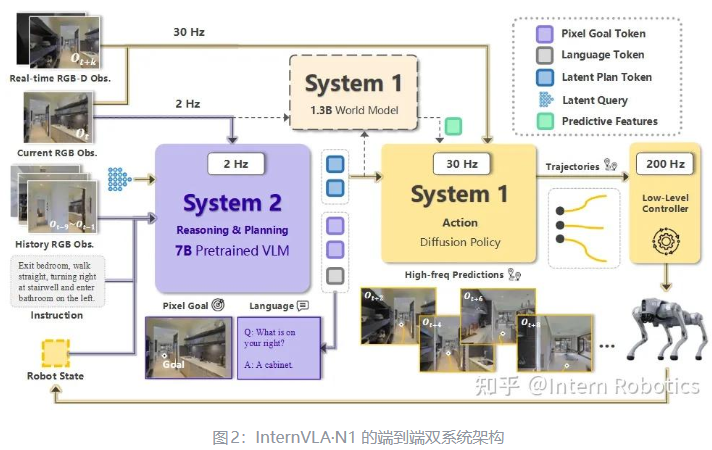
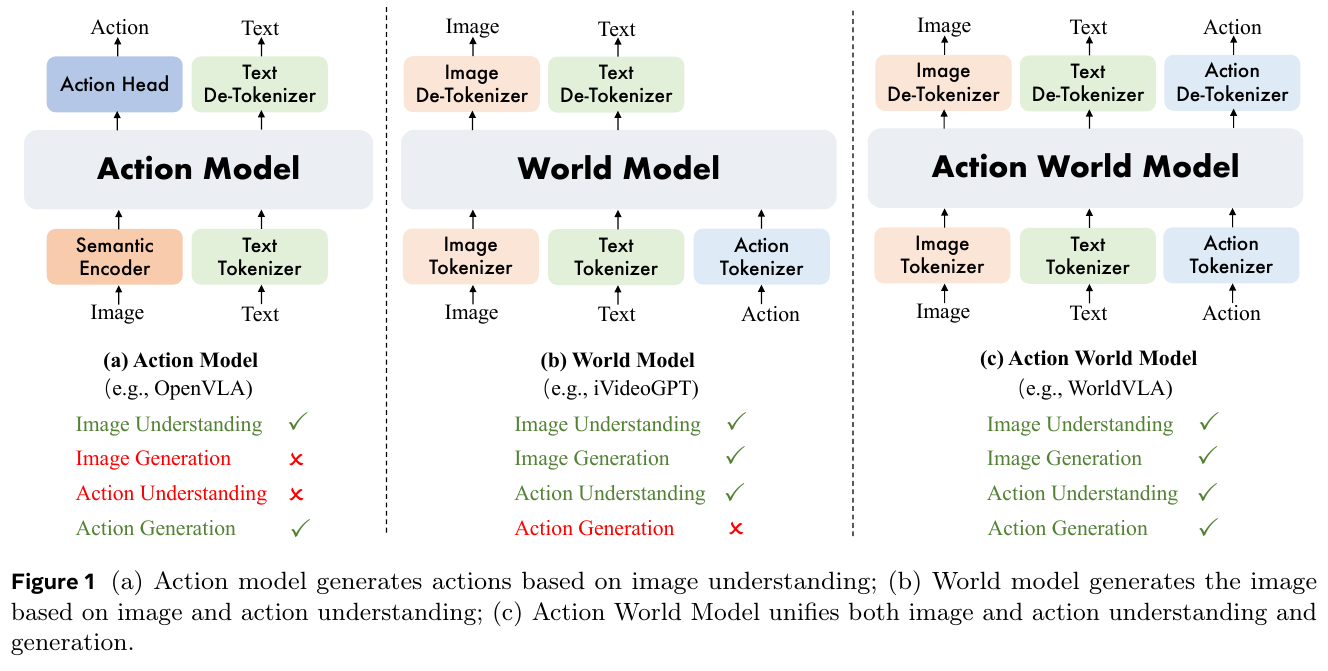
1. 引言
具身智能(Embodied AI)的终极目标是开发能够像人类一样在复杂现实世界中感知、推理并执行任务的通用智能体。近年来,视觉-语言-动作(Vision-Language-Action, VLA)模型的出现,标志着具身智能向通用化迈出了关键一步。VLA 模型利用大规模多模态预训练模型(如 LLMs/VLMs)的语义推理能力,将高层指令转化为底层的机器人控制指令。
然而,现有的 VLA 智能体在实际部署中仍面临三大核心挑战:
- 物理幻觉(Physical Hallucination):生成的动作往往缺乏物理常识约束。
- 计划验证缺失:难以预见动作执行后的物理后果,导致无法在闭环中验证计划的可执行性。
- 数据稀缺:高质量的机器人交互数据获取成本极高,限制了模型的扩展性。
为了应对这些挑战,世界模型(World Models) 被引入具身智能领域,作为一种”未来预测器”,模拟环境的时间演变。通过预测未来状态,世界模型不仅为 VLA 提供了物理接地的引导,还成为了高效的数据引擎和虚拟仿真环境。
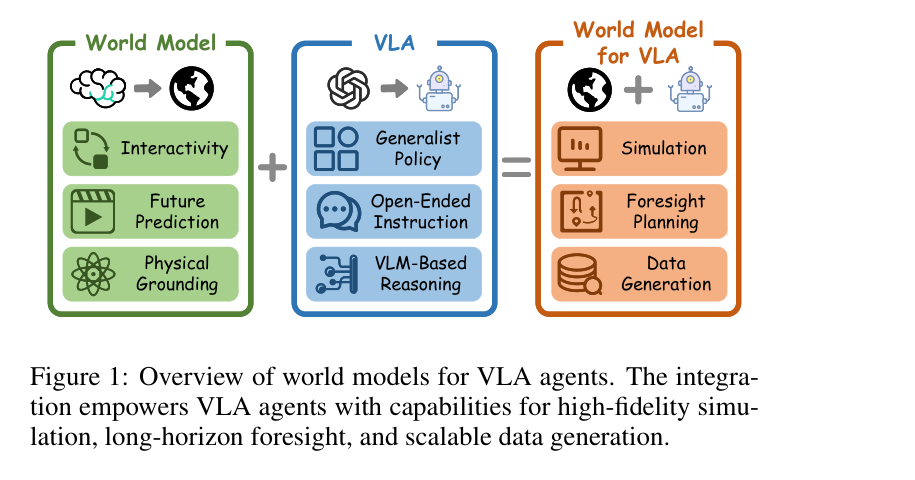
本文基于同济大学 Tan et al.(2026)发布于 TechRxiv 的综述论文 Towards Generalist Embodied AI: A Survey on World Models for VLA Agents,系统梳理具身智能中世界模型的研究进展,为学习和研究该领域提供参考。
2. 具身智能世界模型基本概述
2.1 什么是具身智能世界模型?
在具身智能语境下,世界模型 $W_\phi$ 旨在通过近似状态转移分布 \(P(s_{t+1} \mid s_t, \cdot)\) 来捕捉环境动力学。它通常采用生成式骨干网络(如 Diffusion 或 Transformer)来建模复杂场景的时空演化。
与传统的机器人仿真器不同,具身智能世界模型通常是从大规模多模态数据中”学习”物理规律,能够生成物理上一致的未来预测,从而辅助智能体进行闭环推理。
与 VLA 的关键区别:大型语言模型(LLMs)作为离散世界模型,擅长文本中心的推理,但难以捕捉连续物理动力学。具身世界模型通过预测连续的未来状态,填补了这一关键空白,将高层语义意图与低层物理执行连接起来。
2.2 核心要素与系统架构
世界模型与 VLA 智能体的集成通常包含以下核心能力:
- 交互性(Interactivity):响应动作输入并反馈环境变化。
- 未来预测(Future Prediction):预测像素级或潜空间级的未来状态。
- 物理接地(Physical Grounding):确保生成的轨迹符合物理常识。
其典型的系统架构可分为:
- 感知编码器:将视觉和语言输入转化为特征。
- 动态模型(世界模型核心):预测未来的潜状态或图像序列。
- 策略网络(VLA):根据预测的未来信息生成最终动作。
2.3 研究发展趋势
世界模型的研究从最初的简单动作预测,逐步演进为集感知、推理、生成于一体的复杂系统。下图展示了 2023 年至 2025 年四大范式的演化时间轴。
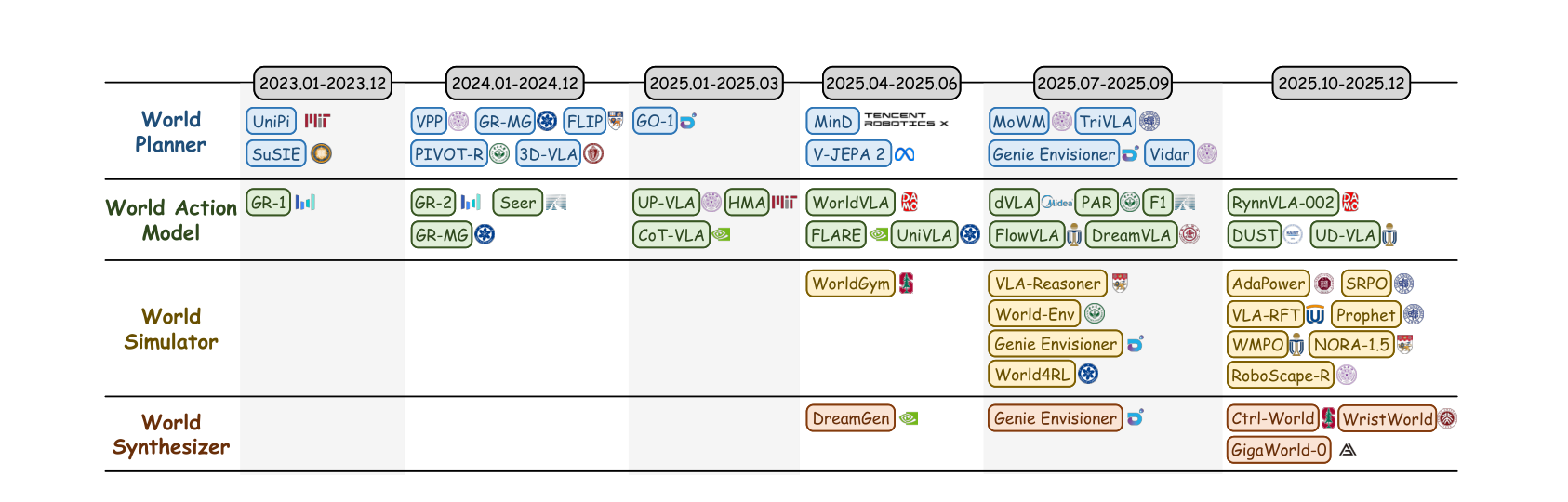
关键趋势:
- 2023年:UniPi、SuSIE 奠定视频生成驱动规划基础;GR-1 开创世界动作模型范式。
- 2024年:PIVOT-R、3D-VLA 引入 3D 感知;GR-2 验证了大规模视频预训练的有效性。
- 2025年初:UP-VLA、CoT-VLA 拓展推理增强方向;WorldGym 成为首批世界模拟器之一。
- 2025年中后期:世界合成器(DreamGen、Ctrl-World、GigaWorld-0)和世界模拟器(VLA-RFT、RoboScape-R、NORA-1.5)爆发式增长,受益于生成式 AI 技术的快速进步。
3. 四大技术范式详解
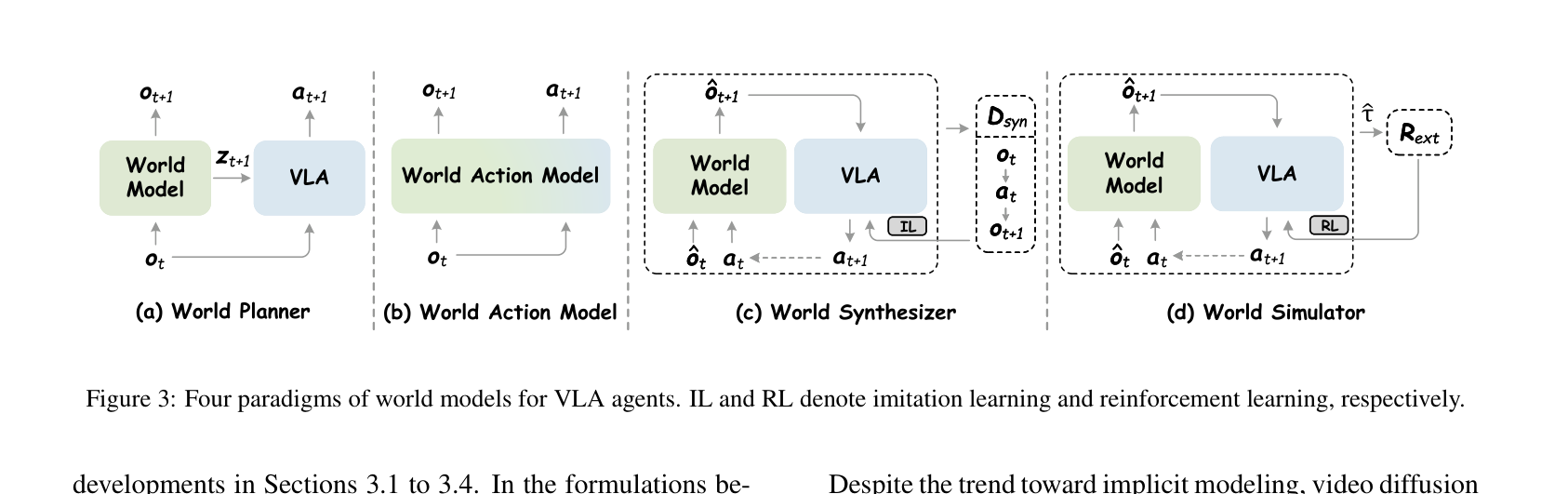
3.1 世界规划器 (World Planner)
定义:该范式采用世界模型 \(\mathcal{W}_\phi\) 作为前向动力学模型,以显式未来观测或隐式潜特征的形式合成前瞻引导,为策略 \(\pi_\theta\) 提供语义条件:
\[\max_\theta \mathbb{E}_{z_{t+1} \sim \mathcal{W}_\phi(\cdot|o_t)} \left[ \sum_t \log \pi_\theta(a_{t+1} | o_t, z_{t+1}) \right]\]世界规划器的核心思路是预测先于行动:先用世界模型预见未来(显式图像或隐式潜向量),再将该前瞻信号作为条件喂给策略,使动作决策具备物理接地的未来感知。两种主流路径的信息流如下:
flowchart LR
O_t["观测 o_t"] --> WM
subgraph WM["世界模型 W_φ(前向动力学)"]
direction TB
ExP["显式路径\n扩散模型生成像素帧\nUniPi / SuSIE / FLIP"]
ImP["隐式路径\n潜空间预测\nV-JEPA 2 / PIVOT-R"]
end
ExP -->|"预测帧 o_{t+1}"| IDM["逆动力学模型\n推断动作 a"]
ExP -->|"潜嵌入 z_{t+1}"| Policy
ImP -->|"潜嵌入 z_{t+1}"| Policy
IDM --> Policy
O_t --> Policy
Policy["策略 π_θ(a | o_t, z_{t+1})"] --> Robot["执行器"]
细粒度分类(根据规划范式和引导信号):
| 范式 | 引导信号 | 代表性方法 |
|---|---|---|
| 显式(Explicit) | 预测图像 | UniPi, SuSIE, GR-MG, Vidar, 3D-VLA, FLIP |
| 隐式(Implicit) | 潜嵌入 | V-JEPA 2, PIVOT-R |
| 显式(Explicit) | 潜嵌入 | VPP, MinD, TriVLA, GO-1, Genie Envisioner |
| 混合(Hybrid) | 混合 | MoWM |
演进路径:UniPi、SuSIE、GR-MG、Vidar、3D-VLA、FLIP 等将规划视为高保真视频生成任务,通过扩散模型合成像素级未来状态,再经逆动力学模型导出动作。近期 V-JEPA 2 和 PIVOT-R 转向隐式规划,直接在潜空间预测未来状态,避免了动力学无关的视觉细节(如光照、纹理)的干扰,提升了引导信号的质量。MoWM 则融合多种动力学先验形成混合方案,进一步简化动作推导。
工业落地案例:GENE-26.5(Genesis AI, 2026)
Genesis AI 于 2026 年发布的 GENE-26.5 是当前世界规划器范式在工业级灵巧操作上的代表性落地之一。它最直观的卖点是:新任务只需 < 1 小时(约 200 episodes、< 20 秒技能)的机器人特定数据即可完成微调,而支撑这一数据效率的,正是”用世界模型为低层动作策略注入物理先验”的世界规划器思想。
三个功能角色,一个统一模型
从系统视角看,GENE-26.5 自然地呈现出三个功能层:
- 语义感知层(VLM):编码自然语言指令与场景语义,对应任务的高层逻辑链(如”做三明治需要先找面包再找火腿”)。
- 物理预测层(World Model):动作条件视频生成模型,从大规模视频中学习”接下来几秒钟内物体如何受力、形变、断裂”,提供物理常识先验。
- 执行转化层(Action Model):高频底层控制,将前两层提供的语义+物理条件翻译为具体的关节扭矩。
但需要指出的是,GENE-26.5 在工程实现上并不是三个独立串联的模块,而是用 Flow Matching 建模 language / vision / proprioception / tactile / action 的联合分布——VLM 与 World Model 是被吸收进来的预训练组件,下游通过条件查询(conditional queries)从同一分布里采样出 control / generative simulation / state estimation / inverse dynamics / goal inference / rendering / value estimation 等不同子任务。这种”一模多用”的设计,让物理预测信号可以无缝、近乎零成本地流向动作生成。
信号路径:从语义到扭矩
flowchart LR
Lang["语言指令\n(intent)"] --> VLM
Img["第一/第三人称视频\n本体感觉 / 触觉"] --> VLM
VLM["VLM\n语义编码"] -->|"语义条件"| Joint
VLM -->|"语义条件"| WM
subgraph Joint["联合分布模型 (Flow Matching)\n language ⊕ vision ⊕ proprioception ⊕ tactile ⊕ action"]
direction TB
WM["World Model\n动作条件视频生成\n→ 物理先验 z_phys"]
Cond["条件查询接口\n control / sim / state est. / IDM / value"]
end
WM -->|"潜空间物理引导"| Cond
Cond -->|"action sample"| Ctrl["500Hz 控制栈\nEtherCAT, 3ms 端到端\n~2mm 追踪误差"]
Ctrl --> Hand["Genesis Hand 1.0\n20-DoF 仿人手"]
训练范式:异构多模态预训练 + 短时下游适配
GENE-26.5 的训练数据规模超过 200,000 小时,覆盖四类异构来源:
| 数据来源 | 提供的物理/语义信息 |
|---|---|
| Glove 数据 | 人手动作轨迹 + 触觉信号 |
| 第一人称(egocentric)视频 | 自然交互行为、任务多样性 |
| 第三人称视频 | 互联网级物理交互场景 |
| 互联网语言 + 视频 | 语义先验、世界知识 |
关键设计是不要求显式跨模态对齐:联合分布模型直接吃部分可观测、异构的多模态数据,在预训练阶段习得”看-想-动”耦合先验。下游任务因此只需做条件适配——这才是”<1 小时微调”真正的来源,而不是简单地”动作模型只是把预测帧翻译成扭矩”那么轻量。新任务评测中 20–30 分钟的适配数据即可达到可用性能,进一步验证了该范式的样本效率。
硬件协同
世界规划器范式落地到真机的瓶颈往往不在模型,而在控制栈延迟。GENE-26.5 自研 EtherCAT 中间件实现 500Hz 控制频率、3ms 端到端延迟,把跟踪误差从基线的 20mm 压到 ~2mm。Genesis Hand 1.0 提供 20 个主动可反驱(back-drivable)自由度、1:1 人手尺寸——只有控制带宽足够高,世界模型预测出的”物理一致轨迹”才不会在执行端被低频/高延迟控制器涂抹掉。这一点对所有走”WM 引导动作”路线的方案都是值得抄的工程经验。
与四大范式的关系
GENE-26.5 主体上属于 §3.1 的世界规划器:World Model 提供前瞻性物理引导信号,策略据此生成动作。但它同时具备 §3.2 世界动作模型的影子——联合分布显式建模观测与动作的耦合,并支持双向条件查询(既能 $a \mid o$ 控制,也能 $o \mid a$ 仿真);并且支持作为世界模拟器为自身评测提供 2700 人-机器人小时的仿真数据。这种单模型、多范式角色的设计趋势,与 §2.3 时间线中 2025–2026 年世界合成器/模拟器的爆发一脉相承,也代表了世界模型与 VLA 进一步收敛为统一基础模型的方向。
3.2 世界动作模型 (World Action Model)
定义:该范式采用生成式建模近似未来观测与动作的联合分布,预测视觉与控制的耦合动力学:
\[\max_\phi \mathbb{E}_{\tau \sim \mathcal{D}} \left[ \sum_t \log \mathcal{W}_\phi(o_{t+1}, a_{t+1} | o_t) \right]\]与世界规划器”策略与预测分离”不同,世界动作模型将两者统一在同一个网络中联合优化:既要能预测未来帧(视频目标),又要能从中直接解码动作(控制目标)。下图展示了其核心数据流:
flowchart LR
subgraph IN["输入"]
O_t["观测 o_t"]
H["历史帧<br/>o_{t-k:t-1}"]
L["语言指令"]
end
subgraph WM["世界动作模型 W_φ(联合动力学)"]
direction TB
Enc["多模态编码器"] --> Joint["自回归 / 扩散骨干\nToken 流统一建模"]
end
subgraph OUT["联合输出"]
O1["预测帧 o_{t+1}\n视频预训练信号"]
A1["控制动作 a_{t+1}\n解码器直接输出"]
end
O_t --> Enc
H --> Enc
L --> Enc
Joint --> O1
Joint --> A1
A1 --> Robot["执行器"]
O1 -.->|"反向梯度约束物理合理性"| Joint
细粒度分类(根据建模范式和实现机制):
| 范式 | 机制 | 代表性方法 |
|---|---|---|
| 自回归(AR) | 视频预训练 | GR-1, HMA, UniVLA, GR-2 |
| 自回归(AR) | 统一序列建模 | WorldVLA, RynnVLA-002, UP-VLA |
| 自回归(AR) | 前瞻推理 | Seer, F1, GR-MG, PAR |
| 自回归(AR) | 推理增强 | FlowVLA, CoT-VLA, DreamVLA |
| 扩散(Diff.) | 离散值 | UD-VLA, dVLA |
| 扩散(Diff.) | 连续值 | DUST, FLARE |
演进路径:GR-1 开创视频预训练范式后,WorldVLA、RynnVLA-002 将动作与观测整合为统一 Token 流,实现端到端的具身一致性。推理增强方向(FlowVLA、CoT-VLA、DreamVLA)引入多模态思维链结构化决策过程。扩散范式中,UD-VLA 和 dVLA 通过离散扩散提升 Token 生成质量;DUST 和 FLARE 利用联合扩散机制实现高精度连续控制,有效缓解动作离散化带来的信息损失。
3.3 世界合成器 (World Synthesizer)
定义:该范式构建可扩展的数据引擎,通过联合生成器 \(\mathcal{G}_{\theta,\phi}\) 合成交错的观测-动作轨迹 \(\tilde{\tau}\) 支持模仿学习:
\[\mathcal{D}_{syn} \triangleq \left\{ \tilde{\tau} \sim p(o_0) \prod_t \mathcal{G}_{\theta,\phi}(\hat{o}_{t+1}, a_{t+1} | \hat{o}_t) \right\}\]世界合成器充当数据飞轮:从少量真实数据出发,生成大量带标注的合成轨迹,再将其反哺 VLA 训练。关键在于有无动作标注的两条合成路径:
flowchart LR
Init["初始帧 o_0"] --> G
Cmd["任务指令"] --> G
subgraph G["世界合成器 G_{θ,φ}"]
direction TB
PathA["有动作路径\n动作条件展开\nGenie Envisioner / Ctrl-World"]
PathB["无动作路径\n先合成视觉轨迹\nDreamGen / GigaWorld-0"]
IDM["逆动力学模型\n从帧差推断动作 a"]
PathB --> IDM
end
PathA -->|"(ô_{t+1}, a_{t+1})"| Dsyn
IDM -->|"(ô_{t+1}, â_{t+1})"| Dsyn
Dsyn["合成数据集 D_syn"] -->|"模仿学习 IL"| Policy["VLA 策略 π_θ"]
细粒度分类(根据合成范式和生成策略):
| 范式 | 机制 | 代表性方法 |
|---|---|---|
| 视角增强(View Aug.) | 腕部视角前瞻 | WristWorld |
| 生成数据(Gen. Data) | 动作条件生成 | Genie Envisioner, Ctrl-World |
| 生成数据(Gen. Data) | 无动作合成 | DreamGen, GigaWorld-0 |
演进路径:WristWorld 通过生成 4D 腕部视角数据进行视角增强,专注于改善自我中心前瞻。Genie Envisioner 和 Ctrl-World 采用动作条件世界模型,基于特定动作序列展开未来观测。DreamGen 和 GigaWorld-0 则首先合成视觉轨迹,再通过逆动力学推断动作——无需动作标注,为突破机器人数据长尾瓶颈提供了重要途径。
3.4 世界模拟器 (World Simulator)
定义:该范式将动作条件世界模型 \(\mathcal{W}_\phi\) 作为虚拟仿真器,通过与外部奖励评估器集成,在想象结果上优化期望奖励:
\[\max_\theta \mathbb{E}_{\substack{a \sim \pi_\theta(\cdot|o) \\ \hat{o} \sim \mathcal{W}_\phi(\cdot|o,a)}} \left[ \mathcal{R}_{ext}(\hat{o}, a) \right]\]世界模拟器将世界模型视为虚拟物理环境,策略在想象空间中通过 RL 优化,无需昂贵的真实机器人交互:
flowchart TB
O["真实/初始观测 o"] --> Policy
O --> WS
Policy["策略 π_θ(a|o)"] -->|"采样动作 a"| WS["世界模拟器 W_φ\n(视频生成模型)"]
WS -->|"想象下一状态 ô"| Reward["外部奖励评估器\nR_ext(ô, a)\n任务成功 / 稠密奖励"]
WS -->|"下一观测 ô"| Policy
Reward -->|"奖励 r"| RL["RL 更新\n(PPO / GRPO / WMPO)"]
RL -->|"优化策略参数 θ"| Policy
style WS fill:#fff4e6,stroke:#d68910
style RL fill:#fde9e9,stroke:#c0392b
细粒度分类(根据仿真范式和实现机制):
| 范式 | 机制 | 代表性方法 |
|---|---|---|
| 评估(Eva.) | 任务成功率 | WorldGym, Genie Envisioner |
| 强化学习(RL) | 稀疏奖励 | World4RL, WMPO, Prophet |
| 强化学习(RL) | 稠密奖励 | World-Env, VLA-RFT, RoboScape-R, SRPO, NORA-1.5 |
| 测试时适应(TTA) | — | VLA-Reasoner, AdaPower |
演进路径:WorldGym 和 Genie Envisioner 将世界模型作为单纯的评估器来验证 VLA 性能。稀疏奖励 RL 方案(World4RL、WMPO、Prophet)引入合成反馈进行策略改进。稠密奖励方案(World-Env、VLA-RFT、RoboScape-R)进一步提供逐步奖励,显著降低对物理部署的依赖;NORA-1.5 融合 V-JEPA 2 特征提升对齐精度;VLA-Reasoner 和 AdaPower 则探索测试时适应,允许模型在线动态更新。
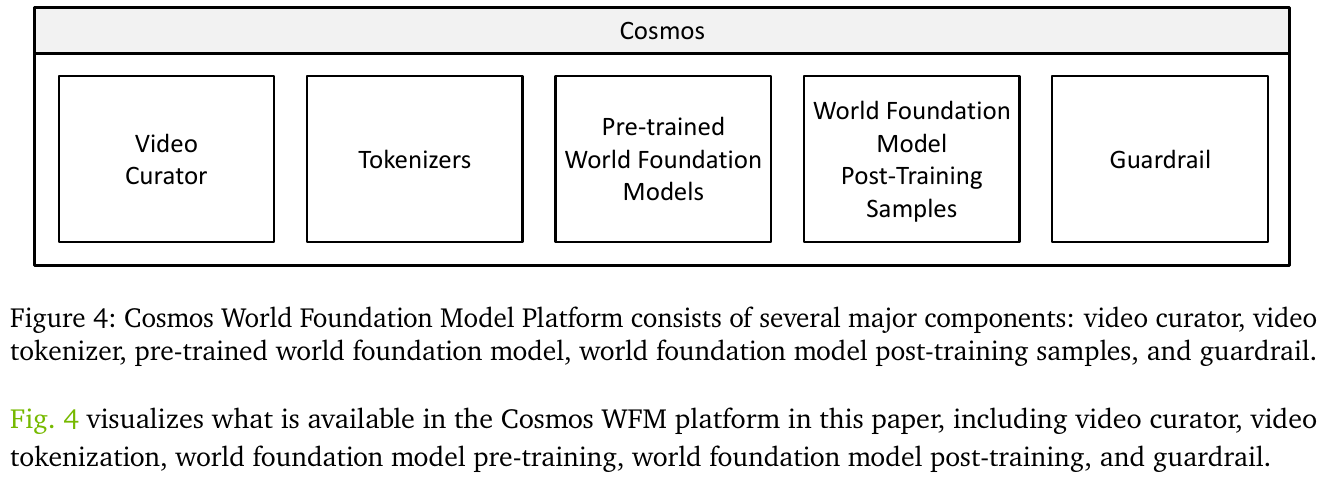
4. Cosmos:物理AI世界基础模型平台
———World Simulation with Video Foundation Models for Physical AI
📄 Cosmos-Predict1 (2025): arxiv.org/abs/2501.03575
📄 Cosmos-Predict2.5 (2026): arxiv.org/abs/2511.00062
🔗 代码: nvidia-cosmos
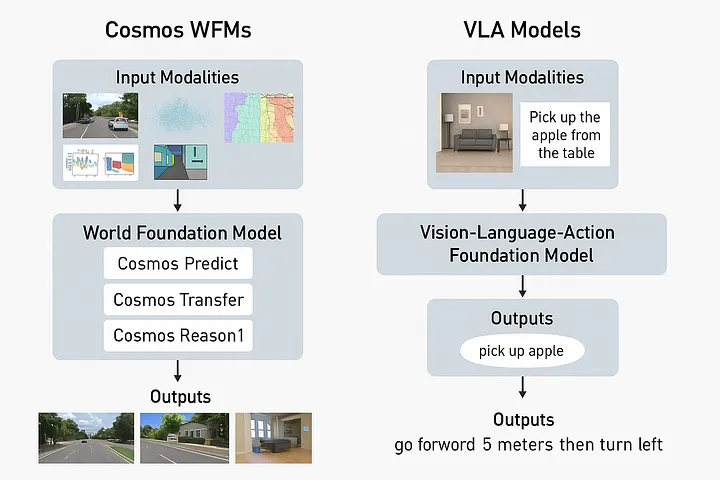
Cosmos 是 NVIDIA 发布的物理 AI 世界基础模型平台。其核心目标是用生成式视频模型替代昂贵的真实世界数据采集与物理仿真器,为机器人、自动驾驶、具身智能等物理 AI 系统提供高质量、大规模、可控的”世界模拟”能力。
与单一视频生成模型不同,Cosmos 是一套分层平台:从数据策展基础设施,到多种预训练模型系列,再到面向具体场景的后训练(Post-training)工作流,构成一条完整的工具链。
4.1 数据基础设施:Cosmos Video Curator
物理 AI 世界模型的训练瓶颈首先是数据质量,而非模型能力。Cosmos 开发了名为 Cosmos Video Curator 的大规模视频处理流水线,分七个阶段将原始视频转化为高质量训练数据:
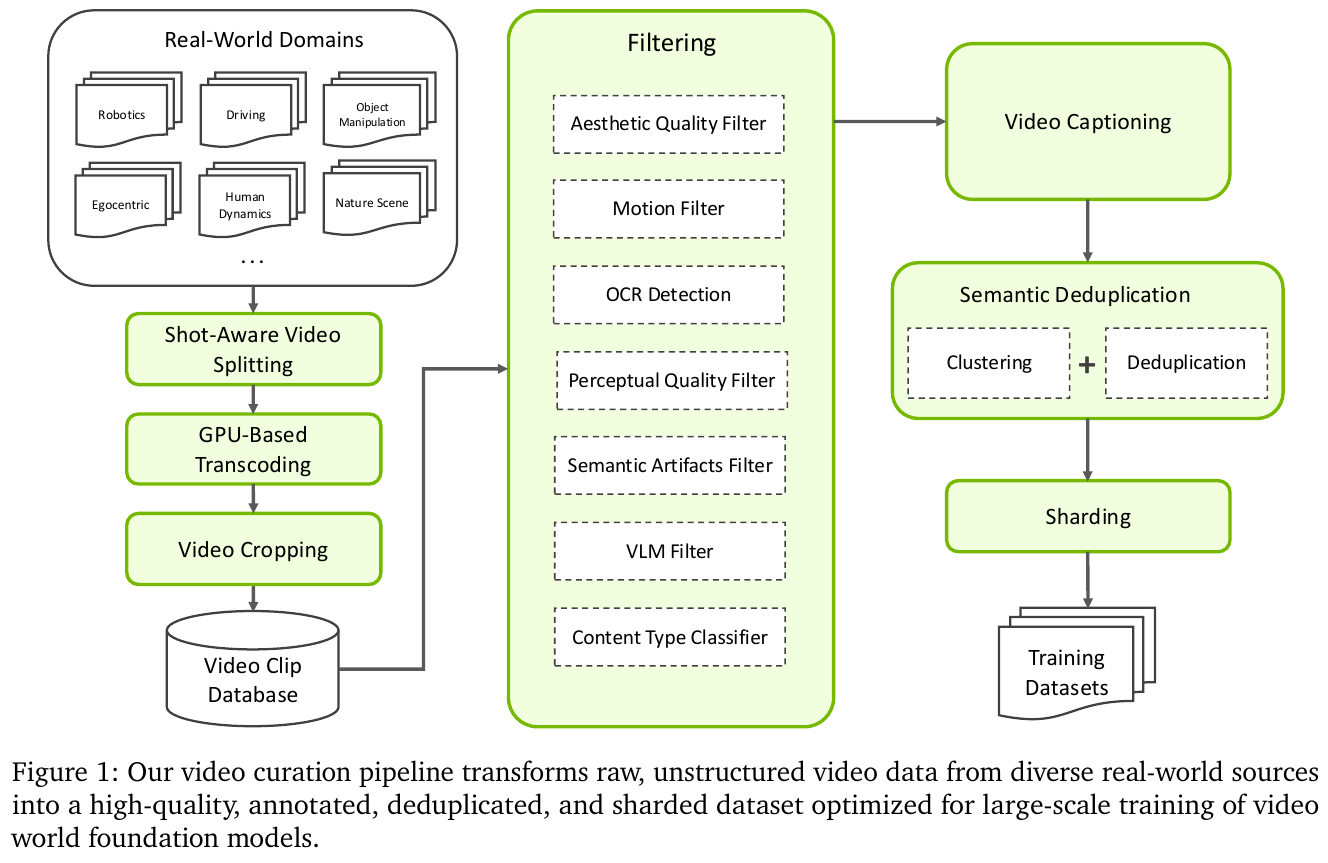
- 镜头感知切分(Shot-Aware Splitting):用高精度边界检测模型将长视频分段,剔除镜头切换片段;
- GPU 加速转码(Transcoding):GPU 加速转码、裁剪黑边,丢弃5秒以下片段;
- 视频裁剪(Cropping):标准化分辨率与画幅比;
- 多级过滤(Filtering):依次经过美学质量、运动检测、OCR 文字、感知质量(DOVER)、语义伪影(VTSS)、VLM 精筛六道过滤,最终仅约 4% 的片段通过;
- 多粒度字幕(Captioning):每个片段切为5秒窗口,用 Qwen2.5-VL-7B 生成短/中/长三种粒度的事实性字幕;
- 语义去重(Deduplication):基于嵌入相似度聚类,保留最高分辨率版本,支持增量在线去重;
- 结构化分片(Sharding):按内容类型(26类)、分辨率、宽高比、长度四维度分片,支持课程学习(Curriculum Learning)与细粒度域平衡采样。
规模:Cosmos-Predict2.5 处理超过 2 亿条原始视频,筛选保留约 2 亿条高质量训练片段(Predict1 时代为 1000 万条)。底层基础设施支持 PB 级处理(Delta Lake 数据湖 + Milvus 向量库),具备 CPU/GPU 动态自动扩缩容能力。
领域专属数据:在通用数据之外,Cosmos 针对五个物理 AI 核心领域构建了专属数据集:
| 领域 | 特点 |
|---|---|
| 机器人操作 | 汇聚 AgiBot-Beta、GR00T、DROID、OpenX 等主流数据集,统一标注动作类型、运动部位与相机视角 |
| 自动驾驶 | ~310 万条 20 秒环视视频,7路相机同步(前宽/前长/左/右/后/后左/后右) |
| 智能空间 | 工厂、仓库、建筑工地等工业场景(~4 万条),VLM 语义验证后保留 |
| 人类动力学 | YOLOX 人体检测 + RTMPose 姿态估计过滤,聚焦人体动态行为 |
| 物理现象 | 覆盖经典力学、流体力学等可观测物理现象,系统化构建物理接地数据 |
4.2 模型体系:三大产品线
Cosmos 平台由三条功能互补的模型产品线构成,共同覆盖物理 AI 世界模拟的完整能力谱:
| 模型 | 核心能力 | 典型输入 | 典型输出 |
|---|---|---|---|
| Cosmos-Predict | 未来世界状态预测 | Text / Image / 历史视频 | 未来多秒视频 |
| Cosmos-Transfer | 结构化世界翻译(Sim2Real) | 边缘/深度/分割图 | 照片级真实视频 |
| Cosmos-Reason | 物理推理 VLM | 视频 + 文本问题 | 带 CoT 自然语言回答 |
Cosmos-Predict:核心预测引擎
Cosmos-Predict 是平台的世界前向动力学模型——给定文本或图像/视频条件,生成未来的世界演化视频。其发展经历了两代:
Cosmos-Predict1(2025):同时提供两种并行架构:
- 扩散模型(Diffusion WFM):基于 DiT + Elucidated Diffusion Model(EDM)、T5 文本编码器,擅长生成高视觉质量、3D 空间一致性强的视频。
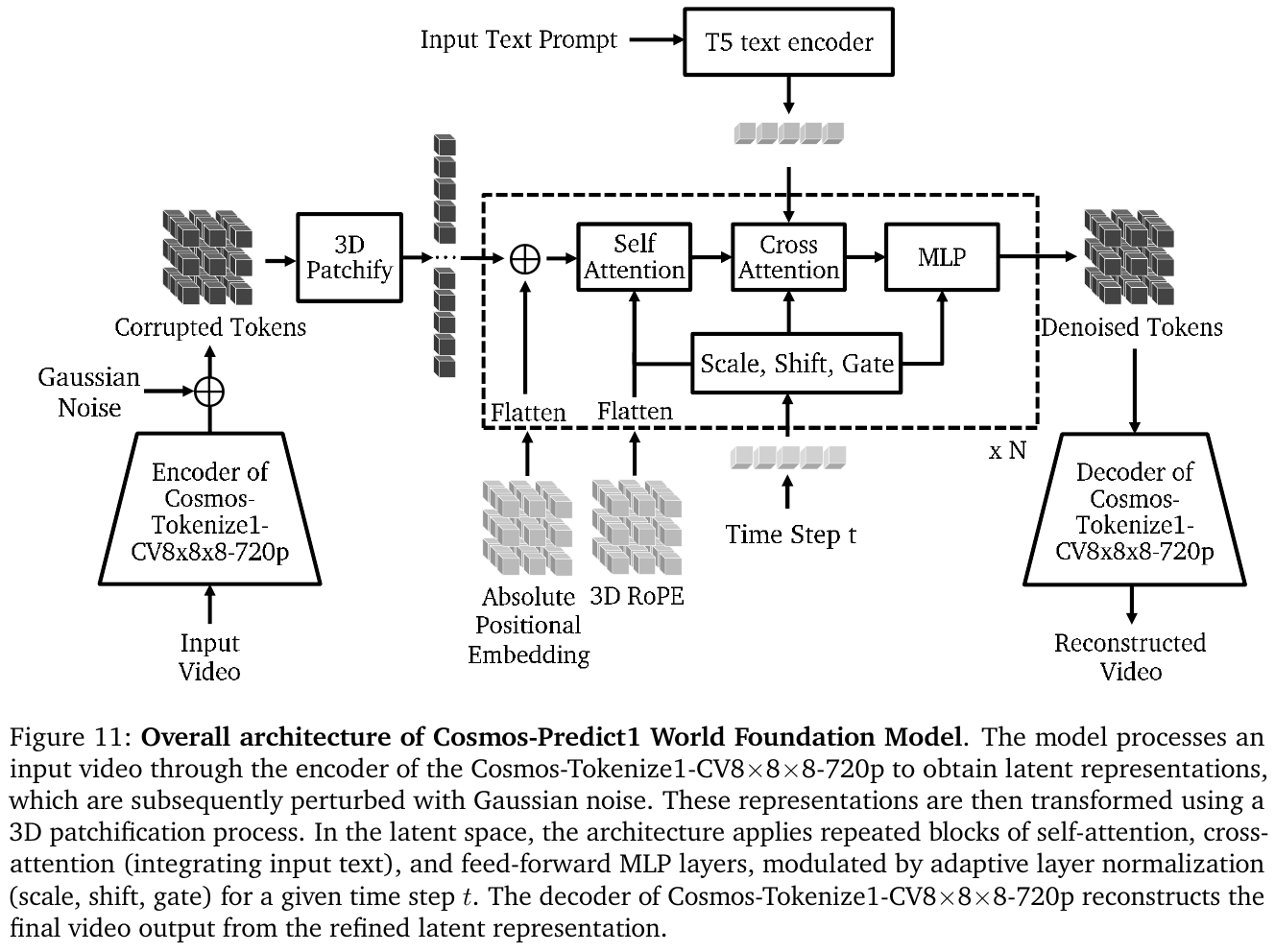
- 自回归模型(Autoregressive WFM):将视频视为离散 Token 序列,通过因果 Transformer 进行 Token 预测,适合长序列、交互式展开。
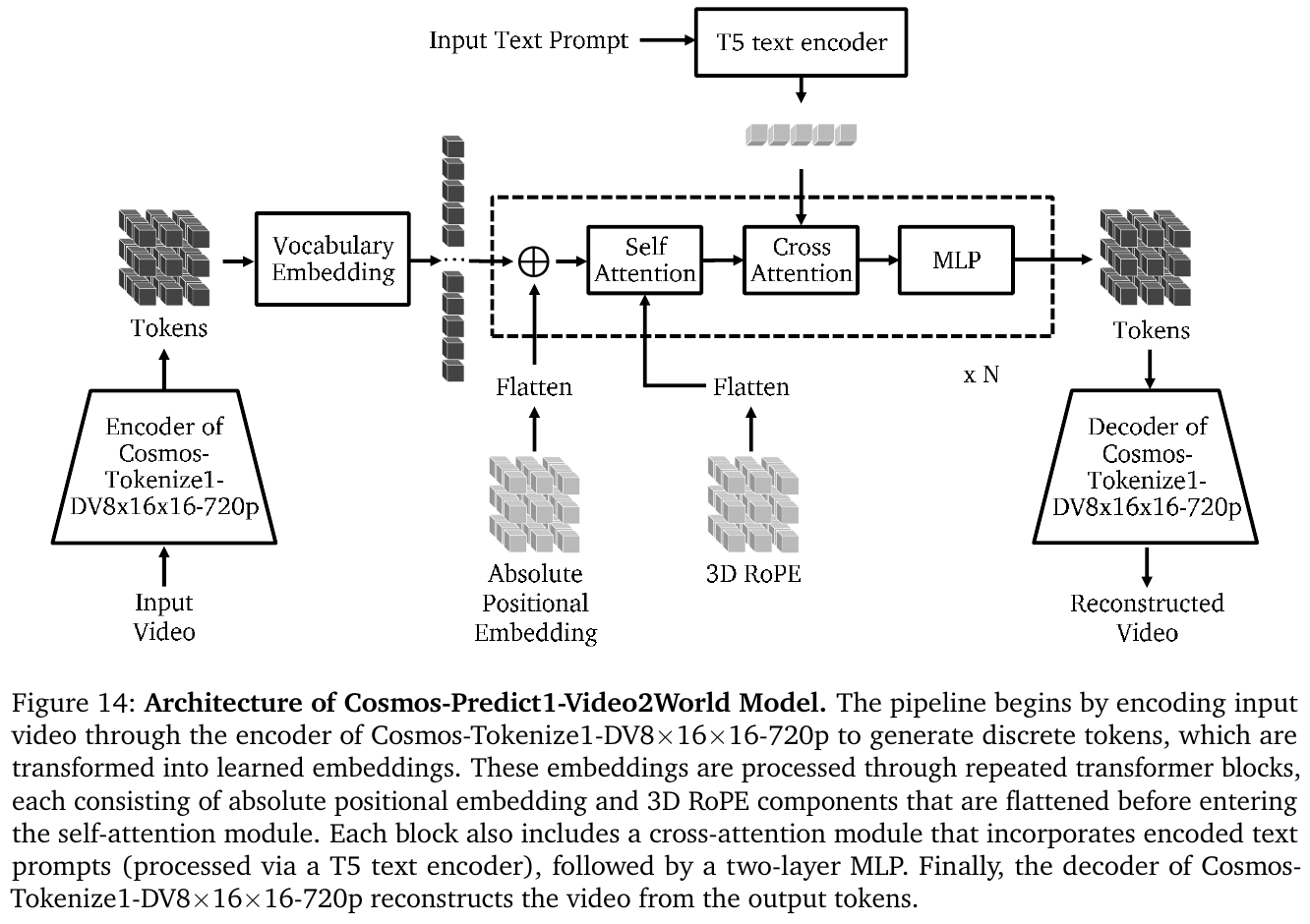
两种模型共用 Cosmos Tokenizer——采用小波变换 + 因果 3D 卷积的编解码结构,支持连续表示(供扩散模型使用)和离散表示(供自回归模型使用),在极高压缩比下优于同期 SOTA(如 Video-MAGVIT2)。
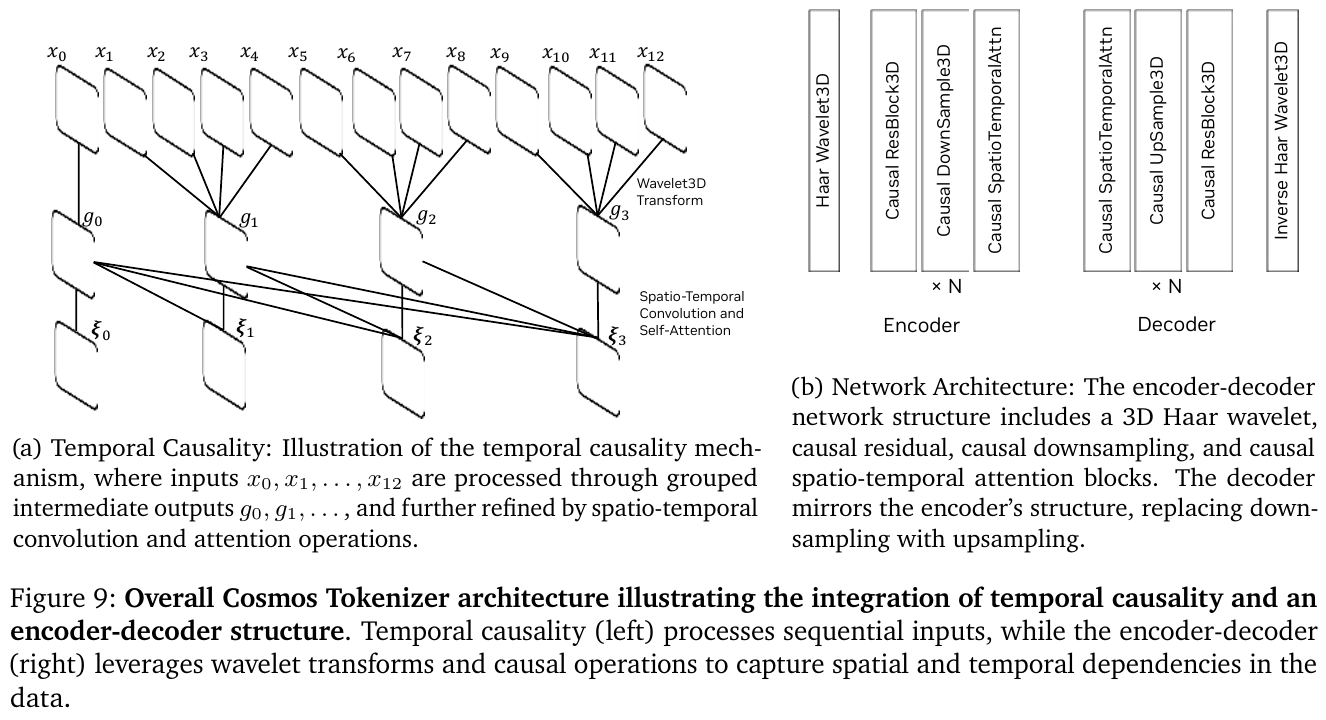
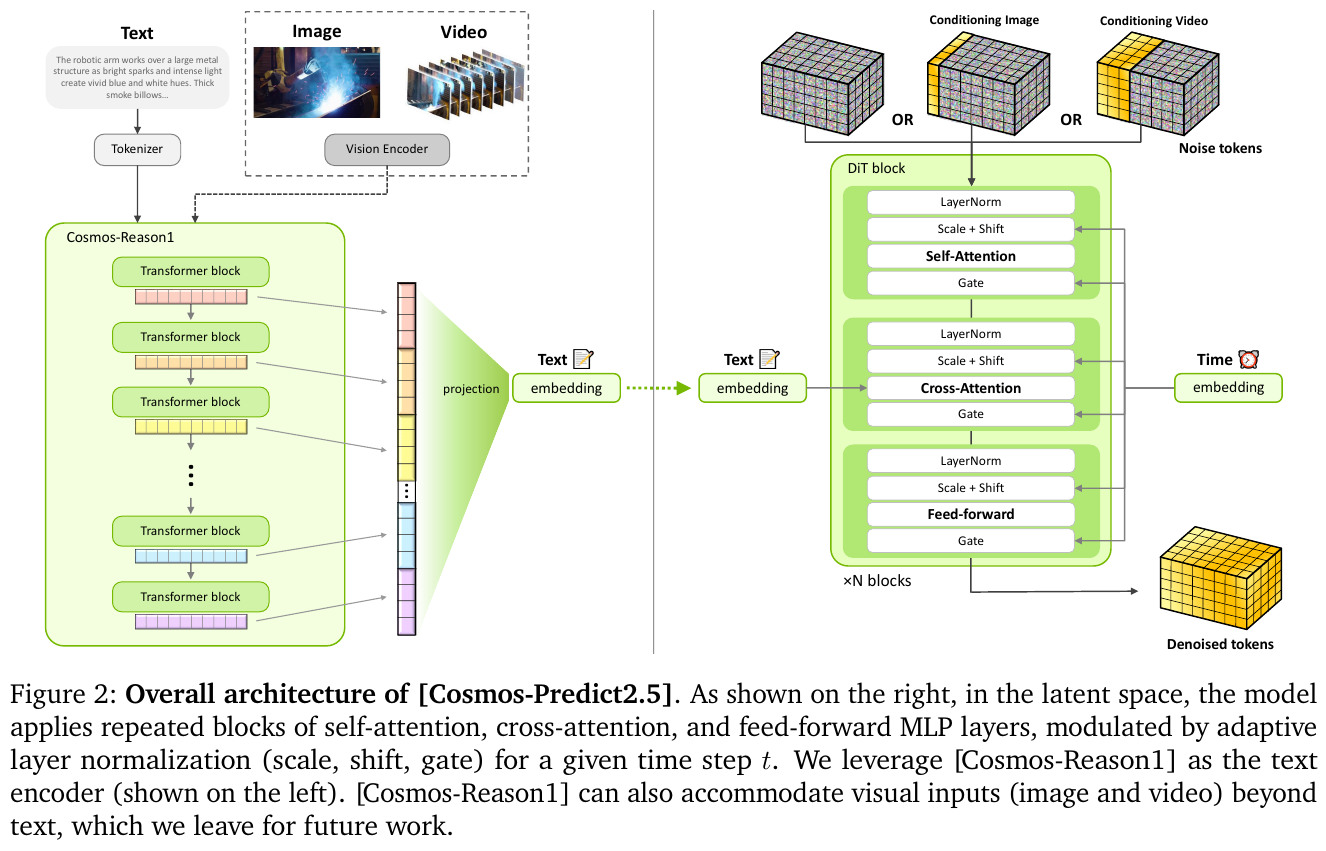
Cosmos-Predict2.5(2026):全面升级,核心改进包括:
- 将 Diffusion 和 Autoregressive 两条路线统一为单一 Flow Matching 模型(Text2World + Image2World + Video2World 三模共用同一套权重);
- 视觉 Tokenizer 换用 WAN2.1 VAE(时间×高×宽方向 4×8×8 压缩,每次生成 93 帧约 5.8 秒);
- 文本编码器从 T5 升级为 Cosmos-Reason1(跨多层激活拼接、投影至 1024 维),提供更细粒度语言接地;
- 移除绝对位置编码、保留相对 3D RoPE,增强对训练外分辨率与序列长度的泛化能力;
- 引入 RL Post-training(VideoAlign 奖励 + GRPO 算法),显著提升生成质量与指令对齐。
可用权重规模:2B(轻量部署)与 14B(最优质量),均提供 pre-trained / post-trained 两种检查点,以及针对机器人操纵、自动驾驶等场景的领域专属微调版本。
Cosmos-Transfer:结构化世界翻译
Cosmos-Transfer 不是”凭空预测未来”,而是将结构化世界表示翻译成感官真实的视频——典型用途是将仿真器(Isaac Sim、CARLA 等)的几何/语义输出提升为照片级真实画面(Sim2Real)。
📄 Cosmos-Transfer1 (2025): arXiv:2503.14492
Cosmos-Transfer1 在 Cosmos-Predict1(7B 扩散模型)基础上后训练而来,核心创新是自适应多模态 ControlNet 架构:
- 多分支 ControlNet:为每种控制模态独立设置一条控制分支(各含 3 个 Transformer Block,权重从主分支继承初始化);各分支独立训练,推理时融合——新模态可随时添加而无需重训全模型;
- 时空控制图(Spatiotemporal Control Map):引入 $N \times X \times Y \times T$ 维权重张量 $\mathbf{w}$,对每个模态在每个时空位置分配不同影响权重,使模型能在不同区域动态偏向最有用的控制信号——例如前景使用边缘图保持细节,背景允许自由生成。
支持的控制模态(通用版 Transfer1-7B):
| 模态 | 提取方法 | 保留特性 |
|---|---|---|
| Blur/Vis(模糊视觉) | 双边滤波 | 颜色与大体形状,允许纹理改变 |
| Edge(边缘图) | Canny 算子 | 场景结构与物体边界 |
| Depth(深度图) | DepthAnything2 | 三维几何布局 |
| Segmentation(分割图) | GroundingDino + SAM2 | 语义类别布局 |
自动驾驶专用版(Transfer1-7B-Sample-AV)额外支持 HDMap(高精地图,控制车道/路面布局与相对轨迹)和 LiDAR(点云投影,保留场景语义细节及光照条件控制)两种模态;另有 4KUpscaler ControlNet 可将 720p 生成视频无缝超分至 4K。
评测(TransferBench:600 例,含 200 机器人操作 / 200 自动驾驶 / 200 第一人称日常场景):三项指标——控制信号遵循度(Adherence)、生成多样性(Diversity)、整体质量(Quality)——Transfer1-7B [Seg] 与 [Depth] 在各场景均达到最优控制精度。
Cosmos-Transfer2.5 继承全部模态能力,模型尺寸缩小 3.5×(7B → ~2B),PAIBench-Transfer 整体质量评分从 6.56 提升至 9.75,并新增 RNDS 指标衡量长视频质量退化。
Cosmos-Reason:物理推理 VLM
Cosmos-Reason 是一个专为物理 AI 强化推理能力的视觉语言模型,输出带 Chain-of-Thought 的自然语言回答。
📄 Cosmos-Reason1 (2025): arXiv:2503.15558
两套本体论(Ontology)
Cosmos-Reason1 从两个维度定义物理 AI 推理能力:
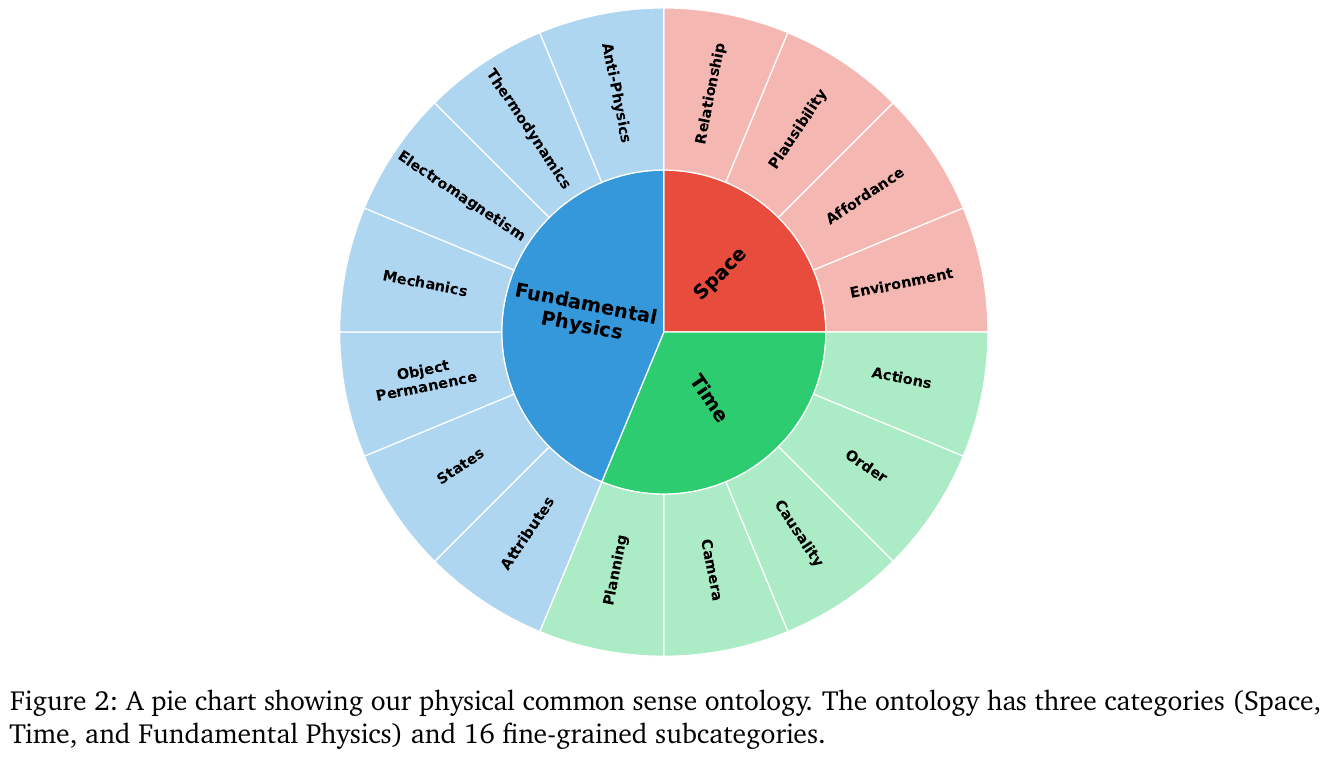
① 物理常识本体(Physical Common Sense Ontology):三大类、16 细分子类:
- Space(空间):Relationship(空间关系)、Plausibility(合理性)、Affordance(可操作性)、Environment(环境理解)
- Time(时间):Actions(动作)、Order(顺序)、Causality(因果)、Camera(镜头运动)、Planning(规划)
- Fundamental Physics(基础物理):Attributes(属性)、States(状态变化)、Object Permanence(物体恒存性)、Mechanics(力学)、Electromagnetism(电磁学)、Thermodynamics(热力学)、Anti-Physics(反物理违例)
② 具身推理本体(Embodied Reasoning Ontology):4 种能力 × 2 类智能体(自然智能体 / 机器人系统)的二维矩阵,重点考察三项核心能力:任务完成验证(Task-Completion Verification)、动作可操作性(Action Affordance)、下一步动作预测(Next Plausible Action Prediction)。
模型架构
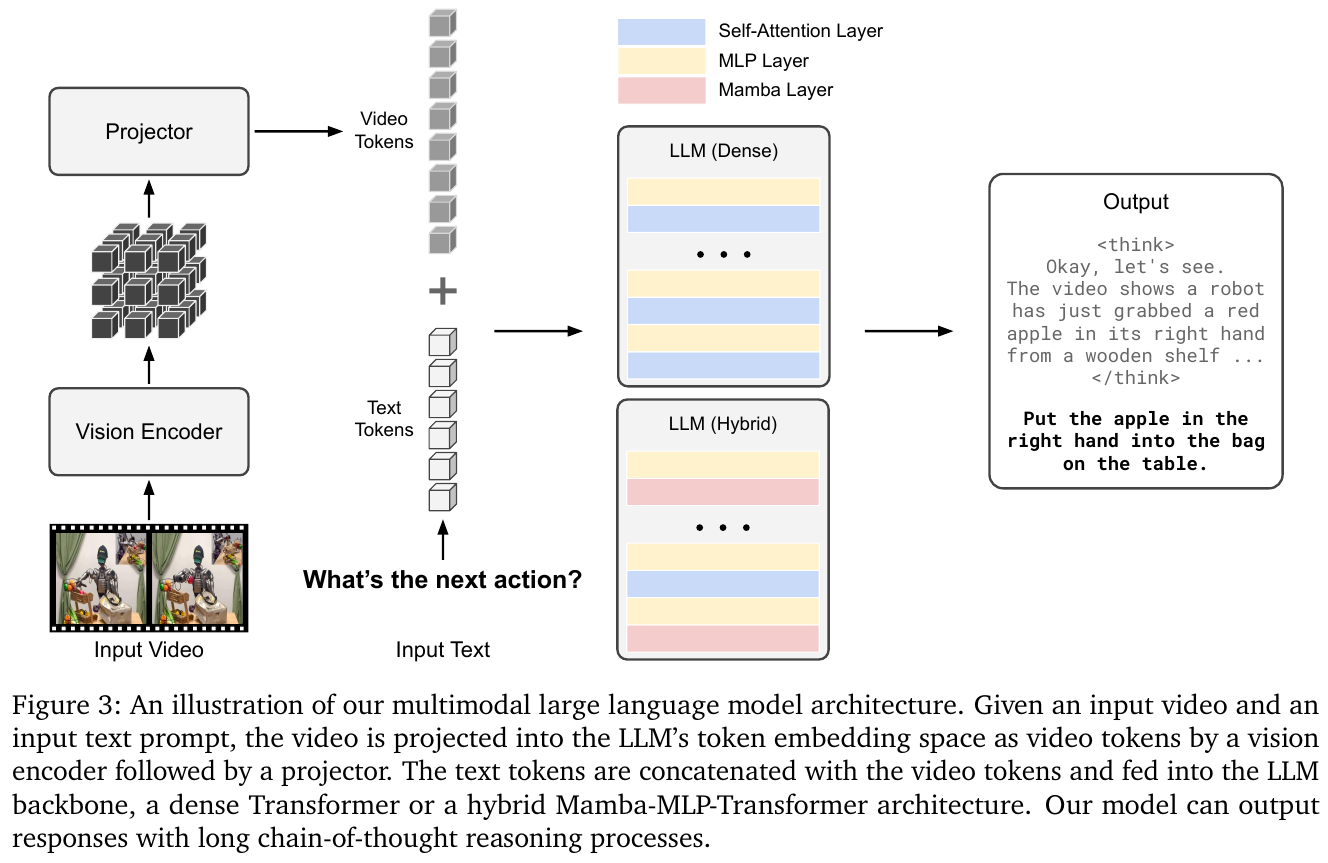
Cosmos-Reason1 为 decoder-only 多模态 LLM:视频帧经 Vision Encoder 提取视觉 token,Projector 下采样后与文本 token 拼接输入 LLM 主干,输出带 <think>...</think> 标签的长链推理回答。
| 配置 | Cosmos-Reason1-7B | Cosmos-Reason1-56B |
|---|---|---|
| Vision Encoder | ViT-676M(动态分辨率) | ViT-300M(固定 448×448) |
| LLM 架构 | 密集 Transformer(28 层) | Mamba-MLP-Transformer 混合(118 层) |
| LLM 预训练底座 | Qwen2.5-VL | Nemotron-H |
56B 模型采用 Mamba-MLP-Transformer 混合架构:交替 Mamba-MLP 模块(线性时间复杂度,高效处理长视频序列)+ 稀疏 Transformer 层(负责长程细节捕获),兼顾效率与能力。
训练范式:Physical AI SFT + Physical AI RL
Physical AI SFT — 精选约 4M 视频-文本标注对,分两类:
- 理解型(Understanding):VQA 自由问答 + 多项选择题,覆盖物理常识与具身推理所有子类(约 1.81M 条);
- 推理型(Reasoning):带完整 CoT 推理链的标注,由 DeepSeek-R1 蒸馏生成,训练模型输出 step-by-step 思考过程(约 1.93M 条)。
Physical AI RL — 在 SFT 基础上采用 GRPO 算法进一步强化物理推理:
- 奖励信号:多项选择题规则验证奖励(可自动校验,免人工标注);
- 自监督 MCQ:从视频数据结构自动生成——如打乱时空块要求模型还原(Spatiotemporal Puzzle)、判断视频播放方向(Time Arrow),完全免标注且与物理 AI 能力高度相关;
- 异步训练框架:Dispatcher–Actor Rollout–Policy Training 三节点异步设计,通信效率较主流共置框架提升约 160%,并支持节点故障动态恢复与弹性扩缩容。
在平台内的多重角色:
- 裁判:评估 Predict / Transfer 输出的物理合理性(自动化评估流水线);
- 文本编码器:Predict2.5 直接将 Reason1 用作多层激活拼接的文本编码器,替代 T5,提供更细粒度语言接地;
- 规划器:作为机器人 / VLA 的高层任务分解与 Affordance 推理模块;
- 数据策展:VLA 合成数据自动打标与质量过滤。
4.3 训练范式:预训练 + 三阶段后训练
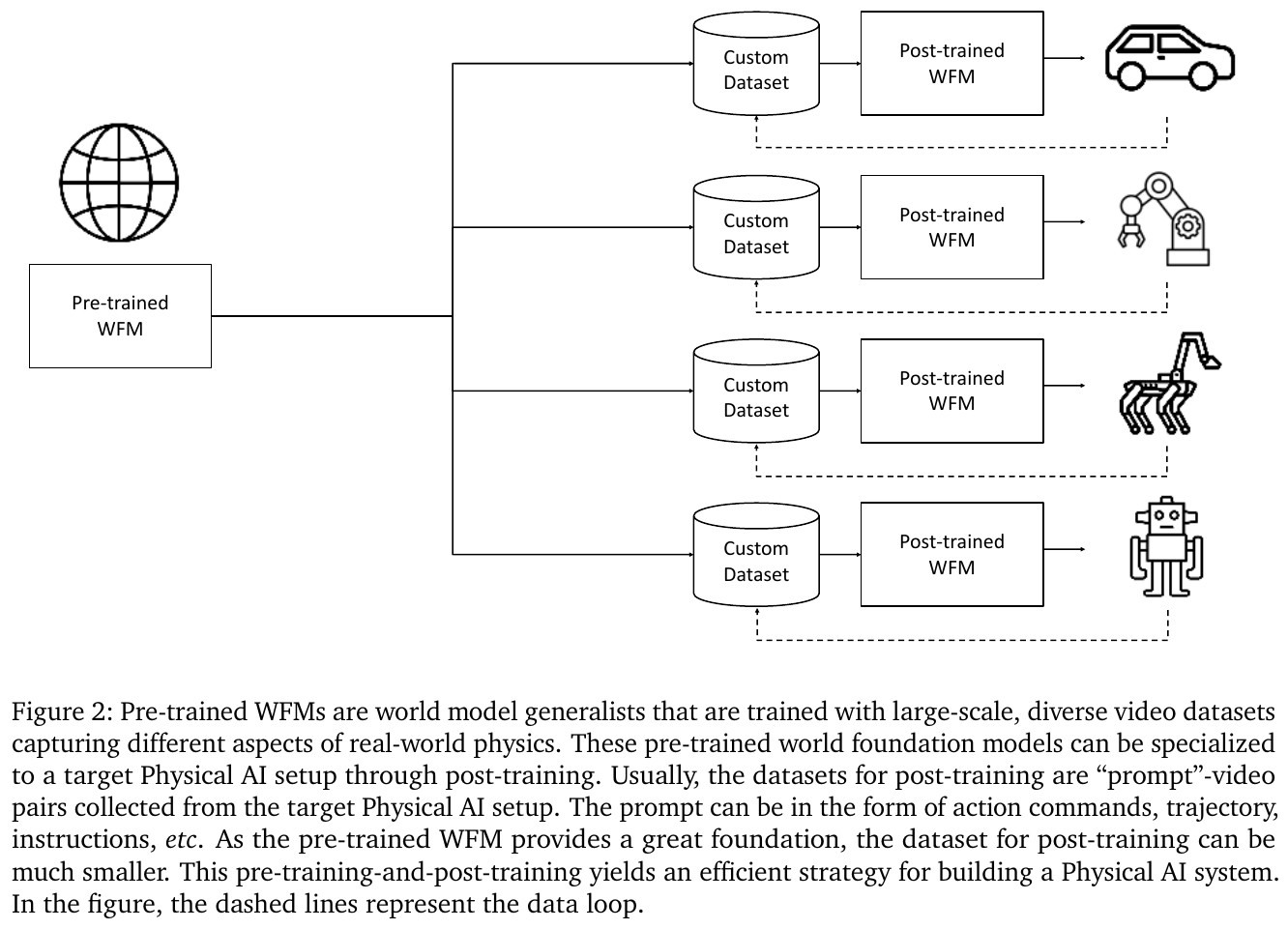
Cosmos-Predict2.5 采用预训练 → SFT → 模型融合 → 强化学习四阶段渐进范式:
① 大规模预训练(Pre-training) — 课程学习,逐步提升任务难度与分辨率:
| 阶段 | 任务 | 分辨率 | 帧数 |
|---|---|---|---|
| 1 | Text2Image | 256p(320×192) | 1 |
| 2 | Text2Image + Image/Video2World | 256p | 1 / 93 |
| 3 | Text2Image + Image/Video2World | 480p → 720p | 1 / 93 |
| 4 | 全部(含 Text2World) | 720p(1280×704) | 1 / 93 |
② 领域 SFT(Supervised Fine-tuning) — 在高质量领域数据上独立训练专域模型(每域 30K 步,batch size 256):
| 领域 | 视频规模 |
|---|---|
| 物体持久性(Object Permanence) | 10.4M |
| 高动态(High Motion) | 1.0M |
| 复杂场景(Complex Scenes) | 1.6M |
| 驾驶(Driving) | 3.1M |
| 机器人操纵(Robotic Manipulation) | 730K |
③ 模型融合(Model Merging) — 将多个专域 SFT 模型通过参数插值(Model Soup、TIES、DARE-TIES 等)融合为单一模型,在保留专域能力的同时维持通用生成质量。人类偏好评测中,融合后模型在所有领域均优于任一单独 SFT 模型。
④ 强化学习(RL Post-training) — 以 VideoAlign(VLM-based 奖励,三维度:文本对齐 + 运动质量 + 视觉质量)为奖励信号,使用 GRPO 算法进行 RL 训练(256 步,batch size 32)。人类评测中 RL 后生成视频胜率较 RL 前提升约 20 个百分点。
加速推理(Timestep Distillation):采用 rCM 混合蒸馏框架将推理步数压缩至 4 步,PAI-Bench 总分损失小于 0.005。
训练规模:4096 台 NVIDIA H100 GPU,2B 模型 MFU 约 36.5%,14B 模型约 33.1%;采用 FSDP2 混合并行 + Ulysses 上下文并行 + 选择性激活检查点(SAC)等多项系统优化。
4.4 典型应用场景
Cosmos 平台在六个物理 AI 场景上展示了多样的适用性:
① 机器人策略视觉增强:用 Cosmos-Transfer2.5 对机器人演示视频进行外观多样化(替换背景、更改物体颜色、添加干扰物),以合成数据增强策略训练。在对抗性视觉扰动(不可见背景、物体变化)评测中,Cosmos 增强数据训练的策略成功率显著高于仅用真实数据训练的基准。
② 自动驾驶多视角仿真:以世界场景图(HD map + 语义信息)为条件,驱动 Cosmos-Transfer2.5 生成 7 路时空同步的环视视频,覆盖多样天气、光照、交通密度,用于驾驶策略闭环训练与测试。
③ 相机可控多视角生成:对 Cosmos-Predict2.5 进行相机位姿条件化后训练,支持任意相机外参组合下的跨视角一致生成。
④ VLA 合成训练数据:以单张初始帧 + 动作条件驱动 Cosmos-Predict2.5 生成机器人操纵视频序列,配合 Cosmos-Reason1 自动打标与质量过滤,低成本构建大规模 VLA 训练数据集。
⑤ 动作条件世界生成(Action-conditioned World Generation):对 Cosmos-Predict2.5 进行低级动作(关节角度 / 末端轨迹)条件化后训练,实现动作驱动的未来视频预测,可直接用于策略评估的闭环模拟。


