1. 引言
视觉-语言模型(Vision-Language Model, VLM)是一类能够同时理解图像和文本的多模态模型,是当前人工智能研究的核心方向之一。VLM的核心挑战在于:如何将视觉信号与语言信号有效地对齐和融合,使模型能够在两种模态之间自由地推理和生成。
从早期基于注意力机制的跨模态对齐,到CLIP提出的对比学习范式,再到以LLaVA、Flamingo为代表的”视觉编码器 + 语言模型”架构,VLM的技术路线不断演进。近年来,随着大语言模型能力的跃升,GPT-4V、Gemini、Qwen-VL等闭源或开源模型相继涌现,展现了强大的视觉理解与推理能力。
VLM在医疗图像分析、自动驾驶、机器人感知、内容审核等领域有着广泛的应用前景。视觉理解能力是VLA(视觉-语言-动作)模型和具身智能系统的基础,VLM研究的突破直接推动了下游具身任务的进步。
本文旨在系统梳理VLM领域的研究进展,重点关注实现多模态的核心技术方法,为学习和研究VLM提供参考。
2. VLM基本概述
2.1 什么是VLM?
视觉-语言模型(VLM)是指能够同时处理图像(或视频)与文本两种模态、在视觉和语言之间建立语义对齐的深度学习模型。广义的VLM涵盖从判别式(discriminative)任务到生成式(generative)任务的多种架构,核心目标是让模型”看懂”图像并用语言表达,或根据语言描述理解图像内容。
VLM通常需要解决以下核心问题:
- 视觉编码:将图像表示为高质量的特征向量或token序列
- 模态对齐:将视觉特征与语言语义空间对齐
- 跨模态融合:在推理过程中让视觉与语言信息相互交互
- 多模态生成(生成式模型):基于视觉+语言输入生成连贯的文本输出
2.2 核心要素
VLM的系统架构通常由三个核心模块构成:
| 模块 | 职责 | 主流实现方案 |
|---|---|---|
| 视觉编码器(Visual Encoder) | 从图像提取特征表示 | CNN(ResNet)→ ViT → CLIP ViT → InternViT |
| 连接模块(Connector / Bridge) | 跨模态对齐与特征融合 | 线性投影(LLaVA)/ Q-Former(BLIP-2)/ 交叉注意力(Flamingo) |
| 语言模型(Language Model) | 语言理解与文本生成 | OPT / Flan-T5 / LLaMA / Qwen / InternLM 等预训练LLM |
视觉编码器(Visual Encoder):负责从图像中提取特征。主流方案从早期的CNN(ResNet、EfficientNet)演进至基于Transformer的ViT,再到专门为跨模态对齐训练的CLIP视觉编码器。编码器输出的特征形式可以是全局向量、patch-level特征序列或混合表示。
连接模块(Connector / Bridge):这是决定多模态融合策略的关键模块,不同方法在此处差异最大。主要形式包括:线性投影层、交叉注意力机制、Q-Former等。
语言模型(Language Model):负责语言理解与生成,是整个系统的”推理大脑”。现代VLM通常直接复用预训练LLM。
2.3 主要挑战
模态对齐鸿沟:视觉特征与文本token处于完全不同的语义空间,直接拼接效果不佳,需要精心设计的对齐机制。
训练数据需求:高质量的图文对数据稀缺,弱监督的网络爬取数据存在噪声,如何利用海量噪声数据仍是难题。
细粒度视觉理解:模型对物体空间关系、属性细节、文字(OCR)等细粒度信息的理解仍不稳定,存在”幻觉”(hallucination)现象。
计算效率:高分辨率图像需要大量视觉token,导致推理成本急剧上升;如何在精度与效率之间取得平衡是重要研究方向。
视频理解扩展:从图像扩展到视频涉及时序建模,如何高效处理长视频序列是当前挑战。
2.4 研究发展趋势
flowchart LR
subgraph G2019 ["2018-2020 预训练萌芽"]
A["ViLBERT\n双流Transformer"] --> B["UNITER\n单流融合"]
end
B --> C
subgraph G2021 ["2021 对比学习爆发"]
C["CLIP\n大规模对比预训练"] --> D["ALIGN\n噪声数据规模化"]
D --> E["DALL-E\n文本生成图像"]
end
E --> F
subgraph G2022 ["2022 指令对齐"]
F["Flamingo\n跨模态少样本"] --> G["BLIP\n统一预训练+微调"]
G --> H["BLIP-2\nQ-Former桥接"]
end
H --> I
subgraph G2023 ["2023 LLM集成"]
I["LLaVA\n视觉指令微调"] --> J["InstructBLIP\n指令感知Q-Former"]
J --> K["MiniGPT-4\n单层投影对齐"]
end
K --> L
subgraph G2024 ["2024-2025 原生多模态"]
L["LLaVA-1.5/NeXT\n高分辨率动态切片"] --> M["InternVL2\n原生多模态大模型"]
M --> N["Qwen2.5-VL\n原生动态分辨率"]
end
N --> O
subgraph G2026 ["2025H2-2026 推理型多模态"]
O["OpenAI o3\n视觉推理新基线"] --> P["Qwen3-VL\n256K上下文+MoE+推理增强"]
P --> Q["Gemini 2.5 Pro\n全模态统一建模"]
end
style C fill:#f96,stroke:#333,stroke-width:2px
style I fill:#69f,stroke:#333,stroke-width:2px
style N fill:#6f9,stroke:#333,stroke-width:2px
style P fill:#f6c,stroke:#333,stroke-width:2px
3. 大语言模型(LLM)运行原理
在第 2 章我们提到,现代 VLM 的“推理大脑”是一个预训练的大语言模型(LLM),视觉编码器与连接模块的全部工作,最终都是为了把图像变成 LLM “看得懂”的输入。因此,在进入多模态融合方法之前,有必要先弄清楚一个纯文本的 LLM 到底是如何工作的:文本是怎样进入模型的、模型内部如何计算、又是怎样一个字一个字地把答案“吐”出来的。理解了这条“文本输入 → 内部计算 → 文本输出”的流水线,再看第 4 章里视觉特征如何“伪装”成 token 注入这条流水线,就会非常自然。
本章以当前主流的 decoder-only(仅解码器)Transformer 为对象,沿着数据流向依次拆解:分词(3.2)、嵌入(3.3)、Transformer 解码器堆叠(3.4)、输出层(3.5)、解码采样(3.6)、自回归生成与 KV Cache(3.7),最后说明这条流水线如何被改造为多模态入口(3.8)。
3.1 LLM 的本质:自回归的下一个词预测
今天几乎所有主流 LLM(GPT、LLaMA、Qwen、InternLM 等)都是 decoder-only 的自回归语言模型。它做的事情本质上只有一件:给定前面所有的词,预测下一个词。
把一段文本看作 token 序列 $t_1, t_2, \ldots, t_n$,LLM 用链式法则把整个序列的概率分解为一连串“预测下一个词”的条件概率之积:
\[P(t_1, t_2, \ldots, t_n) = \prod_{i=1}^{n} P(t_i \mid t_1, t_2, \ldots, t_{i-1})\]训练阶段,模型在海量文本上以下一个 token 预测(next-token prediction)为目标,最小化交叉熵损失;推理阶段,模型则反复执行“预测下一个 token → 把它接到输入末尾 → 再预测下一个”的循环,这就是自回归生成(autoregressive generation)。
整条文本处理流水线可以概括为下图:
flowchart LR
A["输入文本:一只猫"] --> B["分词器\nTokenizer"]
B --> C["Token IDs\n345, 1820, ..."]
C --> D["嵌入层\nEmbedding"]
D --> E["Transformer\n解码器 × N 层"]
E --> F["输出层\nLM Head"]
F --> G["词表概率分布\nsoftmax"]
G --> H["采样 / 解码\nSampling"]
H --> I["输出 Token"]
I -.自回归回填.-> C
style C fill:#fef3c7,stroke:#d97706
style E fill:#dbeafe,stroke:#2563eb,stroke-width:2px
style G fill:#dcfce7,stroke:#16a34a
下面逐段拆解这条流水线上的每一个环节。
3.2 文本输入(一):分词 Tokenization
计算机无法直接处理文字,第一步是把字符串切分成模型词表(vocabulary)中的基本单元——token,再把每个 token 映射为一个整数 ID。这一步称为分词(Tokenization)。
主流 LLM 普遍采用 子词分词(subword tokenization),代表算法是 BPE(Byte-Pair Encoding)及其变体(BBPE、WordPiece、Unigram)。子词的好处是在“字符级”与“词级”之间取得平衡:
- 常见词作为一个完整 token(如英文
the、中文常用字“猫”); - 罕见词被拆成若干子词(如
tokenization→token+ization); - 词表规模可控(典型为 32K~150K),既不会因词表太大而臃肿,也能覆盖任意未登录词(OOV)。
举例来说,“一只猫”可能被切为 一 / 只 / 猫 三个 token,也可能“一只”被合并为一个 token,具体取决于分词器在训练语料上学到的合并规则。英文中一个单词常对应 1~3 个 token,而中文受字节级编码影响,平均每个汉字约 0.6~1.5 个 token。
分词器还会插入若干特殊 token 来标记结构,例如句首 <bos>、句尾 <eos>、填充 <pad>,以及对话模板中的角色标记(如 <|user|>、<|assistant|>)。这一点对 VLM 至关重要:VLM 正是通过引入一个特殊的图像占位 token(如 <image>),在序列中为视觉特征“预留座位”(详见 3.8 与第 4 章)。
经过分词,输入文本变成一串整数 token ID,例如 [1, 345, 1820, 9, ...],这串整数就是送入模型的真正输入。
3.3 文本输入(二):嵌入与位置编码
整数 ID 本身没有语义,需要先转换为稠密向量。模型维护一张嵌入矩阵 $E \in \mathbb{R}^{V \times d}$($V$ 为词表大小,$d$ 为隐藏维度),第 $i$ 个 token 的嵌入向量就是按其 ID 在矩阵中查表得到的那一行:
\[\mathbf{x}_i = E[\,t_i\,], \quad \mathbf{x}_i \in \mathbb{R}^{d}\]这样,长度为 $n$ 的 token 序列就变成了一个 $n \times d$ 的矩阵,作为 Transformer 的输入。
由于自注意力机制本身不感知顺序(对它而言输入是一个无序集合),还必须显式注入位置信息。主流方案有两类:
- 绝对位置编码:早期 Transformer/GPT 把可学习或正弦的位置向量 \(\mathbf{p}_i\) 直接加到词嵌入上,即 \(\mathbf{x}_i = E[\,t_i\,] + \mathbf{p}_i\);
- 旋转位置编码(RoPE):现代 LLM(LLaMA、Qwen 等)主流方案,不再相加,而是在注意力计算时对 query/key 向量施加与位置相关的旋转,使注意力分数天然编码相对位置。RoPE 外推性好、便于扩展长上下文,也更易推广到多模态的二维/三维位置(VLM 中的 M-RoPE 即源于此,见 6.3 节)。
3.4 核心计算:Transformer 解码器堆叠
带位置信息的输入序列会依次穿过 $L$ 个结构相同的 Transformer 解码器层(典型 $L$ 从 7B 模型的 32 层到百亿级模型的 80+ 层)。每一层包含两个核心子模块,并均配有残差连接(residual)与层归一化(LayerNorm / RMSNorm,现代模型多用 Pre-Norm):
① 掩码多头自注意力(Masked Multi-Head Self-Attention)
注意力让每个 token 根据相关性“看”序列中的其他 token,并加权聚合它们的信息。对查询 $Q$、键 $K$、值 $V$:
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}} + M\right)V\]其中 $M$ 是因果掩码(causal mask):它把每个位置对“未来”token 的注意力分数置为 $-\infty$,从而保证位置 $i$ 只能看到 $1 \ldots i$ 的信息。这正是“自回归”在架构上的体现——模型在预测第 $i$ 个 token 时,绝不会偷看答案。“多头”(multi-head)则是把注意力拆成多组并行计算,让不同的头关注不同类型的依赖关系(语法、指代、长距离主题等)。
② 前馈网络(Feed-Forward Network, FFN)
注意力之后接一个逐位置的两层 MLP(现代模型常用 SwiGLU 激活),负责对每个 token 的表示做非线性变换与“知识存储”。FFN 通常占据模型大部分参数量。近年来的 MoE(混合专家) 架构(如 Qwen3-VL)正是把单个 FFN 替换为多个专家并稀疏激活,从而在不显著增加推理计算的前提下大幅扩展参数容量。
逐层堆叠后,序列中每个位置都得到一个融合了全部上文语义的最终隐状态 \(\mathbf{h}_i^{(L)} \in \mathbb{R}^{d}\)。其中最后一个位置的隐状态 \(\mathbf{h}_n^{(L)}\) 浓缩了“在已有上文条件下,下一个词应该是什么”的全部信息。
3.5 文本输出(一):从隐状态到词表概率
要把隐状态变回“词”,需要经过输出层(LM Head)——一个线性映射 $W_o \in \mathbb{R}^{V \times d}$(很多模型让它与输入嵌入矩阵 $E$ 共享权重,称为 weight tying)。它把 $d$ 维隐状态投影回 $V$ 维的logits(每个词表项一个未归一化分数),再经 softmax 得到下一个 token 的概率分布:
\[P(t_{i+1} \mid t_1, \ldots, t_i) = \text{softmax}\!\left(W_o\, \mathbf{h}_i^{(L)}\right)\]输出是一个长度为 $V$ 的概率向量,每一维对应词表中一个 token 的“接下来出现”的概率。至此,模型完成了一次完整的“前向传播”,把输入序列变成了对下一个 token 的概率预测。
3.6 文本输出(二):解码策略与采样
拿到概率分布后,如何从中选出一个具体的 token,称为解码(decoding)或采样(sampling)策略。不同策略在“确定性/质量”与“多样性/创造性”之间做权衡:
| 策略 | 做法 | 特点 | 适用场景 |
|---|---|---|---|
| 贪心解码 Greedy | 每步取概率最大的 token | 完全确定,但易重复、单调 | 抽取式任务、需要可复现 |
| 束搜索 Beam Search | 同时保留 top-$k$ 条候选序列 | 全局更优,但多样性差、算力高 | 机器翻译、摘要 |
| 温度采样 Temperature | 按 $\tau$ 缩放 logits 后采样 | $\tau$ 越大越随机 | 通用对话、创意写作 |
| Top-k 采样 | 仅在概率最高的 $k$ 个 token 中采样 | 截断长尾、避免离谱输出 | 常与温度联用 |
| Top-p(核)采样 Nucleus | 在累计概率达 $p$ 的最小集合中采样 | 动态候选数,质量与多样性兼顾 | 当前最主流 |
其中温度 $\tau$ 通过缩放 logits 调节分布的“尖锐程度”:
\[P(t) = \frac{\exp(z_t / \tau)}{\sum_{j} \exp(z_j / \tau)}\]$\tau \to 0$ 时分布趋于 one-hot(退化为贪心,输出最确定);$\tau > 1$ 时分布被抹平,输出更随机多样。实践中常把 温度 + Top-p 组合使用:先用 Top-p 截掉低概率长尾以保证质量,再用温度在保留集合内调节多样性。
3.7 自回归生成与 KV Cache
单次前向只能预测一个 token。要生成完整回答,模型须自回归循环:把刚采样出的 token 接到输入序列末尾,重新前向,预测再下一个,直到采样到结束符 <eos> 或达到长度上限。
flowchart LR
P["Prompt\n(并行 prefill)"] --> H1["预测 token₁"]
H1 --> H2["拼接 → 预测 token₂"]
H2 --> H3["拼接 → 预测 token₃"]
H3 --> D["... 直到结束符 eos"]
style P fill:#dbeafe,stroke:#2563eb
style D fill:#fee2e2,stroke:#dc2626
实际推理分为两个阶段:
- Prefill(预填充):把整段 prompt 一次性并行送入模型,计算所有位置的隐状态——这一步可高度并行,速度快;
- Decode(解码):之后每次只新增一个 token,逐步串行生成——这一步是逐 token 的,构成生成延迟的主要部分。
朴素实现中,每生成一个新 token 都要对整条序列重算注意力,计算量随序列长度平方增长,极其浪费。KV Cache 是关键优化:由于因果掩码下历史 token 的 Key/Value 不会因新增 token 而改变,可以把它们缓存起来,每步只为新 token 计算一次 Q/K/V,再与缓存的历史 K/V 做注意力。这把每步解码的计算从“重算整条序列”降为“只算一个 token”,是 LLM 实时推理的基石。
但 KV Cache 也带来显存与长度的矛盾:缓存大小随序列长度线性增长,注意力计算仍是 $O(n^2)$ 量级。这正是 VLM 面临的核心成本痛点——一张高分辨率图像可能展开成数百上千个视觉 token,长视频更是动辄上万 token,直接撑爆序列长度与显存。如何压缩视觉 token、在精度与效率间取得平衡,是第 4 章“高效多模态对齐”与“视觉 Token 压缩”(见 4.6 节)的核心议题。
3.8 从 LLM 到 VLM:视觉如何接入这条流水线
理解了文本流水线,多模态的接入点就一目了然了。回顾 3.2~3.3:文本之所以能进入 Transformer,是因为它最终被表示为一串 $d$ 维向量(token 嵌入)。那么——只要能把图像也变成同样维度、同样格式的向量序列,就能让 LLM“读”图。
这正是 VLM 的核心思路:
- 视觉编码器(如 CLIP ViT)把图像编码为一组 patch 特征向量;
- 连接模块(投影层 / Q-Former / 交叉注意力)把视觉特征映射到 LLM 的词嵌入空间,得到一批与文本 token 维度一致的视觉 token;
- 这些视觉 token 替换掉输入序列中预留的
<image>占位符,与文本 token 拼接成同一条序列,一起送入 Transformer 解码器。
从 LLM 的视角看,视觉 token 就像一串“外语词”——它照常用自注意力让文本 token 关注视觉 token、用同一套自回归机制生成回答。多模态融合的全部技巧,本质上就是设计第 2 步那个连接模块,让视觉 token 尽可能“说 LLM 听得懂的语言”。 不同的连接策略,就构成了下一章要系统梳理的各类多模态融合方法。
4. 实现多模态的核心方法
4.1 对比学习范式
对比学习(Contrastive Learning)是目前最成功的视觉-语言预训练范式之一,核心思想是:让配对的图文样本在嵌入空间中相互靠近,让不匹配的样本相互远离。
核心特点:
- 不依赖人工标注,可直接利用互联网上的海量图文对
- 学习到的视觉特征具有优秀的语义性,可迁移到下游任务
- 训练目标简洁(InfoNCE loss),易于大规模扩展
- 推理时通过计算图文相似度完成零样本分类
代表性工作:CLIP(OpenAI, 2021)、ALIGN(Google, 2021)、BLIP(Salesforce, 2022)、SigLIP(Google, 2023)
CLIP(Contrastive Language-Image Pre-training)
CLIP是对比学习范式的奠基性工作。OpenAI从互联网上收集了4亿个图文对(WIT数据集),分别训练图像编码器(ViT或ResNet)和文本编码器(Transformer),通过最大化正样本对相似度、最小化负样本对相似度来对齐视觉与语言空间。
\[\mathcal{L}_{CLIP} = -\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\text{sim}(v_i, t_i)/\tau)}{\sum_{j=1}^{N}\exp(\text{sim}(v_i, t_j)/\tau)}\]CLIP最大的突破在于零样本迁移:通过将类别名嵌入为文本提示(如”a photo of a dog”),无需任何微调即可在ImageNet等基准上取得接近监督学习的性能。
SigLIP(Sigmoid Loss for Language-Image Pre-Training)对CLIP进行改进,将softmax对比损失替换为逐对sigmoid损失,消除了对全局batch负样本的依赖,更适合大规模分布式训练。
BLIP(Bootstrapping Language-Image Pre-training)
BLIP提出了多目标联合预训练框架,同时优化三个目标:
- ITC(Image-Text Contrastive):对比对齐,继承CLIP思路
- ITM(Image-Text Matching):判断图文是否匹配(二分类)
- ITG(Image-grounded Text Generation):以图像为条件生成文本
BLIP还引入了CapFilt(Caption Filtering)机制:用已有模型对噪声网络数据生成伪标题,再过滤低质量样本,从而实现数据自举(bootstrapping)——以较少的高质量数据提升超大规模噪声数据的效果。
4.2 跨模态注意力融合
跨模态注意力(Cross-modal Attention)通过让文本token”关注”(attend to)视觉特征,或让视觉特征关注文本,实现两种模态的深度融合。这种方式允许模型在每一层推理时动态整合两种模态的信息。
核心特点:
- 深度融合,视觉与语言在每层特征提取时相互影响
- 对视觉细节的捕捉能力强,适合精细推理
- 参数量较大,但支持强大的多模态上下文建模
- 可扩展到少样本视觉语言学习
代表性工作:Flamingo(DeepMind, 2022)、ViLBERT(2019)、UNITER(2020)、CoCa(Google, 2022)
Flamingo
Flamingo是将大规模语言模型成功扩展为强多模态模型的早期里程碑工作。其核心设计包含两个关键模块:
Perceiver Resampler(感知重采样器):将任意数量、任意分辨率的图像特征压缩为固定数量(如64个)的视觉token,解决了可变长度视觉输入与固定格式语言模型之间的接口问题。
Gated Cross-Attention(门控交叉注意力层):在冻结的LLM层之间插入新的交叉注意力层,使语言token可以关注视觉token。门控机制(tanh gating)确保在训练初期新插入的层不破坏原有LLM能力。
\[y = y_{LLM} + \tanh(\alpha) \cdot \text{CrossAttn}(y_{LLM}, X_{visual})\]Flamingo冻结原始LLM参数,仅训练Perceiver Resampler和Cross-Attention层,实现了高效的多模态扩展,并在少样本(few-shot)视觉问答任务上取得了突破性性能。
