1. 引言
人工智能(Artificial Intelligence, AI)作为计算机科学皇冠上的明珠,正以前所未有的速度重塑人类社会。而在这场波澜壮阔的技术革命中,机器学习(Machine Learning, ML) 无疑是最核心的驱动引擎。传统基于规则的专家系统受限于人类先验知识的边界,而机器学习则通过让计算机从海量数据中自主”学习”规律,实现了从”授人以鱼”到”授人以渔”的范式跃迁。
从早期以支持向量机(SVM)为代表的统计学习方法,到以随机森林(Random Forest)、XGBoost 为首的集成学习霸主,再到如今席卷全球的深度神经网络(DNN)和基于大语言模型(LLM)的基础模型,机器学习的边界在算力与数据的双重加持下不断拓展。
本文旨在系统梳理机器学习研究进展,为学习和研究机器学习提供参考。
本文速览
适合读者:具备基础编程与数学(线性代数/概率论)知识、希望在一篇长文中鸟瞰机器学习全景的学生、工程师与研究者。
阅读地图:
| 章节 | 内容 | 预计耗时 |
|---|---|---|
| §2 机器学习基本概述 | 定义、四大学习范式、核心要素、发展脉络、挑战、应用与工具生态 | 10 分钟 |
| §3.1–§3.11 传统机器学习 | 线性/逻辑回归、决策树、随机森林、XGBoost、KNN、朴素贝叶斯、HMM、SVM、K-Means、PCA/t-SNE | 20 分钟 |
| §3.12–§3.15 深度学习基础 | MLP、CNN、RNN/LSTM、Transformer | 15 分钟 |
| §3.16 预训练大模型范式 | BERT vs GPT 两大路线与 RLHF/DPO 对齐 | 8 分钟 |
| §3.17–§3.20 生成式模型 | GAN、Autoencoder、VAE、Diffusion(含 DiT / Diffusion Policy / AR vs Diffusion) | 15 分钟 |
| §4 总结 | 算法适用边界与未来趋势 | 3 分钟 |
按需跳读建议:
-
只想了解 ML 是什么 → 读 §2 即可;
-
做结构化/表格数据建模 → 重点看 §3.2–§3.6(线性模型 + 树模型 + XGBoost);
-
做计算机视觉 → 重点看 §3.12、§3.13(MLP、CNN);
-
做自然语言与大模型 → 重点看 §3.15、§3.16(Transformer、BERT/GPT);
-
做图像/视频生成 → 重点看 §3.17–§3.20(GAN、VAE、Diffusion、DiT);
-
做机器人/具身智能 → 重点看 §2.2.3(强化学习)+ §3.20.2(Diffusion Policy)。
2. 机器学习基本概述
2.1 什么是机器学习?
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等。其核心思想是:让计算机通过算法解析数据、从中学习规律,并利用这些规律对真实世界中的未知事件做出预测和决策。相比于传统的硬编码规则,机器学习模型能够随着数据的增加而自动优化其性能。
2.2 学习范式与分类体系
根据训练数据是否带有标签以及模型与环境的交互方式,机器学习主要分为以下四大范式:
2.2.1 监督学习 (Supervised Learning)
监督学习是最成熟、应用最广的范式。其训练数据由输入特征 $\mathbf{x}$ 和对应的标签(Ground Truth)$y$ 组成。模型的目标是学习一个映射函数 $f: \mathbf{x} \rightarrow y$。
-
核心任务:分类(Classification,标签为离散类别)与回归(Regression,标签为连续数值)。
-
代表算法:线性回归、逻辑回归、SVM、决策树、多数深度神经网络。
2.2.2 无监督学习 (Unsupervised Learning)
无监督学习的数据没有标签,模型需要自主发掘数据内部的潜在结构、模式或分布。
-
核心任务:聚类(Clustering)、降维(Dimensionality Reduction)、异常检测(Anomaly Detection)。
-
代表算法:K-Means、PCA、自编码器(Autoencoder)、高斯混合模型(GMM)。
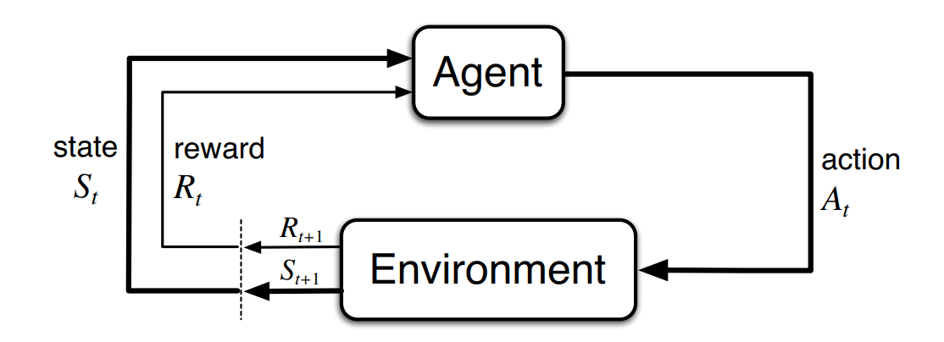
2.2.3 强化学习 (Reinforcement Learning)
强化学习侧重于智能体(Agent)如何在环境(Environment)中采取动作(Action),以最大化累积奖励(Reward)。它没有立即的标注数据,而是通过”试错”(Trial and Error)和”延迟奖励”来进行学习。
-
核心概念:状态(State)、动作(Action)、奖励(Reward)、策略(Policy)、价值函数(Value Function)。
-
代表算法:Q-Learning、DQN、PPO、SAC。
2.2.4 半监督与自监督学习 (Semi/Self-Supervised Learning)
-
半监督学习:利用少量有标签数据和大量无标签数据进行训练,降低标注成本。
-
自监督学习:一种特殊的无监督学习,通过数据本身自动构造伪标签(如预测句子中的下一个词,或图像的部分遮挡恢复),是目前预训练大语言模型(如 GPT)的核心范式。
2.3 核心要素与系统架构
一个完整的机器学习系统通常包含以下五个核心要素:
-
数据 (Data):模型的燃料,决定了学习的上限。包括特征提取与预处理。
-
特征工程 (Feature Engineering):将原始数据转化为模型可理解的特征向量,传统 ML 强依赖于此。
-
模型假设 (Hypothesis Space):决定了模型能表达的函数集合(如线性组合、决策树边界或神经网络流形)。
-
目标函数 (Objective Function):定义”好”与”坏”的度量标准,通常由损失函数(Loss Function)和正则化项(Regularization)组成。
-
优化算法 (Optimization Algorithm):求解目标函数最小化(或最大化)参数的策略,如梯度下降(Gradient Descent)、Adam 等。
2.4 发展历程
机器学习的发展经历了从符号主义、统计学习到深度学习,再到如今大模型时代的演进过程:
graph LR
A["符号主义/专家系统"] --> B["感知机与早期浅层网络"]
B --> C["支持向量机 SVM"]
C --> D["集成学习 Random Forest/GBDT"]
D --> E["CNN/RNN 深度学习"]
E --> F["AlphaGo 深度强化学习"]
F --> G["Transformer架构"]
G --> H["LLM与多模态基础模型"]
subgraph era1 ["80-90年代 专家系统与早期网络"]
A
B
end
subgraph era2 ["90-10年代 统计学习黄金时代"]
C
D
end
subgraph era3 ["2010-2020年代 深度学习爆发"]
E
F
end
subgraph era4 ["2020年代至今 大模型时代"]
G
H
end
2.5 主要挑战
尽管成果丰硕,机器学习在实际落地中仍面临诸多挑战:
-
过拟合与泛化 (Overfitting & Generalization):模型在训练集上表现优异,但在未见过的测试集上表现糟糕。
-
数据维度灾难 (Curse of Dimensionality):特征维度过高导致样本稀疏,计算复杂度呈指数级增长。
-
可解释性黑盒问题 (Interpretability):尤其是深度学习模型,往往难以解释其决策的具体逻辑,阻碍了其在医疗、金融等高风险领域的应用。
-
计算资源瓶颈:大模型时代,训练和推理成本极高,对 GPU/TPU 集群提出了严苛要求。
2.6 关键技术方向与未来展望
机器学习在方法论和应用前沿上持续演进,以下是当前最具影响力的技术方向与未来趋势:
-
表示学习 (Representation Learning):自动学习数据的有效特征表示,取代人工特征工程,是深度学习成功的关键。
-
迁移学习 (Transfer Learning):将一个领域/任务学到的知识迁移到另一个相关领域/任务,极大缓解了数据稀缺问题。
-
元学习 (Meta-Learning):也称”学会学习”,旨在让模型具备快速适应新任务的能力(如 Few-shot Learning)。
-
通用人工智能 (AGI):跨越专用 AI 边界,具备全面认知、推理和执行能力的智能体。
-
可信与对齐 AI (Trustworthy & Aligned AI):确保 AI 系统的目标与人类价值观一致,具备安全性、公平性和透明度。
-
AI for Science:利用机器学习解决物理、化学、生物(如 AlphaFold)等基础科学领域的复杂计算问题。
2.7 主流应用场景
机器学习目前已经深度渗透到数字世界与物理世界的方方面面:
2.7.1 计算机视觉 (CV)
-
核心任务:图像分类、目标检测(如 YOLO 系列)、语义分割、图像生成。
-
应用:人脸识别、医学影像分析、工业缺陷检测。
2.7.2 自然语言处理 (NLP)
-
核心任务:机器翻译、文本摘要、情感分析、对话系统。
-
应用:ChatGPT 等智能助手、智能客服、文档自动审核。
2.7.3 推荐系统与计算广告
- 互联网巨头的变现核心。通过协同过滤(Collaborative Filtering)、深度交叉网络等技术,挖掘用户历史行为与物品之间的匹配概率,实现精准推送。
2.7.4 机器人、自动驾驶与具身智能 (Embodied AI)
- 结合强化学习、视觉与大语言模型,让机器人在复杂的物理环境中实现感知、规划、导航与灵巧操作。这是当前 AI 从数字空间走向物理世界的最前沿阵地。
2.8 主流数据集、评测基准与框架
2.8.1 经典数据集与基准
| 数据集 | 领域 | 特点与历史意义 |
|---|---|---|
| ImageNet | CV (分类) | 包含千万级标注图像,其 2012 年的比赛直接引爆了深度学习革命。 |
| COCO | CV (检测分割) | 微软发布,具有丰富的多目标、多上下文的复杂场景标注。 |
| MNIST | CV (入门) | 手写数字识别集,被誉为机器学习领域的 “Hello World”。 |
| GLUE | NLP | 评估自然语言理解模型的综合基准,推动了 BERT 时代的发展。 |
2.8.2 主流工具与开源框架
-
Scikit-learn:Python 下的传统机器学习库,集成了几乎所有经典 ML 算法(SVM, RF, KNN等),API 设计极为优雅。
-
XGBoost / LightGBM:处理表格数据不可或缺的梯度提升树框架。
-
TensorFlow:Google 开源的深度学习框架,工业界部署生态完善。
-
PyTorch:Meta 开源的深度学习框架,凭借动态计算图和极佳的易用性,已成为目前学术界绝对的主流,并逐渐统治工业界大模型训练底座。
-
HuggingFace:大模型时代的开源基建,提供了海量的预训练模型权重与快捷的
transformers库调用接口。
3. 经典算法与代表性模型
本章系统梳理从传统统计学习到现代深度学习的标志性算法。
3.1 核心算法分类概览
