
SparseVideoNav (2026)
———Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
📄 Paper: https://arxiv.org/abs/2602.05827
精华
SparseVideoNav 最值得借鉴的核心思想:视频生成模型(VGM)天然具备长视野预测能力,可以替代 LLM 作为导航的”大脑”,彻底解决 LLM 短视野导致的短视行为。稀疏化(sparse video generation)是兼顾长预测视野与计算效率的关键设计——不需要预测连续帧,只需关键时间戳处的帧即可提供有效导航指引。四阶段渐进式训练(T2V→I2V→历史注入→扩散蒸馏→动作学习)将大规模预训练视频模型迁移到导航领域,是一套通用的 VGM 适配范式。Diffusion Distillation 将推理步数从 50 步压缩到 4 步(9.6× 加速),使实时部署成为可能。此外,Q-Former + Video-Former 的历史压缩策略解耦了推理延迟与历史长度的关系,保证了稳定的推理效率。
1. 研究背景/问题
现有视觉-语言导航(VLN)系统依赖 LLM,受限于短视野监督(4-8步),在 Beyond-the-View Navigation(BVN)任务中表现欠佳:智能体需要在没有逐步指引的情况下,仅凭高层语义指令(如”找一张桌子并停在旁边”)定位远处不可见目标,LLM-based 方法因此频繁出现意外转向和死路困陷。简单延长监督视野会破坏 LLM 训练稳定性,而视频生成模型天然对齐长视野语言理解,成为解决 BVN 的关键突破口。
2. 主要方法/创新点
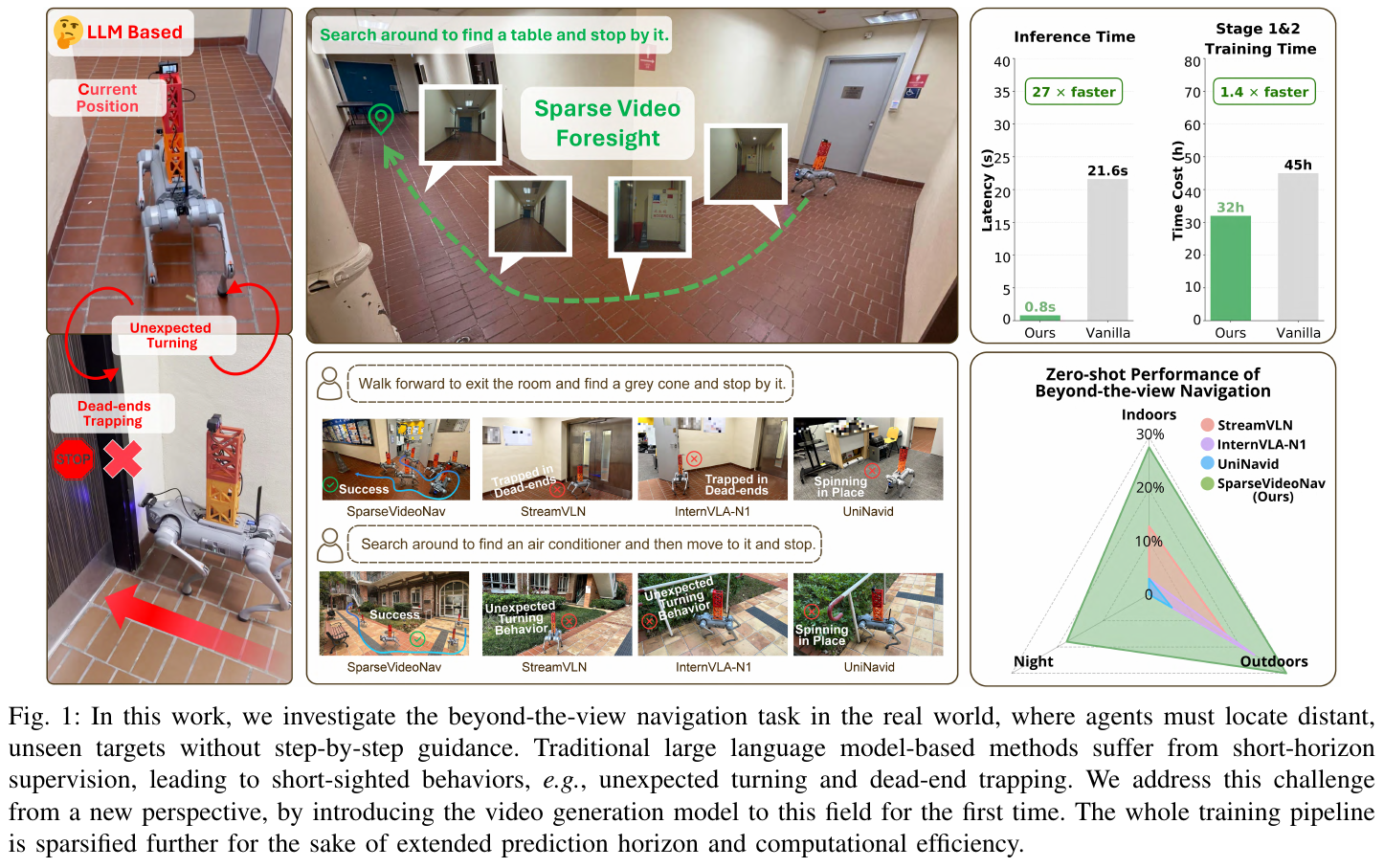
核心思路: 利用视频生成模型(VGM)预测未来稀疏帧序列作为导航预见,将预测视野延伸到 20 秒(20s × 4FPS = 80帧),而非 LLM 仅能处理的 4-8 步。稀疏间隔设为 3 时(sparse interval = 3),在预测视野与视觉保真度之间取得最优平衡。
