引言
视觉语言导航(Vision-Language Navigation, VLN)是一个多学科交叉的研究领域,涵盖了自然语言处理、计算机视觉、多模态信息融合以及机器人导航等多个学科。在该领域,研究人员致力于开发能够理解自然语言指令,并在复杂环境中实现自主导航的智能体。
VLN任务的核心挑战在于如何让机器人或智能体理解人类的自然语言指令,并通过视觉感知在真实或虚拟环境中进行导航。这项技术在服务机器人、自动驾驶、智能家居等领域有着广泛的应用前景。
本博文旨在系统梳理VLN领域的研究进展,为学习和研究VLN提供参考。
VLN基本概述
什么是VLN?
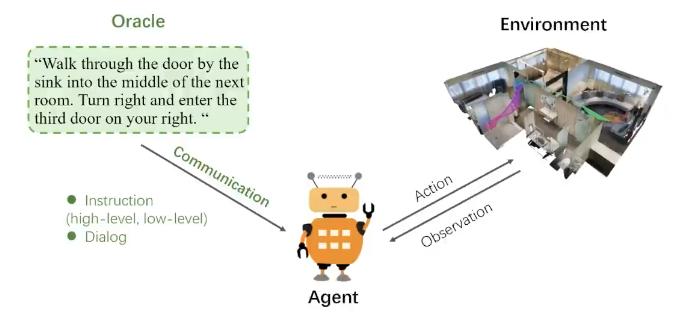
VLN任务的定义是:给定一个自然语言指令(natural language instruction),智能体(agent)被放置在模拟器中的初始位置,需要通过理解指令并观察视觉环境,按照指令给定的路线移动到目的地。
这个任务最早起源于2018年,作者认为让一个5岁左右的孩子去拿一个勺子(”bring me a spoon”)是一个很简单的任务,但是如果想通过语言指令去指导机器人去拿一个勺子却非常困难。
VLN 在具身智能体中的角色
近年来,VLN 越来越多地被视为通用 Vision–Language–Action 智能体的一项核心能力,而非孤立的导航任务。在此背景下,VLN 常作为复杂具身任务(如任务执行或协作导航)的子模块进行研究。
相关任务:TEACh 等具身任务执行基准
VLN的三个核心要素
一个完整的VLN系统包含三个核心要素:
-
Instruction Source(指令源 / Oracle):指令源用于生成或提供自然语言导航指令,模拟人类用户对导航目标的描述。在部分交互式 VLN 设定中,智能体可向指令源请求额外信息或澄清指令,从而形成更接近真实人机交互的导航过程。
-
Agent(智能体/执行者):Agent 是 VLN 系统的核心执行主体,负责感知环境、理解语言指令并输出导航动作。智能体需要根据当前视觉观察、历史状态以及语言指令,与环境进行连续交互,完成从起点到目标位置的导航任务。
-
Environment(环境):Environment 定义了智能体执行导航任务的空间。由于真实环境中的数据采集与训练成本较高,现有研究通常依赖高保真模拟器进行训练与评测。例如,在 Room-to-Room(R2R)任务中,Matterport3D 数据集被广泛用作室内三维仿真环境。
VLN 系统的基本组成
随着具身智能的发展,VLN 系统正从单纯的“指令匹配”向 VLA (Vision-Language-Action) 全能模型演进。其架构通常由感知、大脑、行动三个核心模块组成,并呈现出明显的分层控制(Hierarchical Control)趋势:
1. 感知模块 (Perception Module) —— 从单一特征到语义-几何融合
- 功能:负责从环境中提取基于视觉和语言的观察信息。
- 趋势:从传统的视觉骨干网络(如 CNN)转向视觉-语言对齐的 Transformer(如 SigLIP),以获取更强的指令对齐能力;同时结合具有强空间先验的几何表示模型(如 DINOv2),以提高在复杂环境中的空间感知与操作精度。
2. 大脑模块 (Reasoning Module) —— 慢思考:高层逻辑与战略规划
- 功能:作为系统的“慢系统”,负责融合多模态输入,进行高级逻辑推理、常识判断与任务规划。
- 交互逻辑:低频率输出。大脑模块(通常基于预训练的 VLM)利用大规模互联网知识进行推理,不需要实时输出电机信号。它以较低的频率输出高层决策指令或环境中的目标点像素坐标(Goal Point Coordinates)。
- 优势:支持零样本(Zero-shot)泛化,能够将复杂的自然语言指令分解为可执行的中间目标。
3. 行动模块 (Action Module) —— 快行动:高频生成与物理控制
- 功能:作为系统的“快系统”,将大脑模块的决策指令转化为具体的物理动作。
- 交互逻辑:高频率执行。行动模块接收来自大脑的目标点坐标,利用连续生成建模(如扩散模型 Diffusion Model)以高频率(如 30Hz+)预测平滑、无碰撞的运动轨迹(Trajectory)。
- 控制闭环:基于生成的轨迹,利用 MPC(模型预测控制) 或底层控制器精准驱动电机(如输出扭矩、位移信号),实现平滑且多模态的动作分布建模。
VLN 在 VLA 范式下的独特研究价值
虽然 VLN 属于 VLA 体系,但它与传统的“基于 VLA 的机械臂控制(Manipulation)”在任务逻辑上有着本质区别:
- 长时序环境建模 (Long-Horizon Exploration):机械臂控制通常关注近场操作,视角相对固定;而 VLN 涉及长距离、多房间甚至跨楼层的移动(如 LHPR-VLN),要求智能体在移动中动态维护环境记忆(如拓扑图或语义地图),处理因位移产生的空间迷失风险。
- 指令流与视觉流的“时空动态对齐”:在机械臂任务中,指令(如“抓起杯子”)与目标通常是静态对应的;而在 VLN 中,指令解析是随着位移动态演进的。
- 分层异步协同需求:这决定了 VLN 必须采用“大脑模块(慢系统)”与“行动模块(快系统)”的异步协作——大脑负责高层语义状态跟踪,并周期性地将抽象指令转化为行动模块所需的像素级局部目标点。
- 常识推理与物理约束的博弈:VLN 的独特之处在于如何利用生成式策略(如扩散模型)将大脑模块可能存在的“语义幻觉”转化为符合物理规律的连续轨迹,并由 MPC(模型预测控制) 处理碰撞与环境摩擦。
VLN 区别于传统机器人导航
VLN 与传统的机器人导航(Navigation Stack,如基于 SLAM 的系统)在核心驱动力上有显著不同:
- 从“几何坐标”转向“语义路标” (Semantic vs. Geometric):
- 传统导航:依赖预建的高精度几何地图(点云或占据栅格),通过全局坐标(XY 坐标)驱动。
- VLN:智能体通常置于未见环境(Unseen Environment)中,必须通过理解自然语言中的“语义地标”(如“走过红色的椅子后左转”)进行在线决策,而非单纯的坐标追踪。
- 从“被动避障”转向“主动常识搜索”:
- 传统导航:主要解决“如何不撞到障碍物并到达 A 点”。
- VLN:要求智能体具备具身常识。当指令提到“去厨房拿咖啡”时,即便厨房不在视野内,系统也能利用 VLM 的常识预测厨房的方位并规划搜索路径,这超出了传统导航栈的范畴。
- 端到端语义理解的集成:
- 传统导航:感知、规划、执行是解耦的模块。
- VLN:在 VLA 范式下,视觉感知与语言指令在“大脑模块”中深度融合,直接影响行动模块生成的轨迹分布,实现了从高层语义到低层物理动作的端到端映射。
VLN 的主要挑战
1. 语言–视觉–行动(Language–Vision–Action)的一致性与可控推理
尽管大规模视觉-语言预训练模型在跨模态对齐方面取得了显著进展,但如何在导航过程中实现语言指令、视觉观测与动作决策之间的语义一致性,仍然是 VLN 的核心挑战之一。特别是在基于大语言模型的 VLN 系统中,如何保证高层语义推理结果能够被可靠地转化为可执行的低层导航动作,是当前研究亟需解决的问题。
2. 开放世界场景下的泛化能力
VLN 模型通常在有限数量的场景和指令分布上进行训练,但在实际应用中需要面对开放世界环境,包括未见过的空间布局、物体组合以及多样化的自然语言表达。如何提升模型在跨环境、跨任务和跨指令分布下的零样本或少样本泛化能力,是当前 VLN 研究的关键瓶颈之一。
3. 分层规划中长期目标与短期决策的协同
VLN 任务天然具有长时序和部分可观测的特性,智能体需要在理解全局导航目标的同时,根据局部观测进行实时决策。近年来引入的大语言模型在高层规划和子目标分解方面展现出强大的能力,但如何在分层架构中实现高层推理与低层控制策略之间的稳定协同,以及在规划失败时进行有效恢复,仍然是一个具有挑战性的问题。
4. 长时记忆与环境建模能力
在复杂室内或室外环境中,智能体需要整合跨时间的多次观测以形成对环境的整体理解。如何构建有效的记忆机制和世界模型,以支持长期导航、路径回溯和错误纠正,是提升 VLN 系统鲁棒性和效率的重要方向。
5. 面向真实部署的可靠性与安全性
尽管大多数 VLN 方法仍主要在模拟环境中进行评测,但随着研究逐步向真实机器人系统过渡,导航过程中的安全性、稳定性以及对异常情况的应对能力变得尤为重要。如何在保证导航成功率的同时,避免潜在的危险行为,并提升系统决策过程的可解释性,是 VLN 走向真实应用必须面对的问题。
VLN研究发展趋势
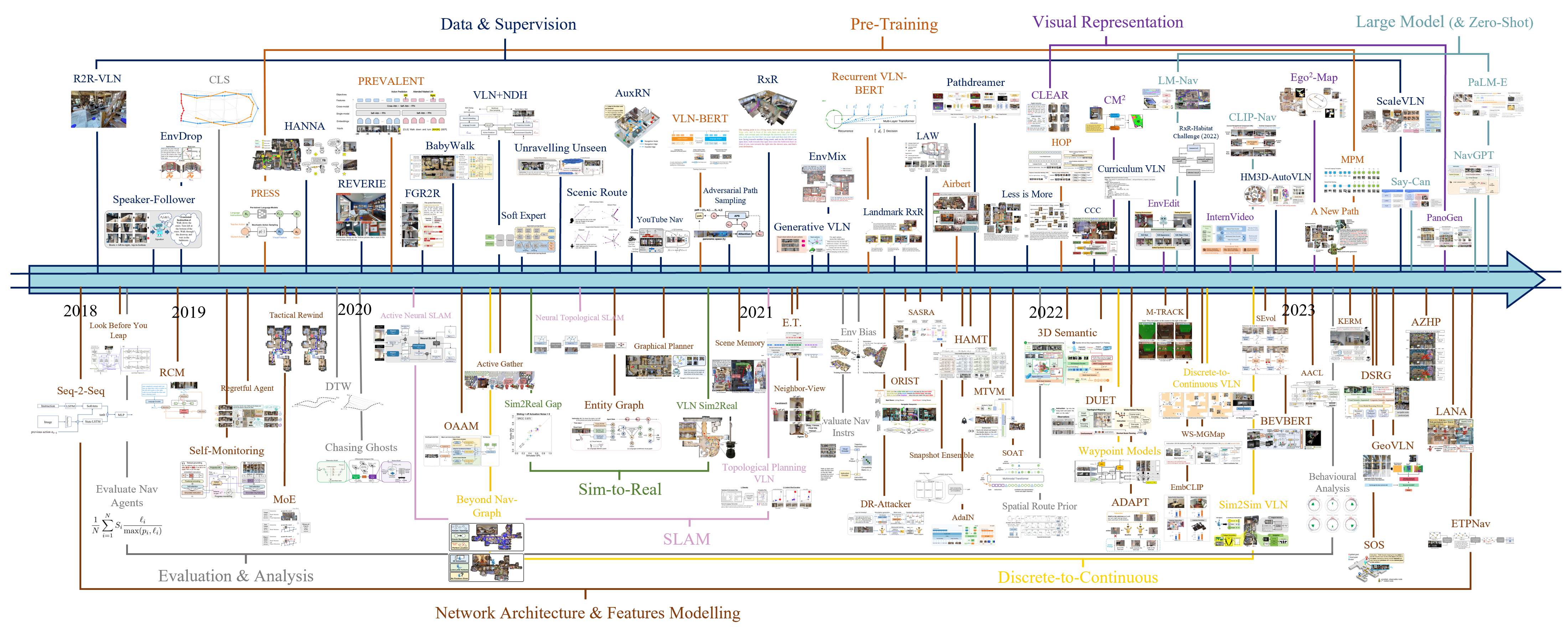
从整体发展脉络来看,VLN 研究经历了从任务驱动模型到具身智能体的重要转变,其研究重心也随之不断演进。
1. 早期阶段:任务驱动的多模态建模(2018–2019)
该阶段的研究主要关注如何构建有效的视觉与语言联合表示,并探索基于循环神经网络或早期 Transformer 架构的导航模型,为 VLN 任务奠定了基础方法论。
2. 中期阶段:数据集与评测基准扩展(2020–2021)
随着研究的深入,多个更大规模、更复杂的 VLN 数据集和评测基准被提出,推动模型从简单场景向更具挑战性的真实环境分布扩展,并促进了对泛化能力的系统性研究。
3. 过渡阶段:大规模预训练模型的引入(2022–2023)
在这一阶段,预训练视觉-语言模型以及大语言模型被引入 VLN 任务,使模型具备更强的语义理解、推理与指令跟随能力。VLN 开始从任务特定模型向通用多模态模型能力迁移。
4. 当前阶段:面向具身智能体的统一建模(2024–至今)
最新研究趋势表明,VLN 正逐步被视为通用具身智能体的重要能力之一,而非孤立的导航任务。研究重点从单一任务性能提升,转向统一感知、推理、规划与执行的多模态智能体框架,并探索其在更广泛现实场景中的应用潜力。
关键技术方向
1. 统一的视觉-语言-行动(Vision-Language-Action, VLA)架构
近年来,VLN 研究逐渐从传统的模块化设计转向端到端的统一建模范式,将视觉感知、语言理解、空间推理与动作决策统一在同一模型中。基于 Transformer 或大语言模型的 VLA 架构能够有效处理长时序决策问题,并提升复杂自然语言指令下的导航性能,成为当前 VLN 研究的重要趋势。
2. 大规模预训练与指令对齐
VLN 模型越来越依赖大规模视觉-语言预训练,以获得更强的跨模态语义对齐与通用表示能力。通过在图文、视频-语言及导航轨迹等多源数据上进行预训练,并结合指令微调(Instruction Tuning),模型在未见环境和复杂指令下的泛化能力显著提升。
3. 基于大语言模型的推理与规划
引入大语言模型进行高层语义推理和路径规划已成为 VLN 的重要研究方向。大语言模型可用于子目标分解、动作规划以及轨迹评估,将 VLN 从纯感知控制问题扩展为具备推理与决策能力的导航任务,从而提升复杂场景和长路径下的导航成功率。
4. 记忆机制与世界模型构建
为应对部分可观测环境和长距离导航挑战,研究者引入显式或隐式记忆机制以及可学习的世界模型,用于累积环境信息并进行跨时间推理。语义地图和视觉记忆模块能够帮助智能体构建对环境的结构化理解,是实现高效 VLN 的关键组成部分。
5. 数据驱动的训练范式与学习策略
相比传统强化学习方法,当前 VLN 更倾向于采用模仿学习、离线强化学习及数据驱动的训练策略。通过轨迹重标注、数据增强以及利用大语言模型生成伪示例,能够有效提升样本效率并降低真实环境交互成本。
6. 从 VLN 到通用具身智能任务
VLN 正逐步与目标导航、具身问答和任务执行等具身智能任务融合,形成统一的具身指令跟随问题设定。这一趋势推动 VLN 从单一任务向多任务、多模态的通用具身智能体发展。
未来研究方向
1. 开放世界环境下的泛化能力
未来 VLN 研究需要突破对封闭场景和固定指令分布的依赖,实现对未知环境、未见物体及组合式指令的零样本或少样本泛化能力。
2. 面向真实机器人的导航能力
缩小模拟环境与真实世界之间的差距是 VLN 走向实际应用的关键挑战。未来研究需充分考虑传感器噪声、动态环境和连续控制等现实因素,以提升 VLN 系统在真实机器人平台上的可靠性。
3. 基于多模态大模型的统一具身智能体
将 VLN 视为多模态大模型的重要能力之一,而非独立任务,是当前的重要发展方向。通过统一感知、推理、规划与执行,构建具备多任务能力的具身基础模型,有望显著提升 VLN 的通用性和扩展性。
4. 持续学习与自主探索
未来的 VLN 智能体需要具备持续学习能力,能够在长期运行过程中自主收集经验、更新环境认知并不断优化导航策略,从而适应不断变化的环境和任务需求。
5. 自然人机交互与协作导航
支持更自然的人机交互形式,如对话式指令修正、不完整或模糊指令理解,以及人类实时干预,将显著提升 VLN 系统在真实应用场景中的可用性。
6. 安全性、可解释性与失败恢复
随着 VLN 系统逐步走向真实部署,其安全性和可解释性问题愈发重要。未来研究需关注导航决策的可解释性、失败检测与自我纠错机制,以保障系统在复杂环境中的安全运行。
VLN 任务类型
随着研究范式的演进,VLN 的任务划分逐渐从早期基于指令形式的分类,转向以智能体能力需求和交互方式为核心的分类方式。
按推理与决策复杂度划分
1. 指令跟随型 VLN(Instruction-Following VLN)
该类任务要求智能体根据给定的自然语言指令,在环境中完成从起点到目标位置的导航,通常不涉及显式目标搜索或复杂语义推理。此类任务主要用于评估模型的语言理解能力和基本导航能力。
代表性数据集:Room-to-Room(R2R)、Room-for-Room(R4R)
2. 语义推理驱动的 VLN(Reasoning-Oriented VLN)
该类任务在导航过程中引入目标物体搜索或语义约束,智能体需要将语言指令与环境中的语义信息进行推理匹配,从而完成导航与定位任务。
代表性数据集:REVERIE、SOON
3. 长时序与组合式 VLN(Long-Horizon VLN)
该类任务强调长距离导航和复杂指令组合,要求智能体具备长期规划、记忆和错误恢复能力,是评估 VLN 系统长期决策能力的重要设定。
按交互方式划分
1. 非交互式 VLN
智能体在接收到初始指令后独立完成导航任务,过程中不与用户进行额外交互。这是当前最常见的 VLN 评测设定。
2. 交互式与对话式 VLN
该类任务允许智能体在导航过程中与用户进行多轮交互,通过提问或反馈不断优化导航目标,更接近真实人机协作场景。
代表性数据集:CVDN
VLN的应用场景
室内场景
室内VLN主要关注家庭或办公环境内的导航。环境通常较为复杂,包含多个房间和各种家具,对智能体的空间理解能力要求较高。

应用示例:
- 家庭服务机器人
- 室内物流配送
- 智能导览系统
室外场景
室外VLN面临更大的环境复杂度,需要处理动态障碍物、天气变化等因素。

应用示例:
- 自动驾驶
- 户外服务机器人
- 城市导航系统
空中场景
空中VLN涉及无人机等飞行器的导航控制。
应用示例:
- 无人机巡检
- 空中搜救
- 航拍导航
VLN主流数据集
VLN研究依赖高质量的数据集来训练和评估导航模型。以下是VLN领域最具影响力的主流数据集(含最新进展):
指令导向数据集
指令导向任务(Instruction-guided)是 VLN 的核心,重点在于将复杂的自然语言指令映射到具体的环境动作序列中。
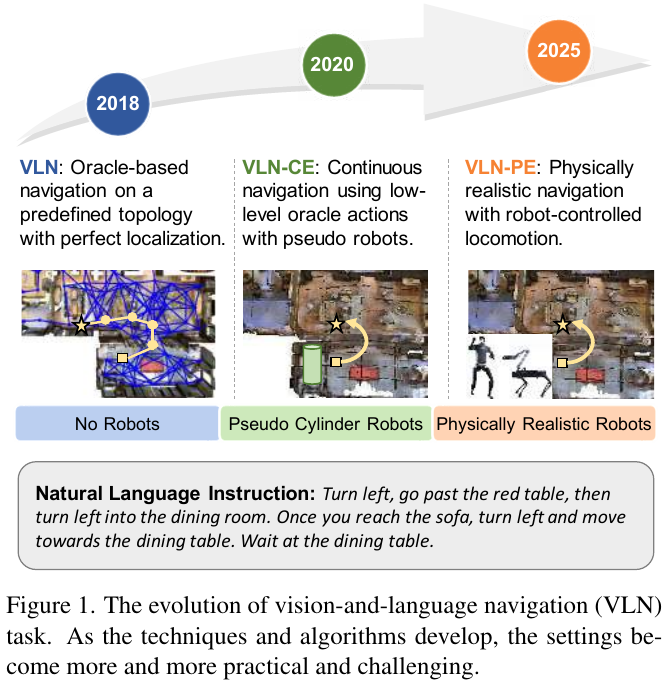
1. VLN (2018)
1.1 R2R (Room-to-Room)
- 发布时间:2018 (CVPR)
- 环境表示:离散拓扑图 (Discrete Graph)。基于 Matterport3D 扫描的真实场景。
- 核心挑战:跨模态对齐(Cross-modal Alignment),要求智能体在复杂的真实图像中识别指令提及的地标。

[数据集目录结构]
R2R/
├── data/
│ ├── R2R_train.json # 训练集:14,025 条指令
│ ├── R2R_val_seen.json # 已见环境:与训练集场景重合,考量记忆力
│ ├── R2R_val_unseen.json # 未见环境:全新场景,考量泛化性 (最关键指标)
│ └── R2R_test.json # 测试集:榜单评测专用,隐藏 GT 路径
├── connectivity/ # 拓扑连接图 (定义 Agent 可移动的范围)
│ └── <Scan_ID>_connectivity.json
└── img_features/ # 视觉特征 (主流采用 ViT-B/16 或 ResNet 离线提取)
└── <Scan_ID>.tsv # 存储各视点 (viewpoint) 的全景特征向量
[数据条目与底层逻辑解析] R2R 的 JSON 不仅仅是文本,它包含了导航初始化的关键位姿信息:
{
"scan": "2n8P_example", // 场景 ID (对应 Matterport3D 中的房屋)
"path": ["vp_1", "vp_2", "vp_3"],// 离散路径节点序列 (Ground Truth)
"heading": 1.57, // 初始水平偏航角 (Radians),决定 Agent 第一眼看哪
"instructions": [ // 每条路径对应的 3 条独立人类标注 (多样性)
"Leave the bedroom and go into the hallway...",
"Walk past the bathroom and stop near the stairs.",
"Go through the door and walk to the end of the hall."