在深入探讨具体模型之前,下表梳理了机器学习中经典的算法分类及其代表性模型:
| 类别 | 代表性模型 / 技术 | 主要特点 | 应用场景 |
|---|---|---|---|
| 线性模型 | 线性回归、逻辑回归 | 简单易懂、计算量小、可解释性强 | 房价预测、点击率预估 (CTR) |
| 集成学习 | 随机森林、XGBoost、LightGBM | 鲁棒性强、处理表格数据效果极佳 | 金融风控、搜索排序 |
| 传统统计/概率 | SVM、KNN、朴素贝叶斯、HMM | 理论严谨、适合小样本任务 | 文本分类、语音识别、生物信息 |
| 聚类与降维 | K-Means、PCA、t-SNE | 无监督、发现数据潜在结构 | 用户画像、数据压缩、可视化 |
| 深度神经网络 | CNN、RNN、LSTM、MLP | 强大的非线性拟合与特征提取能力 | 图像识别、自然语言处理 |
| 大模型基石 | Transformer、BERT、GPT | 并行能力强、捕捉长距离依赖、涌现能力 | 聊天机器人、通用人工智能 |
| 生成式模型 | GAN、VAE、Diffusion Models | 学习数据分布、生成高质量新样本 | AI 绘画、视频生成、分子设计 |
Part A · 传统机器学习(§3.2 – §3.11) —— 统计学习理论时代的黄金算法:假设明确、可解释性强,在中小规模结构化数据上至今仍是工业界主力。
3.2 线性回归与正则化
核心要点:一条直线/超平面拟合数据;L2 正则(Ridge)防过拟合、L1 正则(Lasso)自带特征选择。
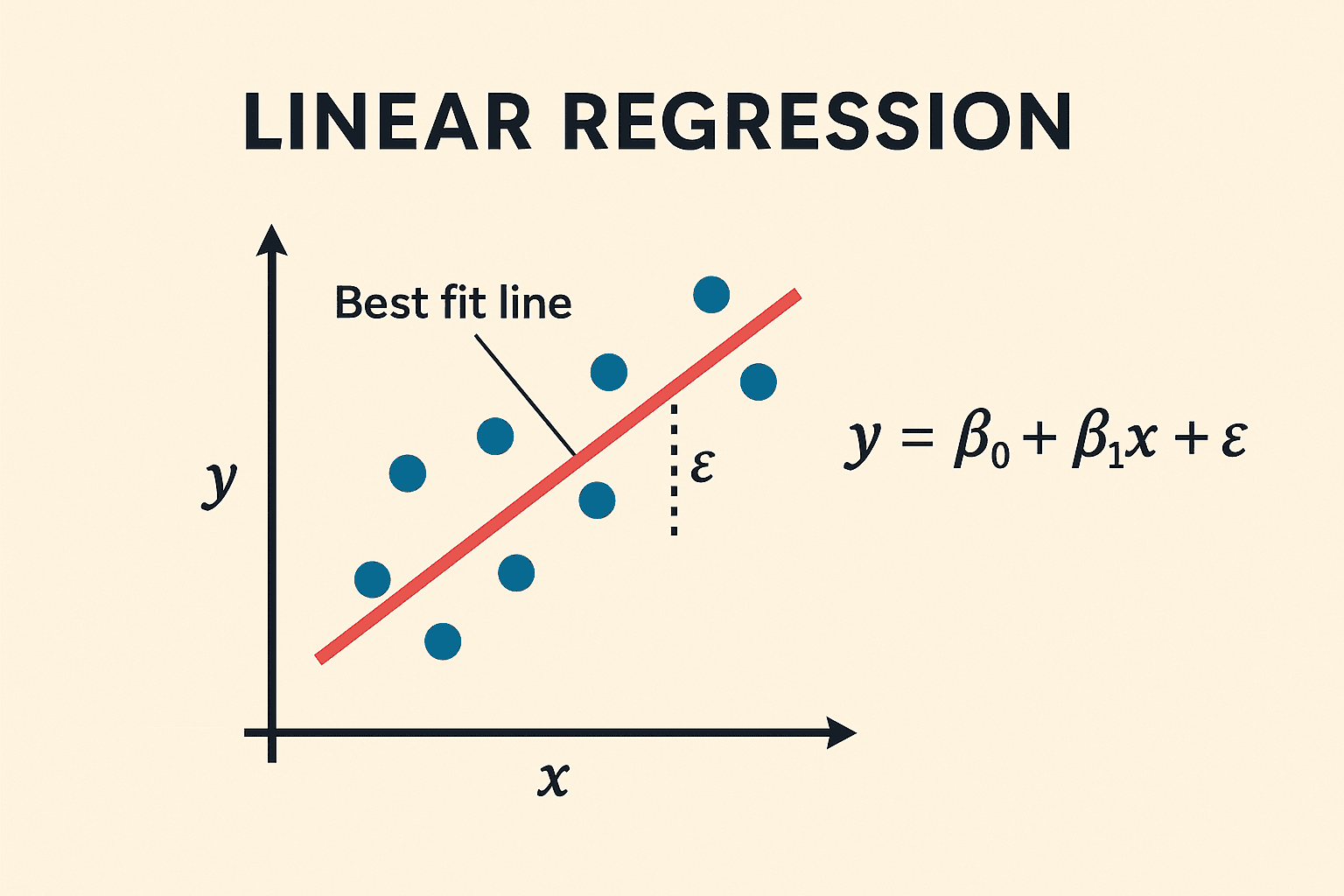
线性回归 (Linear Regression) 是回归分析中最基础的模型,假设目标变量与特征之间存在线性关系。其目标函数通常是最小化均方误差(MSE)。
直觉理解:就像在散点图上画一条”最佳拟合线”——目标是找到那根让所有点到线的距离(误差)平方和最小的直线。正则化则相当于在”拟合好”的基础上再加一条约束:别让权重长得太大。
-
数学表达式:$y = \mathbf{w}^T \mathbf{x} + b$
其中 $\mathbf{w}$ 是各特征的权重向量(权重越大说明该特征越重要),$\mathbf{x}$ 是输入特征向量,$b$ 是偏置(截距)。整个公式就是”加权求和再加个基准”。
-
优化方法:可以通过最小二乘法直接求解闭式解(正规方程),也可以使用梯度下降法进行迭代优化。
-
正则化 (Regularization):为了防止在特征维度较高时发生过拟合,常在损失函数中引入正则化惩罚项:
-
Ridge 回归(L2 正则化):增加 $\lambda |\mathbf{w}|_2^2$ 项,限制参数的平方和,使参数平滑,有效缓解多重共线性问题。
-
Lasso 回归(L1 正则化):增加 $\lambda |\mathbf{w}|_1$ 项,限制参数的绝对值和。L1 正则化的几何特性使其容易产生稀疏解(即将部分权重压缩为0),因此自带特征选择功能。
-
一句话记忆:线性回归找最佳拟合直线;L1 正则(Lasso)能把不重要特征的权重压为 0,自动做特征选择;L2 正则(Ridge)让权重保持小而平滑。
| 适合用 | 不适合用 |
|---|---|
| 特征与目标变量呈线性关系 | 特征与目标存在复杂非线性关系 |
| 需要可解释性强的模型 | 数据中有大量异常值 |
| 特征较少、样本充足 | 特征间存在强多重共线性(此时用 Ridge) |
3.3 逻辑回归 (Logistic Regression)
核心要点:线性回归 + Sigmoid,把连续输出映射为 (0,1) 概率,用于二分类(如 CTR 预估、信用评分)。
虽然名为”回归”,但逻辑回归本质上是一个二分类算法。它在线性回归的基础上,引入了非线性的 Sigmoid 激活函数,将连续的线性输出映射到 $(0, 1)$ 区间,从而赋予其概率意义。
直觉理解:逻辑回归是在线性回归外面套了一个”挤压器”——把任意实数得分挤压到 0 到 1 之间,然后把这个值直接当作”属于正类的概率”。得分越高,概率越接近 1;得分越低,概率越接近 0。
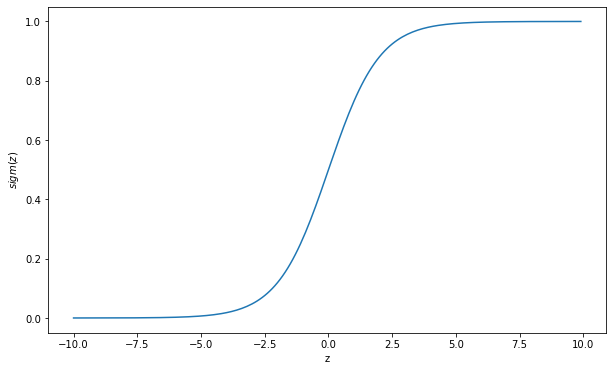
- 核心函数:
其中 $\mathbf{w}^T \mathbf{x} + b$ 是线性”原始得分”,$\sigma(\cdot)$ 是 Sigmoid 函数(那个”挤压器”)。得分为 0 时输出 0.5,得分越大越接近 1,越小越接近 0。
-
损失函数:交叉熵损失(Cross-Entropy Loss),通过最大似然估计推导而来。
-
特点:计算代价低,速度快,输出具有明确的概率解释,常用于金融风控中的信用评分卡、广告点击率(CTR)预估等基础场景。
一句话记忆:逻辑回归 = 线性模型 + Sigmoid 函数 → 二分类概率输出;简单快速,是工业界 CTR 预估和风控评分卡的基础模型。
| 适合用 | 不适合用 |
|---|---|
| 二分类任务、需要概率输出 | 特征之间存在强非线性关系 |
| 样本量大、追求训练和推理速度 | 图像、文本等非结构化数据 |
3.4 决策树 (Decision Tree)
核心要点:由一连串 if-then 规则递归划分数据,天然可解释;但单树方差大、易过拟合,需剪枝或集成。
决策树模仿人类基于规则判断的思维过程,通过树状结构对数据进行分类或回归。每个内部节点表示对某一特征的条件判断,分支代表判断结果,叶节点表示最终预测的类别或数值。
直觉理解:就像小时候玩的”猜人游戏”——”这个水果是红色的吗?→ 是 → 圆的吗?→ 是 → 苹果!”每个分叉点都问一个最能区分当前数据的问题,层层缩小范围,最终做出判断。
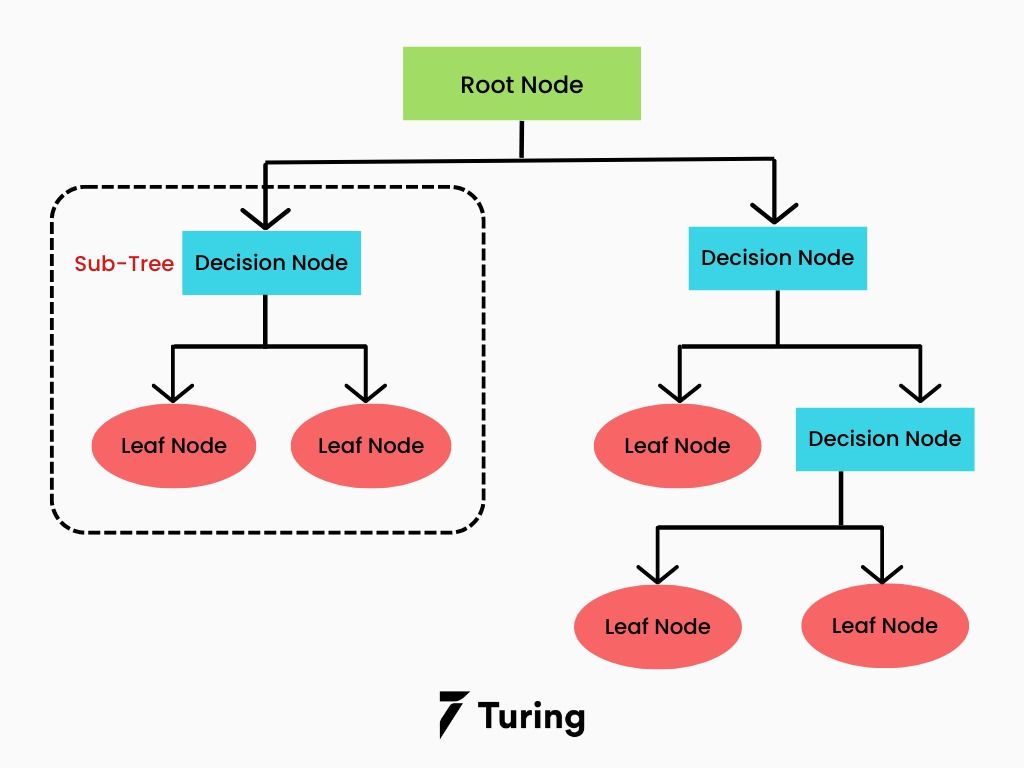
-
分裂准则:
-
ID3 算法:基于信息增益(Information Gain)选择特征,倾向于选择取值较多的特征。
-
C4.5 算法:基于信息增益率(Gain Ratio)进行改进,克服了 ID3 的缺陷。
-
CART 算法:分类树使用基尼指数(Gini Impurity),回归树使用平方误差。CART 是一棵二叉树,是许多集成树模型的基础。
-
-
优缺点:可解释性极强,不需要进行数据标准化,能处理缺失值;但极易产生过拟合,通常需要通过剪枝(Pruning)来控制树的复杂度。
一句话记忆:决策树 = 递归地问最优问题划分数据;可解释性极强,但单棵树容易过拟合,通常配合随机森林或 XGBoost 使用。
| 适合用 | 不适合用 |
|---|---|
| 需要模型可解释(金融审批、医疗决策) | 数据量大时单树过拟合严重 |
| 存在类别型特征,无需标准化 | 追求最高精度(优先考虑集成方法) |
3.5 随机森林 (Random Forest)
核心要点:Bagging 并行集成多棵独立决策树,投票/平均输出;降低方差、抗噪强、可评估特征重要性。
Bagging(Bootstrap Aggregating) 是一种并行的集成学习范式,核心思想是”三个臭皮匠,顶个诸葛亮”。随机森林是 Bagging 的代表作。
直觉理解:相当于组建一个”专家委员会”——每位专家(决策树)只看部分数据和部分特征,各自做出判断,最后投票决定。单个专家可能偏颇,但集体的平均意见往往更准确、更稳健。
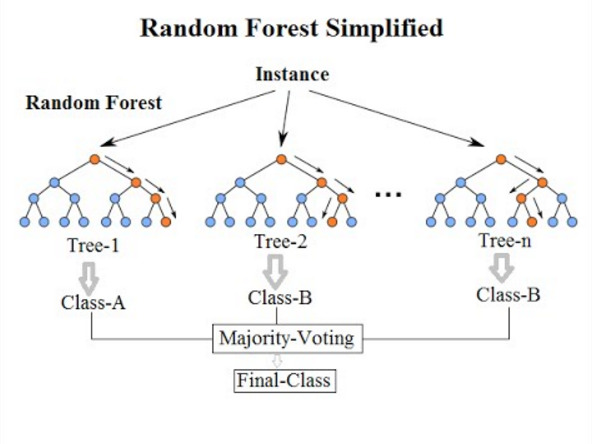
-
核心机制:通过对训练样本进行有放回的随机采样(Bootstrap),构建多棵相互独立的决策树。同时,在每个节点分裂时,也只在随机子集的特征中选择最优划分特征。
-
结果输出:分类任务通过多棵树投票产生最终结果,回归任务则取平均值。
-
特点:极大地降低了单一决策树的方差(Variance),抗噪能力强,不容易过拟合,且能评估特征重要性。
一句话记忆:随机森林 = 多棵随机决策树集体投票;牺牲一点可解释性,换来极强的鲁棒性,是结构化数据的可靠基线。
| 适合用 | 不适合用 |
|---|---|
| 结构化/表格数据,不想调太多参数 | 超高维稀疏数据(如文本 TF-IDF) |
| 数据有缺失值、存在噪声 | 追求极致精度(优先试 XGBoost) |
3.6 梯度提升树
核心要点:Boosting 串行拟合前一棵树的残差/负梯度;XGBoost、LightGBM 是结构化表格数据的工业”卷王”。
Boosting 是一种串行的集成学习范式,核心思想是”不断纠错”。后续的模型重点关注前序模型预测错误的样本,将其加权累积。
直觉理解:就像学生做错题集——第一轮做完后,第二轮重点练上次做错的题,第三轮再练上次还错的……每一轮专注于弥补前一轮的弱点,最终形成一个各方面都强的模型。
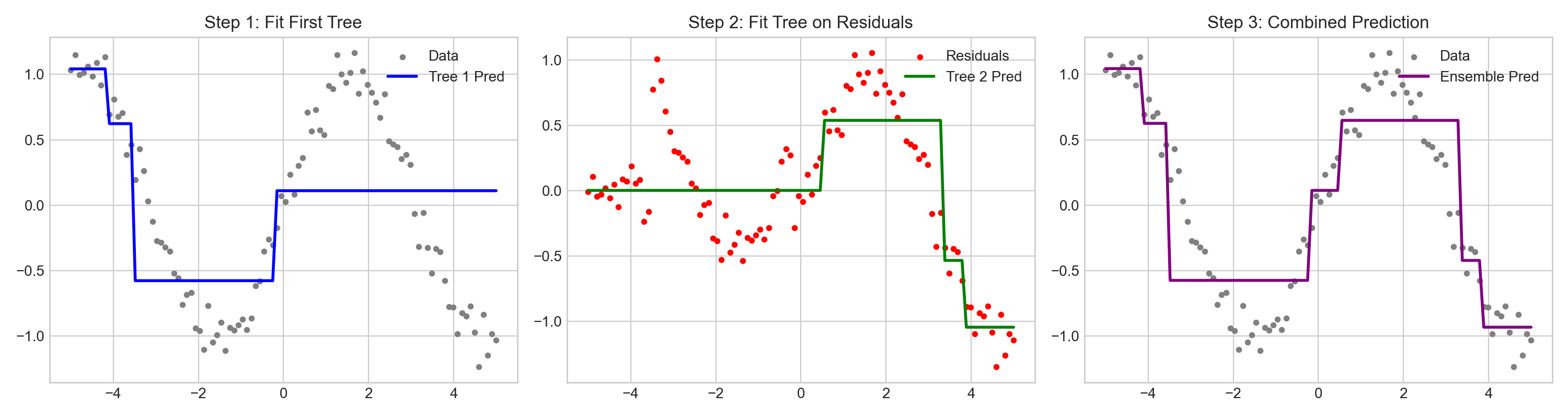
-
GBDT (Gradient Boosting Decision Tree):以 CART 回归树为基分类器,每次迭代通过拟合上一步模型的负梯度(在平方损失下即为残差)来不断逼近真实值。
-
XGBoost (eXtreme Gradient Boosting):GBDT 的工程极致优化版。它不仅在目标函数中引入了二阶导数信息(泰勒展开)以加速收敛,还加入了 L1 和 L2 正则化项以控制模型复杂度。此外,支持缺失值自动处理和特征并行计算,曾在 Kaggle 竞赛中统治了表格数据的预测任务。
-
LightGBM:微软推出的更高效的 Boosting 框架。通过引入基于直方图(Histogram)的决策树算法、单边梯度采样(GOSS)和互斥特征捆绑(EFB),在保证精度的前提下大幅降低了内存消耗和计算时间。
一句话记忆:GBDT 串行纠错、逐步逼近真实值;XGBoost 是其工程极致版,LightGBM 是速度极致版,是 Kaggle 表格数据竞赛的历史统治者。
| 适合用 | 不适合用 |
|---|---|
| 结构化表格数据、追求精度 | 图像/文本等非结构化数据 |
| 数据含缺失值(XGBoost 自动处理) | 训练样本极少,易过拟合 |
3.7 K近邻算法 (KNN)
核心要点:懒惰学习——不训练只记忆,预测时靠最近 K 个邻居投票/平均;简单直观但推理慢、对尺度敏感、受维度灾难影响。
KNN 是一种典型的”懒惰学习(Lazy Learning)”算法,它在训练阶段几乎不进行任何计算,仅保存训练数据。
直觉理解:就像在陌生城市问路——不靠任何地图(不需要训练),直接问你周围最近的 $K$ 个路人,取多数人的意见。完全依赖”物以类聚、人以群分”的朴素假设。
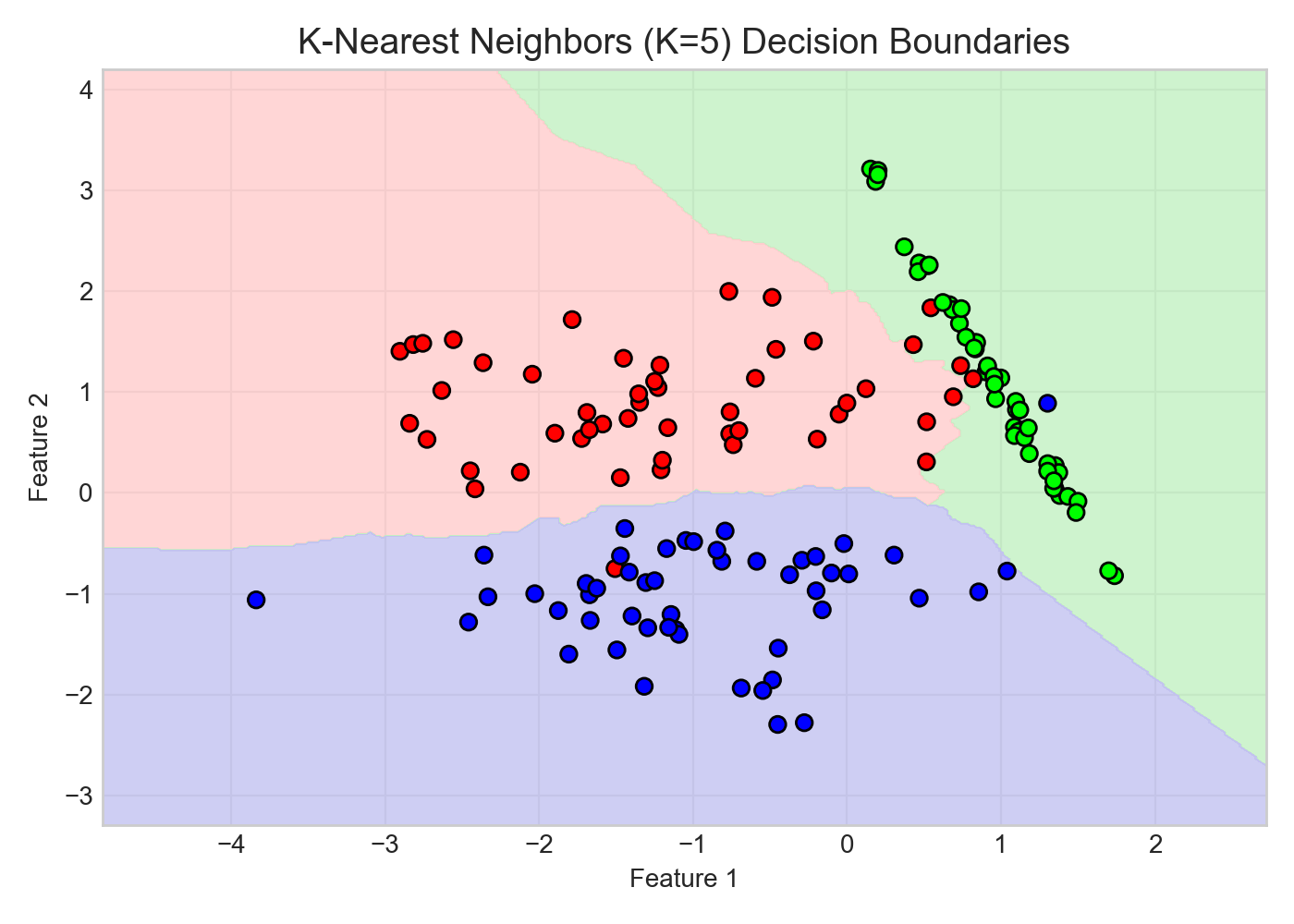
-
预测机制:在预测时,计算测试样本与所有训练样本之间的距离(如欧氏距离、曼哈顿距离),寻找在特征空间中最近的 $K$ 个样本。
-
决策规则:分类任务采取多数表决(Majority Voting),回归任务取均值。可引入距离加权机制,距离越近权重越大。
-
缺点:预测时需要遍历所有数据,计算复杂度随数据量呈线性增长;对数据的尺度(Scale)敏感,使用前必须进行归一化处理;存在维度灾难问题。
一句话记忆:KNN 不训练只记忆,简单直观;代价是预测时要遍历所有样本(慢),且对特征尺度敏感(必须先归一化)。
| 适合用 | 不适合用 |
|---|---|
| 小数据集、快速原型验证 | 大数据集(预测速度随样本量线性下降) |
