 研究背景/问题
- 尽管当前的视觉语言模型(VLM)在高级语义理解上表现出色,但即便最先进的模型(如 GPT-5、Gemini-2.5-Pro)在理解 2D 图像的绝对 3D 深度时仍面临严重瓶颈,其精度 $\delta_1$ 往往低于 0.400,远远落后于纯视觉专家模型(如 DepthPro, Metric3Dv2)。
- 以前的 3D VLM 研究常需添加额外的回归头、深度预测分支,或者蒸馏自其他纯视觉模型。但这导致了设计复杂且容易累积误差。作者提出疑问:能否在不改变 VLM 基础架构、不修改标准文本生成损失的情况下,将 VLM 培养成顶尖的绝对深度估计器?
2. 主要方法/创新点
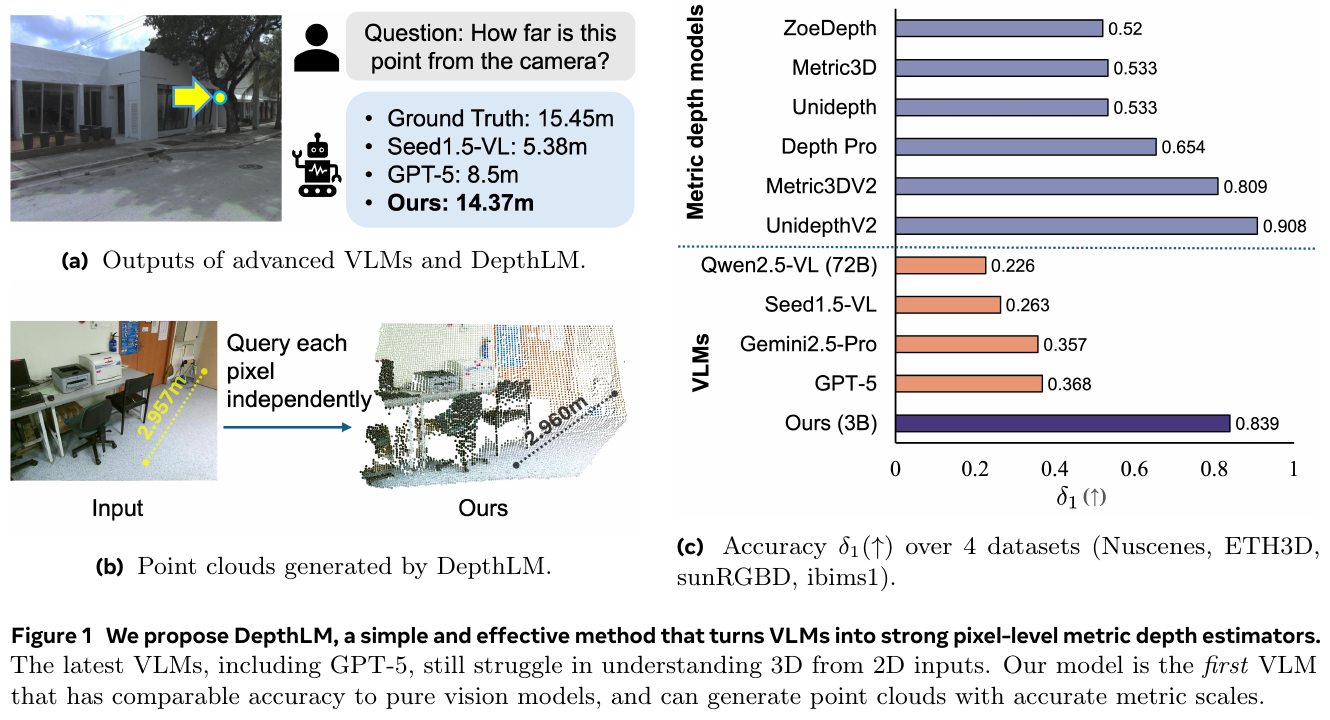
① 整体框架概述
DepthLM 采用标准的 VLM 架构和自回归文本生成范式。其核心思想是,在输入端通过相机焦距归一化消除三维绝对尺度的多相机歧义,在图像空间通过视觉提示渲染引导模型关注特定像素,再通过极稀疏的文本 SFT 训练模型自回归输出距离数值。
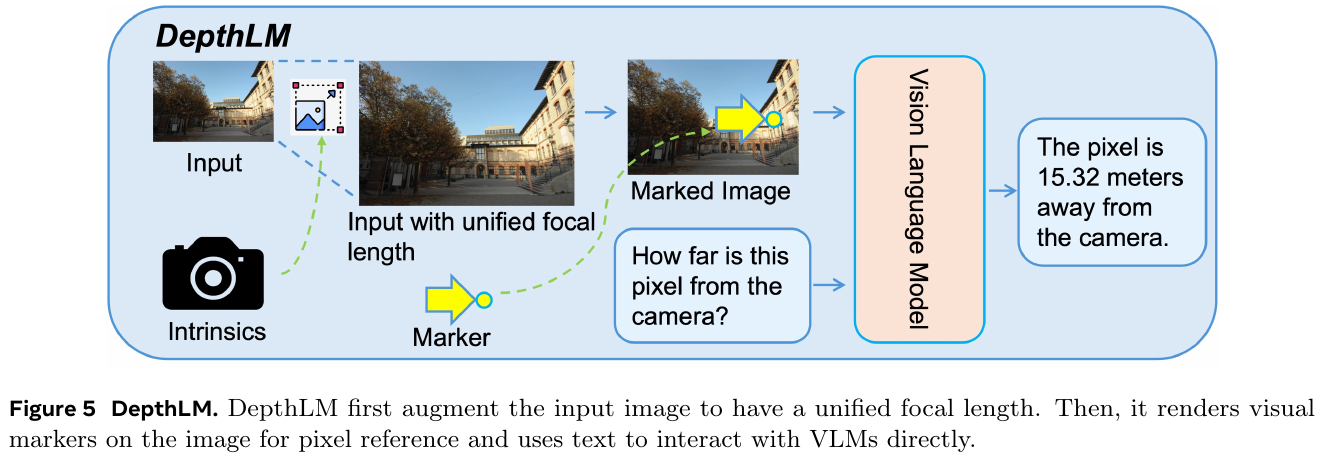
② 逐模块讲解
- 相机焦距重采样 (Intrinsic-conditioned Augmentation):
- 输入:原始输入图像 $I$ 及其相机的焦距内参 $f_x$、$f_y$。
- 处理:为解决不同相机镜头带来的三维尺度模糊,模型根据预设的统一焦距 $f_{uni} = 1000$ 像素对图像进行缩放重采样,缩放后的宽度 and 高度分别为: \(W' = \frac{f_{uni}}{f_x} W\) \(H' = \frac{f_{uni}}{f_y} H\) 在训练时,缩放后的图像还会经过随机裁剪(宽度 $1000 \sim 1400$ 像素,高度 $700 \sim 1200$ 像素)以防止尺寸过拟合。在评估阶段则不需要裁剪。
- 输出:在焦距空间归一化后的图像 $I’$。
- 设计动机:直接将相机内参数值写入文本 Prompt,或让模型先预测相机射线,在 VLM 的注意力机制下都难以有效收敛。而在输入端图像级别统一焦距,能强迫 VLM 隐式学习统一的三维绝对世界尺度。
- 视觉提示 (Visual Prompting):
- 输入:归一化图像 $I’$ 和待查询深度点的像素坐标。
- 处理:在图像的目标像素位置处,渲染一个指向该处的微小标记(通常是 5 像素宽的橙色/红色箭头等)。在文本 Prompt 中配合提问:“How many meters is this point from the camera?”。
- 输出:带有视觉指示箭头的输入图像。
- 设计动机:VLM 没有像传统检测或分割任务那样预设的密集像素格输出空间,如果直接用文字坐标
(X, Y)提问,模型极难实现微观的像素定位,从而导致深度推理偏离到邻近物体上。渲染视觉标记将复杂的“像素-语言”跨模态对齐简化为纯粹的“图像内标记感知”。
③ 训练目标 / 损失函数
- 训练过程采用标准的自回归语言微调(SFT)。答案模板被设为统一的:“The point is around X meters away from the camera.”,其中数值 X 被四舍五入保留两位小数。
- 损失函数:仅使用标准的交叉熵语言损失(Cross-Entropy Loss),在预测的答案 Tokens 上计算: \(\mathcal{L}_{SFT} = -\sum_{i} \log P(t_i \mid t_{<i})\) 实验表明,采用复杂的 GRPO 强化学习算法并以负 $L_1$ 误差作为 Reward 进行训练,虽然能达到相近的精度,但每个样本的计算开销是 SFT 的 8~16 倍,因此 SFT 是规模化训练的最优选择。
④ 推理与多任务扩展
- 单点与点云推理:在推理时,只需将图像缩放、渲染目标点箭头、送入 VLM 推理单点深度。如果要生成点云,则在图像上均匀采 10K 个像素点,独立并行推理这 10K 个点的深度并结合内参反投影即可。
- 多任务联合预测:由于没有绑定深度分支,DepthLM 可以在同一个 VLM 框架下,联合训练并执行主轴距离预测(Principal axis distance)、两点之间绝对距离预测、到达时间预测、到达速度预测以及两帧图像间的相机平移估计(Pose)等任务。
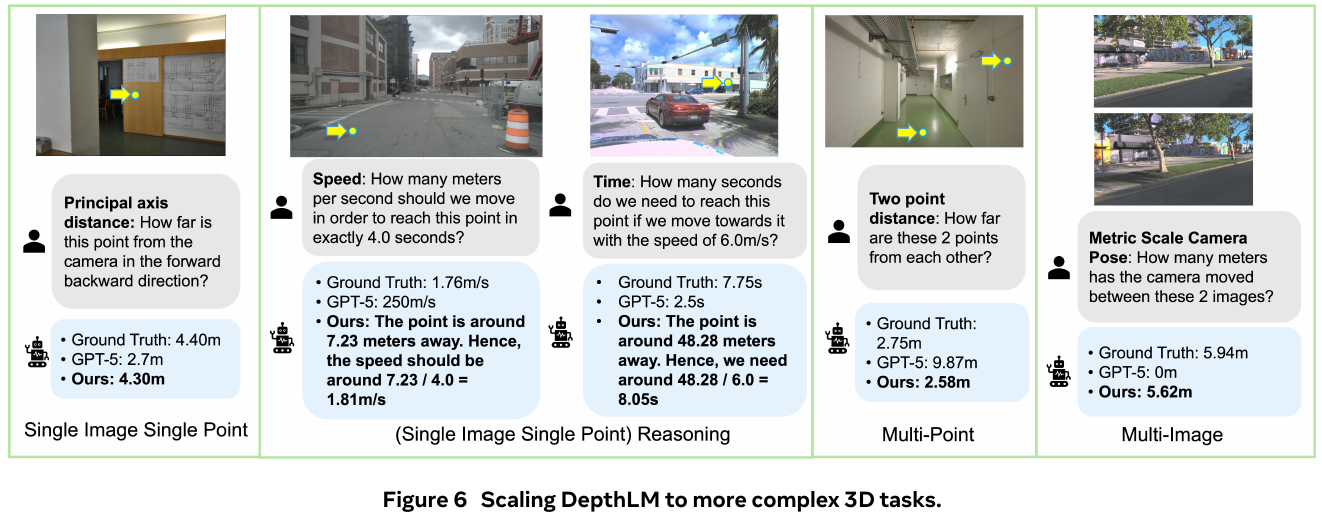
3. 核心结果/发现
- 绝对精度媲美纯视觉模型:在 8 个跨数据集评测(Argoverse2, sunRGBD, ibims1, NYUv2 等)中,基于 3B 和 7B 小尺寸 VLM 的 DepthLM 取得了 0.824 和 0.838 的平均 $\delta_1$(误差在 25% 以内的比例),击败了 DepthPro (0.823) 和 Metric3Dv2 (0.684),达到了与最先进的 UniDepth 相当的精度,而 GPT-5、Gemini-2.5-Pro 在该任务上的精度皆低于 0.400。
- 极其稀疏的标注需求:研究发现,当训练数据从每张图多个点降到仅 1 个点时(但保持 16M 图像多样性),模型性能几乎无损。这表明 VLM 学习 3D 空间感更依赖于场景多样性,而非单张图的标注密度。
- 清晰的三维物边界:定性点云重建分析显示,DepthLM 的点云不存在纯视觉专家模型中因为平滑正则化(如 Smoothness Loss)导致的“边界模糊”和“飞点”问题。物体的边缘界限非常明确(例如细路灯杆、前景与背景的过渡带),这对机器人避障导航非常关键。
- 多任务泛化:联合训练的 7B 模型在 6 个不同的 3D 任务上平均 $\delta_1$ 达到 0.804,而未经针对训练 of Qwen2.5-VL 仅为 0.09,GPT-5 为 0.210。
4. 局限性
- 本文重点在于探索 VLM 极简架构进行三维理解的可行性和基础设计(视觉提示与焦距归一化)。未来的研究方向包括设计更好的自动数据清洗与过滤管道以引入更大规模的数据,以及通过引入更多互补的三维辅助任务进行多任务预训练来进一步提升泛化性能。
参考
- Paper: DepthLM: Metric Depth From Vision Language Models
- Code: github.com/facebookresearch/DepthLM_Official
6.20 RoboRefer (2025)
———首个用于机器人多步空间推理的 3D 感知推理 VLM 模型
📄 Paper: arXiv:2506.04308
精华
- 提出了 RoboRefer,这是首个面向机器人多步空间推理(Multi-Step Spatial Referring)的 3D 感知推理视觉-语言模型(VLM),它能够显式地逐步解析复杂的空间指令并精确定位目标点。
- 在架构上,采用解耦双分支设计,引入一个专用的深度编码器和投影器处理深度模态,避免了共享编码器带来的模态干扰,显著提升了模型对距离、近远关系等 3D 空间线索的感知精度。
- 提出了基于 SFT + RFT(强化微调) 的两阶段训练策略。SFT 阶段引入深度对齐与空间增强,RFT 阶段则采用 GRPO 算法,并设计了对度量敏感的规则化过程奖励函数(Process Reward Functions),在无需大模型打分的情况下实现了对中间推理步骤的精确、无监督引导。
- 构建了 RefSpatial 数据集,包含 250 万样本、2000 万问答对,涵盖 31 种空间关系,支持多达 5 步的复杂空间推理;同时推出了 RefSpatial-Bench 基准,用于评估复杂多步空间推理定位。
- 成功在仿真环境(Open6DOR V2)以及真实机器人平台(UR5 机械臂、Unitree G1 双足人形机器人)上进行了闭环部署,在导航和操作任务中展现出卓越的泛化与动态自适应能力。
1. 研究背景/问题
当前的具身智能机器人虽然在预训练 VLM 的加持下具备了基本的语义理解能力,但在复杂的 3D 物理世界中执行任务时,仍面临以下核心局限:
- 空间感知精度不足:传统的 2D VLM 缺乏直接的 3D 深度感知,而现有的 3D 融合方法要么依赖高成本 of 3D 重建,要么将深度图作为类 RGB 输入输入到共享图像编码器中,这极易导致模态干扰并降低图像编码器的表征能力。
- 缺乏多步空间推理能力:现有的空间定位方法主要针对单步空间关系(如“定位红色的杯子”),但在真实场景中,人类指令往往包含多步关联约束(如“把物体放在笔筒和键盘之间,并与杯子的 logo 对齐”)。目前的 VLM 缺乏显式的思维链(CoT)推理来解析这种长程、多步骤的相对位置定位。
为了填补这一空白,本文提出了 RoboRefer,通过解耦的 3D 结构设计与基于过程奖励的强化学习训练,同时攻克了 3D 空间精确感知与显式多步推理的难题。
2. 主要方法/创新点
① 整体框架概述
RoboRefer 接收包含 RGB(D) 的传感器观测与一段具有多重空间约束的文本指令,首先在自回归解码中显式地输出逻辑推理步骤(如定位各个空间参照锚点并计算相对方向),然后输出最终的目标三维/二维定位坐标点。整个系统在推理时采用类似思维链的格式,先推理再预测动作点。
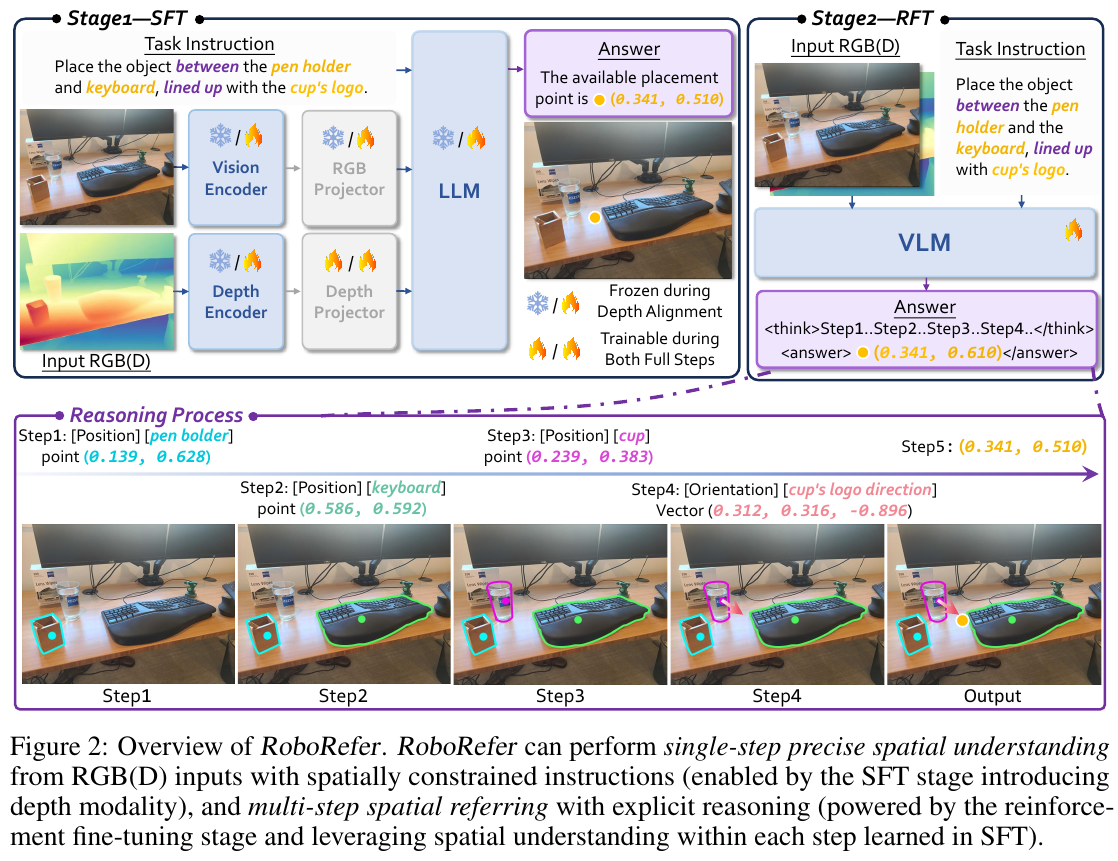
② 逐模块讲解
解耦双分支视觉-深度编码器(Decoupled RGB-D Encoder)
- 输入:RGB 图像 $I_{\mathrm{RGB}}$ 与对应的深度图 $I_{\mathrm{Depth}}$。
- 处理:
- RGB 分支:通过预训练的视觉编码器(如 NVILA 中的 SigLIP 骨干)提取 2D 视觉语义 Token。为了保证通用 VQA 能力不退化,RGB 编码器的参数在深度对齐训练期间保持冻结。
- 深度分支:采用一个独立且专用的深度编码器(结构与 RGB 编码器镜像对称,并由其参数初始化)单独提取深度图像特征。深度特征随后通过专用的深度投影器(Depth Projector)进行对齐。
- 输出:分别生成 RGB 特征 Token 与对齐到文本空间的深度特征 Token,两者拼接后一同送入语言模型。
- 设计动机:避免了将深度数据强行送入 RGB 编码器导致的通道干扰与性能下降,在保留 VLM 原有常识问答能力的同时,显著增强了空间深度信息的表征精度。
大语言模型骨干(LLM Backbone)
- 输入:拼接后的多模态特征 Token(RGB + 深度)以及编码后的空间指令文本。
- 处理:基于 Qwen2 大模型骨干进行自回归推理,不仅支持传统的 VQA,还专门微调以输出显式的推理步骤和定位结果。
- 输出:在 RFT 阶段,输出被规范为包含推理链
<think> ... </think>和最终坐标预测<answer> (x, y) </answer>的统一格式。
③ 两阶段训练策略与训练目标
第一阶段:监督微调 (Supervised Fine-tuning, SFT) SFT 阶段包含两个步骤:
- 深度对齐(Depth Alignment):在 RefSpatial 图像-深度数据集上,仅更新深度投影器,将深度特征空间映射并对齐到大模型的文本语义空间。
