
VLN-Imagine (2025)
———用文本生成图像模型为导航智能体构建”视觉想象”
📄 Paper: https://arxiv.org/abs/2503.16394
精华
- 利用现成的 text-to-image 扩散模型(SDXL)为导航指令中的地标名词短语生成”视觉想象”,将跨模态对齐从隐式学习转化为显式的图像-图像匹配,思路简洁且可迁移。
- 方法设计为 model-agnostic:通过独立的 imagination encoder + 辅助对齐损失即可嵌入任意 VLN 模型,无需修改原有架构。
- 子指令过滤策略(FG-R2R 分割 + 名词短语黑名单)有效控制了生成图像的质量与相关性,是低成本数据增强的好范例。
- 实验表明 imagination 在训练和推理阶段均有增益,且训练阶段的正则化效应独立于推理时的输入增益,说明多模态辅助信号可提升模型泛化。
- cosine similarity 辅助损失足以对齐 imagination 与指令表征,无需更复杂的对比损失(InfoNCE),体现了”够用即可”的工程哲学。
1. 研究背景/问题
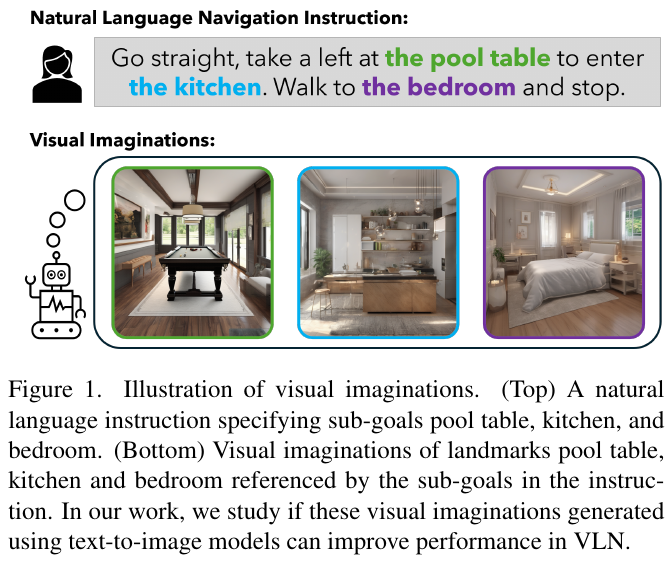
Vision-and-Language Navigation(VLN)任务中,智能体需要根据自然语言指令在未见过的环境中导航。指令常引用视觉地标(如”pool table”“kitchen”),但现有方法依赖隐式跨模态对齐来关联名词短语与实际观察。本文探索是否可以在导航前先用 text-to-image 模型为地标生成”视觉想象”,将语言-视觉对齐转化为更容易的图像-图像匹配任务。
2. 主要方法/创新点
2.1 Visual Imagination 生成管线

- 指令分割:使用 FG-R2R 将完整导航指令分割为子指令序列 $S = (S_0, \cdots, S_m)$,R2R 训练集平均每条指令 3.66 个子指令。
- 子指令过滤:通过 SpaCy 过滤无名词短语的子指令,再用黑名单排除非视觉名词(如计数词、方向词、代词),保留有效子指令集 $S’ \subset S$。
- 图像生成:使用 SDXL 扩散模型,以正向提示词(indoor, house, realistic, real estate)和负向提示词(outdoor, text, humans 等)引导生成室内场景图像。最终构建 R2R-Imagine 数据集,包含超过 41k 张 1024×1024 想象图像。
2.2 Model-Agnostic 集成方法
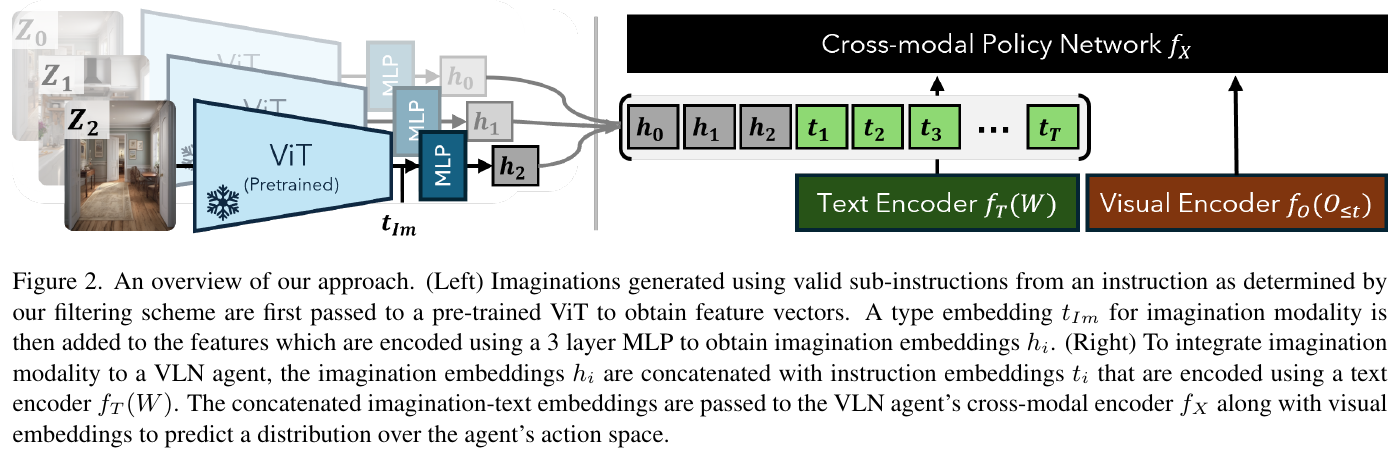
