
RoboClaw (2026)
———An Agentic Framework for Scalable Long-Horizon Robotic Tasks
📄 Paper: https://arxiv.org/abs/2603.11558
精华
RoboClaw 最核心的贡献是将数据采集、策略学习和任务执行统一在同一个 VLM agent 控制环下,从根本上消除了三个阶段之间的语义漂移问题。Entangled Action Pairs (EAP) 机制通过将正向操作与逆向复位动作配对,实现了环境的自动重置,无需人工干预即可持续采集 on-policy 数据——这一思路对所有需要大量真实机器人数据的场景都有借鉴价值。结构化记忆(角色身份、任务级记忆、工作记忆三层)使 VLM 能够有效追踪长时程任务进度,是 VLM 作为 meta-controller 的关键工程实现。MCP (Model Context Protocol) 接口将 VLM 的高层推理与底层策略执行解耦,使系统对具体 VLA 模型无依赖,具有良好的可扩展性。部署阶段产生的轨迹数据可以直接回流训练管线,形成真正的闭环生命周期学习。
1. 研究背景/问题
现有 VLA 系统的数据采集、策略训练和任务执行通常由独立流程完成,导致三个阶段之间存在语义不一致和分布偏移,使得长时程机器人操作任务极为脆弱。此外,每次数据采集后都需要人工重置环境,导致数据获取成本高、规模化困难。
2. 主要方法/创新点
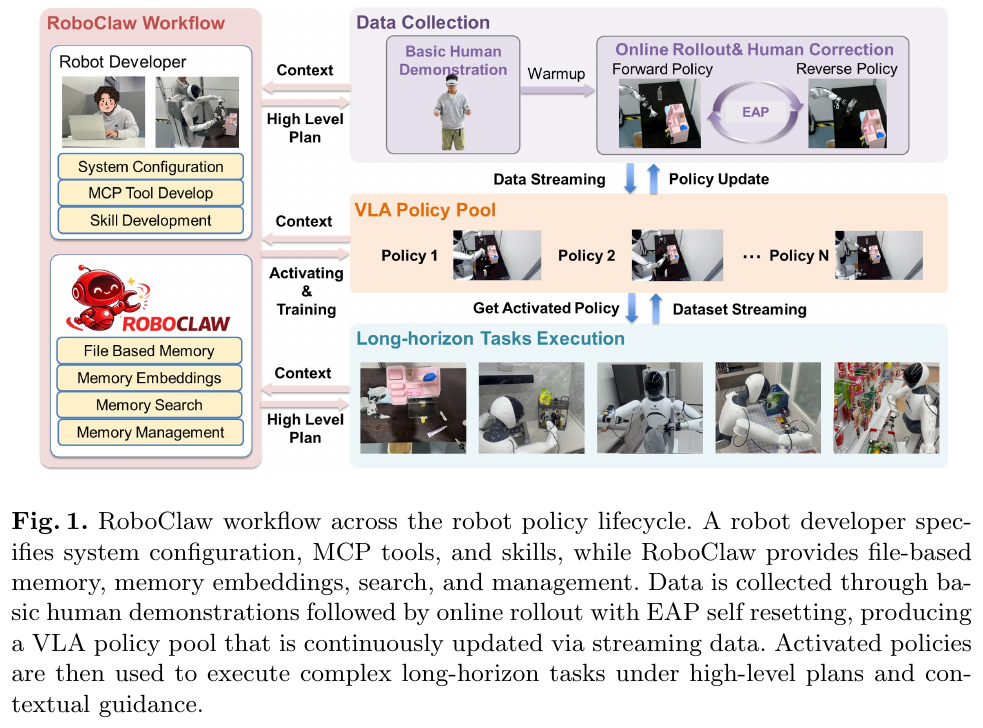
RoboClaw 是一个统一的 agentic 机器人框架,核心思想是用同一个 VLM 驱动的 agent 覆盖机器人的完整生命周期。
系统架构

VLM 作为 meta-controller,通过 in-context learning (ICL) 对多模态观测和结构化记忆进行推理,输出高层决策并通过 MCP 接口调用工具执行。
系统维护三层结构化记忆状态 $m_t = (r_t, g_t, w_t)$:
- 角色身份 $r_t$:指定当前运行模式(数据采集 / 任务执行)和可用工具集
- 任务级记忆 $g_t$:记录全局任务及子任务分解与执行状态,用于追踪长时程进度
- 工作记忆 $w_t$:存储当前激活技能和工具调用历史等短期上下文
VLM 通过 Chain-of-Thought (CoT) 规划对当前场景进行五步结构化推理:观察场景 → 确定当前子任务 → 评估成功标准 → 判断当前状态 → 决定下一步行动。MCP 工具接口提供 Start/Terminate/Change Policy、Env Summary、Fetch Robot Stats、Call Human 等调用能力。
Entangled Action Pairs (EAP):自重置数据采集