],
"instr_id": "1234_0" // 格式:{path_id}_{instruction_index}
}
[关键技术细节:拓扑连接文件]
这是离散 VLN 的核心,connectivity.json 定义了智能体在每个点位可以看到的邻居节点:
// <Scan_ID>_connectivity.json 内部逻辑示例
{
"image_id": "vp_1",
"rel_heading": 0.52, // 目标点相对于当前的水平夹角
"rel_elevation": 0.1, // 目标点相对于当前的俯仰角
"distance": 2.1, // 节点间欧氏距离 (米)
"unobstructed": true // 路径是否通畅 (无墙壁阻隔)
}
[核心评估指标 (Metrics)] 在整理 R2R 时,必须包含这四个核心指标:
- NE (Navigation Error): 预测终点与真值终点的平均距离 (m),越低越好。
- SR (Success Rate): 终点误差小于 3m 的比例,越高越好。
- SPL (Success weighted by Path Length): 核心指标。权衡导航效率与准确度,避免智能体通过“乱绕路”碰巧到达终点。
- OSR (Oracle Success Rate): 路径中任意一点靠近过目标的比例,衡量模型是否曾“经过”正确答案。
1.2 R4R (Room-for-Room)
- 发布时间:2019 (EMNLP)
- 核心特点:通过拼接 R2R 路径形成更长的轨迹。
- 技术突破:引入了 CLS (Coverage weighted by Length Score) 指标,要求模型必须“严格遵循指令路径”而不仅仅是到达终点。
[数据格式差异]
- 路径构成:将两条 R2R 路径首尾相连,平均路径步数从 4-6 步增加到 10-15 步。
- JSON 补充:增加了
path_id追踪原始 R2R 路径来源。
1.3 RxR (Room-across-Room)
- 发布时间:2020 (EMNLP)
- 核心特点:多语言支持(英语、印地语、泰卢固语)及细粒度对齐。
[数据集目录结构]
RxR/
├── annotations/
│ ├── en-US/ # 英语指令文件夹
│ ├── hi-IN/ # 印地语指令文件夹
│ └── te-IN/ # 泰卢固语指令文件夹
├── poses/ # 指令与视点的细粒度对齐数据 (Pose Trace)
└── rxr_train_guide.json # 训练引导文件
[关键技术点:Pose Trace]
- 对齐数据:RxR 不仅提供指令,还记录了标注员在写指令时视线停留的时间戳。
- JSON 字段:包含
pose_trace数组,记录了(time, view_index),允许进行多模态的时间序列对齐训练。
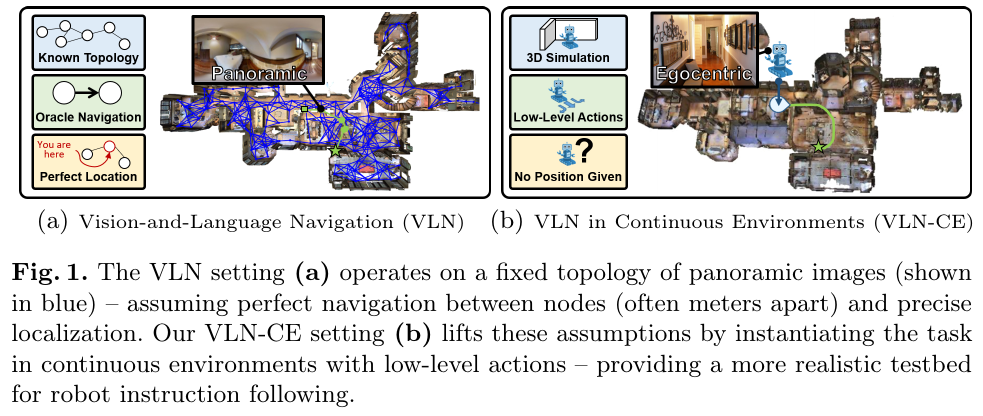
2. VLN-CE (2020)
————Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
- 发布时间:2020 (ECCV)
- 环境表示:连续环境 (Continuous Environment)。基于 Habitat 模拟器渲染 Matterport3D 场景,使用低层动作控制(0.25m 前进,15° 转向)。
- 核心特点:将离散拓扑图导航转换为连续空间导航,移除了预先构建导航图、完美定位和瞬移假设,更贴近真实机器人场景。
📄 Paper: https://arxiv.org/abs/2004.02857
[数据集目录结构]
data/
├── datasets/
│ ├── R2R_VLNCE_v1-3/ # R2R 数据集转换版本
│ │ ├── train/
│ │ │ └── train.json.gz # 训练集(4,475 条轨迹)
│ │ ├── val_seen/
│ │ │ └── val_seen.json.gz # 已见环境验证集
│ │ └── val_unseen/
│ │ └── val_unseen.json.gz # 未见环境验证集
│ │
│ ├── RxR_VLNCE_v0/ # RxR 多语言版本
│ │ ├── train/
│ │ │ ├── train_guide.json.gz # Guide 轨迹
│ │ │ ├── train_guide_gt.json.gz # Ground Truth
│ │ │ ├── train_follower.json.gz # Follower 轨迹
│ │ │ └── train_follower_gt.json.gz
│ │ ├── val_seen/
│ │ ├── val_unseen/
│ │ └── text_features/ # BERT 预编码特征
│ │
├── scene_datasets/
│ └── mp3d/ # Matterport3D 场景资源
│ ├── <scan_id>.glb # 场景网格模型
│ └── <scan_id>.navmesh # 可导航网格
│
└── ddppo-models/ # 预训练强化学习模型
[数据格式示例]
VLN-CE 保留 R2R 的指令和路径信息,但将离散节点路径转换为连续轨迹:
{
"episode_id": 1234,
"scene_id": "2n8kARJN3HM",
"trajectory_id": "4321",
"instruction": {
"instruction_text": "Walk past the bathroom and stop near the stairs.",
"instruction_tokens": ["walk", "past", "the", "bathroom", ...]
},
"reference_path": [ // 离散参考路径(来自 R2R)
"viewpoint_1",
"viewpoint_2",
"viewpoint_3"
],
"start_position": [1.2, 0.15, 3.4], // 连续空间起始坐标 (x, y, z)
"start_rotation": [0, 1.57, 0, 0], // 四元数表示的初始朝向
"goals": [ // 目标位置(可能有多个)
{
"position": [5.6, 0.15, 8.2],
"radius": 3.0 // 成功判定半径(米)
}
],
"shortest_paths": [ // 预计算的最短路径动作序列
[
{"action": "MOVE_FORWARD", "rotation": 0},
{"action": "TURN_LEFT", "rotation": 15},
{"action": "MOVE_FORWARD", "rotation": 0},
...
]
],
"info": {
"geodesic_distance": 9.89, // 最短路径长度(米)
"euclidean_distance": 7.32
}
}
[关键技术特性]
- 轨迹转换方法:通过射线投射和 A* 路径验证,将 77% 的 R2R 离散路径成功转换为连续环境轨迹
- 动作空间:
MOVE_FORWARD (0.25m),TURN_LEFT (15°),TURN_RIGHT (15°),STOP - 观测空间:RGB (480×640) + Depth (480×640),视场角 (FoV) 79°
- 物理约束:支持碰撞检测、可导航网格 (NavMesh)、Agent 高度 1.5m
- Habitat 集成:利用 Habitat-Sim 高性能渲染(1000+ FPS),支持分布式训练
[核心评估指标]
VLN-CE 采用与 R2R 一致的评估指标,但在连续空间中重新定义:
- NE (Navigation Error): 最终位置与目标的欧式距离(米),越低越好
- SR (Success Rate): 终点误差 < 3m 的轨迹比例,越高越好
- SPL (Success weighted by Path Length): 路径效率加权成功率 = SR × (最短路径长度 / 实际路径长度)
- OSR (Oracle Success Rate): 轨迹中任意位置曾接近目标(< 3m)的比例
[性能基准]
| 模型 | Val Unseen SR | Val Unseen SPL | 备注 |
|---|---|---|---|
| Seq2Seq | 18% | 0.16 | 基础模型 |
| CMA (Cross-Modal Attention) | 32% | 0.30 | 最佳基线 |
| 无深度输入 | ≤1% | - | 性能崩溃 |
| 无指令输入 | 17% | - | 单模态基线 |
核心发现:深度信息对 VLN-CE 至关重要,移除深度导致性能崩溃;平均轨迹长度从 VLN 的 4-6 步增加到 55.88 步。
3. VLN-PE (2025)
————Rethinking the Embodied Gap: Physical and Visual Disparities in VLN
- 发布时间:2025 (ICCV)
- 环境表示:物理真实连续环境 (Physically Realistic Environment)。基于 GRUTopia 物理模拟器 (Isaac Sim),支持真实的运动动力学和物理交互。
- 核心特点:首个支持多种机器人具身(人形/四足/轮式)的 VLN 平台,引入物理控制器和真机部署验证,揭示了仿真到真实的具身化差距。
📄 Paper: https://arxiv.org/abs/2507.13019v2
[数据集目录结构]
VLN-PE/
├── datasets/
│ ├── R2R-filtered/ # 过滤楼梯场景的 R2R
│ │ ├── train/ # 8,679 个 episodes
│ │ ├── val_seen/ # 658 个 episodes
│ │ └── val_unseen/ # 1,347 个 episodes
│ │
│ ├── GRU-VLN10/ # 新增合成家居场景
│ │ ├── train/ # 441 个 episodes
│ │ ├── val_seen/ # 111 个 episodes
│ │ └── val_unseen/ # 1,287 个 episodes
│ │
│ └── 3DGS-Lab-VLN/ # 3D Gaussian Splatting 渲染实验室
│ ├── train/ # 160 个 episodes
│ └── val/ # 640 个 episodes
│
├── scenes/
│ ├── mp3d/ # 90 个 Matterport3D 场景
│ ├── GRScenes/ # 10 个高质量合成场景
│ └── 3DGS/ # 3DGS 在线渲染场景
│
├── robots/
│ ├── humanoid/ # 人形机器人配置
│ │ ├── unitree_h1/ # Unitree H1 (相机高度 ~1.5m)
│ │ └── unitree_g1/ # Unitree G1
│ ├── quadruped/ # 四足机器人
│ │ └── unitree_aliengo/ # Unitree Aliengo (相机高度 ~0.5m)
│ └── wheeled/ # 轮式机器人
│ └── jetbot/ # NVIDIA Jetbot
│
└── controllers/
├── physical_controller/ # RL-based 物理控制器
└── simple_controller/ # 简化运动控制器
[数据格式特点]
VLN-PE 扩展了 VLN-CE 数据格式,新增机器人具身和物理状态信息:
{
"episode_id": 5678,
"scene_id": "GRScene_001",
"instruction": "Walk to the living room and find the red pillow.",
"robot_type": "humanoid_h1", // 机器人类型
"controller_type": "physical", // 控制器类型
"camera_height": 1.5, // 相机高度(米)
"start_position": [2.3, 0.0, 4.1],
"start_rotation": [0, 0.785, 0, 0],
"goal_position": [8.7, 0.0, 9.2],
"goal_radius": 3.0,
"lighting_condition": "normal", // 光照条件: normal/low/high
"sensor_config": {
"rgb": true,
"depth": true, // 是否包含深度
"resolution": [270, 480]
}
}
[关键技术特性]
- 跨具身支持:统一接口支持人形(H1, G1)、四足(Aliengo)和轮式(Jetbot)机器人,各具身可独立训练或联合训练
- 物理控制器:基于 RL 训练的低层控制器,模拟真实运动动力学(步态、平衡、碰撞响应)
- 多场景融合:101 个场景(90 MP3D + 10 GRScene + 1 定制),支持光照变化和 3DGS 渲染
- 真机验证:在 Unitree Go2 四足机器人上进行 14 个室内场景的实际部署测试
- 标准化格式:兼容 LeRobot v2.1 格式(InternData-N1),便于跨平台使用
[核心评估指标]
VLN-PE 保留传统指标并新增物理真实性指标:
- TL (Trajectory Length): 轨迹总长度(米)
- NE (Navigation Error): 最终距离目标的误差(米)
- SR (Success Rate): 成功率(< 3m)
- SPL (Success weighted by Path Length): 路径效率加权成功率
- OSR (Oracle Success Rate): 曾接近目标的比例
- FR (Fall Rate): 机器人跌倒的比例(物理真实性指标)⭐
- StR (Stuck Rate): 机器人卡住的比例(碰撞/动力学失败)⭐
[性能基准 - Humanoid H1 on R2R-filtered Val Unseen]
| 模型 | 参数量 | SR (%) | SPL | FR (%) | StR (%) | 备注 |
|---|---|---|---|---|---|---|
| Seq2Seq-Full (VLN-CE) | 36M | 15.2 | 0.13 | 8.3 | 12.1 | 零样本迁移 |
| CMA-Full (VLN-CE) | 36M | 18.7 | 0.16 | 7.5 | 10.8 | 零样本迁移 |
| NaVid (零样本) | 7B | 22.4 | 0.19 | 6.2 | 9.3 | 大模型 |
| CMA (VLN-PE 训练) | 36M | 25.8 | 0.22 | 3.8 | 5.2 | 域内训练 |
| RDP (Diffusion Policy) | 6M | 27.1 | 0.23 | 2.9 | 4.7 | 新方法 |
| CMA+ (跨具身训练) | 36M | 28.7 | 0.24 | 2.1 | 3.9 | 最佳性能 |
核心发现:
- 零样本迁移失败:VLN-CE 模型迁移到 VLN-PE 时 SR 相对下降 34%
- 跨具身泛化:联合训练单一模型可在所有机器人类型上达到 SOTA
- 多模态鲁棒性:RGB+Depth 在低光照下性能下降仅 1-2%,而纯 RGB 下降 12.47%
- 真机验证成功:VLN-PE 训练模型在真实 Unitree Go2 上 SR 达到 28.57%
4. VLN-N1(2025)
————Synthetic Data for InternVLA-N1
- 发布时间:2025
- 环境表示:连续环境 (Continuous Environment)。基于 VLN-CE 等导航数据集转换,采用统一的 LeRobotDataset 格式。
- 核心特点:标准化的机器人学习数据格式,支持视频、指令、动作和元数据的结构化存储,兼容多种导航基准测试。

📊 数据集组成与特性分析
本项目采用的多模态数据集涵盖了从大规模真实扫描到高质量人工合成的多种室内场景。每个数据集均提供 d435i(主动红外立体)与 zed(被动双目)两种传感器仿真配置,以适配不同的硬件特性。
1. 真实世界扫描类 (Real-world Scanned Scenes)
重点用于验证算法在真实物理环境噪声下的鲁棒性。
- HM3D (Habitat-Matterport 3D)
- 定位: 目前规模最大、精细度最高的 3D 扫描数据集。
- 价值: 包含 1000 个超高分辨率场景,是训练长距离导航与具身智能(Embodied AI)的主流基准。
- Matterport3D / MP3D
- 定位: 视觉导航领域的基石数据集。
- 价值: 涵盖 90 个大型建筑的完整扫描,常用于全景视觉处理及跨层区域的复杂导航任务。
- ScanNet
- 定位: 侧重于语义标注的室内房间集合。
- 价值: 包含 1500+ 扫描房间,拥有密集的语义分割与物体实例标注,适合感知层的算法训练。
- Replica
- 定位: 极致精细的少样本数据集。
- 价值: 虽然仅 18 个场景,但其网格密度与重建质量极高,是测试 高精度 SLAM 轨迹误差的黄金标准。
- Gibson
- 定位: 机器人导航的经典验证环境。
- 价值: 经过广泛验证的真实建筑扫描数据,便于与现有 SOTA(领域最优)算法进行性能对标。
2. 程序化合成类 (Synthetic & Procedural Scenes)
重点用于空间布局理解及逻辑泛化能力的提升。
- HSSD (Habitat Synthetic Scene Dataset)
- 定位: Meta 开发的高质量合成数据集。
- 价值: 场景布局遵循真实的居家逻辑(如家具对齐与功能分区),能有效提升算法在复杂布局下的泛化性。
- 3D-FRONT
- 定位: 基于专业室内设计的合成数据集。
- 价值: 包含大量多样化的家具组合与布局变体,是物体识别与空间拓扑关系训练的理想来源。
📌 传感器说明: > * _d435i 系列:模拟主动红外立体视觉,适合对接 Gemini 336L 等相似原理硬件。
- _zed 系列:模拟被动双目视觉,侧重于光照充足环境下的视觉特征提取。
[数据合成流程]
| 阶段 | 流程名称 | 核心操作与技术实现 |
|---|---|---|
| 01 | 轨迹数据渲染合成 | 基于场景资产、全局地图和本体信息,利用传统运动控制方法(Motion Control)设置规则,自动化合成机器人移动轨迹。 |
| 02 | 语料标注与改写 | 利用大语言模型(LLM)对轨迹视频进行语义解析,生成初版导航指令;随后根据特定任务需求进行指令微调与润色。 |
| 03 | 数据质量筛选 | 基于轨迹中包含的有意义语义信息及物体数量进行分档打分,强制滤除 0 分数据。 |
详细阶段说明
(1)轨迹数据渲染合成 (Trajectory Rendering)
- 输入支撑:场景资产 (Assets)、全局地图 (Global Map)、机器人本体参数 (Robot Configuration)。
- 合成逻辑:通过预设规则的运动控制算法,在仿真环境中生成符合物理规律的导航路径。
- 自定义建议:在此阶段可配置自定义相机内参(如 $f_x, f_y, c_x, c_y$)以匹配实际硬件。
(2)语料标注和改写 (Instruction Generation)
- 描述生成:调用 LLM 对合成的轨迹视频进行“视觉到语言”的转换,形成初始自然语言指令。
- 指令优化:针对复杂场景进行语言改写,提升指令的丰富度与对环境特征的覆盖率。
(3)数据筛选 (Data Filtering & Quality Control)
- 量化评分:
- 依据轨迹内涉及的有效语义信息、地标物体数量进行打分。
- 评分体系分为三档,设定阈值过滤无效样本。
- 成效总结:
- 效率提升:最终滤除 23% 的低质量数据,显著降低训练成本。
- 性能表现:筛选后的高质量、多元化场景数据确保了模型性能的可扩展性(Scalability)。
[数据集目录结构]
<datasets_root>/
│
├── <sub_dataset_1>/ # 环境级数据集 (如 3dfront_zed)
│ ├── <scene_dataset_1>/ # 场景级数据集
│ │ ├── <traj_dataset_1>/ # 轨迹级数据集
│ │ │ ├── data/ # 结构化 episode 数据 (.parquet)
│ │ │ │ └── chunk-000/
│ │ │ │ └── episode_000000.parquet
│ │ │ │
│ │ │ ├── meta/ # 元数据与统计信息
│ │ │ │ ├── episodes_stats.jsonl # 每个 episode 的特征统计
│ │ │ │ ├── episodes.jsonl # Episode 元数据 (任务、指令等)
│ │ │ │ ├── info.json # 数据集级别配置信息
│ │ │ │ └── tasks.jsonl # 任务定义
│ │ │ │
│ │ │ └── videos/ # 观测视频
│ │ │ └── chunk-000/
│ │ │ ├── observation.images.depth/ # 深度图序列
│ │ │ │ ├── 0.png
│ │ │ │ ├── 1.png
│ │ │ │ └── ...