- 空间增强微调(Spatial Understanding Enhancement):放开全参数微调,混合 RefSpatial 数据集、指令微调数据集(LLaVA 1.5 等) and 通用 Referring 数据集进行联合训练,使模型初步建立 3D 深度感知与多步推理的“冷启动”能力。其损失函数公式为: \(\mathcal{L}_{\mathrm{SFT}} = -\mathbb{E}_{(\mathcal{O}, \mathcal{Q}, \mathcal{A}) \sim \mathcal{D}} \sum_{t=1}^T \log \pi_\theta(y_t \mid \mathcal{O}, \mathcal{Q}, y_{<t})\)
第二阶段:强化学习微调 (Reinforcement Fine-tuning, RFT) 为解决 SFT 模型容易“死记硬背”推理轨迹而非真正泛化空间规则的问题,RFT 阶段基于 GRPO(Group Relative Policy Optimization) 算法,利用显式推理数据进行训练。
对于输入 $s = (\mathcal{O}, \mathcal{Q})$,模型采样一组响应 ${a_1, a_2, …, a_N}$。每个响应 $a_i$ 获得的综合奖励为: \(r_i = R_{\mathrm{OF}}(a_i) + R_P(a_i) + \alpha R_{\mathrm{PF}}(a_i) + \alpha R_{\mathrm{Acc}}(a_i)\)
其中:
- 格式奖励 $R_{\mathrm{OF}}$:若模型严格遵守
<think> ... </think> <answer> ... </answer>的结构,则给予 1,否则为 0。 - 定位奖励 $R_P$:比较最终预测点与 Ground-truth 坐标,若 L1 距离在 50 像素以内,给予 1,否则为 0。
- 过程格式奖励 $R_{\mathrm{PF}}$:强制推理步骤中的感知步骤遵守
[Perception Type] [Target Object] : [Value]格式(其中感知类型为 Position, Orientation, 或 Size,Value 对应归一化坐标或朝向向量)。 - 步骤准确率奖励 $R_{\mathrm{Acc}}$:利用正则匹配,直接度量中间推理步骤中定位各个锚点坐标的精确度(如 Position L1 距离是否在 50 像素以内),以此提供细粒度的步骤级监督。
通过组内奖励归一化计算相对优势 $A_i$: \(A_i = \frac{r_i - \mathrm{mean}(\{r_j\})}{\mathrm{std}(\{r_j\})}\) 从而更新策略网络,在不需要 Process Reward Model(PRM)打分的前提下,实现规则化的无监督步骤级奖励引导。
3. 核心结果/发现
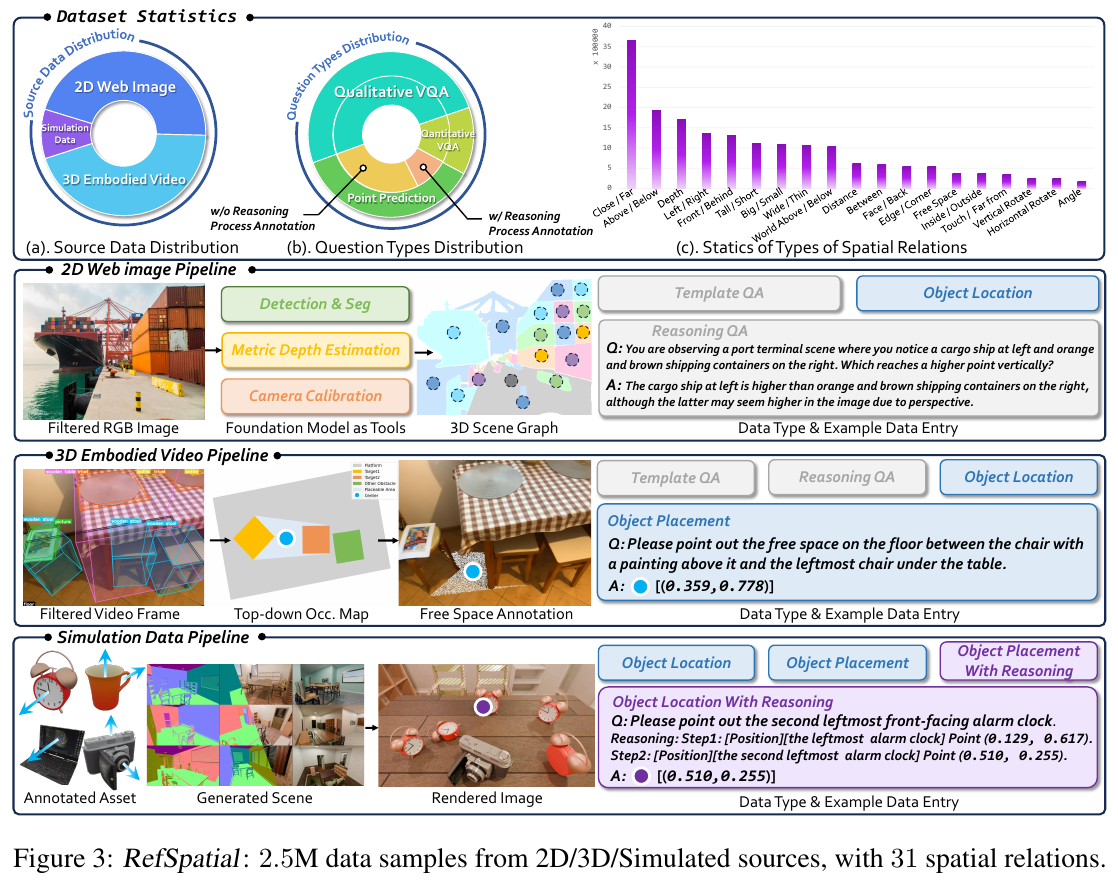
① 基准评测结果
在单步空间理解基准(CV-Bench, BLINK 等)上,RoboRefer-2B-SFT 取得了 89.6% 的平均成功率。 在包含多步复杂推理的 RefSpatial-Bench 评测中:
- SFT 训练的 RoboRefer 大幅超越所有开源基准。
- 引入 RFT(GRPO 过程奖励强化)后,RoboRefer-2B-RFT 表现出极强的逻辑泛化性,在 unseen(未见过的空间关系组合)测试集上相较于 SFT 版本提升了 9.1%,平均精度甚至超越了 Gemini-2.5-Pro 达 17.4%。
② 消融实验与分析
- 解耦深度分支的必要性:消融实验显示,相较于共享视觉编码器的方案,采用独立深度编码器能在空间理解上带来约 5% 的精度提升,并避免了 VQA 常识能力的退化。
- 三源数据融合机制:如上图所示,RefSpatial 数据集融合了 2D 网页数据(丰富感知常识)、3D 具身视频(细化室内深度理解)和仿真生成数据(标注多步 CoT 推理轨迹)。消融研究表明,去除其中任何一部分都会导致模型在特定场景(如户外或多步推理)下性能大幅滑坡。

③ 真实世界部署
在真实世界环境部署中,RoboRefer 被无缝集成进机器人的控制逻辑(如结合 SAM2 进行目标分割并输入 AnyGrasp 预测抓取姿态):
- 动态避障与重规划:在 2.5Hz 的运行频率下,面对人类的随机干扰(如突然移走目标杯子),RoboRefer 能够迅速更新预测点,引导机械臂实现闭环重规划抓取。
- 人形双足协同:在 Unitree G1 双足机器人上部署时,RoboRefer 统一了导航与操作中的相对定位(如下图所示),指导机器人自主走到桌前、定位物体并完成抓取与放置。
4. 局限性
- 深度对准中的累积误差:由于模型预测的是 2D 像素坐标,最终在 3D 空间执行时高度依赖外部相机内参及 monocular 深度估计模型(如 DepthAnything V2)。当相机镜头发生形变或深度估计存在噪点时,定位的 3D 精度会发生漂移。
- 多步推理的计算延迟:GRPO 训练 of CoT 步骤(
<think>标签内内容)往往较长。在需要高频闭环反馈的微秒级控制场景中,自回归文本生成会带来明显的响应延迟(运行频率约 2.5Hz)。
参考
- Paper: RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
- Code: github.com/zhoues/RoboRefer
6.21 Stream3D-VLM (2026)
———基于增量几何先验的在线三维空间理解多模态大模型
📄 Paper: arXiv:2606.06891 · Project Page
精华
- 首个在线三维多模态大模型:突破了传统 3D MLLM 必须输入完整场景或预先剪辑视频的离线限制,实现了直接在实时视频流上的实时三维空间理解与动态交互。
- 自回归流式决策控制:将“何时响应”与“何时保持静默”建模为大模型的下文 Token 预测任务(引入
<SEP>和<END>Token),无需重复编码历史帧,大幅降低计算延迟。 - 轻量级几何先验注入:利用单目视频三维重建模型(StreamVGGT)增量提取相机参数与潜在三维几何特征,通过交叉注意力机制无缝融合进 2D 视觉流,摆脱对昂贵三维点云传感器的依赖。
- 几何自适应体素压缩(GAVC):针对流式长视频带来的视觉 Token 冗余问题,通过三维反投影和三维空间 K-Means 聚类,自适应压缩三维空间内的冗余体素,在保留结构完整性的同时降低 KV 缓存负担。
- 百万级流式 3D QA 数据集与基准:构建了包含 100 万问答对的 Stream3D-1M 数据集及涵盖 29 种任务的 Stream3D-Bench 基准,为流式三维理解提供了首个系统化评测平台。
1. 研究背景/问题
现有的三维多模态大模型(3D LMMs)主要运行在离线(Offline)模式下。它们在与用户交互之前,必须接收完整的 3D 场景观测(如 3D 点云、Mesh 网格)或者一段预先剪辑好的静态视频。这种“先看完、后回答”的范式无法满足具身智能、AR/VR 智能眼镜等实际应用中对流式实时交互的需求,例如机器人在移动过程中需要实时识别并避开障碍物、估计物体的物理尺寸,或者在目标物体出现时主动发出提醒。
虽然在 2D 视频理解领域已有部分流式视频大模型(如 VideoLLM-online),但它们缺乏对三维世界物理几何结构的建模(如物体间的三维距离、物理大小、相机的真实三维轨迹等)。即使在这类 2D 流式大模型上进行大规模 3D 数据微调,其三维空间推理能力依然较弱。因此,迫切需要设计一种能够同时兼顾流式实时决策与三维空间几何建模的通用三维多模态大模型。
2. 主要方法/创新点
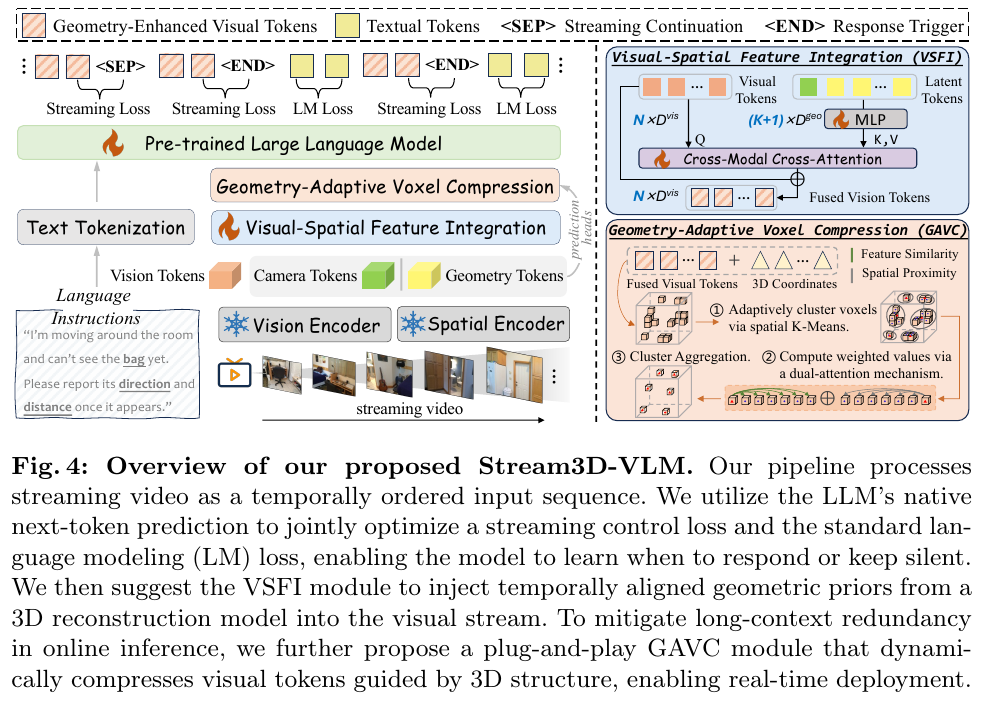
① 整体框架概述
Stream3D-VLM 将流式视频处理为时间有序的帧序列输入。它基于大模型的自回归特性,将流式决策(继续等待还是立即应答)与传统的语言生成统一为下一个 Token 预测任务;利用轻量级的视觉-空间特征集成(VSFI)模块将三维重建模型(StreamVGGT)输出的在线几何与相机特征注入到 2D 视觉特征中;并在推理阶段采用几何自适应体素压缩(GAVC)模块,动态对三维体素进行空间聚类以实现无损的视觉 Token 压缩,保障实时部署。
② 逐模块讲解
- 自回归流式控制建模 (Streaming Control Modeling)
- 输入:当前帧图像、历史上下文、用户查询。
- 处理:在大模型词表中引入两个特殊的决策控制 Token:
<SEP>(Streaming Continuation,代表流式继续,模型保持静默,继续读取下一帧图像)和<END>(Response Trigger,代表触发响应,模型停止读取新帧并开始输出文本答案)。 - 输出:决策 Token(
<SEP>或<END>)以及文本响应内容。 - 设计动机:避免了离线模型每次新输入帧都要对全部历史做一次重新前向推理的高延迟,使得模型能够像人类一样,边看边想,在信息不充足时保持沉默等待,在信息足够时立刻应答。
- 视觉-空间特征集成 (Visual-Spatial Feature Integration, VSFI)
- 输入:原始 RGB 帧图像 \(I_t\)。
- 处理:
- 使用大模型原生的 2D 视觉编码器提取 2D 视觉特征 \(H^{2D}_t\)。
- 并行使用流式三维重建网络 StreamVGGT 提取当前帧对应的三维几何特征 \(G_t\) 和全局相机 Token \(c_t\)。
- 利用一个 2 层 MLP 将三维特征投影至大模型嵌入空间以对齐特征维度: \(H^{3D}_t = \text{MLP}([c_t; G_t])\)
- 以 2D 视觉特征 \(H^{2D}_t\) 作为 Query (Q),投影后的 3D 几何特征 \(H^{3D}_t\) 作为 Key (K) 和 Value (V),通过堆叠的交叉注意力(Cross-Attention)块进行融合,并使用残差连接保留 2D 语义信息: \(H^f_t = \text{softmax}\left(\frac{(W_Q H^{2D}_t)(W_K H^{3D}_t)^\top}{\sqrt{d_k}}\right) (W_V H^{3D}_t) + H^{2D}_t\)
- 输出:几何增强的视觉特征 \(H^f_t\)。
- 设计动机:将 3D 重建模型的隐式三维结构先验动态注入到 2D 图像特征中,使得模型在无需真实 3D 雷达/点云输入的情况下,仅凭单目视频也能实现精准的三维测距和空间感知。
- 几何自适应体素压缩 (Geometry-Adaptive Voxel Compression, GAVC)
- 输入:几何增强的视觉特征 \(H^f_t\)、深度估计图 \(D_t\)、相机内外参 \((K_t, E_t)\)。
- 处理:
- 三维体素构建:将 2D 图像块的坐标 \((u_j, v_j)\) 通过深度 \(D_t(u_j, v_j)\) 和相机参数投影到三维空间,计算其 3D 位置 \(p_{t,j}\)。使用正弦位置编码将其与特征融合,构建带有三维坐标的体素:\(v_{t,j} = H^f_{t,j} + \text{PE}(p_{t,j})\)。
- 动态空间聚类:在 GPU 上对三维点云坐标进行并行的空间 K-Means 聚类,将 \(N\) 个体素划分到 \(K\) 个空间紧邻的聚类簇中。
- 双重注意力聚合:在每个簇内部,根据特征相似度(余弦相似度)和空间邻近度(高斯径向基函数距离)计算加权权重 \(w_j\),对簇内体素做加权值聚合,得到代表该簇的压缩后视觉 Token。
