引言
视觉-语言-动作(Vision-Language-Action, VLA)模型代表了机器人技术的范式转变,将视觉感知、自然语言理解和动作控制统一在单一的端到端学习框架中。VLA模型使机器人能够直接从自然语言指令和视觉观察中学习操作策略,无需显式的中间表示或分离的感知-规划-控制模块。
自2023年Google DeepMind推出RT-2以来,VLA模型在机器人操作任务中展现出强大的泛化能力和零样本学习潜力。这一技术路线继承了大规模视觉-语言模型(VLM)在跨模态理解方面的优势,并将其扩展到具身智能领域,使机器人能够像理解图像和文本一样”理解”物理世界中的交互任务。
VLA模型在服务机器人、工业自动化、智能制造等领域有着广泛的应用前景。本文旨在系统梳理VLA领域的研究进展,为学习和研究VLA提供全面参考。
1. VLA核心技术体系
1.1 什么是VLA?
VLA(Vision-Language-Action)模型是一类端到端的多模态学习模型,能够直接从视觉输入(相机图像)和语言指令中预测机器人的控制动作。与传统的模块化机器人系统不同,VLA将感知、推理和控制统一在单一的神经网络架构中。

VLA的核心特征
1. 端到端学习:直接从原始传感器数据到低层控制信号的映射,无需手工设计的中间表示。
2. 多模态融合:统一处理视觉、语言和动作三种模态,实现跨模态的语义对齐。
3. 指令驱动:通过自然语言指令指定任务目标,支持灵活的任务切换和零样本泛化。
4. 大规模预训练:继承视觉-语言模型的预训练知识,并在机器人演示数据上微调。
VLA的发展里程碑:两年三次范式跃迁
VLA研究时间线:从模块化到端到端统一模型,再到强化学习的自我进化(2022-2026)
flowchart LR
subgraph G2022 ["范式一:从闭眼规划到VLA"]
A["SayCan: LLM规划"] --> B["RT-1/RT-2: 端到端VLA"]
end
B --> C
subgraph G2023 ["范式二:Action Chunking & Diffusion"]
C["ACT: 解决累积误差"] --> D["ALOHA: 硬件普及"]
D --> E["Diffusion Policy: 多模态分布"]
end
E --> F
subgraph G2024 ["范式三:Flow Matching & RL复兴"]
F["OpenVLA: 开源标杆"] --> G["π₀: 50Hz实时控制"]
G --> H["π*₀.₆: RECAP强化学习"]
end
style B fill:#f96,stroke:#333,stroke-width:2px
style E fill:#69f,stroke:#333,stroke-width:2px
style H fill:#f96,stroke:#333,stroke-width:2px
具身智能在短短两年内经历了三次核心的”范式跃迁”:
- 第一次跃迁(2022-2023初)——从语言规划到VLA:早期如SayCan虽然能让LLM进行任务分解,但它是”闭着眼睛”做规划。直到RT-1、RT-2的出现,将视觉、语言和动作Token统一,第一次证明了VLM可以直接生成动作,实现了端到端的感知-控制。
- 第二次跃迁(2023)——Action Chunking与Diffusion Policy:传统的单步动作预测容易产生累积误差(Compounding Error)。ACT(Action Chunking with Transformers)提出一次性预测一段动作序列(Chunk),解决了误差累积问题。结合成本不到2万美元的ALOHA开源双臂硬件,直接引爆了学界的具身研究。随后,Diffusion Policy用扩散模型替代了传统的CVAE,彻底解决了模型在面对多种合理运动路径时容易”取平均”导致失败的问题,天然且优雅地建模了动作的多模态分布。
- 第三次跃迁(2024-2025)——Flow Matching与RL重返舞台:π₀将Diffusion Policy的弯曲去噪路径拉直(Flow Matching),推理速度提升5-7倍,实现了50Hz的高频连续控制(能玩扑克、折衣服)。更关键的是,π*₀.₆提出了RECAP(优势条件化)方法,巧妙绕过了Flow Matching难以计算对数概率的限制,让强化学习(RL)重新与VLA深度融合。这意味着机器人不再是出厂即定型的静态工具,而是能够通过真实部署收集数据实现”越用越好”的学习型智能体,真正转动了数据飞轮(Data Flywheel)。
1.2 VLA系统架构
一个完整的VLA系统包含三个核心组成部分:
flowchart TD
In["视觉观察 + 语言指令"] --> VE["1. 视觉编码器<br/>Vision Encoder"]
In --> LAB["2. 语言-行动骨干网络<br/>Language-Action Backbone"]
VE --> LAB
LAB --> AD["3. 动作解码器<br/>Action Decoder"]
AD --> Out["机器人控制动作"]
style VE fill:#f9f,stroke:#333
style LAB fill:#bbf,stroke:#333
style AD fill:#dfd,stroke:#333
1. 视觉编码器(Vision Encoder):从单眼到多眼
功能:从相机图像中提取视觉特征表示。
主流架构演进:
- 单编码器(早期/RT-2):使用单一 ViT 或 PaLI-X 处理所有信息,效率相对较低。
- 双编码器(OpenVLA 模式):
- DINOv2:负责提取几何与空间特征(理解”在哪里”)。
- SigLIP:负责提取语义与常识特征(理解”是什么”)。
- 多视角融合:通过融合侧方、腕部等多摄像头输入,解决遮挡与深度感知问题。
2. 语言-行动骨干网络(Language-Action Backbone):System 1 与 System 2 的融合
功能:作为”大脑”层,负责指令理解、推理与动作规划。
flowchart LR
%% 高层规划路径
subgraph S2 ["System 2 (慢思考/脑): 高层规划器"]
User[用户指令: 帮我洗杯子] --> VLM[预训练 VLM]
Obs[多视角视觉观察] --> VLM
VLM --> TaskDecomp[任务分解: 1.移动 2.抓取 3.清洗]
TaskDecomp --> SubGoal[子目标生成: 3D 姿态/语义点]
end
%% 动作执行路径
subgraph S1 ["System 1 (快思考/小脑): 动作专家"]
Bridge[低频指令 ~5Hz] --> Controller[Flow Matching/Diffusion]
Controller --> Motor[电机电流/扭矩控制]
Motor --> Feedback[实时触觉/位姿反馈]
Feedback --> Controller
Motor --> Act[物理动作执行]
end
SubGoal --> Bridge
Feedback --> VLM
style S2 fill:#e1f5fe,stroke:#01579b
style S1 fill:#fff3e0,stroke:#e65100
主流架构:
- Transformer-based LLM:如 Qwen3-VL、Llama-2/3、Phi-3 等。
- 双系统架构(NVIDIA GR00T 范式):
- System 2 (慢思考):基于视觉语言模型负责理解环境、解读指令并作出长时序规划(~5Hz)。
- System 1 (快思考):基于扩散 Transformer (DiT) 或流匹配负责高频、精细的反射性动作(~50Hz)。
3. 动作解码器(Action Decoder):从语言 Token 到高频连续轨迹
功能:将模型的高层决策转化为具体的机器人控制信号。
graph LR
subgraph "第一代: 离散 Token (2022-2023)"
T1[动作离散化 bins] --> T2[语言模型自回归生成]
T2 --> T3[执行频率: 1-5Hz]
end
subgraph "第二代: 扩散模型 (2023-2024)"
D1[高斯噪声] --> D2[迭代去噪 Diffusion]
D2 --> D3[多模态分布建模]
D3 --> D4[执行频率: 10-20Hz]
end
subgraph "第三代: 流匹配 Flow Matching (2024-2026)"
F1[概率路径学习] --> F2[直接生成连续轨迹]
F2 --> F3[极精细控制: 折纸/扑克]
F3 --> F4[执行频率: 50Hz+]
end
T3 -.-> D1
D4 -.-> F1
主流范式比较:
- 离散动作建模(RT-2/OpenVLA):将动作视为语言 Token 预测。优点是架构统一,缺点是难以生成连续流畅的高频动作。
- 连续动作建模(Diffusion Policy):使用扩散过程建模动作分布,能捕获多模态动作可能性,在精细操作中表现更优。
- 流匹配(Flow Matching, π₀):直接生成连续的关节轨迹,支持 50Hz 高频控制。这是实现”折纸、玩扑克牌”等极高精度任务的关键。
架构分类:端到端 vs 层级
VLA模型可以从架构层面分为两大类:端到端统一模型和层级架构模型。这种分类反映了不同的设计哲学和应用场景。
End-to-End架构 vs Hierarchical架构对比:
flowchart LR
%% 端到端路径
subgraph E2E ["端到端范式"]
In1["视觉+文本"] --> Model1["单一VLA模型"] --> Act1["底层控制动作"]
end
%% 层级路径
subgraph Hier ["层级范式"]
In2["复杂指令"] --> VLM["高层规划器/VLM"]
VLM -- "语言子任务" --> VLA["低层执行器/VLA"]
Obs["视觉观察"] --> VLM
Obs --> VLA
VLA --> Act2["高频动作流"]
end
style E2E fill:#fff4dd,stroke:#d4a017
style Hier fill:#e1f5fe,stroke:#01579b
| 维度 | End-to-End | Hierarchical |
|---|---|---|
| 设计理念 | 单一统一网络 | 分离规划与执行 |
| 推理方式 | 隐式端到端 | 显式分层推理 |
| 可解释性 | 低 | 高 |
| 适用场景 | 短时域任务 | 长时程复杂任务 |
End-to-End Architecture 代表模型:
| 模型 | 动作解码器 | 参数规模 | 特点 |
|---|---|---|---|
| OpenVLA | 离散token化 | 7B | 首个开源大规模VLA(详见第5.9节) |
| π₀ | Flow Matching | 3B (VLM) + 860M (Action) | 50Hz实时控制(详见第5.10节) |
| Diffusion Policy | DDPM | - | 多模态动作分布(详见第5.5节) |
| RDT-1B | Diffusion Transformer | 1B | 大规模扩散VLA |
Hierarchical Architecture 代表模型:
| 模型 | 高层规划 | 低层执行 | 特点 |
|---|---|---|---|
| π₀.5 | 增强推理VLM | Flow Matching | 多步骤推理链(详见第5.11节) |
| RT-H | VLM子任务分解 | RT-1 | 层级任务执行 |
| Hi Robot | VLM规划器 | VLA执行器 | 两层显式分离 |
| LoHoVLA | 端到端学习的层级 | - | 隐式层级结构 |
最新研究表明,纯端到端和纯层级架构各有优劣,混合方法成为新趋势:ACoT-VLA在动作层面进行显式推理,保持统一架构(详见第5.13节)。
1.3 VLA与传统机器人控制的区别
VLA代表了机器人控制范式的根本性转变:
flowchart TD
subgraph Trad ["传统机器人控制: 模块化"]
T1["感知/检测"] --> T2["规划/路径"] --> T3["控制/PID"]
end
subgraph VLA_Sys ["VLA: 端到端统一"]
V1["视觉+文本"] --> V2(("单一神经网络模型")) --> V3["动作输出"]
end
style V2 fill:#f96,stroke:#333,stroke-width:2px
从模块化到端到端
传统方法:
- 感知模块:物体检测、位姿估计
- 规划模块:轨迹规划、路径优化
- 控制模块:PID控制、力控制
- 各模块独立设计和优化
VLA方法:
- 单一神经网络直接从像素到控制信号
- 联合优化所有组件
- 减少了模块间的信息损失
从任务特定到通用能力
传统方法:为每个任务设计专门的控制策略,难以泛化到新任务和新环境,需要大量的工程调试。
VLA方法:通过自然语言指令指定任务,零样本或少样本泛化到新任务,利用预训练知识处理未见场景。
从显式建模到隐式学习
传统方法:需要精确的环境模型和物体模型,依赖手工设计的特征和规则,对模型误差敏感。
VLA方法:从数据中隐式学习环境动力学,自动发现任务相关的特征,对感知噪声和模型不确定性更鲁棒。
从工程驱动到数据驱动
传统方法:依赖专家知识和人工调参,开发周期长,部署成本高,难以处理长尾场景。
VLA方法:基于大规模演示数据学习,通过数据增强提升泛化能力,持续学习和在线适应。
1.4 VLA任务分类
VLA模型可以应用于多种类型的机器人任务,以下从四个维度进行分类:
mindmap
root((VLA任务分类))
按复杂度
单步操作
多步骤操作
长时程任务
按交互对象
刚体操作
可变形物体
流体操作
工具使用
按控制模式
位置控制
速度控制
力/阻抗控制
按环境类型
桌面操作
厨房环境
移动操作
| 任务类型 | 典型输入 | 典型输出 | 代表方法 | 关键说明 |
|---|---|---|---|---|
| 单步操作 | RGB图像 + 抓取指令 | 单次抓取动作 | RT-1, OpenVLA | 主要考察感知和控制精度,代表数据集:RLBench简单任务 |
| 多步骤操作 | 多帧图像 + 序列指令 | 有序动作序列 | CALVIN, LIBERO | 涉及子目标分解,需维护任务进度状态 |
| 长时程任务 | 多视角视频 + 目标描述 | 分层规划+执行 | π₀.5, ALFRED | 包含数十至上百步,需错误检测与恢复机制 |
| 刚体操作 | RGB/深度图 + 位置指令 | 6-DOF末端执行器 | RT-2, OpenVLA | 关注几何精度,是最基础的操作类型 |
| 可变形物体 | 多视角RGB + 形变状态 | 精细轨迹 | π₀(折衣服) | 物体状态高维,难以在仿真中准确建模 |
| 流体操作 | RGB + 任务描述 | 力矩控制序列 | 专用模型 | 需流体动力学建模,传感器限制明显 |
| 工具使用 | 场景图像 + 工具描述 | 工具-物体交互 | RT-2 | 需理解工具功能,是语义推理能力的体现 |
| 位置控制 | 视觉观测 | Δxyz + 四元数 | OpenVLA, RT-2 | 适合精确定位,7自由度机械臂标准输出 |
| 速度控制 | 连续帧图像 | dx/dy/dz速度 | 连续控制模型 | 轨迹更平滑,适合连续跟踪任务 |
| 力/阻抗控制 | 视觉+力传感 | 接触力指令 | 专用控制器 | 需力/扭矩传感器,适合组装和人机协作 |
| 桌面操作 | 固定视角图像 | 工作台范围动作 | 大多数VLA | 场景相对简单,是VLA的主要测试场景 |
| 厨房任务 | 多视角图像 | 复合操作序列 | π₀.5 | 多样物体和工具,应用于服务机器人 |
| 移动操作 | 导航+操作图像 | 移动+抓取动作 | π₀.5家庭任务 | 结合导航与操作,大范围工作空间 |
1.5 主流VLA模型横向对比汇总
为了直观展示各阶段代表性 VLA 模型的差异,下表汇总了其核心架构与技术指标:
| 模型 | 发布时间 | 参数规模 | 核心架构/特点 | 开源状态 | 备注 |
|---|---|---|---|---|---|
| RT-1 | 2022.12 | 130M | Transformer + 离散 Token | ✅ 数据+代码 | 奠基之作 |
| RT-2 | 2023.07 | 5B/55B | VLM 直接微调 | ❌ 闭源 | 首次验证 VLM 知识迁移 |
| OpenVLA | 2024.06 | 7B | 双编码器 (DINOv2+SigLIP) | ✅ 权重+代码 | 目前最强开源 VLA 标杆 |
| π₀ | 2024.10 | 3.8B | Flow Matching (50Hz) | ✅ 权重+代码 | 擅长折纸等精细操作 |
| GR00T N1.6 | 2026.01 | 2.2B | 双系统 (System 1+2) | ✅ 权重+代码 | 英伟达全栈生态绑定 |
| Xiaomi-R0 | 2025.02 | 4.7B | MoT 架构(分离脑/小脑) | ✅ 权重+代码 | 中国力量,低延迟优化 |
| LingBot-VLA | 2025.02 | - | 跨形态泛化 (9种机器人) | ✅ 权重+代码 | 蚂蚁集团真机预训练 |
| π₀.5 | 2025.04 | - | 异构任务协同训练 | ❌ 闭源 | 开放世界家庭长时程任务 |
| ACoT-VLA | 2026.01 | - | 动作空间推理 | 📄 仅论文 | 显著减少长时域误差累积 |
1.6 架构演进与发展趋势
架构演进时间线(2022-2026)
| 年份 | 里程碑 | 代表工作 | 技术突破 |
|---|---|---|---|
| 2022 | 模块化阶段 | RT-1 | 大规模多任务Transformer,130k轨迹证明数据规模收益 |
| 2023初 | 语言规划探索 | SayCan, PaLM-E | LLM用于任务分解,但感知-控制分离 |
| 2023中 | 端到端VLA诞生 | RT-2, RT-X | VLM直接微调输出动作Token,涌现推理能力 |
| 2023下 | Action Chunking | ACT + ALOHA | 预测动作序列解决累积误差,低成本硬件普及 |
| 2023下 | 扩散策略 | Diffusion Policy | 多模态动作分布建模,精细操作突破 |
| 2024上 | 开源生态 | OpenVLA | 7B开源标杆,双编码器架构,OXE数据集 |
| 2024下 | Flow Matching | π₀ | 50Hz高频控制,折纸/折衣服等极精细任务 |
| 2025上 | 开放世界泛化 | π₀.5 | 未见家庭环境10-15分钟长时程任务 |
| 2025下 | RL重返舞台 | π*₀.₆ | RECAP优势条件化,数据飞轮转动 |
| 2026 | 动作空间推理 | ACoT-VLA | 动作CoT推理,长时域误差抗累积 |
从整体发展脉络来看,VLA研究经历了从模块化系统到端到端模型,再到端到端与层级混合的重要转变。
当前前沿方向:走向通用具身智能(2025-2026)
最新研究趋势表明,VLA正从单一操作任务向通用具身智能体演进,研究重点包括:
- 基于推理的VLA(Reasoning VLA)
- 多任务、多机器人的统一VLA
- VLA与世界模型的结合
- 从模仿学习到强化学习的转变
基于世界模型的VLA:世界模型被认为是机器人学习的”System 2”。如果VLA是”看到就做”的条件反射(System 1),世界模型则允许机器人在脑海中”想象”行动后果后再执行。近期,世界模型正逐渐成为合成数据的终极生成器,转动了VLA的”数据飞轮”:
- UniSim:首次证明可以将3D仿真、真实机器人数据和互联网视频混合训练出统一的世界模拟器
- NVIDIA Cosmos:为具身智能专门设计,能生成符合物理规律的视频轨迹
- GIGA-star:利用世界模型生成的合成数据训练VLA,效果提升可达30%
中国力量:中国在具身智能领域的参与正在从”跟跑”转向”参与定义规则”。
mindmap
root((中国具身智能生态))
巨头派
小米: Xiaomi-Robotics-0 / MoT架构
蚂蚁集团: LingBot-VLA / 跨形态泛化
阿里巴巴: 达摩院 VLA 预训练
创业精英派
智元机器人: Agibot GO-1 / 真机部署
自变量机器人: 空间推理 / 灵巧操作
星海图: G0 Plus / 真实数据集开源
星动纪元: ERA-42 / 人形机器人控制
学术开源派
清华 AIR: X-VLA / 软提示技术
上海 AI Lab: 联合推出 X-VLA / 标准化评测
1.7 VLA开源生态
开源 VLA 的崛起并非单一模型的功劳,而是 模型 + 数据 + 工具 + 硬件 三层生态形成的”组合拳”效应,使其能够与谷歌、特斯拉等闭源巨头抗衡。
graph TD
Data[OXE 数据集: 跨具身/多场景数据] --> Software[LeRobot: 标准化训练/部署工具]
Sim[Genesis: 极速物理仿真/合成数据] --> Software
Software --> Hardware[SO-100/Reachy Mini: $100-$250 低成本硬件]
Hardware --> Data
subgraph "开源生态闭环"
Data
Software
Sim
Hardware
end
subgraph "模型层"
OpenVLA[OpenVLA: 最强开源标杆]
Pi0[π₀: 高频精细控制]
XVLA[X-VLA: 跨具身软提示]
end
Software -.-> OpenVLA
Software -.-> Pi0
Software -.-> XVLA
1. 数据层:Open X-Embodiment (OXE)
OXE 是开源阵营最宝贵的资源,它打破了实验室之间的数据孤岛:
- 跨平台多样性:整合 22 种机器人形态,涵盖厨房、实验室、办公室等数百种场景。
- 涌现能力:实验证明,即使模型规模不是最大,只要数据够多样(如引入 OXE),模型也能涌现出原有的空间推理能力(如理解 “on” 和 “near” 的空间语义差异)。
- 标准化贡献:定义了统一的 RLDS 数据格式,解决了不同实验室数据格式不一的痛点。
2. 工具层:LeRobot 与 Genesis
- LeRobot (Hugging Face):由前特斯拉工程师 Remi Cadene 打造,统一了数据格式并一键集成多种策略模型,打通了从采集、训练到部署的全流程。
- Genesis (CMU):极速仿真工具,在一张 RTX 4090 上可实现每秒 4300 万帧的模拟速度(实时速度的 43 万倍),将”百万美元级别”的训练门槛降至数百美元。
- 生成式仿真谱系:RoboGen → Genesis → Gene 26.5:Genesis 的工程实现最初源自 RoboGen (ICML 2024) 项目(CMU、清华、MIT、UMass 联合)——RoboGen 论文中 Section 3.4 的脚注即明确写道 “Genesis is still under development … We build our system on top of an internal version”。该谱系于 2026 年 5 月由 Genesis AI 公司延伸为商业级基础模型 Gene 26.5:在自研 Genesis World 仿真器与 20w+ 小时多模态数据上训练单一 Flow Matching 模型,可完成 4 分钟级长程烹饪、毫米级移液、双臂魔方还原等任务,新任务仅需 20–30 分钟微调数据。这条主线印证了 RoboGen 提出的 “propose-generate-learn” 生成式仿真范式正从学术原型走向真实通用操作。
3. 硬件层:低成本与标准化
- Hugging Face 生态:推出了 $100 的 SO-100 机械臂和 $250 的 Reachy Mini,极大降低了具身智能研究的门槛。
- 通用软件层:如 OpenMind 平台,致力于构建跨厂商兼容的软件层,打破机器人系统的封闭性。
开源生态的三条核心启示
根据 2025-2026 年机器人行业的开源博弈,总结出以下三条核心技术与商业启示:
1. 数据多样性重于单一规模:实验(如 RT-2-X)证明,轨迹的多样性(Diversity)比纯粹的数据量更关键。引入 OXE 这种跨平台、跨场景的多样化数据,能让模型涌现出理解”空间语义(如 on vs near)”的能力,而单一机器人的海量重复数据则难以实现这种跨越。
2. 模型、数据、工具的”生态联动”:开源阵营之所以能挑战谷歌、特斯拉,靠的是 OXE (数据) + LeRobot (工具链) + Genesis (极速仿真) + $100 硬件 (SO-100) 形成的闭环。这种”组合拳”将具身智能的研究门槛从百万美元降低到了数百美元,让全球研究者能共同参与测试与改进。
3. 开源与闭源的模糊边界:RT-2-X 虽然是谷歌的闭源模型,但其训练依赖了 OXE 开源数据集;英伟达的 GR00T 介于开源与闭源之间(代码开放但深度绑定芯片生态)。这说明未来的博弈不在于单纯的代码是否公开,而在于谁能定义机器人行业的基础设施标准。
1.8 具身智能学习与入门路线
对于想要进入具身智能(特别是操作策略方向)的研究者或开发者,结合当前的开源生态,推荐以下四步递进式的学习路线:
第一步:动手实践(建立直觉)
- 不要上来就看论文,先花数百美元买一个低成本开源机械臂(如 SO-100 或类 ALOHA 单臂)。
- 运行经典算法:用几周时间跑通 ACT(Action Chunking)和 Diffusion Policy 的 Pipeline。不需要一开始就死磕数学原理,先建立起对”遥操作(Teleoperation)”、”数据采集”、”策略训练”和”真机部署推理”的物理体感。
第二步:跑通轻量级VLA(理解链路)
- 尝试小参数模型:例如基于 Hugging Face 的 SmolVLA(450M参数),它能在单张消费级GPU上轻松运行。
- 理解数据流:通过这个步骤理解”视觉 + 语言指令 -> 神经网络 -> 连续动作序列输出”的完整端到端链路是如何打通的。
第三步:体验SOTA模型(微调前沿基座)
- 微调 π₀ (Open Pi):基于 Physical Intelligence 开源的完整训练管线,收集 1-2 小时的特定任务数据,对 π₀ 进行微调。
- 这一步将让你对当前基于 Flow Matching 的 50Hz 高频精细控制能力有一个最前沿的直观认知。
第四步:真机项目落地(跨越Sim-to-Real)
- 必须走向真实物理世界。在仿真(Simulation)中达到100%成功率并不代表模型具有强鲁棒性,因为仿真环境往往缺乏真实的传感器噪声、光照变化和物理机械的间隙误差。
- 在真机上能稳定达到 60% 以上的成功率,才是跨越了真正的工程瓶颈。
2. VLA核心挑战
本章采用挑战驱动分类法(Challenge-Centric Taxonomy),围绕VLA研究的五大核心瓶颈进行组织,而非传统的架构或任务分类。这种分类方式更好地反映了当前VLA领域亟需突破的关键问题。
VLA研究的五大核心挑战体系:
flowchart TD
Root(("VLA 核心挑战体系")) --> C1["1. 表示 Representation"]
Root --> C2["2. 执行 Execution"]
Root --> C3["3. 泛化 Generalization"]
Root --> C4["4. 安全 Safety"]
Root --> C5["5. 数据 Data"]
C1 --> C1a["3D空间表示"]
C1 --> C1b["动态世界模型"]
C2 --> C2a["任务分解规划"]
C2 --> C2b["实时性优化"]
C3 --> C3a["Sim-to-Real 迁移"]
C3 --> C3b["持续技能获取"]
C4 --> C4a["可解释性 CoT"]
C4 --> C4b["人机协作交互"]
C5 --> C5a["多源数据整合"]
C5 --> C5b["标准化评测基准"]
这五大挑战形成了VLA系统的完整开发路径:
💡 核心链路概览:
- 表示 (Representation):建立多模态感知与物理世界的连接(2D → 3D/4D)
- 执行 (Execution):实现指令理解、分层规划与 30Hz+ 实时控制
- 泛化 (Generalization):从仿真迁移(Sim-to-Real)到开放世界持续进化
- 安全 (Safety):确保动作的可解释性(CoT)与人类交互的可靠性
- 数据 (Data):构建多源异构数据集(OXE)与标准化的评测基准(VLABench)
2.1 多模态对齐与物理世界建模
核心问题:弥合语义感知与物理交互之间的鸿沟,实现从2D图像到时空表示的跨越,并发展动态预测世界模型。
多模态对齐与物理世界建模的三层架构:
- 基础对齐层:语义到物理的接地(Vision-Language-Action对齐)
- 时空表示层:从2D图像到3D空间表示
- 动态预测层:世界模型与物理动力学建模
flowchart TB
L1["第一层:基础对齐层<br/>语义接地(OTTER、LIV、CLIP-RT)"]
L2["第二层:时空表示层<br/>2D→3D 空间表示(PointVLA、OccLLaMA)"]
L3["第三层:动态预测层<br/>世界模型与物理动力学(TriVLA、DreamVLA)"]
L1 --> L2 --> L3
style L1 fill:#ffe0b2,stroke:#e65100
style L2 fill:#e1f5fe,stroke:#0277bd
style L3 fill:#e8f5e9,stroke:#2e7d32
VLA模型需要将视觉-语言模型的语义理解能力转化为对物理世界的准确建模,这涉及三个层次的挑战:
2.1.1 语义到物理的接地(Semantic-to-Physical Grounding)
问题描述:如何将抽象的语言描述(如”红色的杯子”)映射到物理世界中的具体对象和可执行动作。
(1)Vision-Language Gap(视觉-语言鸿沟)
- 问题:RGB的高维感知空间与抽象符号语言之间的语义鸿沟
- 解决方案:
- OTTER:文本感知的特征提取机制
- LIV:针对机器人控制数据的对比学习框架
- 符号推理方式:ACT-LLM, Look Leap等利用LLM进行高层符号推理
(2)Vision-Language-Action Gap(视觉-语言-动作三元鸿沟)
- 问题:VLM的感知对齐能力如何转化为实际的物理动作执行
- 解决方案:
- 端到端微调:RT-2, OpenVLA通过动作token化实现VLM到VLA的转化
- 共享中间表示:CLIP-RT, Humanoid-VLA在动作和感知间建立共享语义空间
- 层级架构:引入显式规划层作为语义-动作的桥梁
- VoxPoser:LLM推理生成3D Affordance Map作为中间表示
(3)多模态感觉融合(Sensory Fusion)
- 问题:如何整合触觉、力传感、音频等额外模态
- 解决方案:
- 专业编码器 + 对比学习:TLA, OmniVTLA对齐多感觉模态
- 融合策略:深融合(Tactile-VLA)vs 模块化MoE融合(ForceVLA)
- 生成式方案:MultiGen在模拟器中生成多模态数据
代表性工作:
- CLAP:对齐视频视觉潜在空间与机器人动作空间
- Point-VLA:通过显式视觉提示(边界框)解决指代模糊
- VoxPoser:生成3D可供性图作为强中间表示
- Tactile-VLA/ForceVLA:整合触觉和力传感的多模态VLA
2.1.2 2D到3D的空间表示(2D-to-3D Spatial Representations)
问题描述:从2D图像输入推断3D空间结构,理解深度、遮挡和空间关系。
空间表示层次:
- 2.5D深度地图:Depth Helps, RoboFlamingo-Plus利用深度信息增强空间感知
- 点云表示:PointVLA, GeoVLA, FP3直接操作3D点云进行操作规划
- 体素/占据栅格:OccLLaMA, RoboMM使用体素化占据表示学习场景结构
- 4D表示(新方向):ARM4R预测3D点的时序运动轨迹,实现动态空间建模
代表性工作:
- OccLLaMA:基于占据网络的3D场景理解,学习体素化空间表示
- TraceVLA:3D轨迹追踪与预测,理解物体运动
- PointVLA/GeoVLA:直接在3D点云上进行操作推理
- ARM4R:预测3D点的运动轨迹,实现4D时空建模
2.1.3 动态世界建模(Dynamic World Modeling)
问题描述:预测物体交互的动态变化,理解物理规律和因果关系。
表示空间选择:
- 观察空间预测(高保真):TriVLA, UP-VLA预测未来视觉观察;CoT-VLA, DreamVLA生成视觉子目标
- 潜在空间预测(高效):VLM-in-the-Loop在压缩潜在空间进行快速预测;MinD轻量级潜在动力学模型
代表性工作:
- TriVLA:三角形架构融合过去-现在-未来的视觉表示
- VideoVLA:视频条件的世界模型,预测动作后果
- LUMOS:显式世界模型进行长时程规划
- DreamVLA:在”梦境”中模拟和优化动作序列
未来方向:
- 混合潜在-物理-语义世界模型:整合3D几何、物理动力学和语义属性
- 因果世界模型:显式建模动作-结果的因果关系
- 可学习物理先验:在神经网络中编码物理定律(守恒律、碰撞等)
2.2 指令跟随、规划与鲁棒实时执行
核心问题:解析复杂指令,进行分层任务分解,实现错误检测与自主恢复,并保证实时计算效率。
指令跟随、规划与实时执行的完整流程:
指令理解 → 任务分解与规划 → 动作执行 → 错误检测与恢复 → 实时性优化
flowchart LR
A["指令理解"] --> B["任务分解与规划"] --> C["动作执行"] --> D["错误检测与恢复"] --> E["实时性优化"]
D -->|重规划| B
style A fill:#f3e5f5,stroke:#7b1fa2
style C fill:#e8f5e9,stroke:#2e7d32
style D fill:#ffebee,stroke:#c62828
style E fill:#e3f2fd,stroke:#1565c0
2.2.1 复杂指令解析与理解
问题描述:理解多样化、组合式的自然语言指令,处理模糊性和不完整性。
开放式多模态指令:
- 混合文本+图像+草图:OE-VLA处理开放式混合模态指令;Interleave-VLA交错处理图像和文本序列
模糊和欠指定指令:
- 场景解析与验证:ThinkAct场景分析和反馈验证机制;DeepThinkVLA因果CoT推理和结果驱动RL
- 空间推理:InSpire显式空间推理提示,理解”左边”、”上面”等相对位置
- 主动澄清:AskToAct模糊识别模块+主动请求用户澄清
代表性工作:
- ThinkAct:思考-行动架构,在执行前进行推理验证
- InSpire:空间推理增强的指令理解
- AskToAct:主动询问机制,处理模糊指令
2.2.2 分层任务分解与规划
问题描述:将长时序复杂任务分解为可执行的子任务序列,并进行高层规划。
三大规划范式:
(1)语言驱动规划
- 单推理链方法:π0.5在单一推理链中生成明确的语言子任务;OneTwoVLA在关键决策点进行结构化文本推理
- 层级方法:Hi Robot两层架构(VLM规划 + VLA执行);LoHoVLA端到端学习的层级范式
(2)多模态中间表示规划
- 视觉驱动规划:CoT-VLA生成像素级视觉子目标;HiP三层架构(任务-子任务-动作)
- Affordance驱动规划:RT-Affordance预测可操作性;CoA-VLA的Chain-of-Affordance推理
(3)技能库组合规划
- 显式技能库:VLP预定义技能的组合;RoboBrain大规模技能记忆库
- 隐式技能学习:DexVLA billion参数的隐式技能表示;AgiBot World从大规模数据中自动发现技能
代表性工作:
- π₀.5:增强的推理能力,支持多步骤规划(详见经典论文第5.11节)
- Hi Robot:显式的两层层级架构
- CoT-VLA:视觉子目标作为思维链
- ACoT-VLA:动作空间推理(详见经典论文第5.13节)
- DexVLA:billion参数的灵巧操作专家
2.2.3 错误检测与自主恢复
问题描述:实时检测执行失败,并自主生成恢复策略。
关键技术:
- 失败预测:基于视觉反馈预测潜在失败
- 重规划机制:动态调整执行计划
- 链式思考推理:通过CoT进行故障诊断(如CoT-VLA)
代表性工作:
- Fast-ThinkAct:实时推理与失败恢复
- CoT-VLA:链式思考增强的VLA
2.2.4 实时性与计算效率
问题描述:满足高频控制的实时性要求(30Hz+),同时保证推理准确性。
四大优化方向:
(1)静态架构优化
- 压缩量化:BitVLA 1-bit量化;Evo-1 77M参数的超轻量模型
- 轻量级骨干网络:NORA, TinyVLA专为实时控制设计
- 线性注意力机制:SARA-RT, RoboMamba用Mamba/SSM替代Transformer的二次复杂度
(2)动态优化解码过程
- 动态推理路径:MoLe-VLA跳层推理;CEED-VLA, DeeR-VLA提前退出机制
- Token处理优化:VLA-Cache自适应KV缓存;SpecPrune-VLA token级别剪枝
- 加速解码:OpenVLA-OFT并行解码,25-50倍加速;Spec-VLA推测解码
(3)动作表示和生成范式优化
- 高效token化:FAST频率空间动作序列token化,15倍加速;VQ-VLA向量量化动作表示
- 异步执行:SmolVLA 450M参数实时运行;Real-Time Action Chunking动作块异步执行
- 加速扩散:Time-Diffusion Policy时间条件加速;Discrete Diffusion VLA离散扩散加速
(4)训练范式优化
- 训练时推理,推断时跳过:ECoT-Lite训练中使用推理,推断时直接输出
- 预测压缩表示:V-JEPA 2预测语义压缩表示而非像素
- 双系统架构:Fast-in-Slow快速System 1 + 慢速System 2
代表性工作:
- SmolVLA:450M参数实时运行
- FAST:动作tokenizer,15倍推理加速
- OpenVLA-OFT:优化微调,25-50倍加速
- RoboMamba:Mamba架构的线性复杂度
- MoLe-VLA:动态深度推理
未来方向:
- 自适应架构:根据任务难度自动调整推理深度和模型规模
- 统一决策Token:see-think-act的统一token流
- 硬件协同优化:专用芯片加速VLA推理
2.3 从泛化到持续适应
核心问题:实现开放世界泛化,支持持续学习与增量技能获取,完成sim-to-real迁移,并启用在线强化学习。
从泛化到持续适应的四层递进体系:
- 开放世界泛化:未见环境/物体/任务的零样本能力
- 持续学习:增量技能获取,避免灾难性遗忘
- Sim-to-Real迁移:缩小仿真与真实的差距
- 在线强化学习:从交互中自主学习和改进
flowchart TB
G1["开放世界泛化<br/>未见环境/物体/任务的零样本能力"]
G2["持续学习<br/>增量技能获取,避免灾难性遗忘"]
G3["Sim-to-Real 迁移<br/>缩小仿真与真实世界的差距"]
G4["在线强化学习<br/>从实时物理交互中自主学习"]
G1 --> G2 --> G3 --> G4
style G1 fill:#e3f2fd,stroke:#1565c0
style G2 fill:#e8f5e9,stroke:#2e7d32
style G3 fill:#fff3e0,stroke:#e65100
style G4 fill:#fce4ec,stroke:#880e4f
2.3.1 开放世界泛化(Open-World Generalization)
问题描述:在未见环境、未见物体和未见任务组合上的零样本或少样本泛化。
四大策略:
(1)知识迁移与利用
- 多任务/多机器人预训练:Octo在800k机器人轨迹上预训练;DexVLA billion参数扩散专家跨机器人形态预训练;EO-1在1.5M-EO-Data上预训练共享骨干
- 互联网/人类视频知识迁移:R3M在Ego4D等人类第一人称视频上预训练视觉编码器;GR系列(GR-1, GR-2)从人类视角视频迁移物理和交互知识
(2)范式级创新
- In-Context Learning:ICIL从prompt中的少量演示推断任务,无需重新训练
- 概念泛化:ObjectVLA联合训练机器人轨迹和box标注VL数据,实现零样本操作;LERF融合CLIP和3D NeRF实现自然语言定位和抓取
- 自适应范式:Align-Then-Steer非侵入式适应;Robot Utility Models (RUM)零样本部署
(3)增强数据多样性
- 数据增强:CACTI扩散修补技术生成多样化场景;GenAug文本到图像合成增强训练数据
- 语义增强:ROSIE VLM知识蒸馏到机器人策略
代表性工作:
- Octo:800k轨迹预训练的通用策略
- DexVLA:billion参数跨形态专家
- R3M/GR-2:从人类视频迁移知识
- ICIL:上下文学习范式
- ObjectVLA/LERF:概念级泛化
- Robot Utility Models:零样本家庭部署
2.3.2 持续学习与增量技能获取
问题描述:在不遗忘旧技能的前提下持续学习新技能。
两大策略:
(1)参数隔离与扩展
- 基于提示/码书学习:新技能独立编码为提示或码书向量,保持核心参数不变
- 模块化MoE架构:InstructVLA专家混合架构;iManip PerceiverIO架构实现模块化技能表示
(2)回放知识巩固
- 压缩经验回放:ExpReS-VLA压缩体验回放,高效存储历史经验
- 时间回放策略:iManip关键帧回放,保留重要状态转移
代表性工作:
- InstructVLA:MoE架构的终身学习
- iManip:模块化技能表示
- ExpReS-VLA:压缩经验回放
评测基准:
- LIBERO:首个终身机器人学习基准,评估技能保留和迁移
2.3.3 Sim-to-Real迁移
问题描述:缩小仿真训练与真实部署之间的性能差距。
两大策略:
(1)增强模拟保真度
- 高保真仿真器:ManiSkill3 GPU并行渲染+物理模拟,域随机化
- 稳定中间表示:SLIM使用分割+深度等对光照不敏感的表示,减少视觉域差异
(2)数据驱动模拟器
- 生成增强:GenAug无模拟器直接从文本生成训练数据
- 学习世界模型:DreamGen从真实数据学习生成模型;RynnVLA-001神经模拟器
(3)高效真实适应
- 快速微调:AdaWorld在少量真实数据上高效适应
- 鲁棒视觉表示:学习对光照、纹理变化不敏感的特征;自监督预训练(DINOv2等)
代表性工作:
- ManiSkill3:新一代GPU并行仿真器
- SLIM:稳定中间表示减少域差距
- GenAug:生成式数据增强
- AdaWorld:高效sim-to-real适应
未来方向:
- 神经模拟器:完全从数据学习的可微分模拟器
- 双向迁移:real-to-sim用于改进仿真器
2.3.4 在线强化学习
问题描述:通过与环境交互自主学习和改进策略。
两大方向:
(1)优化学习过程
- 知识迁移加速:RLDG蒸馏预训练VLA知识到RL策略;Refined Policy Distillation MSE约束保持预训练能力;iRe-VLA阶段性冻结-解冻策略
- 算法内部优化:CO-RFT分块时间差分学习,稳定训练
(2)自动化奖励生成
- 感知对齐奖励:VLM-RMs用VLM作为奖励模型;RoboCLIP CLIP对齐的奖励信号
- VLM批评:RL-VLM-F GPT-4V比较不同轨迹;GRAPE VLM生成密集奖励信号
- 代码生成奖励:Eureka LLM生成奖励函数代码;VLA-RL端到端VLA强化学习
代表性工作:
- π*₀.₆:从经验中学习,整合专家干预的RL(详见经典论文第5.12节)
- SERL:样本高效的机器人RL套件
- Eureka:LLM自动生成奖励函数
- VLA-RL:端到端VLA强化学习框架
- RLDG:知识蒸馏加速RL训练
未来方向:
- 形态无关表示:跨具身形态的策略迁移
- 零样本跨具身迁移:在一个机器人上学习,直接部署到另一个
- 自主开放式进化:部署→发现→进化的闭环系统
2.4 安全性、可解释性与可靠交互
核心问题:确保可靠性保证,提升可解释性,实现可信的人机交互,并满足安全约束。
安全性与可解释性的双层结构:
- 第一层:可靠性保证
- 基于约束的安全(规则约束、内部化约束)
- 学习对齐(值对齐、不确定性评估)
- 第二层:透明可信交互
- 增强过程可解释性(CoT、层级结构)
- 行为可预测性(外化决策逻辑)
flowchart TD
subgraph L1 ["第一层:可靠性保证"]
A1["基于约束的安全<br/>AutoRT / SafeVLA / VLSA-AEGIS"]
A2["学习对齐<br/>Gemini Robotics / GPI / RationalVLA"]
end
subgraph L2 ["第二层:透明可信交互"]
B1["增强可解释性<br/>CoT推理 / 层级架构 / ECoT"]
B2["行为可预测性<br/>外化决策逻辑 / CrayonRobo"]
end
L1 --> L2
style L1 fill:#e8f5e9,stroke:#2e7d32
style L2 fill:#e3f2fd,stroke:#1565c0
2.4.1 可靠性保证
三大范式:
(1)基于约束的安全范式
- 规则约束:AutoRT 宪法提示 (Constitutional Prompting) 硬编码安全规则,为机器人建立底线行为准则。
- 区块链硬约束:OpenMind 提出的前卫方案,将机器人安全规则写入以太坊区块链,防止机器人或恶意软件修改安全日志或绕过核心限制。
(2)学习对齐范式
- 值对齐:Gemini Robotics使用 Constitutional AI 后训练,使机器人决策对齐人类价值观。
- 不确定性评估:GPI置信度估计+回溯机制;RationalVLA可学习的拒绝token,主动拒绝不安全/无效指令。
(3)即插即用安全层
- VLSA-AEGIS:基于控制屏障函数(CBF)的安全层,无需修改 VLA 模型即可添加物理硬约束。
代表性工作:
- SafeVLA:约束MDP框架
- RationalVLA:学习拒绝危险指令
- GPI:不确定性感知的安全回溯
2.4.2 可解释性与可信赖性
两大方向:
(1)增强过程可解释性
- 链式思维(CoT):Diffusion-VLA自然语言中间推理步骤;ECoT可编辑的推理链;CoT-VLA视觉子目标作为可视化推理链
- 层级结构天然可解释:RT-H, HiRobot高层语言规划+低层执行;GraSP-VLA分层规划提供可追溯性
- 解码隐藏符号状态:DIARC-OpenVLA线性探针解释内部表示
(2)行为可预测性
- 外化决策逻辑:CrayonRobo视觉提示(箭头、高亮)外化决策过程
- 结构化任务切换:SwitchVLA显式任务切换机制(回滚+平滑过渡)
代表性工作:
- ECoT:可编辑的链式思考推理
- CoT-VLA:视觉CoT增强可解释性
- RT-H/HiRobot:层级架构的天然可解释性
- CrayonRobo:视觉化决策过程
2.4.3 安全约束与主动拒绝
两大技术路线:
- 插件式安全层:VLSA-AEGIS基于控制屏障函数(CBF)的即插即用安全层,在不修改VLA模型的前提下添加硬约束
- 可学习拒绝机制:RationalVLA学习拒绝不安全/无效指令,训练模型识别危险行为并主动拒绝
2.4.4 人机协作交互
关键能力:
- 意图识别:理解人类的隐含意图和目标;从不完整指令中推断完整任务
- 主动询问:AskToAct检测模糊指令时主动请求澄清;OneTwoVLA关键决策点主动询问
- 从反馈学习:Yell At Your Robot实时语言反馈纠正;π*₀.₆从专家干预中学习(详见经典论文第5.12节)
- 协作规划:共享心智模型;预测人类动作在协作环境中避免冲突
未来方向:
- 预测式协作:预测人类下一步动作,主动辅助
- 情境感知安全:根据环境动态调整安全边界
- 自然多模态交互:语言+手势+视觉指向的融合理解
2.5 数据构建与基准测试标准
核心问题:管理多源异构数据整合,建立标准化评测基准。
数据构建与评测标准双轨体系:
- 数据轨:表示层统一对齐 → 数据层增强优化 → 标准化基准构建
- 评测轨:全面性与标准化 → 任务广度与深度扩展 → 真实场景转仿真
flowchart LR
subgraph DataTrack ["数据轨道"]
D1["多源整合<br/>OXE / RLDS 格式"] --> D2["跨具身统一<br/>970k 轨迹 / 22 种机器人"] --> D3["合成数据<br/>InternData-A1 / 630k 轨迹"]
end
subgraph BenchTrack ["评测轨道"]
B1["仿真基准<br/>LIBERO / CALVIN"] --> B2["跨场景泛化<br/>SimplerEnv / RoboCasa"] --> B3["开放世界评测<br/>VLABench / 真实机器人"]
end
D3 -.->|"Sim-to-Real"| B3
style DataTrack fill:#fff3e0,stroke:#e65100
style BenchTrack fill:#f3e5f5,stroke:#6a1b9a
2.5.1 多源异构数据整合
三大层面:
(1)表示层统一对齐
- 离散动作表示:LAPA, Moto, UniVLA统一的动作token化方案;跨平台的动作空间标准化
- 共享语义空间:RDT-1B扩散Transformer学习跨机器人表示;AgiBot World大规模统一语义空间;Scaling Cross-Embodied Learning形态无关表示
- 多模态对齐:RT-1, GR-2视觉-动作对齐;ViSA-Flow视觉-空间-动作三元对齐;Humanoid-VLA全身控制的多模态对齐
(2)数据层增强与优化
- 生成增强:CACTI扩散修补生成多样场景;GenAug文本到图像合成;ROSIE VLM知识蒸馏;Residual RL Data Generation通过残差RL生成数据
- 混合优化:Re-Mix自适应采样权重平衡异构数据源
(3)标准化与基准构建
- 统一采集协议:RH20T严格时间对齐的多模态数据(视觉+触觉+音频);BridgeData V2标准化的桌面操作数据
- 跨域标准化:Open X-Embodiment 60+数据集,970k轨迹,22种机器人;RoboMM多模态跨机器人数据
- 人类中心多视角:Ego4D 3700小时第一人称视频;EPIC-KITCHENS厨房活动数据集;Ego-Exo4D同步的自我-外部视角
代表性工作:
- Open X-Embodiment:最大规模的跨机器人数据集
- WALL-OSS:聚合超过10000小时的自收集机器人轨迹
- RH20T:高质量多模态时间对齐数据
- RDT-1B:billion规模的扩散Transformer,统一表示
2.5.2 评测基准与标准化指标
三大方向:
(1)全面性与标准化
- 统一评测框架:Benchmarking VLAs统一输入/输出接口、标准化指标、多机器人支持
- 多维度评分:EUQ (Evaluating Uncertainty and Quality)人类评估的多维评分,超越简单成功率
- 基础设施:ManiSkill3 GPU并行,支持大规模评测;robosuite模块化仿真框架
(2)任务广度与深度扩展
- 长视距序列:CALVIN连续多任务执行,评估长期规划;5个连续任务成功率作为核心指标
- 终身学习:LIBERO 130个任务,4个套件(Spatial, Object, Goal, Long),评估技能保留和前向/后向迁移
- 多维对象/语言复杂度:From Intention to Execution (VLABench)分离意图理解和执行能力;Intention Score + Progress Score双指标
- 零样本多语言:SimplerEnv-Instruct 80个零样本任务,多语言指令
(3)真实场景转仿真
- 神经重建:PolaRiS将真实视频转化为交互式仿真环境,提供可控的评测环境
代表性工作:
- LIBERO:首个终身机器人学习基准,130个任务
- CALVIN:长时序多任务基准
- VLABench (Intention to Execution):分离意图和执行的评测
- SimplerEnv:标准化VLA评测平台,80个零样本任务
- PolaRiS:真实场景神经重建
- ManiSkill3:GPU并行高效评测
未来方向:
- Simulation-First, Failure-Centric Paradigm:以失败为核心的评测
- Turn Failure into Signal:将失败轨迹用于对比学习
- Comprehensive Diagnostic Stress Testing:超越二元成功率的细粒度诊断
2.5.3 数据高效学习
三大策略:
(1)数据增强
- 视觉增强:CACTI扩散修补生成多样化背景;GenAug文本到图像生成;颜色、光照、遮挡变化
- 轨迹增强:时间插值、噪声注入;反向轨迹生成
(2)主动学习
- 不确定性采样;多样性采样;优先标注难例
(3)迁移学习
- 预训练知识利用:VLM预训练(CLIP, SigLIP);人类视频预训练(Ego4D, GR-2);跨机器人迁移(Octo, RoboCat)
- 少样本微调:适配器方法轻量化微调;LoRA, AdaLoRA等参数高效微调
代表性工作:
- CACTI:扩散增强数据生成
- Octo:10次演示实现新任务适应
- ROSIE:VLM知识蒸馏减少数据需求
未来方向:
- 自监督预训练:利用大规模无标注视频
- 主动数据收集:机器人自主选择探索策略
- 合成到真实:完全在合成数据上训练,零样本迁移到真实
3. VLA主流数据集
VLA模型的性能高度依赖于高质量的训练数据。以下是VLA领域最具影响力的数据集。
快速参考:主流数据集概览
| 数据集 | 类型 | 规模 | 机器人/平台 | 发布年份 |
|---|---|---|---|---|
| Open X-Embodiment | 真实+跨具身 | 970k 轨迹 | 22种机器人 | 2023 |
| RT-1 Dataset | 真实 | 130k 轨迹 | Everyday Robot | 2022 |
| DROID | 真实,In-the-Wild | 76k 轨迹 | Franka Panda | 2024 |
| EO-1 Dataset | 真实+合成 | ~1.5M 轨迹 | 多种机械臂 | 2024 |
| AgiBot World | 真实,多具身 | 100万+ 轨迹 | 多种机器人 | 2025 |
| BridgeData V2 | 真实 | 60k 轨迹 | WidowX 250 | 2023 |
| ALOHA / ACT | 真实,双臂 | ~50条/任务 | ALOHA双臂 | 2023 |
| UMI Dataset | 真实,手持 | 数百~数千条 | 手持夹爪→Franka | 2024 |
| RH20T | 真实,多模态 | 多模态同步 | 多种机械臂 | 2024 |
| LeRobot (HuggingFace) | 数据中台 | 100+个数据集 | 多平台 | 2024 |
| CALVIN | 仿真 | 6小时遥操作 | PyBullet | 2021 |
| LIBERO | 仿真 | 65k 轨迹 | MuJoCo | 2023 |
| RLBench | 仿真 | 100+任务 | CoppeliaSim | 2019 |
| MimicGen | 仿真(自动生成) | ~50k 轨迹 | MuJoCo | 2024 |
| MetaWorld | 仿真 | 50任务标准化 | MuJoCo (Sawyer) | 2020 |
| ManiSkill3 | 仿真 | GPU并行生成 | 多种机器人 | 2024 |
| RoboCasa | 仿真 | 家庭场景 | MuJoCo | 2024 |
| Ego4D | 人类第一视角 | 3600小时视频 | — | 2022 |
| SimplerEnv | 评测基准 | 80任务 | 多平台 | 2024 |
| VLABench | 评测基准 | 多维评测 | 仿真 | 2025 |
3.1 大规模跨机器人数据集
Open X-Embodiment Dataset