│ │ │ ├── observation.images.rgb/ # RGB 图像序列
│ │ │ │ ├── 0.jpg
│ │ │ │ ├── 1.jpg
│ │ │ │ └── ...
│ │ │ ├── observation.video.depth/ # 深度视频
│ │ │ │ └── episode_000000.mp4
│ │ │ └── observation.video.trajectory/# RGB 轨迹视频
│ │ │ └── episode_000000.mp4
│ │ │
│ │ ├── <traj_dataset_2>/
│ │ └── ...
│ │
│ ├── <scene_dataset_2>/
│ └── ...
│
├── <sub_dataset_2>/
└── ...
[核心元数据文件解析]
1. episodes_stats.jsonl - 每个 episode 的特征统计
{
"episode_index": 0,
"stats": {
"observation.images.rgb": {
"min": [[[x]], [[x]], [[x]]], // 最小像素值
"max": [[[x]], [[x]], [[x]]], // 最大像素值
"mean": [[[x]], [[x]], [[x]]], // 平均值
"std": [[[x]], [[x]], [[x]]], // 标准差
"count": [300] // 帧数
},
"observation.images.depth": {...},
"action": {...}
}
}
2. episodes.jsonl - Episode 索引与任务描述
{
"episode_index": 0,
"tasks": [
"Go straight down the hall and up the stairs. When you reach the door to the gym, go left into the gym and stop..."
],
"length": 57 // 该 episode 的总帧数
}
3. info.json - 数据集全局配置
{
"codebase_version": "v2.1", // LeRobot 格式版本
"robot_type": "unknown", // 机器人平台类型
"total_episodes": 1,
"total_frames": 152,
"fps": 30, // 视频与状态采集帧率
"splits": {"train": "0:503"}, // 数据集划分
"features": { // 特征模式定义
"observation.images.rgb": {
"dtype": "image",
"shape": [270, 480, 3], // [height, width, channels]
"names": ["height", "width", "channel"]
},
"observation.camera_intrinsic": { // 相机内参矩阵 (3×3)
"dtype": "float32",
"shape": [3, 3]
},
"observation.path_points": { // 轨迹点云 (N×3)
"dtype": "float64",
"shape": [36555, 3],
"names": ["x", "y", "z"]
},
"action": { // 动作变换矩阵 (4×4)
"dtype": "float32",
"shape": [4, 4]
}
}
}
4. tasks.jsonl - 任务自然语言描述
{
"task_index": 0,
"task": "Go straight to the hallway and then turn left. Go past the bed. Veer to the right and go through the white door. Stop when you're in the doorway."
}
[关键技术特性]
- 格式统一化:将离散节点路径转换为连续的相机轨迹 + 动作序列
- 多模态融合:同时存储 RGB、深度图、点云、相机参数
- 高效存储:Parquet 格式支持快速索引,MP4 视频便于可视化
- 扩展性强:通过继承
NavDataset和NavDatasetMetadata类适配导航任务特性
[核心评估指标]
InternNav 保留 VLN-CE 的标准指标,同时支持 LeRobot 框架的训练评估:
- SR (Success Rate): 终点误差 < 3m 的成功率
- SPL (Success weighted by Path Length): 路径效率加权成功率
- Oracle Success Rate: 轨迹中任意点接近目标的比例
- DtG (Distance to Goal): 最终距离目标的平均距离
-
3D 情景数据
目标导向数据集
目标导向任务(Object-grounded)在路径导航的基础上增加了物体定位和语义理解的要求,更接近真实应用场景。
1. REVERIE (Remote Embodied Visual Referring Expression in Real Indoor Environments)
- 发布时间:2020 (CVPR)
- 环境表示:基于 Matterport3D 的离散拓扑图
- 核心挑战:远程物体定位 + 跨模态指代消解(Referring Expression + Navigation)
[任务定义与创新点]
REVERIE 是 VLN 领域首个将 导航 与 物体定位 深度融合的数据集,智能体需要:
- 根据自然语言指令导航到目标房间
- 在全景视图中识别并定位指令中提及的远程目标物体(目标物体在初始位置不可见)
- 物体候选来自所有可能视点的全景图像,而非单张图片
[数据集目录结构]
REVERIE/
├── data/
│ ├── REVERIE_train.json # 10,466 条训练指令
│ ├── REVERIE_val_seen.json # 已见环境验证集
│ └── REVERIE_val_unseen.json # 未见环境验证集
├── annotations/
│ └── bbox/ # Matterport3D 物体边界框标注
│ └── <Scan_ID>_bbox.json # 每个场景的物体实例信息
└── img_features/ # 物体区域特征(Faster R-CNN 提取)
└── <Scan_ID>_obj.tsv
[核心数据解析]
REVERIE 在 R2R 基础上扩展了物体接地(grounding)标注:
{
"id": 1234,
"scan": "2n8P_example",
"path": ["vp_1", "vp_2", "vp_3"], // 导航路径(与 R2R 相同)
"heading": 1.57,
"instructions": [
"Walk to the living room and find the red pillow on the couch."
],
"objId": 78, // 目标物体 ID(关键新增字段)
"obj_name": "pillow", // 物体类别名称
"viewpoint": "vp_3", // 目标物体所在的最佳观测视点
"bbox": { // 物体边界框(像素坐标)
"image_id": "vp_3_idx_12", // 全景图中的视角索引
"x": 120, "y": 200, "w": 50, "h": 60
}
}
[关键技术点:物体标注机制]
- 物体库:每个 Matterport3D 场景包含预标注的物体实例(来自 Matterport3D Object Annotations),共涉及 4,140 个不同物体实例,21,702 条指令。
- 全景视图挑战:与传统 RefExp 任务在单张图片中选择不同,REVERIE 要求从 所有可能视点的 36 个方向 中定位物体。
- 视点依赖性:同一物体从不同视点观察外观会显著变化(遮挡、光照、角度),增加了视觉识别难度。
[核心评估指标]
REVERIE 使用 三级评估体系:
- RGS (Remote Grounding Success):核心指标。同时满足两个条件:
- 导航成功(终点与目标视点距离 < 3m)
- 物体定位成功(预测物体 ID 与真实 objId 一致)
- RGSPL (RGS weighted by Path Length):在 RGS 基础上加入路径效率惩罚。
- SR (Success Rate):仅评估导航部分,与 R2R 中的 SR 定义相同(终点误差 < 3m)。
[技术难点]
- 长距离指代消解:物体在初始位置不可见,需要结合语言推理和空间记忆。
- 多模态对齐:需要同时理解”房间级导航指令”(如”去客厅”)和”物体级描述”(如”沙发上的红色枕头”)。
- 视点选择:智能体需要学会在目标房间选择最佳观测角度来识别物体。
2. SOON (Scenario Oriented Object Navigation)
- 发布时间:2021 (CVPR)
- 环境表示:基于 Matterport3D 的连续 3D 环境
- 核心挑战:场景级描述理解 + 任意起点导航(From Anywhere to Object)
[任务定义与创新点]
SOON 突破了传统 ObjectNav 固定起点的限制,提出了更贴近真实场景的任务设定:
- 场景描述导航:不提供逐步指令,仅给出目标物体及其周围环境的语义描述(如”客厅角落的书架旁边有一个蓝色花瓶”)
- 任意起点:智能体可以从场景中的任意位置开始导航,而非固定起点
- 零样本泛化:强调对未见过的物体类别和场景布局的理解能力
[数据集目录结构]
SOON/
├── data/
│ └── FAO/ # From Anywhere to Object 数据集
│ ├── train.json # 训练集
│ ├── val_seen.json # 已见场景验证集
│ └── val_unseen.json # 未见场景验证集
├── scene_datasets/ # Matterport3D 场景文件
└── semantic_annotations/ # 语义场景图标注
└── <Scan_ID>_semantic.json # 物体关系与属性标注
[核心数据解析]
SOON 引入了富含语义信息的场景描述,避免目标歧义:
{
"episode_id": "FAO_001",
"scene_id": "17DRP5sb8fy",
"target_object": {
"object_id": "obj_42",
"category": "vase",
"attributes": "blue, ceramic" // 物体属性
},
"scene_description": "In the corner of the living room, next to the bookshelf, there is a blue ceramic vase on a small round table.",
"description_components": { // 结构化描述
"object_attribute": "blue ceramic vase",
"object_relationship": "next to the bookshelf",
"region_description": "corner of the living room",
"nearby_region": "near the fireplace"
},
"start_position": [x, y, z], // 任意起点(非固定)
"start_rotation": [qw, qx, qy, qz]
}
[关键技术点:语义场景图]
- 四级描述体系:
- 物体属性(Object Attribute):颜色、材质、尺寸等
- 物体关系(Object Relationship):空间关系(旁边、上方、里面)
- 区域描述(Region Description):所在房间或区域
- 邻近区域(Nearby Region):周围地标或参考物
- FAO 数据集规模:3,848 条指令,词汇量 1,649 个单词,覆盖多种物体类别和场景配置。
[核心评估指标]
- Success Rate (SR):智能体到达目标物体 1m 范围内的成功率。
- SPL (Success weighted by Path Length):结合路径效率的成功率。
- DTS (Distance To Success):失败案例中,终点与目标的平均距离。
- Zero-shot Generalization:在未见物体类别上的成功率,评估语义理解能力。
[技术难点]
- 语义推理:需要理解物体属性、空间关系等高层语义概念。
- 场景记忆:由于起点不固定,智能体需要快速建立场景的全局认知。
- 描述消歧:在包含多个相似物体的场景中,精确定位符合描述的目标。
3. LHPR-VLN (Long-Horizon Planning and Reasoning in VLN)
- 发布时间:2025 (CVPR)
- 环境表示:Habitat Simulator + 连续 3D 环境(216 个复杂场景)
- 核心挑战:超长程规划(150步) + 多阶段任务分解 + 决策一致性
[任务定义与创新点]
LHPR-VLN 是首个专门针对 长视距导航 设计的数据集,填补了 VLN 领域在长程规划研究上的空白:
- 超长路径:平均 150 个动作步(相比 R2R 的 4-6 步,增长 25 倍)
- 多阶段任务:指令包含多个连贯的子任务(如”先去厨房拿杯子,然后去客厅,最后到卧室”)
- 决策一致性:要求智能体在长时间导航过程中保持对任务目标的记忆和理解
[数据集目录结构]
LHPR-VLN/
├── episodes/
│ ├── train/ # 3,260 个长视距任务
│ │ └── episode_*.json.gz
│ ├── val_seen/
│ └── val_unseen/
├── scenes/ # 216 个复杂 3D 场景
│ └── <Scene_ID>/
│ ├── mesh.ply # 场景网格
│ └── semantic.ply # 语义标注
└── data_generation/ # NavGen 自动生成平台配置
└── config.yaml
[核心数据解析]
LHPR-VLN 引入了多阶段任务结构和细粒度步骤标注:
{
"episode_id": "LHPR_001",
"scene_id": "scene_complex_42",
"instruction": "First, go to the kitchen and pick up a cup from the counter. Then, walk to the living room and place it on the coffee table. Finally, head to the bedroom and sit on the bed.",
"instruction_length": 18.17, // 平均指令长度(单词数)
"num_steps": 152, // 总步数(平均 150 步)
"sub_tasks": [ // 多阶段任务分解
{
"task_id": 1,
"description": "Go to kitchen, pick up cup",
"start_step": 0,
"end_step": 45,
"goal_position": [x1, y1, z1]
},
{
"task_id": 2,
"description": "Walk to living room, place cup",
"start_step": 46,
"end_step": 98,
"goal_position": [x2, y2, z2]
},
{
"task_id": 3,
"description": "Head to bedroom, sit on bed",
"start_step": 99,
"end_step": 152,
"goal_position": [x3, y3, z3]
}
],
"start_position": [x0, y0, z0],
"start_rotation": [qw, qx, qy, qz],
"action_sequence": [ // 完整的动作序列
"MOVE_FORWARD", "TURN_LEFT", ... // 150 个动作
]
}
[关键技术点:NavGen 数据生成平台]
- 双向生成:结合 top-down(从场景语义生成任务)和 bottom-up(从路径生成指令)两种策略
- 多粒度标注:包含任务级、子任务级、步骤级三层标注
- 复杂场景构建:216 个场景专门设计为包含多个房间和复杂空间结构
[核心评估指标]
- SR (Success Rate):完成所有子任务并到达最终目标的成功率(< 3m)
- PSPL (Progressive Success weighted by Path Length):新指标。评估每个子任务的完成情况和路径效率
- Task Completion Rate (TCR):完成的子任务占总子任务的比例
- Decision Consistency Score (DCS):衡量智能体在长程导航中是否保持对目标的一致理解
[技术难点]
- 记忆管理:在 150 步的导航过程中保持对初始指令和中间目标的记忆
- 层次化规划:需要将长指令分解为多个子目标,并协调执行
- 累积误差:长路径中的小错误会累积,导致偏离正确轨迹
- 计算资源:训练和推理成本显著高于短路径任务
对话式导航数据集
对话式导航(Dialog-based Navigation)允许智能体通过多轮交互主动获取信息,模拟人类在不确定情况下的问询行为。
1. CVDN (Cooperative Vision-and-Dialog Navigation)
- 发布时间:2019 (CoRL - Conference on Robot Learning)
- 环境表示:Matterport3D 离散拓扑图(基于 R2R 环境)
- 核心挑战:主动问询 + 对话历史建模 + 不确定性下的导航决策
[任务定义与创新点]
CVDN 引入了 人机协作 的导航范式,智能体(Navigator)可以在导航过程中向 Oracle 提问:
- Navigator:只能看到当前视觉观测,需要通过提问获取导航帮助
- Oracle:拥有最短路径的特权信息,但不能主动提供,只能回答 Navigator 的问题
- 对话交互:平均 4.5 轮对话,Navigator 需要学会何时提问、问什么问题
[数据集目录结构]
CVDN/
├── data/
│ ├── train/
│ │ ├── dialogs.json # 2,050+ 条人类对话标注
│ │ └── navigation.json # 对应的导航路径
│ ├── val_seen/
│ └── val_unseen/
├── tasks/
│ └── NDH/ # Navigation from Dialog History 任务
│ ├── train.json # 基于对话历史的导航数据
│ └── val.json
└── pretrained/
└── oracle_model/ # 预训练的 Oracle 模型
[核心数据解析]
CVDN 数据包含 完整的对话过程 和 导航轨迹:
{
"dialog_id": "CVDN_001",
"scan": "2n8P_example",
"target": {
"object": "blue chair",
"viewpoint": "vp_final"
},
"start_viewpoint": "vp_1",
"start_heading": 0.0,
"dialog_history": [ // 人类标注的对话过程
{
"turn": 1,
"message": "I'm in a bedroom. Where should I go?",
"speaker": "navigator",
"viewpoint_at_turn": "vp_1"
},
{
"turn": 2,
"message": "Go through the door and turn right.",
"speaker": "oracle",
"oracle_action": "vp_2" // Oracle 知道的最佳下一步
},
{
"turn": 3,
"message": "I see a hallway. Am I close?",
"speaker": "navigator",
"viewpoint_at_turn": "vp_2"
},
{
"turn": 4,
"message": "Yes, the chair is in the next room on your left.",
"speaker": "oracle",
"oracle_action": "vp_final"
}
],
"trajectory": ["vp_1", "vp_2", "vp_final"],
"success": true
}
[关键技术点:NDH 任务]
CVDN 提出了 Navigation from Dialog History (NDH) 子任务:
- 给定目标物体和人类对话历史
- 智能体需要理解对话内容,推断目标位置
- 在未探索的环境中执行导航
- 核心难点:对话指代消解(”那个房间”、”左边”等指代如何映射到环境)
[核心评估指标]
- Goal Progress (GP):智能体是否向目标位置移动(距离减少)
- SR (Success Rate):到达目标 3m 范围内的成功率
- SPL (Success weighted by Path Length):路径效率惩罚的成功率
- Dialog Efficiency:平均需要多少轮对话才能成功导航(越少越好)
- Question Quality:提问是否有效(是否获得了有用信息)
[技术难点]
- 主动学习:智能体需要学会在何时提问(不确定性高时)以及提问策略
- 对话历史建模:需要记忆和理解多轮对话的上下文
- 指代消解:对话中的”这里”、”那边”等指代需要映射到视觉环境
- Oracle 建模:训练时需要模拟 Oracle 的回答策略
2. TEACh (Task-driven Embodied Agents that Chat)
- 发布时间:2022 (AAAI)(arXiv 首次发布于 2021 年 10 月)
- 环境表示:AI2-THOR 模拟器 + 可交互家居环境
- 核心挑战:任务级对话 + 物体交互 + 状态变化(如切菜、煮咖啡)
[任务定义与创新点]
TEACh 是首个支持 物体交互和状态变化 的对话式导航数据集:
- Commander(指挥者):拥有任务的完整信息,通过对话指导 Follower
- Follower(执行者):从第一人称视角观察环境,执行导航和物体操作动作
- 任务复杂度:从简单的”煮咖啡”到复杂的”准备早餐”(包含多个子任务)
- 物体交互:支持拾取(PickUp)、放置(Place)、切片(Slice)、加热(Heat)等 20+ 种动作
[数据集目录结构]
TEACh/
├── data/
│ ├── train/ # 3,000+ 人类对话任务
│ │ ├── edh_instances/ # Execution from Dialog History
│ │ └── tfd_instances/ # Talk-through, then Follow-through Demonstration
│ ├── valid_seen/
│ └── valid_unseen/