4.5 开源生态:Cosmos Cookbook
官方仓库 nvidia-cosmos/cosmos-cookbook 提供端到端、可直接跑通的 recipes 集合:
- 推理脚本:Predict(Text2World / Image2World / Video2World)、Transfer(多模态控制信号混合)、Reason 三产品线的最小可运行示例;
- 后训练模板:相机控制、机器人操纵、自动驾驶下游任务的标准微调配置(含 LoRA / 全量微调策略与超参);
- 数据策展:Cosmos Video Curator 自定义数据集接入流程;
- 安全护栏(Guardrail):输入 prompt 到输出内容全链路安全检测调用示例;
- 部署工具链:与 NVIDIA NeMo、Isaac Sim、TensorRT-LLM 的集成示例。
对具身 AI 研究者而言,Cosmos 的实用价值在于:无需从头训练,可直接调用 Predict 做滚动仿真、Transfer 做大规模 Sim2Real 数据增强、Reason 做自动化物理合理性评估,将科研原型到规模化应用的门槛大幅降低。
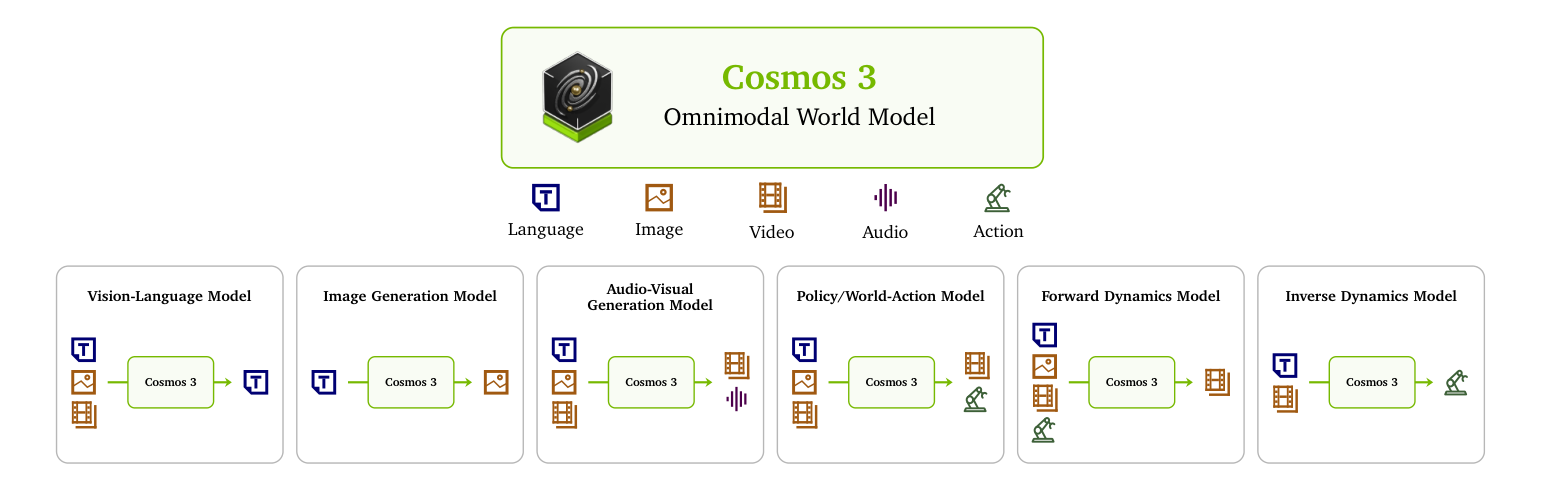
4.6 Cosmos 3:全模态统一世界模型(2026)
———Omnimodal World Models for Physical AI
📄 Cosmos 3 (2026): arxiv.org/abs/2606.02800
🔗 代码/权重: github.com/nvidia/cosmos · huggingface.co/collections/nvidia/cosmos3(OpenMDW-1.1 License)
💡 专题详解: 关于 Mixture-of-Transformers (MoT) 架构的详细数学拆解与分析,可参考我的专题博客 Mixture-of-Transformers (MoT) 架构详解。
如果说 §4.1–§4.5 的 Cosmos 平台是用一条工具链串起多个专用模型(Predict 预测、Transfer 翻译、Reason 推理各司其职),那么 2026 年 6 月 NVIDIA 发布的 Cosmos 3 则把这条路线推到了终点:用单一网络架构同时完成理解与生成、并原生覆盖语言、图像、视频、音频、动作五大模态。它直接把本文 §3 的四大范式——视觉语言模型(VLM)、视频生成 / 前向动力学模型(世界合成器/模拟器)、世界动作模型(WAM/VLA)——吸收进同一个模型,是”单模型、多范式角色”趋势(参见 §3.1 的 GENE-26.5 讨论与 §9.3)最彻底的一次工程落地。
核心动机:终结”范式割裂”
论文的出发点是一个尖锐的判断:理解与生成被人为割裂是根本性的局限。以”晚餐后清理餐桌”的家用机器人为例,当前范式需要拼装一条割裂的流水线——VLM 定位餐具并生成计划、VLA/WAM 生成动作序列、前向动力学模型(”世界模型”)仿真并评估未来状态。这种碎片化架构既不优雅也浪费算力。Cosmos 3 的主张是:理解本就需要推理”世界如何演化、动作有何后果”,而生成本就依赖”对世界与行为的紧凑结构化表示”——两者应当统一在一个可扩展框架里。
架构:双塔 Mixture-of-Transformers(MoT)
Cosmos 3 的核心是一个 MoT 双塔结构:把一条 token 序列切成两段——前段是自回归(AR)子序列负责理解推理,后段是扩散(DM)子序列负责生成。每个 Transformer 解码层内部都并行持有两套独立参数(Reasoner 塔 + Generator 塔),二者均从预训练 VLM 权重初始化,从而继承强语言/视觉推理能力。
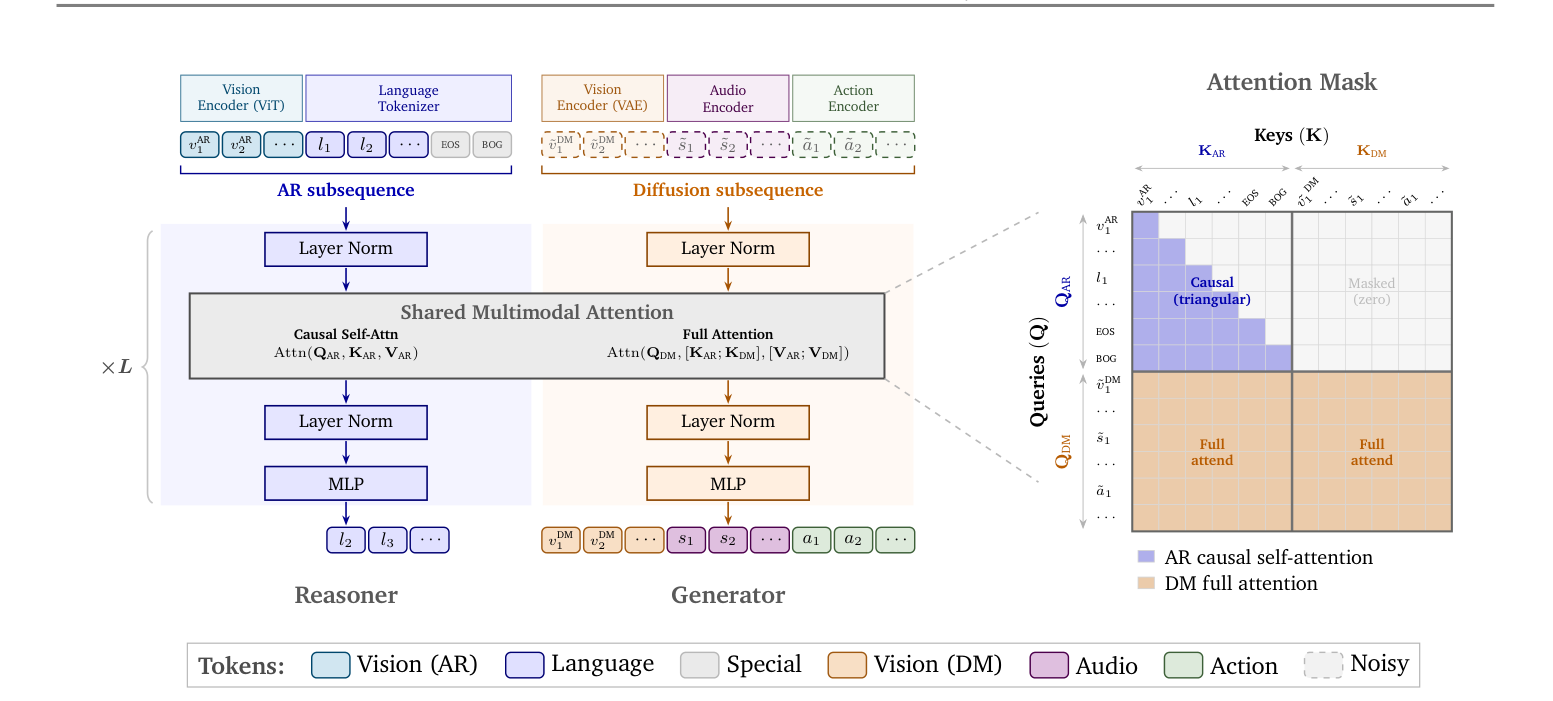
两塔虽参数独立,却通过双流联合注意力(Dual-Stream Joint Attention)耦合:
- AR 子序列使用因果自注意力,只能看到自身前序 token——完整保留了从 VLM 继承的自回归文本生成能力(语言走 next-token prediction);
- DM 子序列使用全双向注意力,以 AR 与 DM token 的并集为 Key/Value,使每个扩散 token 都能自由”读取”文本提示与所有条件帧(生成走迭代去噪,Flow Matching 预测速度场);
- 关键约束:AR token 永远不会被 DM token 更新——保证了条件通路的因果完整性。
这种设计的精妙之处在于:理解(AR)为生成(DM)提供语义条件,而生成不污染理解,二者在同一张注意力图里完成协作,却互不破坏各自的归纳偏置。
编码器:视觉理解用与语言对齐预训练的 ViT(随骨干联合训练),视觉生成用 Wan2.2-TI2V-5B 的视频 VAE(冻结,时间 4×、空间 32×32 压缩);音频用冻结的音频 VAE(48kHz 立体声,25 token/秒);动作用域感知投影层。位置编码采用带绝对时间调制的 3D MRoPE,把不同帧率/采样率的视频、音频、动作 token 对齐到同一条物理时间轴上。
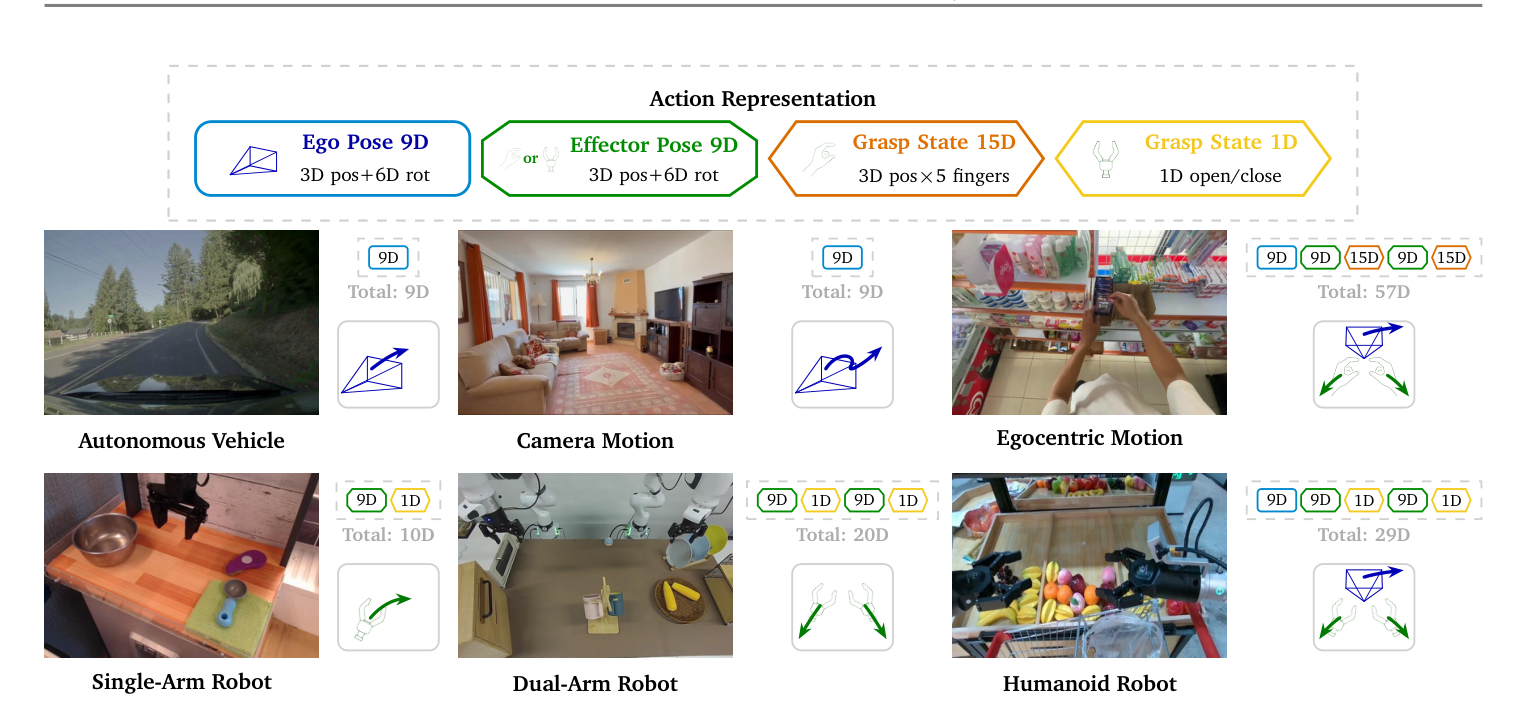
把”动作”当作一等模态
与多数工作把动作当作附属输出不同,Cosmos 3 显式引入一类动作 token,作为连接物理世界与语言推理、视频建模的桥梁。它用一套统一动作表示容纳异构本体(自动驾驶、相机运动、第一人称人体、单臂/双臂/人形机器人):自我位姿(Ego Pose 9D)与执行器位姿(Effector Pose 9D)以”3D 平移 + 6D 旋转”的相对位姿伪动作表示,抓取状态(Grasp State)直接编码当前操作状态。各本体用域感知的输入/输出投影适配不同维度,同时共享 MoT 骨干。动作 token $a_t$ 表示从视频状态 $v_{t-1}$ 到 $v_t$ 的转移。
正因为动作与视频被纳入同一序列模型,Cosmos 3 仅靠”哪些 token 干净、哪些 token 加噪”的不同配置,就统一了三种动作生成模式:
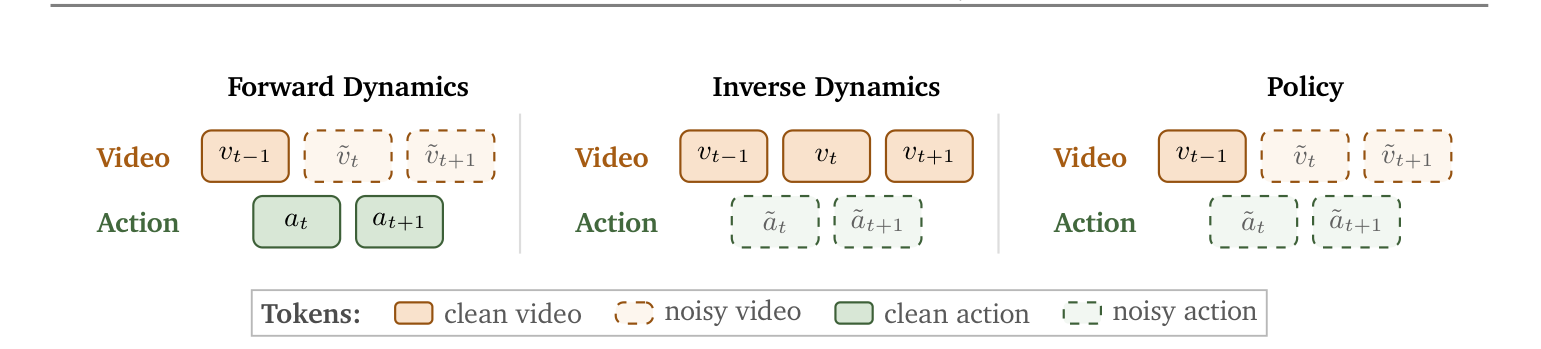
- 前向动力学(Forward Dynamics):以观测上下文 + 干净动作为条件,预测未来视觉状态——即 §3.4 的世界模拟器;
- 逆动力学(Inverse Dynamics):从观测到的视觉转移反推动作——即 §3.3 世界合成器中常用的 IDM 标注器;
- 策略(Policy):同时预测动作与视频,既给出”干预”又给出”预期视觉后果”——即 §3.2 的世界动作模型。
加上作为 VLM 的纯语言理解、Text2Image、Text2Video(可联合生成音频)、Image/Video2Video、Video Transfer 等生成模式,四大范式在 Cosmos 3 中第一次由同一套权重原生支持。
模型变体:Edge / Nano / Super
三个尺度覆盖从端侧部署到数据中心推理。注意总参数约为稠密 Transformer 的 2 倍——这正是双塔(Reasoner + Generator 各持一套参数)的代价:
| 变体 | 总参 / 稠密骨干 | 层数 | 隐藏维 | 注意力头 | KV 头 | FFN 维 | 初始化 |
|---|---|---|---|---|---|---|---|
| Cosmos3-Edge | 4B / 2B | 28 | 2,048 | 16 | 8 | 9,216 | 从零训练(类 Qwen3-1.7B) |
| Cosmos3-Nano | 16B / 8B | 36 | 4,096 | 32 | 8 | 12,288 | Qwen3-VL 8B |
| Cosmos3-Super | 64B / 32B | 64 | 5,120 | 64 | 8 | 25,600 | Qwen3-VL 32B |
本次发布 Nano 与 Super,Edge 留待后续。Reasoner 在约 24.2M 样本(22.0M 预训练 + 2.2M SFT)的图文/视频-文本对上训练;Generator 在大规模图像/视频/音频/动作语料上以重建目标(Flow Matching)训练,经历预训练 → 中训练(mid-training)→ T2I 后训练 → I2V 后训练 → 机器人策略后训练的多阶段课程。
训练范式与 Physical AI 角色
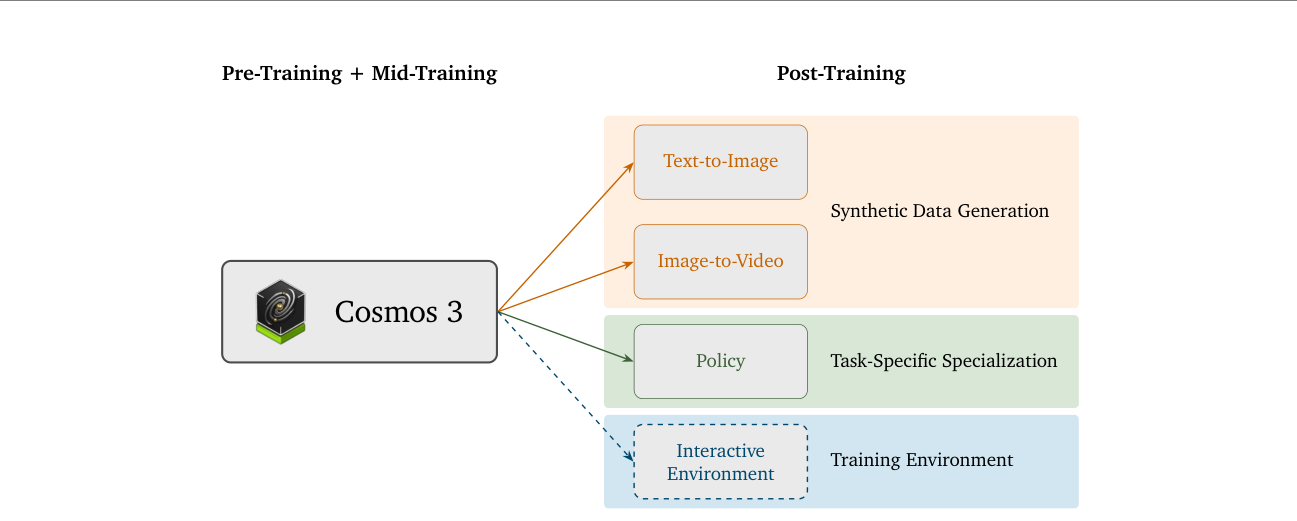
Cosmos 3 把自己定位为破解”数据与环境扩展瓶颈”的三重起点:(i) 合成数据生成——后训练为更强的 T2I / I2V 生成器,低成本合成高保真多样视觉数据;(ii) 任务专域特化——在共享底座上做本体/任务特定微调,保留统一世界表示;(iii) 训练环境——长期目标是生成高质量、可交互的复杂环境用于闭环训练。论文同时开源了 5 个合成数据集(SDG-PhyxSim / RobotSim / DriveSim / SynHuman / Warehouse)与评测基准 Cosmos-HUE。
核心结果
撰写技术报告时,Cosmos 3 的后训练变体取得多项 SOTA:
- Cosmos3-Super-Text2Image:Artificial Analysis 文生图榜单开源权重第 1(含闭源模型计第 4,日期 2026-05-28);
- Cosmos3-Super-Image2Video:Artificial Analysis 图生视频榜单开源权重第 1,整体优于 Veo-3.1 等强闭源模型;
- Cosmos3-Nano-Policy-DROID:在 RoboLab 与 RoboArena 真机策略评测中均排名第 1(从中训练 Nano 续训,在 DROID 76k 轨迹上后训练,15Hz 联合输出动作与未来视频帧);
- 在机器人、智能空间、自动驾驶领域的推理任务上同时超越开源与闭源模型(机器人仅略逊 Gemini 3.1 Pro),且两代视频生成均显著优于前代 Cosmos-Predict2.5。
与四大范式的关系
Cosmos 3 是本文叙事的一个收敛点。GENE-26.5(§3.1)已展示”联合分布 + 条件查询”如何让单模型兼任多角色,而 Cosmos 3 把这一思路推广到全模态、并以双塔 MoT 给出更清晰的工程边界:Reasoner 塔承担世界规划器的高层语义推理,Generator 塔以前向动力学/视频生成承担世界合成器与世界模拟器,Policy 模式则是世界动作模型。§2.3 时间线中 2025–2026 年世界合成器/模拟器的爆发,最终汇流为”理解-生成-动作一体化”的全模态世界模型——这与 §9.3”从想象到验证再到规划”的判断完全一致,也指向 §8 中长航程前瞻、4D 感知、物理一致性等方向的统一载体。
5. 经典代表性工作
本章节梳理了具身智能世界模型演进过程中的几项里程碑式研究。
5.1 Lyra 2.0 (2026)
———Explorable Generative 3D Worlds at Scale
📄 Paper: https://arxiv.org/abs/2604.13036
精华
NVIDIA 推出的 Lyra 2.0 解决了长程(Long-horizon)3D 一致性场景生成的两大核心痛点,值得借鉴的点包括:
- 解耦几何与外观(Decoupled Memory):将显式 3D 几何(点云缓存)仅用于信息路由和建立像素级对应关系,而将外观合成交给 Diffusion Model 的强生成先验,有效避免了渲染伪影的传播。
- 空间记忆路由(Anti-forgetting):通过几何感知检索机制,即便在长距离移动或重新访问(Revisit)区域时,也能通过 3D 投影检索最相关的历史帧,克服了 Transformer 有限上下文导致的”空间遗忘”。
- 自增强训练(Self-augmentation):在训练阶段引入带有自身预测偏差的损坏数据,使模型学会纠正自回归生成的漂移(Temporal Drifting),而非让误差无限累积。
- 生成式重建(Generative Reconstruction):展示了如何通过视频生成模型合成高一致性的多视角序列,进而驱动 Feed-forward 3DGS 模型快速重建高质量 3D 场景资产。
1. 研究背景/问题
当前的视频生成模型在生成长视频时极易出现空间遗忘(Spatial Forgetting)和时间漂移(Temporal Drifting)。当相机移动超出模型的有限上下文窗口时,模型会丢失对早先场景的记忆,导致回看时场景结构崩溃;同时,自回归生成的微小误差会随时间累积,造成颜色偏移和几何扭曲。这限制了生成式 3D 场景重建向大规模、可探索环境的扩展。
2. 主要方法/创新点