| 数据分布不规则、非球形类别边界 | 高维数据(受维度灾难影响严重) |
3.8 朴素贝叶斯与隐马尔可夫模型
核心要点:朴素贝叶斯假设特征条件独立,训练快、文本分类效果好;HMM 建模序列的”隐状态+观测”,曾是语音/标注主力,现已被 RNN/Transformer 替代。
朴素贝叶斯 (Naive Bayes)
朴素贝叶斯是基于贝叶斯定理的分类算法,做出了一个极强但非常高效的”朴素”假设——特征之间相互条件独立。
直觉理解:就像法官凭多条”独立线索”判案——假设每条线索互不影响,把各线索的支持度相乘,哪个结论得分最高就选哪个。这个独立性假设在现实中几乎不成立,但实践中往往够用。
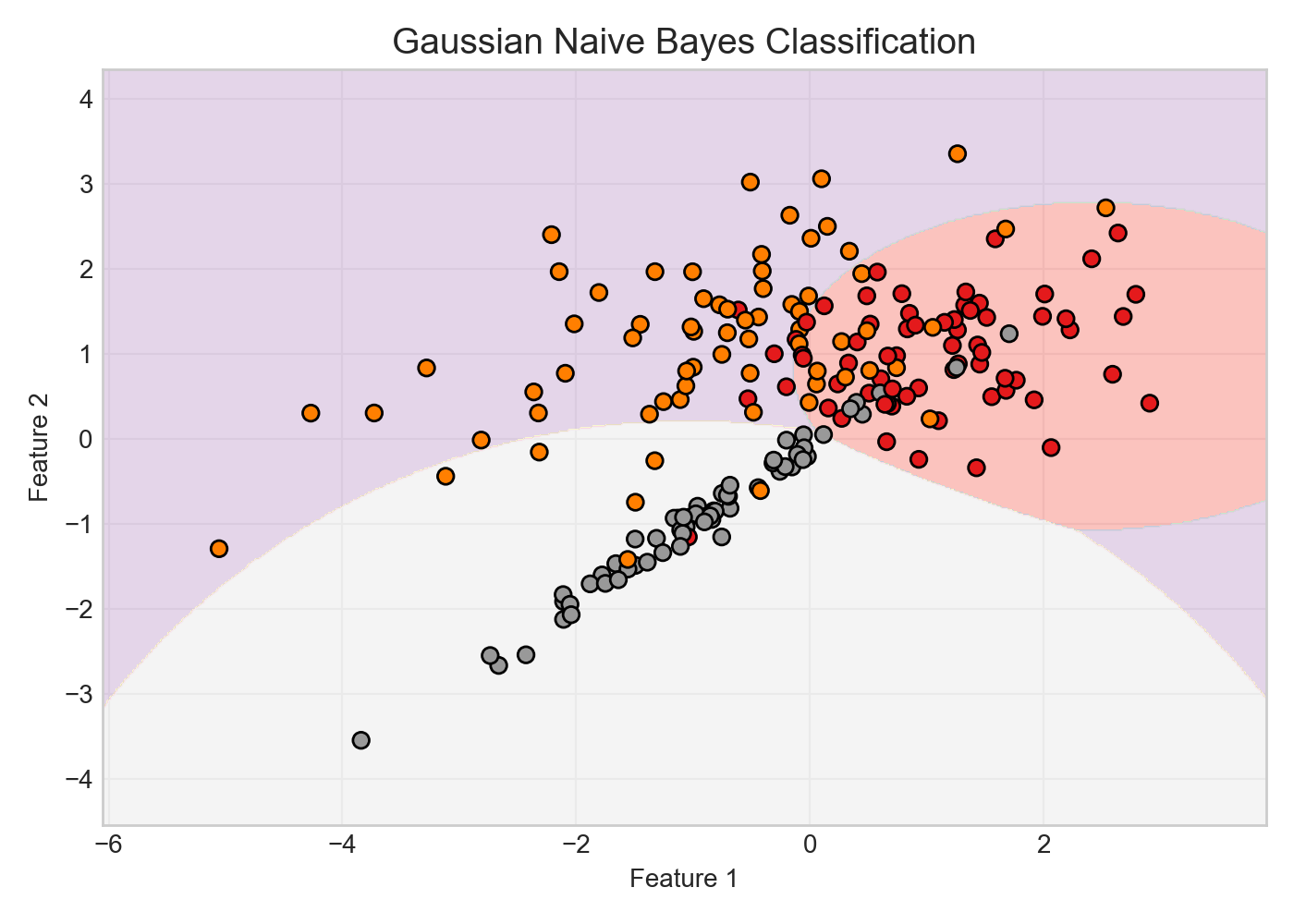
- 贝叶斯定理:给定样本特征 $\mathbf{x} = (x_1, x_2, \dots, x_n)$,后验概率为:
公式解读:$P(y \mid \mathbf{x})$ 是”看到特征 $\mathbf{x}$ 后样本属于类别 $y$ 的概率”(后验);$P(\mathbf{x} \mid y)$ 是”$y$ 类样本出现这组特征的可能性”(似然);$P(y)$ 是该类别的先验概率。分母 $P(\mathbf{x})$ 对所有类别相同,分类时可忽略。
- 朴素假设:假设各特征在给定类别下条件独立,将联合概率分解为各特征概率的乘积:
- 分类决策:选择使后验概率最大的类别,即:
- 特点:尽管条件独立假设在现实中很少严格成立,但朴素贝叶斯在文本分类(垃圾邮件过滤、情感分析)中往往能取得惊人的效果,且训练速度极快,适合超大规模数据。
一句话记忆:朴素贝叶斯 = 特征独立假设 + 贝叶斯定理;对高维稀疏文本特征效果出奇好,训练速度极快。
| 适合用 | 不适合用 |
|---|---|
| 文本分类(垃圾邮件过滤、情感分析) | 特征之间存在强相关性 |
| 样本极少时的快速基线 | 需要精确的概率校准 |
隐马尔可夫模型 (HMM)
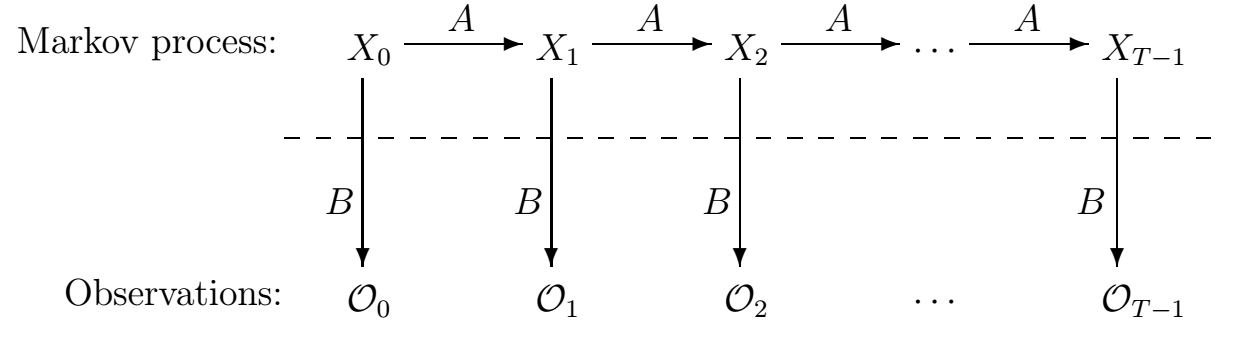
HMM 是一种用于处理序列数据的概率图模型,包含一个不可见的隐藏状态序列和一个可见的观测序列。
直觉理解:就像医生通过观察症状(发烧、咳嗽,这是可见的”观测”)推断内部病因(病毒感染还是细菌感染,这是不可见的”隐状态”)。病因本身看不见,但可以从症状序列反推最可能的病因序列。
-
两个核心假设:
-
马尔可夫假设:当前隐状态 $s_t$ 只依赖于前一个隐状态 $s_{t-1}$,即 $P(s_t \mid s_1, \dots, s_{t-1}) = P(s_t \mid s_{t-1})$。
-
观测独立假设:当前观测 $o_t$ 只依赖于当前隐状态 $s_t$,即 $P(o_t \mid s_1, \dots, s_t) = P(o_t \mid s_t)$。
-
-
三个基本问题:
-
评估问题:给定模型参数,计算某观测序列的概率(前向-后向算法)。
-
解码问题:给定观测序列,求最可能的隐状态序列(Viterbi 算法)。
-
学习问题:从观测数据中估计模型参数(Baum-Welch / EM 算法)。
-
-
应用场景:早期语音识别、词性标注(POS tagging)、基因序列分析。现已大量被深度序列模型(RNN/Transformer)替代。
一句话记忆:HMM = “隐状态 → 观测”的序列概率模型;理论优雅,现已基本被 RNN/Transformer 取代,了解其三大问题(评估、解码、学习)即可。
3.9 支持向量机 (SVM)
核心要点:寻找最大间隔的分类超平面;核技巧把低维线性不可分问题映射到高维可分空间,深度学习前的分类王者。
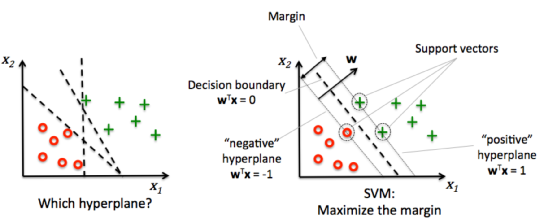
在深度学习爆发之前,SVM(Support Vector Machines)被认为是机器学习中分类效果最好的算法之一。
直觉理解:想象两群点分布在平面上,SVM 要在中间画一条线,使两群点离这条线都尽可能远——就像在两军之间挖一条尽可能宽的”护城河”。只有边界上最靠近分界线的那几个点(支持向量)决定了这条线的位置,其他点都不影响结果。
-
核心思想:试图在特征空间中找到一个超平面,使得不同类别的样本之间不仅被正确分开,而且几何间隔(Margin)最大化。这种”最大间隔”的追求赋予了 SVM 极强的泛化能力。
-
支持向量:决定分类边界的仅仅是距离超平面最近的那些样本点,称为”支持向量”。
-
核技巧 (Kernel Trick):当数据在原始空间线性不可分时,SVM 通过核函数(如线性核、多项式核、高斯 RBF 核)巧妙地将低维特征隐式映射到高维(甚至是无限维)空间,使其变得线性可分,从而解决了非线性分类问题,且避免了高维计算的维度灾难。
一句话记忆:SVM 追求”最宽护城河”分类;核技巧让它能处理非线性问题;在小样本、高维数据(如基因、文本)场景中仍有竞争力。
| 适合用 | 不适合用 |
|---|---|
| 小样本、高维数据(文本、基因特征) | 大数据集(训练复杂度约 $O(n^2)$–$O(n^3)$,极慢) |
| 特征维度 » 样本数的场景 | 需要概率输出(SVM 本身不输出概率) |
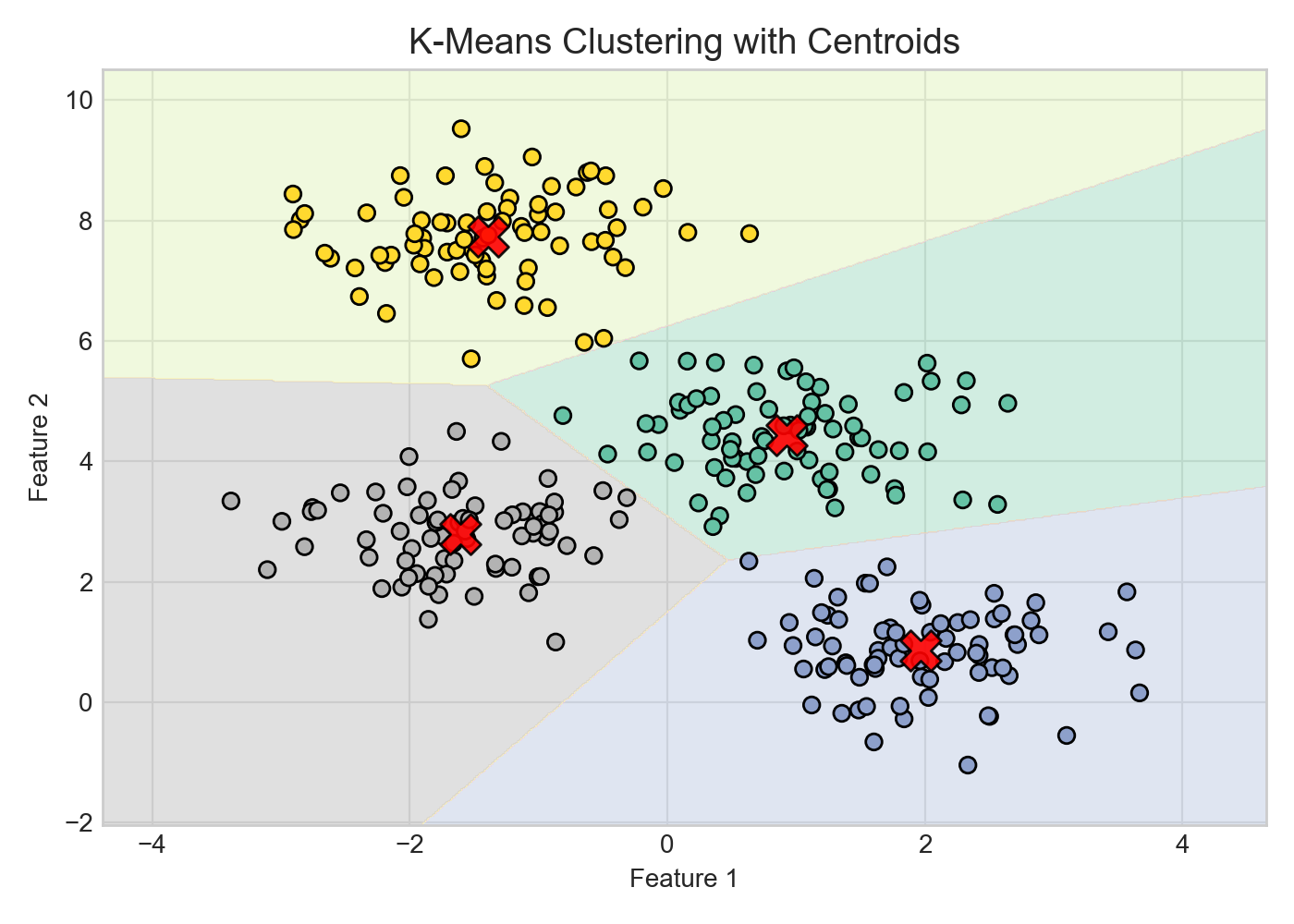
3.10 K-Means 聚类
核心要点:无监督聚类经典基线,交替更新”样本分配 → 质心位置”至收敛;需预设 K 值、仅擅长球形簇、对初值与异常值敏感。
最经典、应用最广泛的无监督聚类算法。
直觉理解:就像选 $K$ 个班长——先随机指定班长,全班同学各自靠近最近的班长;再把每个小组的中心重选为新班长……如此反复,直到班长位置稳定不动。
-
算法流程:
-
随机初始化 $K$ 个聚类中心(Centroids)。
-
遍历所有样本,将其分配给距离最近的聚类中心。
-
根据分配好的簇,重新计算每个簇的质心(即所有样本的均值),更新聚类中心。
-
重复步骤 2 和 3,直到聚类中心不再发生显著变化(收敛)或达到最大迭代次数。
-
-
优缺点:算法简单高效,时间复杂度为 $O(nKt)$;但对初始值的选择和异常值敏感,且必须预先指定 $K$ 值,只能发现球形簇,难以处理复杂流形分布的数据。
一句话记忆:K-Means 简单高效,是聚类入门首选;但需预设 $K$ 值,只擅长球形簇,对初始值敏感,可用 K-Means++ 改善初始化质量。
| 适合用 | 不适合用 |
|---|---|
| 数据分布接近球形、各簇大小相近 | 簇形状不规则(改用 DBSCAN) |
| 快速获得聚类结果、用户画像分群 | $K$ 值难以确定的场景 |
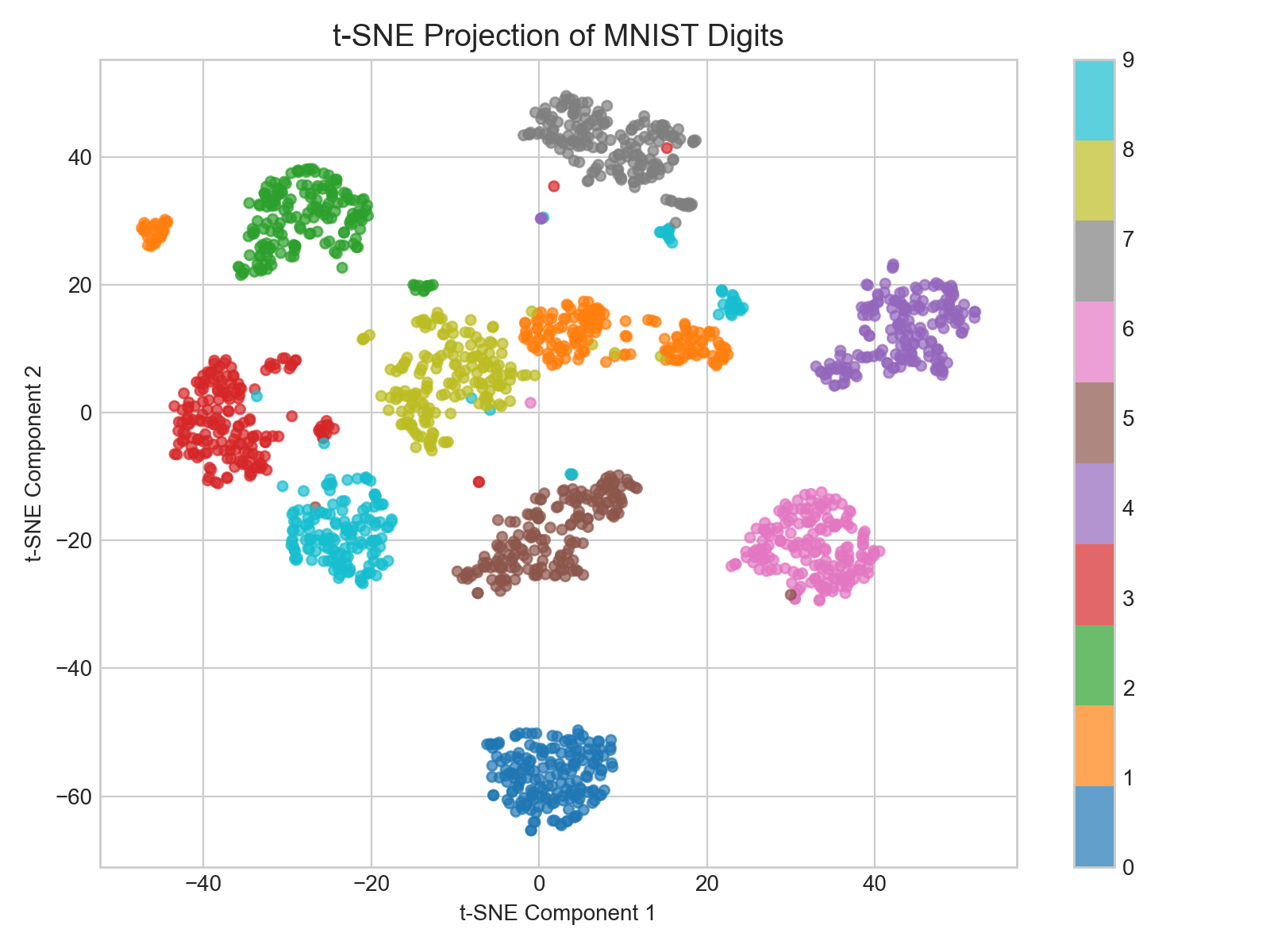
3.11 主成分分析 (PCA) 与 t-SNE
核心要点:PCA 做线性降维、保全局方差;t-SNE 做非线性降维、保局部流形结构,是 2D/3D 可视化首选。
-
主成分分析 (PCA):一种经典的线性降维方法。核心思想是通过正交变换,将可能相关的原始高维特征投影到一个新的正交坐标系中,这些新的坐标轴(主成分)按照数据方差的大小排列。保留前几个方差最大的主成分,可以在损失最少信息的前提下实现降维、数据去相关性和压缩。
直觉理解:就像给一个三维物体拍照——选一个最能保留信息的”拍摄角度”,让投影后的 2D 图像信息量最大(方差最大)。PCA 自动找到这个最佳角度。
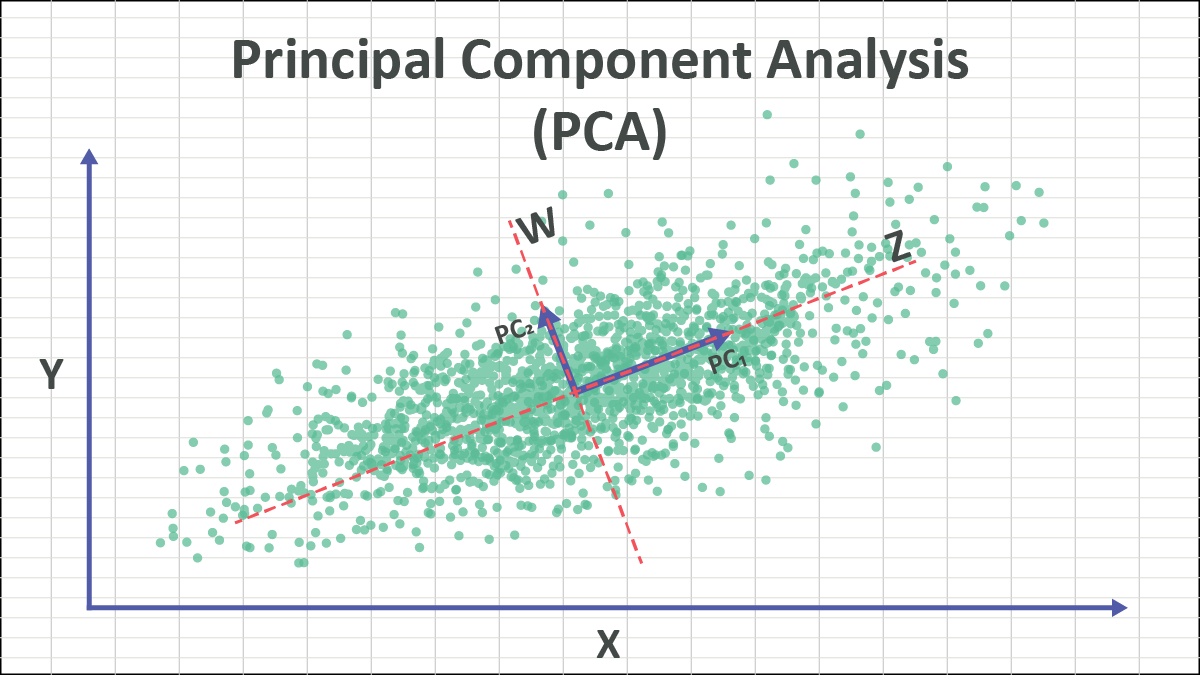
-
t-SNE (t-Distributed Stochastic Neighbor Embedding):一种非线性降维算法,主要用于将高维数据映射到 2D 或 3D 空间进行可视化。它通过将数据点之间的欧氏距离转化为条件概率来表达相似度,并使用 t 分布缓解高维空间映射到低维时的”拥挤问题(Crowding Problem)”,能够非常出色地保持数据的局部流形结构和类内聚集特征。
直觉理解:就像把一团高维”橡皮泥”压扁到桌面上,尽量让原来靠近的点压平后仍然靠近、原来远离的点压平后仍然远离。PCA 保全局结构,t-SNE 保局部结构,两者互补。
Part B · 深度学习基础(§3.12 – §3.15) —— 通过多层非线性堆叠 + 反向传播 + GPU 算力,端到端学习特征表示,是 CV/NLP/语音爆发的技术底座。
本章仅概述核心脉络;若想系统学习深度学习(激活函数、优化器、归一化、正则化、经典骨干网络、训练技巧等),推荐延伸阅读:《深度学习综述》。
3.12 多层感知机 (MLP) 与反向传播
核心要点:全连接层 + 非线性激活 + 反向传播;理论上可逼近任意连续函数(万能逼近定理),实践中增加深度比增加宽度更高效。
深度学习(Deep Learning, DL)通过多层非线性变换提取数据的高阶特征。多层感知机(Multilayer Perceptron, MLP)是最基础的前馈神经网络(Feedforward Neural Network),也是理解所有深度网络的起点。
直觉理解:就像一条流水线——原料(输入特征)经过多道加工工序(隐藏层),每道工序用激活函数引入”弯折”,让流水线能加工出任意复杂的形状(函数)。层越深,能表达的”加工逻辑”越复杂。

- 结构:由输入层、一个或多个隐藏层以及输出层组成,层与层之间全连接。每个神经元接收上一层输出的加权和,并经过非线性激活函数处理。单层的计算可表示为:
其中 $\mathbf{W}$ 是本层的权重矩阵(每个连接的强弱),$\mathbf{x}$ 是上一层的输出,$\mathbf{b}$ 是偏置向量,$\sigma$ 是非线性激活函数——没有它,多层线性变换等价于单层线性变换,网络失去深度的意义。
-
激活函数:引入非线性是深度网络的关键——没有激活函数,多层线性变换等价于单层。常见激活函数:
-
Sigmoid:$\sigma(x) = \frac{1}{1+e^{-x}}$,输出 $(0,1)$,易梯度消失。
-
Tanh:输出 $(-1,1)$,零中心化,但仍有梯度消失问题。
-
ReLU:$\text{ReLU}(x) = \max(0, x)$,计算简单,缓解梯度消失,是当前最广泛使用的激活函数。存在”神经元死亡”问题(输出恒为0),变体 Leaky ReLU、GELU 等进一步改进。
-
-
万能逼近定理(Universal Approximation Theorem):理论证明,只要隐藏层足够宽,单隐层 MLP 可以逼近任意连续函数。但实践中,增加深度(多隐层)比单纯增加宽度更高效,这也是”深度”学习的核心动机。
-
反向传播 (Backpropagation):神经网络训练的基石。
-
前向传播:输入数据逐层计算,得到预测输出和损失 $\mathcal{L}$。
-
反向传播:基于微积分的链式法则,从输出层反向逐层计算损失对每个参数的梯度。例如对权重 $W_{ij}$ 的梯度:$\frac{\partial \mathcal{L}}{\partial W_{ij}} = \frac{\partial \mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial h} \cdot \frac{\partial h}{\partial W_{ij}}$。
-