基本信息:
- 发布时间:2023年10月
- 数据规模:970k条真实机器人轨迹,60+个数据集
- 机器人平台:22种不同的机器人(单臂、双臂、移动操作、人形等)
- 任务类型:多样化的操作任务(抓取、放置、组装、厨房任务等)
数据特点:
- 跨机器人统一格式:RLDS (Reinforcement Learning Datasets)标准
- 多模态观察:RGB图像、深度图、本体感觉
- 语言标注:自然语言任务描述
- 动作表示:统一的动作空间定义
- 支持跨具身形态泛化研究
核心贡献:
- 首个大规模跨机器人数据集
- 定义了机器人数据集的事实标准
- 催生了RT-X、OpenVLA等一系列跨机器人模型
应用模型:
- RT-X:在OXE上训练的跨机器人策略
- OpenVLA:7B参数开源VLA模型
- Octo:通用机器人策略
- DexVLA、RDT-1B等最新VLA模型
获取方式:https://robotics-transformer-x.github.io/
EO-1 Dataset
基本信息:
- 数据规模:约1.5M条轨迹(EO-Data,含真实+合成数据)
- 机器人平台:多种商用机械臂(Franka、UR系列为主)
- 采集方式:大规模人工遥操作 + 自动化数据扩增流水线
数据特点:
- 规模超大:在OXE(970k)基础上进一步扩大规模
- 多任务覆盖:桌面抓取、组装、物体重排、厨房任务等
- 质量筛选:引入自动轨迹评分,过滤低质量演示
- 数据飞轮:EO-1模型部署后持续回收数据,形成闭环迭代
应用:EO-1 通用操作模型预训练
WALL-OSS Dataset
基本信息:
- 数据规模:10,000+ 小时自收集机器人操作轨迹
- 机器人平台:移动操作机器人(Mobile Manipulation)
- 采集方式:大规模自主探索 + 人工标注纠正
数据特点:
- 长时程任务:平均单条轨迹时长远超普通抓取数据集
- 真实家庭场景:厨房、卧室、客厅等多种非结构化环境
- 分层结构:同时记录高层规划决策和低层关节控制动作
- 自主采集优势:大幅降低人工遥操作成本,可持续规模化
应用:大规模分层VLA预训练,支持移动操作长时程任务
RT-1 Dataset
基本信息:
- 发布时间:2022年12月(Google Robotics)
- 数据规模:130k条真实机器人轨迹
- 机器人平台:Everyday Robot(Google定制移动操作机器人)
- 采集周期:17个月持续采集
- 任务类型:700+种日常办公/厨房操作任务
数据特点:
- 高质量专家演示:经专业训练的机器人操作员采集,轨迹成功率高
- 真实办公环境:Google办公楼真实场景,非受控实验室环境
- 丰富语言多样性:同一任务有多种自然语言表达方式(如”把苹果放到碗里” / “将苹果移入容器”)
- 密集标注:动作标注包含末端执行器6DoF位姿、夹爪开合、底盘运动
- 任务层次:包含单步任务(拾取)和多步复合任务(开柜门-取物-关门)
数据格式:
- 观察:单目RGB图像 + 自然语言指令
- 动作:末端执行器位移(x, y, z, roll, pitch, yaw)+ 夹爪状态
应用模型:
- RT-1:在此数据上从零训练的高频控制策略
- RT-2:使用此数据微调PaLI-X/PaLM-E VLM
- 作为OXE数据集子集广泛用于跨机器人训练
3.2 双臂与灵巧操作数据集
ALOHA / ACT Dataset
基本信息:
- 发布时间:2023年(ACT论文,Stanford IRIS Lab)
- 数据规模:每个任务约50条人工演示
- 机器人平台:ALOHA双臂机器人(低成本桌面系统,总成本约$20k)
- 采集方式:人类遥操作——操作者控制”主臂”,机器人跟随复现
数据特点:
- 双臂协同:同时记录左右两臂的关节位置、速度、力矩与抓取状态
- 高频采集:50Hz动作帧率,适配精细操作
- 多样化任务:折叠衣物、整理厨具、穿针引线、手术动作模拟等
- 观察模态:4路RGB相机(左/右腕部 + 左/右侧视)+ 本体感觉
关键任务列表:
| 任务 | 难点 |
|---|---|
| 折叠衬衫 | 柔性物体变形预测 |
| 将碗叠放入碗架 | 双手力协调 |
| 开冰箱取饮料 | 长时序、多子任务 |
| 拧紧瓶盖 | 精细操作+力控制 |
影响:
- 直接催生 ACT(Action Chunking with Transformers)方法论
- ALOHA硬件设计完全开源,引爆学界双臂研究热潮
- 后续 π₀.5 等大量工作均采用 ALOHA 硬件采集数据
获取方式:https://mobile-aloha.github.io/
UMI (Universal Manipulation Interface) Dataset
基本信息:
- 发布时间:2024年(Stanford + Columbia)
- 数据规模:数百至数千条轨迹(按任务)
- 采集方式:手持夹持器(无需机器人),操作者手持装置自由操作
数据特点:
- 设备极简:用GoPro + 3D打印夹爪即可采集,成本极低
- 隐式推理:延迟观察(推理时忽略最近0.2s图像),让模型自动预测接触时刻
- 自然场景多样性:采集者可在任意真实场景自由操作,无需固定机器人工位
- 推理接口统一:采集数据直接迁移到Franka等标准机器人执行
应用模型:
- Diffusion Policy(UMI版本)
- UMI-on-Legs(四足机器人上肢任务)
获取方式:https://umi-gripper.github.io/
3.3 模拟器数据集
CALVIN (Composing Actions from Language and Vision)
基本信息:
- 发布时间:2021年(University of Freiburg)
- 环境:PyBullet仿真器(Franka Panda机械臂)
- 数据规模:约6小时人类遥操作Play数据
- 任务类型:34种语言条件操作任务的长时序组合
数据特点:
- Play Data范式:数据采集时操作者随机操作,不针对特定任务,大幅降低采集成本
- 后验标注:采集完成后将轨迹片段与任务语言描述自动对齐
- 多步骤链:评测时要求连续完成1-5个任务(ABCD→D split)
- 4个场景变体(Split):A、B、C(训练)、D(测试),光照/物体布局各异
标准评测协议(ABCD→D split):
| 指标 | 含义 |
|---|---|
| LH-MTLC 1 | 单任务连续成功率 |
| LH-MTLC 5 | 五任务连续成功率 |
| Avg. Len. | 平均连续成功任务数(最高5) |
目前 SOTA:GR-2 (2024) 实现 Avg. Len. ≈ 4.5+
应用:
- 语言条件长时程操作研究的核心基准
- 广泛用于ACT、Diffusion Policy等方法的评测对比
官网:http://calvin.cs.uni-freiburg.de/
LIBERO (Lifelong Benchmark for Robot Manipulation)
基本信息:
- 发布时间:2023年(CMU + Stanford)
- 环境:MuJoCo/RoboSuite仿真器(Franka Panda)
- 任务数量:130个任务,每任务500条专家演示(共65,000条轨迹)
数据特点:
- 持续学习设计:专为评测”学新任务时遗忘旧任务”问题而设计
- 任务套件阶梯式:从空间推理 → 物体泛化 → 目标泛化 → 长时序,难度递增
- 专家演示质量高:基于RoboSuite的运动规划器自动生成高成功率演示
四个任务套件详解:
| 套件 | 任务数 | 核心评测能力 | 示例任务 |
|---|---|---|---|
| LIBERO-Spatial | 10 | 空间关系推理 | “把碗放到架子左边” |
| LIBERO-Object | 10 | 物体类别泛化 | 识别和操作未见物体 |
| LIBERO-Goal | 10 | 目标状态泛化 | 同样物体、不同目标状态 |
| LIBERO-Long | 10 | 长时序多步骤 | 5个子任务的组合序列 |
持续学习评测指标:
- FWT(前向迁移):学新任务对旧任务的正向影响
- BWT(后向迁移/遗忘):学新任务导致旧任务性能下降
应用:
- VLA持续学习研究的标准基准
- OpenVLA、RoboFlamingo等模型的性能对比平台
官网:https://libero-project.github.io/
RLBench
基本信息:
- 发布时间:2019年
- 环境:CoppeliaSim(V-REP)
- 任务数量:100+任务
数据特点:
- 涵盖多种操作技能
- 提供视觉观察和状态信息
- 支持多种机器人平台
任务类别:
- 抓取和放置
- 工具使用
- 组装任务
官网:https://sites.google.com/view/rlbench
MimicGen
基本信息:
- 发布时间:2024年(NVIDIA + UT Austin)
- 核心思路:用少量人类演示(约10条)自动生成大量(1000+条)多样化轨迹
数据特点:
- 数据扩增:通过分解-重组子任务轨迹,自动适配新物体位置/姿态
- 无需额外标注:完全自动化,人工成本接近于零
- 支持多环境:MuJoCo/RoboSuite,官方提供数千条生成轨迹
数据规模:公开 ~50k 条生成轨迹,涵盖 18 类任务
应用:
- Diffusion Policy、ACT等方法的数据增强基线
- 验证”稀疏人类演示 → 大规模训练数据”可行性
官网:https://mimicgen.github.io/
MetaWorld
基本信息:
- 发布时间:2020年(Stanford)
- 环境:MuJoCo仿真器(Sawyer机械臂)
- 任务数量:50个标准化操作任务
任务结构:
- ML10:10任务元学习基准
- ML45:45任务元学习基准
- MT50:50任务多任务学习基准
数据特点:
- 任务覆盖面广(抓取、推动、翻转、穿孔、拧螺丝等)
- 任务设计极度标准化,统一状态/动作空间
- 评估多任务学习和少样本泛化的经典基准
应用:
- 大量VLA与强化学习方法的对比基线
- 多任务学习研究标配
官网:https://meta-world.github.io/
3.4 真实世界数据集
Bridge Dataset (BridgeData V2)
基本信息:
- 发布时间:2023年(UC Berkeley RAIL Lab)
- 数据规模:60,096条真实机器人轨迹
- 机器人平台:WidowX 250(低成本6DoF桌面机械臂,约$3,500)
- 采集场景:24个不同真实场景(厨房操作台、桌面、架子等)
数据特点:
- 低成本硬件验证:证明廉价机械臂可采集高质量训练数据
- 任务多样性:包括抓取、放置、翻转、拖拉、穿插、扫描等多类操作
- 语言条件:每条轨迹配有语言描述任务目标
- 人类遥操作:通过SpaceMouse采集,轨迹自然流畅
V2相比V1的改进:
- 新增 16,000+ 轨迹,场景扩充至 24 个
- 标准化采集协议,各场景使用统一相机角度
- 引入自动质量筛选流程
- RLDS格式标准化,直接兼容OXE
应用:
- Octo 通用机器人策略的核心训练数据
- OpenVLA预训练数据之一
- 模仿学习与Sim-to-Real研究基线
- 完整收录于Open X-Embodiment数据集
官网:https://rail-berkeley.github.io/bridgedata/
RH20T Dataset
基本信息:
- 发布时间:2024年(上海AI实验室 + 香港大学)
- 数据规模:110,000+ 条多模态同步轨迹
- 机器人平台:多种机械臂(Franka、UR5、xArm等)
- 特点:迄今为止时间同步精度最高的多模态机器人数据集
传感器配置:
- 视觉:RGB-D(Realsense D435i,1280×720@30Hz)
- 触觉:高分辨率触觉传感器(手指接触力/形变)
- 音频:操作声音同步录制(夹取、碰撞等声学信号)
- 本体感觉:关节位置、速度、力矩@500Hz
- 时间同步精度:微秒级硬件触发
数据特点:
- 精细操作覆盖:拧螺丝、剪纸、折纸等需要触觉反馈的精密任务
- 多机器人平台:同一任务在不同机械臂上重复采集,便于跨平台研究
- 失败案例保留:包含部分失败轨迹,用于对比学习
应用:
- 触觉-视觉融合VLA训练(Tactile-VLA, OmniVTLA)
- 接触丰富操作(Contact-rich Manipulation)研究
- 多模态感知对齐研究
DROID Dataset
基本信息:
- 发布时间:2024年(Stanford + Berkeley + CMU 等多机构联合)
- 数据规模:76,188条真实机器人操作轨迹,约350小时
- 机器人平台:Franka Panda
- 采集地点:全球50个不同地点(实验室、厨房、办公室等)
数据特点:
- In-the-Wild多样性:50个采集地点带来极高的场景多样性
- 86类任务:覆盖抓取、推动、翻转、清洁、整理等广泛操作
- 双目视角:腕部摄像头 + 外部固定摄像头
- 语言标注:每条轨迹附带自然语言任务描述
- 数据格式:RLDS标准,兼容OXE生态
质量特点:
- 专业采集员培训保证基础质量
- 跨场景一致的采集协议
- 超出OXE子数据集的场景多样性
应用:
- 大规模真实世界VLA预训练
- 跨地点泛化研究基准
- OpenVLA-OFT等模型微调
获取方式:https://droid-dataset.github.io/
Language-Table
基本信息:
- 发布时间:2022年
- 数据类型:真实桌面操作
- 任务类型:语言条件的物体重排列
数据特点:
- 简化的二维操作任务
- 清晰的语言-动作对应
- 便于快速原型开发
应用:
- 语言理解研究
- 策略学习方法验证
AgiBot World
基本信息:
- 发布时间:2025年(AgiBot / 智元机器人)
- 数据规模:100万条轨迹,覆盖多种机器人平台
- 采集方式:人类遥操作 + 自主采集
数据特点:
- 规模领先:目前公开规模最大的真实机器人操作数据集之一
- 多具身形态:单臂、双臂、移动操作、人形机器人
- 场景多样化:工业制造、家庭服务、餐饮、仓储等场景
- 标准化格式:兼容RLDS,可与OXE生态无缝对接
应用:
- 大规模跨具身VLA预训练
- 国内机器人企业数据生态建设参考
获取方式:https://agibot-world.com/
LeRobot Dataset (HuggingFace)
基本信息:
- 发布时间:2024-2025年(HuggingFace)
- 定位:机器人学习领域的开源数据中台
数据特点:
- 统一接口:100+个数据集(包含OXE子集、ALOHA、Bridge等)通过统一API访问
- 标准化格式:基于Apache Parquet,支持流式加载
- 可视化工具:内置数据浏览器,可在线预览轨迹
- 社区驱动:研究者可直接上传自采数据集,共建生态
支持的数据集示例:lerobot/pusht、lerobot/aloha_sim_、lerobot/xarm_
应用:
- 作为统一接口接入多来源数据训练VLA
- 快速搭建机器人学习基线
官网:https://huggingface.co/lerobot
3.5 人机交互数据集
Ego4D
基本信息:
- 发布时间:2022年
- 数据规模:3,600小时第一人称视频
- 场景类型:日常生活活动
数据特点:
- 人类操作演示
- 丰富的语言标注
- 多样化的交互场景
VLA应用:
- 从人类视频中学习操作策略
- 理解人类意图和目标
3.6 评测基准
SIMPLER / SimplerEnv (Simulation Platform for Embodied Learning and Evaluation Research)
基本信息:
- 发布时间:2024-2025年
- 目标:标准化的VLA评测框架
评测内容:
- SimplerEnv-Instruct:80个零样本任务,多语言指令支持
- 跨任务泛化
- 跨环境泛化
- 鲁棒性测试
特点:
- 统一的输入输出接口
- 标准化的评测指标
- 支持多种机器人平台
应用:
- ICLR 2026等会议广泛使用
- 比较不同VLA模型的性能
- π0, OpenVLA等模型的官方评测平台
官网:https://simpler-env.github.io/
VLABench (From Intention to Execution)
基本信息:
- 发布时间:2025年
- 目标:分离评测VLA的意图理解和执行能力
核心指标:
- Intention Score (IS):评估指令理解的准确性
- Progress Score (PS):评估任务执行进度
- 双指标分离意图和执行两个维度
评测维度:
- Seen objects (已见物体)
- Unseen objects (未见物体)
- Unseen colors (未见颜色)
- Unseen textures (未见纹理)
- Unseen scenes (未见场景)
特点:
- 细粒度诊断VLA能力边界
- 超越二元成功率的多维评估
应用:
- ACoT-VLA等最新模型的评测
- 识别模型的弱点和改进方向
ManiSkill3
基本信息:
- 发布时间:2024年
- 特点:GPU并行高性能仿真器
技术特点:
- GPU加速:大规模并行仿真
- 域随机化:自动生成多样化场景
- 物理精度:高保真物理模拟
- 渲染质量:逼真的视觉渲染
应用:
- 大规模数据生成
- 快速策略评估
- Sim-to-Real研究
官网:https://maniskill.ai/
RoboCasa
基本信息:
- 发布时间:2024年(UT Austin ARISE Lab)
- 环境:MuJoCo/RoboSuite仿真器(Franka Panda双臂)
- 场景类型:逼真的家庭厨房环境
特点:
- 100+种厨房布局:随机化橱柜位置、灶台样式、照明条件
- 150+种家庭物品:覆盖厨房常见食材、餐具、电器
- 长时程任务:超市购物→放入冰箱、备餐→烹饪等多步骤任务
- 自动数据生成:配合MimicGen可大规模生成演示数据
- 人形机器人支持:提供双臂操作接口,适配具身机器人研究
任务类别(共100+任务):
- PnP(Pick and Place):从A处取物放到B处
- Drawer/Cabinet操作:开关抽屉、柜门
- Boil/Fry:烹饪动作模拟
- ArrangeItems:物品摆放整理
应用:
- 家庭服务机器人长时程操作研究
- 高数据多样性的VLA预训练数据源
4. VLA的应用场景
工业制造
VLA模型在工业自动化中展现出巨大潜力,能够处理多样化的生产任务。
工业场景中的VLA应用:
| 应用场景 | VLA能力需求 | 典型任务 |
|---|---|---|
| 质量检测 | 视觉缺陷识别 + 自然语言标准理解 | “检查零件表面是否有划痕” |
| 柔性装配 | 视觉定位 + 精细操作 | “将A部件插入B部件的孔中” |
| 智能分拣 | 多物体识别 + 动态规划 | “将红色零件放入左侧托盘” |
应用示例:
- 智能装配线:基于语言指令调整装配流程
- 质量检测:结合视觉检测和操作反馈
- 柔性制造:快速适应产品变化
服务机器人
在家庭和商业服务场景中,VLA使机器人能够理解和执行多样化的用户指令。
典型应用领域:
- 家庭服务:理解”帮我整理客厅”等开放式指令,执行物体重排列、清洁等复合任务(如π₀.5在新家庭环境中的10-15分钟长时程任务)
- 餐饮服务:识别菜品 + 理解点餐指令 → 配送和上菜动作
- 医疗辅助:理解医护人员指令 + 精确操作 → 递送医疗器械、协助护理
关键技术:开放世界泛化、人机交互、安全性保证
仓储物流
VLA模型使仓储机器人能够处理更复杂、更灵活的物流任务。
| 环节 | VLA优势 | 传统方案痛点 |
|---|---|---|
| 智能拣选 | 自然语言订单理解 + 视觉识别 | 需要预定义所有SKU位置 |
| 动态码垛 | 理解”易碎品放上层”等约束 | 固定码垛模式,缺乏灵活性 |
| 异常处理 | 识别损坏物品并自主决策 | 需要人工介入 |
商业价值:减少人工标注成本,适应SKU快速变化,提升仓储自动化柔性
农业自动化与建筑施工
- 农业:精准采摘(识别成熟果实)、植物护理(修剪、施肥)、自动化收获
- 建筑:自动化砌砖、焊接作业、建筑材料搬运
5. 经典论文深度解析
为了帮助读者深入理解VLA领域的关键突破,本章精选11篇奠基性和前沿论文进行详细解读。这些论文代表了VLA研究从诞生(2022年RT-1)到快速发展(2026年最新工作)的完整脉络,涵盖了架构创新、训练范式、推理增强、开放世界泛化等核心方向。
论文选择标准:
- 奠基性工作:开创新方向或范式(RT-1, RT-2, Diffusion Policy)
- 里程碑模型:显著提升性能或开源影响力(OpenVLA, π₀系列)
- 前沿突破:2025-2026年的最新进展(π*₀.₆, ACoT-VLA, VLM4VLA, TwinBrainVLA)
- 技术多样性:覆盖不同架构、训练方法和应用场景
每篇论文的解读包括:精华提炼、研究背景、核心方法、关键结果和局限性分析,帮助读者快速把握要点并理解技术演进脉络。
5.1 RT-1 (2022) {#5-1-rt-1-2022}
Robotics Transformer for Real-World Control at Scale
📄 Paper: https://arxiv.org/abs/2212.06817
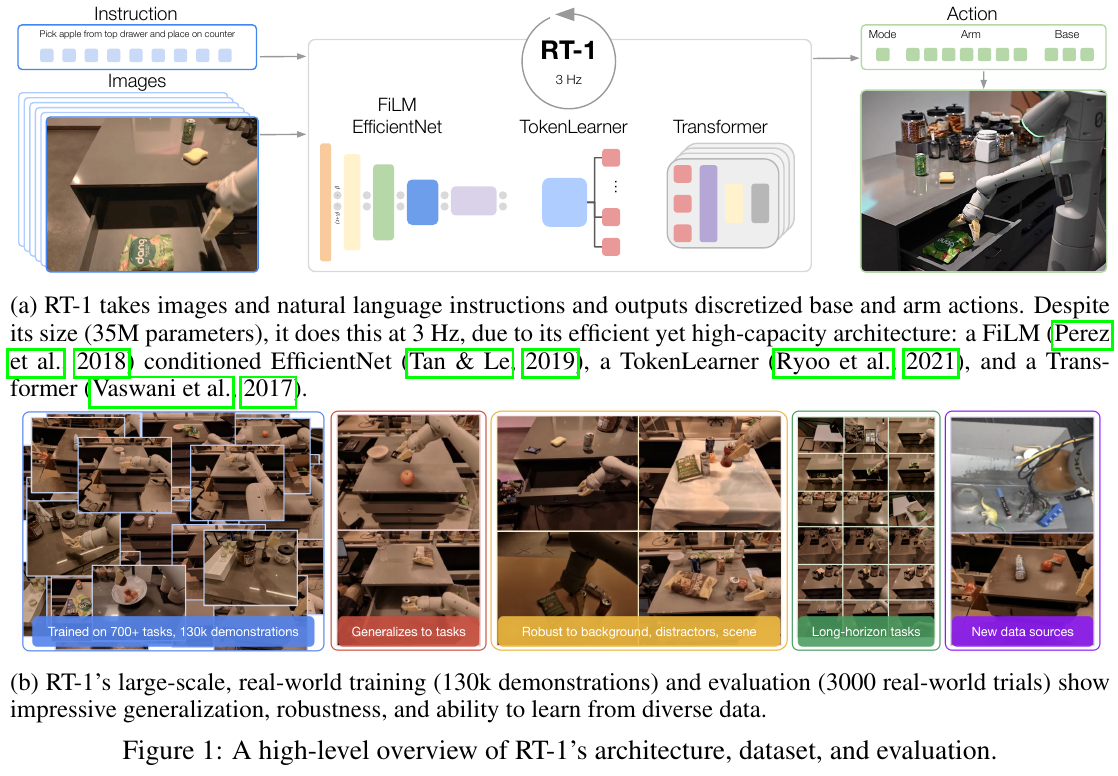
精华
RT-1 的核心贡献在于证明了 Transformer 架构结合大规模真实机器人数据可以在数百种任务上达到实用水平的性能。其关键设计哲学——”大规模数据 + 适度架构”——打破了当时”机器人需要精心设计专用网络”的固有认知。Token Learner 的引入将视觉 token 从 512 压缩到 8,实现了高效推理;动作离散化(256 bins)与自回归生成的组合为后续 VLA 研究奠定了动作建模范式。
研究背景/问题
2022 年以前的机器人控制方法普遍依赖小规模数据训练的专用网络,难以泛化到新任务和新场景。语言和视觉领域已验证 Transformer + 大规模数据的有效性,但能否将同样范式迁移到真实世界机器人控制尚未被证明。核心问题:能否通过大规模多任务真实机器人数据训练单一 Transformer 网络,使其在数百种任务上达到高成功率并泛化到未见任务?
主要方法/创新点
架构设计:
| 模块 | 设计 | 作用 |
|---|---|---|
| 视觉编码 | EfficientNet-B3 + Token Learner | 将图像压缩为 8 个视觉 token,高效提取语义特征 |
| 语言编码 | Universal Sentence Encoder (USE) | 将任务指令映射为固定长度嵌入 |
| 骨干网络 | Transformer(11层,38M 参数) | 融合视觉和语言 token,自回归生成动作 token |
| 动作建模 | 离散化(256 bins/维) | 11 维动作空间(7-DOF 臂 + 2 夹爪 + 终止标志)均匀量化 |
数据规模:在 Everyday Robots 机器人上采集 130k 条真实轨迹,覆盖 700+ 任务、多种物体和场景,历时 17 个月人工遥操作。
推理效率:Token Learner 将 EfficientNet 输出的 512 个空间 token 压缩为 8 个,使单步推理速度达到 3Hz,满足实时控制需求。
核心结果/发现
已见任务(training distribution):
- 平均任务成功率 97.0%,显著超过 BC-Z(66.0%)和 SayCan(65.8%)
- 在 700+ 不同任务上保持稳定高性能,证明大规模多任务训练的有效性
未见任务(zero-shot generalization):
- 未见任务成功率 76.0%,远超先前方法的 20-40% 水平
- 证明 Transformer 架构能从多任务训练中习得可迁移的底层技能
数据规模消融:
- 使用全量数据(130k)vs 1/3 数据:成功率从 97% 降至 68%
- 明确的数据规模收益曲线,验证”更多数据→更好性能”假设
局限性
- 语言指令仅用于任务选择(”pick up the apple”),缺乏真正的语义理解和推理能力
- 数据采集代价高昂(需要专业操作员和特定机器人硬件),难以复现
- 视觉编码器采用固定分辨率,不擅长细粒度精细操作
- 动作量化引入精度损失,在精细接触任务中性能下降明显
- 依赖单一固定机器人平台,不具备跨具身迁移能力
5.2 RT-2 (2023) {#5-2-rt-2-2023}
Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
📄 Paper: https://arxiv.org/abs/2307.15818
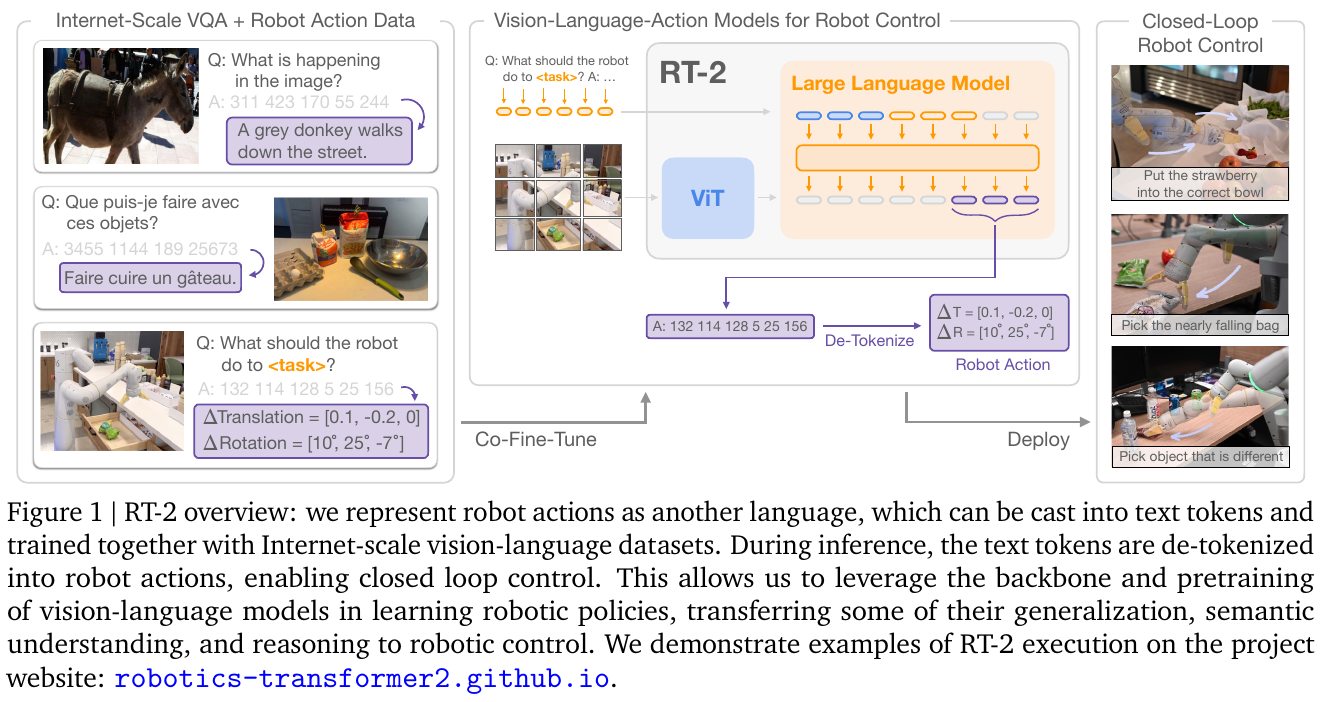
精华
RT-2 是 VLA 领域真正的范式突破:通过将机器人动作表示为语言 token,VLM 的 next-token prediction 能力被无缝扩展到动作生成,无需修改模型架构。最关键的发现是”涌现能力”(emergent capabilities)——RT-2 可以执行从未在机器人数据中出现过的新型推理任务(如”拿起可以灭火的物体”),这直接来自 VLM 的互联网知识。这一发现重新定义了机器人学习的可能性边界。
研究背景/问题
大型视觉-语言模型(VLM)已在跨模态理解和常识推理方面表现出色,但这些能力无法直接用于机器人控制。传统做法是将 VLM 用于高层规划,再配合低层控制器执行动作——这引入了模块间的信息损失和对齐误差。核心问题:能否直接将 VLM 微调为能执行物理动作的 VLA 模型,同时保留预训练的语义理解和推理能力?
主要方法/创新点
核心创新:动作作为语言 token
传统方式: 视觉 + 语言 → VLM → 文本规划 → 低层控制器 → 动作
RT-2方式: 视觉 + 语言 → VLA → 动作token序列(直接控制)
架构:
- 基础模型:PaLI-X(5B 参数)或 PaLM-E(55B 参数)
- 将 7-DOF 机器人动作(末端执行器位姿 + 夹爪)离散化为 256 个 bin,表示为整数字符串 token(如 “128 97 234 45 189 203 1”)
- 与视觉-语言数据联合微调(co-fine-tuning):交替在机器人演示数据和互联网 VL 数据上训练,防止灾难性遗忘
关键设计决策:
- 机器人数据(约 100k 轨迹)与互联网 VL 数据(约 100B token)混合训练
- 动作 token 直接插入语言词表,利用自回归解码生成动作序列
- 支持 chain-of-thought reasoning:在生成动作前先生成推理文本
核心结果/发现
基础性能:
- 在已见任务上成功率 62%(RT-2, 5B),与 RT-1(71%)相近但模型参数增加了 38 倍
- RT-2-X(55B)在 Google 机器人评测上平均成功率 78.3%
涌现推理能力(关键发现): | 评估类型 | RT-2-X 成功率 | RT-1 成功率 | |———|————-|———–| | 场景理解推理(”将最近的物体放到纸板上”) | 55% | 22% | | 符号推理(”执行加法后把结果数量的物体放入碗”) | 50% | 10% | | 常识知识(”拿起可以灭火的物体”) | 60% | 25% |
Chain-of-Thought 推理:
- 在执行动作前先生成自然语言推理步骤,成功率在部分任务上提升 13%
局限性
- 55B 参数模型计算代价极高,无法在边缘设备部署,推理速度仅约 1-3Hz
- 完全闭源(Google 内部),外部研究者无法复现或微调,推动了后续开源工作(OpenVLA)
- 动作 token 化引入精度损失,难以执行需要亚毫米精度的精细操作
- co-fine-tuning 对数据混合比例敏感,调试复杂
- 在全新机器人平台上的跨具身迁移能力仍有限
5.3 RT-X / Open X-Embodiment Dataset (2023) {#5-3-rt-x-2023}
Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition
📄 Paper: https://arxiv.org/abs/2310.08864
精华
OXE 和 RT-X 共同验证了一个重要假设:来自不同机器人的数据可以相互增益,跨具身训练不会因为形态差异而造成干扰,反而带来正迁移。这为机器人学习从”实验室孤岛”走向”共享数据生态”提供了关键证据,是 AgiBot World、InternData-A1 等后续大规模数据集建设的理论基础。
研究背景/问题
机器人学习数据极度碎片化:每个实验室独立采集数据,使用不同机器人、不同任务定义、不同存储格式,导致数据无法共享和复用。即便单个实验室拥有足够的数据,也只能训练适用于本实验室机器人的专用模型。核心问题:能否将来自全球多个实验室、22 种不同机器人的数据统一整合,并证明联合训练的模型优于仅在单一机器人数据上训练的模型?
主要方法/创新点
Open X-Embodiment 数据集:
- 规模:970k 条机器人轨迹,22 种不同机器人平台,来自全球 21 个机构
- 统一格式:采用 RLDS(Reinforcement Learning Datasets)格式标准化异构数据,包含 RGB 图像、语言指令、机器人关节角度/末端执行器动作
- 覆盖范围:从 7-DOF 桌面机械臂(WidowX、Franka)到移动机器人(Hello Stretch),涵盖抓取、推拉、翻转等多种操作技能
RT-X 训练策略:
- 分别在 OXE 数据上训练 RT-1 骨干(RT-1-X)和 RT-2 骨干(RT-2-X)
- 跨具身共训:模型在推理时通过语言指令和视觉观察推断任务,无需机器人类型标识
- 针对不同数据集采用加权混合采样策略,平衡数据规模差异
核心结果/发现
跨具身正迁移(核心发现):
- RT-1-X(130M)在 5/6 个评估机器人上优于仅在该机器人数据上训练的 RT-1
- RT-2-X(55B)在新型任务评估中成功率 62%,比原始 RT-2 的 55% 提升 7%
迁移效率对比:
| 模型 | 训练数据 | WidowX 成功率 | Google 机器人成功率 |
|---|---|---|---|
| RT-1(单机器人) | 仅 Everyday Robots | – | 71% |
| RT-1-X(OXE联合) | 22 种机器人 | +15% vs 单训 | +10% vs 单训 |
| RT-2-X | OXE + 互联网 | 显著提升 | 78.3% |
数据格式标准化:RLDS 格式成为此后机器人数据集的事实标准,被 AgiBot World、InternData-A1 等大规模数据集采用。
局限性
- 22 种机器人平台中数据量严重不均衡,长尾机器人的性能提升有限
- 原始数据质量参差不齐(不同实验室采集标准不同),引入噪声
- 未包含双臂、全身人形等新兴形态,覆盖面仍有局限
- RLDS 统一格式损失了部分传感器细节(如触觉、力传感数据)
- 评估协议不统一,不同实验室间的性能比较存在偏差
5.4 ACT (2023) {#5-4-act-2023}
———Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
📄 Paper: https://arxiv.org/abs/2304.13705
精华
这篇论文展示了如何利用低成本硬件实现高精度双臂协同操作,核心亮点包括:
- 低成本系统设计:利用不到2万美元的现成机器人和3D打印件构建了高性能双臂遥操作和自主学习平台。
- ACT 算法:提出 Action Chunking with Transformers,通过预测动作序列(而不是单步动作)来减少复利误差并提升时序一致性。
- 时间集成 (Temporal Ensembling):通过重叠动作块的加权平均,实现了极其平滑且精准的机器人运动。
- 高效学习:仅需10分钟(约50次)演示即可在开罐头、插电池等高难度精细操作任务中达到 80-90% 的成功率。
1. 研究背景/问题
精细的双臂协同操作(如穿针引线、插拔电池)通常需要昂贵的高精度机器人和复杂的传感器。传统的模仿学习(如行为克隆)在这些任务中面临挑战:复利误差 (Compounding Errors) 会导致动作偏离目标,且人类演示中的非平稳性(如停顿)难以建模。本文探讨能否通过学习,让廉价且精度较低的硬件也能完成 these 精细任务。
2. 主要方法/创新点

