
Skill-Nav (2025)
———Enhanced Navigation with Versatile Quadrupedal Locomotion via Waypoint Interface
📄 Paper: https://arxiv.org/abs/2506.21853
精华
Skill-Nav 的核心贡献在于用 waypoint(路标点) 作为高层规划器与低层运动控制器之间的接口,相比速度命令接口,waypoint 对追踪误差更不敏感,且天然兼容 LLM 和经典路径规划算法。两阶段训练策略(WP-Fixed 先学技能、WP-Random 再强化泛化)解决了单阶段训练的跌步或过度跳跃问题,值得在其他层级化机器人控制任务中借鉴。Teacher-Student 蒸馏架构通过在 Student 训练时引入膨胀虚拟障碍(inflated virtual obstacles),使 Student 策略在不接触特权信息的条件下保持安全导航能力。
1. 研究背景/问题
四足机器人通过 RL 已能完成极限 parkour 等高难度运动,但将丰富的运动技能集成到长距离导航任务中仍未充分探索。现有方法大多以速度命令为接口,高层规划器难以精确跟踪,且与多样化通用规划工具(LLM、A*)耦合困难。
2. 主要方法/创新点
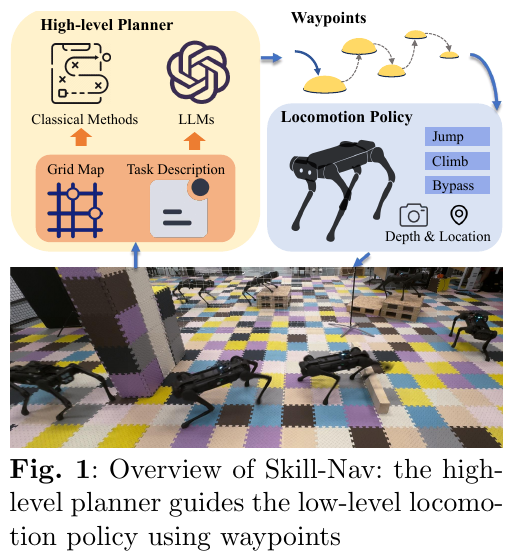
Waypoint 接口设计
Skill-Nav 以 2D 相对位置(相对于机器人 base frame 的坐标)作为 waypoint 命令替代速度命令。高层规划器通过 $\mathcal{W} = \mathcal{H}(\mathbf{M}, p_e, p_s)$ 生成从起点到终点的 waypoint 序列,$\mathcal{H}$ 可以是 A* 算法或 LLM,$\mathbf{M}$ 为粗粒度环境信息(如占用地图或房间布局)。
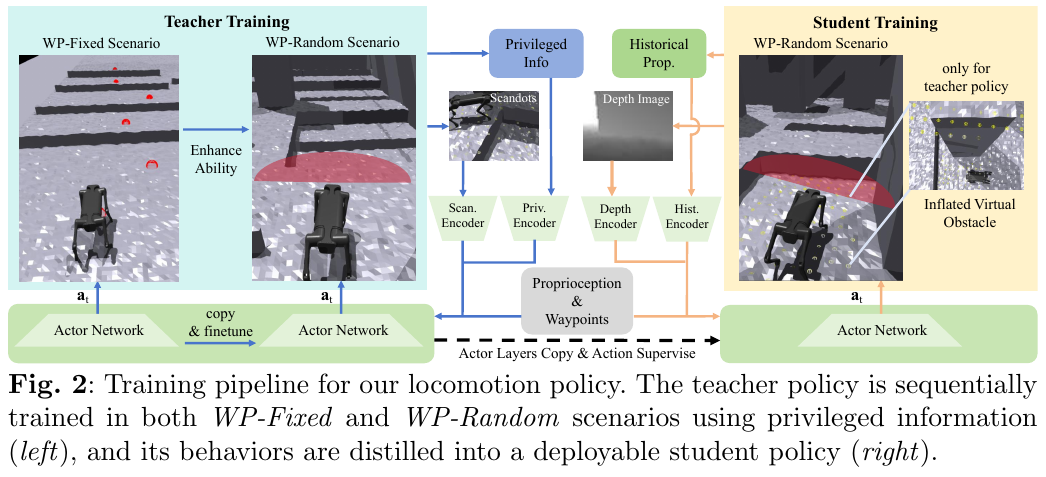
两阶段训练策略
-
WP-Fixed 场景(技能学习):障碍物按行排列,waypoint 预置。策略从零开始学习攀爬箱体、跨越间隙、越过护栏等基础运动技能。设计 $r_{\text{reach}} = n_p/(t + \epsilon)$ 鼓励机器人快速到达更多 waypoint,同时引入 $r_{\text{stay}}$ 使机器人在到达 waypoint 后等待下一条指令。
