
Janus-Pro (2025)
———Unified Multimodal Understanding and Generation with Data and Model Scaling
📄 Paper: https://arxiv.org/abs/2501.17811
精华
Janus-Pro 最值得借鉴的核心思想是解耦视觉编码:理解任务与生成任务对视觉表征的需求本质不同,强行共享编码器会造成任务冲突,解耦后两路可独立优化。此外,训练策略的精细化同样重要——Stage I 充分训练像素依赖建模、Stage II 去除低效的 ImageNet 预热、Stage III 调整多模态数据比例,每一步都针对已知痛点而非盲目堆量。合成数据(1:1 比例)对生成质量的稳定性提升至关重要,是解决真实数据噪声问题的实用路径。模型规模从 1.5B 扩展到 7B 验证了解耦编码方法的强可扩展性,为统一理解与生成框架的规模化提供了实证支撑。
1. 研究背景/问题
当前统一多模态理解与生成的模型通常共享同一视觉编码器处理两类任务,但理解与生成对视觉表征的需求存在本质冲突,导致多模态理解性能受损。前代模型 Janus 虽通过解耦视觉编码验证了该思路,但受限于训练数据量少和模型容量小,在短提示图像生成质量和生成稳定性上表现欠佳。
2. 主要方法/创新点
Janus-Pro 从三个维度对 Janus 进行系统性增强:训练策略优化、数据扩展和模型规模扩展。
架构(与 Janus 相同,解耦视觉编码):