- 输出:空间压缩后的高拟真三维体素 Token。
- 设计动机:流式推理会导致视觉 Token 随着帧数累积呈线性增长。传统的 2D 压缩忽略了三维场景的空间关联(例如桌子的多个局部图像块在空间上是连通的),GAVC 利用 3D 几何邻近性将空间聚集的斑块融合成单个体素,既保护了三维结构,又极大地降低了长视频推理的延迟与显存占用。
③ 端到端数据流
在系统运行过程中,输入视频帧以默认 1 FPS 的速度流式传入。每一帧先经过三维重建模块获取深度和相机参数,将当前帧的 2D 图像特征与 3D 几何特征交叉融合后输入 GAVC 模块进行 3D 空间自适应压缩,然后拼接入大模型的 KV 缓存(KV Cache)。模型在每个帧的时间步自回归预测下一个控制 Token:若预测为 <SEP>,则等待并读入下一帧;若预测为 <END>,则启动文本生成网络输出对用户查询的回答。
④ 训练目标 / 损失函数
为了使模型能够同时学会“何时应答”与“如何应答”,采用了混合训练损失。在训练过程中,对控制 Token 和文本 Token 进行了联合监督:
\(L = \lambda L_{stream} + L_{LM}\)
其中,\(L_{stream}\) 是针对决策控制 Token(<SEP> 与 <END>)交叉熵损失的平均值,而 \(L_{LM}\) 是大模型标准自回归文本生成的交叉熵损失,比例因子 \(\lambda\) 经验上设定为 2.0。
3. 核心结果/发现
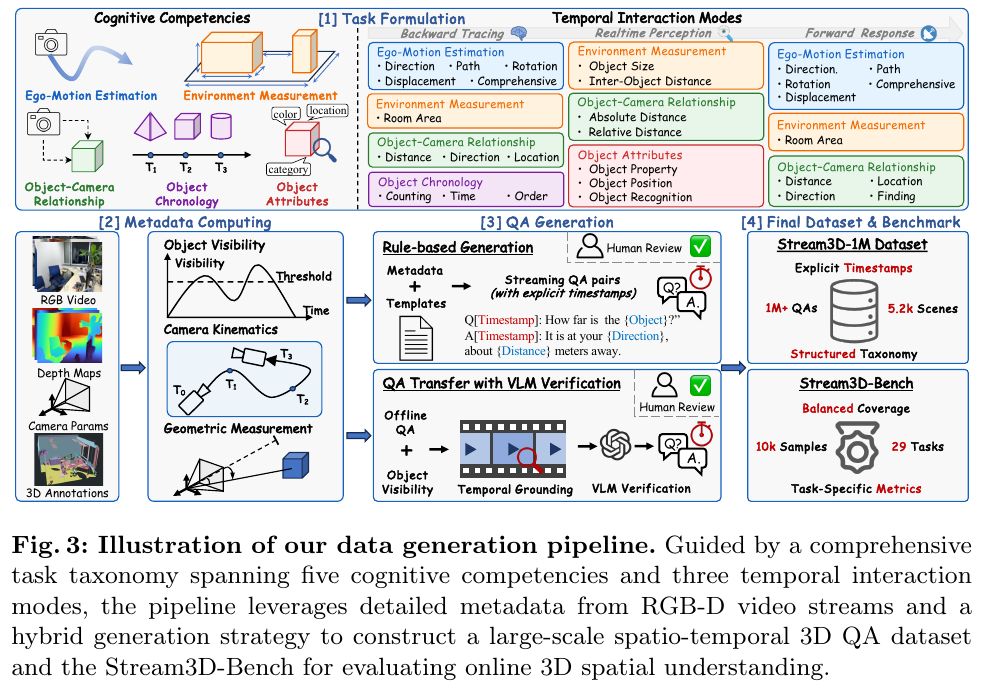
- 在线空间理解领先:在 Stream3D-Bench 上,Stream3D-VLM 8B 取得了平均 58.8% 的高分,不仅大幅超越了现有的开源 2D 流式大模型(Qwen2.5-VL-7B 微调后仅为 47.8%),也明显超过了 GPT-4o(28.0%)和 GPT-5(35.0%)等商业多模态闭源模型。
- 出色的响应时机与极低延迟:得益于 GAVC 的体素压缩和流式自回归决策,Stream3D-VLM 8B 在响应时间精确度(ATA)上达到了 86.7%。同时,其首字生成延迟(TTFT)仅为 62ms,端到端延迟低至 0.39s,显存占用比其他开源基线大模型低 20%~60%,非常适合在算力受限的机器设备上进行实时在线部署。
- 离线推理与下游应用泛化能力强:即使在传统的静态离线 3D 推理基准(VSI-Bench)以及 ScanQA(问答)、ScanRefer(物体定位)、Scan2Cap(密集描述)等下游评测任务中,Stream3D-VLM 依旧在没有真实点云输入的情况下超越了大部分使用显式 point cloud/mesh 训练的离线 3D 大模型(如 3D-LLM、LEO 等)。
4. 局限性
- 依赖深度重建前置模块:模型的空间几何感知依赖于前置的 StreamVGGT 的估计精度。当视频中出现极端的动态模糊、剧烈相机晃动或大面积无纹理区域时,几何特征可能失真,进而影响测距和空间定位的准确性。
- 缺乏多轮对话的决策可回溯性:目前的流式决策是自回归单向进行的,一旦模型在某帧预测了
<SEP>(继续静默)导致错过了最佳答题点,便无法回溯重新决策,未来需要引入软性的流式置信度回溯机制。
6.22 MDM: Masked Depth Modeling for Spatial Perception (2026)
——— 基于遮蔽深度建模与海量 RGB-D 数据的通用三维空间几何感知底座
📄 Paper: arXiv:2601.17895 · Project Page · Code
精华
- 遮蔽深度建模(MDM):将商用深度相机常见的几何和外观歧义(如镜面反射、低纹理、复杂光照等导致的深度缺失)视为一种天然的遮蔽(Masking)信号,并以此构建自监督预训练任务,而不是将其作为噪声丢弃。
- 通用的几何表示底座:通过统一单目深度估计与深度图补全(Depth Completion)两大任务,基于 ViT-Large 主干网络实现了极强的跨模态(RGB 和 Depth)几何表征对齐,在测试集上能够跨越两种任务输出一致的度量深度预测。
- 海量多模态数据集:构建了包含 200 万真实世界捕获和 100 万仿真渲染的多模态 RGB-D 训练集,其中真实数据利用多相机红外(IR)立体匹配生成伪深度监督,并结合 7 个公开数据集形成 1000 万规模的预训练语料。
- 即插即用的感知先验:在无显式时序监督下,展示了出色的零样本(Zero-shot)视频深度补全一致性,能够作为强几何感知先验即插即用集成到 3D 点跟踪(SpatialTrackerV2)与灵巧手操作策略(DP3)中。
- 硬件性能超越:在深度补全和度量级单目重建的多项基准上,LingBot-Depth 在深度精度和像素覆盖率上均优于现有的商业 RGB-D 相机(如 Orbbec, RealSense 等硬件本身自带的算法)以及经典的深度估计大模型。
1. 研究背景/问题
精确的三维世界几何感知(绝对度量尺度、像素对齐的稠密几何、实时获取)是具身智能和机器人控制的基石。RGB-D 相机是实现这一目标最可行的低成本方案,但在现实场景中,受限于硬件限制、表面材质(如透明、强反射镜面)或低纹理等条件,传感器往往会产生严重的局部深度数据缺失(即深度图上的“孔洞”)。以往的工作要么将这些缺失区域视为废弃的噪声,要么依赖于测试时耗时的迭代优化或单对图像前馈对齐。本文提出了一场范式转变:将传感器天然失效导致的缺失区域解释为遮蔽建模中的“天然 Mask”,以自监督的形式强迫模型结合完整的 RGB 图像上下文,推断和重构缺失的度量深度值,以此学习稳健的空间几何表征。
2. 主要方法/创新点

① 整体框架概述
MDM(Masked Depth Modeling)框架采用 Encoder-Decoder 结构,使用 Vision Transformer(ViT-Large)作为骨干编码器,并结合分层卷积解码器(ConvStack)进行稠密几何预测。它的核心流程是:分别提取 RGB 图像和带缺失值的 Sensor Depth 的 patch token,将它们混合后输入 ViT 编码器学习跨模态的联合特征,最后在解码阶段丢弃深度 latent token,仅利用 RGB token 和全局上下文恢复出完整、密集的绝对度量深度图。
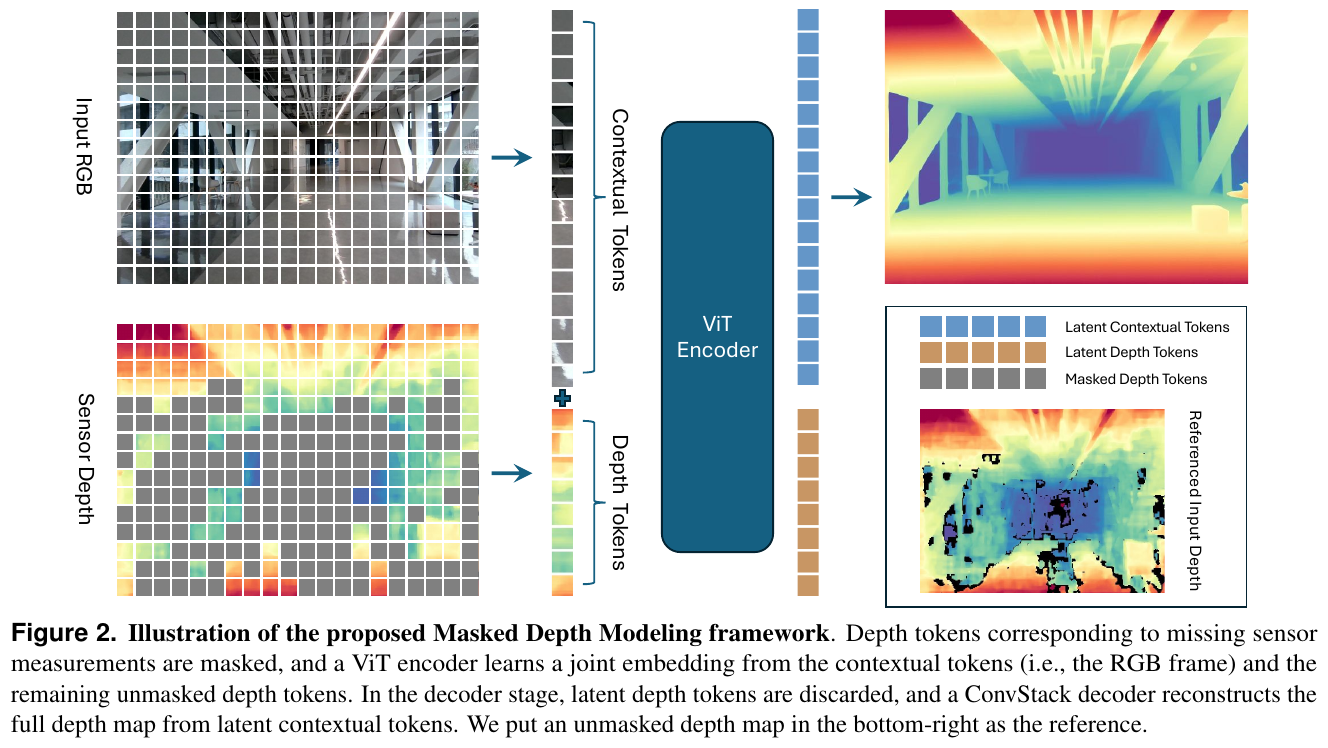
② 逐模块讲解
(a) 分离式 Patch Embedding
- 输入:3 通道 RGB 图像 $I \in \mathbb{R}^{3\times H\times W}$ 与单通道原始深度图 $D_{raw} \in \mathbb{R}^{1\times H\times W}$。
- 处理:应用两个独立的 Patch Embedding 层对两种模态进行降采样投影,Patch 大小设为 14(遵循 DINOv2 规范)。RGB 图像和深度图均投影为 spatially aligned 的 $N = HW/14^2$ 个 Token。
- 输出:RGB 图像 token 序列 $c_i \in \mathbb{R}^n$ 与深度图 token 序列 $d_i \in \mathbb{R}^n$,其中 $n$ 为 Token 嵌入维度(ViT-L 为 1024)。
- 设计动机:分离的 Patch 嵌入层使自注意力层能够直接在网格级交叉学习 RGB 的外观上下文与深度的局部几何,融合近远关系、共面性以及空间连续性等几何特征。
(b) 混合位置编码(Positional Embeddings)
- 处理:由于输入由 RGB 和 Depth 两种模态组成,且具有空间对应性,模型设计了双重位置编码:
- 空间位置编码:RGB 和 Depth 共用一套可学习的 2D 空间位置编码,绑定图像坐标系;
- 模态嵌入编码(Modality Embedding):用于标识输入源,RGB token 加 1,Depth token 加 2。
- 输出:最终输入 Token 为原始投影与空间位置编码、模态编码的求和结果,之后再送入 Attention block。
- 设计动机:帮助 Transformer 隐式感知像素的空间位置,并能清晰区分哪些是外观表示,哪些是测量的粗糙深度。
(c) 天然失效诱导的遮蔽策略(Masking Strategy)
- 处理:在输入 ViT 之前,对深度 Token 实施高比例 Mask(60%–90%),而 RGB Token 保持 100% 可见。Mask 策略分为三个部分:
- 完全缺失区域:深度图上完全无测量值的 patch 必须 100% 进行 Mask;
- 混合测量区域:若 Patch 内包含部分失效值,则赋予较高的 Mask 概率(训练中设为 0.75);
- 随机掩码补充:若上述失效导致的 Mask Token 数量不足以达到目标掩码率,则随机抽取完全有效的深度 Token 进行掩补,确保总 Mask 率维持在 60%–90%。
- 设计动机:传感器天然缺失区往往与高难度的三维外观(强反光、无纹理)直接相关,具有强烈的归纳偏置。通过这种非随机的“天然 Mask”机制,迫使网络必须通过复杂的 RGB 上下文线索来重建深度,显著提升了网络对几何退化区域的推理能力。
(d) ViT-Large Encoder
- 输入:未被 Mask 的深度 Token 与全量 RGB Token 的拼接序列,以及 1 个全局
[cls]token。 - 处理:输入包含 24 层自注意力块的 ViT-Large 编码器。
- 输出:仅保留最终编码层输出的 Latent Token 进行后续预测,不再混合中间层的特征(与 DepthAnythingV2 等多层融合不同,极大地简化了网络设计)。
(e) ConvStack 解码器
- 输入:编码后的 Latent 图像 Token 以及全局广播并加和的
[cls]token。关键操作是:在解码前将深度 Latent Token 直接全部丢弃,只利用 RGB 关联的上下文 Token 重建深度。 - 处理:采用基于 MoGe 的分层卷积解码结构(ConvStack),通过残差块和转置卷积(Kernel size = 2, Stride = 2)将特征图从低分辨率逐级上采样到 $16\times$ 分辨率。在每个尺度中,注入基于图像坐标圆形映射的 UV 位置编码以维持比例和布局。
- 输出:双线性插值还原至原分辨率的稠密深度预测 $D^{pred}$。
- 设计动机:在 vanilla MAE 中采用的浅层 Transformer 解码器在稠密几何重建中容易产生边界模糊和伪影,而 ConvStack 卷积堆叠结构更适合预测高保真的局部分类和连续边界信息,从而极大提升重建的平滑度。
③ 训练目标与损失函数
模型训练时,仅针对 ground-truth 深度图中有效像素计算 L1 损失,以避免未标定或缺失的背景像素干扰优化:
\[L_{depth} = \frac{1}{\sum_i M^{gt}_i} \sum_i M^{gt}_i \lvert d^{pred}_i - d^{gt}_i \rvert\]其中 $d^{pred}_i$ 和 $d^{gt}_i$ 分别表示第 $i$ 个像素的预测深度值与真实深度值,而 $M^{gt}_i \in {0, 1}$ 是指示真值深度在第 $i$ 个像素是否有效的二值掩码。