Lyra 2.0 的核心是一个基于”检索-生成-更新”的自回归循环:
- 抗遗忘机制(Anti-Forgetting):
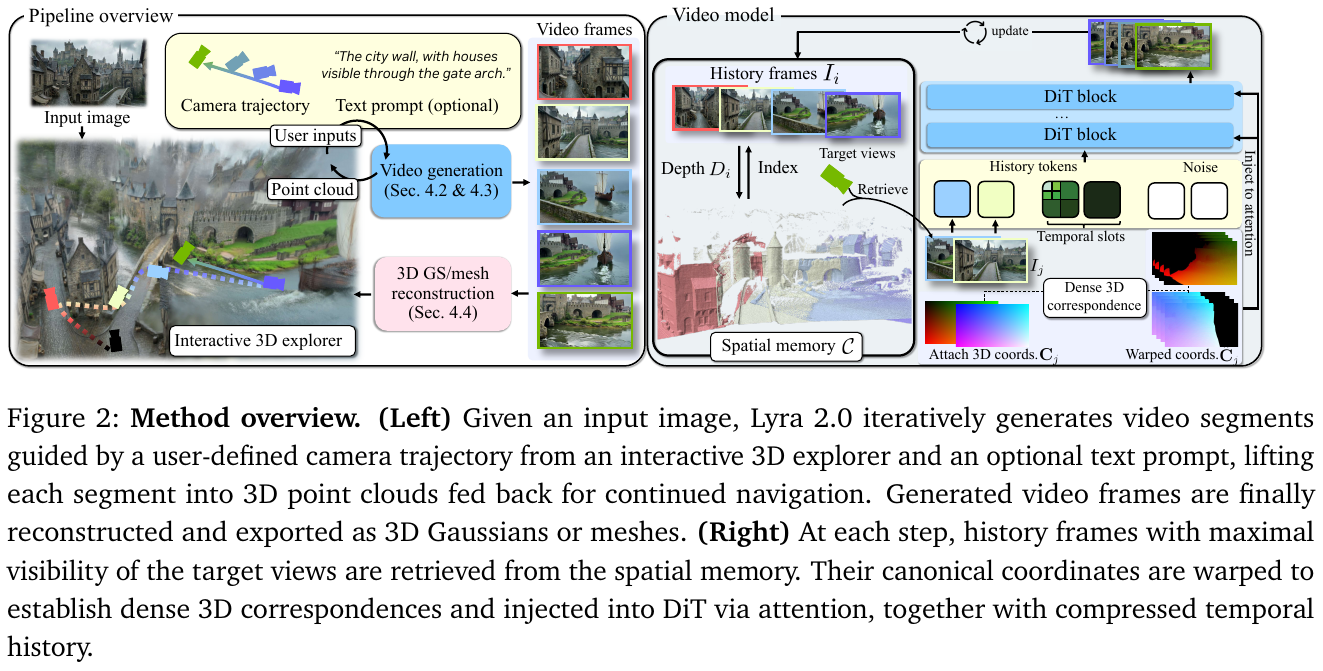
系统维护一个 3D 缓存(3D Cache),存储每帧的深度图和点云。在生成下一段视频时,系统会根据当前相机视角,通过投影计算可见度(Visibility Score),检索出最相关的历史帧。
-
几何引导的上下文注入: 检索到的历史帧不会直接作为 RGB 图像输入,而是通过正则化坐标映射(Canonical Coordinate Warping)建立像素级对应关系。这种方式将几何约束与外观生成分离,允许视频模型在不引入渲染噪声的前提下保持空间一致性。
-
抗漂移训练(Anti-Drifting): 采用了自增强训练策略(Self-augmentation Training)。在训练时,模型不仅在完美的高清图像上训练,还会随机在自己生成的”损坏”潜变量(Latent)上进行去噪。这教导模型在推理过程中识别并修正微小的漂移误差,而非放大它们。
-
实时交互与 3D 导出:

3. 核心结果/发现
- 长程一致性:实验表明,Lyra 2.0 在 800 帧以上的生成序列中仍能保持极其稳定的几何结构和风格一致性,显著优于 GEN3C 和 SPMem 等基线方法。

- 高质量 3D 重建:生成的视频序列通过微调后的 feed-forward 3DGS 流程,可以生成几乎无伪影(Floater-free)的高质量 3D 高斯泼溅模型。

- 具身智能赋能:

4. 局限性
目前 Lyra 2.0 主要聚焦于静态场景的生成,尚未显式建模动态物体(如行人和车辆)。此外,模型生成的质量仍然受限于训练数据(如 DL3DV)中的光照变化和曝光差异。
5.2 Genie (2024)
———Generative Interactive Environments
📄 Paper: arXiv:2402.15391
精华
Genie 是首个仅通过无标注视频学习而成的生成式交互环境(Foundation World Model),其核心贡献在于:1) 无监督动作挖掘:通过潜动作模型(LAM)从纯视频中自动挖掘可控动作空间,解决了世界模型对真实动作标签的依赖;2) 高效时空架构:设计了基于 ST-Transformer 的计算架构,使显存占用随帧数线性增长,支持长序列视频生成;3) 具身智能底座:不仅能将任意图像(素描、照片等)转化为可玩的游戏世界,还展现了在机器人操作和智能体训练方面的巨大潜力,为“通向通用智能体的路径”提供了海量仿真数据。
1. 研究背景/问题
当前的生成式 AI(如 ChatGPT, DALL-E)在文本和图像领域取得了巨大成功,但视频生成模型(如 Video Diffusion)大多缺乏细粒度的交互控制能力。传统的“世界模型”通常需要大量带有真实动作标签(Action Labels)的数据进行训练,这在互联网海量视频面前成了瓶颈。Genie 旨在通过 20 万小时的无标注互联网视频,学习一个能实时响应用户操作、具有物理常识且能无限生成的交互式环境。
2. 主要方法/创新点
Genie 是一个参数量达 110 亿的基础模型,其架构由三个深度集成的组件构成,全部基于改进的 ST-Transformer。
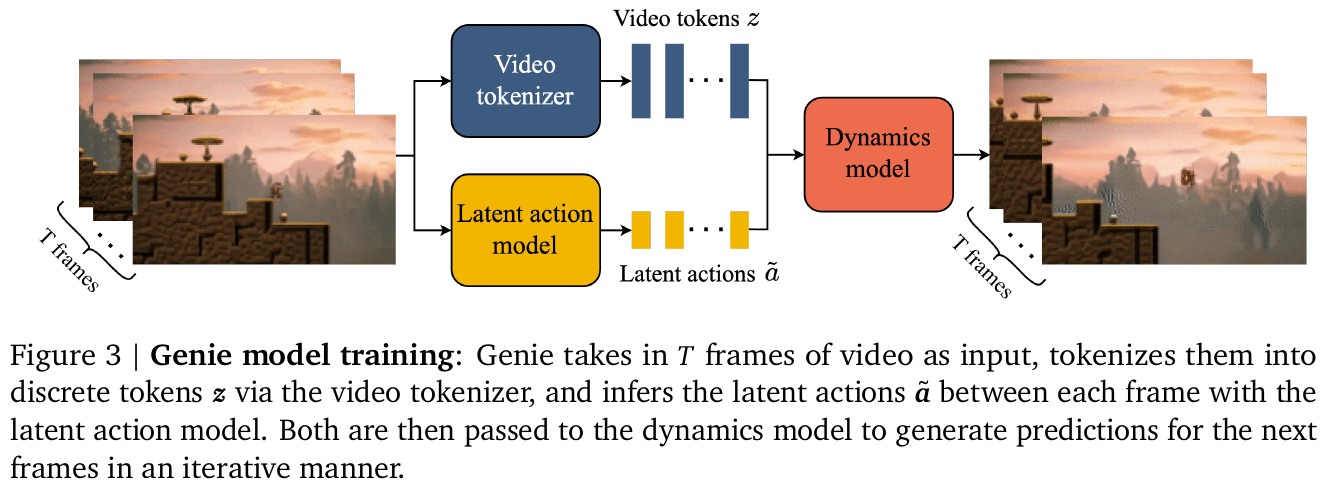
2.1 潜动作模型 (Latent Action Model, LAM)
这是 Genie 的灵魂所在。为了在没有动作标签的情况下实现控制,LAM 采用 VQ-VAE 结构:
- 编码器:同时接收当前帧和下一帧,输出一个离散的潜动作 $\mathbf{a}_t$(通常限制在 8 个离散值以内,以模拟控制器按键)。
- 瓶颈机制:由于解码器只能通过历史帧和 $\mathbf{a}_t$ 来预测下一帧,模型被迫将视频中最具语义一致性的变化(如人物的左右移动、跳跃)编码进这 8 个 Token 中。
- 一致性:实验证明,即使在不同游戏中,相同的潜动作 Token 往往对应相同的物理语义(如 Action 0 始终代表左移)。

2.2 视频分词器 (Video Tokenizer)
Genie 提出了 ST-ViViT 架构:
- 时空压缩:不同于常规只在空间维度压缩的分词器,ST-ViViT 在编码和解码时都引入了时间轴。
- 效率优化:通过交替使用空间注意力和时间注意力,模型避免了计算量随时间呈平方级增长的问题,保证了在大规模数据集上的训练可行性。
2.3 动力学模型 (Dynamics Model)
基于 MaskGIT 的掩码自回归模型:
- 输入:接收当前视觉 Token 和用户选择的潜动作。
- 预测:模型在隐空间内预测下一帧的 Token。通过海量数据的“喂养”,模型学习到了复杂的 2D 平台游戏规则,如碰撞、重力、敌人交互和屏幕卷轴滚动。
3. 核心结果/发现
- “化腐朽为神奇”的生成能力:用户可以上传一张手绘草图、真实的自然景观照片,甚至是通过文生图模型(如 Imagen)生成的图片,Genie 都能立即将其转化为一个可以“玩”的横版过关游戏环境。
- 语义一致的操控感:在 Platformers 数据集上,潜动作展现了极强的泛化性。用户点击对应的潜动作,角色会做出连贯的位移或跳跃,且这种操控在视觉风格迥异的环境中依然有效。
- 机器人领域的潜力:研究人员在 RT1 机器人数据集上验证了 Genie。模型不仅学会了控制机械臂,还学会了模拟复杂物体的物理形变(如挤压面包袋),这证明 Genie 能够捕捉真实的物理世界动态。
- 作为强化学习的“母体”:在 Genie 内部训练的智能体,可以极快地迁移到真实环境中。相比于从零开始训练,使用潜动作预训练的智能体在样本效率上提升了数倍。

4. 局限性
- 分辨率瓶颈:受限于目前的计算资源,Genie 生成的视频分辨率较低(160x90),离高清沉浸式体验仍有距离。
- 自回归发散:由于是自回归生成,随着步数增加,视频内容可能会逐渐偏离物理真实或出现伪影。
- 动作映射:虽然挖掘出了潜动作,但将这些离散 Token 精确映射到人类直觉的复杂多级控制(如手柄的线性摇杆)仍需进一步研究。
5.3 VLA-World (2026)
———Learning Vision-Language-Action World Models for Autonomous Driving
📄 Paper: https://vlaworld.github.io
精华
VLA-World 的核心思想在于通过在单帧未来预测的基础上进行反思性推理,将世界模型的生成能力与 VLA 模型的推理能力相结合。最值得借鉴的设计是其“分步走”的流程:首先根据预测的动作生成一张未来图,再让模型去观察这张自己生成的图,从而识别潜在的碰撞风险并修正动作。这种“脑内模拟后二次评估”的机制(Think with Generated future)极大地增强了端到端驾驶系统的安全性和可解释性。
1. 研究背景/问题
现有的端到端自动驾驶模型(如 VLA)通常缺乏显式的时空建模,难以预测环境中其他交通参与者的演变。而纯世界模型虽然能生成连贯的未来场景,却往往缺乏推理能力,难以评估所生成未来的安全性或优劣。VLA-World 通过统一预测性想象与反思性推理,提升了驾驶前瞻性。
2. 主要方法/创新点
VLA-World 提出了一个结合了感知、动作衍生预测、图像生成、反思推理和规划的完整流程。
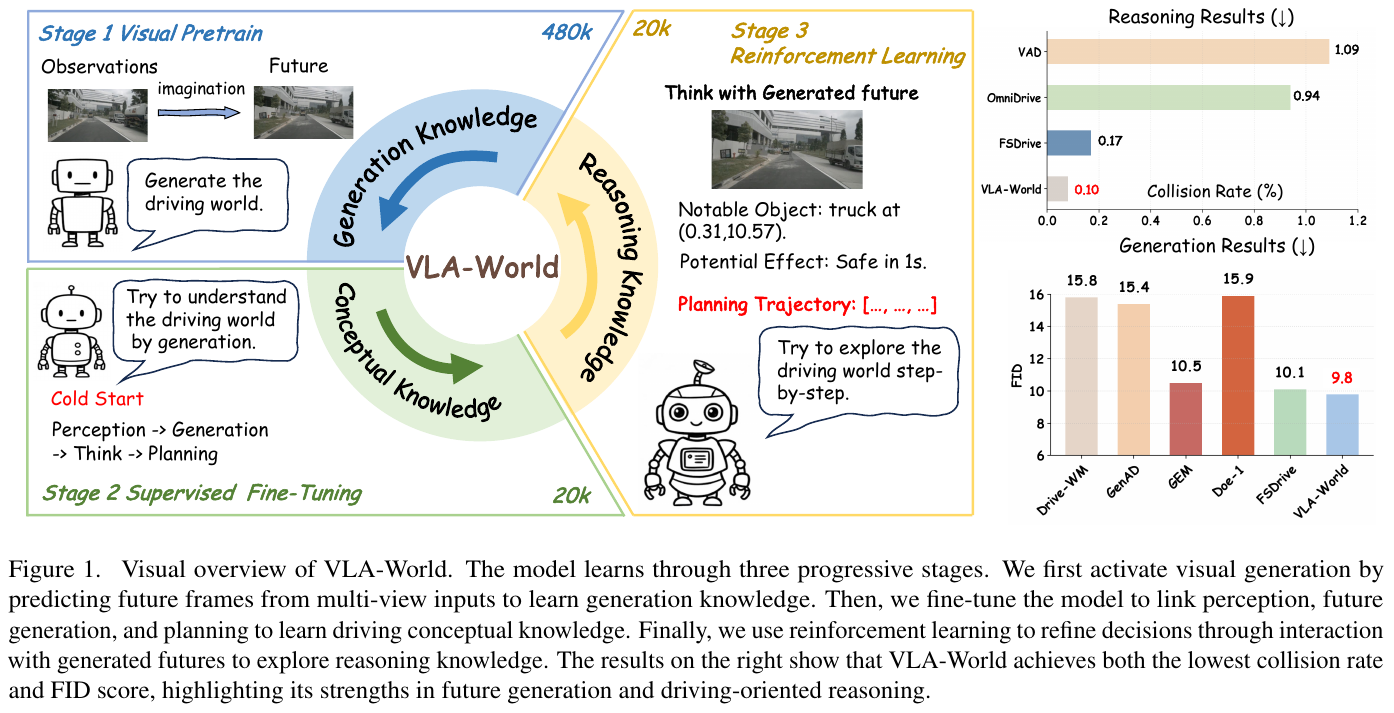
三阶段训练策略
- 阶段 1:视觉预训练:在大规模图像-指令数据集上激活图像生成知识。
- 阶段 2:监督微调 (SFT):通过 nuScenes-GR-20K 混合任务数据集,建立感知、未来生成与规划的逻辑链接。
- 阶段 3:强化学习 (RL):利用 GRPO 算法探索类人推理,使模型能更深入地反思生成的未来是否安全。
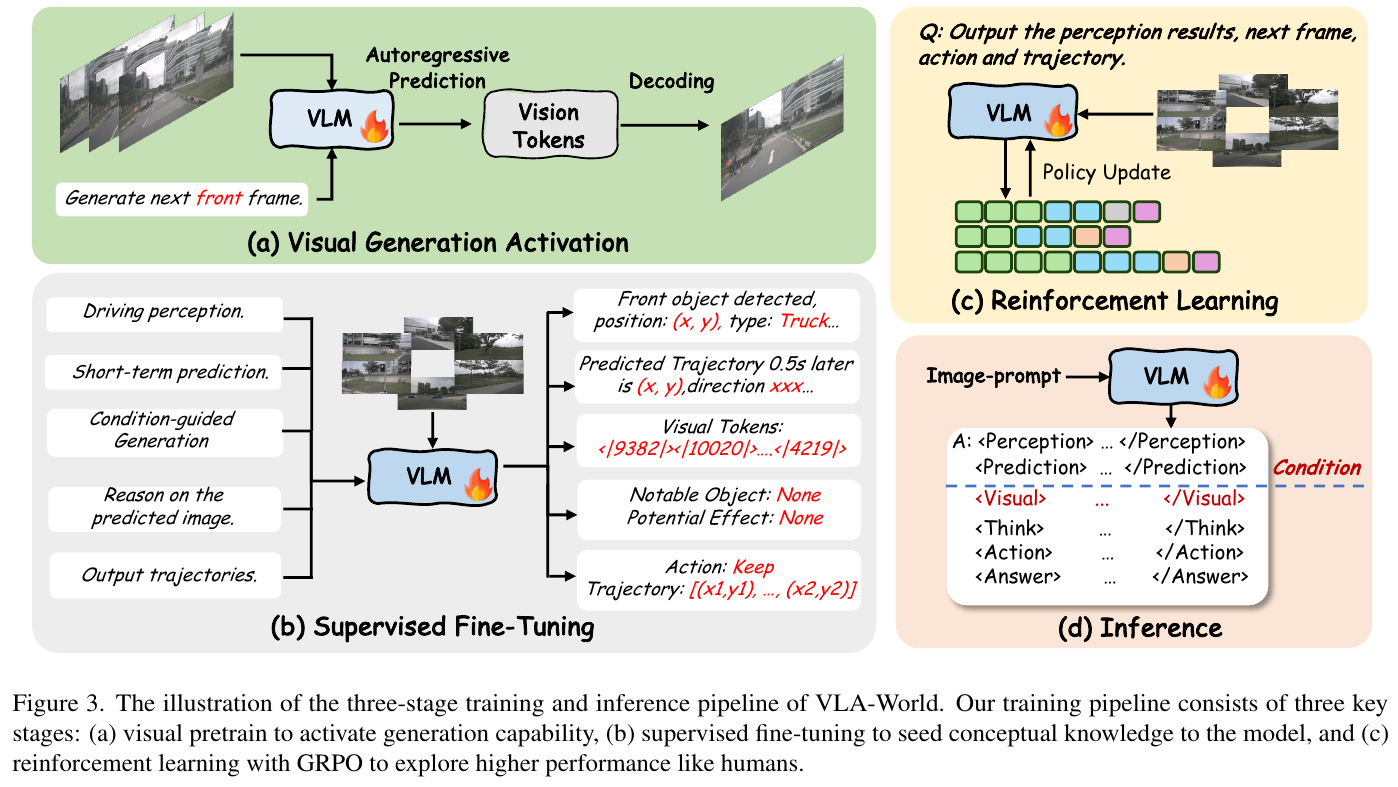
反思推理机制 (Think with Generated future)
模型首先输出一个 0.5 秒内的轨迹预测,并据此生成对应的未来图。随后,模型再次“审阅”这张自生成的图,识别重要物体和潜在风险,最终修正决策,输出最终的长程轨迹。这种机制类似于人类驾驶员遇到突发状况时的二次反思过程。
3. 核心结果/发现
- 性能表现: 在 nuScenes 等基准测试中,VLA-World 达到了比现有 VLA 和世界模型更低的碰撞率(Collision Rate 从 1.09% 降至 0.94%)和更高的 FID 视频生成质量。
- 可解释性: 通过让模型写下对“自己生成的未来”的推理过程(如识别某卡车的碰撞风险),系统的决策过程变得更加透明。

4. 局限性
由于模型需要先生成图像再进行推理,系统的端到端延迟仍然是一个挑战。未来研究将聚焦于提高实时推理速度。
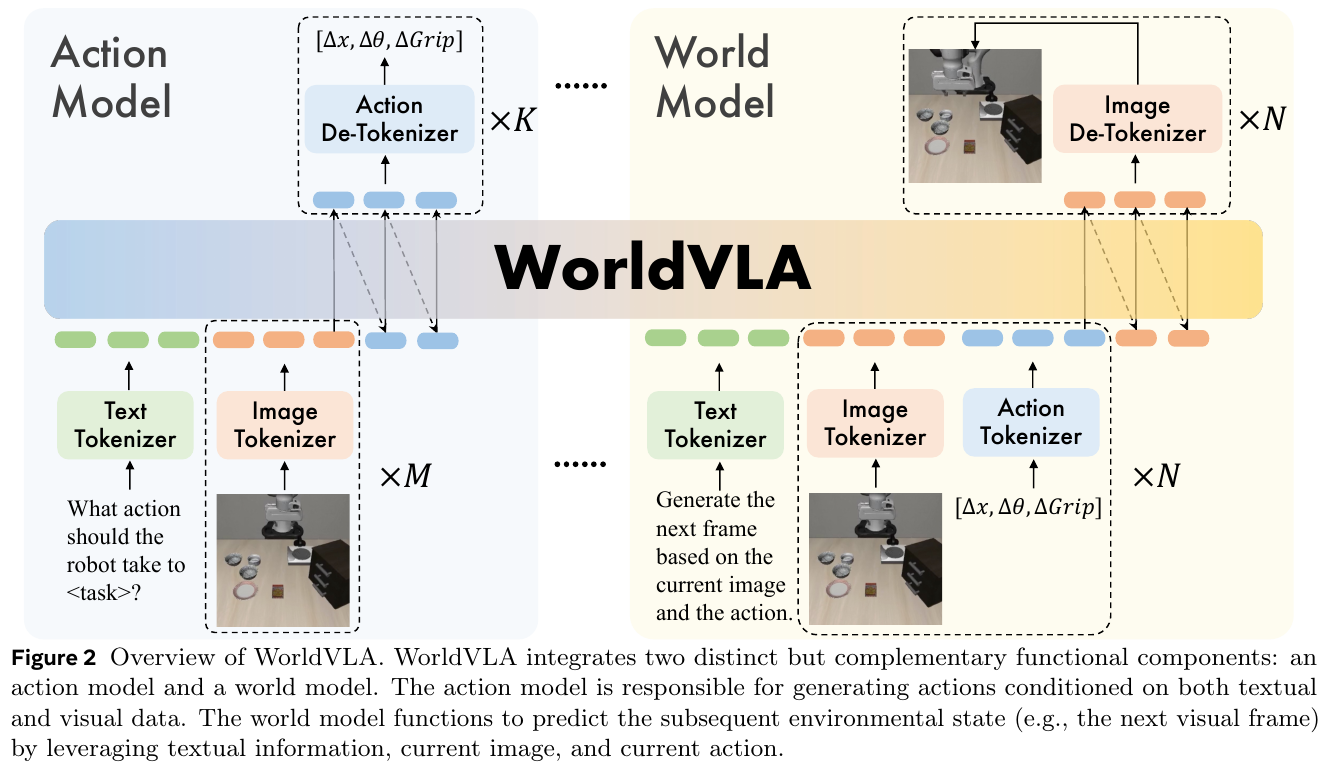
5.4 WorldVLA (2025)
———Towards Autoregressive Action World Model
📄 Paper: https://arxiv.org/abs/2506.21539
精华
这篇论文的核心亮点在于将 Vision-Language-Action (VLA) 模型与世界模型(World Model)统一在单个自回归框架中。值得借鉴的思想包括:利用世界模型预测未来图像的能力来学习环境底层物理规律,从而增强动作生成的准确性;反之,动作模型也辅助视觉理解,提升了图像生成的质量。此外,针对自回归动作序列生成中的误差累积问题,提出的动作注意力掩码策略(Action Attention Masking)能够显著提升动作块(Action Chunk)的生成性能。
1. 研究背景/问题
当前的 VLA 模型主要关注从图像和文本生成动作,但往往缺乏对动作深层次的理解,因为动作仅作为输出而未作为输入。相比之下,世界模型能够通过预测未来视觉状态来理解物理动力学,但通常无法直接生成动作。WorldVLA 旨在打破这一界限,通过统一架构实现动作与图像的协同理解与生成。
2. 主要方法/创新点
WorldVLA 采用自回归架构,集成了图像、文本和动作三种模态的 Tokenizer。
统一架构
模型初始化自 Chameleon,一个统一的图像理解与生成模型。它包含:
- 图像 Tokenizer: VQ-GAN 模型,将图像离散化为 Token。
- 动作 Tokenizer: 将 7 维机器人动作(位置、角度、夹具状态)离散化为 256 个 Bin 的 Token。
- 文本 Tokenizer: 标准的 BPE Tokenizer。
训练策略
训练过程混合了动作模型数据和世界模型数据:
- 动作预测 ($L_{action}$): 给定指令和多帧图像,预测后续动作。
- 未来预测 ($L_{world}$): 给定当前观察和动作,预测下一帧图像。
动作注意力掩码 (Action Attention Masking)
论文发现,由于预训练模型在动作域的泛化能力有限,传统的因果掩码会导致前一动作的错误迅速传播。为此,WorldVLA 设计了一种特殊的掩码:在生成当前动作块时,遮蔽之前的动作,使动作生成仅依赖于视觉和文本输入,从而支持并行生成动作块并减少误差累积。

3. 核心结果/发现
- LIBERO 基准测试: WorldVLA 在 256x256 和 512x512 分辨率下均显著优于 OpenVLA。
- 协同效应: 加入世界模型数据后,动作生成的成功率(SR)有明显提升(例如在 LIBERO-Goal 上从 67.3% 提升至 73.1%);同时,动作模型也帮助降低了视频生成的 FVD 值。
- 动作块生成: 采用新掩码策略后,动作块生成的鲁棒性大幅增强。