├── images/ # 第一人称视角图像序列
│ └── <episode_id>/
│ └── frame_*.jpg
├── object_states/ # 物体状态变化追踪
│ └── <episode_id>.json
└── evaluation/
└── metrics/ # 任务完成度评估脚本
[核心数据解析]
TEACh 数据包含 完整的任务执行过程 和 对话交互:
{
"instance_id": "TEACh_train_001",
"task_type": "Coffee", // 任务类型
"task_description": "Make a cup of coffee and place it on the dining table.",
"scene_id": "FloorPlan1",
"dialog": [
{
"turn": 1,
"utterance": "First, go to the coffee machine on the counter.",
"speaker": "commander",
"timestamp": 0.0
},
{
"turn": 2,
"utterance": "I see the coffee machine. Should I press the button?",
"speaker": "follower",
"timestamp": 5.2
},
{
"turn": 3,
"utterance": "Yes, fill the mug with coffee, then take it to the table.",
"speaker": "commander",
"timestamp": 7.5
}
],
"actions": [ // 执行的动作序列
{
"action": "MoveAhead",
"success": true,
"position": [x, y, z],
"rotation": [rx, ry, rz],
"frame": "frame_001.jpg"
},
{
"action": "PickupObject",
"object_id": "Mug_001",
"success": true,
"frame": "frame_015.jpg"
},
{
"action": "PourInto", // 状态变化动作
"object_id": "Mug_001",
"receptacle": "CoffeeMachine_001",
"success": true,
"frame": "frame_032.jpg"
},
{
"action": "PutObject",
"object_id": "Mug_001",
"receptacle": "DiningTable_001",
"success": true,
"frame": "frame_078.jpg"
}
],
"initial_state": { // 初始环境状态
"Mug_001": {"isFilled": false, "isHot": false, "position": [x1, y1, z1]}
},
"goal_state": { // 目标状态
"Mug_001": {"isFilled": true, "isHot": true, "receptacle": "DiningTable_001"}
}
}
[关键技术点:EDH 与 TFD 任务]
- EDH (Execution from Dialog History):
- 给定 Commander 和 Follower 的对话历史
- Follower 需要理解对话并执行任务
- 类似于 CVDN 的 NDH 任务,但增加了物体交互
- TFD (Two-stage Task):
- Talk-through:Commander 先演示任务,边做边讲解
- Follow-through:Follower 根据之前的讲解在新场景中执行相同任务
- 测试从演示中学习的能力
[核心评估指标]
- GC (Goal-Condition Success Rate):核心指标。所有目标状态是否达成:
- 正确的物体被放置在正确的位置
- 物体状态正确(如咖啡是热的、面包被切片)
- Task Success Rate (TSR):主要任务目标是否完成
- Dialog Score:对话质量和效率
- Action Efficiency:完成任务所需的动作步数
- State Change Accuracy:物体状态变化的准确性
[技术难点]
- 长期依赖:任务平均包含 50+ 个动作步骤,需要长期规划
- 状态追踪:需要记忆物体的当前状态(杯子是否装满、炉子是否开启等)
- 多模态融合:结合对话、视觉、动作历史做决策
- 任务泛化:在未见过的场景和物体配置上执行相同任务类型
3. HA-VLN (Human-Aware Vision-Language Navigation)
- 发布时间:2025 (NeurIPS 2024 Datasets and Benchmarks Track, HA-VLN 2.0 发布于 2025年3月)
- 环境表示:离散(Matterport3D)+ 连续(Habitat)双模式支持
- 核心挑战:社交感知导航 + 人群避让 + 个人空间保护 + Sim2Real 迁移
[任务定义与创新点]
HA-VLN 是首个将 人类社交行为约束 引入 VLN 的数据集:
- 社交感知:智能体需要尊重人类的个人空间(personal space),避免碰撞和过近接触
- 动态人群:环境中包含移动的人类,执行各种日常活动(walking, sitting, talking)
- 真实验证:包含真实机器人实验数据,验证 Sim2Real 迁移能力
- 统一基准:同时支持离散和连续环境,便于不同方法对比
[数据集目录结构]
HA-VLN/
├── data/
│ ├── HAPS_2.0/ # Human Activity Pose Sequences 2.0
│ │ ├── motion_sequences/ # 172 种活动的 3D 人体运动序列
│ │ │ └── activity_*/
│ │ │ ├── frames/ # 58,320 帧精确对齐的姿态
│ │ │ └── annotations.json
│ │ └── descriptions/ # 486 个详细的动作描述
│ ├── episodes/
│ │ ├── discrete/ # 离散环境(Matterport3D)
│ │ │ ├── train.json # 16,844 条社交导航指令
│ │ │ └── val_*.json
│ │ └── continuous/ # 连续环境(Habitat)
│ │ └── episodes.json.gz
│ └── real_world/ # 真实机器人实验数据
│ ├── robot_trajectories/
│ └── human_tracking/
└── simulators/
├── HA3D_discrete/ # 离散环境模拟器
└── HA3D_continuous/ # 连续环境模拟器
[核心数据解析]
HA-VLN 在导航指令中增加了 社交约束 和 人群信息:
{
"episode_id": "HA-VLN_001",
"scan": "2n8P_example",
"instruction": "Walk through the living room to the kitchen, but avoid getting too close to the person sitting on the couch.",
"path": ["vp_1", "vp_2", "vp_3"],
"humans": [ // 动态人类信息
{
"human_id": "person_01",
"activity": "sitting on couch", // 当前活动
"motion_sequence": "HAPS_sitting_01", // 对应的运动序列
"trajectory": [ // 时空轨迹
{"time": 0.0, "position": [x1, y1, z1], "orientation": [r1]},
{"time": 1.0, "position": [x2, y2, z2], "orientation": [r2]},
...
],
"personal_space_radius": 1.2 // 个人空间半径(米)
},
{
"human_id": "person_02",
"activity": "walking to kitchen",
"motion_sequence": "HAPS_walking_03",
"trajectory": [...]
}
],
"social_constraints": { // 社交约束
"min_distance_to_humans": 1.0, // 最小保持距离
"avoid_blocking_paths": true, // 避免阻挡他人路径
"priority_to_humans": true // 人类优先通行
}
}
[关键技术点:HAPS 2.0 数据集]
- 活动类别:172 种日常活动(walking, sitting, reaching, talking, reading 等)
- 精确对齐:486 个高质量 3D 人体运动模型,经过人工验证确保动作-描述对齐
- 时空标注:58,320 帧姿态数据,包含精确的时间戳和空间坐标
- 多人交互:支持多人协同活动(如对话、传递物品)
[核心评估指标]
HA-VLN 2.0 引入了 社交感知评估体系:
- SA-SR (Social-Aware Success Rate):核心新指标。同时满足:
- 导航成功(到达目标 < 3m)
- 无社交违规(未进入他人个人空间)
- 无碰撞(与人类保持安全距离)
- Personal Space Violation Rate (PSVR):违反个人空间的频率
- Collision Rate (CR):与人类发生碰撞的次数
- Path Efficiency with Social Cost (PESC):结合路径长度和社交代价的综合指标
- Sim2Real Transfer Success:真实机器人实验的成功率
[技术难点]
- 动态预测:需要预测人类未来的移动轨迹,提前规划避让路径
- 社交规范建模:不同文化和场景下的个人空间定义可能不同
- 实时性:需要在运动的人群中快速做出导航决策
- Sim2Real Gap:模拟器中的人类行为与真实世界存在差异
- 多目标优化:在导航效率和社交安全之间权衡
[真实世界验证]
HA-VLN 2.0 包含真实机器人实验:
- 在实际室内环境部署导航机器人
- 与真实人类交互,验证算法的安全性和有效性
- 提供了宝贵的 Sim2Real 迁移数据
需求导向数据集
需求导向导航(Demand-driven Navigation)要求智能体理解用户的抽象需求(如”我想喝咖啡”),并自主推理需要找到的物体。
DDN (Demand-driven Navigation)
- 发布时间:2023-2024(基于 ProcThor 数据集)
- 环境表示:AI2-THOR + ProcThor 程序化生成的室内环境
- 核心挑战:需求理解 + 常识推理 + 物体功能性映射
[任务定义与创新点]
DDN 突破了传统”明确物体导航”的限制,模拟真实场景中的高层需求:
- 抽象需求输入:用户不说”找到咖啡机”,而是说”我想喝咖啡”或”我需要清洁工具”
- 物体功能推理:智能体需要理解哪些物体可以满足需求(咖啡机、速溶咖啡、法式压壶都能满足”喝咖啡”的需求)
- 常识知识:需要丰富的常识知识库(如”咖啡机通常在厨房”“清洁工具可能在储藏室”)
[数据集目录结构]
DDN/
├── data/
│ ├── train.json # 1,692 条需求导向指令
│ ├── val.json # 241 条验证指令
│ └── test.json # 485 条测试指令
├── scenes/
│ ├── train/ # 600 个场景(200个/split)
│ │ └── <Scene_ID>.json # ProcThor 场景配置
│ ├── val/
│ └── test/
├── demand_ontology/ # 需求本体(知识图谱)
│ ├── demand_categories.json # 需求分类(饮食、清洁、娱乐等)
│ └── object_functions.json # 物体-功能映射表
└── object_categories/ # 109 个物体类别定义
└── category_definitions.json
[核心数据解析]
DDN 数据强调 需求到物体的映射:
{
"episode_id": "DDN_001",
"scene_id": "ProcThor_train_042",
"demand": "I want to make coffee.", // 用户需求(自然语言)
"demand_category": "food_beverage", // 需求类别
"acceptable_objects": [ // 可接受的目标物体(多个)
"CoffeeMachine",
"InstantCoffee",
"FrenchPress"
],
"preferred_object": "CoffeeMachine", // 首选物体
"required_properties": { // 物体需满足的属性
"functional": true, // 必须可用
"accessible": true // 必须可触及
},
"common_locations": [ // 常见位置(常识)
"Kitchen",
"DiningRoom"
],
"start_position": [x, y, z],
"start_rotation": [rx, ry, rz],
"ground_truth_path": [...] // 参考路径(到首选物体)
}
[关键技术点:需求本体]
- 需求分类体系:
- 饮食需求(Food & Beverage):喝咖啡、吃饭、切菜
- 清洁需求(Cleaning):打扫、擦地、洗碗
- 娱乐需求(Entertainment):看电视、读书
- 工作需求(Work):打电话、使用电脑
- 物体-功能映射:
{ "demand": "clean floor", "objects": [ {"name": "VacuumCleaner", "priority": 1, "effectiveness": 0.9}, {"name": "Mop", "priority": 2, "effectiveness": 0.7}, {"name": "Broom", "priority": 3, "effectiveness": 0.5} ] } - 常识推理链:
- 需求:”我想喝咖啡” → 物体推理:”需要咖啡机或速溶咖啡” → 位置推理:”通常在厨房” → 导航规划
[核心评估指标]
- DSR (Demand Success Rate):核心指标。找到任意可满足需求的物体(< 1m)
- PSR (Preferred Success Rate):找到首选物体的成功率
- Reasoning Accuracy:需求→物体映射的准确性
- Location Prediction Accuracy:预测物体位置的准确性
- SPL (Success weighted by Path Length):结合路径效率
[技术难点]
- 需求歧义消解:同一需求可能对应多个物体,需要根据场景选择最合适的
- 常识知识集成:需要大量常识知识(物体功能、常见位置、使用场景)
- 零样本泛化:对未见过的需求类型进行推理
- 多目标决策:当多个物体都可满足需求时,如何选择最优目标
- 知识库构建:如何构建和维护需求-物体-位置的知识图谱
[与 VLN 的区别]
| 维度 | 传统 VLN | DDN |
|---|---|---|
| 输入 | “去厨房找咖啡机” | “我想喝咖啡” |
| 目标 | 明确的物体/位置 | 抽象的需求 |
| 推理 | 语言→路径映射 | 需求→物体→路径多级映射 |
| 知识 | 视觉-语言对齐 | 常识知识 + 物体功能性 |
特殊场景数据集
特殊场景数据集突破了室内导航的限制,探索无人机、城市航拍等新兴应用场景。
1. AerialVLN (Vision-and-Language Navigation for UAVs)
- 发布时间:2023 (ICCV)
- 环境表示:3D 模拟器 + 近真实感城市场景渲染(25 个城市场景)
- 核心挑战:三维空间推理 + 高度控制 + 城市地标识别
[任务定义与创新点]
AerialVLN 是首个专为 无人机(UAV) 设计的 VLN 数据集:
- 三维导航:需要同时控制水平位置和飞行高度
- 空中视角:俯视和斜视视角与地面导航完全不同
- 城市环境:包含建筑物、道路、公园、工厂等多样化城市场景
- 高密度物体:870+ 种不同物体类别,远超室内数据集
[数据集目录结构]
AerialVLN/
├── data/
│ ├── AerialVLN-S/ # AerialVLN-Simulator 数据集
│ │ ├── train.json # 8,446 条飞行轨迹
│ │ ├── val_seen.json
│ │ └── val_unseen.json
│ └── trajectories/
│ └── <Episode_ID>/
│ ├── waypoints.json # 轨迹关键点
│ └── actions.json # 飞行动作序列
├── scenes/
│ ├── downtown/ # 市中心场景
│ ├── factory/ # 工厂区场景
│ ├── park/ # 公园场景
│ └── village/ # 乡村场景
├── annotations/
│ ├── landmarks/ # 地标标注(建筑名称、特征)
│ └── objects/ # 870+ 物体类别标注
└── pilot_data/ # AOPA 持证飞行员标注数据
└── human_trajectories.json
[核心数据解析]
AerialVLN 需要处理 三维空间的飞行路径:
{
"episode_id": "AerialVLN_001",
"scene_id": "downtown_city_01",
"instruction": "Fly over the blue rooftop building, then descend to 15 meters and head towards the park with the fountain.",
"instruction_length": 22,
"trajectory": [ // 三维轨迹
{
"waypoint_id": 0,
"position": [x0, y0, z0], // z 轴为高度
"heading": 90.0, // 水平朝向(度)
"pitch": -15.0, // 俯仰角(负值为向下看)
"altitude": 30.0, // 海拔高度(米)
"timestamp": 0.0
},
{
"waypoint_id": 1,
"position": [x1, y1, z1],
"heading": 120.0,
"pitch": -20.0,
"altitude": 25.0,
"timestamp": 5.3
},
...
],
"landmarks_mentioned": [ // 指令中提及的地标
{
"name": "blue rooftop building",
"category": "building",
"position": [xb, yb, zb],
"visibility_range": 50.0 // 可见距离(米)
},
{
"name": "park with fountain",
"category": "outdoor_area",
"position": [xp, yp, zp]
}
],
"action_space": { // 飞行动作空间
"horizontal": ["MOVE_FORWARD", "TURN_LEFT", "TURN_RIGHT", "HOVER"],
"vertical": ["ASCEND", "DESCEND", "MAINTAIN_ALTITUDE"]
},
"pilot_certified": true // 是否由持证飞行员标注
}
[关键技术点:AOPA 认证飞行员标注]
- 专业性:所有轨迹由 AOPA(Aircraft Owners and Pilots Association)持证飞行员记录
- 安全性:轨迹符合飞行安全规范(避障、高度控制、速度限制)
- 真实性:飞行模式符合真实无人机的物理特性
[多样化场景类型]
- Downtown(市中心):高楼林立,需要在建筑间导航
- Factory(工厂区):大型工业设施,烟囱、仓库等地标
- Park(公园):开阔区域,树木、池塘、雕塑等自然地标
- Village(乡村):低密度建筑,农田、道路等特征
[核心评估指标]
- SR (Success Rate):到达目标位置的成功率(3D 欧氏距离 < 5m)
- ALT-E (Altitude Error):新指标。高度控制误差(米)
- SPL (Success weighted by Path Length):3D 路径长度惩罚
- Landmark Recognition Accuracy:地标识别准确率
- Collision Rate:与建筑物或障碍物的碰撞率
[技术难点]
- 三维空间推理:需要同时理解”向前飞”和”上升/下降”的空间关系
- 视角变化:不同高度和俯仰角下,同一地标的外观差异巨大
- 地标消歧:城市中可能有多个相似的建筑物(如多个蓝色屋顶)
- 安全约束:需要避免碰撞、保持安全高度、遵守飞行限制区域
- 长距离导航:城市环境尺度大,导航距离远超室内场景
[与室内 VLN 的对比]
| 维度 | 室内 VLN (R2R) | AerialVLN |
|---|---|---|
| 空间维度 | 2D(平面移动) | 3D(含高度) |
| 视角 | 第一人称水平视角 | 俯视 + 斜视 |
| 地标密度 | 稀疏(房间、家具) | 密集(870+ 物体) |
| 场景尺度 | 小(单个建筑) | 大(城市街区) |
| 动作空间 | 前进 + 旋转 | 前进 + 旋转 + 升降 |
2. CityNav (Language-Goal Aerial Navigation Dataset with Geographic Information)
- 发布时间:2025 (ICCV)(arXiv 于 2024 年 6 月首次发布)
- 环境表示:真实城市航拍图像 + 地理语义地图(GSM)
- 核心挑战:真实世界泛化 + 地标空间关系理解 + 地理信息融合
[任务定义与创新点]
CityNav 是首个基于 真实城市 的大规模空中 VLN 数据集:
- 真实场景:覆盖 4.65 km² 实际城市区域(英国剑桥和伯明翰)
- 人类演示:32,637 条人类飞行员标注的真实轨迹
- 地理语义地图(GSM):结合地理信息(地标位置、道路网络)辅助导航
- 零样本挑战:需要在真实世界的复杂性和不确定性下导航
[数据集目录结构]
CityNav/
├── data/
│ ├── trajectories/
│ │ ├── cambridge/ # 剑桥市轨迹(16,000+ 条)
│ │ │ ├── train.json
│ │ │ ├── val.json
│ │ │ └── test.json
│ │ └── birmingham/ # 伯明翰市轨迹(16,000+ 条)
│ │ └── ...