3. 核心结果/发现
- 深度补全(Depth Completion):
- 在 Protocol 1(块遮蔽与模拟噪声)基准上,LingBot-Depth 表现出极强的噪声鲁棒性,在 iBims、NYUv2、DIODE 数据集上的 RMSE 相比当时最好的方法(PromptDA)降低了 40% 以上(如在 iBims Extreme 难度下 RMSE 为 0.345 对比 PromptDA 0.607)。
- 在 Protocol 2(稀疏 SfM 输入,ETH3D 数据集)中,在没有完整边界条件的前提下,RMSE 分别在室内和室外降低了 47% 和 38%,验证了其在稀疏几何输入下的极限重构能力。
- 单目深度估计(Monocular Depth Estimation):
- 在 MoGe-2 架构中,将初始化的 DINOv2 替换为 MDM 预训练的 ViT 权重,在不修改解码器结构的前提下,测试的 10 个跨域基准指标获得全面提升。这证明了经过 Masked Depth 训练的编码器已经能够很好地将度量几何先验吸收进语义 token 中,从而显著增强了纯单目 RGB 的空间感知上限。
- 下游应用 1:视频深度补全与 3D 点跟踪:
- 虽然 MDM 仅基于静态图像训练,但在视频序列上展现出卓越的时序一致性。将其作为 Drop-in 的深度估计模块嵌入 SpatialTrackerV2(替代传统的 VGGT 前端),能在玻璃表面等强干扰场景中提供非常平滑、精准的深度估计,大幅消除轨迹漂移并提高了 2D/3D 轨迹预测的效率。
- 下游应用 2:具身灵巧手抓取:
- 将 LingBot-Depth 结合基于点云输入的 3D 扩散策略(DP3 架构),在六自由度 Rokae XMate-SR5 机械臂与灵巧手(X Hand-1)系统上进行物体抓取。在面对不锈钢杯、透明玻璃杯、透明收纳盒、玩具车四类高反射/透明挑战性物体时,利用 LingBot-Depth 提供的稠密点云,抓取成功率相比原始传感器深度显著提升(例如:透明收纳盒在原始传感器深度下完全无法建立点云导致 N/A 失败,而使用 LingBot-Depth 后抓取成功率达到了 50%)。
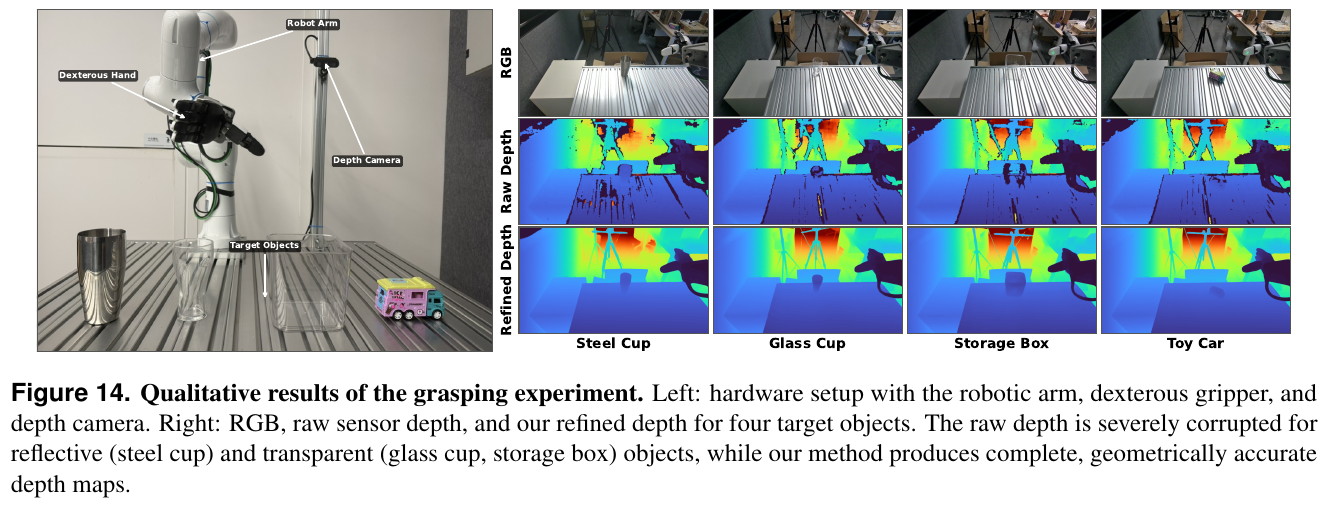
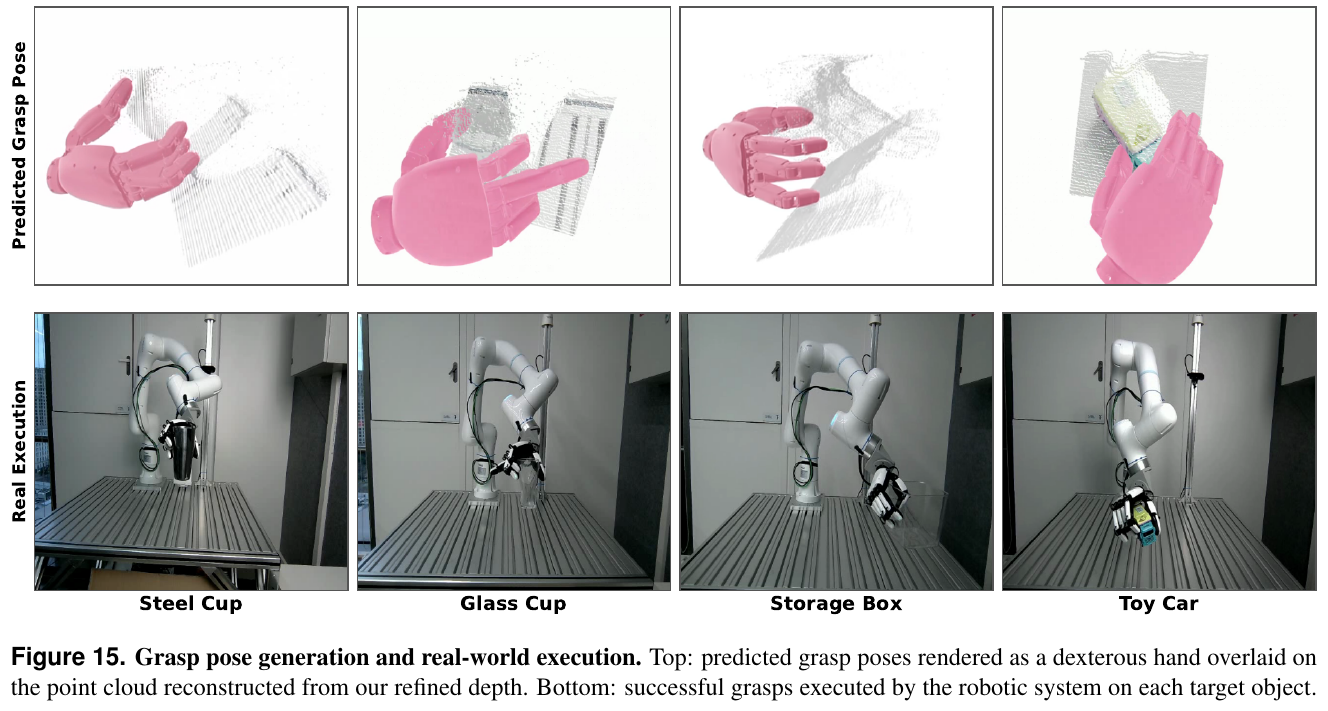
4. 局限性
- 极端透明表面的伪影:尽管抓取成功率翻倍,但在面对极薄、大面积纯透明介质(如某些特定角度的玻璃杯边缘)时,LingBot-Depth 的重构深度仍可能存在轻微的几何收缩与边缘退化。
- 高算力与时延限制:前向推理主要依赖于大型 ViT-L 编码器,在目前嵌入式机器人端上(如 Jetson Orin)部署时,如果不进行 TensorRT量化与剪枝,其帧率表现难以直接满足极高动态避障的要求。
6.23 G2VLM (2025)
——— 融合三维几何重建与空间语义推理的多模态大模型
📄 Paper: arXiv:2511.21688
精华
- 三维重建与空间语义桥接:G2VLM 首次在统一的多模态大模型中,将低级三维几何重建与高级空间语义推理进行深度结合。
- 解耦的双通路设计:借鉴人类视觉的“双通路假说”,采用 Mixture-of-Transformer-Experts (MoT) 架构将几何感知专家(DINOv2 + 3D 几何解码头)与语义感知专家(Qwen2-VL)进行解耦与独立设计。
- 表示层的双向交互:引入共享自注意力机制,使底层的几何表征与高层语义特征在 Transformer block 内部进行双向检索与深度对齐。
- 高泛化与扩展性:在第二阶段空间推理联合微调时,即使选择冻结几何专家(仅利用廉价视频/推理数据优化语义专家),也能在下游高级空间推理任务中表现出优异的性能,展现极好的泛化前景。
1. 研究背景/问题
现有的多模态大模型(VLM)在三维物理世界感知与空间几何推理任务上表现出严重的短板。以往的大模型多把多图或视频帧“扁平化”地当作一维序列,传统方法也缺失了能将 2D 特征“升维”成连贯 3D 表示的显式三维几何学习过程。而专门的 3D-VLM 架构又重度依赖高昂、难以获取的 3D 实景扫描标注,导致训练无法像通用 VLM 那样有效扩展。如何将高效的低级 3D 重建先验与通用的 VLM 语义表示相结合,且保持极佳的扩展性,是空间智能走向通用具身 AI 的关键门槛。
2. 主要方法/创新点
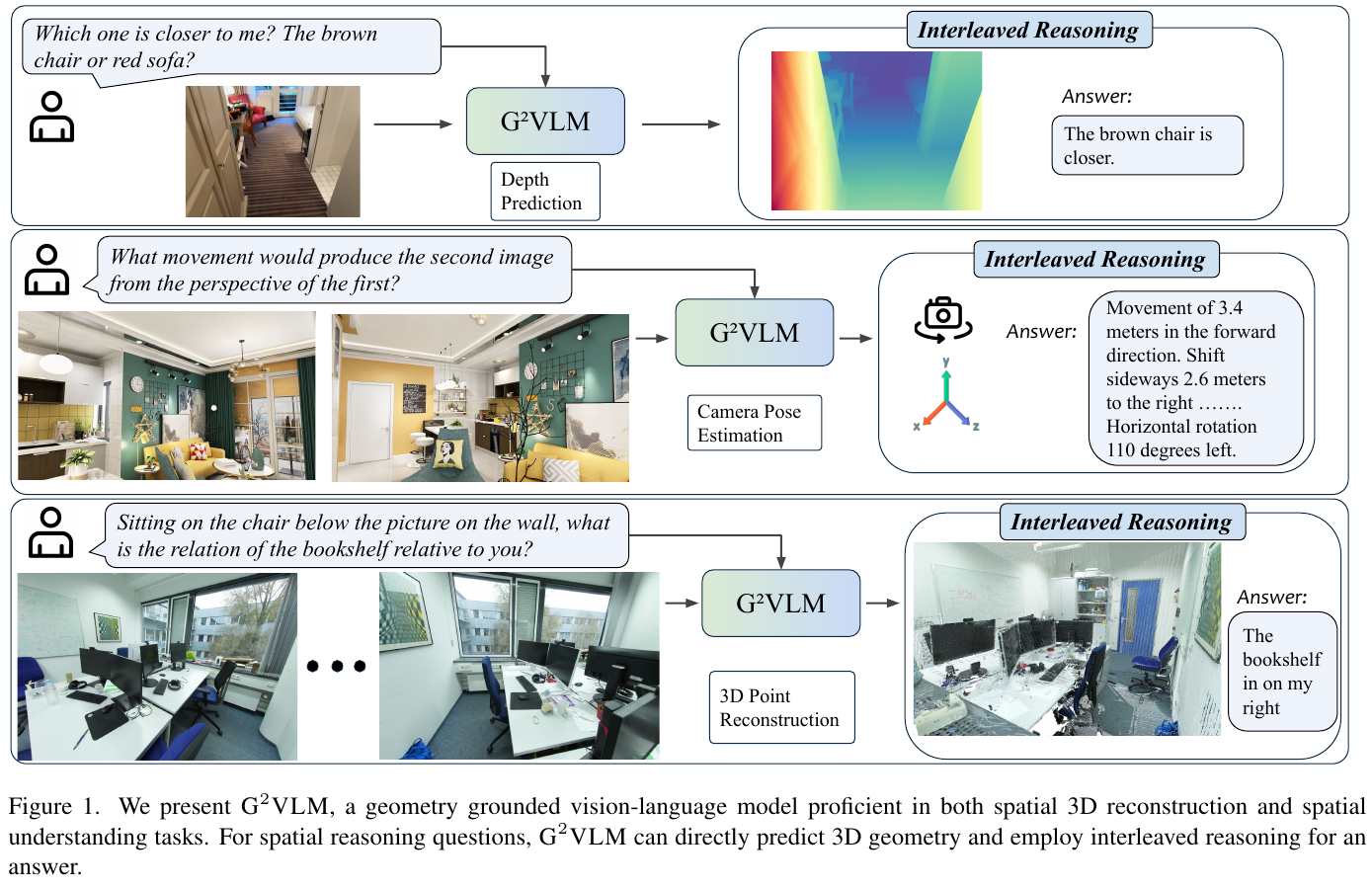
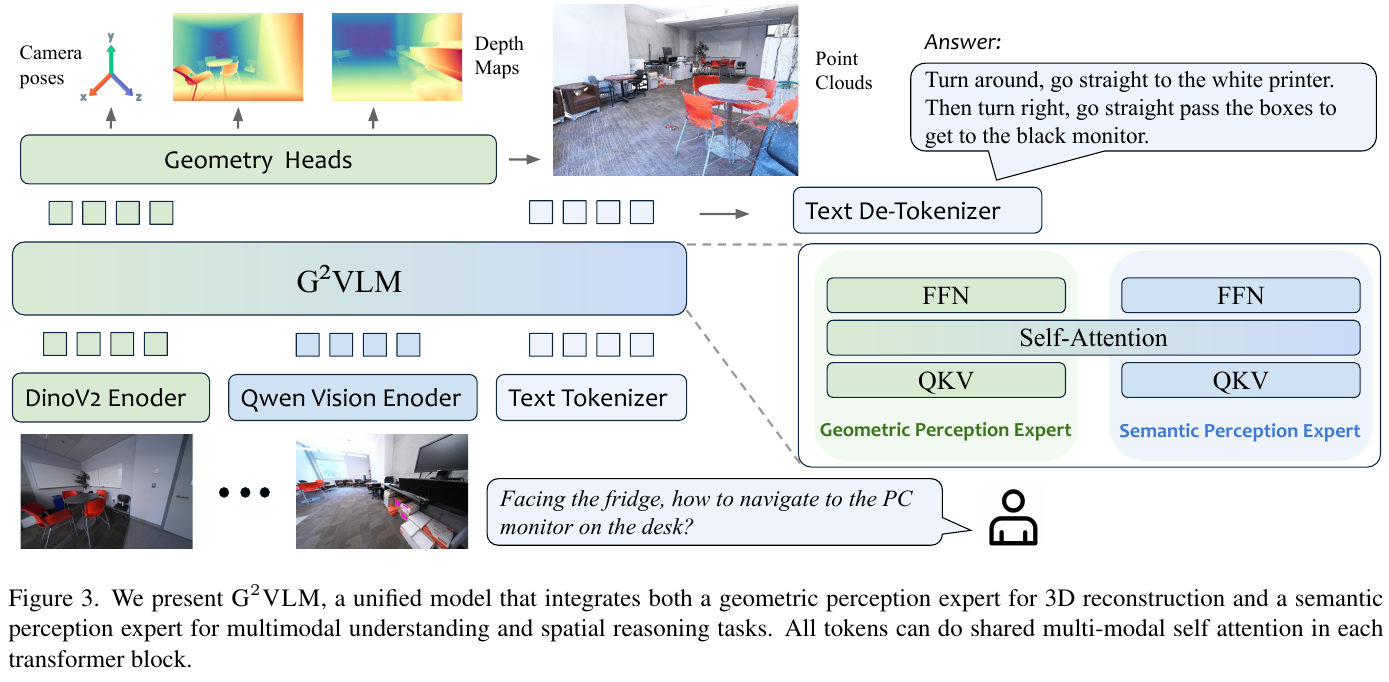
graph TD
%% Inputs
subgraph Inputs ["输入数据"]
Img["N 张 RGB 图像 (I_i)"]
Txt["用户文本问题"]
end
%% Encoders
subgraph Encoders ["双视觉编码器"]
DINO["DINOv2 编码器 (空间敏感)"]
QwenEnc["Qwen2-VL 视觉编码器 (语义丰富)"]
end
Img --> DINO
Img --> QwenEnc
%% Experts HIDDEN states
subgraph MoT ["混合专家 Transformer 架构 (MoT Block)"]
subgraph Expert1 ["几何感知专家 (Geometric Perception Expert)"]
GP_H["几何隐藏状态 h_i"]
end
subgraph Expert2 ["语义感知专家 (Semantic Perception Expert)"]
SP_H["语义/文本隐藏状态"]
end
%% Self-Attention Interaction
GP_H <--> |"共享自注意力 (Shared Self-Attention)"| SP_H
end
DINO --> GP_H
QwenEnc --> SP_H
Txt --> SP_H
%% Decoding & Outputs
subgraph Outputs ["解码与输出"]
%% Geometry Heads
subgraph GP_Heads ["3D 几何解码头"]
LocalHead["局部点云头"]
GlobalHead["全局点云头"]
CamHead["相机位姿头"]
end
%% Text Output
SP_Dec["文本解码器 (Text De-Tokenizer)"]
%% Final predictions
PC["3D 点云图 (X_i)"]
Pose["6-DoF 相机位姿 (T_i)"]
Ans["空间推理文本回答"]
end
GP_H --> GP_Heads
SP_H --> SP_Dec
LocalHead & GlobalHead --> PC
CamHead --> Pose
SP_Dec --> Ans
%% Styles
classDef input fill:#f5f5f7,stroke:#1d1d1f,stroke-width:1px;
classDef encoder fill:#e8f0fe,stroke:#1a73e8,stroke-width:1px;
classDef gp fill:#fce8e6,stroke:#d93025,stroke-width:1px;
classDef sp fill:#e6f4ea,stroke:#137333,stroke-width:1px;
classDef output fill:#fef7e0,stroke:#f9ab00,stroke-width:1px;
class Img,Txt input;
class DINO,QwenEnc encoder;
class GP_H,GP_Heads,LocalHead,GlobalHead,CamHead,PC,Pose gp;
class SP_H,SP_Dec,Ans sp;
① 整体框架概述 G2VLM 采用了受神经科学“双流假说”启发的 Mixture-of-Transformer-Experts (MoT) 架构,包含负责处理 3D 空间几何重构的几何感知专家(Geometric Perception Expert,即 where 路径)和负责多模态文本交互的语义感知专家(Semantic Perception Expert,即 what 路径)。两个专家在每一层通过共享自注意力(Shared Self-Attention)来进行信息穿透。
② 逐模块讲解
- 几何感知专家 (Geometric Perception Expert, GP):
- 输入:接收 $N$ 张 RGB 帧,利用 DINOv2 作为低层空间几何特征编码器。
- 处理:特征首先转换为隐藏状态 $h_i$,然后输入由轻量级 Transformer 组成的几何头(Geometry Heads,包括局部点云头、全局点云头和相机位姿头)。
- 输出:输出绝对度量尺度的三维点云 $X_i \in \mathbb{R}^{H \times W \times 3}$ 和相机 6-DoF 相对位姿 $T_i \in SE(3)$。
- 设计动机:利用 DINOv2 在边界和纹理过渡层中天然保留的空间连续性先验,加速低层重建的收敛。
- 语义感知专家 (Semantic Perception Expert, SP):
- 输入:用户文本问题以及来自预训练 Qwen2-VL 语义图像编码器的特征。
- 处理:使用轻量化 Qwen2-VL-2B 作为基座框架,支持输入帧的多模态旋转位置编码(M-RoPE)与动态分辨率裁剪。
- 输出:生成空间问题的文本回答。
- 设计动机:直接复用强语义基座的能力,使其具备回答复杂位置指令和长上下文推理的常识。
- 共享自注意力机制 (Shared Self-Attention):
- 机制的物理本质:在传统的 MoE 架构中,各个专家通常在 Feed-Forward Network (FFN) 层相互独立,输入 Token 仅被路由(Router)派发给单一的专家 FFN 处理。而 G2VLM 的 Mixture-of-Transformer-Experts (MoT) 架构采用共享自注意力 (Shared Self-Attention) + 解耦前馈专家 (Decoupled FFN Experts) 的设计。其本质是:在每个 Transformer Block 中,将来自“几何感知专家 (GP)”的几何 Token $X_{GP}$ 与来自“语义感知专家 (SP)”的语义/文本 Token $X_{SP}$ 拼接到同一个序列中进行全局自注意力计算。
- Token 交互过程:正如您所料,不同专家输入的 Token 在进行自注意力时会全面进行跨专家交互。GP 通道的 Token 可以 attend 到 SP 通道的语义和文本信息,反之亦然。这允许模型在计算 $Q, K, V$ 时跨越专家的阻隔:
- GP 专家获取高层语义(几何 Token $\to$ 语义 Token):当重建特定 3D 几何结构时,网络可以通过高层语义标签(如“桌面”、“墙壁”、“反光镜”)作为先验指导,提高深度和点云预测的平滑度。
- SP 专家检索底层三维几何(语义 Token $\to$ 几何 Token):大语言模型在进行空间常识推理(如问答 “杯子与显示器哪一个离相机更近”)时,能直接跨通道检索并读取几何专家生成的绝对度量 3D 坐标隐藏状态,从而做出符合物理事实的交织推理 (Interleaved Reasoning)。
