
AgentVLN (2026)
———Towards Agentic Vision-and-Language Navigation
📄 Paper: https://arxiv.org/abs/2603.17670
精华
AgentVLN 最值得借鉴的思想是 VLM-as-Brain 范式:将 VLM 作为大脑纯做高层语义推理与技能调度,把感知、规划、控制等低层能力封装成模块化、即插即用的技能库,彻底解耦了认知与执行。跨空间表示映射(将 3D 拓扑路点反投影为像素对齐的 2D 视觉提示)是一个无需额外参数就能弥合 2D VLM 与 3D 物理世界之间鸿沟的精妙设计。QD-PCoT 展示了如何赋予模型元认知能力:当面对空间歧义时主动提问、调用感知技能获取深度信息,而非盲目输出坐标。3B 参数量在 R2R/RxR 双榜均超越 7B+ 的先前 SOTA,证明结构化分层推理远比暴力扩参数更高效。该框架可直接部署于 Jetson 嵌入式边缘平台,具备极强的落地价值。
1. 研究背景/问题
Vision-and-Language Navigation (VLN) 要求具身智能体将复杂自然语言指令转化为长时域、连续空间的导航行为。当前 VLN 系统面临三大核心瓶颈:VLM 固有的 2D 语义理解与 3D 几何感知之间的跨空间失配;单目 RGB 图像引起的尺度歧义导致局部目标定位失败;以及大参数量模型无法满足边缘设备实时推理需求。
2. 主要方法/创新点
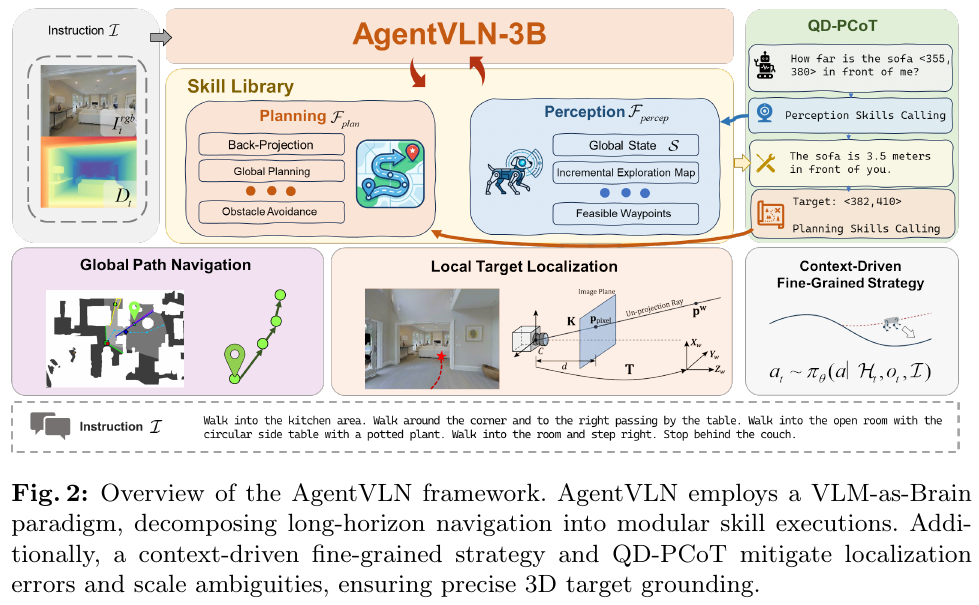
VLM-as-Brain 范式与 POSMDP 建模
AgentVLN 将 VLN 任务形式化为 Partially Observable Semi-Markov Decision Process (POSMDP) $\mathcal{M} = \langle \mathcal{S}, \mathcal{O}, \mathcal{F}, \mathcal{T}, \mathcal{I}, \mathcal{H} \rangle$。VLM 作为中央控制器,在每个决策步 $t$ 基于历史上下文 $\mathcal{H}_t$、视觉观测 $o_t$ 和自然语言指令 $\mathcal{I}$ 生成技能调用指令:
\[c_k \sim \pi_\theta(f \mid \mathcal{H}_{t_k}, o_{t_k}, \mathcal{I}), \quad f \in \mathcal{F}\]技能库 $\mathcal{F}$ 分为两类:感知技能 $\mathcal{F}{percep}$($\tau=0$,无延时地从环境提取几何/语义特征,更新全局状态 $\mathcal{S}$)和规划技能 $\mathcal{F}{plan}$($\tau>0$,执行多步物理动作序列)。具体包括:Back-Projection、Global Planning、Obstacle Avoidance、Incremental Exploration Map、Feasible Waypoints 等模块。这种分层设计使 VLM 完全不接触低层运动细节,专注高层语义-空间匹配。
跨空间表示映射(Cross-Space Representation Mapping)
为解决 VLM 无法直接感知 3D 几何的问题,AgentVLN 设计了一套逆透视投影机制。感知技能首先将 RGB-D 观测通过反投影构建全局占据栅格地图,生成三维路点 $\mathbf{P}^w_{path} = [X_{path}, Y_{path}, 0]^T$;随后通过相机内参矩阵 $K$ 和当前位姿 $T_t$ 将 3D 路点投影回像素坐标:
\[s \cdot \mathbf{p}^{img}_{path} = KR_t^{-1}(\mathbf{P}^w_{path} - \mathbf{t}_t)\]这样 VLM 只需在 2D 像素空间中根据语义选择最匹配的路点,再由规划技能将其恢复为 3D 控制信号,实现了 2D 视觉语义与 3D 物理结构的无缝桥接。
上下文感知的细粒度自校正与主动探索
当当前观测 $o_t$ 中不存在满足指令语义的可行路点时(如遮挡、盲区、轨迹偏差),AgentVLN 不强制执行长距离盲位移,而是输出细粒度原子动作 $a_t \sim \pi_\theta(a \mid \mathcal{H}_t, o_t, \mathcal{I})$,$a \in {\text{Forward, Left, Right}}$,自主环顾恢复可见路点后切回宏观技能调用,有效抑制长轨迹误差累积。
Query-Driven Perceptual Chain-of-Thought (QD-PCoT)
针对局部目标定位阶段的单目尺度歧义,AgentVLN 引入 QD-PCoT 机制。当模型检测到空间歧义时,不盲目回归像素坐标,而是生成中间自然语言查询(如 “How many meters is the chair in front of me?”)并调用感知技能 $\mathcal{F}{percep}$ 获取精确深度反馈。该反馈以增量文本提示形式注入上下文,引导模型最终输出准确的目标像素坐标 $\mathbf{p}^{img}{target} = [u_{target}, v_{target}, 1]^T$,再经深度图反投影转换为 3D 目标坐标 $\mathbf{P}^w_{target}$,实现精准对接。
AgentVLN-Instruct 数据集
构建了大规模指令调优数据集 AgentVLN-Instruct(基于 Habitat 仿真器),包含四个关键组件:目标可见性驱动的动态阶段路由机制(模拟人类”先粗导航、再精定位”的认知模式)、可泛化技能调用标注、局部化推理数据,以及主动问答交互对。基础模型为 Qwen2.5-VL-3B,训练时冻结视觉编码器,以 AdamW 优化,使用 32 块 NVIDIA A100 GPU。
3. 核心结果/发现

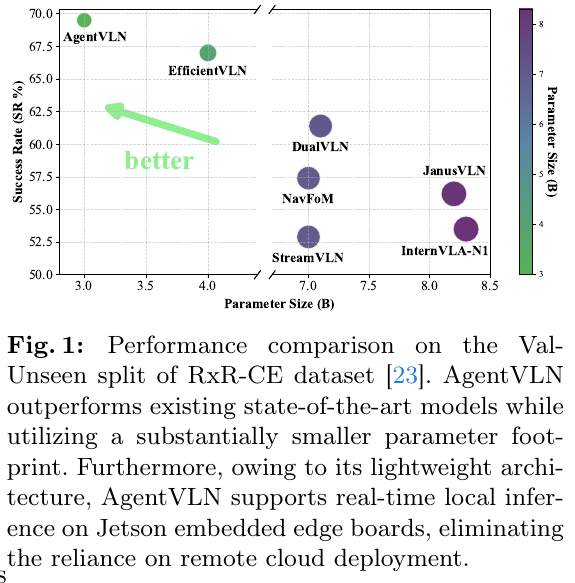
- R2R-CE Val-Unseen: AgentVLN-3B 达到 SR=67.2%, SPL=64.7%,超越同类 SOTA InternVLA-N1-8.3B(SR+9.0%,SPL+10.7%),以不到一半的参数量实现全面超越
- RxR-CE Val-Unseen: SR=69.5%, SPL=61.3%, nDTW=74.6%,同样刷新 SOTA
- 消融分析:仅引入 VLM-as-Brain + 跨空间映射,SR 从基线 38.6% 提升至 59.7%;加入 CDFG 细粒度自校正后达 65.6%;最终集成 QD-PCoT 达 67.2%
- 时序上下文:最优历史帧数 K=8(SR=67.2%,SPL=64.7%),过短则短视,过长则注意力稀释
- 真实世界部署:基于 Unitree Go2 四足机器人 + Intel RealSense D455,结合 RTAB-Map SLAM,在室内外场景均实现准确导航,支持 Jetson 边缘实时推理
4. 局限性
AgentVLN 当前依赖深度传感器(RGB-D)支持精确的 3D 反投影,在纯 RGB 单目场景下的尺度歧义处理能力仍受限;此外,技能库的扩展和维护需要一定的工程成本,对全新场景的零样本适配能力尚待系统评估。