│ └── geographic_maps/
│ ├── GSM_cambridge.json # 剑桥地理语义地图
│ └── GSM_birmingham.json # 伯明翰地理语义地图
├── aerial_images/ # 真实航拍图像序列
│ └── <Episode_ID>/
│ ├── frame_*.jpg # 第一人称视角航拍图像
│ └── metadata.json # GPS 坐标、时间戳
├── landmarks/ # 城市地标数据库
│ ├── landmark_database.json # 地标名称、类别、GPS 坐标
│ └── landmark_images/ # 地标参考图像
└── annotations/
├── spatial_relations.json # 地标间的空间关系标注
└── instruction_annotations.json
[核心数据解析]
CityNav 结合了 真实航拍图像 和 地理信息:
{
"episode_id": "CityNav_Cambridge_001",
"city": "Cambridge",
"instruction": "Fly from the market square towards King's College Chapel, then turn left at the River Cam and follow it northward.",
"instruction_length": 25,
"trajectory": [
{
"waypoint_id": 0,
"gps": {"lat": 52.2053, "lon": 0.1218, "alt": 50.0}, // GPS 坐标
"heading": 45.0,
"image": "frame_000.jpg",
"timestamp": "2024-06-15T10:30:00Z"
},
{
"waypoint_id": 1,
"gps": {"lat": 52.2042, "lon": 0.1167, "alt": 48.0},
"heading": 38.0,
"image": "frame_015.jpg",
"timestamp": "2024-06-15T10:30:23Z"
},
...
],
"landmarks_in_instruction": [ // 指令中的地标
{
"name": "Market Square",
"type": "public_space",
"gps": {"lat": 52.2054, "lon": 0.1190},
"osm_id": "way/123456789" // OpenStreetMap ID
},
{
"name": "King's College Chapel",
"type": "historic_building",
"gps": {"lat": 52.2042, "lon": 0.1165},
"osm_id": "way/987654321"
},
{
"name": "River Cam",
"type": "waterway",
"gps": {"lat": 52.2035, "lon": 0.1180}, // 中心线坐标
"osm_id": "way/111222333"
}
],
"geographic_semantic_map": { // 地理语义地图信息
"landmark_locations": [...], // 地标位置列表
"road_network": [...], // 道路网络拓扑
"spatial_relations": [ // 地标间的空间关系
{
"landmark_1": "Market Square",
"landmark_2": "King's College Chapel",
"relation": "southwest_of",
"distance": 580.0 // 米
},
{
"landmark_1": "King's College Chapel",
"landmark_2": "River Cam",
"relation": "east_of",
"distance": 120.0
}
]
}
}
[关键技术点:地理语义地图(GSM)]
- 地标定位:提供城市中所有主要地标的精确 GPS 坐标
- 空间关系:预计算的地标间方位关系(north_of, southwest_of 等)
- 道路网络:城市道路的拓扑结构,辅助路径规划
- 多模态输入:GSM 可作为额外的输入模态,与视觉观测结合
[GSM 的作用]
// GSM 提供的辅助信息示例
{
"query": "Where is King's College Chapel relative to Market Square?",
"gsm_response": {
"direction": "southwest",
"distance": 580.0,
"intermediate_landmarks": ["Senate House", "Great St Mary's Church"]
}
}
[核心评估指标]
- SR (Success Rate):到达目标区域的成功率(GPS 误差 < 10m)
- GPS-DTG (GPS Distance To Goal):终点与目标的 GPS 距离(米)
- SPL (Success weighted by Path Length):基于 GPS 路径长度的 SPL
- Landmark Recognition Accuracy:正确识别指令中地标的准确率
- Spatial Relation Understanding:理解地标间空间关系的准确率
[技术难点]
- 真实世界复杂性:
- 天气变化(阴天、晴天、雨天)
- 光照变化(不同时间、季节)
- 遮挡(树木、云层、建筑阴影)
- 地标歧义:
- 城市中可能有多个相似建筑
- 地标外观随视角变化显著
- 长距离导航:
- 覆盖 4.65 km²,导航距离可达数千米
- 需要全局路径规划能力
- 跨城市泛化:
- 不同城市的建筑风格、道路布局差异大
- 需要泛化到未见过的城市
- 多模态融合:
- 如何有效融合视觉观测和地理语义地图
- 在 GPS 不可用时如何纯视觉导航
[CityNav vs AerialVLN]
| 维度 | AerialVLN | CityNav |
|---|---|---|
| 场景 | 模拟场景(近真实感) | 真实城市航拍 |
| 规模 | 25 个场景, 8,446 轨迹 | 2 个城市, 32,637 轨迹 |
| 覆盖面积 | 相对较小 | 4.65 km² |
| 地理信息 | 无 | GSM(地标、道路网络) |
| 挑战重点 | 三维空间推理 | 真实世界泛化 |
| 数据来源 | 持证飞行员标注 | 真实飞行数据 |
[应用场景]
- 城市无人机配送导航
- 无人机巡检(基础设施、建筑)
- 搜索救援任务(根据语言描述的位置快速定位)
- 航空摄影(根据拍摄需求规划飞行路径)
3. OpenFly (A Comprehensive Platform for Aerial Vision-Language Navigation)
- 发布时间:2025 (arXiv 首次发布于 2025 年 2 月)
- 环境表示:多引擎集成(Unreal Engine + GTA V + Google Earth + 3D Gaussian Splatting)
- 核心挑战:大规模数据 + 多样化场景 + 自动化工具链 + 关键帧感知
[任务定义与创新点]
OpenFly 是迄今为止 最大规模 的空中 VLN 平台:
- 海量数据:100,000 条飞行轨迹,是 AerialVLN 和 CityNav 总和的 3 倍
- 多引擎支持:整合 4 种不同的渲染引擎,覆盖从游戏级到照片级的真实感
- 自动化工具链:高度自动化的数据采集、场景分割、轨迹生成、指令标注流程
- 18 个场景:覆盖城市、乡村、山区、海岸等多种地形
- 多样化高度和长度:轨迹高度从 10m 到 200m,长度从 50m 到 5km
[数据集目录结构]
OpenFly/
├── data/
│ ├── trajectories/
│ │ ├── unreal_engine/ # Unreal Engine 渲染场景(30,000 条)
│ │ ├── gta_v/ # GTA V 场景(25,000 条)
│ │ ├── google_earth/ # Google Earth 真实场景(25,000 条)
│ │ └── 3d_gaussian/ # 3D Gaussian Splatting 场景(20,000 条)
│ └── split/
│ ├── train.json # 训练集(80,000 条)
│ ├── val.json # 验证集(10,000 条)
│ └── test.json # 测试集(10,000 条)
├── scenes/ # 18 个多样化场景
│ ├── urban_downtown/
│ ├── suburban_residential/
│ ├── rural_countryside/
│ ├── mountain_region/
│ ├── coastal_area/
│ └── ...
├── toolchain/ # 自动化数据生成工具链
│ ├── point_cloud_processor/ # 点云获取与处理
│ ├── semantic_segmentation/ # 场景语义分割
│ ├── trajectory_generator/ # 飞行轨迹创建
│ └── instruction_generator/ # GPT-4o 指令生成
├── keyframe_annotations/ # 关键帧标注
│ └── <Episode_ID>_keyframes.json
└── openfly_agent/ # OpenFly-Agent 模型代码
├── model/
└── configs/
[核心数据解析]
OpenFly 引入了 关键帧(Keyframe) 的概念:
{
"episode_id": "OpenFly_UE_12345",
"engine": "unreal_engine", // 渲染引擎
"scene": "urban_downtown_02",
"instruction": "Take off from the parking lot, fly north along Main Street, ascend to 50 meters when you reach the clock tower, then circle around the stadium and land on the rooftop helipad.",
"instruction_source": "GPT-4o", // 指令由 GPT-4o 生成
"trajectory_stats": {
"length_meters": 1250.0,
"duration_seconds": 180.0,
"max_altitude": 52.0,
"min_altitude": 5.0,
"num_waypoints": 85
},
"keyframes": [ // 关键帧(重点观测点)
{
"keyframe_id": 0,
"waypoint_id": 0,
"description": "parking lot - takeoff point",
"importance": 0.95, // 重要性评分(0-1)
"reason": "navigation_start",
"position": [x0, y0, z0],
"image": "frame_000.jpg"
},
{
"keyframe_id": 1,
"waypoint_id": 22,
"description": "clock tower - altitude reference",
"importance": 0.88,
"reason": "landmark_mentioned", // 指令中提及的地标
"position": [x1, y1, z1],
"image": "frame_022.jpg"
},
{
"keyframe_id": 2,
"waypoint_id": 57,
"description": "stadium - circling point",
"importance": 0.92,
"reason": "action_change", // 动作模式变化(直飞→盘旋)
"position": [x2, y2, z2],
"image": "frame_057.jpg"
},
{
"keyframe_id": 3,
"waypoint_id": 84,
"description": "rooftop helipad - landing zone",
"importance": 0.98,
"reason": "navigation_goal",
"position": [x3, y3, z3],
"image": "frame_084.jpg"
}
],
"full_trajectory": [
{"waypoint_id": 0, "position": [x0, y0, z0], ...},
{"waypoint_id": 1, "position": [...], ...},
...
{"waypoint_id": 84, "position": [x84, y84, z84], ...}
],
"engine_metadata": {
"rendering_quality": "high",
"weather": "clear",
"time_of_day": "noon"
}
}
[关键技术点:自动化工具链]
OpenFly 的核心创新是 高度自动化 的数据生成流程:
- 点云获取(Point Cloud Acquisition):
- 从不同引擎提取 3D 场景点云
- 支持多种格式(.pcd, .ply, .las)
- 场景语义分割(Semantic Segmentation):
- 自动识别建筑物、道路、树木、水体等类别
- 生成语义标签用于地标识别
- 飞行轨迹创建(Trajectory Generation):
- 基于场景拓扑自动生成可行飞行路径
- 考虑安全高度、避障、平滑度等约束
- 指令生成(Instruction Generation):
- 将轨迹和第一人称图像输入 GPT-4o
- 生成自然语言描述:”从…起飞,沿着…飞行,到达…”
- 确保指令与视觉观测一致
[OpenFly-Agent:关键帧感知模型]
OpenFly 提出了 关键帧感知(Keyframe-Aware) 的 VLN 模型:
- 动机:长轨迹中并非所有帧都同等重要,关键帧包含更多导航信息
- 方法:
- 自动识别关键观测帧(地标出现、动作变化、导航节点)
- 对关键帧赋予更高的注意力权重
- 减少计算开销(只处理关键帧而非所有帧)
[多引擎对比]
| 引擎 | 真实感 | 物理准确性 | 场景多样性 | 数据量 |
|---|---|---|---|---|
| Unreal Engine | 高 | 高 | 中 | 30,000 |
| GTA V | 中-高 | 中 | 高(城市) | 25,000 |
| Google Earth | 照片级 | 低(静态) | 最高(全球) | 25,000 |
| 3D Gaussian | 照片级 | 低 | 中 | 20,000 |
[核心评估指标]
- SR (Success Rate):标准成功率(< 5m)
- KF-SR (Keyframe Success Rate):新指标。在关键帧位置的导航准确性
- SPL (Success weighted by Path Length):路径效率
- Keyframe Attention Score:模型对关键帧的注意力分配准确性
- Cross-Engine Generalization:跨引擎泛化能力(在一个引擎训练,在另一个测试)
[技术难点]
- 跨引擎泛化:
- 不同引擎的渲染风格、物理特性差异大
- 需要学习引擎无关的导航策略
- 关键帧识别:
- 如何自动识别哪些帧是关键帧
- 关键帧的重要性如何量化
- 长距离规划:
- 轨迹长度跨度大(50m - 5km)
- 需要多尺度的规划策略
- 指令质量控制:
- GPT-4o 生成的指令可能包含幻觉或不一致
- 需要自动化验证和过滤机制
- 计算效率:
- 100,000 条轨迹的训练规模巨大
- 需要高效的数据加载和模型训练策略
[OpenFly 的独特价值]
- 规模最大:100k 轨迹是目前空中 VLN 数据集中最大的
- 工具开源:提供完整的数据生成工具链,便于社区扩展
- 多引擎支持:可以研究跨领域迁移和鲁棒性
- 关键帧创新:引入新的建模思路,提高长轨迹导航效率
数据集对比总览
| 数据集 | 发布年份 | 任务类型 | 环境类型 | 数据规模 | 核心创新 | 主要指标 |
|---|---|---|---|---|---|---|
| R2R | 2018 | 指令导向 | 室内离散 | 14,025 指令 | VLN 奠基数据集 | SR, SPL, NE |
| R4R | 2019 | 指令导向 | 室内离散 | 长路径拼接 | 路径忠诚度评估 | CLS, nDTW, SDTW |
| RxR | 2020 | 指令导向 | 室内离散 | 126k 指令(多语言) | 细粒度时空对齐 | SR, SPL, DTW |
| VLN-CE | 2020 | 指令导向 | 室内连续 | 基于 R2R 转换 | 连续动作空间 | SR, SPL, DTS |
| REVERIE | 2020 | 目标导向 | 室内离散 | 10,466 指令, 4,140 物体 | 导航+物体定位 | RGS, RGSPL |
| SOON | 2021 | 目标导向 | 室内连续 | 3,848 指令 | 场景描述+任意起点 | SR, SPL, DTS |
| LHPR-VLN | 2025 | 目标导向 | 室内连续 | 3,260 任务, 平均 150 步 | 长程多阶段规划 | SR, PSPL, TCR |
| CVDN | 2019 | 对话导航 | 室内离散 | 2,050+ 对话 | 主动问询+Oracle | SR, SPL, GP |
| TEACh | 2022 | 对话导航 | 室内交互 | 3,000+ 任务对话 | 物体交互+状态变化 | GC, TSR |
| HA-VLN | 2025 | 对话导航 | 室内/混合 | 16,844 指令 | 社交感知+人群避让 | SA-SR, PSVR |
| DDN | 2023-24 | 需求导向 | 室内连续 | 1,692 需求指令 | 抽象需求推理 | DSR, PSR |
| AerialVLN | 2023 | 空中导航 | 城市模拟 | 8,446 轨迹, 25 场景 | 三维空间+无人机 | SR, SPL, ALT-E |
| CityNav | 2025 | 空中导航 | 真实城市 | 32,637 轨迹, 4.65 km² | 真实航拍+地理地图 | SR, GPS-DTG |
| OpenFly | 2025 | 空中导航 | 多引擎 | 100k 轨迹, 18 场景 | 大规模+关键帧感知 | SR, KF-SR, SPL |
图例说明:
- SR: Success Rate(成功率)
- SPL: Success weighted by Path Length(路径效率加权成功率)
- CLS: Coverage weighted by Length Score(路径覆盖度评分)
- RGS: Remote Grounding Success(远程物体定位成功率)
- GC: Goal-Condition Success(目标条件成功率)
- SA-SR: Social-Aware Success Rate(社交感知成功率)
- ALT-E: Altitude Error(高度误差)
- KF-SR: Keyframe Success Rate(关键帧成功率)
VLN主流模拟器
VLN研究需要高质量的3D仿真环境来训练和测试导航模型。以下是VLN领域最常用的主流模拟器(含最新更新和趋势):
Matterport3D Simulator
基本信息:
- 开发者:Peter Anderson et al.