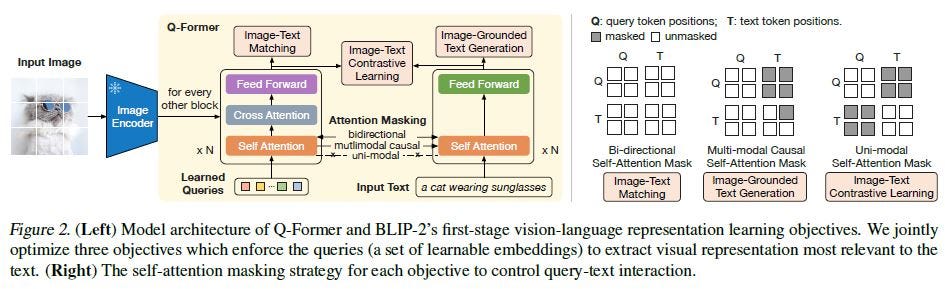
4.3 Q-Former桥接范式
Q-Former(Querying Transformer)是BLIP-2提出的创新性连接模块,通过一组可学习的查询向量(Query Tokens)作为视觉与语言之间的”信息瓶颈”,提取与语言最相关的视觉特征,再传递给语言模型。
核心特点:
- 以少量固定查询token(通常32个)提炼大量视觉patch特征
- 查询token通过self-attention互相交流,通过cross-attention提取视觉信息
- 可以同时连接任意视觉编码器和任意LLM,具有模块化优势
- 训练分两阶段,先对齐视觉-语言,再适配到生成式LLM
代表性工作:BLIP-2(Salesforce, 2023)、InstructBLIP(Salesforce, 2023)
BLIP-2
BLIP-2将视觉编码器(冻结的ViT-G)和大语言模型(冻结的OPT或Flan-T5)通过Q-Former桥接,实现低成本的多模态对齐。Q-Former包含两个共享self-attention层的Transformer模块:一个与视觉编码器交互(image Transformer),另一个与语言目标交互(text Transformer)。
两阶段训练:
- 视觉-语言表示学习:联合优化ITC+ITM+ITG三个目标,使Q-Former学会从图像中提取与语言相关的视觉特征
- 视觉-语言生成学习:将Q-Former输出的视觉查询token投影后拼接到LLM输入,微调Q-Former使其与LLM语义空间对齐
Q-Former仅有188M参数,却能有效”压缩”复杂的视觉信息,大幅降低了视觉-语言联合微调的计算成本。
InstructBLIP
InstructBLIP在BLIP-2基础上引入指令感知(instruction-aware)的Q-Former:将文本指令也输入Q-Former,使查询token能根据当前任务的指令动态地从图像中提取最相关的特征,而非提取固定的通用特征。这一改进显著提升了模型对不同任务指令的泛化能力。
4.4 视觉指令微调
视觉指令微调(Visual Instruction Tuning)是2023年以来最具影响力的VLM训练范式,核心思想是:使用(图像、指令、回答)三元组格式的对话数据对视觉语言模型进行监督微调,使模型能够遵循多样化的视觉相关指令。
核心特点:
- 将图像理解任务统一为对话式问答格式
- 利用GPT-4等强语言模型自动构造高质量指令数据
- 简化了架构:通常仅用线性投影层(MLP)连接视觉编码器与LLM
- 开源生态繁荣,LLaVA系列引领了大量后续工作
代表性工作:LLaVA(2023)、LLaVA-1.5(2023)、LLaVA-NeXT(2024)、MiniGPT-4(2023)
LLaVA(Large Language and Vision Assistant)
LLaVA提出了一套极简而有效的视觉指令微调框架:
- 架构:使用CLIP ViT-L/14作为视觉编码器,通过一个线性投影矩阵W将视觉特征映射到LLM(Vicuna/LLaMA)的词嵌入空间,视觉token与文本token直接拼接后输入LLM
- 数据构建:利用GPT-4(纯文本版本),基于图像的字幕和边界框信息生成多轮对话数据、详细描述和复杂推理题,构建了约158K条指令数据
- 两阶段训练:先预训练投影层(冻结编码器和LLM),再端到端微调投影层+LLM

LLaVA-1.5 与高分辨率扩展
LLaVA-1.5将线性投影升级为两层MLP,并引入更高分辨率的视觉编码器(CLIP ViT-L/14 @ 336px),在多个基准上大幅超越原始LLaVA,同时仍保持简洁的架构。
LLaVA-NeXT(LLaVA-1.6)进一步引入动态高分辨率技术:将高分辨率图像切分为多个小块(tiles),每块单独编码后拼接,同时保留低分辨率的整体视图,有效提升了对文字(OCR)、细节和图表的理解能力,且无需重新训练视觉编码器。
4.5 统一生成模型
统一生成模型(Unified Generative Models)将图像理解与文本生成统一在同一个自回归框架下,图像和文本均以token形式处理,模型以下一token预测的方式完成所有多模态任务。
核心特点:
- 架构极致统一,图像token与文本token在同一序列中处理
- 需要高质量的图像tokenizer(如VQ-VAE或连续特征提取)
- 训练目标统一(next-token prediction),可同时处理理解和生成
- 原生支持图文交错输入,具备强大的上下文学习能力
代表性工作:Gemini(Google DeepMind, 2023)、GPT-4V(OpenAI, 2023)、Qwen-VL/Qwen2.5-VL(Alibaba, 2023-2024)、InternVL2(上海AI Lab, 2024)
Gemini
Google DeepMind的Gemini系列是原生多模态模型的代表,从一开始就以多模态为核心设计目标,而非将LLM改造为多模态模型。Gemini能够无缝处理文本、图像、音频、视频和代码,每种模态都有专门的编码模块,通过统一的Transformer骨干进行联合建模。
Gemini 1.5引入了百万token上下文窗口,使其能够处理超长文档和长视频(可处理长达1小时的视频),在长上下文多模态理解上树立了新的里程碑。
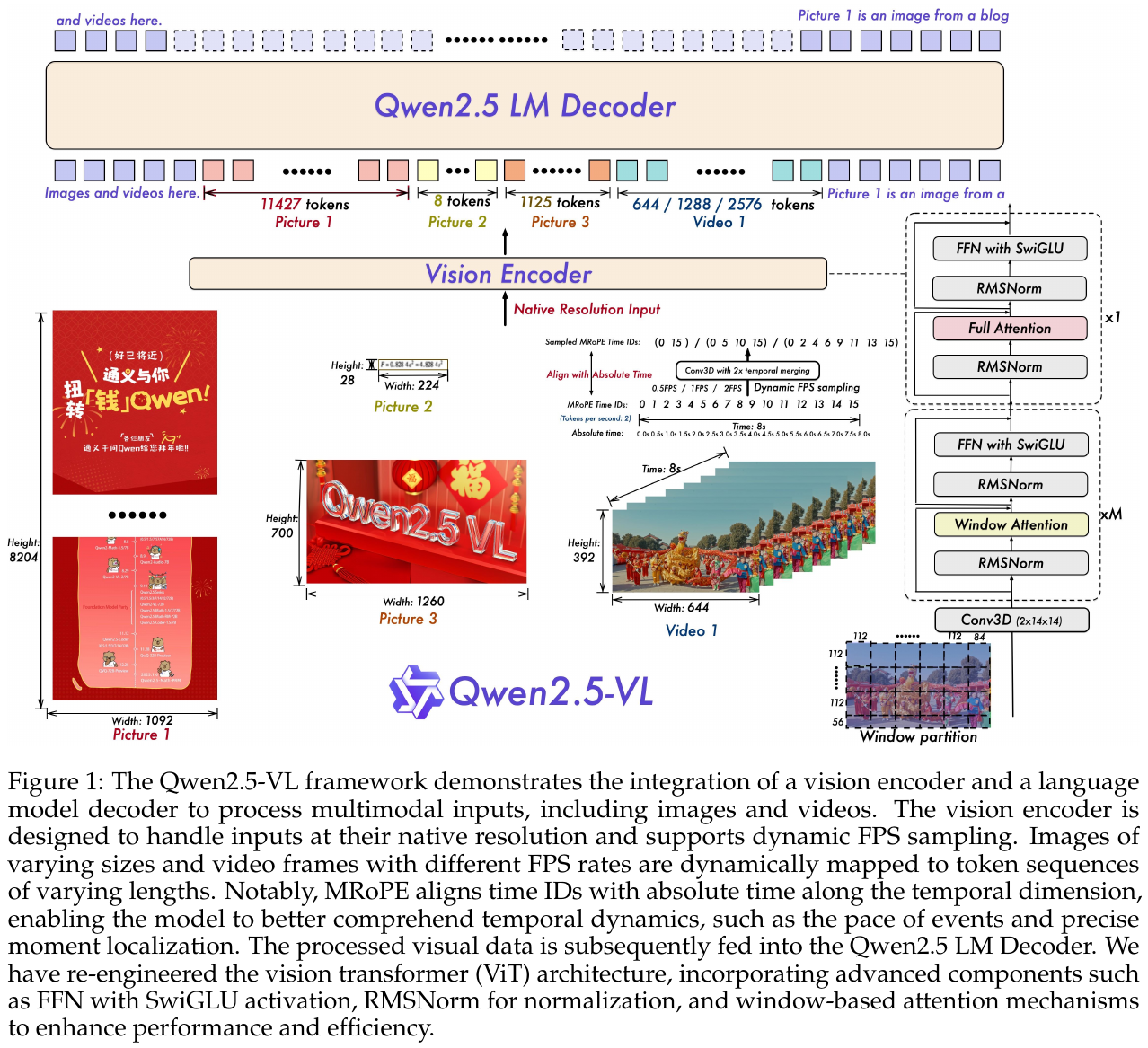
Qwen2.5-VL
Qwen2.5-VL是阿里巴巴推出的高性能开源VLM,在多模态处理技术上有若干创新:
原生动态分辨率(Native Dynamic Resolution):不再将图像resize到固定尺寸,而是直接处理任意长宽比和分辨率的图像,通过2D-RoPE位置编码精确保留空间信息。
窗口注意力(Window Attention):在视觉编码器中引入窗口注意力,减少大分辨率图像的计算量。
时序感知视频理解:对视频帧使用3D-RoPE编码(空间+时间),并动态采样帧率,在保证时序理解的同时降低token数量。
Qwen2.5-VL-72B 主要评测结果:
| 基准 | Qwen2.5-VL-72B | GPT-4o | InternVL2-76B |
|---|---|---|---|
| DocVQA | 96.4 | 92.8 | 94.1 |
| ChartQA | 89.5 | 85.7 | 88.4 |
| OCRBench | 877 | 736 | 794 |
| Video-MME(long) | 65.1 | 65.6 | 55.6 |
| MMBench(EN) | 88.0 | 83.4 | 86.5 |
在文档理解、图表理解和 OCR 任务上,Qwen2.5-VL-72B 全面超越 GPT-4o。它代表了开源 VLM 从”视觉插件”(视觉编码器 + LLM 双阶段拼装)向原生多模态架构演进的方向:动态分辨率打破固定尺寸限制,更强的视觉编码器提取更丰富的细粒度特征。
全模态与推理增强:GPT-4o、o3 与 Gemini 2.5
GPT-4o(OpenAI,2024)将图像、音频、视频整合为统一的全模态(omni)模型,实现了实时多模态交互(如视频通话中的实时视觉理解);Gemini 2.5 Pro(Google,2025)延续原生多模态路线,长上下文多模态处理能力尤为突出,是评测新一代开源模型时最重要的闭源参照。OpenAI o3(2025)则将推理模型扩展到多模态——其视觉能力不依赖独立的视觉微调,而是把视觉推理视为通用推理能力的自然延伸,这与 Qwen3-VL”更强文本基座支撑多模态推理”(见 8.8 节)的思路高度一致,共同揭示了 2025-2026 年的核心趋势:推理能力是多模态理解的天花板,而非模态对齐技术本身。中文生态中,智谱 GLM-4.5 代表”以工具调用和 Agent 能力为差异化”的路线,与端到端推理路线形成互补。
4.6 高效多模态对齐方法
随着VLM参数量不断增大,如何以更低的计算成本实现高质量的多模态对齐成为重要研究方向。
核心特点:
- 冻结大部分预训练权重,仅微调少量参数
- 通过精心设计的对齐模块弥补视觉与语言之间的语义鸿沟
- 高效利用已有的视觉编码器和LLM的知识
代表性工作:MiniGPT-4(KAUST, 2023)、mPLUG-Owl(阿里达摩院, 2023)、Otter(南洋理工, 2023)
MiniGPT-4
MiniGPT-4证明了极简对齐方案的可行性:仅用一个线性投影层连接冻结的BLIP-2视觉编码器(含Q-Former)和冻结的Vicuna(LLaMA微调版),通过两阶段训练——先大规模对齐预训练,再小量高质量数据指令微调——即可达到接近GPT-4的图像描述和视觉理解能力。MiniGPT-4揭示了Q-Former与LLM之间的语义鸿沟并非难以弥合,关键在于高质量的指令微调数据。
视觉 Token 压缩
视觉 token 数量直接决定 VLM 的推理成本,压缩技术是高效化的关键:
| 方法 | 原理 | 压缩比 | 代表模型 |
|---|---|---|---|
| Pixel Shuffle | 相邻4个 patch token 合并为1个 | 4:1 | InternVL2、SmolVLM |
| TokenPacker | 交叉注意力从密集特征中提取少量高语义 token | 可变 | TokenPacker(2024) |
| 平均池化 | 对相邻 token 取平均 | 可变 | LLaVA-HD |
| Q-Former | 固定32个 Query Token 提炼所有视觉信息 | 高倍 | BLIP-2、InstructBLIP |
轻量化 VLM 与端侧部署
随着端侧部署(手机、边缘设备)需求快速增长,在极低参数量下实现有竞争力的多模态理解成为热点。SigLIP 视觉编码器(sigmoid 损失对小 batch 更友好,见 8.6 节)已成为轻量 VLM 的首选视觉骨干:
- Phi-3.5-Vision(Microsoft,2024):3.8B 总参数,靠超高密度 SFT 数据在 MathVista、TextVQA 等基准上超越同参数级所有模型
- SmolVLM(HuggingFace,2024):256M / 2B 两个版本,SigLIP + Pixel Shuffle(每 patch 的 token 从729压缩至64),2B 版 DocVQA 达 81.7,优于 PaliGemma-3B(74.0)
- MobileVLM V2(2024):专为手机端设计,通过知识蒸馏与轻量视觉连接器在骁龙 8 Gen 3 上实现约 20 token/s 实时推理
- moondream2(2024):仅 1.86B 参数,可在 Raspberry Pi 4 等低功耗设备本地运行
- MoE-LLaVA(2024):稀疏激活混合专家结构,2.2B 激活参数超越 3.5B 密集模型
- Gemma 3(Google,2025,27B 主力版本):”轻量级强多模态开源基座”的代表,人类偏好评测超过部分更大体量模型
| 模型 | 参数量 | TextVQA | DocVQA | 特点 |
|---|---|---|---|---|
| SmolVLM-2B | 2B | 72.7 | 81.7 | 极低内存,HF生态 |
| Phi-3.5-Vision | 3.8B | 72.0 | 72.3 | 微软高密度SFT |
| PaliGemma-3B | 3B | 73.1 | 74.0 | Google多任务 |
| MoE-LLaVA-2.2B | 2.2B | 59.4 | — | 稀疏激活MoE |
| moondream2 | 1.86B | 70.5 | — | 树莓派可运行 |
后贴合范式:复用最强指令 LLM
Ovis2-34B(AIDC-AI)代表另一条高效路线——后贴合(post-hoc alignment):aimv2-1B 视觉编码器 + 现成的 Qwen2.5-32B-Instruct 语言模型,无需从零联合训练,通过高质量对齐数据快速跟进最新 LLM。与 Qwen3-VL 的端到端统一训练相比,这条工程路线具备快速迭代优势,在资源受限场景中有实用价值。
4.7 视觉特征提取:ViT与视觉编码器的演进
实现高质量多模态融合的前提是强大的视觉表示。VLM中视觉编码器的设计经历了从CNN到Transformer的重大转变。
核心演进路线:
- CNN时代(2018-2020):ResNet、EfficientNet提取区域特征,与文本编码器拼接
- ViT时代(2021-2022):将图像切分为patch序列,用Transformer编码,与NLP架构统一
- CLIP ViT时代(2021至今):针对图文对比学习训练的ViT,成为VLM的主流视觉编码器
- 纯视觉自监督路线(2021至今):DINO→DINOv2,无语言监督,patch级密集特征更优,适合密集预测任务和 VLM 视觉骨干初始化
- 高分辨率ViT时代(2023至今):支持任意分辨率、动态切片的视觉编码方案
Vision Transformer(ViT)
ViT将图像分割为固定大小的patch(如16×16像素),每个patch线性嵌入后加上位置编码,作为Transformer的输入token序列。ViT在大规模图像数据上预训练后,可以提取丰富的全局语义特征,并与文本Transformer共享相似的架构,极大简化了视觉-语言的融合设计。
\[z_0 = [x_{cls}; x_1^p E; x_2^p E; \ldots; x_N^p E] + E_{pos}\]主流VLM采用的视觉编码器通常是在CLIP目标或SigLIP目标下训练的ViT-L(307M参数)或ViT-G(1.8B参数)。
DINOv2:纯视觉自监督的另一条路线
论文:DINOv2: Learning Robust Visual Features without Supervision 机构:Meta AI Research 发表:TMLR 2024,作者:Maxime Oquab, Timothée Darcet, Théo Moutakanni 等
DINOv2 代表了与 CLIP/SigLIP 完全不同的视觉编码器训练路线——全程无语言监督,仅用图像自身的结构信息学习视觉表示。其 patch 级别的空间语义特征在密集预测任务(语义分割、深度估计)上显著优于同等规模的 CLIP ViT,并已被用于部分 VLM 的视觉编码器初始化。
精华:DINOv2 的核心价值在于摆脱语言偏置,提取纯视觉语义。CLIP 的视觉特征是为了与语言嵌入对齐而优化的,天然带有语言标注所引入的语义粒度偏差;而 DINOv2 完全基于图像自监督,其 patch 特征具有更细腻的空间语义一致性——简单的线性探测就能精准分割物体,无需任何分割标注。这种能力来源于学生-教师自蒸馏的”局部-全局一致性”目标:网络被迫让局部 crop 与全局视图在语义上一致,从而习得强大的空间感知表示。局限在于 DINOv2 不含语言对齐,无法直接用于零样本图文检索或分类,必须配合语言模型才能发挥 VLM 能力。
训练方法:学生-教师自蒸馏
DINOv2 使用自蒸馏(Self-Distillation)框架,无需任何标注数据:
网络结构:
- 学生网络(Student):参数由梯度下降更新
- 教师网络(Teacher):参数为学生网络的指数移动平均(EMA),不接受梯度,充当”稳定的伪标签生成器”
多尺度裁剪策略:
- 每张图像随机裁剪出 2 个全局视图(global crops,覆盖原图 ≥50% 面积,分辨率 224×224)和 多个局部视图(local crops,覆盖原图 20%–50%,分辨率 96×96)
- 教师网络只处理全局视图,学生网络处理所有视图(全局 + 局部)
- 训练目标:学生网络从局部视图预测的表示,与教师网络从全局视图提取的表示保持一致
这一局部-全局一致性目标迫使网络习得”从局部 patch 推断整体语义”的能力,是 DINOv2 patch 特征空间一致性优异的根本原因。
联合训练目标
DINOv2 在原始 DINO(2021)基础上,同时优化三个目标:
| 目标 | 作用 | 操作粒度 |
|---|---|---|
| DINO loss(自蒸馏交叉熵) | [CLS] token 级别的表示对齐 | 图像级 |
| iBOT loss(在线 tokenizer 蒸馏) | 随机遮蔽 patch 的重建,学习 patch 级别语义 | Patch 级 |
| SwAV 正则化(聚类一致性) | 避免特征坍缩(collapse),保持特征多样性 | 批次级 |
其中 iBOT 目标是 DINOv2 patch 特征质量远超原版 DINO 的关键——网络必须通过上下文重建被遮蔽的 patch,从而学习每个 patch 的细粒度空间语义。
数据策略:LVD-142M 精选数据集
数据质量对自监督学习至关重要。DINOv2 专门构建了 LVD-142M(Large-scale curated image dataset, 1.42亿图像):
- 去重:对原始爬取数据进行 copy-detection,移除近似重复图像
- 自监督过滤:用已有自监督模型提取特征,基于特征近邻保留视觉内容多样的图像,剔除低质量样本
- 领域平衡:从 ImageNet-22K、Google Landmarks 等 curated 数据集中抽取种子图像,再用最近邻检索扩充相近风格的网络图像,保证内容分布均衡
LVD-142M 无需任何人工标注,却比直接使用 400M 未筛选网络图像的效果更好——说明数据质量 > 数据规模。
模型规格
| 模型 | 参数量 | 层数 | 隐层维度 | 注意力头 | Patch Size |
|---|---|---|---|---|---|
| ViT-S/14 | 21M | 12 | 384 | 6 | 14×14 |
| ViT-B/14 | 86M | 12 | 768 | 12 | 14×14 |
| ViT-L/14 | 307M | 24 | 1024 | 16 | 14×14 |
| ViT-g/14 | 1.1B | 40 | 1536 | 24 | 14×14 |
所有变体均使用 patch size 14×14(比 CLIP 常用的 32×32 或 16×16 更细),提供更高密度的 patch token,适合需要精细空间感知的任务。
核心能力:密集预测的天然优势
DINOv2 的 patch 特征具有强大的空间语义一致性,直接用于密集预测任务时无需复杂解码头:
语义分割(线性探测,ADE20K,mIoU):
| 模型 | 参数量 | 训练方式 | ADE20K mIoU |
|---|---|---|---|
| CLIP ViT-L/14 | 307M | 图文对比 | 39.9 |
| OpenCLIP ViT-G/14 | 1.8B | 图文对比 | 40.4 |
| DINOv2 ViT-L/14 | 307M | 纯视觉自监督 | 53.8 |
| DINOv2 ViT-g/14 | 1.1B | 纯视觉自监督 | 55.1 |
DINOv2 ViT-L(307M)在仅添加线性探测头(无卷积解码器)的情况下,mIoU 达到 53.8,比参数量是其6倍的 OpenCLIP ViT-G(40.4)高出约14个点,验证了语言监督在密集任务上的固有局限。
单目深度估计(NYUd,δ1 精度):
| 方法 | 主干 | δ1(↑) | Rel(↓) |
|---|---|---|---|
| DPT + CLIP ViT-B/16 | 86M | 0.863 | 0.105 |
| DPT + DINOv2 ViT-B/14 | 86M | 0.935 | 0.069 |
| DPT + DINOv2 ViT-g/14 | 1.1B | 0.957 | 0.058 |
无监督语义分割(Emergent Segmentation):
DINOv2 最令人印象深刻的涌现能力是无需任何分割标注即可产生语义一致的 patch 分组。对 patch 特征做简单的 PCA 或 k-means 聚类,就可以得到语义一致的物体分割结果:

DINOv2 vs CLIP:两条路线的对比
| 维度 | CLIP ViT-L/14 | DINOv2 ViT-L/14 |
|---|---|---|
| 训练监督 | 图文对比(语言监督) | 纯图像自蒸馏(无语言) |
| 特征粒度 | 图像级对齐为主 | Patch 级语义更细腻 |
| 零样本分类 | 强(75.3% ImageNet Top-1) | 需配合分类头(82.1%,kNN) |
| 语义分割(线性探测) | 39.9 mIoU(ADE20K) | 53.8 mIoU |
| 深度估计 | 一般 | 显著更优 |
| 图文检索 | 强(原生支持) | 不支持(无语言对齐) |
| 语言偏置 | 有(受标注语言分布影响) | 无 |
| VLM 中的角色 | 主流视觉骨干(直接用于图文对齐) | 初始化/密集任务增强(需配合语言对齐) |
核心结论:CLIP 的视觉特征为”语言可感知”的图像级语义而优化,适合图文检索和分类;DINOv2 的特征为”纯视觉”的 patch 级空间语义而优化,适合密集预测。两者并非竞争关系,而是互补——部分 VLM 研究(如 Cambrian-1)探索了将 DINOv2 与 CLIP 特征融合,同时获得语言对齐能力和密集空间感知能力。
在 VLM 中的应用
尽管 DINOv2 本身不含语言模块,但已在 VLM 研究中发挥重要作用:
- InternViT 初始化:InternViT-6B 的预训练借鉴了 DINO 系自监督目标,在视觉编码器规模扩大的同时保持了 patch 特征的空间一致性
- Cambrian-1(NYU,2024):提出空间视觉聚合器(Spatial Vision Aggregator),将 DINOv2 ViT-L(密集 patch 特征)与 SigLIP(语言对齐特征)融合,在 MMBench、Science-QA 等多个基准上超越单一视觉编码器方案
- Dense VLM 任务:在需要精细视觉定位的任务(Referring Expression Comprehension、视觉 Grounding、医学图像分析)中,以 DINOv2 特征作为额外输入可显著提升定位精度
4.8 视频理解:向时序维度扩展
视频理解要求模型同时处理空间视觉内容(每帧图像)和时序动态信息(帧间变化),是 VLM 能力扩展的重要前沿方向。
核心挑战:
- Token 爆炸:一段10秒视频(3fps)约30帧,每帧256~1024个 token,总计数千至数万 token,远超 LLM 的高效处理范围
- 时序推理:模型需理解动作顺序、因果关系、运动轨迹等跨帧语义
- 长视频理解:数分钟甚至数小时的视频对记忆与检索机制提出极高要求
VideoLLaMA2(阿里达摩,2024)引入时空卷积连接器(Spatiotemporal Convolution Connector):对连续帧的 ViT 特征施加 3D 卷积(时间 × 高 × 宽),同时建模帧内空间结构与帧间时序变化,并通过时序池化将视频 token 压缩为固定数量,在 MVBench(时序推理)和 EgoSchema(第一人称视角理解)上超越早期 Video-LLaVA 约10个百分点。
LongVA(2024)探索百万级 token 上下文的长视频理解:直接利用长上下文 LLM(Yi-9B-200K),将视频帧稀疏采样后拼接为超长序列,无需专用时序模块,在 Video-MME 长视频子集上取得竞争性结果。
Qwen2.5-VL 通过 3D-RoPE 和动态帧率采样支持数十分钟的超长视频;Qwen3-VL 进一步以显式文本时间戳与 Interleaved MRoPE 将多模态上下文扩展到 256K(30分钟视频内 Needle-in-a-Haystack 100% 准确率,见 8.10 节)。
主流视频理解基准:
| 基准 | 视频长度 | 主要任务 | 顶尖模型(分数) |
|---|---|---|---|
| Video-MME(short) | <2分钟 | 短视频综合理解 | Qwen2.5-VL-72B(71.6) |