- Imagination Encoder:使用预训练 ViT-B/16 编码想象图像,加上 imagination modality 的类型嵌入 $t_{Im}$,再通过三层 MLP(768→512→768,ReLU + Dropout 0.15)得到 imagination embedding $h_i = \text{MLP}(\text{ViT}(Z_i) + t_{Im})$。
- 模态融合:imagination embedding 与指令的文本编码拼接后,一起送入 VLN 智能体的跨模态编码器。本文在 HAMT 和 DUET 两个代表性模型上验证了该方法。
- 辅助对齐损失:计算 imagination embedding $h_i$ 与对应子指令名词短语的平均文本嵌入 $\bar{S}i$ 之间的 cosine similarity 损失 $\mathcal L{cos}$,总损失为 $\mathcal L_{\text{base}} + \lambda \mathcal L_{cos}$($\lambda=0.5$)。
- 三阶段微调:为缓解灾难性遗忘,先训练 MLP + 类型嵌入(25% 迭代)→ 联合训练所有模块(25%)→ 统一学习率训练(50%),总计 100k 迭代。
3. 核心结果/发现
- R2R 数据集:在 HAMT 和 DUET 基础上,VLN-Imagine 在 val-unseen 上分别提升约 1.0 SR 和 0.5 SPL(HAMT: 67.26 SR / 62.02 SPL;DUET: 79.9 SR / 73.75 SPL)。DUET 在 test split 上 SR 提升 2 个点。
- REVERIE 数据集:DUET-Imagine 在粗粒度指令设置下 SR 提升 1.3 点,RGS 提升 0.82 点,说明想象对目标定位也有帮助。
- 训练与推理双重增益:即使在推理时 nullify imagination(置零注意力掩码),模型仍优于 baseline,暗示 imagination-based 训练具有正则化效果。
- 对齐是关键:随机 imagination 反而降低性能;正确对齐的 imagination 才能带来提升。
- 视觉优于文本:用子指令文本嵌入代替 imagination embedding 效果不如视觉想象,说明视觉表征与语言起互补作用。
- Imagination 高保真度:通过 LangSAM 开放词汇检测器验证,98.78% 的子指令至少有一个名词短语被检测到。
4. 局限性
生成和编码想象图像增加了计算开销,对实际机器人部署尤为不利(H100 上单张 3.2 秒,微调需 V100 约 1.5 天)。此外,想象图像无法捕捉环境中物体和位置的个性化命名,终身学习的持久化视觉 grounding 仍是开放问题。