- 发布时间:2018年
- 开源地址:GitHub
核心特点:
- 真实场景扫描:基于Matterport3D数据集,包含90个真实室内环境的高精度3D扫描
- 全景视图:提供360度全景RGB-D图像
- 离散导航:采用预定义的导航图,智能体在固定视点间移动
- 高效渲染:优化的渲染引擎,支持快速视觉观测生成
- 经典基准:R2R、R4R等经典数据集的官方模拟器
应用场景:
- 指令导向的室内导航任务(R2R、R4R)
- 离散动作空间的VLN研究
- 基于真实场景的导航模型训练
优势:
- 真实感强,场景来自实际建筑扫描
- 与经典VLN数据集无缝集成
- 社区支持完善,大量研究基于此平台
局限性:
- 仅支持离散导航,灵活性受限
- 物理交互能力有限
- 场景数量相对较少(90个环境)
Habitat
基本信息:
- 开发者:Facebook AI Research (FAIR)
- 发布时间:2019年(最新3.1版本2024–2025年更新)
- 开源地址:GitHub
核心特点:
- 高性能仿真:超快速渲染(10,000+ FPS)
- 连续环境:支持连续动作空间和自由移动
- 多数据集支持:兼容Matterport3D、Gibson、HM3D、LHPR-VLN等
- 模块化设计:灵活的任务定义和传感器配置
- Sim2Real支持:提供真实机器人部署工具链
- 新特性:
- 动态环境支持(移动物体/人群)
- 空中和户外环境支持
- 长程任务和复杂子任务支持
应用场景:
- 连续动作空间导航研究(VLN-CE)
- 长视距任务(LHPR-VLN)
- 目标导航(ObjectNav)、语义导航(SemanticNav)
- 具身AI和Sim2Real研究
优势:
- 仿真速度极快,训练效率高
- 支持连续导航,更贴近真实机器人控制
- 大规模数据集(HM3D 800+场景)
- 动态场景、空中任务支持
- 强大的扩展性和社区生态
局限性:
- 配置复杂,学习曲线陡
- 对硬件要求较高(GPU加速)
Isaac Sim / Isaac Lab
基本信息:
- 开发者:NVIDIA
- 核心组件:
- Isaac Sim:基于 NVIDIA Omniverse 的高保真机器人仿真环境
- Isaac Lab:基于 Isaac Sim 的模块化机器人学习与强化学习框架(GPU 加速)
- 开源地址:
- Isaac Lab 文档: https://isaac-sim.github.io/IsaacLab/main/index.html :contentReference[oaicite:0]{index=0}
- Isaac Sim 官方页面: https://developer.nvidia.com/isaac-sim :contentReference[oaicite:1]{index=1}
核心特点:
- 高保真物理与渲染:基于 RTX 加速的 PhysX 物理引擎与真实感渲染,可模拟碰撞、摩擦、传感器噪声等真实物理特性 :contentReference[oaicite:2]{index=2}
- 机器人学习集成:Isaac Lab 提供强化学习、模仿学习、策略训练等端到端机器人学习工作流,可批量训练数千个并行环境 :contentReference[oaicite:3]{index=3}
- 多机平台资产库:包括四旋翼、差分驱动机器人、步态机器人、机械臂等多种机器人模型,可自定义场景与任务 :contentReference[oaicite:4]{index=4}
- 导航与控制支持:
- 支持 ROS2、Nav2 等机器人导航栈集成,可用于路径规划与多机器人导航测试 :contentReference[oaicite:5]{index=5}
- 虽主要用于强化学习与策略训练,但同样可用于评估视觉导航策略、连续控制与视觉感知组合任务
- 数据生成与 Sim‑to‑Real:结合 Omniverse Replicator,可生成训练用合成数据并辅助现实迁移训练 :contentReference[oaicite:6]{index=6}
应用场景:
- 连续控制与导航策略训练(强化学习 / 模仿学习)
- 多传感器 SLAM、视觉感知与导航策略评估
- 多机器人协作与动态环境测试
- 合成数据生成与 Sim‑to‑Real 迁移训练
优势:
- 高保真模拟:比传统离散图导航能更真实模拟连续物理行为与多传感器数据
- 学习框架支持:内置强化学习训练工作流,可扩展到大规模并行环境
- 集成生态:与 Omniverse、ROS、RTX GPU 加速等生态联动良好
局限性:
- 复杂度高:上手门槛比简易模拟器如 Habitat、AI2‑THOR 更陡峭
- 计算资源要求高:需要强 GPU 才能充分利用高保真渲染与物理仿真
- 目前在视觉导航(VLN)Benchmark 领域的专用数据集支持较少:相比 Matterport/Habitat 等,社区内 VLN benchmark 评测还不如它们成熟
AI2-THOR
基本信息:
- 开发者:Allen Institute for AI
- 发布时间:2017年(持续更新,最新4.0版本)
- 开源地址:官网
核心特点:
- 物理交互:基于Unity3D,支持完整物理模拟
- 可交互对象:环境中的物体可抓取、移动、操作
- 多样化场景:厨房、卧室、客厅、浴室等200+场景
- 语义分割:内置语义标注和实例分割
- 多智能体支持:支持同时多个智能体任务
- 新特性:
- 多智能体协作
- 可定制动作和交互
- 可与VLN-CE、TEACh、EQA数据集结合
应用场景:
- 具身问答(EQA)
- 视觉语言导航+操作任务
- 家庭服务机器人研究
优势:
- 强大的物理引擎和真实物体交互
- 可多模态任务训练
- API友好,易上手
局限性:
- 渲染速度较慢
- 场景规模相对较小
- 资源消耗大
Gibson / iGibson
基本信息:
- 开发者:Stanford University
- Gibson发布时间:2018年
- iGibson发布时间:2021–2024(最新3.0版本)
- 开源地址:iGibson GitHub
核心特点:
Gibson 1.0:
- 基于真实建筑扫描(1000+)
- 快速光栅化渲染
- 支持基础物理模拟
iGibson 3.0:
- 交互式场景:完整物理交互和对象操作
- 逼真渲染:PBR物理渲染
- 语义信息:丰富的语义标注和物体属性
- 大规模场景:完整房屋、办公楼等
- 任务多样性:导航、操作、家务任务
- 新特性:
- 动态物体与人群模拟
- 多智能体与社交导航约束
- Sim2Real优化
应用场景:
- 大规模室内导航
- 导航+操作任务
- Sim2Real迁移研究
- 家庭服务机器人仿真
优势:
- 场景数量多,环境多样性高
- 真实感强,基于实际建筑扫描
- iGibson 3.0功能全面,支持复杂交互
局限性:
- 安装复杂
- 部分场景质量参差不齐
AirSim
基本信息:
- 开发者:Microsoft
- 发布时间:2017年(持续更新)
- 开源地址:GitHub
核心特点:
- 无人机/车辆仿真:面向飞行器和地面车辆
- 高保真物理:基于Unreal或Unity
- 多传感器支持:相机、LiDAR、IMU、GPS
- 新特性:
- 城市大规模航拍场景
- 长航程导航、多机协作
- 与CityNav/OpenFly数据集配合
应用场景:
- 空中VLN(AerialVLN)
- 无人机导航与控制
- 自动驾驶与户外导航任务
优势:
- 专业飞行器仿真平台
- 高精度物理模拟
- 支持大规模户外环境
局限性:
- 室内导航支持有限
- 配置复杂,对硬件要求高
InternUtopia
基本信息:
- 开发者:Shanghai AI Laboratory (上海人工智能实验室)
- 发布时间:2024年
- 开源地址:GitHub
核心特点:
- 大规模开放世界:支持超大规模城市场景模拟(10+ km²)
- 高保真渲染:基于Unreal Engine 5的照片级真实感渲染
- 物理交互:完整的物理引擎,支持动态物体和环境交互
- 多智能体支持:支持多智能体协同导航和交互任务
- 丰富的动态元素:包含动态交通流、行人、天气变化等
- 语义信息:提供详细的场景语义标注和3D边界框
- 多模态感知:支持RGB、深度、语义分割、LiDAR等多种传感器
- 新特性:
- 大规模城市场景的自动生成
- 实时物理模拟与照片级渲染
- 支持VLN、具身智能、自动驾驶等多种任务
- 可扩展的任务定义框架
应用场景:
- 大规模城市导航任务
- 开放世界具身智能研究
- 多智能体协作与社交导航
- 自动驾驶与户外导航
- 长距离导航规划
优势:
- 超大规模场景支持,适合长程导航研究
- 高保真视觉渲染,接近真实世界
- 动态环境模拟,更贴近实际应用
- 灵活的任务定义和可扩展性
- 多模态传感器支持
局限性:
- 计算资源需求极高(需要高性能GPU)
- 配置和使用复杂度较高
- 社区生态相对较新,文档和资源仍在完善
模拟器对比
| 模拟器 | 环境类型 | 动作空间 | 物理交互 | 渲染速度 | 主要应用 | 场景数量 | 新增特性 (2024–2025) |
|---|---|---|---|---|---|---|---|
| Matterport3D | 室内 | 离散 | 有限 | 快 | R2R/R4R | 90 | 保持经典基准 |
| Habitat 3.1 | 室内/空中/户外 | 连续 | 基础 | 极快 | VLN-CE, LHPR-VLN | 800+ (HM3D) | 动态物体、空中/长程导航、Sim2Real强化 |
| Isaac Sim / Lab | 室内/室外/空中 | 连续 | 强 | 高 | 强化学习、连续VLN | 可定制 | 高保真物理、动态环境、多机协作、Sim2Real |
| AI2-THOR 4.0 | 室内 | 离散/连续 | 强 | 中等 | 交互任务 | 200+ | 多智能体、可定制交互、家庭场景扩大 |
| iGibson 3.0 | 室内 | 连续 | 强 | 快 | 综合任务 | 1000+ | 动态人群、社交导航、Sim2Real强化 |
| AirSim | 室内外 | 连续 | 强 | 中等 | 无人机/车辆 | 可定制 | 城市航拍、大规模航程、多机协作 |
| InternUtopia | 开放世界/城市 | 连续 | 强 | 中等 | 大规模城市导航 | 可定制 | 超大规模场景、照片级渲染、动态环境 |
| iThorAir / Aerial Sim | 室外/空中 | 连续 | 基础 | 中等 | 空中VLN | 可定制 | 多机协作、长程规划、动态障碍物 |
选择建议
- 经典VLN基准(R2R/R4R):Matterport3D Simulator
- 连续环境与长程任务:Habitat 3.1
- 需要物理交互任务:AI2-THOR 4.0 / iGibson 3.0
- 无人机/空中导航:AirSim / Isaac Sim
- 大规模场景训练:Gibson/iGibson 或 Habitat + HM3D
- 大规模城市/开放世界导航:InternUtopia
- Sim-to-Real部署:Habitat 3.1 / iGibson 3.0 / Isaac Sim
评估指标
评估指标是衡量VLN模型性能的关键工具。一个完善的评估体系应该同时考虑导航的精度、效率和轨迹质量。以下是VLN领域最常用的评估指标:
导航精度指标
Success Rate (SR)
定义: 成功到达目标位置的episode比例。
计算方法: \(SR = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[d_i < \tau]\)
其中:
- $N$ 是测试episode的总数
- $d_i$ 是第 $i$ 个episode结束时智能体与目标位置的距离
- $\tau$ 是成功阈值(通常设为3米)
- $\mathbb{1}[\cdot]$ 是指示函数,条件满足时为1,否则为0
取值范围:
- 0 到 1(或0%到100%)
- 越高越好
优点:
- 直观易懂,反映任务完成率
- 最常用的主要评估指标
缺点:
- 忽略了导航效率(路径长度)
- 对成功阈值敏感
Navigation Error (NE)
定义: 智能体停止时与目标位置的平均距离误差(米)。
计算方法: \(NE = \frac{1}{N} \sum_{i=1}^{N} d_i\)
其中:
- $d_i$ 是第 $i$ 个episode结束时智能体与目标的欧氏距离
取值范围:
- $[0, +\infty)$ 米
- 越低越好
优点:
- 提供连续的性能度量
- 不依赖成功阈值的设定
缺点:
- 受场景规模影响较大
- 难以跨数据集比较
Oracle Success Rate (OSR)
定义: 在整个导航轨迹中,智能体曾经距离目标最近的位置是否满足成功条件。
计算方法: \(OSR = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[\min_{t} d_i^{(t)} < \tau]\)
其中:
- $d_i^{(t)}$ 是第 $i$ 个episode在时间步 $t$ 时智能体与目标的距离
- $\min_{t} d_i^{(t)}$ 是整个轨迹中与目标的最小距离
取值范围:
- 0 到 1(或0%到100%)
- 越高越好
优点:
- 评估智能体是否”到过”目标附近
- 反映路径规划的潜在能力
- 有助于区分”到达但没停”和”从未到达”两种失败情况
缺点:
- 不能反映最终导航结果
- 通常作为辅助指标使用
导航效率指标
Success weighted by Path Length (SPL)
定义: 考虑路径效率的成功率,同时衡量成功率和路径长度。
计算方法: \(SPL = \frac{1}{N} \sum_{i=1}^{N} S_i \frac{l_i^*}{\max(p_i, l_i^*)}\)
其中:
- $S_i$ 是成功指示符(到达目标为1,否则为0)
- $l_i^*$ 是最短路径长度(从起点到终点的理论最短距离)
- $p_i$ 是智能体实际走过的路径长度
- $\max(p_i, l_i^*)$ 确保分母不小于最短路径
取值范围:
- 0 到 1
- 越高越好
- SPL = 1 表示以最短路径成功到达目标
优点:
- 最重要的综合指标,同时考虑成功率和效率
- 惩罚绕路行为,鼓励高效导航
- 被广泛用作主要性能指标(与SR并列)
缺点:
- 需要计算最短路径(需要环境图信息)
- 对失败的episode惩罚较重(直接计为0)
典型取值:
- 早期模型(2018-2019):R2R上SPL约20-30%
- 中期模型(2020-2021):R2R上SPL约30-40%
- 近期模型(2022-2024):R2R上SPL约40-50%
- SOTA模型(2024+):R2R上SPL可达50%以上
Coverage weighted by Length Score (CLS)
定义: 衡量智能体按照指令覆盖参考路径的程度,同时考虑效率。
计算方法: \(CLS = \frac{1}{N} \sum_{i=1}^{N} \frac{C_i \times l_i^*}{\max(p_i, l_i^*)}\)
其中:
- $C_i$ 是覆盖率(智能体经过的参考路径节点比例)
- $l_i^*$ 是参考路径长度
- $p_i$ 是实际路径长度
取值范围:
- 0 到 1
- 越高越好
优点:
- 评估轨迹与参考路径的匹配度
- 适合评估指令跟随能力
缺点:
- 依赖参考路径的质量
- 计算相对复杂
轨迹质量指标
normalized Dynamic Time Warping (nDTW)
定义: 衡量智能体轨迹与参考路径之间的相似度,使用动态时间规整算法。
计算方法: \(nDTW = e^{-\frac{DTW(\mathcal{P}_{agent}, \mathcal{P}_{ref})}{\sigma}}\)
其中:
- $DTW(\cdot, \cdot)$ 是动态时间规整距离
- $\mathcal{P}_{agent}$ 是智能体的实际轨迹
- $\mathcal{P}_{ref}$ 是参考路径
- $\sigma$ 是归一化参数
取值范围:
- 0 到 1
- 越高越好
- nDTW = 1 表示轨迹完全匹配
优点:
- 评估轨迹的时序一致性
- 对轨迹的局部偏差容忍度高
- 考虑了路径的整体形状
缺点:
- 计算复杂度较高
- 需要时序对齐,计算开销大
Success weighted by normalized Dynamic Time Warping (SDTW)
定义: 结合成功率和轨迹相似度的综合指标。
计算方法: \(SDTW = \frac{1}{N} \sum_{i=1}^{N} S_i \cdot nDTW_i\)
优点:
- 同时考虑成功率和轨迹质量
- 更全面的性能评估
其他辅助指标
Trajectory Length (TL)
定义: 智能体实际走过的平均路径长度。
用途:
- 分析导航效率
- 检测模型是否过度探索或原地打转
Steps Taken
定义: 智能体完成任务所需的平均步数。
用途:
- 评估导航速度
- 分析决策效率
Collision Rate
定义: 发生碰撞的步数占总步数的比例。
用途:
- 评估导航安全性(在连续环境中)
- 检测路径规划质量
Human Collision Rate
定义: 与动态行人发生碰撞的次数(用于社交导航)。
用途:
- 评估社交导航能力
- 测试动态避障性能
评估指标速查表
核心指标总览
| 指标 | 英文全称 | 定义 | 取值范围 | 方向 | 首次提出 | 备注 |
|---|---|---|---|---|---|---|
| SR | Success Rate | 终点距目标≤3m的任务比例 | 0-100% | ↑ | Anderson et al., 2018 | 最核心指标,反映任务完成率 |
| SPL | Success weighted by Path Length | SR × (最短路径/实际路径) | 0-100% | ↑ | Anderson et al., 2018 | 综合成功率和路径效率 |
| NE | Navigation Error | 智能体终点与目标点的距离(米) | 0-∞ | ↓ | Anderson et al., 2018 | 衡量定位精度 |
| OSR | Oracle Success Rate | 轨迹中任意点距目标≤3m的比例 | 0-100% | ↑ | Anderson et al., 2018 | 评估是否路过正确位置 |
| nDTW | normalized Dynamic Time Warping | 预测轨迹与真实轨迹的归一化对齐距离 | 0-1 | ↑ | Ilharco et al., 2019 | 评估轨迹相似度 |
| SDTW | Success-normalized DTW | nDTW × SR | 0-100 | ↑ | Jain et al., 2019 | 同时考虑成功和轨迹质量 |
| CLS | Coverage weighted by Length Score | 指令覆盖率 × 路径效率 | 0-100% | ↑ | Jain et al., 2019 | 评估指令跟随细粒度 |
| TL | Trajectory Length | 实际行走的路径长度(米) | 0-∞ | - | - | 分析路径效率 |
| CR | Collision Rate | 发生碰撞的任务比例 | 0-100% | ↓ | Krantz et al., 2020 | VLN-CE核心安全指标 |
| HCR | Human Collision Rate | 与人类碰撞的任务比例 | 0-100% | ↓ | Wei et al., 2025 | Social-VLN关键指标 |
| FR | Fall Rate | 机器人跌倒的任务比例 | 0-100% | ↓ | Wang et al., 2025 | VLN-PE物理仿真指标 |