整体架构:
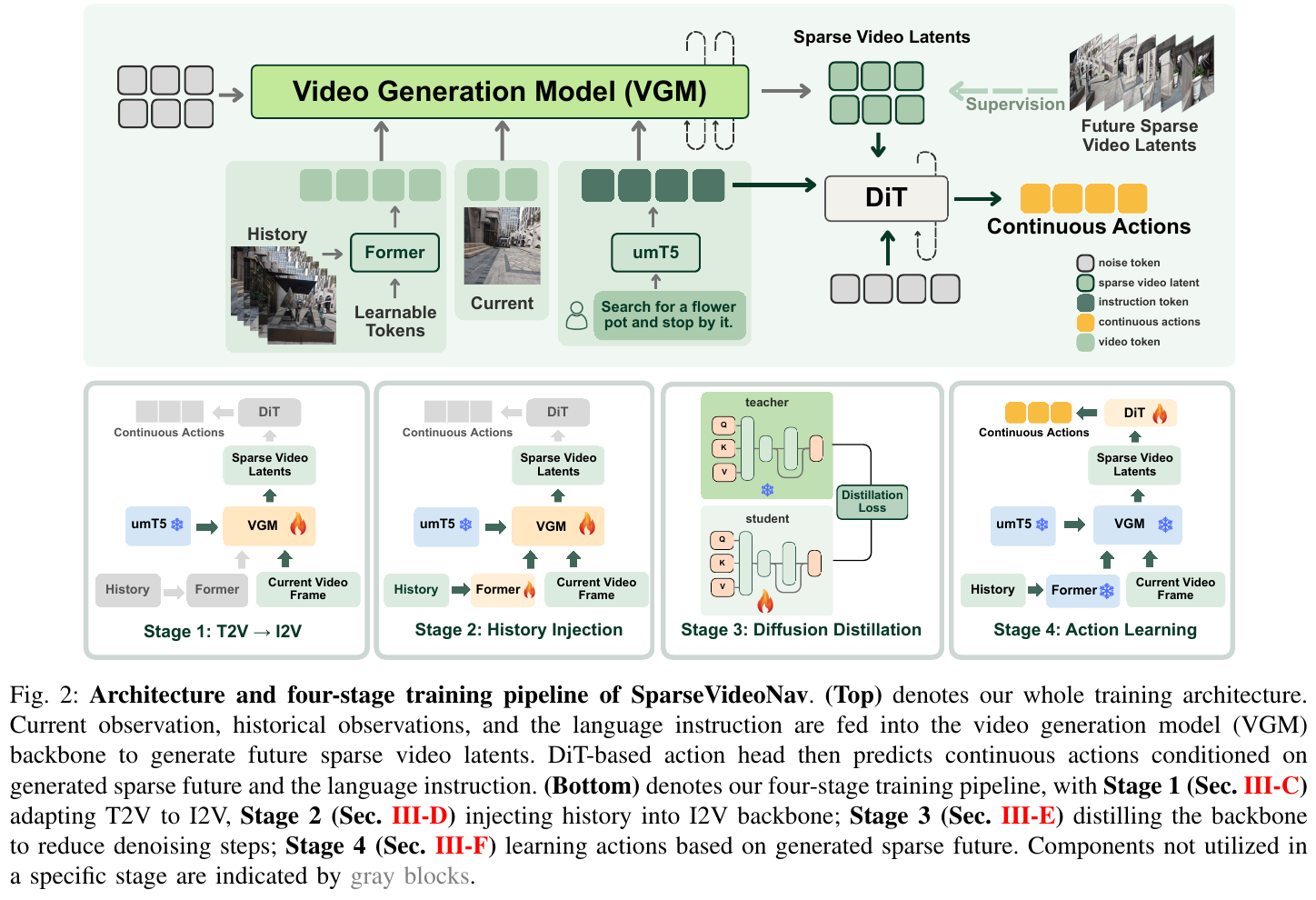
架构由三个核心组件构成:
- VGM Backbone(Wan 2.1-1.3B):接收当前帧、历史嵌入(h_T)和语言指令(umT5),输出未来稀疏视频 latents
- Former 模块:Q-Former 处理时间维度历史压缩,Video-Former 处理空间维度,联合生成固定维度的历史嵌入,使推理延迟不随历史长度增长
- DiT Action Head:以生成的稀疏未来 latents 和语言指令为条件,通过 cross-attention 预测连续动作序列(DDIM 重建)
四阶段训练流程:
-
Stage 1 — T2V → I2V 适配:保留 Wan 的 flow matching 目标,将文本到视频模型适配为图像条件的视频生成(Image-to-Video),引入稀疏帧监督,以稀疏 chunk latents
[c_{T+1}, c_{T+2}, c_{T+5}, c_{T+8}, ..., c_{T+20}]作为训练目标 -
Stage 2 — 历史注入:在 Wan backbone 每个 transformer block 中新增 cross-attention block,注入历史信息 h_T(Q-Former + Video-Former 编码);新增层以零初始化保留预训练生成先验
-
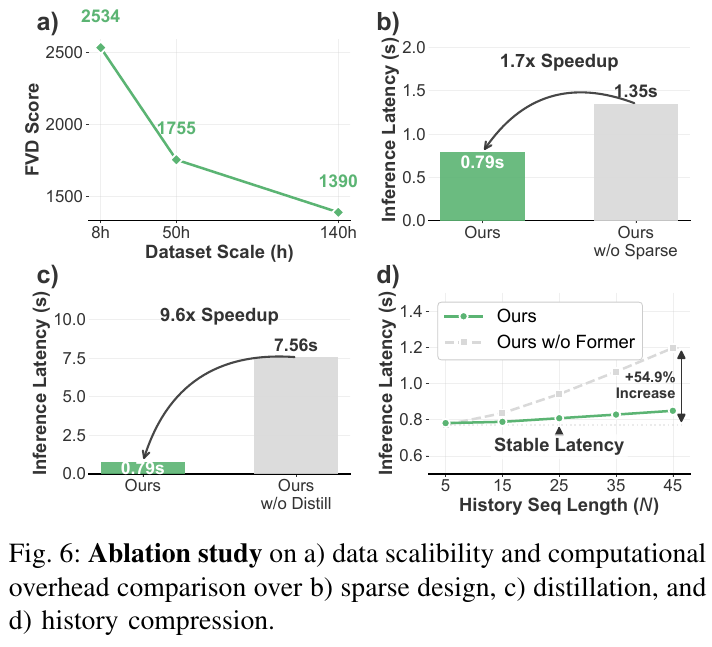
Stage 3 — Diffusion Distillation:采用 PCM(Phased Consistency Models)进行蒸馏,以 history-injected I2V 模型为 teacher,训练结构相同的 student 模型,将推理步数从 N=50 压缩至 M=4,实现 9.6× 推理加速,同时保持视觉保真度
-