ALOHA 硬件系统
论文设计了一套名为 ALOHA 的低成本开源双臂系统。

- 结构:包含两组 ViperX 6自由度机械臂(作为执行器)和两组较小的 WidowX 机械臂(作为遥操作控制器)。
- 遥操作:用户通过操作较小的控制臂来实时驱动执行臂。为了提升精细操作能力,设计了3D打印的“手柄与剪刀”机构,支持连续的夹爪控制。
- 感知:系统配备4个普通的网络摄像头(两个固定在前方/上方,两个固定在执行臂手腕上),提供多视角视觉反馈。
ACT 学习算法
为了解决模仿学习中的误差积累问题,论文提出了 Action Chunking with Transformers (ACT)。
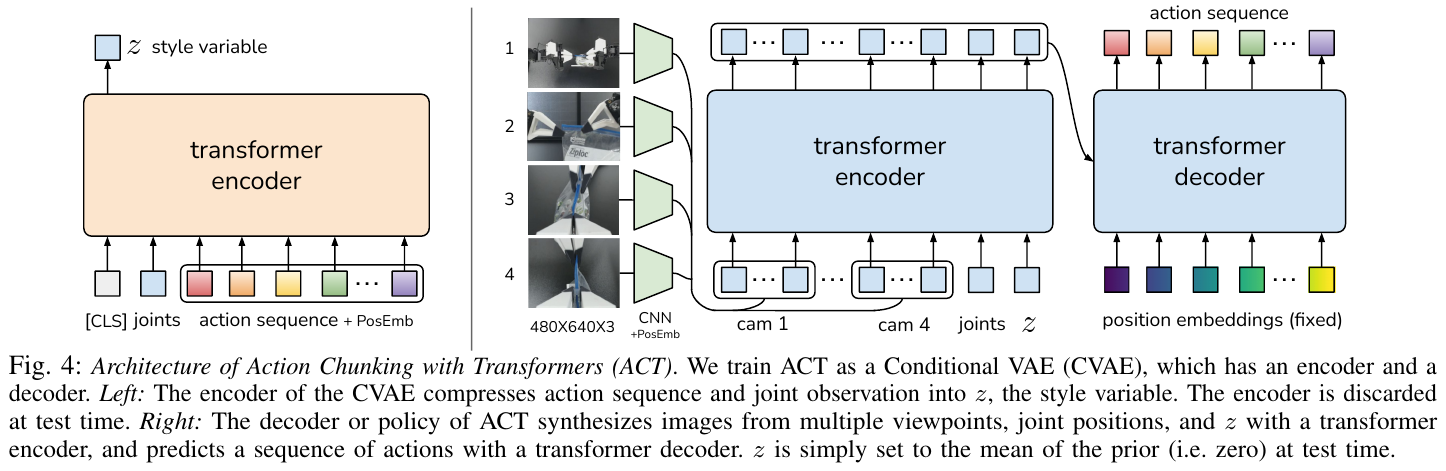
- 动作块 (Action Chunking):不同于传统方法预测单步动作 $a_t$,ACT 在每个观测点 $s_t$ 预测未来 $k$ 步的动作序列 $a_{t:t+k}$。这大大缩短了任务的有效时序跨度(减少了 $k$ 倍),从而缓解复利误差。
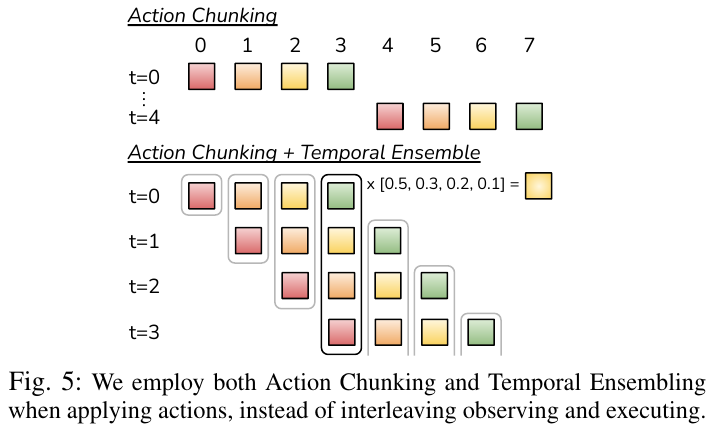
- CVAE 建模:使用条件变分自编码器 (CVAE) 处理人类演示中的多峰性(即同一场景下可能有多种有效路径)。
-
Transformer 架构:利用 Transformer 的编码器-解码器结构来融合多视角图像 and 关节位置信息,并生成连贯的动作块。
-
时间集成 (Temporal Ensembling):在推理时,系统在每一帧都进行预测,并对重叠的动作块进行加权平均。这种方式不仅提高了预测的鲁棒性,还消除了“动作块”切换时的动作不连续感。
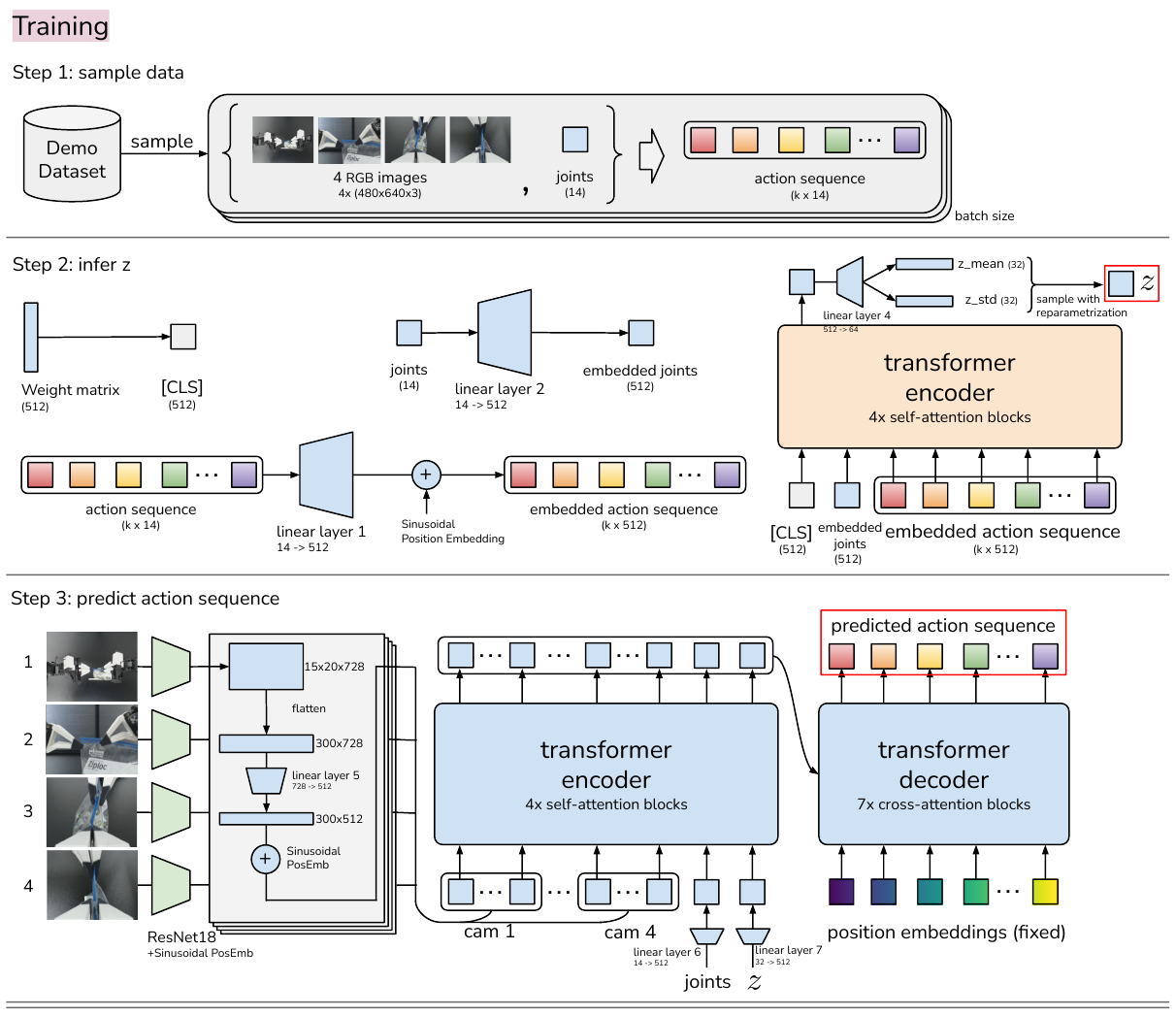
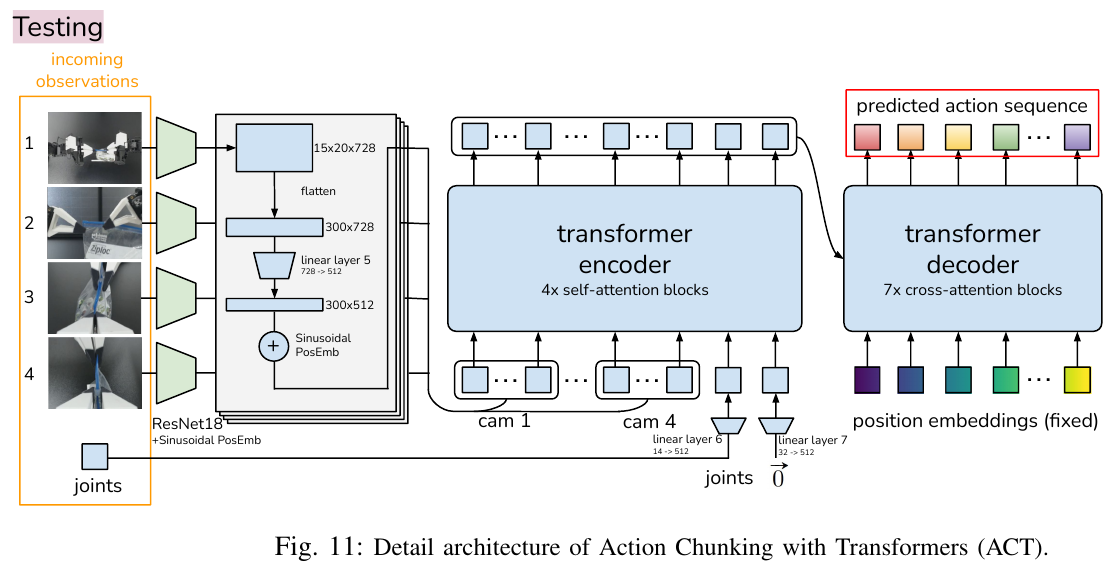
3. 核心结果/发现
- 性能卓越:在多个复杂的双臂操作任务中,ACT 显著优于之前的 SOTA 方法(如 BC-ConvMLP, BeT, RT-1)。例如在“插电池”任务中,ACT 的成功率达到 96%,而基线方法几乎无法完成。
- 数据高效:每个任务仅需 50 次人类演示(约 10 分钟数据),模型即可学会在动态和随机环境中进行闭环调整。
- 高频率必要性:实验证明 50Hz 的控制频率对于精细操作至关重要,将频率降至 5Hz 会导致操作完成时间增加 62% 以上。
- 闭环鲁棒性:得益于多视角视觉反馈和 ACT 架构,机器人能够实时纠正演示中的小偏差,并适应物体位置的轻微变动。
4. 局限性
- 硬件限制:由于低成本电机的扭矩限制,ALOHA 难以处理需要大力量的任务(如拧紧瓶盖或抬起重物)。
- 感官缺失:目前的系统仅依赖视觉,缺乏力觉反馈,在处理极度复杂的接触(如拆解复杂的糖果包装)时仍有挑战。
5.5 Diffusion Policy (2023) {#5-5-diffusion-policy-2023}
Visuomotor Policy Learning via Action Diffusion
📄 Paper: https://arxiv.org/abs/2303.04137
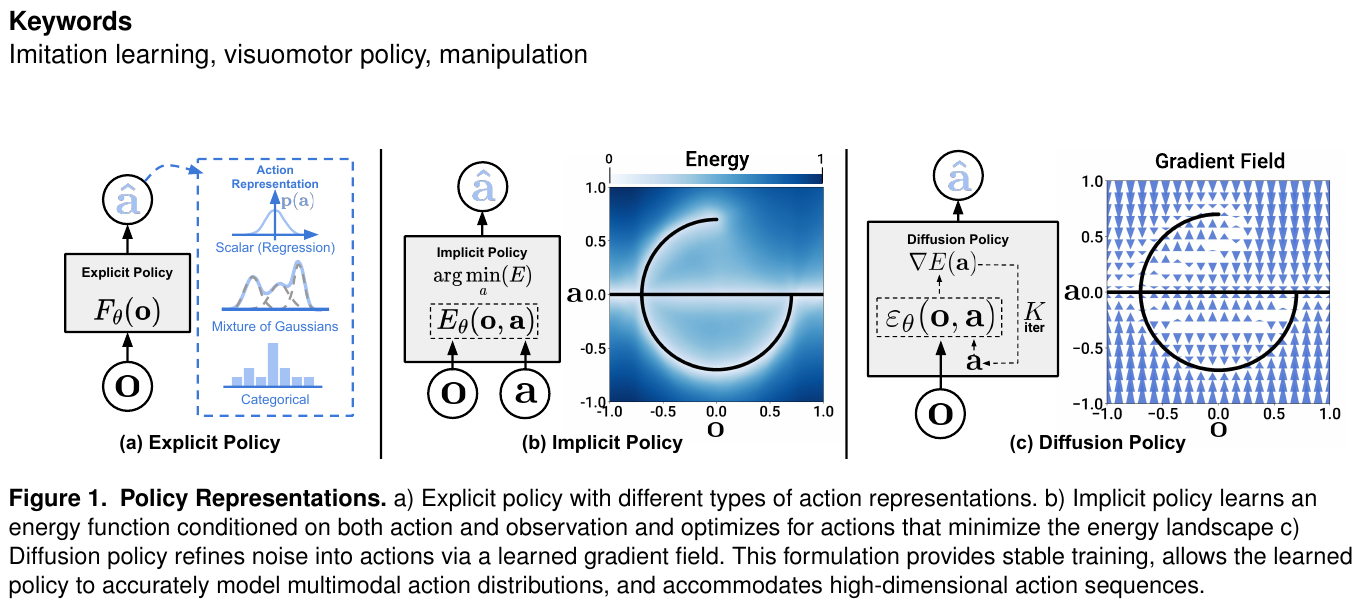
精华
Diffusion Policy 的核心洞见是:机器人动作分布本质上是多峰的(同一任务有多种合理执行方式),而传统的均方误差损失函数会将这些模式平均掉,导致”平均动作”——既不像任何一种合理动作。扩散模型天然能够表达多峰分布,Action Chunking(一次预测多步动作)进一步提升了长时序任务的流畅性。这两个设计已成为后续 VLA 动作解码(π₀ 的 Flow Matching、ACoT-VLA 的动作推理)的共同基础。
研究背景/问题
模仿学习方法(如 BC-RNN、IBC)在精细操作任务上性能不稳定。核心问题在于机器人演示数据天然具有多模态性:同一任务,专家可以从左侧抓取也可以从右侧抓取,两种轨迹都是正确的。传统回归损失(MSE)会将两种模式平均,导致输出”模糊中间状态”动作而失败。核心问题:如何为机器人策略学习建模多模态、高维的动作分布,使其能够可靠执行需要精细接触的复杂操作?
主要方法/创新点
扩散模型作为策略:
传统策略: π(o_t) → a_t (确定性映射)
扩散策略: a_t ~ p_θ(·|o_t) (条件分布采样)
通过迭代去噪: a^K → a^(K-1) → ... → a^0
两种架构变体:
| 架构 | 视觉骨干 | 去噪网络 | 推理速度 |
|---|---|---|---|
| CNN-Diffusion | ResNet-18(时序堆叠) | 1D-UNet | 快(~20Hz) |
| Transformer-Diffusion | ViT + 位置编码 | Transformer | 稳定但较慢 |
关键设计:
- Action Chunking:一次预测 $T_p=16$ 步动作序列(而非单步),缓解 compounding error,提升长任务流畅性
- DDIM 加速推理:使用 DDIM 从原始 100 步 DDPM 压缩到 10 步,满足实时控制需求
- Receding horizon 执行:每次仅执行预测动作序列的前 $T_a=8$ 步,保持闭环反馈
训练目标: \(\mathcal{L} = \mathbb{E}_{t, a_0, \epsilon}\left[\|\epsilon - \epsilon_\theta(a_t, t, o_t)\|^2\right]\)
核心结果/发现
仿真基准(与 BC-RNN、IBC 对比):
| 任务 | Diffusion Policy(CNN) | Diffusion Policy(Trans) | BC-RNN |
|---|---|---|---|
| Push-T(轨迹精度) | 91.5% | 95.0% | 82.5% |
| Block Pushing | 99.0% | 98.0% | 78.0% |
| Kitchen(多步序列) | 79.7% | 86.0% | 66.1% |
真实机器人实验(Franka 臂):
- 在 6 个精细操作任务(餐具摆放、罐头开盖、插头连接等)上平均成功率 76.3%
- 显著优于 BC-RNN(56.2%)和 IBC(51.0%)
多峰性验证:在”杯子放置”任务中,Diffusion Policy 稳定生成两种不同的合理轨迹(正面放/侧面放),而 BC-RNN 只能生成”中间状态”失败动作。
局限性
- 扩散推理需要多步迭代(即使用 DDIM 也需 10 步),与直接预测相比推理延迟更高,限制了超高频控制(>50Hz)
- 仅使用视觉和本体感知输入,没有语言指令跟随能力,无法处理多任务场景
- 在语义场景理解和任务泛化方面没有改善(专为低层动作建模设计)
- 对演示数据质量敏感,噪声或不一致的演示会影响分布建模质量
- 缺乏显式的任务推理机制,不适合需要长时程规划的复杂多步骤任务
5.6 UMI (2024) {#5-6-umi-2024}
———Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
📄 Paper: https://arxiv.org/abs/2402.10329 💻 Project: https://umi-gripper.github.io
精华
UMI 是由斯坦福、哥大和丰田研究院(TRI)共同提出的一种极低成本、高效率的机器人学习框架,其核心亮点包括:
- 便携式采集硬件:仅需一个带 GoPro 的手持夹爪(BOM 约 370 美元),即可在任何真实场景(如咖啡馆、厨房、公园)采集数据,无需真实机器人参与采集。
- 巧妙的传感器设计:利用 GoPro 的鱼眼镜头获取超广视角,并通过侧向反光镜(Side Mirrors)实现隐式双目视觉(Stereo),从而获得深度感知。
- 硬件无关的策略接口:引入了基于相对轨迹 (Relative Trajectory) 的动作表示和推理时延迟匹配 (Latency Matching),使得在一处采集的数据和训练的模型可以无缝部署到不同品牌、不同自由度的机器人上。
- 强大的泛化能力:在多样化的“野生”数据训练下,机器人表现出了极强的 Zero-shot 泛化能力,能够应对从未见过的环境、光照和物体。
1. 研究背景/问题
传统机器人模仿学习面临两大难题:
- 遥操作成本高:需要昂贵的硬件和熟练的操作员,且通常局限在实验室。
- 人类视频存在具身间隙 (Embodiment Gap):直接学习人类徒手操作视频很难转换成机器人的关节/夹爪控制。 UMI 采用了“手持夹爪”这一中间形态,既保留了人类操作的灵活性,又在视觉和动作上与机器人高度对齐。
2. 主要方法/创新点