4. 局限性
目前使用的离散图像 Tokenizer 在感知表现力上仍有局限。未来工作将探索更大规模的数据和模型,以及设计能够更平衡理解与生成的统一 Tokenizer。
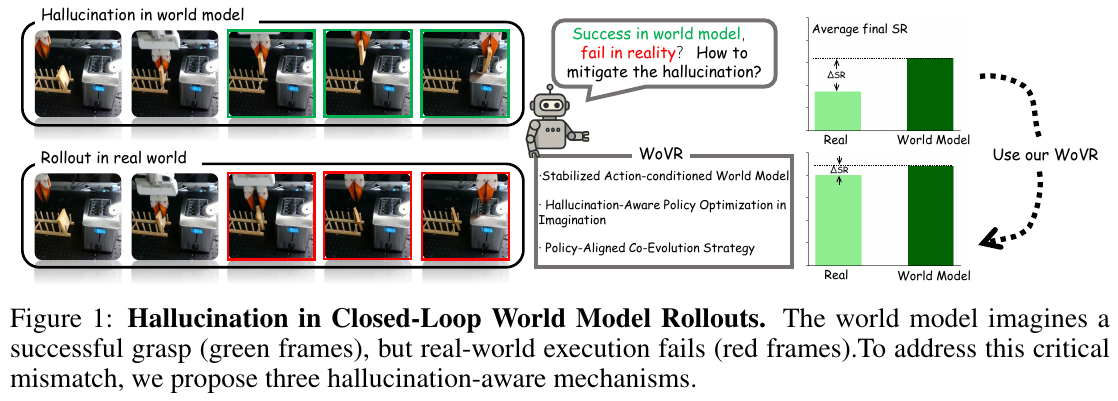
5.5 WoVR (2026)
———World Models as Reliable Simulators for Post-Training VLA Policies with RL
📄 Paper: https://arxiv.org/abs/2602.13977
精华
WoVR 提出了一种基于世界模型的机器人强化学习(RL)框架,核心贡献在于解决了世界模型中的“幻觉(Hallucination)”问题对 RL 优化信号的干扰。值得借鉴的三个机制包括:稳定的动作调节视频模型(Stabilized Action-conditioned Video World Model)通过双通道动作注入提升稳定性;关键帧初始化回放(Keyframe-Initialized Rollouts, KIR)通过在任务关键点附近初始化轨迹,缩短了有效预测深度并限制误差累积;以及世界模型与策略的协同演化策略(PACE),通过迭代精调世界模型来恢复策略更新带来的分布漂移,确保了在想象空间中 RL 训练的可靠性。
1. 研究背景/问题
利用学习到的世界模型作为仿真器进行强化学习是机器人领域的热门方向,但闭环想象中的“幻觉”——即模型生成的视觉序列与真实物理规律不符——会误导 RL 优化,使其利用模型的错误而非真实的任务进度。随着策略演化,动作分布发生漂移,进一步加剧了幻觉问题。
2. 主要方法/创新点
WoVR 并不假设世界模型是完美的,而是通过三个层面显式地调节 RL 与不完美模拟器的交互。
稳定的世界模型架构
WoVR 引入了一种增强型 DiT(Diffusion Transformer)世界模型,通过双通道动作注入机制实现更稳定的动作控制,减少了长程漂移和结构崩溃。
关键帧初始化回放 (KIR)
为了防止自回归生成的误差随时间累加,WoVR 采用了 Keyframe-Initialized Rollouts。它利用人类演示中的关键帧作为起始点,在这些状态附近进行短程想象探索。这种做法大大限制了有效预测深度,抑制了幻觉的积累。
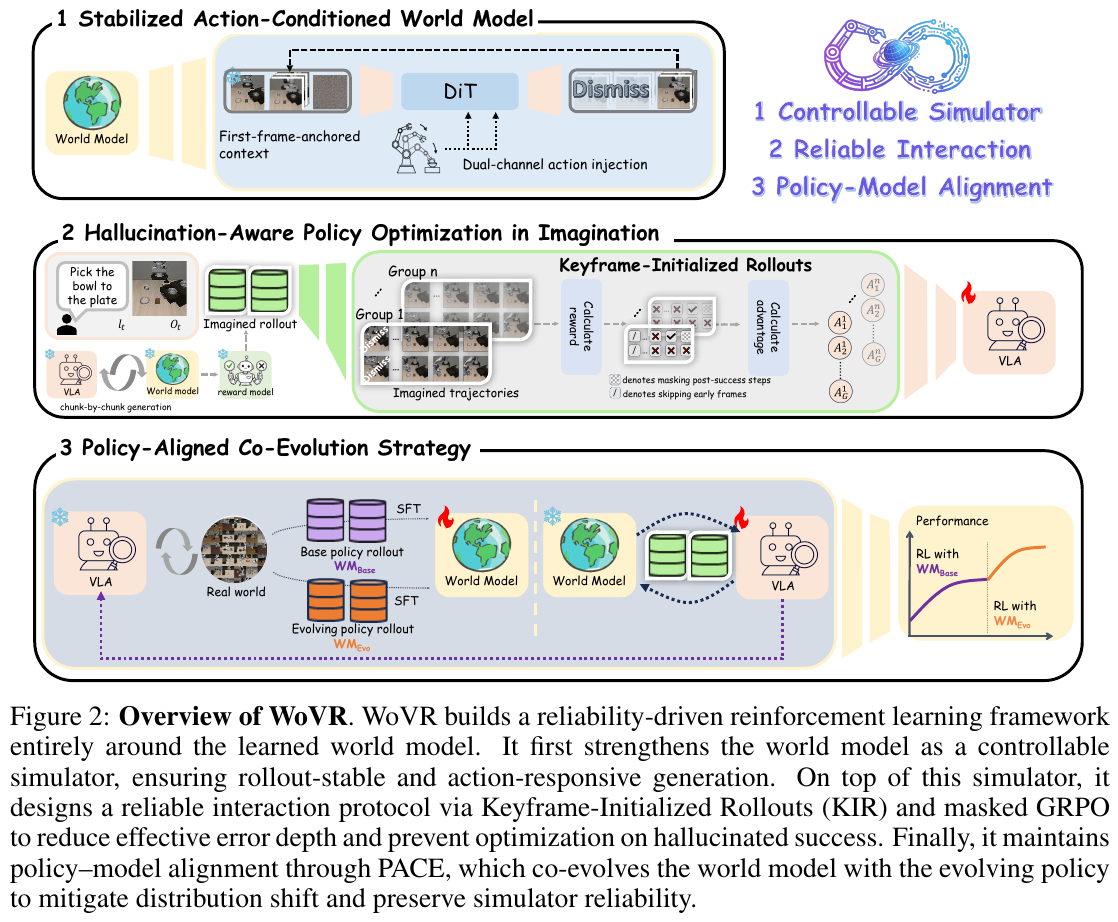
策略对齐协同演化 (PACE)
为了应对策略更新导致的动作分布漂移(Distribution Shift),PACE 策略会定期在当前演化策略生成的动作轨迹上对世界模型进行微调。这种协同演化机制使模拟器能够动态适应新的动作分布,保持了策略与模拟器的对齐。
3. 核心结果/发现
- LIBERO 基准测试: WoVR 将 LIBERO 的平均成功率从 39.95% 提升至 69.2%(+29.3个百分点)。
- 真机验证: 在真实机器人操作任务中,成功率从 61.7% 提升至 91.7%。
- 生成效率: WoVR 达到了 23 FPS 的生成速度,使其成为一种高效的训练模拟器。
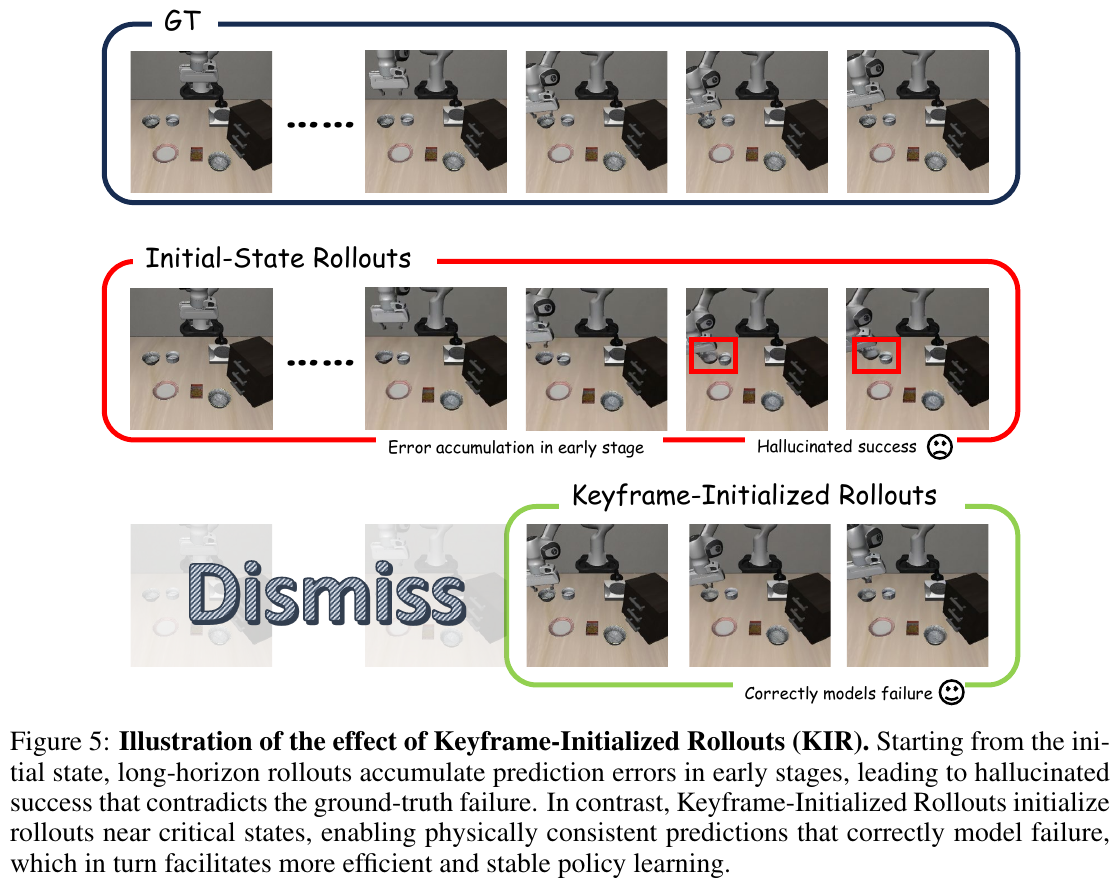
4. 局限性
虽然 WoVR 缓解了幻觉,但对于极其复杂的多步长程任务,其稳定性仍有待提升。此外,协同演化过程中的计算开销也是一个需要优化的方向。
5.6 Janus-Pro (2025)
———Unified Multimodal Understanding and Generation with Data and Model Scaling
📄 Paper: https://arxiv.org/abs/2501.17811
精华
Janus-Pro 最值得借鉴的核心思想是解耦视觉编码:理解任务与生成任务对视觉表征的需求本质不同,强行共享编码器会造成任务冲突,解耦后两路可独立优化。此外,训练策略的精细化同样重要——Stage I 充分训练像素依赖建模、Stage II 去除低效的 ImageNet 预热、Stage III 调整多模态数据比例,每一步都针对已知痛点而非盲目堆量。合成数据(1:1 比例)对生成质量的稳定性提升至关重要,是解决真实数据噪声问题的实用路径。模型规模从 1.5B 扩展到 7B 验证了解耦编码方法的强可扩展性,为统一理解与生成框架的规模化提供了实证支撑。
1. 研究背景/问题
当前统一多模态理解与生成的模型通常共享同一视觉编码器处理两类任务,但理解与生成对视觉表征的需求存在本质冲突,导致多模态理解性能受损。前代模型 Janus 虽通过解耦视觉编码验证了该思路,但受限于训练数据量少和模型容量小,在短提示图像生成质量和生成稳定性上表现欠佳。
2. 主要方法/创新点
Janus-Pro 从三个维度对 Janus 进行系统性增强:训练策略优化、数据扩展和模型规模扩展。
架构(与 Janus 相同,解耦视觉编码):
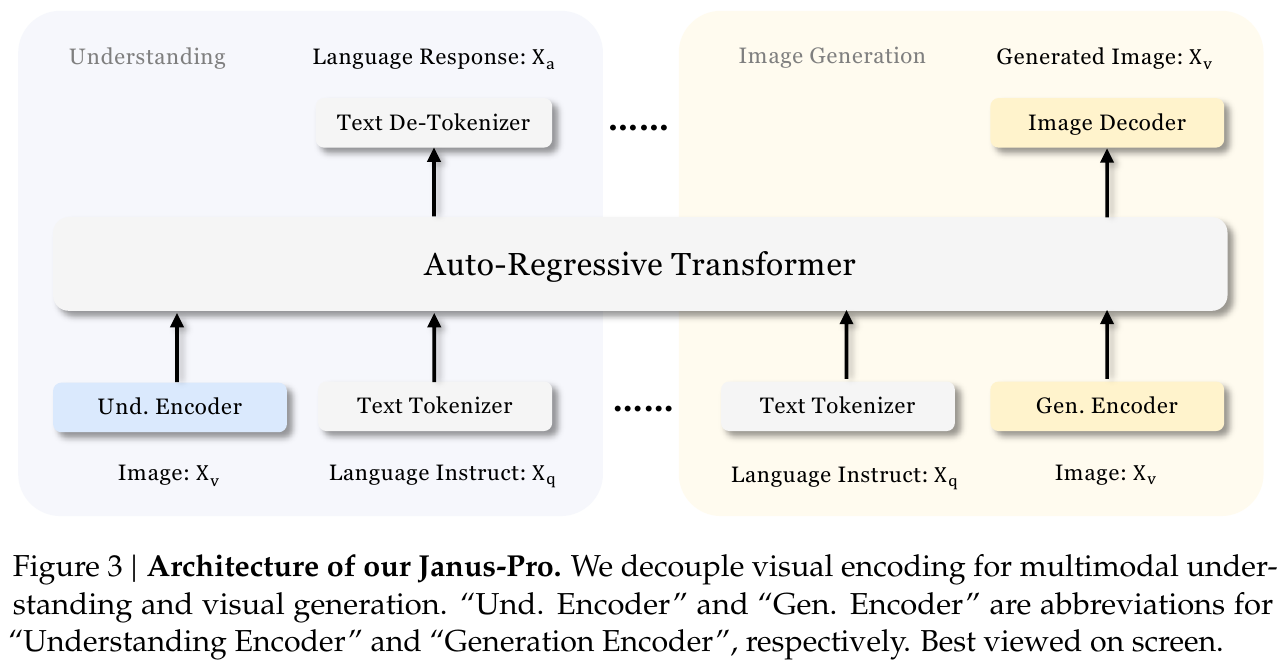
为便于理解,下图是我对 Janus-Pro 架构的手绘版本整理(核心:自回归统一框架,图像侧解耦为理解与生成两条编码路径):
flowchart TB
TextIn["文本输入"] --> TextTok["Text Tokenizer"]
ImgIn["图像输入"] --> UndEnc["理解 Encoder<br/>(SigLIP)"]
ImgIn --> GenEnc["生成 Encoder<br/>(VQ-Tokenizer)"]
UndEnc --> UndFeat["理解特征"]
GenEnc --> GenFeat["生成特征<br/>(视觉 Token 词表)"]
UndFeat --> UndAdapt["Understanding Adaptor<br/>(MLP, 理解时使用)"]
GenFeat --> GenAdapt["Generation Adaptor<br/>(MLP)"]
TextTok --> LLM
UndAdapt --> LLM
GenAdapt --> LLM
LLM["LLM / 自回归 Transformer"] -->|自回归| TextOut["文本输出"]
LLM -->|预测视觉 Tokens 16×16| VisTok["多模态视觉 Tokens"]
VisTok --> VQDec["VQ-Decoder"]
VQDec --> ImgOut["图像输出"]
classDef input fill:#e8f4fd,stroke:#2c7fb8,stroke-width:1px;
classDef enc fill:#fff4e6,stroke:#d68910,stroke-width:1px;
classDef core fill:#fde9e9,stroke:#c0392b,stroke-width:2px;
classDef output fill:#e8f8e8,stroke:#27ae60,stroke-width:1px;
class TextIn,ImgIn input;
class TextTok,UndEnc,GenEnc,UndFeat,GenFeat,UndAdapt,GenAdapt,VisTok,VQDec enc;
class LLM core;
class TextOut,ImgOut output;
整体框架基于统一的自回归 Transformer。对于多模态理解任务,使用 SigLIP-Large-Patch16-384 编码器提取高维语义特征,经 Understanding Adaptor(两层 MLP)映射到 LLM 输入空间;对于视觉生成任务,使用来自 LlamaGen 的 VQ tokenizer 将图像离散化为 ID 序列,经 Generation Adaptor 映射 codebook embedding 输入 LLM,最终通过 Image Decoder 输出 $384 \times 384$ 图像。
三阶段训练流程:
Janus 与 Janus-Pro 均采用三阶段训练范式,下图(取自原 Janus 论文)展示了每个阶段中各模块的冻结(❄️)与可训练(🔥)状态:
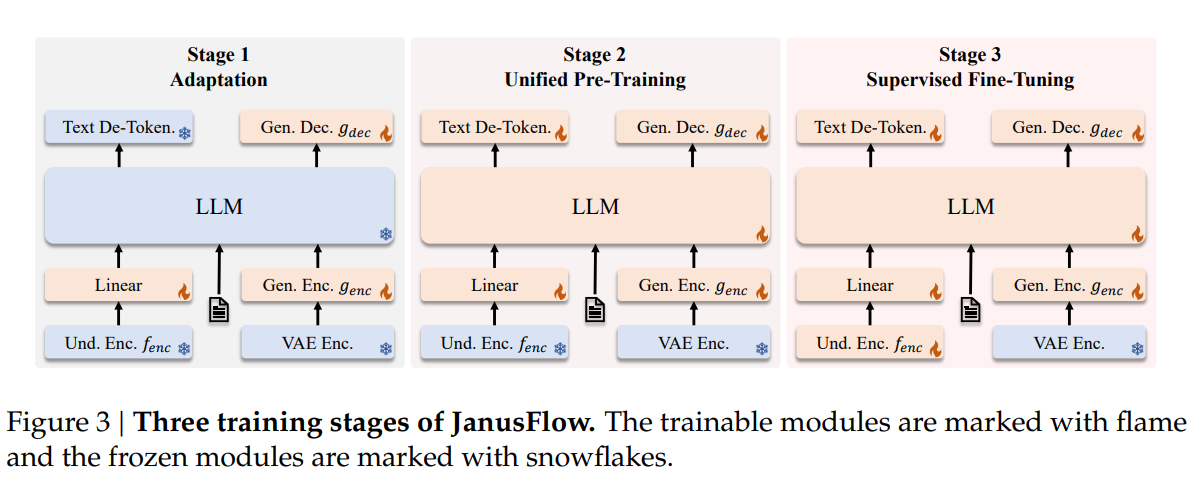
-
Stage 1 — Adaptation(适配):目标是让新引入的模块与预训练组件协同工作。此阶段冻结 LLM 与 图像理解编码器(Und. Enc.),仅训练将图像编码映射到 LLM 输入空间的 Linear 映射层 和 图像生成头(Gen. Dec.)。训练数据为 ImageNet(基于类别名提示生成图像)。Janus-Pro 的改动:显著增加 Stage 1 的训练步数,让模型在 LLM 参数固定的情况下更充分地建模像素依赖。
-
Stage 2 — Unified Pre-Training(统一预训练):在继续训练新模块的基础上,解冻 LLM 及其文本预测头(Text De-Token),使其能够处理多模态嵌入序列。训练样本包括多模态理解、图像生成与纯文本数据三类。Janus-Pro 的改动:完全移除 ImageNet 数据,直接使用密集描述的真实文生图数据——原版 Janus 在此阶段以 ImageNet 开始并逐步提升文生图数据比例,Janus-Pro 则跳过该预热阶段,训练效率显著提升。此外,图像编码器的表征会与图像生成潜在输出做对齐,以增强生成过程的语义一致性。
-
Stage 3 — Supervised Fine-Tuning(监督微调):在指令微调数据(对话 + 高质量文生图样本)上进行 SFT。此阶段图像理解编码器(Und. Enc.)也加入训练,即除 VAE 编码器外的全部模块都被解冻。Janus-Pro 在此阶段与原版 Janus 流程一致。
Stage 3 数据比例调整:将多模态理解数据、纯文本数据、文生图数据的比例从原版 Janus 的 7:3:10 调整为 5:1:4,在保持生成能力的同时提升多模态理解性能。
数据扩展:
- 多模态理解:参考 DeepSeek-VL2,增加约 9000 万样本(图像描述、表格、图表、文档理解等),Stage III 额外加入 MEME 理解、中文对话等数据;
- 视觉生成:引入约 7200 万合成图像样本,将真实与合成数据比例调整为 1:1,有效解决原始真实数据噪声大、生成不稳定的问题。
模型扩展:
将基础 LLM 从 1.5B 扩展至 7B(使用 DeepSeek-LLM),形成 Janus-Pro-1B 和 Janus-Pro-7B 两个版本。实验表明更大规模 LLM 使两类任务的 loss 收敛速度均显著加快。
3. 核心结果/发现
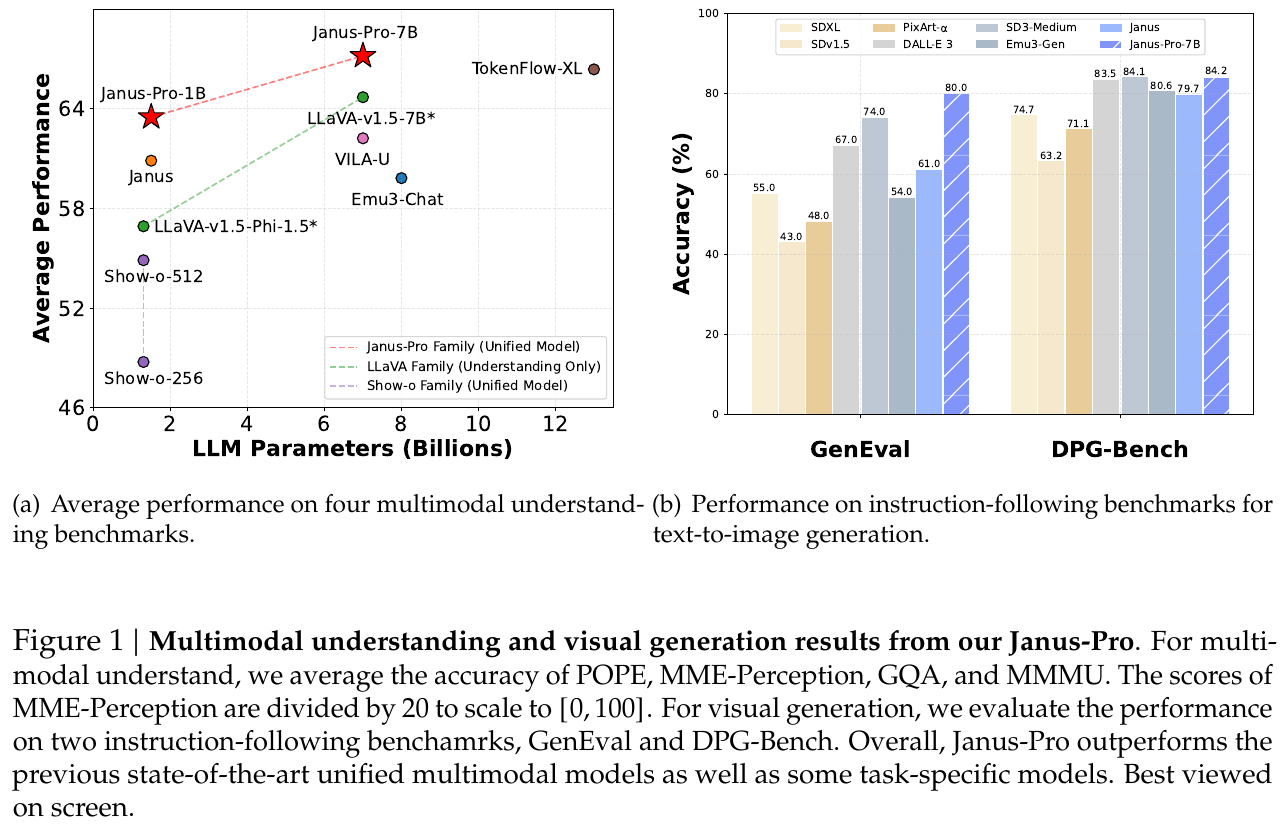
多模态理解(Table 3):
- Janus-Pro-7B 在 MMBench 上达到 79.2,超越同类统一模型 Janus(69.4)、TokenFlow-XL(68.9,13B)、MetaMorph(75.2,8B)
- MMMU 得分 50.0,GQA 62.0,全面领先统一理解+生成类模型
文生图生成(Table 4 & 5):
- GenEval 整体得分 0.80,超越 Janus(0.61)、DALL-E 3(0.67)、SD3-Medium(0.74)
- DPG-Bench 得分 84.19,超越所有对比方法(含生成专用模型)
定性结果:
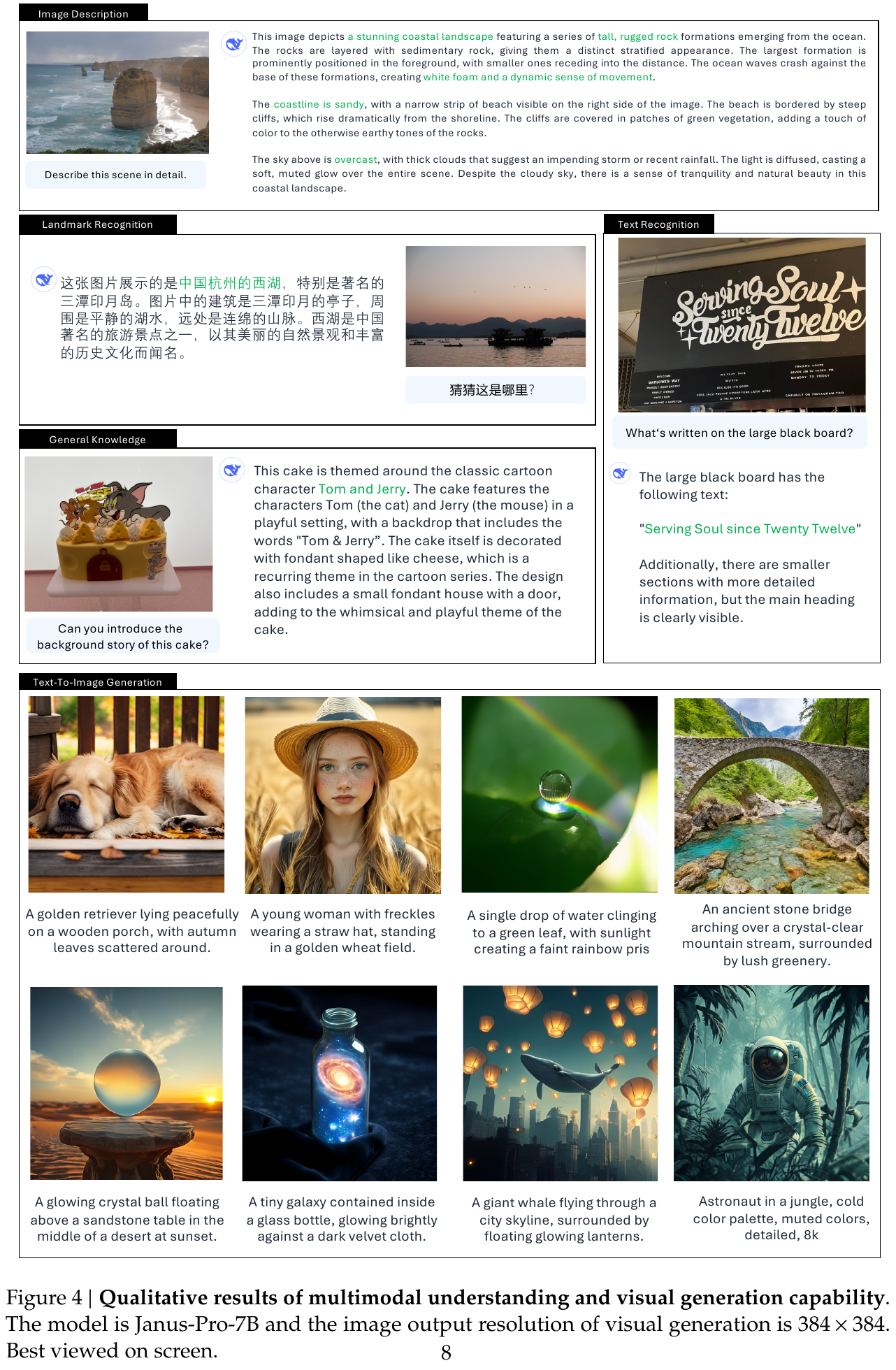
4. 局限性
多模态理解输入分辨率限制在 $384 \times 384$,影响 OCR 等细粒度任务性能;VQ tokenizer 的重建损失导致生成图像中小面部区域等细节欠缺,提升分辨率是解决上述两个问题的主要方向。
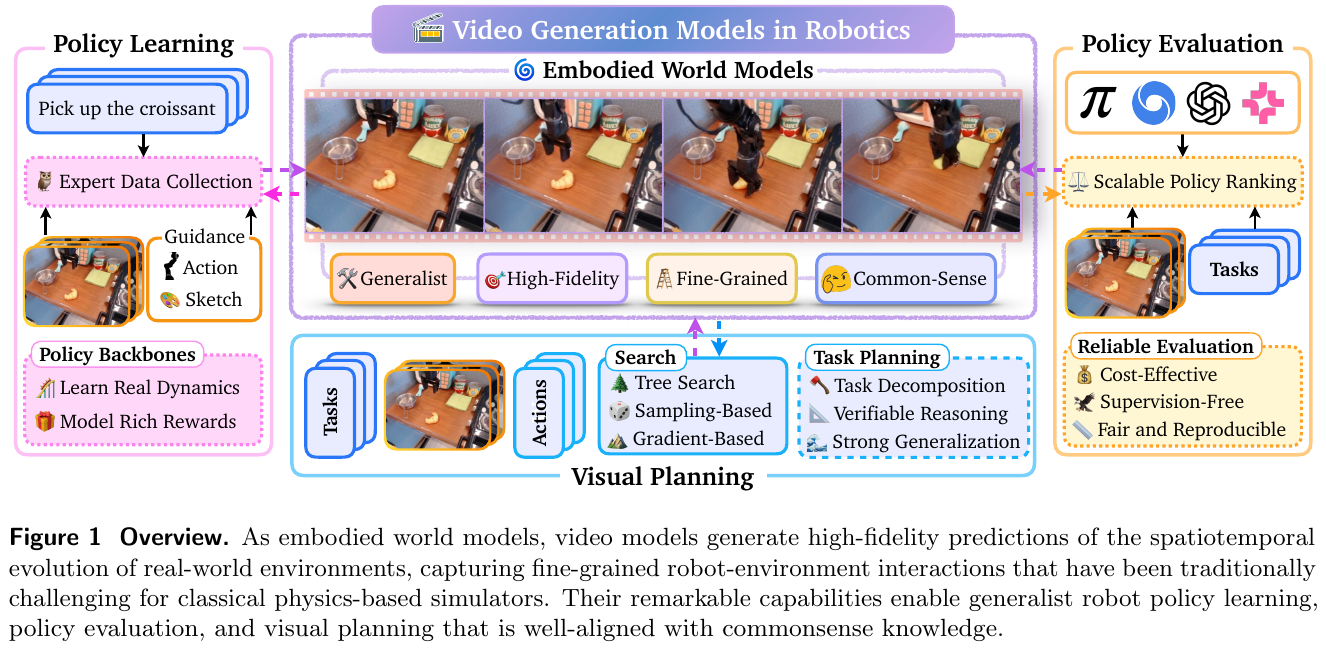
5.7 Video Generation Models in Robotics (2026)
———Applications, Research Challenges, Future Directions
📄 Paper: arXiv:2601.07823
精华
- 核心价值:视频生成模型作为高保真物理世界模拟器,能克服物理仿真器的简化假设,为机器人提供精细的交互感知。
- 具身世界模型:视频模型不仅是视觉输出工具,更是能够预测时空演变的”具身世界模型”,支持策略学习与视觉规划。
- 关键应用:涵盖模仿学习(数据增强)、强化学习(动力学建模)、策略评估(免真实环境部署)和视觉规划。
- 主要挑战:包括违反物理规律的幻觉(Hallucinations)、指令遵循能力弱、长视频生成的连贯性以及极高的推理成本。
- 未来方向:整合物理先验(物理引擎作为约束)、不确定性量化、更高效的推理架构(如 DiT)以及长序列生成。
1. 研究背景/问题
传统的机器人研究依赖物理仿真器进行策略验证和训练,但仿真器通常需要复杂的参数调整且难以模拟柔性体或精细物理交互。与此同时,仅依赖语言抽象的大模型(LLMs)缺乏对物理世界细粒度时空动态的理解。视频生成模型(Video Generation Models)凭借其在互联网规模数据上学习到的丰富视觉和动作知识,展现出作为具身世界模型(Embodied World Models)的巨大潜力。
2. 主要方法/创新点
论文系统地梳理了视频生成模型在机器人中的架构分类、应用范式及评估体系。
核心分类学 (Taxonomy)
视频生成模型在机器人中的角色主要分为:
- 模仿学习中的数据生成器:合成多样化的专家演示,缓解数据稀缺问题。
- 强化学习中的动力学/奖励模型:预测未来状态并提供视觉反馈。
- 视觉规划器:通过合成未来视频序列来辅助机器人进行任务分解和搜索。
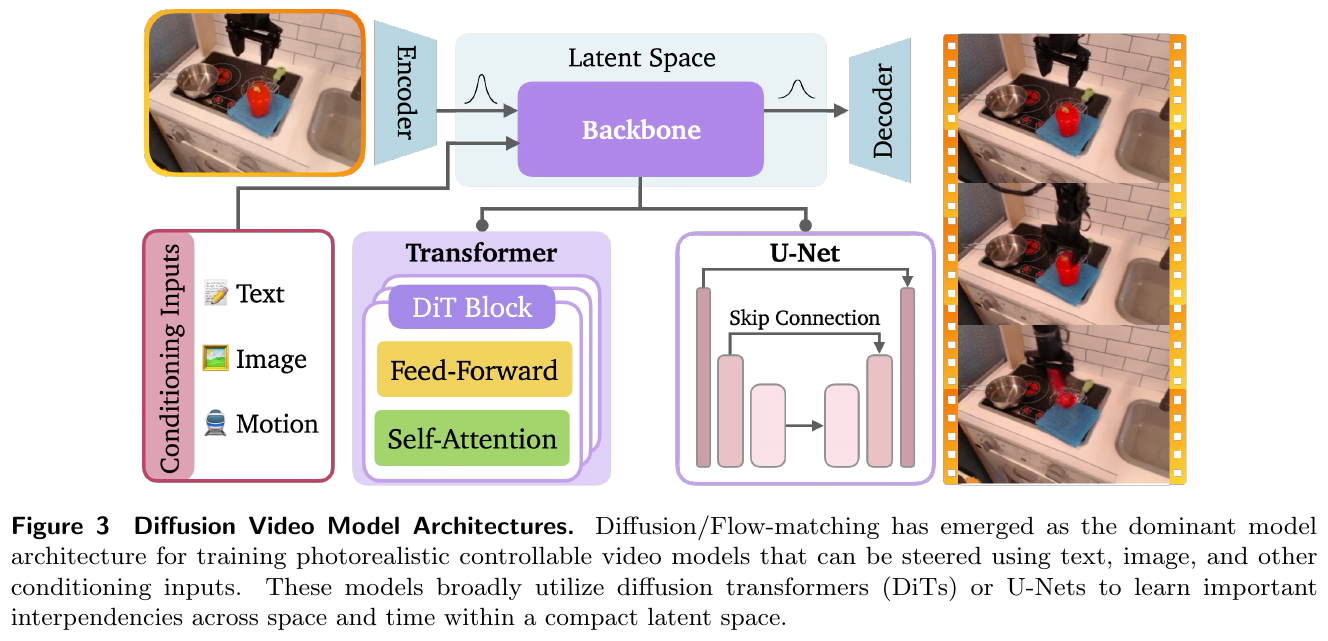
模型架构演进
从传统的基于 RNN/CNN 的预测模型演进到如今主流的基于 Diffusion 和 Flow-matching 的架构。
- 扩散模型 (Diffusion Models):利用逐步去噪过程合成高质量视频帧,结合 Transformer (DiT) 或 U-Net 实现条件控制。
- 联合嵌入预测架构 (JEPA):通过学习隐藏特征空间中的动态,实现更鲁棒的非像素级世界建模。
显式与隐式世界模型
- 隐式模型:通过视觉像素或潜空间表示世界状态。
- 显式模型:输出如点云(Point Cloud)、体素网格(Voxel Map)或 3D 高斯泼溅(3DGS)等显式 3D 表示,以增强物理一致性。