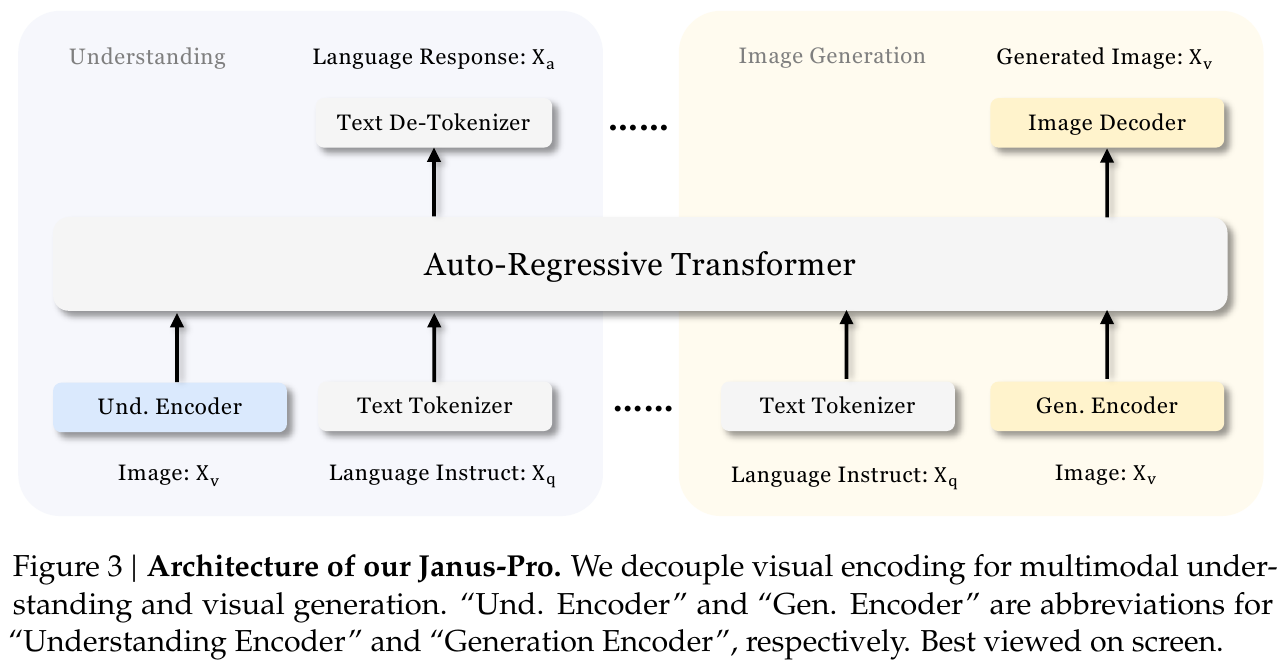
整体框架基于统一的自回归 Transformer。对于多模态理解任务,使用 SigLIP-Large-Patch16-384 编码器提取高维语义特征,经 Understanding Adaptor(两层 MLP)映射到 LLM 输入空间;对于视觉生成任务,使用 VQ tokenizer 将图像离散化为 ID 序列,经 Generation Adaptor 映射 codebook embedding 输入 LLM,最终通过 Image Decoder 输出 $384 \times 384$ 图像。
优化训练策略:
原版 Janus 的三阶段训练中,Stage II 将 66.7% 的文生图训练步数分配给 ImageNet 类别名称提示,效率低下。Janus-Pro 做出两处关键修改:
- Stage I 延长训练:增加 Stage I 训练步数,让模型在 LLM 参数固定时充分学习像素依赖建模;
- Stage II 聚焦训练:Stage II 完全去除 ImageNet 数据,直接使用密集描述的真实文生图数据,提升训练效率;
- Stage III 数据比例调整:将多模态理解数据、纯文本数据、文生图数据的比例从 7:3:10 调整为 5:1:4,在保持生成能力的同时提升多模态理解性能。
数据扩展:
- 多模态理解:参考 DeepSeek-VL2,增加约 9000 万样本(图像描述、表格、图表、文档理解等),Stage III 额外加入 MEME 理解、中文对话等数据;