硬件设计:信息丰富的演示接口
- 鱼眼镜头 (Fisheye):155度超广角,在提供丰富上下文的同时,避免了近距离操作时的遮挡。
- 侧向反光镜 (Side Mirrors):在图像边缘添加两面镜子,相当于增加了两个虚拟摄像头,提供了关键的深度信息。
- IMU 感知跟踪:利用 GoPro 记录的 IMU 数据配合 SLAM,在快速运动或视觉特征缺失时仍能保持高精度的 6DoF 姿态跟踪。
- 连续夹爪控制:通过视觉标记跟踪夹爪开合度,支持比二进制开合更精细的力度和时机控制(如抛掷物体)。
算法设计:跨平台的策略接口
- 延迟匹配 (Latency Matching):精准测量并补偿相机采集、推理和执行的延迟,确保动作同步,这对于“抛掷”等动态任务至关重要。
- 相对轨迹表示:动作不以全局坐标定义,而是相对于当前夹爪的位置。这使得机器人无需复杂标定,甚至在移动机器人底座时也能正常工作。
- Diffusion Policy:利用扩散模型建模人类演示中复杂的多峰分布(如绕过障碍物可以选左边也可以选右边)。
3. 核心实验结果
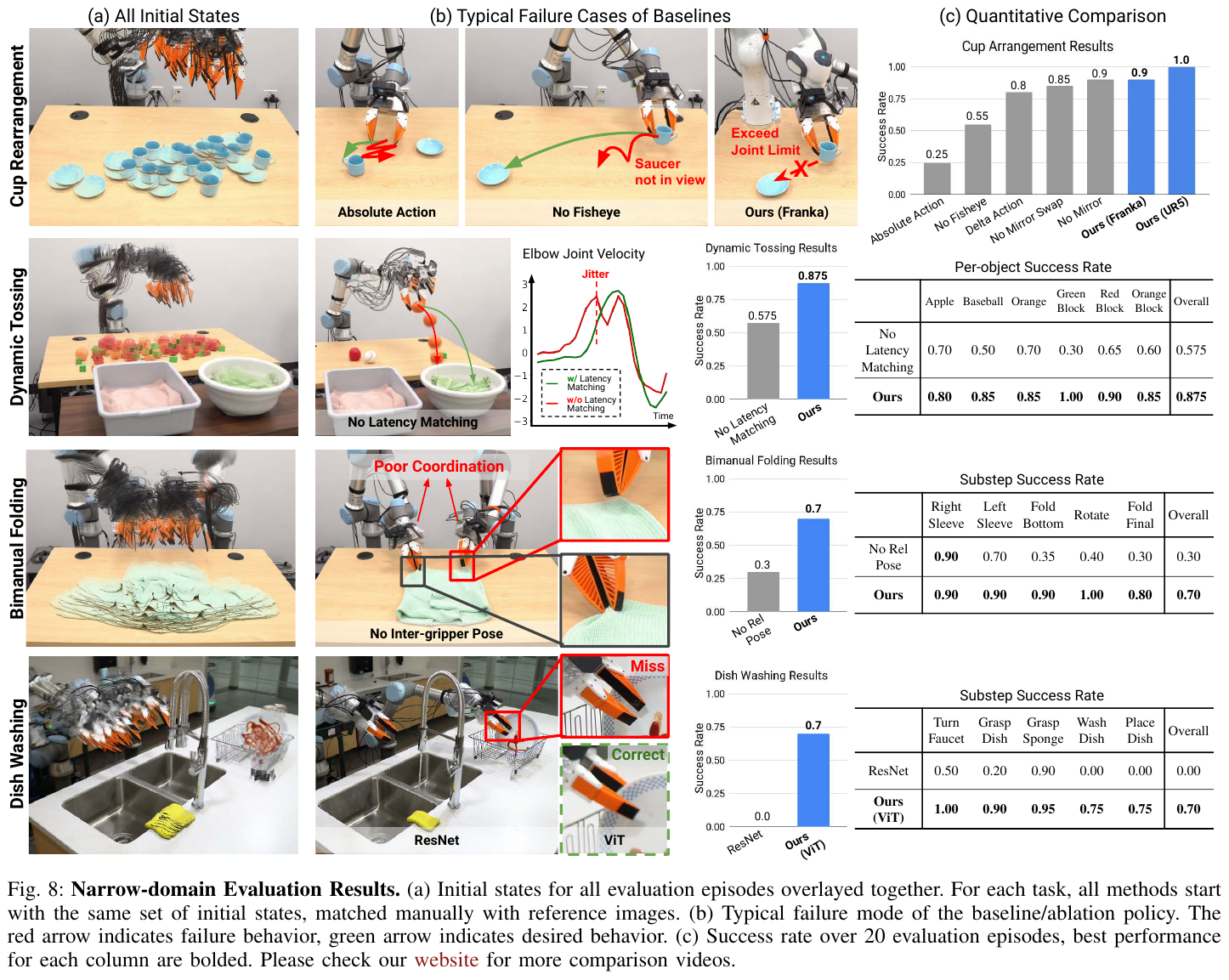
- 复杂任务能力:
- 动态抛物 (Dynamic Tossing):成功将物体准确抛入机器人触及不到的篮筐,成功率 87.5%。
- 双臂折叠 (Bimanual Folding):两臂高度协同完成衣物折叠,体现了相对姿态表示的重要性。
- 长程洗碗 (Dish Washing):涉及开关水龙头、涂抹洗洁精、擦拭、漂洗等 7 个步骤,且对干扰(如突然加料、移动底座)具有极强鲁棒性。
- Zero-shot 泛化:
- 在咖啡馆、喷泉等全新户外场景下,针对从未见过的杯子,UMI 策略达到了 71.7% 的成功率。而仅在窄域(实验室)数据训练的模型成功率为 0%。
- 跨平台部署:
- 同一套训练好的模型,可以直接在 UR5 和 Franka 机器人上运行,成功率保持在 90% 左右。
4. 总结与意义
UMI 证明了数据多样性优于模型微调。与其在单一环境下费力优化模型,不如利用 UMI 极其便携的特性,在数小时内采集大量真实世界场景的数据。这种“农村包围城市”的策略,为实现真正通用的机器人操作策略指明了方向。
5.7 DP3 (2024) {#5-7-dp3-2024}
———3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
📄 Paper: https://arxiv.org/abs/2403.03954 💻 Project: https://3d-diffusion-policy.github.io
精华
DP3 是上海期智研究院、清华大学和上海交大等机构合作的研究成果,其核心贡献在于证明了 3D 空间理解能力对机器人策略学习的巨大价值:
- 数据极其高效:在 72 个仿真任务中,仅需 10 次人类演示 即可完成大多数任务,比基线方法(如 2D Diffusion Policy)有 24.2% 的相对提升。
- 3D 视觉表征:放弃了复杂的 2D 图像处理,采用从单视角深度图提取的稀疏点云 (Sparse Point Clouds)。使用轻量级 MLP 编码器即可获得紧凑且强大的 3D 特征。
- 卓越的泛化性:得益于 3D 模态的本质属性,DP3 在空间位置、视角、物体外观和实例等多个维度上展现出天然的泛化能力。
- 部署安全可靠:在真实机器人实验中,DP3 极少发出超出安全限制的异常指令,这与 2D 基线方法频繁出现异常行为形成鲜明对比。
1. 研究背景/问题
视觉模仿学习虽然能让机器人学会多种技能,但通常需要海量数据(如 2D Diffusion Policy 通常需要 100-200 次演示)。 其核心瓶颈在于:
- 2D 信息的局限性:2D 图像难以提供精确的深度和空间拓扑信息,导致模型需要更多数据来“脑补”空间关系。
- 泛化困难:2D 策略极易受到视角变换、光照变化和背景干扰的影响。 DP3 旨在通过引入 3D 视觉表征,让模型“天生”理解三维空间,从而降低数据需求并提升泛化性。
2. 主要方法/创新点
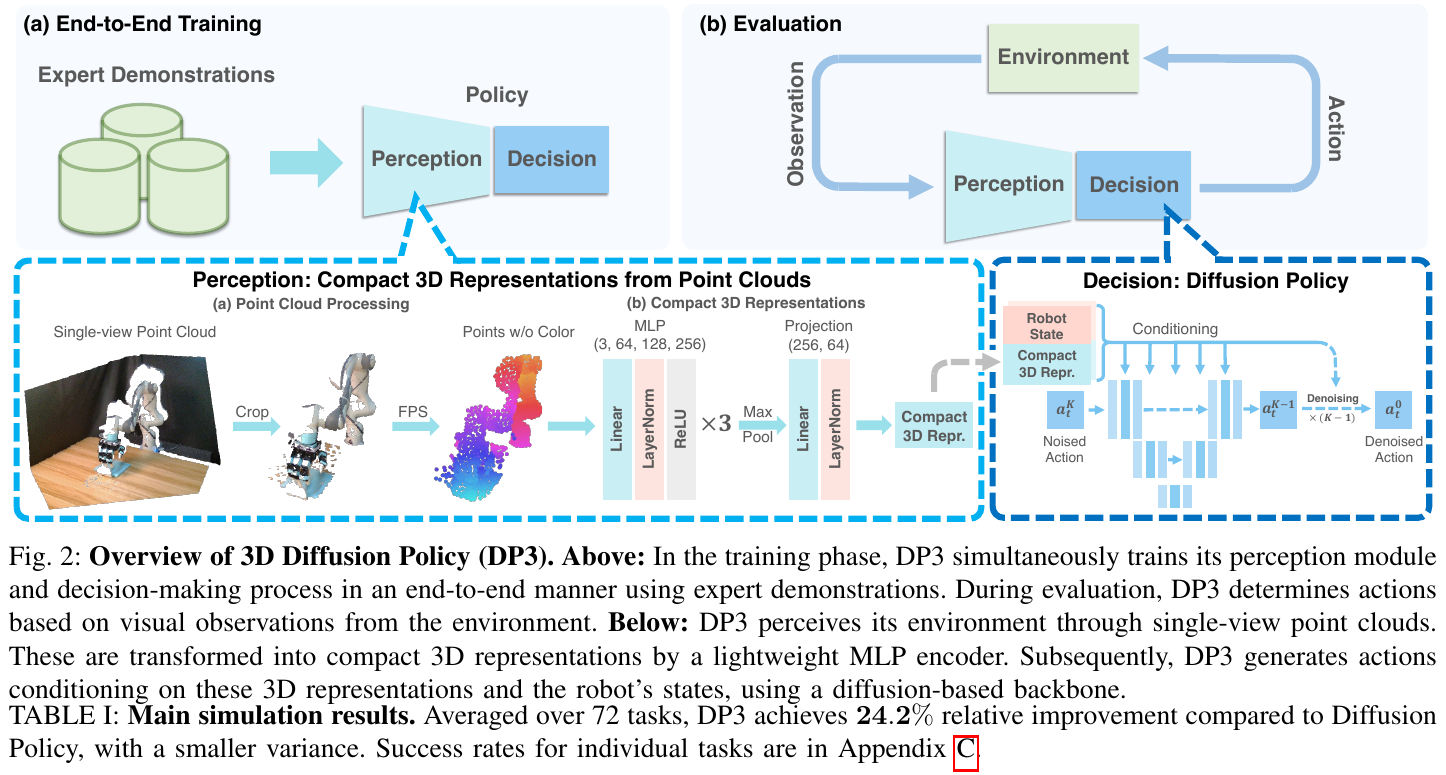
感知 (Perception):紧凑的 3D 表征
- 点云处理:从单视角深度相机获取深度图并转换为点云。为了排除背景干扰,模型会进行裁剪(Crop)并使用最远点采样 (FPS) 下采样至 512 或 1024 个点。
- 无颜色处理:实验发现,舍弃颜色通道反而有助于提高模型对物体外观(如不同颜色的杯子)的泛化能力。
- 轻量级编码器:使用简单的三层 MLP + Max Pooling 提取 64 维特征。这种“小而精”的设计在机器人控制任务中优于大型预训练点云模型。
决策 (Decision):3D 条件下的扩散策略
- 条件动作生成:扩散模型以提取的 3D 特征和机器人的关节位姿(q)为条件,通过迭代去噪过程,将高斯噪声转换为连贯的动作序列。
- 时空理解:扩散模型负责捕捉复杂的动作多峰分布,而 3D 特征负责提供精准的空间位置参考。
3. 核心实验结果
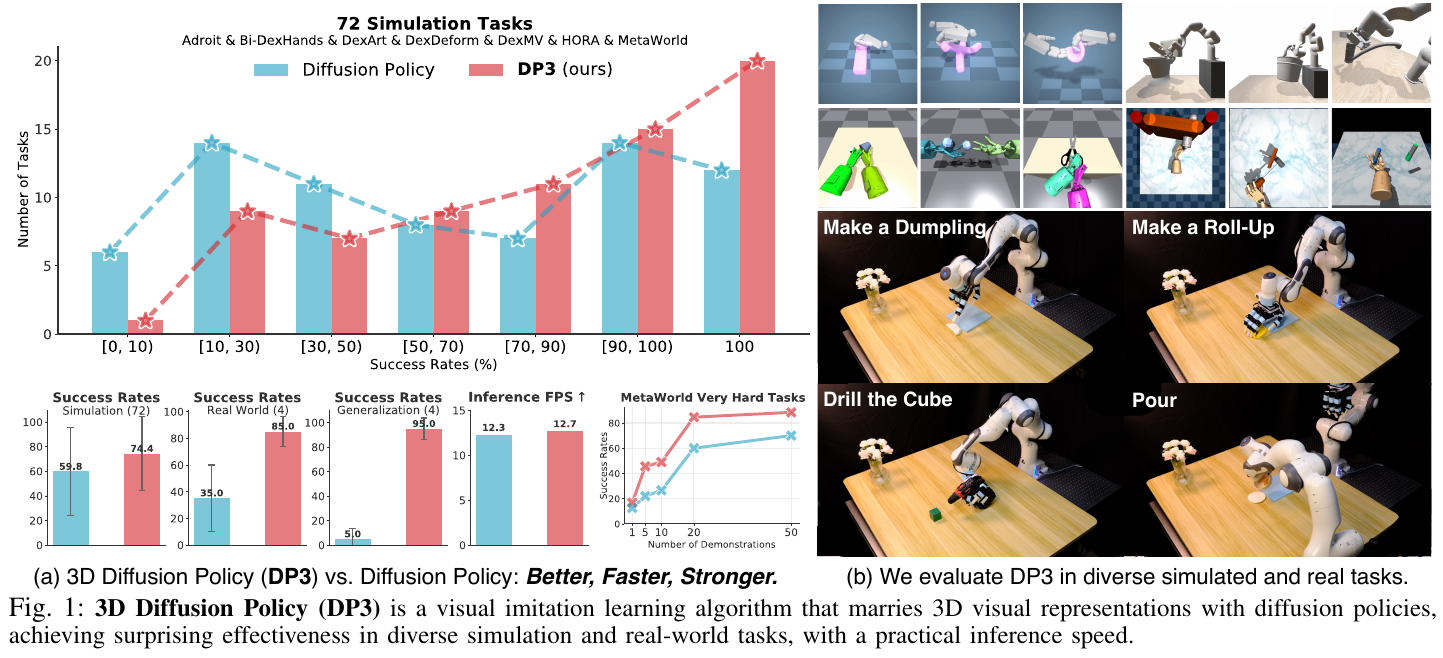
- 小样本学习:
- 在仿真环境下,仅 10 次演示,DP3 平均成功率遥遥领先。
- 在真实环境下(如做饺子、卷物、钻孔等灵巧手任务),仅需 40 次演示,成功率达到 85%。
- 全方位泛化:
- 空间泛化:在训练范围之外的 3D 空间内,DP3 依然能精准操作。
- 外观泛化:能够处理颜色、纹理完全不同的新物体。
- 推理效率:
- 虽然引入了 3D 处理,但得益于极简的编码器设计,DP3 在 NVIDIA 2080 Ti 上仍能保持较高的推理速度,满足实时控制需求。
4. 总结与意义
DP3 的成功再次强调了感知表征 (Visual Representation) 在机器人学习中的重要性。通过将 3D 表征与强大的扩散策略结合,DP3 为解决具身智能中的“数据饥渴”问题提供了一条高效、简洁且泛化能力极强的技术路径。
5.8 UniSim (2024) {#5-8-unisim-2024}
———Learning Interactive Real-World Simulators
📄 Paper: https://arxiv.org/abs/2310.06114 💻 Project: https://universal-simulator.github.io
精华
UniSim 是 Google DeepMind 在 ICLR 2024 上提出的一项重要工作,旨在构建一个能够模拟现实世界交互的通用模拟器:
- 统一接口:提出了“动作输入-视频输出” (Action-in-Video-out) 的统一框架,将不同模态的动作(语言、机器人控制、相机路径)映射到统一的动作空间。
- 海量异构数据融合:巧妙地整合了互联网图文数据、机器人操作数据、人类活动视频和 3D 扫描数据,利用不同数据的侧重点(如互联网数据的丰富场景和机器人数据的高频动作)来补全模拟器的能力。
- 自回归长程模拟:采用视频扩散模型作为核心,通过条件观察预测(Observation Prediction)实现了时序连贯的长程模拟。
- 闭环应用:证明了在 UniSim 中训练的高层视觉语言策略(VLM)和底层强化学习(RL)策略,可以无需修改直接部署到真实机器人(Zero-shot Sim-to-Real)。
1. 研究背景/问题
构建现实世界模拟器的最大障碍在于数据集的异质性。互联网数据(LAION)有丰富的物体和场景但缺乏动作;机器人数据有精准的动作但场景单一且规模小;人类活动数据有复杂的交互但动作标签模糊。UniSim 的核心思路是:能否通过一个统一的模型,将这些在不同维度上“丰富”的数据缝合在一起,构建一个无所不包的模拟器?
2. 主要方法/创新点
数据编排 (Data Orchestration)
为了处理来自不同源的异构数据,UniSim 采用了以下策略:
- 统一动作空间:所有动作最终被转换为连续的表示。语言指令通过 T5 嵌入处理,底层控制(如 Δx, Δy)则被离散化并与语言嵌入拼接。
- 多模态对齐:对于静态图像,将标题视为动作;对于 3D 扫描,利用相机姿态差构建动作;对于视频,则利用动作标签或预测的运动轨迹。
核心架构:基于视频扩散的观察预测
UniSim 被建模为一个条件概率模型 $p(o_t | h_{t-1}, a_{t-1})$,即给定历史观察 $h_{t-1}$ 和当前动作 $a_{t-1}$,预测下一段观察帧 $o_t$。
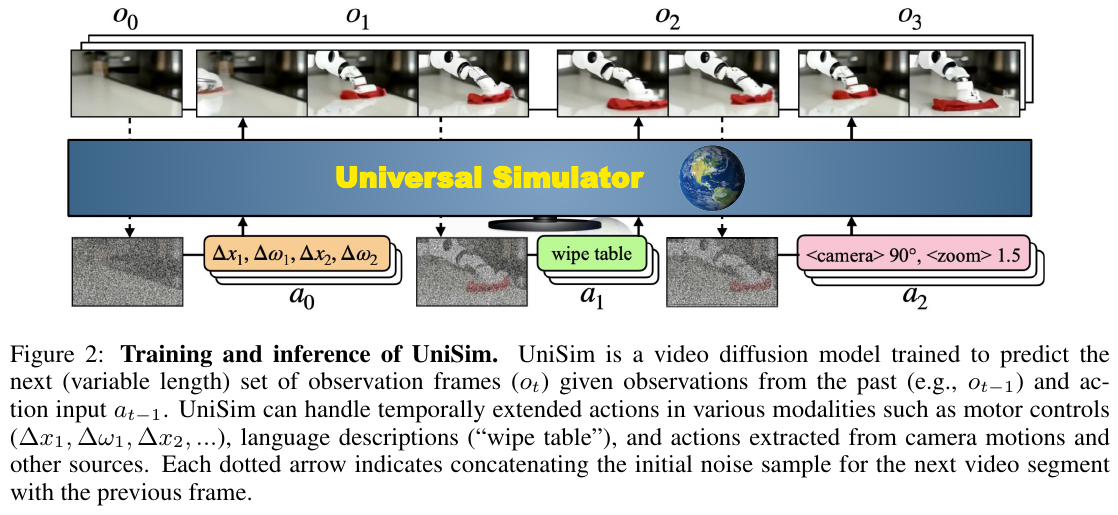
- Video U-Net:使用包含 56 亿参数的视频 U-Net 架构,通过交错的时间/空间注意力层来保证视频的质量和连贯性。
- 自回归生成:通过将上一段生成的最后一帧作为下一段生成的条件(History Conditioning),UniSim 能够生成长达数十步的连贯交互序列。
3. 应用场景展示
动作丰富且长程的模拟
UniSim 不仅能模拟简单的移动,还能根据语言指令模拟复杂的交互。


策略训练与 Zero-shot 迁移
UniSim 最强大的地方在于它能作为一个“训练场”:
- VLM 策略:通过在模拟器中生成带有事后标签(Hindsight Relabeling)的长程数据,显著提升了视觉语言模型处理复杂任务的能力。
- RL 训练:底层 RL 代理可以在 UniSim 中进行数百万次的闭环交互学习,由于模拟器视觉上极度接近真实世界,训练出的策略可以直接在真实机器人上运行。
4. 核心实验结果
- Sim-to-Real 性能:在 Language Table 机器人任务中,使用 UniSim 增强训练的 VLM 策略在真实环境下的目标达成率(RDG)提升了 3-4 倍。
- 底层控制提升:通过在模拟器中进行 REINFORCE 优化,VLA 策略在“指物”等缺乏专家演示的任务上成功率从 12% 提升到了 71%。
- 数据增强:仅使用 UniSim 生成的视频数据对 PaLI-X 进行微调,在视频描述(Video Captioning)任务上的表现接近使用真实数据的 84%,且具有更好的泛化性。
5. 局限性与思考
尽管 UniSim 迈出了重要一步,但仍面临以下挑战:
- 幻觉问题:当输入不切实际的指令时(如在桌面上要求“洗手”),模型会产生背景剧烈变动的幻觉。
- 长程记忆限制:由于条件观察只覆盖了有限的历史帧,极长程的记忆保持(如多轮交互后的物体一致性)仍有待提高。
- 物理真实性:目前的模拟主要集中在视觉层面,缺乏力学、触觉等非视觉维度的物理反馈。
5.9 OpenVLA (2024) {#5-9-openvla-2024}
———开源视觉-语言-动作模型
📄 Paper: https://arxiv.org/abs/2406.09246v3
精华
这篇论文展示了如何构建开源的大规模机器人控制模型,值得借鉴的核心思想包括:
- 利用预训练的视觉-语言模型作为基础,通过将机器人动作视为语言token的方式实现端到端训练
- 在大规模多样化机器人数据集(97万条轨迹)上训练可以显著提升泛化能力
- 融合多个视觉编码器(SigLIP + DINOv2)能够同时捕获语义和空间信息,提升机器人控制性能
- 参数高效微调(LoRA)和量化技术使得7B参数模型可以在消费级GPU上部署和微调
- 完全开源模型、代码和训练流程为社区研究提供了重要基础设施
研究背景/问题
现有的机器人操作策略难以泛化到训练数据之外的物体、场景和任务。虽然视觉-语言基础模型在互联网规模数据上展现了强大的泛化能力,但现有的视觉-语言-动作模型(VLA)要么是闭源的,要么缺乏高效微调到新机器人设置的方法,阻碍了VLA在机器人领域的广泛应用。
主要方法/创新点
OpenVLA是一个7B参数的开源视觉-语言-动作模型,在Open X-Embodiment数据集的97万条机器人演示轨迹上训练。模型架构包含三个关键组件:
- 融合视觉编码器(”三个臭皮匠”协作逻辑): 采用多骨干视觉编码策略,将视觉特征物理隔离并各自优化:
- DINOv2: 提供强大的几何和空间特征(理解”在哪里”,擅长物体定位与深度感知)。
- SigLIP: 提供强大的语义理解(理解”是什么”,擅长对齐自然语言指令)。
- CLIP/其他: 提供互补的视觉特征。 这种”组合拳”模式使得 7B 的模型在信息处理效率上击败了单一编码器的 55B 巨量模型。
-
投影器: 2层MLP将视觉特征投影到语言模型的输入空间。
- 语言模型骨干(”诸葛亮”大脑): 基于Llama 2 7B,作为统一决策中心,融合空间信息与语义信息进行指令推理。

训练策略:
- 动作离散化:将连续动作的每个维度量化为256个bin,使用1-99分位数作为量化范围
- 使用Llama tokenizer中最少使用的256个token表示离散化动作
- 端到端微调所有参数(包括视觉编码器),在64个A100 GPU上训练14天
- 完成27个epoch,直到动作token准确率超过95%
数据处理:
- 从Open X-Embodiment筛选具有第三人称相机和单臂末端执行器控制的数据集
- 采用Octo的数据混合权重,对多样性高的数据集上采样
- 过滤Bridge数据集中的全零动作,提升模型性能
OpenVLA训练流程:在970k条机器人轨迹(Open X-Embodiment数据集)上微调预训练VLM(Llama-2 7B)以预测机器人动作,采用动作token化表示实现端到端学习。详见论文Figure 2。
flowchart LR
A["预训练 VLM<br/>Prismatic-7B(Llama-2)"] --> B["动作 Token 化<br/>256 bins 均匀离散化"]
B --> C["OXE 数据微调<br/>970k 机器人轨迹"]
C --> D["自回归动作预测头<br/>next-token prediction"]
D --> E["7-DOF 连续动作<br/>Δxyz + ΔRxyz + gripper"]
style A fill:#e3f2fd,stroke:#1565c0
style C fill:#e8f5e9,stroke:#2e7d32
style E fill:#fff3e0,stroke:#e65100
微调和部署优化:
- LoRA微调: rank=32的LoRA可以匹配全参数微调性能,仅需训练1.4%参数,单个A100 GPU即可完成
- 量化推理: 4-bit量化将GPU内存需求从16.8GB降至7.0GB,性能无明显下降
- 推理速度: 在RTX 4090上以6Hz运行(bfloat16),4-bit量化可进一步提升速度
核心结果/发现
- 跨机器人泛化能力:
- 在BridgeData V2 WidowX机器人上,OpenVLA达到70.6%平均成功率,比RT-2-X(55B参数)高16.5%,参数量仅为其1/7
- 在Google机器人上与RT-2-X性能相当(85.0% vs 78.3%)
- 显著优于Octo(20.0%)和RT-1-X(18.5%)等开源方法
- 多种泛化能力测试:
- 视觉泛化(未见背景、干扰物):52.0% vs RT-2-X 29.0%
- 运动泛化(未见物体位置/方向):60.0% vs RT-2-X 25.0%
- 物理泛化(未见物体尺寸/形状):55.0% vs RT-2-X 26.7%
- 语义泛化(未见物体和概念):36.3% vs RT-2-X 38.8%
- 语言grounding(多物体场景):85.0% vs RT-2-X 76.7%
BridgeData V2评估结果:OpenVLA在多种泛化任务上均优于现有方法(Octo、RT-2等),特别是在未见物体和场景的零样本泛化上表现突出。详见论文Figure 3。
| 任务类型 | OpenVLA | Octo | RT-2 |
|---|---|---|---|
| 已见任务 | ✅ 高 | ✅ 中 | ✅ 高 |
| 未见物体 | ✅ 高 | ⚠️ 低 | ✅ 中 |
| 未见场景 | ✅ 高 | ⚠️ 低 | ⚠️ 中 |
- 数据高效适应:
- 在Franka机器人7个任务上(10-150条演示),OpenVLA微调后平均成功率63.8%
- 在单指令任务上,Diffusion Policy表现更好(66.7% vs 53.5%)
- 在多指令任务上,OpenVLA显著优于Diffusion Policy(91.7% vs 19.4%)
- OpenVLA是唯一在所有任务上达到≥50%成功率的方法
数据高效适应实验:OpenVLA高度多样化多指令任务上表现最佳,仅需少量演示(10-50条)即可在新任务上实现高成功率,显著优于从头训练和其他预训练VLA模型。详见论文Figure 4。
- 计算效率:
- LoRA微调(rank=32)匹配全参数微调性能,GPU内存需求从163.3GB降至59.7GB
- 4-bit量化推理性能无下降(71.9% vs 71.3%),内存占用减半
- 在消费级GPU上即可部署和微调
- 开源影响:
- 首个开源的大规模VLA模型,包含完整训练代码和流程
- 支持HuggingFace集成,提供微调notebook
- 为社区研究VLA提供重要基础设施
开发者快速开始 (OpenVLA 使用示例):
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
# 加载预训练模型
model_id = "openvla/openvla-7b"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForVision2Seq.from_pretrained(
model_id, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True
).to("cuda")
# 准备指令和图像
prompt = "In: What action should the robot take to pick up the red bowl?\nOut:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to("cuda", dtype=torch.bfloat16)
# 生成动作
action = model.predict_action(**inputs, unnorm_key="bridge_orig")
print(f"Predicted Action: {action}")
局限性
模型目前仅支持单图像观察输入,不支持多相机视角、本体感知信息或观察历史。推理速度(6Hz)对于高频控制任务(如50Hz的ALOHA)仍不够快。虽然优于现有泛化策略,但在测试任务上的成功率通常<90%,可靠性还有提升空间。由于计算限制,许多VLA设计问题(如基础VLM规模、协同训练策略、最佳视觉特征等)尚未充分探索。
5.10 π₀ (2024) {#5-10-pi0-2024}
: A Vision-Language-Action Flow Model for General Robot Control ———首个基于 Flow Matching 的通用机器人策略基础模型
📄 Paper: https://arxiv.org/abs/2410.24164