3. 核心结果/发现
- 性能评估标准:除了传统的视觉指标(PSNR, SSIM, FVD),机器人领域更关注物理一致性(Physics-IQ)、指令遵循度(VBench)和策略部署后的成功率。
- 跨模态优势:视频模型能整合文本指令、参考图像和动作序列,生成的视频轨迹可直接用于训练 VLA(Vision-Language-Action)策略。
- 成本效益:通过视频生成进行大规模策略评估,可减少对真实物理站点的依赖,降低硬件损耗和人工成本。
4. 局限性
- Hallucinations:生成的视频常出现物体凭空消失或违反重力等现象,限制了其在安全敏感场景的应用。
- 长序列漂移:随着生成步数增加,视频的物理真实度和连贯性会迅速下降。
- 实时性瓶颈:扩散模型的采样过程极其耗时,难以满足机器人闭环控制的需求。
5.8 AIM (2026)
———Intent-Aware Unified World Action Modeling with Spatial Value Maps
📄 Paper: https://arxiv.org/abs/2604.11135
精华
这篇论文最值得借鉴的是用显式的空间价值图 (Spatial Value Map, ASVM) 作为 world model 和 action head 之间的中间接口,把”未来视觉预测”与”动作解码”之间缺失的”在哪里交互、为什么交互”这一 manipulation intent 补齐,从而避免 action head 从 dense RGB 未来中隐式反推 inverse-dynamics。具体可迁移的设计包括:(1) intent-causal attention——通过显式 attention mask 强制 action 分支只能经由 value map 访问未来信息,而不能直接看未来 RGB tokens,形成结构化的信息瓶颈;(2) mixture-of-transformers 的共享 self-attention + 分支 FFN 让 video / value / action 三个 stream 既紧耦合又各自保留特征空间;(3) self-distillation RL post-training——冻结 video 和 value 分支,只用 projected value-map response 产生的 dense reward 训练 action head,相当于让预训练的价值头自监督动作头,无需额外人工标签。这种”把语义意图落成空间热图”的抽象在 VLA 领域具有很强的可迁移性。
1. 研究背景/问题
预训练视频生成模型为机器人控制提供了强大的视觉先验,但已有的 unified world-action 模型在不做大量机器人特定训练的情况下难以解码出可靠的动作。作者认为这不是统计问题,而是结构性 mismatch:视频模型捕获的是”场景如何演化”,而动作生成还需要显式推理”在哪里交互 (where)”以及”背后的操作意图 (intent)”;直接从 future RGB latents 解码动作会迫使模型从一个并非为控制优化的表征中隐式恢复 manipulation intent。
2. 主要方法/创新点
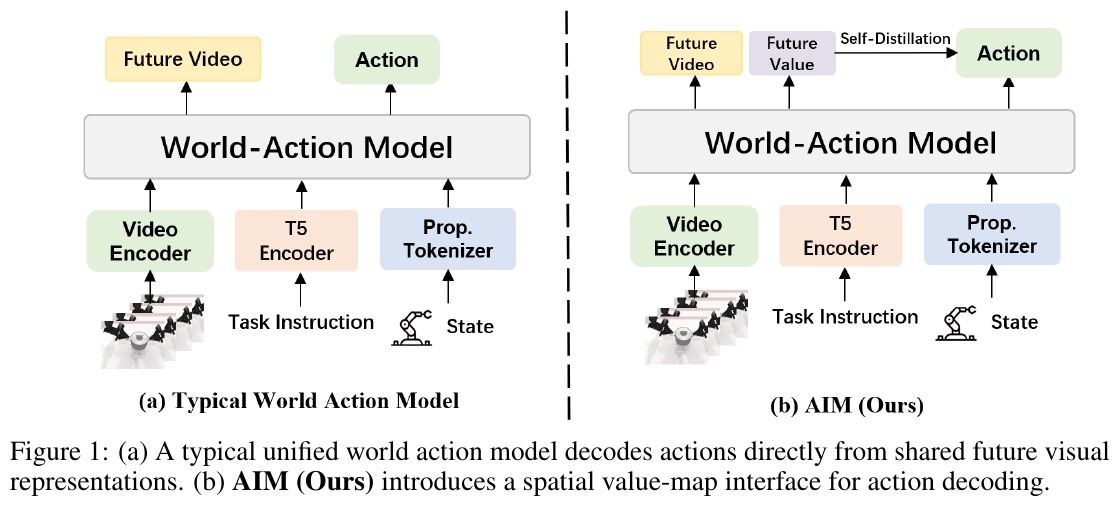
核心思路:显式空间接口 (Explicit Spatial Interface)。 AIM 不直接从未来视觉特征解码动作,而是联合预测 future RGB frames $X^+$ 和与之空间对齐的 Action-aligned Spatial Value Map $M^+ \in [0,1]^{H \times W \times 3}$;value map 高亮任务相关的交互区域(例如抓取的 grasp affordance 区域、放置的 placement contact 区域),作为 manipulation intent 的 control-oriented 抽象。条件分布被分解为:
\[p(X^+, M^+, A^+ \mid \mathcal H_t) = p(X^+, M^+ \mid \mathcal H_t)\, p(A^+ \mid \mathcal H_t, M^+).\]动作生成只通过预测出的 value map 获取未来信息,而不直接访问未来 RGB tokens。
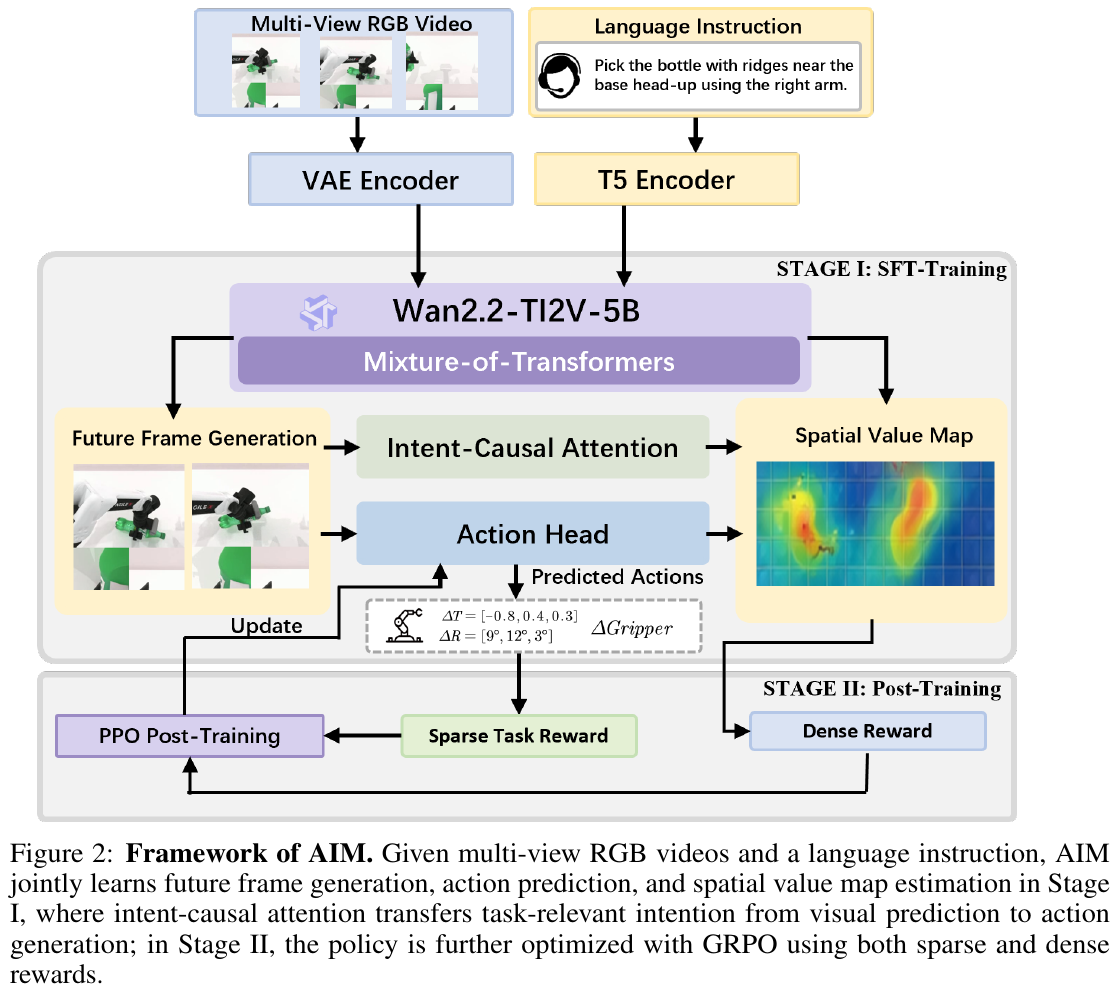
架构 (Architecture)。 基于预训练视频生成模型 Wan2.2-TI2V-5B 初始化 video 分支,加入一个与之同深度但 hidden width 更小的 action head。采用 mixture-of-transformers:video / value / action 三个 stream 在每个 block 共享 self-attention sublayer,但各自拥有独立的 $W_{Q,s}^\ell, W_{K,s}^\ell, W_{V,s}^\ell$ 投影和独立的 feed-forward。T5 编码的指令只通过 cross-attention 注入 video 分支,保证 action head 仅经由共享的世界表征接收任务语义。Tokenization 上把三个视角(head-up / left / right wrist)拼成 T-pose canvas,并复用 Wan2.2 VAE 同时编码 RGB 观测 $z_t^o$ 和 value map $z_t^m$,使 value tokens 与 visual tokens 天然几何对齐。
Intent-Causal Self-Attention。 这是 AIM 的关键结构性创新,通过一个对 shared self-attention 的 visibility mask 实现:
\[\mathcal V_x = [z_t^o,\, z_{t-k:t-1}^o,\, z_{t-k:t-1}^a,\, z^\ell,\, z^x],\] \[\mathcal V_m = [z_t^o,\, z_{t-k:t-1}^o,\, z^x,\, z^m],\] \[\mathcal V_a = [z_t^o,\, z_{t-k:t-1}^a,\, z^o,\, z^a].\]语义上:future video tokens 能看到当前观测、指令、历史观测动作,从而预测 task-conditioned 未来世界;future value tokens 能看到当前/历史观测与未来 video tokens,从而把 value prediction 锚定到预测出的未来状态;action tokens 只能看到当前观测、历史动作和未来 value tokens,而看不到未来 RGB tokens——这一 mask 的效果是把任务语义先经过 T5 cross-attention 进入 video → 再凝聚到 value stream → 最后才被 action head 读取,形成 “video → value → action” 的因果瓶颈。
训练目标。 整体损失是 RGB flow-matching、value-map flow-matching 和 action 的 inverse-dynamics 损失的加权和:
\[\mathcal L = \mathcal L_{rgb} + \lambda_m \mathcal L_{map} + \lambda_a \mathcal L_{act}.\]Future RGB 和 future value-map tokens 由 video generation model 沿同一条 flow-matching 轨迹联合去噪,action tokens 由 action head 去噪为连续双臂控制向量 $\hat A^+$。推理时 AIM 自回归 chunk-wise rollout 并利用 KV cache 复用历史 tokens,显著提升 long-horizon 效率。
Self-Distillation RL Post-Training。 监督训练只能模仿 action 分布而不能直接优化闭环成功率。因此引入第二阶段:冻结 video generator 和 value-map head,仅用 GRPO 更新 action head。奖励由两部分组成:
\[r_t = \lambda_d r_t^{dense} + \lambda_s r_t^{sparse},\qquad r_t^{dense} = M_t(\Pi(p_t)),\]其中 $r_t^{sparse}$ 是任务级稀疏信号,$p_t$ 是预测动作的 landing point 或末端目标,$\Pi(\cdot)$ 是相机投影,$M_t$ 是冻结 value head 预测的 value map。直观地,action head 被奖励去把动作投影到冻结 value head 预测的高价值交互区域——这是一种用自己的 spatial value 预测作为 dense reward 的自蒸馏,无需额外人工标签。GRPO 目标:
\[\mathcal L_{GRPO}(\phi) = \mathbb E_t\left[\min\!\Big(\rho_t(\phi)\hat A_t,\, \mathrm{clip}(\rho_t(\phi), 1-\epsilon, 1+\epsilon)\hat A_t\Big)\right].\]Value-Map 标注方案。 对 pick 任务,在 gripper 与目标物建立有效抓取接触时记录接触表面点云,用校准投影矩阵投影到图像平面并做高斯平滑,得到 grasp affordance region;高斯核宽度按相机参数和投影点距离动态调整,保证在不同视角与距离下图像空间支持尺寸一致。对 place 任务,检测被操作物达到稳定构型(质心速度阈值)时的接触区域,得到 placement contact region。作者在 RoboTwin 2.0 上构建了 30K 轨迹的大规模仿真数据集,包含同步多视角视频、动作序列和 per-step value-map 标注。
3. 核心结果/发现
在 RoboTwin 2.0 的 50 个仿真任务上评测,Easy / Hard 分别用 SR 作为主指标:
- 平均 SR:AIM 达到 94.0% / 92.1%(Easy / Hard),平均 93.1%,显著高于 $\pi_0$ (62.2%)、$\pi_{0.5}$ (79.8%)、X-VLA (72.8%)、Motus (87.8%)、Fast-WAM (91.8%)、Giga-World (86.0%)、LingBot-VA (92.2%) 等 baseline。
- RL post-training 的增益明显。 Stage1(仅 SFT)已达 93.0% / 92.0%;RL 阶段再带来约 +1% 平均提升,且在 Place Mouse Pad (97%/95%)、Scan Object (100%/98%)、Turn Switch (100%/98%) 等 contact-sensitive / stage-dependent 任务上增益最大。
- 相对 Motus (同类 unified WAM) 平均 SR +5.3%/+5.0%;相对 $\pi_{0.5}$ 高达 +11.3%/+15.3%。说明把 “spatial intent” 显式化带来的收益超过单纯扩大动作模型或世界模型。
- 定性: 未来帧预测与操作阶段时序对齐,value map 聚焦于有语义的交互区域(而非一般 saliency),projected action 目标落在高价值区域内,表明性能提升来自预期中的”空间桥梁”而非 shortcut correlation。
4. 局限性
论文工作仅在仿真(RoboTwin 2.0)中构建数据并评测,缺少真实机器人平台上的迁移验证;value-map 标注依赖仿真器的 contact detection API 和物理状态,不清楚在真实数据上如何获得同等质量的 grasp / placement affordance 标签。
5.9 LingBot-World (2026)
———首个开源、支持实时交互的长程世界模型
📄 Paper: arXiv:2601.20540
精华
- LingBot-World 是一个开源的实时交互世界模型,支持分钟级的长程生成一致性。
- 提出了包含分层语义的数据引擎,通过叙事、静态场景和密集时间描述解决了交互数据稀缺问题。
- 采用了三阶段进化训练策略:预训练(通用视频先验)、中训练(知识注入与 MoE 架构)和后训练(因果适配与蒸馏)。
- 实现了亚秒级(<1s)的推理延迟,支持 16 fps 的实时生成。
- 展示了在可控世界事件编辑、具身智能 Action Agent 和 3D 重建等领域的广泛应用潜力。
1. 研究背景/问题
当前的视频生成模型虽能生成高质量短片,但本质上是“梦想家”而非“模拟器”,缺乏对物理规律(如因果性、物体恒久性)的理解,且难以实现实时交互。此外,高质量交互数据的匮乏、长程一致性的维持以及扩散模型高昂的计算开销,也是阻碍世界模型发展的核心瓶颈。
2. 主要方法/创新点

① 数据引擎与分层描述
为了解决高质量交互数据稀缺的问题,LingBot-World 构建了一个混合数据引擎,结合了真实世界视频、游戏录像和 Unreal Engine (UE) 合成数据。关键创新在于分层描述策略:
- 叙事描述 (Narrative Caption):描述整体环境和摄像机轨迹,作为全局语义提示。
- 静态场景描述 (Scene-Static Caption):仅聚焦环境,实现动作与场景的解耦。
- 密集时间描述 (Dense Temporal Caption):对视频事件进行细粒度的时间对齐描述。
② 三阶段进化训练管线
模型采用了从视频生成器向交互式模拟器进化的三阶段策略:
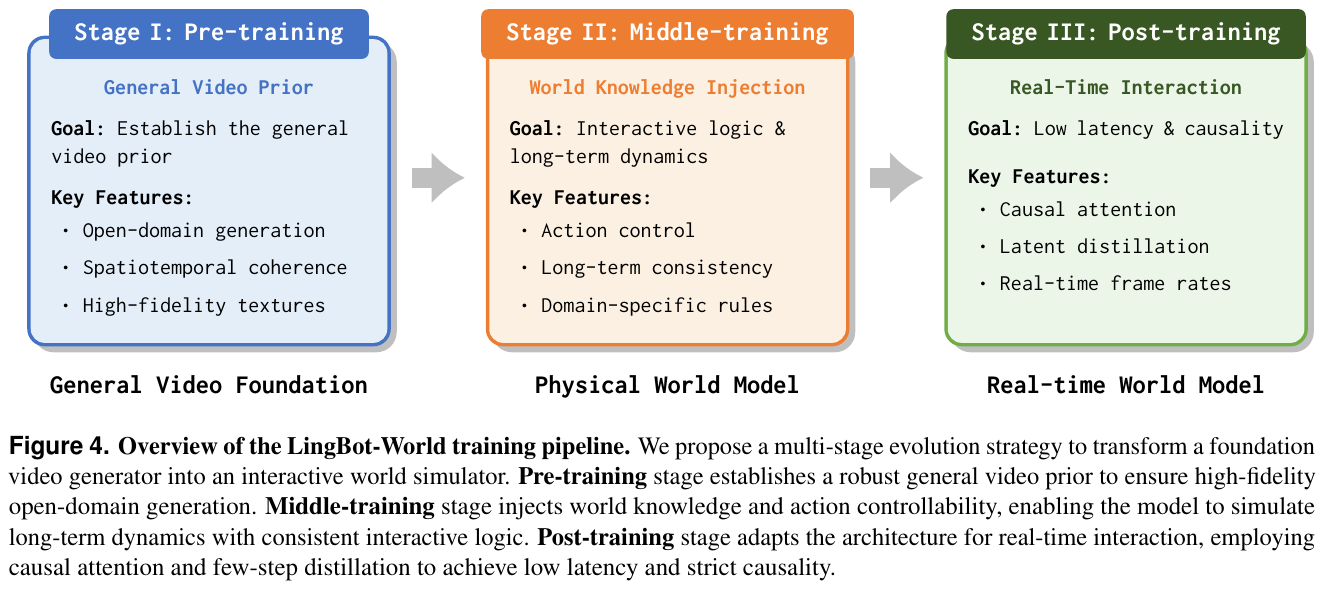
- Stage I: 预训练:利用 14B 参数的 Wan2.2 扩散模型建立强大的时空相干性和视觉先验。
- Stage II: 中训练 (MoE 知识注入):引入 Mixture-of-Experts (MoE) 架构(总参数 28B,激活 14B),通过 progressive curriculum 策略将训练时长从 5 秒扩展到 60 秒,并注入 Plücker 编码的动作信号。
- Stage III: 后训练 (实时化):将双向扩散模型适配为因果自回归系统,并结合分布匹配蒸馏 (DMD) 和对抗优化,将推理延迟降低至亚秒级。
③ 模型架构与动作注入
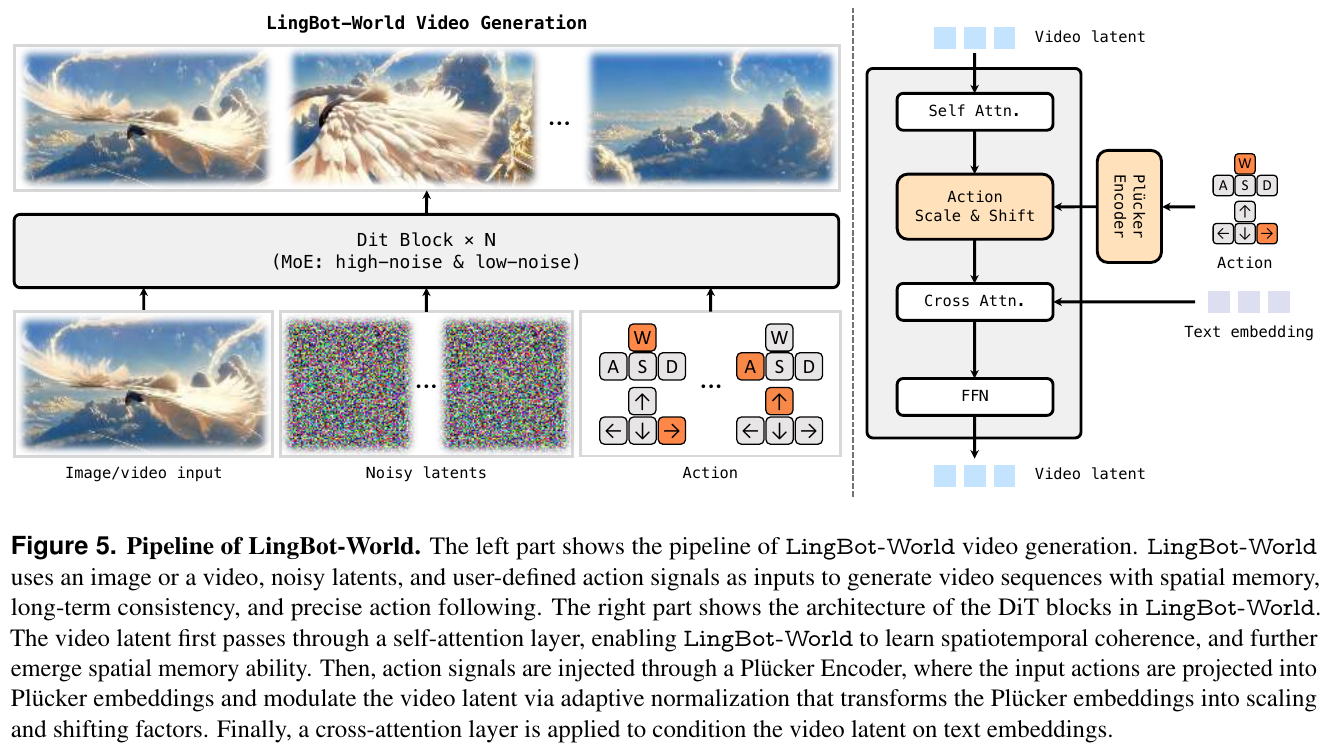
LingBot-World 基于 DiT (Diffusion Transformer) 架构。动作信号(离散键盘输入和连续摄像机旋转)通过 Plücker Encoder 投影为嵌入向量,再通过 Adaptive Layer Normalization (AdaLN) 注入到 DiT 块中,实现对视频生成的精确控制。
3. 核心结果/发现

- 长程一致性:模型表现出显著的涌现记忆能力,即使物体长时间离开视野,返回时仍能保持结构完整。
- 实时性与质量平衡:LingBot-World-Fast 在单 GPU 节点上实现了 16 fps 的吞吐量,同时保持了与教师模型相当的视觉质量。
- 可控编辑:支持通过文本指令(如“Firework”、“Fish”)对生成的世界进行实时干预。

4. 局限性
- 记忆稳定性:长程一致性仍是基于上下文窗口的涌现能力,缺乏显式的存储模块。
- 交互精度:对细粒度物体操作(如抓取特定物体)的支持尚不足。
- 算力成本:推理仍需企业级 GPU 支持。
5.10 Marble & World Labs (2025–2026)
———大型世界模型 (LWM) 与空间智能
🔗 产品: marble.worldlabs.ai
🔗 技术博客: Marble: A Multimodal World Model
🔗 API: World Labs API
精华
World Labs 代表了一种与主流 LLM 路线截然不同的 AGI 追求路径——空间智能(Spatial Intelligence)。其旗舰模型 Marble 是首个面向大众商用的大型世界模型(Large World Model, LWM),能够从单张图片、一段视频或文本提示生成可探索、可编辑的持久 3D 世界。值得借鉴的核心思想包括:
- 超越 2D 的多模态建模:传统视频生成模型将世界压平为像素序列,LWM 直接在 3D 空间中建模——输入多模态,输出空间一致的 3D 环境,而非平面视频帧。
- 3D 高斯泼溅作为世界表示(3DGS):Marble 采用 3D 高斯粒子作为最高保真度的世界表示,支持精确相机控制、交互式场景编辑,并能跨平台(手机到 VR 头显)实时渲染——这是 §8.2 时空 4D 感知方向的首个大规模工业落地。
- 无限可探索的持久世界:与生成单段视频不同,Marble 生成的 3D 世界没有时间限制,可以持续探索和扩展,支持导出为 Gaussian splats、传统网格(mesh)或视频。
- 空间智能 × 具身 AI 评测:通过 World API(2026 年初开放)和与光轮智能的战略合作,World Labs 正将 LWM 推向具身智能评测基础设施,解决”可规模化评估”这一机器人 AI 的核心瓶颈。
1. 研究背景/问题
李飞飞在 ImageNet 时代奠定了计算机视觉的数据基础,World Labs 的创立反映了她对 AI 下一阶段的判断:当前 AI 缺失的核心能力是空间智能——即理解、生成和推理三维物理世界的能力。
现有 LLM / VLM 的局限在于:它们本质上是”语言生物”,将世界压缩为 token 序列,缺乏在连续 3D 空间中感知和行动的能力。视频生成模型虽能生成逼真的 2D 视频序列,但无法支持视角自由移动、交互式编辑或精确的 3D 几何建模。
World Labs 提出的解决方案是构建 LWM:以多模态输入为条件,直接生成空间一致、高保真、持久化的 3D 环境。这与具身世界模型的终极目标高度契合——世界模型不应仅仅预测下一帧像素,而应理解和生成完整的三维物理世界。
2. 主要方法/创新点

Marble 多模态输入体系
Marble 支持四类输入模态,真正实现了多模态 → 3D 世界的生成:
| 输入类型 | 说明 |
|---|---|
| 文本提示(Text) | 直接描述目标世界的外观、风格和内容 |
| 单张图像(Image) | 将单张室内照片、风景图或艺术插画外推为可探索 3D 世界 |
| 视频片段(Video) | 从短视频或 360° 全景视频中重建空间结构 |
| 粗糙 3D 布局(Coarse 3D Layout) | 通过 Chisel 工具手绘草图或导入 3D 资产作为结构框架 |


3DGS 作为世界表示:选型的核心逻辑
Marble 的核心技术选型为 3D 高斯泼溅(3D Gaussian Splatting, 3DGS)。3DGS 将 3D 场景表示为一组半透明粒子集合,在世界模型场景下具有显著优势:

| 特性 | NeRF | 3DGS(Marble) |
|---|---|---|
| 实时渲染 | ✗ | ✓ |
| 精确相机控制 | 有限 | ✓ |
| 交互式编辑 | ✗ | ✓ |
| 跨设备兼容 | ✗ | ✓(手机→VR) |
| 物理引擎集成 | 困难 | 自然兼容 |
四大核心功能模块

① Chisel(AI 原生 3D 雕刻):实验性的 AI-native 3D 建模工具,允许用户在 3D 空间中直接用粗糙几何体(盒子、平面)或导入现有 3D 资产布置世界结构框架。核心设计原则是结构与风格解耦——粗糙 3D 场景决定世界的空间结构,文本 prompt 控制整体视觉风格,二者独立可控。
② World Expansion(世界扩展):一键扩展已生成的世界边界,用户选定需要扩展的区域,Marble 自动生成更多连续一致的内容填充选定区域,支持无限延伸。
③ Composition Mode(合成模式):将任意数量的独立世界组合为超大规模空间。各子世界的位置和衔接完全由用户控制,适用于游戏场景、VFX 大型布景或机器人仿真测试场的构建。
④ Video Enhancement(视频增强):对生成的 3D 世界渲染输出进行后处理,去除伪影、添加动态元素(如人物、粒子效果),同时保持像素级精确的相机控制和 3D 结构一致性。
多格式导出与生态集成
| 导出格式 | 用途 |
|---|---|
| Gaussian Splats | 最高保真度,用于实时渲染、VR/AR |
| Collider Mesh | 低精度碰撞网格,用于物理引擎仿真 |
| High-Quality Mesh | 高精度三角网格,用于 CG 生产管线 |
| Video | 固定路径视频导出,用于内容创作 |
持久世界 vs. 视频流:设计哲学的差异
与本文 §5.1 Lyra 2.0 的视频流路线不同,Marble 追求的是空间中持久存在的 3D 世界:用户可以自由导航、探索任意角度,世界不会因为”走远了”而消失。这种”持久性(Persistency)”设计原则,使 Marble 更接近传统游戏引擎的能力边界,而非视频生成模型。
3. 核心结果/发现
具身智能 × 评测基础设施:与光轮智能的战略合作(2026 年 1 月)
2026 年 1 月,World Labs 与国内仿真合成数据公司光轮智能联手,目标是系统性解决具身智能的规模化评测难题。行业三大困境被明确点名:
- 学术级基准已跟不上模型进化速度(对应 §7.1 中 LIBERO/CALVIN 性能饱和现象);
- 真机测试成本高、周期长(对应 §8.5 失效感知动力学的数据瓶颈);
- 传统仿真评测停留在理想化场景(对应 §9.5 展望中提到的真实世界泛化鸿沟)。
两者的分工互补,形成完整的评测驱动闭环:
flowchart LR
WL["World Labs\n(世界从哪来)\nLWM 生成多样化 3D 虚拟环境\n作为机器人策略测试场"] --> Eval
GR["光轮智能\n(进步如何被衡量)\n可扩展评测框架\n多维度、自动化基准"] --> Eval
Eval["具身智能评测基础设施\n可规模化 · 自动化 · 接近真实"] --> Robot["机器人 VLA 策略\n持续迭代优化"]
Robot --> WL
商业规模与行业认可
| 指标 | 数据 |
|---|---|
| Marble 发布时间 | 2025 年 11 月 |
| 2026 年 2 月融资 | $10 亿美元(总融资 $12.3 亿) |
| 公司估值 | ~$50 亿(较创立时 $10 亿增长 5×) |
| 主要投资方 | NVIDIA、AMD、Autodesk 等 |
| 行业认可 | Forbes AI 50 2026 |
| 世界模型赛道融资变化 | $14 亿(2024)→ $69 亿(2025) |
4. 局限性
- 技术细节未公开:World Labs 目前尚未发表技术论文,Marble 的具体模型架构、训练数据规模和方法细节尚未披露,学术社区难以复现与跟进。
- 物理动力学有限:当前 Marble 更侧重于静态/准静态场景的高保真生成,对复杂动力学(流体、碰撞、软体形变)的仿真能力尚不明确,与 Cosmos(§4)在物理精度上的定位有所差异。
- 机器人专用验证缺失:公开应用案例主要集中在游戏、VFX、设计领域,机器人操控任务上的量化评测尚未公开。
- 实时交互延迟:复杂场景下 3DGS 渲染的计算开销仍是规模化部署的瓶颈,尤其在低端设备上。
5.11 SANA-WM (2026)
———Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
📄 Paper: arXiv:2605.15178
🔗 项目主页: nvlabs.github.io/Sana/WM
精华
SANA-WM 最值得借鉴的核心思想是以效率为第一设计目标的世界模型:用 2.6B 参数、64 块 H100、15 天训练,在单 GPU 上生成分钟级 720p 视频,达到与 14B+14B 工业级模型相当的视觉质量。具体可迁移的设计包括:(1) 混合线性-Softmax Attention(Hybrid GDN/Softmax)——以帧粒度 Gated DeltaNet 替代大多数 Softmax 层,使 KV 状态保持 $D \times D$ 常数,内存不随序列长度增长,Softmax 层仅保留 5/20 块用于长程精确回忆,巧妙平衡效率与质量;(2) 双分支相机控制(Dual-Branch Camera Control)——粗分支 UCPE 在潜帧率上捕获全局 6-DoF 轨迹结构,细分支 Plücker 在原始帧率上补偿 VAE 压缩丢失的帧内运动细节,两者协同实现高精度连续轨迹跟随;(3) 两阶段视觉精化(Two-Stage Refiner)——第一阶段生成结构正确但质量稍逊的视频,第二阶段用截断 Flow Matching 的 17B LoRA 精化器无缝修复细节,整体吞吐仍达 22 个 60s 视频/小时;(4) 鲁棒度量标注管线——用 VIPE+Pi3X+MoGe-2 从公开视频恢复度量尺度 6-DoF 姿态,无需昂贵专有数据,仅 213K 片段即完成训练。
1. 研究背景/问题
现有开源分钟级世界模型(LingBot-World 14B+14B、HY-WorldPlay 8B)普遍需要大模型参数量、海量专有数据、多 GPU 推理,对学术界和小团队门槛极高。另一种替代——用短视频生成器蒸馏长程模型——因短程教师对分钟级场景持久性和轨迹跟随的监督信号不足而效果有限。SANA-WM 的目标是:在严格效率约束下原生训练一个高保真、可相机控制的分钟级世界模型,使其在单 GPU 上可推理、在 64 块 H100 上 15 天可收敛。
2. 主要方法/创新点

整体框架:SANA-WM 由四个核心组件构成:① 混合线性 DiT 骨干(Hybrid GDN/Softmax)负责高效长程上下文建模;② 双分支相机控制(UCPE + Plücker)负责精确 6-DoF 轨迹注入;③ 第二阶段视觉精化器(LTX-2 LoRA)负责提升最终帧质量;④ 鲁棒度量标注管线(VIPE+Pi3X+MoGe-2)负责从公开视频提取高质量训练数据。
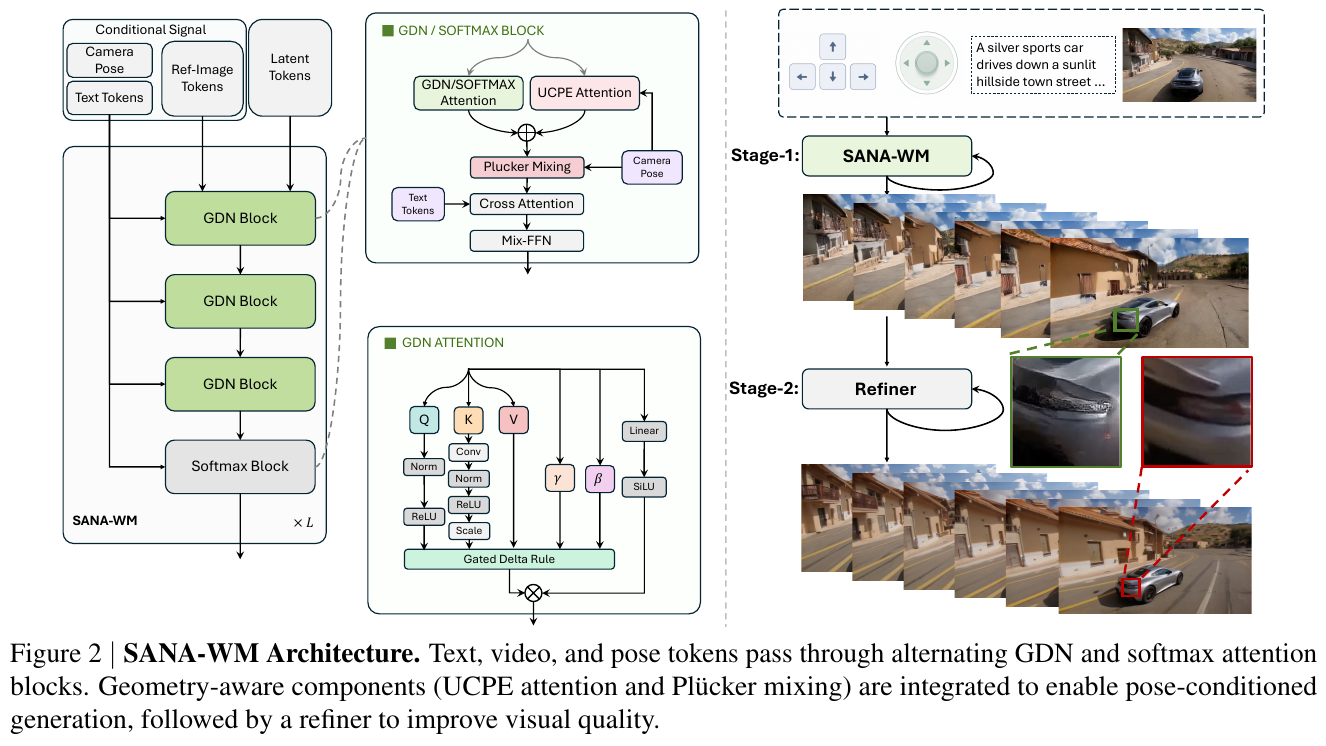
① 混合线性-Softmax Attention(Hybrid GDN/Softmax)
输入:时序潜帧序列(LTX2 VAE 编码,时间×高×宽压缩比远高于 Wan 2.1-VAE,尺寸缩小 8×)。
处理:SANA-WM 共 20 个 Transformer Block,其中 15 个为帧粒度 Gated DeltaNet(GDN)块,5 个(位于层 3/7/11/15/19)为标准 Softmax Attention 块。GDN 块的关键是将 token 级递推(每步一个 token)升级为帧级递推(每步消费一个潜帧的全部 $S$ 个空间 token),状态矩阵 $S_t \in \mathbb R^{D \times D}$ 通过衰减门 $\gamma_t$ 和 delta-rule 修正实现”遗忘旧信息、精准更新当前帧”:
\[S_t = S_{t-1} M_t + U_t, \quad M_t = \gamma_t(I - \hat K_t \beta_t \hat K_t^\top), \quad U_t = V_t \beta_t \hat K_t^\top\]为防止空间 token 数 $S$ 导致转移矩阵 $M_t$ 膨胀,对 key 施加 $1/\sqrt{DS}$ 缩放(代替 token 级的 $1/\sqrt{D}$),确保 $\lVert M_t \rVert_2 \le \gamma_t \le 1$,训练稳定不出现 NaN。Softmax 块负责精确长程回忆,在 60s 序列中引入局部注意力窗口和 attention sink,使推理时 Softmax 内存保持常数。
设计动机:60s 720p 视频展开为约 961 个潜帧;纯 Softmax 的 KV Cache 随序列长度平方增长,60s 时直接 OOM;纯线性注意力(如 SANA-Video 的累积线性注意力)缺乏衰减机制,旧特征与新特征等权累积,导致分钟级建模出现漂移。混合设计兼顾了”大多数时间步高效更新 + 关键时刻精确回忆”的需求。
② 双分支相机控制(Dual-Branch Camera Control)
粗分支(Coarse - UCPE):在潜帧率上建模全局 6-DoF 轨迹。对每个潜帧 $t$ 和空间格 $s$,由相机外参计算世界空间射线,构建射线局部坐标系变换 $D_{t,s} \in \mathbb R^{4 \times 4}$,将 QKV 的几何通道经 $D^\top / D^{-1}$ 旋转,其余通道保留 RoPE——本质是将相机位姿编码进注意力位置编码。该分支有独立 QKV 投影,但与主分支共享 GDN 门,通过零初始化投影叠加到主注意力输出上。
细分支(Fine - Plücker Mixing):弥补粗分支因 VAE 将 8 个原始帧压缩为 1 个潜帧而丢失的帧内运动细节。对每个原始帧 $r$ 和像素 $p$,计算 Plücker 射线 $\rho_{r,p} = (d_{r,p},\, o_r \times d_{r,p}) \in \mathbb R^6$,将 VAE 步内 8 帧的 Plücker 图堆叠为 48 通道张量,经零初始化 3D Patch Embedder 处理后逐块叠加至自注意力输出后。
消融验证:UCPE+Plücker 组合在 OmniWorld 验证集上 CamMC 达 0.2047,优于单独 UCPE(0.2453)和单独 Plücker(0.4742),FVD 也更低。
③ 两阶段视觉精化
第一阶段(SANA-WM 主模型)生成结构正确的 60s 视频。第二阶段精化器基于 LTX-2 17B 模型,只训练秩 384 LoRA(附于 Q/K/V/O 和 FFN),用截断-$\sigma$ Flow Matching 对第一阶段噪化潜变量进行精化(3 步 Euler,推理时与主模型完全解耦)。精化后 VBench Overall 从 79.29 提升至 80.62(Simple Trajectory),同时将晚期质量退化 $\Delta IQ$ 从 3.79 压缩至 1.17。
④ 鲁棒度量标注管线与数据
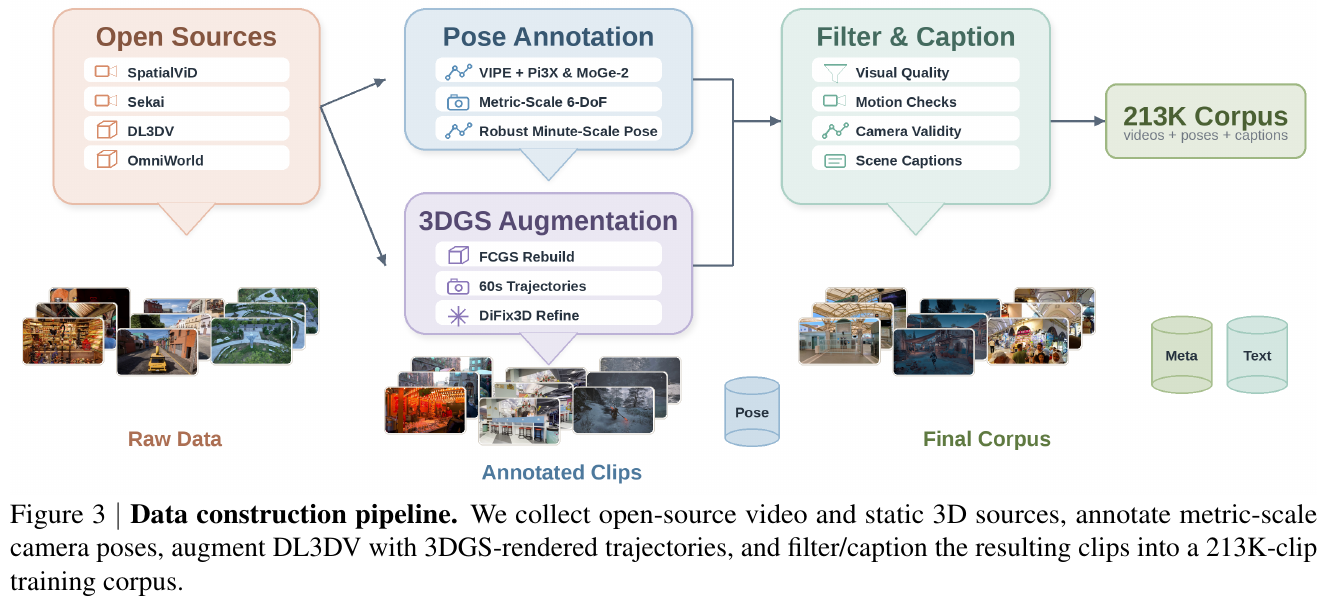
标注引擎基于 VIPE,将深度估计后端替换为 Pi3X(多帧一致结构)+ MoGe-2(度量尺度锚点),支持公开视频的鲁棒度量尺度 6-DoF 姿态提取。对 DL3DV 等静态 3D 数据集,用 FCGS 拟合 3DGS 重建后渲染多样化一分钟相机路径,再经 DiFix3D 精化减少拼接伪影,生成 14,881 条合成 60s 片段。最终语料共 212,975 条片段,涵盖室内、室外、游戏、合成场景。
渐进式训练策略(4 阶段,共约 15 天 64× H100):
| 阶段 | 目标 | 序列长度 | 训练步数 |
|---|---|---|---|
| Stage 1 | VAE 适配(LTX2 空间对齐) | 5s | 50K(VAE)+ 30K(DiT) |
| Stage 2 | 混合架构适配(GDN/Softmax) | 5s | 30K |
| Stage 3 | 分钟级扩展 + 相机控制 | 60s | 31K |
| Stage 4 | Chunk-Causal 微调 + 4步蒸馏 | 60s | 10K |
3. 核心结果/发现