| Video-MME(long) | >30分钟 | 长视频问答 | GPT-4o(65.6) |
| MVBench | <1分钟 | 时序动作推理 | VideoLLaMA2-7B(58.1) |
| EgoSchema | ~3分钟 | 第一人称视角 | GPT-4V(76.2) |
| ActivityNet-QA | ~3分钟 | 视频内容问答 | Qwen2.5-VL-72B(61.8) |
5. VLM任务类型
1. 图像描述(Image Captioning)
给定图像,生成自然语言描述。是最基础的视觉生成任务,也是VLM训练的常见预训练目标之一。
代表性数据集:COCO Captions、nocaps、Flickr30k
2. 视觉问答(Visual Question Answering, VQA)
给定图像和问题,输出答案。分为开放式(生成型)和闭集(分类型)两种形式。
代表性数据集:VQA v2、OK-VQA、GQA、ScienceQA
3. 视觉推理(Visual Reasoning)
要求模型对图像进行多步推理,如计数、空间关系判断、因果推断等。
代表性数据集:NLVR2、CLEVR、MMStar、MMBench
4. 视觉定位(Visual Grounding / Referring Expression Comprehension)
根据自然语言描述,在图像中定位目标区域(输出边界框)。
代表性数据集:RefCOCO、RefCOCO+、Visual7W
5. 文档与图表理解(Document / Chart Understanding)
理解包含文字、表格、图表的复杂文档图像,是近年VLM能力提升的重点方向。
代表性数据集:DocVQA、ChartQA、TextVQA、OCRBench
6. 图文检索(Image-Text Retrieval)
给定图像检索相关文本(或反之),是对比学习范式的核心应用场景。
代表性数据集:MSCOCO Retrieval、Flickr30k Retrieval
7. GUI Agent / 多模态智能体(GUI Automation)
VLM 正从”被动理解”演化为”主动执行”:感知屏幕状态、规划操作序列、执行鼠标键盘动作。这要求模型具备四项核心能力——精确视觉定位(在截图中定位按钮、输入框等 UI 元素)、操作序列规划(将”帮我订机票”分解为具体操作步骤)、状态追踪(判断操作是否成功并实现错误恢复)、跨应用协同。
UI-TARS(字节跳动,2025)是目前性能最强的开源 GUI Agent 模型:基于数百万 GUI 截图样本(元素识别、状态感知、操作预测三层精细标注)训练,并引入 System 2 慢思考推理——执行操作前先生成操作理由、预期效果与风险判断,大幅减少误操作:
| 基准 | UI-TARS-7B | GPT-4V | Claude 3.5 Sonnet |
|---|---|---|---|
| ScreenSpot(定位精度) | 82.8% | 44.8% | 70.7% |
| OSWorld(截图+动作) | 24.6% | 11.8% | 22.0% |
| AndroidWorld | 46.6% | — | 27.8% |
其他代表工作:SeeClick(2024)专攻 GUI 元素定位,可作轻量级定位骨干;ShowUI(2024)用 UI 连接图建模元素间结构关系;ScreenAgent(2024)将规划(Planner)、执行(Actor)、验证(Critic)分离为三个专用模块。闭源侧,Claude 3.5 Sonnet(Computer Use,2024)率先开放 API 级电脑操作接口,Gemini 2.0 Flash 将浏览器与 Android 操作原生集成进模型服务。
代表性基准:ScreenSpot、OSWorld、AndroidWorld
6. VLM训练流程与关键技术
VLM 的训练旨在将视觉的感性认知与语言的理性推理相结合,构建起跨模态的理解和生成能力。与传统的单模态模型训练相比,VLM 的训练往往不是”从头开始”(from-scratch),而是利用已有的强大预训练成果(如预训练的 ViT 视觉编码器和 LLM 大语言模型),重点解决模态对齐、多任务泛化以及指令对齐等核心问题。
这一节我们将详细介绍经典的 VLM 三阶段训练范式(6.1)、偏好对齐技术(6.2)、训练中涉及的关键支撑技术(6.3);随后转向实操视角——超参数如何设置与调整(6.4)、训练过程中如何监控指标与解读 loss 曲线(6.5)、训练出问题时如何排查(6.6);最后对 Qwen-VL 系列模型的训练演进路径进行深度案例剖析(6.7)。
6.1 经典三阶段训练范式 (Three-Stage Training Pipeline)
现代大语言模型驱动的 VLM(如 LLaVA、MiniGPT-4、InternVL 等)通常遵循一个经典的三阶段训练 pipeline。这一流水线通过逐步解冻参数和优化不同规模与质量的数据集,使得视觉与语言表征能够层层对齐。
flowchart TD
%% Define styles
classDef frozen fill:#f3f4f6,stroke:#9ca3af,stroke-width:1px,stroke-dasharray: 5 5,color:#6b7280;
classDef active fill:#dbeafe,stroke:#2563eb,stroke-width:2px,color:#1e3a8a;
classDef data fill:#fef3c7,stroke:#d97706,stroke-width:1.5px,color:#78350f;
subgraph Stage1 ["第一阶段:模态特征对齐 (Visual-Language Alignment)"]
direction LR
D1["弱监督/粗粒度图文对\n(如 LAION, CC3M, 亿级)"]:::data --> S1_Model
subgraph S1_Model ["模型状态"]
S1_VE["视觉编码器\n(Frozen)"]:::frozen
S1_Proj["连接模块/投影层\n(Active)"]:::active
S1_LLM["LLM 语言模型\n(Frozen)"]:::frozen
S1_VE --> S1_Proj --> S1_LLM
end
end
subgraph Stage2 ["第二阶段:多任务联合预训练 (Joint Multi-task Pre-training)"]
direction LR
D2["精细化多模态数据\n(OCR, Grounding, VQA)"]:::data --> S2_Model
subgraph S2_Model ["模型状态"]
S2_VE["视觉编码器\n(Active/Unfrozen)"]:::active
S2_Proj["连接模块/投影层\n(Active)"]:::active
S2_LLM["LLM 语言模型\n(Active/Unfrozen)"]:::active
S2_VE --> S2_Proj --> S2_LLM
end
end
subgraph Stage3 ["第三阶段:监督指令微调 (Supervised Fine-Tuning, SFT)"]
direction LR
D3["高质量对话与指令对\n(LLaVA-Instruct, 交互对话)"]:::data --> S3_Model
subgraph S3_Model ["模型状态"]
S3_VE["视觉编码器\n(Frozen/Selective)"]:::frozen
S3_Proj["连接模块/投影层\n(Active)"]:::active
S3_LLM["LLM 语言模型\n(Active/Unfrozen)"]:::active
S3_VE --> S3_Proj --> S3_LLM
end
end
Stage1 --> Stage2 --> Stage3
1. 第一阶段:模态特征对齐(Pre-training / Alignment)
- 训练目标:将视觉特征投影到大语言模型的文本嵌入空间,建立最初步的”语义桥梁”。
- 参数冻结策略:冻结视觉编码器(Vision Encoder)与大语言模型(LLM),仅训练连接模块(Connector / Projection layer,如简单的 MLP 投影层、Q-Former 或 Cross-Attention 层)。
- 训练数据:海量、弱监督的短文本图文对(通常为数千万至数亿对),如 LAION-5B、CC3M、CC12M。这一阶段的数据噪音较大,但可以提供宽广的视觉概念覆盖。
- 核心逻辑:这一阶段模型主要进行”概念配对”,即让 LLM 认识到图像中的实体与特定的文本 token 存在映射关系。由于 LLM 保持冻结,其原本的语言生成和推理能力不会受到干扰。
2. 第二阶段:多任务联合预训练(Joint Pre-training)
- 训练目标:提升模型在细粒度视觉任务(如定位、密集文本阅读 OCR、高精度视觉问答等)上的泛化能力,实现深度的跨模态感知。
- 参数冻结策略:通常全部解冻(Unfreeze),包括视觉编码器、连接模块和 LLM。在某些轻量级微调方案中,也会选择冻结视觉编码器或对其使用 LoRA。
- 训练数据:高质量、混合格式的多任务多模态数据集(例如,包含边界框定位 Grounding、密集 OCR 识别、图表解析和长视频描述的混合数据)。
- 核心逻辑:通过让视觉编码器也参与参数更新,模型可以根据跨模态任务的要求对视觉表示进行自适应微调(例如,学习识别图像中极小的文字或精确的目标边界)。这使得模型在处理细粒度特征时更加得心应手。
3. 第三阶段:监督指令微调(Supervised Fine-Tuning, SFT)
- 训练目标:使模型对齐人类的对话习惯、遵循复杂的推理指令,形成类似 Chat 助手的交互式对话能力。
- 参数冻结策略:解冻 LLM 和连接模块,通常冻结视觉编码器(防止在纯文本指令微调和多模态对话训练中出现视觉特征的灾难性遗忘,并保护 LLM 原有的纯文本性能)。
- 训练数据:精心清洗的高质量指令跟随数据集(通常在几万到百万级),例如 LLaVA-Instruct、ShareGPT4V,以及通过 GPT-4/GPT-4V 自动生成的复杂多轮对话数据。
- 核心逻辑:模型在此阶段学习如何以流畅的语气回答用户的开放式问题,进行多轮追问,并能够安全地拒绝不合理的输入。
6.2 偏好对齐与后训练 (Preference Alignment & Post-Training)
随着 VLM 被广泛应用于复杂的实际场景,仅通过 SFT 训练的模型仍面临两个严峻问题:多模态幻觉(Multimodal Hallucination)(即编造图像中不存在的物体或关系)以及生成格式失控/对齐不良。为此,现代 VLM 开始引入后训练(Post-training)偏好对齐技术。
flowchart LR
classDef step fill:#f0fdf4,stroke:#16a34a,stroke-width:1.5px,color:#14532d;
classDef loss fill:#fef2f2,stroke:#dc2626,stroke-width:1.5px,color:#7f1d1d;
subgraph DPO ["直接偏好优化 (DPO)"]
direction TB
InputD["输入图像 + 问题"] --> RespA["生成回答 A (更优偏好)"]:::step
InputD --> RespB["生成回答 B (多幻觉/劣质)"]:::loss
RespA & RespB --> LossDPO["DPO 损失函数\n(拉近 A, 拉远 B)"]:::loss
end
subgraph GRPO ["群体相对策略优化 (GRPO)"]
direction TB
InputG["输入图像 + 推理题"] --> Samples["采样群体 [R1, R2, ..., Rn]"]:::step
Samples --> RewardFunc["混合奖励函数\n(准确率奖励 + 格式奖励)"]:::step
RewardFunc --> PolicyUpdate["策略梯度更新\n(无需 Critic 模型)"]:::loss
end
1. 直接偏好优化 (Direct Preference Optimization, DPO)
在多模态场景下,研究者会收集或使用强模型(如 GPT-4V)来评判 VLM 自身的输出,从而构建偏好对齐数据集:
- 更优样本 ($y_w$):准确描述图像、无幻觉且符合人类偏好的回答。
- 更差样本 ($y_l$):包含事实错误、视觉幻觉或格式混乱的回答。
DPO 通过直接在偏好数据上最大化正负样本的似然差值,使 VLM 更加”诚实”,大幅减少无脑编造现象。
2. 群体相对策略优化 (Group Relative Policy Optimization, GRPO)
在训练诸如 Qwen2.5-VL 等具备强推理能力(Reasoning)的视觉大模型时,传统的 PPO (Proximal Policy Optimization) 算法由于需要加载一个与 Actor 模型同等大小的 Critic 模型,会带来极大的显存开销。
GRPO 针对每个问题采样一组模型输出(群体),通过这组输出的相对奖励来计算策略梯度,彻底丢弃了 Critic 模型:
- 奖励函数(Reward Function):通常包含规则奖励(如对数学题、视觉推理题的判题对错)和格式约束奖励(如强制模型在
<thought>标签中输出思维链,并在最后给出答案)。 - 作用:引导 VLM 进行长思维链(CoT)推理,自主纠正图像中难以察觉的视觉细节错误。
3. 视觉推理增强的代表性实践
受 o1/DeepSeek-R1 推理突破的启发,2024-2025 年涌现出一批将结构化思维链与 RLVR(可验证奖励强化学习)应用于 VLM 的工作:
LLaVA-CoT(2024)构建了四阶段结构化推理框架——摘要(Summary)→ 描述(Caption)→ 推理(Reasoning)→ 结论(Conclusion),在 GPT-4V 生成的结构化推理数据上 SFT 后,11B 模型在 ScienceQA 等推理基准上超越参数量多10倍的 GPT-4V;还引入测试时 Best-of-N 采样(并行采样多条推理链取最优)进一步提升准确率。
R1-V(2025)将 GRPO 框架引入 VLM,针对可验证的视觉推理任务(数学、几何、计数)设计奖励函数,7B 模型在 MathVista 上的准确率从约 35% 提升至约 55%,超越同规模 SFT 方法。Visual-RFT(清华,2025)将 RLVR 应用于细粒度视觉识别(目标检测、医学图像),以 IoU 作为奖励函数优化定位精度。InternVL2-MPO 通过混合偏好优化(MPO)与拒绝采样显著减少幻觉,在 MMHal-Bench 和 POPE 上大幅领先基础版本。
| 基准 | 任务类型 | 顶尖开源模型 | 参考分数 |
|---|---|---|---|
| MathVista(testmini) | 数学视觉推理 | InternVL2.5-78B | ~72% |
| MMStar | 综合多模态推理 | Qwen2.5-VL-72B | ~69% |
| ScienceQA(img) | 多学科科学推理 | LLaVA-CoT-11B | ~96% |
| MMMU(val) | 大学级多学科 | Qwen2.5-VL-72B | ~70% |
6.3 核心技术关键点 (Key Training Technologies)
要想让 VLM 训练既高效又精确,离不开一系列底层架构与算法的支撑:
1. 原生动态分辨率 (Naive Dynamic Resolution)
早期的 VLM(如 LLaVA-1.0)通常强行将不同宽高比的图像裁剪并缩放为固定的方形像素(如 $224 \times 224$ 或 $336 \times 336$)。这导致长条形图片被拉伸变形、细小物体失真,且高分辨率图像信息丢失严重,无法识别小字(OCR)。
动态分辨率方案(如 Qwen2-VL 的 Naive Dynamic Resolution 或 InternVL 的 Dynamic Patching):
- 根据原始宽高比,将图片自适应划分为若干个局部 Patch,同时保留一张整图的低分辨率缩略图。
- 训练时,模型需处理动态长度的视觉 token 序列。
flowchart LR
classDef step fill:#fafaf9,stroke:#78716c,stroke-width:1.5px;
classDef concept fill:#f0fdfa,stroke:#0d9488,stroke-width:1.5px;
Img["原始图像\n(任意宽高比 H x W)"] --> Split["自适应切片\n(Split into Patches/Blocks)"]:::step
Split --> ViT["ViT 视觉编码器\n(Window Attention 提取)"]:::step
ViT --> Tokens["动态长度视觉 Token 序列"]:::concept
Tokens --> MROPE["3D M-RoPE\n(时序、高度、宽度编码)"]:::step
MROPE --> LLM["LLM 融合理解"]:::concept
2. 多模态旋转位置编码 (Multimodal Rotary Position Embedding, M-RoPE)
在传统的 LLM 中,RoPE 是一维的(只对文本顺序编码)。但在多模态输入下,图像包含二维空间坐标(高度 $H$、宽度 $W$),视频则包含三维空间+时间坐标(时间 $T$、高度 $H$、宽度 $W$)。
M-RoPE 的解决方案:
- 将旋转位置编码解耦为时间、高度、宽度三个维度。
- 对于文本,仅在 1D 维度上递增;对于图像中的视觉 token,其位置编码表示为 $(h, w)$ 组合;对于视频,位置编码表示为 $(t, h, w)$ 组合。
- 在训练中,这使得模型即使在处理极长的视频或极高分辨率的拼接图片时,也能够清晰辨别不同帧、不同像素块之间的相对时序和空间物理关系。
6.4 训练超参数实战指南 (Hyperparameter Tuning in Practice)
论文中的超参数表往往只告诉你”最终用了什么值”,但实践中更有价值的是:为什么是这些值?当自己的算力、数据与论文不同时,该往哪个方向调?本节把 VLM 训练中最关键的几组超参数逐一拆解。
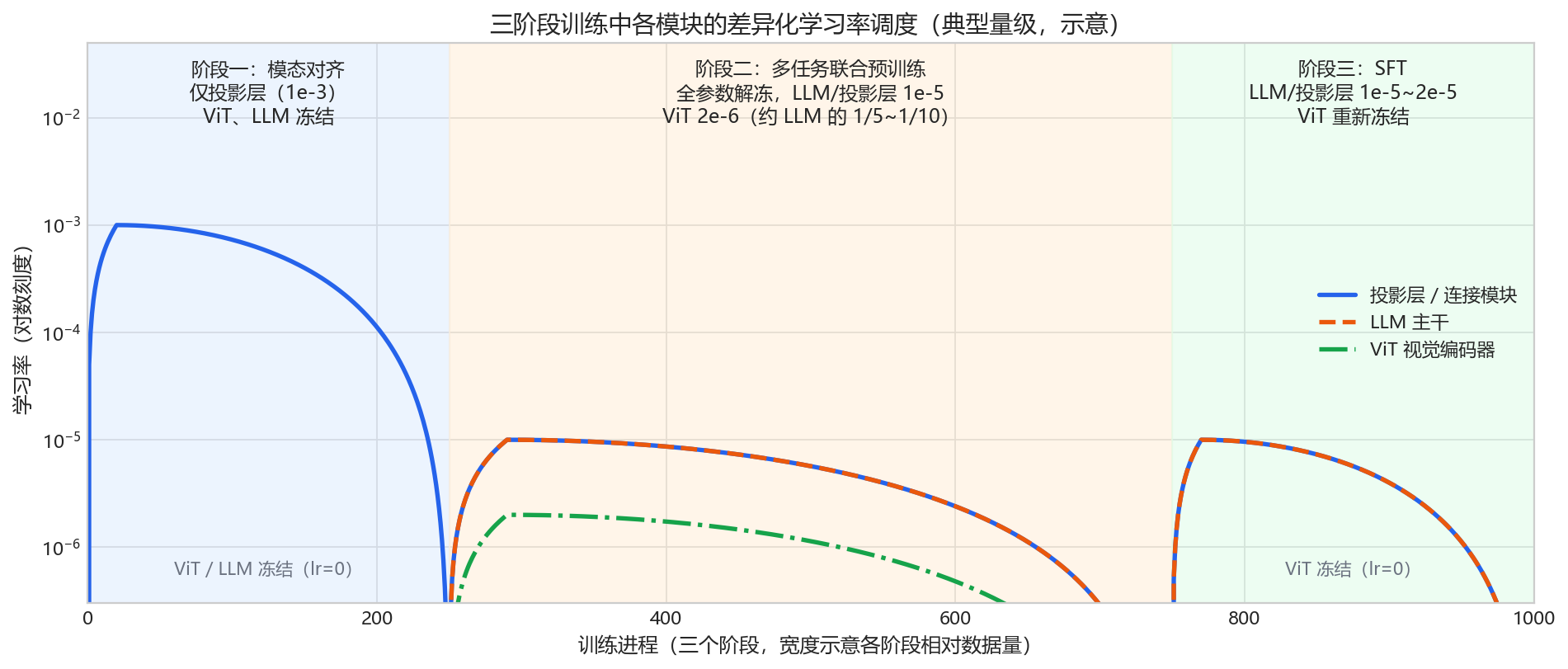
1. 第一原则:分模块差异化学习率
VLM 是”拼装”出来的模型——随机初始化的连接模块、预训练好的 ViT 与 LLM,三类参数的”成熟度”完全不同,绝不能共用同一个学习率:
| 模块 | 初始化来源 | 典型峰值学习率 | 设置依据 |
|---|---|---|---|
| 连接模块(Projector / Q-Former) | 随机初始化 | 1e-3(对齐阶段)→ 1e-5~2e-5(后续阶段) | 随机参数离收敛点远,需要大步长快速收敛 |
| LLM 主干 | 预训练 LLM | 1e-5 ~ 2e-5 | 保护已有语言能力,防止灾难性遗忘 |
| ViT 视觉编码器 | CLIP / SigLIP 预训练 | 2e-6 ~ 1e-5(约为 LLM 的 1/5~1/10) | 对比学习得到的视觉特征空间极其精细,大学习率几步就可能破坏 patch 语义结构 |
一个实用的直觉:学习率应与”参数当前的质量”成反比。对齐阶段投影层的学习率(1e-3)是 SFT 阶段 LLM 学习率(2e-5)的 50 倍,正是因为前者从零开始、后者只需”轻微修正”。”ViT 学习率低于 LLM”有明确出处:LLaVA-OneVision 论文写明视觉编码器学习率取 LLM 的 1/5(2e-6 vs 1e-5),NVILA 给出的区间更宽(比 LLM 低 5~50 倍)。Qwen-VL 还对 ViT 使用逐层学习率衰减(layer-wise lr decay 0.95;初代 InternVL 用 0.9):越靠近输入的层学到的特征越通用,越应该少动。有趣的是 InternVL2.5 反其道而行——为保持配方简单,刻意全模型统一学习率。两条路线都能训出强模型,说明核心收益来自”随机新模块 vs 预训练主干”的区分,ViT 内部是否再细分属于锦上添花。
2. 两份可直接参考的配方
LLaVA-1.5 官方配置(官方仓库 scripts/v1_5/pretrain.sh 与 finetune.sh)是社区使用最广的起点配方:
| 超参数 | 阶段一:对齐预训练 | 阶段二:指令微调(SFT) |
|---|---|---|
| 可训练参数 | 仅 MLP 投影层 | 投影层 + LLM 全参数 |
| 全局 batch size | 256 | 128 |
| 峰值学习率 | 1e-3 | 2e-5 |
| 学习率调度 | 余弦衰减,warmup ratio 0.03 | 余弦衰减,warmup ratio 0.03 |
| 训练轮数 | 1 epoch(558K 图文对) | 1 epoch(665K 指令数据) |
| weight decay | 0 | 0 |
| 优化器 / 精度 | AdamW / bf16 | AdamW / bf16 |
| 最大序列长度 | 2048 | 2048 |
| 梯度裁剪 | max_norm = 1.0(HF 默认) | max_norm = 1.0(HF 默认) |
| DeepSpeed | ZeRO-2 + gradient checkpointing | ZeRO-3 + gradient checkpointing |
一个值得注意的细节:原版 LLaVA 预训练学习率是 2e-3,1.5 把线性投影换成两层 MLP 后将其减半为 1e-3(论文明言”because of the MLP projector”)——连接模块表达能力增强后,学习率反而要相应收缩。LLaVA-NeXT 在解冻 ViT 时为 vision tower 单独设置 2e-6 的学习率(基础学习率 2e-5 的 1/10),这一惯例被后续大量开源工作沿用。
Qwen-VL 的三阶段配置(论文 arXiv:2308.12966 附录 Table 8)则代表”工业级大规模训练”的取向:
| 超参数 | 阶段一:预训练 | 阶段二:多任务预训练 | 阶段三:SFT |
|---|---|---|---|
| 可训练模块 | ViT + 连接模块(LLM 冻结) | 全部解冻 | LLM + 连接模块(ViT 冻结) |
| 峰值学习率 | 2e-4 | 5e-5 | 1e-5 |
| 最小学习率 | 1e-6 | 1e-5 | 1e-6 |
| 全局 batch size | 30720 | 4096 | 128 |
| 训练步数 | 50k | 19k | 8k |
| ViT 逐层学习率衰减 | 0.95 | 0.95 | —(ViT 冻结) |
| 图像分辨率 | 224×224 | 448×448 | 448×448 |
| 优化器 | AdamW(β₁=0.9,β₂=0.98,eps=1e-6) | 同左 | 同左 |
| weight decay | 0.05 | 0.05 | 0.05 |
| 梯度裁剪 | 1.0 | 1.0 | 1.0 |
两份配方的差异本身就是教科书:训练数据规模决定正则强度与超参形态。LLaVA 用几十万精选数据训 1 epoch,weight decay 设 0、batch 一两百即可;Qwen-VL 一阶段要消化 14 亿噪声图文对,batch 飙到 30720、weight decay 提到 0.05,并把 AdamW 的 β₂ 从默认的 0.999 调低到 0.98(GPT-3/LLaMA/OPT 等纯文本预训练更激进,普遍用 0.95)——二阶矩估计对梯度分布变化反应更快,可降低大 batch 训练中 loss 尖刺的风险。另外注意 batch size 随阶段骤降(30720 → 4096 → 128),与数据从十亿级噪声图文对收缩到 35 万精标指令完全同步。