参数更新:利用梯度下降算法更新参数,如 SGD:$\mathbf{W} \leftarrow \mathbf{W} - \eta \frac{\partial \mathcal{L}}{\partial \mathbf{W}}$。
-
-
常用优化器:
-
SGD + Momentum:引入动量项加速收敛并跨越局部极小值。
-
Adam:自适应学习率优化器,结合了 Momentum 和 RMSProp 的优点,是当前最常用的默认优化器。
-
一句话记忆:MLP = 多层全连接 + 反向传播;万能逼近定理保证理论能力,实践中加深比加宽更高效,是理解所有深度网络的基础。
| 适合用 | 不适合用 |
|---|---|
| 通用表格数据的深度学习入门 | 图像(用 CNN)、序列(用 RNN/Transformer) |
| 特征工程完善后的分类/回归任务 | 数据量极少(参数量多,容易过拟合) |
3.13 卷积神经网络 (CNN)
核心要点:局部感受野 + 权重共享 + 池化,为图像等网格数据而生;ResNet 残差连接让网络得以训练到上百层,是计算机视觉的基石。
CNN 是专门为处理网格状拓扑数据(如图像的 2D 像素网格)而设计的神经网络架构,是计算机视觉领域的基石。
直觉理解:CNN 的卷积核像一个滑动的”放大镜”,在图像上逐区域扫描——浅层识别边缘和颜色,中层识别纹理和形状,深层组合出”耳朵”“眼睛”等高级语义。层层抽象,最终认出”这是一只猫”。

-
核心机制:
-
局部感受野与卷积核:利用小型滤波器(卷积核)在输入特征图上滑动,提取局部特征(如边缘、纹理),极大地减少了参数量。
-
权重共享:同一个卷积核遍历整张图像,使得模型具有平移等变性。
-
池化层 (Pooling):如最大池化,用于下采样操作,降低特征图维度,增加平移不变性,扩大感受野。
-
-
经典架构:LeNet-5 (早期手写数字识别)、AlexNet (引爆深度学习)、VGG (堆叠小卷积核)、ResNet (引入残差连接解决深层网络退化问题,深度可达上百层)。
一句话记忆:CNN = 局部感受野 + 权重共享 → 参数少、平移不变;ResNet 残差连接解决了深层网络退化问题,是计算机视觉的基石架构。
| 适合用 | 不适合用 |
|---|---|
| 图像、视频等网格状数据 | 纯序列/文本数据(改用 Transformer) |
| 需要平移不变性、提取局部特征 | 数据量极少(可用迁移学习缓解) |
3.14 循环神经网络 (RNN & LSTM/GRU)
核心要点:隐状态赋予网络时间记忆;LSTM/GRU 用门控机制解决长距离依赖与梯度消失,是 Transformer 出现前的序列建模主力。
循环神经网络家族经历了 RNN → LSTM → GRU 的演进,每一代都在修复上一代的核心缺陷。
RNN — 基础循环结构
RNN 专门用于处理文本、语音、时间序列等变长序列数据。与普通神经网络不同,它在处理每个时间步时保留一个”隐状态”传递给下一步,赋予网络时间上的记忆。
直觉理解:就像一个边读边记的阅读者——每步都把”当前输入 + 上一步记忆”合并成新的记忆传给下一步。
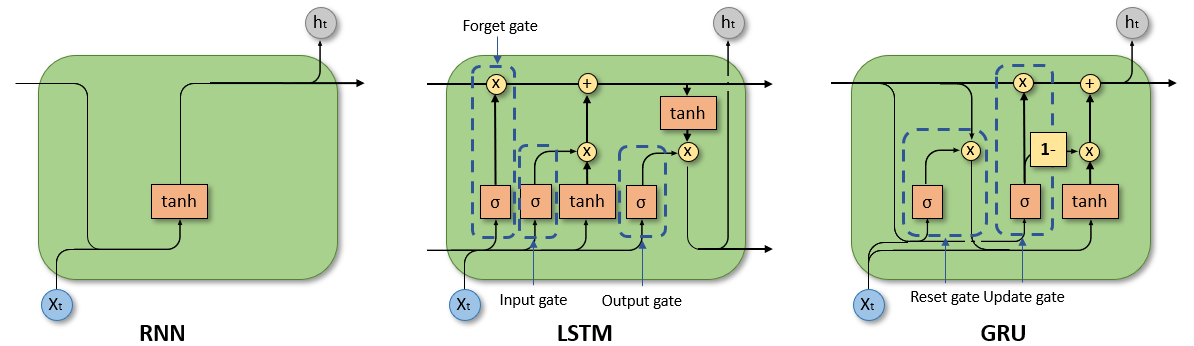
-
隐状态机制:每个时间步的计算为 $h_t = \tanh(W_h h_{t-1} + W_x x_t + b)$,其中 $h_{t-1}$ 是上一步的隐状态,$x_t$ 是当前输入。
-
致命缺陷——梯度消失:时间维度上的反向传播(BPTT)需要将梯度连乘数百次,梯度指数级缩小(消失)或膨胀(爆炸),导致 RNN 几乎无法学习句子中相距较远词之间的依赖关系。
LSTM — 门控记忆
长短期记忆网络(Long Short-Term Memory)通过引入细胞状态(Cell State)和三个门控机制,从根本上解决了梯度消失问题。
直觉理解:LSTM 给记忆装了三个开关——遗忘门决定”哪些旧记忆可以删掉”,输入门决定”哪些新信息值得记住”,输出门决定”现在对外输出哪部分记忆”。细胞状态就像一条高速公路,信息可以几乎无损地流过很长的时间跨度。
-
遗忘门:$f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)$,输出 0~1 决定旧细胞状态中哪些被保留(0 = 完全遗忘,1 = 完全保留)。
-
输入门:$i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)$,决定哪些新信息写入;候选内容为 $\tilde{C}t = \tanh(W_C [h{t-1}, x_t] + b_C)$。
-
细胞状态更新:$C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t$,旧记忆选择性遗忘后加入选择性新信息($\odot$ 为逐元素乘)。
-
输出门:$o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)$,最终输出 $h_t = o_t \odot \tanh(C_t)$,决定当前步对外输出什么。
GRU — 轻量化改进
门控循环单元(Gated Recurrent Unit,Cho et al. 2014)是对 LSTM 的简化:将三个门合并为两个,取消独立的细胞状态,参数量减少约 25%,训练更快,大多数任务上效果与 LSTM 相当。
直觉理解:GRU 把遗忘门和输入门合并成一个更新门(”该保留多少旧的、引入多少新的”),用重置门控制历史信息的影响程度。结构更简洁,推理更快。
-
重置门:$r_t = \sigma(W_r [h_{t-1}, x_t])$,控制上一步隐状态对候选状态的影响,接近 0 时相当于”重新开始”。
-
更新门:$z_t = \sigma(W_z [h_{t-1}, x_t])$,同时扮演遗忘门和输入门:$h_t = (1-z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t$。
-
选型建议:序列较长、数据充足 → LSTM;追求训练速度或资源受限 → GRU;两者性能差异通常小于 1%,可优先试 GRU。
一句话记忆:RNN 有记忆但健忘(梯度消失);LSTM 用三个门精细管理长期记忆;GRU 用两个门做同样的事,更快更轻。三者现已被 Transformer 大量取代,但在边缘设备和实时序列任务中仍有价值。
| 适合用 | 不适合用 |
|---|---|
| 短到中等长度序列(时间序列预测、语音帧) | 超长序列(Transformer 并行处理更高效) |
| 资源受限需要轻量实时推理(优先 GRU) | 需要捕捉文本中的远距离上下文 |
3.15 Transformer 架构
核心要点:完全基于 Self-Attention,并行捕捉全局长距离依赖;是当前所有大模型(LLM、Diffusion、VLA)的底层基石架构。
Transformer(Vaswani et al., 2017, “Attention Is All You Need”)彻底抛弃了 RNN 和 CNN 的结构,完全基于注意力机制,是当前大模型时代的最底层基石架构。
直觉理解:Transformer 就像一个”全局会议室”——每个词都能直接与所有其他词对话(自注意力),不需要像 RNN 那样靠”传话”来传递信息。因此它能并行处理、高效捕捉任意距离的上下文依赖。
自注意力机制 (Self-Attention)
自注意力允许序列中每个元素都能”关注”到其他所有元素,计算出它们之间的关联权重,从而并行地捕捉全局长距离依赖。
-
输入序列通过三个线性变换分别生成 Query ($Q$)、Key ($K$)、Value ($V$) 矩阵。
-
注意力权重通过 $Q$ 和 $K$ 的点积计算,再经 Softmax 归一化后加权 $V$:
公式解读:$Q$ = “我在找什么”,$K$ = “我能提供什么关键词”,$V$ = “我的实际内容”。$Q \cdot K^T$ 计算每对 token 的相关性得分,除以 $\sqrt{d_k}$ 防止得分过大导致 Softmax 梯度消失,最终对 $V$ 加权求和,得到每个 token 融合了上下文信息的新表示。
多头注意力 (Multi-Head Attention)
将 $Q, K, V$ 拆分为 $h$ 个独立的”头”,每个头在不同的子空间中计算注意力,最后拼接:
\[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O\]不同的头可以同时关注不同层面的关系(语法关系、语义关系、位置关系等),大幅提升表达能力。
Transformer Block 结构
每个 Block 包含两个子层,每个子层都使用残差连接 + LayerNorm(保证训练稳定):
- 多头自注意力层:捕捉 token 间的依赖关系。
- 前馈网络 (FFN):两层线性变换夹一个激活函数,对每个位置独立做非线性变换:$\text{FFN}(x) = W_2 \cdot \text{ReLU}(W_1 x + b_1) + b_2$。
位置编码 (Positional Encoding)
Self-Attention 本身对输入顺序不敏感(打乱词序结果不变),因此必须显式注入位置信息。原始方案使用正弦/余弦函数编码绝对位置;后续发展出 RoPE(旋转位置编码,LLaMA 系列采用)、ALiBi 等相对位置编码方案。
Encoder-Decoder 架构
- Encoder:$N$ 个 Block 堆叠,输入 token 可以双向互相关注,适合”理解”类任务(如机器翻译的源语言编码)。
- Decoder:同样 $N$ 个 Block,但自注意力层加因果掩码(Causal Mask)——每个 token 只能看到它之前的内容(自回归生成);并增加交叉注意力层,$Q$ 来自 Decoder,$K, V$ 来自 Encoder,实现对源语言的关注。
为什么 Transformer 能替代 RNN
RNN 必须按时间步串行处理($O(n)$ 串行依赖),无法充分利用 GPU 并行;Self-Attention 一次并行计算所有 token 对的关系(训练复杂度 $O(n^2 d)$),在中等长度序列上训练效率远超 RNN,且不存在梯度消失问题。
一句话记忆:Transformer = 纯注意力机制,并行高效、全局依赖;是 LLM、图像生成(DiT)、机器人(VLA)等一切大模型的底层基石。
| 适合用 | 不适合用 |
|---|---|
| 长序列、需要全局上下文(NLP、多模态) | 超长序列时显存消耗大($O(n^2)$,需 Flash Attention 等优化) |
| 数据量充足的大规模预训练场景 | 极小数据集(归纳偏置弱,不如 CNN 收敛快) |
Part C · 预训练大模型范式(§3.16) —— Transformer × 海量无标签语料,”预训练 + 微调/Prompt” 的新范式彻底改变了 NLP,并催生大模型时代。
3.16 BERT 与 GPT 系列模型范式
核心要点:BERT 用双向 Encoder 擅长理解类任务(分类、抽取);GPT 用自回归 Decoder 擅长生成,凭借 Scaling Laws 与 RLHF 成为 LLM 绝对主流。
基于 Transformer 架构,自然语言处理衍生出两大主流预训练范式,分别代表了”理解”和”生成”两条技术路线:
直觉理解:BERT 就像做填空题——把句子里随机抠掉几个词,让模型结合前后文猜出来,迫使它理解双向上下文。GPT 则像续写故事——给你前半段,一个词一个词接龙,模型规模越大,续写能力越惊人,甚至涌现出推理、代码等意料之外的能力。
BERT — 双向编码器范式
BERT(Bidirectional Encoder Representations from Transformers, Google 2018)采用 Transformer 的 Encoder 部分,核心创新在于双向上下文建模。
-
预训练任务:
-
掩码语言模型(MLM):随机将输入中 15% 的 token 替换为
[MASK],让模型结合双向上下文预测被遮挡的词。这使得每个 token 的表示都融合了左右两侧的语境信息,优于 GPT 的单向可见性。 -
下一句预测(NSP):判断两个句子是否为上下文连续关系,帮助模型学习句间语义。
-
-
使用范式 ——”预训练 + 微调”:先在大规模无标注语料上预训练,然后在具体下游任务上用少量标注数据微调。BERT 在 GLUE、SQuAD 等基准上大幅刷新纪录,定义了 NLU 时代的标准范式。
-
局限:MLM 的
[MASK]标记在推理时不存在,导致预训练与推理之间存在分布不匹配(Pretrain-Finetune Discrepancy);且 Encoder 架构不擅长文本生成任务。 -
后续发展:RoBERTa(去掉 NSP、更大数据更长训练)、ALBERT(参数共享压缩)、DeBERTa(解耦注意力)等进一步优化。
GPT — 自回归解码器范式
GPT(Generative Pre-trained Transformer, OpenAI)采用 Transformer 的 Decoder 部分,通过自回归方式逐 token 生成文本。
- 预训练任务 — 下一 token 预测:给定前文 $x_1, x_2, \dots, x_{t-1}$,预测下一个 token $x_t$。训练目标是最大化序列的对数似然:
通过因果掩码(Causal Mask)确保每个位置只能看到之前的 token,保证自回归约束。
-
Scaling Laws 与涌现能力:随着模型参数量、数据量和计算量的指数级扩大,GPT 系列展现出了明确的幂律缩放关系(Kaplan et al., 2020)。当模型规模跨过某些临界点后,出现了小模型上不存在的涌现能力(Emergent Abilities),如 In-context Learning、思维链推理(Chain-of-Thought)等。
-
演进路线:
| 模型 | 参数量 | 关键突破 |
|---|---|---|
| GPT-1 | 1.17 亿 | 验证了”无监督预训练 + 有监督微调”的可行性 |
| GPT-2 | 15 亿 | 展示零样本(Zero-shot)能力,文本生成质量引发社会关注 |
| GPT-3 | 1750 亿 | In-context Learning,少样本(Few-shot)能力惊艳,无需微调 |
| GPT-4 | 未公开 | 多模态(文本+图像输入)、RLHF 对齐、更强的推理能力 |
| o1/o3 系列 | 未公开 | 推理时计算扩展(Test-time Compute Scaling),深度思维链推理 |
- 对齐技术 — RLHF:GPT-3.5/4 引入了基于人类反馈的强化学习(Reinforcement Learning from Human Feedback):先训练奖励模型(Reward Model)学习人类偏好,再用 PPO 算法优化语言模型,使输出更安全、有用、诚实。后续 DPO(Direct Preference Optimization)等方法进一步简化了对齐流程。
两大范式对比
配图说明:建议在此处配一张 BERT(双向 Encoder,可看全句)vs GPT(单向 Decoder,只看前文)的架构对比示意图,直观展示注意力方向的差异。
| 维度 | BERT(Encoder) | GPT(Decoder) |
|---|---|---|
| 注意力方向 | 双向(完整上下文) | 单向(仅看前文) |
| 预训练任务 | 掩码语言模型(填空) | 下一 token 预测(续写) |
| 擅长任务 | 理解类(分类、抽取、匹配) | 生成类(对话、写作、推理) |
| 使用范式 | 预训练 + 微调 | 预训练 + Prompting / In-context Learning |
| 当前趋势 | 逐渐被 Decoder-only 架构统一 | 成为 LLM 的绝对主流架构 |
一句话记忆:BERT 擅长理解(分类/抽取/匹配),GPT 擅长生成(对话/创作/推理);当前大模型主流是 Decoder-only 的 GPT 路线,RLHF/DPO 对齐让它更安全有用。
Part D · 生成式模型(§3.17 – §3.20) —— 从对抗博弈(GAN)到概率建模(VAE)再到去噪扩散(Diffusion),AI 从”理解数据”走向”创造数据”。
3.17 生成对抗网络 (GAN)
核心要点:生成器与判别器博弈对抗,G 造假、D 鉴伪;生成质量高但训练不稳定、易模式崩溃,逐渐被 Diffusion 取代。
GAN(Generative Adversarial Network)开创了生成式 AI 的新纪元,其灵感来源于博弈论中的零和博弈。
直觉理解:就像造假币者(生成器 G)和验钞员(判别器 D)的博弈——G 不断提升造假水平,D 不断提升鉴别能力。两者相互竞争、共同进化,直到 G 造出的”假币”真假难辨(判别器输出 0.5)。
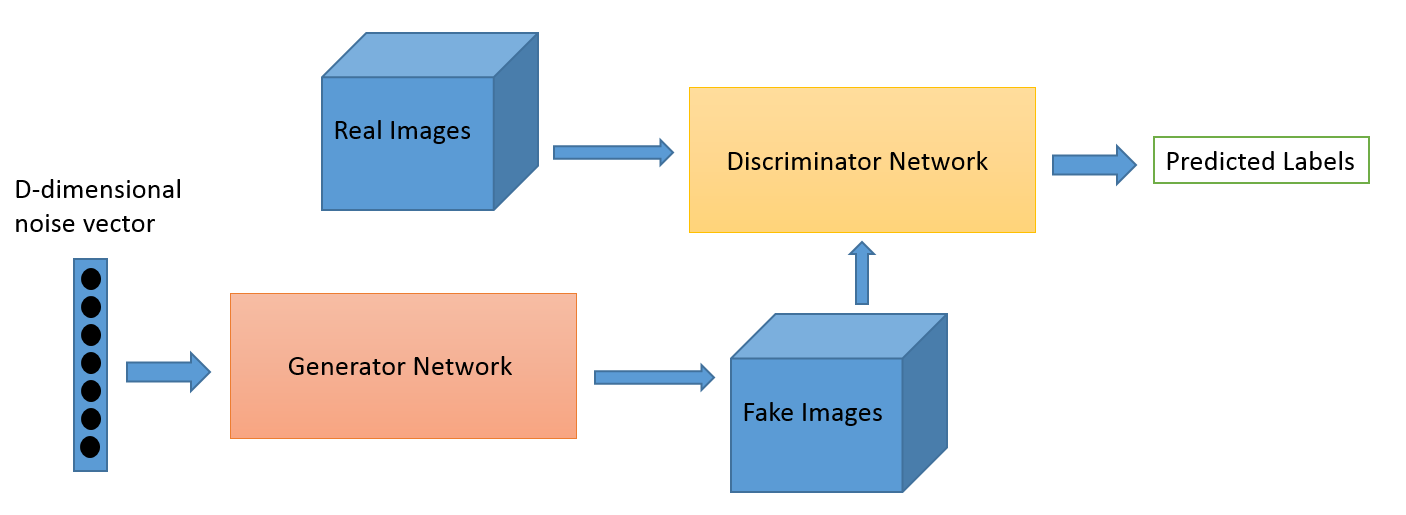
-
架构:包含两个相互对抗的神经网络——生成器(Generator, G) 和 判别器(Discriminator, D)。
-
核心思想:生成器从随机噪声 $\mathbf{z} \sim p_z(z)$ 出发,试图生成逼真的假样本 $G(\mathbf{z})$;判别器则接收真实样本 $\mathbf{x}$ 和生成样本 $G(\mathbf{z})$,输出一个概率值 $D(\cdot) \in [0,1]$,表示”该样本为真”的置信度。两者在训练中不断博弈、共同进化。
-
目标函数(极小极大博弈):
公式解读:$\mathbb{E}[\log D(\mathbf{x})]$ 是 D 对真实样本的得分(越大越好);$\mathbb{E}[\log(1-D(G(\mathbf{z})))]$ 是 D 对假样本的判断——D 希望这项大(假样本得低分),G 希望这项小(让假样本骗过 D)。当训练达到纳什均衡时,$D(\cdot) = 0.5$,即判别器完全无法区分真假,生成器已完美拟合真实数据分布。
-
训练流程:
-
固定 G,训练 D 若干步:用真实样本(标签=1)和生成样本(标签=0)训练二分类器。
-
固定 D,训练 G 一步:生成假样本送入 D,用 D 的反馈梯度更新 G,使生成样本更逼真。
-
交替重复上述过程直到收敛。
-
-
常见问题与改进:
-
模式崩溃(Mode Collapse):G 只学会生成少数几种样本,丢失了数据的多样性。
-
训练不稳定:G 和 D 的能力需要保持平衡,否则梯度消失或爆炸。
-
改进变体:WGAN(用 Wasserstein 距离替代 JS 散度,缓解训练不稳定)、StyleGAN(引入风格控制,生成高分辨率人脸)、CycleGAN(无配对数据的图像风格迁移)。
-
-
应用场景:图像生成、超分辨率重建(SRGAN)、图像修复(Inpainting)、风格迁移、数据增强。
一句话记忆:GAN = 生成器与判别器博弈对抗;生成质量高,但训练不稳定、易模式崩溃,已逐渐被 Diffusion 模型取代。
| 适合用 | 不适合用 |
|---|---|
| 图像风格迁移、超分辨率重建 | 需要训练稳定性和生成多样性 |
| 数据增强(扩充小数据集) | 需要精确概率建模 |
3.18 自编码器 (Autoencoder)
核心要点:Encoder-Decoder 瓶颈结构学习压缩表示,可视作非线性 PCA;擅长去噪/降维/异常检测,但隐空间不规则,不适合直接生成新样本。
自编码器(Autoencoder, AE)是一种无监督学习的神经网络模型,核心目标是学习数据的压缩表示。
直觉理解:就像”压缩文件再解压”——把一张图片先压缩成几十个数字(编码),再从这几十个数字还原出图片(解码)。瓶颈结构迫使网络把最精华的信息塞进少数几个数字里,自动学会数据的本质特征。
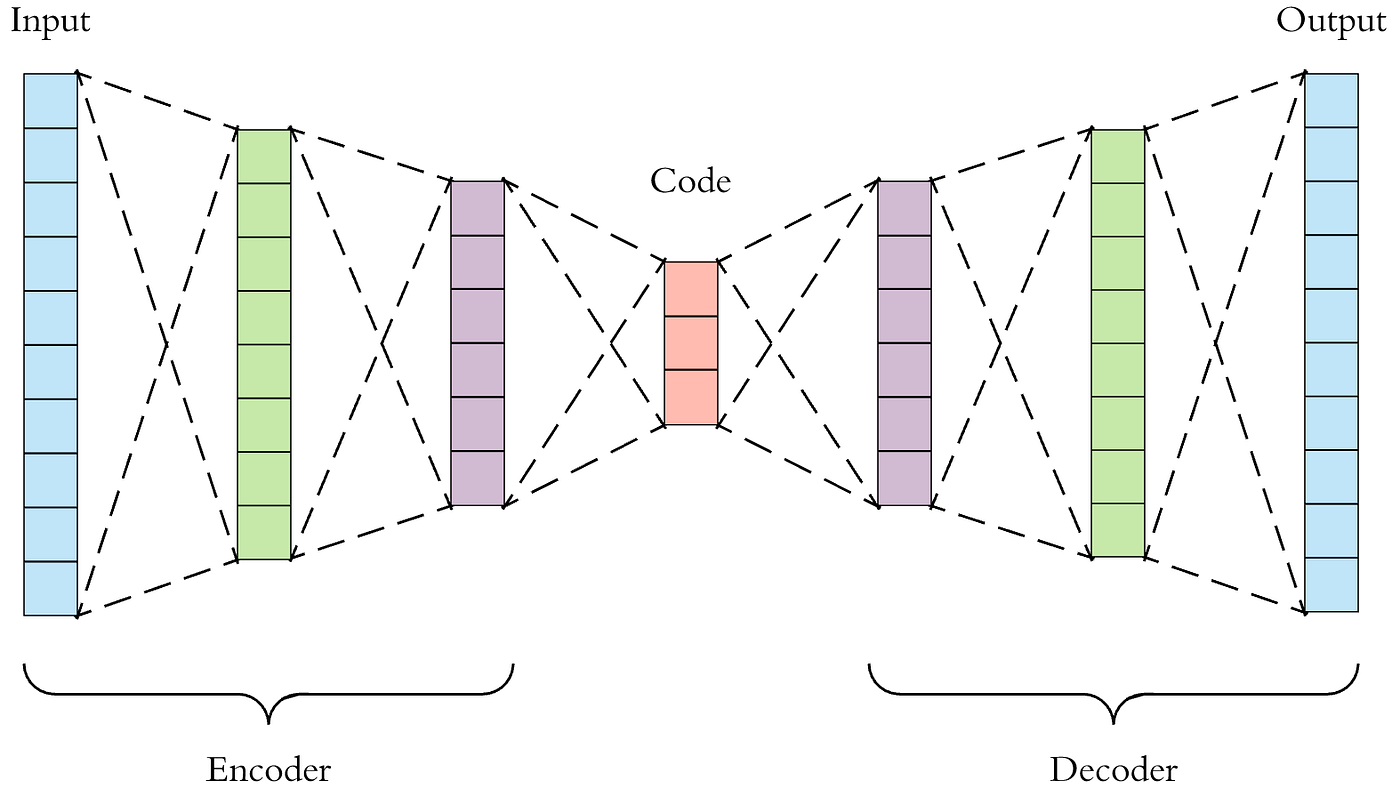
-
架构:由编码器(Encoder) $f_\theta$ 和解码器(Decoder) $g_\phi$ 两部分组成。编码器将高维输入 $\mathbf{x} \in \mathbb{R}^n$ 压缩为低维潜在表示 $\mathbf{z} = f_\theta(\mathbf{x}) \in \mathbb{R}^d$(其中 $d \ll n$),然后解码器再将 $\mathbf{z}$ 映射回原始空间,生成重构 $\hat{\mathbf{x}} = g_\phi(\mathbf{z})$。
-
核心思想:通过”瓶颈”结构(低维隐层)迫使网络学习数据中最本质的特征,丢弃冗余信息。可以类比为一种非线性的 PCA。
-
损失函数:最小化重构误差,如均方误差:
公式解读:$\mathbf{x}$ 是原始输入,$\hat{\mathbf{x}}$ 是重构输出,损失就是”还原有多失真”。训练完成后,编码器 $f_\theta$ 提取到的隐向量 $\mathbf{z}$ 就是数据的压缩表示($d \ll n$)。
-
主要变体:
-
去噪自编码器(Denoising AE, DAE):输入人为加噪的 $\tilde{\mathbf{x}}$,训练模型恢复出干净的 $\mathbf{x}$,迫使网络学习更鲁棒的特征。
-
稀疏自编码器(Sparse AE):在隐层上施加稀疏约束(如 KL 散度惩罚),使得只有少数神经元被激活,得到可解释性更强的特征。
-
收缩自编码器(Contractive AE):在损失中加入编码器雅可比矩阵的 Frobenius 范数惩罚,使隐层表示对输入微小扰动不敏感。
-
-
局限性:AE 的潜在空间是不规则、不连续的——不同样本的编码可能在隐空间中分布散乱,无法对未见过的隐向量进行有意义的解码。因此 AE 擅长压缩和重构,但不适合直接用于生成新样本,这正是 VAE 要解决的问题。
-
应用场景:非线性降维与特征学习、图像去噪、异常检测(正常数据重构误差低,异常数据重构误差高)。
一句话记忆:AE = 编码器压缩 + 解码器重建;隐空间不规则,适合去噪/异常检测,不适合直接生成新样本(VAE 解决了这个问题)。
| 适合用 | 不适合用 |
|---|---|
| 数据降维、特征学习、图像去噪 | 需要生成全新样本(改用 VAE/Diffusion) |
| 异常检测(重构误差作为异常分数) | 隐空间可解释性和连续性要求高 |
3.19 变分自编码器 (VAE)
核心要点:AE + 概率建模,把每个样本编码成隐空间中的分布而非点;隐空间连续可插值,兼具压缩与生成能力,但生成图像偏模糊。