- 视觉生成:引入约 7200 万合成图像样本,将真实与合成数据比例调整为 1:1,有效解决原始真实数据噪声大、生成不稳定的问题。
模型扩展:
将基础 LLM 从 1.5B 扩展至 7B(使用 DeepSeek-LLM),形成 Janus-Pro-1B 和 Janus-Pro-7B 两个版本。实验表明更大规模 LLM 使两类任务的 loss 收敛速度均显著加快。
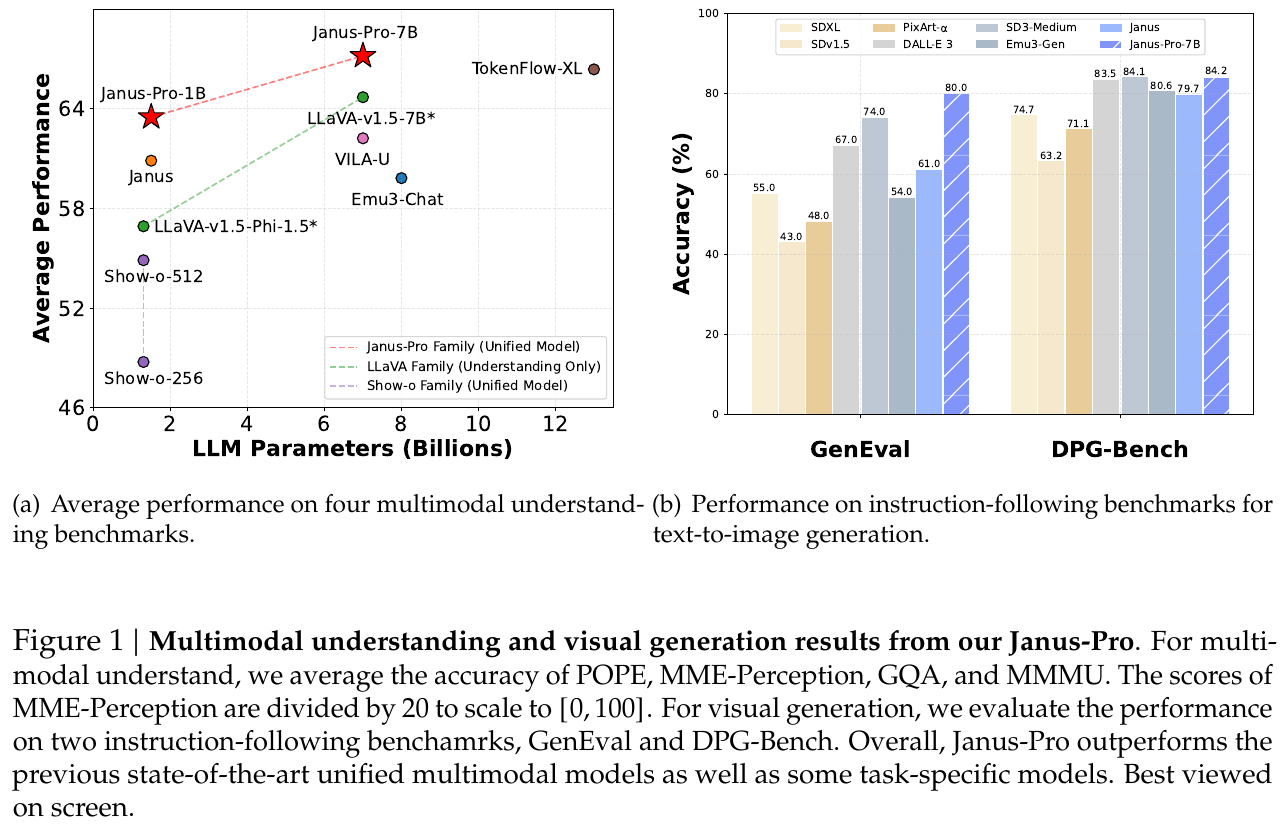
3. 核心结果/发现
多模态理解(Table 3):
- Janus-Pro-7B 在 MMBench 上达到 79.2,超越同类统一模型 Janus(69.4)、TokenFlow-XL(68.9,13B)、MetaMorph(75.2,8B)
- MMMU 得分 50.0,GQA 62.0,全面领先统一理解+生成类模型
文生图生成(Table 4 & 5):
- GenEval 整体得分 0.80,超越 Janus(0.61)、DALL-E 3(0.67)、SD3-Medium(0.74)
- DPG-Bench 得分 84.19,超越所有对比方法(含生成专用模型)
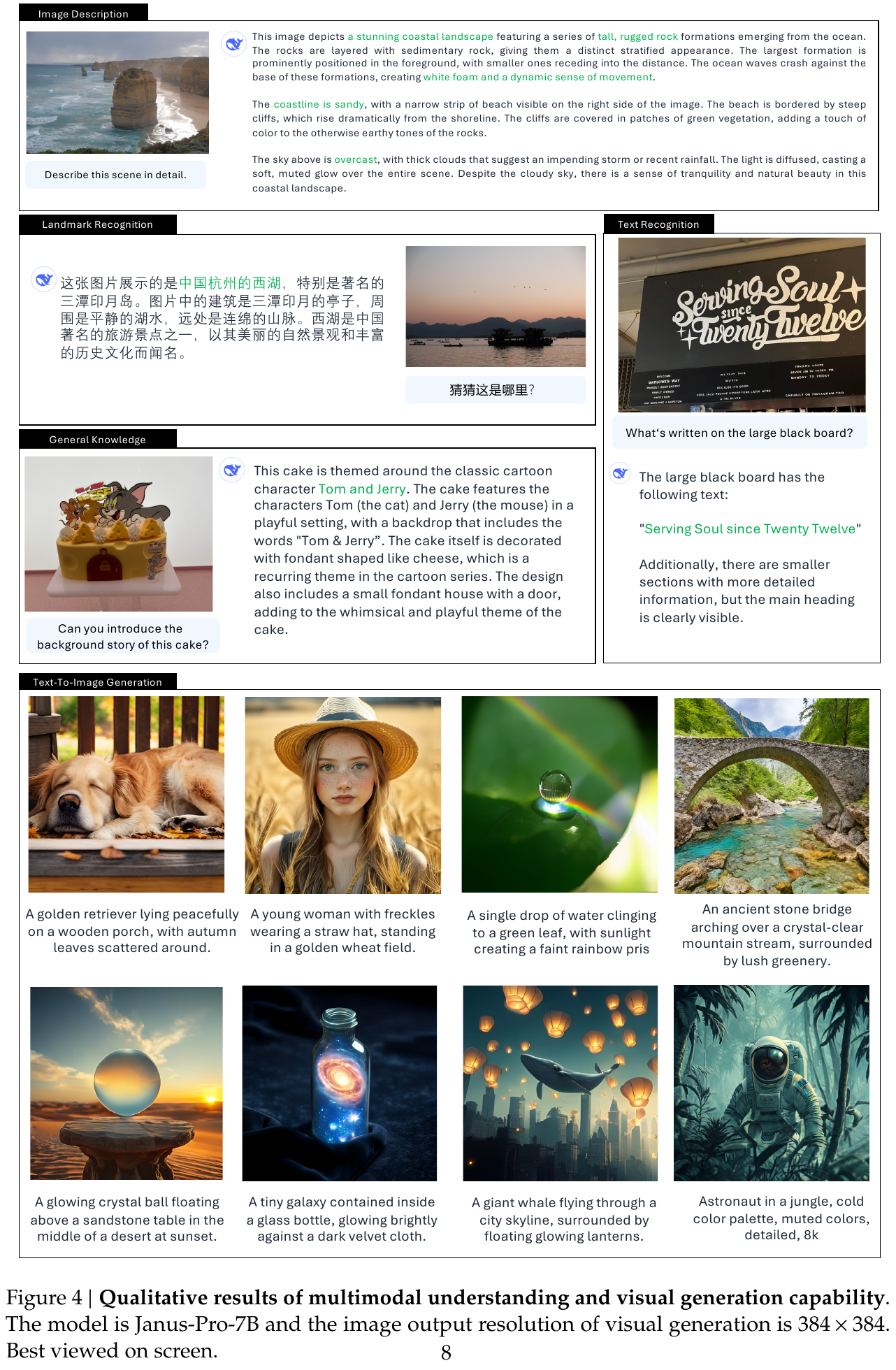
定性结果:
4. 局限性
多模态理解输入分辨率限制在 $384 \times 384$,影响 OCR 等细粒度任务性能;VQ tokenizer 的重建损失导致生成图像中小面部区域等细节欠缺,提升分辨率是解决上述两个问题的主要方向。