精华
这篇论文展示了如何构建真正的通用机器人策略基础模型,值得借鉴的点包括:在预训练 VLM 之上通过 flow matching 添加连续动作输出能力、利用互联网规模的语义知识指导机器人控制、设计专门的注意力掩码处理视觉-语言-动作的异构 token、在多个机器人平台上联合训练实现跨平台泛化。这种方法论为构建能够快速适应新任务的通用机器人智能提供了清晰路径,特别是 flow matching 相比扩散模型在实时控制中的优势值得在其他具身 AI 系统中借鉴。
研究背景/问题
现有的机器人学习方法主要依赖针对特定任务和特定机器人平台的专门训练,难以实现跨任务和跨平台的泛化。虽然大规模视觉语言模型展示了强大的语义理解能力,但如何将其应用于需要实时、精确、连续动作输出的机器人控制仍是挑战。本文探索如何构建能够处理多样化任务的通用机器人策略基础模型。
主要方法/创新点
论文提出了 π₀ (Pi-Zero),一个基于 flow matching 的视觉-语言-动作 (VLA) 模型,用于通用机器人控制。
1. 整体架构设计
预训练 VLM 骨干网络:
- 使用 PaliGemma 作为基础,这是一个结合了 SigLIP (视觉编码器) 和 Gemma (语言编码器) 的 3B 参数 VLM
- 继承互联网规模的语义知识,理解自然语言指令和视觉场景
Flow Matching 动作专家:
- 在预训练 VLM 之上添加专门的动作生成模块
- 使用 flow matching 技术生成连续、平滑的动作轨迹
- 实现 50Hz 的实时控制频率,满足灵巧操作需求
2. Flow Matching 方法:从”迷宫”到”高速公路”
核心数学原理: π₀ 放弃了 Diffusion Policy 中基于随机微分方程(SDE)的弯曲去噪路径,转而采用基于常微分方程(ODE)的 Flow Matching 技术。其核心直觉是将概率路径”拉直”: \(x_t = (1 - t)x_0 + tx_1\) 其中 $x_0 \sim \mathcal{N}(0, I)$ 是高斯噪声,$x_1$ 是真实动作轨迹。模型学习的是一个时间相关的向量场 $v_t(x)$,它指向从噪声到动作的最短路径。
为什么 π₀ 能实现 50Hz?
- 采样步数骤减: 扩散模型通常需要 10-50 步迭代来消除噪声,而流匹配的直线特性使得模型在 1-3 步内就能收敛到极高精度的动作序列。
- 计算开销对冲: 尽管单步推理的 VLM 骨干很大(3B),但由于采样步数极少,总延迟反而低于多步采样的轻量级扩散模型。
性能飞跃:
- 极高精度: 能够执行 折纸、玩扑克牌、折叠衣物 等 OpenVLA 和 Octo 难以胜任的灵巧任务。
- 动作连续性: 生成一段长度约 1 秒(50 步)的平滑控制计划,大幅减少了机器人的抖动和迟滞。
3. 专门的注意力机制
VLA vs VLM 的关键区别:
| 特性 | VLM | VLA |
|---|---|---|
| 输入 | 图像、文本 | 图像、文本、观察状态 |
| 输出 | 文本、嵌入 | 连续动作序列 |
| 注意力模式 | 标准因果 | 块稀疏因果 |
Token 类型设计:
- 前缀 Token (图像 + 文本指令):
- 完全双向注意力,类似标准 Transformer
- 编码场景理解和任务描述
- 状态 Token (机器人观察):
- 可访问所有前缀 token
- 与之前时间步的状态呈三角形因果关系
- 编码当前机器人状态
- 动作 Token (电机命令):
- 可访问所有非 padding 的 token
- 完全可见的因果注意力
- 生成具体的控制信号
FlexAttention 优化:
- 使用 PyTorch 的 FlexAttention 高效处理 VLA 的块稀疏注意力模式
- 相比 FlashAttention2(设计用于严格因果模式),FlexAttention 更适合不规则块掩码
- 提供纯 PyTorch 接口,易于定制和优化
4. 大规模多任务训练
训练数据来源:
- Open X-Embodiment Dataset: 开源机器人轨迹数据
- 互联网规模预训练: 从 PaliGemma 继承的视觉语言知识
- π Dataset: Physical Intelligence 自己收集的多机器人数据
多平台训练:
- 7-8 个机器人平台: 单臂(UR5e)、双臂(Franka)、移动操纵器
- 68 个独特任务: 覆盖灵巧操作、物体取回、整理等多样场景
- 跨平台联合训练实现形态无关的通用策略
数据整合策略:
- 统一的观察-动作序列表示
- 处理不同机器人平台的动作空间差异
- 利用 VLM 的语义理解能力实现跨任务知识迁移
5. π₀-FAST:加速版本
FAST (频率空间行动序列标记化):
- 将连续动作序列转换为离散 token,支持自回归生成
- 通过 DCT 变换到频域,保留低频重要系数
- 使用 BPE 编码频域系数,实现高效压缩
FAST 优势:
- 比基于扩散的 VLA 快 5 倍
- 改进的动作表示减少冗余
- 更强的跨环境和机器人形态泛化
- 已在 100 万个动作序列上训练,支持多种机器人类型
主要创新包括:
- 首次将 flow matching 应用于大规模通用机器人策略
- 设计了适合 VLA 的块稀疏注意力机制
- 实现了真正的多平台、多任务联合训练
- 开源了模型权重和代码(openpi repository)
核心结果/发现
零样本性能(无任务特定微调)
在 5 个零样本评估任务上的平均成功率:
| 任务 | π₀ | OpenVLA | Octo |
|---|---|---|---|
| Bussing Easy (收拾桌子-简单) | 97.1% | 34.3% | 4.3% |
| Shirt Folding (折叠衬衫) | 100% | 0% | 0% |
| Grocery Bagging (装袋杂货) | 78.6% | 0% | 0% |
| Box Assembly (组装盒子) | 高成功率 | - | - |
| Object Retrieval (物体取回) | 高成功率 | - | - |
关键发现:
- π₀ 在所有任务上显著优于开源模型 OpenVLA 和 Octo
- 即使在最简单的任务上,π₀ 也展示了 2-3 倍的性能优势
- 在复杂任务(如折叠衬衫、装袋杂货)上,其他模型完全失败而 π₀ 仍保持高成功率
微调性能(少量任务特定数据)
在相同微调数据下,与其他机器人学习方法对比:
| 模型 | Bowl Stacking (碗堆叠) | 平均跨任务成功率 |
|---|---|---|
| π₀ | ~100% | ~80% |
| Diffusion Policy | ~55% | ~35% |
| ACT | ~45% | - |
| OpenVLA | <10% | - |
| Octo | <10% | - |
关键观察:
- π₀ 微调后在几乎所有任务上接近完美表现
- 相比专门的行为克隆方法(ACT、Diffusion Policy),性能提升超过 2 倍
- 预训练带来的零样本能力使微调更高效
消融实验
VLM 预训练的价值:
- π₀-small(无 VLM 预训练)vs 完整 π₀:性能差距超过 2 倍
- 证明了互联网规模语义知识对机器人控制的重要性
Flow Matching vs 扩散模型:
- 实时性:50Hz 控制频率,满足灵巧操作需求
- 平滑性:生成的动作轨迹更连续、更适合物理系统
- 效率:相比多步扩散采样,推理速度显著提升
真实世界长时运行
部署验证:
- 在真实家庭环境中折叠多种衣物(T恤、毛巾、裤子)
- 收拾真实餐桌,处理不同大小和形状的餐具
- 在超市场景中装袋杂货,处理软硬不同的物品
- 组装各种尺寸的纸箱,展示精细操作能力
跨平台泛化:
- 在未见过的机器人平台上通过少量微调实现高性能
- 展示了通用策略基础模型的实用价值
开源影响
- 2025 年 2 月开源代码和权重(GitHub: Physical-Intelligence/openpi)
- 集成到 Hugging Face LeRobot 框架
- FAST 标记器已集成到 Hugging Face Transformers
局限性
当前模型仍需要针对具体任务进行微调才能达到生产级别的可靠性,特别是在处理完全未见过的任务类型时。模型的成功依赖于高质量的训练数据,在数据分布外的长尾场景(如极端光照、复杂遮挡)下性能可能下降。50Hz 的控制频率虽然适合大多数操作任务,但对于需要更高频率反馈的动态任务(如接球、快速避障)可能不够。未来工作可以探索更大规模的预训练、主动学习策略和更高效的在线适应机制。
Sources:
5.11 π₀.5 (2025) {#5-11-pi05-2025}
———a Vision-Language-Action Model with Open-World Generalization
📄 Paper: https://arxiv.org/abs/2504.16054 💻 Project: https://pi.website/blog/pi05
精华
这是 Physical Intelligence 团队关于 开放世界泛化 (Open-World Generalization) 的最新突破性工作。π0.5 是建立在 π0 基础上的全新 VLA 模型:
- 异构数据协同训练:仅有少部分数据(第一阶段训练的 2.4%)来自真实的移动操作机器人。其余 97.6% 的数据来自其他固定机器人、高层语义预测、人类的口头指令以及网络多模态数据(如图像描述、问答、目标检测)。
- 层次化推理架构:在执行阶段,模型首先预测“高层语义子任务”(如“拿起盘子”),然后再基于该子任务预测底层的机器人动作(Low-level Action Chunks)。
- 超强的泛化能力:这是首次证明端到端学习的机器人系统可以在完全陌生的真实家庭环境中,执行长达 10 到 15 分钟的长程、多阶段灵巧操作任务(如打扫厨房或卧室)。
1. 研究背景/问题
如果要让机器人真正变得有用,它们必须离开实验室,去应对真实世界中各种各样、不可预见的情况。尽管近期的 VLA 模型在端到端控制上取得了令人瞩目的成绩,但它们在“野生环境”中的泛化能力究竟能走多远,依然是一个未解之谜。
如果一个移动机器人被要求打扫一个它从未见过的厨房,它需要多层次的泛化能力:
- 简单的抓取技能需要泛化到新物体上。
- 现有的技能需要被组合成新的序列。
- 机器人需要理解场景的语义(例如,哪个是抽屉,哪个可能是晾碗架)。
传统的通过“暴力堆数据”来覆盖所有家庭场景的做法是不现实的。π0.5 的核心思想是:像人类一样,利用来自其他渠道的知识(书本、他人的经验等),通过多模态的协同训练来实现泛化。
2. 主要方法/创新点

多样化/异构的知识来源 (Heterogeneous Knowledge Sources)
π0.5 的训练数据不仅仅是“机器人动作视频”。它整合了:
- 多模态网络数据:利用互联网级别的图像问答、目标定位等任务,为模型提供先验的场景理解能力。
- 高层语义预测与语言指令:将包含长程任务结构的人类口头指导引入训练。
- 其他机器人数据:利用实验室内的固定机械臂或其他平台的数据来丰富底层运动技能库。
层次化的架构设计 (Hierarchical Architecture)
模型的设计非常直接:先在包含网络数据和多机器人的混合数据上预训练,然后再使用包含底层动作和高层语义标签的数据进行微调。 在推理(Inference)时:
- 高层推理:模型首先推断出当前最合适的“语义子任务”(Semantic Subtask),比如“捡起切菜板”。
- 底层执行:随后,模型根据该子任务标签,输出对应的底层机器人控制动作。 这种将复杂任务拆解的设计,使得底层动作可以受益于其他简单机器人的数据,而高层推理则可以受益于网络文本和图像数据。
3. 核心实验结果

- 长程任务的突破:实验证明,π0.5 可以仅凭一条高层 Prompt,连续控制移动操作机器人 10 到 15 分钟,完成诸如打扫厨房、铺床、挂毛巾等极其复杂的日常家务。
- 环境迁移:所有评估任务都是在训练数据中完全不存在的全新家庭中进行的,证明了系统具备极其强大的 Open-World Generalization 能力。
- 协同训练的必要性:消融实验表明,如果不进行异构数据的协同训练,模型将无法在这些陌生的真实环境中完成复杂的长程任务。
4. 总结与意义
π0.5 证明了通过混合异构数据源(而非单纯扩大目标机器人的训练数据),能够促使端到端的机器人系统涌现出强大的泛化能力。这种将互联网规模的语义知识与机器人底层的动作技能通过“层次化推理”结合的方式,为未来通用家用机器人的大规模落地提供了一个极为可行的技术范式。
5.12 π₀.6 (2025) {#5-12-pi06-2025}
———a VLA That Learns From Experience
📄 Paper: https://arxiv.org/abs/2511.14759 💻 Project: https://pi.website/blog/pistar06
精华
这是 Physical Intelligence 团队在具身智能领域的又一重磅突破,核心在于解决了大规模视觉-语言-动作(VLA)模型如何在真实世界中通过强化学习(RL)持续自我进化的难题:
- RECAP 框架:提出了一种名为 RECAP(基于优势对齐策略的经验与修正强化学习)的通用方法。它允许 VLA 模型整合极其多样的数据源:专家演示、自主执行数据、以及人类在机器人出错时进行的实时遥操作干预。
- 优势对齐 (Advantage Conditioning):不同于传统的策略梯度(PPO 等)难以应用于大型 Flow-matching 模型,RECAP 通过在模型输入中加入一个简单的“优势指示符”(Advantage Indicator),让模型直接学习“什么样的动作是更好的”。
- 性能飞跃:在最困难的任务上,RECAP 使机器人的吞吐量(单位时间成功次数)提升了一倍以上,同时将任务失败率降低了约 50%。
- 工程壮举:训练出的 π*0.6 模型能够连续 13 小时不间断地制作浓缩咖啡,或是在完全陌生的家庭中连续两小时自动折叠各类复杂衣物。
1. 研究背景/问题
“熟能生巧”是人类学习的核心。虽然现有的 VLA 模型可以通过模仿学习(BC)掌握技能,但它们很难超越人类演示者的水平,也无法在部署后自我纠错。
将强化学习应用于大型 VLA 模型面临三大挑战:
- 算法稳定性:传统 RL 算法在大规模模型上往往极不稳定。
- 数据异构性:如何同时利用“完美的演示”和“充满错误但包含修正的自主尝试”?
- 真实世界反馈:在没有仿真环境的情况下,如何高效地获取奖励信号?
2. 主要方法/创新点
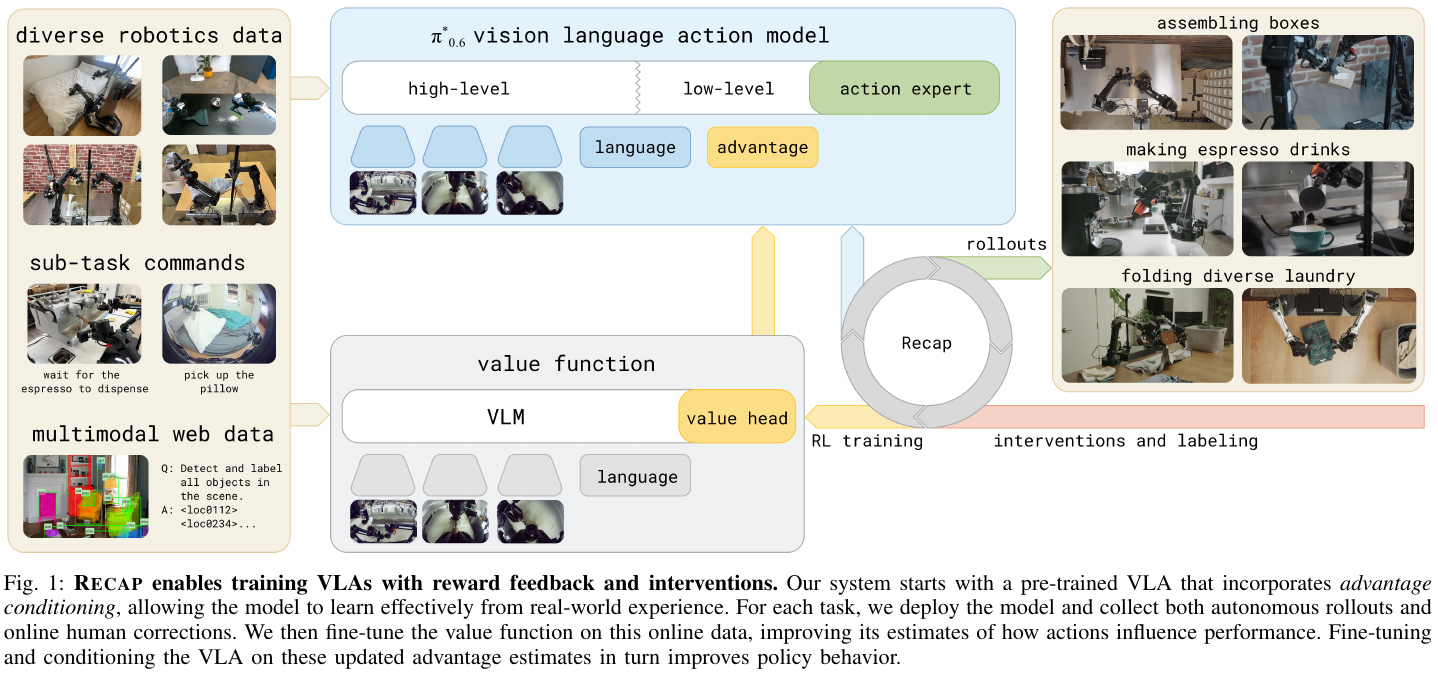
RECAP 训练循环
- 数据采集:让机器人自主尝试任务。如果出错,人类可以介入进行干预修正。
- 价值函数(Value Function)训练:训练一个多任务的分布价值函数,用来评估当前观察距离成功的“步数”。
- 优势对齐训练:根据价值函数的评估,为每个动作贴上“优势正向/负向”的标签。在训练时,模型被要求根据这个标签来学习预测动作。
核心模型:π*0.6
π*0.6 是 π0.6 模型的 RL 版本,其底层是 40 亿参数的 Gemma 3 VLM 加上一个 8.6 亿参数的流匹配(Flow-matching)动作专家。
- 条件化优势:在模型的 Prompt 中加入“Advantage: positive/negative”作为输入,使得模型在推理时可以通过设置正向优势来提取最优动作。
- 知识绝缘 (Knowledge Insulation):确保动作生成与高层推理互不干扰,提升系统稳定性。
3. 核心实验结果

- 极高的鲁棒性:
- 制作咖啡:包括磨粉、压粉、锁柄、萃取、端杯等一系列精细动作,支持长达 13 小时的连续运行。
- 纸箱组装:在真实的工厂场景中,处理会互相粘连、变形的纸板,将吞吐量从初始的每小时 5 次提升到 10 次以上。
- 显著的指标提升:
- 在复杂衣物折叠任务中,成功率从 70% 提升至 90% 以上。
- 实验证明,RECAP 的优势对齐方法在性能上远超传统的 AWR(优势加权回归)和 PPO 算法。
4. 总结与意义
π*0.6 和 RECAP 标志着机器人学习从“静态模仿”向“动态进化”的跨越。它证明了即便没有模拟器,大型 VLA 模型也可以通过在真实世界中的自主尝试和少量的人类引导,迅速掌握那些极其精细、长程且充满不确定性的工业及家务技能。
5.13 π₀.7: a Steerable Generalist Robotic Foundation Model (2026)
———可控的通用型机器人基础模型,具备零样本跨构型迁移与任务组合能力
📄 Paper: arXiv:2604.15483
精华
- 提出了 π0.7,一个 5B 参数的通用视觉-语言-动作(VLA)模型,通过引入多模态上下文(子任务指令、子目标图像、训练元数据)实现了强大的开箱即用能力。
- 核心创新在于“可控性”:通过在训练中随机丢弃和注入详细的执行细节(如动作质量、速度、是否有错误),使模型在推理时可以通过 Prompt 引导(Steering)来执行高质量、高难度的灵巧任务。
- 实现了显著的零样本跨构型迁移:模型能将在轻量级平台上学到的灵巧技能(如叠衣服)直接迁移到载荷更高的工业机械臂(如 UR5e)上。
- 引入了基于语言“教练(Coaching)”的组合式泛化,用户可以通过分步指令引导模型完成从未见过、长达 5 分钟的长程任务。
- 成功整合了包括机器人演示、自主运行失败数据、人类视频及互联网多模态数据在内的异构数据集,并证明了多模态 Prompt 能够解决数据质量不一带来的歧义问题。
1. 研究背景/问题
当前的机器人基础模型(VLA)虽然在规模和泛化性上有所进步,但仍面临几个核心挑战:
- 无法执行复杂任务:即便经过大规模预训练,模型在处理从未见过的灵巧任务或长程任务时往往需要针对性微调。
- 数据异构性难题:大规模数据(如人类视频、自主失败数据)往往包含不同的执行策略和质量,简单地进行训练会导致模型学到“平均”后的亚优性能。
- 跨构型泛化差:技能很难在不同形态、不同动力学特性的机器人之间无缝迁移。
2. 主要方法/创新点
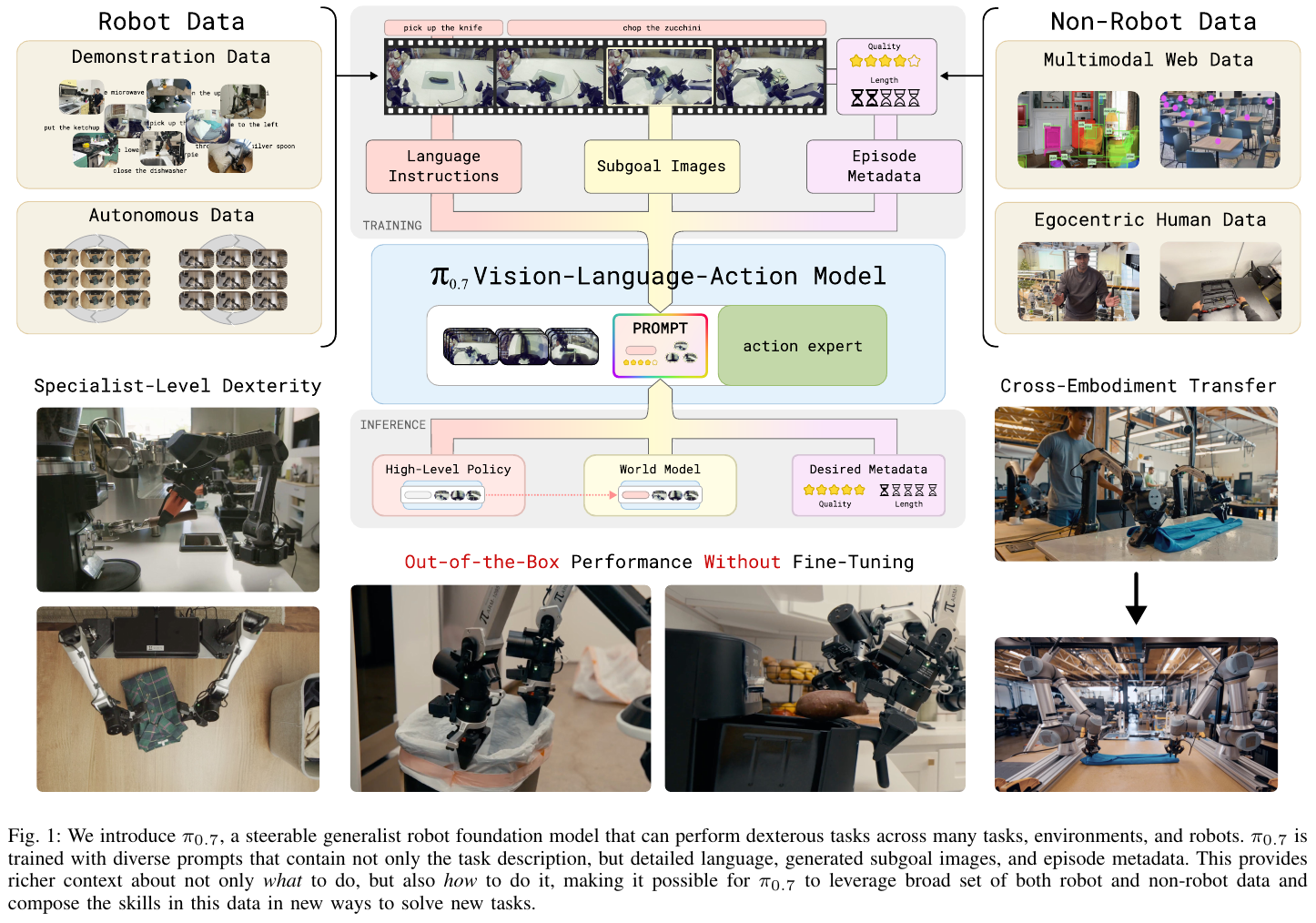
① 整体框架概述
π0.7 是一个 50 亿参数的 VLA 模型,其核心架构由 4B 参数的视觉-语言模型(VLM)主干、一个 MEM 风格的视频历史编码器(400M 参数)以及一个轻量级的动作专家模块(860M 参数)组成。该系统通过接收当前的视觉观测、历史信息以及一组丰富的上下文信息(Prompt),直接生成连续的动作块。

② 核心模块讲解
多模态上下文引导(Steerable Prompting): 这是 π0.7 的灵魂所在。为了处理异构数据并实现精准控制,模型在训练时会接收以下 Ct 信息:
- 子任务指令(Subtask Instructions):在总任务(如“清理厨房”)的基础上,提供当前步骤的语义指令(如“拿起小刀”)。
- 子目标图像(Subgoal Images):由一个 14B 参数的 BAGEL 世界模型生成,描绘机器人应达到的近未来状态,为模型提供空间落地的视觉线索。
- 情节元数据(Episode Metadata):显式标记该段数据的质量(1-5分)、速度(执行步数)以及是否有错误。这使得模型能从失败数据中学习(标记为“错误”),并在推理时通过设定“高质量、无错误”来引导生成最优动作。

动作专家与流匹配(Flow Matching): 与传统的离散 Token 预测不同,π0.7 使用流匹配目标来训练动作专家。该模块是一个小型 Transformer,它关注 VLM 主干的激活,并生成 50 步的连续动作块(Action Chunk)。这种设计不仅能捕捉动作的多模态分布,还能实现高速推理(在 H100 上低至 38ms)。
③ 端到端数据流
- 输入阶段:接收最多 4 路摄像头画面(正面、手眼等)及历史 6 帧。
- 特征编码:视频编码器压缩历史观测,与当前观测一同输入 Gemma3 VLM。
- 上下文融合:子任务文本、生成的子目标图、期望的元数据(如速度=高质量)作为 Token 拼接。
- 动作生成:动作专家基于 VLM 输出的隐空间表示,通过 5 步去噪迭代生成 50 步动作。
3. 核心结果/发现
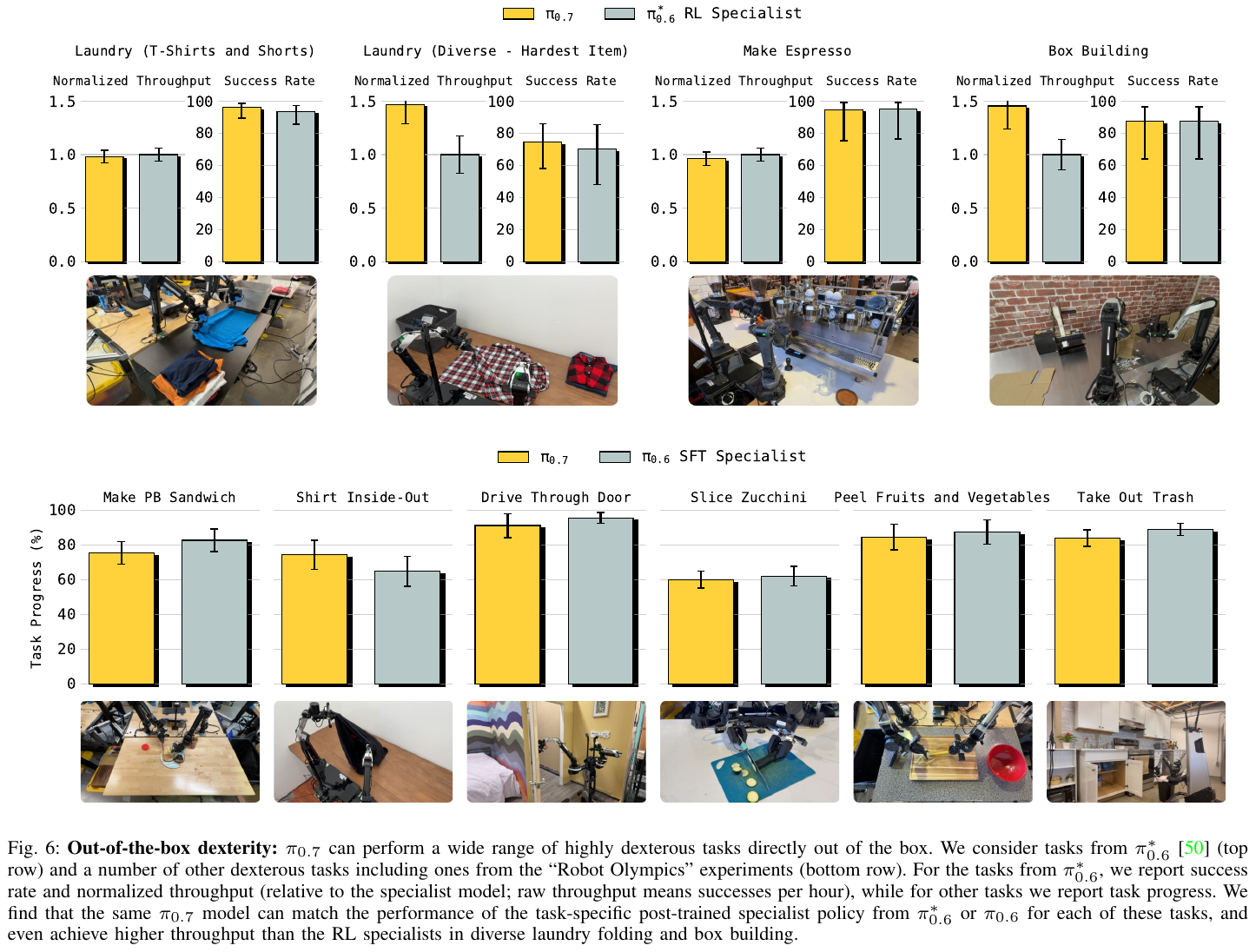
- 强大的开箱即用(Out-of-the-box):无需任何任务特定的后期训练,π0.7 即可完成极具挑战性的灵巧任务,如切黄瓜、剥皮、操作咖啡机。
- 卓越的跨构型泛化:在完全没有 UR5e 叠衣服数据的情况下,模型成功将军舰机械臂上学到的技能迁移到了 UR5e,性能接近经验丰富的人类远程操作员。
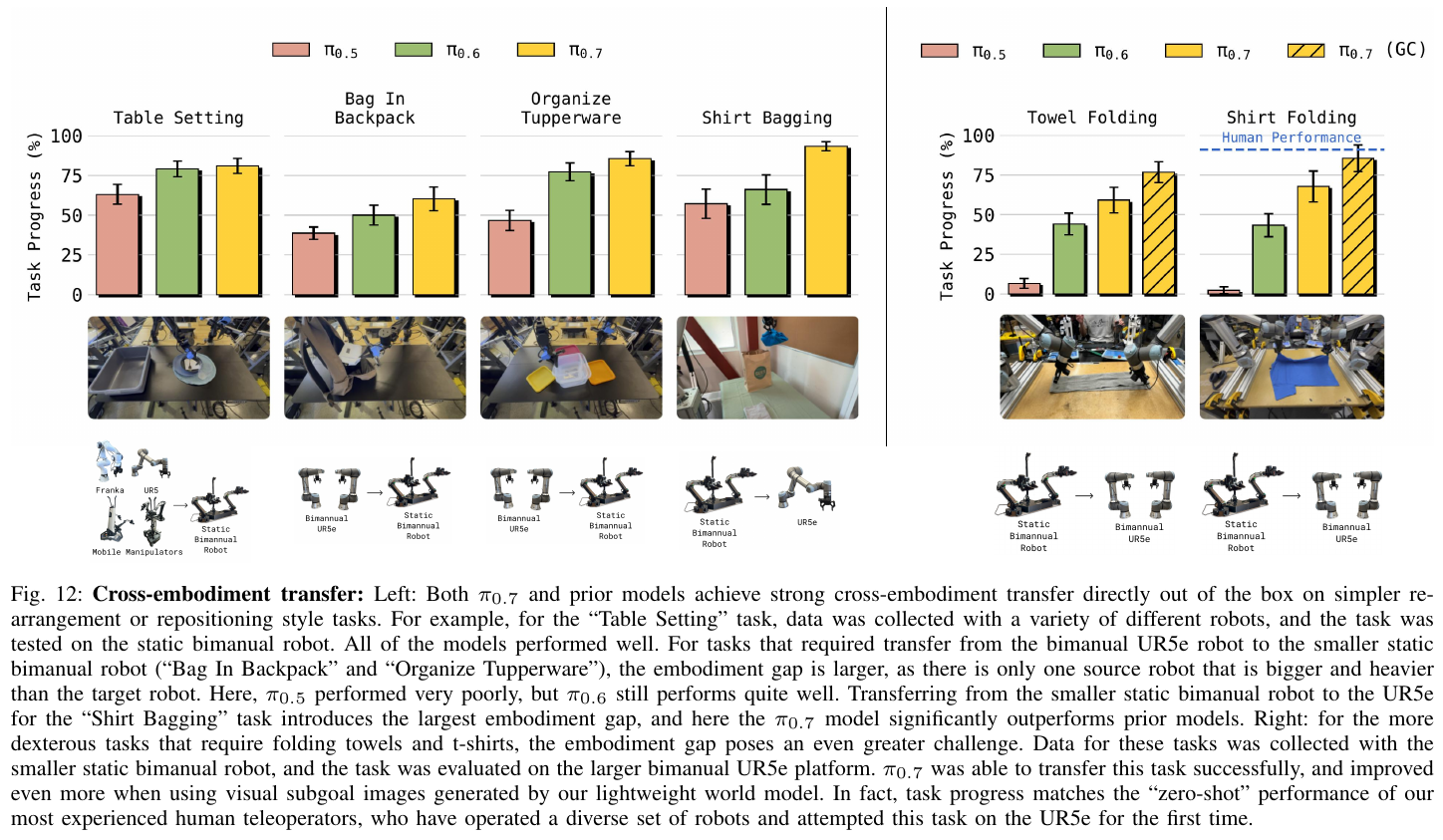
- 组合式新任务执行:通过语言“教练”,用户可以现场教会机器人完成全新的任务,如使用从未见过的空气炸锅。