InternVL2.5 的渐进复用配方(技术报告 arXiv:2412.05271)代表与前两者截然不同的训练哲学——用已充分预热的 InternViT-6B 视觉编码器换取极低的总 token 消耗:
| 超参数 | 阶段一:MLP 预热 | 阶段二:ViT 增量解冻 | 阶段三:全参数 SFT |
|---|---|---|---|
| 可训练模块 | 仅 MLP 连接层(ViT + LLM 全冻结) | ViT + MLP(LLM 冻结) | 全部参数解冻 |
| 峰值学习率 | 2e-4 | 1e-5 | 2e-5 ~ 4e-5 |
| 模块间学习率 | 统一(无逐层衰减倍率) | 统一 | 统一 |
| 学习率调度 | 余弦衰减 | 余弦衰减 | 余弦衰减 |
| 图像分辨率 | 448×448(固定低分辨率) | 448×448(动态分块逐步启用) | 448×448(动态分块,最多 12 tile) |
| 优化器 / 精度 | AdamW / bf16 | AdamW / bf16 | AdamW / bf16 |
| 梯度裁剪 | 1.0 | 1.0 | 1.0 |
| 78B 累计 token | — | — | 全三阶段合计约 1200 亿 |
三份配方的差异本身就是一张关于训练哲学的完整图谱。InternVL2.5 相比前两者有两处鲜明对比:第一,全程统一学习率——各可训练模块共享同一 lr,不施加 LLaVA-NeXT 式的”ViT lr = 基础 lr 的 1/10”乘子,也不做 Qwen-VL 式的逐层衰减(decay = 0.95);这依赖于 InternViT-6B 已经过多代训练、视觉特征空间足够稳定,无需额外”保护”。第二,极低 token 消耗——78B 模型全三阶段合计仅约 1200 亿 token,约为 Qwen2-VL(1.4 万亿)的 1/10;靠的是”冷启动最小化”:阶段一只激活 MLP(最省 token),阶段二逐步解冻 ViT(居中),阶段三才全参数放开(最集中),配合多阶段动态分辨率课程学习(低分辨率 → 高分辨率渐进),将数据效率最大化。“全量重训”(Qwen2-VL)与”渐进复用”(InternVL2.5)是当前并存的两种训练哲学。
3. batch size 与学习率的联动
显存不够时人们首先想到压缩 batch size,但 batch size 变了,学习率必须跟着变:
\[\eta' = \eta \cdot \frac{B'}{B} \;\text{(线性缩放规则,适用于 SGD)}, \qquad \eta' = \eta \cdot \sqrt{\frac{B'}{B}} \;\text{(平方根缩放规则,适用于 Adam/AdamW)}\]- 线性缩放规则源自 CNN 时代的大 batch 训练研究(Goyal et al., 2017,针对 SGD);对 Adam/AdamW,理论与实验支持的是平方根规则(Malladi et al., NeurIPS 2022)。VLM 训练几乎都用 AdamW,平方根规则更适用。
- 等效全局 batch = 单卡 batch × 梯度累积步数 × GPU 数。Transformer 使用 LayerNorm(无 BatchNorm),梯度累积与直接增大 batch 在数学上基本等价,是显存受限时维持原配方有效性的首选手段——LLaVA 官方 README 就明确要求换 GPU 数量时通过梯度累积保持全局 batch 不变。
- 例:照抄 LLaVA-1.5 配方(batch 128、lr 2e-5),但显存只够开全局 batch 32——按平方根规则学习率应下调到约 1e-5,否则训练容易震荡。
- 缩放公式只是初值参考:Google 的 Deep Learning Tuning Playbook 明确指出 batch size 不应被当作调性能的旋钮——改了 batch 之后重新扫一遍学习率,比机械套公式更可靠。
4. warmup、衰减与 epoch 数
为什么必须 warmup?训练初期 Adam 的二阶矩估计只基于极少数样本,极不可靠;同时随机初始化的投影层会向预训练权重回传”垃圾梯度”。线性 warmup 让模型在学习率很小的阶段先把最离谱的参数修正掉,再进入全速学习。常用设置:微调用 warmup ratio 0.03(即总步数的 3%,LLaVA 系全线如此),预训练用固定步数(Qwen-VL 500 步、LLaMA 2000 步)。
衰减到哪里?HF Trainer 的余弦调度默认衰减到 0(LLaVA 即如此);预训练惯例则是衰减到峰值的 10%(LLaMA、Qwen-VL 的最小/峰值学习率之比均为 1/10 量级)。单 epoch 微调两者差别不大;需要多阶段续训时保留 10% 下限更稳。注意训练末期 loss 会随学习率衰减再下探一截(见 6.5 节图),这是调度器的正常效果,不代表”还能再训很久”。
训几个 epoch?SFT 的主流选择是 1~2 个 epoch:指令数据规模小、格式统一,多训几轮模型很快从”学习能力”滑向”背诵答案”,验证集 loss 普遍在第 2~3 个 epoch 开始回升(过拟合,见 6.5 节异常模式图 (d))。对齐预训练与多任务预训练几乎都只过 1 epoch——大规模数据下”见更多新数据”永远优于”重复旧数据”。
5. 数据配比:防止文本能力退化
多模态训练会天然侵蚀 LLM 的纯文本能力——VILA 的消融显示,只用图文对训练会让纯文本任务精度下跌 17% 以上。常用对策有两个:
- 混入纯文本数据:比例从 LLaVA-1.5 的约 6%(665K 指令数据中含 40K ShareGPT 纯文本对话),到 MM1 预训练配比中的 10%(45% 图文交错 + 45% 图文对 + 10% 纯文本),再到 Qwen2.5-VL SFT 阶段的 50%(约 200 万条数据中纯文本与多模态各半)。VILA 的”joint SFT”实验最有说服力:混入 100 万条 FLAN 纯文本指令后,MMLU 恢复到与纯文本微调持平,视觉任务成绩反而同步提升。
- 逐 token 损失重加权:多模态样本的序列远长于纯文本样本,朴素的逐 token 平均会让多模态梯度主导训练。Qwen3-VL 的 square-root reweighting(对每样本的 token 数做平方根归一化)正是针对这一问题(见 8.10 节)。
任务类型内部的配比同样有讲究:Cambrian-1 的消融发现单一数据源的样本数以 25 万~35 万为上限最优;OCR 数据占比与 OCR 能力成正比,但占比过高会损害通用 VQA——配比要对着自己的评测目标调。
6. 调参工作流:先小后大
学习率是所有超参数中敏感度最高的一个,调参预算应优先花在学习率上:
flowchart TD
classDef step fill:#eff6ff,stroke:#2563eb,stroke-width:1.5px,color:#1e3a8a;
classDef warn fill:#fef3c7,stroke:#d97706,stroke-width:1.5px,color:#78350f;
A["确定显存预算\n单卡 batch × 梯度累积 × 卡数 = 等效全局 batch"]:::step
A --> B["小规模代理实验:\n同规模模型 + 5%~10% 数据子集\n对数网格扫学习率(如 5e-6 / 1e-5 / 2e-5 / 5e-5 / 1e-4)"]:::step
B --> C["观察 loss 曲线形态(见 6.5 节):\n选出下降最快且无震荡的最大学习率"]:::step
C --> D["取该值的 1/2 作为正式学习率\n(为全量数据中的长尾样本留出安全边际)"]:::step
D --> E["全量训练:\n每 N 步保存 checkpoint 并跑下游小评测"]:::step
E --> F{"曲线或评测异常?"}:::warn
F -->|是| G["按 6.6 节决策树排查"]:::warn
F -->|否| H["训练完成 → 全量评测"]:::step
“学习率优先”有经典出处——Goodfellow《Deep Learning》第 11 章:”如果只有时间调一个超参数,那就调学习率。”另外注意一个陷阱:标准参数化下,小模型扫出的最优学习率不能直接搬到大模型(最优点会随模型宽度漂移),所以上面的代理实验建议用同规模模型在数据子集上做。若确实需要跨规模迁移超参数,μP / μTransfer(Yang et al., 2022)通过修改参数化使最优学习率随宽度保持稳定——微软用 4000 万参数的代理模型调参后迁移到 6.7B 的 GPT-3,效果超过原版,而调参开销仅占预训练总算力的 7%。
7. 显存不够时的工程开关
| 手段 | 原理 | 代价 |
|---|---|---|
| 梯度累积 | 用时间换等效 batch size | 训练变慢;数学上与大 batch 等价 |
| Gradient Checkpointing | 不存储中间激活,反向传播时重算 | 训练时间增加约 30%~40% |
| DeepSpeed ZeRO-2 / ZeRO-3 | 优化器状态/梯度/参数分片到多卡(ZeRO-1 省约 4 倍、ZeRO-2 省约 8 倍显存) | ZeRO-3 通信量约增加 50% |
| LoRA / QLoRA | 冻结主干,只训练低秩增量矩阵 | 能力上限略低于全参微调 |
| 序列打包(packing) | 多条短样本拼成一条长序列,消除 padding 浪费 | 需正确处理注意力掩码与位置编码 |
| 降低分辨率 / tile 数 | 直接减少视觉 token 数量 | OCR、细粒度任务明显掉点 |
6.5 训练监控与 Loss 曲线解读 (Monitoring & Reading Loss Curves)
VLM 训练动辄几天到几周,及时从曲线中读出问题远比事后补救便宜。本节回答两个问题:盯什么、怎么读。
1. 盯什么:四个必看面板
| 指标 | 看什么 | 异常信号 |
|---|---|---|
| 训练 loss(平滑后) | 整体趋势是否持续下降 | 尖刺、平台期、上升 |
| 梯度范数(grad norm) | 是否稳定在窄带内 | 持续抬升、频繁触顶裁剪阈值 |
| 学习率 | 调度曲线是否符合预期 | warmup / 衰减配置错误 |
| 验证 loss + 下游评测 | 能力是否真的在提升 | train/val 分叉、评测得分饱和或回落 |
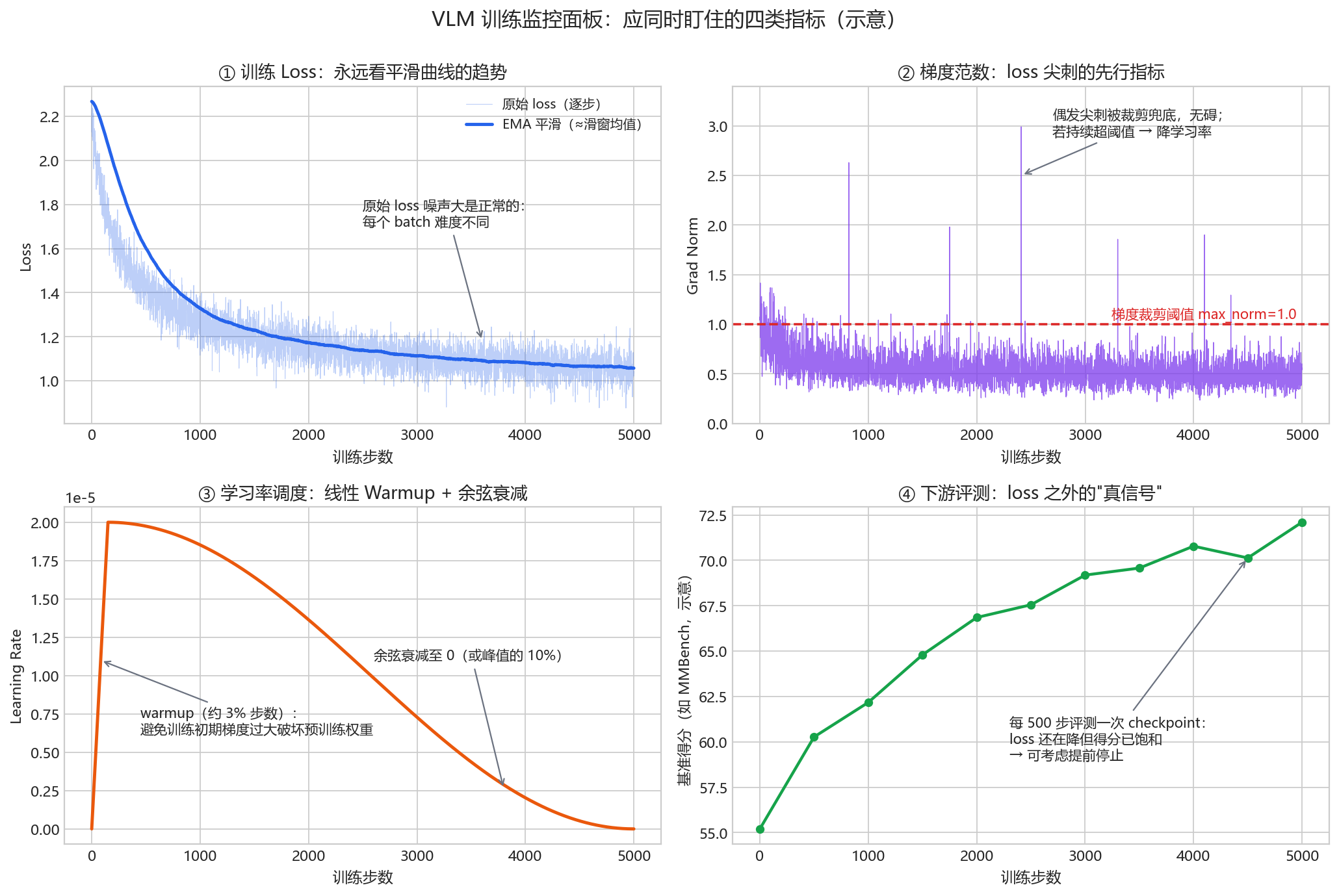
三条实践建议:
- 永远看平滑后的 loss(EMA 或滑动窗口均值):逐 step 的原始 loss 受各 batch 难度差异影响,噪声很大,盯着原始值容易疑神疑鬼。
- 按数据源拆分 loss:把 caption、OCR、grounding、纯文本等各数据源的 loss 分开记录。”总 loss 正常但 OCR loss 不降”这类问题,混在一起根本看不出来。
- 记录 token 级准确率作为 loss 的补充:即预测下一 token 的 top-1 命中率,对 SFT 阶段尤其直观(HF TRL 的 SFTTrainer 默认就记录 mean_token_accuracy),可以发现”loss 在降但命中率不涨”的退化。
补充:平滑系数(Smoothing Factor)怎么选
EMA 的更新公式为 \(\hat{L}_t = \alpha \cdot \hat{L}_{t-1} + (1-\alpha) \cdot L_t\),其中 \(\alpha \in (0,1)\) 越大曲线越平滑。EMA 等效的”记忆窗口”约为 \(\frac{1}{1-\alpha}\) 步——这是连接 EMA 与滑动窗口两种视角的桥梁:
| α(EMA 衰减系数) | 等效滑动窗口 | 适用场景 |
|---|---|---|
| 0.9 | ~10 步 | 短 SFT(总步数 < 1K);训练速度快、想快速发现尖刺 |
| 0.95 | ~20 步 | 中等规模 SFT(1K~5K 步);TensorBoard 的经验推荐值 |
| 0.99 | ~100 步 | 大规模预训练(5K~50K 步);最常用的”生产”默认值 |
| 0.999 | ~1000 步 | 超长预训练(> 100K 步,如 LLaMA 预训练);smoothed 曲线几乎只显示趋势 |
工具默认值与推荐调整:TensorBoard 的 Smoothing 滑块默认值为 0.6(等效窗口仅 2.5 步),对几千步的 VLM 训练曲线噪声太大——实践中推荐调到 0.95~0.99。Weights & Biases 在 UI 上不默认平滑,可在 “Smoothing” 下拉框中手动选 EMA 并设定系数。
两侧权衡:α 过大(过度平滑)→ 真实尖刺被掩盖、问题发现滞后,无法作为 grad norm 的早期预警补充;α 过小(平滑不足)→ 曲线抖动不止,难以判断下降趋势与平台期。经验法则:平滑后曲线”细节模糊但趋势清晰”时即为合适,若周期性尖刺在平滑曲线上还清晰可见,再增大 α 约 0.01~0.02。
2. 健康的 loss 曲线长什么样
先做初始值 sanity check。语言模型从随机初始化开始训练时,第一步的 loss 应约等于词表大小的自然对数(等价于均匀分布预测下的交叉熵):
\[\mathcal{L}_0 \approx \ln |V|\]例如 LLaMA 词表 32K 对应约 10.4,Qwen 词表 152K 对应约 11.9。VLM 对齐阶段由于 LLM 已经预训练过,初始 loss 通常只有 4~6——如果看到初始 loss 接近 ln(词表大小),几乎可以断定预训练权重没有正确加载,这是最值得熟记的 debug 技巧之一。
形态上,健康的 loss 是幂律下降——前期快、后期慢,在双对数坐标下近似直线;训练末期随学习率余弦衰减还会小幅下探。三个阶段的曲线各有特点:
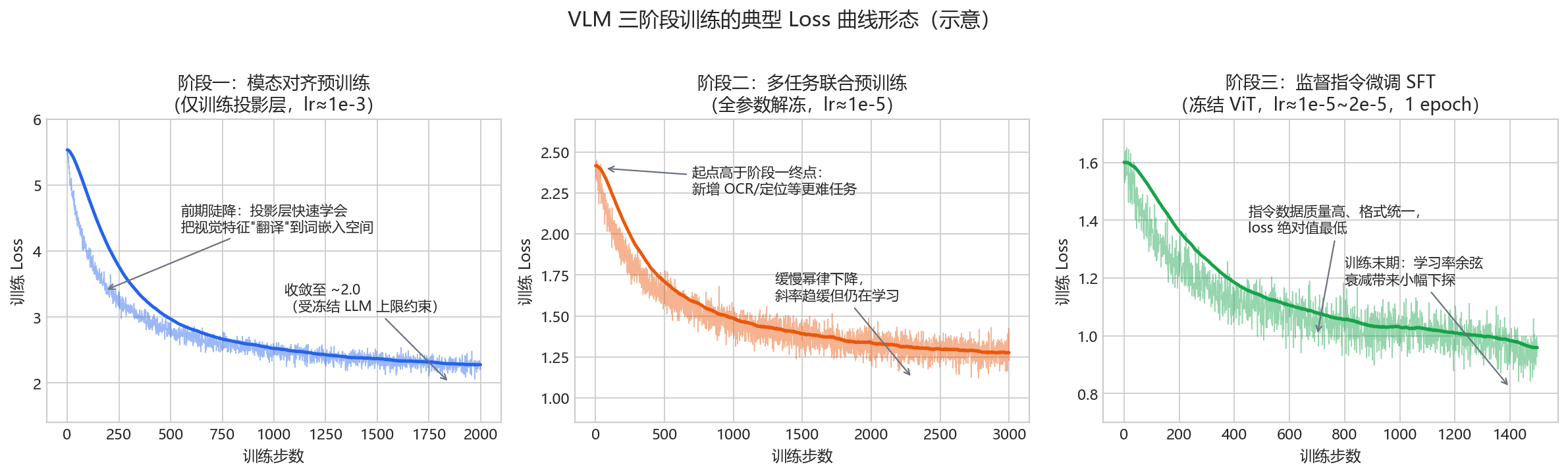
两个常见误读:
- 跨阶段比较 loss 没有意义:阶段二的 loss 高于阶段一终点不代表”练坏了”,只是数据分布变了(新增 OCR、grounding 等更难的任务)。
- loss 绝对值没有统一标准:不同词表、不同数据、不同 loss mask 策略下的 loss 不可横向比较;要比就比同配置下的相对变化。
- loss 永远降不到 0:Chinchilla 的拟合公式中,自然语言存在约 1.69 nats 的不可约熵项——后期曲线趋平既有学习率衰减的因素,也有数据本身信息熵下限的因素,”看起来不动了”不等于没在学(对数坐标下看仍是直线下降)。
3. 四种异常模式与处置
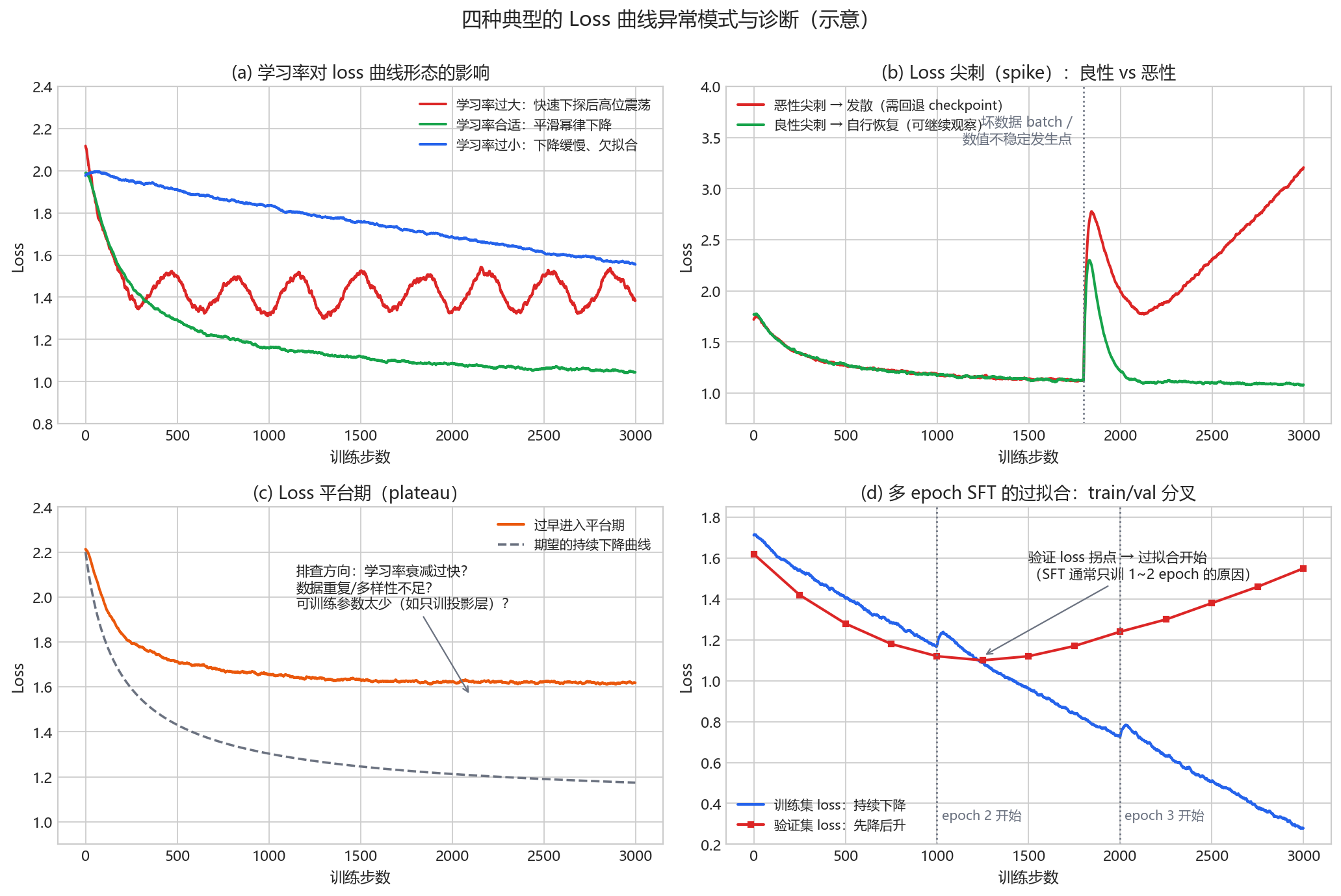
| 现象 | 可能原因 | 处置 |
|---|---|---|
| 快速下探后高位震荡(图 a 红线) | 学习率过大 | 学习率降 2~5 倍 |
| 下降极慢、远未收敛(图 a 蓝线) | 学习率过小、warmup 过长 | 学习率升 2~5 倍 |
| 尖刺后数百步内自行恢复(图 b 绿线) | 个别坏 batch / 极难样本 | 良性,继续观察;频繁出现则需清洗数据 |
| 尖刺后持续上升、发散(图 b 红线) | 学习率过大放大了坏 batch 的冲击;fp16 数值溢出;Adam 二阶矩状态被污染 | 回退到尖刺前的 checkpoint 并跳过该数据段续训(PaLM 的标准做法);或降学习率、调低 β₂、收紧梯度裁剪 |
| 过早进入平台期(图 c) | 学习率衰减过快;数据重复/多样性不足;可训练参数太少(如只训投影层却期望学会 OCR) | 检查调度器配置;数据去重;解冻更多参数 |
| train 持续降、val 回升(图 d) | 过拟合(SFT 训多个 epoch 的典型现象) | 减少 epoch、提前停止、扩充数据多样性 |
| loss 变为 NaN / Inf | fp16 上溢或下溢;学习率过大;损坏样本(空图像、超长文本) | 换 bf16;降学习率;定位并剔除坏样本 |
关于 loss 尖刺,大模型训练史上有不少公开经验可以借鉴:PaLM-540B 全程遇到约 20 次尖刺,标准操作是回退到尖刺前约 100 步的 checkpoint、跳过其后 200~500 个 batch 再续训——把同一批数据从更早的 checkpoint 重放并不会复现尖刺,说明尖刺是”参数状态 × 特定数据”的组合事件,而非单纯的坏数据;OPT-175B 两个月训练中手动重启 35 次,期间把梯度裁剪阈值从 1.0 收紧到 0.3;GLM-130B 定位到尖刺主因是 embedding 层梯度异常(比其他层大几个数量级),通过将该层梯度缩小到 0.1 倍显著减少了尖刺;PaLM、Falcon、OLMo 2 还使用 z-loss(系数 1e-4)正则项抑制 logits 漂移。VLM 在第二阶段的大规模联合训练中最容易遇到这类问题。
4. grad norm:尖刺的先行指标
梯度范数往往比 loss 更早暴露问题:
- 健康形态:warmup 结束后稳定在相对窄的区间(如 0.2~1.0),并随训练缓慢下降;
- 预警信号:grad norm 先于 loss 持续抬升——这通常是发散的前兆,此时降学习率还来得及。”先行指标”有正式出处:GLM-130B 训练日志明确记录”崩溃通常滞后于 grad norm 尖峰”,OLMo 2 论文也写道 loss 尖刺”often preceded by spikes in the gradient norm”;
- 梯度裁剪 max_norm=1.0 是几乎所有大模型训练的标配兜底(PaLM、LLaMA、LLaVA 均为 1.0;OPT 为求稳中途降到 0.3)。但若 grad norm 长期贴着裁剪阈值,说明学习率设大了——裁剪只应偶尔触发,不应常态化;
- 按模块分组记录:embedding、attention、FFN、投影层分开记 grad norm,能精确定位问题层——GLM-130B 正是这样发现 embedding 层的梯度异常。VLM 中还要确认冻结边界是否真的冻结(如阶段一中 LLM 与 ViT 的 grad norm 应恒为 0)。
5. loss 之外:一定要在训练中跑评测
loss 低不等于能力强。SFT 的 loss 衡量的是”复读参考答案的精确度”,与”回答得好不好”只有松散关联;更隐蔽的是,幻觉率可能在 loss 同步下降的同时不降反升(模型学会了更流利地编造)。因此:
- 每隔固定步数(如 500~1000 步)保存 checkpoint,自动跑一组小而快的评测:MMBench-dev 子集(综合能力)、POPE(物体幻觉)、TextVQA 子集(OCR);
- 当评测得分已饱和而 loss 仍在缓降时,继续训练的边际收益已经很低,提前停止可节约大量算力;
- 反过来,val loss 也会”假报警”:InstructGPT 的 SFT 在 1 个 epoch 后验证 loss 就开始过拟合,但继续训到 16 个 epoch,奖励模型分数与人类偏好评分仍在持续上升——最终按下游指标而非 val loss 选 checkpoint。loss 与能力的分歧在对齐训练中是常态,下游评测才是金标准;
- 评测时必须使用与训练完全相同的对话模板(chat template)——模板不一致是”loss 正常但评测分数离谱地低”的最高频原因。
6.6 常见训练问题排查 (Troubleshooting)
把 6.4、6.5 节的要点收敛为一棵决策树,训练出问题时按图索骥:
flowchart TD
classDef q fill:#fef3c7,stroke:#d97706,stroke-width:1.5px,color:#78350f;
classDef fix fill:#f0fdf4,stroke:#16a34a,stroke-width:1.5px,color:#14532d;
A["训练异常"] --> B{"loss = NaN / Inf?"}:::q
B -->|是| B1["① fp16 → bf16\n② 降低学习率\n③ 排查坏样本(损坏图像/空文本/超长样本)\n④ 收紧梯度裁剪"]:::fix
B -->|否| C{"loss 从一开始就不下降?"}:::q
C -->|是| C1["① 初始 loss ≈ ln(词表大小)?→ 预训练权重没加载\n② 检查 loss mask 是否只对回答 token 计损失\n③ 检查可训练参数是否被误冻结\n④ 学习率是否过小"]:::fix
C -->|否| D{"loss 异常地低(如 < 0.1)?"}:::q
D -->|是| D1["大概率是标签泄漏:\nloss mask 配置错误,把 prompt 或\n图像占位 token 也算进了训练目标"]:::fix
D -->|否| E{"loss 正常但评测得分差?"}:::q
E -->|是| E1["① 训练/推理对话模板是否完全一致(最高频问题)\n② 图像分辨率与预处理是否与训练一致\n③ 是否过拟合(看验证集 loss)\n④ 数据配比是否严重偏科"]:::fix
E -->|否| F{"纯文本能力退化 / 幻觉加重?"}:::q
F -->|是| F1["① 混入 10%~30% 纯文本指令数据\n② 降低 LLM 学习率或改用 LoRA\n③ 清洗编造性 caption 数据\n④ 引入 DPO 偏好对齐抑制幻觉(见 6.2)"]:::fix
F -->|否| G["对照 6.5 节异常模式图逐项排查"]:::fix
几个高频”暗坑”值得单独强调:
- loss mask 错误是新手最常见的 bug:多模态对话样本中,只有助手回答部分的 token 应计入损失;prompt、系统提示、图像占位 token 都必须 mask 掉。把 prompt 算进 loss 会让 loss 虚低,模型学会的是复读问题而非回答问题。
- 对话模板不一致:训练时用
<|im_start|>风格、推理时用[INST]风格,模型表现会莫名其妙地差。务必用同一份代码管理训练与推理的模板。 - 图像 token 数对不上:动态分辨率方案中,文本序列里
<image>占位符展开的 token 数必须与视觉编码器实际输出的 token 数严格一致,错位一个就会导致整个序列的标签全部偏移。 - 评测驱动开发:不要等训练完才评测。任何配置改动(数据、超参、模板)都应先在小规模代理实验上验证(见 6.4 节调参工作流),确认曲线与小评测正常后再上全量。
6.7 案例剖析:Qwen-VL系列训练演进 (Case Study: Evolution of Qwen-VL Training)
阿里巴巴开源的 Qwen-VL(千问视觉大模型)是多模态领域的标杆性工作。从 Qwen-VL 到 Qwen2-VL,再到 Qwen2.5-VL,其训练策略的演进路径清晰地反映了多模态模型技术的发展趋势。
flowchart TD
classDef qwen fill:#eff6ff,stroke:#3b82f6,stroke-width:2px,color:#1e3a8a;
V1["Qwen-VL (2023)\n经典三阶段训练\nViT-bigG 1.9B + Cross-Attention 连接器\n固定分辨率 448×448"]:::qwen
V2["Qwen2-VL (2024)\n原生动态分辨率\n3D Tubelet Embedding + 3D M-RoPE\n视频原生支持"]:::qwen
V3["Qwen2.5-VL / Qwen3-VL (2025–2026)\n4.1 万亿 Token 超大规模预训练\nWindow Attention + GRPO 推理强化"]:::qwen
V1 --> V2 --> V3
1. Qwen-VL (2023)
flowchart TD
classDef s fill:#f0fdf4,stroke:#22c55e,stroke-width:1.5px,color:#14532d;
S1["Stage 1 预训练对齐\n可训练:ViT + Cross-Attention 连接器\n冻结:LLM\n数据:14 亿图文对 · 224×224"]:::s