-
WP-Random 场景(泛化增强):障碍物以矩阵形式随机分布,waypoint 根据机器人位置和偏航角动态选取。引入修改后的 $r_{\text{track}}$,当速度方向与 waypoint 方向余弦相似度 $< 0.1$ 时给予 $-1$ 惩罚,鼓励机器人向目标前进。Student 训练时在深度图中加入虚拟膨胀障碍,使学生策略保持安全距离。
双规划器高层架构
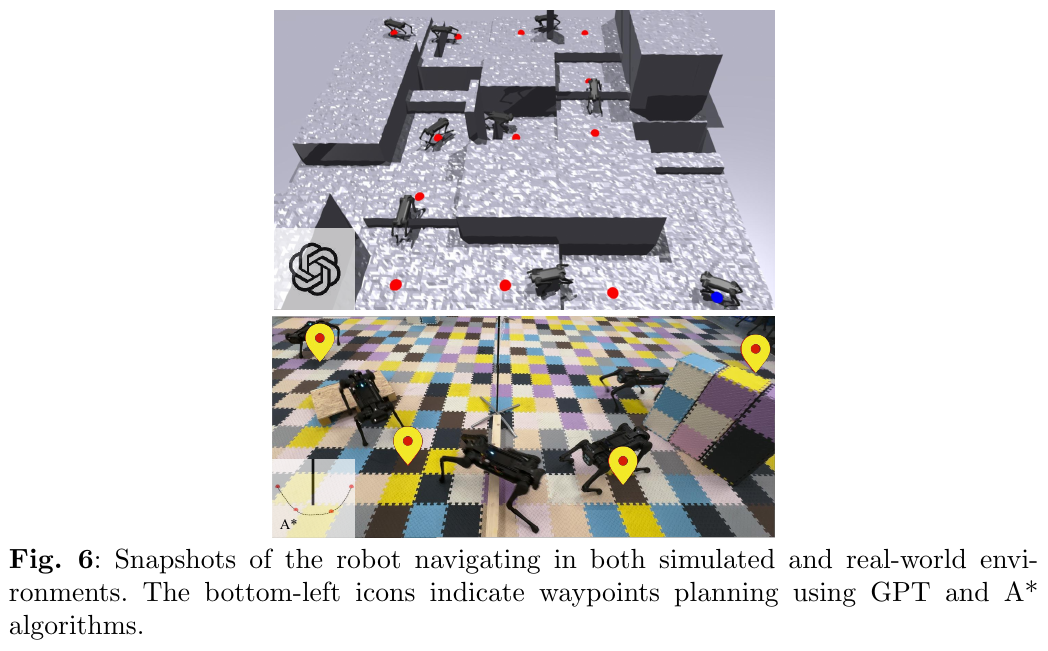
- 经典规划(A*):输入仅含墙体标注的占用地图,输出连续路径点序列,以 0.5–3m 间隔采样为 waypoint 输入低层控制器。
- LLM 规划:向 LLM 提供任务描述、粗粒度地形图、机器人运动能力(最高攀爬 0.45m、最大跨越 0.7m 间隙)等信息,由 LLM 生成 waypoint 索引序列(以 GPT-4 验证)。
3. 核心结果/发现
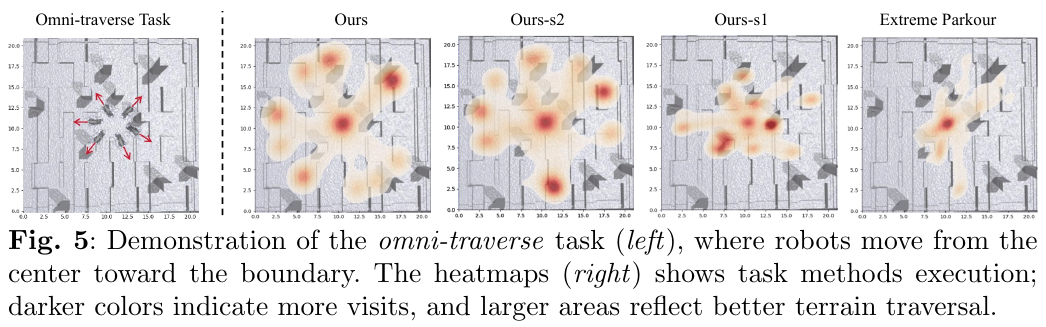
- Single-traverse 任务:在有无高障碍物场景中,Skill-Nav 均达到 SR=1.00、ATD=15.8m,是唯一在两种条件下均成功的方法。
- Omni-traverse 任务:SR=0.89、ATD=8.2m,超越所有对比方法(RMA SR=0.00,Extreme Parkour SR=0.44/0.28)。
- 消融分析:仅 WP-Fixed 训练(Ours-s1)因 waypoint 分布规则,泛化能力差;仅 WP-Random 训练(Ours-s2)导致过度跳跃步态,实际部署困难;两阶段结合效果最优。
- 真实机器人部署:在 Unitree AlienGo 上成功验证,可应对深度相机未检测到的低矮障碍,并在受到外力干扰后恢复平衡继续导航。
4. 局限性
高层规划器(尤其是 LLM)可能生成位于间隙中央或箱体边缘等异常 waypoint,低层控制器难以从这类极端位置恢复;未来工作将设计边缘无碰撞低层控制器,并探索运动与导航的端到端统一策略。