| StR | Stuck Rate | 机器人卡住无法移动的比例 | 0-100% | ↓ | Wang et al., 2025 | VLN-PE鲁棒性指标 |
指标选择速查
标准评估(必须报告):
- SR + SPL(所有VLN任务)
- NE(定位精度要求高时)
特定场景补充:
- 连续环境(VLN-CE):+ CR
- 物理仿真(VLN-PE):+ FR + StR + TL
- 社交导航(Social-VLN):+ HCR
- 轨迹质量研究:+ nDTW / SDTW
- 指令跟随研究:+ CLS
指标权衡关系
常见矛盾:
- SR ↑ vs SPL ↑:高成功率可能伴随低效路径
- SR ↑ vs CR ↓:激进策略提高成功率但增加碰撞
- SR ↑ vs FR/StR ↓:探索更多区域增加失败风险
理想模型特征:
- SR > 60%(R2R Val-Unseen基准)
- SPL/SR > 0.85(路径效率高)
- CR < 5%(安全导航)
- NE < 5m(精确定位)
评估最佳实践
报告规范:
1. 必须分别报告 Val-Seen 和 Val-Unseen
2. 标注成功阈值(默认3m,如有不同需说明)
3. 说明是否使用 ground truth 路径(OSR计算)
4. 标注传感器配置(RGB-only / RGB-D / Panoramic)
公平对比检查清单:
- ✅ 相同数据集划分
- ✅ 相同成功阈值
- ✅ 相同传感器输入
- ✅ 相同评估环境(Habitat / 真实世界)
历史演进
| 阶段 | 年份 | 代表工作 | 核心指标 | 新增关注点 |
|---|---|---|---|---|
| 1.0 | 2018-2019 | R2R, RxR | SR, SPL, NE | 基础任务完成 |
| 2.0 | 2020-2021 | VLN-CE, nDTW | + CR, nDTW | 连续环境 + 轨迹质量 |
| 3.0 | 2022-2024 | VLN-PE, REVERIE | + FR, StR | 物理真实性 + 多任务 |
| 4.0 | 2025- | Social-VLN, DualVLN | + HCR | 动态环境 + 社交感知 |
未来趋势:
- 真实世界部署指标(能耗、时间)
- 长期任务鲁棒性评估
- 人机交互质量指标
学习资源与框架
VLN-Survey-with-Foundation-Models ⭐⭐⭐⭐⭐
- 类型:GitHub资源仓库
- 重点:专注于LLM/VLM时代的VLN方法(2023-至今),持续更新最新论文
- 适合:想了解大模型如何革新VLN领域的研究者
Awesome-Embodied-AI ⭐⭐⭐⭐⭐
- 类型:全栈资源合集
- 重点:涵盖VLN、VLA、机器人操作等完整具身智能技术栈
- 适合:系统学习具身AI全貌的研究者
Embodied-AI-Guide ⭐⭐⭐⭐⭐
- 类型:入门教程 + 实践指南
- 重点:提供代码实践、论文解读、学习路径规划
- 适合:零基础入门或需要结构化学习路径的新人
Vision-and-Language Navigation: A Survey ⭐⭐⭐⭐
- 类型:综述论文(IJCV 2023)
- 重点:系统梳理VLN发展脉络,截至2022年的方法总结
- 适合:需要全面了解VLN历史演进的研究者
🎓 重要会议与研讨会
具身智能专项会议:
- Embodied AI Workshop - CVPR官方Workshop,最新趋势和挑战赛发布地
- CoRL (Conference on Robot Learning) - VLN向真实机器人迁移的主要阵地
- RSS (Robotics: Science and Systems) - 顶级机器人会议,强调Sim-to-Real
主流顶会VLN论文分布:
| 会议 | 侧重点 | 近期代表作 |
|---|---|---|
| CVPR / ICCV / ECCV | 视觉-语言方法创新 | NaVILA (CVPR’25), DualVLN (投稿中) |
| NeurIPS | 基础模型 + 强化学习 | StreamVLN (NeurIPS’24) |
| CoRL | 真实机器人部署 | GNM (CoRL’23), NoMad (CoRL’24) |
| ICRA / IROS | 导航算法工程化 | VLN-PE (ICRA’25), ViPlanner (ICRA’24) |
主流 VLN 研究路线
0. 技术演进脉络与历史发展
VLN 研究从 2018 年至今经历了显著的范式演进:
早期范式 (2018-2020):判别式跨模态匹配
- 代表工作:VLN-BERT, Recurrent VLN-BERT, PREVALENT
- 核心思想:通过文本编码器与视觉编码器提取特征,利用跨模态注意力实现语言-视觉对齐,预测动作 \(P(a_t \mid o_t, I)\)
- 本质:reactive policy learning,无显式长期规划
- 关键局限:缺乏空间记忆、泛化能力弱、难以处理复杂指令
演进路径:
- Matching → Planning (2020-2022):引入语义地图与拓扑规划,赋予智能体显式空间建模能力
- Planning → Reasoning (2023-2024):基于大模型的双系统/单系统架构,实现从匹配到推理的升级
- Reasoning → Imagination (2024-2025):生成式世界模型,智能体在”想象空间”中前瞻性规划
- Imagination → Agency (2025-2026):Agent 导航框架,VLM 作为中控大脑编排模块化技能库
1. 语义地图与拓扑规划框架
——Semantic Map & Graph-based Planning
- 起始时间:2020–2022
- 代表工作:DUET, DualVLN, ETPNav, LagMemo
核心思想
该类方法引入显式环境建模机制,在导航过程中构建 拓扑图或语义地图,将空间连通关系与语义信息存储在外部记忆中。智能体基于该地图进行全局路径规划与局部执行。
以 LagMemo 为代表的方法进一步将语言中涉及的目标(如 sofa, kitchen)投影到所构建的语义地图上,实现 language-grounded SLAM-style navigation。
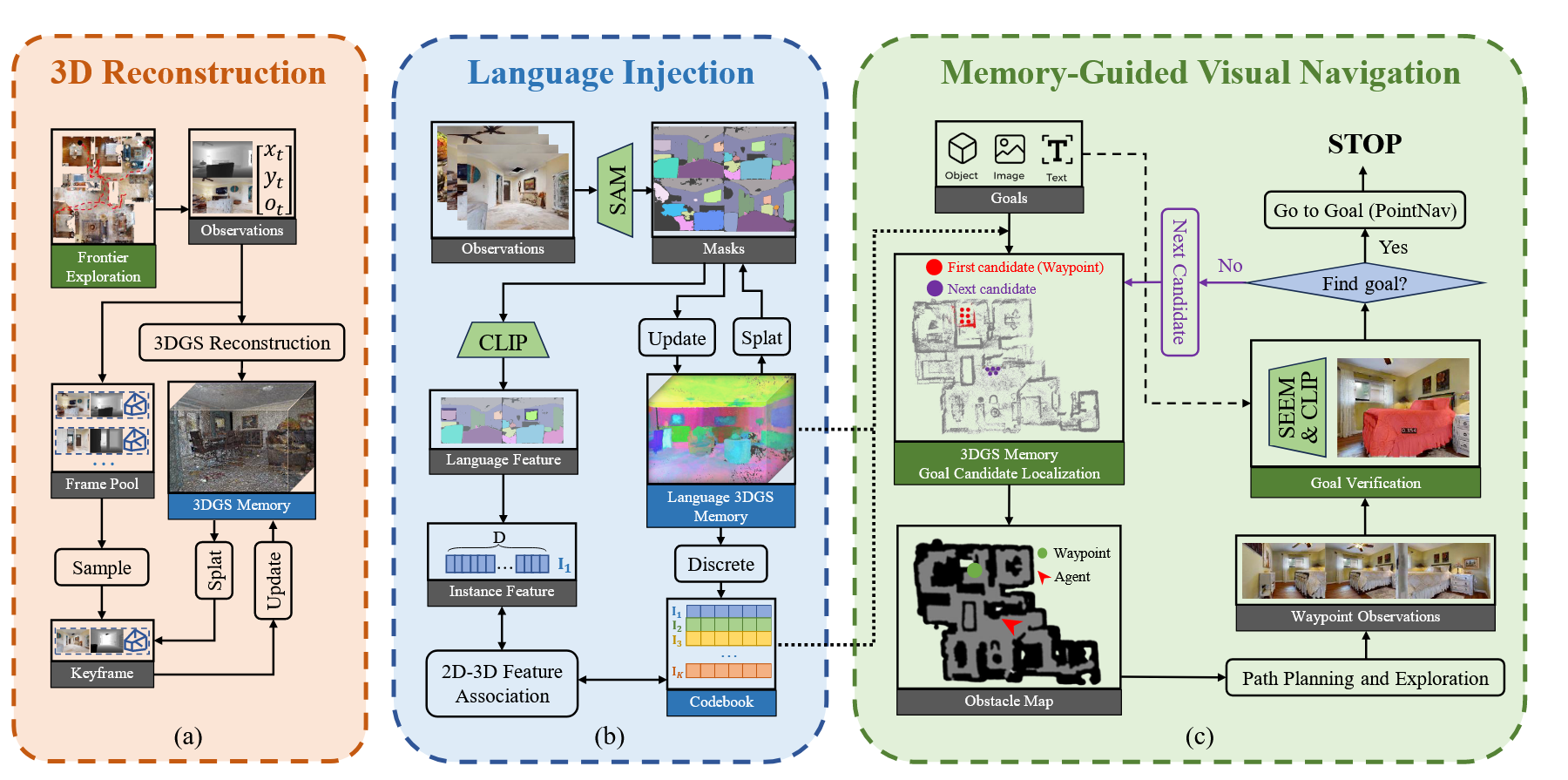
典型 Pipeline
RGB / Depth → Mapping Module → Topological / Semantic Map
↑
Instruction → Language Parser → Goal / Constraint Projection
↓
Global Planner → Local Policy → Action
优势
- 支持长距离规划与路径回溯。
- 显式空间结构提升可解释性。
- 有效缓解 partial observability。
关键缺陷
- ❌ 地图构建误差会累积传播。
- ❌ 对动态环境与遮挡鲁棒性有限。
- ❌ 语义投影通常依赖检测器或规则。
- ❌ 缺乏高层语言推理能力。
2. VLN双系统架构
——Dual-System VLN
- 起始时间:2023–2024
- 代表工作:DualVLN, InternVLN
核心思想
该类方法受认知科学”双过程理论”(快思考/慢思考)启发,采用 双系统分层架构:
- System-2(慢思考,”大脑”):基于 VLM/LLM 的高层推理与规划模块
- 负责:语言理解、指令分解、全局规划、子目标生成
- 频率:低频(约2 Hz),深度推理
- 代表:Qwen-VL, GPT-4V, InternVL
- System-1(快行动,”小脑”):基于 VN System(Vision-Navigation)的快速轨迹执行模块
- 负责:高频轨迹生成、局部避障、快速导航决策
- 频率:高频(30 Hz),实时响应
- 代表:DD-PPO, iPlanner, ViPlanner, GNM, ViNT, NoMad, NavDP, InternVLA-N1(DiT策略)
两个系统异步协作:System-2 提供高层语义引导,System-1 负责流畅的低层执行,实现 “Ground Slow, Move Fast”。
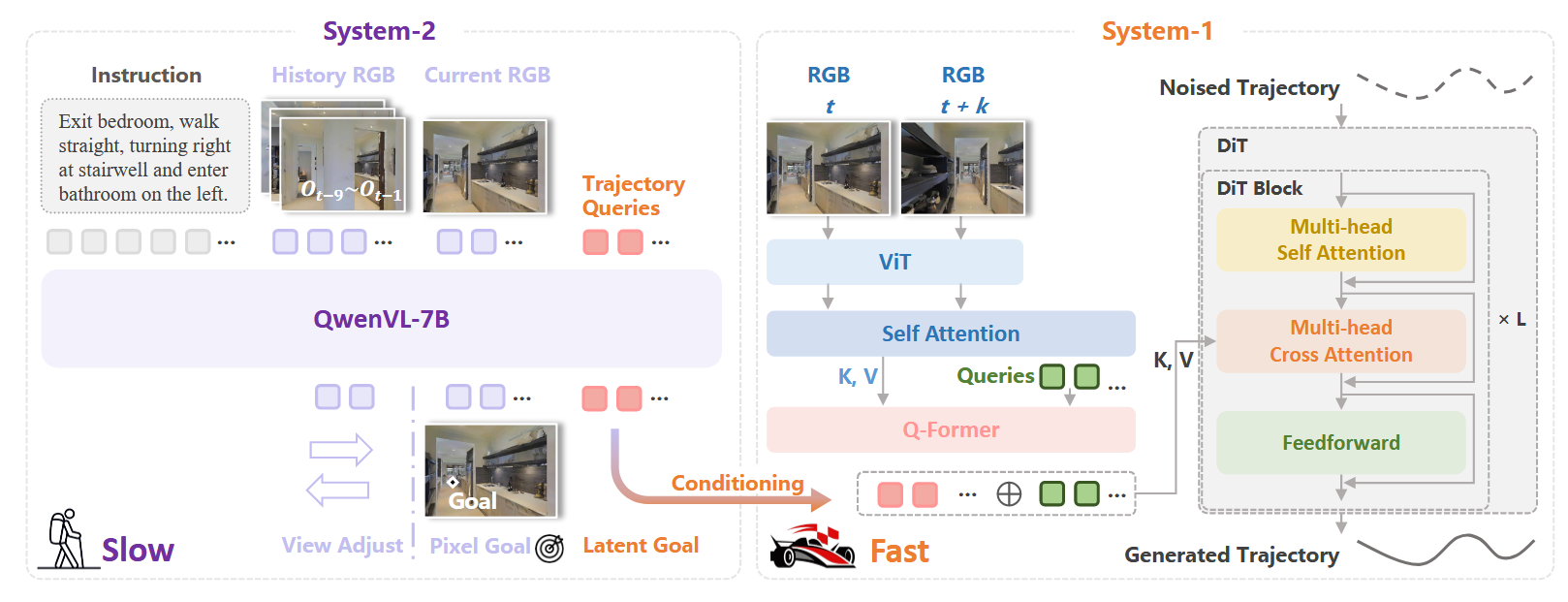
典型 Pipeline
Instruction + Observation → System-2 (VLM/LLM) → Pixel Goal / Subgoal
↓
Latent Features
↓
Current RGB Observation → System-1 (VN System / DiT) → High-Freq Trajectory
↓
Low-Level Controller (MPC)
↓
Action Execution
优势
- ✅ 强语言理解与常识推理能力(System-2)
- ✅ 高频流畅导航,低延迟实时响应(System-1)
- ✅ 优秀的 zero-shot 泛化性能
- ✅ 支持复杂指令分解与多步规划
- ✅ 异步推理流水线,充分利用 KV-cache
关键缺陷
- ❌ 系统架构复杂,需要两个独立模型
- ❌ 系统间信息传递需要精心设计(如像素目标、潜在特征)
- ❌ System-2 易产生 hallucination 行为
- ❌ 需要大规模轨迹数据训练 System-1
3. 单系统端到端 VLN 架构
——Single-System End-to-End VLN
- 起始时间:2019–2024
- 代表工作:Seq2Seq, CMA, RDP, StreamVLN
核心思想
该类方法采用 统一的端到端模型,直接从多模态输入(视觉观测 + 语言指令 + 历史动作)生成下一步动作,无需显式的系统分层或模块划分。
以 StreamVLN 为代表的最新方法将 VLN 建模为 多轮对话式的交错生成任务:\(o_1 \to a_1 \to o_2 \to a_2 \to ... \to o_T \to a_T\),通过滑动窗口 KV cache 和体素化空间剪枝实现高效的流式导航。
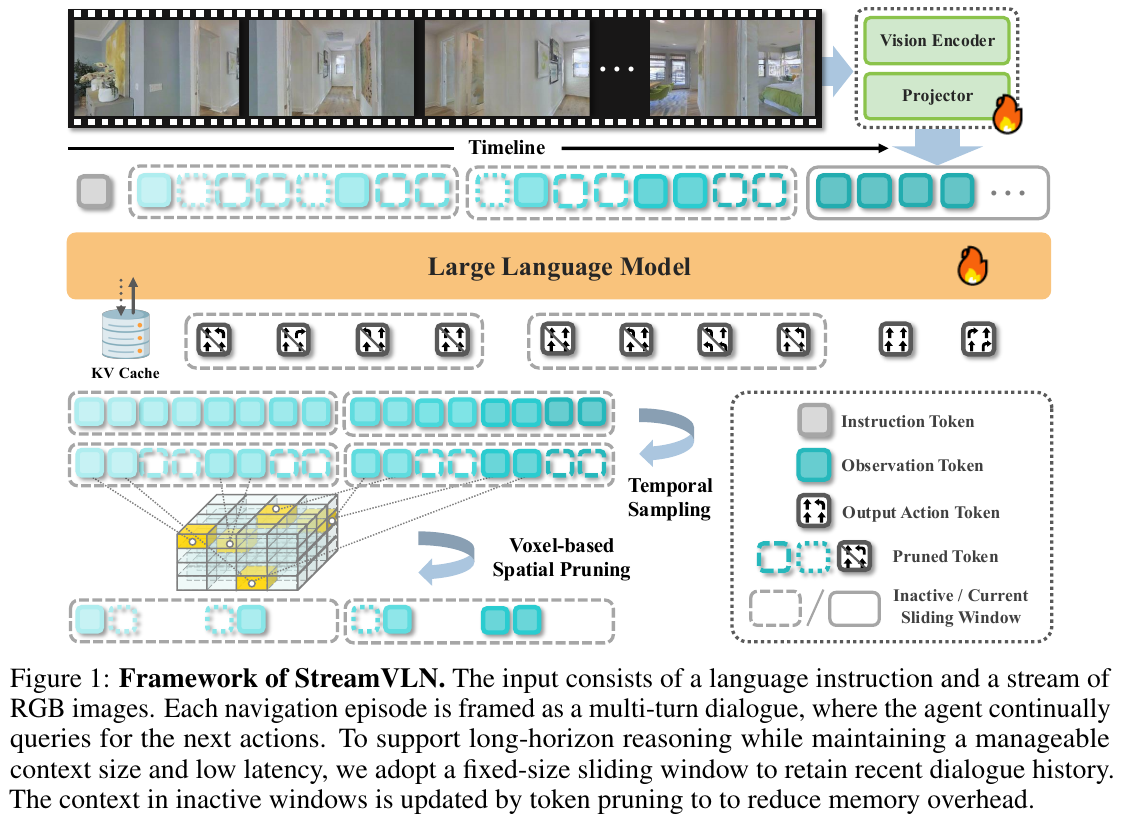
典型 Pipeline
[Instruction, o_1, a_1, ..., o_{t-1}, a_{t-1}, o_t] → Unified VLM
↓
Autoregressive Generation
↓
Action Token a_t
优势
- ✅ 端到端优化,无模块间信息损耗
- ✅ 推理延迟低(StreamVLN: 0.27s/step),适合实时部署
- ✅ 训练简洁,无需多阶段训练或手工设计模块
- ✅ 通过 KV cache 复用高效处理长对话历史
关键缺陷
- ❌ 决策过程黑盒,可解释性较弱
- ❌ 需要大规模多源数据联合训练(VLA + VQA + 通用视觉数据)
- ❌ grounding 稳定性依赖数据质量与模型规模
- ❌ 对复杂多步推理的建模能力弱于双系统架构
架构对比:双系统 vs 单系统
| 维度 | 双系统(DualVLN) | 单系统(StreamVLN) |
|---|---|---|
| 架构设计 | System-2(VLM/LLM)+ System-1(VN System)分离 | 统一端到端 VLA |
| 推理方式 | VLM规划(2Hz)→ VN高频执行(30Hz) | 观测-动作交错自回归生成 |
| 训练方式 | 分阶段训练(System-2微调 + System-1监督) | 端到端联合训练 |
| 推理延迟 | System-2: 0.7s, System-1: 0.03s | 单次推理: 0.27s |
| 控制频率 | 高频(30 Hz)流畅轨迹 | 低频(约4 Hz)离散动作 |
| 可解释性 | 强(显式像素目标 + 推理链) | 弱(黑盒) |
| 复杂推理 | 强(VLM/LLM显式推理) | 弱(隐式编码) |
| 部署复杂度 | 高(两个模型 + 异步协调) | 低(单模型 + KV cache) |
— –>
4. 生成式世界模型框架
——Generative World Models for VLN
- 起始时间:2024–2025
- 代表工作:
- Dynam3D (NeurIPS’25 Oral)
- Navigation World Models (NWM) (CVPR’25, Best Paper Honorable Mention, Meta AI)
- DreamVLA (NeurIPS’25)
- WMNav (IROS’25 Oral)
- InternVLA-A1 (2025, Shanghai AI Lab)
- NVIDIA Cosmos (2025, NVIDIA) — 面向物理 AI 的大规模世界基础模型
- Video Generation Models in Robotics – Applications, Research Challenges, Future Directions (2025)
核心思想
该类方法引入 Predictive World Modeling,使智能体能够:
- 预测未来:在执行动作前,在”想象空间”中模拟可能的未来观测
- 前瞻性规划:通过评估多条候选轨迹的未来结果,选择最优路径
- 减少试错:显著降低真实环境中的碰撞和探索成本
VLN 从 reactive execution 转向 deliberative planning with imagination,更接近人类”先想象后行动”的认知方式。
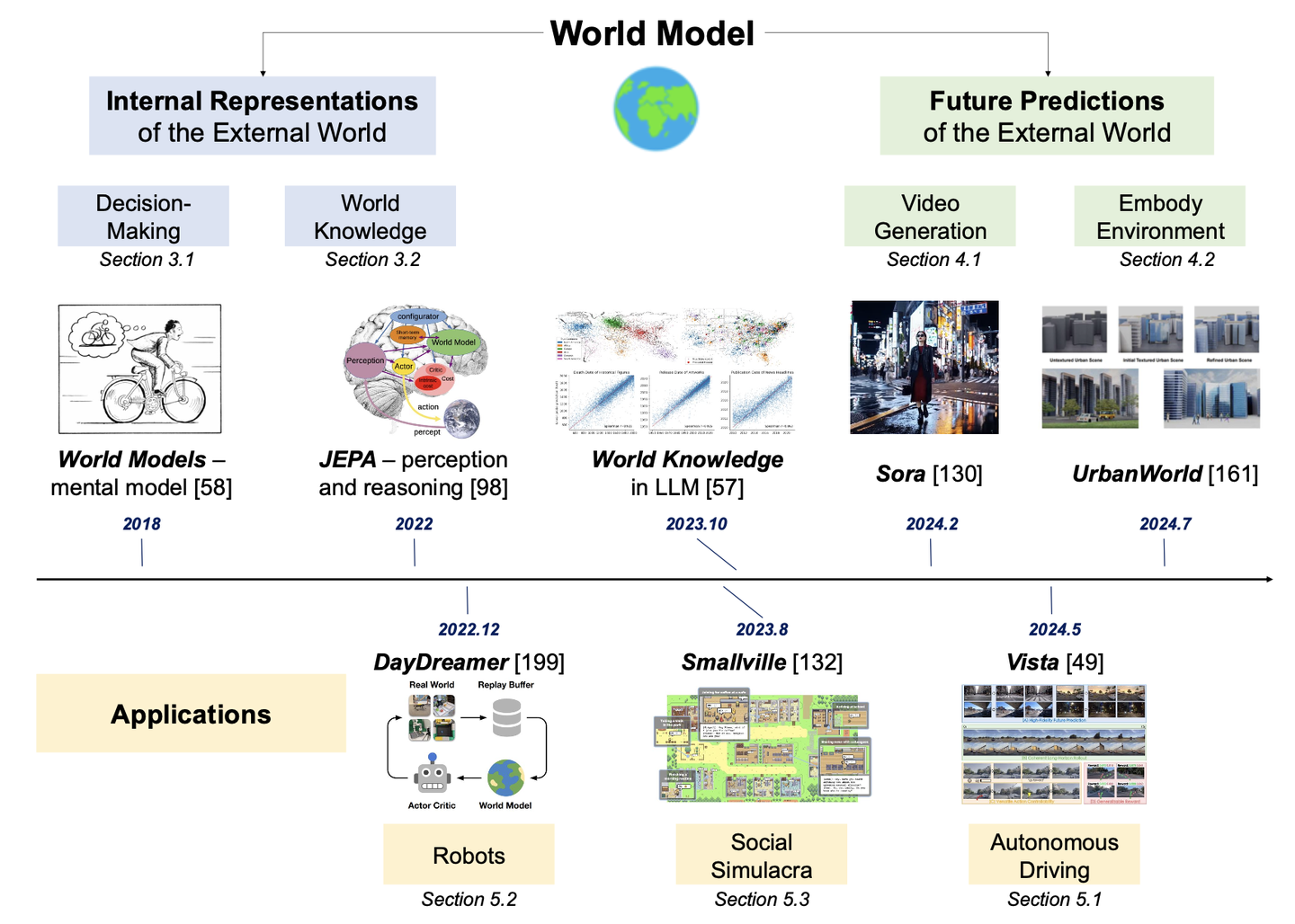
典型 Pipeline
flowchart TD
A["Current Observation\n+ Action Candidate"] --> B["World Model\n(Diffusion / Autoregressive)"]
B --> C["Future Visual Rollouts\n想象未来观测帧"]
C --> D["Trajectory Evaluation\n评估多候选轨迹"]
D --> E["Optimal Action Selection\n选择最优动作"]
style A fill:#4a90d9,color:#fff,stroke:#2c6fad
style B fill:#7b5ea7,color:#fff,stroke:#5a3e8a
style C fill:#5aa67a,color:#fff,stroke:#3a7a5a
style D fill:#d98c4a,color:#fff,stroke:#b06820
style E fill:#d94a4a,color:#fff,stroke:#a82020
主流技术路线
🗂 3D 空间建模方向
在三维空间中显式建模环境,侧重空间记忆与动态适应。
1. 3D动态表示 + 世界模型(Dynam3D)
- 核心创新:多层级 patch-instance-zone 3D 表示,动态在线更新
- 技术特点:
- 将 2D CLIP 特征投影到 3D 空间
- 在线编码和定位 3D 实例
- 动态适应环境变化,提供长期记忆
- 性能:SOTA on R2R-CE, REVERIE-CE, NavRAG-CE
- 优势:大规模探索 + 长期记忆 + 动态环境适应
🎬 2D 视频生成方向
通过生成未来视觉帧进行前瞻性规划,侧重想象力与泛化能力。
2. 可控视频生成模型(Navigation World Models, Meta AI)
- 核心创新:1B 参数 Conditional Diffusion Transformer (CDiT)
- 技术特点:
- 基于过去观测和导航动作预测未来视觉观测
- 在熟悉环境中模拟轨迹并评估是否达到目标
- 从单张图像想象未知环境的轨迹
- 训练数据:多样化的自我中心视频(人类 + 机器人)
- 优势:灵活的约束规划 + 单图像泛化能力
- 荣誉:CVPR 2025 Best Paper Honorable Mention
3. 多模态世界知识预测(DreamVLA)
代表操作侧的世界模型范式,其扩散 Transformer + 多模态推理链的设计对 VLN 具有直接迁移价值。
- 核心创新:动态区域引导的世界知识预测机制
- 预测内容:视觉 + 深度 + 几何 + 语义 + 分割
- 技术特点:
- 扩散 Transformer 建模动作条件分布
- 先形成抽象多模态推理链,再执行动作
- 性能:76.7% 真实机器人任务成功率
- 应用:操作任务,范式可迁移到 VLN
🧠 VLM 推理 + 世界模型方向
将语言推理能力与世界模型预测结合,侧重语义理解与零样本泛化。
4. VLM + 世界模型融合(WMNav)
- 核心创新:将 Vision-Language Models 集成到世界模型中
- 关键组件:
- PredictVLM:预测决策的可能结果
- Curiosity Value Map:构建记忆并提供反馈
- 导航策略模块:动态决策
- 性能:
- HM3D: +3.2% SR, +3.2% SPL(zero-shot SOTA)
- MP3D: +13.5% SR(所有方法中最优)
- 优势:模块化设计 + zero-shot 泛化
5. 具身推理世界模型(InternVLA-A1,Shanghai AI Lab)
- 核心创新:将世界模型预测与 VLA 统一框架融合,在动作前生成链式空间推理
- 技术特点:
- 推理阶段先输出”思维链”式空间分析,再生成动作
- 世界模型辅助数据合成,缓解真实导航标注稀缺问题
- 支持导航、操作等多种具身任务,VLN 与 VLA 统一建模
- 意义:VLN 领域向通用具身智能体演进的重要里程碑,语言推理与世界模型预测深度融合的代表
优势
- ✅ 支持前瞻性规划,在行动前”想象”结果
- ✅ 显著降低真实试错成本和碰撞率
- ✅ 更接近人类认知导航方式(先思考再行动)
- ✅ 可以评估多条候选轨迹,选择最优路径
- ✅ 单图像即可想象未知环境的导航轨迹(NWM)
关键缺陷
- ❌ 想象误差会累积,长期预测不稳定
- ❌ 训练成本极高(需要大规模视频数据 + 大模型)
- ❌ 推理延迟较高(视频生成模型较慢)
- ❌ 与语言约束的融合仍需改进(语义漂移问题)
- ❌ sim2real gap:模拟的未来可能与真实不符
基础设施与数据引擎
上述方法的共同瓶颈是大规模高质量训练数据的稀缺。以 NVIDIA Cosmos 为代表的物理 AI 世界基础模型,正在成为解决这一问题的底层基础设施。
NVIDIA Cosmos(2025)
- 定位:面向物理 AI 的世界基础模型平台,而非特定导航算法
- 核心能力:
- 支持文本 / 图像 / 视频条件驱动的物理世界视频生成
- 提供 Tokenizer + Diffusion WFM + Autoregressive WFM 全套组件
- 针对机器人、自动驾驶场景优化,具备物理一致性
- 三大功能模块:
| Predict | Transfer | Reason | |
|---|---|---|---|
| 类型 | World Generation | Multi-Controlnet | Reasoning VLM |
| 功能 | 给定初始帧,预测未来新帧 | 将控制帧转化为视频中的真实感帧 | 对视频片段内的帧进行推理 |
| 用途 | 数据生成 & 策略评估 | 数据增强 | 数据筛选、机器人规划、视觉 AI Agent |
| 输入 | 文本、图像、视频 | RGB、深度图、语义分割等多模态视频 | 视频、图像、文本 |
| 输出 | 视频 | 视频 | 文本 |
- 对 VLN 的价值:
- Predict 模块:作为合成数据引擎,生成多样化室内/室外导航轨迹,缓解真实标注数据稀缺
- Transfer 模块:将深度图、语义分割等传感器数据转化为真实感视频,降低 sim2real gap