相机控制精度(↓ 越低越好):SANA-WM+精化器在 60s 基准上取得最优 RotErr(4.50°/8.34°,Simple/Hard),CamMC 1.41/1.44,全面优于 LingBot-World(14B+14B,RotErr 10.47°/18.99°)、Matrix-Game 3.0(5B)和 HY-WorldPlay(8B)。
视觉质量:精化后 VBench Overall 80.62/81.89(Simple/Hard),与 LingBot-World(81.82/81.89)相当,但 LingBot-World 需要 8 块 H100(454.1 GB 显存),SANA-WM 单 GPU 仅需 74.7 GB。
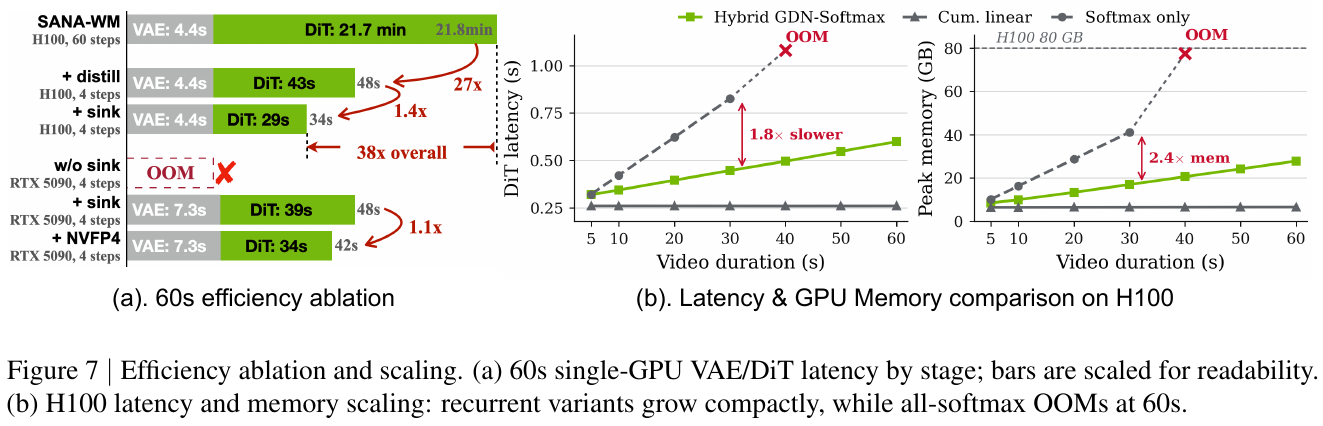
推理效率:SANA-WM 生成吞吐 24.1 视频/小时(8× H100),比最快 480p 基线 Infinite-World 快 4.1×;4步蒸馏+NVFP4 量化后,单 RTX 5090 仅需 34s 生成一条完整 60s 720p 视频(36× 高于 LingBot-World 的吞吐)。
渐进训练消融(VBench-I2V):
| 配置 | VBench Total ↑ | 峰值内存 (GB) ↓ | 推理速度 (steps/s) ↑ |
|---|---|---|---|
| SANA-Video(原始) | 0.838 | 8.90 | 0.79 |
| + LTX2 VAE | 0.839 | 5.40 | 2.69 |
| + Hybrid GDN/Softmax | 0.853 | 5.68 | 2.31 |
4. 局限性
SANA-WM 受限于规模(2.6B 参数与 213K 片段),在动态场景、罕见视角或超长序列中仍可能产生漂移,且缺乏显式 3D 场景记忆(无法像 Lyra 2.0 那样精确”重访”旧区域)。未来工作需要扩大模型与数据规模、引入机器人动作或点跟踪控制、强化持久场景记忆,以及开发鲁棒的实时或流式精化器。
5.12 Qwen-RobotWorld (2026)
———用自然语言统一具身世界模型:机械臂操作、自动驾驶、室内导航和人到机器人迁移
📄 Paper: arXiv:2606.17030
精华
把”语言指令”当成唯一的统一动作接口,不同具身领域(操作、驾驶、导航、人到机器人迁移)的视频生成任务就能被改写成同一个 $s_{t+1} = f(s_t, a_t)$ 问题,从而联合训练而不互相冲突。用冻结的 MLLM(Qwen2.5-VL)做动作编码器,比 T5/CLIP 更能利用其内部世界知识(刚体约束、关节限制)隐式约束生成的物理合理性。双流 MMDiT 通过逐层联合注意力,让语言条件与视觉隐变量在每一层都双向融合,而不是只在输入端拼接一次。Scene2Robot 用”分段拼接 + 仅对生成段计损失”的方式,在不改架构的前提下把同一个 TI2V 骨干复用成跨具身视频编辑工具。数据侧的核心是把 20+ 机器人本体、500+ 动作类别全部映射到统一的自然语言描述,这比堆数据量本身更关键。
1. 研究背景/问题
通用视频生成模型(Sora2、Veo3 等)从互联网数据学到了丰富的视觉先验,但不懂接触动力学、刚体约束等具身物理规律;而 Cosmos、LVP 等领域专用具身世界模型虽然懂物理,却依赖关节角、路径点等机器人专属动作表示,无法跨本体、跨任务泛化。Qwen-RobotWorld 希望用自然语言作为统一动作接口,把操作、驾驶、导航、人到机器人迁移这四类互补的物理知识在同一个骨干网络里联合训练,相互增强而不是各自为战。
2. 主要方法/创新点
Qwen-RobotWorld 由三部分构成:架构(双流 MMDiT + MLLM 动作编码)、数据(EWK 具身世界知识数据集)、训练(通用先验+专家能力的渐进式课程)。这三者紧密耦合:数据提供统一语言接口下的多领域监督信号,架构保证语言语义和视觉状态在每一层都能融合,训练策略则决定先学什么再学什么。