S2["Stage 2 多任务预训练\n全参数解冻(ViT + 连接器 + LLM)\n数据:7700 万多任务混合 · 448×448"]:::s
S3["Stage 3 SFT 指令对齐\n可训练:LLM + 连接器\n冻结:ViT\n数据:35 万指令对话"]:::s
S1 --> S2 --> S3
- 架构特征:
- 视觉编码器:ViT-bigG (1.9B 参数)。
- LLM:Qwen-7B。
- 连接器:单层 Cross-Attention 模块(用 256 个可学习 query 将 ViT 输出的图像特征压缩为固定 256 个 visual tokens)。
- 三阶段训练策略:
- Stage 1 (预训练/特征对齐):
- 冻结策略:冻结 LLM,训练 ViT 与 Cross-Attention 连接器(注意与 LLaVA 只训连接器不同:Qwen-VL 从第一阶段起就让 ViT 参与训练,并对 ViT 使用 0.95 的逐层学习率衰减;详细超参数表见 6.4 节)。
- 训练数据:14 亿图文对(从 50 亿原始数据清洗而来,保留率 28%)。
- 目的:打通图像特征和文本语义的连接通道。
- Stage 2 (多任务预训练):
- 冻结策略:全参数解冻,ViT、连接器和 LLM 同时参与训练。
- 训练数据:约 7700 万条高质量多任务混合数据(图像描述 19.7M、OCR 24.8M、VQA 3.6M、Grounding 定位类约 21M、纯文本 7.8M 等七类),分辨率提升至 $448 \times 448$。引入边界框坐标标注进行 Grounding(目标定位)训练。
- 目的:极大地丰富模型的定位与细粒度感知能力。
- Stage 3 (SFT/指令对齐):
- 冻结策略:冻结 ViT,仅更新连接器与 LLM 的参数。
- 训练数据:约 35 万条高质量人工标注与强模型生成的指令对话样本。
- 目的:提高模型的对话流畅度和多轮追问的连贯性。
- Stage 1 (预训练/特征对齐):
2. Qwen2-VL (2024)
flowchart TD
classDef s fill:#eff6ff,stroke:#3b82f6,stroke-width:1.5px,color:#1e3a8a;
S1["Stage 1 ViT 预训练\n大规模图文对增强视觉特征\n适配 3D Tubelet + M-RoPE 位置编码"]:::s
S2["Stage 2 联合训练(全参数解冻)\n视频·OCR·图文表格·长视频混合\n动态分辨率跨帧全局注意力"]:::s
S3["Stage 3 SFT\n冻结 ViT\nLLM + Projector 精细指令微调\n防止通用语言能力退化"]:::s
S1 --> S2 --> S3
- 架构升级:
- 支持任意分辨率的图像输入,引入 Naive Dynamic Resolution,移除固定 Patch 的物理缩放。
- 使用 3D 卷积 (3D Tubelet Embedding) 将视频流编码为时空 token,实现高效的视频理解。
- 引入 3D M-RoPE,在时空和文本三维空间上统一相对位置感知。
- 训练策略变化:
- Stage 1 (ViT 预训练):
- 特征:直接针对视觉编码器进行特征增强。着重于在大规模图文对上优化 ViT,使其适应 3D Tubelet 和 mRoPE positional embeddings。
- Stage 2 (联合训练/解冻):
- 特征:解冻 LLM 和 ViT 联合训练。在此阶段喂入大量复杂的视频-文本对、OCR、图文表格和长视频数据,让模型能够跨视频帧和超高分辨率 Patch 建立全局注意力。
- Stage 3 (SFT):
- 特征:为防止模型在通用自然语言任务上退化,依然选择冻结 ViT,对 LLM 和 Projector 进行精细的指令微调,优化多模态问答和长文本输出。
- Stage 1 (ViT 预训练):
3. Qwen2.5-VL / Qwen3-VL (2025-2026)
flowchart TD
classDef s fill:#fdf4ff,stroke:#a855f7,stroke-width:1.5px,color:#581c87;
P["超大规模预训练\n4.1 万亿 Token(图文 + 视频 + 纯文本)\nWindow Attention · 绝对时间 mRoPE"]:::s
S["SFT 监督微调\n多模态指令对齐\n升级版 mRoPE 时间维度标注"]:::s
D["DPO 偏好对齐\n抑制幻觉与编造"]:::s
G["GRPO 推理强化\n答案正确性奖励 + 格式规范奖励\n激发视觉链式推理(审题→放大→比对)"]:::s
P --> S --> D --> G
- 架构升级:
- 视觉编码器引入 Window Attention 机制,将超高分辨率图像/长视频的 ViT 注意力计算复杂度限制在局部窗口内,显著降低了显存开销,支持高达 256K 级别的超长多模态上下文。
- 升级版 mRoPE,支持绝对时间维度对齐(如将视频帧精确对齐到物理时钟的毫秒/秒)。
- 训练与对齐革新:
- 数据量跃升:预训练阶段总 Token 量达到 4.1 万亿(Trillions),深度整合纯文本与多模态语料。
- 强化学习后训练 (RL Post-training):
- 这是 Qwen2.5-VL 及后续推理型多模态模型的核心技术。
- 在 SFT 之后,采用 DPO 抑制幻觉,并首次大规模采用 GRPO (群体相对策略优化) 进行推理对齐。
- 训练机制:设计自动化评测奖励(如判断模型在回答几何、物理、编码等复杂多模态问题时,最后的
\boxed{答案}是否正确),并通过格式奖励惩罚不使用思考标签(<thought>)的行为。 - 效果:极大地激发了模型的自主视觉推理能力,模型在回答前会主动”审题”,在思考链中对图像的各个网格进行局部放大和比对,从而显著提升了在 MMStar、MathVista 等高难度推理基准上的准确率。
7. 主流数据集与评测基准
LAION-5B
| 属性 | 内容 |
|---|---|
| 发布年份 | 2022 |
| 规模 | 58.5亿图文对 |
| 场景 | 网络爬取(多语言) |
| 特点 | 目前最大规模的开源图文对数据集 |
LAION-5B由LAION非营利组织发布,从Common Crawl中筛选出图文对,利用CLIP相似度过滤低质量样本。Stable Diffusion、OpenCLIP等开源模型均在此数据集上训练。
COCO(Common Objects in Context)
| 属性 | 内容 |
|---|---|
| 发布年份 | 2014(持续更新) |
| 规模 | 33万张图像,每张5条人工标注描述 |
| 场景 | 日常生活场景 |
| 特点 | VLM标准评测基准,覆盖描述、检索、VQA等多个任务 |
COCO是VLM领域最重要的综合评测数据集,几乎所有VLM论文都在COCO上报告图像描述(CIDEr分数)和图文检索(R@1分数)指标。
VQA v2
| 属性 | 内容 |
|---|---|
| 发布年份 | 2017 |
| 规模 | 100万个问题,基于COCO图像 |
| 场景 | 日常图像 |
| 特点 | 平衡设计消除语言偏置,真正考验视觉理解 |
VQA v2针对VQA v1的语言偏置问题进行了平衡处理,确保模型必须真正理解图像才能回答正确。分为开放式问题(颜色、数量、是非等类别)。
MMBench
| 属性 | 内容 |
|---|---|
| 发布年份 | 2023 |
| 规模 | 3000+题 |
| 场景 | 多样化能力评测 |
| 特点 | 系统性评测VLM在20+能力维度上的表现 |
MMBench将VLM能力分解为感知、推理等多个层次,每个层次下细分多个子能力(如属性识别、空间关系、动作识别等),是目前最全面的VLM评测基准之一。
ScienceQA
| 属性 | 内容 |
|---|---|
| 发布年份 | 2022 |
| 规模 | 21208道科学题 |
| 场景 | K-12科学教育(多模态) |
| 特点 | 包含图文混合的多步推理题,附带解题过程注释 |
ScienceQA要求模型结合图像和文本进行科学领域的多步推理,是VLM推理能力评测的重要基准,LLaVA等模型在此基准上展示了接近人类水平的表现。
TextVQA / OCRBench
| 属性 | 内容 |
|---|---|
| 发布年份 | 2019 / 2023 |
| 规模 | 28408 / 1000张图像 |
| 场景 | 包含文字的自然场景图像 |
| 特点 | 专门测试模型读取图像中文字的能力(OCR) |
图像中文字的理解(OCR)是VLM的重要能力,TextVQA要求模型读取图像中的文字来回答问题,OCRBench则更系统地测试多种OCR场景,是评测VLM文字理解能力的主流基准。
MVL-SIB
| 属性 | 内容 |
|---|---|
| 发布年份 | 2025(ACL Findings) |
| 规模 | 205 种语言 |
| 场景 | 多语言图文匹配 |
| 特点 | 覆盖语言最广的多模态基准,同时提供纯文本版本,可精确对比”视觉输入对不同语言的增益” |
MVL-SIB 揭示了多模态的”语言公平性”瓶颈:低资源语言下,即使 GPT-4o 等顶级模型的图文对齐质量也显著下降——高性能 VLM 在英文基准上的领先,并不意味着对全球语言的均等服务能力。
评测趋势:从静态 VQA 向交互、时序、多语言扩展
2025 年以来,VLM 评测呈现三个重要趋势:Agent 导向评测(将多模态任务与工具调用绑定,统一测试感知-规划-执行能力)、时序知识新鲜度(专门构造训练截止后的新闻与稀有知识,测试知识时效性)、空间与 3D 推理(多视角场景问答、带空间约束的 3D QA 进入主流)。评测重心正从”静态感知能力”向“感知-推理-行动一体化”演进,多语言公平性(MVL-SIB)也成为新的关注维度。
8. 经典方法与代表性工作
本节按时间顺序梳理VLM领域的经典工作,每篇从架构设计、训练方案、关键结果三个维度详细展开。
8.1 ViLBERT(2019)
论文:ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks 机构:Facebook AI Research 发表:NeurIPS 2019,作者:Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee
ViLBERT是最早将BERT扩展到视觉语言联合理解的里程碑工作,开创了”视觉语言预训练”研究方向。
精华:ViLBERT 最值得借鉴的思想是双流 + 协同注意力设计——两个模态在各自的流中独立处理,仅通过协同注意力层有选择地交换信息,既保留了各模态的独立特性,又实现了深度跨模态交互,避免了过早融合导致的信息损失。其”大规模无标注图文对预训练 + 轻量级任务头微调”范式直接启发了后续几乎所有视觉-语言预训练工作。局限在于视觉特征依赖离线 Faster R-CNN 提取,推理速度慢,且双流架构参数量较大,难以规模化扩展。
架构设计:双流协同注意力
ViLBERT采用双流(Two-Stream)设计,两种模态在独立的流中处理,再通过协同注意力层相互交换信息:
- 语言流(Linguistic Stream):继承BERT-base的12层Transformer,768维隐层,12个注意力头
- 视觉流(Visual Stream):6层Transformer,1024维隐层,8个注意力头;以Faster R-CNN提取的图像区域特征(每张图像固定抽取36个region proposals)作为输入
- 协同注意力层(Co-Attentional Transformer Layer):两个流通过交换 Key 和 Value 矩阵来实现跨模态信息融合——视觉流的 Query 与语言流的 Key/Value 进行注意力计算(反之亦然),使每个流能够有选择地”关注”另一模态的内容
这种设计的核心优势在于:允许两个流保持各自的模态特性,同时在特定层次进行深度交互,避免了过早融合导致的信息损失。
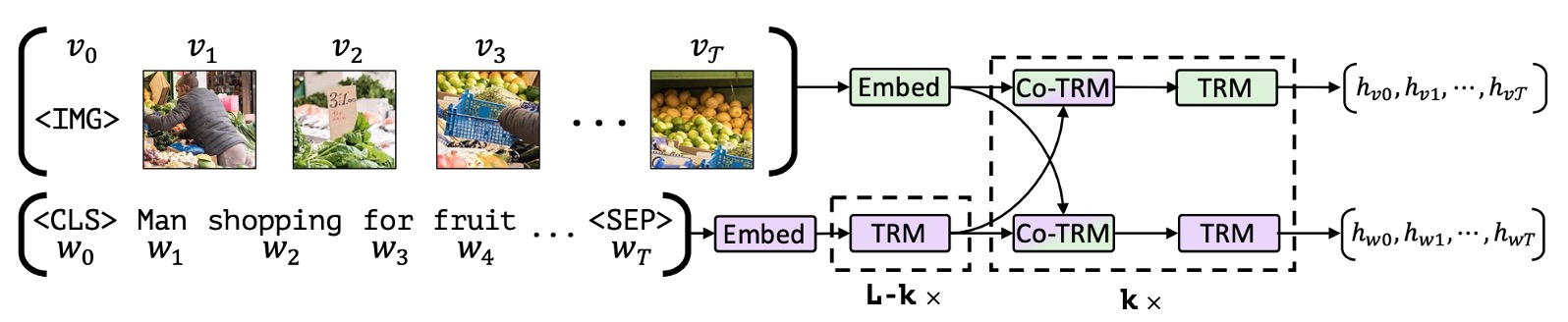
预训练方案
在 Conceptual Captions 数据集(约330万图文对,来自网络爬取并自动过滤的图像描述)上进行预训练,使用三个目标:
- 遮蔽语言模型(MLM):随机遮蔽15%的文本token,预测被遮蔽词
- 遮蔽图像区域预测:随机遮蔽15%的图像区域,预测该区域对应的语义类别分布(从Faster R-CNN检测头的softmax输出)
- 图文对齐预测(Image-Text Alignment):将50%的图文对替换为随机不匹配的样本,训练模型判断图文是否语义匹配(二分类)
下游任务与结果
ViLBERT在预训练后通过轻量级微调适配多个下游任务,均取得当时的SOTA:
| 任务 | 数据集 | ViLBERT | 之前SOTA | 提升 |
|---|---|---|---|---|
| 视觉问答 VQA test-dev | VQA v2 | 70.55% | 67.9% | +2.65% |
| 视觉问答 VQA test-std | VQA v2 | 70.92% | — | — |
| 视觉常识推理 Q→A | VCR | 73.3% | 62.8% | +10.5% |
| 视觉常识推理 QA→R | VCR | 74.6% | — | — |
| 视觉常识推理 Q→AR | VCR | 54.8% | — | — |
| 视觉定位 | RefCOCO+ | 72.34% | 64.5% | +7.8% |
| 图文检索(R@1) | Flickr30K | 58.20% | 54.0% | +4.2% |
历史意义:ViLBERT直接启发了VisualBERT、UNITER、OSCAR、VinVL等一系列视觉语言预训练工作,奠定了”通用视觉语言表示预训练 + 任务微调”的研究范式。
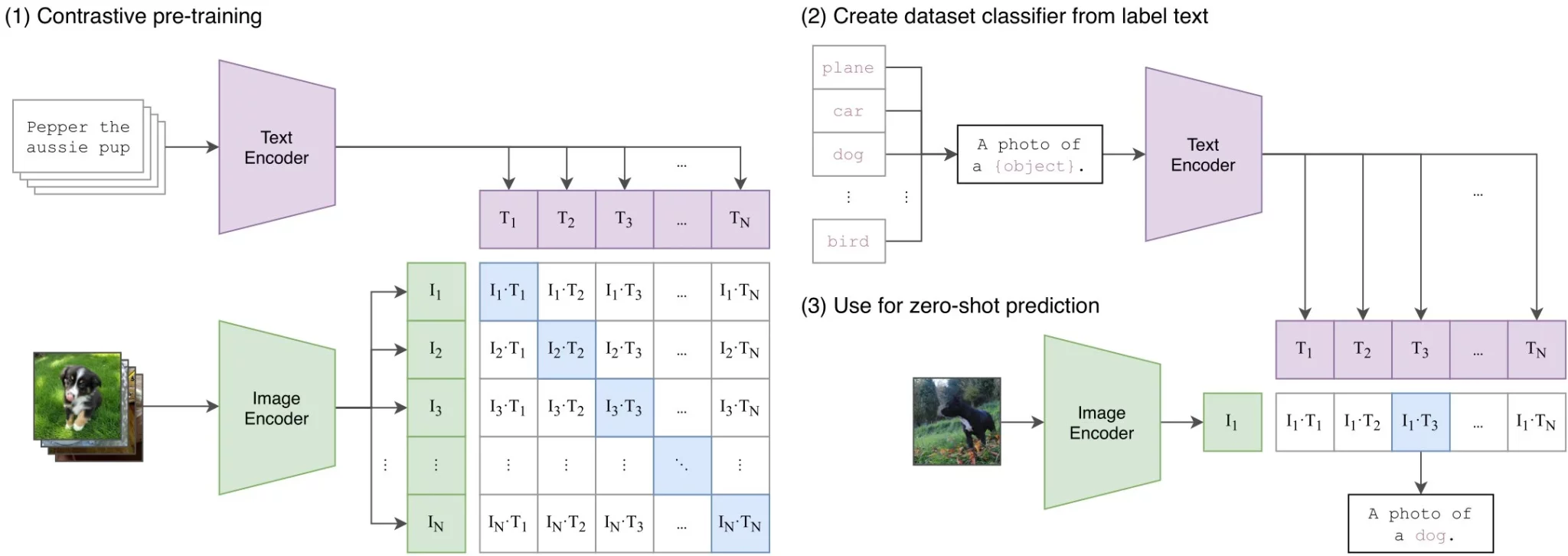
8.2 CLIP(2021)
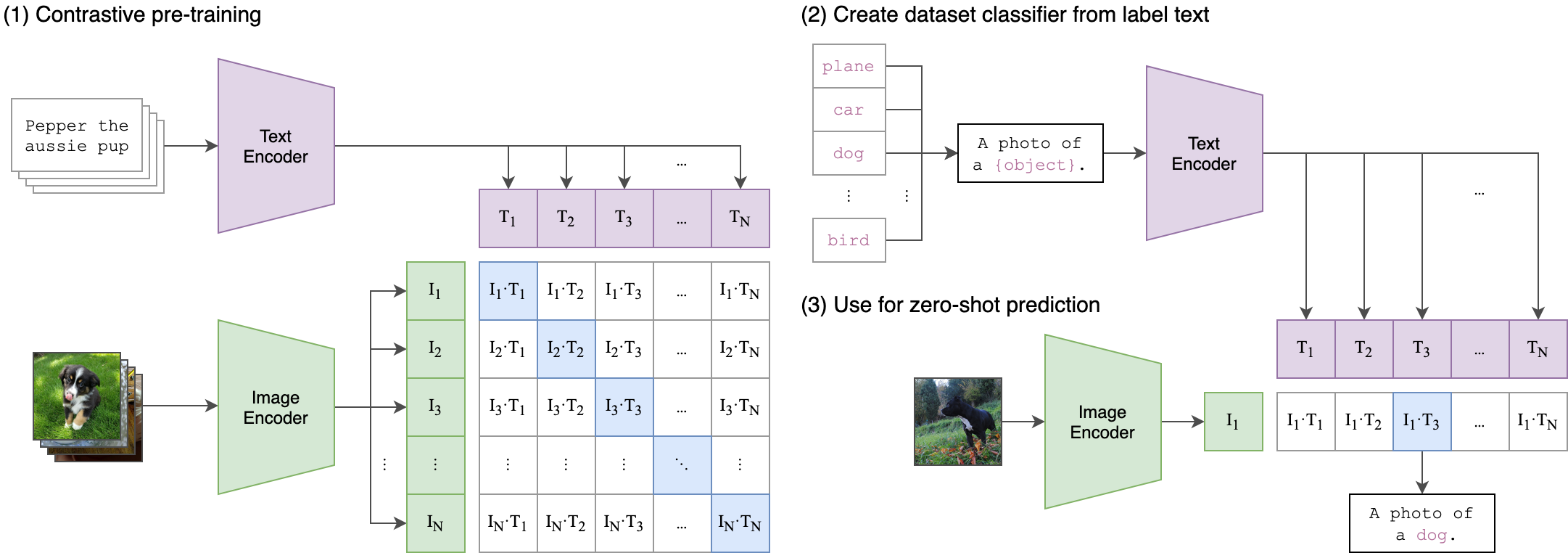
论文:Learning Transferable Visual Models From Natural Language Supervision 机构:OpenAI 发表:ICML 2021,作者:Alec Radford, Jong Wook Kim, Chris Hallacy 等
CLIP是现代VLM体系的基石,其训练的视觉编码器至今仍是绝大多数VLM(LLaVA、BLIP-2、InternVL等)的标配视觉骨干。
精华:CLIP 的革命性在于用自然语言监督替代人工标注——4亿网络图文对 + 对称 InfoNCE 损失,使视觉编码器学到了可直接迁移的语义特征。零样本迁移(通过 prompt engineering 将类别名嵌入文本)是其最具影响力的创新,打破了”必须在目标数据集上微调”的惯性思维。CLIP ViT-L/14 至今仍是绝大多数开源 VLM 的标配视觉骨干,说明预训练数据规模与目标设计的选择远比架构创新更关键。局限在于图文对之间的对比目标是”粗粒度”的——整张图对整段描述,难以捕捉细粒度的区域级语义对齐。
数据规模:WIT-400M
OpenAI从互联网上构建了 WIT(WebImageText) 数据集,通过搜索50万个常见词汇(Wikipedia词汇表)的同义词等方式筛选,最终获得 4亿个图文对,覆盖极为多样化的视觉概念,规模远超当时任何公开数据集(如ImageNet的128万张、Conceptual Captions的330万对)。
架构设计
CLIP包含两个独立的编码器,共享同一嵌入空间:
图像编码器:提供两个系列:
- ResNet系列:RN50、RN101、RN50x4(ResNet-50的约4倍计算量)、RN50x16、RN50x64
- ViT系列:ViT-B/32、ViT-B/16、ViT-L/14(307M参数,24层,1024维,14×14 patch)、ViT-L/14@336px
文本编码器:63M参数的Transformer,12层,512维,8个注意力头,最大序列长度76个token(BPE tokenization);取 [EOS] token的最终隐层表示作为文本嵌入
两个编码器的输出分别经过线性投影层映射到同一维度的嵌入空间,通过余弦相似度衡量图文匹配程度。

训练目标
对于一个包含 $N$ 个图文对的 batch,CLIP从 $N \times N$ 的可能配对矩阵中识别出 $N$ 个正确匹配。使用对称 InfoNCE 损失(同时对图像到文本和文本到图像两个方向计算):
\[\mathcal{L} = -\frac{1}{2N}\left[\sum_{i=1}^{N}\log\frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^{N}\exp(s_{ij}/\tau)} + \sum_{i=1}^{N}\log\frac{\exp(s_{ii}/\tau)}{\sum_{j=1}^{N}\exp(s_{ji}/\tau)}\right]\]其中 $s_{ij} = \text{cos}(v_i, t_j)$ 为图像 $i$ 与文本 $j$ 的余弦相似度,$\tau$ 为可学习的温度参数(初始化为 0.07,训练过程中自动调整)。训练使用超大 batch size(32,768)以获得充足的负样本对,在256块 V100 GPU 上训练约32个epoch。
零样本迁移能力
CLIP最核心的贡献是其零样本(Zero-Shot)迁移能力:无需任何目标数据集的训练,仅通过将类别名称嵌入为文本提示(prompt engineering,如 “a photo of a {class name}”),即可通过计算图文相似度完成分类。
在 ImageNet 上的零样本 Top-1 精度:
| 模型 | 参数量 | ImageNet 零样本 Top-1 |
|---|---|---|
| RN50 | ~102M | 59.6% |
| RN101 | ~119M | 62.4% |
| ViT-B/32 | ~150M | 63.3% |
| ViT-B/16 | ~150M | 68.3% |
| ViT-L/14 | ~428M | 75.3% |
| ViT-L/14@336px | ~428M | 76.2% |
其中,ViT-L/14@336px 的 76.2% 与有监督训练的 ResNet-50(76.1%)持平,而后者需要全部128万张 ImageNet 训练数据。CLIP 在27个分类数据集上的零样本评测中,在16个数据集上超越了完全监督的 baseline。
对后续研究的深远影响
- 视觉骨干标准化:LLaVA、BLIP-2、InstructBLIP 等几乎所有开源 VLM 均以 CLIP ViT-L/14 或 CLIP ViT-L/14@336px 作为视觉编码器
- 文生图基础:DALL-E 2 使用 CLIP 图像嵌入作为扩散模型的条件;Stable Diffusion 使用 CLIP 文本编码器
- 开放词汇检测:GLIP、Grounding DINO 利用 CLIP 将目标检测扩展到开放词汇设定
- 跨模态检索:CLIP 嵌入成为图文检索引擎的核心表示
8.3 Flamingo(2022)
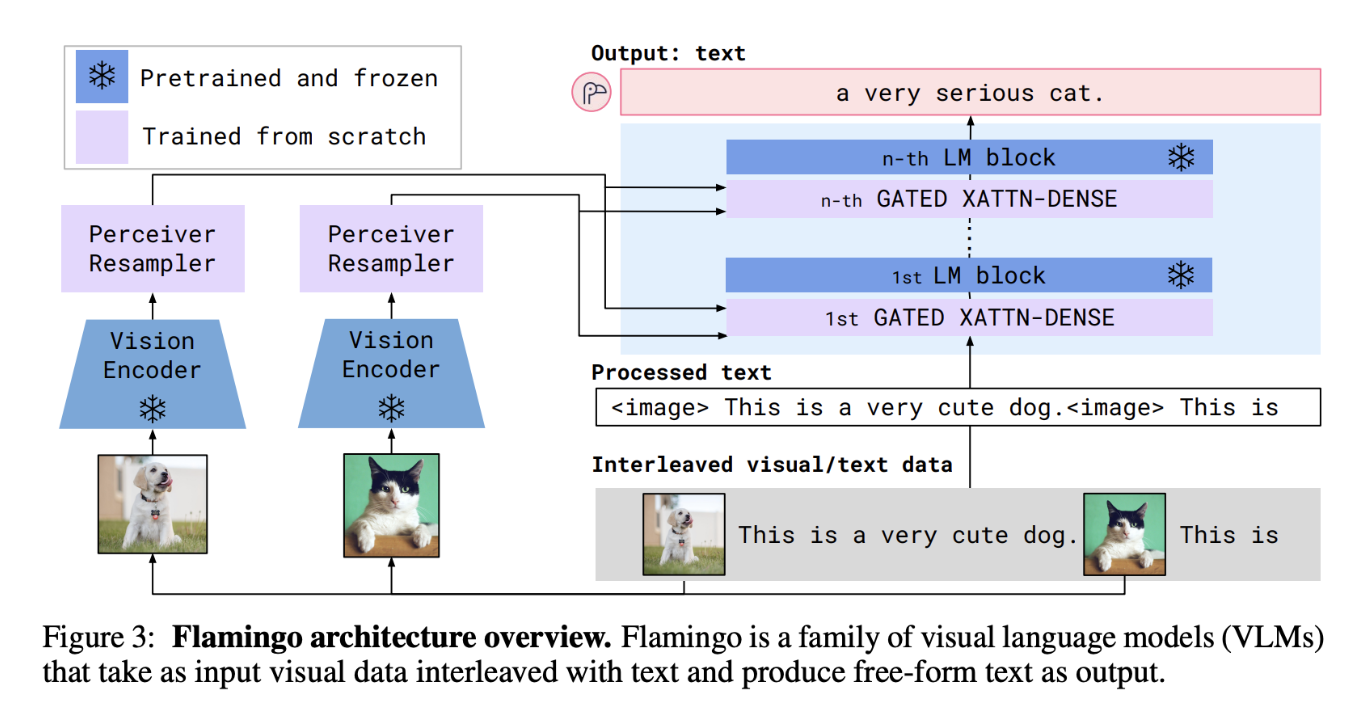
论文:Flamingo: a Visual Language Model for Few-Shot Learning 机构:DeepMind 发表:NeurIPS 2022,作者:Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc 等
Flamingo 是第一个成功将超大规模语言模型扩展为强多模态模型、实现强大少样本视觉语言推理的工作。其核心设计哲学是:保持 LLM 不变,只添加最小化的视觉接口。
精华:Flamingo 的核心价值在于冻结 LLM + 插入视觉接口的设计哲学——用 Perceiver Resampler 将任意长度的视觉特征压缩为固定的64个 latent token,再通过门控交叉注意力层(tanh 门初始化为0)让语言模型”渐进式”地获得视觉感知能力,完全不破坏原有 LLM 的语言能力。交错图文训练数据使模型天然支持多图上下文(few-shot)输入,这一范式直接启发了后续 BLIP-2、LLaVA 等所有”冻结 LLM + 轻量对齐模块”的路线。局限在于 Perceiver Resampler 的信息压缩会丢失细粒度视觉细节,且闭源限制了其生态发展。
核心架构
Flamingo 在冻结的 Chinchilla LLM(70B)基础上插入两个新模块:
① Perceiver Resampler(感知重采样器)
图像特征通常包含数百至数千个空间位置(取决于分辨率),而 LLM 对输入长度非常敏感。Perceiver Resampler 通过可学习的 latent 向量将任意长度的视觉特征压缩为固定数量(64个)的视觉表示:
- 64个 latent 向量通过 self-attention 相互交流
- 通过 cross-attention 从图像特征(含位置编码的 2D patch 特征)提取信息
- 支持任意分辨率的图像输入和任意帧数的视频输入(不同帧的特征被拼接后一同压缩)
② Gated Cross-Attention Dense(GXATTN)层
在冻结 LLM 的每两个 Transformer 层之间,插入一个新的跨模态注意力层:
- 语言 token 作为 Query,Perceiver Resampler 输出的64个视觉 latent 向量作为 Key/Value
- 门控机制:$y = y_{\text{LLM}} + \tanh(\alpha) \cdot \text{CrossAttn}(y_{\text{LLM}}, X_{\text{visual}})$,其中 $\alpha$ 初始化为 0,确保训练初期新层对 LLM 输出无影响,避免破坏原有语言能力
- 仅 GXATTN 层和 Perceiver Resampler 的参数参与训练(原始 LLM 参数完全冻结)
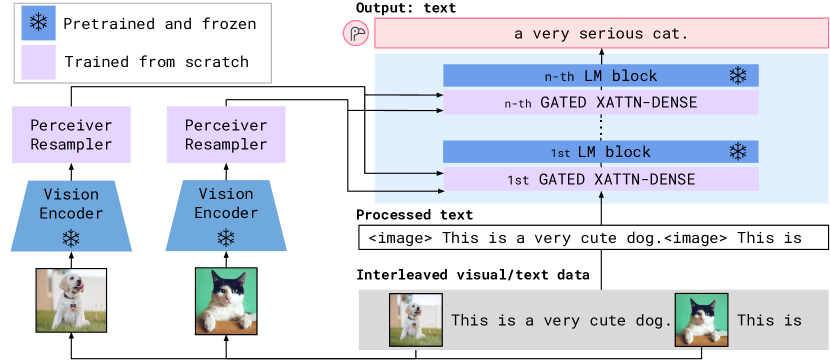
训练数据
三类数据混合训练:
| 数据集 | 规模 | 说明 |
|---|---|---|
| ALIGN | 18亿图文对 | 网络爬取的图像描述 |
| MultiModal MassiveWeb(M3W) | 4300万网页 | 含图文交错内容,用于学习多图上下文 |
| 视频文本对 | 约2700万视频 | 与字幕配对的视频片段 |
交错图文数据是 Flamingo 能够处理多图输入(如对话历史中穿插多张图片)的关键。
少样本性能
Flamingo(80B)在6个视觉语言基准上以少样本(Few-Shot)方式评测(仅提供4-32个示例,无需梯度更新),全面超越当时所有专门微调的模型:
| 任务 | Flamingo 80B(4-shot) | 之前微调SOTA |
|---|---|---|
| VQAv2 | 56.3% | 80.0%(微调) |
| COCO Captioning(CIDEr) | 84.3 | 138.6(微调) |
| TextVQA | 54.1% | 71.8%(微调) |
注:少样本设定与微调不可直接比较,但 Flamingo 展示了无需任何任务特定训练的强大泛化能力,在业界引发了广泛关注。
8.4 BLIP-2(2023)
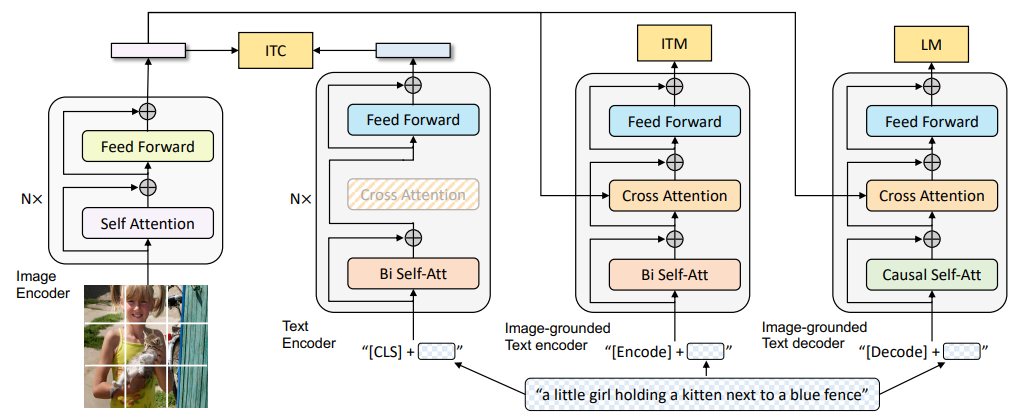
论文:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models 机构:Salesforce Research 发表:ICML 2023,作者:Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi
BLIP-2 的核心问题是:在两个已经预训练好的”大模型”(冻结的视觉编码器 + 冻结的 LLM)之间,如何以最低的计算代价建立有效的语义桥梁?