- MoT 与 传统 MoE 的架构对比:
| 维度 | 传统 MoE (Mixture of Experts) | G2VLM 中的 MoT (Shared Self-Attention) |
|---|---|---|
| 专家粒度 | 通常仅在 FFN (Feed-Forward Network) 层 | 扩展到整个 Transformer Block 通道级(解耦的 FFN 专家) |
| Token 分流 | 通过 Router (门控路由) 动态分流,每个 Token 只分给 1-2 个 FFN 专家 | 双通道并行静态分流:几何 Token 送入 GP 通道,文本 Token 送入 SP 通道 |
| 自注意力机制 | 全局共享自注意力,不分通道类型 | 共享自注意力 (Shared Self-Attention),但在计算后会分流至独立的专家 FFN |
| 设计目的 | 增加大模型参数量与容量,节省计算开销 | 融合异构特征,促使低层三维几何与高层空间语义双向对齐 |
-
传统 MoE 与 G2VLM MoT 的 Block 内部数据流对比示意图:
- 1. 传统 MoE Block (基于门控路由动态分配 Token):
graph TD
%% Inputs to Block
X["输入 Token 序列 X"]
%% Shared Self-Attention
subgraph AttentionBlock ["共享自注意力层 (Shared Self-Attention)"]
Shared_Q["计算 Q = X * W_Q"]
Shared_K["计算 K = X * W_K"]
Shared_V["计算 V = X * W_V"]
X --> Shared_Q & Shared_K & Shared_V
AttnCalc["Softmax(Q K^T / √d) * V"]
Shared_Q & Shared_K & Shared_V --> AttnCalc
end
%% Router/Gating Network
Router["门控路由网络 (Router / Gating Network)"]
AttnCalc --> Router
%% Decoupled FFN Experts
subgraph Experts ["并列前馈专家 (Parallel FFN Experts)"]
FFN_1["专家 1 (FFN_1)"]
FFN_2["专家 2 (FFN_2)"]
FFN_N["专家 N (FFN_N)"]
end
%% Routing lines
Router --> |"根据路由概率分配 Token"| FFN_1
Router --> |"根据路由概率分配 Token"| FFN_2
Router --> |"根据路由概率分配 Token"| FFN_N
%% Combine/Sum
Combine["加权汇聚 (Weighted Sum / Combine)"]
FFN_1 --> Combine
FFN_2 --> Combine
FFN_N --> Combine
%% Output of Block
Out["输出 Token Y"]
Combine --> Out
%% Style
classDef input fill:#f5f5f7,stroke:#1d1d1f,stroke-width:1px;
classDef router fill:#fef7e0,stroke:#f9ab00,stroke-width:1px;
classDef expert fill:#e6f4ea,stroke:#137333,stroke-width:1px;
class X,Out input;
class Router,Combine router;
class FFN_1,FFN_2,FFN_N expert;
* **2. G2VLM MoT Block (基于静态 Token 序列切片路由,无门控网络)**:
graph TD
%% Inputs to Block
X_GP["几何 Token X_GP"]
X_SP["语义 Token X_SP"]
%% Concatenation
Concat["拼接 (Concatenate)"]
X_GP --> Concat
X_SP --> Concat
%% Shared Self-Attention
subgraph AttentionBlock ["共享自注意力层 (Shared Self-Attention)"]
Shared_Q["计算 Q = [X_GP, X_SP] * W_Q"]
Shared_K["计算 K = [X_GP, X_SP] * W_K"]
Shared_V["计算 V = [X_GP, X_SP] * W_V"]
Concat --> Shared_Q & Shared_K & Shared_V
AttnCalc["Softmax(Q K^T / √d) * V"]
Shared_Q & Shared_K & Shared_V --> AttnCalc
end
%% Split
Split["分割 (Split / Slice)"]
AttnCalc --> Split
%% FFN Experts
subgraph Experts ["解耦前馈专家 (Decoupled FFN Experts)"]
FFN_GP["几何前馈专家 (FFN_GP)"]
FFN_SP["语义前馈专家 (FFN_SP)"]
end
Split --> |"几何部分 (前 Tg 个 Token)"| FFN_GP
Split --> |"语义部分 (后 Ts 个 Token)"| FFN_SP
%% Outputs of Block
Out_GP["输出几何 Token Y_GP"]
Out_SP["输出语义 Token Y_SP"]
FFN_GP --> Out_GP
FFN_SP --> Out_SP
%% Style
classDef gp fill:#fce8e6,stroke:#d93025,stroke-width:1px;
classDef sp fill:#e6f4ea,stroke:#137333,stroke-width:1px;
classDef shared fill:#e8f0fe,stroke:#1a73e8,stroke-width:1px;
class X_GP,FFN_GP,Out_GP gp;
class X_SP,FFN_SP,Out_SP sp;
class Concat,Shared_Q,Shared_K,Shared_V,AttnCalc,Split shared;
③ 训练目标与损失函数 G2VLM 采用了两阶段解耦的训练策略,在保护底层 3D 物理重建精度的同时,利用大语言模型(LLM)的强泛化能力来拟合高层空间语义。
- 两阶段训练详细对比:
| 训练阶段 | 优化目标 (Objective) | 激活/优化模型参数 | 冻结模型参数 | 训练损失 (Loss) | 主要数据集 (Datasets) |
|---|---|---|---|---|---|
| 第一阶段:几何预训练 (GP Pre-training) | 训练几何感知专家 (GP) 的底层 3D 几何感知能力 | 几何感知专家 (GP) 的特征网络及 3D 几何解码头从头训练 | 语义感知专家 (SP) (基于 Qwen2-VL-2B) 保持冻结 | 视觉几何损失 $L_{VG}$ (点云损失 + 位姿损失 + 法线损失) | ScanNet, Co3Dv2, MegaDepth 等大规模 3D 标注集 |
| 第二阶段:空间推理联训 (SP Joint-training) | 优化语义感知专家 (SP) 的三维场景问答与推理能力 | 语义感知专家 (SP);默认冻结 GP (也可选微调 GP) | 几何感知专家 (GP) (在默认的 CE Loss Only 策略下冻结) | 交叉熵损失 $L_{CE}$ (Language Modeling Loss) | SPAR-7M, Omnispatial, Mindcube 等空间推理/问答数据集 |
- 两阶段训练流程示意图:
graph TD
%% Stage 1
subgraph Stage1 ["第一阶段:几何专家预训练 (GP Pre-training)"]
S1_Data["海量 3D 标注数据集"] --> S1_Inputs["RGB 图像输入 (I_i)"]
S1_Inputs --> S1_GP["几何专家 GP (从头学习 3D 几何特征)"]
S1_Inputs --> S1_SP["语义专家 SP (冻结 Qwen2-VL)"]
S1_GP --> S1_Loss["优化 LVG (点云重建 + 位姿估计 + 法线损失)"]
end
%% Transition
S1_GP -.-> |"加载预训练几何权重"| S2_GP
%% Stage 2
subgraph Stage2 ["第二阶段:空间推理联合训练 (SP Joint-training)"]
S2_Data["空间问答与推理数据集"] --> S2_Inputs["多视角/视频图像 + 文本问题"]
S2_Inputs --> S2_GP["几何专家 GP (默认冻结/可选微调)"]
S2_Inputs --> S2_SP["语义专家 SP (解冻微调)"]
S2_GP & S2_SP --> S2_Shared["共享自注意力机制 (Shared Self-Attention)"]
S2_Shared --> S2_Loss["优化 LCE (交叉熵文本预测损失)"]
end
%% Styles
classDef freeze fill:#ebebeb,stroke:#7f7f7f,stroke-width:1px,stroke-dasharray: 5 5;
classDef active fill:#e8f0fe,stroke:#1a73e8,stroke-width:2px;
classDef loss fill:#fef7e0,stroke:#f9ab00,stroke-width:1px;
class S1_SP,S2_GP freeze;
class S1_GP,S2_SP active;
class S1_Loss,S2_Loss loss;
- 具体损失函数数学表述:
- 阶段一几何损失:优化几何感知专家(GP)时,视觉几何损失函数 $L_{VG}$ 定义为点云重建、相机位姿与法线损失的加权和: \(L_{VG} = L_{points} + \lambda_{cam} L_{cam} + \lambda_{normal} L_{normal}\) 其中,尺度不变的点云重建损失 $L_{points}$ 计算如下: \(L_{points} = \frac{1}{3NHW} \sum_{i=1}^N \sum_{j=1}^{H \times W} \frac{1}{z_{i,j}} \lVert s^* \hat{x}_{i,j} - x_{i,j} \rVert_1\) \(s^* = \arg\min_s \sum_{i=1}^N \sum_{j=1}^{H \times W} \frac{1}{z_{i,j}} \lVert s \hat{x}_{i,j} - x_{i,j} \rVert_1\) 相机损失 $L_{cam}$ 平衡了 geodesic 旋转偏差和平移的 Huber 损失: \(L_{cam} = \frac{1}{N(N-1)} \sum_{i \neq j} (L_{rot}(i, j) + \lambda_{trans} L_{trans}(i, j))\) \(L_{rot}(i, j) = \arccos\left(\frac{\text{Tr}(R_{i\leftarrow j}^\top \hat{R}_{i\leftarrow j}) - 1}{2}\right)\) 表面法线损失 $L_{normal}$ 保证几何的局部平滑一致性: \(L_{normal} = \sum_{i=1}^N \sum_{j=1}^{H \times W} \arccos(\hat{n}_{i,j} \cdot n_{i,j})\)