变分自编码器(Variational Autoencoder, VAE)在 AE 的基础上引入概率建模,使潜在空间具备良好的数学结构,从而既能压缩数据,又能生成新样本。
直觉理解:AE 把图片压缩成隐空间里的一个固定点;VAE 则把它压缩成一个”模糊区域”(概率分布)。生成时从这个区域随机采一个点解码——由于区域是连续的,采到的任意点都能解码出合理图片,隐空间还可以平滑插值(如从微笑人脸渐变到大笑人脸)。
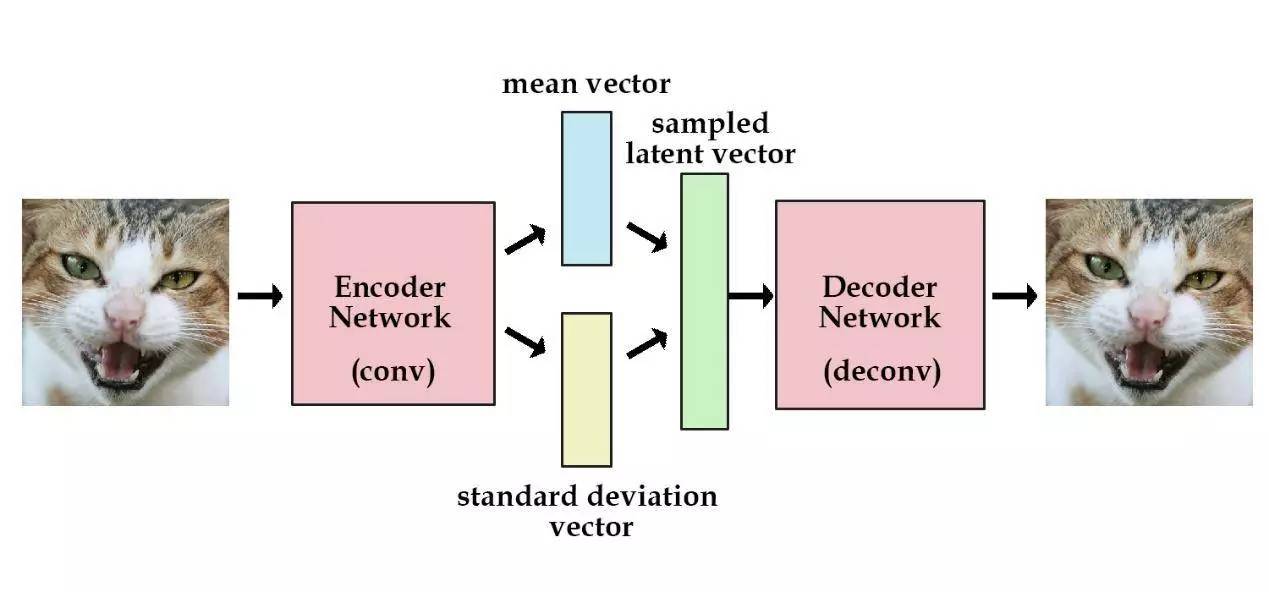
-
核心思想:AE 将输入编码为一个确定的隐向量点;而 VAE 将输入编码为隐空间中的一个概率分布(均值 $\boldsymbol{\mu}$ 和方差 $\boldsymbol{\sigma}^2$),再从该分布中采样得到隐向量 $\mathbf{z}$。这确保了隐空间是连续、平滑的——相邻的隐向量解码出语义上相近的样本。
-
编码器输出:不再直接输出 $\mathbf{z}$,而是输出分布参数 $\boldsymbol{\mu}$ 和 $\log \boldsymbol{\sigma}^2$;通过重参数化技巧(Reparameterization Trick) $\mathbf{z} = \boldsymbol{\mu} + \boldsymbol{\sigma} \odot \boldsymbol{\epsilon}$($\boldsymbol{\epsilon} \sim \mathcal{N}(0, I)$)实现可微采样,使梯度能够反向传播。
-
损失函数(ELBO):
公式解读:两项损失缺一不可——重构损失确保解码输出”看得懂”(像原图);KL 散度约束编码器输出的分布尽量接近标准正态 $\mathcal{N}(0, I)$,防止隐空间退化成离散孤立点,保证任意采样点都能被合理解码。两者的权衡让隐空间既有结构又能重建。
-
重构损失:确保解码输出与原始输入尽量接近。
-
KL 散度:约束编码器输出的分布 $q_\theta(\mathbf{z} \mid \mathbf{x})$ 尽量接近先验分布 $p(\mathbf{z}) = \mathcal{N}(0, I)$,防止隐空间退化为离散点集。
-
生成新样本:训练完成后,直接从标准正态分布 $\mathcal{N}(0, I)$ 采样 $\mathbf{z}$,送入解码器即可生成全新样本。由于隐空间的连续性,还可以通过在两个隐向量之间线性插值实现平滑的语义过渡(如人脸从微笑到大笑的渐变)。
-
与 AE 的关键区别:AE 的隐空间无结构约束,只能用于重构;VAE 通过概率约束获得了规则的隐空间,兼具压缩与生成能力,但生成图像通常偏模糊(因为重构损失倾向于均值化)。
-
应用场景:图像生成与插值、药物分子设计、异常检测、数据增强。
一句话记忆:VAE = 概率化的 AE;隐空间连续可插值,兼具压缩和生成能力,代价是生成图像偏模糊(重构损失倾向于均值化)。
| 适合用 | 不适合用 |
|---|---|
| 需要平滑可插值隐空间(分子/蛋白质设计) | 追求极高生成质量(改用 Diffusion) |
| 异常检测、数据增强 | 对生成图像清晰度要求高 |
3.20 扩散模型 (Diffusion Models)
核心要点:把”生成”转化为”多步去噪”;训练稳定、质量极高,Stable Diffusion / Sora / DALL-E 3 均基于此构建,已是当前图像/视频生成的 SOTA。
扩散模型(Diffusion Models)是近年来在图像和音频生成领域全面超越 GAN 的新一代生成模型(Stable Diffusion、Midjourney、DALL-E 系列均基于此构建)。其核心灵感来源于热力学中的扩散过程。
直觉理解:就像雕刻家的创作过程——不直接雕出成品,而是从一块大理石(纯噪声)开始,一刀一刀地精心雕刻(每步去噪),最终呈现出清晰的作品。每一刀都很小、很可控,整体过程稳定可靠。
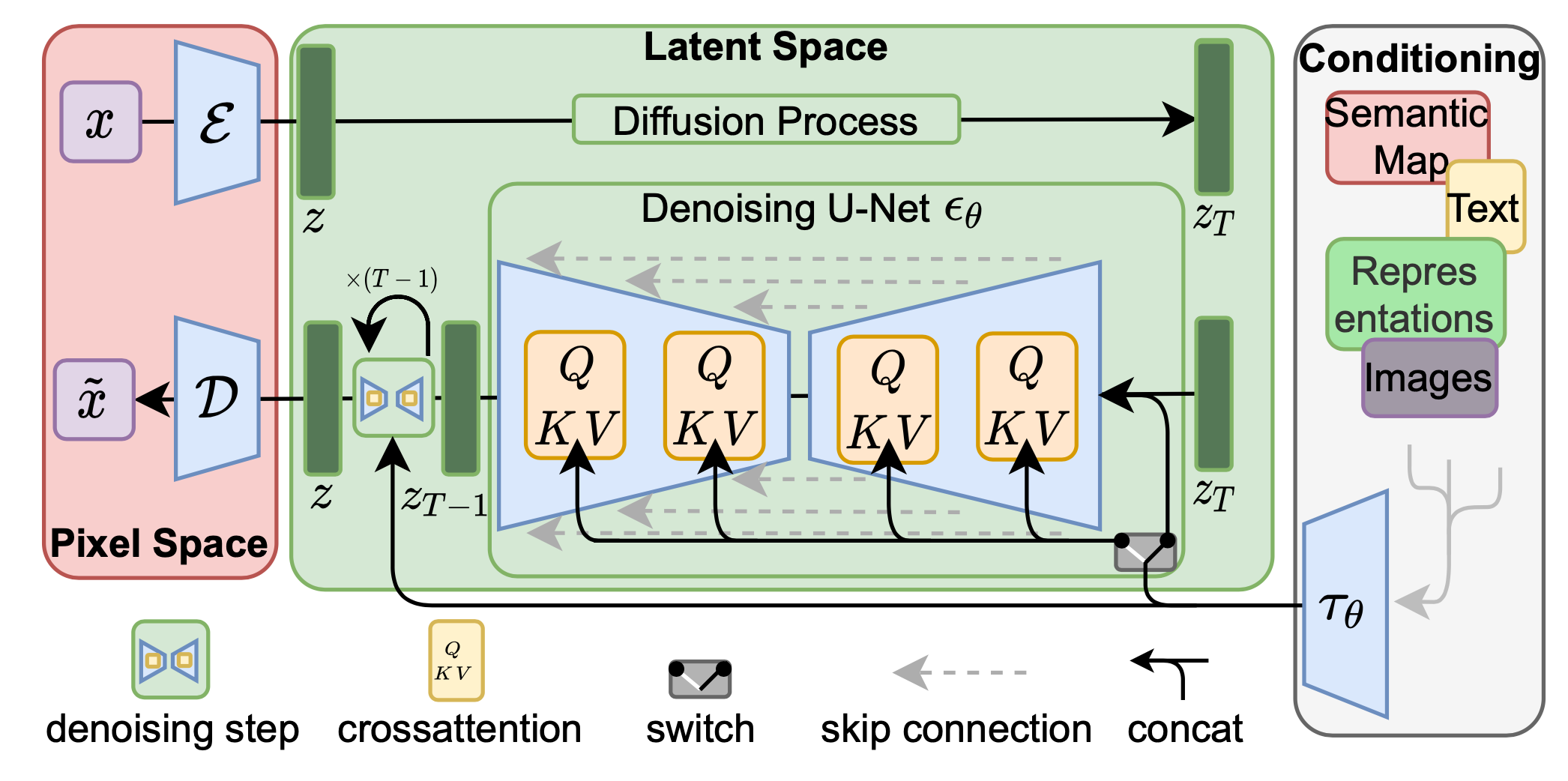
-
核心思想:将”生成”问题转化为”去噪”问题。模型不直接学习如何从噪声一步生成图像,而是学习如何一步一步地从纯噪声中恢复出清晰图像。
-
前向扩散过程(加噪,Fixed):给定一张真实图像 \(\mathbf{x}_0\),按照预定义的噪声调度 \(\beta_1, \beta_2, \dots, \beta_T\),逐步叠加高斯噪声:
经过 $T$ 步(通常 $T=1000$)后,\(\mathbf{x}_T\) 近似变为纯高斯噪声 \(\mathcal{N}(0, \mathbf{I})\)。利用累积参数 \(\bar{\alpha}_t = \prod_{s=1}^t (1-\beta_s)\),可以直接从 \(\mathbf{x}_0\) 一步跳到任意时间步:
\[\mathbf{x}_t = \sqrt{\bar{\alpha}_t}\,\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\,\boldsymbol{\epsilon}\]- 反向去噪过程(生成,Learned):训练一个噪声预测网络 \(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\)(通常基于 U-Net 架构),学习在每个时间步 $t$ 预测所添加的噪声 \(\boldsymbol{\epsilon}\)。损失函数极其简洁:
公式解读:\(\boldsymbol{\epsilon}\) 是前向过程中实际添加的噪声,\(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\) 是网络在第 $t$ 步对这个噪声的预测——训练目标就是让两者的均方误差最小。训练完成后,生成时从纯噪声 \(\mathbf{x}_T\) 出发,反复调用网络预测并去除噪声,逐步还原出清晰图像 \(\mathbf{x}_0\)。
-
条件生成与引导:
-
Classifier-Free Guidance:同时训练有条件和无条件的去噪模型,推理时通过调节引导强度 $w$ 控制生成结果与条件(如文本提示)的吻合程度。这是 Stable Diffusion 等文生图模型的关键技术。
-
文本条件:将文本通过 CLIP 等编码器转为向量,注入 U-Net 的交叉注意力层,实现”文字描述→图像生成”。
-
-
与 GAN/VAE 的对比:
| 特性 | GAN | VAE | Diffusion |
|---|---|---|---|
| 训练稳定性 | 差(博弈不平衡) | 好 | 好 |
| 生成质量 | 高(但易模式崩溃) | 中(偏模糊) | 极高 |
| 多样性 | 中 | 高 | 极高 |
| 生成速度 | 快(一次前向) | 快 | 慢(需多步迭代) |
| 可控性 | 弱 | 中 | 强(条件引导) |
-
加速采样:原始扩散模型需要数百步迭代,速度较慢。DDIM(去马尔可夫化,跳步采样)、DPM-Solver(高阶 ODE 求解器)等方法可将采样步数降至 20-50 步,大幅提升推理效率。
-
应用场景:文本到图像生成(Stable Diffusion、DALL-E 3)、图像编辑与修复(Inpainting)、视频生成(Sora)、音频合成、3D 内容生成、蛋白质结构预测。
一句话记忆:Diffusion = 多步去噪生成;训练稳定、生成质量极高、多样性强,已全面超越 GAN,是当前图像/视频/音频生成的 SOTA 范式。
| 适合用 | 不适合用 |
|---|---|
| 高质量图像/视频/音频/分子生成 | 对生成速度要求极高(需多步采样,比 GAN 慢) |
| 需要多样性、可控性和高保真度 | 简单场景(GAN 更快,开销更小) |
进阶阅读:以下两节(§3.20.1 DiT、§3.20.2 Diffusion Policy)内容较深,适合已对扩散模型基础有所了解的读者延伸阅读,初学者可跳过。
3.20.1 架构演进:传统 U-Net Diffusion vs DiT (Diffusion Transformer)
扩散模型的骨干网络(Backbone)主要经历了从 U-Net 到 DiT (Diffusion Transformer) 的演进。两者使用同样的扩散训练范式(前向加噪 + 反向去噪),但在噪声预测网络 \(\boldsymbol{\epsilon}_\theta\) 的架构设计上有本质差异。
-
传统 U-Net Diffusion(DDPM、Stable Diffusion 1.x/2.x 代表):
- 结构:编码器-解码器对称的卷积 U 型网络,带跳跃连接(Skip Connection),在不同分辨率下提取多尺度特征。
- 条件注入:时间步 $t$ 通过正弦位置编码送入残差块;文本/类别条件通过 交叉注意力(Cross-Attention) 注入中间层。
- 优势:归纳偏置强(卷积的局部性与平移不变性),在中小数据规模下收敛快、参数效率高。
- 劣势:卷积感受野受限,难以建模全局长程依赖;扩展到超大规模时 scaling 效果弱于 Transformer。
-
DiT (Diffusion Transformer)(Peebles & Xie, 2023;Sora、Stable Diffusion 3、PixArt-α 代表):
- 结构:完全抛弃 U-Net,采用 纯 Transformer 主干。将含噪潜变量(通常在 VAE 的 latent space 中)切分为 Patch Token 序列,经过若干 Transformer Block 后再重建为噪声预测图。
- 条件注入:通过 adaLN-Zero(自适应 LayerNorm,将时间步和类别条件映射为 LayerNorm 的 scale/shift/gate 参数)替代传统的残差条件注入,零初始化残差分支保证训练稳定。
- 优势:严格遵循 Transformer 的 Scaling Law——参数量和计算量越大,FID 越低;对视频、长序列、多模态条件的适应性远强于 U-Net。Sora、Stable Diffusion 3 的成功验证了 DiT 是通往大规模生成模型的主流路径。
- 劣势:缺乏卷积的归纳偏置,小数据下需要更多样本;计算成本随 Token 数平方增长。
对比总结:
| 维度 | U-Net Diffusion | DiT (Diffusion Transformer) |
|---|---|---|
| 主干 | 卷积 U-Net + 注意力 | 纯 Transformer (Patch Token) |
| 归纳偏置 | 强(局部、多尺度) | 弱(依赖数据) |
| 条件注入 | Cross-Attention + 残差 | adaLN-Zero |
| 可扩展性 | 中等 | 极强(Scaling Law) |
| 代表作 | DDPM、SD 1.5/2.1 | Sora、SD3、PixArt-α、MovieGen |
3.20.2 Diffusion Policy:扩散模型在机器人决策中的应用
Diffusion Policy(Chi et al., 2023)将扩散模型的强大分布建模能力迁移到 机器人模仿学习(Imitation Learning) 领域,成为当前 VLA (Vision-Language-Action) 和具身智能中的主流动作生成范式。