- Reason 模块:作为视觉 AI Agent 的推理底座,支持导航策略评估与数据筛选
- 为上层世界模型方法(NWM、WMNav 等)提供预训练基础
5. Agent 导航框架
——Agentic VLM Navigation
- 起始时间:2025–2026
- 代表工作:
- AgentVLN (arXiv 2603.17670, 南京航空航天大学)
- RoboClaw (arXiv 2603.11558, AgiBot / 上海交大)
核心思想
该框架将 VLM 作为导航大脑 (VLM-as-Brain),彻底解耦高层认知推理与低层技能执行:
- 模块化技能库:感知技能(深度估计、目标定位)与规划技能(全局路径、避障)以插件化形式挂载,VLM 按需调度
- Agent 决策循环:VLM 基于当前多模态观测和历史记忆,通过链式推理输出高层决策,再映射到具体技能调用
- 主动纠错:遇到遮挡、盲点或轨迹偏离时,系统自主生成探索动作以恢复,抑制长轨迹中的误差累积
- 跨空间表示对齐:将 3D 拓扑路点投影到 2D 图像平面,生成像素对齐的视觉提示,消除 VLM 固有的 2D-3D 表示鸿沟
与传统方法的关键区别:VLM 不再是特征提取器或打分函数,而是具有自主决策能力的中控大脑,整个系统的行为随 VLM 能力提升而自动受益。
典型 Pipeline
Language Instruction + Egocentric Observation
↓
VLM (Central Brain) ←→ Structured Memory
↓ CoT Reasoning
Skill Scheduling (Perception / Planning Skills)
↓
Cross-Space Representation Mapping
↓
Navigation Action / Self-Correction
代表方法详解
1. VLM-as-Brain 导航(AgentVLN)
- 核心范式:将 VLN 建模为 POSMDP,VLM 作为中央控制器
- 技术特点:
- 跨空间表示映射:3D 路点 → 像素对齐视觉提示,消除 2D-3D 表示鸿沟
- QD-PCoT(Query-Driven Perceptual Chain-of-Thought):主动查询几何深度信息消解空间歧义
- 上下文感知自纠错:遇遮挡/轨迹偏离时自主生成细粒度探索动作
- AgentVLN-Instruct:动态阶段路由的大规模指令微调数据集
- 3B 参数,支持 Jetson 边缘设备实时推理
- 性能:在 RxR-CE Val-Unseen 以更小参数规模超越所有 SOTA
2. 全生命周期 Agentic 框架(RoboClaw)
- 核心范式:统一数据采集、策略学习与任务执行于单一 VLM Agent(机器人操作,范式可迁移至 VLN)
- 技术特点:
- 纠缠动作对 EAP(Entangled Action Pairs):正向操作 + 反向复位,构建自复位闭环
- 结构化记忆(角色身份 + 任务记忆 + 工作记忆)+ MCP 工具调用
- 推理时监控子任务状态,动态触发恢复行为
- 性能:长时序任务成功率 +25%,人工介入减少 53.7%
优势
- ✅ VLM 能力提升直接惠及导航性能,无需重新训练
- ✅ 模块化设计:增加新技能无需修改核心 VLM
- ✅ 支持边缘设备轻量部署,消除云端依赖
- ✅ 主动纠错机制大幅提升长轨迹鲁棒性
- ✅ 将 VLN 从”任务特定模型”扩展为”通用具身 Agent”
关键挑战
- ❌ VLM 推理引入额外延迟,实时控制频率受限
- ❌ 技能库设计依赖领域专家,扩展至新环境仍需适配
- ❌ 长上下文推理中的幻觉问题可能导致错误动作链
- ❌ 结构化记忆与历史轨迹的有效检索机制仍待优化
总结
VLN 的研究已从早期的判别式匹配演进为当前的五大主流路线:
- 语义地图与拓扑规划:显式空间建模,支持长距离规划与回溯
- VLN双系统架构:认知分层,System-1快速感知 + System-2推理规划
- 单系统端到端架构:统一优化,低延迟流式导航
- 生成式世界模型:前瞻性规划,在”想象空间”中搜索最优路径
- Agent 导航框架:VLM 作为中控大脑,编排模块化技能库实现自主纠错与长程导航
未来趋势是融合 语言理解、空间建模、双系统推理、端到端优化、世界模型预测与 Agent 决策,形成”语言引导 + 想象规划 + Agent 执行”的统一具身智能体架构。
2024-2026 技术趋势 (Key Trends)
| 技术趋势 | 描述 | 关键论文/项目 |
|---|---|---|
| Long-Horizon | 处理超长距离路径(>150步)及涉及多房间、跨楼层的复杂多阶段导航任务。 | LHPR-VLN (CVPR ‘25), L-VLN |
| Dynamic Environment | 针对真实世界中移动行人、开关门、光照突变等非稳态场景的适应性导航。 | DynamicVLN (2025), DynaNav |
| World Models | 引入预测学习,智能体通过生成未来视觉帧预测动作结果,实现”脑内模拟规划”。2025年重大突破:Dynam3D (NeurIPS’25 Oral)、NWM (CVPR’25 Best Paper)、DreamVLA (NeurIPS’25)、WMNav (IROS’25 Oral)。 | Dynam3D, NWM (Meta AI), DreamVLA, WMNav |
| VLA Models | 视觉-语言-动作 (VLA) 一体化。直接从多模态输入输出底层控制指令,消除感知与动作的鸿沟。 | OpenVLA (2024), Helix, RT-2 |
| Self-Evolving VLN | 2025-2026 新趋势。智能体在测试阶段通过自我反思和经验检索,在无需重新训练的情况下实现性能进化。 | SE-VLN (ICLR ‘26 / 2025), Reflection-Nav |
| 3DGS-based Map | 利用 3D高斯泼溅 (3D Gaussian Splatting) 进行环境重建,提供比点云更精细、渲染更快的神经导航地图。 | GS-Nav (2025), Splat-Nav |
趋势深度解析
1. 从“固定模型”到“自我演进 (Self-Evolving)”
这是目前最前沿的方向(如 SE-VLN)。传统的 VLN 模型在部署后能力是固定的,而最新的研究让智能体拥有一个“经验库”。当它导航失败时,它会记录失败原因并在下次遇到类似场景时进行自我修正。这种“闭环进化”让模型更像真实的生物。
2. 生成式 AI 赋予智能体“想象力”
World Models 的引入改变了 VLN 的本质。以前智能体是“应激式”移动,现在它能利用 Diffusion 或 Video Generation 技术预判:“如果我右转,我会看到什么?”这种前瞻性规划显著降低了碰撞率。
3. 具身大模型 (VLA) 的统领地位
随着 OpenVLA 等模型的成熟,VLN 不再是一个独立的视觉匹配任务,而是被纳入了通用的具身机器人大脑中。现在的趋势是:一个模型既能做 R2R 导航,也能在到达终点后完成“把杯子放进微波炉”的操作任务。
参考资料
论文精读:经典论文与基石论文详见 VLN经典论文与基石论文
数据集与基准
指令导向数据集
-
R2R — Anderson et al., Vision-and-Language Navigation: Interpreting Visually-Grounded Navigation Instructions in Real Environments, CVPR 2018.
-
R4R — Jain et al., Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation, ACL 2019.
-
RxR — Anderson et al., RxR: Multilingual Vision-and-Language Navigation Beyond English, EMNLP 2020.
-
VLN-CE — Krantz et al., Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments, ECCV 2020. [Paper]
-
VLN-PE — Wang et al., Rethinking the Embodied Gap: Physical and Visual Disparities in VLN, ICCV 2025. [Paper]
目标导向数据集
-
REVERIE — Qi et al., REVERIE: Remote Embodied Visual Referring Expression in Real Indoor Environments, CVPR 2020.
-
SOON — Zhu et al., SOON: Scenario Oriented Object Navigation with Graph-based Exploration, CVPR 2021.
-
LHPR-VLN — Long-Horizon Planning and Reasoning in Vision-Language Navigation, CVPR 2025.
对话式导航数据集
-
CVDN — Thomason et al., Vision-and-Dialog Navigation, CoRL 2019.
-
TEACh — Padmakumar et al., TEACh: Task-driven Embodied Agents that Chat, AAAI 2022.
-
HA-VLN — Wei et al., Human-Aware Vision-Language Navigation, NeurIPS 2024 Datasets and Benchmarks Track.
需求导向与特殊场景数据集
-
DDN — Demand-driven Navigation, AI2-THOR + ProcThor, 2023–2024.
-
AerialVLN — Vision-and-Language Navigation for UAVs, ICCV 2023.
-
CityNav — Language-Goal Aerial Navigation Dataset with Geographic Information, ICCV 2025.
-
OpenFly — A Comprehensive Platform for Aerial Vision-Language Navigation, arXiv 2025.
核心模型与方法
跨模态对齐基线
-
VLN-BERT — Majumdar et al., Improving Vision-and-Language Navigation with Image-Text Pairs from the Web, ECCV 2020.
-
Recurrent VLN-BERT — Hong et al., A Recurrent Vision-and-Language BERT for Navigation, CVPR 2021.
-
PREVALENT — Hao et al., Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training, CVPR 2020.
语义地图与拓扑规划
-
DUET — Chen et al., Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation, CVPR 2022.
-
ETPNav — An et al., ETPNav: Evolving Topological Planning for Vision-Language Navigation in Continuous Environments, IEEE TPAMI 2024.
-
LagMemo — Language-grounded Memory for Vision-and-Language Navigation, 2024.
双系统架构
-
DualVLN — DualVLN: Dual-System Vision-Language Navigation, 2024.
-
NaVILA — NaVILA: Legged Robot Vision-Language-Action Model for Navigation, CVPR 2025.
-
NavDP — NavDP: Navigation with Diffusion Policy, 2025.
-
InternVLA-N1 — Shanghai AI Laboratory, InternVLA-N1, 2025.
端到端方法
-
CMA — Krantz et al., Waypoint Models for Instruction-guided Navigation in Continuous Environments, ICCV 2021.
-
StreamVLN — StreamVLN: Streaming Vision-Language Navigation via Interleaved Multimodal Sequence Modeling, NeurIPS 2024.
-
NaVid — Zhang et al., NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation, RSS 2024.
底层视觉导航策略
-
DD-PPO — Wijmans et al., DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames, ICLR 2020.
-
GNM — Shah et al., GNM: A General Navigation Model to Drive Any Robot, CoRL 2023.
-
ViNT — Shah et al., ViNT: A Foundation Model for Visual Navigation, CoRL 2023.
-
NoMad — Sridhar et al., NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration, ICRA 2024.
-
ViPlanner — Roth et al., ViPlanner: Visual Semantic Imperative Learning for Local Navigation, ICRA 2024.
生成式世界模型
-
Dynam3D — Dynam3D: Dynamic 3D World Models for Vision-Language Navigation, NeurIPS 2025 Oral. [Paper]
-
Navigation World Models (NWM) — Bar et al., Navigation World Models, CVPR 2025 (Best Paper Honorable Mention), Meta AI. [Project]
-
DreamVLA — Zhang et al., DreamVLA: Dreaming Visual-Language-Action Models for Robot Manipulation, NeurIPS 2025. [Project]
-
WMNav — WMNav: Integrating Vision Language Models into World Models for Object Goal Navigation, IROS 2025 Oral. [Project]
-
InternVLA-A1 — Shanghai AI Lab, InternVLA-A1: Reasoning World Model for Embodied Intelligence, 2025. [Project]
-
NVIDIA Cosmos — NVIDIA, Cosmos World Foundation Model Platform for Physical AI, 2025. [Project]
自我进化与通用 VLA
-
SE-VLN — Self-Evolving Vision-Language Navigation, ICLR 2026.
-
OpenVLA — Kim et al., OpenVLA: An Open-Source Vision-Language-Action Model, arXiv 2024.
-
RT-2 — Brohan et al., RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, CoRL 2023.
模拟器
-
Matterport3D Simulator — Anderson et al., CVPR 2018. [GitHub]
-
Habitat — Savva et al., Habitat: A Platform for Embodied AI Research, ICCV 2019. [GitHub]
-
AI2-THOR — Kolve et al., AI2-THOR: An Interactive 3D Environment for Visual AI, arXiv 2017. [Website]
-
iGibson — Shen et al., iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks, CoRL 2021. [GitHub]
-
AirSim — Shah et al., AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles, 2018. [GitHub]
-
Isaac Sim / Isaac Lab — NVIDIA, 2024. [Docs]
-
InternUtopia — Shanghai AI Laboratory, 2024. [GitHub]
综述论文
-
VLN Survey — Gu et al., Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions, ACL 2022.
-
VLN Survey (IJCV) — Vision-and-Language Navigation: A Survey, International Journal of Computer Vision 2023. [Paper]
-
Thinking-VLN — Thinking Before Acting: Unified Human-Embodied Alignment for VLN, 2025.
学习资源与代码库
-
VLN-Survey-with-Foundation-Models — 专注 LLM/VLM 时代 VLN 方法的 GitHub 资源仓库(持续更新). [GitHub]
-
Awesome-Embodied-AI — 涵盖 VLN、VLA、机器人操作的全栈具身智能资源. [GitHub]
-
Embodied-AI-Guide — 具身 AI 入门教程与实践指南. [GitHub]
重要会议与研讨会
| 会议 / 研讨会 | 侧重点 |
|---|---|
| CVPR / ICCV / ECCV | 视觉-语言方法创新 |
| NeurIPS / ICLR | 基础模型、强化学习与理论创新 |
| CoRL (Conference on Robot Learning) | VLN 向真实机器人迁移 |
| ICRA / IROS | 导航算法工程化与真实部署 |
| Embodied AI Workshop @ CVPR | 最新趋势与挑战赛发布 |