- 阶段二联合训练优化策略:在此阶段解冻语义专家进行联合训练,作者对比了三种微调策略:
- CE Loss Only(默认):仅对 SP 专家进行交叉熵(CE)损失微调,GP 专家完全冻结。该策略不仅能完全保留 GP 第一阶段学到的 3D 感知性能,而且可以使用海量无 3D 标注的视频及对话数据训练,具有极佳的可扩展性。
- CE + CE Loss(G2VLM-SR):两专家同时通过交叉熵优化。这使得 GP 被强制微调用于空间推理,整体的高级空间推理表现最好,但在低层几何重建精度上会有所下滑。
- VG + CE Loss:同时采用几何监督 $L_{VG}$ 与语义监督 $L_{CE}$。训练得到的参数最全面,但由于联合训练阶段需要同时具有 3D 标签与语义问答的复杂混合数据集,因此扩展难度极大。
3. 核心结果/发现
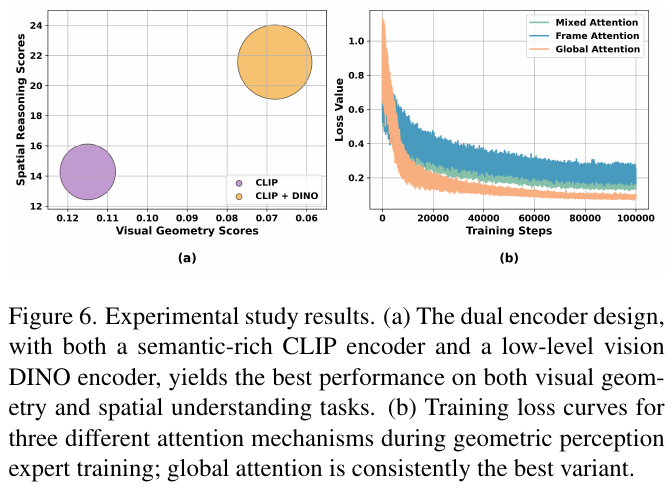

- 三维重建逼近专有模型:在未引入专门相机 Token 且采用更精简全局自注意力的前提下,G2VLM 在 monocular depth 等多项几何任务上达到了与 SOTA 专有重建算法(如 VGGT、$\pi^3$)相当的精度,Sintel 下的 Abs Rel 降低至 0.297(优于 VGGT 的 0.335)。
- 空间推理大幅超越闭源模型:
- G2VLM-SR-2B 在主流三维高级推理基准上取得了惊人的突破。在 SPAR-Bench 平均精度得分上达到了 54.87,不仅大幅度拉开了基座模型 Qwen2-VL-2B(24.60 分),也成功击败了体量更大的商业闭源大模型 GPT-4o(36.39 分)和 Claude-3.7-Sonnet(21.77 分)。
- 在 MindCube 和 OmniSpatial 上同样取得同体量开源模型中最佳的表现。
- 低级几何与高级语义的互促:消融实验证明,随着几何专家预训练阶段的重建精度(即 $L_{VG}$ 表现)逐渐提升,联合微调后语义专家的空间推理分数呈强正相关上升,揭示了底层 3D 几何特征对高级空间智能存在至关重要的正向互促(Interplay)作用。
4. 局限性
- 大参数模型联合训练的稳定性:在 7B 或 72B 等超大型 VLM 框架下同时微调低层视觉专家与 LLM 存在收敛不稳定的问题,对学习率曲线的调整和混合 3D 重建数据集的配比提出了更高的工程要求。
6.24 SparseOccVLA (2026) {#6-24-sparseoccvla}
——首个将 3D 语义占用(Occupancy)与视觉-语言模型(VLM)原生融合的具身自动驾驶规划模型
📄 Paper: https://arxiv.org/abs/2601.06474v2
精华
- 首次实现将 3D 语义占用表示(Semantic Occupancy)与视觉-语言模型(VLM)进行高效融合,完全摆脱对稠密视觉 Token 或 BEV 特征的依赖,仅通过稀疏占用查询(Sparse Occupancy Queries)作为视觉与语言的桥梁。
- 提出轻量化稀疏占用编码器(Sparse Occupancy Encoder),利用 SparseBEV 结构进行跨帧多尺度特征采样,通过粗到细逐层预测三维坐标并利用 Chamfer Distance 和 Focal Loss 进行监督,最终经 MLP 投影对齐得到高信息密度的占用 Token。
- 引入特征级蒸馏损失(Feature-level Distillation),利用预训练 CLIP 视觉编码器提取单帧多尺度特征,并通过 LayerNorm 独立归一化后计算余弦相似度,拉近稀疏无序点云与语言空间的距离,有效解决 LLM 训练初期收敛慢或崩塌的问题。
- 提出大语言模型引导的锚点扩散规划器(LLM-guided Anchor-Diffusion Planner),将轨迹锚点(Trajectory Anchors)的分类打分与去噪回归解耦。LLM 根据语义理解对 K-means 聚类的锚点进行评分,并以此作为条件引导 Diffusion 阶段生成更合理的控制轨迹。
- 在 OmniDrive-nuScenes(CIDEr +7%)、Occ3D-nuScenes(mIoU +0.51)并 nuScenes 开环轨迹规划三个基准上全部达到 SOTA 水平,大幅压缩视觉 Token 数量(仅需 300 或 600 个 Token)的同时兼顾几何感知与高层语义推理。
1. 研究背景/问题
自动驾驶端到端规划中,视觉语言模型(VLM)擅长高层逻辑推理,但受制于 Token 爆炸(Token Explosion)和时空三维感知能力弱的问题;而语义占用(Semantic Occupancy)提供了精细且显式的几何空间表征,但其数据过于稠密,难以直接与 VLM 整合。现有方法多是通过 BEV 编码器或 Q-Former 压缩特征,容易在此过程中丢失细粒度几何和三维时空连续性。因此,如何设计一种既保留 3D 几何与语义细节,又能保持低 Token 开销,并实现与 VLM 原生深度融合 of 具身驾驶规划框架,是领域内的重要课题。SparseOccVLA 正是为此设计。
2. 主要方法/创新点
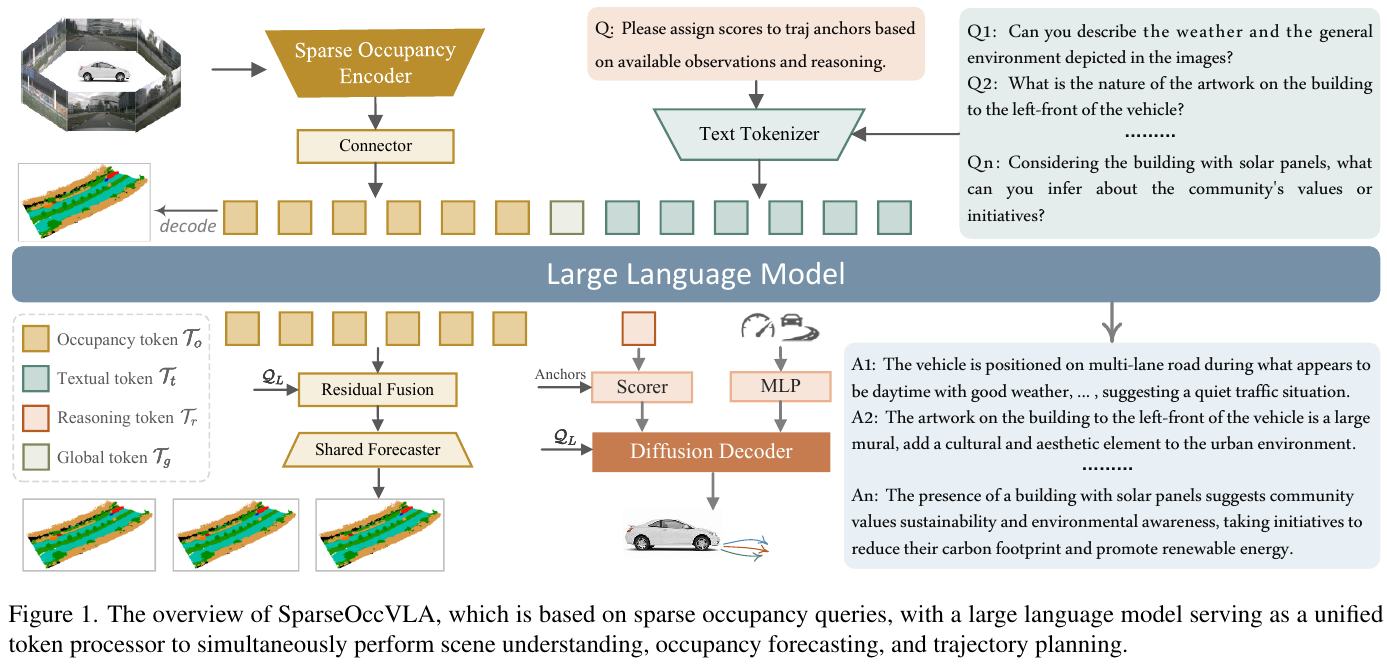
① 整体框架概述
SparseOccVLA 包含三个核心组件:稀疏占用编码器(Sparse Occupancy Encoder)、统一大语言模型(Unified Large Language Model) 和 LLM 引导的锚点扩散规划器(LLM-guided Anchor-Diffusion Planner)。它抛弃了传统的稠密视觉 Token 或 BEV 特征,仅通过稀疏占用查询(Sparse Occupancy Queries)来建立视觉和语言之间的唯一桥梁。
② 逐模块讲解
- 稀疏占用编码器(Sparse Occupancy Encoder):
- 输入:多视角、多帧的 RGB 图像序列 $I$。
- 处理:利用 ResNet-50 提取图像特征,然后采用类 SparseBEV 结构,通过 $L$ 层编码器(Feature Sampling, Adaptive Mixing, Spatial-aware MHSA, FFN)更新随机初始化的 $N$ 个三维占用查询 $Q_0$ 和三维坐标位置 $P_0$。逐层逐步增多预测 of 3D 点云点数,并在各层对预测点集与真实稀疏化占用点集 $G$ 之间计算 Chamfer Distance(CD 损失)和语义 Focal 损失进行深度监督。
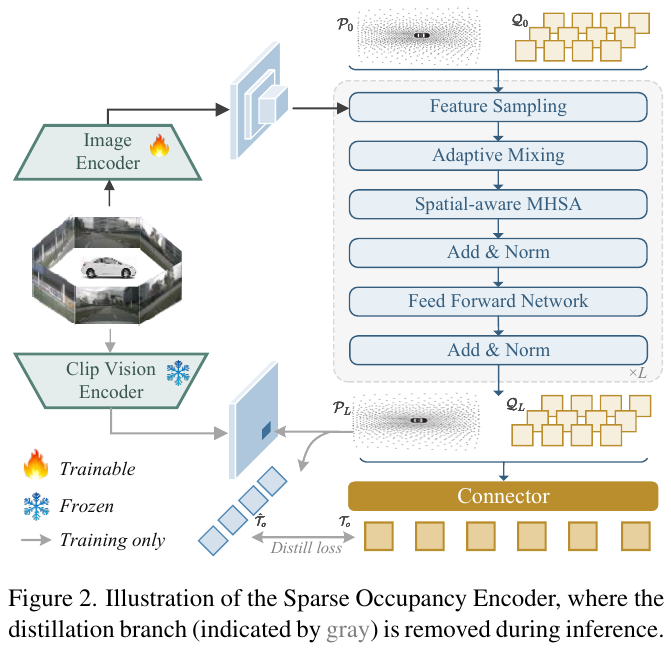
稀疏占用编码器(Sparse Occupancy Encoder)结构,在训练时引入特征级蒸馏分支对齐 CLIP 特征,推理时移除该分支 - 输出:经轻量化 MLP 对齐连接器(Connector)转换得到的高维 占用 Token(Occupancy Tokens) $T_o = \text{MLP}(Q_L + \text{PE}(P_L))$。
- 特征级蒸馏(Feature-level Distillation):为克服无序稀疏点云与语言空间极大的对齐鸿沟、避免训练初期的崩溃,训练阶段使用预训练的 CLIP-336 视觉编码器提取单帧特征。占用 Token $T_o$ 基于其 3D 坐标投影并插值得到教师特征 $\hat{T}_o$。二者通过独立 LayerNorm 归一化并放宽对齐强度限制后,使用余弦相似度计算蒸馏损失: \(L_{\mathrm{distill}} = 1 - \mathrm{cosine}(\mathrm{Norm}_1(T_o), \mathrm{Norm}_2(\hat{T}_o))\)
- 统一大语言模型(Unified Large Language Model):
- 输入:稀疏占用 Token $T_o$、通过交叉注意力生成的全局场景 Token $T_g$ 以及文本 Token $T_t$。
- 处理:将输入 Token 序列拼接后送入大语言模型(Vicuna-7B)进行因果自回归推理。在推理过程中,模型基于占用 Token 的 3D 位置编码推导空间拓扑。
- 任务实现:对于 场景理解,利用 MLE 损失自回归生成答案;对于 占用预测(Forecasting),将 LLM 推理后的占用 Token $T’_o$ 与原始占用查询 $Q_L$ 进行残差线性融合:$\hat{Q}_o = \text{MLP}([T’_o, Q_L])$,并融入 Ego 车辆状态和时空位置编码,经 forecaster 逐帧预测未来 3 秒内的三维占用网格。
- LLM引导的锚点扩散规划器(LLM-guided Anchor-Diffusion Planner):
- 输入:通过 K-means 聚类学习得到的 $K=18$ 个轨迹锚点(Trajectory Anchors) $a_k$。
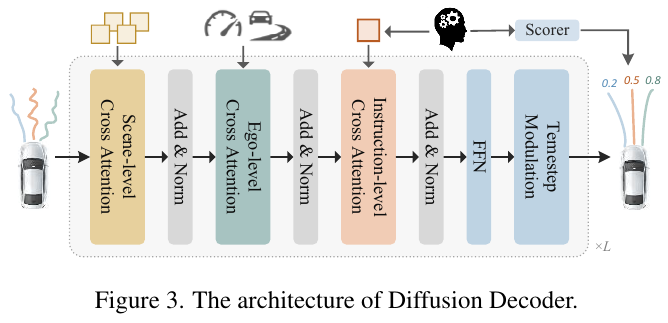
扩散解码器(Diffusion Decoder)的层级交叉注意力结构,依次对齐三维占用查询、本体车辆状态和来自 LLM 的决策 Token - 处理:将规划打分与去噪回归解耦。首先,利用 Scorer 基于车辆状态与 LLM 生成的推理决策 Token $T_r$ 对轨迹锚点进行评分,使用 BCE 损失监督(最接近 ground-truth 的锚点为正样本,其余为负样本)。然后,对所有锚点施加 Gaussian 噪声: \(\tau_k^i = \sqrt{\bar{\alpha}_i} a_k + \sqrt{1 - \bar{\alpha}_i} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\) 并送入扩散解码器进行去噪。扩散解码器(Diffusion Decoder)堆叠了多层层级交叉注意力,按顺序依次对齐 3D 占用查询 $Q_0$、车辆 Ego 状态和 LLM 的推理决策 Token,实现端到端的去噪轨迹生成。整个规划网络在训练时仅对正样本计算 $L_1$ 轨迹损失。
- 输出:在推理时,通过 DDIM 迭代去噪(2个步长),并选择 LLM 评分最高的主锚点去噪结果作为最终输出轨迹。
3. 核心结果/发现
- 场景理解(Scene Understanding):在 OmniDrive-nuScenes 基准上,SparseOccVLA 以仅 300 个 Occupancy Tokens 的轻量级开销取得了大幅超越此前 BEV/Image 稠密方法的成绩,其中 CIDEr 比 HERMES 提高了 7%(0.762 vs 0.741,600 个 Token 时达 0.796),展示出稀疏三维占用极高的语义 and 几何信息密度。