- 核心思想:把机器人的动作序列(Action Chunk,未来 $H$ 步的关节位姿或末端执行器轨迹)视作需要生成的”图像”,用扩散模型从高斯噪声中逐步去噪,生成以当前观测 \(\mathbf{o}_t\) 为条件的动作序列 \(\mathbf{a}_{t:t+H}\):
其中 $k$ 为扩散去噪步。
-
相较传统 BC(Behavior Cloning)的优势:
- 多模态动作分布:人类演示数据常存在”多种正确解法”(如绕过障碍可向左或向右),MSE 回归会平均成错误的中间路径;扩散模型天然支持多峰分布,能忠实建模多模态策略。
- 高维动作序列:一次性生成一个 Action Chunk(通常 8-16 步),而非逐步自回归,避免误差累积、提升时序一致性。
- 稳定训练:相比 GAN-based Policy,扩散训练目标(噪声 MSE)简单稳定;相比 EBM,避免了对比散度采样的高方差。
-
架构选择:早期 Diffusion Policy 采用 1D 卷积 U-Net(处理时间维度上的动作序列),近期趋势转向 Transformer 主干(如 RDT、π₀ 等 VLA 模型),以便与视觉-语言编码器深度融合。
-
代表工作:Diffusion Policy(CMU/TRI)、3D Diffusion Policy、RDT-1B(清华)、π₀(Physical Intelligence)、Octo 等;在真实机器人操作、双臂协作、灵巧手等任务上均显著超越 BC-RNN、BC-Transformer 等基线。
3.20.3 扩散架构 vs 自回归架构:两种生成范式的对比
在序列/内容生成领域,Diffusion(扩散) 和 Autoregressive(自回归,AR) 是两条主导性的技术路线。理解它们的差异对于选择合适的架构至关重要。
| 维度 | Autoregressive (AR) | Diffusion |
|---|---|---|
| 生成方式 | 逐 Token 串行生成:\(p(x) = \prod_i p(x_i \mid x_{<i})\) | 并行迭代去噪:\(\mathbf{x}_T \to \mathbf{x}_{T-1} \to \cdots \to \mathbf{x}_0\) |
| 并行度 | 训练并行(Teacher Forcing),推理串行 | 训练并行,推理步内并行(但需多步) |
| 生成长度 | 变长、灵活(可逐步终止) | 固定长度(需预先设定输出尺寸) |
| 误差累积 | 存在(Exposure Bias) | 无(每步基于全局噪声预测) |
| 概率建模 | 精确似然($\log p$ 可计算) | 变分下界(ELBO),近似似然 |
| 多模态分布 | 依赖 temperature/top-k 采样 | 天然支持(噪声注入即多样性) |
| 连续 vs 离散 | 擅长离散 Token(文本、代码) | 擅长连续信号(图像、音频、动作) |
| Scaling Law | 成熟(GPT 系列验证) | 逐步成熟(DiT、Sora 验证) |
| 代表模型 | GPT、LLaMA、PaLM;VQ-VAE + AR(DALL-E 1) | Stable Diffusion、Sora、Diffusion Policy |
- 文本生成:AR 几乎是唯一主流(LLM 全家桶);但近期 Diffusion-LM、LLaDA 等尝试将扩散用于文本,展示了并行解码、可控编辑的潜力。
- 图像/视频生成:Diffusion 已成为主流;AR 路线(如 Parti、VAR)通过 Tokenizer + AR 也能取得竞争力,但推理延迟高。
- 机器人动作:Diffusion Policy 凭借多模态分布建模占优;AR-based VLA(如 OpenVLA)则在与 LLM 统一架构上更自然。
- 融合趋势:近期出现 MAR (Masked AR)、Transfusion(Zhou et al., 2024)等混合架构,在单一 Transformer 中统一 AR(文本)与 Diffusion(图像),是通往真正多模态基础模型的潜在路径。
直观理解:AR 像”逐字写作”,每一步都决定最终结果;Diffusion 像”雕刻”,先有一团大致的形状(噪声),再逐步精修到清晰。前者擅长有严格因果顺序的符号序列,后者擅长需要全局一致性的连续信号。
4. 总结
机器学习是一场关于数据与算法的演化史。从早期的专家规则,到严谨的统计概率模型,再到大力出奇迹的深度神经网络和基础大模型,其核心始终是寻找更优的表示和更高效的优化路径。
对于研究者和工程师而言,了解每一种算法的边界与假设至关重要:在海量非结构化数据(图、文、音)面前,深度学习与 Transformer 无可替代;但在中小规模的结构化表格数据中,XGBoost 等树模型依然具有极高的性价比和解释性。未来,随着算法、算力和数据的进一步交融,机器学习必将朝着通用性(AGI)和可信性稳步迈进。
参考资料
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2nd ed.). Springer.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. https://www.deeplearningbook.org/
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press.
- Tibshirani, R. (1996). Regression Shrinkage and Selection via the Lasso. Journal of the Royal Statistical Society, Series B, 58(1), 267–288.
- Quinlan, J. R. (1986). Induction of Decision Trees. Machine Learning, 1(1), 81–106. (ID3)
- Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. Morgan Kaufmann.
- Breiman, L., Friedman, J., Olshen, R., & Stone, C. (1984). Classification and Regression Trees. Wadsworth. (CART)
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32.
- Friedman, J. H. (2001). Greedy Function Approximation: A Gradient Boosting Machine. The Annals of Statistics, 29(5), 1189–1232. (GBDT)
- Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. KDD 2016. arXiv:1603.02754
- Ke, G., et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NeurIPS 2017.
- Cover, T., & Hart, P. (1967). Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13(1), 21–27. (KNN)
- Rabiner, L. R. (1989). A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77(2), 257–286.
- Cortes, C., & Vapnik, V. (1995). Support-Vector Networks. Machine Learning, 20(3), 273–297.
- MacQueen, J. (1967). Some Methods for Classification and Analysis of Multivariate Observations. Proc. 5th Berkeley Symp. on Math. Statist. and Prob. (K-Means)
- Pearson, K. (1901). On Lines and Planes of Closest Fit to Systems of Points in Space. Philosophical Magazine, 2(11), 559–572. (PCA)
- van der Maaten, L., & Hinton, G. (2008). Visualizing Data using t-SNE. Journal of Machine Learning Research, 9, 2579–2605.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning Representations by Back-Propagating Errors. Nature, 323(6088), 533–536.
- Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer Feedforward Networks are Universal Approximators. Neural Networks, 2(5), 359–366.
- Kingma, D. P., & Ba, J. (2015). Adam: A Method for Stochastic Optimization. ICLR 2015. arXiv:1412.6980
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11), 2278–2324. (LeNet-5)
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS 2012. (AlexNet)
- Simonyan, K., & Zisserman, A. (2015). Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015. arXiv:1409.1556 (VGG)
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR 2016. arXiv:1512.03385 (ResNet)
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780.
- Cho, K., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP 2014. arXiv:1406.1078 (GRU)
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017. arXiv:1706.03762
- Su, J., et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864 (RoPE)
