
Open-Nav (2025)
———Zero-Shot VLN in Continuous Environment with Open-Source LLMs
📄 Paper: https://arxiv.org/abs/2409.18794
精华
Open-Nav 的核心贡献在于将昂贵的 GPT-4 API 替换为本地部署的开源 LLM,同时维持竞争力性能,这对隐私敏感的真实场景机器人部署有重要意义。论文设计的三阶段空间-时序 CoT(指令理解 → 进度估计 → 决策制定)是一种可复用的 LLM 导航推理框架,值得借鉴。用 SpatialBot + RAM 联合增强视觉感知的思路——一个负责空间关系理解,一个负责细粒度目标识别——有效弥补了开源 LLM 相比 GPT-4 在视觉感知上的差距。真实世界评估结果显示,无训练的 Open-Nav 甚至超越了有监督训练的 SOTA 方法,说明 LLM 的泛化能力在分布外场景中优势显著。
1. 研究背景/问题
Vision-and-Language Navigation in Continuous Environments (VLN-CE) 要求 agent 在未见过的 3D 室内环境中,根据自然语言指令进行导航。现有基于 LLM 的零样本方法(如 NavGPT、DiscussNav)严重依赖 GPT-4 API,存在高昂 token 费用和用户环境数据隐私泄露风险,且主要在离散环境中验证,难以直接应用于连续真实场景。
2. 主要方法/创新点
Open-Nav 框架由三个核心模块组成:
1. Waypoint Prediction 模块
使用基于 Transformer 的路径点预测模型,融合 RGB 和深度图像特征(两个专用 ResNet50 分支):
\[v_i^{rgbd} = W_m(f_{\text{ResNet-RGB}}(I_i^{rgb}) \| f_{\text{ResNet-Depth}}(I_i^d))\]经 Transformer 处理后生成候选路径点热力图,再通过 NMS 筛选出 K 个候选方向点 $\Delta W = {\Delta w_i}_{i=1}^K$,每个候选点由角度和距离表示。
2. Scene Perception 模块
针对连续环境中需要精确空间理解的挑战,使用两个互补模型增强场景描述:
- SpatialBot:空间理解 VLM,输入 RGB+深度图,输出包含物体间距离和空间关系的文本描述
- RAM(Recognize Anything Model):细粒度目标检测,识别场景中所有物体的类别和三维位置
两者输出合并为统一的文本化场景观测 $O_{text} = \langle D_{spatial}, {o_i}\rangle$,为 LLM 提供丰富的空间语境。

3. LLM Navigator:三阶段空间-时序 Chain-of-Thought
这是 Open-Nav 的核心创新。每个导航步骤,LLM 按顺序完成三个推理阶段:
- 指令理解(Instruction Comprehension):将导航指令分解为动作序列和地标列表,使用专用 prompt 提取结构化信息
- 进度估计(Progress Estimation):综合历史轨迹和当前观测,通过地标验证、方向分析、动作完成度评估四步判断已完成哪些子任务
- 决策制定(Decision Making):整合当前候选路径点的空间描述、历史轨迹摘要和进度估计结果,生成推理过程并选择最优方向点
框架通过 Ollama 在本地部署四种开源 LLM:Llama3.1-70B、Qwen2-72B、Gemma2-27B、Phi3-14B。
3. 核心结果/发现
模拟环境(R2R-CE 数据集):
| 方法 | SR↑ | SPL↑ | nDTW↑ |
|---|---|---|---|
| DiscussNav-GPT4 | 15 | 10.51 | 42.87 |
| Open-Nav-Llama3.1(本文) | 16 | 12.90 | 44.99 |
| Open-Nav-GPT4(本文) | 19 | 16.10 | 45.79 |
Open-Nav 使用开源 LLM 在 SR 和 SPL 上均超过 DiscussNav-GPT4,证明开源 LLM 配合良好的感知增强可媲美闭源方案。
真实世界环境(Office / Lab / Game Room):

在全部真实场景中:Open-Nav-Llama3.1 达到 SR=35, NE=2.39,超越有监督训练的 CMA(SR=23)、RecBERT(SR=27)、BEVBert(SR=20),验证了 LLM 泛化能力在分布外场景的优越性。
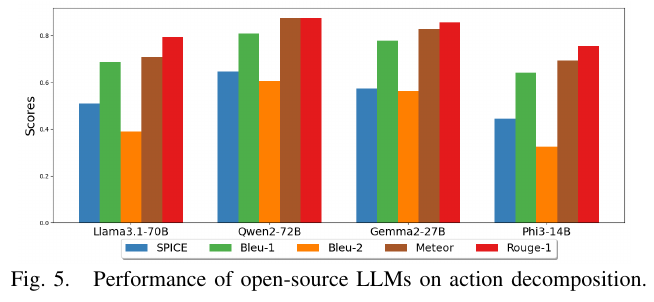
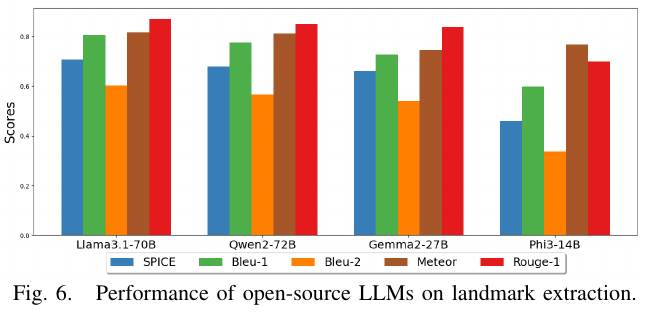
不同开源 LLM 对比(模拟环境导航性能):

4. 局限性
当前开源 LLM 的推理速度较慢,在真实环境中计算效率仍有待提升;论文未探索针对导航任务微调开源 LLM 的潜力,未来可进一步缩小与 GPT-4 的性能差距。