- 占用预测(Occupancy Forecasting):在 Occ3D-nuScenes 预测未来 3 秒 mIoU 的任务中,相较于同样稀疏表示的 SparseWorld,mIoU 平均提升了 0.51(13.71 vs 13.20),验证了 LLM 全局高层语义和时序常识对未来感知演变的巨大增强作用。
- 开环规划(Open-loop Planning):在 nuScenes 自动驾驶开环轨迹规划测试中,SparseOccVLA 以 0.23m 的平均 L2 误差和 0.19% 的碰撞率显著超越了 UniAD (0.46m / 0.37%)、VAD (0.37m / 0.33%) 以及 VLA 系列如 OpenDriveVLA (0.33m / 0.25%) 等前沿模型,达到最新的 SOTA 表现。
- 消融研究:去除特征级蒸馏约束会导致理解性能显著下降(CIDEr 降低 0.8);去除 LLM 轨迹打分引导仅让 Planner 单独决策时,规划性能(L2 和碰撞率)将发生严重退化,表明解耦打分与去噪的有效性。
4. 局限性
- 高度依赖稠密且高质量的 3D 语义占用真实标签(Occupancy Ground Truth),获取和生成此类监督标签具有极高的标注成本;
- 仅在 nuScenes 等开环自动驾驶规划基准上完成了验证,其在闭环仿真环境下的规划与控制稳定性仍有待在未来工作中进一步探究。
6.25 GenCeption (2026) {#6-25-genception}
——视频生成模型是通用视觉学习器
📄 Paper: https://arxiv.org/abs/2607.09024
精华
- 本文提出了 GenCeption,展示了大规模文本到视频生成模型可以作为通用的视觉表示学习器,其中生成式预训练(类似于 NLP 中的 next-token prediction)能为感知任务赋予强大的时空先验与图文对齐能力。
- GenCeption 通过将多步迭代去噪的扩散模型改造为高效的单步前向传播(Feed-Forward)感知模型,避免了传统生成式推理极其缓慢的缺陷。
- 提出在连续像素空间(RGB通道)中统一多种密集感知任务(深度、法线、分割、相机射线图等)的方案,将任务说明直接编码在文本提示(Text Prompt)和数据表示中,实现了极简 of 无特定任务头/损失函数设计。
- 针对稀疏坐标回归任务(2D/3D人脸/人体关键点),设计了可学习 Token 与 3D 旋转位置编码(3D RoPE)的外挂机制,保证了时序位置对齐且无需破坏预训练注意力结构。
- GenCeption 在只用合成数据微调的情况下展现出惊人的 Sim-to-Real 跨域泛化能力和数据效率,仅需极少样本即可媲美甚至超越 DepthAnything 3、SAM 3 等高度定制化的专业领域模型。
1. 研究背景/问题
- 核心问题:自然语言处理已经通过大规模自回归预训练成功过渡到统一的通用大模型时代。然而,计算机视觉仍停留在”专用模型”阶段(例如 Depth Anything 用于几何、SAM 用于分割),需要针对具体任务定制网络结构、解码头与损失函数,缺乏一个能统一万千视觉感知任务的、即插即用的通用底座。
- 核心动机:作者认为解决视觉通用大模型的关键在于寻找一个类似于”Next-token prediction”的预训练任务。大型文本到视频生成(Text-to-Video Generation)正好满足三大黄金标准:(1)时空演化(Spatio-Temporal Evolution):要求模型内化物理规律与4D几何;(2)图文原生对齐(Vision-Language Alignment):天生具备指令遵循能力;(3)大规模可扩展(Scaled up):视频数据无监督且商业价值大、易规模化。
2. 主要方法/创新点
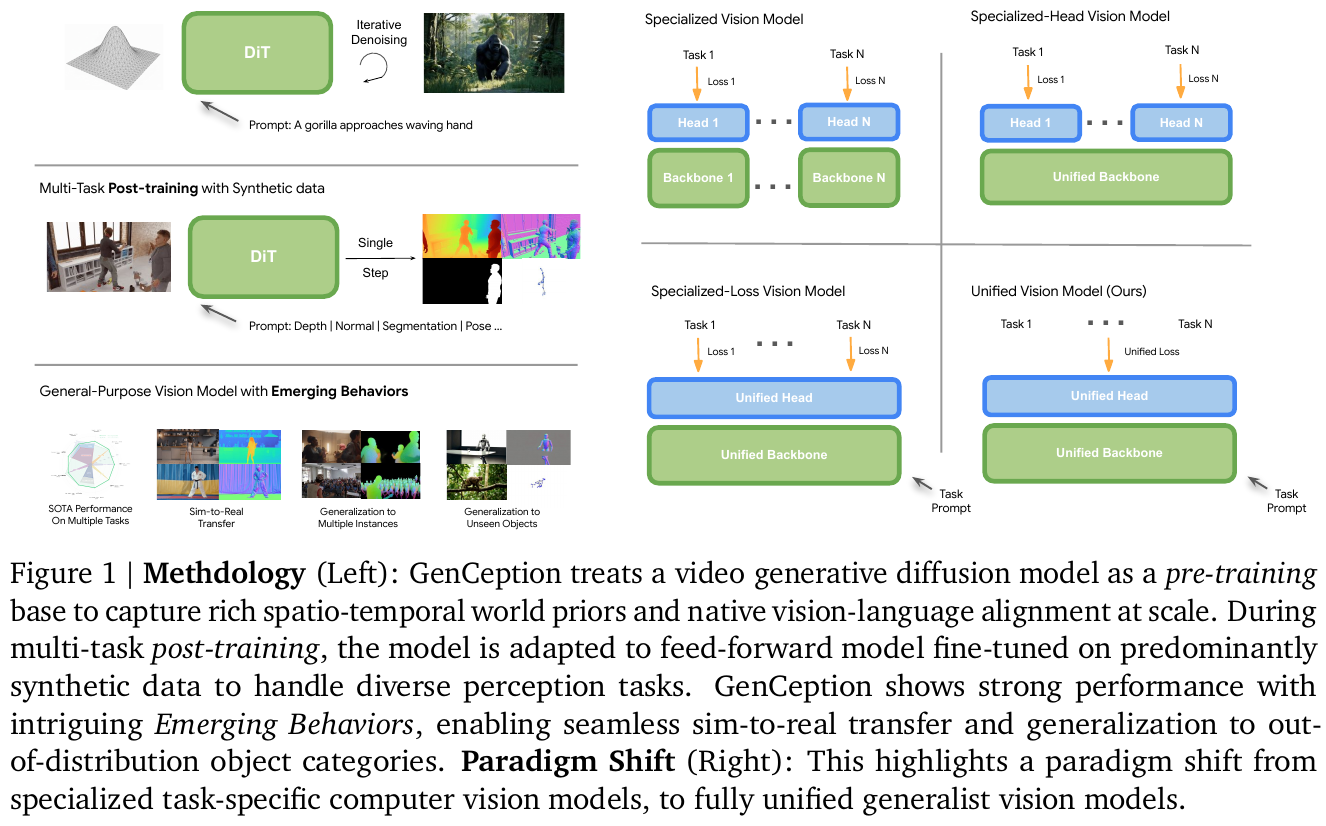
① 整体框架概述
GenCeption 的核心设计极为精简,它重用了文本到视频生成模型(WAN 2.1)的预训练权重,包括 VAE 编码器-解码器、文本编码器和基于 Transformer 的潜空间扩散模型(DiT)。通过将原多步反向去噪过程重构为单步前向传播,并直接将不同的感知任务映射到统一的 3 通道连续像素空间(RGB),实现了共享骨干网络、解码器及损失函数的全能视觉感知器。
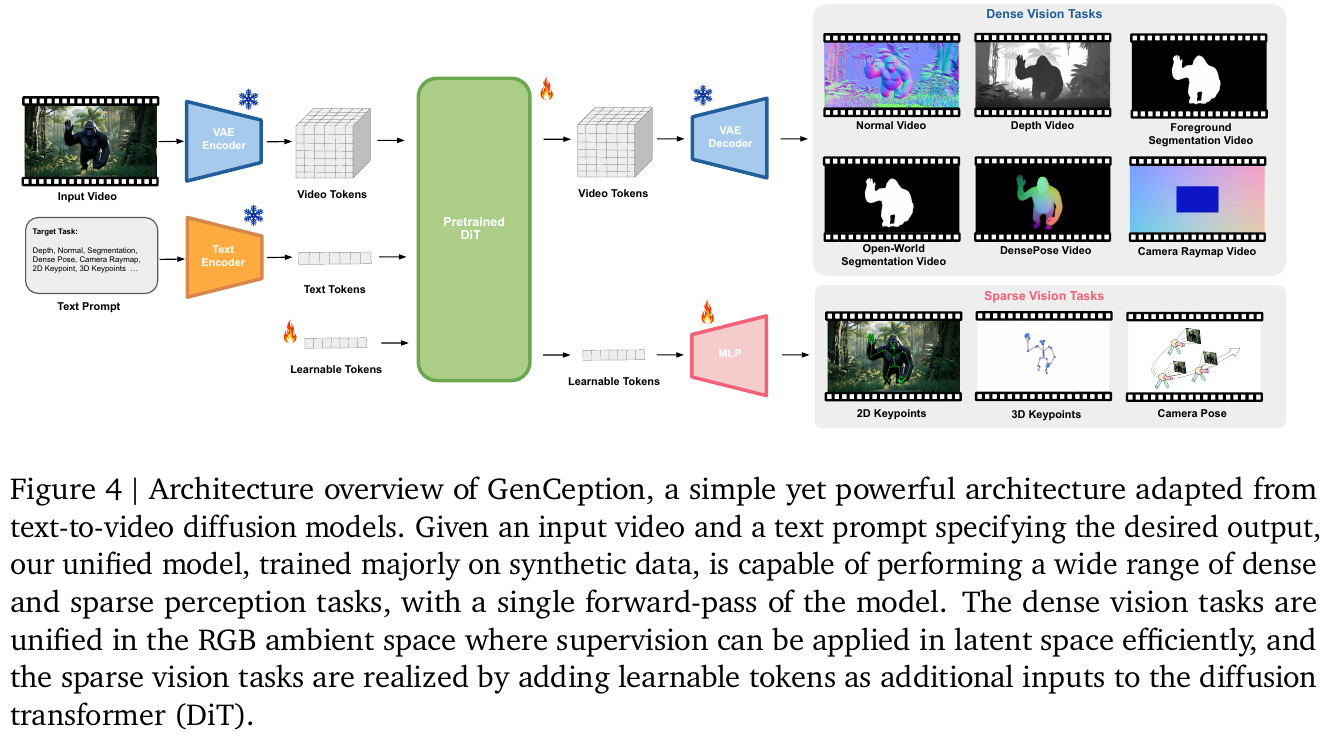
② 逐模块讲解
- 单步前向推理感知(Feed-forward Perception)
- 输入:无噪声的视频原始 Latent 表征 $x_0$(由 VAE 编码器从 RGB 视频提取)以及由任务 Prompt(例如
"output: depth")转换得到的文本 Embedding。 - 处理:在常规视频扩散模型中,输入是高斯噪声并通过多步迭代进行去噪。GenCeption 将去噪时间步固定为 $t = 0$(即去噪终点),并只执行单次 DiT 前向推理。由于 WAN 2.1 采用 Rectified Flow 目标进行预训练,其 DiT 模块输出为预测速度 $v = \epsilon - x_0$。
- 输出:在网络最后一层直接对 DiT 输出取反,即 $-v = x_0 - \epsilon$。经验表明,这个取反操作能让预测的 Latent 极大程度地向目标感知视频靠拢。
- 设计动机:彻底消除了慢速的迭代采样过程,将生成式模型低成本地转变为确定性的前向特征提取器,且完全不改动骨干网络任何中间层,保证了其提取能力的完整性。
- 输入:无噪声的视频原始 Latent 表征 $x_0$(由 VAE 编码器从 RGB 视频提取)以及由任务 Prompt(例如
- 密集任务的像素空间统一(Unified Dense Task Representation)
- 输入:调制不同任务的文本 Prompt(如
"Depth","Normal","Segmentation","DensePose"等)。 - 处理:所有的密集感知结果均被映射到统一的 3 通道 RGB 空间内,取值范围规范在 $[0, 1]$。对于一维的密集任务(深度估计、视频分割),3 个 RGB 通道内容被直接复制;对于三维密集任务(表面法线、DensePose 映射),每个通道对应不同的物理维度。
- 输出:在 RGB 图像空间内的感知结果视频。
- 设计动机:如同大语言模型将各类异构数据格式化为纯文本一样,GenCeption 将不同的高维度、多任务几何与语义感知转换到连续像素空间。这免去了对特定解码结构的微调,最大化复用了预训练模型的视觉先验。
- 输入:调制不同任务的文本 Prompt(如
- 相机射线图 “Rothko” 编码(Rothko Raymap for Camera Pose)
- 输入:6 通道相机射线数据(3 通道原点 Ray Origins + 3 通道方向 Ray Directions)。
- 处理:提出空间分区拼贴的 “Rothko” 编码(如下图所示),将射线起点(Origins)图填充在图像中央,而将射线方向(Directions)图平铺在图像四周,从而把 6 通道的位置矩阵数据压缩封装至 3 通道 RGB 内。
- 输出:3 通道 Rothko 射线图视频,后经过解析算法解算得到相机的连续位姿与轨迹。
- 设计动机:将高度抽象的矩阵与位姿估计转化为空间连续的图像渲染感知,保证解码器的一致性。

- 稀疏感知可学习 Token 机制(Sparse Perception with Learnable Tokens)
- 输入:除原视频 Latents 外,外挂 $T$ 个可学习的查询 Token(每个视频帧对应一个)。
- 处理:为兼容预训练 DiT 内生的 3D 旋转位置编码(3D RoPE),对新增的 $T$ 个 Token 应用 3D RoPE。其空间位置初始化为可学习变量;而时序位置上,采用位置插值(Position Interpolation)对帧索引进行尺度缩放,使其处于 DiT 预训练的时序边界内。
- 输出:经过 DiT 网络提取后,通过轻量级 MLP 头解码出每帧 $K$ 维的稀疏特征坐标(如人脸/人体关键点)。
- 设计动机:外挂查询 Token 比引入新的 Cross-Attention 模块能更好地维护预训练注意力机制的稳定性,从而避免特征失真。
③ 端到端数据流
输入 RGB 视频经过 VAE 编码 $\rightarrow$ 与任务控制文本 Embedding 拼接 $\rightarrow$ 输入 DiT 进行单步前向传播 $\rightarrow$ 密集任务特征取反 $-v$ 并经过统一 VAE 解码器生成目标感知视频;稀疏任务通过外挂 Token 经由轻量级 MLP 输出 2D/3D 坐标。
④ 训练目标与损失函数
GenCeption 统一使用标准的 $L_2$ 损失函数。在数据层面上,通过对深度图等数据进行尺度中值归一化,并进行非线性映射: \(d' = \text{clip}(\alpha \log(d+1), 0, 1)\) 这从源头上消除了几何感知的尺度不确定性。
- 密集任务直接在 VAE 的隐空间(Latent Space)计算 $L_2$ 损失: \(L_{\text{dense}} = \lVert \mathbf{z}_{\text{pred}} - \mathbf{z}_{\text{gt}} \rVert_2^2\)
- 稀疏任务在解算出的输出坐标空间计算 $L_2$ 损失: \(L_{\text{sparse}} = \lVert \mathbf{p}_{\text{pred}} - \mathbf{p}_{\text{gt}} \rVert_2^2\)
3. 核心结果/发现
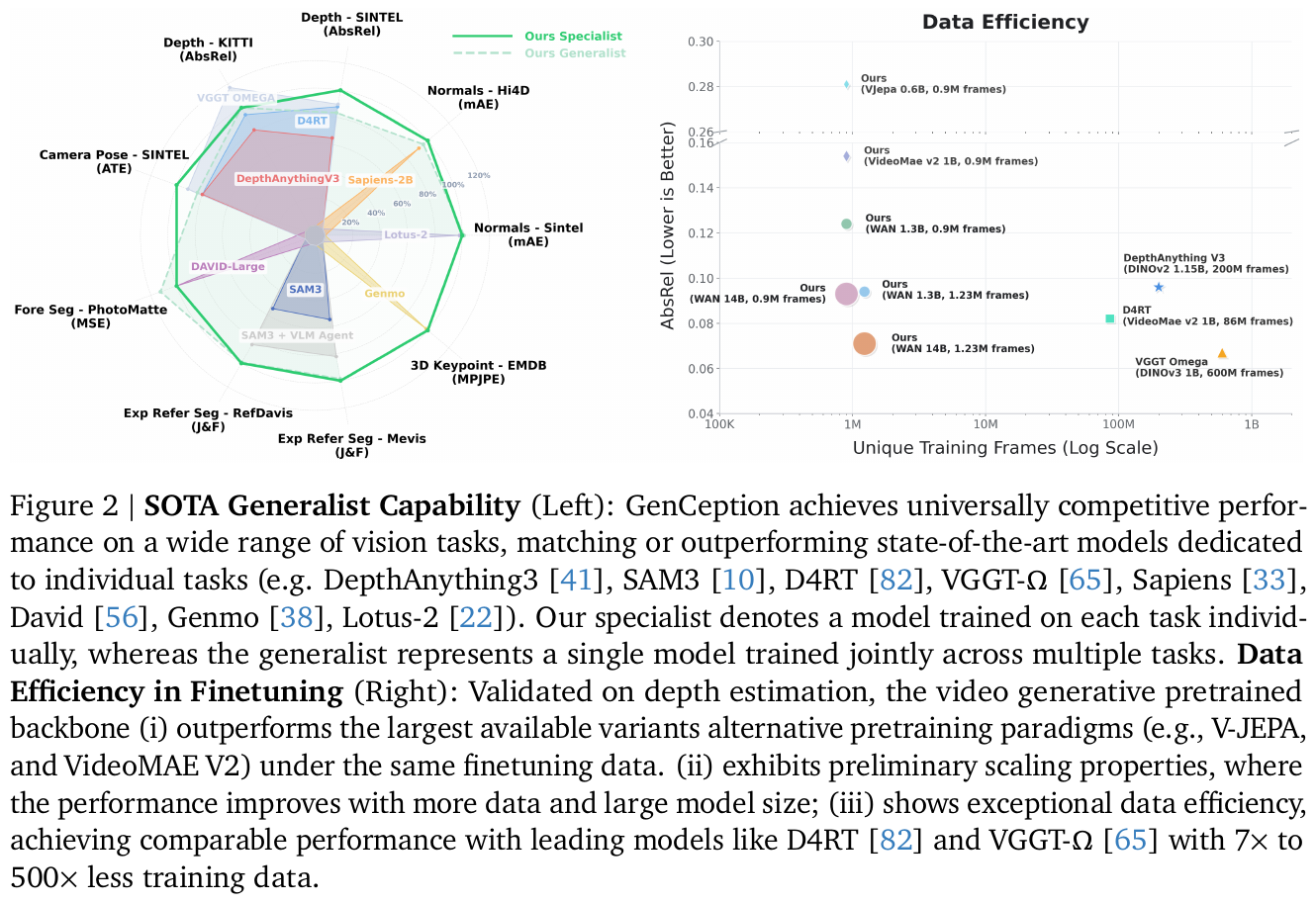
- 超越专用 SOTA 模型:在法线估计、深度估计、相机姿态与 3D 人体关键点预测上,虽然没有使用对应数据集的训练集进行有监督训练,但 GenCeption 的预测精度依然全面超越了 Lotus-2(FLUX 12B)和 NormalCrafter(SVD 1.5B),并超越或持平了 DepthAnything 3 及 D4RT。
- 远胜自监督视频底座:在控制微调样本数(7.5k 视频)相同的前提下,GenCeption (1.3B/14B) 模型的几何和深度预测表现显著优于 VideoMAE V2 (1B) 与 V-JEPA (0.6B)。
- 极高的数据效率:在深度估计任务上,GenCeption 仅依靠 7.5k 的合成视频进行多任务微调,表现就媲美了在数百万/数亿真实多源数据上训练的 D4RT 和 VGGT-Ω,使训练所需的数据规模大幅下降了 $7\times$ 至 $500\times$。
- 零样本泛化与跨域能力:由于继承了预训练视频生成模型中蕴含的宏大世界物理常识,GenCeption 表现出极其突出的 Sim-to-Real 与 Out-of-Distribution(OOD)泛化能力:
- 实例泛化:虽然微调时仅在单人合成视频上进行训练,但可以直接推理具有多实例、高复杂度的真实场景视频。
- 类别泛化:能够直接准确泛化到完全未在训练数据中出现的动物、恐龙和人形机器人等类别上。

4. 局限性