精华:BLIP-2 的核心创新是 Q-Former 信息瓶颈——32个可学习的 Query Token 通过 cross-attention 从 ViT-G(1.8B)中提取与语言最相关的视觉特征,整个 Q-Former 仅188M参数,却能驱动110B+的冻结 LLM 完成多模态生成任务,极大降低了多模态对齐的计算门槛。两阶段训练(先视觉-语言表示对齐,再生成式语言对齐)的渐进式策略同样值得借鉴。局限在于 Q-Former 固定的 Query Token 数量限制了其处理高分辨率精细图像的能力,且 Q-Former 与 LLM 之间的语义鸿沟需要后续工作(如 InstructBLIP)通过指令感知机制进一步弥合。
Q-Former:轻量级信息瓶颈
Q-Former(Querying Transformer)是 BLIP-2 的核心创新。它包含两个共享 self-attention 权重的 Transformer 模块:
- Image Transformer:通过 cross-attention 从冻结的视觉编码器(ViT-G,1.8B参数)提取信息
- Text Transformer:处理文本输入,功能类似 BERT
两个模块共享同一套 self-attention 层,但 cross-attention 层仅存在于 Image Transformer 中。32个可学习的 Query Token 负责从 ViT 的视觉特征中提取与语言最相关的视觉信息,再通过一个线性投影层连接到 LLM 的输入空间。
Q-Former 整体仅有 188M 参数,而 ViT-G 有 1.8B、OPT-6.7B 有 6.7B、FlanT5-XXL 有 11B——Q-Former 以极小的可训练参数量,成为这些大模型之间的”翻译器”。
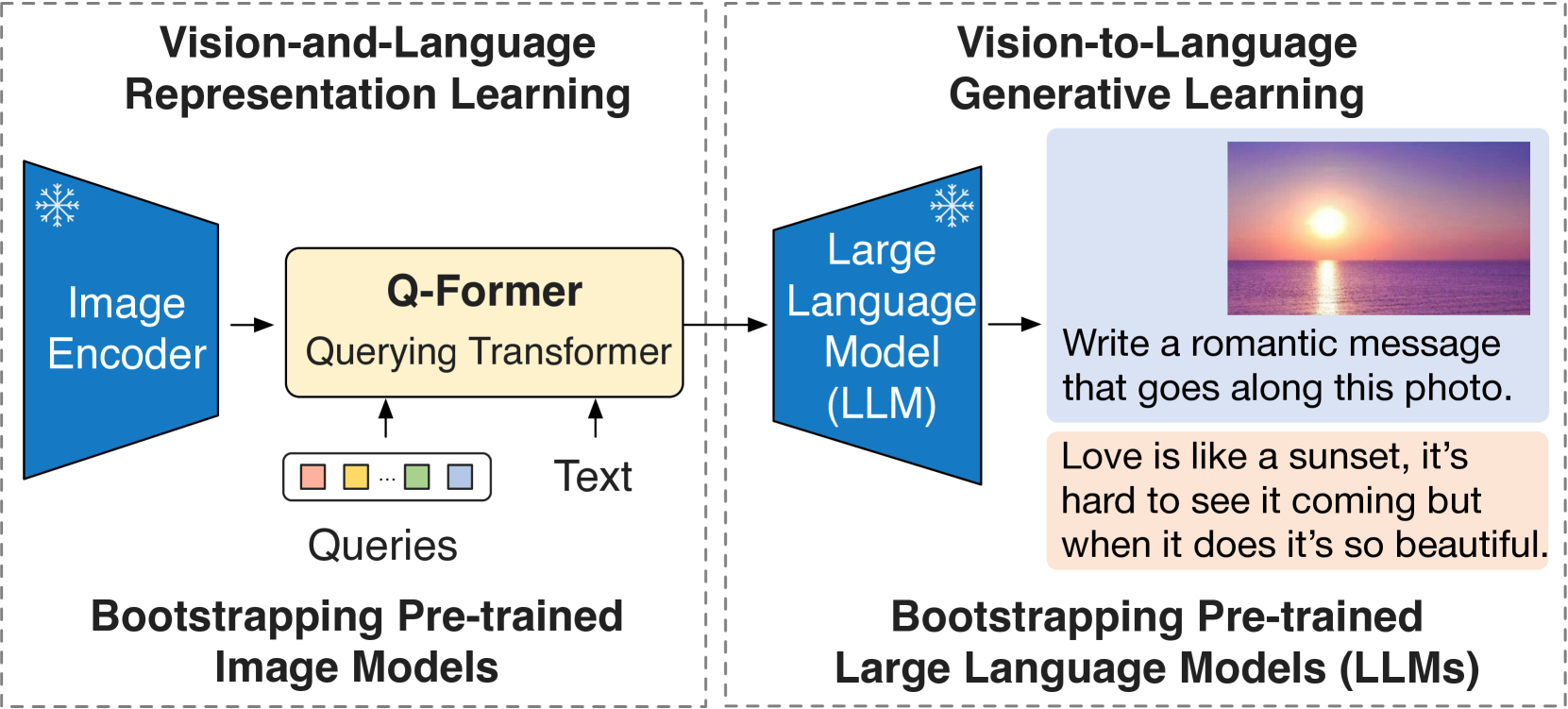
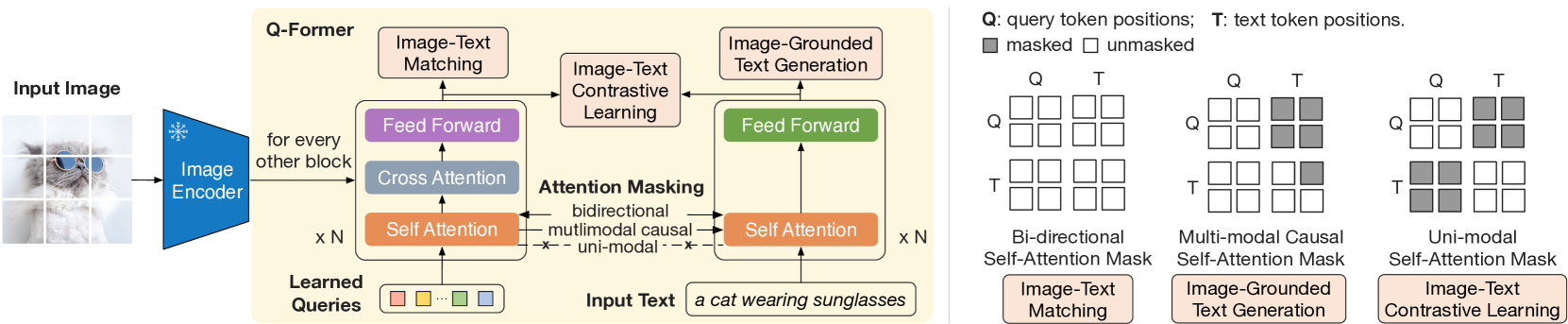
两阶段训练
第一阶段:视觉-语言表示学习 冻结 ViT-G,解冻 Q-Former,联合优化三个目标:
- ITC(Image-Text Contrastive):对齐 Query Token 提取的视觉特征与文本嵌入
- ITM(Image-Text Matching):判断图文是否匹配(利用 bi-directional attention mask)
- ITG(Image-grounded Text Generation):以视觉 Query Token 为条件,自回归生成对应的图像描述
第二阶段:视觉-语言生成学习 冻结 LLM(OPT-6.7B 或 FlanT5-XXL),将 Q-Former 输出的32个 Query Token 经线性投影后拼接到 LLM 的文本输入前缀,训练 Q-Former 使其产生的视觉软提示(visual soft prompt)能有效引导 LLM 执行多模态生成任务。
结果
BLIP-2 在视觉问答(VQAv2)上以更少的可训练参数量超越 Flamingo(80B)的零样本性能。在零样本 VQAv2 测试中,BLIP-2 FlanT5-XXL(11B LLM)超越 Flamingo-80B,而仅需训练约 188M 参数(Q-Former),其余均为冻结的预训练权重,大幅降低了对多模态训练计算资源的需求。
8.5 LLaVA(2023)
论文:Visual Instruction Tuning 机构:University of Wisconsin-Madison / Microsoft Research 发表:NeurIPS 2023,作者:Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
LLaVA 以极简的架构和创新的指令数据构建方法,开创了开源多模态大模型的繁荣生态,发布后迅速成为最具影响力的开源 VLM 之一(截至2024年被引超万次)。
精华:LLaVA 的价值在于证明了极简架构 + 高质量指令数据的组合可以超越复杂设计——一个线性投影层(后升级为两层 MLP)足以连接 CLIP 视觉编码器与 LLM,关键在于如何获得高质量的视觉指令数据。用 GPT-4 基于图像标题和边界框文本代理生成多轮对话数据的方法,是一种低成本构建指令数据的范式创新,无需直接人工标注图像。LLaVA-NeXT 引入的动态分辨率切片(tile-based high resolution)成为后续几乎所有开源 VLM 的标配。局限在于早期 LLaVA 的线性投影过于简单,存在视觉-语言语义鸿沟,且对高分辨率精细内容(OCR、小目标)的识别能力不足。
架构:三件套极简设计
图像 → [CLIP ViT-L/14] → 视觉特征 Z_v
↓
线性投影 W
↓
视觉 token H_v ──→ [LLM: Vicuna-13B / LLaMA] → 回答
↑
文本指令 H_q
仅用一个线性投影矩阵 $W$ 将 CLIP ViT 输出的视觉特征映射到 LLM 的词嵌入空间。视觉 token 与文本指令直接拼接后输入 LLM,结构极为简洁。
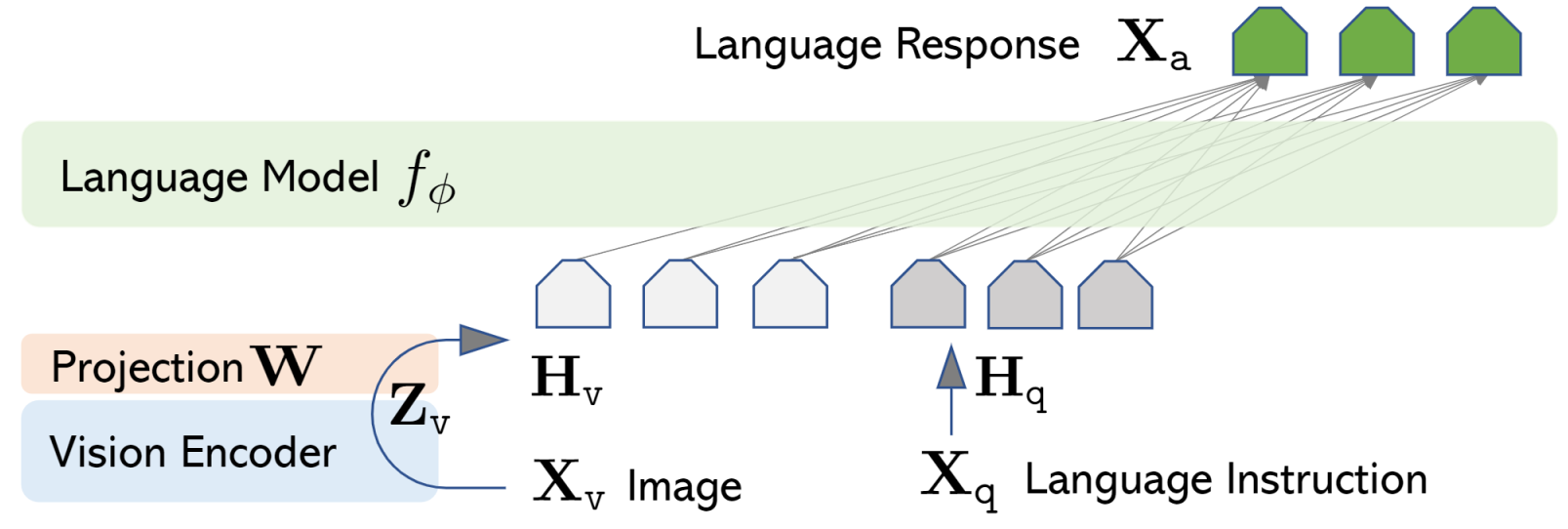
指令数据构建:GPT-4辅助生成
LLaVA 的关键创新在于如何获得高质量的视觉指令数据。由于直接标注大量图像多轮对话数据成本极高,LLaVA 采用了一个巧妙的方案:
利用 COCO 数据集中已有的图像标题(captions)和边界框信息(bounding boxes),将这些文本信息作为图像内容的”代理”,喂给纯文本版 GPT-4,让其生成三种类型的指令数据:
- 对话式(Conversation):58K条,模拟用户就图像内容进行多轮问答
- 详细描述(Detailed Description):23K条,对图像进行全面、详细的文字描述
- 复杂推理(Complex Reasoning):77K条,需要结合图像内容进行逻辑推理
合计 ~158K 条高质量指令数据,构建成本极低(无需人工标注图像),却实现了出色的视觉指令遵循能力。
两阶段训练
| 阶段 | 可训练参数 | 目标 | 数据 |
|---|---|---|---|
| 预训练(特征对齐) | 仅投影层 W | 对齐视觉特征与 LLM 词嵌入空间 | 595K CC图文对 |
| 微调(指令遵循) | 投影层 W + LLM | 端到端学习视觉指令遵循 | 158K 指令数据 |
LLaVA-1.5:MLP升级
LLaVA-1.5(2023年底)将线性投影层升级为两层 MLP(含 GELU 激活),并将视觉编码器从 ViT-L/14 升级为 CLIP ViT-L/14@336px(更高分辨率),在 VQAv2、GQA、TextVQA 等多个基准上大幅超越原始 LLaVA,同时仍保持同等简洁的架构。
LLaVA-NeXT:动态高分辨率
LLaVA-NeXT(2024年初,也称 LLaVA-1.6)引入动态分辨率切片技术:
- 根据图像的原始长宽比,将其切分为 2×2 或 1×3 等不同网格(最多4个小块)
- 每个小块单独用 CLIP ViT 编码(每块336×336),获得更细粒度的局部特征
- 保留一张低分辨率(336px)的整体图像(缩略图),提供全局上下文
- 所有块的特征拼接后送入 LLM
这一设计将有效输入分辨率提升到 672×672 或更高,在 TextVQA(OCR理解)、DocVQA(文档理解)和图表理解任务上有显著提升。
8.6 SigLIP(2023)
论文:Sigmoid Loss for Language-Image Pre-Training 机构:Google DeepMind 发表:ICCV 2023,作者:Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer
SigLIP 是对 CLIP 对比学习范式的关键改进,用逐对 sigmoid 损失替代 softmax 对比损失,消除了对全局 batch 负样本的依赖,已成为轻量 VLM(PaliGemma、SmolVLM、Qwen3-VL 等)的首选视觉编码器。
精华:CLIP 的 softmax 对比损失要求在整个 batch 内归一化,batch 越大效果越好,但也意味着必须在少数超算节点上集中训练。SigLIP 将问题拆解为 $N^2$ 个独立的二元分类——每对图文是否匹配——用 sigmoid 激活函数独立计算损失,天然支持分布式并行(每台机器只需本地 batch 的负样本)。这一改动不仅让训练更易扩展,还使 SigLIP 在小 batch size 下也能取得与 CLIP 相当乃至更优的性能。SigLIP-SO/400M(4亿参数 ViT-SO,patch size 14,分辨率 224/384/512px)作为轻量视觉骨干被广泛采用;SigLIP-2(2025)进一步引入自监督蒸馏、掩码预测、多分辨率训练等改进,成为 Qwen3-VL 等旗舰模型的视觉编码器。
核心:Sigmoid 损失替换 Softmax
CLIP 的 softmax 对比损失(对称 InfoNCE):
\[\mathcal{L}_\text{CLIP} = -\frac{1}{2N}\left[\sum_{i}\log\frac{e^{s_{ii}/\tau}}{\sum_j e^{s_{ij}/\tau}} + \sum_{i}\log\frac{e^{s_{ii}/\tau}}{\sum_j e^{s_{ji}/\tau}}\right]\]每个样本的归一化分母依赖 整个 batch 的所有负样本,要求全局 all-reduce 操作。
SigLIP 的 sigmoid 损失:
\[\mathcal{L}_\text{SigLIP} = -\frac{1}{N^2}\sum_{i,j} \log \sigma\!\left(z_{ij} \cdot (2 y_{ij} - 1)\right)\]其中 $z_{ij} = t \cdot \langle v_i, t_j\rangle + b$($t$ 为可学习温度,$b$ 为可学习偏置),$y_{ij} = 1$ 当 $i=j$(正对)否则 $0$,$\sigma$ 为 sigmoid 函数。每对 $(i,j)$ 的损失独立计算,无需跨设备的全局归一化,各机器仅需本地 batch 的数据。
实验结果
在 ImageNet 零样本分类(Top-1)上,SigLIP 以相近的训练成本超越 CLIP:
| 模型 | 参数量 | Batch Size | ImageNet ZS(Top-1) |
|---|---|---|---|
| CLIP ViT-L/16 | 307M | 32,768 | 75.3% |
| SigLIP ViT-L/16 | 307M | 32,768 | 76.3% |
| SigLIP ViT-L/16 | 307M | 1,024(小 batch) | 75.9% |
| SigLIP ViT-SO/14(400M) | ~400M | 32,768 | 82.0% |
在小 batch size(1,024)下,SigLIP 的性能衰退极小(76.3% → 75.9%),而 CLIP 在同等小 batch 下会出现明显性能下降,验证了 sigmoid 损失的分布式友好性。
影响与后续
SigLIP 的影响远超其论文本身:
- PaliGemma(Google,2024):直接以 SigLIP-SO/400M 作为视觉骨干,与 Gemma-2B 结合
- SmolVLM(HuggingFace,2024):SigLIP 视觉编码器 + Pixel Shuffle 压缩,支持 256M/2B 端侧部署
- Qwen3-VL(阿里,2025):升级至 SigLIP-2(引入自监督蒸馏、掩码图像预测、多分辨率训练),旗舰版使用 SigLIP2-SO-400M
- SigLIP-2(Tschannen et al., 2025)在 SigLIP 基础上加入类 MAE 的掩码预测目标、自监督蒸馏损失和多分辨率训练,进一步提升细粒度理解能力
8.7 InternVL2(2024)
论文:InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks(原始版本,CVPR 2024 Oral) 机构:上海人工智能实验室(Shanghai AI Laboratory) 发表:CVPR 2024 Oral,作者:Zhe Chen, Jiannan Wu, Wenhai Wang 等
InternVL2 是截至 2024 年底开源 VLM 中综合性能最强的系列,在多个权威评测基准上超越或持平 GPT-4V。
精华:InternVL2 的核心洞察是扩大视觉编码器规模是提升多模态理解能力的关键杠杆——InternViT-6B(5.9B参数)是 CLIP ViT-L(307M)的约19倍,能提取更丰富的细粒度视觉特征,在文档、图表、数学题图等精细理解任务上优势尤为明显。Pixel Shuffle 压缩(4:1)将高分辨率 tile 的 token 从1024压缩至256,高效降低 LLM 输入长度的同时保留视觉细节。提供从1B到76B的完整模型系列(共享同一视觉编码器,仅替换语言骨干)的策略,也是开源生态建设的典范。局限在于 InternViT-6B 推理成本较高,端侧部署需使用参数更少的 InternViT-300M 变体,性能有所折损。
核心:InternViT-6B 超大视觉编码器
InternVL2 的关键差异化在于使用了 InternViT-6B——目前参数量最大的开源视觉编码器(约 5.9B 参数,后在 V2.5 中精简至 5.5B):
- 架构:48层(后精简至45层)ViT,隐层维度 3200,patch size 14×14,输入分辨率 448×448
- 训练策略:先用 OpenAI CLIP 的蒸馏目标初始化,再以对比学习和生成目标联合预训练,在图像分类(ImageNet 88.2%)、语义分割(ADE20K 58.9 mIoU)等纯视觉任务上均达到 SOTA
- 与 CLIP ViT-L 的对比:CLIP ViT-L 仅有 307M 参数,InternViT-6B 参数量是其约19倍,能提取更丰富的细粒度视觉特征
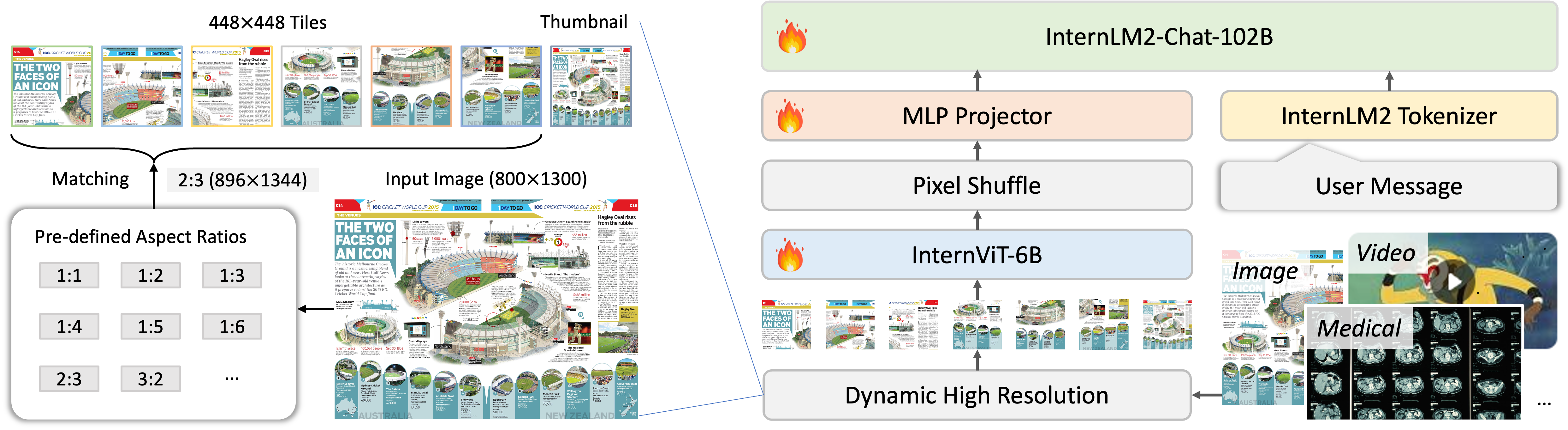
动态高分辨率处理
InternVL2 支持最高 4K 分辨率的图像输入,通过以下流程处理任意分辨率:
- 自适应切片:根据输入图像分辨率和长宽比,动态决定分割为最多 6个 tile(每个 448×448),同时保留1张整体缩略图,共最多7张子图
- 独立编码:每个子图通过 InternViT-6B 独立编码,产生 $(448/14)^2 = 1024$ 个 token
- Pixel Shuffle 压缩:将2×2的4个相邻 token 合并为1个,将每张子图的 token 从1024压缩至 256(4:1压缩比),显著降低 LLM 的输入长度
模型规格与语言骨干
InternVL2 家族通过替换语言骨干,提供从端侧到服务器端的完整模型系列:
| 模型 | 视觉编码器 | 语言骨干 | 总参数 |
|---|---|---|---|
| InternVL2-1B | InternViT-300M | InternLM2-1.8B | 约1B |
| InternVL2-2B | InternViT-300M | InternLM2-1.8B | 约2B |
| InternVL2-4B | InternViT-300M | Phi-3-Mini-3.8B | 约4B |
| InternVL2-8B | InternViT-300M | InternLM2.5-7B | 约8B |
| InternVL2-26B | InternViT-6B | InternLM2-20B | 约26B |
| InternVL2-40B | InternViT-6B | Nous-Hermes-2-Yi-34B | 约40B |
| InternVL2-Llama3-76B | InternViT-6B | LLaMA-3-70B-Instruct | 约76B |
评测结果
InternVL2-76B 在多个权威多模态基准上的表现:
| 基准 | InternVL2-76B | GPT-4V | Gemini 1.5 Pro |
|---|---|---|---|
| MMBench(EN) | 86.5 | 81.4 | 75.0 |
| MMStar | 67.1 | 56.0 | 59.0 |
| DocVQA | 94.1 | 88.4 | 93.1 |
| ChartQA | 88.4 | 78.5 | 81.3 |
| MathVista | 65.5 | 49.9 | 57.7 |
InternVL2 的成功验证了扩大视觉编码器规模(相较于 CLIP ViT-L)在提升多模态理解能力方面的有效性,尤其在需要细粒度视觉理解的任务(文档、图表、数学题图)上优势明显。
InternVL2.5 演进(2024年底)
InternVL2.5 在 InternVL2 基础上引入多阶段动态分辨率训练策略——从低分辨率到高分辨率渐进训练,配合混合课程学习(Curriculum Learning)平衡不同难度的视觉任务。InternVL2.5-78B 在 MMBench、MathVista 等基准上全面超越 GPT-4V,成为 2024 年底开源 VLM 的综合性能标杆。其训练配方(MLP 预热 → ViT 增量学习 → 全参数微调,全程统一学习率、总计仅约 1200 亿 token)详见 6.4 节。