4. 局限性
- 零样本成功率仍有差距:虽然在灵巧任务上表现惊人,但在从未见过的任务/构型组合上,其成功率(60-80%)仍低于已知任务(>90%)。
- 世界模型依赖:视觉子目标的生成对世界模型质量要求极高,生成失败会直接影响 VLA 的决策。
- 难以界定“从未见过”:由于训练集规模巨大且复杂,很难严格证明某个任务在数据集中完全没有相关的影子。
5.14 ACoT-VLA (2026) {#5-13-acot-vla-2026}
副标题: Action Chain-of-Thought for Vision-Language-Action Models 中文标题: 在动作空间中进行推理的视觉-语言-动作模型
📄 Paper: arXiv:2601.11404
精华 这篇论文的核心创新在于将推理过程从语言/视觉空间转移到动作空间,值得借鉴的点包括:(1) 直接在动作空间进行推理,提供同质化的运动指导,弥合语义与运动学之间的鸿沟;(2) 显式推理器(EAR)与隐式推理器(IAR)的互补设计,同时提供轨迹级和语义级指导;(3) Teacher Forcing稳定化训练策略,避免推理模块对动作头的优化干扰;(4) 通过action-level guidance大幅提升长时域任务的鲁棒性和误差抗累积能力。 不同CoT范式对比:
| 范式 | 中间表示 | 优势 | 局限 |
|---|---|---|---|
| (a) 语言CoT | 子任务描述 | 可解释性强 | 语义-动作鸿沟大 |
| (b) 视觉CoT | 目标图像 | 视觉直观 | 缺少运动学信息 |
| (c) 动作CoT(本文) | 粗粒度动作轨迹 | 同质化指导,直接可执行 | 需要额外推理模块 |
研究背景/问题 现有VLA模型主要在视觉-语言空间进行推理(如语言CoT预测子任务、视觉CoT合成目标图像),但这些推理形式对动作执行的指导是间接且次优的。VLM预训练主要聚焦语义理解而非物理动力学,世界模型虽能预测未来视觉状态但仍局限于视觉表征,两者都存在语义-运动学鸿沟(semantic-kinematic gap),难以为精确的低层动作生成提供充分的细粒度指导。
主要方法/创新点
本文提出 Action Chain-of-Thought (ACoT) 范式,将推理过程重新定义为结构化的动作意图序列,直接在动作空间进行deliberation。ACoT-VLA框架包含三个核心组件:
ACoT-VLA整体架构(三大核心模块):
VLM特征 ────┬─→ EAR (Explicit Action Reasoner)
│ ↓ 粗粒度参考轨迹 Z^ex
│
noisy action├─→ IAR (Implicit Action Reasoner)
│ ↓ 隐式动作先验 Z^im
│
└─→ AGP (Action-Guided Prediction)
↓ 融合显式+隐式指导
最终动作预测
详细架构图见ACoT-VLA论文Figure 2
1. Explicit Action Reasoner (EAR)
- 设计为轻量级Transformer,以noisy action sequence作为输入
- 通过self-attention捕获时序依赖,cross-attention从VLM的key-value cache注入多模态上下文
- 采用flow matching训练,自主生成粗粒度参考轨迹 $a^{ref}_{t:t+H^{ref}-1}$
- 参考轨迹编码后形成显式动作空间指导 $Z^{ex}$
2. Implicit Action Reasoner (IAR)
- 直接操作VLM的key-value cache,提取隐式运动线索
- 对每层VLM特征,使用可学习query矩阵 $Q_i$ 通过cross-attention提取动作相关信息
- 下采样策略降低计算开销:将KV cache降维至 $d’ \ll d$
- 跨层聚合后形成隐式动作指导 $Z^{im}$,捕获visual affordances和action semantics
3. Action-Guided Prediction (AGP)
- 将noisy action embedding视为query $Q_{action}$,与 $Z^{ex}$ 和 $Z^{im}$ 进行dual cross-attention
- 通过self-attention融合显式与隐式指导:$\bar{h} = \text{Self-Attn}([S^{ex}; S^{im}])$
- 最终action head $\pi^{head}_\theta$ 基于聚合表征预测去噪动作序列
训练策略:
- Flow matching损失同时优化EAR和action head
- Teacher Forcing稳定化:训练时 $Z^{ex}$ 直接从ground-truth轨迹计算,推理时切换为自条件模式
核心结果/发现
仿真实验:
- LIBERO: 98.5%平均成功率(SOTA),相比π0.5提升1.6%,在LIBERO-Long(长时域)提升最显著(96.0% vs 92.4%)
- LIBERO-Plus: 84.1%,在鲁棒性测试中大幅超越,尤其在相机视角变化(+11.6%)、机器人初始状态扰动(+16.3%)、传感器噪声(+12.5%)上表现突出
- VLABench: Intention Score 63.5%、Progress Score 47.4%,在unseen-texture track上获得+12.6% IS和+7.2% PS的显著提升
真实世界部署:
- 在AgiBot G1机器人上平均成功率66.7%(vs π0.5的61.0%、π0的33.8%)
- 跨embodiment验证:在AgileX平台上同样有效,证明方法的通用性
真实世界实验:在AgiBot G1机器人上评估三项操作任务
| 任务 | 描述 | ACoT-VLA | π₀.5 | π₀ |
|---|---|---|---|---|
| 擦拭污渍 | 检测并擦除桌面污渍 | 70.0% | 65.0% | 38.0% |
| 倒水 | 抓取水瓶倒入杯中 | 66.7% | 60.0% | 32.0% |
| 开放集抓取 | 根据指令抓取未见物体 | 63.3% | 58.0% | 31.5% |
| 平均成功率 | - | 66.7% | 61.0% | 33.8% |
关键发现:ACoT-VLA在跨具身平台(AgiBot G1、AgileX)上均表现优异,证明动作空间推理的通用性。
消融研究关键发现:
- EAR单独使用提升1.4%(LIBERO),IAR单独提升1.2%
- EAR+IAR联合使用达到最优,证明显式与隐式指导的互补性
- 参考动作horizon在15-30时效果最佳,过长或过短均不利
- EAR参数量在300M时性能最优,过度参数化反而导致过拟合
- 推理延迟仅增加约20ms(91ms→112ms),性能-效率权衡优秀
局限性 该方法需要额外的推理模块,虽然计算开销相对较小但在资源受限平台上可能存在挑战。此外,当前动作表征仍采用action chunks(关节角度/末端执行器位姿),缺乏显式几何结构,未来可将动作表征扩展至几何可解释的3D空间,进一步释放ACoT的推理潜力。
5.15 VLM4VLA (2026) {#5-14-vlm4vla-2026}
副标题: Revisiting Vision-Language Models in Vision-Language-Action Models 中文标题: 重新审视视觉-语言-动作模型中的视觉-语言模型
📄 Paper: arXiv:2601.03309
精华
这篇论文最值得借鉴的核心思想包括:通过最小化适配管道公平评估不同 VLM 对下游任务性能的影响;发现 VLM 的通用能力与具身控制性能并不强相关,挑战了常见假设;识别出视觉编码器(而非语言组件)是性能瓶颈,揭示了 VLM 预训练目标与具身动作规划需求之间存在领域差距;提出通过向视觉编码器注入控制相关监督信号可获得持续性能提升的策略。
研究背景/问题
当前 Vision-Language-Action (VLA) 模型研究主要关注网络架构、训练范式和动作解码方案的改进,但很少系统研究一个核心问题:底层 Vision-Language Model (VLM) 的选择和能力如何影响 VLA 策略的性能。现有工作缺乏公平的实验框架来评估不同 VLM 对下游机器人任务性能的贡献。
主要方法/创新点
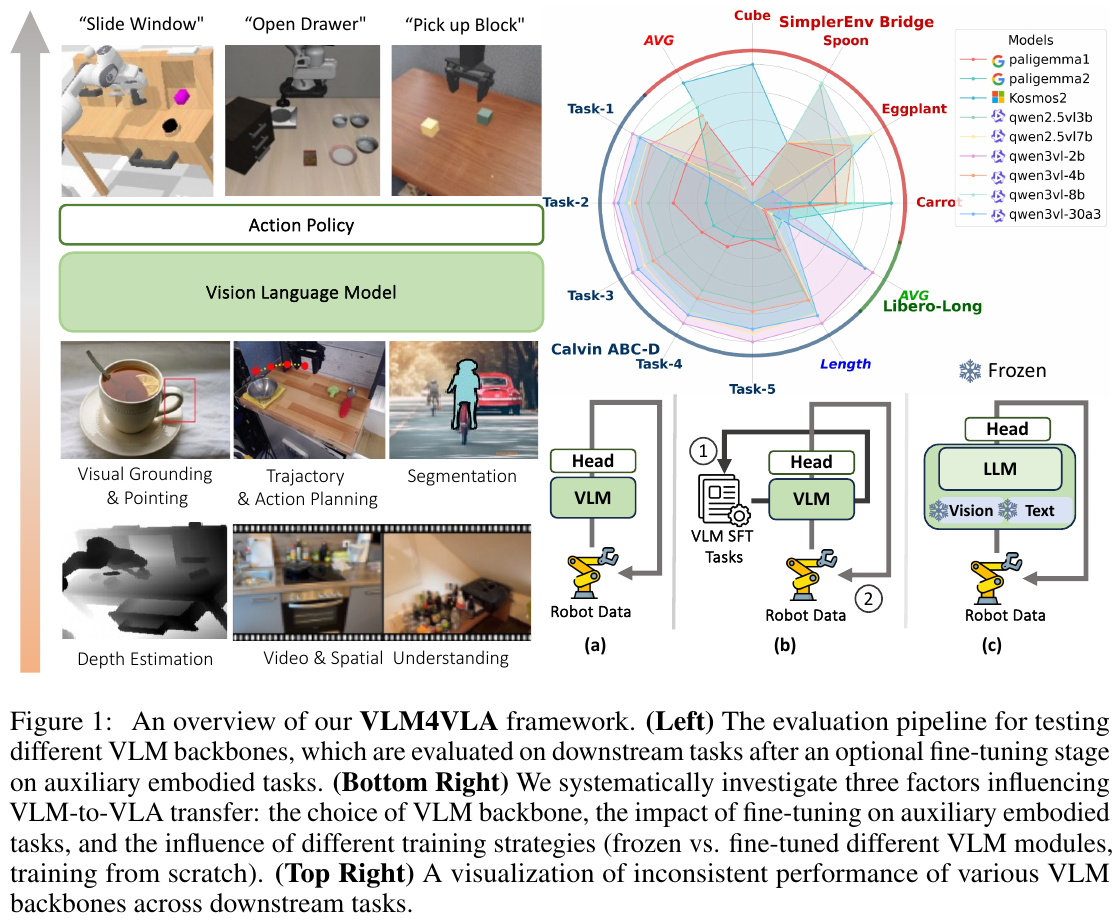
论文提出了 VLM4VLA 框架,这是一个最小化适配管道,通过引入少于 1% 的新参数将通用 VLM 转换为 VLA 策略,确保公平高效的比较。
VLM4VLA 框架概览:最小化适配管道,公平评估不同VLM对VLA性能的影响
评估流程:
- VLM骨干网络选择(Qwen2.5VL、Paligemma、Kosmos-2等9种)
- 可选辅助具身任务微调(visual pointing、depth estimation等)
- 下游控制任务评估(Calvin、SimplerEnv、Libero)
- 系统性分析(通用能力相关性、模态级消融、训练策略影响)
核心架构设计:
VLM4VLA 网络架构:
图像 + 语言指令
↓
[VLM Encoder] (冻结或微调)
↓
Action Query Token (可学习,<1%参数)
↓
[MLP Policy Head] (L1/L2 loss,非扩散)
↓
动作块输出
设计原则:最小化新增参数(<1%),使用简单MLP而非diffusion,确保公平比较。
- 引入可学习的 Action Query token 从 VLM 中提取具身相关知识
- 使用简单的 MLP-based policy head 解码动作,避免 diffusion/flow-matching 引入的随机性
- 采用 L1/L2 loss 而非 diffusion loss,提高推理稳定性和评估鲁棒性
- 所有 VLM 参数(vision encoder、LLM、word embeddings)在下游任务微调时全部训练
三维实验设计:
- 通用能力评估: 比较 9 个开源 VLM(1B-30B 参数)作为 VLA 骨干网络的性能,包括 Qwen2.5VL/Qwen3VL 系列、Paligemma 系列、Kosmos-2
- 具身特定能力评估: 使用 7 种辅助具身任务(visual grounding、depth estimation、trajectory prediction 等)微调 VLM,测试对下游控制任务的影响
- 模态级消融: 独立冻结/微调视觉和语言编码器,并测试向 vision encoder 注入控制相关信息(FAST tokenizer)的效果
评估基准: 在三个模拟环境上测试
- Calvin ABC-D: 训练于 ABC 场景,测试于 D 场景(跨场景泛化)
- SimplerEnv-Bridge: 训练于真实 BridgeV2 数据,测试于仿真环境
- Libero-Long: 10 个长视距操作任务
核心发现:
核心发现:VLM通用能力与VLA性能的相关性分析
| 评测基准 | VLM能力相关系数 | 结论 |
|---|---|---|
| Calvin ABC-D | r = 0.839 (强正相关) | VLM通用能力对跨场景泛化有帮助 |
| SimplerEnv-Bridge | r ≈ 0 (无相关) | VLM通用能力无法预测控制性能 |
| Libero-Long | r ≈ 0 (无相关) | VLM通用能力无法预测控制性能 |
启示:VLM预训练是必要但不充分的,通用VQA能力不等同于具身控制能力。
- VLM 通用能力是必要但不充分的: VLM 初始化相比从头训练提供一致性收益,但 VLM 的通用 VQA 能力无法预测其在具身控制任务上的表现
- 辅助具身任务微调效果有限: 在 visual pointing、spatial understanding、embodied VQA 等任务上微调 VLM 并未提升下游控制性能,甚至略有下降
辅助具身任务微调效果:令人意外的发现
| 辅助任务 | 理论预期 | 实际效果 |
|---|---|---|
| Visual Pointing | ✅ 应该提升空间理解 | ❌ 性能略降 |
| Depth Estimation | ✅ 应该增强3D感知 | ❌ 性能略降 |
| Trajectory Prediction | ✅ 应该改善动作规划 | ❌ 性能略降 |
| Embodied VQA | ✅ 应该强化具身理解 | ❌ 性能略降 |
结论:辅助具身任务微调未能提升下游控制性能,甚至略有负面影响。这挑战了”具身预训练有益”的常见假设。
- Vision encoder 是关键瓶颈: 冻结视觉编码器导致显著性能下降(Calvin 上下降 1.0-3.0 分),而冻结 word embeddings 几乎无影响
- 存在视觉-语言理解与低级控制的语义差距: 通过向 vision encoder 注入动作 token 预测任务,即使冻结 encoder 也能获得 +18.1% 性能提升,证明 VLM 视觉特征与控制需求存在根本性不对齐
VLM与VLA训练轨迹分歧:
参数空间
VLM任务最优区域 ←──────┐
│ 分歧点
共同起点 ──→ ○ ────┘
│
VLA任务最优区域 ←──────┘
关键洞察:
- VLM和VLA训练初期沿相同方向学习(共享视觉-语言理解)
- 但在某个时间点产生分歧,走向不同的最优区域
- 这解释了为何冻结vision encoder会导致性能下降
- 视觉-语言理解与低级控制存在本质差异
核心结果/发现
- Calvin ABC-D: Qwen3VL-2B 达到最佳性能(平均完成 4.142 个任务),接近 SOTA VLA(pi0: 3.509)
- SimplerEnv-Bridge: 最小的 Kosmos-2 (1.7B) 达到最高成功率(60.4%),超越更大的 Qwen 系列模型
- Libero-Long: Qwen3VL-2B 和 Kosmos-2 均达到 55%+ 成功率,优于其他 VLM
- 从头训练性能崩溃: 不使用 VLM 预训练的模型性能下降 60-70%,证明 VLM 预训练对 VLA 泛化至关重要
- Real-to-Sim 差距非主因: 在真实图像上微调 VLM 的动作预测任务后,冻结 vision encoder 仍导致性能下降,表明问题源于视觉-语言任务与低级控制任务的本质差异
- Vision encoder 微调必要性: 在 SimplerEnv-Bridge 任务上,解冻 vision encoder 并注入控制信息使性能从 27.6% 提升至 45.7%(+18.1%)
局限性
研究未在物理机器人上进行实验,主要受限于公平性和可重复性考虑。虽然分析表明 VLM-VLA 差距源于任务异质性而非简单的 sim-to-real 差距,但真实世界部署仍是最终目标。论文的全面模拟基准结果可为未来研究提供有价值的参考。
5.16 TwinBrainVLA (2026) {#5-15-twinbrain-vla-2026}
副标题: Unleashing VLM Potential in Embodied Tasks via Asymmetric Dual-Transformer Mixture 中文标题: 通过非对称双Transformer混合机制释放通用VLM在具身任务中的潜力
📄 Paper: arXiv:2601.14133
精华
这篇论文展示了如何通过结构化解耦来解决VLA模型中的灾难性遗忘问题,值得借鉴的核心思想包括:利用双流架构分离高层语义理解和低层运动控制、通过冻结”通才”分支保留预训练知识同时训练”专才”分支学习具身技能、采用非对称注意力机制实现知识迁移而不破坏原始能力、使用Flow-Matching生成连续动作而非离散token化。这种”左右脑”设计哲学为构建既有认知能力又有物理灵巧性的通用机器人提供了新范式。
研究背景/问题
当前的Vision-Language-Action (VLA)模型通常直接对预训练的Vision-Language Model (VLM)进行机器人控制任务的微调。然而,这种方法在维持高层语义理解和学习低层精细运动技能之间存在根本性冲突,导致”灾难性遗忘” (catastrophic forgetting)——模型为适应机器人操作而牺牲了原有的开放世界语言能力和视觉推理能力。
主要方法/创新点
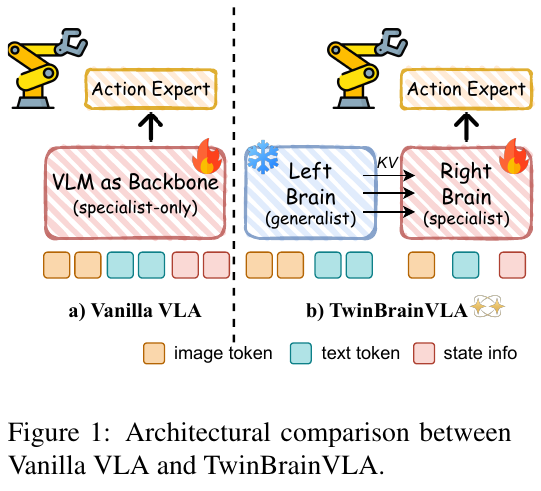
Vanilla VLA与TwinBrainVLA架构对比:
| 架构 | VLM使用 | 灾难性遗忘 | 本体感知 | 性能 |
|---|---|---|---|---|
| Vanilla VLA | 单一VLM微调 | ✅ 严重 | ❌ 有限 | ⚠️ 中等 |
| TwinBrainVLA | 双VLM(冻结+可训练) | ❌ 避免 | ✅ 专门编码 | ✅ 优异 |
论文提出了 TwinBrainVLA,一个受大脑半球侧化 (hemispheric lateralization) 启发的双流VLA架构,通过协调”通才VLM”和”具身专才VLM”来实现联合机器人控制:
1. 非对称双VLM骨干网络 (Asymmetric Dual-VLM Backbone)
-
Left Brain (左脑 - 通才): 冻结的预训练VLM,保留开放世界知识和指令跟随能力。输入仅包含视觉和语言token:
H⁰_L = [V(I); T(T)] -
Right Brain (右脑 - 专才): 可训练的VLM,专门用于具身运动控制。输入融合视觉、语言和本体感受状态信息:
H⁰_R = [V(I); T(T); φ(s)],其中φ是将机器人状态s (关节角度、末端执行器位姿等) 投影到VLM嵌入空间的轻量级MLP State Encoder
2. AsyMoT机制 (Asymmetric Mixture-of-Transformers)
TwinBrainVLA框架及AsyMoT机制:
Left Brain (冻结通才VLM) Right Brain (可训练专才VLM)
[V; T] [V; T; φ(s)]
↓ 独立Self-Attn ↓ AsyMoT
H_L (语义特征) ─────sg───→ [K_L; K_R] ← Q_R
[V_L; V_R]
↓
融合特征 H_R
↓
Flow-Matching Action Expert
↓
连续动作输出
AsyMoT核心机制:
- Left Brain独立运行,保留预训练能力
- Right Brain的Query attend到双分支的Key-Value(通过stop-gradient)
- 实现知识迁移而不破坏原始语义锚点
核心创新在于双流的交互方式:
- Left Brain: 保持冻结,独立运行自注意力机制以保留预训练能力
H^(l+1)_L = Attn(Q^l_L, K^l_L, V^l_L) + FFN(H^l_L) - Right Brain: 可训练,采用非对称联合注意力 (Asymmetric Joint Attention)——Query来自Right Brain,而Key和Value通过拼接两个分支构建:
K_joint = [sg(K^l_L); K^l_R] V_joint = [sg(V^l_L); V^l_R] H^(l+1)_R = Softmax(Q^l_R(K_joint)^T / √d_k) V_joint + FFN(H^l_R)其中sg(·)表示stop-gradient操作,确保Left Brain作为稳定的”语义锚点”提供高层推理特征,而Right Brain动态融合这些语义与精细的本体感受线索来推理空间动作。
3. Flow-Matching Action Expert
-
采用Diffusion Transformer (DiT) 架构,通过flow matching训练策略生成高精度连续控制信号,超越离散token化范式
-
关键区别在于condition的来源:使用可训练Right Brain的空间丰富表征H_R通过交叉注意力注入DiT
-
Flow-Matching损失函数:
L_FM(ψ) = E_{t,a₀,a₁}[||v_ψ(a_t, t, H_R) - (a₁ - a₀)||²]
4. 非对称训练策略
-
训练目标:
L_total = L_FM(θ_R, ψ, φ; D_robot),仅使用机器人动作损失,不混合通用视觉-语言数据集 -
参数更新策略: 严格冻结Left Brain参数
∇θ_L = 0,梯度仅在Right Brain (θ_R)、Action Expert (ψ) 和State Encoder (φ) 中传播 -
在AsyMoT融合层,通过stop-gradient显式阻断来自Left Brain的梯度流,确保其作为稳定语义锚点不被机器人控制任务的高方差梯度扰动
主要创新总结:
- 首个通过非对称双流设计显式解耦通用语义理解和具身感知的VLA架构
- AsyMoT机制实现两个同构VLM路径的信息交互和联合训练
- 结构化免疫灾难性遗忘——Right Brain专注控制动力学,Left Brain隐式保护语言和语义先验
核心结果/发现
SimplerEnv基准测试 (WidowX机器人):
- TwinBrainVLA + Qwen3-VL-4B-Instruct 达到 62.0% 平均成功率,超越最强基线Isaac-GR00T-N1.6 (57.1%) +4.9%
- TwinBrainVLA + Qwen2.5-VL-3B-Instruct 达到 58.4%,同样超越所有基线方法
- 在”Put Eggplant in Yellow Basket”任务上达到83.3%,展现强大的物体操作能力
RoboCasa基准测试 (GR1机器人桌面操作,24项任务):
- TwinBrainVLA + Qwen3-VL-4B-Instruct 达到 54.6% 平均成功率,大幅超越:
- Isaac-GR00T-N1.6 (47.6%) +7.0%
- QwenGR00T (47.8%) +6.8%
- QwenPI (43.9%) +10.7%
- 在复杂桌面场景中展现优异的精细操作技能,验证了解耦语义理解与具身感知的有效性
关键发现:
- 尽管未经过大规模机器人动作预训练,TwinBrainVLA在两个基准测试中均达到SOTA性能
- 双脑架构在不同VLM家族间展现强泛化性 (Qwen2.5-VL和Qwen3-VL)
- 显式保留预训练VLM的综合视觉理解能力,同时实现卓越的操作性能
局限性
当前实现要求Left Brain和Right Brain共享相同的模型架构以确保兼容的隐藏状态维度。未来研究方向包括:探索更解耦的模型架构 (如通过可学习投影层支持异构backbone)、整合专门的具身VLM checkpoints初始化Right Brain、扩展到完整OXE数据集训练以充分发挥双流架构容量、以及在更广泛基准和真实机器人场景中评估。
5.17 InternVLA-A1 (2026) {#5-16-internvla-a1-2026}
——Unifying Understanding, Generation and Action for Robotic Manipulation
📄 Paper: https://arxiv.org/abs/2601.02456

精华
InternVLA-A1 的核心创新在于将语义理解、视觉预见(visual foresight)与动作执行统一到单一 Mixture-of-Transformers (MoT) 框架中,用”想象未来”来指导当前动作,特别适合动态场景。其层级数据金字塔(合成仿真数据 + 真实数据混合预训练)有效弥合了 sim-to-real gap,值得 VLA 研究者借鉴。Generation Expert 的引入通过联合训练视觉预测和动作预测目标,使模型内化了动作与环境动力学之间的因果关系,是提升动态鲁棒性的关键设计。Flow Matching 作为动作解码器既保留了 MLLM 语义理解能力,又获得了对多模态动作分布的精细建模。
研究背景/问题
主流 VLA 模型(如 π₀、GR00T N1.5)基于 MLLM 构建,具有强大的语义理解能力,但本质上缺乏对物理世界动态的推理能力——它们执行的是反应式感知到动作映射,而非预判状态将如何演变。现有引入 World Model 的视频预测方法(如 VPP、Genie Envisioner)虽然能预测未来观测,但语义接地弱且对预测误差敏感。本文的目标是构建一个能同时紧密耦合语义理解与动态预测的统一架构。
主要方法/创新点
InternVLA-A1 采用 Mixture-of-Transformers (MoT) 架构,协调三个专家模块共同工作:
(1)Understanding Expert(理解专家)
直接复用现有 MLLM 架构(InternVL3-1B 或 Qwen3-VL-2.13B),通过 ViT 视觉编码器处理多视角观测 o_t,通过文本 Tokenizer 处理语言指令 l,将二者拼接为 prefix tokens h_und,为下游专家提供语义上下文。
(2)Generation Expert(生成专家)
受 Janus Pro 启发,采用解耦视觉编码策略——理解用 ViT(高层语义),生成用 VAE(像素级保真)。具体使用 Cosmos CI8×8 连续 VAE tokenizer 将输入图像编码为 latent features z_t,再经卷积层压缩空间维度至 4×4(每帧仅 16 个 tokens),对齐 Transformer 隐维度后送入生成专家。生成专家在历史帧 z_{t-m} 和当前帧 z_t 基础上,以 h_und 为条件,预测未来帧的 latent ẑ_{t+m},最终经反卷积和 Cosmos decoder 重建预测图像。
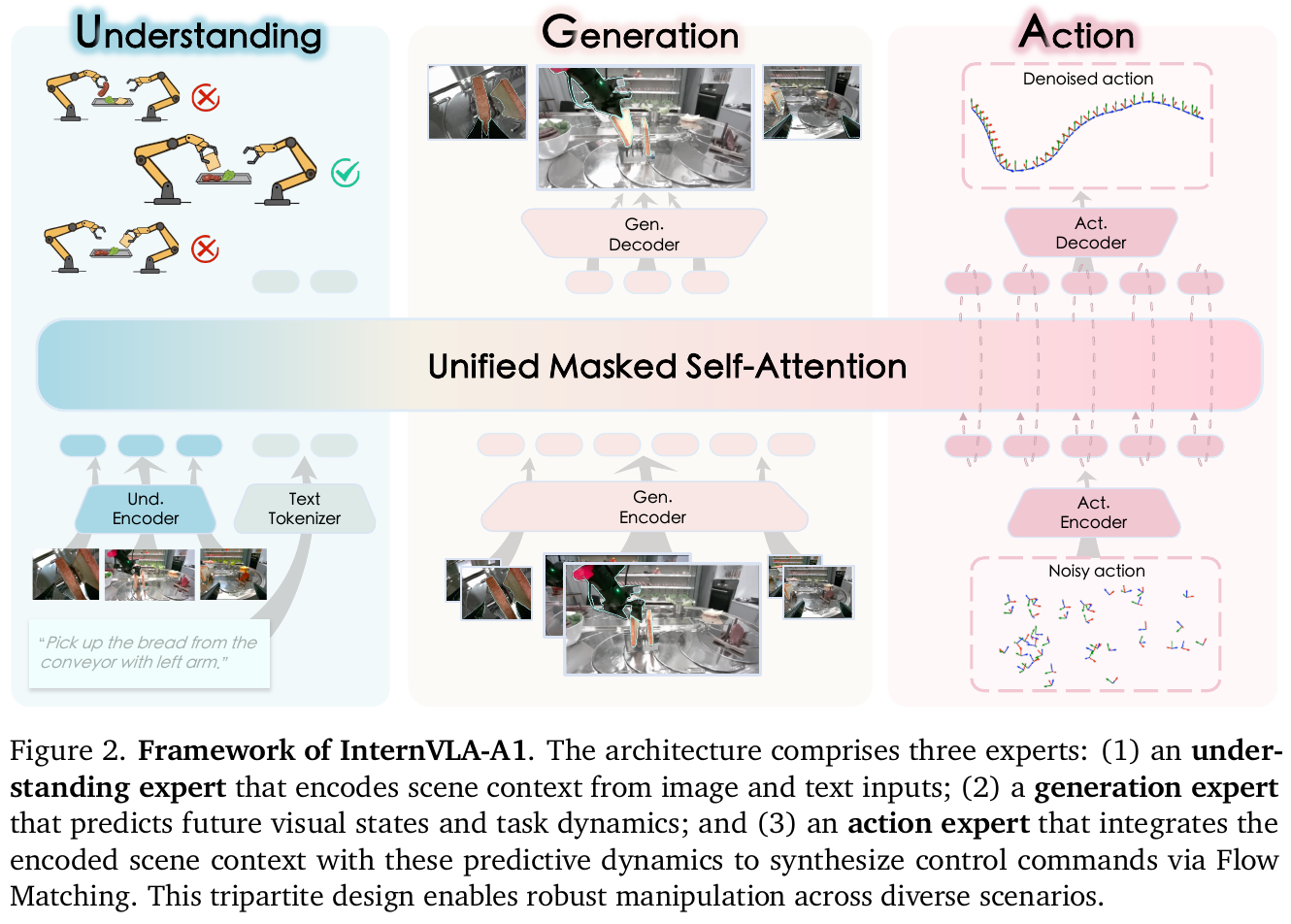
(3)Action Expert(动作专家)
以语言目标 l、当前观测(经 h_und)、本体感知 q_t 和生成专家的预测 latent ẑ_{t+m} 为条件,使用 Flow Matching 目标预测动作块 â_{t:t+k}。采样时从高斯噪声出发,通过 Euler 迭代法解 ODE 得到目标动作。
(4)Unified Masked Self-Attention 实现三专家间信息流的分块注意力掩码:累积分段掩码确保信息流单向传递(理解 → 生成 → 动作);前缀块(视觉+语言)完全双向;生成块完全双向且仅接收 Cosmos latent tokens;动作块分为状态 token(只关注自身和更早块)和动作 tokens(相互关注)。
(5)优化目标 联合优化两个目标:
- 视觉预见生成:
- Flow Matching 动作预测:
- 总损失(其中 $\lambda = 0.01$):
(6)层级数据金字塔

预训练数据混合配方(共 533M+ 帧):
- InternData-A1(ARX Lift-2):96M 帧(18%)
- InternData-A1(AgileX):122.5M 帧(23%)
- InternData-A1(Franka):90.5M 帧(17%)
- InternData-A1(Genie-1):16M 帧(3%)
- AgiBot-World(Beta):208M 帧(39%)
预训练后,使用少量专项真实数据进行 post-training 微调,适配目标部署环境。
(7)模型规模
- InternVLA-A1(2B):Understanding=InternVL3(0.94B)+ Gen/Act=Qwen2.5(各 0.36B),共 1.8B
- InternVLA-A1(3B):Understanding=Qwen3-VL(2.13B)+ Gen/Act=Qwen3(各 0.44B),共 3.2B
- 推理速度:两者均约 13 Hz(NVIDIA RTX 4090)
核心结果/发现
通用任务(10 个真实任务,Table 4):
- InternVLA-A1(3B)平均成功率 75.1%,比 π₀(3.3B)的 60.6% 提升 14.5%
- InternVLA-A1(2B)以 64.7% 超越更大的 π₀(3.3B)模型,凸显架构与数据质量优势
- 在精细操作任务(Make Sandwich: 93.3% vs 66.7%;Operate Oven: 86.7% vs 73.3%)表现尤为突出
动态场景专项任务(Figure 6):
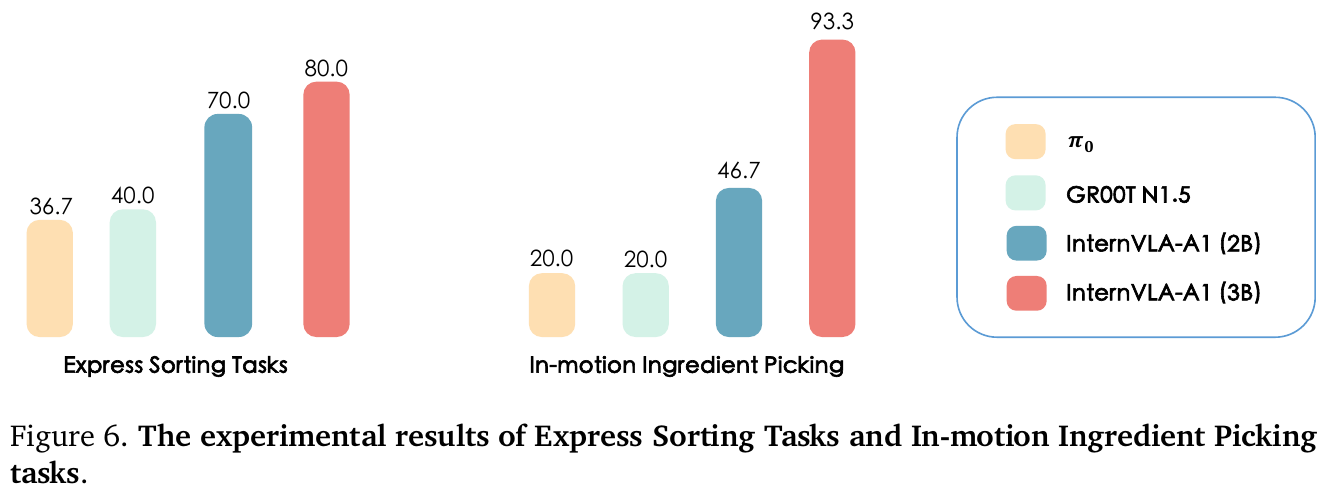
- Express Sorting:π₀ 仅 36.7%,GR00T N1.5 仅 40.0%,InternVLA-A1(3B)达 80.0%(+40%以上)
- In-motion Ingredient Picking:基线均仅 20.0%,InternVLA-A1(3B)达 93.3%(+73.3%)
仿真基准(RoboTwin 2.0, 50 任务):InternVLA-A1(3B)Easy/Hard 分别为 65.0%/25.4%,超越 π₀ 的 54.5%/19.8%(+10.5%/+5.6%)
消融实验:
- 去除预训练:平均成功率从 77.0% 降至 25.4%(↓51.6%)
- 去除 Generation Expert:平均成功率从 77.0% 降至 57.6%(↓19.4%),11/12 个任务均退化
局限性
理解专家缺乏与多模态 VQA 数据集的联合训练,导致通用语义推理和复杂指令跟随能力有所退化;视觉预见模块为保证实时推理效率而牺牲了图像预测的保真度,生成未来帧的粒度有限。
5.18 InternData-A1 (2025) {#5-17-interndata-a1-2025}
副标题: Pioneering High-Fidelity Synthetic Data for Pre-training Generalist Policy
📄 Paper: https://arxiv.org/abs/2511.16651

