
VLN-Cache (2026)
———Enabling Token Caching for VLN Models with Visual/Semantic Dynamics Awareness
📄 Paper: https://arxiv.org/abs/2603.07080
精华
VLN-Cache 的核心洞见是:现有 token caching 方案在 VLN 场景下失效的根本原因有两个相互独立的维度——视觉动态(视角偏移导致空间位置错配)和语义动态(任务阶段推进导致缓存 token 语义过时)。将 “视图对齐重映射” 与 “任务相关性语义门控” 分别针对这两种动态进行正交设计是本文最值得借鉴的思路:先用几何对应恢复可复用集合,再用语义相关性做一票否决,二者缺一不可。层自适应熵策略(layer-adaptive entropy policy)将每层的复用预算与注意力分布的不确定性挂钩,也为其他需要跨层差异化处理的 inference 优化工作提供了参考范式。整个框架训练自由、无需架构修改,可作为即插即用的推理加速包裹层,具有很强的实用价值。
1. 研究背景/问题
现代 VLN 系统依赖大型视觉-语言模型(VLM)作为规划器,每个导航步骤都需完整的前向推理,导致每步延迟成为实时部署的瓶颈。Token caching 是一种无需训练的推理加速策略,通过复用帧间稳定 token 的 KV 表示来跳过冗余计算;然而现有方法基于静态相机和固定语义的假设,在 Agent 连续平移旋转的 VLN 场景下会出现两类系统性失效:视角偏移导致位置对齐失效,任务阶段推进导致语义相关性突变,使得缓存 token 在视觉上”看起来稳定”但语义上已经过时。
2. 主要方法/创新点
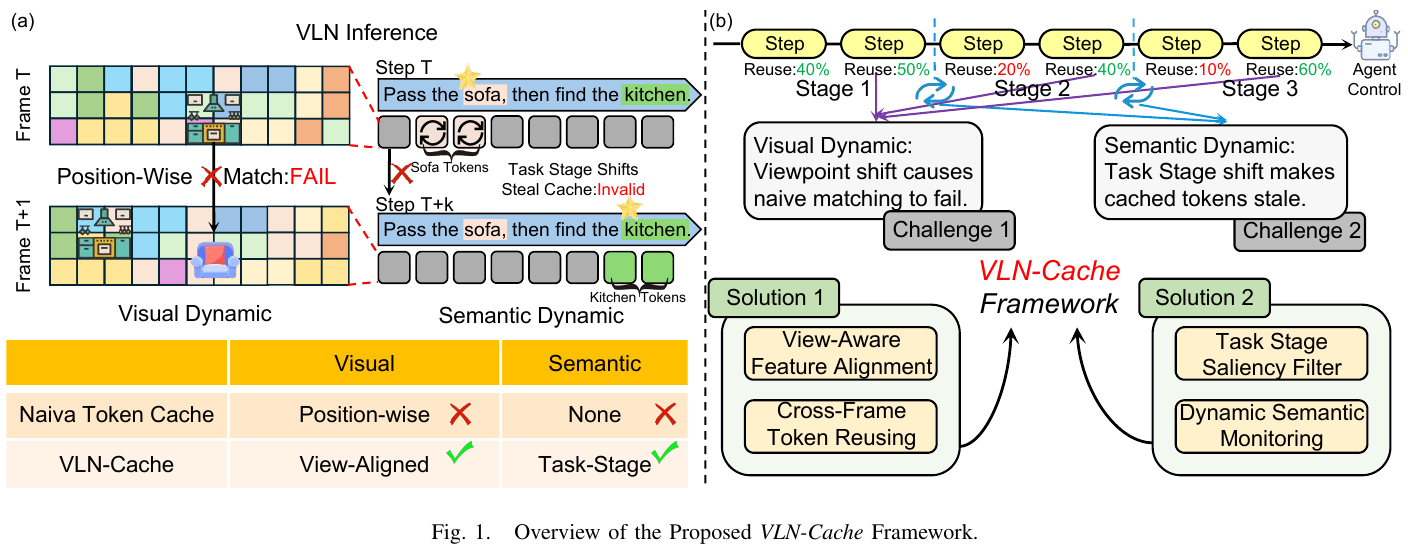
VLN-Cache 是一个双感知 token caching 框架,针对视觉动态和语义动态分别设计了正交的处理机制:
A. 视觉动态感知 Token Caching
由于 Agent 连续移动,帧 t 中位置 i 的 token 对应的物理表面与帧 t-1 中同一位置 i 的表面完全不同。VLN-Cache 通过 视图对齐重映射(View-Aligned Remapping) 解决这一问题:
- 利用深度图将每个 token 中心 $u_t^{(i)}$ 反投影到 3D 空间,结合相机相对位姿变换矩阵 $T_{t \to t-1}$,重新投影到上一帧图像平面,得到对应位置 $\pi_t(i)$
- 通过 3×3 邻域细化($\mathcal{N}$)处理连续坐标到离散 patch 索引的量化误差
- 仅当重映射后的 token 对余弦相似度超过阈值 $\tau_{vis}$ 且在有效视野内时才标记为可复用
B. 语义动态感知 Token Caching
即便两帧间 token 在几何上完美对齐、视觉上高度相似,若 Agent 已完成当前子目标并转向下一阶段,该区域的任务相关性可能已骤降,复用其缓存状态会向语言解码器注入过时的注意力模式。VLN-Cache 引入 任务阶段显著性过滤器(Task-Stage Saliency Filter):
- 为每个 token 计算指令条件相关性分数 $s_t^{(i)}$(top-k 注意力集中区域的 Jaccard 距离衡量语义转变幅度 $D_t^{sem}$)
-