- Press, O., Smith, N. A., & Lewis, M. (2022). Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. ICLR 2022. (ALiBi)
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019. arXiv:1810.04805
- Liu, Y., et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692
- Lan, Z., et al. (2020). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. ICLR 2020.
- He, P., et al. (2021). DeBERTa: Decoding-Enhanced BERT with Disentangled Attention. ICLR 2021.
- Radford, A., et al. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI Tech Report. (GPT-1)
- Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Tech Report. (GPT-2)
- Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020. arXiv:2005.14165 (GPT-3)
- OpenAI. (2023). GPT-4 Technical Report. arXiv:2303.08774
- Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361
- Wei, J., et al. (2022). Emergent Abilities of Large Language Models. TMLR 2022. arXiv:2206.07682
- Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903
- Ouyang, L., et al. (2022). Training Language Models to Follow Instructions with Human Feedback. NeurIPS 2022. arXiv:2203.02155 (InstructGPT / RLHF)
- Rafailov, R., et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. NeurIPS 2023. arXiv:2305.18290 (DPO)
- Goodfellow, I., et al. (2014). Generative Adversarial Nets. NeurIPS 2014. arXiv:1406.2661
- Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN. ICML 2017. arXiv:1701.07875
- Karras, T., Laine, S., & Aila, T. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019. (StyleGAN)
- Zhu, J. Y., et al. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. ICCV 2017. (CycleGAN)
- Vincent, P., et al. (2008). Extracting and Composing Robust Features with Denoising Autoencoders. ICML 2008.
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. ICLR 2014. arXiv:1312.6114 (VAE)
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239 (DDPM)
- Song, J., Meng, C., & Ermon, S. (2021). Denoising Diffusion Implicit Models. ICLR 2021. arXiv:2010.02502 (DDIM)
- Lu, C., et al. (2022). DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling. NeurIPS 2022.
- Ho, J., & Salimans, T. (2022). Classifier-Free Diffusion Guidance. arXiv:2207.12598
- Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022. arXiv:2112.10752 (Stable Diffusion)
- Ramesh, A., et al. (2022). Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv:2204.06125 (DALL-E 2)
- Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023. arXiv:2212.09748 (DiT)
- Brooks, T., et al. (2024). Video Generation Models as World Simulators. OpenAI Tech Report. (Sora)
- Chen, J., et al. (2024). PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis. ICLR 2024.
- Esser, P., et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. ICML 2024. (Stable Diffusion 3)
- Chi, C., et al. (2023). Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. RSS 2023. arXiv:2303.04137
- Ze, Y., et al. (2024). 3D Diffusion Policy. RSS 2024.
- Liu, S., et al. (2024). RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation. arXiv:2410.07864
- Black, K., et al. (2024). π₀: A Vision-Language-Action Flow Model for General Robot Control. Physical Intelligence. arXiv:2410.24164
- Octo Model Team. (2024). Octo: An Open-Source Generalist Robot Policy. RSS 2024.
- Kim, M. J., et al. (2024). OpenVLA: An Open-Source Vision-Language-Action Model. arXiv:2406.09246
- Tian, K., et al. (2024). Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. NeurIPS 2024. (VAR)
- Zhou, C., et al. (2024). Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model. arXiv:2408.11039
- Nie, S., et al. (2025). Large Language Diffusion Models. arXiv:2502.09992 (LLaDA)
- Deng, J., et al. (2009). ImageNet: A Large-Scale Hierarchical Image Database. CVPR 2009.
- Lin, T. Y., et al. (2014). Microsoft COCO: Common Objects in Context. ECCV 2014.
- Wang, A., et al. (2019). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. ICLR 2019.
- Pedregosa, F., et al. (2011). Scikit-learn: Machine Learning in Python. JMLR, 12, 2825–2830.
- Abadi, M., et al. (2016). TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv:1603.04467
- Paszke, A., et al. (2019). PyTorch: An Imperative Style, High-Performance Deep Learning Library. NeurIPS 2019.
- Wolf, T., et al. (2020). Transformers: State-of-the-Art Natural Language Processing. EMNLP 2020 (System Demos). (HuggingFace)
- Jumper, J., et al. (2021). Highly Accurate Protein Structure Prediction with AlphaFold. Nature, 596, 583–589.
- Silver, D., et al. (2016). Mastering the Game of Go with Deep Neural Networks and Tree Search. Nature, 529, 484–489. (AlphaGo)
- Mnih, V., et al. (2015). Human-Level Control through Deep Reinforcement Learning. Nature, 518, 529–533. (DQN)
- Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347 (PPO)
- Haarnoja, T., et al. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. ICML 2018. (SAC)
本文所有示意图均来自对应论文或公开教程/博客资源,版权归原作者所有,仅用于学术交流与学习整理。