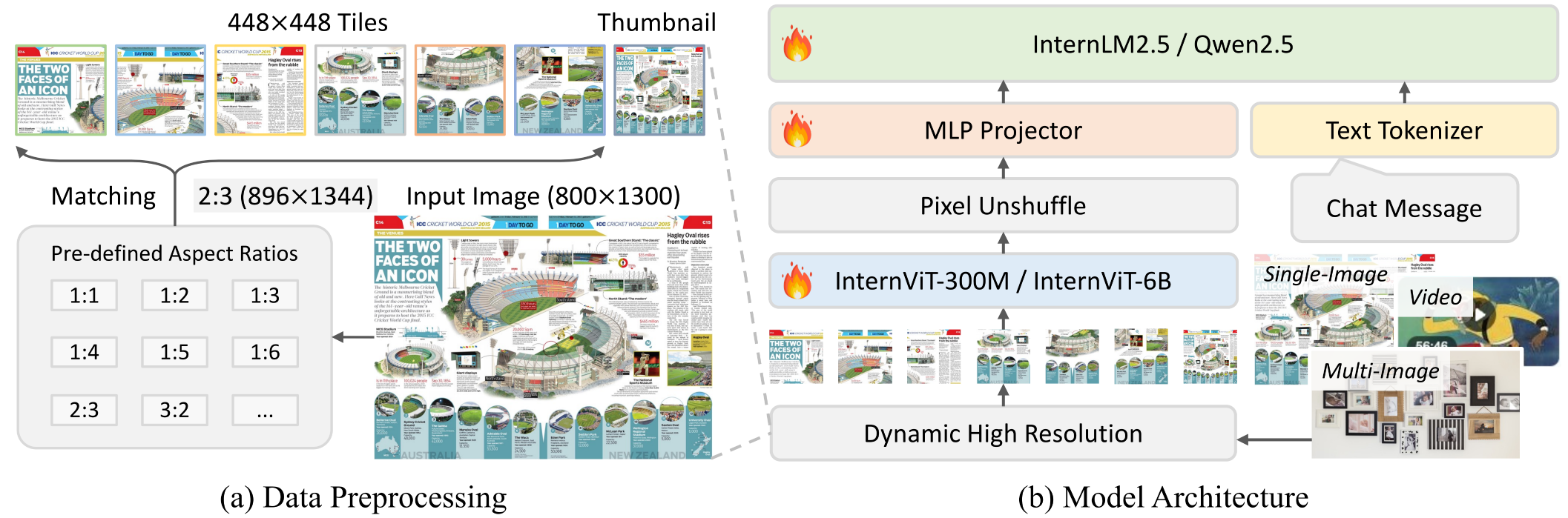
8.8 InternVL3.5(2025)
———开源多模态模型的全面升级:推理能力、通用性与推理效率三管齐下
📄 Paper: arXiv:2508.18265
精华
- 推理能力的提升不一定要靠单一的强化学习算法堆到底:离线RL(MPO)做”暖场”再用在线RL(GSPO)精修的级联策略,比单独跑在线RL更省算力、效果更好,且对模型规模和稀疏度(dense/MoE)都稳定有效。
- 视觉token的压缩率可以是输入自适应的,而不是固定写死:用一致性蒸馏训练模型本身先学会”在不同压缩率下输出一致”,再单独训一个轻量路由器按patch语义内容选压缩率,比按图像宽高切分的传统Dynamic High Resolution更细粒度。
- 多模态推理效率的瓶颈往往不是计算量本身,而是视觉编码器和语言模型的计算特性不匹配(视觉强并行、语言强自回归依赖历史state)导致互相阻塞;把两者解耦部署到不同GPU/Server上做异步流水线,能直接换来可观的吞吐提升,且分辨率越高收益越大。
- 这两项效率手段(动态压缩率 + 解耦部署)几乎是正交可叠加的:单独DvD最高2.01×加速,叠加ViR后能到4.05×,说明”省token”和”省调度阻塞”是两类不同的瓶颈,值得同时治理。
- 大规模文本数据与多模态数据按约1:2.5~1:3.5混合的原生预训练策略,是开源MLLM在纯文本任务(GAOKAO、MMLU-Pro等)上逼近商业模型的重要前提,提醒”多模态化”不应以牺牲语言能力为代价。
1. 研究背景/问题
当前开源MLLM在文本任务、复杂推理任务和Agent任务上与GPT-5等商业模型仍有明显差距,社区已尝试用RL方法缩小差距,但稳定、高效、可扩展的MLLM强化学习框架仍是开放问题。同时,长视觉上下文和高分辨率理解带来的计算成本持续上升,已成为实际部署的核心瓶颈。InternVL3.5即针对”推理能力”和”推理效率”这两个相对独立但同等重要的维度同时发力。
2. 主要方法/创新点
InternVL3.5沿用InternVL系列的”ViT–MLP–LLM”范式(语言模型基于Qwen3 / GPT-OSS,视觉编码器为InternViT-300M / InternViT-6B),并在此基础上引入三项核心技术:Cascade RL(提升推理能力)、Visual Resolution Router, ViR(降低视觉token开销)、Decoupled Vision-Language Deployment, DvD(解耦部署提升推理吞吐)。
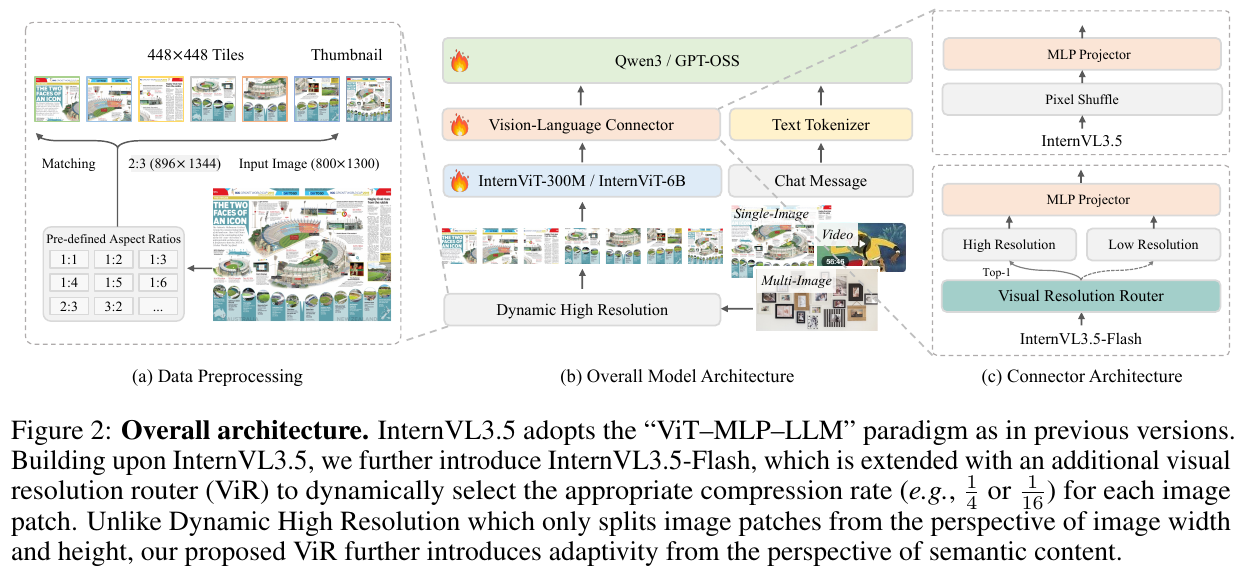
① 整体框架概述:系统由三个核心模块构成——视觉编码器(InternViT)将动态切分后的图像tile编码为视觉token;Vision-Language Connector通过Pixel Shuffle和MLP Projector把视觉token压缩并投影到语言模型的embedding空间;语言模型(Qwen3 / GPT-OSS)负责融合视觉token与文本token并自回归生成回复。InternVL3.5-Flash在Connector中额外引入ViR,使视觉token的压缩率可以按patch内容动态调整而非固定不变。
② 训练流程(四阶段递进):
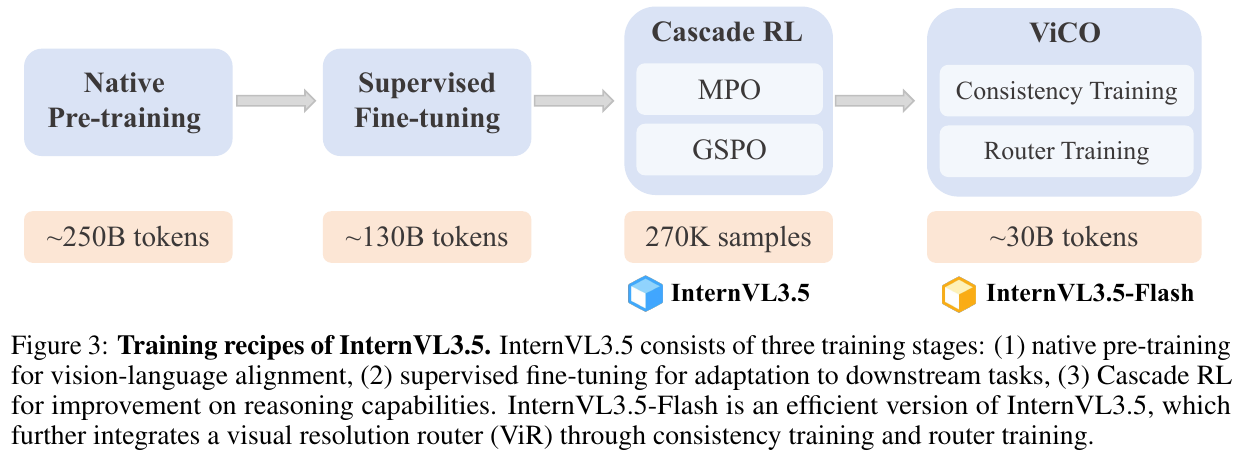
- 原生预训练(~250B token):联合更新全部参数,文本数据与多模态数据混合比例约1:2.5,最大序列长度32K。损失采用对每个样本做”平方根加权”的NTP loss(权重 $w_i=1/N^{0.5}$,$N$为样本内计算损失的token数),避免长/短回复带来的偏置;同时引入随机JPEG压缩增强真实场景鲁棒性。
- 监督微调(SFT,~130B token):复用InternVL3的指令数据保证覆盖面,新增”Thinking模式”的长链推理数据(由大模型采样rollout后严格过滤思维清晰度、冗余度、格式一致性),并加入GUI交互、具身交互、SVG理解生成等能力扩展数据。
- Cascade RL(核心创新):分两个互补子阶段。离线RL阶段用Mixed Preference Optimization(MPO)做高效”暖机”,损失为偏好损失(DPO)、质量损失(BCO)、生成损失(LM loss)的加权和: \(\mathcal{L}_{MPO} = w_p \mathcal{L}_p + w_q \mathcal{L}_q + w_g \mathcal{L}_g\) 离线RL把rollout采集和参数更新解耦,训练效率高且能为下一阶段保证高质量rollout。在线RL阶段用GSPO(不带参考模型约束)在自身采样的rollout上精修输出分布,优势函数定义为同query下多个响应reward的标准化值: \(\hat A_i = \frac{r(x,y_i) - \mathrm{mean}\{r(x,y_i)\}_{i=1}^G}{\mathrm{std}\{r(x,y_i)\}_{i=1}^G}\) 重要性采样比取每个token概率比的几何平均(即整段响应级别的比值): \(s_i(\theta) = \left(\frac{\pi_\theta(y_i\mid x)}{\pi_{\theta_{old}}(y_i\mid x)}\right)^{1/|y_i|}\) 级联设计的优势:(1) 离线阶段rollout采集与更新解耦,缓解reward hacking,且更强的MPO模型能让后续GSPO训练更稳定;(2) 离线阶段的rollout可在多个模型间共享,分摊在线RL的采样成本;(3) 经MPO预热的模型在GSPO阶段只需更少步数即可达到更高性能上限。
- ViCO(构建InternVL3.5-Flash):分两步。一致性训练:冻结一个以InternVL3.5初始化的参考模型(固定用1/4压缩率推理),让policy模型在1/4或1/16两种压缩率下(均匀采样)的输出分布向参考模型对齐,最小化KL散度: \(\mathcal{L}_{ViCO} = \mathbb{E}_{\xi\sim R}\left[\frac{1}{N}\sum_{i=1}^N \mathrm{KL}\big(\pi_{\theta_{ref}}(y_i\mid y_{<i},I)\,\|\,\pi_{\theta_{policy}}(y_i\mid y_{<i},I_\xi)\big)\right]\) 路由器训练:冻结整个MLLM主干,只训练ViR这个二分类器。先计算每个patch在低/高压缩率下的loss比值 $r_i = \mathcal{L}{ViCO}(y_i\mid I{1/16}) / \mathcal{L}{ViCO}(y_i\mid I{1/4})$,再用滑动窗口历史值的k百分位作动态阈值 $\tau$,按 $r_i$ 是否超过 $\tau$ 生成0/1标签训练路由器,使其学会判断”哪些patch压缩了也不掉性能”。最终InternVL3.5-Flash可减少50%视觉token,性能几乎不掉(DocVQA等高分辨率任务保持~100%原性能)。
③ Decoupled Vision-Language Deployment(DvD):
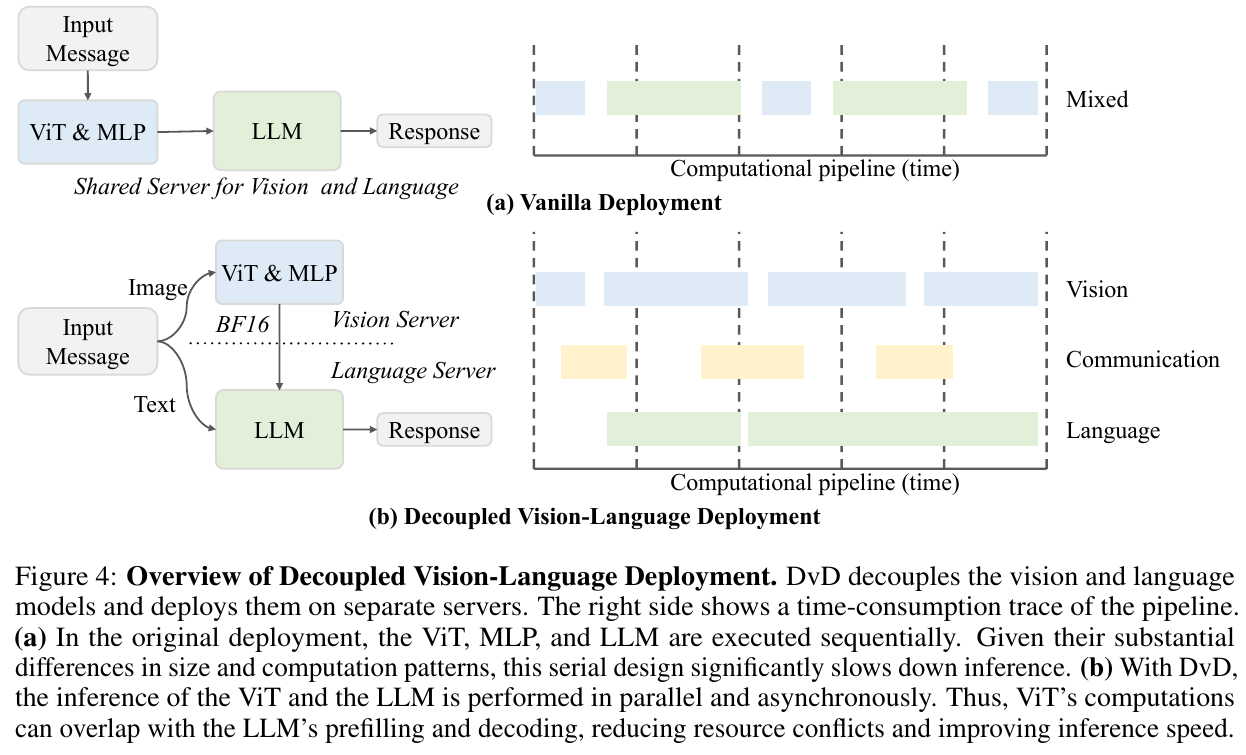
动机:视觉编码器高度可并行且不依赖长程历史state,语言模型则因自回归特性对内存带宽和延迟更敏感;二者放在同一服务器上会相互阻塞,分辨率/视觉模型越大阻塞越严重。DvD把视觉子系统(批处理图像产生紧凑特征embedding)与语言子系统(融合文本上下文做decoding)拆分到独立服务器,让视觉计算与LLM的prefilling/decoding重叠执行,同时也便于独立优化两侧的硬件成本,新增视觉模块也无需改动语言服务器。
训练目标小结:预训练/SFT阶段为加权NTP loss;Cascade RL阶段为MPO的三项加权损失(公式见上)和GSPO的clip目标;ViCO阶段为KL一致性损失+路由器的交叉熵损失。
推理流程:默认不开启test-time scaling;针对推理类benchmark额外提供两种TTS手段——Deep Thinking(开启Thinking模式做分步推理)和Parallel Thinking(用VisualPRM-v1.1作为critic在多个候选回答中做Best-of-N选择),二者可与Cascade RL叠加进一步提升推理分数。
3. 核心结果/发现
- 整体能力:InternVL3.5-241B-A28B在通用、推理、文本、Agent四大类35个benchmark上取得开源模型中的最高综合分,整体得分74.1对GPT-5的74.0几乎持平,与GPT-5的差距收窄至3.9%。
- 推理能力提升显著:相比上一代InternVL3,同等规模下推理类benchmark平均提升超10分;MMMU上8B/241B模型分别达到73.4/77.7。Cascade RL的逐阶段消融显示:SFT后的Instruct模型已大幅超过InternVL3(如8B提升+9.3%),MPO阶段再提供最高+3.5%的平均增益,完整Cascade RL相比SFT基线最高带来+16.0%(如2B模型推理任务+12.2%,241B模型+6.5%)增益,且训练效率上仅需GSPO一半的GPU时数即可取得更优效果(8B模型:Cascade RL耗时~5.8K GPU小时综合分60.3,对比GSPO两轮~11.0K GPU小时综合分仅58.2)。
- 效率提升可叠加:DvD单独最高带来2.01×(241B模型)/1.97×(38B模型)的吞吐加速,且分辨率越高加速越明显(448→1344分辨率下38B模型加速比从1.19×提升到1.97×);在DvD基础上叠加ViR后总加速比最高达4.05×(38B模型,1344分辨率)。ViR带来的视觉token减半几乎不损失性能(InternVL3.5-Flash在DocVQA、InfoVQA等高分辨率任务上保持原模型~100%的分数)。
- versatility:在SGP-Bench(SVG理解)、ScreenSpot/OSWorld-G(GUI grounding)、VSI-Bench/ERQA/SpaCE-10/OmniSpatial(具身/空间推理)等agentic任务上均取得开源模型中的领先表现,验证了模型在GUI交互和具身智能方向的潜力。
4. 局限性
论文未设置独立的局限性章节,但在结果分析中指出:HallusionBench(幻觉评测)等任务上InternVL3.5仍落后于部分开源/商业模型,表明视觉幻觉问题尚未被现有训练策略充分解决,需要进一步改进;此外当前TTS仅在推理类benchmark上验证有效,对一般感知/理解类任务的增益尚不明显。
8.9 Qwen2.5-VL(2025){#qwen25-vl}
———Native Resolution, Dynamic FPS, Temporal-Aware Vision-Language Model
📄 Paper: arXiv:2502.13923
精华
Qwen2.5-VL 最核心的思路是”让模型看到和人类一样的原始输入”:图像以原始分辨率送入(不强制缩放),视频以动态 FPS 采样(而非固定帧率截帧)。时间感知通过 MRoPE 实现——把帧的绝对时间戳编码到位置嵌入里,使模型能真正理解”事件发生在第几秒”而非”事件发生在第几帧”。视觉编码器从根本上重建:引入窗口注意力 + 全局注意力混合、SwiGLU FFN、RMSNorm,并用 Conv3D 2×2 对视频做时序下采样降低 token 数。这套设计在不修改 LLM 解码器的前提下,让视觉 token 数量可随输入动态变化,为超长视频和超高分辨率图像提供了统一的处理框架。
1. 研究背景/问题
主流 VLM(如 LLaVA 系列)在视觉编码时通常把图像缩放到固定分辨率,视频则以固定帧率截帧,导致细节信息丢失、时序理解不准确。此外,早期 ViT 在 VLM 中直接沿用图像预训练结构,缺乏对视频时序建模的原生支持,也没有与 LLM 位置编码体系的深度融合。Qwen2.5-VL 旨在从视觉编码器架构和位置编码设计两个维度根本性地解决这些问题。
2. 主要方法/创新点
① 整体框架概述
Qwen2.5-VL 由三个核心部分构成:重新设计的 Vision Encoder(负责多分辨率图像和动态 FPS 视频的 token 化)、MRoPE 位置编码(负责图像空间 + 视频时间的统一对齐)、以及 Qwen2.5 LM Decoder(负责多模态理解与生成)。
② Vision Encoder — 重构后的 ViT
- 输入:原始分辨率图像 patch(不做强制缩放);视频则按动态 FPS 采样得到帧序列
- 处理:
- Window Attention(局部注意力):在非最终层中,每帧内仅做窗口内自注意力,大幅降低计算复杂度
- Full Attention(全局注意力):在特定层(如最后一层)做完整的帧间/跨窗口注意力,捕获全局关系
- Conv3D 2×2:在时序维度做步长为 2 的 3D 卷积,把连续两帧合并为一个视觉 token,压缩视频 token 数量
- SwiGLU FFN + RMSNorm:替代原始 ViT 的 GELU FFN + LayerNorm,提升效率与稳定性
- 输出:变长视觉 token 序列(图像约几百至千余 token,视频按帧数和 FPS 动态调整)
- 设计动机:窗口注意力解决高分辨率下 self-attention 的 \(O(n^2)\) 计算开销;Conv3D 降低视频 token 数避免上下文长度爆炸
③ MRoPE(Multimodal Rotary Position Embedding)
传统 1D RoPE 无法表达图像的二维空间位置或视频的时间戳信息。MRoPE 将旋转位置编码扩展为三通道:
- 图像:分别在高度(H)、宽度(W)维度施加 2D RoPE,时间 ID 固定为 0
- 视频:在 H、W 之外,时间维度 ID 对齐帧的绝对时间戳(而非帧序号),使模型能感知”这一帧发生在第 $t$ 秒”
这让模型在视频 QA 任务中具备精确的时刻定位能力(moment retrieval),而不只是判断事件的相对顺序。
④ 动态分辨率与动态 FPS
- 图像按原始宽高送入,token 数由图像面积动态决定,不强制统一至固定尺寸
- 视频支持不同 FPS 输入,模型无需假设固定帧率;低帧率视频不会因插值引入伪影
⑤ 训练目标
Qwen2.5-VL 采用自回归语言建模目标,在多模态指令对上做监督微调(SFT):
\[\mathcal{L} = -\sum_{t} \log P(y_t \mid y_{<t}, x_{\text{visual}}, x_{\text{text}})\]视觉 token 和文本 token 统一进入 LM Decoder 做 next-token prediction;视觉 token 位置不计入语言损失(仅对文本输出 token 计算 loss)。
3. 核心结果/发现
- DocVQA:96.5%,超越 Claude-3.5-Sonnet(91.1%)和 GPT-4o(95.2%),是文档理解任务最强开源模型之一
- VideoMME:79.1%,优于 Claude-3.5-Sonnet(77.8%)、GPT-4o(77.2%)
- MathVista:70.5%,优于 GPT-4o(67.7%)
- 纯文本基准:在 HumanEval(87.8%)、CSMRK(95.8%)等纯语言基准上,Qwen2.5-VL-72B 匹敌同参数量的纯语言模型(Qwen2.5-72B: 95.3%),说明引入视觉能力几乎不损失语言性能
- 提供 3B / 7B / 72B 三档模型,3B 在移动端可部署;72B 达到 GPT-4o 级别
4. 局限性
窗口注意力在视频帧数极大时仍存在信息瓶颈,全局帧间交互依赖少数几层 Full Attention,对超长视频(数百帧)的长程依赖建模能力有限。动态 token 数在批推理时会导致变长序列,增加工程实现复杂度(需 padding 或动态 batch)。
8.10 Qwen3-VL (2025)
——最强视觉-语言模型系列,原生支持256K上下文
📄 Paper: arXiv:2511.21631
精华
这篇论文展示了如何构建一个全面的视觉-语言模型系列,值得借鉴的核心思想包括:
- 平衡文本和多模态能力:通过square-root reweighting确保多模态训练不损害文本能力,甚至在某些文本任务上超越纯文本模型
- 渐进式上下文扩展:采用四阶段预训练(8K→32K→256K),逐步扩展上下文窗口,而不是一步到位
- 架构优化的实用主义:Interleaved MRoPE、DeepStack、文本时间戳等创新都针对实际问题(长视频理解、视觉-语言对齐、时序定位)
- 分层式后训练:区分non-thinking和thinking变体,针对不同应用场景优化
- 全栈式能力整合:将感知(grounding)、推理(reasoning)和行动(agentic)能力统一到单一模型框架中
研究背景/问题
现有的视觉-语言模型在发展过程中面临几个关键挑战:一是多模态训练往往会损害底层LLM的语言能力;二是长上下文支持不足,难以处理长文档和长视频;三是在STEM推理、文档理解、视频理解等专业任务上性能参差不齐;四是缺乏统一的框架整合感知、推理和决策能力。Qwen3-VL旨在系统性地解决这些问题。