- 密集与稀疏任务的联合冲突:实验发现,在同时微调密集像素任务与稀疏坐标任务时,稀疏任务的表现会大幅下滑,且连带密集感知任务也会产生轻微退化。分析表明,外挂的可学习 Token 会在没有充分多任务微调数据的情况下,破坏 DiT 原本的注意力权重,且在几何表征层面上与连续的像素空间重构具有一定冲突。在进行微调时,应更加小心设计以保证网络骨干的“零侵入性”。
6.26 S-Agent (2026) {#6-26-s-agent}
——空间工具调用激发具身空间智能推理
📄 Paper: arXiv:2606.20515 · Project Page
精华
- 证据积累新范式:将连续多视角与视频空间推理重新建模为”时空证据积累”(Spatio-Temporal Evidence Accumulation)的主动交互过程,摆脱了传统 VLM 仅依赖静态单帧图像做无状态推断的局限。
- 分级空间工具体系:构建由低至高三级空间工具与专家系统(2D 视觉感知 $\rightarrow$ 2D-to-3D 几何提升 $\rightarrow$ 空间知识聚合专家),将复杂的 3D 空间计算从语言模型预测中彻底解耦。
- 时空持久双记忆:设计 Scene Memory 追踪跨帧实体标识并融合几何属性,Agent Memory 记录推理轨迹与工具失败反馈,实现自洽的连续推导与自我纠错。
- 高质量轨迹蒸馏:通过 GPT-5.4 老师模型自动生成并筛选 51.5K 优质推理轨迹,解耦导出 292K 样本的 S-300K 数据集,成功将强大的空间工具调用与推理能力蒸馏至 8B 轻量级模型(S-Agent-8B)。
1. 研究背景/问题
- 核心问题:真实物理世界中的具身空间智能要求智能体在连续演化和多视角的 3D 环境中具备几何理解与推理能力。然而,现有视觉语言模型(VLM)和工具增强 Agent 主要局限于静态单张图像的无状态推理,无法跨视角和时间维持久维持物体状态。
- 关键 Gap:VLM 擅长定性语义推理,但缺乏高保真的 3D 几何表征,容易依赖文本先验而非扎实的几何证据;同时,直接将密集 3D 几何(如深度图、点云、相机位姿)输入 VLM 容易产生冗余干扰与无法直接理解的数值噪声。
2. 主要方法/创新点
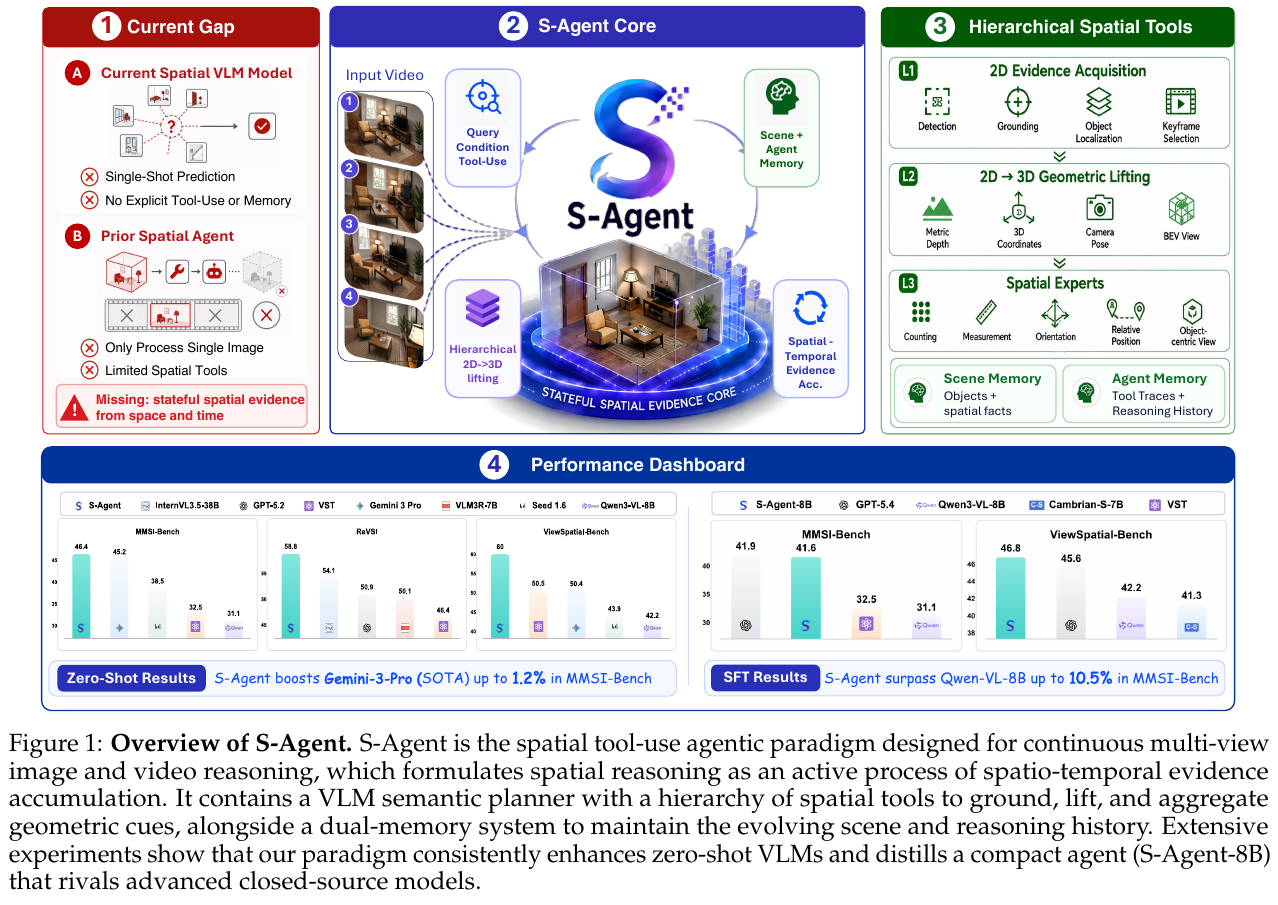
① 整体框架概述
S-Agent 是一种由 VLM 协调的时空推理框架。它将 VLM 扮演为语义规划器(Semantic Planner $\pi_{\theta}$),将空间计算与感知任务交由分级空间工具与专家(Hierarchical Spatial Tools & Experts)处理,并通过持久化时空记忆(Persistent Spatial Memory)在推理步骤和视频帧之间累积证据。
给定问题 $q$ 和连续观测图像集 $\mathcal{F}$,S-Agent 在每个推理步骤 $t$ 保持两个记忆状态:用于储存物理事实的场景记忆 $\mathcal{S}_t$ 和用于储存推理历史的 Agent 记忆 $\mathcal{H}_t$。规划器生成证据请求: \(r_t = \pi_{\theta}(q, \mathcal{F}, \mathcal{S}_t, \mathcal{H}_t)\) 工具或专家执行 $r_t$ 并返回观察结果 $o_t$,进而更新记忆状态: \((\mathcal{S}_{t+1}, \mathcal{H}_{t+1}) = \text{Update}(\mathcal{S}_t, \mathcal{H}_t, r_t, o_t)\)
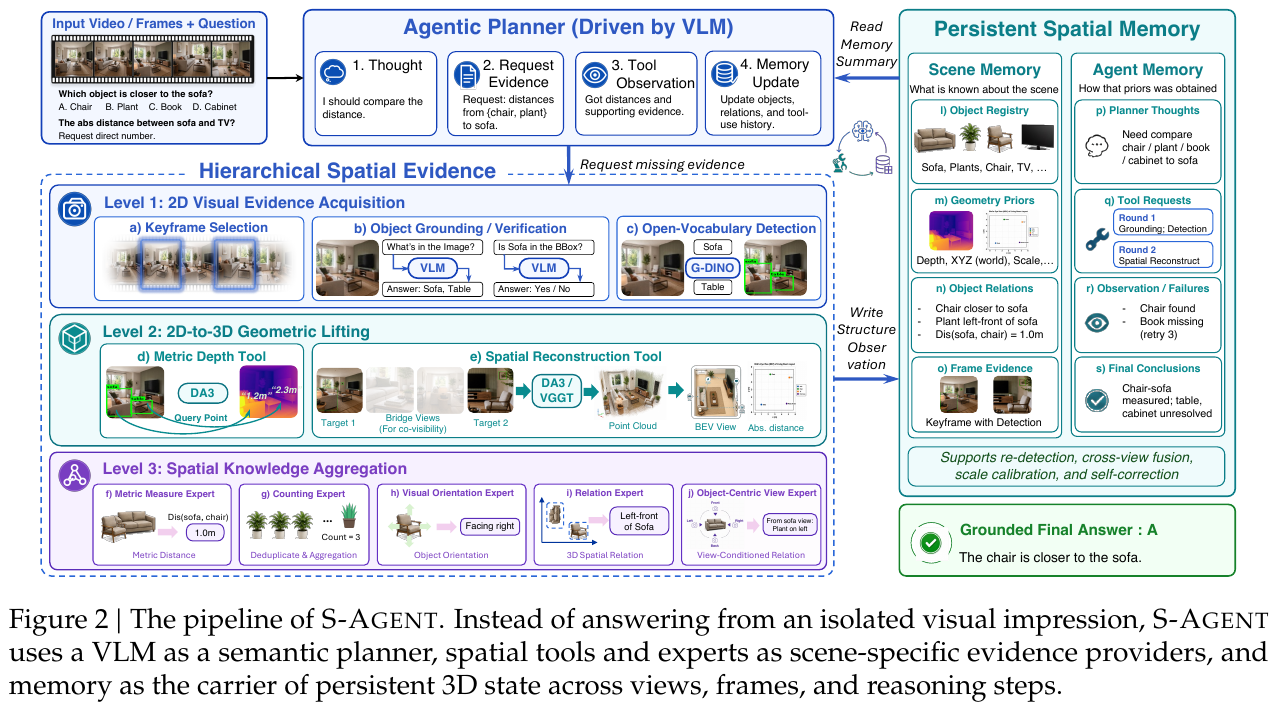
② 逐模块讲解
1. Level 1: 2D 视觉证据获取(2D Visual Evidence Acquisition)
- 输入:原始视频帧或多视角图像 $\mathcal{F}$,以及规划器的目标实体请求。
- 处理:包含关键帧提取(
TStarKeyframeSearchTool)、VLM 目标定位与可见性投票(vlm_ground_objects)、GroundingDINO 开放词汇检测(detect_objects_tool)以及轻量级图像深度估计(depth_estimation_tool)。 - 输出:目标物体的 2D 边界框(Bounding Box)、置信度与过滤后的关键帧。
2. Level 2: 2D-to-3D 几何提升(2D-to-3D Geometric Lifting)
- 输入:Level 1 获取的 2D 目标区域与多视角图像。
- 处理:调用基于 Depth-Anything-3 的 3D 度量几何工具
metric_depth3d_tool,从多视图重建度量深度、3D 空间点云坐标、相机位姿以及鸟瞰图(BEV)表示。 - 输出:统一在共享 3D 度量坐标系下的空间几何基质,解决视错觉与尺度的不确定性。
3. Level 3: 空间知识聚合专家(Spatial Knowledge Aggregation Experts)
- 输入:Level 1 的 2D 观测与 Level 2 的 3D 重建几何。
- 处理与专家分工:
- 度量测量专家(Metric Measurement Expert):确定性计算相机到物体距离、物体间绝对距离及物理尺寸。
- 计数专家(Counting Expert):执行跨帧候选检测框匹配,使用 NMS 去重并进行条件约束统计。
- 视觉朝向专家(Visual Orientation Expert):分析物体朝向表面、屏幕、开口等视觉线索,判断物体的自洽朝向与姿态。
- 相对位置专家(Relative Position Expert):在 3D 坐标系中推理以物体/相机/方位角为参照系的相对方向(如左/右、前/后)。
- 物体中心视角专家(Object-Centric View Expert):基于特定物体的局部坐标系评估周围物体的空间分布。
- 输出:直接可供 VLM 规划器读取的高层结构化空间知识(如:”距离为 1.0m”、”数量为 3”)。
4. 时空双记忆机制(Persistent Spatial Memory)
- 场景记忆(Scene Memory $\mathcal{S}_t$):跨视角与跨帧绑定同一实体的多次观测,维护对象注册表(Object Registry)、几何先验、空间关系与帧级证据,避免重复计算与实体识别冲突。
- Agent 记忆(Agent Memory $\mathcal{H}_t$):记录规划器的中间思考(Thought)、发出的工具请求、工具成功/失败反馈及阶段性结论,支持自我修正与策略调整。
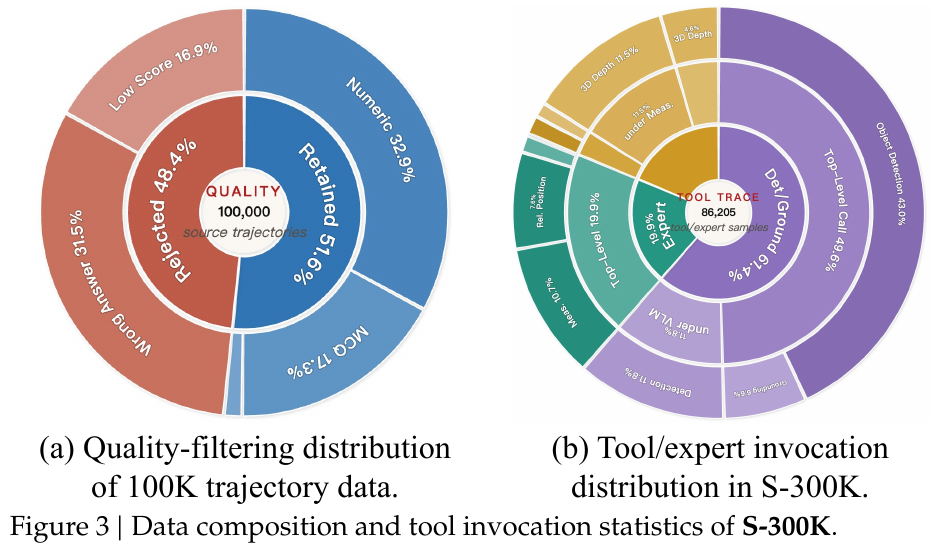
③ 训练期轨迹蒸馏(Training-Time Distillation & S-300K)
为将强大的空间推理能力部署到轻量化开馆模型中,S-Agent 提出了轨迹蒸馏管线:
- 数据生成:在 SenseNova-SI-800K 数据集上用 Qwen3-VL-8B 进行预筛选,挑选学生模型表现不稳定的难例 100K 题,用 GPT-5.4 驱动的 S-Agent 生成完整的工具调用轨迹。
- 质量过滤:根据题型(选择题选项严格匹配、数值题 MRA $\ge$ 0.6、文本题规范匹配)过滤出 51,596 条高质量轨迹。
- 轨迹分解:拆解为 51,596 条 Final-Answer 轨迹、154,590 条 Turn-Level 规划轨迹及 86,205 条 Expert 工具调用轨迹,合成包含 292,391 个 SFT 样本的 S-300K 数据集。
- 模型微调:使用 LLaMA-Factory 在 8$\times$B200 GPU 上对 Qwen3-VL-8B-Instruct 进行 SFT,得到轻量级空间 Agent S-Agent-8B。
3. 核心结果/发现

- 多图空间推理(MMSI-Bench):Zero-Shot S-Agent 取得 46.4% 的最高平均准确率,超越闭源顶尖模型 Gemini 3 Pro(45.2%)与 GPT-5.4(41.9%)。在相机运动(46.0%)、物体运动(48.7%)和多步推理(44.4%)维度表现极其突出。蒸馏模型 S-Agent-8B 达到 41.6%,相比 Qwen3-VL-8B 基线(31.1%)提升了 10.5%。
- 视角感知定位(ViewSpatial-Bench):Zero-Shot S-Agent 取得 60.0% 平均准确率,超出 GPT-5.4 14.4%。在相机相对方向(C-RD, 62.5%)和人称相对方向(P-RD, 81.1%)上均显著领先。S-Agent-8B 达到 46.8%。
- 视频 3D 空间推理(ReVSI Leaderboard):S-Agent 取得 58.8% 平均分,位列榜单第二(仅次于 Gemini 3 Pro 的 60.9%),且在相对方向(66.4%)和路径规划(66.1%)等多选任务上高居榜首。S-Agent-8B 达到 52.8%,超越了许多更大尺寸的模型(如 InternVL3.5-38B 的 54.1% 及其 8B 变体)。
- 消融实验(ViewSpatial):
- 纯 VLM 基线为 45.6%;
- 仅加入 Level-1 2D 视觉证据提升至 49.0%;
- 直接引入密集 Level-2 3D 几何仅微升至 49.8%(因为密集点云和深度数值容易干扰 VLM 规划器);
- 结合 Level-3 空间专家后大幅提升至 56.7%;
- 进一步开启 Scene Memory(58.2%)与 Agent Memory 后达到完整版的 60.0%。这验证了分级专家与双记忆机制在空间证据提取中的核心作用。
4. 局限性
- 依赖底层视觉感知工具的可靠性:若 Level-1 检测或 Level-2 3D 重建(如 Depth-Anything-3)在剧烈遮挡、低照度或极大尺度变化下发生严重偏差,专家模块可能产生错误的空间结果。
- 多轮调用的延迟开销:由于涉及多轮 VLM 规划以及 2D/3D 工具的协同计算,系统在推理时相比 Single-Shot 预测具有更高的时延,目前更适合非实时的复杂空间决策与分析任务。
7. 总结与展望
空间智能是迈向具身通用人工智能的核心能力之一。本文系统梳理了从基础离散几何学习到最新的大模型驱动空间推理的技术路径。
空间智能与世界模型 (World Models)
在 2025-2026 年的语境下,空间智能不再仅仅是机器人或自动驾驶的一个组件,它正在成为 “物理世界模型” 的几何骨架。目前的 SOTA 模型如 GaussianVLM 已能处理复杂的空间问答,但真正的挑战在于 “物理推理(Physical Reasoning)”:
- 因果关系预测:理解物体间的物理约束(如:如果撤掉底部的积木,上方的积木会如何塌陷?)。
- 具身常识推理:在交互过程中理解物体的材质、质量与摩擦力。
未来趋势
- 统一 3D 基础模型 (Spatial Foundation Models):超越特定任务,构建能处理任意 3D 场景并与语言深度融合的通用感知模型。
- 动态与时序空间智能:从静态重建转向 4D 动态感知,实时捕捉物理世界的演变。
- 闭环具身交互:将空间推理直接转化为动作指令,缩短从感知到操控的闭环。
空间智能的发展将为通用人工智能(AGI)打通感知物理世界的“任督二脉”,推动 AI 从虚拟数字空间真正步入三维物理现实。