精华
本文首次证明纯合成数据预训练的 VLA 模型可以匹配甚至超越使用真实机器人数据的最强基线(π-dataset),打破了”仿真数据无法替代真实数据”的固有认知。数据合成 pipeline 完全解耦(环境构建、技能组合、Domain Randomization、轨迹生成独立模块化),极大降低人工成本(每条 episode 低于 0.003 美元)。消融实验揭示轨迹多样性(articulation + long-horizon tasks)而非单一规模是有效 VLA 预训练的核心驱动力,这对数据采集策略有重要指导意义。大规模 domain randomization 使仿真与真实的视觉 gap 缩小到约 1:8 的仿真对真实数据等效比例,强调了渲染保真度和随机化的重要性。开源数据集和生成 pipeline 为 embodied AI 社区提供了可复现的大规模数据基础设施。
研究背景/问题
现有 VLA 模型已证明大规模真实机器人数据预训练的有效性,但合成数据单独能否达到相同效果尚未被系统验证。真实数据采集代价高昂,需要专业遥操作员、特殊硬件和大量人力,大多数研究机构难以复现;现有仿真数据集覆盖的技能集窄(主要是 pick-and-place)、仅涉及 rigid 物体,且未在大规模 VLA 预训练中验证有效性。
主要方法/创新点
InternData-A1 是一个包含 630k 轨迹、7,433 小时、覆盖 4 种机器人体态(AgiBot Genie-1、Franka Emika Panda、AgileX Split Aloha、ARX Lift-2)、18 种技能、70 个任务、227 个室内场景的大规模高保真合成数据集。
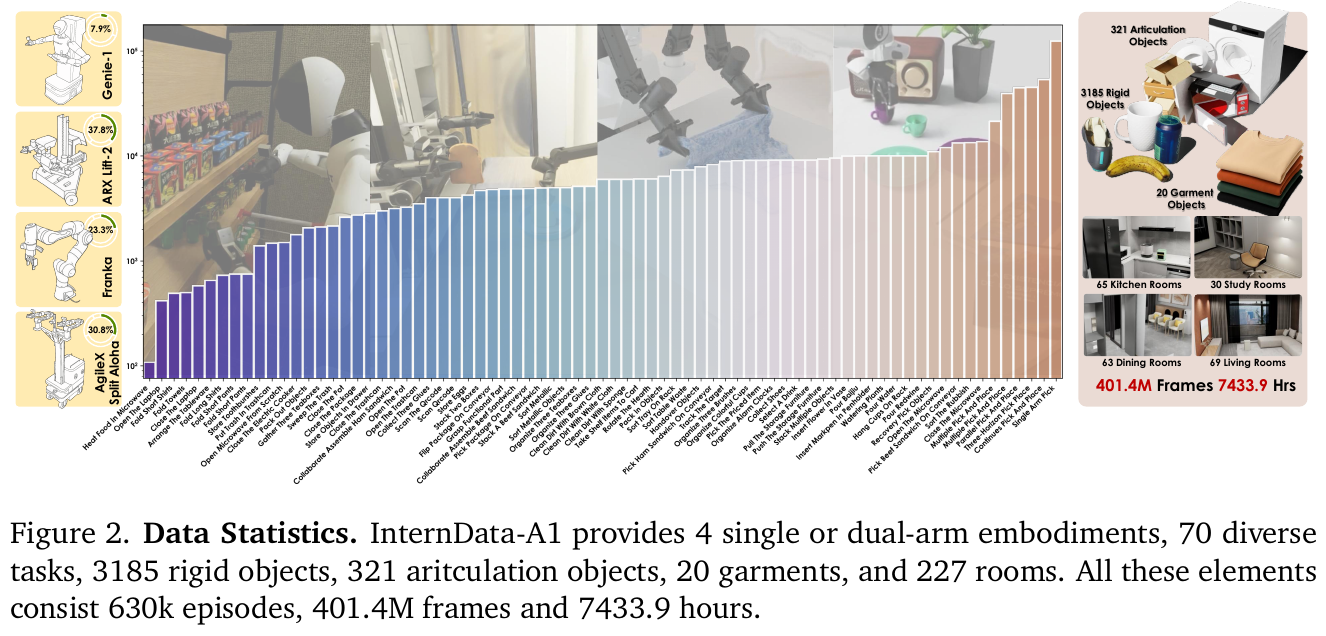
数据合成 Pipeline(4 阶段全自动)
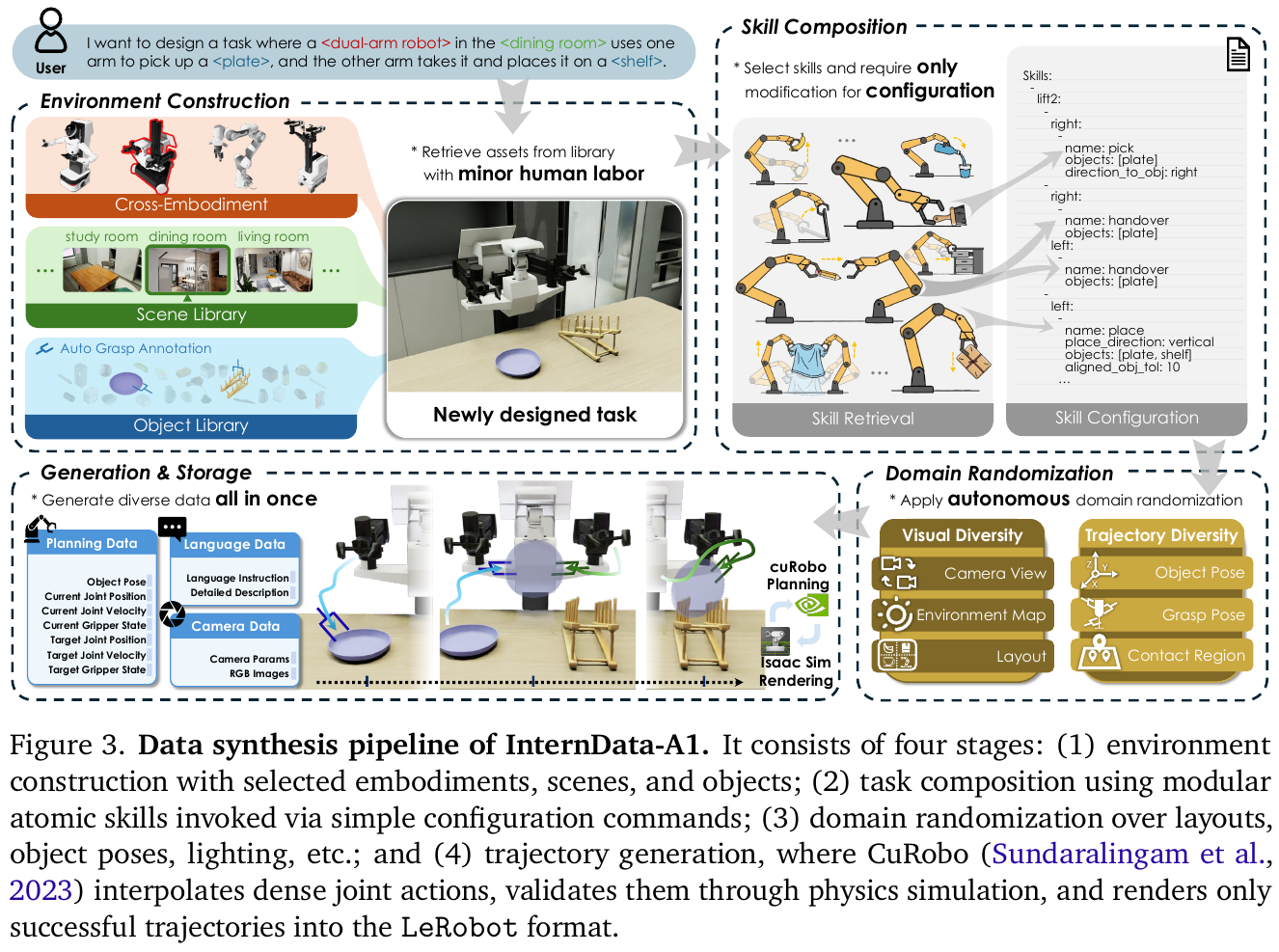
1. Environment Construction(环境构建)
- Embodiment: 支持 4 种体态,均以 USD 格式定义,经过碰撞动力学验证
- Scene Library: 227 个室内场景(厨房、书房、餐厅、客厅)来自 GRScenes-100,每个场景标注了详细的操作区域元数据
- Object Library: 覆盖 rigid(3185 个,含自动 grasp pose 标注)、articulated(321 个,含关节轴和物理参数)、deformable(20 件真实扫描服装,用 Vertex Block Descent 模拟)、fluid(粒子系统 + isosurface 渲染)四类物体
2. Skill Composition(技能组合)
- 每个技能是模块化脚本策略,输入:物体状态、机器人状态、用户约束;输出:waypoints 序列(end-effector 6D pose)
- 包含 Pick、Place、Push 等 18 种原子技能,通过简单配置文件组合成完整任务
- 支持双臂并行和顺序执行,无需额外代码即可扩展到新物体、场景、体态
- 18 个 long-horizon 任务(每个涉及至少 3 个连续技能),共 124,789 条轨迹
3. Domain Randomization(域随机化)
- 视觉多样性: 相机视角 ±5° 旋转、±5cm 平移;174 个环境光照图(随机光温和强度);目标物体可从同类资产中替换
- 轨迹多样性: 物体位姿在任务特定空间范围内随机采样;AnyGrasp 生成数百万 grasp 候选,最终随机选取 top-40 之一;articulated 和 deformable 物体的接触区域扩展为邻域
4. Generation & Storage(生成与存储)
- 使用 CuRobo 运动规划器在 waypoints 间插值密集关节空间动作
- 仅存储成功完成的轨迹(Isaac Sim 物理验证),转换为 LeRobot 格式
- 记录:物体元数据、语言指令、多视角 RGB、相机参数、机器人本体感知状态和动作标签
5. Framework Optimization(框架优化)
- Stage Decoupling: 轨迹规划(CPU-bound)与视觉渲染(GPU-bound)解耦为 pipeline 架构,规划失败不触发冗余渲染
- Dynamic Resource Scheduling: Planner 和 Renderer 内部均采用并行批处理策略 + 动态调度算法
- Stack Render: 堆叠渲染技术进一步提升 GPU 利用率
- Cluster Stability: Balancer 模块负载均衡 + Supervisor 模块监控,整体吞吐量提升 2–3×,生产成本低于 $0.003/episode
核心结果/发现
与 π-dataset 对比(49 个仿真任务)
- π₀(InternData-A1) vs 官方 π₀:Easy 模式 60.0% vs 55.0%(+5%),Hard 模式 26.5% vs 20.0%(+6.5%)
- 在 Hard 模式下的提升说明 InternData-A1 的大规模 domain randomization 提供的鲁棒性在下游 fine-tuning 中持续保留
与 π-dataset 对比(9 个真实世界任务)
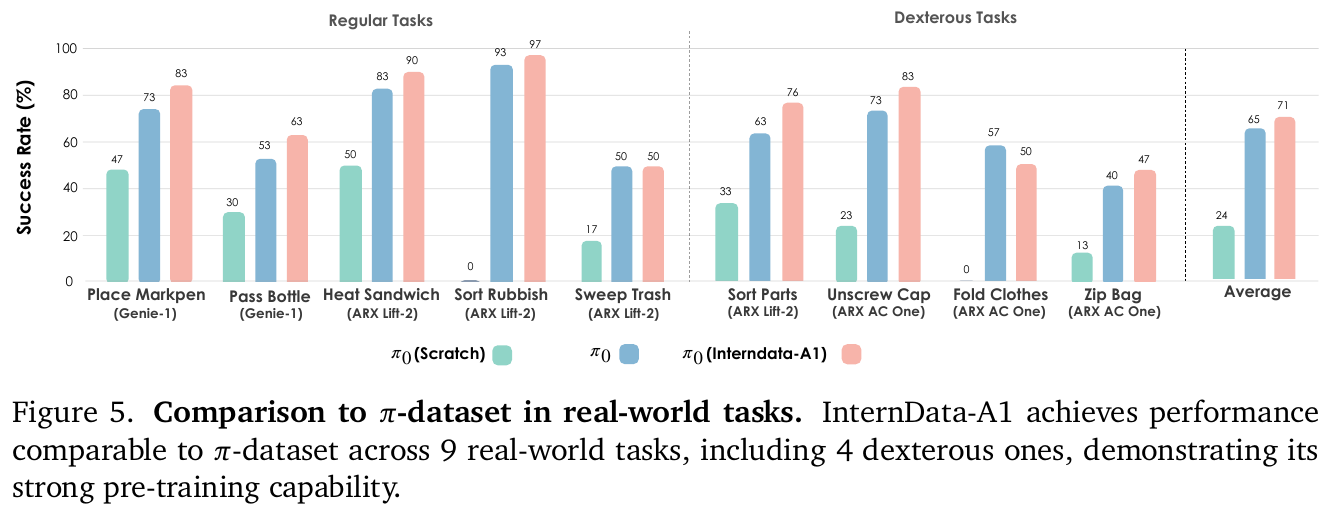
- 在 5 个常规任务上平均超越 π-dataset 6.2%(包括 Place Markpen、Pass Bottle、Heat Sandwich、Sort Rubbish、Sweep Trash)
- 在 4 个灵巧任务(Sort Parts、Unscrew Cap、Fold Clothes、Zip Bag)上性能与 π-dataset 相当,使用了全新体态 ARX AC One(训练数据中未见过)
与开源数据集对比(49 个仿真 + 2 个真实任务)
- InternData-A1 大幅领先:Easy 60.0% vs OXE 32.5% / Agibot World 52.5% / RoboCasa 50.0%
- 真实任务 Sort Rubbish:90.0% vs OXE 40.0%;Pass Bottle:60.0% vs RoboCasa 13.3%
Sim-to-Real 迁移
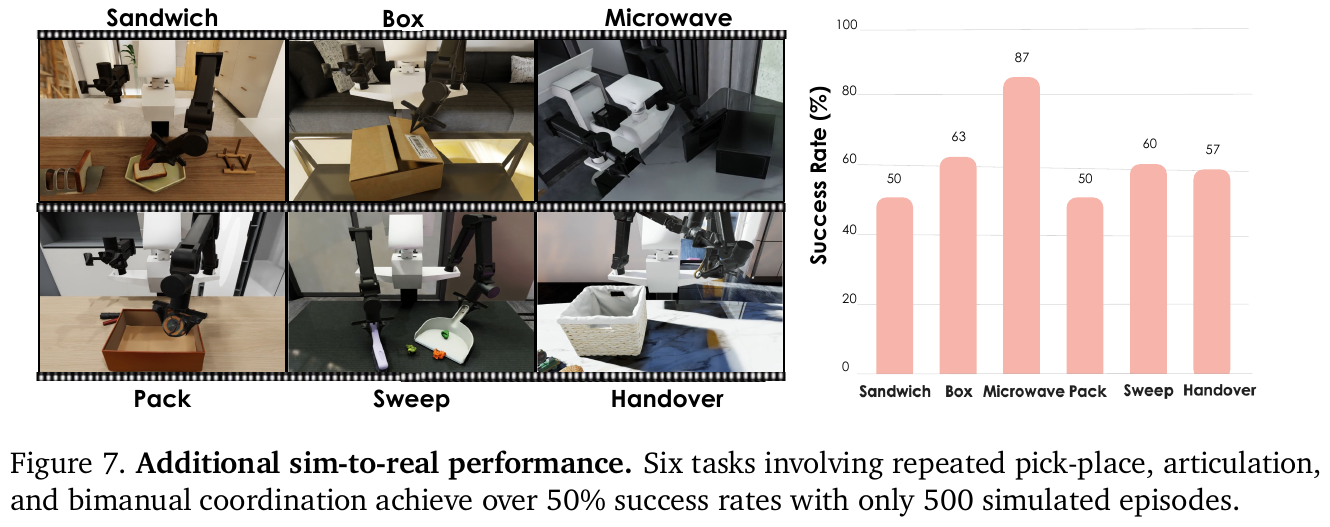
- 10 个任务中直接零样本迁移成功率超过 50%;仅需 500 条仿真数据即达到高成功率
- 对于基础技能任务(Sort Rubbish、Wipe Stain),200 条仿真 episodes ≈ 200 条真实数据
- 对于复杂任务(Flip Package、Instructional Pick),仿真对真实等效比约为 8:1
消融实验(数据组成分析)
- 去除 Base 或 Long-horizon 任务的性能下降 > 去除 PnP 任务,说明任务多样性比单一任务规模更重要
- 去除 Articulation 任务(仅 11.67%)导致显著下降,说明 articulated 操作能扩展 action space 多样性
- 核心结论:轨迹多样性(Trajectory Diversity)是有效预训练的核心驱动
5.19 Isaac GR00T (2025-2026) {#5-18-gr00t-2025}
Generalist Robot 00 Technology ———英伟达全栈具身智能生态
📄 Paper: NVIDIA Isaac Blog

精华
GR00T 代表了”模型开源 + 生态锁定”的典型范式。其核心贡献在于提出了 System 1 (快思考) & System 2 (慢思考) 的双系统架构:System 2 基于 VLM 负责语义理解和长程规划(约 5Hz);System 1 基于 Diffusion Transformer 负责高频、精细的反射性动作(120Hz)。此外,英伟达通过打通 Isaac Sim(仿真)、Cosmos(视频生成)和 Jetson Thor(边缘芯片),构建了目前最完整的具身智能开发工具链。
研究背景/问题
人形机器人需要同时具备处理复杂语义指令的能力和在不确定环境中保持动态稳定性的精细控制能力。单一频率的端到端模型往往难以兼顾”深度思考”的计算延迟与”即时反应”的实时性需求。
主要方法/创新点
- 双系统架构:
- System 2 (Cognitive): 处理多模态输入(语音、手势、视频),生成任务子目标。
- System 1 (Reactive): 将子目标实时转化为关节力矩,处理平衡和避障。
- 全栈生态联动:
- Omniverse & Isaac Sim: 提供超大规模合成数据生成能力。
- Cosmos: 专门用于生成符合物理规律的视频轨迹,缓解真实数据稀缺。
- Jetson Thor: 专用具身智能芯片,优化了 Transformer 的推理速度。
核心结果/发现
- 在多种人形机器人平台上实现了零样本迁移。
- 展示了极强的指令跟随能力,能够根据自然语言指令学习舞蹈、搬运等复杂动作。
- 证明了通过大规模仿真训练(Sim-to-Real)可以显著提升人形机器人的步态稳定性和操作灵巧度。
局限性
- 生态绑定: 训练和部署深度依赖英伟达的 H100 集群和 Jetson 芯片,对于非 NVIDIA 硬件用户存在较高的迁移门槛。
- 闭源核心: 虽然开源了部分模型权重,但完整的训练 Pipeline 和专有数据集仍处于闭源状态。
5.20 Xiaomi-Robotics-0 (2026) {#5-19-xiaomi-r0-2026}
MoT Architecture for Real-Time Bimanual Manipulation ———国产开源 VLA 的实时性标杆
📄 Paper: 小米机器人实验室
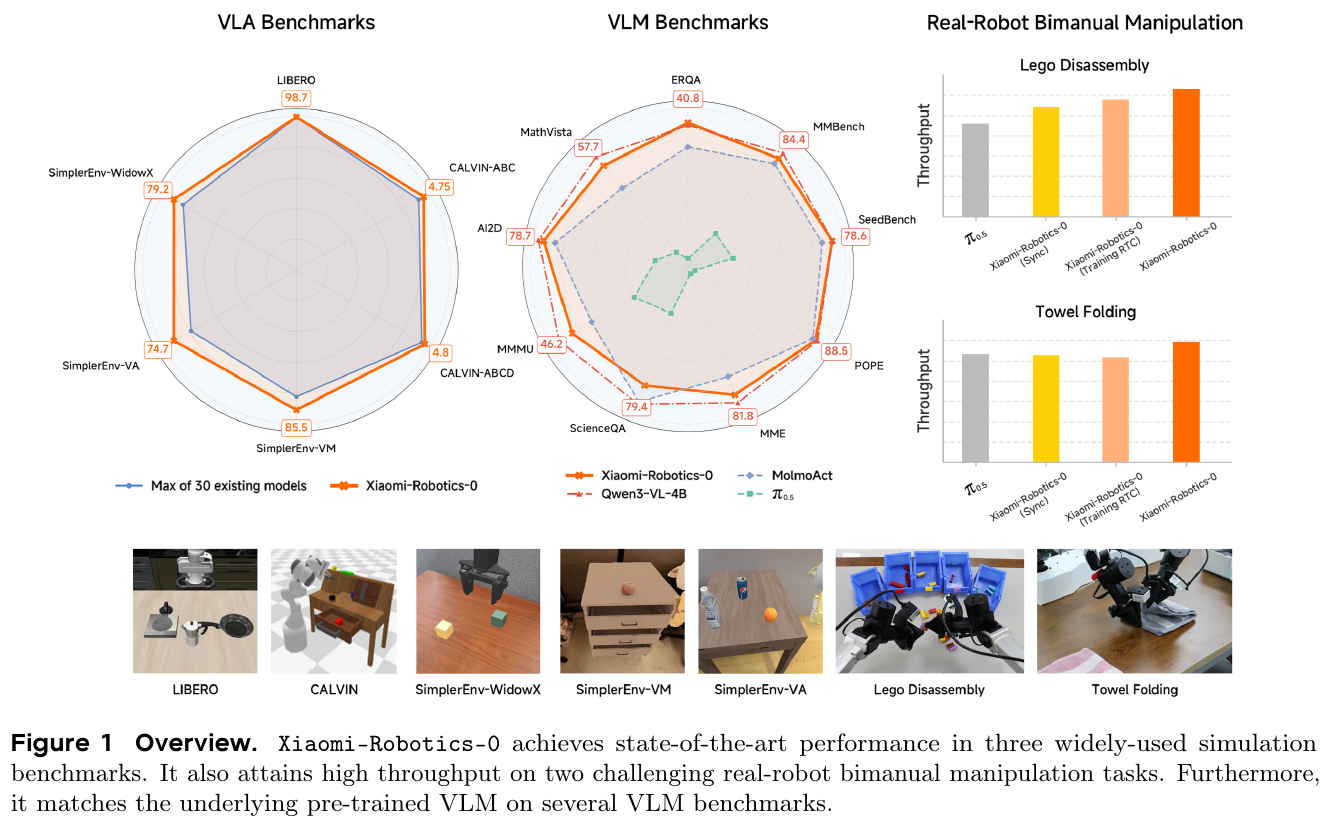
精华
Xiaomi-R0 针对 VLA 模型在实际部署中常见的推理延迟问题,提出了 Mixture-of-Transformers (MoT) 架构。通过将感知与控制模块进行解耦并行化处理,Xiaomi-R0 成功在消费级 GPU(如 RTX 4090)上实现了高频闭环控制。该模型在双臂灵巧操作(如拆解乐高、折叠毛巾)任务中表现优异,是国产开源阵营中工程化落地最快的代表作之一。
研究背景/问题
大型 VLA 模型(如 7B+ 参数)在进行实时推理时,往往难以达到机器人控制所需的 20Hz+ 频率,导致动作出现”卡顿”或由于视觉滞后导致的执行失败。
主要方法/创新点
- MoT 架构: 采用混合专家模式,将模型分为”推理专家”和”执行专家”。推理专家处理慢速语义,执行专家在高频视觉流下快速调整动作。
- 低延迟优化: 针对动作 Token 生成路径进行了极致压缩,大幅缩短了从图像输入到信号输出的时间链路。
- 双臂协同增强: 专门针对双臂操作中的时空一致性进行了数据增强,提升了左右手配合的流畅度。
核心结果/发现
- 在 LIBERO 等通用榜单上成功率达到 98.7%。
- 首次在开源领域展示了在未见物体上的实时、高动态双臂协同操作。
- 证明了通过合理的架构优化,即使是中等规模的 VLA 也能在实时性上挑战巨量闭源模型。
局限性
- 模型的长程逻辑推理能力相比 π₀.5 略显单薄。
- 对复杂光照和极端动态场景的鲁棒性仍有待提升。
5.21 X-VLA (2025) {#5-20-xvla-2025}
Scalable Cross-Embodied Learning with Soft Prompting ———学术界彻底开源的具身范本
📄 Paper: Tsinghua AIR & Shanghai AI Lab

精华
X-VLA 是由清华 AIR 和上海 AI 实验室联合推出的彻底开源项目。其核心贡献在于通过 Soft Prompting(软提示) 技术解决了”一个大脑控制所有机器人”的难题。相比于传统的对每种硬件进行微调,X-VLA 仅需学习极小规模的机器人特定 Prompt,即可将通用的物理规律迁移到不同的机械臂和人形机器人上。该项目从代码、数据、权重到评估基准全量公开,是学术界最彻底的开源范本。
研究背景/问题
机器人硬件形态各异(关节数、臂长、自由度不同),如何用一个统一的预训练模型适配所有硬件而不产生性能冲突(负迁移)?
主要方法/创新点
- Soft Prompting: 在 VLM 输入层引入可学习的”硬件描述 Token”,自动对齐不同机器人的动作空间。
- 大规模跨域数据集: 整合了包括操作、导航乃至部分自动驾驶在内的异构数据,验证了物理知识的跨域通用性。
- 开放评估基准: 刷新了五大主流仿真基准,并提供了标准化的物理测试协议。
核心结果/发现
- 适配新硬件的成本降低了 90% 以上,仅需极少量新数据即可完成部署。
- 证明了”基础模型+硬件适配层”是实现通用具身智能的高效路径。
局限性
- 在需要极端精细力反馈的任务中,软提示的精度上限受限于骨干网络的感知分辨率。
- 目前主要聚焦于运动学对齐,对于复杂的接触动力学建模尚在早期阶段。
5.22 Motus (2025)
——A Unified Latent Action World Model
📄 Paper: arXiv:2512.13030
研究背景/问题
当前具身智能体的理解、世界建模和控制能力被孤立地建模在不同模型中,这种碎片化阻碍了统一多模态生成能力的实现,也限制了从大规模异构数据中学习。现有方法将本应统一的系统分割为5个独立的建模任务:VLA(视觉-语言-动作模型)、WM(世界模型)、IDM(逆动力学模型)、VGM(视频生成模型)和视频-动作联合预测模型。两个核心挑战包括:如何在单一框架中统一这些多模态生成能力,以及如何利用大规模异构数据(互联网视频、自我中心人类演示、多机器人轨迹)进行动作专家的预训练。
主要方法/创新点
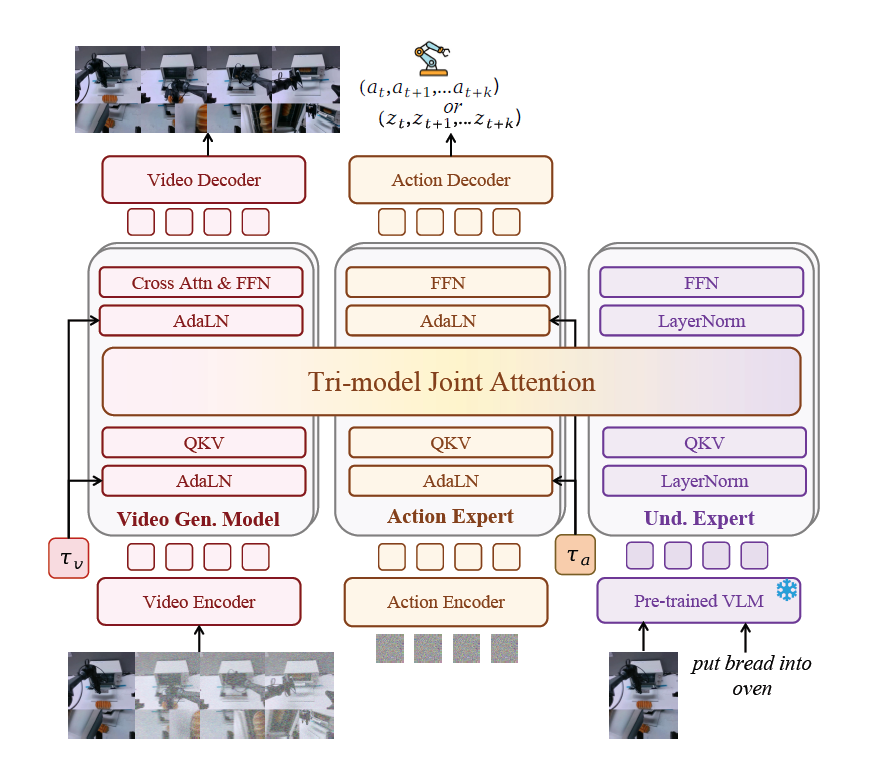
Motus提出了统一的潜在动作世界模型,通过以下创新实现五种建模范式的融合:
1. Mixture-of-Transformer (MoT)架构:
- 三模态联合注意力(Tri-model Joint Attention):将三个专家的多头自注意力层连接起来,在保留各专家特定功能的同时实现跨模态知识融合
- 理解专家(Understanding Expert):基于Qwen3-VL-2B(253.5M参数),具备3D定位和空间理解能力
- 视频生成专家(Video Generation Expert):采用Wan 2.2 5B作为视频基础模型
- 动作专家(Action Expert):Transformer结构(641.5M参数),与Wan相同深度
- 总模型规模:8B参数(VGM 5.00B + VLM 2.13B + Act Expert 641.5M + Und Expert 253.5M)
2. UniDiffuser式调度器:
- 为视频和动作分配不同的时间步τ_o、τ_a和噪声尺度
- 支持五种推理模式的灵活切换:VLA、世界模型、IDM、VGM、视频-动作联合预测
- 使用rectified flow目标函数:
- \[l_{\text{action}} = \mathbb{E} \left[ \left\| v^{\theta_a} - (\epsilon_a - a_{t+1:t+k}) \right\|^2 \right]\]
- \[l_{\text{obs}} = \mathbb{E} \left[ \left\| v^{\theta_o} - (\epsilon_o - o_{t+1:t+k}) \right\|^2 \right]\]
3. 潜在动作(Latent Actions) - 像素级”增量动作”:
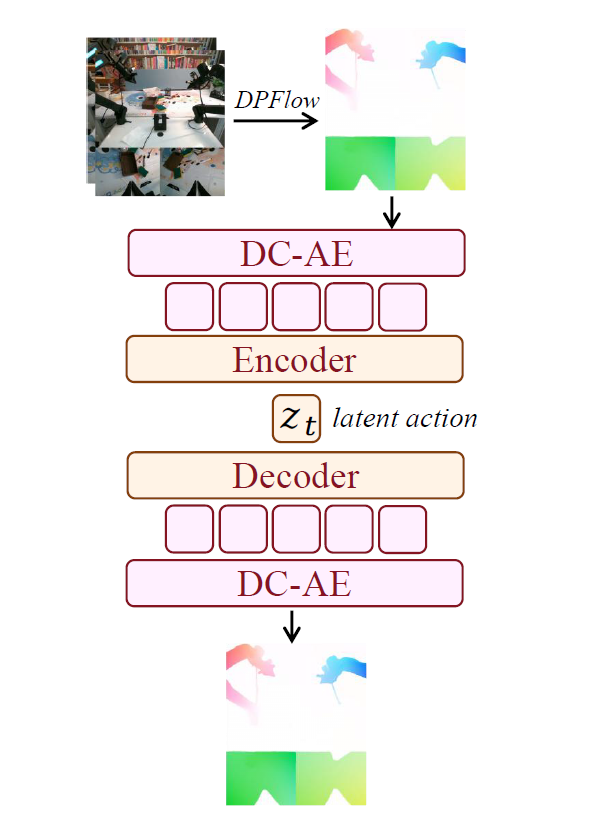
- 光流表示:使用DPFlow计算光流作为通用运动表示,将其转换为RGB图像
- 深度压缩自编码器(DC-AE):将高维光流压缩为4×512维token,再通过轻量级编码器投影到14维潜在动作向量
- 训练策略:混合90%无标注数据(自监督重建)+10%有标注轨迹(任务无关数据+标准演示)
- 分布对齐:引入任务无关数据(AnyPos方法),使用Curobo随机采样目标机器人动作空间
- 损失函数:\(\mathcal{L} = \mathcal{L}_{\text{recon}} + \lambda_a \left\| a_{\text{real}} - a_{\text{pred}} \right\|^2 + \beta \mathcal{L}_{\text{KL}}\)
4. 动作密集-视频稀疏预测策略:
- 视频帧率:8帧 @ 5Hz
- 动作块:48步 @ 30Hz
- 通过下采样视频帧平衡token数量,防止过拟合视频预测而削弱动作预测能力
5. 三阶段训练流程:
- 阶段1(视频生成):使用多机器人轨迹、自我中心人类视频和合成数据适配VGM(仅训练VGM,约8000 GPU小时)
- 阶段2(潜在动作统一训练):冻结VLM,在视频、语言和潜在动作上预训练整个Motus模型(约10000 GPU小时)
- 阶段3(监督微调):在目标机器人数据上使用真实动作微调(约400 GPU小时)
6. 六层数据金字塔:
- Level 1: Web数据(VGM和VLM预训练)
- Level 2: 自我中心人类视频(Egodex: 230,949样本)
- Level 3: 合成数据(RoboTwin: 27,500样本)
- Level 4: 任务无关数据(AnyPos: 1,000样本)
- Level 5: 多机器人任务轨迹数据(Agibot: 728,209 + RDT: 6,083 + RoboMind: 16,861)
- Level 6: 目标机器人任务轨迹数据(In-house: 2,000样本)
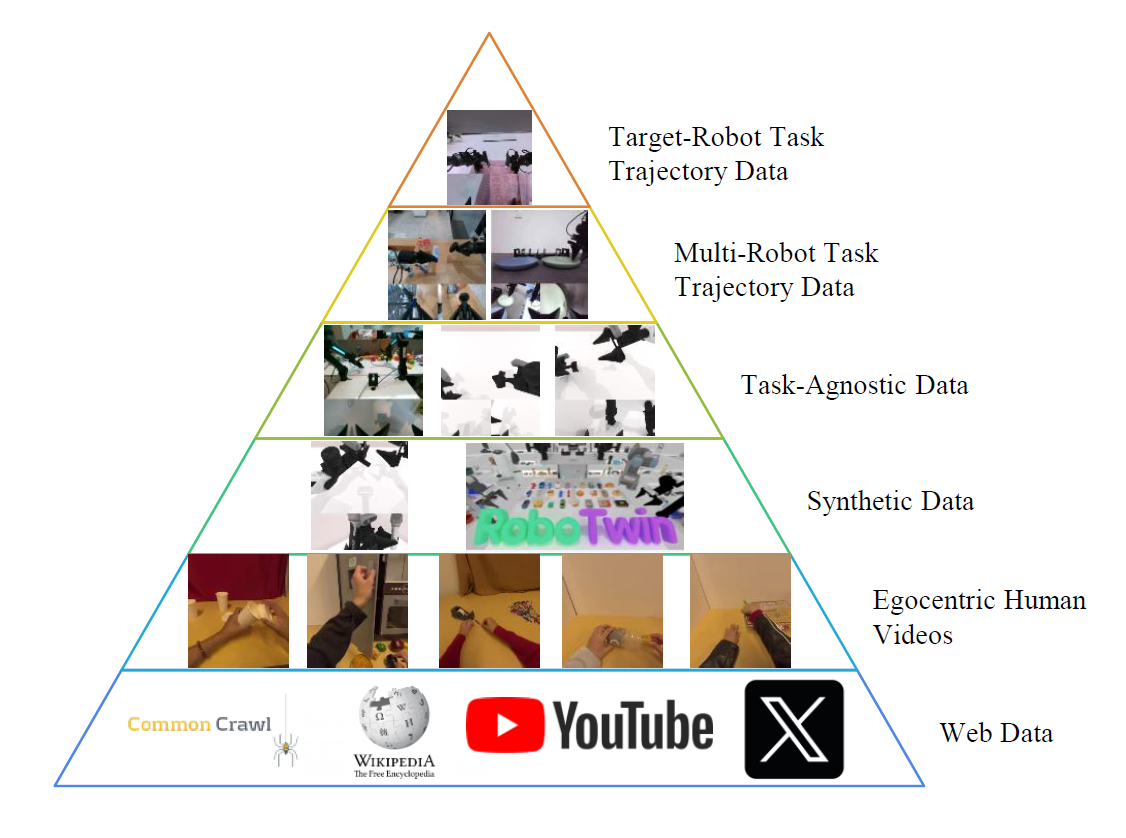
核心结果/发现
仿真环境(RoboTwin 2.0)性能:
- 随机化场景平均成功率:87.02%(Motus) vs 72.84%(X-VLA) vs 43.84%(π0.5)
- 相比X-VLA提升15%,相比π0.5提升45%
- 在50个任务上评估,包含强背景和环境随机化(随机背景、杂乱桌面、桌高扰动、随机光照)
- 清洁场景成功率:88.66%(Motus) vs 72.80%(X-VLA) vs 42.98%(π0.5)
真实世界实验:
- 两个平台:AC-One和Agilex-Aloha-2双臂机器人
- 9个复杂任务:测试空间理解、可变形物体操作、精确流体控制、视觉理解、长时域规划
- 任务包括:叠毛巾、使用滴滤咖啡机煮咖啡、研磨咖啡豆、将面包放入烤箱、从饮水机取水、倒水浇花、按键盘按键
- AC-One平台:平均部分成功率63.22%(Motus) vs 25.86%(无预训练) vs 14.79%(π0.5)
- 突出任务:研磨咖啡豆92% vs 0%(无预训练),煮咖啡62% vs 0%,放立方体入盘100% vs 60%
- Agilex-Aloha-2平台:平均59.30%(Motus) vs 26.60%(无预训练) vs 48.60%(π0.5)
- 突出任务:从饮水机取水96% vs 8%(无预训练),叠毛巾39% vs 0%
其他基准测试:
- LIBERO-Long:97.6%成功率(与X-VLA并列最优,达到state-of-the-art)
- VLABench: In Distribution平均0.48(vs π0.5的0.43),Cross Category平均0.25(vs π0.5的0.22)
消融实验验证:
- 训练阶段重要性:完整Motus(阶段2预训练) 87.02% vs 仅阶段1 81.86%(+10.02%提升)
- IDM模式性能:动作MSE 0.014(Motus) vs 0.044(ResNet18+MLP) vs 0.122(DINOv2+MLP),显著优于专门训练的IDM基线
- VLA模式竞争力:83.90%成功率,与联合模式87.02%性能接近
- 世界模型生成质量:FID 11.209,FVD 61.209,SSIM 0.866,PSNR 25.07(在两个平台上评估)
五种统一模式实证验证: \(\begin{aligned} \text{1. VLA:} & \quad p(a_{t+1:t+k} \mid o_t, \ell) && \text{--- 从观察和语言预测动作} \\ \text{2. 世界模型:} & \quad p(o_{t+1:t+k} \mid o_t, a_{t+1:t+k}) && \text{--- 从当前观察和动作预测未来观察} \\ \text{3. IDM:} & \quad p(a_{t+1:t+k} \mid o_{t:t+k}) && \text{--- 从观察序列推断动作} \\ \text{4. VGM:} & \quad p(o_{t+1:t+k} \mid o_t, \ell) && \text{--- 从观察和语言生成未来视频} \\ \text{5. 联合预测:} & \quad p(o_{t+1:t+k}, a_{t+1:t+k} \mid o_t, \ell) && \text{--- 同时生成视频和动作} \end{aligned}\)
局限性
当前方法需要大量计算资源(总计约18,400 GPU小时训练)。某些复杂任务(如叠毛巾)的性能仍有限,部分成功率仅为39%。尽管通过潜在动作改进了跨具身泛化,但仍需进一步研究。未来工作将探索更先进的统一模型架构,追求更通用的运动先验,并从互联网规模的通用视频中学习潜在动作。此外,需要研究如何降低部署成本并提升模型在极端条件下的鲁棒性。
5.23 RoboGen (2024) {#5-23-robogen-2024}
———Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
📄 Paper: arXiv:2311.01455 (ICML 2024) 🌐 Project: https://robogen-ai.github.io/ 🔗 Genesis 仿真器: 由本工作衍生,后续支撑 Gene 26.5(Genesis AI, 2026.05)
精华
RoboGen 是 CMU、清华、MIT、UMass 等团队提出的”生成式仿真”(Generative Simulation)首个完整实现,核心思想可一句话概括:用基础模型自动产出”任务–场景–监督信号–策略”全流程,让机器人技能学习摆脱人工标注,实现近乎无限的数据扩展。
- Propose-Generate-Learn 自驱循环:智能体自主提出任务 → 自动构建仿真场景 → 自动生成训练监督 → 自动学习策略,可被无限轮询。
- 覆盖范围空前:单一管线同时覆盖刚体、铰接体、软体、双足/四足运动等任务谱,论文展示了 106+ 种自动生成的技能(开抽屉、解锁保险箱、揉面团、爬楼梯、后空翻……)。
- 任务多样性显著优于人工数据集:在 Self-BLEU、SentenceBert、ViT、CLIP 四项指标上均超越 Behavior-100、RLBench、MetaWorld、Maniskill2 以及同期 GenSim。
- Genesis 仿真平台的发源工程:RoboGen 内部版即 Genesis 的雏形——一个支持多材质耦合、可微分的统一仿真平台,后由原班人马商业化为 Genesis AI,并孕育出 2026 年的 Gene 26.5 通用操作基础模型。