① 整体框架概述
模型核心是一个 60 层的双流 Multimodal Diffusion Transformer(MMDiT):理解流(understanding stream)处理冻结 Qwen2.5-VL 抽取的语言语义特征,代表动作 $a_t$;生成流(generation stream)处理视频 VAE 编码出的视觉隐变量,代表状态 $s_t$。两条流在每一个 block 都通过联合注意力交互,而不是只在输入层做一次拼接,这样去噪的每一步都能让视觉隐变量同时关注语义动作信号。
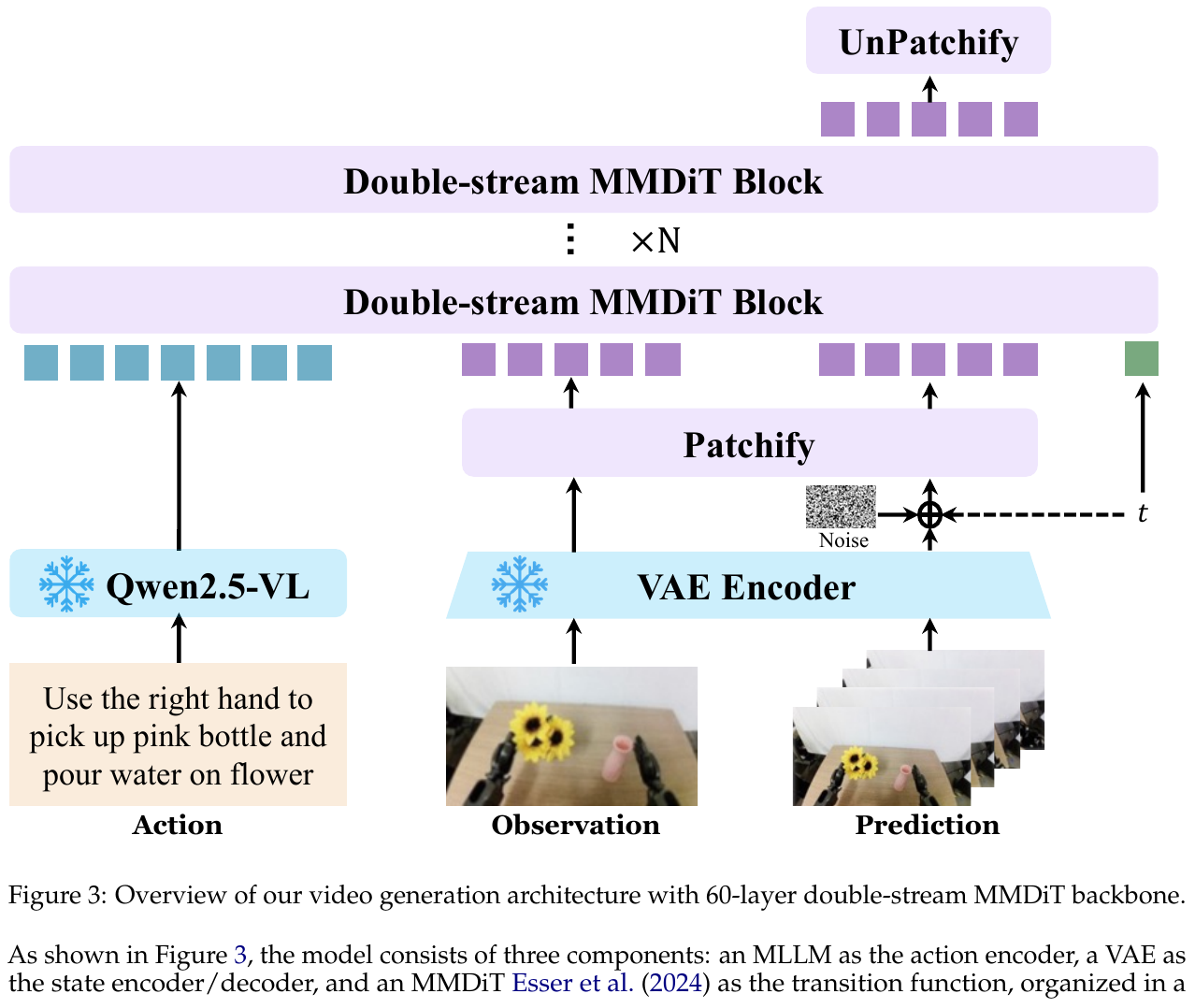
② 逐模块讲解
- MLLM 动作编码器:输入是一句自然语言指令(如”用右手拿起粉色瓶子,把水倒在花上”),通过冻结的 Qwen2.5-VL 提取末层隐藏状态 $h = \phi(S)$ 作为条件信号。用 MLLM 而非轻量编码器(T5、CLIP)的原因有两点:(1) 深层语言理解能把复杂的组合式指令精确解析为细粒度的状态转移条件;(2) MLLM 内部沉淀的世界知识(例如机械臂是刚体、有固定连杆长度和关节约束)能隐式约束生成空间中物理合理的状态转移,配合 T2I 联合训练可以防止视频帧间的物体形变,这是缺乏语义接地的模型常见的失败模式。
- VAE 状态编码/解码器:采用 Wan-VAE 架构,把视频帧编码为隐变量 $z = \mathcal{E}(x)$,并把预测的隐变量解码回视觉观测,同时支持图像和视频两种模态。
- MMDiT 转移函数:双流设计中,理解流接收经可训练 connector 投影后的 MLLM 编码,生成流接收 VAE 输出的带噪状态隐变量。骨干共 60 个双流 block,24 个注意力头(每头维度 128),隐藏维度 3072,patch size 2×2;总参数量 MLLM 7B、VAE 127M(编码器 54M+解码器 73M)、MMDiT 20B,最长支持 48,360 个视频 token。
- 3D RoPE 位置编码:时间、空间高、空间宽三个维度独立编码,采用非对称划分(pe_axes_dim = [16, 56, 56])——时间轴维度少是因为相邻帧强相关,空间轴维度多是为了捕捉更丰富的物体位置和场景布局差异;同时配合 Scalable RoPE 支持推理时泛化到不同分辨率和时长。
③ Scene2Robot:跨具身视频编辑
人到机器人迁移本质是一个视频编辑问题:模型需要同时参考场景上下文(背景、物体布局、光照)和目标机器人的运动轨迹。Scene2Robot 在不改架构的前提下,把输入组织成三个连续分段:场景条件段(人类示范视频,人手已被遮罩处理,F 帧)、机器人参考段(MuJoCo 渲染的仿真机器人执行,F 帧)、生成段(待去噪的噪声隐变量,F 帧)。前两段都被赋予时间步 $t=0$ 并排除在去噪损失之外,只有生成段参与梯度更新;3D RoPE 给每个分段分配各自的时间索引范围。每一层 MMDiT 的联合注意力让生成段同时关注场景外观、机器人运动轨迹和语言动作语义,从而合成既保留场景上下文又遵循指令操作的逼真机器人执行视频。
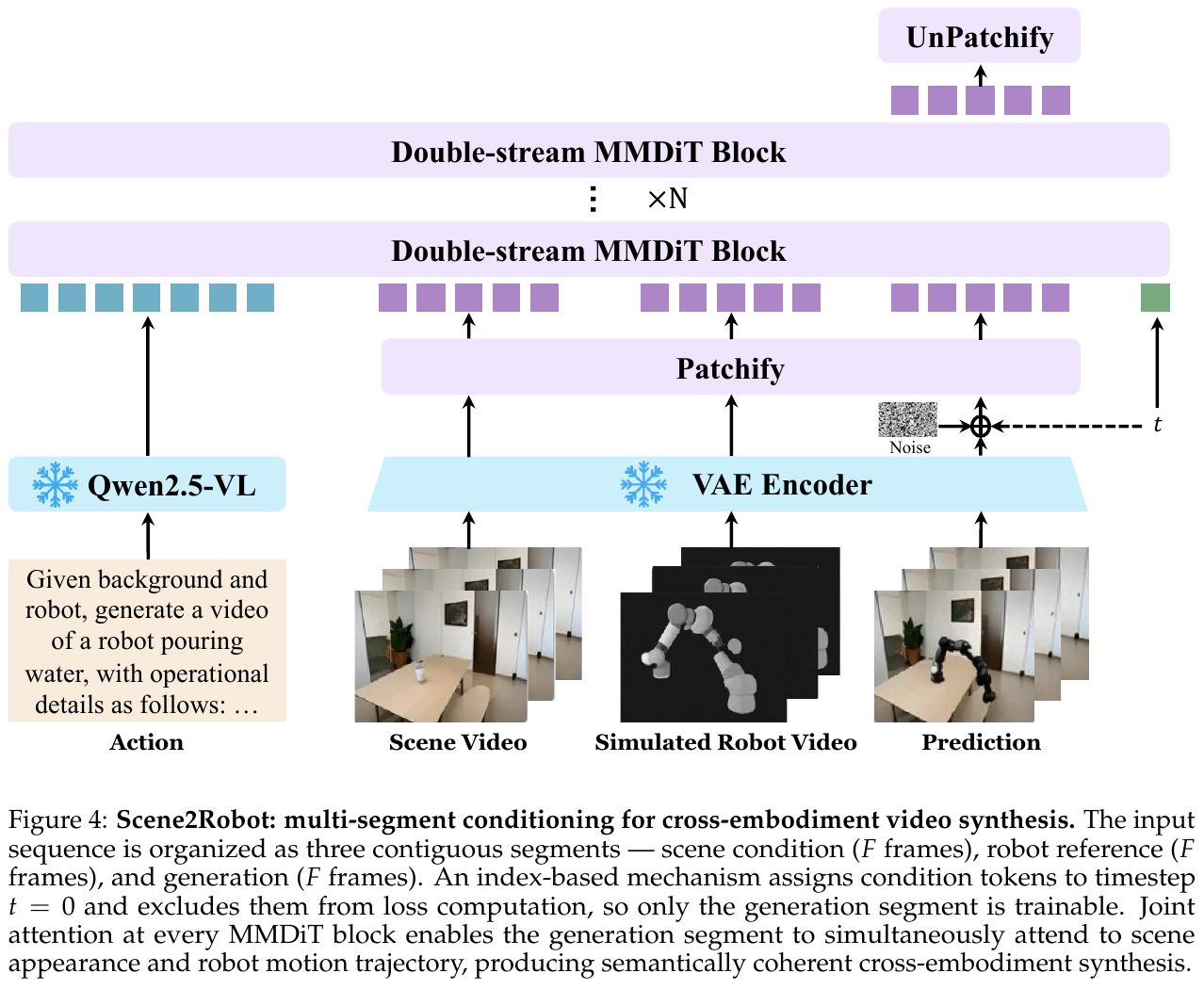
④ 数据:EWK 数据集与动作-语言映射
核心数据贡献是动作-语言映射框架:把 20+ 机器人本体类型、500+ 动作类别统一投射到自然语言空间,使 Franka 夹爪、自动驾驶车辆、室内导航 agent 的视频都变成”同一种语言条件视频生成任务”的实例。最终构成约 860 万视频-文本对、超过 2 亿观测帧的 EWK 数据集:操作领域约 590 万样本(20+ 机器人形态、1300+ 技能)为核心,自动驾驶约 20 万样本(Waymo、NVIDIA PhysicalAI-AD、Bench2Drive、Sekai),室内导航 6000+ 语言引导轨迹(VLNVerse),以及通过 MANO 重建+逆动力学渲染自动生成的人到机器人迁移数据(覆盖 14 种机器人形态)。
标注上采用五层分层标注框架:任务目标层(要发生什么状态转移)→ 动作细节层(拆解为时空轨迹、微动作、速度力度,并显式声明视角:第一人称主视角/手腕视角/外部视角/多视角拼接)→ 物理反馈层(物体位移、形变、接触状态等可视化验证的后果)→ 综合描述(50-100词)和简要描述(15-30词)两种粒度,训练时按 50%/50% 概率采样,让模型既能执行详细轨迹指令也能响应简短高层命令。
⑤ 训练目标
采用 flow matching 目标,输入视频经 VAE 编码到隐空间,噪声采样自标准正态分布;时间步采用基于视频序列长度自适应偏移的对数正态分布采样;TI2V 任务中首帧时间步固定为 0 以确保生成过程以给定观测帧为条件。训练分两阶段:预训练阶段联合训练 T2I/T2V/TI2V 任务建立通用视觉先验(T2I 锚定几何正确的物体形态,迁移到视频生成防止形变);SFT 阶段按四阶段课程逐步注入具身数据(70%具身/30%通用混合):单视角操作 → 多视角扩展 → 多视角拼接生成 → 复杂任务与跨域数据,具身部分中操作任务占约 90% 采样权重保证物理理解深度,多视角拼接和导航/驾驶各占约 5% 保证广度。
3. 核心结果/发现
在四个基准上评测:EWMBench 综合得分 4.60 排名第一(领先第二名 LVP 的 4.05 达 +0.55),其中运动保真度 HSD 达 0.566,比第二名高 33%。DreamGen Bench(GR1 机器人三个子集)总分 4.952 排名第一,物体级组合泛化能力(GR1-Object IF 0.878)最强。PBench 总分 0.804,超过所有开源模型,领域理解 0.857 排第 3,运动平滑度 0.990 在开源模型中排第 2。WorldModelBench 总分 8.99,超过所有开源模型(仅次于闭源 Wan2.6、Veo3),物理符合性(牛顿定律、质量守恒、流体动力学、重力)四项均满分。
定性结果显示该模型支持细粒度语言接地(仅改变指令中的一个关键词即可产生不同的操作视频)、跨本体泛化(同一指令驱动单臂夹爪、双臂系统、人形机器人、灵巧手等四种形态而无需专门适配)、多视角一致性,以及人到机器人迁移、自动驾驶场景合成、室内导航生成等跨域能力。在 RoboTwin-IF 零样本基准上,尽管训练时只混入了少量 RoboTwin 开源数据,仍展现出较强的零样本指令跟随和多视角一致性,优于 LVP 和 Cosmos2.5-14B 两个强基线。
4. 局限性
由于模型专为具身任务设计且输出分辨率低于通用视频生成器,PBench 上的美学质量(0.455)和成像质量(0.649)相对较低;WorldModelBench 上的常识维度(帧/时序质量)也因分辨率原因落后于通用模型。DreamGen Bench 的长时程行为泛化(GR1-Behavior IF 0.832)略逊于 LVP 和 GigaWorld,仍有提升空间。
5.13 Wan (2025) {#5-13-wan}
——阿里巴巴开源的高效视频生成基础模型家族
📄 Paper: https://arxiv.org/abs/2503.20314
精华
- 提出了 Wan2.1 视频生成模型家族,采用主流的 Diffusion Transformer (DiT) 架构,包含 1.3B 和 14B 参数两个版本,开源了全部代码 and 权重。
- 引入了创新的 Spatio-Temporal VAE (Wan-VAE),能够将视频在时空维度上压缩 4x8x8 倍,并引入 RMSNorm 和特征缓存机制以支持任意长度的长视频流式重建与低内存推理。
- 针对 DiT 训练,优化了特征调制(AdaLN)参数共享设计,不仅使模型参数量减少约 25%,还显著加快了收敛速度并提升了指令遵循能力。
- 采用 2D 上下文并行(Ulysses + Ring Attention) 和 FSDP 混合分布式并行策略,解决了超长序列(达 1M 级别 tokens)所带来的显存和计算瓶颈。
- 构建了统一的视频控制与编辑框架 VACE,通过对掩码区域和非掩码区域的“概念解耦”时空编码,实现了高质量的局部视频编辑、视频外扩等下游任务。
1. 研究背景/问题
- 现有的视频生成模型在生成大幅度动作、高保真画面、超长视频以及复杂的文本提示词理解上仍面临巨大挑战。
- 同时,大模型的高显存消耗和计算复杂度使得它们难以在消费级显卡(如 RTX 4090)上运行,极大地限制了开源社区的二次开发与应用。
- 此外,时空自编码器(VAE)往往缺乏良好的时空因果性保证,且在流式长视频生成中面临内存溢出和边界不连续等缺陷。
2. 主要方法/创新点
Wan-T2V (Text-to-Video) 整体架构
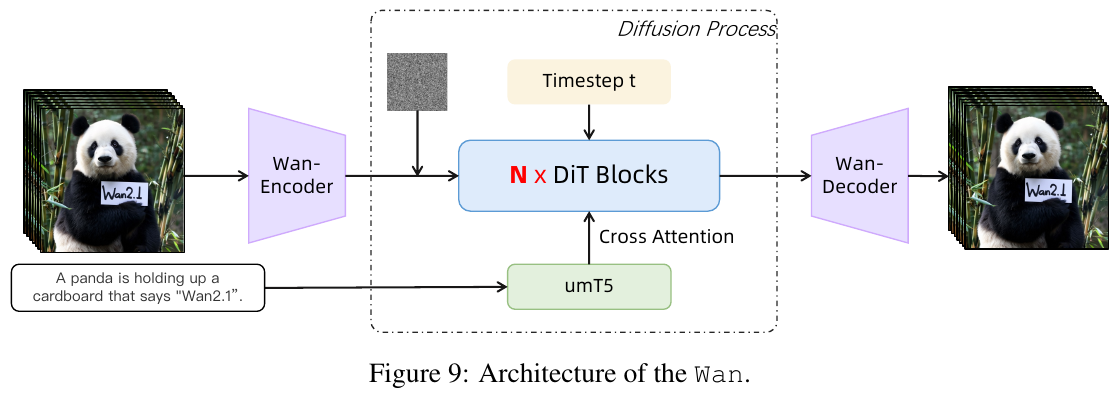
① 整体框架概述 Wan2.1 整体架构基于 Diffusion Transformer (DiT) 范式,包含三个核心模块:用于将视频/图像从像素空间压缩到低维潜空间的 Wan-VAE、执行流匹配去噪过程的 Diffusion Transformer (DiT) 以及用于文本理解的 umT5 文本编码器。
② 逐模块讲解
- Wan-VAE (Spatio-Temporal VAE):
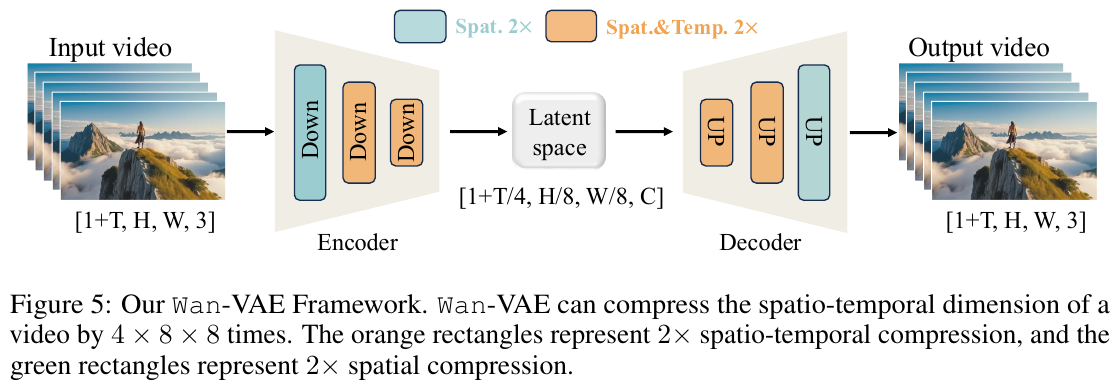
Wan-VAE 时空压缩自编码器架构图 - 输入:大小为 $(1+T) \times H \times W \times 3$ 的高维原始视频。
- 处理:采用 3D 因果卷积结构,其中第一帧仅进行空间压缩(以保留图像先验),其余帧进行时空联合压缩。模型将所有 GroupNorm 替换为 RMSNorm 以保持严格的临时因果性,并支持特征缓存机制(Feature Cache Mechanism)。在空间上采样层中,将输入特征通道减半,以降低 33% 的推理显存。
- 输出:时空维度压缩了 $4 \times 8 \times 8$ 倍、通道数为 16 的低维潜空间表征 $x \in \mathbb{R}^{(1+T/4) \times H/8 \times W/8 \times 16}$。
- 特征缓存推理:在处理超长视频时,将视频按 Latent 帧拆分为 Chunks(每块最多 4 帧),在块与块之间传递和复用前一阶段的最后两帧特征缓存,确保在受限的显存内实现连续、无缝的流式重建。
- umT5 文本编码器:
- 输入:用户输入的自然语言提示词(支持中英双语以及复杂的排版描述)。
- 处理:利用双向注意力机制编码,相比于单向注意力 LLM 更加注重全局语义表示 and 空间排版。
- 输出:长度为 512 的语义 Token 序列 $ctxt \in \mathbb{R}^{512 \times D_{text}}$。
- Diffusion Transformer (DiT):
- 输入:经由 3D 卷积(Patchify,核大小为 $(1, 2, 2)$,步长为 $(1, 2, 2)$)打块并展平后的潜空间序列 $x_{flat} \in \mathbb{R}^{B \times L \times D}$,以及文本 Token 和时间步 $t$。
- 处理:由 $N$ 层堆叠的 Wan Transformer Block 构成。
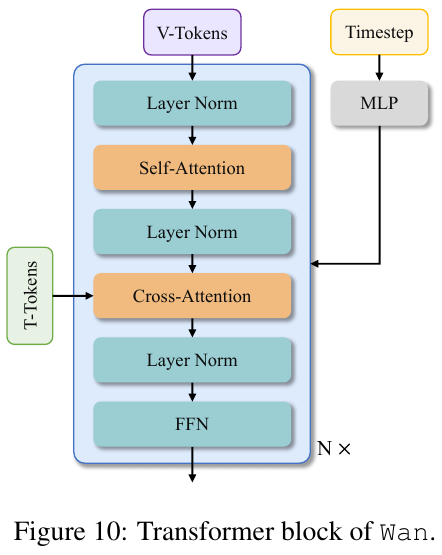
Wan Transformer Block 结构细节 在 Block 内部,通过自注意力(Self-Attention)机制捕获时空关系,通过交叉注意力(Cross-Attention)将文本 Token 注入到图像 Token 中。时间步 $t$ 编码经由一个全局共享的 MLP (Linear + SiLU) 映射为调制参数,以调节各 LayerNorm 的尺度与偏置。
- 输出:预测的去噪速度向量 $v_t$。
③ 端到端数据流 训练时,原始视频经 Wan-VAE 编码为 Latent 状态,与高斯噪声进行 Flow Matching(流匹配)线性插值得到 $x_t$,通过 Patchify 模块转换为 1D Token 序列;同时文本经 umT5 编码为文本 Embedding。在 DiT Blocks 中,文本与时空 Token 通过 Cross-Attention 进行交互。最后,利用预测的 Velocity $v_t$ 引导 ODE 求解去噪,生成的 Latent 再由 Wan-VAE Decoder 恢复出清晰的视频画面。
④ 训练目标 / 损失函数 基于 Rectified Flows (RFs) 框架,中间潜空间 $x_t$ 通过对干净视频潜特征 $x_1$ 和高斯噪声 $x_0 \sim \mathcal{N}(0, I)$ 实施线性插值获得: \(x_t = tx_1 + (1-t)x_0\) 真值变化速率为 $v_t = x_1 - x_0$。模型学习参数 $\theta$ 以拟合这个变化率 $u(x_t, ctxt, t; \theta)$,损失函数采用均方误差 (MSE): \(\mathcal{L} = \mathbb{E}_{x_0, x_1, ctxt, t} \left[ \lVert u(x_t, ctxt, t; \theta) - v_t \rVert^2 \right]\)
Wan-I2V (Image-to-Video) 架构与控制框架
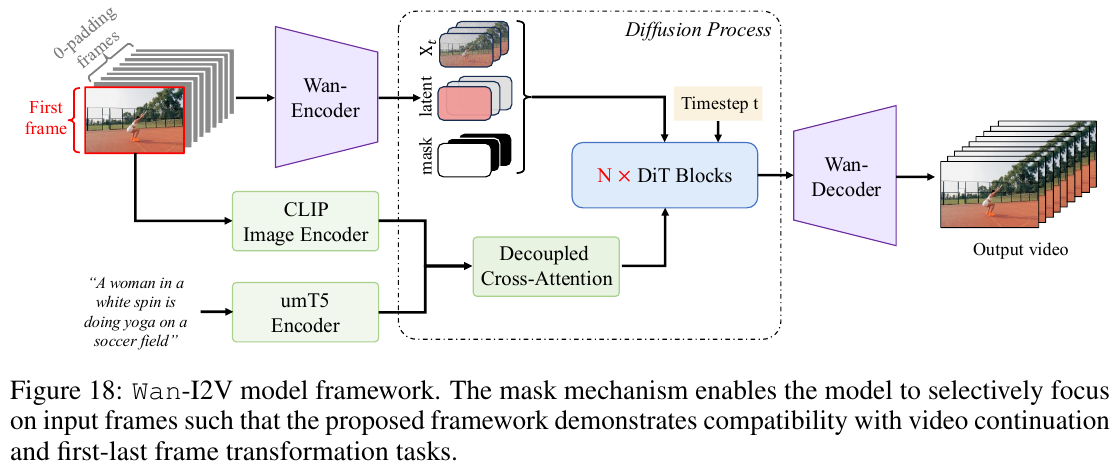
① 整体框架概述 为了兼容图片生成视频(I2V)、视频续写(Video Continuation)以及首尾帧过渡(First-Last Frame Transition)等多种下游任务,Wan 引入了掩码(Mask)机制和双编码器联合调节策略。
② 模块与数据流详解
- 双图像编码器:同时输入第一帧像素,一方面经由 Wan-Encoder 编码为 Latent,作为与噪声等维度的掩码提示,并和掩码矩阵 $M$ 一起与嘈杂的潜空间特征 $x_t$ 进行 Channel-wise Concatenation(通道级拼接)作为 DiT 的主轴输入;另一方面,通过 CLIP Image Encoder 提取全局语义特征,在 DiT 的 Decoupled Cross-Attention(解耦交叉注意力) 中与 umT5 文本 Embedding 一起分别与时空特征进行交互,提供高保真视觉细节与空间语义。
- 掩码通道设计:对第一帧画面(或已知参考帧)赋予值为 0 的掩码(代表需要被重建的区域),对其余生成帧赋予值为 1 的掩码(代表生成区域)。该设计使用户能自由指定参考帧的空间与时间排布。
VACE:统一的可控生成与编辑框架
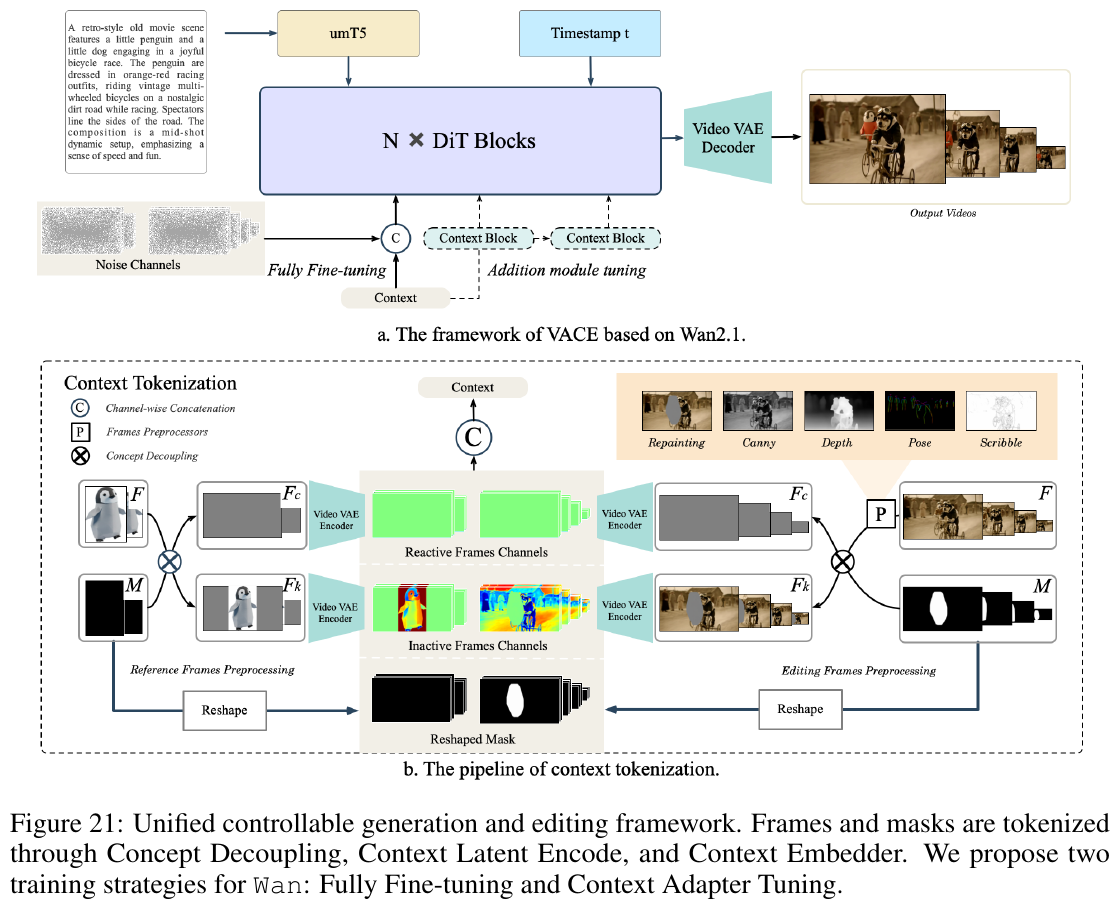
① 整体框架概述 VACE (Video Condition Unit) 旨在将局部重绘(Repainting)、Canny 边缘提取、深度估计(Depth)、姿态引导(Pose)以及线稿引导(Scribble)等多种编辑和生成条件统一到同一种输入范式中。
② 数据流与概念解耦 (Concept Decoupling) 详解
- 概念解耦策略:为保证在各种不同控制任务下模型能够平稳收敛,VACE 将输入视频 $F$ 和掩码 $M$ 解耦为两个相同尺寸的序列:活性帧 $F_c = F \times M$(包含所有需要被修改的像素)与 惰性帧 $F_k = F \times (1-M)$(保留所有需要保持原样的像素)。
- 编码与注入:$F_c$ 和 $F_k$ 分别通过同一个冻结的 Wan-VAE Encoder 映射到潜空间,并在通道维度与噪声拼接后输入到 DiT 中。VACE 提供两种训练模式:Fully Fine-tuning(全参数微调)以及 Context Adapter Tuning(通过外挂的 Context Block 以残差形式集成到原 DiT block 中,支持无损基础权重插拔)。
3. 核心结果/发现
- 性能优异:14B 模型在大规模图像与视频数据集上训练,在各项内部和外部基准测试中超越了当时的主流开源模型(如 CogVideoX、Hunyuan Video 等)及闭源商业模型。
- 高压缩比与高质量:Wan-VAE 的时空压缩比达到 $4 \times 8 \times 8$,潜表征维度为 16 维。在 720p 分辨率及 25 帧的视频重建测试中,重建质量(PSNR)与 Hunyuan Video 相当甚至更好,同时重建速度快了 2.5 倍。
- 极低的计算硬件门槛:1.3B 模型专门为消费级 GPU(如 RTX 4090)设计,开启 int8 甚至 TensorRT 量化后,推理时仅需 8.19 GB 显存,却在 T2V 任务上能产生媲美更大模型的流畅度和一致性。
- 首创双语字符生成:在视频中实现了中英双语的高清、正确字符排版生成能力(如生成包含 “Wan2.1” 和中文牌匾的视频)。
4. 局限性
- 模型在处理极其复杂的极速物理交互(如破碎、流体变化等细微碰撞细节)时,依然会出现一定程度的幻觉或时空扭曲。
- 尽管 1.3B 模型实现了消费级显卡部署,但 14B 参数模型在单卡推理时仍具有较高的计算延迟,在大规模生产部署中仍然需要多卡 Context Parallel 协同。
6. 基础模型
世界模型的强大离不开底层生成式基础模型的支持。根据功能定位,可分为三大类别:
6.1 图像/视频生成模型
作为世界模型的”想象引擎”,建模文本、图像或动作条件下的未来视频演变,参数规模从 0.6B 到 2B 不等。
| 模型 | 参数量 | 代表应用 |
|---|---|---|
| iVideoGPT | 0.6B | VLA-RFT, VLA-Reasoner |
| NOVA | 0.6B | WMPO |
| OpenSora | 0.7B | WMPO |
| InstructPix2Pix | 1B | SuSIE, GR-MG |
| WAN2.1 | 1.3B | WristWorld, DreamGen |
| DynamiCrafter | 1.4B | MinD |
| Stable Video Diffusion | 1.5B | Ctrl-World, MoWM, HMA, VPP |
| Cosmos-Predict2 | 2B | AdaPower, Prophet |
| SANA-WM | 2.6B | 分钟级 720p 世界生成、具身仿真 |
6.2 统一理解与生成模型
在单一框架中整合感知与生成,原生支持图像生成,同时具备指令理解和视觉生成规划能力,为多模态任务提供端到端建模。
| 模型 | 参数量 | 代表应用 |
|---|---|---|
| Show-o | 1.3B | UP-VLA |
| VILA-U | 7B | CoT-VLA |
| Chameleon | 7B | WorldVLA, RynnVLA-002 |
| MMaDA | 8B | dVLA |
| Emu3 | 8.5B | FlowVLA, UniVLA, UD-VLA |
6.3 表示学习模型
将感觉输入编码为紧凑、可迁移的状态表示,而非直接生成像素。通过提取本质结构与时序特征,显著提升样本效率和鲁棒性。
| 模型 | 参数量 | 代表应用 |
|---|---|---|
| V-JEPA 2 | 1B | NORA-1.5, MoWM, SRPO |
V-JEPA 2 是目前最具代表性的具身表示学习基础模型,其自监督视频表示学习框架为预测性规划提供了高效的状态空间,被多个 SOTA 方法广泛采用。
7. 评测基准与指标
7.1 评测基准
具身智能世界模型的评测基准分为仿真环境和真实世界数据集两类。
仿真环境基准
| 基准 | 领域 | 长航程 | 平台 | 轨迹数 | 任务数 |
|---|---|---|---|---|---|
| LIBERO | 桌面 | ✓ | Franka Panda | 6.5k | 130 |
| CALVIN | 桌面 | ✓ | Franka Panda | 24k | 34 |
| RLBench | 桌面 | ✓ | Franka Panda | 1.8k | 100 |
| ManiSkill 2 | 室内 | ✗ | Franka Panda | 30k+ | 20 |
| Meta-World | 桌面 | ✗ | Sawyer | 25k | 50 |
| RoboCasa | 室内 | ✓ | Franka Panda(移动) | 100k+ | 100 |
| SimplerEnv | 室内 | ✓ | Google Robot, Widow X | — | 8 |
真实世界数据集
| 数据集 | 领域 | 长航程 | 轨迹数 | 任务数 |
|---|---|---|---|---|
| BridgeData | 桌面 | ✗ | 60k | 13 |
| Droid | 室内 | ✓ | 76k | 86 |
| RT-1 | 室内 | ✓ | 130k | 744 |
| OXE | 混合 | ✓ | 1M+ | 160k+ |
性能趋于饱和:当前方法在 LIBERO 和 CALVIN ABC→D 上已接近饱和。SRPO(Online)在 LIBERO 达到 99.2% 平均成功率,DreamVLA 在 CALVIN 达到 4.44 平均序列长度。这表明现有仿真环境已不足以充分验证真实世界具身智能的复杂性。
7.2 基准性能对比
LIBERO 基准(成功率 %,越高越好)
| 方法 | Spatial | Object | Goal | Long | Avg. |
|---|---|---|---|---|---|
| World-Env | 87.6 | 86.6 | 86.4 | 57.8 | 79.6 |
| VLA-Reasoner | 91.2 | 90.6 | 82.4 | 59.8 | 81.0 |
| CoT-VLA | 87.5 | 91.6 | 87.6 | 69.0 | 81.1 |
| WorldVLA | 87.6 | 96.2 | 83.4 | 60.0 | 81.8 |
| TriVLA | 91.2 | 93.8 | 89.8 | 73.2 | 87.0 |
| FlowVLA | 93.2 | 95.0 | 91.6 | 72.6 | 88.1 |
| VLA-RFT | 94.4 | 94.4 | 95.4 | 80.2 | 91.2 |
| SRPO(离线) | 92.5 | 96.8 | 92.0 | 88.7 | 92.5 |
| DreamVLA | 97.5 | 94.0 | 89.5 | 85.2 | 92.6 |
| UD-VLA | 94.1 | 95.7 | 91.2 | 89.6 | 92.7 |
| UniVLA | 95.4 | 98.8 | 93.6 | 94.0 | 95.5 |
| dVLA | 97.4 | 97.9 | 98.2 | 92.2 | 96.4 |
| RynnVLA-002 | 99.0 | 99.8 | 96.4 | 94.4 | 97.4 |
| SRPO(在线) | 98.8 | 100.0 | 99.4 | 98.6 | 99.2 |
CALVIN ABC→D 基准(连续完成任务成功率 %,Avg. Len. 越高越好)
| 方法 | 1 | 2 | 3 | 4 | 5 | Avg. Len.↑ |
|---|---|---|---|---|---|---|
| GR-1 | 85.4 | 71.2 | 59.6 | 49.7 | 40.1 | 3.06 |
| GR-MG | 96.8 | 89.3 | 81.5 | 72.7 | 64.4 | 4.04 |
| UP-VLA | 92.8 | 86.5 | 81.5 | 76.9 | 69.9 | 4.08 |
| MoWM | 94.3 | 87.3 | 81.2 | 75.0 | 67.5 | 4.10 |
| Seer | 96.3 | 91.6 | 86.1 | 80.3 | 74.0 | 4.28 |
| VPP | 95.7 | 91.2 | 86.3 | 81.0 | 75.0 | 4.29 |
| TriVLA | 96.8 | 92.4 | 86.8 | 83.2 | 81.8 | 4.37 |
| UniVLA | 98.9 | 94.8 | 89.0 | 82.8 | 75.1 | 4.41 |
| DreamVLA | 98.2 | 94.6 | 89.5 | 83.4 | 78.1 | 4.44 |
7.3 评估指标体系
视频生成质量指标
| 指标 | 缩写 | 趋势 | 描述 |
|---|---|---|---|
| 均方误差 | MSE | ↓低 | 计算均方像素误差评估重建保真度 |
| 峰值信噪比 | PSNR | ↑高 | 峰值信号与噪声的对数比 |
| 结构相似性 | SSIM | ↑高 | 亮度、对比度和结构的感知相似性 |
| 感知图像块相似度 | LPIPS | ↓低 | 深度特征距离评估感知相似性 |
| Fréchet 起始距离 | FID | ↓低 | 衡量图像分布间的 Fréchet 距离 |
| Fréchet 视频距离 | FVD | ↓低 | 衡量视频分布间的 Fréchet 距离 |
光流精度与机器人任务指标
| 指标 | 缩写 | 趋势 | 描述 |
|---|---|---|---|
| 平均距离误差 | ADE | ↓低 | 所有查询点的平均像素距离误差 |
| 小于 Delta 比率 | LTDR | ↑高 | 距离阈值内的点的百分比 |
| 端点误差 | EPE | ↓低 | 光流端点误差幅度 |
| 成功率 | SR | ↑高 | 达成目标的试验百分比 |
| 平均任务进度 | ATP | ↑高 | 子任务完成的平均进度(长航程任务) |
专项综合基准
| 基准 | 主要评估维度 | 代表方法 |
|---|---|---|
| VBench | 时序质量、帧级质量、语义、风格、整体一致性 | Vidar |
| EWMBench | 场景、运动和语义质量(物理场景仿真) | Genie Envisioner |
| DreamGen Bench | 指令遵循与物理对齐(可控视频生成) | DreamGen, GigaWorld-0 |
| PAI-Bench (PBench) | 质量分和领域分(文本到世界生成) | GigaWorld-0 |
| 进度奖励基准 (PRBench) | 进度对齐(SC/Mono)和目标判别(MMD/JS/SMD) | SRPO |
8. 未来研究方向
尽管取得了显著进展,要实现可泛化的物理接地世界模型仍面临多项关键挑战:
8.1 物理一致性
当前模型在处理复杂物理场景时仍会产生幻觉和累积误差。需要将显式物理约束和长程因果推理整合到模型中。具体方向包括可微物理先验(将物理方程嵌入可微渲染管线)、因果学习(建模干预与结果的因果关系)以及反事实推理(评估”如果采取不同动作会发生什么”)。
8.2 时空 (4D) 感知
现有方法大多基于 2D 中心的控制范式,难以捕捉 3D 环境的精细几何变换。研究应聚焦于将控制信号与底层 3D 环境演变相互交织,探索动态高斯泼溅(Dynamic Gaussian Splatting)处理动态物体、持久点跟踪(Persistent Point Tracking)维持跨帧物体标识,以及神经占据场(Neural Occupancy Fields)表征 3D 空间结构。
工业界,李飞飞创立的 World Labs 正以大型世界模型(LWM)为核心推进这一方向,将 3D 高斯泼溅(3DGS)作为持久 3D 世界的主要表示形式,其 Marble 模型(§5.10)是该方向首个大规模商业落地——从单张图片生成可自由探索、可交互编辑的完整 3D 世界。这一路线将世界模型的目标从”预测下一帧”提升到”生成完整的可交互三维宇宙”,代表了具身世界模型的长期演进方向。
8.3 安全性与可靠性
作为高保真仿真器,世界模型需在物理动作发生前预判潜在危险,同时提供可解释的推理过程。关键方向包括几何约束整合、不确定性量化(Uncertainty Quantification)和可解释性框架建设,确保系统在安全关键的机器人应用场景中可信赖。
8.4 长航程前瞻
在复杂多阶段任务中,模型需在扩展的推理过程中持续维持对物体属性、空间关系和任务目标的正确理解。潜在方案包括层次化时序抽象(分层建模不同时间尺度的动力学)、子目标分解(将长航程任务分解为可验证的子目标序列)和记忆增强机制(在长时间窗口内保持关键状态信息)。
8.5 失效感知动力学
现有方法主要从成功演示中学习,导致对成功分布的过拟合,在面对失败情形时泛化能力不足。需要引入对比学习(区分成功与失败轨迹)、次优数据离线学习(从不完美数据中提取有用信息)和错误引导轨迹合成(主动生成包含错误模式的训练数据)来增强模型的失效感知能力。
9. 总结
9.1 核心进展回顾
本文系统梳理了 2023 年至 2026 年具身智能世界模型的快速演进,从初期的孤立方案演变为一整套完整的理论、工程、评测生态。
技术范式的演进与融合
第 3 章回顾:四大范式形成了世界模型与 VLA 集成的完整技术谱系:
-
世界规划器(World Planner):通过前向动力学模型为 VLA 提供显式图像或隐式潜向量的前瞻信号,实现”预测先于行动”的决策模式。显式路径(UniPi、SuSIE)与隐式路径(V-JEPA 2、PIVOT-R)的分化反映了高保真视觉 vs. 抽象表示的不同取舍。
-
世界动作模型(World Action Model):将观测与动作联合建模,统一在同一生成网络中。从自回归视频预训练(GR-1 / GR-2)演进到前瞻推理(Seer / F1)和推理增强(CoT-VLA / DreamVLA),再到扩散范式(DUST / FLARE),体现了如何将视频生成与动作解码深度耦合。
-
世界合成器(World Synthesizer):构建数据飞轮的关键创新。从带动作标注的 Genie Envisioner / Ctrl-World,到无动作路径的 DreamGen / GigaWorld-0,突破了真实机器人数据的长尾稀缺性,使合成数据成为规模化 VLA 训练的可靠来源。
-
世界模拟器(World Simulator):将世界模型转化为虚拟 RL 训练环境,配合外部奖励评估器。从任务验证(WorldGym)到 RL 优化(VLA-RFT / NORA-1.5),再到测试时适应(VLA-Reasoner / AdaPower),体现了”想象空间训练 → 真实部署迁移”的完整闭环。
这四大范式并非严格分割,而是高度互补且不断融合。例如,Cosmos-Predict2.5 既可作为规划器提供前瞻信号,也可作为合成器生成训练数据,还可用于仿真评估。
大规模基础模型平台的出现
第 4 章重点:Cosmos 代表了从点式研究到平台化生态的转变——不仅提出创新方法,更重要的是系统化的训练、评测和部署基础设施。
- Cosmos Video Curator 的七阶段数据策展流水线处理超 2 亿条原始视频,建立了工业级数据质量标准,打破了”好数据难获取”的桎梏。
- 三条产品线(Predict / Transfer / Reason)分别覆盖未来预测、结构化翻译(Sim2Real)和物理推理,形成了端到端的技术闭环——单个方案不能解决的问题,通过产品线组合可以有效应对。
- 预训练 + SFT + 模型融合 + RL 的四阶段训练范式展示了如何在通用基础上逐步增强专域能力,并通过 RL 进一步优化对齐——这为后续工作提供了可复现、可扩展的蓝图。
代表性工作的多维创新
第 5 章案例分析:不同研究在各自关键问题上的突破:
- Lyra 2.0:抗遗忘机制与自增强训练解决了长程 3D 一致性生成的空间幻觉与时间漂移。
- Genie:潜动作模型(LAM)无监督挖掘动作空间,证明了无标注视频学习的可行性,为机器人领域提供了巨大的数据源。
- VLA-World:反思推理机制(Think with Generated Future)体现了想象能力与评估能力的结合,提升了自动驾驶安全性。
- WorldVLA:统一架构中的注意力掩码策略展示了如何缓解自回归误差累积。
- WoVR:协同演化策略(PACE)与关键帧初始化回放(KIR)解决了世界模型中幻觉对 RL 的干扰。
- Janus-Pro:解耦视觉编码突破了理解与生成任务冲突的瓶颈,验证了从 1.5B 到 7B 的可扩展性。
- Marble(World Labs):以大型世界模型(LWM)路线推进空间智能,将 3DGS 作为持久 3D 世界的核心表示,首次在商业产品中实现从多模态输入到可探索 3D 世界的完整闭环。
- SANA-WM(NVIDIA,2026):以效率为第一目标,用 2.6B 参数实现分钟级 720p 世界生成,混合 GDN/Softmax 架构使内存随序列长度线性增长,单 RTX 5090 34s 即可生成 60s 视频,相机控制精度超越 LingBot-World(14B+14B)等大型基线,代表了”效率友好型世界模型”的重要研究方向。
这些工作的共同特点是有针对性地解决具体瓶颈,而非简单堆量。
评测基准的完善
第 7 章体系:从仿真基准(LIBERO / CALVIN)到多样化评测维度(视频质量 FID / FVD、光流精度、任务成功率、长航程进度)再到专项综合基准(VBench / EWMBench / PAI-Bench),形成了多层次的性能刻画体系。尤其值得注意的是,当前方法在 LIBERO 和 CALVIN 上已接近饱和(SRPO 在 LIBERO 达 99.2%,DreamVLA 在 CALVIN 达 4.44),这既反映了技术进步,也说明了仿真基准的评估天花板效应——需要更复杂的真实世界任务来进一步验证泛化能力。
9.2 未来研究的关键挑战与机遇
第 8 章延展:五大未来方向并非孤立,而是深度交织的系统化挑战:
物理一致性的多层次需求
- 微观层:确保单个物体的运动符合牛顿力学(质量、摩擦、碰撞)。
- 中观层:刻画物体间的相互作用(堆积、卡顿、碎裂)。
- 宏观层:理解场景级别的因果关系(施力导致运动,运动导致碰撞)。
当前模型在微观层表现尚可,但中宏观层仍有显著空间。关键创新方向包括可微物理先验嵌入(如微分方程求解器)、反事实推理(通过对比完成与失败轨迹学习因果结构)以及监督信号的充分利用(将显式物理约束作为正则化项)。
4D 时空感知与动态场景建模
- 当前瓶颈:大多方法基于 2D 中心的像素空间,难以精确跟踪 3D 运动轨迹。
- 技术机遇:整合动态高斯泼溅(Dynamic 3DGS)、持久点跟踪(Persistent Point Tracking)和神经占据场(Neural Occupancy Fields),建立点云级别的世界模型,既能捕捉精细的几何变化,又能保持计算高效。
安全性与可靠性的系统性考量
- 失败预测(Failure Prediction):在执行前预判危险动作。
- 不确定性量化(Uncertainty Quantification):区分模型的高置信预测 vs. 低置信预测。
- 可解释推理(Interpretable Reasoning):让系统能够说明”为什么认为这个动作会失败”。
这三个环节的打通对于机器人在安全关键领域(医疗、工业)的部署至关重要。
长航程前瞻与记忆增强
- 当前困境:自回归生成的误差积累使得超 10 步的规划效能显著下降。
- 可能方案:
- 层次化时序抽象(将任务分解为不同时间尺度的子问题);
- 显式记忆模块(维持关键状态、子目标完成度等跨步骤信息);
- 规划约束(在动作生成时加入前瞻规划约束,避免无谓的长期偏离)。
失效感知与次优数据利用
- 核心需求:真实世界充满失败演示(卡顿、打翻、碰撞),但当前方法大多仅从成功数据学习。
- 研究方向:
- 对比学习:同时学习什么导致成功,什么导致失败;
- 次优轨迹恢复(Learning from Suboptimal Trajectories):从不完美但仍有价值的数据中提取有用的动力学信息;
- 主动失败数据生成:用世界模型合成失败模式,扩充训练集中的失败多样性。
9.3 生态融合的三个关键观察
1. 从方法论到工程化
早期研究强调单个创新点(新的架构、新的损失函数、新的训练策略),而当前趋势是整合这些创新点形成可复现、可部署的完整系统。Cosmos 的成功在于它系统性地解决了:
- 数据获取与清理(Cosmos Video Curator)
- 模型预训练与后训练(多阶段、课程学习)
- 下游应用适配(LoRA / 全量微调、领域专属数据)
- 开源生态建设(Cookbook、集成示例)
这种从”论文方法” → “工业化系统”的转变是领域走向成熟的标志。
2. 从通用到专域再到通用
虽然题目强调”通用 VLA 智能体”,但现阶段的实际路线是通用基础模型 + 领域专属微调的混合:
- Cosmos-Predict2.5 在通用预训练后,针对机器人操纵、自动驾驶、人类动力学等领域分别进行 SFT;
- 模型融合(Model Soup)将多个专域模型融合回单一权重,在保留专域优势的同时维持通用性。
这体现了对”通用性”更现实的理解——不是一次性的全能系统,而是基础模型 + 快速适配的灵活架构。
3. 从想象到验证再到规划
世界模型的价值链逐步完善:
- 想象能力(Imagination):高质量的多秒视频生成;
- 验证能力(Verification):通过 Cosmos-Reason 等推理模型评估生成内容的物理合理性;
- 规划能力(Planning):基于验证结果调整策略,形成反馈闭环。
这一链路的完善使得世界模型从”任意生成器”演进为”可信的虚拟训练伙伴”。
9.4 对实践工作者的启示
对于从事具身 AI 研究的团队,本综述的关键启示包括:
-
数据为王:Cosmos 在数据策展上的投入(处理 2 亿条视频、建立多维度过滤流水线)对生成质量的贡献可能不亚于模型创新本身。重视数据质量与多样性将更高效地提升性能。
-
架构设计要”可嵌入”:优秀的世界模型设计应该既能独立工作(预测、合成),也能被嵌入更大系统(作为 VLA 的规划器、RL 的仿真器、推理模型的约束)。解耦设计的重要性不可低估。
-
评测要超越单指标:视频 FID、光流精度、任务成功率各有偏差,需要多维度、多场景、多尺度的综合评测。仿真基准的高度饱和提示了尽快建立更接近真实世界的评测框架的紧迫性。
-
RL 优化的双刃剑:强化学习后训练(如 VideoAlign 奖励 + GRPO)能显著提升生成质量,但也可能引入对奖励函数的过拟合。需要谨慎设计奖励、充分验证泛化性。
-
开源生态的外部性:Cosmos Cookbook、官方参考实现、领域适配模板等配套生态的价值往往被低估。投资于生态建设将大幅降低下游用户的集成成本。
9.5 展望
世界模型的发展正处于从技术探索向工程落地转变的关键阶段。当前的核心矛盾是:
- 评测饱和 vs. 真实泛化的鸿沟:LIBERO / CALVIN 上的饱和成绩掩盖了对真实机器人、真实环境、真实失败的有限理解。
- 生成能力 vs. 推理能力的不平衡:视频生成技术已相当成熟,但物理因果推理、安全评估等”思维”能力仍显不足。
- 通用性 vs. 专域深度的权衡:追求通用性可能牺牲特定领域的极致性能。
解决这些矛盾的路径在于:
- 建立更具挑战性的真实世界基准——不局限于仿真室内任务,拓展至室外、长期、多智能体协作场景。
- 融合符号推理与神经生成——显式物理知识图谱与隐式神经模型的混合架构。
- 投资于多模态一体化——将视觉生成、语言理解、动作规划、物理推理更深层次地交织,而非浅层模块堆砌。
- 关注失败与鲁棒性——不仅学习成功轨迹,更要深入理解失败模式,构建具备自我纠正能力的系统。
随着生成式 AI、具身智能、机器人技术的持续融合,基于世界模型的通用具身智能体已从理论设想演变为日益可达的工程现实。本综述希望为广大研究者提供清晰的技术地图,加速这一进程的演进。
10. 参考资料
- Tan, Z., et al. (2026). Towards Generalist Embodied AI: A Survey on World Models for VLA Agents. TechRxiv.
- Video Generation Models in Robotics: Applications, Research Challenges, Future Directions (2026). arXiv:2601.07823
- Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. arXiv:2003.08934
- Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. SIGGRAPH 2023. 项目主页
- NVIDIA. (2025). Cosmos World Foundation Model Platform for Physical AI. arXiv:2501.03575 5a. NVIDIA. (2025). Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control. arXiv:2503.14492 5b. NVIDIA. (2025). Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning. arXiv:2503.15558
- NVIDIA. (2026). Lyra 2.0: Explorable Generative 3D Worlds at Scale. arXiv:2604.13036
- Bruce, J., et al. (2024). Genie: Generative Interactive Environments. arXiv:2402.15391
- VLA-World: Learning Vision-Language-Action World Models for Autonomous Driving (2026). 项目主页
- Cen, J., et al. (2025). WorldVLA: Towards Autoregressive Action World Model. arXiv:2506.21539
- WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL (2026). arXiv:2602.13977
- Chen, X., et al. (2025). Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling. arXiv:2501.17811
- Du, Y., et al. (2023). Learning Universal Policies via Text-Guided Video Generation (UniPi). NeurIPS 2023.
- Black, K., et al. (2024). Zero-Shot Robotic Manipulation with Pre-trained Image-Editing Diffusion Models (SuSIE). ICLR 2024.
- Wu, H., et al. (2023). Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation (GR-1). ICLR 2024.
- Cheang, C., et al. (2024). GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge.
- Li, H., et al. (2024). GR-MG: Leveraging Partially-Annotated Data via Multi-Modal Goal-Conditioned Policy.
- Tian, R., et al. (2024). Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation (Seer). ICLR 2025.
- Assran, M., et al. (2025). V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. Meta AI.
- World Labs. (2025). Marble: A Multimodal World Model. worldlabs.ai/blog/marble-world-model 19a. World Labs. (2026). Generating Bigger and Better Worlds. worldlabs.ai/blog/bigger-better-worlds 19b. World Labs & 光轮智能. (2026). 具身智能进入评测驱动时代. 量子位报道
- Zhen, H., et al. (2024). 3D-VLA: A 3D Vision-Language-Action Generative World Model. ICML 2024.
- Gao, C., et al. (2024). PIVOT-R: Primitive-Driven Waypoint-Aware World Model for Robotic Manipulation.
- Hu, Y., et al. (2024). Video Prediction Policy (VPP): A Generalist Robot Policy with Predictive Visual Representations.
- Gao, X., et al. (2025). FLIP: Flow-Centric Generative Planning as General-Purpose Manipulation World Model. ICLR 2025.
- Liu, J., et al. (2025). CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models.
- Zhang, W., et al. (2025). DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge.
- Zhang, Z., et al. (2025). FlowVLA: Thinking in Flow for Vision-Language-Action Models.
- Bu, Q., et al. (2025). UniVLA: Learning to Act Anywhere with Task-centric Latent Actions.
- Bu, Q., et al. (2025). AgiBot World Colosseum: Large-Scale Manipulation Platform for Scalable and Intelligent Embodied Systems (GO-1).
- Liao, Y., et al. (2025). Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation.
- Zhao, J., et al. (2025). DreamGen: Unlocking Generalization in Robot Learning through Neural Trajectories. NVIDIA.
- GigaWorld-0: World Models as Data Engine to Empower VLA Models (2025).
- WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation (2025).
- Ctrl-World: A Controllable Generative Framework for Robotic Manipulation (2025).
- VLA-RFT: Vision-Language-Action Reinforcement Fine-tuning with Verified Rewards in World Simulators (2025).
- WMPO: World Model-based Policy Optimization for Vision-Language-Action Models (2025).
- SRPO: Scaffolded Reinforcement Policy Optimization for Robotic Manipulation (2025).
- NORA-1.5: A Small Open Vision-Language-Action Model for Embodied Tasks with Flow-Matching Action Expert (2025).
- VLA-Reasoner: Empowering Vision-Language-Action Models for Complex Tasks with Future Imagination (2025).
- AdaPower: Adaptive Test-Time Scaling for Vision-Language-Action Models (2025).
- Liu, B., et al. (2023). LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. 项目主页
- Mees, O., et al. (2022). CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks. 代码仓库
- James, S., et al. (2020). RLBench: The Robot Learning Benchmark & Learning Environment.
- Gu, J., et al. (2023). ManiSkill 2: A Unified Benchmark for Generalizable Manipulation Skills.
- Yu, T., et al. (2020). Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning.
- Nasiriany, S., et al. (2024). RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots.
- Li, X., et al. (2024). SimplerEnv: Simulated Manipulation Policy Evaluation Environments for Real Robot Setups.
- Walke, H., et al. (2023). BridgeData V2: A Dataset for Robot Learning at Scale.
- Khazatsky, A., et al. (2024). DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset.
- Brohan, A., et al. (2022). RT-1: Robotics Transformer for Real-World Control at Scale.
- Open X-Embodiment Collaboration (2023). Open X-Embodiment: Robotic Learning Datasets and RT-X Models.
- Huang, Z., et al. (2024). VBench: Comprehensive Benchmark Suite for Video Generative Models.
- Team Chameleon (Meta AI). (2024). Chameleon: Mixed-Modal Early-Fusion Foundation Models.
- Xie, J., et al. (2024). Show-o: One Single Transformer to Unify Multimodal Understanding and Generation.
- Wu, Y., et al. (2024). VILA-U: A Unified Foundation Model Integrating Visual Understanding and Generation.
- Wang, X., et al. (2024). Emu3: Next-Token Prediction is All You Need.
-
NVIDIA Cosmos 开源生态 — nvidia-cosmos;Cookbook:cosmos-cookbook;Isaac Sim:developer.nvidia.com/isaac-sim。
- Zhu, H., et al. (2026). SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer. arXiv:2605.15178
🔗 项目主页: nvlabs.github.io/Sana/WM
本文所有示意图、架构图、实验对比图均来自上述论文或对应官方项目主页,版权归原作者所有,仅用于学术交流与学习整理。