EAP 是 RoboClaw 的核心数据引擎:对每个操作策略 $k$,同时学习正向执行策略 $\pi^{\rightarrow}{\theta_k}$(完成操作)和逆向复位策略 $\pi^{\leftarrow}{\phi_k}$(恢复初始状态)。两条轨迹构成 entangled pair $\tau_k = (\tau^{\rightarrow}_k, \tau^{\leftarrow}_k)$,使环境无需人工介入即可自动复位,从而持续、循环地采集 on-policy 数据。
底层操作策略使用 $\pi_{0.5}$ VLA 模型实现,通过 flow matching 目标训练,预测短时程动作序列 $A_t = \pi_{0.5}(o_t, l_t, q_t)$,其中语言指令 $l_t$ 由 RoboClaw agent 动态生成而非人工提供。
部署阶段:过程监督与技能调度
部署时 RoboClaw 切换为任务执行模式,同一 agent 通过 CoT 推理动态选择并调度已学策略。agent 定期查询环境状态和机器人状态以监控子任务进度;当子任务失败时,可重试同一策略、切换备选策略,或在重复失败时触发 Call Human。部署产生的轨迹直接回流训练数据集,实现持续改进。
3. 核心结果/发现
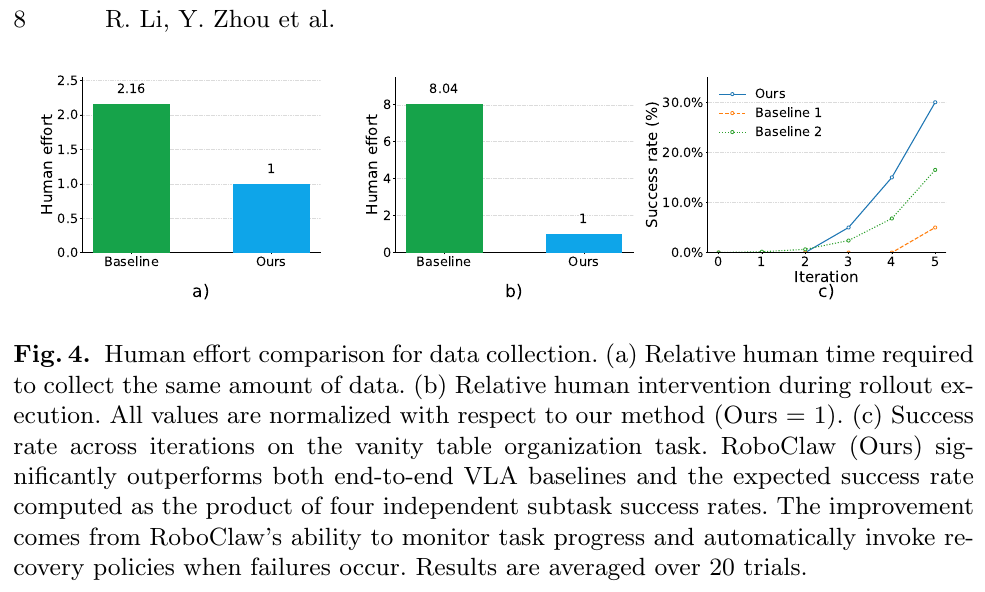
- 数据采集效率:与纯人工采集基线相比,RoboClaw 将所需人力时间减少至 1/2.16,将 rollout 过程中的人工干预减少至 1/8.04
- 策略迭代提升:4 个操作任务的正向策略成功率随迭代均稳步提升(例如 Body Lotion: 21→43/50,Lipstick: 2→23/50,经 5 次迭代)
- 长时程任务:在梳妆台整理任务上,RoboClaw 比端到端 VLA 基线(Baseline 1)和独立子任务成功率乘积估计(Baseline 2)显著更高,最终成功率提升约 25%
- 逆向复位策略:4 个任务的逆向策略成功率均在 36-43/50 之间,保障了 EAP 循环的稳定性

- 故障学习:系统将运行故障分为非降级故障(可直接重试)和降级故障(需恢复动作),后者随迭代逐渐被纳入策略库,减少对人工干预的依赖
4. 局限性
云端 VLM 推理引入额外延迟,影响实时控制性能;EAP 机制依赖逆向复位行为在实践中确实可行这一假设,对部分操作任务可能难以设计合理的逆向策略。