Stage 4 — 动作学习:冻结蒸馏后的 I2V 模型,采用逆动态范式(inverse dynamics paradigm),利用 DA3 对生成的稀疏未来帧重新标注动作标签,确保动作监督与合成动态精确对齐;训练 DiT action head 以去噪方式预测连续动作
数据采集: 使用手持 DJI Osmo Action 4(RockSteady+ 稳像)采集 140 小时真实室外导航视频,处理为约 13,000 条轨迹(均值 140 帧 × 4FPS),使用 DA3 估计相机位姿提取连续动作标签;语言指令由人工专家标注——构建了目前最大规模的真实世界 VLN 数据集。
3. 核心结果/发现

零样本真实世界性能:
- SparseVideoNav 在 6 种真实场景(室内 Room/Lab、室外 Yard/Park、夜间 Square/Mountain)上全面超越所有 LLM-based 基线
- IFN 任务平均成功率 50.0%(vs StreamVLN 35.0%、UniNavid 10.0%)
- BVN 任务平均成功率 25.0%(vs 所有基线几乎为 0%,StreamVLN 仅 10.0%)
- 夜间场景成功率 17.5%(LLM 基线在夜间 BVN 全部失败)
效率提升:
- 推理延迟 9.8s vs 基线 21.6s(27× 加速对比未优化版本)
- Stage 1+2 训练时间 32h vs 从头训练 64h(2× 加速)
- 稀疏设计带来 1.7× 推理加速,Distillation 带来 9.6× 加速
鲁棒性: 在训练高度(1m)与部署高度(50cm)不一致时仍能正确导航,展示出对相机高度变化的强鲁棒性;能够动态规避行人障碍(emergent ability,非显式训练)。
4. 局限性
当前 140 小时数据集相较于网络规模数据仍然有限,数据扩展是进一步提升的关键方向;推理延迟(9.8s)仍略高于现有 LLM-based 导航范式(StreamVLN),加速蒸馏与 VGM 量化是未来研究的重要课题。