主要方法/创新点
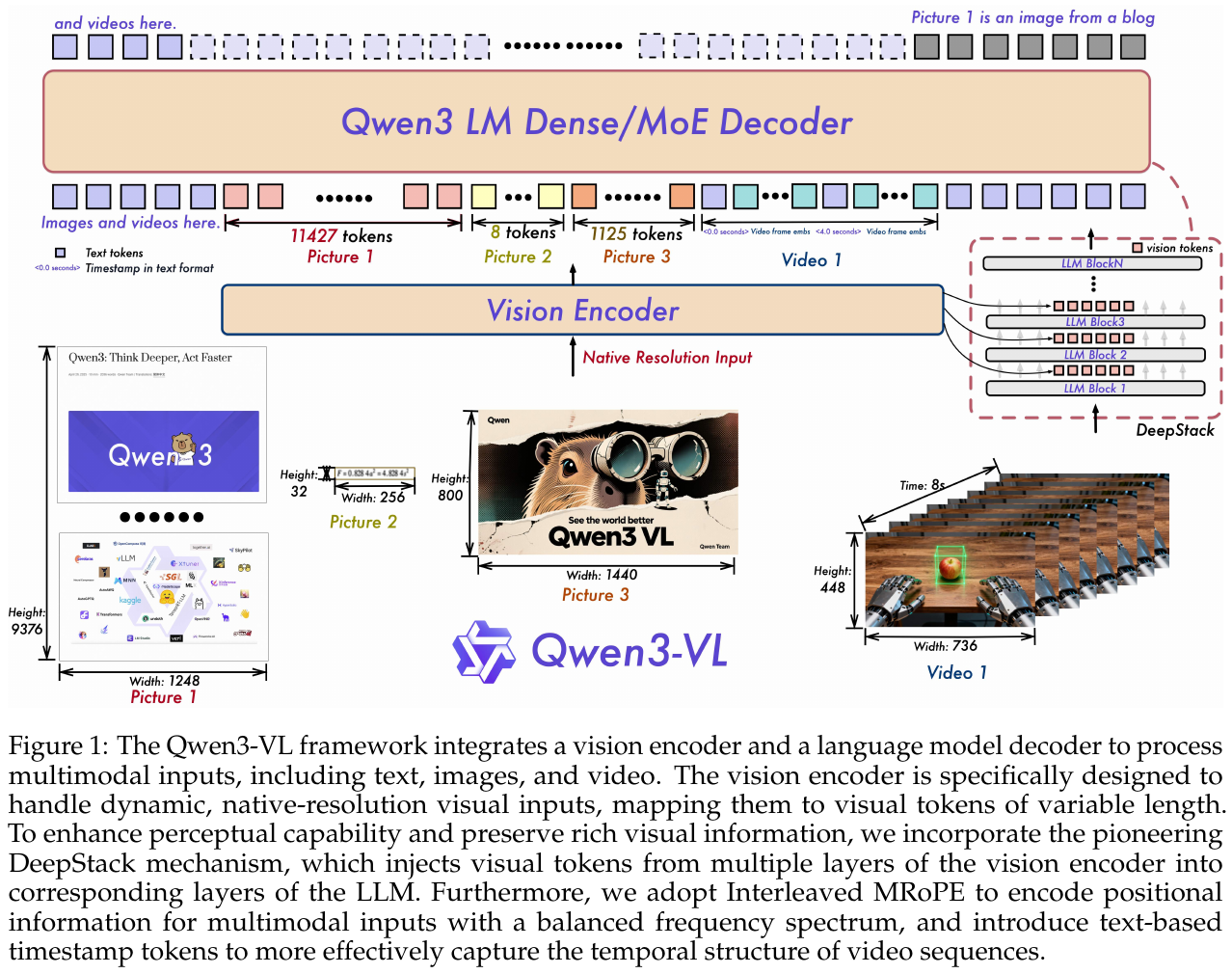
Qwen3-VL提出了一个完整的视觉-语言模型系列,包括4个dense模型(2B/4B/8B/32B)和2个MoE模型(30B-A3B/235B-A22B),均原生支持256K token的交错式上下文:
| 类型 | 规模 | 说明 |
|---|---|---|
| Dense | 2B / 4B / 8B / 32B | 标准密集模型,每个规模均提供 thinking/non-thinking 双变体 |
| MoE | 30B-A3B | 混合专家路由,3B 激活参数 |
| MoE | 235B-A22B | 旗舰规模,22B 激活参数,兼顾质量与延迟 |
架构创新:
-
Interleaved MRoPE - 针对Qwen2.5-VL中MRoPE频谱不平衡的问题,将时间(t)、水平(h)、垂直(w)维度交错分布在低频和高频频段,显著改善长视频理解能力
-
DeepStack跨层融合 - 从ViT的多个层提取视觉特征,通过轻量级残差连接路由到LLM的对应层,增强多层次视觉-语言对齐,不增加额外上下文长度
-
显式视频时间戳 - 用文本token(如
<3.0 seconds>)标记视频帧组,替代Qwen2.5-VL中的绝对时间位置编码,提供更简单直接的时序表示,支持seconds和HMS两种格式 -
视觉编码器升级为 SigLIP-2 - 支持动态输入分辨率:旗舰版(8B/32B/MoE)使用 SigLIP2-SO-400M,小型版(2B/4B)使用 SigLIP2-Large(300M);视觉-语言连接器为两层 MLP,将 2×2 patch 特征压缩为单个 token
训练策略:
预训练分为四个阶段:
- S0 (67B tokens, 8K): 仅训练merger层进行视觉-语言对齐
- S1 (~1T tokens, 8K): 全参数多模态预训练,混合VL数据和文本数据
- S2 (~1T tokens, 32K): 长上下文预训练,增加文本数据比例和视频/agent数据
- S3 (100B tokens, 256K): 超长上下文适应,聚焦长视频和长文档理解
后训练包含三个阶段:
- SFT - 分为32K和256K两个阶段,提供non-thinking和thinking两个变体
- Strong-to-Weak蒸馏 - 用text-only数据微调LLM backbone,显著提升推理能力
- 强化学习 - 分为Reasoning RL(数学、代码、逻辑推理等)和General RL(指令遵循、格式控制等),使用SAPO算法
数据优化:
- 高质量caption - 使用Qwen2.5-VL-32B对web图像重新标注,基于视觉embedding聚类增强稀疏概念覆盖
- 交错文本-图像 - 收集多模态文档,用domain classifier过滤低质量内容,构建256K长序列
- 知识数据 - 覆盖12+语义类别(动物、植物、地标等),采用importance-based采样平衡长尾分布
- OCR扩展 - 从10种语言扩展到39种语言,合成3000万高质量样本
- Grounding归一化 - 统一采用[0, 1000]归一化坐标系统,支持2D/3D grounding和counting
- 视频数据 - 密集caption合成(short-to-long策略)和时空grounding数据
- STEM数据 - 6M图表caption + 60M+ K-12/本科习题 + 12M长CoT推理样本
- Agent数据 - GUI感知(描述、grounding)+ 自进化轨迹生成框架
优化技巧:
- Square-root reweighting - 对per-token loss进行平方根归一化,平衡文本和多模态数据贡献
- 分层式训练 - 预训练阶段逐步扩展上下文,后训练阶段区分thinking/non-thinking模式
核心结果/发现
综合性能:
- 在多模态reasoning任务上(MMMU、MathVista、MathVision等),Qwen3-VL-235B-A22B-Thinking达到SOTA水平
- 在文本任务上超越或持平纯文本模型(如DeepSeek V3、Qwen3-235B),证明多模态训练未损害语言能力
- 小模型(2B/4B/8B)表现出色,8B模型在很多任务上接近Qwen2.5-VL-72B
旗舰模型(235B-A22B)与 Gemini 2.5 Pro 对比(论文 Table 2):
| 基准 | 类别 | Qwen3-VL-235B Thinking | Qwen3-VL-235B Instruct | Gemini 2.5 Pro Thinking |
|---|---|---|---|---|
| MMMU | 综合多模态 | 80.6 | 78.7 | 81.3 |
| MathVista_mini | 视觉数学 | 85.8 | 84.9 | 82.7 |
| MathVision | 视觉数学 | 74.6 | 66.5 | 73.5 |
| MMBench-EN | 通用 VQA | 88.8 | 89.3 | 83.8 |
| RealWorldQA | 真实场景 | 81.3 | 79.2 | 82.8 |
| MMStar | 开放域 QA | 78.7 | 78.4 | 77.5 |
| DocVQA_test | 文档理解 | 96.5 | 97.1 | 94.0 |
| ChartQA_test | 图表理解 | 90.3 | 90.3 | 83.3 |
| OCRBench | OCR | 875 | 920 | 866 |
| Video-MME w/o sub | 视频理解 | 79.0 | — | 85.1 |
| OSWorld(Agent) | GUI Agent | 38.1 | 31.6 | — |
| AndroidWorld(Agent) | GUI Agent | 62.0 | 63.7 | — |
长上下文能力:
- Needle-in-a-Haystack评估:256K token(30分钟视频)内100%准确率,外推到1M token(2小时视频)仍保持99.5%准确率
- MMLongBench-Doc: 57.0%准确率,SOTA表现
领域专项:
- OCR/文档: OCRBench 920分,支持39种语言,32/39语言准确率>70%
- 2D/3D Grounding: RefCOCO 91.9%,ODinW-13 48.6 mAP,3D grounding在SUNRGBD上超越Gemini-2.5-Pro 5.2点
- 视频理解: VideoMME 79.2%,MLVU 84.3%,在长视频理解上超越Gemini-2.5-Pro
- GUI Agent: ScreenSpot Pro 62.0%,OSWorld 38.1%,AndroidWorld 63.7%
- Fine-grained Perception: 使用工具后V* 93.7%,HRBench4K 85.4%
- STEM推理: MathVista 85.8%(thinking),MathVision 74.6%,MMMU 80.6%
思考模式收益:
- Thinking模式在推理密集型任务上带来显著提升(如AIME-25: 89.7% vs 74.7%, HMMT-25: 77.4% vs 57.4%)
- 在某些任务上instruct模式反而更好(如RealWorldQA),说明需要针对应用场景选择模式
局限性
论文未明确指出局限性,但从架构和实验设计可推断:训练成本较高(四阶段预训练+三阶段后训练),对于资源受限的场景可能难以复现;虽然支持256K上下文,但在超长序列(>256K)上仍需YaRN外推;thinking模式虽然提升推理能力,但会增加推理延迟和成本。
8.11 DINOv3 (2025)
——— 自监督视觉大模型的规模化与局部特征修复:从互联网图像到地理空间数据
📄 Paper: arXiv:2508.10104
精华
- 自监督学习(SSL)在规模化(Scaling)时面临密集(dense)特征退化的瓶颈,DINOv3 通过引入 Gram Anchoring(Gram 锚定)正则化成功解决了这一难题。
- Gram Anchoring 作用于特征相似度矩阵(Gram 矩阵),通过约束学生模型的特征相似度结构逼近具有良好局部一致性的早期教师模型,在不改变特征本身的全局辨别力的同时,大幅提升局部特征的一致性。
- 通过引入 Rotary Positional Embeddings (RoPE-box) 抖动和混合分辨率的高分辨率自适应阶段,DINOv3 实现了无缝适配极高分辨率(如 4096×4096)和任意宽高比的推理。
- 提出了一种单教师多学生(Single-Teacher Multiple-Students)的蒸馏方案,将 7B 大模型的知识高效压缩至 ViT-S/B/L 等实用小模型中,保留了优异的局部特征表达。
- 验证了通用自监督学习在地理空间数据(SAT-493M 卫星图像)上的广泛适用性,在树冠高度预测等密集预测任务中显著刷新了 SOTA。
1. 研究背景/问题
- 密集特征退化问题:自监督学习(SSL)通过无标注数据训练视觉编码器具有极佳的泛化性。然而,在将模型参数(如 ViT)和数据规模扩大到 7B 参数和数十亿张图像时,模型虽然在全局任务(如图像分类)上持续提升,但其密集/局部特征(如用于分割和深度估计)却在训练中后期发生严重退化。
- 根本原因:分析表明,随着长周期训练的进行,局部 patch 特征与 CLS token 的相似度逐渐升高,导致局部特征逐渐失去局部特异性,Cosine 相似度图变得模糊、多噪点。
2. 主要方法/创新点
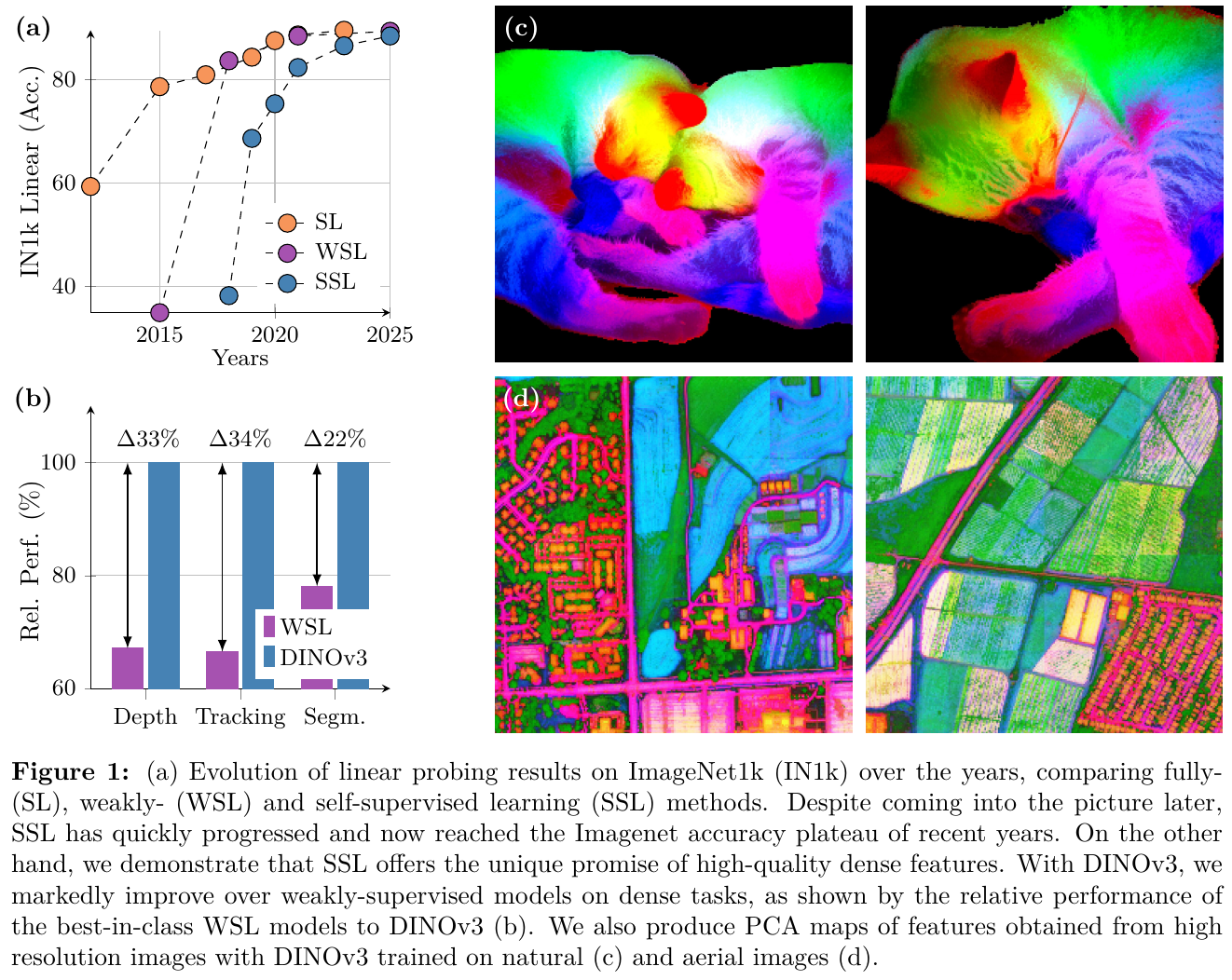
① 整体框架概述
DINOv3 继承自 DINOv2,基于自监督 ViT 架构进行规模化扩展。整个预训练由两个阶段构成:第一阶段(Initial Pre-training)在无约束的大大规模多源数据集(Web 图像 LVD-1689M、检索数据及常规数据集混合)上进行 1M 步的常规 SSL 训练;第二阶段(Refinement Step)引入 Gram Anchoring(Gram 锚定)损失,利用包含良好密集特征的早期教师模型作为引导,修复并在中后期稳定密集特征的表达。
② 逐模块讲解
- 网络骨干(Backbone):将模型扩展至 7B 参数(ViT-7B),包含 40 个 Block,嵌入维度为 4096,前馈网络(FFN)使用 SwiGLU 激活,隐藏维度为 8192,注意力头数 32,头维度 128。
- 位置编码(Positional Embeddings):采用了 Rotary Position Embedding (RoPE)。在训练中,通过 RoPE-box 抖动(Jittering)机制,将 patch 相对坐标 box 从 $[-1, 1]$ 随机缩放至 $[-s, s]$(其中 $s \in [0.5, 2]$),增强了模型对不同分辨率和宽高比的适应性。
- 分类头(Heads):包含 global DINO head (MLP: 8192-8192-512,具有 256k 个原型) 和 local iBOT head (MLP: 8192-8192-384,具有 96k 个原型)。
③ 端到端数据流
- 训练数据流:输入图像首先生成 2 个全局 Crop(分辨率为 256×256)和 8 个局部 Crop(分辨率为 112×112)。这些 Crop 输入到 ViT-7B 学生模型中。教师模型(由学生模型的指数移动平均 EMA 更新而来)仅处理全局 Crop。通过计算学生与教师在全局/局部表征上的差异(DINO 损失和 iBOT 损失)来优化参数。
- Gram 锚定数据流:在 refinement 阶段,除常规损失外,将全局 Crop 同时输入学生网络与 Gram 教师网络(选择早期 200k 步的教师网络,或定期更新的 EMA 教师)。计算学生模型和 Gram 教师模型的 patch 特征 Gram 矩阵,通过二者的 F-范数距离更新学生,从而在保证全局特征的辨别力下恢复局部特征的平滑与一致性。
④ 训练目标与损失函数
在 refinement 阶段,模型最终的优化目标为: \(L_{Ref} = w_D L_{DINO} + L_{iBOT} + w_{DKL} L_{Koleo} + w_{Gram} L_{Gram}\) 其中 $L_{Gram}$(Gram 锚定损失)被定义为: \(L_{Gram} = \lVert X_S \cdot X_S^\top - X_G \cdot X_G^\top \rVert_F^2\) 这里 $X_S$ 和 $X_G$ 分别为学生模型和 Gram 教师模型经过 $L_2$ 归一化后的 $P \times d$ 维局部特征矩阵($P$ 为 patch 数量,$d$ 为特征通道数)。为了进一步利用高分辨率特征的平滑度,DINOv3 提出了 $L_{HRef}$,即让 Gram 教师接收两倍分辨率(512×512)的图像输入,并将输出的特征图通过双三次插值降采样对齐学生的分辨率后计算 Gram 矩阵。
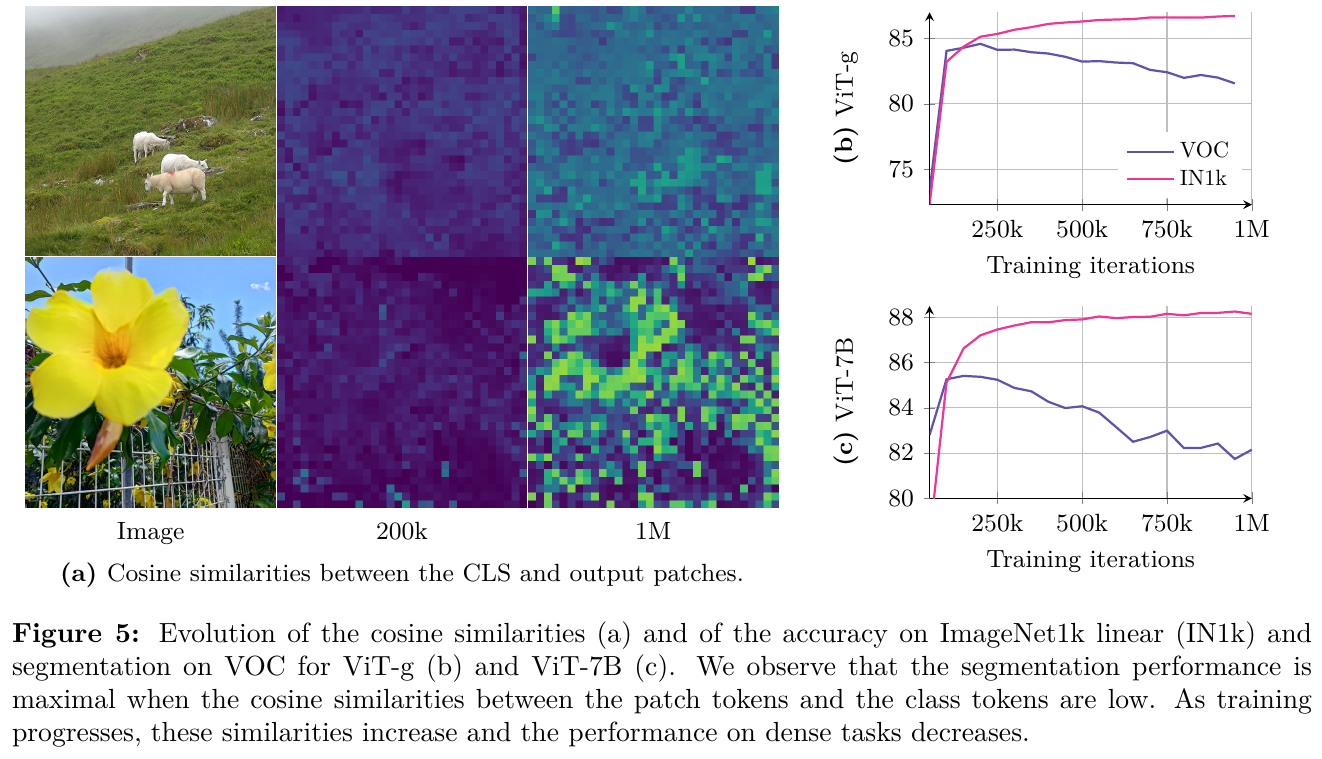
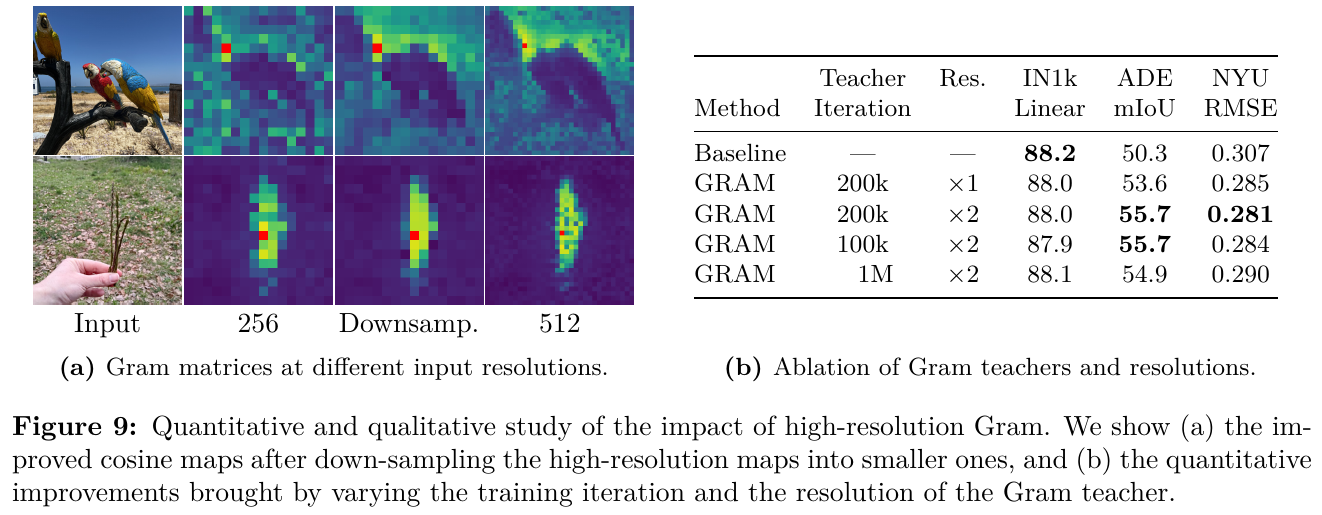

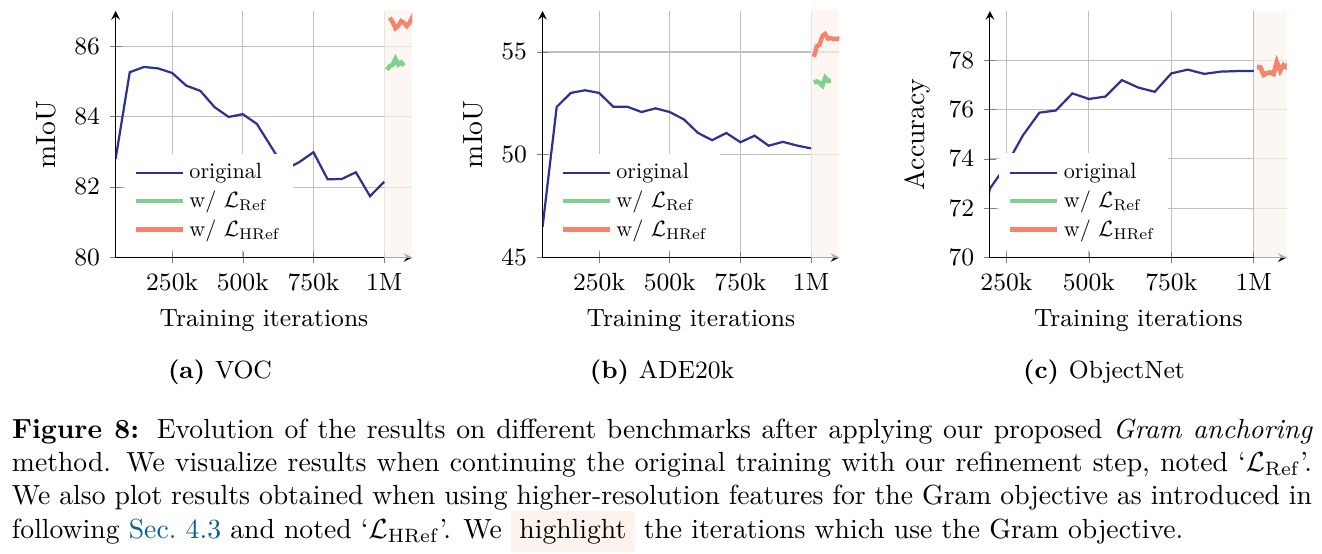
⑤ 推理流程与分辨率自适应
推理时,主干网络完全冻结,只输出 dense patch features 用于下游任务。为了更好地处理极高分辨率,DINOv3进行 10k 步的高分辨率自适应,利用包含全局和局部各种尺寸 Crop 的混合分辨率 batch 进行微调,期间同样施加 Gram 锚定损失以维持多分辨率下的一致性,使得模型能直接支持 4096×4096 及更高分辨率的稳定推理。
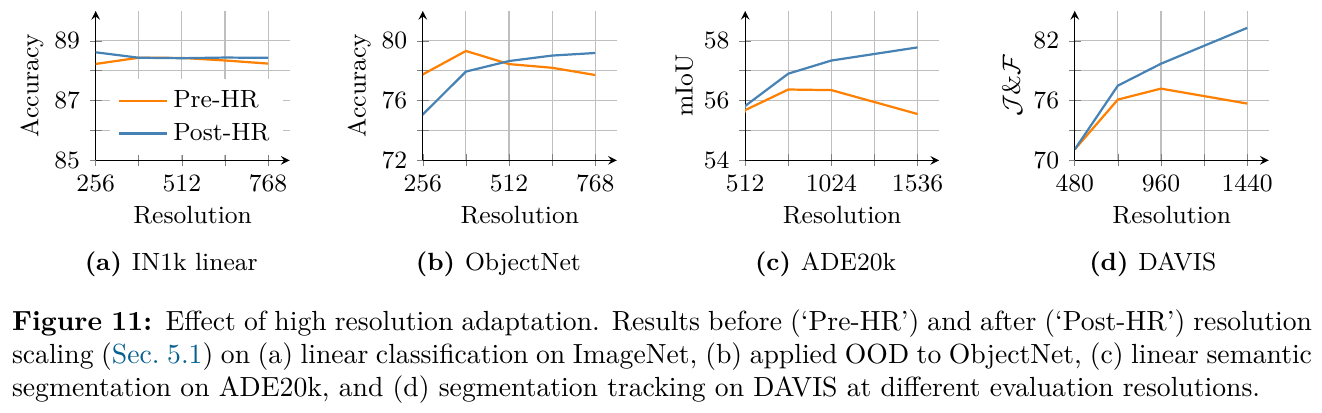
3. 核心结果/发现
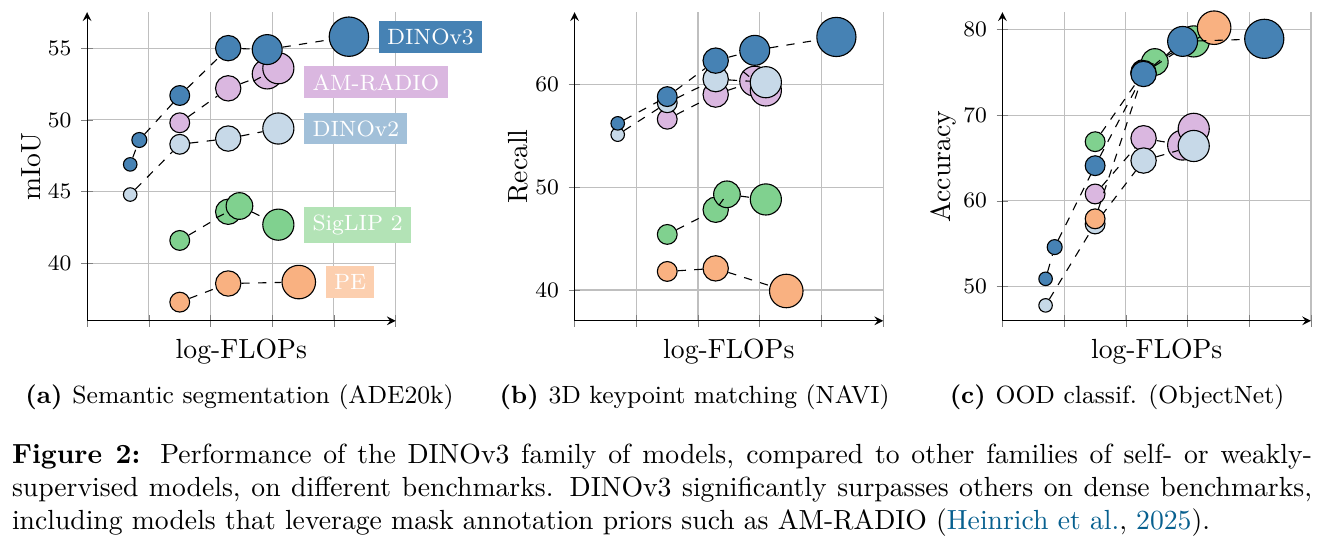
- 主流密集与全局视觉任务:使用冻结的 vision backbone,DINOv3-7B 在 COCO 目标检测上达到了 66.1 mAP,在 ADE20k 语义分割上达到了 63.0 mIoU,均超越了传统的微调和弱监督模型。在 ObjectNet 等全局鲁棒性分类任务上也极具竞争力。
- 蒸馏家族性能:通过单教师多学生蒸馏,将 7B 知识性能迁移至 ViT-S/B/L 等。ViT-L(0.3B 参数)表现非常接近 7B 教师模型,在保持小模型极高运行速度的同时继承了大模型的局部特征品质。
- 地理空间地球观测任务:
- 将 DINOv3 用于 SAT-493M 卫星图像(4.93 亿张 512×512 图像)上训练得到 DINOv3 Sat,并配合 DPT 解码器用于树冠高度预测。
- DINOv3 Sat 7B 在 SatLidar1M 验证集(MAE 从 2.4 降低至 2.2)、SatLidar1M 测试集(MAE 从 3.4 降至 3.2)、以及 Open Canopy(MAE 从 2.42 降至 2.02)上均刷新了 SOTA,相比 Tolan 等模型具有更加清晰的树木边缘和准确的高度预测。
- 在 GEO-Bench 的 12 项分类和分割任务中,冻结的 DINOv3 仅使用 RGB 输入,就超越了利用 Sentinel-2/Landsat 所有波段(6+ bands)的专门模型(如 Prithvi-v2、DOFA)以及针对特定任务的微调方法。
4. 局限性
- 两阶段依赖:尽管 Gram Anchoring 能有效修复局部特征的一致性,但该方法依然依赖于两阶段训练,需要先获得早期具备良好密集特征的中间模型作为 Gram 教师。
- 模型开销与边端部署:7B 参数模型在单卡和边缘设备上的微调和推理开销较大,实际部署极度依赖于蒸馏后的小模型(如 ViT-L/B/S)。
9. 总结
视觉-语言模型的核心技术演进可以归纳为三条主线:
-
对齐方式的演进:从基于区域特征的硬对齐(ViLBERT),到大规模对比学习的软对齐(CLIP),再到通过指令微调实现的语义对齐(LLaVA)
-
连接模块的演进:从简单线性投影(LLaVA),到Q-Former信息瓶颈(BLIP-2),再到深度交叉注意力(Flamingo),体现了在表达能力与计算效率之间的不同权衡(此处按架构复杂度而非时间排列;时间上 Flamingo 2022 年最早,LLaVA 与 BLIP-2 均于 2023 年发布)
-
规模与统一性的演进:从图文双模态,到图文视频多模态统一,再到原生多模态大模型(Gemini、Qwen2.5-VL),视觉与语言的边界正在消融
截至2026年初,VLM领域的技术重心已从”如何有效对齐视觉与语言”转向”如何在多模态条件下实现强推理”。Qwen3-VL、OpenAI o3 等新一代模型表明:更强的文本推理基座、更长的多模态上下文、以及强化学习驱动的推理增强,是当前突破性能天花板的三条主线。
当前仍待解决的核心挑战:减少幻觉(尤其是细粒度定位类幻觉)、提升低资源语言的多模态公平性(MVL-SIB揭示的差距)、降低超长视频处理成本,以及真正实现感知-推理-行动的端到端一体化。
未来,VLM将成为具身智能、多模态Agent和人机交互系统的核心感知与推理模块,持续推动人工智能能力边界的扩展。