满足以下任一条件则强制刷新:当前相关性过高($s_t^{(i)} > \tau_{abs}$,缓存版本无法代表该区域重要性)或相关性快速变化($ s_t^{(i)} - s_{t-1}^{(i)} > \tau_\Delta$,正在经历语义转变) - 语义门控为 一票否决(hard veto):视觉稳定性是复用的必要条件但不充分,语义过时则无条件刷新
C. 双感知融合与层自适应缓存策略
最终复用掩码采用乘法形式 $m_t^{(i)} = m_{vis,t}^{(i)} \cdot (1 - m_{sem,t}^{(i)})$,仅当几何稳定且无语义转变时才复用。
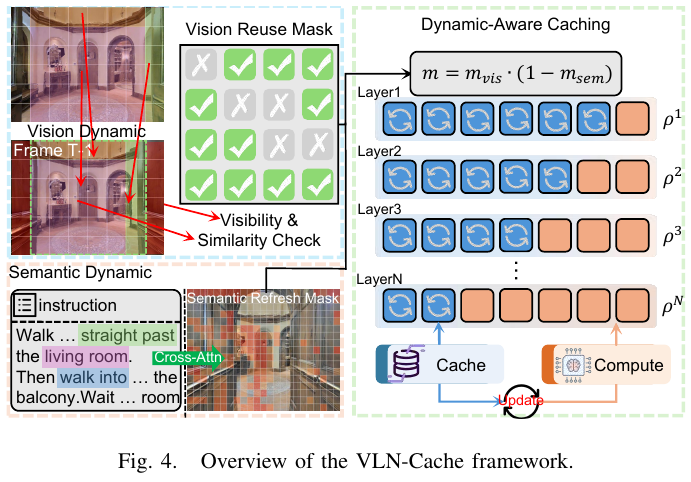
对于 Transformer 不同层,早期层处理低层次视觉特征(变化较慢),深层编码任务相关表示(在指令转变时变化更剧烈)。VLN-Cache 通过 层自适应熵策略 调节每层复用预算: \(\rho_t^\ell = \text{clip}(\rho_{max} - \alpha H_t^\ell, \rho_{min}, \rho_{max})\) 其中 $H_t^\ell$ 是从现有注意力 softmax 读取的层熵代理,高熵层(不确定层)分配更保守的复用预算,低熵层可更激进地复用。
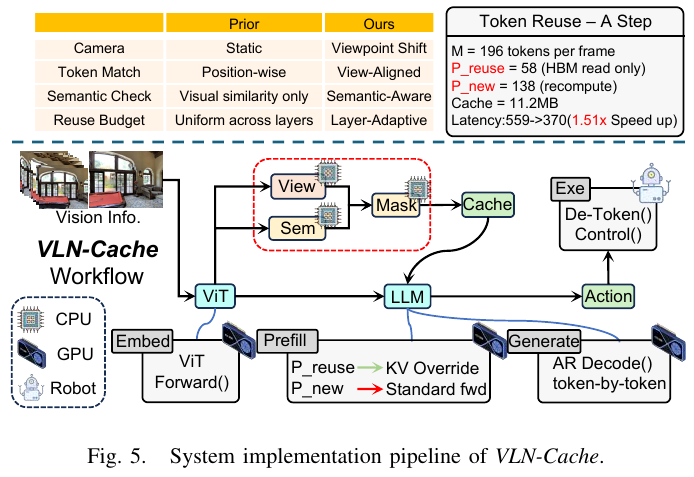
在系统实现上,VLN-Cache 不修改模型权重或注意力核,作为 drop-in 包裹层集成到任意基于 Transformer 的 VLA backbone:复用 token 从视图对齐缓存位置 $\pi_t(i)$ 直接拼接 KV 状态,新 token 经标准投影;RoPE 位置编码仅对新 token 更新,复用 token 继承原有编码。每帧缓存占用约 85.8 MB(A100 VRAM 的 0.21%),无需 CPU 卸载。
3. 核心结果/发现
在 R2R-CE val_unseen 基准(1,839 个 episode,基于 InternVLA-N1 / QwenVL-2.5 7B backbone)上:
- 推理加速:每步延迟从 637 ms 降至 419 ms,实现 1.52× 步级加速,episode 级别同样达到 1.52× 加速(114.7s → 75.5s)
- 导航精度保持:SR = 63.1(vs. 基线 64.3),SPL = 57.6(vs. 基线 58.5),SR 下降仅 1.2%
- Token 复用率:平均每步 31% 的 VLA token 从缓存复用;83% 的帧完全绕过 ViT 视觉编码器
- 消融分析:移除视图对齐重映射后 SR/SPL 显著下降(回退到位置对齐方案),移除语义门控后精度下降(视觉相似但语义过时的 token 被错误复用),二者均为不可或缺的正交贡献
- 效率-精度帕累托最优:在所有 RGB-only VLN 方法(NaVid, MapNav, UniNaVid, NaVILA, StreamVLN, DualVLN)中,VLN-Cache 达到最低 NE(3.93)和最高 OS(71.4),同时具备最快推理速度
4. 局限性
VLN-Cache 目前仅针对 RGB-based 连续 VLN,不支持深度传感器或地图导航设置;四个超参数($\tau_v, \tau_s, k, \rho_{max}$)缺乏自动调节方法,需在小型保留轨迹集上手动校准,自动超参确定方案留作未来工作。