1. 研究背景/问题
仿真数据被视为打破真机数据瓶颈的关键,但传统仿真基准(RLBench、MetaWorld、Behavior-100 等)严重依赖人工搭建:每条任务都要人手设计资产、布局、奖励函数与评价逻辑,扩展成本极高,导致即便是最大型的人工 benchmark 也只能覆盖几十到一百多个任务。与此同时,FM/LLM/VLM 在语义先验、代码生成、3D 资产检索/生成等环节已具备能力,但既有”基础模型 + 机器人”工作(Code as Policies、VoxPoser、SayCan 等)大多直接让 LLM 输出策略或子任务,仍需要现成的仿真环境。
核心问题:能否利用基础模型的”语义+代码+生成”能力,自动产出一整条”任务–场景–资产–奖励–算法选择–策略”的训练流水线?
2. 主要方法/创新点
RoboGen 的整体管线由四个阶段组成(论文 Figure 2):
A) Task Proposal → B) Scene Generation → C) Training Supervision Generation → D) Skill Learning
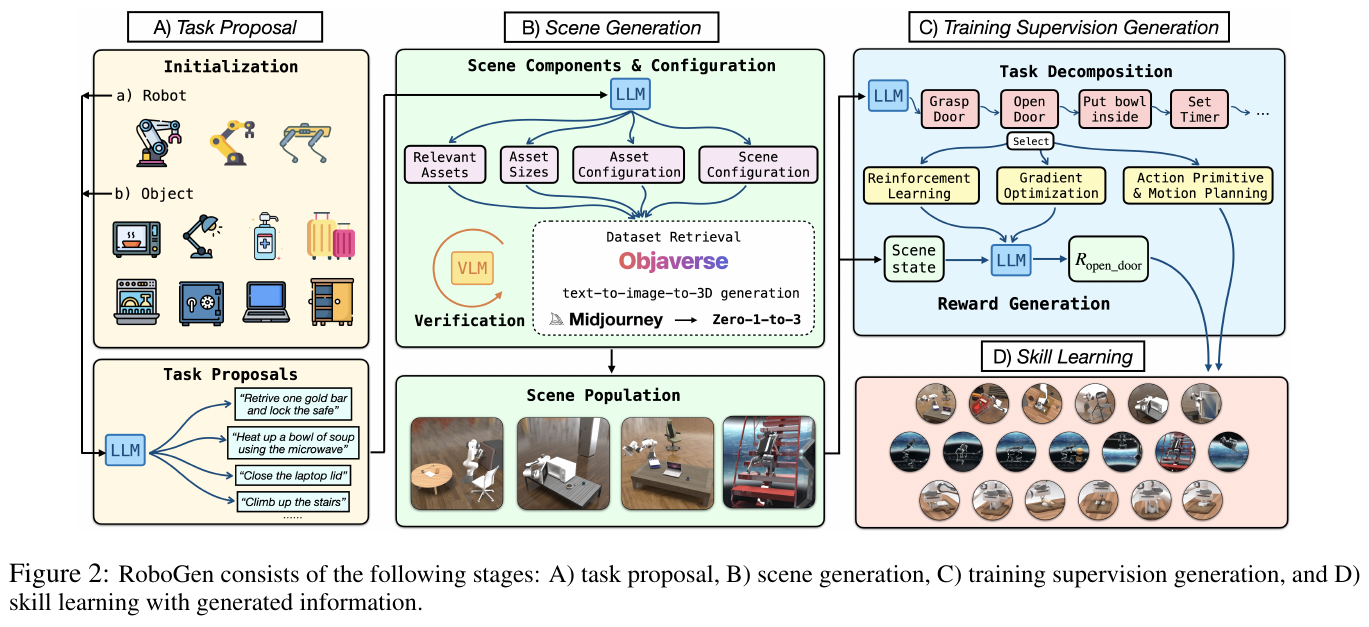
A. Task Proposal(任务提议)
- 以”机器人类型 + 随机采样的物体”作为种子(object-based initialization),或采用 11 类范例任务作为 example-based seed(适用于足式 / 软体)。
- 由 GPT-4 接收 PartNetMobility 的 URDF 关节信息与语义标注,生成:1) 任务名;2) 自然语言描述;3) 完成任务所需的额外物体;4) 涉及的关节/链路。
- 通过反复采样不同物体与示例,可产出语义无重复的开放式任务流。
B. Scene Generation(场景生成)
四个子产物全部由 GPT-4 自动决定:
| 子产物 | 实现方式 |
|---|---|
| Relevant assets | LLM 提出的额外物体 → 在 Objaverse(800k+ 资产)中检索 top-k=10,由 Gemini-Pro VLM 二次验证语义匹配 |
| Asset size | LLM 推理”现实尺寸 + 任务相对尺寸”(如抽屉应大于书) |
| Initial configuration | LLM 设定铰接物体初始关节角(关窗口任务下窗户应为打开状态) |
| Scene configuration | LLM 给出空间关系(”刀放在砧板上”),并保证免碰撞 |
对软体任务,则用 GPT-4 生成目标形状描述 → Midjourney 文生图 → Zero-1-to-3 图生 3D Mesh,构建可控的目标几何。
C. Training Supervision Generation(监督信号生成)
- 任务分解:GPT-4 把长程任务拆为子任务(如”开微波炉 → 抓汤碗 → 放入 → 关门 → 设定时器旋钮”)。
- 算法选择:每个子任务自动从 RL(SAC)、Gradient-based Trajectory Optimization、Action Primitive + Motion Planning(BIT*)三选一:
- 接触密集 / 连续控制 / 旋钮类 → RL;
- 软体形变(揉面团、塑形)→ 梯度优化(基于可微仿真);
- 抓取 / 接近 / 释放 / 路径规划 → 动作原语 + 运动规划。
- 奖励生成:刚体/运动任务用低层状态量构造奖励;软体任务用 earth-mover distance 对齐当前形状与目标形状。
D. Skill Learning(技能学习)
- 使用 Genesis(一个可微、多材质耦合的统一仿真器,本工作内部版即其前身)作为执行后端。
- RL:SAC + 256-256-256 MLP,每子任务训练 1M 环境步;长程任务采用 N=8 次回合,最高奖励状态作为下一段初始状态。
- 软体:Adam 做梯度优化;运动规划:BIT*。
3. 核心结果/发现
任务多样性(论文 Table 1,越小越好):
| 指标 | RoboGen | Behavior-100 | RLBench | MetaWorld | Maniskill2 | GenSim |
|---|---|---|---|---|---|---|
| 任务数 | 106 | 100 | 106 | 50 | 20 | 70 |
| Self-BLEU ↓ | 0.284 | 0.299 | 0.317 | 0.322 | 0.674 | 0.378 |
| SentenceBert Sim ↓ | 0.165 | 0.210 | 0.200 | 0.263 | 0.194 | 0.288 |
| Scene ViT Sim ↓ | 0.193 | 0.389 | 0.375 | 0.517 | 0.332 | 0.717 |
| Scene CLIP Sim ↓ | 0.762 | 0.833 | 0.864 | 0.867 | 0.828 | 0.932 |
→ RoboGen 在语义与视觉两个维度上多样性均显著优于既有人工基准与并行工作 GenSim,验证了”基础模型 + 开放资产库”的可扩展性。
消融与失败分析:
- 移除 size verification 会让 BLIP-2 场景对齐分数大幅下降;移除 object verification 同样恶化。
- 在 12 个铰接物体操作任务上,若仅用纯 RL(去掉动作原语),成功率从平均 ~0.92 跌至接近 0。
- 全自动生成的 155 个任务中:13 个因检索物体不匹配而失败;6 个因 LLM 误解关节角语义(如把”开”和”关”角度搞反)而奖励错配;少量因复杂功能(订书机插钉)超出资产能力。
长程任务示例(论文 Figure 3):
- “Retrieve a gold bar from the safe”、”Heat up a bowl of soup using the microwave”、”Put the toy into the storage”、”Move the toy out of the box” 均能被自动拆解、自动赋奖、自动学成完整序列。

4. 局限性与意义
局限性:
- 仍依赖闭源 LLM(GPT-4)与外部资产库,长尾物体(如订书钉)检索/生成质量不稳定;
- LLM 对铰接关节状态的语义判断仍可能出错,需人工校验少量奖励函数;
- 视觉真实性与触觉/力学反馈尚未统一进生成管线;
- Sim-to-Real 未在论文中端到端验证。
意义与后续影响:
- 范式价值:RoboGen 是首个把”任务–场景–监督–策略”四阶段全部交给基础模型的系统,奠定了”生成式仿真”作为继真机遥操作、互联网视频之后的第三条数据来源。
- 工程遗产:论文中提到的内部版 Genesis 仿真器,正是后来开源 Genesis(CMU 主导,每秒 4300 万帧,见 §1.7)以及 Genesis AI 商业化版本 Genesis World 的基础。
- 通向 Gene 26.5:Genesis AI 在 2026 年 5 月发布的 Gene 26.5 系统将这一范式推向真实世界——以 Genesis World 做大规模仿真预训练 + 200k+ 小时真实多模态数据微调,产出能完成烹饪、移液、魔方、钢琴等长程灵巧任务的统一 Flow Matching 基础模型,新任务仅需 20–30 分钟数据即可微调。可以认为:RoboGen 提出的 propose-generate-learn 循环 + Genesis 的可微极速仿真,正是 Gene 26.5 数据飞轮的学术原型。
5.24 Qwen-VLA (2026)
———统一操作、导航与轨迹预测的具身基础模型
📄 Paper: https://arxiv.org/abs/2605.30280
精华
- 操作、导航、人体视角动作等异构具身任务,本质上共享同一计算结构:给定视觉观察、语言指令和 embodiment 描述,预测未来动作序列——Qwen-VLA 用一个统一的 action-and-trajectory 预测框架将它们全部吸收进单一模型。
- DiT-based flow matching 是将离散 VLM token 空间与连续高维动作空间”解压缩”的关键桥梁;在 CPT/SFT 前先用文本-to-action 预训练(T2A)预热 DiT,让解码器无需视觉捷径即可学会语言→动作先验。
- Embodiment-aware prompt conditioning 将机器人平台、控制频率、预测时域全部编码进文本 prompt,无需任何架构改动即可支持 10+ 种机器人形态跨模型共享。
- Zero-padding 统一异构 action 空间:不同机器人动作维度对齐到最大维度并补零,per-channel 有效性掩码防止 padding 污染梯度,架构参数量最轻且效果与复杂方案相当。
- RL 微调(PPO + GAE)仅在单一仿真环境中收集稀疏 reward,但改进能跨环境正向迁移:在未参与 RL rollout 的 RoboCasa、DOMINO 等基准上同样出现性能提升。
1. 研究背景/问题
现有具身智能系统高度专业化:操作模型专为桌面/灵巧操作设计,导航模型专注室内路径点预测,二者无法跨任务、跨环境、跨机器人形态迁移,也难以像通用视觉-语言预训练那样规模化扩展。核心挑战在于操作与导航在输出格式、控制频率、动作维度、评估协议上看似完全异质,实则共享同一计算结构——均需 agent 对视觉观察、语言指令和 embodiment 约束进行条件化,预测物理与语义一致的未来动作序列。Qwen-VLA 正是利用这一洞察,将两者统一进单一 VLA 模型。
2. 主要方法/创新点
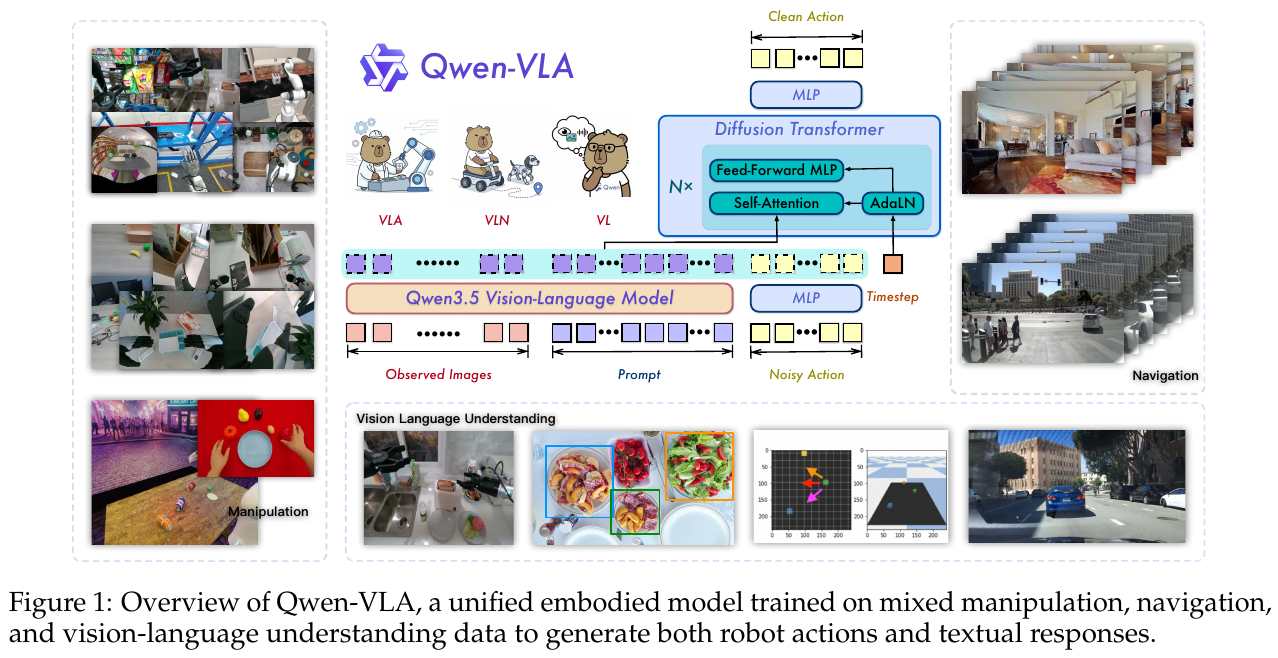
① 整体框架概述
Qwen-VLA 由两个核心模块构成:Qwen3.5-4B 视觉-语言主干(负责高层感知与推理)和单流 DiT 风格的 flow-matching 动作专家(负责精细连续动作生成),二者通过 VLM 隐状态拼接共同服务于操作、导航和视觉语言理解三类任务。
② 逐模块讲解
VLM 主干(Qwen3.5-4B)
- 输入:多视角 RGB 图像(ego、左腕、右腕摄像头,每路用视图标记
<|tag_start|> <image> <|tag_end|>包裹)+ 语言指令 + embodiment 描述 prompt - 处理:ViT 生成视觉 token,经 spatial merging 后与文本 token 交错输入混合注意力 Transformer(大多数层为门控线性注意力,少数层为 GQA softmax 注意力),实现图像、视频与语言的统一编码
- 输出:VLM 隐状态序列,供动作专家条件化
- 设计动机:复用强大的视觉语言预训练能力,避免从头学习感知与 grounding;混合注意力在长多模态序列上兼顾效率与精度
动作专家(DiT flow-matching,约 1.15B 参数,16 个 DiT block)
- 输入:VLM 隐状态 + 带噪声的动作 chunk(维度 \(\mathbf Y \in \mathbb{R}^{H \times K}\),K 为所有 embodiment 共享的最大通道数,有效维度 c ≤ K,其余补零)
- 处理:VLM 隐状态拼接 noisy action chunk 后,经 16 个 DiT block 联合 self-attention,以 AdaLN timestep conditioning 和多段 RoPE 处理;per-channel 有效性掩码 M 确保 padding 不参与梯度
- 输出:预测速度场 \(v_\theta\),推理时通过数步 Euler 积分(从 τ=1 到 τ=0)产出干净动作 chunk
- 设计动机:flow-matching 自然处理连续高维动作分布的多峰性;单流设计让 VLM 语义特征与动作序列充分交互
Embodiment-aware Prompt Conditioning
每条训练样本前添加文本描述(唯一的平台专属接口,无需任何架构改动):
The robot is {robot_tag} with {arms}. The control frequency is {FPS} Hz.
Please predict the next {chunk_size} control actions to execute: {instruction}.
覆盖 WidowX、Franka、ALOHA、AgiBot、人形机器人等 10+ 种平台,控制模式涵盖 ΔEF、绝对关节角、灵巧手等。
统一 Action-and-Trajectory 表示(Zero-Padding)
目标张量 \(\mathbf Y \in \mathbb{R}^{H \times K}\),有效动作 c 维放在前 c 维,其余补零:
- 操作:Δ末端执行器位姿 / 关节角 / 夹爪开合
- 导航:$(\Delta x, \Delta y, \Delta\theta)$ 路径点序列
- 人体视角:SE(3) 腕部运动 + 10 维 eigengrasp 系数(45 维手势 PCA 压缩),共 32 维/步
③ 端到端数据流
embodiment prompt + 图像 → VLM 主干生成隐状态 → 拼接带噪动作 chunk → 16 个 DiT block 联合处理 → 预测速度场 → Euler 积分输出干净动作 chunk
④ 训练目标
Flow-matching 动作损失(per-channel 两级平均,防止 padding 主导梯度):
\[\ell_k = \frac{\sum_{h=1}^{H} M_{h,k} \left\lVert \left(v_\theta(\mathbf Y_\tau, \tau \mid o_{1:t}, x, e, z) - (\mathbf Y_1 - \mathbf Y_0)\right)_{h,k} \right\rVert_2^2}{\sum_{h=1}^{H} M_{h,k}}\] \[\mathcal{L}_\text{act} = \mathbb{E}_{\tau, \mathbf Y_0, \mathbf Y_1} \left[ \frac{1}{c} \sum_{k=0}^{c-1} \ell_k \right]\]视觉语言损失(next-token prediction,防止灾难性遗忘):
\[\mathcal{L}_\text{vl} = -\sum_i \log p_\theta(w_i \mid w_{<i}, o_{1:t})\]联合损失:\(\mathcal{L} = \lambda_\text{act} \mathcal{L}_\text{act} + \lambda_\text{vl} \mathcal{L}_\text{vl}\)
⑤ 四阶段渐进式训练
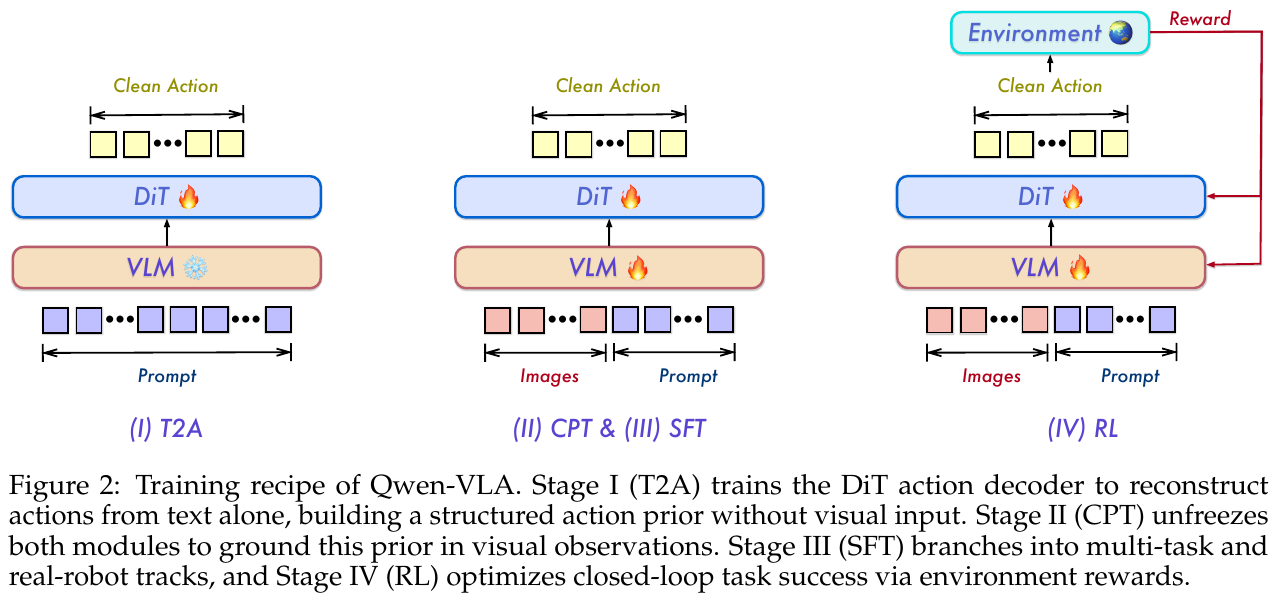
- Stage I — T2A(Text-to-Action 预训练):冻结 VLM,仅凭文本 + embodiment prompt 训练 DiT,不引入图像。目标是让 DiT 学会”语言→动作解压缩”先验;用 Sigmoid-Normal 采样中间 timestep(最大化信息量),最优 2000 步(过多则过拟合,带来 −10.7pp 劣化)。纯合成数据(Syn only)→ 64.1%,纯真实数据(Real only)→ 51.0%,20% Syn + 80% Real 混合最优 → 71.1%(+10.2pp vs. 无 T2A)。
- Stage II — CPT(继续预训练):解冻全部参数,在多源异构数据混合(74.2% 操作轨迹、7.5% 导航、6.0% 人体、3.7% 合成仿真、8.5% VL 数据)上联合训练,将 T2A 动作先验 grounding 到视觉观察。
- Stage III — SFT(监督微调):从 CPT checkpoint 分两路并行微调——多任务 SFT(VQA + 操作 + 导航均衡采样)和真实机器人 SFT(ALOHA 遥操作数据)。
- Stage IV — RL(强化学习):从多任务 SFT 出发,在 SimplerEnv 中用 PPO + GAE 优化稀疏二元成功奖励(R=1 完成 / R=0 未完成),128 并行环境实例。Flow-matching 的 log-probability 通过将确定性 ODE 转为 SDE 注入噪声的方式在 Euler 步上解析计算,无需数值积分。
大规模合成数据(ROBOINF 流水线)
ROBOINF 流水线在 IsaacLab 中自动构建场景(20 桌面场景 × 10 姿态配置 = 200 基础场景),生成 450 个任务(短/长时域各半),每任务 300 条轨迹,随机化光照/视角/背景/纹理/控制器参数。同时构建纯语言-动作数据(7.2M 条),覆盖 6 种单臂机器人 × 6 种操作模板,作为 T2A Stage I 的主体语料。
3. 核心结果/发现
操作(仿真,单一通用模型 vs. 各基准专家模型):
| 基准 | Qwen-VLA-Instruct | 最强专家 |
|---|---|---|
| LIBERO | 97.9% | ABot-M0 98.6% |
| Simpler-WidowX | 73.7% | StarVLA-OFT 64.6% |
| RoboTwin-Easy | 86.1% | ABot-M0 86.0% |
| RoboTwin-Hard | 87.2% | ABot-M0 85.0% ✓ |
| RoboCasa-GR1 | 56.7% | Being-H0.5 53.3% |
操作(真实机器人 ALOHA 双臂):微调后域内任务平均 83.6%,OOD 成功率 76.9%(vs. π0.5 的 41.5%),有预训练 vs. 无预训练差距高达 +35.1pp(83.6% vs. 48.5%),证明预训练表示迁移价值显著。
导航(VLN-CE Val-Unseen):R2R 最高 OSR 69.0%、SR 57.5%;RxR SR 59.6%、SPL 47.8%,均超越 StreamVLN、NaVILA 等开源基线。
OOD 动态操作(DOMINO,零样本):SR 26.6%、MS 39.5,仅凭当前帧观察、无动态操作训练数据,超越专门 DOMINO 微调的 PUMA(17.2%/35.0%)。
消融关键发现:T2A 预热带来 +10.2pp;VL 数据联合训练在复杂任务(RoboCasa)带来 +4.9pp;RL 后训练在训练环境 +2.9pp,且在其他所有基准上无灾难性遗忘(最大波动 <0.6pp);不加入本体感觉状态仅损失 ≤1.3pp,视觉信息已足够。
4. 局限性
具身动作数据规模远小于 VL 数据,长尾物体、接触丰富任务(如布料折叠、插槽)的鲁棒性仍有不足;操作/导航/VL 联合训练存在优化权衡,动作增强训练会轻微损伤纯 VL 和导航评测指标;当前评估以短时域、基准驱动为主,长时域真实部署(故障恢复、情景记忆)仍是未解挑战。
5.25 Diffusion Policy (2023)
——通过动作扩散实现视觉运动策略学习
📄 Paper: arXiv:2303.04137
精华
这篇论文展示了如何将扩散模型应用于机器人策略学习,值得借鉴的核心思想包括:1)利用扩散模型的梯度场表示能力来优雅地处理多模态动作分布;2)通过预测高维动作序列而非单步动作来确保时间一致性;3)将 receding horizon control 与扩散模型结合实现闭环规划;4)位置控制相比速度控制在扩散策略中表现更优;5)训练稳定性显著优于基于能量的隐式策略。
研究背景/问题
现有的机器人模仿学习方法在处理多模态动作分布、高维动作空间和训练稳定性方面面临挑战。显式策略(如 LSTM-GMM)难以表达复杂的多模态分布,而隐式策略(如 IBC)虽然理论上可以建模任意分布,但由于需要负采样估计归一化常数,导致训练不稳定。
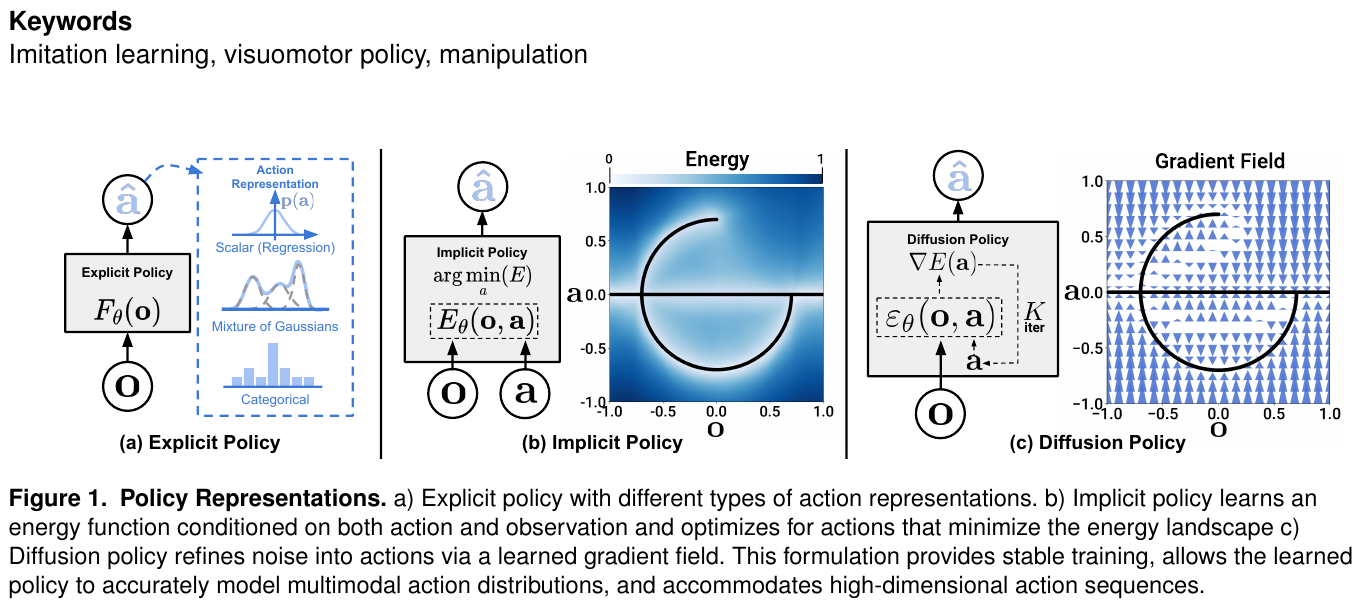
主要方法/创新点
Diffusion Policy 将机器人的视觉运动策略表示为条件去噪扩散过程。核心思想是通过迭代去噪过程从噪声中生成动作序列,而不是直接预测动作。
核心技术贡献:
-
闭环动作序列预测: 结合 receding horizon control,策略预测 Tp 步未来动作,但只执行 Ta 步,之后重新规划。这在长期规划和响应性之间取得平衡。
-
视觉条件化: 将视觉观察作为条件而非联合分布的一部分,使得视觉特征只需提取一次,显著降低计算成本,实现实时控制。
-
时间序列扩散 Transformer: 提出基于 Transformer 的扩散网络,减少 CNN 模型的过度平滑效应,在需要高频动作变化和速度控制的任务上达到最优性能。
-
位置控制的协同效应: 发现位置控制相比速度控制更适合扩散策略,因为位置空间的多模态性更明显,且扩散策略能更好地利用位置控制的优势。
训练过程:
- 随机采样演示数据 A⁰ₜ 和去噪迭代 k
- 添加噪声 εₖ 得到 A⁰ₜ + εₖ
- 训练噪声预测网络 εθ 最小化 MSE(εₖ, εθ(Oₜ, A⁰ₜ + εₖ, k))
推理过程:
- 从高斯噪声 Aᴷₜ 开始
- 迭代 K 次去噪: Aᵏ⁻¹ₜ = α(Aᵏₜ - γεθ(Oₜ, Aᵏₜ, k) + N(0, σ²I))
- 使用 DDIM 加速推理,将迭代次数从 100 降至 10-16
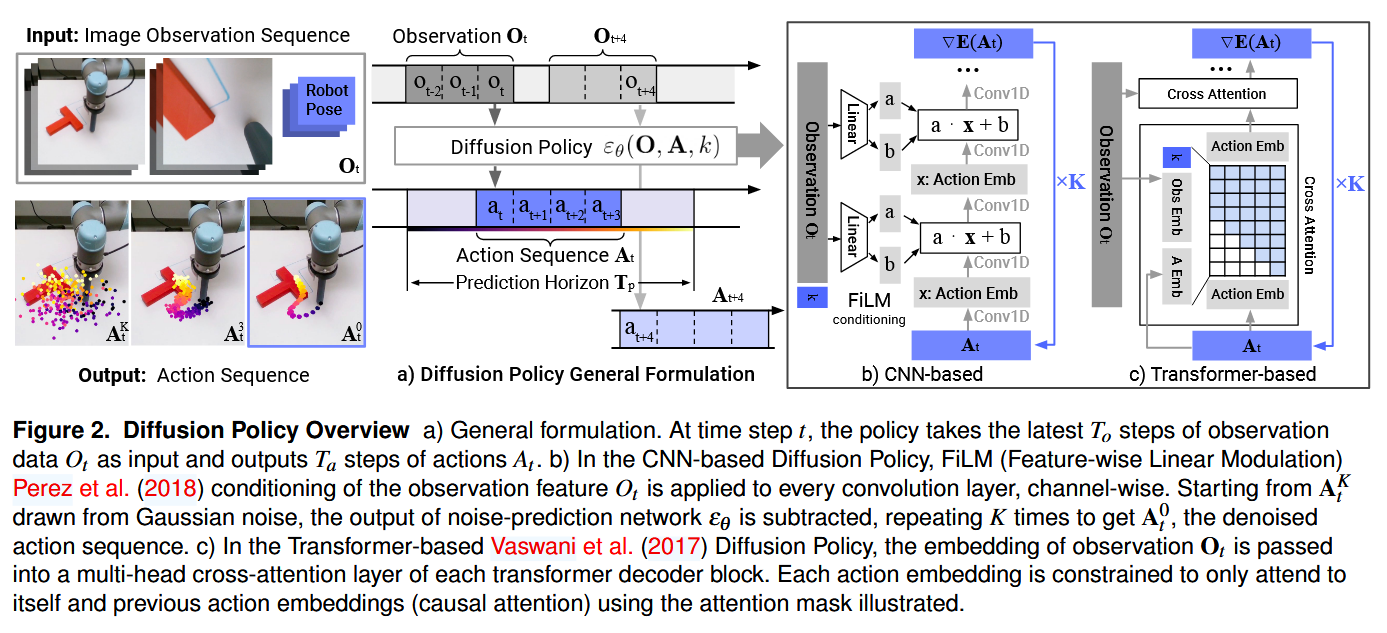
核心结果/发现
论文在 4 个基准测试的 15 个任务上进行了系统评估,包括模拟和真实环境:
- 显著性能提升: 相比现有最优方法平均提升 46.9% 的成功率
- RoboMimic 基准:在所有 9 个变体上均显著优于 LSTM-GMM、IBC 和 BET
- Push-T 任务:95% 成功率(IBC 0%, LSTM-GMM 0-20%)
- Kitchen 环境:p4 指标提升 213%
-
多模态建模能力: 能够准确表达短期和长期多模态行为,并在执行时稳定地选择单一模式
-
训练稳定性: 无需负采样,训练过程稳定,评估性能曲线平滑,易于选择检查点
- 真实世界验证: 在 7 个真实机器人任务上验证,包括:
- 6 自由度倒酱汁和涂抹任务(接近人类水平)
- 双臂协作任务(打蛋器、展开垫子、叠衬衫)
- 延迟鲁棒性: 使用位置控制的 Diffusion Policy 对最多 4 步延迟具有鲁棒性
局限性
继承了行为克隆的局限性,在演示数据不足时性能次优。推理延迟高于简单方法(如 LSTM-GMM),尽管动作序列预测部分缓解了这一问题。未来工作可以探索将扩散策略应用于强化学习,以及利用最新的扩散模型加速技术(如一致性模型)进一步降低推理迭代次数。
6. 总结与展望
Vision-Language-Action (VLA) 模型代表了机器人技术的重要范式转变,通过统一视觉、语言和行动三个模态,实现了从自然语言指令到机器人控制的端到端学习。自2022年RT-1和2023年RT-2开创这一方向以来,VLA研究取得了爆发式进展。
VLA领域在架构、规模、能力和生态四个维度均取得了显著进展:动作表示从离散token演进到Flow Matching;模型参数从130M (RT-1) 扩展到billion级 (RDT-1B);数据从130k轨迹增长到1.5M+ (EO-Data);开源生态(OpenVLA, LeRobot)和评测基准(LIBERO, SimplerEnv)逐步成熟。
五大核心挑战的现状与展望如下:
| 挑战 | 当前进展 | 未来方向 |
|---|---|---|
| 表示 | 多模态对齐成熟;3D空间表示(点云/体素);世界模型快速发展 | 原生多模态统一token化;因果世界模型 |
| 执行 | CoT/ACoT推理增强;层级规划成熟;FAST等轻量化方案 | 自适应架构;see-think-act一体化 |
| 泛化 | 跨机器人预训练为标准;Sim-to-Real差距缩小;在线RL结合(π*0.6) | 形态无关表示;自主开放式进化闭环 |
| 安全 | 约束+学习对齐双范式;可学习拒绝机制(RationalVLA) | 不确定性感知;主动风险规避;共享心智模型 |
| 数据与评测 | OXE/EO-Data大规模数据集;SimplerEnv/VLABench标准化评测 | Simulation-First;Failure-Centric评测 |
从RT-1到ACoT-VLA,VLA的演进代表了具身智能研究范式的根本转变:从手工设计到数据驱动,从任务特定到通用能力,从离线学习到在线适应。ICLR 2026收录164篇VLA论文,标志着这一领域正步入爆发期。
声明:本文旨在为VLA领域的研究者和学习者提供全面的技术综述。由于该领域发展迅速,部分内容可能随时间推移而更新。欢迎读者在评论区讨论和补充最新进展。
7. 参考资料
- An Anatomy of Vision-Language-Action Models (2512.11362v3) - IEEE TPAMI 2025,本文核心参考综述,提出挑战驱动的分类法
- VLA-Survey-Anatomy GitHub - 上述综述配套项目页面
- Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
- 10 Open Challenges Steering the Future of Vision-Language-Action Models
- State of VLA Research at ICLR 2026 - 分析164篇ICLR 2026 VLA论文
- Muhayyuddin’s VLA Repository - 整合102个模型、26个数据集和12个仿真平台
- OpenVLA - 7B参数开源VLA模型
- π₀ (openpi) - Physical Intelligence Flow Matching VLA
- Octo - 通用机器人策略
- LeRobot - Hugging Face机器人学习库
- RT-2 Blog - Google DeepMind
- Open X-Embodiment - 970k真实机器人轨迹,22种机器人
- Bridge Dataset - 60k桌面操作轨迹
- LIBERO - 终身机器人学习基准
- CALVIN - 长时序组合任务基准
- RLBench - 100+仿真操作任务
- SIMPLER - 标准化VLA评测平台